Web自动化之Selenium 超详细教程(python)
Selenium是一个开源的基于WebDriver实现的自动化测试工具。WebDriver提供了一套完整的API来控制浏览器,模拟用户的各种操作,如点击、输入文本、获取页面元素等。通过Selenium,我们可以编写自动化脚本,实现网页的自动化测试、数据采集等功能。它支持多种浏览器,如Chrome、Firefox、Edge等,并且提还供了丰富的语言绑定,包括Python、Java、C#等,使得开发者可以根据自己的需求选择合适的语言和工具链进行开发。
本文所有内容基于作者本人在使用python selenium进行web自动化任务时所遇到的实际问题和解决方案进行整理和总结。希望这些经验能够帮助到正在学习或使用python selenium进行web自动化的朋友们。
selenium下载
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple seleniumWebDriver下载
在使用python Selenium进行web自动化测试或数据采集之前,我们需要下载与浏览器相对应的WebDriver。WebDriver是Selenium与浏览器进行交互的桥梁,不同的浏览器需要下载对应的WebDriver。对于Chrome浏览器,我们需要下载ChromeDriver;对于Firefox浏览器,我们需要下载GeckoDriver。这些WebDriver可以从各自浏览器的官方网站或Selenium的官方GitHub仓库中下载。
下载完成后,我们需要将WebDriver的路径添加到系统的环境变量中,或者在代码中指定WebDriver的路径,以便Selenium能够正确地找到并使用它。正确下载和配置WebDriver是使用Selenium进行web自动化的第一步。
这里以edgedriver为例,其他浏览器的webdriver配置大同小异。
前往Edge的webdriver官网,https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH![]() https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH 
根据自己的电脑配置选择一个版本下载即可(不需要选择特别新的版本,稳定版本的就可以)
下载时有的用户不知道自己的windows电脑的cpui架构是x86还是x64的,这里,我们只需要在cmd中输入systeminfo命令后在弹出的提示符中的系统类型中便可以看到自己电脑的cpu架构。
下载完成之后将edgedriver.exe文件的路径复制,并添加到环境变量中即可,
添加到环境变量
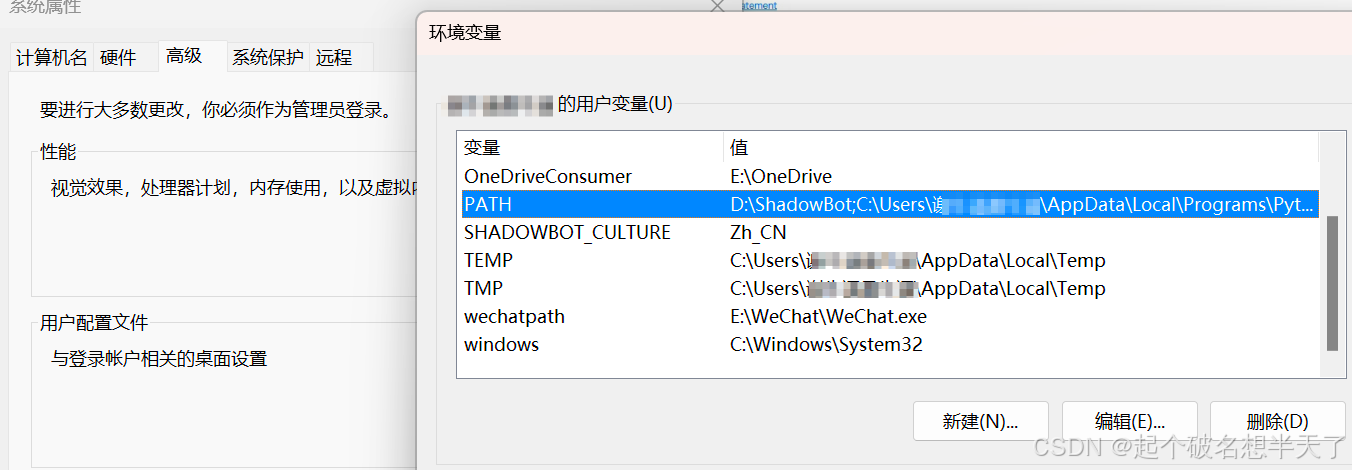
win+s搜索编辑系统环境变量,点击第一个搜索结果后,点击环境变量按钮,选中上方用户变量中的PATH(python安装时默认添加到系统的的那个环境变量名称) 点击编辑按钮进入到PATH中。
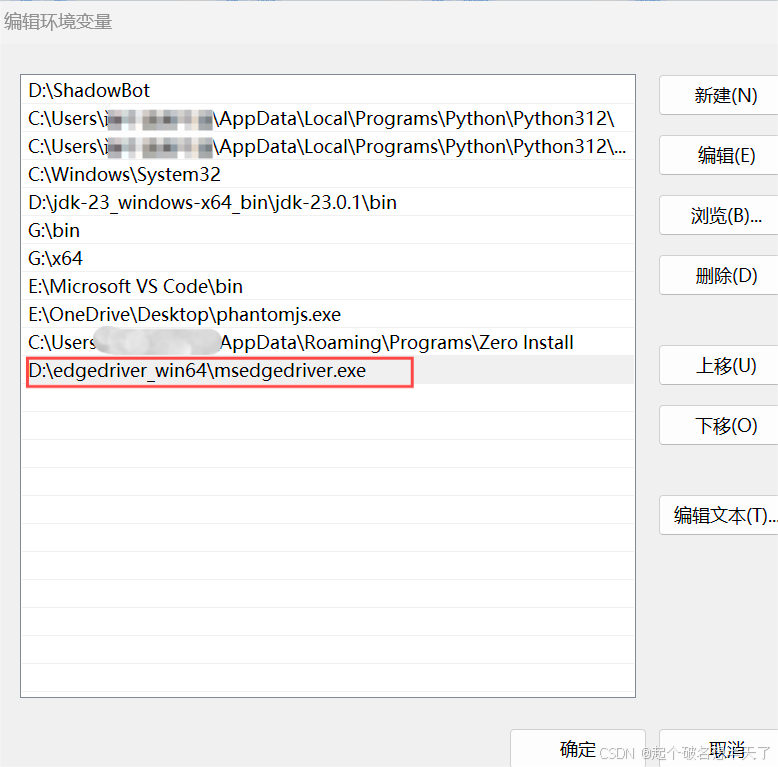
将刚刚下载好的edgedriver.exe的路径复制到里边,然后点击三个已经打开的窗口的确定,退出设置系统环境变量的窗口后,至此已将edgedriver的路径添加到了环境变量中。我们可以使用python代码来进行web自动化了
selenium教程
以下的python selenium代码和操作技巧是作者本人在进行web自动化过程中常用到的一些基本方法,基本涵盖了常见操作。
导入的库
from selenium import webdriver#webdriver对象
from selenium.webdriver.edge.options import Options#options选项因webdriver类型而异,这里使用edge
from selenium.webdriver.common.by import By#定位元素By类
from selenium.webdriver.common.keys import Keys#模拟按键操作Keys类
from selenium.webdriver.support.ui import WebDriverWait#显性等待
from selenium.webdriver import ActionChains#用来模拟人为操作鼠标的一系列动作
from selenium.webdriver.support import expected_conditions as EC#条件等待,配合显性等待使用
from selenium.common.exceptions import TimeoutException#超时错误
from selenium.common.exceptions import NoSuchElementException#元素定位错误设置webdriver对象
browser=webdriver.ChromiumEdge()#设定一个webdriver对象,Edge浏览器
browser=webdriver.Chrome()#设定一个webdriver对象,Chrome浏览器
browser=webdriver.Firefox()#设定一个webdriver对象,Firefox浏览器这里需要注意的是,要使用哪一个类型的浏览器作为webdriver,那么我们需要下载该浏览器的driver.exe文件,并按照之前的流程将其添加到环境变量中,这里我们使用Edgedriver,故webdriver对象是ChromiumEdge()
设定options
selenium中的options是用来设定浏览器的一些属性和必要的操作选项的。
同样的,options也因浏览器的类型而异,导入时也应该按照你的webdriver类型选择
from selenium.webdriver.firefox.options import Options#火狐浏览器
from selenium.webdriver.edge.options import Options#Edge浏览器
from selenium.webdriver.chrome.options import Options#Chrome浏览器以下是一些常见的options选项(主要是用来隐藏自动化控制的痕迹并且设置文件下载路径)
options=Options()#先声明一个options变量
Options.add_argument(‘--disable-blink-features=AutomationControlled)#隐藏自动化控制标头
Option.add_experimental_option('excludeSwitches',['enable-automation'])#隐藏自动化标头
Options.add_argument('--ignore-ssl-errosr')#忽略ssl错误
Options.add_argument('--ignore-certificate-errors')#忽略证书错误
prefs = {'download.default_directory': '文件夹路径', # 设置文件默认下载路径"profile.default_content_setting_values.automatic_downloads": True # 允许多文件下载}options.add_experimental_option("prefs", prefs)#将prefs字典传入options
最后,我们需要将已经设定好的options传入到先前设定的webdriver对象中
browser=webdriver.ChromiumEdge(options)#将options传入到webdriver中这样,我们便可以使用browser(已经设定好的options 的webdriver对象进行web自动化时,浏览器就会带有options中的特性了)进行后续自动化流程了。
打开网页
接着我们使用已经配置好的webdriver使用get方法即可打开网页
url=''
browser.get(url)查找和定位元素
查找元素
selenium中查找元素有两种方法:find_element()与find_elements()
使用find_element或find_elements方法时,其内部第一个参数为定位方式,使用By类下的8个属性指明,后边紧跟着的是元素的在html页面中的定位值,类型为字符串。
browser.find_element(By.XPATH,'')#根据条件查找单个元素,返回结果为webelementbrowser.find_elements(By.XPATH,'')#查找所有符合条件的元素,返回结果为webelement构成的列表特别地,在使用find_elements方法时,它会返回所有匹配给定定位器和值的元素列表。如果没有找到任何元素,它将返回一个空列表。这与find_element方法不同,后者在找不到元素时会抛出NoSuchElementException异常。因此,在使用find_elements方法时,我们需要检查返回的列表是否为空,以避免出现错误。
同时,selenium还支持链式查找,即:你可以在查找到一个顶层元素后,直接对该元素使用find_element()和find_elements()方法来定位其内部的子元素。
top_element=browser.find_element(By.ID,'')
sub_elements=top_element.find_elements(By.TAG_NAME,'')定位元素
selenium定位元素时共有八种方式:
brwoser.find_element(By.XPATH,’’)#根据元素xpath定位元素,因为获取简单,所以用的最多
brwoser.find_element(By.CSS_SELECTOR,’’)#根据元素的css_selector定位,因为获取简单,用的最多
#除xpath和css-selector是可以在浏览器直接复制得到以外,其余定位方法都需要观察html源代码来定位
brwoser.find_element(By.ID,’’)
brwoser.find_element(By.CLASS_NAME,’’)
brwoser.find_element(By.PARTIAL_LINK_TEXT,’’)
brwoser.find_element(By.LINK_TEXT,’’)
brwoser.find_element(By.TAG_NAME,’’)
brwoser.find_element(By.NAME,’’)
XPATH和CSS_SELECTOR 定位

XPATAH和CSS_SELECTOR,在浏览器中打开开发者工具,找到指定元素后,右击,点击复制,便可以直接复制该元素的XPATH和CSS_SELECTOR路径用于定位。
#复制到的XPATH用于定位
element=browser.find_element(By.XPATH,'//*[@id="home-content-box"]/div[3]/div[2]/div[5]/div/div/div/div/a[1]')#复制到的CSS_SELECTOR用于定位
element=browser.find_element(By.CSS_SELECTOR,'#home-content-box > div.home-article > div.home-article-cont > div:nth-child(5) > div > div > div > div > a.article-title.word-1')ID定位
使用ID定位元素时需要待定位元素具有id属性才可以,id属性通常在Input输入框和Button按钮这两个组件中较为常见。

该组件为一个id为“toolbar-search-button”名为搜索的按钮,那么我们在定位该元素时便可以
search_button=browser.find_element(By.ID,'toolbar-search-button')
search_button.click()#点击search_buttonCLASS_NAME定位
同样的,使用CLASS_NAME定位元素时,元素需要具有class_name属性,一般来说class_name在html中常见于div标签(盒子)。

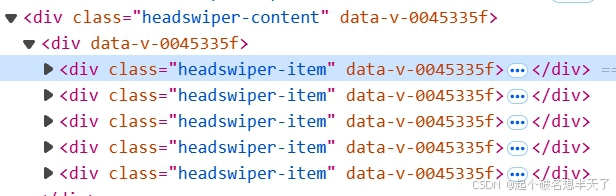
上边是一些由div组件构成的新闻列表,我们想要获得每个div组件内的所有新闻名称,即每个div元素的text属性,那么便可以使用class_name的定位方式。
divs=brower.find_elements(By.CLASS_NAME.'headswiper-item')#定位到所有div
titles=[div.text for div in divs]#在所有div中遍历获取text属性
print(titles)#打印结果结果:

LINK_TEXT与PARTIAL_LINK_TEXT定位
LINK_TEXT与PARTIAL_LINK_TEXT在定位元素时主要根据链接的全部文本或部分文本进行定位。LINK_TEXT指的是完整的链接文本,而PARTIAL_LINK_TEXT则是链接文本的一部分。
例如,如果页面中有一个链接是“点击这里访问百度”,那么可以使用LINK_TEXT('点击这里访问百度')或PARTIAL_LINK_TEXT('点击这里')来定位这个链接。这种定位方式对于页面中的链接元素非常有效,尤其是当链接文本较为独特,不容易与其他元素混淆时。

这里我们以csdn网页中的最顶层一栏为例

对于顶层一栏中的下载文本,在开发者工具中观察其原码,我们不难发现这就是一个典型的LinkText,并且当我们点击这个文本后,页面便会跳转到新的链接。对此,我们便可以使用LINK_TEXT方法定位。
download=browser.find_element(By.LINK_TEXT,'下载')
download.click()#点击下载文字TAG_NAME定位
TAG_NAME是HTML标签的名称,通过元素的标签名来定位元素时,若html中不止一个元素具有此标签名的话,我们通常使用find_elements()函数查找。

比如上边的网页中,每个论文的都被放在标签名为'li'的容器内

其内部的text属性是我们想要获取的文章标题,那么我们的代码便可以这样写:
ssay_container=browser.find_element(By.XPATH,'//*[@id="new-article-list"]/div/ul ')#这是一个存放多篇论文题目的div容器
essaies=essay_container.find_elements(By.TAG_NAME,"li")#在div容器中遍历查找tagname是li的元素
essay_titles=[essay.text for essay in essaies]#遍历essaies内所有元素,使用text方法获取essay题目NAME定位
NAME定位是通过元素的name属性来定位元素。在HTML中,一些元素如input、select等都可以设置name属性。使用NAME定位时,我们只需传入元素的name属性值即可。
input=browser.find_element(By.NAME,'username')#定位NAME属性为username的输入框
input.send_keys('user')#向输入框内填写user总结
在使用selenium定位元素时,最简单好用的是XPATH和CSS_SELECTOR,因为其获取方式简单,但是XPATH和CSS_SELECTOR,在定位速度上不如ID等其他定位方式,因为ID和其他的定位方式都是html元素的属性,其在DOM树中是唯一的,查找速度最快。
同时,还有一点值得注意的是,虽然XPATH和CSS_SELECTOR可以非常灵活地定位页面元素,但是在一些复杂的页面中,XPATH和CSS_SELECTOR可能会变得非常冗长和复杂,且由于网页内容的变动二者也会随之产生变化,这会增加代码的复杂性和维护难度。
因此,在进行web自动化任务时我们应该先观察网页原码,定位元素时尽量先考虑使用元素的属性来进行定位,实在找不到再使用XPATH和CSS_SELECTOR对其进行定位。
webDriver常用方法
打开网页
browser.get(url)#打开网页获得当前浏览器界面内打开过的所有窗口句柄列表
browser.window_handles#获得当前所有打开的窗口句柄,是一个列表,获得最新的当期界面可以用利用browser.window_handles切换当前窗口至最新打开的窗口
#利用browser.window_handles切换当前窗口至最新打开的窗口
Latest_window=browser.window_handles[-1]
browser.switch_to.window(Latest_window)切换到iframe
browser.switch_to.frame()#切换到iframe给当前webdriver添加cookie
browser.add_cookie()#给当前webdriver添加cookie,通常出现在免登录情境下获得当前页面url的cookies
browser.get_cookies()#获得当前页面url的cookies删除当前webdriver已经添加过的所有cookies
browser.delete_all_cookies()#删除当前所有cookies关闭警告或广告弹窗
browser.switch_to.alert.dismiss()回退至上一个网页
browser.back()#回退至前一个网页跳转至下一个网页
browser.forward()#跳转至下一个网页关闭当前窗口
browser.close()#关闭当前窗口获得当前窗口的url
browser.current_url#返回当前窗口的url获得当前的窗口句柄
browser.current_window()#获得当前的窗口句柄,常与browser.switch_to.window()配合使用在当前页面内执行js脚本
browser.execute_script()#在当前页面内执行js脚本,传入参数是js代码的字符串形式在当前页面内执行异步js脚本
browser.execute_async_script()#在当前页面内执行异步js脚本向元素输入指定内容
send_keys()#用来向一个输入框输入字符串
Input_element=browser.find_element(By.XPATH,’’)
Input_element.send_keys('待输入内容')
模拟元素被按下键盘上的指定按键
Send_keys(Keys.按键名称(英文单词大写))#可以模拟按下键盘上的某个按键
#使用Keys需要from selenium.webdriver.common.keys import Keys
Input_element.send_keys(Keys.ENTER)#按下enter健页面截图
获取当前网页页面截图有以下3种方法:
browser.get_screenshot_as_png()
browser.get_screenshot_as_base64()
browser.get_screenshot(filename)用法详解:
pic_data=browser.get_screenshot_as_png()
#使用get_screenshot_as_png获得的是当前页面截图的bytes型数据
#若要保存至本地需要使用with open语句写入
with open('页面截图.png','wb') as f:f.write(pic_data)base64_string=browser.get_screenshot_as_base64()#直接返回页面截图的base64字符串browser.get_screenshot(filename)#直接将页面截图保存到本地,需要传入一个filename参数,注意文件名的结尾必须是.png否则会引发warning元素截图
获取某个元素的截图有以下3种方法:
element.screenshot_as_png
element.screenshot_as_base64
element.screenshot(filename)用法详解:
element=browser.find_element(By.XPATH,’’)pic_data=element.screenshot_as_png
#使用screenshot_as_png获得的是图片的bytes型数据,若要保存本地需要with open保存
with open('filename.png','wb') as f:f.write(pic_data)base64_sring=element.screenshot_as_base64#直接返回元素截图的base64字符串element.screenshot(filename)#直接将元素截图保存到本地,需要传入一个filename参数,注意文件名的结尾必须是.png否则会引发warning
关闭webdriver
browser.quit()等待机制
在使用selenium进行web自动化任务时,有三种等待机制,隐性等待,显性等待,以及time.sleep
隐形等待
implicately_wait
browser.implicately_wait(秒数)等待页面内的元素在dom中出现,在全局中只需要设定一次即可,不需要到处写
显性等待
WebdriverWait,可以结合expected_conditions查找元素时进行条件等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC#最多等待10秒直到元素出现
#等待时间内没有找到元素超时会抛出TimeoutException
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH,'')))#还可以等待这个元素不出现
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH,'')))
#等待时间内找到元素超时会抛出TimeoutException#二者唯一的区别是until和until_nottime.sleep
这个最常用,他的作用就是阻塞当前程序内线程,让整个程序停下来,等待打开的webdriver内的元素加载完毕,相较于implicately_wait不具有太多的灵活性,但确实是最稳定的等待机制。
使用时需要
import time
time.sleep(秒数)异常处理机制
在selenium进行web自动化任务过程中,最常见的两个异常分别是:NoSuchElementExecption与TimeoutException。
其中,TimeoutException主要出现在显性等待元素中,NoSuchElementExecption主要出现在find_element的失败情况中。对此,我们使用try except语句捕获异常进行处理即可,不过,在这之前我们需要先从selenium内的exceptions模块中导入这两个异常
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import NoSuchElementExceptiontry:element=browser.find_element(By.XPATH,'')element.click()
except NosuchElementException:print('无法找到该元素!')browser.quit()ActionChains常用方法
首先,我们需要将Actionchains导入并与webdriver绑定
from selenium.webdriver import ActionChains
action=ActionChains(browser)#绑定之前的webdriver接着对于action,我们便可以用来模拟鼠标的一系列复杂动作,如拖动、点击、双击、悬停等。
假设我们已经定位到一个元素
element=browser.find_element(By.XPATH,’’)鼠标左键单击元素
action.click(element).perform()鼠标右键单击元素
action.context_click(element).perform()鼠标移动并悬停在元素
action.move_to_element(element).perform()鼠标左键单击长按一个元素
action.click_and_hold(element).perform()双击元素
action.double_click(element).perform(将元素1拖动到元素2上(比如:上传文件)
action.drag_and_drop(element1,element2).perform()模拟鼠标从当前位置按照偏移量移动到指定位置
action.move_by_offset(xoffset,yoffset).perform()将一个元素按照指定偏移量拖转到目的地(滑块验证)
action.drag_and_drop_by_offset(element,xoffset,yoffset).perform()点击元素时出现 element click intercepted exception的两个解决办法
1.使用webdriver的execute_script()方法执行"arguments[0].click()"这个js代码
button=browser.find_element(By.XPATH,“”)#假设我们查找到一个按钮
在使用button.click()时可能会出现报错:element click intercepted exception,这时我们使用下边这行代码,可以解决这个问题
browser.execute_script(‘arguments[0].click()’,button)#即执行点击按钮的js代码2.使用ActionChains 的模拟鼠标移动到元素上后单击
action.move_to_element(element).click(element).perform()结语:
以上便是作者本人关于python Selenium在web自动化中的使用方法与常用技巧的总结。当然,Selenium的功能远不止于此,它还有许多高级特性和用法等待我们去探索和掌握。但无论如何,掌握以上这些基础知识和技巧,已经能够帮助我们解决大部分Web自动化测试中的问题了。希
望这篇文章能够对正在学习python Selenium的你有所帮助,让你在Web自动化的道路上越走越远。
相关文章:
)
Web自动化之Selenium 超详细教程(python)
Selenium是一个开源的基于WebDriver实现的自动化测试工具。WebDriver提供了一套完整的API来控制浏览器,模拟用户的各种操作,如点击、输入文本、获取页面元素等。通过Selenium,我们可以编写自动化脚本,实现网页的自动化测试、数据采…...

物联网简介集合
物联网(IoT)指的是物理设备(如电器和车辆)之间的互联互通。这些设备嵌入了软件、传感器和连接功能,使其能够相互连接并交换数据。这项技术实现了从庞大的设备网络中收集和共享数据,为打造更高效、自动化的系…...
)
【设计模式精讲】结构型模式之代理模式(静态代理、JDK动态代理、cglib动态代理)
文章目录 第五章 结构型模式5.1 代理模式5.1.1 代理模式介绍5.1.2 代理模式原理5.1.3 静态代理实现5.1.4 JDK动态代理5.1.4.1 JDK动态代理实现5.1.4.2 类是如何动态生成的5.1.4.3 代理类的调用过程 5.1.5 cglib动态代理5.1.5.1 cglib动态代理实现5.1.5.2 cglib代理流程 5.1.6 代…...

node 使用 Redis 缓存
缓存是什么? 高并发下,一个项目最先出问题的,并不是程序本身,而是数据库最先承受不住。 在数据库上我们可以做很多优化,例如优化 SQL 语句,优化索引,如果数据量大了,还可以分库、分表…...

nginx反向代理负载均衡
反向代理原理: 反向代理服务器架设在服务器端,通过缓冲经常被请求的页面来缓解服务器的工作量,将客户机请求 转发给内部网络上的目标服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此 时代理服务…...

国产编辑器EverEdit - 独门暗器:自动监视剪贴板内容
1 监视剪贴板 1.1 应用场景 如果需要对剪贴板的所有历史进行记录,并进行分析和回顾,则可以使用监视剪贴板功能,不仅在EverEdit中的复制会记录,在其他应用的复制也会记录。 1.2 使用方法 新建一个空文档(重要:防止扰乱…...
)
AI全栈开发_人工智能AI大模型 Prompt提示词工程详解(全方位介绍及运用)
AI引领的第四次工业革命正席卷而来,如何精准把握这一历史性的机遇,将成为我们这一代人不容忽视且需深入思考与积极行动的重要课题。未来几年AI将会像计算机一样快速普及,面对这一历史性的第一波红利,你是否已准备好把握机遇&#…...

PHP图书借阅小程序源码
📚 图书借阅小程序:一键开启智慧阅读新篇章 🌟 这是一款由ThinkPHP与UniApp两大技术巨擘强强联手精心打造的图书借阅微信小程序,它犹如一座随身携带的移动图书馆,让您无论身处何地都能轻松畅游知识的海洋。创新的多书…...

sourcetree gitee 详细使用
SSH 公钥设置 | Gitee 帮助中心 先配置公钥,输入gitee密码完成验证 gitee仓库创建完成 打开sourcetree 如果你本地有项目(vite )需要 git init 在设置中完成远程仓库的添加 (ssh ,https) 直接提交推送,完成后…...

Hive JOIN过滤条件位置玄学:ON vs WHERE的量子纠缠
Hive JOIN过滤条件位置玄学:ON vs WHERE的量子纠缠 作为数据工程师,Hive JOIN就像吃火锅选蘸料——放错位置味道全变!今天带你破解字节/阿里等大厂高频面试题:ON和WHERE后的过滤条件究竟有什么不同? 一、核心差异对比表 特性ON子句WHERE子句执行时机JOIN操作时JOIN完成后…...

破局与重构:水务企业数字化转型路径探索
随着数字化技术的发展和智慧城市建设进程的推进,水务行业正经历以数据为驱动的深刻变革。本文深入探讨水务行业数字化发展的趋势、水务企业数字化转型的痛点、水务行业标杆企业数字化转型实践以及水务企业数字化转型的方向和路径,为水务企业十五五期间把…...
)
stm32hal库寻迹+蓝牙智能车(STM32F103C8T6)
简介: 这个小车的芯片是STM32F103C8T6,其他的芯片也可以照猫画虎,基本配置差不多,要注意的就是,管脚复用,管脚的特殊功能,(这点不用担心,hal库每个管脚的功能都会给你罗列,很方便的.)由于我做的比较简单,只是用到了几个简单外设.主要是由带霍尔编码器电机的车模,电机…...

云服务中的“高可用性架构”是怎样的?
在云计算中,“高可用性架构”(High Availability Architecture,简称HA架构)是指通过设计和配置,使得系统、服务或应用能够在发生硬件故障、软件故障、网络问题等情况下,依然保持正常运行,最大程…...

StableDiffusion+ComfyUI
一、AI、AIGC、AIAgent基本概念 图形生成大模型:StableDiffusion(逼真,开源)、Midjourney(艺术性,商业)、FLUX(复杂场景,开源商业)工作流程构建工具:ComfyUI智能体:COZE、Dify、FastGPTAI视频编辑工具&…...

MATLAB基础学习相关知识
MATLAB安装参考:抖音-记录美好生活 MATLAB基础知识学习参考:【1小时Matlab速成教程-哔哩哔哩】 https://b23.tv/CnvHtO3 第1部分:变量定义和基本运算 生成矩阵: % 生成矩阵% 直接法% ,表示行 ;表示列 a [1,2,3;4,5,6;7,8,9];%…...
(C++))
设计模式 之 工厂模式(简单工厂模式、工厂方法模式、抽象工厂模式)(C++)
文章目录 C 工厂模式引言一、简单工厂模式概念实现步骤示例代码优缺点 二、工厂方法模式概念实现步骤示例代码优缺点 三、抽象工厂模式概念实现步骤示例代码优缺点 C 工厂模式 引言 在 C 编程中,对象的创建是一个常见且基础的操作。然而,当项目规模逐渐…...

windows下docker使用笔记
目录 镜像的配置 镜像的拉取 推荐镜像源列表(截至2025年2月测试有效) 配置方法 修改容器名字 如何使用卷 创建不同的容器,每个容器中有不同的mysql和java版本(不推荐) 1. 安装 Docker Desktop(Win…...

SQLMesh 系列教程6- 详解 Python 模型
本文将介绍 SQLMesh 的 Python 模型,探讨其定义、优势及在企业业务场景中的应用。SQLMesh 不仅支持 SQL 模型,还允许通过 Python 编写数据模型,提供更高的灵活性和可编程性。我们将通过一个电商平台的实例,展示如何使用 Python 模…...
用N-S流程图表示算法)
【时时三省】(C语言基础)用N-S流程图表示算法
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 N-S流程图 既然用基本结构的顺序组合可以表示任何复杂的算法结构,那么,基本结构之间的流程线就是多余的了。1973年,美国学者I.Nassi和B .Shneiderman提出…...

【HarmonyOS Next】鸿蒙监听手机按键
【HarmonyOS Next】鸿蒙监听手机按键 一、前言 应用开发中我们会遇到监听用户实体按键,或者扩展按键的需求。亦或者是在某些场景下,禁止用户按下某些按键的业务需求。 这两种需求,鸿蒙都提供了对应的监听事件进行处理。 onKeyEvent 默认的…...

Unreal5从入门到精通之在编辑器中更新 UserWidgets
前言 在虚幻中创建越来越复杂和灵活的 UserWidget 蓝图时,一个问题是它们在编辑器中的外观与它们在游戏中的最终外观可能有很大不同。 库存面板示例 假设你想创建一个通用的库存显示小部件。我们可以在整个 UI 中使用它,无论我们需要在哪里显示某些内容。 标题,描述所显示…...
模板系统)
Django 5实用指南(五)模板系统
Django5的模板系统是其核心功能之一,允许开发者将动态数据嵌入到HTML模板中,并根据不同的业务需求渲染页面。Django模板系统基于 Django模板语言(DTL),它提供了一些强大的功能,如模板标签、过滤器、条件语句…...

游戏引擎学习第114天
打开内容并回顾 目前正在讨论一个非常重要的话题——优化。当代码运行太慢,无法达到所需性能时,我们该怎么办。昨天,我们通过在代码中添加性能计数器,验证了一些性能分析的数据,这些计数器帮助我们了解每个操作需要的…...

Python 赋能 AI:从零实现图像分类
人工智能(AI)热度持续攀升,而 Python 作为 AI 开发的利器,以其简洁易学、生态丰富的特点,成为众多开发者的首选。本文以图像分类为例,带你用 Python 实现一个简单的 AI 模型。 1. 环境准备 首先,我们需要安装一些必要的 Python 库: pip install tensorflow keras nu…...

UE引擎游戏加固方案解析
据VGinsights的报告,近年来UE引擎在过去几年中市场占比显著增长,其中亚洲市场增幅达到了30%,随着UE5的推出和技术的不断进步,UE引擎在独立开发者和移动游戏开发中的应用也在逐步增加。 UE引擎的优势在于强大的画面表现与视觉特效…...

Http升级为Https - 开发/测试服环境
1.应用场景 主要用于开发/测试服环境将http升级为https, 防止前端web(浏览器)出现Mixed Content报错; 2.学习/操作 1.文档阅读 deepseek 问答; 2.整理输出 报错信息: Mixed Content: The page at <URL> was loaded over HTTPS, but requested an insecure XMLHttpRequ…...

SaaS系统租户隔离方案分析:基于域名与请求头的比较
在设计SaaS系统时,租户隔离是非常重要的设计考虑因素。租户隔离的方式决定了系统的可扩展性、安全性和维护性。常见的租户隔离方案包括基于域名和基于**请求头(header)**的隔离方式。每种方式都有其优缺点,具体选择应根据系统的需…...
时Windows PyCharm无法模拟键盘输入)
调用click.getchar()时Windows PyCharm无法模拟键盘输入
文章目录 问题描述解决方案参考文献 问题描述 调用 click.getchar() 时,Windows PyCharm 无法模拟键盘输入 解决方案 Run → Edit Configurations… → Modify options → Emulate terminal in output console 参考文献 Terminal emulator | PyCharm Documentati…...

科普:“docker”与“docker compose”
一、安装Docker Desktop 安装Docker Desktop,则既安装了Docker,也安装了Docker Compose 从Docker Desktop官方下载页面(https://www.docker.com/products/docker-desktop/),选择适合Windows系统的版本进行下载安装。 验证: do…...

Windows 快速搭建C++开发环境,安装C++、CMake、QT、Visual Studio、Setup Factory
安装C 简介 Windows 版的 GCC 有三个选择: CygwinMinGWmingw-w64 Cygwin、MinGW 和 mingw-w64 都是在 Windows 操作系统上运行的工具集,用于在 Windows 环境下进行开发和编译。 Cygwin 是一个在 Windows 上运行的开源项目,旨在提供类Uni…...

【分布式理论12】事务协调者高可用:分布式选举算法
文章目录 一、分布式系统中事务协调的问题二、分布式选举算法1. Bully算法2. Raft算法3. ZAB算法 三、小结与比较 一、分布式系统中事务协调的问题 在分布式系统中,常常有多个节点(应用)共同处理不同的事务和资源。前文 【分布式理论9】分布式…...

GPT2 模型训练
GPT2 预训练模型 基座 专门供给别人使用的。 对中文分词是一个字一个字分,是Bert的分类方法 好处:灵活。 词库可以适应任何文章。 坏处:训练的难度更大。需要增加数据量 中文分词如果按词组分词 好处:需要的数据量小&#…...

蓝桥杯备考:递归初阶
什么是递归? 相信我们已经不陌生了,函数自己调用自己就叫递归 为什么要有递归? 当处理主问题时,遇到子问题,子问题的解决方法和主问题是一样的,这时候我们就要用到递归 解决流程:问题—》相…...

[C语言]指针进阶压轴题
下面代码打印结果是什么? #include<stdio.h> int main() {char* c[] { "ENTER","NEW","POINT","FIRST" };char** cp[] { c 3,c 2,c 1,c };char*** cpp cp;printf("%s\n", **cpp);printf("%s\n…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-build.py
build.py ultralytics\data\build.py 目录 build.py 1.所需的库和模块 2.class InfiniteDataLoader(dataloader.DataLoader): 3.class _RepeatSampler: 4.def seed_worker(worker_id): 5.def build_yolo_dataset(cfg, img_path, batch, data, mode"train"…...
落地实践Demo——借助大模型生成报表,推动AI赋能企业决策)
智能体(AI Agent、Deepseek、硅基流动)落地实践Demo——借助大模型生成报表,推动AI赋能企业决策
文章目录 一、 引言二、 系统设计与技术细节2.1 系统架构2.2 核心组件说明 三、 Demo 代码推荐博客: 四、输出年度营销报告1. 总销售额 根据提供的数据,年度总销售额为:740.0。2. 各产品销售额3. 各地区销售额4. 各产品在各地区的销售情况 分…...

mac os设置jdk版本
打开环境变量配置文件 sudo vim ~/.bash_profile 设置不同的jdk版本路径 # 设置JAVA_HOME为jdk17路径 export JAVA_HOME$(/usr/libexec/java_home -v 17)# 设置JAVA_HOME为jdk8路径 export JAVA_HOME$(/usr/libexec/java_home -v 1.8) 设置环境变量 # 将jdk加入到环境变量…...

Llama 3.1 本地电脑部署 Linux系统 【轻松简易】
本文分享在自己的本地电脑部署 llama3.1,而且轻松简易,快速上手。 这里借助Ollama工具,在Linux系统中进行大模型部署~ Llama3.1,有三个版本:8B、70B、405B Llama 3.1 405B 是第一个公开可用的模型,在常识…...

计算机网络安全之一:网络安全概述
1.1 网络安全的内涵 随着计算机和网络技术的迅猛发展和广泛普及,越来越多的企业将经营的各种业务建立在Internet/Intranet环境中。于是,支持E-mail、文件共享、即时消息传送的消息和协作服务器成为当今商业社会中的极重要的IT基础设施。然而࿰…...

docker 部署JAR
docker pull openjdk:23 使用Docker运行生成的JAR包是一个将应用程序容器化的好方法,它确保了你的应用可以在任何安装了Docker的环境中以相同的方式运行。以下是创建一个Docker镜像并运行包含你Java应用程序的JAR包的基本步骤。1. 准备 Dockerfile首先,在…...

深研究:与Dify建立研究自动化应用
许多个人和团队面临筛选各种网页或内部文档的挑战,以全面概述一个主题。那么在这里我推荐大家使用Dify,它是一个用于LLM应用程序开发的低代码,开源平台,它通过自动化工作流程的多步搜索和有效汇总来解决此问题,仅需要最小的编码。 在本文中,我们将创建“ Deepresearch”…...

第1章:LangChain4j的聊天与语言模型
LangChain4J官方文档翻译与解析 目标文档路径: https://docs.langchain4j.dev/tutorials/chat-and-language-models/ 语言模型的两种API类型 LangChain4j支持两种语言模型(LLM)的API: LanguageModel:这种API非常简单,…...

IPv6报头40字节具体怎么分配的?
目录 IPv6报头结构 字段详解 示例代码:IPv6报头的Python实现 输出示例 IPv6协议是为了解决IPv4地址耗尽问题而设计的下一代互联网协议。与IPv4相比,IPv6不仅提供了更大的地址空间,还简化了报头结构,提高了网络设备的处理效率。…...

Ubuntu ARM / aarch64 CPU 镜像下载:如何在 ARM 设备上安装和使用 Ubuntu
随着 ARM 架构的逐渐普及,尤其是在移动设备和高效能计算设备中的应用,许多开发者和用户开始关注基于 ARM 架构的操作系统。Ubuntu 作为一款广泛使用的 Linux 发行版,自然也为 ARM 架构提供了优化的版本。本文将详细介绍如何下载适用于 ARM / …...
)
图论入门算法:拓扑排序(C++)
上文中我们了解了图的遍历(DFS/BFS), 本节我们来学习拓扑排序. 在图论中, 拓扑排序(Topological Sorting)是对一个有向无环图(Directed Acyclic Graph, DAG)的所有顶点进行排序的一种算法, 使得如果存在一条从顶点 u 到顶点 v 的有向边 (u, v) , 那么在排序后的序列中, u 一定…...
和count(*) 的区别)
MySQL中count(1)和count(*) 的区别
MySQL中count(1)和count(*) 的区别 在 MySQL 中,COUNT(1) 和 COUNT(*) 均用于统计查询结果中的行数,但它们在语义及其背后的机制上有一些区别。 基本功能 COUNT(*):统计表中所有行的数量,无论列是否为 NULL。 COUNT(1)…...

Android 14输入系统架构分析:图解源码从驱动层到应用层的完整传递链路
一、资料快车 1、深入了解Android输入系统:https://blog.csdn.net/innost/article/details/47660387 2、书籍 - Android系统源代码情景分析 二、Perface 1、参考: 2、系统程序分析方法 1)加入log,并跟着log一步步分析 -logc…...

Web入侵实战分析-常见web攻击类应急处置实验2
场景说明 某天运维人员,发现运维的公司站点被黑页,首页标题被篡改,你获得的信息如下: 操作系统:windows server 2008 R2业务:公司官网网站架构:通过phpstudy运行apache mysqlphp开放端口&…...

Jenkins 配置 Credentials 凭证
Jenkins 配置 Credentials 凭证 一、创建凭证 Dashboard -> Manage Jenkins -> Manage Credentials 在 Domain 列随便点击一个 (global) 二、添加 凭证 点击左侧 Add Credentials 四、填写凭证 Kind:凭证类型 Username with password: 配置 用…...

Android Http-server 本地 web 服务
时间:2025年2月16日 地点:深圳.前海湾 需求 我们都知道 webview 可加载 URI,他有自己的协议 scheme: content:// 标识数据由 Content Provider 管理file:// 本地文件 http:// 网络资源 特别的,如果你想直接…...