可信大模型:LLM + 神经符号推理,解决复杂推理任务
可信大模型:LLM + 神经符号推理,解决复杂推理任务
- 论文大纲
- 一、Why:研究要解决的现实问题
- 二、What:核心发现或论点
- 三、How:研究的整体方法与关键细节
- 3.1 前人研究的局限性
- 3.2 创新方法/视角
- 3.3 关键数据或实验支持
- 3.4 可能的反驳及应对
- 四、How good:理论贡献与实践意义
- 解法拆解
- 1. 知识库创建阶段 (KB Creation)
- 2. 推理阶段 (Inference)
- 3. 迭代与系统组件
- 子解法1:知识库创建(Phase 1)
- 子解法2:任务检测
- 子解法3:简单数据提取
- 子解法4:复杂公式构建
- 子解法5:IDP-Z3 符号推理执行
- 子解法6:结果组织与输出
- 提问
- 1. 关于“通用性”与任务切换的细节
- 2. 关于“自我修正”性能与极端场景
- 3. 关于 IDP-Z3 引擎选型的可替代性
- 4. 关于 OWA (Open World Assumption) 与 CWA (Closed World Assumption)
- 5. 关于自定义推理任务的扩展难度
- 6. 关于多轮对话场景的连贯推理
- 7. 关于实验结果的统计显著性
- 8. 关于知识库与数据隐私、保密问题
- 9. 关于自定义细粒度解释(Explain)
- 10. 关于大规模复杂场景下的推理效率
论文:VERUS-LM: a Versatile Framework for Combining LLMs with Symbolic Reasoning
代码:https://gitlab.com/EAVISE/bca/verus-lm
论文大纲
├── 1 引言【研究动机与背景】
│ ├── LLM 在推理能力上取得进展,但无法保证结果透明且易出错【问题现状】
│ ├── 符号推理具有可验证性和可解释性,却难以处理自然语言输入【问题现状】
│ └── 结合 LLM 与符号推理可望发挥双方优势【研究目标】 ├── 2 相关工作【已有研究与不足】
│ ├── 使用 ASP 的方法【典型神经符号融合】
│ │ ├── [Ishay et al., 2023] 生成 ASP 表示并借助求解器【方法示例】
│ │ └── [Yang et al., 2023] 通过手工“知识模块”配合 LLM 提取信息【方法示例】
│ ├── LINC 方法【FOL 表达与求解】
│ │ └── 利用多次生成并投票的方式减少错误【技术特点】
│ ├── Logic-LM 方法【多逻辑形式统一】
│ │ ├── 支持逻辑程序、FOL、CSP、SAT 等多种推理【广泛适用性】
│ │ └── 内置“自我修正”机制应对语法错误【技术特点】
│ └── SymbCoT【LLM 内部模拟逻辑推理】
│ ├── 将问题转为 FOL 再用 LLM 自身执行推理【不依赖外部引擎】
│ └── 对比其他方法时可减少语法错误依赖【优缺点并存】 ├── 3 VERUS-LM 系统设计【核心框架】
│ ├── 3.1 需求分析【设计目标】
│ │ ├── 多样化:可支持不同推理任务【多种推理模式】
│ │ ├── 知识复用:区分领域知识与查询【避免重复生成】
│ │ └── 通用性:与具体领域或任务弱耦合【易扩展】
│ ├── 3.2 推理引擎选择——IDP-Z3【实现手段】
│ │ ├── 基于 FO(-) 逻辑的扩展,支持多种高级特性【表达能力】
│ │ └── 统一知识库的多种推理操作(满足、优化、解释等)【功能多样】
│ └── 3.3 体系架构【流程概述】
│ ├── 第一步:构建知识库【预处理】
│ └── 第二步:根据推理任务自动调用引擎【多步推理】 ├── 4 知识库构建【第一阶段】
│ ├── 4.1 符号提取【步骤一】
│ │ ├── 从原始文本中识别类型、谓词、函数等【概念识别】
│ │ └── 补充自然语言解释,便于后续阶段【可读性】
│ ├── 4.2 公式抽取【步骤二】
│ │ ├── 将文本内容翻译为 FO(-) 形式【逻辑表达】
│ │ └── 根据通用提示语,无需数据集特定示例【通用性】
│ └── 4.3 自我修正【步骤三】
│ ├── 语法修正:若求解器报错则迭代修复【自动纠错】
│ └── 语义修正:若逻辑不满足则收集最小不满足子集并迭代修复【一致性检查】 ├── 5 推理阶段【第二阶段】
│ ├── 5.1 任务检测【识别推理模式】
│ │ ├── 通过 BERT 分类识别是哪种推理需求【模型分类】
│ │ └── 适配 IDP-Z3 的八种操作(求模、可满足性、优化等)【灵活调用】
│ └── 5.2 信息抽取【获取数据与目标】
│ ├── 针对简单数据可用小型 LLM 提取【效率考量】
│ └── 若需复杂公式由大型 LLM 构造【准确性考量】 ├── 6 实验【性能验证】
│ ├── 6.1 基础验证【方法可行性】
│ │ ├── 构造多推理任务数据集 DivLR【测试全面性】
│ │ └── 与单纯 LLM 对比,显著提升推理准确率【实验结论】
│ ├── 6.2 与现有方法对比【对标 SOTA】
│ │ ├── 在 PrOntoQA、ProofWriter、FOLIO 等数据集表现优异【竞争性】
│ │ └── 在 AR-LSAT 上明显优于其他 neurosymbolic 方法【难度优势】
│ └── 6.3 自我修正影响【提升效果】
│ ├── 语法修正显著提高知识库可执行率【增加成功率】
│ └── 语义修正可解决不一致但略增推理难度【局部平衡】 ├── 7 局限性【方法不足】
│ ├── 不适合高阶逻辑或极大规模的 SAT 问题【表达范围局限】
│ ├── 完全依赖 FO(-) 框架,不同逻辑范式或需额外工作【通用性边界】
│ └── 复杂情境下对语义冲突的修正仍有一定失败率【改进空间】 └── 8 结论【总结与展望】 ├── VERUS-LM 在通用多任务推理中具有强大表现【研究贡献】 ├── 通过语法与语义自我修正保证正确性【技术创新】 └── 未来可扩展到更广阔的神经符号场景【后续工作】
核心方法:
├── 核心方法【VERUS-LM 的两阶段流程】
│ ├── 阶段 1:知识库创建【从领域知识文本到 FO(-) 逻辑】
│ │ ├── 输入:领域知识的自然语言描述【文本输入】
│ │ │ └── 【用于】大语言模型(LLM)将非结构化文本转化为逻辑表示
│ │ ├── 步骤 1:符号提取【LLM 解析】
│ │ │ ├── 【识别】类型(type)、谓词(predicate)、函数(function)
│ │ │ └── 【输出】带有自然语言注释的符号表
│ │ ├── 步骤 2:公式抽取【LLM 翻译】
│ │ │ ├── 【根据】FO(-) 语法规则
│ │ │ └── 【生成】初版逻辑公式(包含背景知识与约束)
│ │ ├── 步骤 3:自我修正【迭代检验】
│ │ │ ├── 【若语法出错】则由求解器报错信息反馈,LLM 修补公式
│ │ │ └── 【若语义冲突】则进行可满足性检查,最小不满足子集定位并修复
│ │ └── 输出:可满足且无语义冲突的 FO(-) 知识库【阶段 1 产物】
│
│ ├── 阶段 2:推理阶段【回答用户查询】
│ │ ├── 输入:用户问题【自然语言文本】
│ │ │ └── 【依赖】已创建的 FO(-) 知识库
│ │ ├── 步骤 1:任务检测【BERT 分类器】
│ │ │ ├── 【识别】推理类型(模型生成、优化、可满足性等 8 类)
│ │ │ └── 【决定】具体需要哪种逻辑推理操作
│ │ ├── 步骤 2:信息抽取【小/大 LLM 协作】
│ │ │ ├── 【若仅简单数据】小型 LLM 提取所需常量、参数
│ │ │ └── 【若复杂公式】大型 LLM 生成逻辑表达式以补充到查询中
│ │ ├── 步骤 3:IDP-Z3 执行【符号推理引擎】
│ │ │ ├── 【基于】推理类型(如 SAT、优化、解释等)
│ │ │ └── 【输出】推理结果(模型、真值、证明等)
│ │ └── 输出:问题答案或解释性结果【阶段 2 产物】
│
│ └── 最终输出【完整回答】
│ ├── 【结合】知识库推理结果与用户问题
│ └── 【呈现】可选的模型展开、最优解、或逻辑解释等
│
└── 整体流程【输入—处理—输出的衔接】 ├── 输入:领域文本 & 用户问题【自然语言】 │ └── 【经过】LLM/BERT 与自我修正模块 ├── 处理:IDP-Z3 符号推理【FO(-) 知识库为核心】 │ └── 【组合】语法/语义校验、推理任务识别、公式构建 └── 输出:最终回答、可视化逻辑解释【对用户可见】
一、Why:研究要解决的现实问题
-
现实需求与不足
- 现有的大语言模型(LLM)在处理复杂推理任务时,往往无法保证推理过程的透明度与正确性。
- 符号推理系统则能够提供可验证的、透明的推理过程,但是在面对高度自然语言化、模糊性和多样性的输入时存在困难。
-
痛点与机遇
- 大语言模型拥有自然语言理解和生成的强大能力,但难以确保其对逻辑关系的精准捕捉,容易出现“幻觉”或不一致推理。
- 符号推理引擎拥有可证性和解释性,但缺少对自然语言的直接理解能力。
- 因此,需要一种将二者优势结合、互补不足的新方法,以在应对多种形式推理问题时,既保证推理的灵活性和易用性,又保持结果的可信度。
-
研究问题聚焦
- 如何在保持大语言模型自然语言处理能力的同时,借力符号推理的形式化机制,实现对多样化、高难度推理任务的统一支持?
- 如何有效地将领域知识与多种逻辑推理过程区分开来,以实现灵活、可扩展的复杂推理场景?
二、What:核心发现或论点
-
主要贡献
- 提出一个名为 VERUS-LM 的通用神经符号框架,利用大语言模型进行知识获取、问题理解,并调用符号推理引擎(IDP-Z3)执行多样化的逻辑推理任务。
- 该框架突出“可复用的知识库 + 多类型推理”的设计,使得不同问题只需一次知识库构建便可进行多次推理,大大节省计算成本并提高可扩展性。
-
关键观点
- 与现有大多基于单一推理任务的模型不同,VERUS-LM 支持包括模型生成、可满足性检查、优化、蕴涵验证、区间推断、解释和相关性分析等多种推理形式。
- 不依赖与特定数据集强耦合的提示或手工示例,具有“跨领域”与“跨任务”的通用性。
可以把 VERUS-LM 类比成一位「多功能翻译官 + 数学逻辑家」的组合:
- 多功能翻译官(LLM):把大家五花八门的口头话或自然语言文档,先翻译成一门“逻辑语言”(一阶逻辑),这就像翻译官能听懂各种地方方言,然后标准化成“普通话”。
- 数学逻辑家(符号引擎):在得到标准化“普通话”(逻辑表达式)后,用严谨的数学推理来给出最可靠的答案。不管问的问题是“为什么会这样?”还是“能不能这么做?”,逻辑家都能给出精确证明或结果。
这样,你既拥有了大语言模型“懂人话、能理解上下文”的长处,又能用严格的符号推理来避免出错,实现“又快又准又可解释”。
三、How:研究的整体方法与关键细节
3.1 前人研究的局限性
- 现有神经符号框架往往使用特定任务提示或依赖大量人工示例,导致可迁移性和通用性不足。
- 大部分方法主要关注形式化表达(将自然语言转成某种逻辑表达式),但只有单一或有限几类推理操作,难以支持不同类型的逻辑需求。
- 现有工作在处理复杂或混合型问题(例如 LSAT 类推理时)表现欠佳,尤其是当知识表达和推理类型都更加多样化时。
3.2 创新方法/视角
-
双阶段框架
- 知识库创建(KB Creation):使用 LLM 提取领域概念与逻辑规则,将其转换成 FO(·)(第一阶逻辑扩展)表达,支持多种逻辑特征。
- 第一步通过小模型或大模型,提取符号(类型、谓词、函数等)
- 第二步将领域描述转换为 FO(·) 逻辑句子。
- 第三步进行自我修正(Self-Refinement):若推理引擎报告语法或语义不一致,则引导模型进行纠错和改进。
- 推理阶段(Inference):针对不同用户问题,自动识别所需的推理类型,然后在已构建的知识库上执行合适的推理操作。
- 知识库创建(KB Creation):使用 LLM 提取领域概念与逻辑规则,将其转换成 FO(·)(第一阶逻辑扩展)表达,支持多种逻辑特征。
-
多任务推理能力
- 基于 IDP-Z3 提供的可扩展推理接口,实现从可满足性检查、模型生成/扩展、优化、区间推断、解释生成到蕴涵验证等功能,满足实际场景里多样化的需求。
-
分类器与小模型相结合的流程
- 基于 BERT 分类器自动判断推理任务类型。
- 若仅需简单的信息提取则使用小模型(SLM),如需生成复杂的逻辑公式则调用大模型(LLM),在保证推理准确度与可扩展性的同时,降低了算力与数据隐私压力。
3.3 关键数据或实验支持
- 在新建的多类型推理数据集(DivLR)上,对不同推理任务(如可满足性、优化、蕴涵验证等)进行评估,展示 VERUS-LM 的检测推理类型与准确回答能力。
- 与现有神经符号方法(Logic-LM, SymbCoT 等)在常用数据集(ProofWriter, FOLIO, PrOntoQA, AR-LSAT)上的对比:
- AR-LSAT 复杂推理场景下,VERUS-LM 的准确率大幅领先,证明了其在处理多样化逻辑和自然语言问题时的强适应性。
- 消融实验显示:引入语义自我修正(Semantic Refinement)能显著提升可执行率与最终准确度。
3.4 可能的反驳及应对
- 反驳:是否只能处理第一阶逻辑扩展,遇到更高阶或其他推理范式怎么办?
- 应对:本文选用 FO(·) 主要因为其已能表达许多实用场景,且与大语言模型预训练内容贴合。若需更复杂语义,可基于同样思路替换或扩展推理引擎。
- 反驳:大模型生成的知识库部分仍可能存在错误或幻觉。
- 应对:通过“语法+语义”两重自我修正,尽可能提升一致性,且可在应用层面引入更多约束或人工校验机制。
四、How good:理论贡献与实践意义
-
理论贡献
- 提出了一种通用性更强的神经符号融合架构,将知识库与推理任务解耦,为后续在混合逻辑推理、复杂动态场景等领域的拓展打下基础。
- 将基于 LLM 的自然语言理解能力与成熟的符号推理技术紧密结合,为可解释性和可验证性提供了新的思路。
-
实践意义
- 在需要多种类型逻辑推理的真实应用场景(保险理赔、法律推理、策略规划等),能够显著提高自动化程度与正确率,同时保留对复杂逻辑的可解释性。
- 降低企业/开发者在不断变化需求下的研发成本:只需一次性构建或更新知识库,面对不同问题无需从头开始,也无需修改底层推理逻辑。
-
未来工作
- 探索将 VERUS-LM 应用于跨模态推理(如文本与图像/图结构结合)或更大规模知识库场景。
- 提升对高阶逻辑的扩展能力;或与其他编程范式(如约束规划、Probabilistic Logic 等)结合,进一步增强对不确定性的处理与优化。
总结而言,VERUS-LM 在整合大语言模型与符号推理的设计中兼顾了灵活的自然语言接口与强大的多类型逻辑推理能力,为混合推理场景提供了一种可扩展、可解释、可复用的新范式。
解法拆解
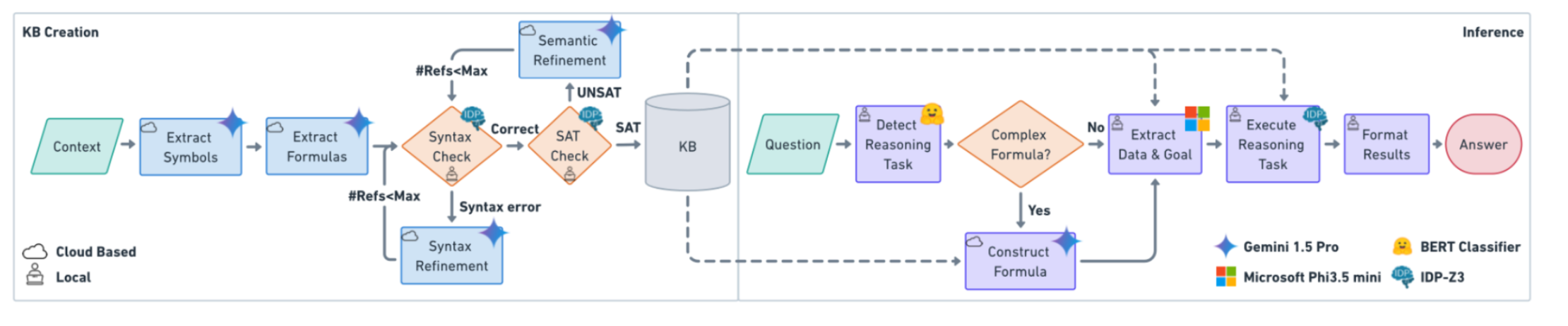
图展示了 VERUS-LM 框架从「知识库创建 (KB Creation)」到「推理 (Inference)」的完整流程,左半部分是知识库的构建过程,右半部分是基于该知识库来回答用户问题的推理过程。可以将它分解为以下关键步骤:
1. 知识库创建阶段 (KB Creation)
-
Context(原始文本/上下文输入)
- 首先输入的是一段自然语言描述(如领域知识或问题背景),用来提取并构建后续步骤所需的逻辑元素。
-
Extract Symbols(提取符号)
- 系统从输入文本中解析出需要的类型 (type)、谓词 (predicate)、**函数 (function)**及常量等符号信息。
- 该步骤对应的图标中标注了“云端”或“本地”两种可能的运行位置,表示提取符号可用不同大小/能力的语言模型(例如在云端用大模型,或在本地用小模型)。
-
Extract Formulas(提取公式)
- 在获得符号后,再从文本中自动抽取或生成逻辑公式(使用 FO(·) 形式)。
- 这些公式代表对领域知识的正式化描述。
-
Syntax Check(语法检查)
- 将生成的符号和公式输入给逻辑引擎(IDP-Z3)进行语法校验。
- 如果发生Syntax error(语法错误),会进入“Syntax Refinement(语法修正)”环节,让语言模型根据报错信息对之前的输出做修改,直至语法通过。
-
SAT Check(可满足性检查)
- 当语法正确后,系统还要验证这些公式是否存在自相矛盾的地方,即进行可满足性检查。
- 若出现UNSAT(不可满足)情况,则会触发“Semantic Refinement(语义修正)”,提示语言模型对刚才的逻辑表述或假设进行调整,确保最终的知识库既语法无误,又在语义上可满足。
-
KB(知识库完成)
- 一旦语法和语义都通过检查,便得到最终构建好的知识库,里面包含了经过验证的符号和逻辑规则。
2. 推理阶段 (Inference)
-
Question(用户问题)
- 用户提出一个自然语言问题,需要在之前构建好的知识库基础上进行推理。
-
Detect Reasoning Task(识别推理类型)
- 系统(此处用到了 BERT 分类器)对问题进行分类,判断它需要什么类型的逻辑推理(例如:可满足性、模型生成、蕴涵验证、优化等)。
-
Complex Formula?(是否需要复杂公式)
- 根据所需的推理类型和问题本身的表述,如果问题需要额外的逻辑表达(如蕴涵验证时给出新的假设公式),系统会调用大语言模型重新“Construct Formula(构造公式)”。
- 若不需要,直接“Extract Data & Goal(提取具体数据与目标)”即可。
-
Execute Reasoning Task(执行推理)
- 根据“已完成的知识库 + 用户问题中新提到的数据/目标 +(可能额外构造的)新公式”,在 IDP-Z3 中运行对应的推理操作(如求解模型、检查可满足性、执行优化、推导结论等)。
-
Format Results(结果格式化)
- 将推理引擎输出的形式化结果(如最优解、一组满足条件的解、是否蕴涵成功等)转换回自然语言或者易于理解的答案形式。
-
Answer(最终回答)
- 最后以自然语言的方式呈现给用户。
3. 迭代与系统组件
- 迭代修正(Refinement Loops):图中可以看到在知识库创建阶段,若遇到语法或语义层面的错误,会有一个循环往复的修正过程,直到满足要求或达到最大迭代次数(#Refs < Max)。
- 多种模型/引擎协同
- Gemini 1.5 Pro 与 Microsoft Phi3.5 mini 等大/小语言模型分别承担不同的自然语言解析任务(如公式构造、符号提取等)。
- BERT Classifier 用于快速识别推理任务类型。
- IDP-Z3 是底层逻辑推理引擎,执行可满足性、蕴涵验证、模型扩展等操作。
该流程图清晰地展示了 VERUS-LM 框架是如何分成知识库创建与推理两个主要阶段的。
通过在左侧阶段反复进行“提取—检查—修正”操作,可以确保知识库本身正确且可满足。
右侧针对问题进行推理时,先自动识别所需的推理类型,必要时再生成额外的逻辑公式,最后调用 IDP-Z3 执行推理并返回可解释的结果。
这种设计使得多次问答可以复用同一知识库,既提高了准确性又减少重复计算,为神经与符号推理的结合提供了高效可扩展的方案。

子解法1:知识库创建(Phase 1)
之所以用“知识库创建”子解法,是因为:
- 特征 A:自然语言提供的背景知识往往是非结构化的,需要转成可供符号推理的逻辑形式。
- 特征 B:要实现对同一领域多次查询的高效性,必须预先构建并复用同一个 FO(-) 知识库。
在这一子解法中,包含了三个更细的步骤(可视为子解法1a、1b、1c):
-
子解法1a:符号提取
-
之所以用“符号提取”步骤,是因为我们需要从背景文本中识别出所有会用到的概念(类型、函数、谓词),以便后续严格遵守 FO(-) 的语法。
-
形式上可表示为:
ExtractSymbols ( Text ) → { Types , Predicates , Functions } \text{ExtractSymbols}(\text{Text}) \rightarrow \{ \text{Types}, \text{Predicates}, \text{Functions} \} ExtractSymbols(Text)→{Types,Predicates,Functions}
-
与同类方法对比:多数神经-符号方法也需要该步骤,但有的方案是直接人工定义(不依赖 LLM 自动识别),VERUS-LM 则依靠通用提示+LLM 识别,更通用。
-
-
子解法1b:公式抽取
-
之所以用“公式抽取”步骤,是因为将自然语言规则转换成逻辑公式是核心:需要将背景知识翻译成 FO(-) 语句。
-
形式上可表示为:
GenerateFormulas ( Text , Grammar F O ( − ) ) → Theory \text{GenerateFormulas}(\text{Text}, \text{Grammar}_{FO(-)}) \rightarrow \text{Theory} GenerateFormulas(Text,GrammarFO(−))→Theory
-
与同类方法对比:
- 有些方法(如 LINC、Logic-LM)也做类似的第一阶逻辑生成,但往往需要大量示例和 in-context learning;VERUS-LM 使用更通用的提示,不局限于特定任务。
-
-
子解法1c:自我修正
-
之所以用“自我修正”步骤,是因为初次生成的逻辑表述常存在语法/语义冲突,需要迭代修正。
-
进一步拆解为:
- 语法修正:若求解器(IDP-Z3)检测到语法错误,LLM 根据报错信息修复。
- 语义修正:若理论不可满足,则寻找最小不满足子集,要求 LLM 修正冲突公式。
-
形式可简要表示为:
Refine ( Theory , SolverFeedback ) → CorrectedTheory \text{Refine}( \text{Theory}, \text{SolverFeedback} ) \rightarrow \text{CorrectedTheory} Refine(Theory,SolverFeedback)→CorrectedTheory
-
与同类方法对比:例如 Logic-LM 也做“自我修正”,但仅限语法层面;VERUS-LM 还会进一步做“不可满足”层面的纠正。
-
综上,子解法1 负责将背景文本一次性转为 FO(-) 知识库,供后续重复使用。
子解法2:任务检测
之所以用“任务检测”子解法,是因为:
- 特征 C:用户查询可对应不同推理模式(如可满足性检查、优化、模型生成等),系统需自动识别具体类型。
在这一子解法中:
- 通过 BERT 或类似分类模型,识别“这条自然语言问题”落在哪个推理任务上。
- 不同于多数同类方法(Logic-LM、SymbCoT),它们通常只支持少量推理模式(如只做“是否为真”),VERUS-LM 覆盖更多推理形式(8 种)。
形式可写为:
DetectTask ( Question ) → TaskType ∈ { SAT , OPT , … } \text{DetectTask}(\text{Question}) \rightarrow \text{TaskType} \in \{\text{SAT}, \text{OPT}, \dots\} DetectTask(Question)→TaskType∈{SAT,OPT,…}
子解法3:简单数据提取
之所以用“简单数据提取”子解法,是因为:
- 特征 D:某些问题仅需附加一些结构化常量或具体数值,就能完成推理,无需构造复杂公式。
在这一子解法中:
- 使用小型 LLM(如量化后的 Phi 3.5)来提取或填充问题中出现的具体数值、对象名称等。
- 与同类算法对比:大多数神经-符号方法直接一次性把所有信息都由大型 LLM 输出,VERUS-LM 则将“简单提取”与“复杂公式构建”分开,节省算力且提高效率。
形式可写为:
ExtractDataSimple ( Question , Vocabulary ) → PartialStructure \text{ExtractDataSimple}(\text{Question}, \text{Vocabulary}) \rightarrow \text{PartialStructure} ExtractDataSimple(Question,Vocabulary)→PartialStructure
子解法4:复杂公式构建
之所以用“复杂公式构建”子解法,是因为:
- 特征 E:某些问题需要添加新的逻辑约束(比如“给定假设 (\phi) 是否可被知识库 T 蕴涵”),此时需生成较复杂的 FO(-) 公式。
在这一子解法中:
- 借助大型 LLM(如 GPT-4、Gemini)来翻译用户给定的假设、条件为正式逻辑表达式。
- 与同类算法对比:传统做法往往由人工手动编写公式或使用一套已定义的模板;VERUS-LM 可以更灵活地解析用户自然语言并生成公式。
形式可写为:
ConstructComplexFormula ( Question ) → ϕ F O ( − ) \text{ConstructComplexFormula}(\text{Question}) \rightarrow \phi_{FO(-)} ConstructComplexFormula(Question)→ϕFO(−)
子解法5:IDP-Z3 符号推理执行
之所以用“IDP-Z3”子解法,是因为:
- 特征 F:需要一个通用逻辑求解引擎,支持多种推理操作(模型生成、可满足性、优化、解释等),IDP-Z3 对 FO(-) 有原生支持。
在这一子解法中:
- 将已完成的知识库(T)及所需的结构信息(PartialStructure 或复杂公式)输入 IDP-Z3,执行相应操作,如:
- SAT:判断 T 是否有模型。
- 优化:寻找使某项值最小/最大的模型。
- 模型生成:列举满足 T 的模型。
- 逻辑蕴涵:检查是否 ( T \models \phi ) 。
- 与同类方法对比:很多系统用 ASP(如 clingo)或 Z3(纯 SMT),但不一定对 FO(-) 做扩展;VERUS-LM 的特征在于统一 FO(-) 形式。
子解法6:结果组织与输出
之所以用“结果输出”子解法,是因为:
- 特征 G:将推理后的模型、真值判定或解释性信息转回自然语言,对用户友好呈现。
在这一子解法中:
- 最终将符号推理引擎的结果进行格式化;必要时可提供证明或最小不满足子集之类的解释。
- 与同类算法对比:SymbCoT 会把推理过程在 LLM 内部进行并直接产出“Chain-of-Thought”,VERUS-LM 则在引擎和 LLM 之间来回交互,但输出同样可读。
(小结)
所以 VERUS-LM 在逻辑上可拆解为 6 大子解法,每个子解法都有其对应的必要特征和操作,互相组合形成完整流程。
额外举个简单例子:
- 用户输入:“在这个城市中,小王是 18 岁,小张是 16 岁,问谁符合成人条件?”
- 子解法1:先把“成人定义”“城市人员类型”等背景写成 FO(-) 知识库。
- 子解法2:分类器判断这是“模型生成”或“可满足性/命题真值”问题。
- 子解法3:若只需填“age(小王)=18, age(小张)=16”等常量,小型 LLM 即可搞定。
- 子解法5:IDP-Z3 判断哪些人满足“age ≥ 18”。
- 子解法6:输出“小王是成人,小张不是”,返回自然语言结果。
- 子解法之间的逻辑链与决策树表示
在决策树视角下,各子解法如何衔接?可示意如下(简化):
├── VERUS-LM 解法
│ ├── 子解法1:知识库创建
│ └── 推理阶段
│ ├── 子解法2:任务检测
│ │ ├── 若仅需简单数据 → 子解法3:简单数据提取 → 子解法5
│ │ └── 若需复杂公式 → 子解法4:复杂公式构建 → 子解法5
│ └── 子解法5:IDP-Z3 执行
│ └── 结果完成后 → 子解法6:输出
整体上是一条主要链条,中间在“子解法2”之后根据需求分支到“子解法3”或“子解法4”,然后再统一进入“子解法5”,最后到“子解法6”。
- 是否存在隐性方法?若有,则定义关键方法
通过逐行对比可以发现,VERUS-LM 在以下方面可能存在隐性方法:
-
自我修正中的“最小不满足子集”分析:在很多介绍中只是说“如果不可满足就让 LLM 修正”,但实际上求解器(IDP-Z3)返回的“冲突子集”信息,如何精确转述给 LLM 并在 LLM 内部解析、对症下药,往往是一个关键但容易被忽视的过程。
- 我们可将它定义为 “子解法1c-隐性关键方法:基于最小冲突子集的语义修正”。
- 之所以说这是隐性方法,是因为传统文本不会单列“如何把冲突子集信息映射回自然语言”的流程,但它在实际系统中必不可少。
- 这一步可能跨越多行多步,需要将逻辑冲突信息打包、简化成提示,再让 LLM 重新生成正确的子句。
-
任务检测与信息抽取的自动衔接:当分类器判断需求后,如何让小型 LLM 或大型 LLM 只提取或构建所需信息,也是一个隐性的衔接过程:
- 可定义为 “子解法2-隐性关键方法:推理任务与信息提取的自动分配逻辑”。
- 之所以说它隐性,是因为多数论文里只说“BERT 检测问题类型,然后对数据进行提取”,但实际有一层中间逻辑决定“调小模型还是大模型”,以及如何把上下文给到对应模型。
- 是否有隐性特征?
- 在上述“隐性关键方法”中,都体现了某些**“额外的中间步骤”**,如把最小冲突子集转换为可读的提示信息、从分类器输出到调用不同大小 LLM 的策略等。
- 这些中间步骤往往不是书本里标准的“知识表示”或“逻辑推理”方法,而是工程实现的辅助特征,可以说是**“隐性特征”**:
- 例如,“LLM 修正时如何吸收最小冲突子集”——这是个工程特征,它能够提升修正成功率,但难以在一行代码或一个数学公式里描述清楚,需要多行实现与提示模板。
- 这样的特征既不是传统意义上的推理规则,也不是纯粹数据提取,而是驱动 LLM 与求解器交互的关键机制。
-
潜在局限性
-
对高阶逻辑或极大规模问题的处理:IDP-Z3 基于 FO(-) 以及底层 SMT,对非常大的(尤其是高阶)问题可能性能欠佳。
-
隐性方法的可迁移性:将“最小不满足子集”或“分类器—提取器”中的工程逻辑移植到新场景,可能需要重新设计提示模板、分类器。
-
对模型的依赖:当背景知识与 LLM 训练分布差异较大时,自动生成公式的质量会下降;此外,自我修正也不一定能 100% 成功。
-
隐性特征带来的复杂性:中间步骤过多,增加了系统调试的难度,一旦某个环节出问题,整体性能可能受影响。
提问
1. 关于“通用性”与任务切换的细节
问:
论文中宣称 VERUS-LM 能“一次构建知识库,多种推理任务复用”。可是在实际场景下,如果不同用户提出的任务间差异极大,比如前一个问题是“求最优解”,后一个问题要“列出所有解”,中间还穿插一些“因果解释”或“假设检验”类型的问题,是否真的不需要重新 formalize 知识库?
如果要不断生成新公式或新定义,岂不是还是得多次翻译?这是否与“只用一次翻译”相矛盾?
答:
论文的核心思想不是“所有问题都用同一个逻辑公式”,而是“同一个领域知识(KB)可以在很大程度上被复用”。
因为大多数领域知识(如某些医疗、法务、商业规则)在逻辑层面是稳定的,只要将它们一次性翻译、修正、并存储在符号推理引擎里,就能对后续许多问题(不管是满足性、优化还是解释类)共用那一套核心规则。
确实,遇到非常不一样的查询,有时仍需要局部追加一些逻辑公式或数据(例如新的优化目标、新的辅助谓词等),但并非要从头再把全部领域知识重写。
两者并不矛盾:持续小规模增量与核心大规模复用可以并行存在。
2. 关于“自我修正”性能与极端场景
问:
论文里提到有“语法修正”和“语义修正”两个环节,用于处理翻译后的逻辑公式错误。
但如果一个用户提供了极度模糊、彼此冲突或包含完全无关概念的文本,比如同时讨论“BMI 计算公式”和“量子纠缠态的塌缩机理”,这时系统生成的逻辑往往会出现荒诞的混用。
你们的自我修正机制如何能分辨清楚?会不会卡在无限循环或干脆放弃?
答:
从论文角度,自我修正基于两个步骤:
- 语法修正:先检查基本逻辑语法是否可解析;
- 语义修正:判断是否可满足、是否与给定结构冲突。
在输入文本极度不一致或跨域杂糅严重的场景下,如果逻辑引擎发现无穷多条冲突,系统的确可能多次尝试修正而依旧无法生成自洽模型,最终会得出“无法满足”或“KB 不可用”的结论。
换言之,VERUS-LM 并不保证能自动分块“剥离量子纠缠”与“BMI 公式”来构造两个正确小 KB,它只能尽力修正,并在无解时报错或给出“不满足”结果。这种情况也正是自我修正无法“神奇地化解一切”的局限所在。
3. 关于 IDP-Z3 引擎选型的可替代性
问:
你们在论文中说选择了 IDP-Z3 作为推理核心,因为它支持 FO(-) 以及一系列丰富的推理方式。那么如果其他研究者想用 ASP(Answer Set Programming)或 SMT(Satisfiability Modulo Theories)工具来替换,会有哪种兼容问题?
你们做过可移植性测试吗?为什么不直接用通用的 SMT 求解器如 Z3 原生版本,而是要“IDP-Z3”这款混合引擎?
答:
- 可移植性:从理论角度看,FO(-) 在表达力上接近一阶逻辑加上一些扩展(如聚合、定义式等),与 ASP 或 SMT 有一定交集,但也有特性差异(如定义式、类型系统、聚合函数等处理方式不同)。若想切换到纯 ASP,需要先把 FO(-) 里许多显式定义和聚合翻译成 ASP 规则;SMT 同理,需要在理论组合上支持不同整数/实数运算、聚合等等。
- IDP-Z3 的好处:它在保留 Z3 的底层能力之余,增加了一些高层的知识库范式(KBP)特性,易于实现多种推理任务(模型扩展、解释等),而不必手动书写 SMT 公式。对应用开发者比较友好,因此作者选择了这款。
- 可移植测试:论文没有针对 ASP 或其他 SMT 做系统对比实验,只是指出 FO(-) 的灵活度与 IDP-Z3 的可用性;若真要替换,基本思路上可行,但需额外做逻辑表达式的转换层,以及处理一些内置功能的差异。
4. 关于 OWA (Open World Assumption) 与 CWA (Closed World Assumption)
问:
你们在论文里承认,IDP-Z3 不支持开放世界假设,因此对某些需要“未知事实也可能存在”的推理任务会造成麻烦。那面对像 FOLIO 或 ProofWriter 这类需要 OWA 的数据集时,你们采取了“往每个类型里添加一个特殊‘unknown’元素”的近似手段。为什么这么做就足够了?如果真实世界里有许多“潜在未知实体”,光加一个“unknown”常量是不是过于简化?能否分析一下可能带来的不准确性?
答:
- 目的:添加一个“unknown”元素是为了模拟一种“不确定是否属于该类型”的默认情况,从而让 IDP-Z3 在 CWA 框架下依旧能处理“不存在确切证据”的情形。
- 局限性:确实,这只是一种技巧,不是真正的 OWA。若真实世界有无数未知实体,这个方法的概括能力有限。
- 为什么还算“足够”:对 FOLIO、ProofWriter 等常见基准,测试集中“未提及的实体”通常都可以通过“unknown”兜底来处理,实践上效果不错。但在超大规模或极度开放的场景里,仍可能不准确或不健壮,这是当前框架的局限,无法完全替代真正的 OWA 推理。
5. 关于自定义推理任务的扩展难度
问:
VERUS-LM 里列出了 8 种主要推理方式(如模型扩展、优化、解释等)。如果我们想自定义新任务,比如多目标优化、分层因果分析,是否可以在你们的系统里“一键添加”?还是说要改动很大?
论文中似乎没有举例说明如何拓展更多的推理模式。这个扩展成本到底如何?
答:
目前 8 种推理模式属于作者根据 IDP-Z3 提供的核心功能或易实现功能做的封装:如 SAT、MAX-SAT(优化)、逻辑蕴涵、模型扩展、最小不满足子集(解释)等。
如果要做更加定制化的任务,如多目标优化、分层因果推理,需要:
- 在 FO(-) 语言层面做额外的形式化;
- 在 IDP-Z3 引擎或其上层写专门的“调用逻辑”,可能涉及把问题拆解成已有功能的组合,或对底层做插件式开发。
因此并不一定是“一键添加”,但“二次开发”难度也不算无解,取决于新功能与现有功能的重合度。如果某些新需求能被表达为现有推理的叠加,那么改动不算太大;但若要求非常定制化的推理过程,就需要更深入的引擎改造。
6. 关于多轮对话场景的连贯推理
问:
论文里着重介绍了 VERUS-LM 如何将一次性的自然语言描述翻译成逻辑知识库,但没有深入讨论“多轮对话”场景下的动态更新——假如用户在第 1 轮问题后又补充新条件,第 2 轮再修改已有假设,第 3 轮还要回滚某些知识,你们的系统能否支持?会不会导致需要反复大规模地重新生成公式,且引擎内部如何做版本控制?
答:
- 动态更新:因为使用了“知识库范式(KBP)”,理论上我们可以对已经构建的 KB 进行增量修改或版本化,直接在 IDP-Z3 中增加或移除某些公式。
- 频繁大规模变化:若用户频繁地大改逻辑,大概率需要多次调用 LLM 来重新生成或删除那部分公式,否则原 KB 中的部分公理/定义可能与新事实冲突。
- 论文局限:的确,论文主要针对单次(或少量)更新的情形,没有做大规模实验来证明多轮对话的效率。但在实现层面,有可能借助“版本化”或“模块化”手段让更新更可控。多轮对话带来的同步问题属于未来工作的一大挑战。
7. 关于实验结果的统计显著性
问:
在 AR-LSAT 数据集上,你们说自己的方法比第二名高约 25% 的准确率,确实非常令人印象深刻。然而这里的题量只有 231 道,在统计学上,这个绝对量也未必很大。是否做过统计显著性检验(如 p-value 或置信区间)来证明这个差距真的不是偶然?
答:
论文中给出的对比通常是平均准确率形式,并没有在文本中明确报告统计显著性检验。然而:
- AR-LSAT 本身难度高、题型多样,已有基准方法的准确率普遍不太高;
- 作者强调了自己在多种数据集(PrOntoQA、ProofWriter、FOLIO、LogicalDeduction、AR-LSAT)都有稳定表现,只有在 AR-LSAT 上差距尤其显著。
若从研究严格性角度看,确实可以进一步做例如 Bootstrap 或 t-test 来佐证差异显著性,这部分在论文中未详细展开,可能是篇幅所限,也可能是作者认为 25% 优势已足够明显。在实际发表时,若需要更严谨,可以附上这些检验。
8. 关于知识库与数据隐私、保密问题
问:
在很多企业应用场景,数据(尤其医疗、金融等)存在保密要求,而你们的方法常需要将自然语言数据发送给 LLM(可能在云端)做翻译,还需要保留知识库在推理引擎里,甚至可能记录修正过程。
如何避免数据泄露?论文似乎没有过多探讨隐私保护机制,是否意味着在真实隐私场景下无法落地?
答:
隐私安全确实是一个重要问题。论文给出的原则性方案包括:
- **用本地小模型(SLM)**代替云端大模型,尤其对“信息提取”这一步,可保存在企业内网中执行,避免敏感数据离开本地。
- 若必须调用云端 LLM,可对文本先做匿名化、加密或脱敏处理,如去掉姓名、身份证号等直接信息。
- 知识库生成后的逻辑规则本身可能相对“抽象”,不会直接暴露用户隐私;关键要保证翻译前或翻译中对数据做最小化暴露。
论文属于研究性质,没专章讨论隐私合规,但在真实落地时需结合安全策略或隐私合规工具,这确实是后续工程化的一大挑战。
9. 关于自定义细粒度解释(Explain)
问:
论文提出了“Explain”这个推理模式,可以“解释为何某个原子公式为真、为假,或为什么理论不一致”。
然而在实际复杂应用里,用户往往需要“更细粒度”的解释,如具体使用了哪些规则、哪几步推导才得出结论。
你们目前给出的示范似乎只是说“哪条规则被触发,或哪个子集有冲突”,不够直观。作者能否完善一下这个解释过程,让它变成一条能够读懂的推理链?
答:
- 现状:IDP-Z3 能够输出最小不满足子集、或指出某些公式如何导致冲突,也能列出触发哪些规则;但要形成类似“多步自然语言推导链”需要额外格式化或二次生成。
- 可行方案:可以让 LLM 根据 IDP-Z3 的内部信息(如模型冲突点、关键规则 ID)自动生成可读解释,比如“某则规则导致 x,进而与 y 冲突”。
- 论文贡献:主要展示了 IDP-Z3 的内置解释功能,但对更细粒度、多步Chain-of-Reasoning解释并未深入实现,可能留给应用层做定制化开发。目前例子里给出的解释已能定位“为什么为真/假”或“哪两个公式冲突”,但不一定像人类推理过程那样详尽。
10. 关于大规模复杂场景下的推理效率
问:
如果知识库规模非常庞大,比如包含成千上万个公理、数千个函数或谓词,IDP-Z3 的推理效率本身可能会大幅下滑,而每次用户询问时还要先确认哪些公理可用或不冲突。此时,VERUS-LM 会不会在性能上难以支撑实际工业级应用?为什么论文中没有提供在上百万规模公理场景下的测试结果?
答:
- 效率瓶颈:确实,如果知识库极度庞大,任何一阶逻辑推理工具(包括 IDP-Z3)都可能面临严重的组合爆炸。作者并没有声称可以解决所有规模的推理问题,依旧受制于通用逻辑求解的复杂度。
- 场景假设:论文聚焦于中等规模的领域知识(如题库、常规法条、医学知识库等),并展示在多个基准数据集上性能良好。对上百万公理级别的工业场景,势必需要额外的索引、分区、增量求解或启发式策略,这在当前论文中未做深入报告。
- 下一步研究:作者亦提到今后可能做局部加载或分区推理等策略来提升大规模效率,但这已超出本论文的核心范畴。
相关文章:

可信大模型:LLM + 神经符号推理,解决复杂推理任务
可信大模型:LLM 神经符号推理,解决复杂推理任务 论文大纲一、Why:研究要解决的现实问题二、What:核心发现或论点三、How:研究的整体方法与关键细节3.1 前人研究的局限性3.2 创新方法/视角3.3 关键数据或实验支持3.4 可…...

基于大数据的全国热门旅游景点数据分析系统的设计与实现
【大数据】基于大数据的全国热门旅游景点数据分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统主要包括登录注册、系统首页、图表分析、数据管理和个人信息五大功能模…...

Moya 网络框架
Moya 网络框架 定义enum类型,有多种接口就定义多少种,然后实现TargetType协议 import Foundation //导入网络框架 import Moyaenum DefaultService {//广告列表case ads(position : Int)case sheets(size:Int)case sheetDetail(data: String)case regi…...

【环境安装】重装Docker-26.0.2版本
【机器背景说明】Linux-Centos7;已有低版本的Docker 【目标环境说明】 卸载已有Docker,用docker-26.0.2.tgz安装包安装 1.Docker包下载 下载地址:Index of linux/static/stable/x86_64/ 2.卸载已有的Docker 卸载之前首先停掉服务 sudo…...

std::ranges::set_intersection set_union set_difference set_symmetric_difference
std::ranges::set_intersection:是 C20 引入的一个算法,用于计算两个已排序范围的交集。它将两个范围的交集元素复制到输出范围中。 std::ranges::set_intersection 用于计算两个已排序范围的交集。它将两个范围的交集元素复制到输出范围中。 注意事项…...

消息中间件深度剖析:以 RabbitMQ 和 Kafka 为核心
在现代分布式系统和微服务架构的构建中,消息中间件作为一个不可或缺的组件,承担着系统间解耦、异步处理、流量削峰、数据传输等重要职能。尤其是在面临大规模并发、高可用性和可扩展性需求时,如何选择合适的消息中间件成为了开发者和架构师们…...

笔试题笔记#6 模拟三道题和总结知识
两小时快乐模拟,最终三百分耻辱下播,(刷的题三道一组,时长两小时,第一题100分,第二题200分,第三题300分),第三题完全想错了,其实挺简单的,就是好久…...
的“对抗“过程解析:从图像合成到药物发现的跨领域应用)
生成对抗网络(GAN)的“对抗“过程解析:从图像合成到药物发现的跨领域应用
技术原理(数学公式示意图) 核心对抗公式 min G max D V ( D , G ) E x ∼ p d a t a [ log D ( x ) ] E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D,G) \mathbb{E}_{x\sim p_{data}}[\log D(x)] \mathbb{E}_{z\sim p_…...

[鸿蒙笔记-基础篇_自定义构建函数及自定义公共样式]
在开发中遇到比较复杂的界面的时候都会用到自定义组件,但是在自定义组件内部也会有一些公共的布局及公共的样式,这时就需要用到自定义构建函数和自定义构建样式。说白了就是:在ets文件中进行构建函数和构建样式的抽取封装。比较常用记录一下。…...

【C】初阶数据结构4 -- 双向循环链表
之前学习的单链表相比于顺序表来说,就是其头插和头删的时间复杂度很低,仅为O(1) 且无需扩容;但是对于尾插和尾删来说,由于其需要从首节点开始遍历找到尾节点,所以其复杂度为O(n)。那么有没有一种结构是能使得头插和头删…...
【nodejs实现】)
【动态路由】系统Web URL资源整合系列(后端技术实现)【nodejs实现】
需求说明 软件功能需求:反向代理功能(描述:apollo、eureka控、apisix、sentinel、普米、kibana、timetask、grafana、hbase、skywalking-ui、pinpoint、cmak界面、kafka-map、nacos、gateway、elasticsearch、 oa-portal 业务应用等多个web资…...

解读 Flink Source 接口重构后的 KafkaSource
前言 Apache Kafka 和 Apache Flink 的结合,为构建实时流处理应用提供了一套强大的解决方案[1]。Kafka 作为高吞吐量、低延迟的分布式消息队列,负责数据的采集、缓冲和分发;而 Flink 则是功能强大的流处理引擎,负责对数据进行实时…...

一场始于 Selector Error 的拯救行动:企查查数据采集故障排查记
时间轴呈现事故进程 17:00:开发人员小李正在尝试利用 Python 爬虫从企查查(https://www.qcc.com)抓取公司工商信息。原本一切正常,但突然发现信息采集失败,程序抛出大量选择器错误。17:15:小李发现&#x…...

代码随想录刷题攻略---动态规划---子序列问题1---子序列
子序列(不连续)和子序列(连续)的问题 例题1: 最长递增子序列 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列是由数组派生而来的序列,删除(或不删除)数组中的…...

QEMU 搭建arm linux开发环境
Qemu 作为一款强大的开源虚拟化软件,为我们提供了一个便捷且经济实惠的方式来模拟各种硬件环境,从而在上面安装和学习 Linux 系统。本文将详细介绍如何使用 Qemu 搭建 Linux 学习环境, 环境准备 操作系统:建议使用 Ubuntu 20.04…...

PyQt组态软件 拖拽设计界面测试
PyQt组态软件测试 最近在研究PyQt,尝试写个拖拽设计界面的组态软件,目前实现的功能如下: 支持拖入控件,鼠标拖动控件位置 拖动控件边缘修改控件大小支持属性编辑器,修改当前选中控件的属性 拖动框选控件,点选控件 控…...

JAVA泛型介绍与举例
Java中,泛型用于编译阶段限制集合中元素的类型,或者限制类中某个属性的类型,编译过程中发生类型擦除,最终还是Object类型。 1. 集合中的泛型 集合默认可以存储任何类型的元素,即Object类型,当使用一个集合…...

JavaScript 内置对象-Math对象
在JavaScript中,Math 对象提供了一系列与数学相关的静态方法和属性,帮助开发者执行复杂的计算任务。无论是简单的算术运算还是高级的几何、统计计算,Math 对象都能提供强大的支持。本文将详细介绍 Math 对象的主要功能及其使用方法。 一、简…...

Ubuntu 22.04 Desktop企业级基础配置操作指南
一、网络配置 cd /etc/netplan vi 00-installer-config.yaml 设置如下所示: network:version: 2ethernets:eth0: # 替换为你的实际网络接口名称,如 ens33, enp0s3 等dhcp4: noaddresses:- 192.168.1.100/24 # 静态IP地址和子网掩码gateway4: 192.16…...

UE_C++ —— UObject Instance Creation
目录 一,UObject Instance Creation NewObject NewNamedObject ConstructObject Object Flags 二,Unreal Object Handling Automatic Property Initialization Automatic Updating of References Serialization Updating of Property Values …...

WPF的MVVMLight框架
在NuGet中引入该库: MVVMLight框架中的命令模式的使用: <StackPanel><TextBox Text"{Binding Name}"/><TextBox Text"{Binding Title}"/><Button Content"点我" Command"{Binding ShowCommand…...

【云安全】云原生- K8S kubeconfig 文件泄露
什么是 kubeconfig 文件? kubeconfig 文件是 Kubernetes 的配置文件,用于存储集群的访问凭证、API Server 的地址和认证信息,允许用户和 kubectl 等工具与 Kubernetes 集群进行交互。它通常包含多个集群的配置,支持通过上下文&am…...

binance python
binance-futures-connector 4.1.0 from binance.um_futures import UMFutures # U本位 USDT-M Futures /fapi/* # 币本位 COIN-M Delivery /dapi/* proxies { https: http://localhost:7890 } client UMFutures(proxiesproxies)apiKey"" apiSecret"" cl…...

LLaMA-Factory DeepSeek-R1 模型 微调基础教程
LLaMA-Factory 模型 微调基础教程 LLaMA-FactoryLLaMA-Factory 下载 AnacondaAnaconda 环境创建软硬件依赖 详情LLaMA-Factory 依赖安装CUDA 安装量化 BitsAndBytes 安装可视化微调启动 数据集准备所需工具下载使用教程所需数据合并数据集预处理 DeepSeek-R1 可视化微调数据集处…...

利用亚马逊云科技RDS for SQL Server配置向量数据存储
生成式人工智能(AI)正迎来又一个快速发展期,引起了开发者们的广泛关注。将生成式能力集成到商业服务和解决方案中变得非常重要。当前的生成式AI解决方案是机器学习和深度学习模型逐步进化迭代的结果。从深度学习到生成式AI的质变飞跃主要是由…...

ASP.NET Core SixLabors.ImageSharp v1.0 的图像实用程序类 web示例
这个小型实用程序库需要将 NuGet SixLabors.ImageSharp包(版本 1.0.4)添加到.NET Core 3.1/ .NET 6 / .NET 8项目中。它与Windows、Linux和 MacOS兼容。 这已针对 ImageSharp v3.0.1 进行了重新设计。 它可以根据百万像素数或长度乘以宽度来调整图像大…...

JVM 底层探秘:对象创建的详细流程、内存分配机制解析以及线程安全保障策略
文章目录 1. 类加载检查2. 内存分配① 指针碰撞② 空闲列表线程安全问题: 3. 内存空间初始化4. 对象头设置5. 对象初始化 当Java虚拟机遇到一条 new指令时,会执行以下步骤来创建对象: 1. 类加载检查 首先检查new指令的参数是否能在常量池中…...

SpringCloud框架下的注册中心比较:Eureka与Consul的实战解析
摘要 在探讨SpringCloud框架中的两种注册中心之前,有必要回顾单体架构与分布式架构的特点。单体架构将所有业务功能集成在一个项目中,优点是架构简单、部署成本低,但耦合度高。分布式架构则根据业务功能对系统进行拆分,每个模块作…...

应对DeepSeek总是服务器繁忙的解决方法
最近由于访问量过大,DeepSeek服务器官网经常弹出:“服务器繁忙,请稍后再试”的提示,直接卡成PPT怎么办?服务器繁忙直接看到视觉疲劳: 解决DeepSeek卡顿问题 DeepSeek使用卡顿问题,是因为访问量…...
)
C++ 实践扩展(Qt Creator 联动 Visual Studio 2022)
这里我们将在 VS 上实现 QT 编程,实现如下: 一、Vs 2022 配置(若已安装,可直接跳过) 点击链接:Visual Studio 2022 我们先去 Vs 官网下载,如下: 等待程序安装完成之…...
)
JENKINS(全面)
一.linux系统中JENKINS的安装 注意:安装jenkins需要安装jdk,而且具体版本的jenkins有相对应的jdk版本。可参考以下链接。 Redhat Jenkins 软件包https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/r…...
)
72.git指南(简单)
Git 操作指南 在开始之前,请确保你已经提前配置好 .gitignore 文件,以避免不必要的文件被 Git 跟踪。如果在初始化仓库后再配置 .gitignore 文件,之前添加的文件仍会被跟踪,需要手动移除。 如下例子忽略了文件夹及文件夹内所有内…...

LeetCode 232: 用栈实现队列
LeetCode 232: 用栈实现队列 题目描述 使用栈实现队列的操作。支持以下操作: MyQueue():初始化队列。push(x):将元素 x 推入队列。pop():从队列中移除元素。peek():返回队列头部的元素。empty():检查队列…...

C#关于静态关键词static详解
Demo代码: public class HomeController : Controller {private DateTime time1 DateTime.Now; // 实例字段private static DateTime time2 DateTime.Now; // 静态字段[HttpGet("index")]public async Task Index(){Console.WriteLine($"now&am…...

【Pico】使用Pico进行无线串流搜索不到电脑
使用Pico进行无线串流搜索不到电脑 官串方式:使用Pico互联连接电脑。 故障排查 以下来自官方文档 请按照以下步骡排除故障: 确认电脑和一体机连接了相同的路由器WiFi网络(相同网段) IP地址通常为192.168.XX,若两设备的IP地址前三段相同&…...

细说STM32F407单片机RTC的基本原理及闹钟和周期唤醒功能的使用方法
目录 一、RTC基础知识 1、 RTC的功能 2、RTC工作原理 (1)RTC的时钟信号源 (2)预分频器 (3)实时时钟和日历数据 (4)周期性自动唤醒 (5)可编程闹钟 &a…...

ES用脚本更新异常
因为需要向原有的es结构中增加一个检索字段,但因为历史es数据都没有该字段,需要批量刷新es的该字段,本地使用了脚本的方式进行刷新,在测试环境测试,出现了以下错误: 500 Internal Server Error: [{"e…...
)
Navicat导入海量Excel数据到数据库(简易介绍)
目录 前言正文 前言 此处主要作为科普帖进行记录 原先Java处理海量数据的导入时,由于接口超时,数据处理不过来,后续转为Navicat Navicat 是一款功能强大的数据库管理工具,支持多种数据库系统(如 MySQL、PostgreSQL、…...

C++学习
C对C语言的加强 1.命名空间(namespace) 为了避免,在大规模程序的设计中,以及在程序员使用各种各样的C库时,这些标识符的命名发送冲突。 标准C引入了关键字namespace,可以更好地控制标识符的作用域。 st…...

Linux Mem -- Where the mte store and check in the real hardware platform
目录 1 前言 2 MTE tag分类 3 Address tag 4 Memory tag 5 Tag Check 6 Cortex-A710 和 CI-700 系统示例: 1 前言 ARM的MTE允许分配、设置、比较一个 4bit的allocation tag 为16字节粒度的物理地址。当对MTE有一定了解后,应该会产生如下疑问&#…...

老牌软件,如今依旧坚挺
今天给大家介绍一个非常好用的老牌电脑清理软件,这个软件好多年之前就有人使用了。 今天找出来之后,发现还是那么的好用,功能非常强大。 Red Button 电脑清理软件 软件是绿色版,无需安装,打开这个图标就能直接使用了…...

springboot整合modbus实现通讯
springboot整合modbus4j实现tcp通讯 前言 本文基于springboot和modbus4j进行简单封装,达到开箱即用的目的,目前本方案仅实现了tcp通讯。代码会放在最后,按照使用方法操作后就可以直接使用 介绍 在使用本方案之前,有必要对modb…...

【java面试】线程篇
1.什么是线程? 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。 2.线程和进程有什么区别? 线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任…...

DeepSeek官方发布R1模型推荐设置
今年以来,DeepSeek便在AI领域独占鳌头,热度一骑绝尘。其官方App更是创造了惊人纪录,成为史上最快突破3000万日活的应用,这一成绩无疑彰显了它在大众中的超高人气与强大吸引力。一时间,各大AI及云服务厂商纷纷投身其中&…...

Vue CLI 配置与插件
Vue CLI 配置与插件 今天我们来聊聊 Vue CLI 的配置与插件。随着项目复杂度的增加,合理配置 Vue CLI 可以帮助我们更高效地管理项目,同时利用插件机制快速集成各种功能。下面我就和大家详细介绍如何配置 Vue CLI,以及如何使用和开发插件&…...
分页3.0版本 通用版)
Spring Boot (maven)分页3.0版本 通用版
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...

pip 与 conda 的故事
pip 换源 pip 官方源 -i https://pypi.python.org/simple pip 清华源 -i https://pypi.tuna.tsinghua.edu.cn/simple pip 阿里源 -i https://mirrors.aliyun.com/pypi/simple PyTorch 安装 pip3 install torch torchvision torchaudio pip3 install torch torchvision torchaud…...

清华大学KVCache.AI团队联合趋境科技联合的KTransformers开源项目为什么那么厉害
KTransformers是一个由清华大学KVAV.AI团队开发的开源项目,旨在优化大语言模型(LLM)的推理性能,特别是在有限显存资源下运行大型模型。以下是KTransformers的详细介绍: 1. 核心特点 高性能优化:KTransfor…...

DeepSeek 遭 DDoS 攻击背后:DDoS 攻击的 “千层套路” 与安全防御 “金钟罩”_deepseek ddos
当算力博弈升级为网络战争:拆解DDoS攻击背后的技术攻防战——从DeepSeek遇袭看全球网络安全新趋势 在数字化浪潮席卷全球的当下,网络已然成为人类社会运转的关键基础设施,深刻融入经济、生活、政务等各个领域。从金融交易的实时清算…...

4090单卡挑战DeepSeek r1 671b:尝试量化后的心得的分享
引言: 最近,DeepSeek-R1在完全开源的背景下,与OpenAI的O1推理模型展开了激烈竞争,引发了广泛关注。为了让更多本地用户能够运行DeepSeek,我们成功将R1 671B参数模型从720GB压缩至131GB,减少了80%ÿ…...