RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter

标题:RAP:基于稀疏相关适配器的高效文本视频检索
原文链接:RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter - ACL Anthology
发表:ACL-2024(NLP领域CCF A类)
摘要
文本-视频检索(TVR)旨在将相关视频内容与自然语言查询进行匹配。目前,大多数先进的TVR方法都是基于大规模预训练的视觉语言模型(如CLIP)进行图像到视频的迁移学习。然而,对这些预训练模型进行全量微调以用于TVR会带来极高的计算成本。为此,我们提出使用稀疏相关适配器(RAP)进行高效的文本-视频检索,即通过少量参数化层对预训练模型进行微调。为适应文本-视频场景,我们赋予RAP两个不可或缺的特性:时间稀疏性和相关性。具体而言,我们提出了一个低秩调制模块,用于优化来自固定CLIP骨干网络的逐图像特征,该模块可突出视频特征中的显著帧,同时减轻时间冗余。此外,我们引入了一种异步自注意力机制,该机制首先选择响应性最高的视觉补丁,并通过可学习的时间和补丁偏移增强它们之间的相关性建模。在四个TVR数据集上进行的大量实验表明,与全量微调的方法以及其他参数高效微调方法相比,RAP取得了更优或相当的性能。
1 引言
文本-视频检索(TVR)(Gabeur等人,2020;Gorti等人,2022;He等人,2021a;Lei等人,2021;Luo等人,2022;Ma等人,2022;Wang等人,2022)是多模态研究领域中的一项关键任务,旨在根据文本查询在视频库中找到最相关的视频内容,反之亦然。随着大规模图像文本预训练的快速发展(Jia等人,2021;Radford等人,2021;Yu等人,2022;Yuan等人,2021),当前的研究重点在于如何将预训练的图像文本模型(如CLIP(Radford等人,2021))迁移到视频文本领域。然而,对视频模型进行全量微调在计算上成本高昂,并且可能存在过拟合的风险。

图1:时间稀疏性和时间相关性示意图
- 上方:时间稀疏性的示例。我们可视化了进行或未进行低秩分解的调制权重。
- 下方:时间相关性的示例。查询补丁用黄色十字标记,并绘制了其他帧内的相似性图。
为缓解这一困境,源自自然语言处理的参数高效微调(PEFT)(Houlsby等人,2019;Lester等人,2021;Zaken等人,2022;Hu等人,2021)在计算机视觉(Chen等人,2022b,a)和跨模态学习(Sung等人,2022)领域也引起了广泛的研究兴趣。最近,一些探索性工作(Zhang等人,2023;Jiang等人,2022;Diao等人,2024)也尝试将PEFT引入TVR。然而,这些方法只是简单地引入现有的PEFT算法(Houlsby等人,2019;You等人,2022;Karimi Mahabadi等人,2021),而没有考虑视频数据的固有特性。
为此,我们认为适用于VTR的理想PEFT方法应具备两个特性:
- 时间稀疏性:如图1所示,视频数据在时间维度上固有地包含大量冗余或重复信息。可视化的逐帧嵌入CLIP特征过于平滑,导致视频数据中的重要细节或细微差别丢失。相比之下,从预训练CLIP适配得到的视频特征应捕捉最具信息性的帧,从而实现更稀疏的表示。
- 时间相关性:理想的视频适配器应考虑连续帧之间的依赖关系,特别是在处理跨多帧发生的动作或事件时,因为这些特征可以封装随时间演变的上下文信息。例如在图1中,查询语句包含 “狗” 和 “鸟” 两个实体。给定查询补丁(在第3帧),我们可视化其他补丁内的相似性分布。在此示例中,普通的自注意力机制只能关注到狗的实例,而忽略了另一个鸟的实例。
在视频处理和分析领域,由于相邻帧之间的固有相关性,时间维度往往存在冗余。在处理大规模视频数据时,这种冗余会导致计算资源和存储的低效。因此,需要在减少时间冗余的同时提取有意义和信息丰富的特征。
为缓解上述问题,我们提出了一种基于稀疏相关适配器(简称为RAP)的高效文本-视频检索框架。我们提出的RAP不仅精简了可训练参数,提高了计算资源的利用效率,还对架构进行了优化,以巧妙地捕捉和建模视频数据细微的时间特征。
为实现时间稀疏性,我们提出了低秩调制(LoRM)模块,基于减少冗余和提取关键信息的原则对预训练的CLIP特征(Radford等人,2021)进行优化。这一设计基于一个简单的假设,即时间权重的变化处于低内在秩(Zhang和Tao,2012)。因此,我们引入了逐层低秩缩放参数和偏移参数,这些参数可视为方差和均值,用于调制CLIP特征。具体而言,缩放参数和偏移参数均由两个低秩可训练矩阵相乘得到。这些参数与输入无关,因此更加灵活。LoRM使我们能够校准视频特征,突出显著帧并减轻时间冗余。
对于时间相关性建模,我们用提出的异步自注意力(ASA)机制取代了普通的自注意力机制,该机制引入了视频帧之间的时间动态性以捕捉时间关系。由于预训练CLIP中的注意力计算被限制在每个帧特征内,由于视频帧的时间动态特性,将其应用于视频领域具有挑战性。以往的方法采用时间Transformer(Jiang等人,2022;Yang等人,2022;Zhang等人,2023)或3D卷积网络(Yao等人,2023;Liu等人,2023)来编码时间依赖关系。我们没有引入额外的模块,而是提出了一种异步自注意力机制,仅以参数化的方式对部分补丁令牌进行变形。首先,对于每一帧,我们通过一种无参数的文本条件选择机制筛选出语义重要的补丁。具体而言,我们计算补丁特征与相应句子之间的相似度,并选择响应最高的补丁。其次,当前帧内每个选定的补丁会动态变形,以关注其他帧中与时间相关的补丁。所提出的异步自注意力机制在细粒度的补丁级别上灵活地捕捉视频帧之间的相关性。
总体而言,这项工作的主要贡献如下:
- 我们提出了RAP,使预训练的CLIP能够高效地应用于TVR,不仅减少了可训练参数,还生成了具有时间稀疏性和相关性的视频特征。
- 为减轻时间冗余,我们引入了低秩调制模块,以线性方式校准逐帧表示。
- 我们提出了一种异步自注意力机制,能够在计算开销可忽略的情况下捕捉长距离依赖关系。
- 大量实验表明,我们的RAP与以前的PEFT方法和全量微调方法相比,性能相当甚至更优。
2 相关工作
2.1 文本-视频检索
TVR(Yu等人,2018;Croitoru等人,2021;Yang等人,2021;Wang等人,2021;Chen等人,2020;Wang和Shi,2023;Jin等人,2022,2023a,b;Liu等人,2022)是视频语言领域的一个基础研究课题,旨在根据给定的文本/视频查询检索相关的视频/文本。早期的工作(Yu等人,2018;Gabeur等人,2020)依赖于从固定的视频和文本编码器中预提取的特征。为便于端到端训练,ClipBERT(Lei等人,2021)提出了一种稀疏采样策略,用于高效的文本-视频训练。随着大规模图像文本预训练模型CLIP(Radford等人,2021)的巨大成功,大多数先进的TVR方法(Luo等人,2022;Ma等人,2022;Wang等人,2023;Hannan等人,2023;Jin等人,2022)专注于通过设计各种跨模态对齐策略,将强大的CLIP编码器迁移到视频文本领域。作为首次尝试,CLIP4Clip(Luo等人,2022)采用均值池化或Transformer来聚合视频特征 ` ·,并进行粗粒度(视频-句子级别)的对比对齐。与使用与文本无关的聚合方式不同,X-CLIP (Ma等人,2022)提出根据文本的注意力权重聚合视频表示,并在帧-词、视频-句子、视频-词和句子-帧级别进行多粒度对比学习。为实现更全面的对齐,UCOFIA(Wang等人,2023)将粗粒度和细粒度对齐统一起来,以捕捉文本和视频之间的高级和低级对应关系。
目前大多数TVR方法都遵循全量微调范式。然而,这种方案计算量巨大,并且可能存在过拟合风险。此外,还需要额外的时间建模模型来弥合图像和视频之间的差距。在本文中,我们提出了RAP,它对TVR进行参数高效微调,提供了一种计算效率更高且可能更稳健的方法。此外,我们RAP中的可训练参数还承担了时间建模的责任,从而无需外部时间模块。
2.2 参数高效迁移学习
PEFT(Houlsby等人,2019;Hu等人,2021;Lester等人,2021;He等人,2021b;Zaken等人,2022;Sung等人,2021)最初在自然语言处理领域被提出,旨在减少可训练参数的数量,同时保持与全量微调设置相当的性能。继承了自然语言处理领域的优点,计算机视觉中的PEFT(Jia等人,2022;Bahng等人,2022;Jie和Deng,2022;Sung等人,2022)也受到了广泛的研究关注。VPT(Jia等人,2022)遵循提示微调策略,在视觉Transformer上引入特定任务的可学习提示。为了更好地与视觉任务兼容,Convpass(Jie和Deng,2022)通过卷积操作重构令牌序列的空间结构,引入了卷积层的归纳偏差。VL - Adapter(Sung等人,2022)开创性地在多任务设置中对不同类型的PEFT技术进行了基准测试,包括Adapter(Houlsby等人,2019)、Hyperformer(Mahabadi等人,2021)和Compacter(Karimi Mahabadi等人,2021)。
也有一些工作(Yang等人,2022;Pan等人,2022;Lin等人,2022;Li和Wang,2023;Yao等人,2023;Jiang等人,2022;Zhang等人,2023;Lu等人,2023)专注于图像到视频的迁移学习。基于预训练的CLIP模型,这些方法要么以顺序(Zhang等人,2023;Jiang等人,2022)或并行(Yao等人,2023)的方式引入时间卷积(Pan等人,2022)或Transformer(Lu等人,2023)。然而,它们忽略了视频数据固有的时间结构,而我们的RAP指出了视频特征建模中的两个关键问题,并生成了更具代表性的视频特征。
3 方法
文本-视频检索旨在通过评估视频-句子对之间的相似度,根据文本/视频查询搜索和检索相关的视频/文本。我们提出的RAP致力于通过引入可忽略的参数开销,弥合固定的CLIP特征与动态视频场景之间的差距。
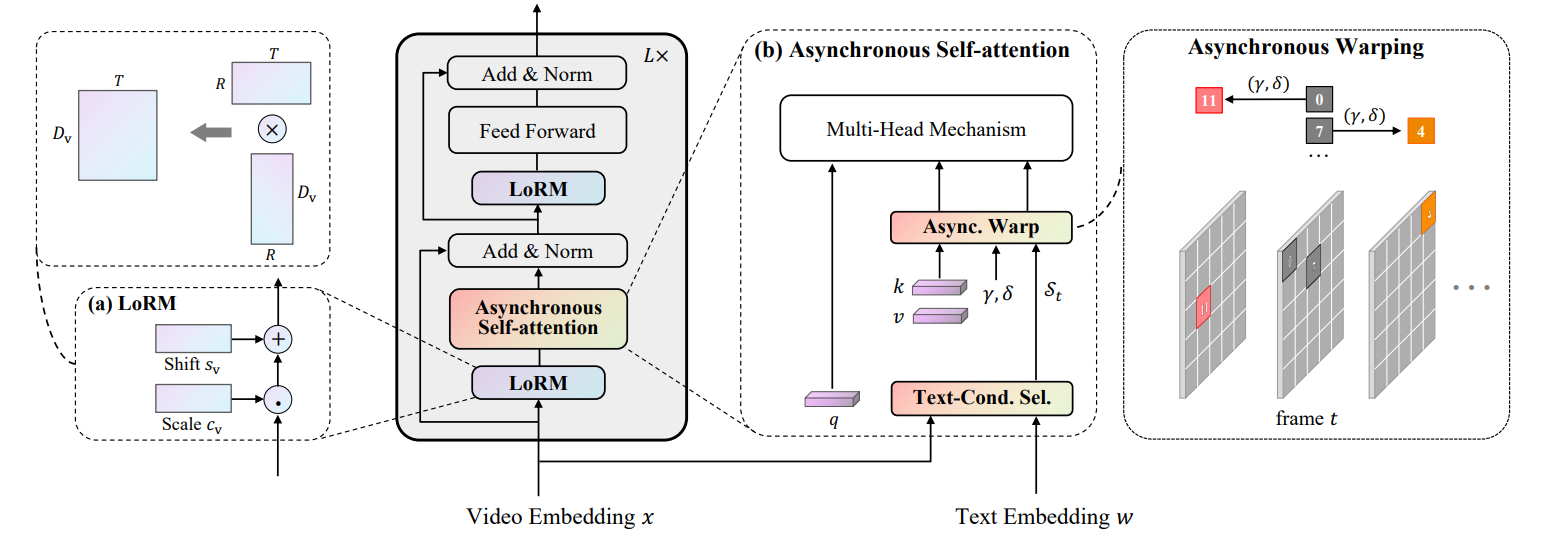
图3:RAP概述(a)LoRM设置了可学习的偏移参数c和缩放参数 S V S_{V} SV,以校准普通的CLIP特征。为满足时间稀疏性要求,c和s通过在时间维度上的低秩分解生成。(b)异步自注意力首先通过文本条件选择筛选出补丁集 S t S_{t} St。然后,根据可学习的补丁偏移γ和时间偏移δ对筛选出的补丁进行变形。
图3展示了我们RAP的示意图。在3.1节中,我们首先介绍RAP的预备知识,包括视频和文本特征嵌入。然后在3.2节和3.3节中分别描述提出的低秩调制和异步自注意力机制。
3.1 特征嵌入
视频嵌入
我们利用CLIP的视觉骨干网络(ViT(Dosovitskiy等人,2020))作为视频编码器。对于视频数据,我们按照ViT(Dosovitskiy等人,2020)的方法独立处理每一帧。具体而言,每个形状为 H × W H×W H×W的帧被分割成不重叠的形状为 P × P P×P P×P的补丁,然后线性投影到嵌入空间。这种线性投影为每一帧生成 N = H W / P 2 N = HW/P^{2} N=HW/P2个补丁特征。此外,一个可学习的[CLS]标记被添加到每个帧补丁特征序列的开头,以表示全局帧表示。位置嵌入也被添加进来,以显式地融入位置信息。通过上述过程,我们得到第 t t t帧的特征 x t 0 ∈ R ( N + 1 ) × D v x_{t}^{0} \in \mathbb{R}^{(N + 1)×D_{v}} xt0∈R(N+1)×Dv,其中 t ∈ [ 1 , T ] t \in [1, T] t∈[1,T], D v D_{v} Dv是视觉特征维度, T T T是总帧数。
应用具有串行连接的多头自注意力(MHSA)和多层感知器(MLP)的残差结构,以捕捉每个帧补丁序列内的顺序依赖关系和上下文关系。对每一帧重复上述步骤,我们得到第 l l l层的视频嵌入 x l ∈ R T × ( N + 1 ) × D v x^{l} \in \mathbb{R}^{T×(N + 1)×D_{v}} xl∈RT×(N+1)×Dv,其中 l ∈ [ 1 , L ] l \in [1, L] l∈[1,L], L L L表示层数。具体而言,我们将 x l x^{l} xl分解为 x l = [ f l , p l ] x^{l} = [f^{l}, p^{l}] xl=[fl,pl],其中 f l ∈ R T × D f^{l} \in \mathbb{R}^{T×D} fl∈RT×D表示逐帧特征(即[CLS]标记特征),而 p l ∈ R T × N × D v p^{l} \in \mathbb{R}^{T×N×D_{v}} pl∈RT×N×Dv是第 l l l层的补丁级表示。
文本嵌入
对于文本嵌入,我们直接使用CLIP的文本编码器来生成文本表示。文本编码器是一个Transformer(Vaswani等人,2017),其架构修改如(Radford等人,2019)所述。一个[EOS]标记也被添加到编码全局句子特征中。具体而言,我们将第 l l l层的句子特征表示为 w l ∈ R 1 × D t w^{l} \in \mathbb{R}^{1×D_{t}} wl∈R1×Dt,其中 D t D_{t} Dt是文本特征维度。
3.2 低秩调制
在本节中,我们详细阐述视频和文本特征的特征调制。由于所有层都共享相同的调制过程,为简洁起见,我们省略层索引 l l l的上标。
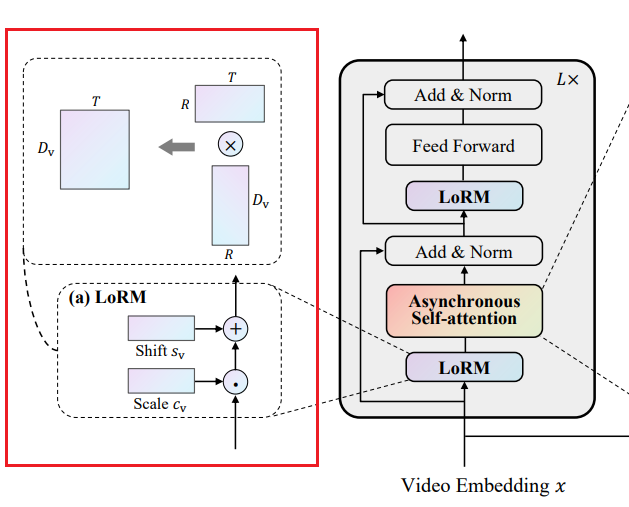
视频的低秩调制
逐帧编码的视频特征 x x x无法反映视频数据的特征。时间维度上的冗余是视频区别于静态图像的主要特征。为此,我们引入低秩缩放参数和偏移参数,它们作为方差和均值来调制预训练的CLIP特征。这些参数与输入无关,本质上相对轻量级,并且有望具有更好的可扩展性。具体而言,视频缩放参数 c v ∈ R T × D v c_{v} \in \mathbb{R}^{T×D_{v}} cv∈RT×Dv和视频偏移参数 s v ∈ R T × D v s_{v} \in \mathbb{R}^{T×D_{v}} sv∈RT×Dv分解如下:
c v = c a ⋅ c b , s v = s a ⋅ s b , ( 1 ) c_{v}=c^{a} \cdot c^{b}, s_{v}=s^{a} \cdot s^{b}, (1) cv=ca⋅cb,sv=sa⋅sb,(1)
其中 c a c^{a} ca, s a ∈ R T × R s^{a} \in \mathbb{R}^{T×R} sa∈RT×R, c b c^{b} cb, s b ∈ R R × D v s^{b} \in \mathbb{R}^{R×D_{v}} sb∈RR×Dv是可学习参数,我们设置秩 R ≪ m i n ( T , D v ) R \ll min (T, D_{v}) R≪min(T,Dv)以满足低秩要求。低秩调制应用如下:
u = c v ⊙ x + s v , ( 2 ) u=c_{v} \odot x+s_{v}, \quad(2) u=cv⊙x+sv,(2)
其中 ⊙ \odot ⊙表示广播的逐元素乘法。在训练过程中,普通特征 x x x通过固定的CLIP骨干网络提取,可学习的 c v c_{v} cv和 s V s_{V} sV帮助将 x x x修改为时间低秩的特征。 u ∈ R T × ( N + 1 ) × D v u \in \mathbb{R}^{T×(N + 1)×D_{v}} u∈RT×(N+1)×Dv是调制后的视频特征。
3.2.2 文本的调制
我们还使用参数 c t c_{t} ct和 s t s_{t} st对文本嵌入 w w w进行如下调制:
z = c t ⊙ w + s t , ( 3 ) z=c_{t} \odot w+s_{t}, \quad(3) z=ct⊙w+st,(3)
其中 c t c_{t} ct, s t ∈ R 1 × D v s_{t} \in \mathbb{R}^{1×D_{v}} st∈R1×Dv是可学习参数。由于文本数据不具有稀疏性特征,我们不在词级别进行调制,也不使用参数低秩分解。
异步自注意力
让我们回顾一下视频编码器中的普通自注意力机制。为清晰起见,我们以输入视频的第 t t t帧为例进行说明。相应的调制特征表示为 u t ∈ R N × D v u_{t} \in \mathbb{R}^{N×D_{v}} ut∈RN×Dv, t ∈ [ 1 , T ] t \in [1, T] t∈[1,T](参见公式(2))。请注意,这里我们将 u t u_{t} ut定义为不包含全局[CLS]标记特征的补丁级特征。我们也省略层索引 l l l的上标。
普通自注意力首先对输入特征 u t u_t ut进行三种不同的线性投影,以获得查询、键和值的三元组,即:
q t = u t ⋅ W q , k t = u t ⋅ W k , v t = u t ⋅ W v ( 4 ) q_t = u_t \cdot W_q, k_t = u_t \cdot W_k, v_t = u_t \cdot W_v \ (4) qt=ut⋅Wq,kt=ut⋅Wk,vt=ut⋅Wv (4)
其中 W q W_q Wq、 W k W_k Wk、 W v ∈ R D v × D v W_v \in \mathbb{R}^{D_v×D_v} Wv∈RDv×Dv是固定的变换权重。然后计算缩放点积注意力以获取上下文信息。
普通自注意力仅关注帧内相关性建模,这导致了视频和图像之间的模态差距。我们没有引入额外的串行或并行时间建模模块(时间Transformer(Liu等人,2023;Yang等人,2022)或3D卷积(Pan等人,2022)),而是提出了一种新颖的异步自注意力机制,该机制引入了补丁级的时间偏移来对帧间关系进行建模。此外,为了稳定训练过程,我们提出了一种文本条件选择机制。
文本条件选择
这里我们以视频到文本检索为例来说明这一点。对于给定的逐帧视频特征 f ∈ R T × D v f \in \mathbb{R}^{T×D_v} f∈RT×Dv,我们在帧维度上进行平均池化,以获得视频级特征 f ˉ ∈ R 1 × D v \bar{f} \in \mathbb{R}^{1×D_v} fˉ∈R1×Dv。然后我们如下选择最相似的句子 w ∗ ∈ W w^* \in W w∗∈W:
w ∗ = a r g m a x w ∈ W ( P r o j ( f ‾ ) ⋅ w ⊤ ) ( 5 ) w^* = \underset{w \in \mathcal{W}}{argmax}(Proj(\overline{f}) \cdot w^{\top}) \ (5) w∗=w∈Wargmax(Proj(f)⋅w⊤) (5)
其中 w ∈ R 1 × D t w \in \mathbb{R}^{1×D_t} w∈R1×Dt是候选句子特征。 P r o j ( ⋅ ) Proj(·) Proj(⋅)是一个线性投影层,用于将视觉维度 D v D_v Dv转换为文本维度 D t D_t Dt。
然后,我们计算句子 - 补丁相似度,并选择响应最高的 K K K个补丁。
S t = a r g t o p k t ∈ [ 1 , T ] ( P r o j ( u t ) ⋅ w ∗ ⊤ ) ( 6 ) \mathcal{S}_t = \underset{t \in [1, T]}{argtopk}(Proj(u_t) \cdot w^{* \top}) \ (6) St=t∈[1,T]argtopk(Proj(ut)⋅w∗⊤) (6)
其中 S t \mathcal{S}_t St是筛选后的补丁索引集。
异步自注意力
然后我们仅对由集合 S t \mathcal{S}_t St索引的补丁应用所提出的异步自注意力。具体来说,查询特征调整如下:
k ^ t n , v ^ t n = { k t + δ t n + γ n , v t + δ t n + γ n , n ∈ S t k t n , v t n , n ∉ S t ( 7 ) \hat{k}_t^n, \hat{v}_t^n = \begin{cases} k_{t+\delta_t}^{n+\gamma_n}, v_{t+\delta_t}^{n+\gamma_n}, & n \in \mathcal{S}_t \\ k_t^n, v_t^n, & n \notin \mathcal{S}_t \end{cases} \ (7) k^tn,v^tn={kt+δtn+γn,vt+δtn+γn,ktn,vtn,n∈Stn∈/St (7)
其中 γ ∈ R N × 1 \gamma \in \mathbb{R}^{N×1} γ∈RN×1, δ ∈ R T × 1 \delta \in \mathbb{R}^{T×1} δ∈RT×1是层共享的可学习参数,分别表示补丁和时间维度上的偏移距离。 k t + δ t n + γ n k_{t+\delta_t}^{n+\gamma_n} kt+δtn+γn和 v t + δ t n + γ n v_{t+\delta_t}^{n+\gamma_n} vt+δtn+γn分别表示第 ( t + δ t ) (t + \delta_t) (t+δt)帧中第 ( n + γ n ) (n + \gamma_n) (n+γn)个补丁的键和值特征。 k ^ t \hat{k}_t k^t, v ^ t ∈ R N × D v \hat{v}_t \in \mathbb{R}^{N×D_v} v^t∈RN×Dv表示调整后的特征。最后,异步自注意力计算如下:
A t t e n ( q t , k ^ t , v ^ t ) = s o f t m a x ( q t k ^ t ⊤ D v ) v ^ t ( 8 ) Atten(q_t, \hat{k}_t, \hat{v}_t) = softmax(\frac{q_t \hat{k}_t^{\top}}{\sqrt{D_v}}) \hat{v}_t \ (8) Atten(qt,k^t,v^t)=softmax(Dvqtk^t⊤)v^t (8)
其中 q t q_t qt如公式(4)所示,而 k ^ t \hat{k}_t k^t和 v ^ t \hat{v}_t v^t在公式(7)中定义。
4 实验
4.1 实验设置
4.1.1 数据集
我们在四个基准数据集上验证所提出的RAP的性能。
- MSR-VTT(Xu等人,2016)包含10,000个YouTube视频,每个视频关联20条文本描述。我们遵循1k-A分割(Yu等人,2018),其中9,000个视频用于训练,1,000个视频用于测试。
- MSVD(Chen和Dolan,2011)由1,970个视频组成。按照官方分割,我们分别使用1,200个视频进行训练,670个视频进行测试。
- ActivityNet Captions(Krishna等人,2017)涵盖20,000个未修剪的复杂人类活动视频,平均时长为两分钟。我们报告“val1”分割(10,009个训练视频和4,917个测试视频)的结果,如(Gabeur等人,2020)所示。
- DiDemo(Anne Hendricks等人,2017)由10,464个未经编辑的个人视频组成,这些视频具有不同的视觉场景,并带有40,543条文本描述。我们遵循(Luo等人,2022)中的训练和评估协议。
4.1.2 评估指标
遵循先前的工作(Luo等人,2022),我们使用标准检索指标评估性能:召回率(R@K,越高越好)、中位数排名(MdR,越低越好)和平均排名(MnR,越低越好)。R@K定义为在检索结果前K名中找到正确结果的样本百分比。在我们的实验中,我们将K设置为{1, 5, 10}。MdR计算真实结果在排名中的中位数,而MnR计算所有正确结果的平均排名。
4.1.3 实现细节
我们将MSR-VTT、DiDeMo、MSVD和ActivityNet Captions的输入帧长度分别设置为12、64、12、64,字幕令牌长度分别设置为32、64、32、64。采用预训练的CLIP(Radford等人,2021)作为视频和文本编码器。使用BertAdam作为优化器,采用0.1比例的热身余弦退火,学习率为 1 e − 4 1e - 4 1e−4。除了在DiDeMo上进行10个epoch的微调外,所有模型都训练5个epoch。时间秩R和选择的令牌数K都设置为3。所有实验均在4个NVIDIA Tesla A100 GPU上进行。

4.2 与最先进方法的比较
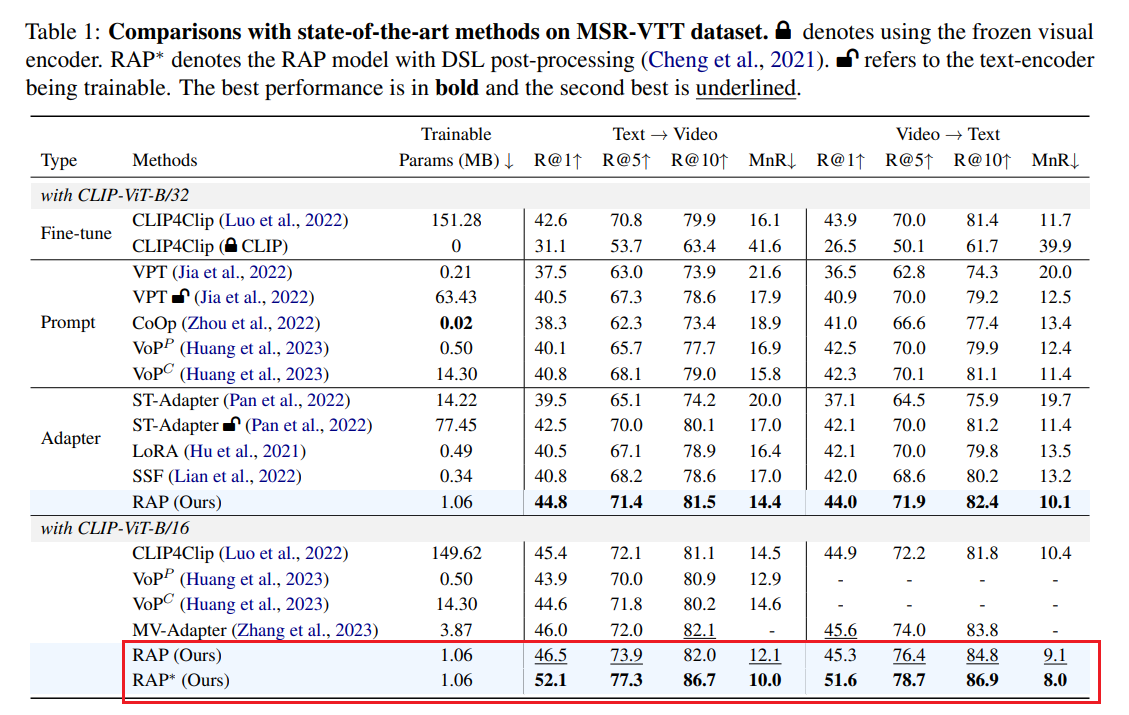
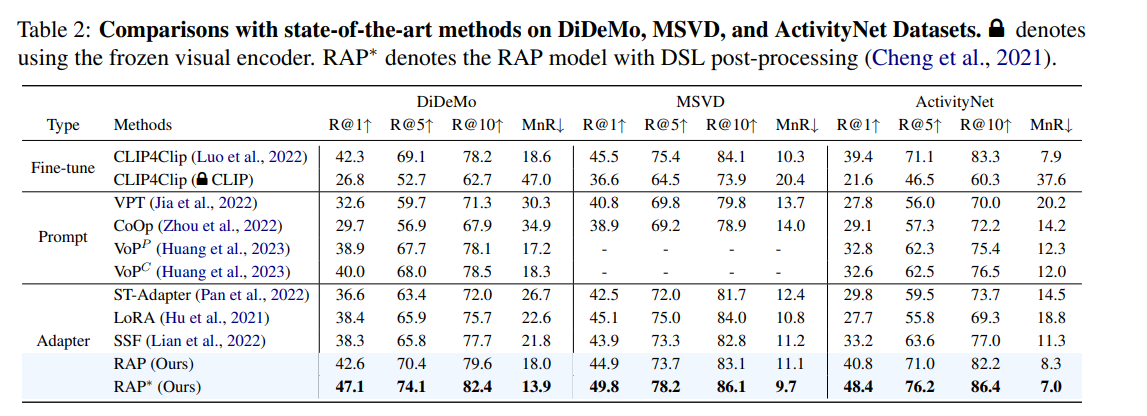
比较结果总结在表1和表2中。具体来说,我们设置了三组比较实验:
- 微调:我们将全量微调的CLIP4clip(Luo等人,2022)作为比较对象。此外,我们还在表1中列出了CLIP4clip的零样本性能,即CLIP,用于比较。
- 提示微调:我们将提出的RAP与提示微调方法进行比较,包括CoOp(Zhou等人,2022)、VPT(Jia等人,2022)和VoP(Huang等人,2023)。由于VPT是为纯视觉任务量身定制的,我们分别对CLIP的文本分支进行微调或冻结进行实验。
- 适配器:我们使用最先进的适配器进行实验,包括ST-Adapter(Pan等人,2022)、LoRA(Hu等人,2021)和SSF(Lian等人,2022)。值得注意的是,ST-Adapter应用于视觉分支,文本分支要么微调要么冻结。对于CoOP的实验,我们在文本编码器的输入处插入32个可学习的提示令牌。
比较结果证明了我们提出的RAP的优越性能。例如,在MSR-VTT数据集上,使用CLIP-ViT-B/32骨干网络时,我们的RAP在R@1上比全量微调的CLIP4clip高出2.2%(42.6对比44.8),而参数仅为其0.7%(1.06M对比151.28M)。此外,与当前的提示微调及适配器微调方法相比,我们也取得了更优的性能。尽管我们的RAP的参数略高于LoRA和SSF,但考虑到性能的显著提升,我们的RAP在参数和性能之间达到了更好的平衡。
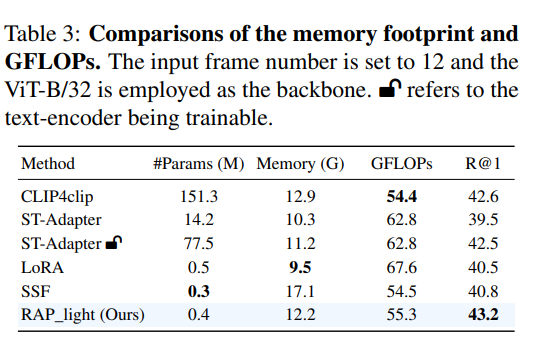
此外,为了进一步探究所提出模型的内存使用和计算复杂度,我们在表3中总结了训练过程中的GPU内存使用情况和模型的GFLOPs。为了公平比较,我们将每个模型的输入帧数均设置为12帧,并使用ViT-B/32骨干网络进行实验。我们设置了一个轻量级的RAP,仅在最后四层应用LoRM和ASA。如表所示,与全量微调的Clip4clip相比,RAP_light显著减少了可训练参数,略微降低了内存占用,并提升了性能。简而言之,我们的RAP_light在计算开销和性能之间实现了平衡,即付出可承受的开销,同时获得显著的性能提升。
4.3 消融实验
我们在MSR-VTT数据集上使用ViT-B/32骨干网络进行所有消融实验。输入帧数设置为12。
4.3.1 组件消融实验
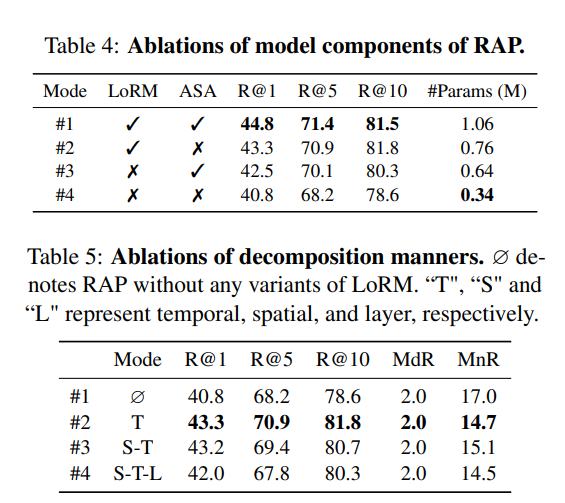
我们对提出的低秩调制模块和异步自注意力机制进行消融实验。结果总结在表4中。我们可以得出结论,这两个组件对于在可忽略的参数开销下获得优异性能至关重要。例如,LoRM在R@1上带来了2.3%的性能提升,代价是增加了0.42M的参数(模式#1与模式#3相比)。
4.3.2 LoRM低秩分解方式的消融实验
在公式(1)中,我们在时间维度上进行低秩分解,调制权重的维度为 R T × D v \mathbb{R}^{T×D_v} RT×Dv,即 R T × D v ← R T × R ⋅ R R × D v \mathbb{R}^{T×D_v} \leftarrow \mathbb{R}^{T×R} \cdot \mathbb{R}^{R×D_v} RT×Dv←RT×R⋅RR×Dv。
这里我们对更多分解选项进行消融实验:
- 时空分解:在时空维度上应用调制,权重为 R T × N × D v \mathbb{R}^{T×N×D_v} RT×N×Dv,即 R T × N × D v ← R T × N × R ⋅ R R × D v \mathbb{R}^{T×N×D_v} \leftarrow \mathbb{R}^{T×N×R} \cdot \mathbb{R}^{R×D_v} RT×N×Dv←RT×N×R⋅RR×Dv,其中T和N分别表示帧数和每帧内的补丁数。
- 时空层分解:我们在所有层上统一分解所有调制权重。具体来说,调制权重的形状为 R M × T × N × D v \mathbb{R}^{M×T×N×D_v} RM×T×N×Dv,即 R M × T × N × D v ← R M × R ⋅ R R × T × N × R ⋅ R R × D v \mathbb{R}^{M×T×N×D_v} \leftarrow \mathbb{R}^{M×R} \cdot \mathbb{R}^{R×T×N×R} \cdot \mathbb{R}^{R×D_v} RM×T×N×Dv←RM×R⋅RR×T×N×R⋅RR×Dv,其中M表示所有层插入的模块数。
比较结果总结在表5中。从比较结果可以看出,单独使用时间分解带来了最佳性能。额外在空间和层维度上进行分解会导致性能下降。这些结果表明,视频数据在时间维度上存在大量冗余。
4.3.3 文本条件选择方式的消融实验
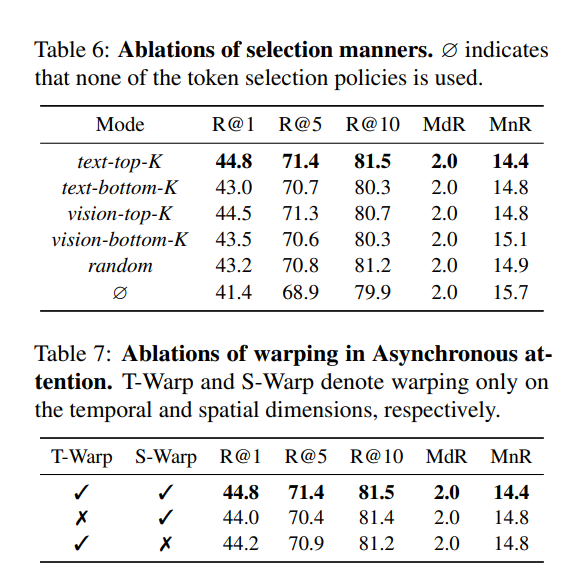
为了稳定ASA的训练过程,我们提出了一种文本条件选择策略,将异步注意力计算限制在选定的最相关补丁特征内(参见3.3节)。为清晰起见,我们将这种筛选方式表示为text-top-K。这里我们对更多视觉令牌选择方式进行实验:
- random:在每一帧内随机选择K个补丁特征。
- text-bottom-K:对于每个补丁令牌特征,我们计算句子 - 补丁相似度,并选择响应最低的K个补丁。
- vision-top-K:不使用句子特征,而是计算每个补丁特征与帧的[CLS]标记特征之间的相似度。通过选择响应最高的K个补丁来构成筛选集。
- vision-bottom-K:与vision-top-K类似,我们计算补丁与[CLS]标记的相似度,并选择响应最低的K个补丁。
- ø:不使用任何选择策略,对所有补丁特征进行变形。
上述选择策略的比较结果总结在表6中。我们有以下发现。首先,不使用令牌选择策略(即表6中的∞)会导致性能大幅下降,例如在R@1上仅达到41.4%。这可能是因为对每个补丁令牌进行变形会破坏预训练的CLIP权重。其次,我们提出的text-top-K策略在所有五个指标上均优于其他策略。这表明以参数化方式选择性地对部分补丁令牌进行变形可以更好地使普通CLIP适应视频场景。
4.3.4 ASA变形方式的消融实验
在3.3节中,我们在时间和空间维度上预测补丁级的变形距离。这里我们对两个维度分别进行消融实验,以观察差异。如表7所示,限制在时间或空间维度上的变形会导致性能下降,这表明自由形式的补丁级变形对最终性能至关重要。
4.3.5 即插即用性能的消融实验
所提出的LoRM和ASA模块均作为即插即用模块,可以与多种基于CLIP的方法兼容。为了证明这一点,我们基于更先进的基于CLIP的方法X-CLIP(Ma等人,2022)进行实验。具体来说,我们冻结CLIP骨干网络,然后在每个Transformer层内插入LoRM,并用我们提出的ASA取代普通自注意力机制。表8中的比较结果表明,即使使用更先进的X-CLIP作为基线,我们的LoRM和ASA也能持续提升检索性能。此外,与全量微调的方法相比,我们提出的LoRM和ASA在可训练参数方面具有很大优势。
4.3.6 超参数的消融实验
我们在表9中对时间秩R和选择的令牌数K进行消融实验。我们设置 R = 3 R = 3 R=3和 K = 3 K = 3 K=3以实现最佳检索性能。
5 结论
在这项工作中,我们提出了RAP,以有效地将预训练的CLIP模型迁移到TVR。为了适应固有的视频结构和跨模态设置,我们引入了低秩调制模块以实现逐帧稀疏表示,并引入了异步自注意力模块以增强跨帧相关性。大量实验表明,RAP的性能与先前方法和全量微调方法相当,甚至更优。
影响声明
5.1 伦理声明
我们的RAP旨在通过时间稀疏和相关的适配器进行参数高效的文本-视频检索。伦理问题可能存在于以下两个方面。首先,与许多数据驱动的方法类似,存在数据隐私、匿名化以及遵守相关数据保护法规的问题。其次,应认识到与数据集中潜在偏差以及检索模型相关的考虑因素,特别是在敏感主题方面。我们在研究中对伦理考量保持透明,以维护学术过程的完整性,并确保这项工作符合该领域的伦理标准和规范。
5.2 局限性
尽管取得了显著进展,但我们的RAP仍然面临一些局限性。首先,我们使用文本条件选择来筛选最具代表性的视觉补丁。由于文本和视觉信号之间存在语义差距,不同模态之间复杂概念和上下文的对齐应以更细粒度的方式进行。其次,由于计算资源的限制,我们使用ViT-B/32和ViT-B/16骨干网络进行实验。在ViT-L/14和ViT-E/14骨干网络上进行可扩展实验留待未来工作。
相关文章:

RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter
标题:RAP:基于稀疏相关适配器的高效文本视频检索 原文链接:RAP: Efficient Text-Video Retrieval with Sparse-and-Correlated Adapter - ACL Anthology 发表:ACL-2024(NLP领域CCF A类) 摘要 文本-视频检索(TVR࿰…...

C++ ++++++++++
初始C 注释 变量 常量 关键字 标识符命名规则 数据类型 C规定在创建一个变量或者常量时,必须要指定出相应的数据类型,否则无法给变量分配内存 整型 sizeof关键字 浮点型(实型) 有效位数保留七位,带小数点。 这个是保…...
API的流式输出与非流式输出比较)
用Python之requests库调用大型语言模型(LLM)API的流式输出与非流式输出比较
文章目录 1. 非流式输出与流式输出概述2. 非流式输出2.1 代码实例12.2 代码实例2 3. 流式输出3.1 流式输出的定义和作用3.2 流式输出适用的场景3.3 流式输出的实现方式与实现技术3.4 代码实例33.5 代码实例4 4. 小结 1. 非流式输出与流式输出概述 大模型收到输入后并不是一次性…...

JavaEE基础之- 过滤器和监听器Filter and Listener
目录 1. 过滤器 Filter 1.1. 初识过滤器 1.1.1. 过滤器概念 1.1.2. 过滤器例子 1.2. 过滤器详解 1.2.1. 过滤器生命周期 1.2.2. FilterConfig 1.2.3. FilterChain 1.1.4. 过滤器执行顺序 1.2.5. 过滤器应用场景 1.2.6. 过滤器设置目标资源 1.2.7. 过滤器总结 1.3 过滤…...

JavaAdv01——字节流和字符流
一、核心概念解析 1. 字节流(Byte Streams) 字节流家族: 输入流:InputStream(抽象类) FileInputStream ByteArrayInputStream BufferedInputStream 输出流:OutputStream FileOutputStream…...

HarmonyOS 5.0应用开发——多线程Worker和@Sendable的使用方法
【高心星出品】 文章目录 多线程Worker和Sendable的使用方法开发步骤运行结果 多线程Worker和Sendable的使用方法 Worker在HarmonyOS中提供了一种多线程的实现方式,它允许开发者在后台线程中执行长耗时任务,从而避免阻塞主线程并提高应用的响应性。 S…...

AI赋能传热学研究:创新与乐趣的深度融合
在科技飞速发展的当下,人工智能(AI)已逐渐渗透到各个领域,为不同行业带来了前所未有的变革与机遇。对于传热学研究而言,AI的介入不仅极大地提高了研究效率,还为研究者带来了全新的体验和思考。本文将深入探…...

Hive-03之传参、常用函数、explode、lateral view、行专列、列转行、UDF
大数据分析利器之hive 一、目标 掌握hive中select查询语句中的基本语法掌握hive中select查询语句的分组掌握hive中select查询语句中的join掌握hive中select查询语句中的排序 二、要点 1、hive的参数传递 1、Hive命令行 语法结构 hive [-hiveconf xy]* [<-i filename&…...

如何将Vue项目部署至 nginx
一、准备工作 1.确保安装了开发软件VS Code(此处可查阅安装 VS Code教程),确保相关插件安装成功 2.安装Node.js和创建Vue项目(此处可查阅安装创建教程) 3.成功在VS Code运行一个Vue项目(此处可查阅运行教…...

SwiftUI之状态管理全解析
文章目录 引言一、`@State`1.1 基本概念1.2 初始化与默认值1.3 注意事项二、`@Binding`2.1 基本概念2.2 初始化与使用2.3 注意事项三、`@ObservedObject`3.1 基本概念3.2 初始化与使用3.3 注意事项四、`@EnvironmentObject`4.1 基本概念4.2 初始化与使用4.3 注意事项五、`@Stat…...
Web应用与服务端技术概念知识讲解)
Java-servlet(一)Web应用与服务端技术概念知识讲解
Java-servlet(一)Web应用与服务端技术概念知识讲解 前言一、Web 应用1.WEB CS BS 对比2.WEB 介绍3.web 与 http 的关系 二、servlet服务端技术1. 公共网关接口(CGI)2. servlet 是什么3.servlet 作用4. servlet 特性 前言 在当今时…...

多个pdf合并成一个pdf的方法
将多个PDF文件合并优点: 能更容易地对其进行归档和备份.打印时可以选择双面打印,减少纸张的浪费。比如把住宿发票以及滴滴发票、行程单等生成一个pdf,双面打印或者无纸化办公情况下直接发送给财务进行存档。 方法: 利用PDF24 Tools网站 …...

数据集笔记:新加坡停车费
data.gov.sg 该数据集包含 新加坡各停车场的停车费,具体信息包括: 停车场名称(Carpark):如 Toa Payoh Lorong 8、Ang Mo Kio Hub、Bras Basah Complex 等。停车区域类别(Category):…...

易错点abc
在同一个输入流上重复创建Scanner实例可能会导致一些问题,包括但不限于输入流的混乱。尤其是在处理标准输入(System.in)时,重复创建Scanner对象通常不是最佳实践,因为这可能导致某些输入数据丢失或者顺序出错。 为什么…...

leetcode第39题组合总和
原题出于leetcode第39题https://leetcode.cn/problems/combination-sum/description/题目如下: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以…...
)
【iOS】小蓝书学习(七)
小蓝书学习(七) 前言第47条:熟悉系统框架第48条:多用枚举块,少用for循环第50条:构建缓存使选用NSCache而非NSDictionary第51条:精简initialize与load的实现代码第52条:别忘了NSTimer…...

基于第三方SDK的Windows平台全功能RTMP|RTSP直播播放器深度解析
一、引言 在当今数字化时代,直播技术的应用场景不断拓展,从娱乐直播到教育、医疗、工业等多个领域,都对直播播放器的功能和性能提出了更高的要求。本文将介绍一款基于第三方SDK实现的全功能直播播放器,从技术实现、功能特点、用户…...

命名实体识别与文本生成算法
在自然语言处理(NLP)的浩瀚星空中,命名实体识别(Named Entity Recognition, NER)与文本生成算法如同两颗璀璨的星辰,各自闪耀,又相互辉映,共同推动着人工智能技术在语言理解与生成领…...

题解 | 牛客周赛83 Java ABCDEF
目录 题目地址 做题情况 A 题 B 题 C 题 D 题 E 题 F 题 牛客竞赛主页 题目地址 牛客竞赛_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ 做题情况 A 题 输出两个不是同一方位的字符中的任意一个就行 import java.io.*; import java.math.*; import java…...
)
样式和ui(待更新)
element-plus 先在项目下执行安装语句执行按需导入的命令按照官方文档修改vitest.json sass样式定制 npm -i sass -D在项目下准备定制的样式文件 styles/element/index.scss(!注意这里是.scss文件在vitest.json 修改配置文件 Components({resolvers: [ElementPlusResolver(…...
)」)
「Selenium+Python自动化从0到1②|2025浏览器操控7大核心API实战(附高效避坑模板))」
Python 自动化操作浏览器基础方法 在进行 Web 自动化测试时,操作浏览器是必不可少的环节。Python 结合 Selenium 提供了强大的浏览器操作功能,让我们能够轻松地控制浏览器执行各种任务。本文将详细介绍如何使用 Python 和 Selenium 操作浏览器的基本方法…...

C++的类和对象入门
目录 目录 目录 一、类 1.1类的定义 1.2访问限定符 1.3类域 1.4类的命名规范 1.5class和struct的默认访问权限 二、类的实例化 2.2对象的大小和存储 2.3空类的大小 三、this指针 3.1this指针的定义 3.2this指针的作用 3.2.1区分同名变量和局部变量 3.2.2返回对象…...

【清华大学】DeepSeek从入门到精通完整版pdf下载
DeepSeek从入门到精通.pdf 一共104页完整版 下载链接: https://pan.baidu.com/s/1-gnkTTD7EF2i_EKS5sx4vg?pwd1234 提取码: 1234 或 链接:https://pan.quark.cn/s/79118f5ab0fd 一、DeepSeek 概述 背景与定位 DeepSeek 的研发背景 核心功能与技术特点(…...

deepseek使用记录18——文化基因之文化融合
文明长河中的生命浪花 在洛阳白马寺的银杏树下,年轻母亲指着"农禅并重"碑刻给孩子讲述祖辈耕作的故事;在哔哩哔哩的直播间里,00后女孩穿着汉服跳起街舞,弹幕飘过"这才是文化缝合怪"。当文明交融的宏大叙事照…...
)
Java 大视界 -- Java 大数据在智慧文旅游客流量预测与景区运营优化中的应用(110)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

面试题:说一下你对DDD的了解?
面试题:说一下你对DDD的了解? 在面试中,关于 DDD(领域驱动设计,Domain-Driven Design) 的问题是一个常见的技术考察点。DDD 是一种软件设计方法论,旨在通过深入理解业务领域来构建复杂的软件系统。以下是一个清晰、详细的回答模板,帮助你在面试中脱颖而出: DDD 的定义…...

网络编程——UDP
UDP编程使用套接字(Socket)进行通信。下面是基于UDP协议进行网络编程的基本步骤。 1. 创建套接字 首先,客户端和服务器都需要通过 socket() 系统调用创建一个UDP套接字。 2. 配置地址和端口 UDP是无连接的,因此你不需要像TCP一…...

【网络安全 | 渗透测试】GraphQL精讲二:发现API漏洞
未经许可,不得转载。 推荐阅读:【网络安全 | 渗透测试】GraphQL精讲一:基础知识 文章目录 GraphQL API 漏洞寻找 GraphQL 端点通用查询常见的端点名称请求方法初步测试利用未清理的参数发现模式信息使用 introspection探测 introspection运行完整的 introspection 查询可视化…...

代码随想录Day23 | 39.组合总和、40.组合总和II、131.分割回文串
39.组合总和 自己写的代码: class Solution { public:vector<int> path;vector<vector<int>> res;int sum0;void backtracking(vector<int>& candidates,int target,int startIndex){if(sum>target) return;if(sumtarget){res.pus…...

MyBatis 新手入门教程:基础操作篇
MyBatis 新手入门教程:基础操作篇 适合人群:无 MyBatis 使用经验者 (完整版3.3准时发,此篇为新手入门的基础操作) 一、MyBatis 是什么? 简单理解: MyBatis 是一个帮你操作数据库的工具&#x…...

zjbdt
嵌入式软件工程师可以通过考取相关职业证书来提升专业能力和职业竞争力。以下是几种含金量较高且广受认可的证书: 1. NIEH 嵌入式技术工程师证书 颁发机构:教育部考试中心级别:初级、中级、高级内容:涵盖嵌入式系统的基础理论、开…...
)
行为型模式 - 中介者模式 (Mediator Pattern)
行为型模式 - 中介者模式 (Mediator Pattern) 中介者模式的核心思想是将对象之间的复杂交互封装到一个中介者对象中,从而降低对象之间的耦合度。 import java.util.ArrayList; import java.util.List;// 抽象中介者类 abstract class TowerMediator {public abstra…...

如何使用C#与SQL Server数据库进行交互
一.创建数据库 用VS 创建数据库的步骤: 1.打开vs,创建一个新项目,分别在搜素框中选择C#、Windows、桌面,然后选择Windows窗体应用(.NET Framework) 2.打开“视图-服务器资源管理器”,右键单击“数据连接”࿰…...

同步类型对比
同步类型对比 特性准同步 (Quasi-Synchronization)完全同步 (Complete Synchronization)渐进同步 (Asymptotic Synchronization)定义系统状态在有限时间内接近同步,但存在微小误差。系统状态在有限时间内完全一致。系统状态随时间趋近于同步,但可能需要…...
)
python爬虫Scapy框架(1)
简介 什么是框架? 所谓的框,其实说白了就是一个【项目的半成品】,该项目的半成品需要被集成了各种功能且具有较强的通用性。 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非…...

java容器 LIst、set、Map
Java容器中的List、Set、Map是核心数据结构,各自适用于不同的场景 一、List(有序、可重复) List接口代表有序集合,允许元素重复和通过索引访问,主要实现类包括: ArrayList 底层结构:动态数组…...

2W8000字 LLM架构文章阅读指北
❝ 大模型架构专栏已经更新了30多篇文章。完整的专栏内容欢迎订阅: LLM 架构专栏 1、LLM大模型架构专栏|| 从NLP基础谈起 2、 LLM大模型架构专栏|| 自然语言处理(NLP)之建模 3、 LLM大模型架构之词嵌入(Part1) 3、 LLM…...

Milkv-duo256 接入tuya 云并实现远程智能控制
tuyaopen-embedded-core 是将 https://github.com/tuya/tuyaopen 连接 tuya 云相关核心组件重新组织,可快速嵌入至各种嵌入式平台使用。 tuyaopen-embedded-core 可通过 WiFi、有线以太网、CAT-1、4G 等多种方式接入涂鸦云,实现设备远程控制、OTA 等功能…...

Hadoop之02:MR-图解
1、不是所有的MR都适合combine 1.1、map端统计出了不同班级的每个学生的年龄 如:(class1, 14)表示class1班的一个学生的年龄是14岁。 第一个map任务: class1 14 class1 15 class1 16 class2 10第二个map任务: class1 16 class2 10 class…...

YOLOv8目标检测推理流程及C++代码
这部分主要是使用c++对Onnx模型进行推理,边先贴代码,过段时间再详细补充下代码说明。 代码主要分成三部分,1.main_det.cpp推理函数主入口;2.inference_det.h 头文件及inference_det.cpp具体函数实现;3.CMakeList.txt. 1.main_det 推理配置信息全部写在config.txt中,执行…...

【AVRCP】深入解析AVRCP应用层:功能支持与映射
在最近的项目开发中,深入研究了Audio/Video Remote Control Profile(AVRCP)的应用层特性。在蓝牙音频/视频远程控制规范(AVRCP)的架构中,应用层扮演着至关重要的角色,它定义了符合该规范的设备所…...

springboot之HTML与图片生成
背景 后台需要根据字段动态生成HTML,并生成图片,发送邮件到给定邮箱 依赖 <!-- freemarker模板引擎--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-freemarker</artifa…...

Hive-04之存储格式、SerDe、企业级调优
一、主题 hive表的数据压缩和文件存储格式hive的自定义UDF函数hive的JDBC代码操作hive的SerDe介绍和使用hive的优化 二、要点 1. hive表的文件存储格式 Hive支持的存储数的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC&…...

链表的概念和结构
文章目录 1. 链表的概念2. 链表的分类3. 单向不带头非循环链表3.1 接口设计(SList.h)3.2 接口实现(SList.c)1)打印和创建结点2)头尾插入删除3)查找和插入4)删除和销毁 3.3 完整代码S…...

使用AI后为什么思考会变得困难?
使用AI后为什么思考会变得困难? 我总结了四篇近期的研究论文,来展示AI是如何以及为什么侵蚀我们的批判性思维能力。 作者使用AI制作的图像 前言:作者在这篇文章中,借AI技术的崛起,揭示了一场悄然发生的思想博弈。表面…...

Github 2025-03-02 php开源项目日报Top10
根据Github Trendings的统计,今日(2025-03-02统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量PHP项目10Blade项目1JavaScript项目1Nextcloud服务器:安全的数据之家 创建周期:2796 天开发语言:PHP, JavaScript协议类型:GNU Affero Gene…...

智能座舱介绍
目录 智能座舱智能座舱的核心技术组成车载信息娱乐系统(IVI)数字仪表盘与HUD(抬头显示)语音交互与AI助手多屏联动与场景化交互生物识别技术智能座舱的发展趋势沉浸式体验情感化与个性化多模态交互融合车联网(V2X)生态扩展应用场景挑战与未来硬件系统软件系统关键技术智能…...

2025年能源工作指导意见
2025年是“十四五”规划收官之年,做好全年能源工作意义重大。为深入贯彻落实党中央、国务院决策部署,以能源高质量发展和高水平安全助力我国经济持续回升向好,满足人民群众日益增长的美好生活用能需求,制定本意见。 一、总体要求…...

豪越科技:智慧园区后勤单位消防安全管理,实时告警与整改闭环
在当今数字化、智能化飞速发展的时代,智慧园区已成为现代产业发展的重要载体。而园区后勤单位的消防安全管理,作为保障园区安全运营的关键环节,正面临着前所未有的挑战与机遇。豪越科技凭借其先进的技术和丰富的经验,为智慧园区后…...

zookeeper-docker版
Zookeeper-docker版 1 zookeeper概述 1.1 什么是zookeeper Zookeeper是一个分布式的、高性能的、开源的分布式系统的协调(Coordination)服务,它是一个为分布式应用提供一致性服务的软件。 1.2 zookeeper应用场景 zookeeper是一个经典的分…...