MQ 笔记
什么是消息队列?
消息队列(Message Queue, MQ)是一种用于在分布式系统中传递消息的中间件技术。
它允许应用程序通过发送和接收消息进行异步通信。
消息队列的核心思想是解耦生产者和消费者,生产者将消息发送到队列中,消费者从队列中获取消息并进行处理。
- 生产者(Producer):负责生成消息并发送到队列。
- 消费者(Consumer):负责从队列中获取消息并进行处理。
- 队列(Queue):存储消息的缓冲区,确保消息在传递过程中不会丢失。
消息队列可以是内存中的数据结构,也可以是独立的中间件服务(如 Kafka、RabbitMQ、RocketMQ 等)。
消息队列的使用场景?
消息队列在分布式系统 和 高并发场景 中扮演着重要角色,其主要作用包括:
-
异步通信:
- 生产者和消费者不需要同时在线,生产者发送消息后可以立即返回,消费者可以在稍后处理消息。
- 例如:用户注册后,发送欢迎邮件的操作可以通过消息队列异步处理。
-
解耦系统:
- 生产者和消费者之间没有直接依赖,通过消息队列进行通信。
- 例如:订单系统和库存系统通过消息队列解耦,订单系统生成订单后,通过消息队列通知库存系统扣减库存。
-
流量削峰:
- 在流量突增时,消息队列可以缓冲请求,避免系统过载。
- 例如:电商大促期间,订单系统将订单消息放入队列,由后端服务逐步处理。
-
可靠性:
- 消息队列可以确保消息不丢失,即使消费者暂时不可用,消息也会存储在队列中,直到被成功处理。
- 例如:支付系统通过消息队列处理支付请求,即使支付服务暂时不可用,支付请求也不会丢失。
-
顺序性:
- 消息队列可以保证消息的顺序性,确保消息按照发送的顺序被处理。
- 例如:日志系统通过消息队列保证日志的顺序性。
-
分布式事务:
- 通过消息队列实现最终一致性,解决分布式系统中的事务问题。
- 例如:订单系统生成订单后,通过消息队列通知支付系统处理支付。
-
扩展性:
- 通过消息队列,可以轻松扩展系统的处理能力,增加更多的消费者来处理消息。
- 例如:图片处理服务通过消息队列分发任务,增加更多的工作节点来提高处理能力。
-
广播消息:
- 消息队列支持发布/订阅模式,可以将消息广播给多个消费者。
- 例如:配置中心将配置变更消息广播给所有服务。
消息队列的核心概念
- 生产者(Producer):消息的发送方。
- 消费者(Consumer):消息的接收方。
- 消息(Message):传递的基本单位,包含消息体和元数据。
- 队列(Queue):消息的存储容器,具有 FIFO 特性。
- 主题(Topic):消息的分类标识,用于发布/订阅模式。
- 订阅(Subscription):消费者与主题之间的绑定关系。
消息队列的通信模式
消息队列的通信模式主要分为两种:点对点(Point-to-Point)模式和发布/订阅(Publish/Subscribe)模式。
1. 点对点(Point-to-Point)模式
定义
- 点对点模式是一种
一对一的通信模式,生产者将消息发送到队列中,消费者从队列中获取消息并进行处理。 - 每条消息只能被一个消费者处理,处理完成后消息从队列中移除。
特点
- 一对一通信:每条消息只有一个消费者。
- 消息持久化:消息存储在队列中,直到被消费者处理。
- 顺序性:消息按照发送顺序被处理(FIFO)。
- 可靠性:消息被消费者确认(ACK)后才会从队列中移除,确保消息不丢失。
适用场景
- 任务分发:将任务分配给多个工作节点处理。
- 异步处理:生产者不需要等待消费者处理完成。
- 分布式事务:通过消息队列实现最终一致性。
示例
- 订单系统将订单消息发送到队列,库存系统从队列中获取消息并扣减库存。
2. 发布/订阅(Publish/Subscribe)模式
定义
- 发布/订阅模式是一种
一对多的通信模式,生产者将消息发布到主题(Topic),所有订阅该主题的消费者都会收到消息。 - 每条消息可以被多个消费者处理。
特点
- 一对多通信:每条消息可以被多个消费者处理。
- 主题和订阅:消息通过主题进行分类,消费者通过订阅主题接收消息。
- 灵活性:可以动态添加或移除消费者,不影响生产者。
- 广播机制:消息被广播给所有订阅者。
适用场景
- 事件通知:将事件通知给多个订阅者。
- 日志收集:将日志消息广播给多个日志处理服务。
- 配置更新:将配置变更消息广播给所有服务。
示例
- 配置中心将配置变更消息发布到配置主题,所有订阅该主题的服务都会收到配置变更通知。
3. 两种模式的对比
| 特性 | 点对点(Point-to-Point)模式 | 发布/订阅(Publish/Subscribe)模式 |
|---|---|---|
| 通信方式 | 一对一 | 一对多 |
| 消息消费 | 每条消息只能被一个消费者处理 | 每条消息可以被多个消费者处理 |
| 消息存储 | 消息存储在队列中 | 消息存储在主题中 |
| 顺序性 | 消息按照发送顺序被处理(FIFO) | 消息可能被多个消费者并行处理 |
| 适用场景 | 任务分发、异步处理、分布式事务 | 事件通知、日志收集、配置更新 |
消息队列如何保证消息不丢失?
1. 生产者端保证消息不丢失
1.1 消息确认机制(ACK)
- 生产者发送消息后,消息队列会返回一个确认(ACK)信号,表示消息已成功接收。
- 如果生产者未收到 ACK,可以重试发送消息。
- 示例:RabbitMQ 的 Publisher Confirms 机制。
1.2 持久化消息
- 生产者可以将消息标记为持久化,确保消息在队列中存储到磁盘,即使消息队列服务重启也不会丢失。
- 示例:Kafka 和 RabbitMQ 都支持消息持久化。
1.3 事务机制
- 生产者可以使用事务机制,确保消息发送和业务逻辑的原子性。
- 示例:RabbitMQ 的事务机制。
1.4 重试机制
- 生产者在发送失败时,可以通过重试机制重新发送消息。
- 示例:Kafka 的 Producer 重试机制。
2. 消息队列端保证消息不丢失
2.1 消息持久化
- 消息队列将消息持久化到磁盘,确保即使服务重启,消息也不会丢失。
- 示例:Kafka 将消息存储到日志文件(Log Segment),RabbitMQ 将消息存储到磁盘。
2.2 副本机制
- 消息队列通过多副本机制(Replication)保证消息的高可用性。
- 即使某个节点故障,其他副本节点仍可以提供服务。
- 示例:Kafka 的多副本机制。
2.3 高可用性
- 消息队列通过集群部署,确保在单点故障时仍能正常服务。
- 示例:RabbitMQ 的镜像队列,Kafka 的集群部署。
2.4 消息确认机制
- 消息队列在消费者成功处理消息后,会返回一个确认(ACK)信号,确保消息被成功消费。
- 如果消费者未发送 ACK,消息队列会重新投递消息。
- 示例:RabbitMQ 的 Consumer ACK 机制。
3. 消费者端保证消息不丢失
3.1 手动确认机制
- 消费者在处理完消息后,手动发送 ACK 确认消息已处理。
- 如果消费者未发送 ACK,消息队列会重新投递消息。
- 示例:RabbitMQ 的 Manual ACK 机制。
3.2 幂等性设计
- 消费者需要设计幂等性逻辑,确保即使消息被重复消费,也不会对业务造成影响。
- 示例:通过唯一 ID 判断消息是否已处理。
3.3 重试机制
- 消费者在处理失败时,可以通过重试机制重新处理消息。
- 示例:Kafka 的 Consumer 重试机制。
3.4 死信队列(DLQ)
- 如果消息多次处理失败,可以将其转移到死信队列,避免消息丢失。
- 示例:RabbitMQ 的死信队列机制。
4. Kafka 和 RabbitMQ 具体实现
Kafka 的保证机制
- 生产者端:通过 ACKS 参数控制消息确认级别(如
acks=all确保所有副本确认)。 - 消息队列端:通过多副本和 ISR(In-Sync Replicas)机制保证消息不丢失。
- 消费者端:通过 Offset 提交机制和幂等性设计保证消息不丢失。
RabbitMQ 的保证机制
- 生产者端:通过 Publisher Confirms 和持久化消息保证消息不丢失。
- 消息队列端:通过持久化队列和镜像队列保证消息不丢失。
- 消费者端:通过 Manual ACK 和死信队列保证消息不丢失。
如何处理消息重复消费的问题?
重复消费可能导致数据不一致、业务逻辑错误等问题。为了解决这个问题,可以从 消息队列本身 和 业务逻辑设计 两个方面入手,采取多种措施来避免或处理重复消费。
1. 消息队列本身的机制
1.1 消息确认机制(ACK)
- 问题:如果消费者未正确发送 ACK,消息队列可能会重新投递消息,导致重复消费。
- 解决方案:
- 使用手动确认机制,确保消费者在处理完消息后发送 ACK。
- 在 RabbitMQ 中,使用
basic.ack手动确认消息。 - 在 Kafka 中,手动提交 Offset,确保消息已处理。
1.2 消息幂等性设计
消息队列支持幂等性投递,确保同一条消息不会被重复投递。
例如,Kafka 通过 enable.idempotence=true 开启生产者幂等性。
1.3 消息去重
消息队列支持消息去重,避免重复存储。
例如,RocketMQ 支持消息去重机制。
2. 业务逻辑设计
2.1 幂等性设计
在消费者端设计幂等性逻辑,确保即使消息被重复消费,也不会对业务造成影响。
比如,为每条消息分配 唯一 ID,消费者在处理消息前检查该 ID 是否已处理。
2.2 消息去重表
使用消息去重表,记录已处理的消息 ID。
在处理消息前,检查消息 ID 是否已存在于去重表中。
示例:
CREATE TABLE message_dedup (message_id VARCHAR(64) PRIMARY KEY,processed_at TIMESTAMP
);
2.3 分布式锁
使用分布式锁(如 Redis 或 ZooKeeper)确保同一消息不会被多个消费者同时处理。
示例:
lockKey := "message_lock_" + messageIDsuccess, err := redis.SetNX(lockKey, 1, time.Minute).Result()if success {// 处理消息}
SetNX是"Set if Not Exists"的缩写,表示
- 当键 lockKey 不存在时,才会设置它的值为 1,并返回 true;
- 如果键已经存在,则不会设置值,并返回 false。
time.Minute 是锁的过期时间,表示这个键值对会在 1 分钟后自动过期(删除)。
2.4 消息状态标记
在数据库中为消息添加状态字段(如 status),标记消息是否已处理。
在处理消息前,检查消息状态,避免重复处理。
示例:
UPDATE messages SET status = 'processed' WHERE id = ? AND status = 'pending';
消息队列如何保证消息的顺序性?
在分布式系统中,消息顺序性 是一个重要的需求,尤其是在某些业务场景中(如订单处理、日志记录等),消息的处理顺序必须与发送顺序一致。
1. 消息队列本身的顺序性保证
1.1 单分区/单队列顺序
- 实现方式:将消息发送到同一个分区(Partition)或队列(Queue),确保消息按照发送顺序被处理。
- 示例:
- Kafka:将消息发送到同一个分区。
- RabbitMQ:将消息发送到同一个队列。
- 适用场景:适用于消息量较小的场景。
1.2 全局顺序
- 实现方式:在整个消息队列中保证消息的全局顺序。
- 示例:
- RocketMQ:通过全局顺序消息(Global Ordered Message)实现。
- 适用场景:适用于严格要求全局顺序的场景。
1.3 分区/队列顺序
- 实现方式:将消息按某种规则(如业务键)分配到不同的分区或队列,确保每个分区或队列内的消息顺序性。
- 示例:
- Kafka:通过消息的 Key 进行分区,确保同一 Key 的消息发送到同一分区。
- RabbitMQ:通过路由键(Routing Key)将消息发送到不同的队列。
- 适用场景:适用于消息量较大且需要局部顺序的场景。
2. 生产者端的顺序性保证
2.1 同步发送
- 实现方式:生产者按顺序发送消息,并等待消息队列返回确认(ACK)后再发送下一条消息。
- 示例:
- Kafka:通过同步发送(
acks=all)确保消息顺序。
- Kafka:通过同步发送(
- 适用场景:适用于对顺序性要求较高的场景。
2.2 消息编号
- 实现方式:为每条消息添加序号(Sequence Number),消费者根据序号处理消息。
- 示例:
- RocketMQ:通过消息序号保证顺序性。
- 适用场景:适用于需要严格顺序的场景。
3. 消费者端的顺序性保证
3.1 单线程消费
- 实现方式:消费者使用单线程处理消息,确保消息按顺序处理。
- 示例:
- Kafka:使用单线程消费同一个分区。
- 适用场景:适用于消息量较小的场景。
3.2 消息缓冲
- 实现方式:消费者将消息缓存到本地队列,按顺序处理。
- 示例:
- RabbitMQ:使用本地队列缓存消息。
- 适用场景:适用于需要批量处理的场景。
3.3 状态机
- 实现方式:通过状态机控制消息的处理顺序,确保业务逻辑的顺序性。
- 示例:
- 订单处理:根据订单状态(如创建、支付、发货)顺序处理消息。
- 适用场景:适用于复杂业务逻辑的场景。
4. Kafka、RabbitMQ、RocketMQ 具体实现
4.1 Kafka 的顺序性保证
- 分区顺序:将消息发送到同一个分区,确保分区内的消息顺序性。
- 生产者同步发送:使用同步发送(
acks=all)确保消息顺序。 - 消费者单线程消费:使用单线程消费同一个分区。
4.2 RabbitMQ 的顺序性保证
- 单队列顺序:将消息发送到同一个队列,确保队列内的消息顺序性。
- 消费者单线程消费:使用单线程消费同一个队列。
4.3 RocketMQ 的顺序性保证
- 全局顺序消息:通过全局顺序消息实现全局顺序性。
- 分区顺序消息:通过分区顺序消息实现局部顺序性。
5. 其他技术
5.1 分布式锁
- 实现方式:使用分布式锁(如 Redis 或 ZooKeeper)确保同一资源的消息按顺序处理。
- 示例:
- 订单处理:对同一订单 ID 加锁,确保订单消息按顺序处理。
- 适用场景:适用于资源竞争的场景。
5.2 消息编号和状态
- 实现方式:为每条消息添加序号和状态,消费者根据序号和状态处理消息。
- 示例:
- 日志处理:根据日志序号和状态顺序处理日志消息。
- 适用场景:适用于需要严格顺序的场景。
在分布式场景下,如何保证消息的顺序性?
- 单分区/单队列顺序性
- 原理:将需要保证顺序的消息发送到同一个分区(如 Kafka 的 Partition)或同一个队列中,确保这些消息由同一个消费者按顺序处理。
- 实现:
- 在 Kafka 中,可以通过指定相同的消息键(Key)将消息路由到同一个 Partition(分区)。
- 在 RabbitMQ 中,可以将消息发送到同一个队列,并由单个消费者处理。
- 优点:简单易实现。
- 缺点:限制了系统的扩展性,无法充分利用分布式系统的并行处理能力。
- 消息键(Message Key)路由
- 原理:使用消息键将相关消息路由到同一个分区或队列中,确保这些消息按顺序处理。
- 实现:
- 在 Kafka 中,可以为同一组相关的消息指定相同的消息键(如用户 ID、订单 ID 等),确保它们被路由到同一个 Partition(分区)。
- 在 RocketMQ 中,可以使用消息的
MessageQueue来实现类似的功能。
- 优点:在保证顺序性的同时,可以支持一定程度的并行处理。
- 缺点:如果消息键分布不均匀,可能导致某些分区或队列负载过高。
- 消费者顺序处理
- 原理:在消费者端保证消息的顺序处理,即使消息可能来自多个分区或队列。
- 实现:
- 使用单线程处理消息,避免并行消费。
- 使用本地队列或缓存,将消息按顺序排列后再处理。
- 优点:实现简单。
- 缺点:处理效率较低,无法充分利用多核 CPU 和分布式系统的优势。
- 分布式锁或顺序标记
- 原理:使用分布式锁或顺序标记来确保消息的全局顺序性。
- 实现:
- 使用分布式锁(如 Redis 或 Zookeeper)确保同一组相关消息按顺序处理。
- 为消息添加顺序标记(如时间戳或序列号),消费者根据标记顺序处理消息。
- 优点:可以支持全局顺序性。
- 缺点:引入分布式锁会增加系统复杂性和性能开销。
消息队列如何实现消息的持久化?
RabbitMQ
- 持久化队列:在声明队列时设置
durable=true,这样队列的元数据会被持久化到磁盘。channel.queue_declare(queue='my_queue', durable=True) - 持久化消息:在发送消息时设置
delivery_mode=2,表示消息会被持久化到磁盘。channel.basic_publish(exchange='',routing_key='my_queue',body='Hello World!',properties=pika.BasicProperties(delivery_mode=2) )
Kafka
- 日志持久化:Kafka 将所有消息以日志文件的形式持久化到磁盘,并支持多副本机制(Replication)来保证高可用性。
- 消息保留策略:可以配置消息的保留时间(
retention.ms)或大小(retention.bytes),确保消息在指定时间内不会被删除。
RocketMQ
- CommitLog:RocketMQ 将所有消息写入一个统一的 CommitLog 文件,并异步刷盘到磁盘。
- 消息索引:通过索引文件(ConsumeQueue)快速定位消息,同时支持多副本机制。
如何实现消息的延迟发送?
许多消息队列系统(如 RabbitMQ、RocketMQ、Kafka)提供了内置的延迟消息功能,可以直接使用。
RabbitMQ
RabbitMQ 通过 延迟消息插件(rabbitmq-delayed-message-exchange)支持延迟消息。
- 安装插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange - 声明延迟交换机:
args = {'x-delayed-type': 'direct'} channel.exchange_declare(exchange='delayed_exchange', exchange_type='x-delayed-message', arguments=args) - 发送延迟消息:
headers = {'x-delay': 5000} # 延迟 5 秒 channel.basic_publish(exchange='delayed_exchange',routing_key='my_queue',body='Hello World!',properties=pika.BasicProperties(headers=headers) )
RocketMQ
RocketMQ 支持延迟消息,提供多个固定的延迟级别(如 1s、5s、10s 等)。
- 发送延迟消息:
Message message = new Message("my_topic", "Hello World!".getBytes()); message.setDelayTimeLevel(3); // 延迟 10 秒 producer.send(message);
Kafka
Kafka 本身不支持延迟消息,但可以通过自定义实现(如使用时间戳和消费者轮询)来实现。
基于数据库的延迟消息
如果消息队列不支持延迟消息,可以使用数据库来实现。
实现步骤:
- 创建消息表,包含消息内容、状态、发送时间等字段。
CREATE TABLE delayed_messages (id INT AUTO_INCREMENT PRIMARY KEY,content TEXT,status ENUM('pending', 'sent') DEFAULT 'pending',send_time DATETIME ); - 插入延迟消息:
INSERT INTO delayed_messages (content, send_time) VALUES ('Hello World!', NOW() + INTERVAL 5 MINUTE); - 定时任务扫描:
使用定时任务(如 Cron Job)定期扫描表,将到期的消息发送到消息队列。SELECT * FROM delayed_messages WHERE status = 'pending' AND send_time <= NOW(); - 更新消息状态:
发送成功后,更新消息状态为sent。
基于定时任务的延迟消息
通过 linux 系统定时任务(如 Cron )实现延迟消息。
实现步骤:
- 将延迟消息存储到数据库或缓存中。
- 使用定时任务定期扫描未发送的消息。
- 将到期的消息发送到消息队列。
具体实现示例(RabbitMQ)
以下是基于 RabbitMQ 和延迟插件的完整示例:
安装插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
Python 代码:
import pika# 连接 RabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()# 声明延迟交换机
args = {'x-delayed-type': 'direct'}
channel.exchange_declare(exchange='delayed_exchange', exchange_type='x-delayed-message', arguments=args)# 声明队列
channel.queue_declare(queue='my_queue', durable=True)
channel.queue_bind(exchange='delayed_exchange', queue='my_queue')# 发送延迟消息
headers = {'x-delay': 5000} # 延迟 5 秒
channel.basic_publish(exchange='delayed_exchange',routing_key='my_queue',body='Hello World!',properties=pika.BasicProperties(headers=headers)
)print("Sent delayed message")
connection.close()
Kafka、RabbitMQ、RocketMQ 的区别?
| 特性/消息队列 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 设计目标 | 高吞吐量、分布式日志系统 | 通用的消息队列,支持多种消息模式 | 高吞吐量、低延迟、分布式消息队列 |
| 消息模型 | 发布/订阅模型 | 支持多种模型(点对点、发布/订阅) | 发布/订阅模型 |
| 消息存储 | 持久化到磁盘,支持长时间存储 | 内存或磁盘,取决于配置 | 持久化到磁盘,支持长时间存储 |
| 吞吐量 | 非常高(适合大数据场景) | 中等(适合中小规模场景) | 高(适合大规模场景) |
| 延迟 | 较高(适合批处理场景) | 低(适合实时场景) | 低(适合实时场景) |
| 消息顺序 | 保证分区内消息顺序 | 不保证全局消息顺序 | 保证分区内消息顺序 |
| 消息可靠性 | 高(多副本机制) | 高(持久化、ACK 机制) | 高(多副本机制) |
| 消息重试 | 不支持(需手动实现) | 支持(通过死信队列) | 支持(通过重试队列) |
| 消息过滤 | 不支持(需消费者自行过滤) | 支持(通过 Header 或 Routing Key) | 支持(通过 Tag 或 SQL 过滤) |
| 事务支持 | 支持(0.11 版本及以上) | 支持(事务模式) | 支持(事务消息) |
| 消息广播 | 不支持(需多个消费者组) | 支持(Fanout 交换机) | 支持(广播模式) |
| 消息堆积能力 | 强(适合海量消息堆积) | 中等(适合中小规模堆积) | 强(适合海量消息堆积) |
| 扩展性 | 高(分布式架构,易于扩展) | 中等(集群模式,扩展性有限) | 高(分布式架构,易于扩展) |
| 适用场景 | 大数据日志采集、流处理、实时分析 | 任务队列、RPC、实时消息传递 | 订单处理、支付系统、实时消息传递 |
| 开发语言 | Scala/Java | Erlang | Java |
| 社区生态 | 非常活跃,广泛应用 | 活跃,广泛应用 | 活跃,主要在中国广泛应用 |
| 学习曲线 | 较高(需要理解分区、副本等概念) | 较低(易于上手) | 中等(需要理解分布式概念) |
总结:
- Kafka:适合大数据场景,高吞吐量,但延迟较高,适合日志采集、流处理等。
- RabbitMQ:通用性强,低延迟,适合中小规模场景,如任务队列、RPC 等。
- RocketMQ:高吞吐量、低延迟,适合大规模实时场景,如订单处理、支付系统等。
消息队列的性能指标有哪些(如吞吐量、延迟)?
消息队列的性能指标是衡量其效率和可靠性的重要标准。以下是消息队列的主要性能指标及其解释:
- 吞吐量(Throughput)
- 定义:单位时间内消息队列能够处理的消息数量(通常以消息/秒或字节/秒为单位)。
- 重要性:高吞吐量意味着消息队列能够高效处理大量消息,适合高并发场景。
- 影响因素:
- 消息大小
- 网络带宽
- 磁盘 I/O 性能
- 消息队列的架构和配置
- 延迟(Latency)
- 定义:消息从生产者发送到消费者接收到的时间间隔。
- 重要性:低延迟意味着消息能够快速传递,适合实时性要求高的场景。
- 影响因素:
- 网络传输时间
- 消息队列的处理时间
- 消费者的处理能力
- 消息堆积能力(Backlog Capacity)
- 定义:消息队列能够存储的未处理消息的最大数量。
- 重要性:高堆积能力意味着消息队列能够应对突发流量或消费者处理能力不足的情况。
- 影响因素:
- 磁盘存储空间
- 消息队列的存储机制
- 消息的保留策略
- 可靠性(Reliability)
- 定义:消息队列确保消息不丢失、不重复、按顺序传递的能力。
- 重要性:高可靠性是消息队列的核心要求,尤其对金融、支付等关键业务。
- 影响因素:
- 持久化机制
- 多副本机制
- 消息确认机制(ACK)
- 扩展性(Scalability)
- 定义:消息队列能够通过增加资源(如节点)来提升性能的能力。
- 重要性:高扩展性意味着消息队列能够适应业务增长和流量变化。
- 影响因素:
- 分布式架构
- 负载均衡机制
- 集群管理能力
- 并发能力(Concurrency)
- 定义:消息队列能够同时处理的生产者和消费者数量。
- 重要性:高并发能力意味着消息队列能够支持大量客户端连接。
- 影响因素:
- 网络连接数
- 线程模型
- 资源分配策略
消息队列如何实现高可用性?
1. 多副本机制(Replication)
多副本机制是消息队列实现高可用性的核心,通过将数据复制到多个节点,确保即使某个节点故障,数据仍然可用。
实现方式:
- 主从复制:一个主节点负责写入,多个从节点负责复制数据。主节点故障时,从节点可以接管。
- 多主复制:多个节点都可以写入数据,数据在节点间同步。
- 分区复制:将数据分区,每个分区有多个副本,分布在不同的节点上。
示例:
- Kafka:通过分区副本(Replica)机制,每个分区有多个副本,分布在不同的 Broker 上。
- RabbitMQ:通过镜像队列(Mirrored Queue)机制,将队列数据复制到多个节点。
- RocketMQ:通过多副本机制,将消息存储在不同的 Broker 上。
2. 集群化部署
将消息队列部署在多个节点上,形成一个集群,通过负载均衡和故障转移实现高可用性。
实现方式:
- 无中心化集群:所有节点对等,数据分布在多个节点上(如 Kafka)。
- 中心化集群:有一个主节点负责协调,其他节点为从节点(如 RabbitMQ)。
示例:
- Kafka:通过 ZooKeeper 管理集群状态,实现故障转移。
- RabbitMQ:通过 Erlang 分布式机制实现集群化。
- RocketMQ:通过 NameServer 管理集群状态,实现故障转移。
3. 自动故障转移(Failover)
当某个节点故障时,系统能够自动将流量切换到其他健康节点,确保服务不中断。
实现方式:
- 选举机制:通过选举算法(如 Raft)选出新的主节点。
- 健康检查:定期检查节点状态,发现故障后触发故障转移。
示例:
- Kafka:通过 Controller 选举机制实现故障转移。
- RabbitMQ:通过镜像队列的自动故障转移机制。
- RocketMQ:通过主从切换机制实现故障转移。
4. 数据持久化
将消息持久化到磁盘,确保即使节点故障,数据也不会丢失。
实现方式:
- 同步刷盘:消息写入磁盘后才确认成功,确保数据不丢失,但性能较低。
- 异步刷盘:消息先写入内存缓冲区,再异步刷盘,性能较高,但可能丢失少量数据。
示例:
- Kafka:将消息持久化到日志文件(Log Segment)。
- RabbitMQ:将消息持久化到磁盘(持久化队列和消息)。
- RocketMQ:将消息持久化到 CommitLog 文件。
5. 负载均衡
通过负载均衡机制,将流量均匀分配到多个节点,避免单点过载。
实现方式:
- 客户端负载均衡:客户端根据策略(如轮询、哈希)选择节点。
- 服务端负载均衡:通过负载均衡器(如 Nginx、HAProxy)分配流量。
示例:
- Kafka:客户端根据分区策略选择 Broker。
- RabbitMQ:通过负载均衡器将请求分发到集群节点。
- RocketMQ:客户端根据 Broker 状态选择节点。
6. 异地多活
将消息队列部署在多个地域(Region),确保即使某个地域故障,其他地域仍能提供服务。
实现方式:
- 数据同步:通过跨地域复制(Cross-Region Replication)同步数据。
- 流量路由:通过 DNS 或全局负载均衡器(GSLB)将流量路由到最近的地域。
示例:
- Kafka:通过 MirrorMaker 工具实现跨地域复制。
- RabbitMQ:通过 Federation 或 Shovel 插件实现跨地域复制。
- RocketMQ:通过多地域部署和跨地域复制实现高可用性。
7. 监控和告警
通过监控和告警机制,及时发现和处理故障,确保系统高可用。
实现方式:
- 监控关键指标:如节点状态、消息堆积、延迟等。
- 自动化告警:当指标异常时,触发告警并通知运维人员。
示例:
- Kafka:通过 Kafka Manager、Prometheus 监控集群状态。
- RabbitMQ:通过 RabbitMQ Management Plugin 监控队列状态。
- RocketMQ:通过 RocketMQ Console 监控集群状态。
8. 容灾演练
定期进行容灾演练,验证高可用方案的有效性,确保在真实故障时能够快速恢复。
实现方式:
- 模拟故障:如关闭某个节点、断开网络连接等。
- 验证恢复流程:检查故障转移、数据恢复等流程是否正常。
什么是消息积压?
在消息队列(MQ,Message Queue)系统中,消息积压是指消息生产者发送消息的速度超过了消息消费者处理消息的速度,导致消息在队列中堆积,无法及时被消费和处理。
消息积压会导致什么问题?
-
队列长度增加
- 消息积压会导致队列中的消息数量不断增加,队列长度逐渐变大。
- 如果队列有长度限制,可能会导致队列满,新的消息无法进入队列。
-
消息处理延迟
- 消息积压会导致消息的消费延迟,消息无法及时被处理,影响系统的实时性和响应速度。
-
资源消耗增加
- 消息积压会占用更多的存储资源(如磁盘或内存),增加系统的负载。
- 如果消息队列基于内存存储,积压可能导致内存不足,甚至系统崩溃。
-
消费者压力增大
- 消费者需要处理更多的消息,可能会导致消费者过载,处理速度进一步下降,形成恶性循环。
-
系统稳定性下降
- 消息积压可能导致系统整体性能下降,甚至引发系统故障或服务不可用。
消息积压的常见原因
-
生产者发送速度过快
生产者发送消息的速度远超消费者的处理能力。 -
消费者处理能力不足
消费者处理消息的速度较慢,可能是由于业务逻辑复杂、资源不足或代码效率低。 -
消费者故障或宕机
消费者出现故障或宕机,导致消息无法被消费。 -
网络或系统瓶颈
网络延迟、磁盘 I/O 瓶颈或系统资源不足,导致消息处理速度下降。 -
突发流量
系统遇到突发流量,生产者短时间内发送大量消息,消费者无法及时处理。
如何解决消息积压
-
增加消费者数量
通过增加消费者实例或线程数,提高消息处理能力。 -
优化消费者逻辑
优化消费者的业务逻辑,提高处理效率,减少单条消息的处理时间。 -
限流控制
对生产者进行限流,控制消息发送的速度,避免消息积压。 -
异步处理
将耗时的操作异步化,减少消费者处理消息的时间。 -
监控和告警
实时监控队列长度和消息处理速度,及时发现积压问题并采取措施。 -
扩容和负载均衡
对消息队列系统进行扩容,增加资源(如 CPU、内存、磁盘),并合理分配负载。 -
死信队列
对于无法处理的消息,可以将其转移到死信队列,避免阻塞正常消息的处理。
什么是死信队列?
死信队列(Dead Letter Queue,DLQ) 是消息队列(MQ)系统中的一种特殊队列,用于存储无法被正常消费或处理的消息。当消息在队列中因某些原因无法被成功消费时,系统会将这些消息转移到死信队列中,以便后续进行特殊处理或分析。
死信队列的作用
-
防止消息丢失
将无法处理的消息保存到死信队列中,避免消息丢失,便于后续排查和处理。 -
隔离异常消息
将异常消息与正常消息隔离,避免异常消息阻塞正常消息的处理。 -
问题排查和分析
通过分析死信队列中的消息,可以快速定位和解决系统中的问题。 -
重试机制
死信队列可以作为消息重试机制的一部分,当消息多次消费失败后,将其转移到死信队列中。
消息进入死信队列的常见原因
-
消息消费失败
消费者在处理消息时发生异常,导致消息无法被成功消费。 -
消息超时未消费
消息在队列中停留时间过长,超过了设置的超时时间(TTL,Time to Live)。 -
消息被拒绝
消费者明确拒绝处理某条消息(如返回 NACK 或手动拒绝)。 -
队列已满
队列达到最大长度限制,无法再接收新的消息,导致部分消息被转移到死信队列。 -
路由失败
消息无法被正确路由到目标队列,导致其进入死信队列。
死信队列的实现(RabbitMQ、Kafka、RocketMQ)
不同的消息队列系统对死信队列的实现方式可能有所不同,以下是一些常见的实现方式:
-
RabbitMQ
RabbitMQ 通过x-dead-letter-exchange和x-dead-letter-routing-key参数来指定死信队列。当消息满足进入死信队列的条件时,会被路由到指定的交换机和队列中。 -
Kafka
Kafka 本身没有原生的死信队列概念,但可以通过自定义消费者逻辑将处理失败的消息发送到一个专门的 Topic 中,作为死信队列。 -
RocketMQ
RocketMQ 通过设置DLQ属性,将消费失败的消息自动转移到死信队列中。
死信队列的使用场景
-
异常消息处理
当消息处理失败时,将其转移到死信队列中,以便后续手动处理或重试。 -
监控和告警
通过监控死信队列中的消息数量,可以及时发现系统中的异常情况。 -
重试机制
对于暂时无法处理的消息,可以先将其转移到死信队列中,等待条件满足后再重新处理。 -
审计和日志
死信队列可以作为消息处理的审计日志,记录所有未能正常处理的消息。
消息队列如何存储消息?
消息队列(MQ)存储消息的方式是保证消息可靠性和高效性的关键。不同的消息队列系统在存储消息时采用了不同的技术和策略,但通常都包括以下几个核心方面:
1. 存储介质
消息队列通常将消息存储在以下介质中:
- 内存:消息存储在内存中,读写速度快,但容量有限,且系统重启或崩溃时消息会丢失。
- 磁盘:消息存储在磁盘上,容量大,且可以持久化,但读写速度较慢。
- 混合存储:结合内存和磁盘的优势,将热数据(频繁访问的消息)存储在内存中,冷数据(不常访问的消息)存储在磁盘上。
2. 存储结构
消息队列的存储结构通常包括以下几种:
- 队列(Queue):消息按照先进先出(FIFO)的顺序存储在队列中,消费者从队列头部读取消息。
- 主题(Topic):消息按照主题分类存储,多个消费者可以订阅同一个主题。
- 分区(Partition):将消息队列划分为多个分区,每个分区可以独立存储和处理消息(如 Kafka)。
- 日志(Log):将消息以追加日志的方式存储,保证消息的顺序性和持久性(如 Kafka)。
3. 持久化机制
为了确保消息的可靠性,消息队列通常支持持久化存储:
- 写日志(Write-Ahead Log, WAL):在消息写入内存之前,先将其追加到磁盘日志中,确保消息不会丢失。
- 同步刷盘:消息写入磁盘后,才返回成功响应,保证消息的持久性。
- 异步刷盘:消息先写入内存,然后异步写入磁盘,提高性能,但可能丢失部分消息。
4. 消息索引
为了提高消息的检索效率,消息队列通常会对消息建立索引:
- 偏移量(Offset):为每条消息分配一个唯一的偏移量,消费者可以通过偏移量快速定位消息(如 Kafka)。
- 消息 ID:为每条消息分配一个唯一的 ID,消费者可以通过 ID 快速查找消息。
- 时间戳索引:根据消息的时间戳建立索引,支持按时间范围检索消息。
5. 消息压缩
为了节省存储空间和提高传输效率,消息队列通常支持消息压缩:
- 压缩算法:使用 Gzip、Snappy、LZ4 等压缩算法对消息进行压缩。
- 批量压缩:将多条消息打包压缩,减少存储和传输开销。
6. 消息清理
为了防止存储空间无限增长,消息队列通常支持消息清理策略:
- 基于时间清理:删除超过指定时间(TTL, Time to Live)的消息。
- 基于大小清理:当存储空间达到上限时,删除旧消息。
- 基于偏移量清理:删除已经被所有消费者成功消费的消息(如 Kafka 的 Log Compaction)。
7. 存储实现(RabbitMQ、Kafka、RocketMQ)
不同的消息队列系统在存储消息时有不同的实现方式:
- Kafka:
- 使用追加日志(Log)的方式存储消息,每个分区对应一个日志文件。
- 消息按偏移量(Offset)索引,支持高效的范围查询。
- 支持消息压缩和日志清理(Log Compaction)。
- RabbitMQ:
- 消息存储在队列中,支持内存和磁盘持久化。
- 使用消息 ID 和索引来管理消息。
- 支持消息的 TTL 和死信队列。
- RocketMQ:
- 使用 CommitLog 存储消息,所有消息按顺序追加到日志文件中。
- 使用 ConsumeQueue 和 IndexFile 建立消息索引,支持高效查询。
- 支持消息压缩和定时清理。
什么是日志存储(Log Storage)?
在消息队列(MQ)中,日志存储(Log Storage) 是一种将消息以追加(Append-Only)的方式写入日志文件的技术。
这种存储方式因其高性能、高可靠性和简单性,被广泛应用于现代消息队列系统(如 Kafka、RocketMQ 等)。
MQ 中日志存储的核心特点
-
追加写入(Append-Only)
- 消息只能以追加的方式写入日志文件,
不能修改或删除已写入的消息。 - 这种设计简化了写入操作,避免了随机写入带来的性能开销。
- 消息只能以追加的方式写入日志文件,
-
顺序写入
- 消息按顺序写入磁盘,充分利用磁盘的顺序写入性能,远高于随机写入。
-
不可变性(Immutable)
- 一旦消息写入日志,就不能被修改或删除,只能通过追加新消息来更新状态。
-
高效检索
- 通过偏移量(Offset)、时间戳或索引等机制,可以快速定位和检索日志中的消息。
-
持久化
- 消息写入日志后会被持久化到磁盘,确保消息不会因系统崩溃或重启而丢失。
MQ 中日志存储的工作原理
-
消息写入
- 生产者发送的消息以追加的方式写入日志文件的末尾。
- 每条消息通常包含一个唯一的偏移量(Offset),用于标识消息的位置。
-
消息索引
- 为了提高检索效率,日志存储通常会建立索引。
- 例如,Kafka 使用偏移量(Offset)作为索引,RocketMQ 使用 ConsumeQueue 和 IndexFile。
-
消息清理
- 为了防止日志文件无限增长,日志存储会定期清理旧消息。
- 清理策略可以基于时间、大小或消息状态(如 Kafka 的 Log Compaction)。
-
消息读取
- 消费者通过偏移量或索引定位日志中的特定消息,并按顺序读取。
日志存储的实现
1. Kafka 的日志存储
- 存储结构:
- Kafka 将消息存储在分区(Partition)中,每个分区对应一个
日志文件(Log Segment)。 - 消息按偏移量(Offset)顺序写入日志文件。
- Kafka 将消息存储在分区(Partition)中,每个分区对应一个
- 索引机制:
- Kafka 为每个日志文件建立索引文件(Index File),通过偏移量快速定位消息。
- 清理策略:
- 基于时间或大小清理旧日志文件。
- 支持 Log Compaction,保留每个键(Key)的最新消息。
2. RocketMQ 的日志存储
- 存储结构:
- RocketMQ 使用
CommitLog存储消息,所有消息按顺序追加到日志文件中。 - 使用 ConsumeQueue 和 IndexFile 建立消息索引。
- RocketMQ 使用
- 索引机制:
- ConsumeQueue 存储消息的偏移量和大小,IndexFile 存储消息的时间戳和偏移量。
- 清理策略:
- 基于时间或大小清理旧消息。
消息队列如何将消息分发给消费者?
1. 消息分发的核心机制
1.1 消息拉取(Pull)
- 原理:消费者主动从消息队列中拉取消息。
- 实现:
- 消费者定期向消息队列发送请求,获取新消息。
- 例如,Kafka 和 RocketMQ 主要采用拉取模式。
- 优点:消费者可以控制拉取速度,避免过载。
- 缺点:如果拉取频率过高,可能增加系统开销;如果拉取频率过低,可能导致消息处理延迟。
1.2 消息推送(Push)
- 原理:消息队列主动将消息推送给消费者。
- 实现:
- 消息队列在收到新消息后,立即将其推送给消费者。
- 例如,RabbitMQ 和 ActiveMQ 主要采用推送模式。
- 优点:消息可以实时推送给消费者,减少延迟。
- 缺点:如果消费者处理能力不足,可能导致消息积压或消费者过载。
2. 消息分发的策略
2.1 轮询分发(Round-Robin)
- 原理:消息队列将消息依次分发给每个消费者。
- 适用场景:消费者处理能力相近,消息无优先级要求。
- 优点:简单公平,负载均衡。
- 缺点:无法根据消费者处理能力动态调整。
2.2 加权分发(Weighted Distribution)
- 原理:根据消费者的处理能力分配不同的权重,消息队列按权重分发消息。
- 适用场景:消费者处理能力不同。
- 优点:可以根据消费者能力动态调整负载。
- 缺点:需要维护消费者的权重信息。
2.3 广播分发(Broadcast)
- 原理:消息队列将消息分发给所有消费者。
- 适用场景:需要多个消费者同时处理同一条消息。
- 优点:适用于广播场景。
- 缺点:可能导致重复处理,增加系统负载。
3. 消息确认机制
为了确保消息被成功处理,消息队列通常支持消息确认机制:
- 自动确认:消费者收到消息后,消息队列自动认为消息已处理。
- 手动确认:消费者在处理完消息后,手动向消息队列发送确认信号(ACK)。
- 重试机制:如果消费者未发送确认信号,消息队列会重新分发消息。
4. 消息分发的实现示例
4.1 Kafka
- 分发模式:拉取模式。
- 分发策略:基于分区(Partition)的分发,每个分区只能由一个消费者消费。
- 确认机制:消费者定期提交偏移量(Offset),表示已处理的消息。
4.2 RabbitMQ
- 分发模式:推送模式。
- 分发策略:轮询分发或基于标签的分发。
- 确认机制:手动确认(ACK)或自动确认。
4.3 RocketMQ
- 分发模式:拉取模式。
- 分发策略:基于队列的分发,支持负载均衡。
- 确认机制:消费者定期提交消费进度。
5. 消息分发的优化
-
负载均衡
- 根据消费者的处理能力动态调整消息分发策略,避免某些消费者过载。
-
批量处理
- 消费者可以批量拉取或处理消息,减少网络开销和提高处理效率。
-
流量控制
- 通过限流或背压机制,控制消息分发的速度,避免消费者过载。
-
故障处理
- 如果消费者故障,消息队列可以将消息重新分发给其他消费者。
消息队列的集群架构是怎样的?
RocketMQ:
https://rocketmq.io/course/baseLearn/rocketmq_learning-framework/
RabbitMQ

- Channel: 信道,通信使用
- Exchange 交换机,用于接收生产者发送的消息,并路由到队列
官方文档:
https://www.rabbitmq.com/docs
安装启动:
docker run -itd --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:4.0-management
可视化管理界面:
http://localhost:15672/#/
初始用户名/密码: guest/guest
1. 简单模式
一个生产者、一个对列、一个消费者。Exchange 不参与。

生产者:
package mainimport ("context""fmt""log""time"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}func main() {// 1、建立连接, amqp 协议conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()// 2、创建 Channelch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()// 3、简单模式中需要声明队列(不需要 Exchange)q, err := ch.QueueDeclare("hello", // name 队列名称false, // durable 是否持久化false, // delete when unused 是否自动删除队列,若是,则当最后一个消费者取消订阅时,自动删除队列false, // exclusive 是否独享队列(只能有一个连接)false, // no-wait false:等待服务器确认nil, // arguments 额外参数)failOnError(err, "Failed to declare a queue")ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)defer cancel()body := "Hello World !"// 4、通过 Channel 发送消息err = ch.PublishWithContext(ctx,"", // exchange :简单模式下设置为默认交换器q.Name, // routing key :队列名称false, // mandatory :false 表示如果交换机无法找到符合条件的队列,则丢弃消息false, // immediate :false 表示消息不需要立即被消费者接收amqp.Publishing{ // 消息的配置ContentType: "text/plain",Body: []byte(body), // 消息})failOnError(err, "Failed to publish a message")log.Printf(" [x] Sent %s\n", body)
}
消费者:
package mainimport ("log"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}func main() {// 1、建立连接conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()// 2、配置信道ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()// 3、配置队列(需要和生产者保持一致)q, err := ch.QueueDeclare("hello", // namefalse, // durablefalse, // delete when unusedfalse, // exclusivefalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare a queue")// 4、消费消息msgs, err := ch.Consume(q.Name, // queue 队列名称"", // consumer 消费者标签,用于区分不同的消费者true, // auto-ack 是否自动确认,true 自动回复;false 手动回复,建议为 false,可控性更强false, // exclusive 是否独占,表示当前消息队列只能给一个消费者使用false, // no-local true 表示生产者和消费者不能是同一个 connectfalse, // no-wait 是否阻塞,ture 阻塞,表示创建交换器的请求发送后,阻塞等待 MQ server 响应。false 则不会阻塞等待响应nil, // args)failOnError(err, "Failed to register a consumer")var forever chan struct{}// 输出信息go func() {for d := range msgs {log.Printf("Received a message: %s", d.Body)// d.Ack(false) // 手动确认// false:表示只确认当前这一条消息。服务器会将这一条消息从队列中移除。// true:表示批量确认消息。会确认从上次确认之后到当前消息为止的所有消息,服务器会将这些消息都从队列中移除。}}()log.Printf(" [*] Waiting for messages. To exit press CTRL+C")<-forever // 阻塞监听
}
2. 工作队列模式(Work Queues)
- 结构:也称为任务队列,有一个生产者、一个队列和多个消费者。多个消费者竞争从队列中获取消息进行处理,以实现任务的并行处理。
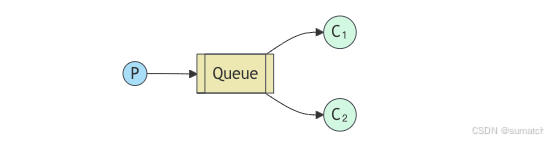
- 应用场景:适用于需要处理大量耗时任务的场景,例如图片处理、数据清洗等。将任务发送到队列,多个消费者同时从队列中获取任务进行处理,提高处理效率。
- 关键特性:默认情况下,RabbitMQ 会采用轮询的方式将消息分发给消费者。也可以通过设置
prefetch count来实现公平分发,确保每个消费者在处理完当前消息后再获取下一条消息。
生产者:
package mainimport ("context""log""os""strings""time"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()q, err := ch.QueueDeclare("task_queue", // nametrue, // durablefalse, // delete when unusedfalse, // exclusivefalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare a queue")ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)defer cancel()body := bodyFrom(os.Args)err = ch.PublishWithContext(ctx,"", // exchangeq.Name, // routing keyfalse, // mandatoryfalse,amqp.Publishing{DeliveryMode: amqp.Persistent,// DeliveryMode 用于指定消息的投递模式。// amqp.Persistent 代表消息采用持久化投递模式。ContentType: "text/plain",Body: []byte(body),})failOnError(err, "Failed to publish a message")log.Printf(" [x] Sent %s", body)
}func bodyFrom(args []string) string {var s stringif (len(args) < 2) || os.Args[1] == "" {s = "hello"} else {s = strings.Join(args[1:], " ")}return s
}
消费者:
package mainimport ("bytes""log""time"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}// 启动 2 个消费者func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()q, err := ch.QueueDeclare("task_queue", // nametrue, // durablefalse, // delete when unusedfalse, // exclusivefalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare a queue")// ch.Qos 方法用于设置信道(Channel)的 QoS(Quality of Service,服务质量)属性err = ch.Qos(1, // prefetch count(预取计数) 在消费者确认一条消息之前,RabbitMQ 最多会向该消费者发送的未确认消息的数量0, // prefetch size(预取大小) 设置为 0 表示不限制消息的总大小false, // global 是否将 QoS 设置应用于整个连接(全局)还是仅应用于当前信道)failOnError(err, "Failed to set QoS")msgs, err := ch.Consume(q.Name, // queue"", // consumerfalse, // auto-ackfalse, // exclusivefalse, // no-localfalse, // no-waitnil, // args)failOnError(err, "Failed to register a consumer")var forever chan struct{}go func() {for d := range msgs {log.Printf("Received a message: %s", d.Body)dotCount := bytes.Count(d.Body, []byte("."))t := time.Duration(dotCount)time.Sleep(t * time.Second)log.Printf("Done")d.Ack(false)}}()log.Printf(" [*] Waiting for messages. To exit press CTRL+C")<-forever}
3. 发布 - 订阅模式(Publish/Subscribe)
-
结构:包含一个生产者、一个交换机(Exchange)、多个队列和多个消费者。生产者将消息发送到交换机,交换机将消息广播到所有绑定到它的队列,每个队列对应一个或多个消费者。
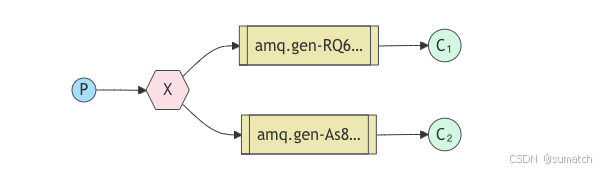
-
应用场景:适用于系统中需要将一条消息同时通知多个服务或模块的场景,例如系统的配置更新通知等。
-
示例代码(Go 语言)
// 生产者
package mainimport ("log""github.com/streadway/amqp"
)func failOnError(err error, msg string) {if err != nil {log.Fatalf("%s: %s", msg, err)}
}func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()err = ch.ExchangeDeclare("logs", // name"fanout", // typetrue, // durablefalse, // auto-deletedfalse, // internalfalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare an exchange")body := "Hello World!"err = ch.Publish("logs", // exchange"", // routing keyfalse, // mandatoryfalse, // immediateamqp.Publishing{ContentType: "text/plain",Body: []byte(body),})failOnError(err, "Failed to publish a message")log.Printf(" [x] Sent %s", body)
}// 消费者
package mainimport ("log""github.com/streadway/amqp"
)func failOnError(err error, msg string) {if err != nil {log.Fatalf("%s: %s", msg, err)}
}func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()err = ch.ExchangeDeclare("logs", // name"fanout", // typetrue, // durablefalse, // auto-deletedfalse, // internalfalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare an exchange")q, err := ch.QueueDeclare("", // namefalse, // durablefalse, // delete when unusedtrue, // exclusivefalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare a queue")err = ch.QueueBind(q.Name, // queue name"", // routing key"logs", // exchangefalse,nil)failOnError(err, "Failed to bind a queue")msgs, err := ch.Consume(q.Name, // queue"", // consumertrue, // auto-ackfalse, // exclusivefalse, // no-localfalse, // no-waitnil, // args)failOnError(err, "Failed to register a consumer")forever := make(chan bool)go func() {for d := range msgs {log.Printf(" [x] %s", d.Body)}}()log.Printf(" [*] Waiting for messages. To exit press CTRL+C")<-forever
}
4. 路由模式(Routing)
-
结构:与发布 - 订阅模式类似,但交换机类型为
direct。生产者将消息发送到交换机时需要指定路由键(routing key),交换机根据路由键将消息路由到绑定了相应路由键的队列。
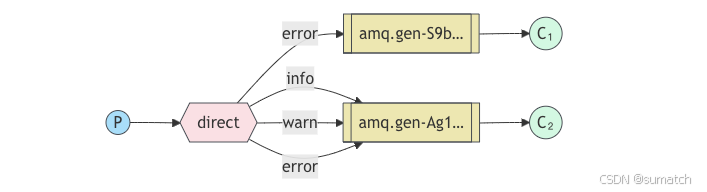
-
应用场景:适用于根据不同的条件将消息发送到不同队列的场景,例如根据日志级别(如
info、error)将日志消息发送到不同的队列进行处理。
生产者:
package mainimport ("context""log""os""strings""time"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()err = ch.ExchangeDeclare("logs_direct", // name"direct", // type 直连模式,根据路由键(routing key)绑定消息true, // durablefalse, // auto-deletedfalse, // internalfalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare an exchange")ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)defer cancel()body := bodyFrom(os.Args)err = ch.PublishWithContext(ctx,"logs_direct", // exchangeseverityFrom(os.Args), // routing key 路由键false, // mandatoryfalse, // immediateamqp.Publishing{ContentType: "text/plain",Body: []byte(body),})failOnError(err, "Failed to publish a message")log.Printf(" [x] Sent %s", body)
}func bodyFrom(args []string) string {var s stringif (len(args) < 3) || os.Args[2] == "" {s = "hello"} else {s = strings.Join(args[2:], " ")}return s
}func severityFrom(args []string) string {var s stringif (len(args) < 2) || os.Args[1] == "" {s = "info"} else {s = os.Args[1]}return s
}// go run emit_log_direct.go error "Run. Run. Or it will explode."
消费者:
package mainimport ("log""os"amqp "github.com/rabbitmq/amqp091-go"
)func failOnError(err error, msg string) {if err != nil {log.Panicf("%s: %s", msg, err)}
}func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()err = ch.ExchangeDeclare("logs_direct", // name"direct", // typetrue, // durablefalse, // auto-deletedfalse, // internalfalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare an exchange")q, err := ch.QueueDeclare("", // namefalse, // durablefalse, // delete when unusedtrue, // exclusivefalse, // no-waitnil, // arguments)failOnError(err, "Failed to declare a queue")if len(os.Args) < 2 {log.Printf("Usage: %s [info] [warning] [error]", os.Args[0])os.Exit(0)}for _, s := range os.Args[1:] {log.Printf("Binding queue %s to exchange %s with routing key %s", q.Name, "logs_direct", s)err = ch.QueueBind(q.Name, // queue names, // routing key"logs_direct", // exchangefalse,nil)failOnError(err, "Failed to bind a queue")}msgs, err := ch.Consume(q.Name, // queue"", // consumertrue, // auto ackfalse, // exclusivefalse, // no localfalse, // no waitnil, // args)failOnError(err, "Failed to register a consumer")var forever chan struct{}go func() {for d := range msgs {log.Printf(" [x] %s", d.Body)}}()log.Printf(" [*] Waiting for logs. To exit press CTRL+C")<-forever
}// go run receive_logs_direct.go info
// go run receive_logs_direct.go warning error
5. 主题模式(Topics)
-
结构:交换机类型为
topic,路由键采用*.#或*.*等形式进行匹配。生产者发送消息时指定路由键,交换机根据路由键的匹配规则将消息路由到绑定了相应匹配规则的队列。
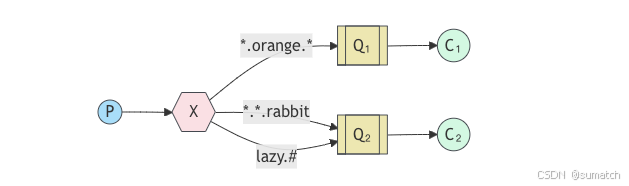
-
创建了三个 topic:Q1 绑定
*.orange.*,Q2 绑定*.*.rabbit和lazy.#。 -
应用场景:适用于根据消息的主题进行分类和分发的场景,例如新闻系统中根据不同的新闻类别(如
sports.news、business.news)将新闻消息发送到不同的队列。 -
在 RabbitMQ 的主题模式(Topic Exchange)里,路由键规则是实现消息灵活路由的关键,它允许根据消息的主题将消息分发到不同的队列。下面为你详细介绍主题模式中路由键的规则和使用方式。
主题模式通配符规则
*(星号)
*用于匹配一个单词。例如,*.news可以匹配sports.news、business.news等,但不能匹配news或者sports.business.news。也就是说,*只能替代一个完整的单词,不能匹配多个单词或者空字符串。
#(井号)
#用于匹配零个或多个单词。例如,sports.#可以匹配sports、sports.news、sports.business.news等。#可以匹配任意数量的单词,包括零个单词。
package mainimport ("log""github.com/streadway/amqp"
)func failOnError(err error, msg string) {if err != nil {log.Fatalf("%s: %s", msg, err)}
}func main() {// 连接到 RabbitMQ 服务器conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()// 打开一个通道ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()// 声明一个主题交换器err = ch.ExchangeDeclare("topic_logs", // 交换器名称"topic", // 交换器类型true, // 是否持久化false, // 是否自动删除false, // 是否为内部交换器false, // 是否不等待服务器响应nil, // 额外参数)failOnError(err, "Failed to declare an exchange")// 声明队列 Q1 并绑定到路由键 *.newsq1, err := ch.QueueDeclare("Q1",false,false,false,false,nil,)failOnError(err, "Failed to declare queue Q1")err = ch.QueueBind(q1.Name, // 队列名称"*.news", // 路由键"topic_logs", // 交换器名称false,nil,)failOnError(err, "Failed to bind queue Q1 to the exchange")// 声明队列 Q2 并绑定到路由键 sports.#q2, err := ch.QueueDeclare("Q2",false,false,false,false,nil,)failOnError(err, "Failed to declare queue Q2")err = ch.QueueBind(q2.Name, // 队列名称"sports.#", // 路由键"topic_logs", // 交换器名称false,nil,)failOnError(err, "Failed to bind queue Q2 to the exchange")// 发送消息,路由键为 sports.newsbody := "This is a sports news message"err = ch.Publish("topic_logs", // 交换器名称"sports.news", // 路由键false, // mandatoryfalse, // immediateamqp.Publishing{ContentType: "text/plain",Body: []byte(body),},)failOnError(err, "Failed to publish a message")log.Printf(" [x] Sent %s with routing key 'sports.news'", body)
}
RabbitMQ 交换器的类型有哪些?
在 RabbitMQ 中,交换器(Exchange)是消息路由的核心组件,它接收生产者发送的消息,并根据不同的规则将消息路由到一个或多个队列。RabbitMQ 提供了多种类型的交换器,每种类型都有其独特的路由策略,以下是常见的几种交换器类型:
1. 扇形交换器(Fanout Exchange)
- 路由规则:扇形交换器会忽略消息的路由键(routing key),将接收到的消息广播到所有绑定到它的队列中。也就是说,只要有队列绑定到该交换器,那么生产者发送到这个交换器的每一条消息都会被复制并发送到这些队列。
- 应用场景:适用于需要将一条消息同时通知多个服务或模块的场景,例如系统的日志通知、配置更新通知等。在日志系统中,可能有多个不同的日志存储服务(如文件存储、数据库存储等),可以将这些服务对应的队列绑定到一个扇形交换器上,当有新的日志消息产生时,交换器会将消息广播到所有绑定的队列,各个服务从自己的队列中获取消息进行处理。
- 示例代码(Go 语言)
// 声明扇形交换器
err = ch.ExchangeDeclare("logs", // 交换器名称"fanout", // 交换器类型true, // 是否持久化false, // 是否自动删除false, // 是否为内部交换器false, // 是否不等待服务器响应nil, // 额外参数
)
2. 直连交换器(Direct Exchange)
- 路由规则:直连交换器根据消息的路由键和队列绑定的路由键进行精确匹配。当生产者发送消息时指定了路由键,直连交换器会将消息路由到绑定了相同路由键的队列。如果有多个队列绑定了相同的路由键,那么消息会被发送到所有这些队列。
- 应用场景:适用于根据不同的条件将消息发送到不同队列的场景,例如根据日志级别(如
info、error)将日志消息发送到不同的队列进行处理。可以将记录info级别的日志队列绑定到路由键为"info"的直连交换器上,将记录error级别的日志队列绑定到路由键为"error"的直连交换器上,这样生产者就可以根据日志级别选择不同的路由键发送消息。 - 示例代码(Go 语言)
// 声明直连交换器
err = ch.ExchangeDeclare("direct_logs", // 交换器名称"direct", // 交换器类型true, // 是否持久化false, // 是否自动删除false, // 是否为内部交换器false, // 是否不等待服务器响应nil, // 额外参数
)// 绑定队列到直连交换器
err = ch.QueueBind(q.Name, // 队列名称"info", // 路由键"direct_logs", // 交换器名称false,nil,
)
3. 主题交换器(Topic Exchange)
- 路由规则:主题交换器的路由键采用
*.#或*.*等形式进行匹配,其中*表示匹配一个单词,#表示匹配零个或多个单词。生产者发送消息时指定路由键,交换器根据路由键的匹配规则将消息路由到绑定了相应匹配规则的队列。 - 应用场景:适用于根据消息的主题进行分类和分发的场景,例如新闻系统中根据不同的新闻类别(如
sports.news、business.news)将新闻消息发送到不同的队列。可以将关注体育新闻的队列绑定到路由键为sports.#的主题交换器上,将关注商业新闻的队列绑定到路由键为business.#的主题交换器上,这样当有新的新闻消息产生时,交换器会根据消息的路由键将其路由到相应的队列。 - 示例代码(Go 语言)
// 声明主题交换器
err = ch.ExchangeDeclare("topic_logs", // 交换器名称"topic", // 交换器类型true, // 是否持久化false, // 是否自动删除false, // 是否为内部交换器false, // 是否不等待服务器响应nil, // 额外参数
)// 绑定队列到主题交换器
err = ch.QueueBind(q.Name, // 队列名称"sports.#", // 路由键"topic_logs", // 交换器名称false,nil,
)
4. 头交换器(Headers Exchange)
- 路由规则:头交换器不依赖于路由键来进行消息路由,而是根据消息的头部(headers)属性和队列绑定的头部属性进行匹配。在绑定队列时,可以指定一些头部属性和对应的匹配规则(如相等、存在等),当生产者发送消息时,交换器会根据消息的头部属性和绑定的规则来决定将消息路由到哪些队列。
- 应用场景:适用于根据消息的元数据(如消息的类型、来源等)进行消息路由的场景,当消息的路由规则不仅仅基于路由键,还需要考虑消息的其他属性时,可以使用头交换器。
- 示例代码(Go 语言)
// 声明头交换器
err = ch.ExchangeDeclare("headers_logs", // 交换器名称"headers", // 交换器类型true, // 是否持久化false, // 是否自动删除false, // 是否为内部交换器false, // 是否不等待服务器响应nil, // 额外参数
)// 绑定队列到头交换器
args := amqp.Table{"x-match": "all", // 匹配规则,all 表示所有头部属性都要匹配"type": "info",
}
err = ch.QueueBind(q.Name, // 队列名称"", // 路由键,头交换器忽略路由键"headers_logs", // 交换器名称false,args,
)
相关文章:

MQ 笔记
什么是消息队列? 消息队列(Message Queue, MQ)是一种用于在分布式系统中传递消息的中间件技术。 它允许应用程序通过发送和接收消息进行异步通信。 消息队列的核心思想是解耦生产者和消费者,生产者将消息发送到队列中ÿ…...

leetcode第216题组合总和Ⅲ
原题出于leetcode第216题https://leetcode.cn/problems/combination-sum-iii/description/题目为: 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9 每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表…...

【零基础C语言】第四节 数组
【零基础C语言系列】 【零基础C语言】第一节 C语言概述【数制进制码制】-CSDN博客 【零基础C语言】第二节 数据类型、运算符、表达式-CSDN博客 【零基础C语言】第三节 控制结构-CSDN博客 一、一维数组...

20250225-代码笔记03-class CVRPModel AND other class
文章目录 前言一、class CVRPModel(nn.Module):__init__(self, **model_params)函数功能函数代码 二、class CVRPModel(nn.Module):pre_forward(self, reset_state)函数功能函数代码 三、class CVRPModel(nn.Module):forward(self, state)函数功能函数代码 四、def _get_encodi…...

京准电钟快讯:NTP时钟同步服务在智造行业应用
京准电钟快讯:NTP时钟同步服务在智造行业应用 京准电钟快讯:NTP时钟同步服务在智造行业应用 一、NTP技术概述 基本原理 NTP(Network Time Protocol)是一种用于同步计算机系统时间的网络协议,通过分层时钟源ÿ…...

【Qt】详细介绍如何在Visual Studio Code中编译、运行Qt项目
Visual Studio Code一只用的顺手,写Qt的时候也能用VS Code开发就方便多了。 理论上也不算困难,毕竟Qt项目其实就是CMake(QMake的情况这里就暂不考虑了)项目,VS Code在编译、运行CMake项目还是比较成熟的。 这里笔者打…...

jsherp importItemExcel接口存在SQL注入
一、漏洞简介 很多人说管伊佳ERP(原名:华夏ERP,英文名:jshERP)是目前人气领先的国产ERP系统虽然目前只有进销存财务生产的功能,但后面将会推出ERP的全部功能,有兴趣请帮点一下 二、漏洞影响 …...

Node.js, Bun, Deno 比较概述
以下是 Node.js、Bun 和 Deno 的对比分析 概览 对比维度Node.jsDenoBun首次发布200920202022创始人Ryan DahlRyan Dahl(Node.js 原作者)Jarred Sumner运行时引擎V8(Chrome)V8(Chrome)JavaScriptCore&#…...

大白话跨域问题怎么破,解决方法有啥?
大白话跨域问题怎么破,解决方法有啥? 啥是跨域问题 咱先说说啥是跨域。你可以把每个网站想象成一个独立的小房子,每个房子都有自己的地址(也就是域名)。正常情况下,一个房子里的东西只能在这个房子里用&a…...

DeepSeek R1满血+火山引擎详细教程
DeepSeek R1满血火山引擎详细教程 一、安装Cherry Studio。 Cherry Studio AI 是一款强大的多模型 AI 助手,支持 iOS、macOS 和 Windows 平台。可以快速切换多个先进的 LLM 模型,提升工作学习效率。下载地址 https://cherry-ai.com/ 认准官网,无强制注册。 这…...

Pytorch中的ebmedding到底怎么理解?
在 PyTorch 中,nn.Embedding 是一个用于处理离散符号映射到连续向量空间的模块。它通常用于自然语言处理(NLP)任务(如词嵌入)、处理分类特征,或任何需要将离散索引转换为密集向量的场景。 核心理解 功能&am…...

【JAVA面试题】什么是面向对象?谈谈你对面向对象的理解。
【JAVA面试题】什么是面向对象?谈谈你对面向对象的理解 在 Java 面试中,面向对象 是一个高频考点。它不仅是一种编程思想,更是现代软件开发的核心方法论。本文将从 面向对象的概念、与面向过程的对比、以及 面向对象的三大特性(封…...

【C】链式二叉树算法题1 -- 单值二叉树
leetcode链接https://leetcode.cn/problems/univalued-binary-tree/description/ 1 题目描述 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。只有给定的树是单值二叉树时,才返回 true;否则返回 false。 示例 1࿱…...

基于单片机的GPS定位系统设计
1 系统硬件 1.1单片机模块 单片机的种类和型号可以说是有成百上千种,很多大的公司和企业都生产开发自己的单片机芯片,并且广泛应用于各种产品。Intel、 philips、 摩托罗拉、凌阳、宏晶等等种类繁多。大体上可以分为51系列单片机和非51系列单片机。 其…...

[React]Render Props、自定义Hooks和Context API优化详解
关于React中的Render Props、自定义Hooks和Context API优化的详解。我需要根据我搜索到的资料来综合回答这三个部分。首先,我需要分别理解每个概念的定义、用途以及优化方法。 首先看Render Props。根据Render Props是一种通过传递函数作为prop来共享组件间逻辑的技…...

关于大型语言模型的结构修剪
本文介绍了一种名为 **LLM-Pruner** 的方法,用于对大型语言模型(LLMs)进行结构化剪枝,以减少模型大小和计算需求,同时保留其多任务解决和语言生成能力。LLM-Pruner 通过依赖检测和重要性估计实现高效剪枝,并…...

【语法】C++中string类中的两个问题及解答
贴主在学习string类时遇到过两个困扰我的问题,今天拿出来给大家分享一下我是如何解决的 一、扩容时capacity的增长问题 在string的capacity()接口中,调用的是这个string对象的容量(可以存多少个有效字符),而size()是调用的string对象现在有…...
 命令提示符格式修改(PS1))
Linux(centOS) 命令提示符格式修改(PS1)
1. 命令提示符的组成 命令提示符(PS1)通常由以下部分组成: 部分示例说明[ 和 ][...]提示符的开头和结尾,用于视觉分隔。用户名root 或 tianjiajie当前登录的用户。root 是超级用户,普通用户可能是其他名称。分隔用户…...

QwenVL 2.5-本地安装编译布署全教程
开篇 DeepSeek开源后我国又开源了一个震撼大模型,QwenVL2.5,这是一个多模态的模形,它可以认图、识图、更能作图,还能读懂video。 Qwen2.5-VL 的主要特点如下所示: 感知更丰富的世界:Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表…...

Hutool - JWT:轻松玩转 JSON Web Token
各位开发者朋友们,在现代的前后端分离开发模式里,身份验证和授权可是至关重要的环节。JSON Web Token(JWT)作为一种轻量级的身份验证和授权机制,在很多项目中都得到了广泛应用。它可以在客户端和服务器之间安全地传输信…...

2024年第十五届蓝桥杯大赛软件赛省赛Python大学A组真题解析《更新中》
文章目录 试题A: 拼正方形(本题总分:5 分)解析答案试题B: 召唤数学精灵(本题总分:5 分)解析答案试题C: 数字诗意解析答案试题D:回文数组试题A: 拼正方形(本题总分:5 分) 【问题描述】 小蓝正在玩拼图游戏,他有7385137888721 个2 2 的方块和10470245 个1 1 的方块,他需…...

【2025年2月28日稳定版】小米路由器4C刷机Immortalwrt 23.05.4系统搭载mentohust 0.3.1插件全记录
小米路由器4C刷机Immortalwrt系统搭载mentohust插件全记录 首先将路由器按住后面的reset,用一个针插进去然后等待5s左右,松开,即可重置路由器。 然后要用物理网线物理连接路由器Lan口和电脑,并将路由器WAN口连接至网口。确保电脑…...

W3C标准和ES规范之一文通
W3C标准和ES规范之一文通 以下是关于W3C标准和ES规范的透彻解析,通过结构化对比和生活化类比帮助理解和记忆: 一、核心概念对比(总览) 维度W3C标准ES规范(ECMAScript)定位Web技术的建筑蓝图JavaScript的语…...

Linux:应用层协议
协议是一种 "约定". socket api的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢? 无论我们采用什么方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的. 这种…...
深度学习五大模型:CNN、Transformer、BERT、RNN、GAN详细解析
# 深度学习五虎将:当CNN遇见Transformer的奇幻漂流 ## 序章:AI江湖的兵器谱排行 2012年,多伦多大学的厨房里,Hinton的学生们用GPU煎了个"AlexNet"荷包蛋,从此开启了深度学习的热兵器时代。如今五大模型各显…...

微服务组件详解——sentinel
1.启动sentinel: 下载jar sentinel-dashboard-1.8.0.jar 使用以下命令直接运行 jar 包(JDK 版本必须≥ 1.8): java -Dserver.port9999 -jar D:\sentinel-dashboard-1.8.0.jar 控制台访问地址:http://localhost:9999…...

波导阵列天线 学习笔记11双极化全金属垂直公共馈电平板波导槽阵列天线
摘要: 本communicaition提出了一种双极化全金属垂直公共馈电平板波导槽阵列天线。最初提出了一种公共馈电的单层槽平板波导来实现双极化阵列。此设计消除了传统背腔公共馈电的复杂腔体边缘的必要性,提供了一种更简单的天线结构。在2x2子阵列种发展了宽十…...

swift 开发效率提升工具
安装github copliot for xcode github/CopilotForXcode brew install --cask github-copilot-for-xcode安装swiftformat for xcode brew install swiftformatXcode Swift File代码格式化-SwiftFormat...

3-5 WPS JS宏 工作表的移动与复制学习笔记
************************************************************************************************************** 点击进入 -我要自学网-国内领先的专业视频教程学习网站 *******************************************************************************************…...
)
Centos7部署k8s(单master节点安装)
单master节点部署k8s集群(Centos) 一、安装前准备 1、修改主机名 按照资源准备修改即可 # master01 hostnamectl set-hostname master01 ; bash # node1 hostnamectl set-hostname node1 ; bash # node2 hostnamectl set-hostname node2 ; bash2、修改hosts文件 以下命令所…...

Tomcat
1.Tomcat是什么? Tomcat 是一个开源的、轻量级的 Servlet 容器,也被称为 Web 服务器,由 Apache 软件基金会的 Jakarta 项目开发,在 Java Web 开发领域应用广泛。 1)Servlet 容器:Servlet 是 Java 语言编写…...
)
基于SpringBoot+Vue的电影订票及评论网站的设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

地基简识Spring MVC 组件
Spring MVC 是一个基于 MVC 设计模式的框架,其核心组件协同工作以处理 HTTP 请求并生成响应。以下是各组件的详细说明及其协作流程: 一、核心组件 DispatcherServlet(前端控制器) 作用:接收所有请求并协调其他…...

如何通过Python网络爬虫技术应对复杂的反爬机制?
要使用Python网络爬虫技术绕过复杂的反爬虫机制,可以采取以下几种策略: 设置User-Agent:通过设置不同的User-Agent,模拟正常用户的浏览器访问,避免被网站识别为爬虫。可以使用fake_useragent库来随机生成User-Agent。…...

深入浅出:Spring AI 集成 DeepSeek 构建智能应用
Spring AI 作为 Java 生态中备受瞩目的 AI 应用开发框架,凭借其简洁的 API 设计和强大的功能,为开发者提供了构建智能应用的强大工具。与此同时,DeepSeek 作为领先的 AI 模型服务提供商,在自然语言处理、计算机视觉等领域展现了卓…...

Node.js二:第一个Node.js应用
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 创建的时候我们需要用到VS code编写代码 我们先了解下 Node.js 应用是由哪几部分组成的: 1.引入 required 模块:我们可以使用 requi…...

【HarmonyOS Next】鸿蒙状态管理装饰器V1和V2混用方案
【HarmonyOS Next】鸿蒙状态管理装饰器V1和V2混用方案 一、V1和V2为什么需要混用 自从api7开始,一直到api10。V1的实际使用中,开发人员发现Observed和ObjectLink 监听实现多层级嵌套对象的更新的方案,太过于臃肿。当需要监听处理更新的多层…...
详解Kafka的数据结构与存储机制)
【技海登峰】Kafka漫谈系列(三)详解Kafka的数据结构与存储机制
【技海登峰】Kafka漫谈系列(三)详解Kafka的数据结构与存储机制 Kafka 使用消息日志(Log)机制来持久化保存数据,我们知道Kafka实际是以Partition分区为单位进行负载均衡和资源分配,每个Partition又由多个Replica副本组成,副本之间分布于不同的Broker上来保证高可用,因此…...

PyCharm接入本地部署DeepSeek 实现AI编程!【支持windows与linux】
今天尝试在pycharm上接入了本地部署的deepseek,实现了AI编程,体验还是很棒的。下面详细叙述整个安装过程。 本次搭建的框架组合是 DeepSeek-r1:1.5b/7b Pycharm专业版或者社区版 Proxy AI(CodeGPT) 首先了解不同版本的deepsee…...

腾讯云扩容记录
腾讯云扩容: sudo yum install -y cloud-utils-growpart 安装扩容工具 sudo file -s /dev/vda1 有数据 sudo LC_ALLen_US.UTF-8 growpart /dev/vda 1 sudo resize2fs /dev/vda1 df -Th 完毕 以下是对执行的命令的详细解释以及背后的原理: 1. 安装 cloud…...

计算机毕业设计Hadoop+Spark+DeepSeek-R1大模型音乐推荐系统 音乐数据分析 音乐可视化 音乐爬虫 知识图谱 大数据毕业设计
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

本地部署大语言模型-DeepSeek
DeepSeek 是国内顶尖 AI 团队「深度求索」开发的多模态大模型,具备数学推理、代码生成等深度能力,堪称"AI界的六边形战士"。 Hostease AMD 9950X/96G/3.84T NVMe/1G/5IP/RTX4090 GPU服务器提供多种计费模式。 DeepSeek-R1-32B配置 配置项 规…...

Windows逆向工程入门之MASM数据结构使用
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 第一章:MASM数据定义体系精要 1.1 基础数据类型全景 1.1.1 整型数据规范 1.1.2 浮点数据编码 1.2 复合数据结构 1.2.1 多维数组定义 1.2.2 复杂结构体 第二章…...

python 之协程笔记
协程 协程的本质是用户态线程,由程序自行控制切换时机,无需操作系统介入。与线程相比,协程的三大核心优势: 资源占用极低:一个协程仅需KB级内存,可轻松创建数万个切换效率惊人:上下文切换在用户…...

使用 REINFORCE 算法强化梯度策略
一、整体概述 此代码利用 REINFORCE 算法(一种基于策略梯度的强化学习算法)来解决 OpenAI Gym 中的 CartPole-v1 环境问题。CartPole-v1 环境的任务是控制一个小车,使连接在小车上的杆子保持平衡。代码通过构建一个神经网络作为策略网络&…...

【C++并发编程实战】第1章 你好,C++的并发世界!
文章目录 1. 何谓并发2. 为什么使用并发?3. 什么时候不使用并发4. C多线程历史5. 第一个并发程序 1. 何谓并发 最简单和最基本的并发,是指两个或更多独立的活动同时发生。计算机领域的并发指的是在单个系统里同时执行多个独立的任务,而非顺序的进行一些…...

【QT线程】子线程阻塞主线程的一次网络api请求案例
阻塞源码赏析 这是最近一次项目遇到的问题,原因是我觉得子线程里俩次请求间隔太短了,会引起服务器屏蔽我的api因此,我故作聪明加多了一个延时函数,欢迎各位鉴赏代码。 // 并行发起双请求 QNetworkRequest liveRequest(liveUrl);…...

DockerでOracle Database 23ai FreeをセットアップしMAX_STRING_SIZEを拡張する手順
DockerでOracle Database 23ai FreeをセットアップしMAX_STRING_SIZEを拡張する手順 はじめに環境準備ディレクトリ作成Dockerコンテナ起動 データベース設定変更コンテナ内でSQL*Plus起動PDB操作と文字列サイズ拡張設定検証 管理者ユーザー作成注意事項まとめ 中文版请访问这里…...
)
【计算机网络入门】初学计算机网络(五)
目录 1.编码&解码、调制&解调 2.常用编码方法 2.1 不归零编码(NRZ) 2.2 归零编码(RZ) 2.3 反向非归零编码(NRZI) 2.4 曼彻斯特编码 2.5 差分曼彻斯特编码 3. 各种编码的特点 4.调制 5.有线传输介质 5.1 双绞线 5.2 同轴电缆 5.3 光…...

unity学习60: 滑动条 和 滚动条 滚动区域
目录 1 滚动条 scrollbar 1.1 创建滚动条 1.2 scrollbar的子物体 1.3 scrollbar的属性 2 滚动视图 scroll View 2.1 创建1个scroll View 2.1.1 实际类比,网页就是一个 scroll view吧 2.2 子物体构成 2.3 核心component : Scroll Rect 3 可视区域 view p…...