七、Redis集群高可用
一、节点与插槽管理
添加主节点
准备节点
首先准备一个新的节点,添加配置文件。
vi /usr/local/redis/cluster/conf/redis-6377.conf
# 放行访问IP限制
bind 0.0.0.0
# 端口
port 6377
# 后台启动
daemonize yes
# 日志存储目录及日志文件名
logfile "/usr/local/redis/cluster/log/redis-6377.log"
# rdb数据文件名
dbfilename dump-6377.rdb
# aof模式开启和aof数据文件名
appendonly yes
appendfilename "appendonly-6377.aof"
# rdb数据文件和aof数据文件的存储目录
dir /usr/local/redis/cluster/data
# 设置密码
requirepass 123456
# 从节点访问主节点密码(必须与 requirepass 一致)
masterauth 123456
# 是否开启集群模式,默认 no
cluster-enabled yes
# 集群节点信息文件,会保存在 dir 配置对应目录下
cluster-config-file nodes-6377.conf
# 集群节点连接超时时间
cluster-node-timeout 15000
# 集群节点 IP
cluster-announce-ip 192.168.10.103
# 集群节点映射端口
cluster-announce-port 6377
# 集群节点总线端口
cluster-announce-bus-port 16377
启动新的节点。
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6377.conf
添加主节点
使用以下命令添加主节点。
redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-master-id node_id
# 例子
/usr/local/redis/bin/redis-cli -a 123456 --cluster add-node 192.168.10.103:6377 192.168.10.103:6375 --cluster-master-id 4568a2560a688898a5d2337bce3a288f12355ae8
new_host:new_port:为要新添加的主节点 IP 和端口existing_host:existing_port:表示的是环境中已存在的最后一个主节点的 IP 和端口,这个可以通过查看节点信息得知,根据 slots 槽数,192.168.10.103:6375 对应的节点槽数是 10923-16383,16383 表示的是最后的槽数--cluster-master-id:表示的是最后一个主节点的节点 ID,表示的是新添加的主节点要在这个节点后面

# 再次查看集群信息
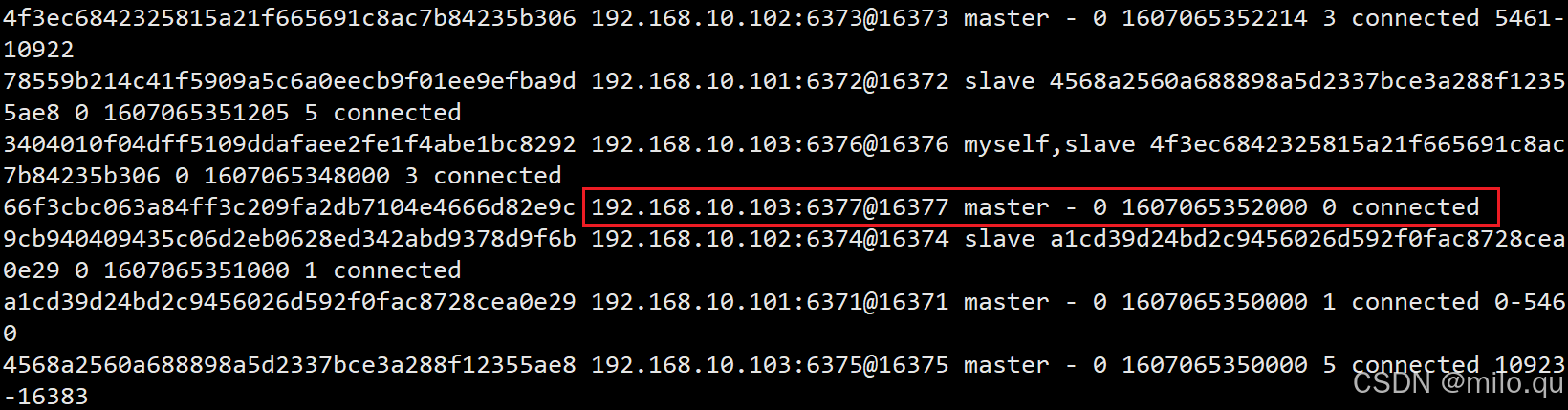
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
会发现 6377 端口对应的节点已经加入到集群中,是主节点,但是没有从节点,也没有分配槽数。
重新分片
添加完新节点后,需要对新添加的主节点进行 hash 槽重新分配,这样该主节点才能存储数据,Redis 共有16384个槽。
redis-cli --cluster reshard host:port --cluster-from node_id --cluster-to node_id --cluster-slots <args> --cluster-yes
# 例子
/usr/local/redis/bin/redis-cli -a 123456 --cluster reshard 192.168.10.103:6377 --cluster-from a1cd39d24bd2c9456026d592f0fac8728cea0e29 --cluster-to 66f3cbc063a84ff3c209fa2db7104e4666d82e9c --cluster-slots 2000
host:port:集群中随便一个节点的 IP:PORT 连接集群用的--cluster-from node_id:表示的是从哪个节点取出槽,节点 ID--cluster-to node_id:表示的是取出的槽添加给哪个节点,也就是新添加的那个主节点 ID--cluster-slots 2000:表示的是给新主节点分配多少,此处 2000 表示是分配从0-1999个 slots 槽数,然后需要输入 yes 重新进行槽分配。--cluster-yes:不回显槽分配信息直接移动。

# 再次查看集群信息
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
# 会发现 6377 端口对应的主节点已经有 slots 槽数了,并且是从 0 开始的

添加从节点
准备节点
首先准备一个新的节点,添加配置文件。
vi /usr/local/redis/cluster/conf/redis-6378.conf
# 放行访问IP限制
bind 0.0.0.0
# 端口
port 6378
# 后台启动
daemonize yes
# 日志存储目录及日志文件名
logfile "/usr/local/redis/cluster/log/redis-6378.log"
# rdb数据文件名
dbfilename dump-6378.rdb
# aof模式开启和aof数据文件名
appendonly yes
appendfilename "appendonly-6378.aof"
# rdb数据文件和aof数据文件的存储目录
dir /usr/local/redis/cluster/data
# 设置密码
requirepass 123456
# 从节点访问主节点密码(必须与 requirepass 一致)
masterauth 123456
# 是否开启集群模式,默认 no
cluster-enabled yes
# 集群节点信息文件,会保存在 dir 配置对应目录下
cluster-config-file nodes-6378.conf
# 集群节点连接超时时间
cluster-node-timeout 15000
# 集群节点 IP
cluster-announce-ip 192.168.10.103
# 集群节点映射端口
cluster-announce-port 6378
# 集群节点总线端口
cluster-announce-bus-port 16378
启动新的节点。
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6378.conf
添加从节点
使用以下命令添加从节点。
redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id node_id
# 例子
/usr/local/redis/bin/redis-cli -a 123456 --cluster add-node 192.168.10.103:6378 192.168.10.103:6377 --cluster-slave --cluster-master-id 66f3cbc063a84ff3c209fa2db7104e4666d82e9c
new_host:new_port:表示的是要添加的那个从节点的 IP 和端口existing_host:existing_port:表示的是要给哪个主节点添加从节点--cluster-slave:表示的是要添加从节点--cluster-master-id node_id:表示要给哪个主节点添加从节点,该主节点节点 ID
# 再次查看集群信息
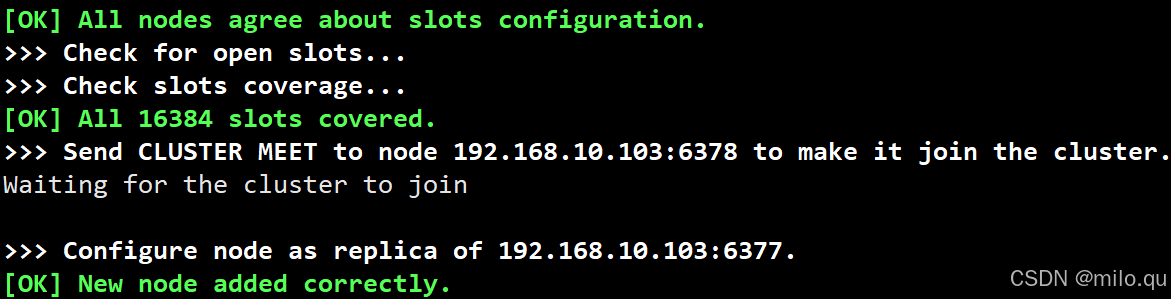
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
# 会发现 6378 端口对应的节点已经是 6377 端口对应的从节点
删除从节点
redis-cli --cluster del-node host:port node_id
# 例子
/usr/local/redis/bin/redis-cli -a 123456 --cluster del-node 192.168.10.103:6378 5800786da604cedb56eb1b50d83e9f82bb09b421
host:port:表示的是要删除的那个节点的 IP 和端口node_id:表示的是删除的那个节点的节点 ID

# 再次查看集群信息
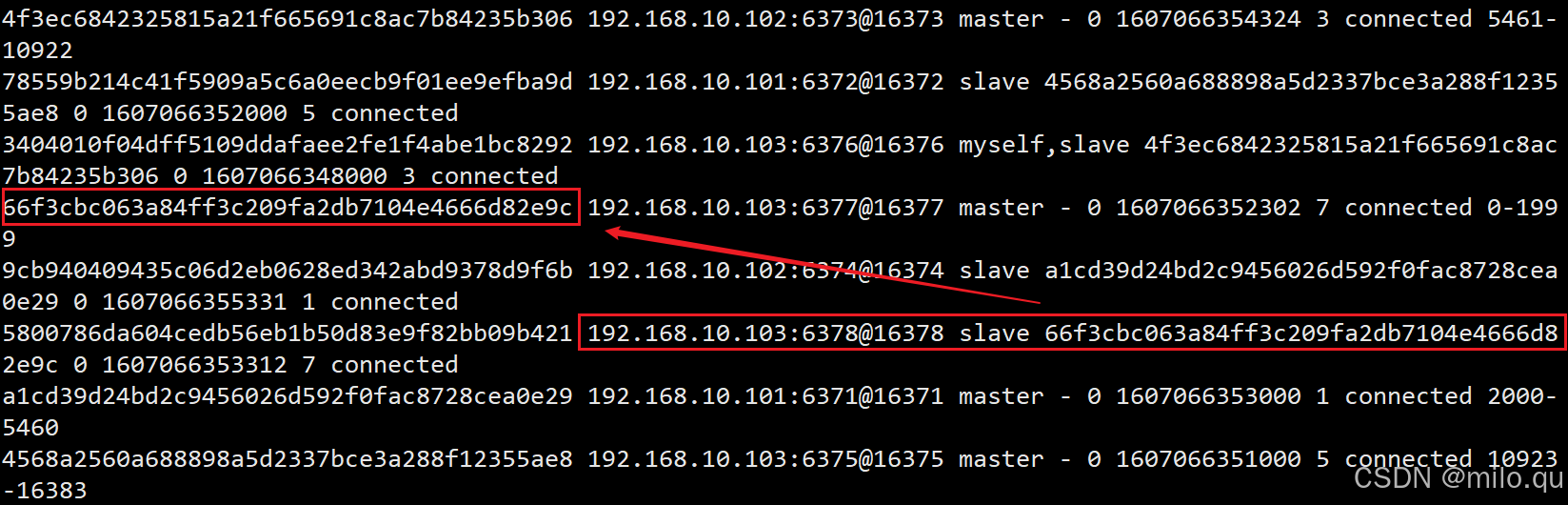
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
# 环境中 6378 从节点已被移除
删除主节点
删除主节点稍微麻烦一点,因为主节点分配了 slots 槽,所以必须先把 slots 槽放到其他可用节点中去,然后再进行移除节点操作才行,不然会出现数据丢失问题。
重新分片
把数据移动到其它主节点中去,执行重新分片命令。
/usr/local/redis/bin/redis-cli -a 123456 --cluster reshard 192.168.10.103:6377
192.168.10.103:6377 分配了 2000 个槽,这里输入 2000 即可。

回车以后,出现 what is the receiving node ID?意思是你想移动到那个节点上。
我想移动到 6371 的节点上,那么此处输入 6371 节点的 ID。

回车以后,需要填写数据源节点 ID,就是 6377 节点的 ID,因为我们要把 6377 节点的数据移动至其他节点去。
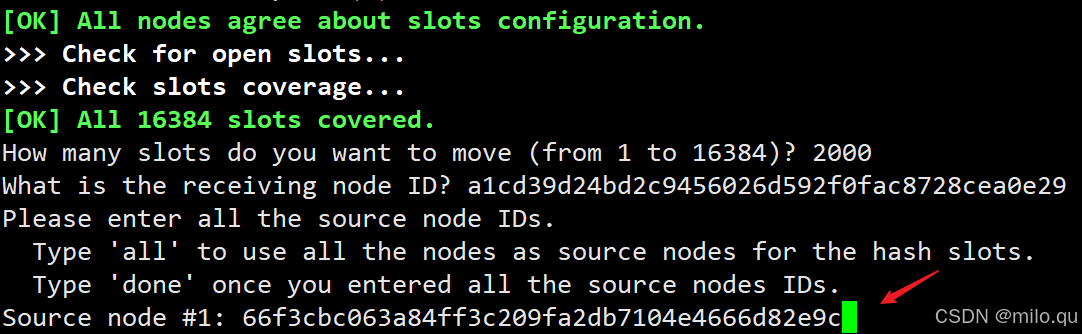
回车以后,还可以继续选择其他源节点,但是我这里只想把 6377 节点分到其它地方就行,此处输入 done 即可,否则输入其它节点的 ID,最后输入 done。
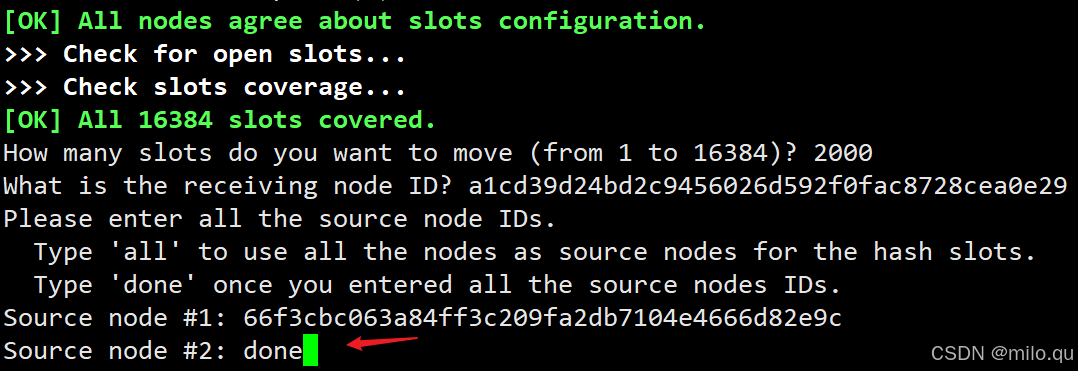
最后输入 yes 等待转移结束。
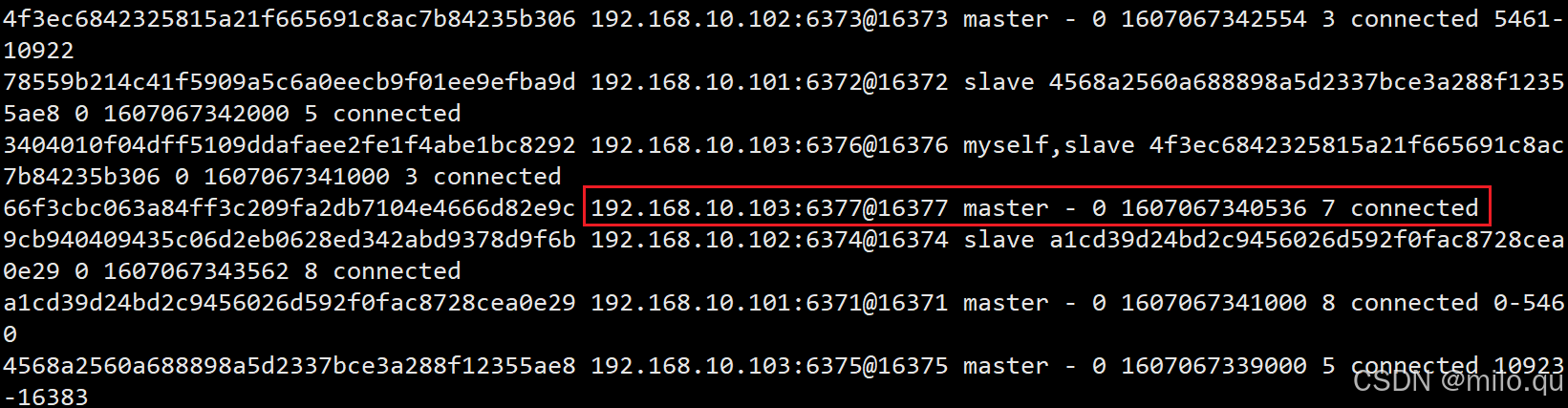
# 再次查看集群信息
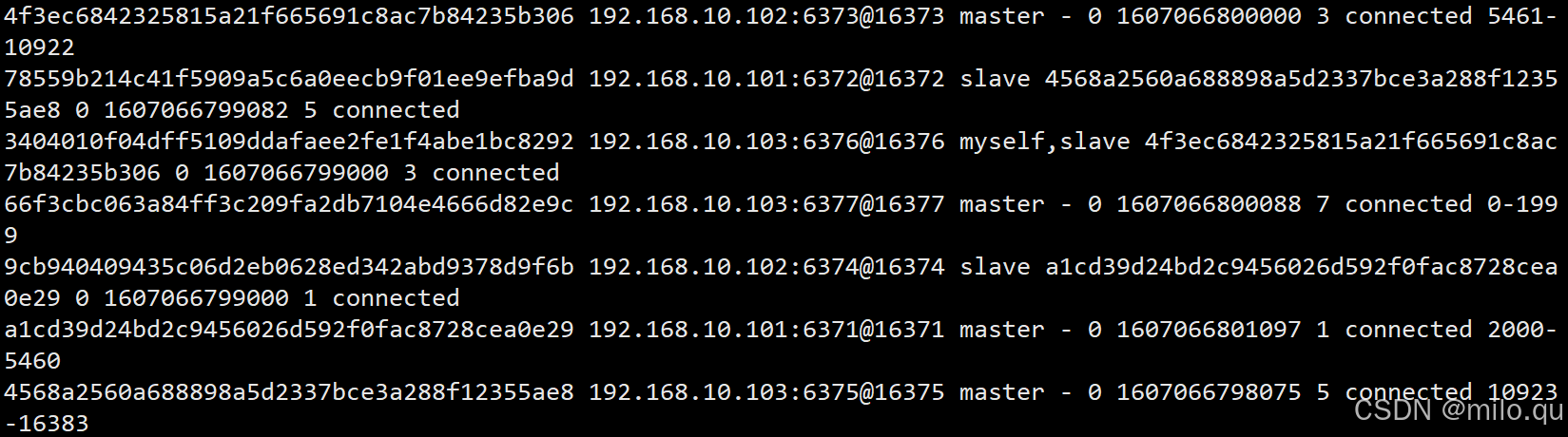
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
# 发现 6377 已经没有 slots 槽分配了
删除节点
接下来,调用删除从节点的方式,删除主节点。
/usr/local/redis/bin/redis-cli -a 123456 --cluster del-node 192.168.10.103:6377 66f3cbc063a84ff3c209fa2db7104e4666d82e9c

# 再次查看集群信息
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376 cluster nodes
# 环境中 6377 主节点已被移除
二、MOVED转向
当我们使用操作 Redis 单节点的 Client 来操作集群时,比如使用以下方式登入客户端。
/usr/local/redis/bin/redis-cli -a 123456 -h 192.168.10.103 -p 6376
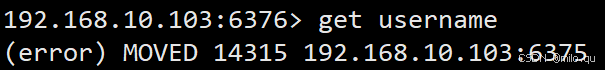
常常能够遇到上面的报错。按照 Redis 官方规范,一个 Redis 客户端可以向集群中的任意节点(包括从节点)发送命令请求。节点会对命令请求进行分析,如果该命令是集群可以执行的命令,那么节点会查找这个命令所要处理的键所在的槽。如果处理该命令的槽位于当前节点,那么命令可以顺利执行,否则当前节点会返回 MOVED 错误,让客户端到另一个节点执行该命令。
Redis 官方规范要求所有客户端都应处理 MOVED 错误,从而实现对用户的透明。我们上面看到的错误就是 MOVED 错误。表示执行该命令所需要的 slot 是 14315 号哈希槽,负责该槽的节点是 192.168.10.103:6375。
单机模式/集群模式下 MOVED 错误的显示区别。
- 集群模式的
redis-cli在接到 MOVED 错误时不会打印错误,而是自动根据错误提供的 IP 地址和端口进行转向动作 - 单机模式的
redis-cli客户端会打印 MOVED 错误,客户端需要做出处理
Redis 的哲学
为什么服务端不对客户端的请求作出处理?因为 Redis 的哲学:保持 Server 端的尽量简洁,能不在 Server 端做的事情都不在 Server 端做。
解决方案
客户端使用集群模式连接
启动时使用 -c 参数来启动集群模式。
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376
如果是第三方客户端也使用集群方式进行连接。比如我们课程代码中的 Spring Data Redis 中就是使用了集群模式进行连接的。
客户端优化
对于不支持集群模式连接的客户端,可以通过以下方式进行解决。
节点在 MOVED 错误中会直接返回目标节点的 IP 和端口号。客户端可以记录槽 14315 由节点 192.168.10.103:6375 负责处理“这一信息, 这样当再次有命令需要对槽 14315 执行时, 客户端就可以加快寻找正确节点的速度。这样,当集群处于稳定状态时,所有客户端最终都会保存有一个哈希槽至节点的映射记录,使得集群非常高效: 客户端可以直接向正确的节点发送命令请求,无须转向、代理或者其他任何可能发生单点故障(single point failure)的实体(entiy)。
三、ASK转向
除了 MOVED 转向,Redis 规范还要求客户端实现对 ASK 转向的处理。
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况:被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
当客户端向源节点发送一个命令,并且命令要处理的键恰好就属于正在被迁移的槽时:
- 源节点会先在自己的数据里面查找指定的键,如果找到的话,就直接执行客户端发送的命令
- 相反地,如果源节点没能在自己的数据里面找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个 ASK 错误,指引客户端转向正在导入槽的目标节点,并再次发送之前想要执行的命令
单机模式/集群模式下 ASK 错误的显示区别。
- 集群模式的
redis-cli在接到 ASK 错误时不会打印错误,而是自动根据错误提供的 IP 地址和端口进行转向动作 - 单机模式的
redis-cli客户端会打印 ASK 错误,客户端需要做出处理
解决方案
客户端使用集群模式连接
启动时使用 -c 参数来启动集群模式。
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376
如果是第三方客户端也使用集群方式进行连接。比如我们课程代码中的 Spring Data Redis 中就是使用了集群模式进行连接的。
ASKING命令
ASKING命令功能:打开发送该命令的客户端的 REDIS_ASKING 标识。
我们可以使用普通模式的 redis-cli 客户端,向正在导入某个槽的节点先发送 ASKING 命令,然后其他命令例如 GET 就会被正在导入槽的目标节点执行。
192.168.10.103:6376> ASKING # 打开 REDIS_ASKING 标识
OK
192.168.10.103:6376> get username # 移除 REDIS_ASKING 标识
"zhangsan"
192.168.10.103:6376> get username # REDIS_ASKING 标识未打开,执行失败
注意:客户端的 REDIS_ASKING 标识是一个一次性标识,当节点执行了一个带有 REDIS_ASKING 标识的客户端发送的命令之后,客户端的 REDIS_ASKING 标识就会被移除。
ASK错误和MOVED错误的区别
ASK 错误和 MOVED 错误都会导致客户端转向,它们的区别在于:
- MOVED 错误代表槽的负责权已经从一个节点转移到了另一个节点。当节点需要让一个客户端长期地(permanently)将针对某个槽的命令请求发送至另一个节点时,节点向客户端返回 MOVED 转向。
- ASK 错误只是两个节点在迁移槽的过程中使用的一种临时措施。当节点需要让客户端仅仅在下一个命令请求中转向至另一个节点时,节点向客户端返回 ASK 转向。客户端是不能直接请求 ASK 转向的目标机器的,而是必须先发送一个 ASKING 命令。
四、自动故障转移
启动 6 个 Redis 节点
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6371.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6372.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6373.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6374.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6375.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6376.conf
查看集群状态
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.101 -p 6372 cluster nodes
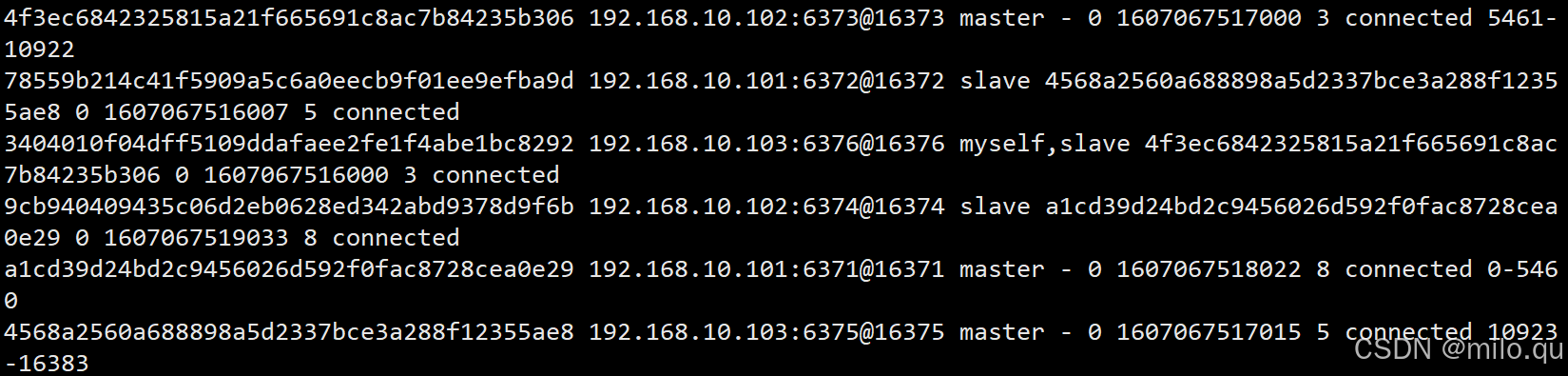
我们使用 6371 <> 6374 这对主从节点给大家演示故障转移。
d3028e6da602735c18f5917102a818daaf4f5a8a 192.168.10.103:6376@16376 slave 339e0d0b6f92322fb269a83c0b43c44850e7e0aa 0 1607409600000 3 connected
afe0b3936c837a46972055c7b9b691bdd8149b7d 192.168.10.101:6371@16371 myself,master - 0 1607409603000 1 connected 0-5460
339e0d0b6f92322fb269a83c0b43c44850e7e0aa 192.168.10.102:6373@16373 master - 0 1607409603857 3 connected 5461-10922
b444cc7e6a6ee077e2d2292c68abde22977c7e5d 192.168.10.102:6374@16374 slave afe0b3936c837a46972055c7b9b691bdd8149b7d 0 1607409603000 1 connected
70613e4ec9d16162808accd9e5e2da0792c9ec12 192.168.10.101:6372@16372 slave f3353d11eae2dae1e46cdee9134beea872d1c6e8 0 1607409604000 5 connected
f3353d11eae2dae1e46cdee9134beea872d1c6e8 192.168.10.103:6375@16375 master - 0 1607409604868 5 connected 10923-16383
模拟主节点故障
# 查看 6371 节点的 pid 进程号
/usr/local/redis/bin/redis-cli -a 123456 -h 192.168.10.101 -p 6371 info server | grep process_id
# 杀死进程
kill -9 进程号
查看从节点日志
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6374.log
# 与主节点失去联系
1181:S 2020 15:00:02.044 # Connection with master lost.
1181:S * Caching the disconnected master state.# (集群节点连接超时时间由 cluster-node-timeout 15000 决定)
# 连接主节点 192.168.10.101:6371
1181:S * Connecting to MASTER 192.168.10.101:6371
# 主从同步开始
1181:S * MASTER <-> REPLICA sync started
# SYNC 出错:拒绝连接
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused# 将节点 ae0b3936c837a46972055c7b9b691bdd8149b7d 标记为失败(达到法定人数)
1181:S 2020 15:00:20.561 * Marking node afe0b3936c837a46972055c7b9b691bdd8149b7d as failing (quorum reached).
# 集群状态改为:失败
1181:S # Cluster state changed: fail
# 选举开始
1181:S # Start of election delayed for 595 milliseconds (rank #0, offset 1624).
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S # Error condition on socket for SYNC: Connection refused
# 启动第7次纪元的故障切换选举
1181:S # Starting a failover election for epoch 7.
# 选举成功,自己(192.168.10.102:6374)是新主节点
1181:S # Failover election won: I'm the new master.
# 故障切换成功后,配置文件 config epoch 设置为 7
1181:S # configEpoch set to 7 after successful failover
# 抛弃之前缓存的主节点状态
1181:M * Discarding previously cached master state.
# 将二级主从 ID 设置为 xxx 有效偏移量为 1625 新的主从 ID 为 xxx
1181:M # Setting secondary replication ID to 0b35768c25c0a463cb73b9056dc832897a815ba7, valid up to offset: 1625. New replication ID is 9668c0e62ba28defda2b0360daa6b7f0fe5f89e0
# 集群状态 OK
1181:M # Cluster state changed: ok
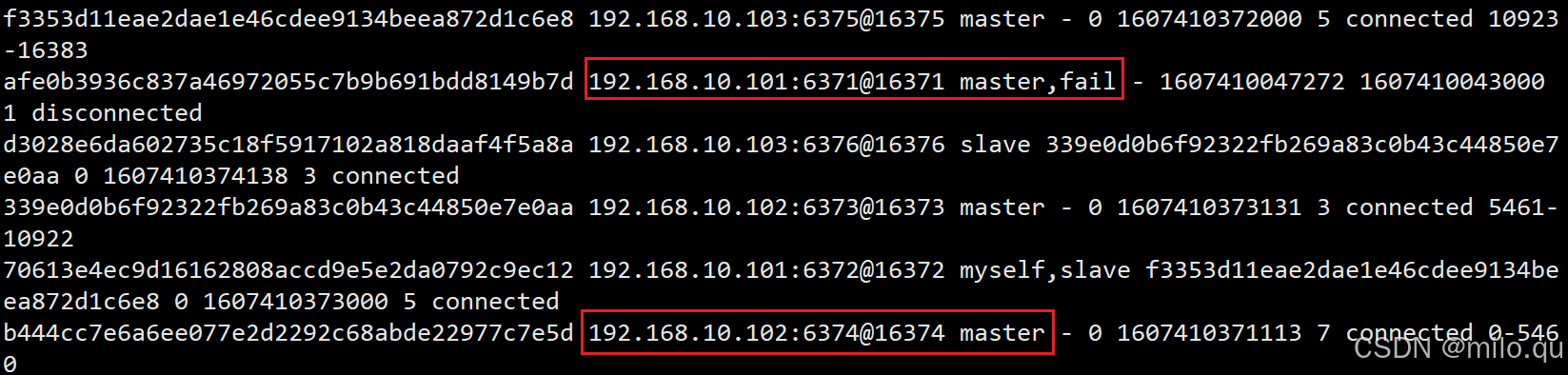
查看集群状态
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.101 -p 6372 cluster nodes
发现 6371 主节点显示 fail 状态,原来的 6374 从节点已经升级为主节点。
启动原主节点
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6371.conf
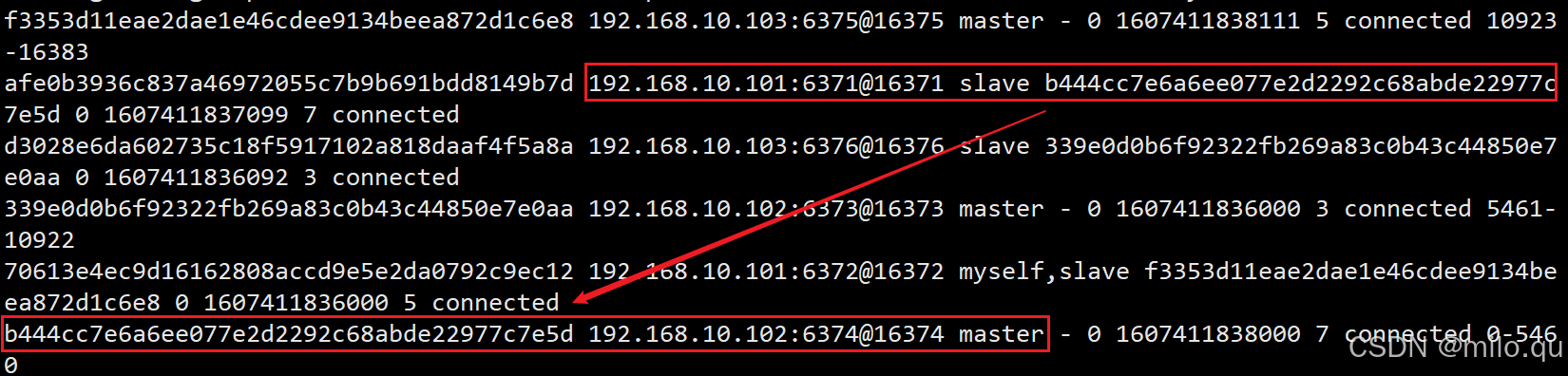
查看集群状态
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.101 -p 6372 cluster nodes
查看主从日志
原主节点现在是从节点
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6371.log
1265:C # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1265:C # Redis version=6.0.9, bits=64, commit=00000000, modified=0, pid=1265, just started
1265:C # Configuration loaded
1265:M * Increased maximum number of open files to 10032 (it was originally set to 1024).
1265:M * Node configuration loaded, I'm afe0b3936c837a46972055c7b9b691bdd8149b7d
1265:M * Running mode=cluster, port=6371.
1265:M # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1265:M # Server initialized
1265:M # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1265:M # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvise > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never').
1265:M * DB loaded from append only file: 0.462 seconds
1265:M * Ready to accept connections
# 检测到配置变更。将自己重新配置为 b444cc7e6a6ee077e2d2292c68abde22977c7e5d 的副本
1265:M # Configuration change detected. Reconfiguring myself as a replica of b444cc7e6a6ee077e2d2292c68abde22977c7e5d
# 变为副本前的准备工作
1265:S * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
1265:S # Cluster state changed: ok
# 连接主节点 192.168.10.102:6374
1265:S * Connecting to MASTER 192.168.10.102:6374
# 主从同步开始
1265:S * MASTER <-> REPLICA sync started
# 触发 SYNC 的非阻塞连接事件
1265:S * Non blocking connect for SYNC fired the event.
# 主节点已回复 PING 命令,同步可以继续
1265:S * Master replied to PING, replication can continue...
# 尝试部分重同步
1265:S * Trying a partial resynchronization (request 0e17197fbbd478907a28c62aea61f7d1486f5adf:1).
# 全量复制主节点
1265:S * Full resync from master: 9668c0e62ba28defda2b0360daa6b7f0fe5f89e0:1624
# 抛弃之前缓存的主节点状态
1265:S * Discarding previously cached master state.
# 主从复制:从主节点接收 4640673 个字节存储到磁盘
1265:S * MASTER <-> REPLICA sync: receiving 4640673 bytes from master to disk
# 主从复制:刷新旧数据
1265:S * MASTER <-> REPLICA sync: Flushing old data
# 主从复制:将数据加载到内存
1265:S * MASTER <-> REPLICA sync: Loading DB in memory
# 加载 RDB
1265:S * Loading RDB produced by version 6.0.9
1265:S * RDB age 1 seconds
1265:S * RDB memory usage when created 27.06 Mb
# 主从复制:顺利完成
1265:S * MASTER <-> REPLICA sync: Finished with success
# 后台开启进程执行 AOF 写入
1265:S * Background append only file rewriting started by pid 1270
1265:S * AOF rewrite child asks to stop sending diffs.
1270:C * Parent agreed to stop sending diffs. Finalizing AOF...
1270:C * Concatenating 0.00 MB of AOF diff received from parent.
1270:C * SYNC append only file rewrite performed
# 2 MB数据被写入 AOF 文件
1270:C * AOF rewrite: 2 MB of memory used by copy-on-write
# 后台 AOF 进程成功终止
1265:S * Background AOF rewrite terminated with success
1265:S * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
# 后台 AOF 重写顺利完成
1265:S * Background AOF rewrite finished successfully
原从节点现在是主节点
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6374.log
# 清除节点 ae0b3936c837a46972055c7b9b691bdd8149b7d 的 fail 状态
1181:M * Clear FAIL state for node afe0b3936c837a46972055c7b9b691bdd8149b7d: master without slots is reachable again.
# 192.168.10.101:6371 从节点发起 SYNC 请求
1181:M * Replica 192.168.10.101:6371 asks for synchronization
# 拒绝部分重同步
1181:M * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '0e17197fbbd478907a28c62aea61f7d1486f5adf', my replication IDs are '9668c0e62ba28defda2b0360daa6b7f0fe5f89e0' and '0b35768c25c0a463cb73b9056dc832897a815ba7')
# 通过 BGSAVE 指令将数据写入磁盘(RBD操作)
1181:M * Starting BGSAVE for SYNC with target: disk
# 开启一个子守护进程执行写入
1181:M * Background saving started by pid 1216
# 数据已写入磁盘
1216:C * DB saved on disk
# 有 4MB 数据已写入磁盘
1216:C * RDB: 4 MB of memory used by copy-on-write
# 保存结束
1181:M * Background saving terminated with success
# 从节点同步数据结束
1181:M * Synchronization with replica 192.168.10.101:6371 succeeded
查看数据
原来 address 和 age 这两个 Key 都在 6371 中,现在查看一下数据是否会被转向到 6374 中去获取。
五、手动故障转移
有的时候在主节点没有任何问题的情况下强制手动故障转移也是很有必要的,比如想要升级主节点的 Redis 进程,我们可以通过故障转移将其转为 Slave 再进行升级操作来避免对集群的可用性造成很大的影响。
Redis 集群使用 CLUSTER FAILOVER 命令来进行故障转移,不过要在被转移的主节点的从节点上执行该命令。
手动故障转移比主节点失败自动故障转移更加安全,因为手动故障转移时客户端的切换是在确保新的主节点完全复制了失败的旧的主节点数据的前提下下发生的,所以避免了数据的丢失。
执行手动故障转移以后,客户端不再链接我们淘汰的主节点,同时主节点向从节点发送复制偏移量,从节点得到复制偏移量后故障转移开始,接着通知主节点进行配置切换。
执行命令
在刚才降级为从几点的 6371 中执行 CLUSTER FAILOVER 开启手动故障转移。
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.102 -p 6374 cluster failover
查看集群状态
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.101 -p 6372 cluster nodes
查看主从日志
原主节点现在是从节点
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6374.log
# 从节点 ae0b3936c837a46972055c7b9b691bdd8149b7d 请求手动故障切换
1181:M # Manual failover requested by replica afe0b3936c837a46972055c7b9b691bdd8149b7d.
# 授予 afe0b3936c837a46972055c7b9b691bdd8149b7d epoch 8 的故障转移授权
1181:M # Failover auth granted to afe0b3936c837a46972055c7b9b691bdd8149b7d for epoch 8
# 与从节点失去联系
1181:M # Connection with replica 192.168.10.101:6371 lost.
# 检测到配置变更。将自己重新配置为 afe0b3936c837a46972055c7b9b691bdd8149b7d 的副本
1181:M # Configuration change detected. Reconfiguring myself as a replica of afe0b3936c837a46972055c7b9b691bdd8149b7d
# 变为副本前的准备工作
1181:S * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
# SYNC 过程
1181:S * Connecting to MASTER 192.168.10.101:6371
1181:S * MASTER <-> REPLICA sync started
1181:S * Non blocking connect for SYNC fired the event.
1181:S * Master replied to PING, replication can continue...
1181:S * Trying a partial resynchronization (request 9668c0e62ba28defda2b0360daa6b7f0fe5f89e0:4537).
1181:S * Successful partial resynchronization with master.
1181:S # Master replication ID changed to aa3c95e0f57609775000dd12deaaa122feb792dc
1181:S * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
原从节点现在是主节点
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6371.log
# 接受手动故障切换请求
1265:S # Manual failover user request accepted.
# 收到暂停服务的主节点动故障切换的复制偏移 4536
1265:S # Received replication offset for paused master manual failover: 4536
# 所有主复制流处理完毕,可以开始手动故障切换
1265:S # All master replication stream processed, manual failover can start.
# 选举开始
1265:S # Start of election delayed for 0 milliseconds (rank #0, offset 4536).
# 开始进行第8纪元的故障切换选举
1265:S # Starting a failover election for epoch 8.
# 选举成功,自己(192.168.10.101:6371)是新主节点
1265:S # Failover election won: I'm the new master.
# 故障切换成功后,配置文件 config epoch 设置为 8
1265:S # configEpoch set to 8 after successful failover
1265:M # Connection with master lost.
1265:M * Caching the disconnected master state.
# 抛弃之前缓存的主节点状态
1265:M * Discarding previously cached master state.
# 将二级主从 ID 设置为 xxx 有效偏移量为 4537 新的主从 ID 为 xxx
1265:M # Setting secondary replication ID to 9668c0e62ba28defda2b0360daa6b7f0fe5f89e0, valid up to offset: 4537. New replication ID is aa3c95e0f57609775000dd12deaaa122feb792dc
# 192.168.10.102:6374 请求同步
1265:M * Replica 192.168.10.102:6374 asks for synchronization
# 接受来自 192.168.10.102:6374 的部分重新同步请求。从偏移量 4537 开始
1265:M * Partial resynchronization request from 192.168.10.102:6374 accepted. Sending 0 bytes of backlog starting from offset 4537.
查看数据
原来 address 和 age 这两个 Key 都在 6374 中,现在查看一下数据是否会被转向到 6371 中去获取。
六、集群迁移
手动迁移
- 取消密码(有密码的话,最好先不要用密码)
- 创建与原集群结构一致的新集群(目标集群)环境
- 先从后主停掉目标集群服务
- 清除目标集群所有节点 appendonly.aof 和 dump.rdb
- 原集群手动触发 bgrewriteaof
- 复制原集群所有节点 appendonly.aof 文件到目标集群
- 启动新集群并设置密码
- 检查状态,迁移完毕
思考题:如果源集群与目标集群结构不一致该如何迁移?
Redis-Shark
很多人在升级时选用唯品会开源的 redis-migrate-tool 做数据迁移,但是这个工具太老,redis4 及以上版本的支持不太友好。
所以我们使用阿里开源的 Redis-Shark 数据迁移工具。
Redis-Shark开源项目:GitHub - tair-opensource/RedisShake: RedisShake is a Redis data processing and migration tool.
Redis-Shark中文文档:GitHub - tair-opensource/RedisShake: RedisShake is a Redis data processing and migration tool.
Redis-Shark官方编译包:Releases · tair-opensource/RedisShake · GitHub
环境准备
源集群:
| IP | 端口 |
|---|---|
| 192.168.10.101 | 6371、6372 |
| 192.168.10.102 | 6373、6374 |
| 192.168.10.103 | 6375、6376 |
Key 分布情况:
192.168.10.101:6371 (afe0b393...) -> 210683 keys | 5461 slots | 1 slaves.
192.168.10.102:6373 (339e0d0b...) -> 9 keys | 5462 slots | 1 slaves.
192.168.10.103:6375 (f3353d11...) -> 3 keys | 5461 slots | 1 slaves.
目标集群:
| IP | 端口 |
|---|---|
| 192.168.10.104 | 6371、6372 |
| 192.168.10.105 | 6373、6374 |
| 192.168.10.106 | 6375、6376 |
Key 分布情况:
192.168.10.104:6371 (15d444c6...) -> 0 keys | 5461 slots | 1 slaves.
192.168.10.106:6375 (77772ed7...) -> 0 keys | 5461 slots | 1 slaves.
192.168.10.105:6373 (32069c23...) -> 0 keys | 5462 slots | 1 slaves.
解压工具包
下载官方编译好的工具包,直接解压后就能使用。
tar -zxvf redis-shake-v2.0.3.tar.gz
编写配置
官方文档中给出了很多迁移模式的配置案例,比如单个节点到单个节点、集群版cluster到集群版cluster、集群版cluster到proxy、主从版/单节点到cluster等等。
集群版cluster到proxy配置
redis-shark.conf
# 当前配置文件的版本号,请不要修改该值。
conf.version = 1
# 默认即可。
id = redis-shake
# 源端 Redis 的类型,支持 standalone,sentinel,cluster 和 proxy 四种模式。
source.type = cluster
# 源端所有 Master 或者 Slave 地址。
source.address = 192.168.10.101:6371;192.168.10.102:6373;192.168.10.103:6375
# 源端验证类型
source.auth_type = auth
# 源端 Redis 密码
source.password_raw = 123456
# 目标 Redis 的类型,支持 standalone,sentinel,cluster 和 proxy 四种模式。
target.type = cluster
# 目标所有 Master 或者 Slave 地址。
target.address = 192.168.10.104:6371;192.168.10.105:6373;192.168.10.106:6375
# 目标验证类型
target.auth_type = auth
# 目标 Redis 密码
target.password_raw = 123456
迁移
使用相应平台对应的 redis-shark 工具,此处是在 Linux 上做的操作,故选择 redsi-sharke.linux。

./redis-shake.linux -conf=redis-shake.conf -type=sync
-conf:指定配置文件路径-type:指定操作类型sync:全量+增量同步
该工具如果不停止运行,可以起到一直监听源集群的作用,当源集群有数据改动会直接备份到目标集群。
检查
先来人工检查一下,查看两个集群的状态。
原集群:
192.168.10.101:6371 (afe0b393...) -> 210683 keys | 5461 slots | 1 slaves.
192.168.10.102:6373 (339e0d0b...) -> 9 keys | 5462 slots | 1 slaves.
192.168.10.103:6375 (f3353d11...) -> 3 keys | 5461 slots | 1 slaves.
目标集群:
192.168.10.104:6371 (15d444c6...) -> 210683 keys | 5461 slots | 1 slaves.
192.168.10.106:6375 (77772ed7...) -> 3 keys | 5461 slots | 1 slaves.
192.168.10.105:6373 (32069c23...) -> 9 keys | 5462 slots | 1 slaves.
RedisFullCheck
若要检查源和目标是否数据统一,还可选择阿里配套工具 RedisFullCheck。
RedisFullCheck开源项目:GitHub - tair-opensource/RedisFullCheck: redis-full-check is used to compare whether two redis have the same data. Support redis version from 2.x to 7.x (Don't support Redis Modules).
RedisFullCheck中文文档:Home · tair-opensource/RedisFullCheck Wiki · GitHub
RedisFullCheck官方编译包:Releases · tair-opensource/RedisFullCheck · GitHub
下载官方编译好的工具包,直接解压后就能使用。
tar -zxvf redis-full-check-1.4.8.tar.gz
运行。
./redis-full-check -s "192.168.10.101:6371;192.168.10.102:6373;192.168.10.103:6375" --sourcepassword=123456 -t "192.168.10.104:6371;192.168.10.105:6373;192.168.10.106:6375" --targetpassword=123456 --comparemode=1 --comparetimes=1 --qps=10 --batchcount=100 --sourcedbtype=1 --targetdbtype=1
-s:源redis库地址(ip:port),如果是集群版,那么需要以分号--sourcepassword:源redis库密码-t:目标redis库地址(ip:port)--targetpassword:目标redis库密码--comparemode:比较模式,1表示全量比较,2表示只对比value的长度,3只对比key是否存在,4全量比较的情况下,忽略大key的比较--comparetimes:比较轮数--qps:qps限速阈值--batchcount:批量聚合的数量--sourcedbtype:源库的类别,0:db(standalone单节点、主从),1: cluster(集群版),2: 阿里云--targetdbtype:目的库的类别
结果。
--------------- finished! ----------------
all finish successfully, totally 0 key(s) and 0 field(s) conflict
相关文章:

七、Redis集群高可用
一、节点与插槽管理 添加主节点 准备节点 首先准备一个新的节点,添加配置文件。 vi /usr/local/redis/cluster/conf/redis-6377.conf # 放行访问IP限制 bind 0.0.0.0 # 端口 port 6377 # 后台启动 daemonize yes # 日志存储目录及日志文件名 logfile "/us…...

WPF12-MVVM
目录 1. 什么是MVVM2. 实现简单MVVM2.1. Part 12.2. Part 21. 什么是MVVM MVVM 是 Model-View-ViewModel 的缩写,是一种用于构建用户界面的设计模式,是一种简化用户界面的事件驱动编程方式。 MVVM 的目标是实现用户界面和业务逻辑之间的彻底分离,以便更好地管理和维护应用…...

多智能体博弈代码案例
多智能体博弈代码案例 直接可用,我不吝啬 from openai import OpenAI import random# 定义不同人物角色的提示 CHARACTER_PROMPTS = {"专家": "你是该领域的权威专家,知识渊博,回答严谨专业。"...

【AHK】资源管理器自动化办公实例/自动连点设置
此处为一个自动连续点击打开检查的自动化操作案例,没有quicker的鼠键录制,不常用了,做个备份 #MaxThreadsPerHotkey 2 ; 这个是核心!!!!确保可以同时运行多个热键或标签global isRunning : tru…...

Python安装环境变量
1、确保已经安装python到电脑上 2、到系统上环境变量位置 3、新建 系统变量,变量名为PYTHON_HOME,变量值为python安装目录 4、 点击系统变量的path,并新建环境变量 5、测试 ,windowsR,并输入cmd,尝试命令python --ver…...

Flink同步数据mysql到doris问题合集
Flink同步数据mysql到doris 官方同步流程Doris安装下载地址导入镜像启动配置 Flink-cdc安装(自制)下载地址导入镜像启动命令 启动问题修复Flink报错Could not acquire the minimum required resources.作业报错 Mysql8.0 Public Key Retrieval is not al…...

Pytest测试用例执行跳过的3种方式
文章目录 1.前言2.使用 pytest.mark.skip 标记无条件跳过3.使用 pytest.mark.skipif 标记根据条件跳过4. 执行pytest.skip()方法跳过测试用例 1.前言 在实际场景中,我们可能某条测试用例没写完,代码执行时会报错,或者是在一些条件下不让某些…...

spring boot 连接FTP实现文件上传
spring boot 连接FTP实现文件上传 maven: <!--ftp--><dependency><groupId>commons-net</groupId><artifactId>commons-net</artifactId><version>3.8.0</version></dependency>接口示例: ApiO…...

深入解析/etc/hosts.allow与 /etc/hosts.deny:灵活控制 Linux 网络访问权限
文章目录 深入解析/etc/hosts.allow与 /etc/hosts.deny:灵活控制 Linux 网络访问权限引言什么是 TCP Wrappers?工作原理 什么是 /etc/hosts.allow 和 /etc/hosts.deny?匹配规则配置语法详解配置示例允许特定 IP 访问 SSH 服务拒绝整个子网访问…...

短跑怎么训练提高最快·棒球1号位
棒球运动员的短跑能力直接影响跑垒、防守和进攻效率,提升短跑速度需结合专项需求(如爆发力、加速度、变向能力)进行系统训练。以下为针对性训练方案: 一、专项爆发力训练(提升起跑速度) 抗阻冲刺 用弹力带…...

USRP7440-通用软件无线电平台
1、产品描述 USRP7440基于第三代XILINX Zynq UltraScale RFSoC架构,它将射频ADC、DAC、ARM、FPGA等集成一体,瞬时带宽可以达到2.5GHz,尤其适合于射频直采应用,比如通信与雷达。 第一代RFSOC高达4GHz • 8x 或 16x 6.554GSPS DAC…...

51c大模型~合集48
我自己的原文哦~ https://blog.51cto.com/whaosoft/11940475 #Mini-Omni 让大模型能听会说,国内机构开源全球首个端到端语音对话模型 本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥&…...

004-利用Docker安装Mysql
利用Docker安装Mysql 一、在镜像仓库找到 Mysql1.镜像仓库地址2.复制命令3.下载Mysql镜像4.查看镜像 二、创建实例并启动三、用本地工具连接数据库四、设置 Mysql 配置 一、在镜像仓库找到 Mysql 1.镜像仓库地址 https://hub.docker.com 2.复制命令 docker pull mysql:8.0…...

Web自动化之Selenium添加网站Cookies实现免登录
在使用Selenium进行Web自动化时,添加网站Cookies是实现免登录的一种高效方法。通过模拟浏览器行为,我们可以将已登录状态的Cookies存储起来,并在下次自动化测试或爬虫任务中直接加载这些Cookies,从而跳过登录步骤。 Cookies简介 …...

UEditor集成Markdown编辑功能方案
分步解决方案: 1. 推荐免费开源Markdown库 推荐使用 markdown-it(MIT协议) 官网:https://github.com/markdown-it/markdown-it 特点:轻量级(15KB)、扩展性强、支持CommonMark规范、中文文档丰…...

综合练习 —— 递归、搜索与回溯算法
目录 一、1863. 找出所有子集的异或总和再求和 - 力扣(LeetCode) 算法代码: 代码思路 问题分析 核心思想 实现细节 代码解析 初始化 DFS 函数 时间复杂度 空间复杂度 示例运行 输入 运行过程 总结 二、 47. 全排列 II - 力扣&a…...

Python之使用动态导包优化软件加载速度
在开发大型 Python 软件时,可能会遇到以下问题:由于静态导入了大量模块,导致软件启动时间过长,用户体验不佳。例如,一个复杂的桌面应用程序或 Web 服务可能依赖于多个大型库(如 numpy、pandas、torch 或 Yolo),这些库在启动时被静态导入,即使某些功能模块在启动时并不…...

第16天:C++多线程完全指南 - 从基础到现代并发编程
第16天:C多线程完全指南 - 从基础到现代并发编程 一、多线程基础概念 1. 线程创建与管理(C11) #include <iostream> #include <thread>void hello() {std::cout << "Hello from thread " << std::this_…...

建筑兔零基础人工智能自学记录33|基础知识1
插入学习一下一些基础概念: 1、基本概念 人工智能:让机器像人一样思考。机器学习ML:计算机获取知识的过程。深度学习:机器的一种思考方式(借助神经网络)。 三者关系 2、机器学习的方式 监督学习&#x…...

win11编译pytorchaudio cuda128版本流程
1. 前置条件 本篇续接自 win11编译pytorch cuda128版本流程,阅读前请先参考上一篇配置环境。 访问https://kkgithub.com/pytorch/audio/archive/refs/tags/v2.6.0.tar.gz下载源码,下载后解压; 2. 编译 在visual studio 2022安装目录下查找…...
)
Python—Excel全字段转json文件(极速版+GUI界面打包)
目录 专栏导读1、背景介绍2、库的安装3、核心代码4、完整代码(简易版)5、进阶版(GUI)总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文章专栏:请点击——…...

NLP学习记录十一:位置编码
目录 一、位置编码的意义 二、位置编码方法 三、代码实现 一、位置编码的意义 在标准的注意力机制中,每个查询都会关注所有的键-值对并生成一个注意力输出,模型并没有考虑到输入序列每个token的顺序关系。 以["我&qu…...

算法之算法主题
程序员数学 《程序员数学 v2.0》 | 小傅哥 bugstack 虫洞栈 智力题 头脑风暴题目 | Java 全栈知识体系...
)
【三维分割】LangSplat: 3D Language Gaussian Splatting(CVPR 2024 highlight)
论文:https://arxiv.org/pdf/2312.16084 代码:https://github.com/minghanqin/LangSplat 文章目录 一、3D language field二、回顾 Language Fields的挑战三、使用SAM学习层次结构语义四、Language Fields 的 3DGS五、开放词汇查询(Open-voca…...

Wireshark:自定义类型帧解析
文章目录 1. 前言2. 背景3. 开发 Lua 插件 1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。 2. 背景 Wireshark 不认识用 tcpdump 抓取的数据帧,仔细分析相关代码和数据帧后,…...

ES6 特性全面解析与应用实践
1、let let 关键字用来声明变量,使用let 声明的变量有几个特点: 1) 不允许重复声明 2) 块儿级作用域 3) 不存在变量提升 4) 不影响作用域链 5) 暂时性死区 6)不与顶级对象挂钩 在代码块内,使用let命令声明变量之前&#x…...

Qt跨线程信号槽调用:为什么信号不能像普通函数那样调用
1. 信号与槽机制的基本原理 在 Qt 中,信号与槽机制是一种事件驱动的通信方式,用于对象之间的解耦交互。其关键特点如下: 信号不能直接调用 信号只是一个声明,并没有实际的函数实现。它们通过 emit 关键字在对象内部被触发&…...
如何进行Zookeeper的监控?)
Zookeeper(79)如何进行Zookeeper的监控?
对 Zookeeper 进行监控是确保其高可用性和性能的关键步骤。监控 Zookeeper 通常包括以下几个方面: 健康检查:检查 Zookeeper 节点是否在线。性能指标:监控关键性能指标,如请求延迟、事务处理量等。日志监控:监控 Zook…...
)
【江科大STM32】TIM输出比较-PWM功能(学习笔记)
一、PWM驱动LED呼吸灯 接线图: PWM的初始化: 具体步骤: ①RCC开启时钟(把要用的TIM外设和GPIO外设时钟都打开) ② 配置时基单元,包括前面的时钟源选择 ③配置输出比较单元,里面包括CCR的值ÿ…...

playbin之autoplug_factories源码剖析
一、autoplug_factories_cb /* Called when we must provide a list of factories to plug to pad with caps.* We first check if we have a sink that can handle the format and if we do, we* return NULL, to expose the pad. If we have no sink (or the sink does not…...

Spring Cloud之注册中心之Nacos的使用
目录 Naacos 服务注册/服务发现 引⼊Spring Cloud Alibaba依赖 引入Nacos依赖 引入Load Balance依赖 配置Nacos地址 服务端调用 启动服务 Naacos Nacos是Spring Cloud Alibaba的组件, Spring Cloud Alibaba遵循Spring Cloud中定义的服务注册, 服务发现规范. 因此使⽤Na…...

React antd的datePicker自定义,封装成组件
一、antd的datePicker自定义 需求:用户需要为日期选择器的每个日期单元格添加一个Tooltip,当鼠标悬停时显示日期、可兑换流量余额和本公会可兑流量。这些数据需要从接口获取。我需要结合之前的代码,确保Tooltip正确显示,并且数据…...

【tplink】校园网接路由器如何单独登录自己的账号,wan-lan和lan-lan区别
老式路由器TPLINK,接入校园网后一人登录,所有人都能通过连接此路由器上网,无法解决遂上网搜索,无果,幸而偶然看到一个帖子说要把信号源网线接入路由器lan口,开启新世界。 一、wan-lan,lan-lan区…...
)
散户情绪周期模型(情绪影响操作)
目录 一、个股上涨阶段情绪演化二、个股下跌阶段情绪演化三、底部震荡阶段情绪演化四、情绪观察与操作工具箱1. 情绪自测量表(每日收盘后记录)2. 情绪-指标对照表 五、高阶情绪管理技巧1.认知重构训练2.生理指标监控(需配合智能手表ÿ…...

对比Grok3 普通账户与 30 美元 Super 账户:默认模式、Think 和 DeepSearch 次数限制以及如何升级
面对这个马斯克旗下的"最聪明"的人工智能,很多人都不知道他们的基本模式,本期将从几个方面开始说明: Grok3的背景与功能 账户类型及其详细背景 使用限制 使用限制对比表 如何充值使用 Super 账户 纯干货,带你了解…...

小程序Three Dof识别 实现景区AR体验
代码工程 GitCode - 全球开发者的开源社区,开源代码托管平台 dof...
)
主流Linux发行版优缺点整理及对比指南(文末附表格)
Linux发行版种类繁多,各有其设计理念和适用场景。本文整理常见发行版的优缺点,并附对比表格,帮助用户根据需求选择最适合的系统。 1. Ubuntu 定位:适合新手的通用型桌面/服务器系统优点: 安装简单,社区支持…...

用大白话解释搜索引擎Elasticsearch是什么,有什么用,怎么用
Elasticsearch是什么? Elasticsearch(简称ES)就像一个“超级智能的图书馆管理系统”,专门帮你从海量数据中快速找到想要的信息。它底层基于倒排索引技术(类似书籍的目录页),能秒级搜索和分析万…...
)
坐标变换及视图变换和透视变换(相机透视模型)
文章目录 2D transformationScaleReflectionShear(切变)Rotation around originTranslationReverse变换顺序复杂变换的分解 齐次坐标(Homogenous Coordinates)3D transformationScale&TranslationRotation Viewing / Camera t…...

C# 基于.NET Framework框架WPF应用程序-MQTTNet库实现MQTT消息订阅发布
C# 基于.NET Framework框架WPF应用程序-MQTTNet库实现MQTT消息订阅发布 MQTT简述MQTTNet简述创建项目(基于.NET Framework框架)安装MQTTNet库项目源码运行效果 MQTT简述 mqtt官网 MQTTNet简述 MQTTnet MQTTnet 是一个强大的开源 MQTT 客户端库&#…...

Python实现视频播放器
Python实现视频播放器 Python实现视频播放器,在如下博文中介绍过 Python实现本地视频/音频播放器https://blog.csdn.net/cnds123/article/details/137874107 Python简单GUI程序示例 中 “四、视频播放器” https://blog.csdn.net/cnds123/article/details/122903…...

介绍一款飞算JavaAI编程工具,集成到idea,图文并茂
飞算的插件下载地址,里边也有安装步骤: JavaAI 下载 从file-》setting-》plugin,然后走图中所示 选择从磁盘安装插件:找到下载好的压缩包然后进行idea重启 根据提示模块可以生成代码,就是需要等待,后期不…...

【大数据】Spark Executor内存分配原理与调优
【大数据】Spark Executor内存管理与调优 Executor内存总体布局 统一内存管理 堆内内存 (On-heap Memory) 堆外内存 (Off-heap Memory) Execution 内存和 Storage 内存动态占用机制 任务内存管理(Task Memory Manager) 只用了堆内内存的示例 用了…...

Python 课堂点名桌面小程序
一、场景分析 闲来无事,老婆说叫我开发一个课堂点名桌面小程序,给她在课堂随机点名学生问问题。 人生苦短,那就用 Python 给她写一个吧。 二、依赖安装 因为要用到 excel,所以安装两个依赖: pip install openpyxl…...

配置Spring Boot中的Jackson序列化
配置Spring Boot中的Jackson序列化 在开发基于Spring Boot的应用程序时,Jackson是默认的JSON序列化和反序列化工具。它提供了强大的功能,可以灵活地处理JSON数据。然而,Jackson的默认行为可能无法完全满足我们的需求。例如,日期格…...

Rust学习总结之-match
Rust 有一个叫做 match 的极为强大的控制流运算符,它允许我们将一个值与一系列的模式相比较,并根据相匹配的模式执行相应代码。模式可由字面量、变量、通配符和许多其他内容构成。 一:match定义 可以把 match 表达式想象成某种硬币分类器&a…...

实践教程:使用DeepSeek实现PDF转Word的高效方案
🎈Deepseek推荐工具 PDF文件因其跨平台、格式稳定的特性被广泛使用,但在内容编辑场景中,用户常需将PDF转换为可编辑的Word文档。传统的付费工具(如Adobe Acrobat)或在线转换平台存在成本高、隐私风险等问题。本文将使…...

鸿蒙 ArkUI 实现 2048 小游戏
2048 是一款经典的益智游戏,玩家通过滑动屏幕合并相同数字的方块,最终目标是合成数字 2048。本文基于鸿蒙 ArkUI 框架,详细解析其实现过程,帮助开发者理解如何利用声明式 UI 和状态管理构建此类游戏。 一、核心数据结构与状态管理…...

az devops login报错:Failed to authenticate using the supplied token.
PowerShell,az devops login报错: Failed to authenticate using the supplied token. 检查了一下PAT token是对的。 检查命令: az devops login --organization https://dev.azure.com/xxxxxxxx/ 乍一看好像没问题问题,然后想…...

C ++ 静态存储区+堆空间
静态存储区 特点: 1:生命周期很长,main函数开始之前就存在,main函数结束,才结束 2:同名变量的管理,与栈不一样(重名变量前提,作用域一样): 栈:遇到重名变…...