算法——结合实例了解广度优先搜索(BFS)搜索
一、广度优先搜索初印象
想象一下,你身处一座陌生的城市,想要从当前位置前往某个景点,你打开手机上的地图导航软件,输入目的地后,导航软件会迅速规划出一条最短路线。这背后,就可能运用到了广度优先搜索(BFS,Breadth-First Search)算法。
广度优先搜索是一种用于遍历或搜索图(Graph)或树(Tree)的算法 ,它的核心思想是从起始节点开始,以广度为优先逐层向外扩展。就像平静湖面投入一颗石子,激起的涟漪会一圈一圈向外扩散,BFS 从起始节点出发,先访问与它直接相连的所有节点,再依次访问这些节点的未访问过的邻居节点,以此类推,直到找到目标节点或遍历完所有可达节点。这和深度优先搜索(DFS,Depth-First Search)形成鲜明对比,DFS 是沿着一条路径尽可能深地探索下去,直到无法继续才回溯到前一个节点继续探索其他分支。
在实际应用中,BFS 特别适合解决需要寻找最短路径、层级结构或者连通性等问题。比如在地图导航中找最短路线,在社交网络分析中寻找两人之间的最短关系链,在迷宫游戏里寻找从起点到终点的最短路径等。
二、BFS 的工作原理
(一)关键步骤
选择起始节点:在开始搜索前,首先要确定一个起始节点。这个节点是整个搜索过程的起点,后续的搜索都是基于这个节点展开的。比如在一个社交网络中寻找用户 A 和用户 B 之间的最短关系链,用户 A 就可以作为起始节点。
用队列维护顺序:BFS 使用队列(Queue)这种数据结构来存储待访问的节点。队列具有先进先出(FIFO,First-In-First-Out)的特性,这与 BFS 逐层扩展的思想相契合。在搜索开始时,将起始节点加入队列。
循环处理队列:只要队列不为空,就从队列中取出一个节点进行处理。假设当前取出的节点为 X,接着检查节点 X 是否为目标节点。如果是,那么就找到了目标,搜索过程结束;如果不是,则访问节点 X 的所有未访问过的邻居节点,并将这些邻居节点加入队列。这个过程不断重复,直到队列为空或者找到目标节点。例如在一个地图中寻找从地点 A 到地点 Z 的最短路径,从地点 A 开始,将其相邻的地点(如 B、C、D)加入队列,然后处理队列中的 B,再将 B 的未访问过的相邻地点加入队列,如此循环,直到找到地点 Z 或者队列为空。
(二)核心数据结构
队列在 BFS 中起着至关重要的作用。它保证了搜索过程按照层次顺序进行,即先访问的节点的邻居节点在后续被访问。以二叉树的层次遍历为例,首先将根节点入队,然后从队列中取出根节点进行访问,接着将根节点的左子节点和右子节点依次入队。此时队列中存储的是根节点的下一层节点,下一次循环时,会从队列中取出这两个子节点进行访问,并将它们的子节点入队,以此类推,从而实现了二叉树的层次遍历,这正是 BFS 在二叉树结构中的应用体现。
(三)与 DFS 的对比
搜索策略:DFS 是尽可能深地搜索图的分支,当节点的所有边都已被探寻过,搜索将回溯到发现该节点的那条边的起始节点。而 BFS 从根节点(或某个任意节点)开始访问,并探索最近邻的节点,如果所有最近邻的节点都已被访问过,搜索将回溯到发现最近邻节点的节点 ,逐层向外扩展。例如在一个迷宫中,DFS 会沿着一条通道一直走到底,直到无法继续才回头换另一条通道;BFS 则是从起点开始,同时向所有相邻的通道探索,一层一层地向外扩散。
数据结构:DFS 通常使用栈(Stack)来实现,因为栈的后进先出(LIFO,Last-In-First-Out)特性与 DFS 的回溯策略相匹配,在递归实现 DFS 时,系统栈会自动记录函数调用的层次和返回地址,从而实现回溯。而 BFS 通常使用队列来实现,利用队列的先进先出特性保证先访问的节点的邻居节点在后续被访问。
遍历顺序:DFS 的遍历顺序取决于搜索树的深度,通常不是按照节点的层次顺序。比如对于一个简单的树结构,根节点为 A,A 有两个子节点 B 和 C,B 又有子节点 D 和 E,C 有子节点 F,DFS 的遍历顺序可能是 A - B - D - E - C - F 。而 BFS 按照节点的层次顺序遍历,对于上述树结构,BFS 的遍历顺序是 A - B - C - D - E - F。
搜索效率:对于某些图,DFS 可能需要更长的时间才能访问所有节点,因为它会深入搜索一个分支直到无法继续,然后再回溯,在一个非常深且分支众多的树中,DFS 可能会在一个很深的分支中浪费大量时间,而目标节点可能在较浅的其他分支。对于某些图,特别是当目标节点距离根节点较近时,BFS 可能更快找到目标节点,因为它会首先访问所有与根节点相邻的节点 ,如果目标节点就在根节点的下一层,BFS 能迅速找到,而 DFS 可能会深入到其他分支而错过。
空间复杂度:DFS 在递归实现中,空间复杂度可能取决于递归调用的深度(或栈的大小),在最坏情况下,当图是一条链状结构时,DFS 的空间复杂度为 O (V),V 为节点数。在迭代实现中,DFS 的空间复杂度通常较低 。BFS 的空间复杂度可能更高,因为它需要存储当前层次的所有节点,这通常需要一个与节点数量成比例的队列空间,在最坏情况下,当图是一个完全二叉树时,BFS 需要存储最底层的节点,数量接近节点总数的一半,空间复杂度为 O (V)。
应用场景:DFS 适用于需要找到所有解或需要回溯的场景,如迷宫问题中寻找所有从起点到终点的路径、图的连通性问题、拓扑排序等。BFS 适用于需要找到最短路径或最小值的场景,如在地图导航中找最短路线、社交网络分析中寻找两人之间的最短关系链、在无权图中寻找最短路径等。
三、BFS 的时间复杂度
(一)邻接表表示
在使用邻接表表示图时,BFS 的时间复杂度为 O (V + E) ,其中 V 是顶点数,E 是边数。这是因为在 BFS 过程中,每个顶点都会被访问一次,其时间复杂度为 O (V) 。同时,对于每个顶点,都需要遍历其所有的邻接边,而每条边恰好会被访问一次,这部分的时间复杂度为 O (E)。例如,在一个社交网络中,将用户看作顶点,用户之间的好友关系看作边,使用邻接表存储这个社交网络。在进行 BFS 时,每个用户(顶点)都会被访问一次,以查找其好友(邻接边),而每条好友关系(边)也只会被访问一次,所以总的时间复杂度为 O (V + E) 。
(二)邻接矩阵表示
当图使用邻接矩阵表示时,BFS 的时间复杂度为 O (V²) 。因为在邻接矩阵中,判断两个顶点之间是否有边相连,需要遍历整个矩阵的对应行和列,对于每个顶点,查找其邻接顶点的操作时间复杂度为 O (V) 。由于有 V 个顶点,所以总的时间复杂度为 O (V²) 。比如在一个表示城市交通网络的邻接矩阵中,城市是顶点,城市之间的道路是边,在进行 BFS 时,对于每个城市(顶点),都需要遍历整个矩阵来确定其与其他城市(顶点)的连接情况,这就导致了较高的时间复杂度。
四、BFS 的应用场景
(一)最短路径查找
在无权图(边没有权重的图)中,BFS 是寻找最短路径的有效方法。以一个简单的地图为例,地图上的各个地点可以看作是图的节点,地点之间的连接(如道路)看作是边,且这些边没有权重(即所有道路通行成本相同)。假设我们要从城市 A 前往城市 Z,使用 BFS,从城市 A 开始,将其所有相邻的城市(如 B、C、D)加入队列,此时队列中的城市距离 A 的距离都为 1。然后从队列中取出城市 B,将 B 的所有未访问过的相邻城市加入队列,这些城市距离 A 的距离为 2。不断重复这个过程,直到找到城市 Z。由于 BFS 是逐层扩展的,所以当找到城市 Z 时,所经过的路径就是从 A 到 Z 的最短路径。在实际的导航应用中,如百度地图、高德地图等,在规划最短路线时,如果不考虑路况、道路收费等因素(即可以简化为无权图),BFS 就可以作为一种基础的路径规划算法。
(二)层级遍历
在二叉树的层序遍历中,BFS 能很好地实现按层级顺序访问节点。以一个简单的二叉树为例,根节点为 A,A 有左子节点 B 和右子节点 C,B 又有左子节点 D 和右子节点 E,C 有右子节点 F。使用 BFS 进行层序遍历,首先将根节点 A 加入队列。然后从队列中取出 A 并访问,接着将 A 的子节点 B 和 C 加入队列,此时队列中存储的是二叉树的第二层节点。下一次循环,从队列中取出 B 并访问,将 B 的子节点 D 和 E 加入队列;再取出 C 并访问,将 C 的子节点 F 加入队列,此时队列中存储的是二叉树的第三层节点。不断重复这个过程,直到队列为空,最终得到的访问顺序就是 A - B - C - D - E - F,这正是二叉树的层序遍历结果。在实际的数据库索引结构中,如 B 树、B + 树,其节点的层级遍历就可以利用 BFS 来实现,这有助于对索引结构进行分析和维护。
(三)社交网络分析
在社交网络中,BFS 可以用于寻找两个用户之间的最短关系链。假设我们有一个社交网络,用户是节点,用户之间的好友关系是边。要寻找用户 A 和用户 B 之间的最短关系链,从用户 A 开始,将 A 的所有好友加入队列,这些好友是 A 的一度关系。然后从队列中取出 A 的一个好友,比如用户 C,将 C 的所有未访问过的好友加入队列,这些好友是 A 的二度关系。持续这个过程,直到找到用户 B。此时,从 A 到 B 经过的路径就是他们之间的最短关系链。例如在微信的社交关系中,如果要查找用户张三和用户李四之间的最短联系路径,就可以运用 BFS 算法来实现。
(四)网络广播
在网络广播中,BFS 可以模拟信息在网络中的传播过程。假设我们有一个计算机网络,节点代表计算机,边代表计算机之间的连接。当某个节点(比如节点 X)发送广播消息时,使用 BFS,首先将节点 X 的所有直接连接的节点加入队列,这些节点接收到消息,这是第一轮传播。然后从队列中取出一个节点,将该节点的所有未接收到消息的直接连接节点加入队列,这些节点接收到消息,这是第二轮传播。不断重复这个过程,直到所有可达节点都接收到消息。通过这种方式,可以清晰地模拟出广播消息在网络中的传播路径和传播范围。在实际的局域网广播中,BFS 的这种原理可以用于分析广播风暴的传播情况,从而采取相应的措施进行防范。
(五)Web 爬虫
在 Web 爬虫中,BFS 可以按照广度优先的方式遍历网页。从一个起始网页开始,将该网页的所有链接(即该网页与其他网页的 “边”)加入队列,这是第一层。然后从队列中取出一个链接,访问对应的网页,并将该网页中的所有新链接加入队列,这是第二层。不断重复这个过程,爬虫就可以按照广度优先的方式遍历整个网站或者互联网的一部分。例如,百度搜索引擎的爬虫在抓取网页时,就可以采用 BFS 策略,从一些种子网页开始,逐层抓取新的网页,从而建立起庞大的网页索引库。
(六)图的连通性判断
在判断图是否连通时,BFS 可以发挥作用。从图中的任意一个节点开始进行 BFS 搜索,如果在搜索结束后,所有节点都被访问到,那么说明图是连通的;如果存在未被访问到的节点,那么图是非连通的,并且可以通过多次从不同的未访问节点开始 BFS 搜索,找出图中的连通分量。例如在一个城市的交通网络中,如果把城市看作节点,道路看作边,通过 BFS 判断交通网络是否连通,有助于分析城市交通的完整性和可靠性。如果发现某个区域的节点在 BFS 搜索中未被访问到,就意味着该区域与其他区域的交通连接存在问题,可能需要进一步规划和建设交通设施。
(七)二分图检测
BFS 可以用于判断图是否为二分图。二分图是一种特殊的图,其节点可以被分成两个不相交的集合 A 和 B,使得图中的每条边的两个端点分别属于集合 A 和集合 B。从图中的任意一个节点开始进行 BFS,将该节点标记为集合 A 中的节点,然后将其所有邻居节点标记为集合 B 中的节点。接着,对于这些邻居节点,将它们的邻居节点标记为集合 A 中的节点(如果这些邻居节点还未被标记)。在这个过程中,如果发现某个节点的邻居节点已经被标记为与它相同的集合,那么说明图不是二分图;如果遍历完所有节点都没有出现这种情况,那么图是二分图。在实际的任务分配场景中,比如将任务分配给不同的团队,每个任务可以看作一个节点,任务之间的关联看作边,如果任务分配图是二分图,就可以将任务合理地分配给两个不同的团队,利用 BFS 判断图是否为二分图,有助于实现这种合理的任务分配。
五、BFS 的实例解析

(一)BFS 遍历二叉树
在二叉树的遍历中,层序遍历是 BFS 的典型应用。下面通过 Python 代码实现二叉树的层序遍历,并详细解释其执行过程。
from collections import dequeclass TreeNode:def \_\_init\_\_(self, value):self.value = valueself.left = Noneself.right = Nonedef bfs\_level\_order(root):if root is None:returnqueue = deque()queue.append(root)while queue:node = queue.popleft()print(node.value, end=' ')if node.left:queue.append(node.left)if node.right:queue.append(node.right)\# 创建一个简单的二叉树\# A\# / \\\# B C\# / \ \\\# D E Froot = TreeNode('A')root.left = TreeNode('B')root.right = TreeNode('C')root.left.left = TreeNode('D')root.left.right = TreeNode('E')root.right.right = TreeNode('F')print("BFS层序遍历结果:")bfs\_level\_order(root)
代码解释如下:
TreeNode 类定义:定义了一个TreeNode类,用于表示二叉树的节点。每个节点包含一个value值,以及指向左子节点left和右子节点right的引用。
bfs_level_order 函数实现:
首先判断根节点root是否为空,如果为空,直接返回,因为空树无需遍历。
创建一个deque队列queue,并将根节点root加入队列。这是 BFS 的起始点,队列用于存储待访问的节点。
使用while循环,只要队列不为空,就继续循环。在每次循环中:
从队列的左侧取出一个节点node,这是当前要访问的节点。
打印当前节点node的值,实现对节点的访问操作。
检查当前节点node的左子节点是否存在,如果存在,将其加入队列。这是为了后续访问左子节点。
检查当前节点node的右子节点是否存在,如果存在,将其加入队列。这是为了后续访问右子节点。
构建二叉树并执行遍历:创建了一个简单的二叉树结构,并调用bfs_level_order函数对其进行层序遍历,打印出遍历结果。
执行过程:
初始时,队列中只有根节点A。
从队列中取出A,打印A,然后将A的左子节点B和右子节点C加入队列,此时队列中有B和C。
从队列中取出B,打印B,将B的左子节点D和右子节点E加入队列,此时队列中有C、D和E。
从队列中取出C,打印C,将C的右子节点F加入队列,此时队列中有D、E和F。
依次从队列中取出D、E和F并打印,直到队列为空,遍历结束。最终输出的层序遍历结果为A B C D E F。
(二)使用 BFS 解决迷宫最短路径问题
迷宫问题是 BFS 的常见应用场景之一,主要目标是在给定的迷宫中找到从起点到终点的最短路径。以下是一个用 Python 实现的示例,假设迷宫用二维列表表示,其中0表示可通行的路径,1表示墙壁。
from collections import dequedef is\_valid\_move(maze, visited, row, col):rows = len(maze)cols = len(maze\[0])return (0 <= row < rows) and (0 <= col < cols) and \\(maze\[row]\[col] == 0) and (not visited\[row]\[col])def bfs\_shortest\_path\_maze(maze):if not maze or not maze\[0]:return Nonerows, cols = len(maze), len(maze\[0])visited = \[\[False for \_ in range(cols)] for \_ in range(rows)]queue = deque()\# 起点位置和路径start = (0, 0)end = (rows - 1, cols - 1)if maze\[start\[0]]\[start\[1]]!= 0 or maze\[end\[0]]\[end\[1]]!= 0:return None # 无法从起点或到达终点queue.append((start, \[start]))visited\[start\[0]]\[start\[1]] = True\# 定义四个可能的移动方向:上、右、下、左directions = \[(-1, 0), (0, 1), (1, 0), (0, -1)]while queue:current\_pos, path = queue.popleft()row, col = current\_pos\# 检查是否到达终点if current\_pos == end:return path\# 尝试所有可能的移动方向for dr, dc in directions:new\_row, new\_col = row + dr, col + dcif is\_valid\_move(maze, visited, new\_row, new\_col):visited\[new\_row]\[new\_col] = Truequeue.append(((new\_row, new\_col), path + \[(new\_row, new\_col)]))return None # 无路径\# 示例迷宫maze = \[\[0, 1, 0, 0, 0],\[0, 1, 0, 1, 0],\[0, 0, 0, 0, 0],\[0, 1, 1, 1, 0],\[0, 0, 0, 1, 0]]shortest\_path = bfs\_shortest\_path\_maze(maze)if shortest\_path:print("找到最短路径,路径长度为", len(shortest\_path))print("路径为:", shortest\_path)else:print("没有找到从起点到终点的路径")
代码解释如下:
is_valid_move 函数:用于判断在当前迷宫状态下,从当前位置(row, col)向某个方向移动是否合法。合法的条件包括:移动后的位置在迷宫范围内,该位置是可通行的(值为0),并且该位置尚未被访问过。
bfs_shortest_path_maze 函数:
首先检查迷宫是否为空或为空列表,如果是,则直接返回None,因为无法在空迷宫中寻找路径。
获取迷宫的行数rows和列数cols,并创建一个与迷宫大小相同的二维布尔列表visited,用于记录每个位置是否被访问过,初始时所有位置都为False。
创建一个deque队列queue,用于存储待探索的位置和从起点到该位置的路径。
定义起点start为(0, 0),终点end为(rows - 1, cols - 1)。如果起点或终点位置是墙壁(值不为0),则无法从起点到达终点,直接返回None。
将起点和包含起点的路径[(0, 0)]加入队列,并将起点标记为已访问。
定义四个可能的移动方向:上(-1, 0)、右(0, 1)、下(1, 0)、左(0, -1)。
使用while循环,只要队列不为空,就继续循环。在每次循环中:
从队列左侧取出当前位置current_pos和从起点到当前位置的路径path。
检查当前位置是否为终点,如果是,则返回当前路径,因为找到了从起点到终点的路径。
遍历四个移动方向,计算新的位置(new_row, new_col)。
如果新位置是合法的移动位置(通过is_valid_move函数判断),则将新位置标记为已访问,并将新位置和更新后的路径加入队列。
如果循环结束后仍未找到终点,则返回None,表示没有找到从起点到终点的路径。
测试部分:定义了一个示例迷宫,并调用bfs_shortest_path_maze函数寻找最短路径。如果找到路径,则打印路径长度和路径;如果未找到路径,则打印提示信息。
执行过程:
初始时,队列中只有起点(0, 0)和路径[(0, 0)],并将起点标记为已访问。
从队列中取出起点(0, 0)和路径[(0, 0)],检查是否为终点,不是则尝试四个方向的移动。只有向右移动(0, 1)是合法的,将(0, 1)和路径[(0, 0), (0, 1)]加入队列,并将(0, 1)标记为已访问。
从队列中取出(0, 1)和路径[(0, 0), (0, 1)],检查是否为终点,不是则尝试四个方向的移动。向下移动(1, 1)是合法的,将(1, 1)和路径[(0, 0), (0, 1), (1, 1)]加入队列,并将(1, 1)标记为已访问。
不断重复上述过程,依次探索新的合法位置并加入队列,直到找到终点(4, 4)。最终返回从起点到终点的最短路径,例如[(0, 0), (1, 0), (2, 0), (2, 1), (2, 2), (3, 2), (4, 2), (4, 3), (4, 4)] 。
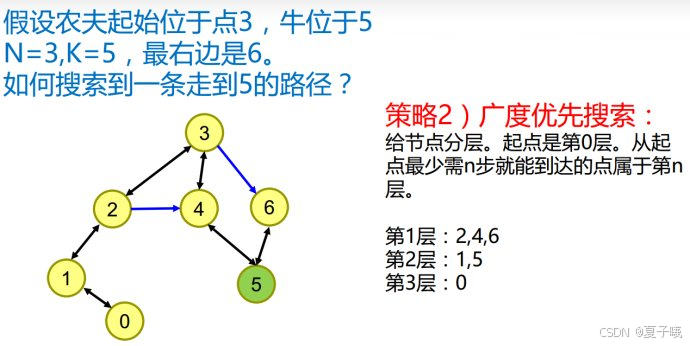
(三)农夫找牛
一位农夫在点n上,他要到奶牛所在的点k上,他可以每次从点X到点X-1或点X+1或点2*X,问他到达点k的最短次数.(0 ≤ N ≤ 100,000,0 ≤ K ≤ 100,000)
思路:看到这一道题,第一反应就是看看能否找到规律,然而很显然它没有规律可言,我们需要靠一种近似暴力的方法,而DFS在这里是行不通的,于是只能用BFS来解这道题了。
#include <iostream>
#include <stdio.h>
#include <cstring>
#include<queue>
#define pp pair<int,int>
using namespace std;
int n,k,ans;
queue<pp>q;
bool v[200004];
void bfs() {q.push(pp(n,0));//先将n丢进队列v[n]=1;while(!q.empty()) {if(q.empty())break;pp now=q.front();q.pop();if(now.first==k) {ans=now.second;break;}now.second++;//接下来我们有3种操作,将现在的位置now.second 加1 或 减1 或 乘2if(!v[now.first+1]&&now.first<k) {//边界条件不能少了q.push(pp(now.first+1,now.second));v[now.first+1]=1;//将已经走过的点标记为1,为什么呢??q队列中到这个数的次数是从小到大排序的,now.first+1这个点刚通过now.first被拜访过,它的此时次数肯定小于等于下一次拜访的次数.想一想为什么.}if(!v[now.first-1]&&now.first-1>=0) {q.push(pp(now.first-1,now.second));v[now.first-1]=1;}if(now.first<k&&(!v[now.first*2])) {q.push(pp(now.first*2,now.second));v[now.first*2]=1;}}return;
}
int main() {scanf("%d%d",&n,&k);bfs();printf("%d\n",ans);return 0;
}
(四)找到质数所需的最少次数
给你两个四位数的质数a,b,让你通过一个操作使a变成b.这个操作可以使你当前的数x改变一位上的数使其变成另一个质数,问操作的最小次数
注意:没有前导0!!!;
例如:1033到8179可以从1033->1733->3733->3739->3779->8779->8179
思路:可以先将10000以内所有的质数记录下来,再进行BFS。
#include<iostream>
#include<stdio.h>
#include<cstring>
#include<queue>
#include<time.h>
#define N 10003
#define pp pair<int,int>
using namespace std;
int T,n,m,ans;
bool v[N],vis[N],t[N];
queue<pp>q;
void pre() {//记录10000以内的质数for(int i=2; i<=9999; i++) {if(!v[i]) {t[i]=1;//t[i]=1表示i是质数for(int j=i; j<=9999; j+=i) {v[j]=1;}}}
}
void BFS() {q.push(pp(n,0));//先将给我们的初始数加入q队列while(!q.empty()) {while(!q.empty()&&vis[q.front().first])q.pop();if(q.empty())break;pp now=q.front();vis[q.front().first]=1;q.pop();if(now.first==m) {ans=now.second;break;}for(int i=1; i<=1000; i*=10) {//枚举位数int r=now.first-((now.first/i)%10)*i;for(int j=0; j<=9; j++) {//枚举当前位数更改的值if(i==1000&&j==0)continue;//特判前导0的情况!!!if(t[r+j*i]&&!vis[r+j*i]) {q.push(pp(r+j*i,now.second+1));//BFS的核心转移代码}}}}return;
}
int main() {pre();scanf("%d",&T);while(T--) {while(!q.empty())q.pop();memset(vis,0,sizeof vis);ans=-1;scanf("%d%d",&n,&m);BFS();if(ans==-1)printf("Impossible\n");else printf("%d\n",ans);}return 0;
}
六、总结 BFS 的要点与应用价值

广度优先搜索(BFS)是一种基础且重要的搜索算法,其核心在于从起始节点出发,借助队列实现逐层扩展搜索,直到找到目标节点或遍历完所有可达节点。在工作原理上,BFS 通过选择起始节点,将其加入队列,然后不断从队列中取出节点,访问该节点并将其未访问的邻居节点加入队列,从而实现按层次遍历。
从时间复杂度来看,使用邻接表表示图时,BFS 的时间复杂度为 O (V + E) ,这是因为每个顶点和每条边都会被访问一次;使用邻接矩阵表示图时,时间复杂度为 O (V²) ,因为需要遍历整个矩阵。
BFS 在众多领域有着广泛应用。在最短路径查找方面,它能在无权图中高效地找到从起点到终点的最短路径;层级遍历中,二叉树的层序遍历是其典型应用;社交网络分析里,可用于寻找两个用户之间的最短关系链;网络广播时,能模拟信息在网络中的传播过程;Web 爬虫按照广度优先的方式遍历网页;判断图的连通性以及检测二分图时,BFS 也发挥着重要作用。
通过二叉树层序遍历和迷宫最短路径问题这两个实例,我们深入了解了 BFS 的实现过程和应用方法。在二叉树层序遍历中,BFS 能够按照层次顺序依次访问节点,清晰地展示树的结构;在迷宫最短路径问题中,BFS 通过逐层探索,找到从起点到终点的最短路径,充分体现了其在解决实际问题中的优势。
BFS 以其独特的搜索策略和广泛的应用场景,在算法领域占据着重要地位,为解决各种实际问题提供了有力的工具和方法。
相关文章:
搜索)
算法——结合实例了解广度优先搜索(BFS)搜索
一、广度优先搜索初印象 想象一下,你身处一座陌生的城市,想要从当前位置前往某个景点,你打开手机上的地图导航软件,输入目的地后,导航软件会迅速规划出一条最短路线。这背后,就可能运用到了广度优先搜索&am…...

2025年3月营销灵感日历
2025年的第一场营销大战已经拉开帷幕了! 三月可是全年最值钱的营销黄金月——妇女节、植树节、315消费者日三大爆点连击,还有春分、睡眠日、世界诗歌日等20隐藏流量密码。 道叔连夜扒了18个行业数据,整理了这份《2025年3月营销灵感日历》&a…...

【认证授权FAQ】SSL/TLS证书过期导致的CLS认证失败
问题现象 问题分析 属于Agent操作系统的根认证机构过期问题,需要下载CA然后在系统安装。 DigiCert根证书和中间证书将在未来几年过期,一旦证书过期,基于证书颁发的SSL/TLS证书将不再信任,导致网站无法HTTPs访问。需要迁移到新的根…...

飞书专栏-TEE文档
CSDN学院课程连接:https://edu.csdn.net/course/detail/39573...
)
自己部署 DeepSeek 助力 Vue 开发:打造丝滑的时间线(Timeline )
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 自己…...

机器学习:集成学习和随机森林
集成学习 集成学习通过构建并合并多个模型来完成学习,从而获得比单一学习模型更显著优越的泛化能力,集成学习就是利用模型的"集体智慧",提升预测的准确率,根据单个模型方式,集成学习可分为两大类: 个体之间存在强依赖关系,其代表为Boosting算法个体之间不存在强依赖…...
)
力扣刷题(数组篇)
日期类 #pragma once#include <iostream> #include <assert.h> using namespace std;class Date { public:// 构造会频繁调用,所以直接放在类里面(类里面的成员函数默认为内联)Date(int year 1, int month 1, int day 1)//构…...

Jenkins 新建配置 Freestyle project 任务 六
Jenkins 新建配置 Freestyle project 任务 六 一、新建任务 在 Jenkins 界面 点击 New Item 点击 Apply 点击 Save 回到任务主界面 二、General 点击左侧 Configure Description:任务描述 勾选 Discard old builds Discard old builds:控制何时…...

5.8 软件质量与软件质量保证
文章目录 软件质量模型软件质量保证 软件质量模型 软件质量模型有ISO/IEC9126,McCall。 ISO/IEC9126从功能性、可靠性、易使用性、效率、可维护性、可移植性这6个方面对软件质量进行分析。功能性包含适合性、依从性、准确性、安全性、互用性。可靠性包含成熟性、容错…...

二次封装axios解决异步通信痛点
为了方便扩展,和增加配置的灵活性,这里将通过封装一个类来实现axios的二次封装,要实现的功能包括: 为请求传入自定义的配置,控制单次请求的不同行为在响应拦截器中对业务逻辑进行处理,根据业务约定的成功数据结构,返回业务数据对响应错误进行处理,配置显示对话框或消息形…...

Flutter项目试水
1基本介绍 本文章在构建您的第一个 Flutter 应用指导下进行实践 可作为项目实践的辅助参考资料 Flutter 是 Google 的界面工具包,用于通过单一代码库针对移动设备、Web 和桌面设备构建应用。在此 Codelab 中,您将构建以下 Flutter 应用。 该应用可以…...
)
Java 大视界 -- 边缘计算与 Java 大数据协同发展的前景与挑战(85)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

【第1章:深度学习概览——1.2 深度学习与机器学习、传统人工智能的区别与联系】
在科技飞速发展的时代,AI 技术如同一颗璀璨的明星,照亮了我们生活的方方面面。今天,让我们一起深入探寻 AI 技术的演进历程,看看它是如何从最初的简单规则系统,一步步发展成为如今强大的智能技术。 一、开篇故事:三杯咖啡看懂三代 AI 想象一下,你经营着一家充满温馨氛…...

游戏引擎学习第99天
仓库:https://gitee.com/mrxiao_com/2d_game_2 黑板:制作一些光场(Light Field) 当前的目标是为游戏添加光照系统,并已完成了法线映射(normal maps)的管道,但还没有创建可以供这些正常映射采样的光场。为了继续推进&…...

NixHomepage - 简单的个人网站
💻 NixHomepage - 简单的个人网站 推荐下个人的开源项目,演示网站,项目链接 https://github.com/nixgnauhcuy/NixHomepage,喜欢的话可以为我的项目点个 Star~ 📷 预览 ⚙️ 功能特性 多平台适配 明亮/暗黑模式切换 W…...

window patch按块分割矩阵
文章目录 1. excel 示意2. pytorch代码3. window mhsa 1. excel 示意 将一个三维矩阵按照window的大小进行拆分成多块2x2窗口矩阵,具体如下图所示 2. pytorch代码 pytorch源码 import torch import torch.nn as nn import torch.nn.functional as Ftorch.set_p…...

Dockerfile 详解:构建自定义镜像
Dockerfile 是一种文本文件,包含了一系列指令,用于描述如何构建一个 Docker 镜像。通过 Dockerfile,我们可以将应用程序及其所有依赖打包成镜像,确保应用在不同环境中运行时保持一致性。掌握 Dockerfile 的写法和最佳实践,能够帮助我们高效地构建和管理容器镜像。 本文将…...

vue2老版本 npm install 安装失败_安装卡主
vue2老版本 npm install 安装失败_安装卡主 特别说明:vue2老版本安装慢、运行慢,建议升级vue3element plus vite 解决方案1: 第一步、修改npm 镜像为国内镜像 使用淘宝镜像: npm config set registry https://registry.npmmir…...
)
【细看open_r1】精读训练和评估模型以及生成合成数据的脚本(src/open_r1)
src/open_r1 目录下主要包含了一些用于训练和评估模型以及生成合成数据的Python脚本,下面我们对其中几个主要的Python文件进行深度剖析。 configs.py 这个文件定义了两个数据类 GRPOConfig 和 SFTConfig,它们分别继承自 trl.GRPOConfig 和 trl.SFTConf…...

数据库数据恢复—MongoDB丢失_mdb_catalog.wt文件导致报错的数据恢复案例
MongoDB数据库存储模式为文档数据存储库,存储方式是将文档存储在集合之中。 MongoDB数据库是开源数据库,同时提供具有附加功能的商业版本。 MongoDB中的数据是以键值对(key-value pairs)的形式显示的。在模式设计上,数据库受到的约束更少。这…...

Qt 控件整理 —— 按钮类
一、PushButton 1. 介绍 在Qt中最常见的就是按钮,它的继承关系如下: 2. 常用属性 3. 例子 我们之前写过一个例子,根据上下左右的按钮去操控一个按钮,当时只是做了一些比较粗糙的去演示信号和槽是这么连接的,这次我们…...

当 LSTM 遇上 ARIMA!!
大家好,我是小青 ARIMA 和 LSTM 是两种常用于时间序列预测的模型,各有优劣。 ARIMA 擅长捕捉线性关系,而 LSTM 擅长处理非线性和长时间依赖的关系。将ARIMA 和 LSTM 融合,可以充分发挥它们各自的优势,构建更强大的时…...

SpringBoot实战:高效获取视频资源
文章目录 前言技术实现SpringBoot项目构建产品选取配置数据采集 号外号外 前言 在短视频行业高速发展的背景下,海量内容数据日益增长,每天都有新的视频、评论、点赞、分享等数据涌现。如何高效、精准地获取并处理这些庞大的数据,已成为各大平…...

MySQL索引数据结构详解
索引的定义:方便Mysql更高效的获取排好序的数据结构 数据结构分为: 二叉树红黑树hash表B-Tree 二叉树规则:可视化二叉树 从父节点查找数据,每个节点最多有两个子节点,左子节点比父节点小,右子节点比父节…...
)
Python----PyQt开发(PyQt基础,环境搭建,Pycharm中PyQttools工具配置,第一个PyQt程序)
一、QT与PyQT的概念和特点 1.1、QT QT是一个1991年由The Qt Company开发的跨平台C图形用户界面应用程序开发 框架,可构建高性能的桌面、移动及Web应用程序。也可用于开发非GUI程序,比如 控制台工具和服务器。Qt是面向对象的框架,使用特殊的代…...
)
C语言——排序(冒泡,选择,插入)
基本概念 排序是对数据进行处理的常见操作,即将数据按某字段规律排列。字段是数据节点的一个属性,比如学生信息中的学号、分数等,可针对这些字段进行排序。同时,排序算法有稳定性之分,若两个待排序字段一致的数据在排序…...

物联网智能语音控制灯光系统设计与实现
背景 随着物联网技术的蓬勃发展,智能家居逐渐成为现代生活的一部分。在众多智能家居应用中,智能灯光控制系统尤为重要。通过语音控制和自动调节灯光,用户可以更便捷地操作家中的照明设备,提高生活的舒适度与便利性。本文将介绍一…...
哪吒闹海!SCI算法+分解组合+四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测
哪吒闹海!SCI算法分解组合四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测 目录 哪吒闹海!SCI算法分解组合四模型原创对比首发!SGMD-FATA-Transformer-LSTM多变量时序预测效果一览基本介绍程序设计参考资料 效果一览…...
算法)
Python实现决策树(Decision Tree)算法
在 Python 中实现一个决策树算法,可以使用 sklearn 库中的 DecisionTreeClassifier 类。这个类实现了分类任务中的决策树算法。下面是一个简单的例子,展示如何使用 DecisionTreeClassifier 来训练决策树并进行预测。 1. 安装 scikit-learn 如果你还没有…...

刷题日记---二叉树递归专题
文章目录 1. 从根到叶的二进制数之和2. 二叉树的坡度3. 总结 1. 从根到叶的二进制数之和 描述: 给出一棵二叉树,其上每个结点的值都是 0 或 1 。每一条从根到叶的路径都代表一个从最高有效位开始的二进制数。 例如,如果路径为 0 -> 1 ->…...

【C++】智能指针的使用及其原理
1. 智能指针的使用场景分析 下⾯程序中我们可以看到,new了以后,我们也delete了,但是因为抛异常导,后⾯的delete没有得到 执⾏,所以就内存泄漏了,所以我们需要new以后捕获异常,捕获到异常后dele…...

Jenkins 安装插件 二
Jenkins 安装插件 二 一. 打开 Dashboard 打开 Jenkins 界面,不管在任何界面,只需要点击左上角 Dashboard 按钮即可 二. 打开 Manage Jenkins 找到 Manage Jenkins -> System Configuration -> Plugins 点击 Plugins 打开界面如下 Updates&a…...

C++自研游戏引擎-碰撞检测组件-八叉树AABB检测算法实现
八叉树碰撞检测是一种在三维空间中高效处理物体碰撞检测的算法,其原理可以类比为一个管理三维空间物体的智能系统。这个示例包含两个部分:八叉树部分用于宏观检测,AABB用于微观检测。AABB可以更换为均值或节点检测来提高检测精度。 八叉树的…...
)
Java 大视界 -- 云计算时代 Java 大数据的云原生架构与应用实践(86)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

学习threejs,使用HemisphereLight半球光
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.HemisphereLight 二、…...

XML 命名空间
XML 命名空间 引言 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。在XML中,命名空间(Namespace)是一个非常重要的概念,它主要用于解决XML文档中元素和属性的命名冲突问题。本文将详细介绍XML命…...

kubernetes-cni 框架源码分析
深入探索 Kubernetes 网络模型和网络通信 Kubernetes 定义了一种简单、一致的网络模型,基于扁平网络结构的设计,无需将主机端口与网络端口进行映射便可以进行高效地通讯,也无需其他组件进行转发。该模型也使应用程序很容易从虚拟机或者主机物…...

【嵌入式Linux应用开发基础】ioctl函数
目录 一、概述 1.1. ioctl 的功能 1.2. 函数原型 1.3. 参数说明 1.4. 返回值 1.5. request 命令的定义 二、典型应用场景 2.1. 串口通信控制 2.2. 网络设备配置与管理 2.3. 字符设备控制 2.4. 块设备管理 2.5. 多媒体设备控制 三、关键注意事项 3.1. request 命令…...

开源的轻量级分布式文件系统FastDFS
FastDFS 是一个开源的轻量级分布式文件系统,专为高性能的分布式文件存储设计,主要用于解决海量文件的存储、同步和访问问题。它特别适合以中小文件(如图片、视频等)为载体的在线服务,例如相册网站、视频网站等。 FastD…...
从VGG到Transformer:深度神经网络层级演进对模型性能的深度解析与技术实践指南
一、技术原理(数学公式示意图) 1. 层深与模型容量关系 数学表达:根据Universal Approximation Theorem,深度网络可表达复杂函数: f ( x ) f L ( f L − 1 ( ⋯ f 1 ( x ) ) ) f(x) f_L(f_{L-1}(\cdots f_1(x))) f…...

深入了解 Oracle 正则表达式
目录 深入了解 Oracle 正则表达式一、正则表达式基础概念二、Oracle 正则表达式语法(一)字符类(二)重复限定符(三)边界匹配符(四)分组和捕获 三、Oracle 正则表达式函数(…...

机器学习-监督学习
1. 定义与原理 监督学习依赖于标记数据(即每个输入样本都对应已知的输出标签),模型通过分析这些数据中的规律,建立从输入特征到目标标签的映射函数。例如,在垃圾邮件检测中,输入是邮件内容,输出…...

Leetcode:学习记录
一、滑动窗口 1. 找出数组中元素和大于给定值的子数组的最小长度 右指针从左到右遍历,在每个右指针下,如果去掉左边元素的元素和大于等于给定值则左指针右移一次,直到小于给定值,右指针右移一个。 2.找到乘积小于给定值的子数组…...

探索顶级汽车软件解决方案:驱动行业变革的关键力量
在本文中,将一同探索当今塑造汽车行业的最具影响力的软件解决方案。从设计到制造,软件正彻底改变车辆的制造与维护方式。让我们深入了解这个充满活力领域中的关键技术。 设计软件:创新车型的孕育摇篮 车辆设计软件对于创造创新型汽车模型至…...

AI前端开发:解放创造力,而非取代它
近年来,人工智能技术飞速发展,深刻地改变着各行各业,前端开发领域也不例外。越来越多的AI写代码工具涌现,为开发者带来了前所未有的效率提升。很多人担心AI会取代程序员的创造力,但事实并非如此。本文将探讨AI辅助前端…...

探讨使用ISVA代替“Open Liberty使用指南及微服务开发示例”中日志审计功能
在Open Liberty使用指南及开发示例(四)一文开始日志审计功能占有了一定的开发工作量,那么是否可以使用IBM Security Verify Access(ISVA)代替以节省开发工作?如果可行,那么以后各类应用的日志审…...

log4j2日志配置文件
log4j2配置文件每个项目都会用到,记录一个比较好用的配置文件,方便以后使用时调取,日志输出级别为debug,也可以修改 <?xml version"1.0" encoding"UTF-8"?> <Configuration monitorInterval"180" packages""><prope…...

python专栏导读
由于本人非python工程师,是在自学python,所以本专栏的内容会显得很基础,甚至有些内容在python工程师看来实在太过于简单,在此清楚嘲笑,因为毕竟每个人都是从不懂、从基础开始的。 本篇作为导读和目录形式存在…...

Ollama与Vllm使用对比与优劣
Ollama和vLLM是两个用于优化大型语言模型(LLM)推理的框架,它们在性能、资源利用率、部署复杂性等方面各有优劣。以下是对这两个框架的详细介绍: 1. Ollama Ollama是一个轻量级且易于使用的框架,旨在简化大型语言模型…...

K8s之存储卷
一、容忍、crodon和drain 1.容忍 即使节点上有污点,依然可以部署pod。 字段:tolerations 实例 当node01上有标签test11,污点类型为NoSchedule,而node02没有标签和污点,此时pod可以在node01 node02上都部署,…...