大模型-ALIGN 详细介绍
ALIGN模型(A Large-scale ImaGe and Noisy-text embedding)是一种大规模图像和噪声文本嵌入模型,它通过对比学习的方式将图像和文本嵌入到同一个向量空间中,使得匹配的图像-文本对的嵌入向量接近,不匹配的则远离。这种嵌入方式使得ALIGN模型非常适合于跨模态匹配和检索任务,例如图像检索、图文匹配等。
ALIGN模型的主要特点包括:
-
大规模噪声数据集:ALIGN模型使用了超过18亿个有噪声的图像和替代文本对的数据集进行训练。这些数据集虽然存在噪声,但规模庞大,可以弥补噪声带来的影响,并实现强大的性能。
-
双编码器架构:ALIGN采用了简单的双编码器架构,分别对图像和文本进行编码,然后通过对比损失函数进行学习,使得匹配的图像-文本对的嵌入向量在向量空间中更接近。
-
跨模态检索能力:ALIGN模型能够支持零样本的视觉分类和跨模态搜索,包括以图搜文、以文搜图,甚至联合使用图像+文本进行搜索。在ImageNet数据集上,ALIGN实现了76.4%的top-1零样本准确率。
-
图像分类性能:在ImageNet数据集上,ALIGN模型展现了卓越的图像分类性能,甚至在没有使用任何训练样本的情况下,通过零样本学习就能实现较高的分类准确率。
-
多模态嵌入:ALIGN模型的图像和文本编码器可以单独使用,获取多模态嵌入,这些嵌入可以用于各种下游任务的模型训练,例如目标检测、图像分割和图像字幕生成。
-
开源实现:Kakao Brain发布了ALIGN模型的开源版本,该版本在COYO数据集上进行训练,表现比Google的结果更好,这也是ALIGN模型首次公开发布供开源使用。
总的来说,ALIGN模型通过使用大规模的噪声数据集和简单的双编码器架构,实现了在多种视觉和视觉语言任务上的优异性能,特别是在跨模态检索和零样本图像分类方面展现了强大的能力。它的开源实现进一步促进了多模态学习领域的研究和应用。
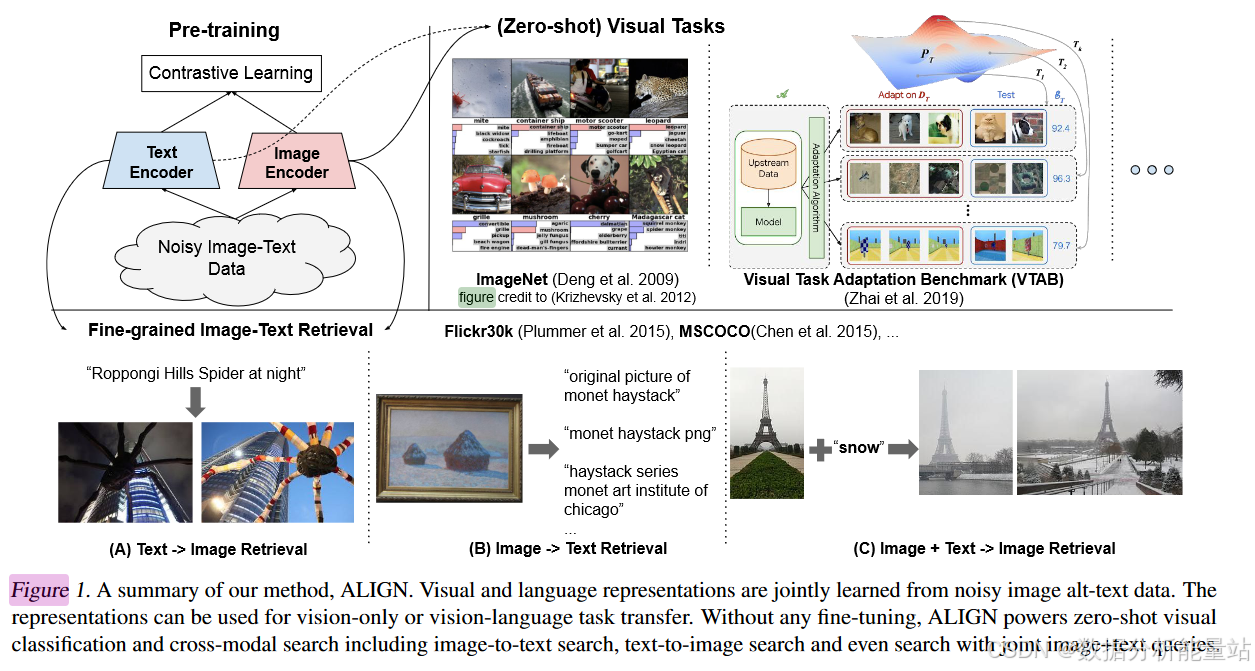
Abstract
作者描述了一种新的方法,用于从大规模且未经精细筛选的图像-文本对数据集中学习高质量的视觉和语言表示。这种方法旨在克服传统方法中存在的几个挑战,包括数据集构建的成本高、依赖于大量手动标注的数据以及数据集规模受限等问题。
-
主要贡献
-
数据集的规模与质量:该研究使用了一个包含超过十亿张图像及其对应的alt-text(替代文本)的数据集。这些数据是直接从网络上抓取的,没有经过昂贵的手动筛选或清理过程,这意味着数据集中可能含有大量的噪声。然而,研究表明,数据集的巨大规模能够弥补数据质量上的不足,从而使得模型能够学习到有用的特征表示。
-
模型架构:采用了相对简单的双编码器架构,其中一个编码器负责处理图像输入,另一个编码器则处理文本输入。两个编码器通过对比损失函数联合训练,以确保图像和文本表示之间的对齐。这种设计允许模型在不需要复杂结构的情况下,有效地学习视觉和语言信息之间的关系。
-
性能表现:实验结果显示,所提出的模型不仅在传统的图像分类任务(如ImageNet和VTAB)上取得了良好的成绩,而且在跨模态任务(如零样本图像分类、图像-文本检索等)中也表现出了优异的性能。特别是在Flickr30K和MSCOCO图像-文本检索基准测试中,该模型达到了新的最先进水平,甚至超越了一些更加复杂的模型(例如那些使用交叉注意力机制的模型)。
-
实际应用:除了在标准基准测试中的优秀表现外,这些对齐的视觉和语言表示还支持了更为复杂的应用场景,比如基于文本或文本加图像的查询进行跨模态搜索。
-
总结
这项研究证明了,即使使用非常简单的方法,只要具备足够大的数据规模,也能够训练出高性能的视觉和语言表示模型。这为未来的研究提供了新的思路,即如何更高效地利用互联网上广泛存在的未标注数据资源来推动人工智能技术的发展。
1 Introduction
-
背景
-
视觉领域:传统的视觉表示学习通常依赖于大规模的监督数据集,如ImageNet、OpenImages和JFT-300M。这些数据集的构建需要大量的手动标注工作,因此成本高昂且难以扩展。
-
视觉-语言领域:视觉-语言表示学习同样依赖于专门的数据集,如Conceptual Captions、Visual Genome Dense Captions和ImageBERT。这些数据集不仅需要大量的手动标注,还需要复杂的清洗和平衡工作,因此规模相对较小,通常只有几百万条记录。
-
-
研究动机
由于现有的视觉和视觉-语言数据集存在规模小和成本高的问题,本研究提出了一种新的方法,利用互联网上广泛存在的噪声图像-alt-text对数据集来扩展表示学习。这种方法的关键在于:
-
数据集构建:作者采用了一种类似于Conceptual Captions数据集的构建方法,但省去了复杂的过滤和后处理步骤,只进行了简单的基于频率的过滤。这使得最终的数据集规模达到了十亿级别,远大于现有的视觉-语言数据集。
-
模型架构:使用了一个简单的双编码器架构,其中一个编码器处理图像,另一个编码器处理文本。这两个编码器通过对比损失函数联合训练,以确保图像和文本表示在共享的潜在嵌入空间中对齐。
-
实验结果
-
跨模态匹配/检索任务:在Flickr30K和MSCOCO等基准测试中,模型在零样本和微调的R@1指标上超过了之前的方法7%以上。
-
零样本图像分类:当将类别名称输入文本编码器时,模型在ImageNet上实现了76.4%的top-1准确率,而没有使用任何ImageNet的训练样本。
-
下游视觉任务:图像表示本身在各种下游视觉任务中也表现出色,例如在ImageNet上实现了88.64%的top-1准确率。
-
-
方法概述
-
对比损失:通过对比损失函数(归一化softmax)训练模型,该损失函数将匹配的图像-文本对的嵌入拉近,同时将不匹配的对推开。这种损失函数类似于传统的基于标签的分类目标,但文本编码器生成了“标签”权重。
-
模型命名:该模型被命名为ALIGN(大规模图像和噪声文本嵌入),强调了其在大规模噪声数据集上的训练能力。
-
-
结论
这项研究展示了如何利用大规模且带有噪声的数据集来训练高性能的视觉和视觉-语言表示模型。通过简单的双编码器架构和对比损失函数,模型在多个任务上取得了非常优秀的性能,特别是在跨模态匹配和零样本图像分类任务中。这为未来的表示学习研究提供了一种新的思路,即如何更高效地利用互联网上的大规模数据资源。
什么是噪声图像-alt-text ?
“噪声图像-alt-text”是指从互联网上抓取的图像及其对应的替代文本(alt-text),这些数据对可能存在错误、不准确或不相关的问题。具体来说:
图像:从网页上抓取的图片,这些图片可以来自各种来源,如社交媒体、新闻网站、博客等。
替代文本 (alt-text):在HTML中,
<img>标签的alt属性用于提供图像的文本描述。当图像无法加载或用户使用屏幕阅读器时,替代文本会被显示或读出。替代文本通常是为了提高网页的可访问性而设置的。
噪声的来源
不准确的描述:替代文本可能不是对图像的准确描述。例如,一张猫的图片可能被标记为“狗”。
无关的描述:替代文本可能与图像内容完全无关。例如,一张风景照片可能被标记为“点击这里了解更多”。
缺失的描述:有些图像可能根本没有替代文本,或者替代文本为空。
语法错误或拼写错误:替代文本可能包含语法错误或拼写错误,影响模型的理解和学习。
为什么使用噪声数据
尽管这些数据对存在噪声,但它们的数量非常庞大,可以从互联网上轻松获取。大规模的数据集可以帮助模型学习到更多的特征和模式,从而在一定程度上弥补数据质量的不足。研究表明,通过适当的设计和训练方法,模型可以在这样的噪声数据上学习到有用的表示。
映射到同一个潜在嵌入空间中,具体是如何映射的?
“映射到同一个潜在嵌入空间中”是指将不同模态的数据(例如图像和文本)转换成相同维度的向量表示,使得这些向量可以在同一个向量空间中进行比较和操作。具体来说,这涉及到以下几个步骤:
1. 编码器的作用
图像编码器:将图像数据转换成一个固定长度的向量。这个向量被称为图像嵌入。
文本编码器:将文本数据转换成一个固定长度的向量。这个向量被称为文本嵌入。
2. 潜在嵌入空间
潜在嵌入空间:这是一个高维向量空间,其中每个向量代表一个数据点的表示。这个空间是“潜在”的,因为它是由模型学习到的,而不是直接从原始数据中提取的。
3. 映射过程
图像映射:图像编码器将输入的图像 I 映射到一个固定长度的向量 f(I)。这个向量 f(I) 在潜在嵌入空间中表示图像。
文本映射:文本编码器将输入的文本 T 映射到一个固定长度的向量 g(T)。这个向量 g(T) 在相同的潜在嵌入空间中表示文本。
4. 对齐目标
匹配对:对于一对匹配的图像和文本(即图像和文本描述的是同一内容),希望它们的嵌入在潜在嵌入空间中尽可能接近。也就是说,希望 | f(I) - g(T) | 尽可能小。
不匹配对:对于一对不匹配的图像和文本(即图像和文本描述的内容不同),希望它们的嵌入在潜在嵌入空间中尽可能远离。也就是说,希望 | f(I) - g(T') | 尽可能大。
5. 对比损失函数
为了实现上述对齐目标,通常使用对比损失函数(Contrastive Loss)或其他类似的损失函数。对比损失函数的目的是:
拉近匹配对:通过最小化匹配对的嵌入距离,使得 | f(I) - g(T) | 尽可能小。
推开不匹配对:通过最大化不匹配对的嵌入距离,使得 | f(I) - g(T') | 尽可能大。
具体公式
对比损失函数的一个常见形式是:
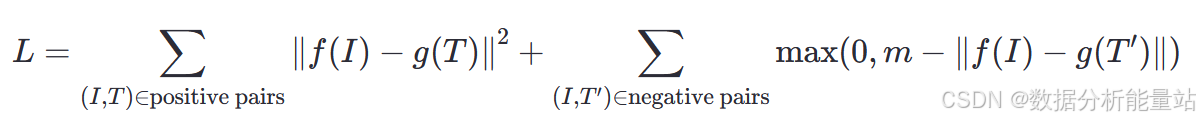
其中:
f(I) 是图像 I 的嵌入。
g(T) 是文本 T 的嵌入。
|| f(I) - g(T) ||^2 表示匹配对的嵌入距离。
m 是一个超参数,表示负样本对的最小距离阈值。
max(0, m - || f(I) - g(T') ||) 表示不匹配对的嵌入距离。
举例说明
假设有一个图像 I 和一个描述它的文本 T,以及一个不相关的文本 T'。
图像编码器 f 将图像 I 映射到向量 f(I)。
文本编码器 g 将文本 T 映射到向量 g(T)。
文本编码器 g 将不相关的文本 T' 映射到向量 g(T')。
训练过程中,模型会尝试:
最小化 | f(I) - g(T) |,使得匹配的图像和文本嵌入尽可能接近。
最大化 | f(I) - g(T') |,使得不匹配的图像和文本嵌入尽可能远离。
通过这种方式,图像和文本的嵌入被映射到同一个潜在嵌入空间中,并且在这个空间中对齐,从而实现跨模态的表示学习。
2 Related Work
高质量的视觉表示通常在大规模标记数据集上进行预训练,以用于分类或检索(Mahajan等人,2018年;Kolesnikov等人,2020年;Dosovitskiy等人,2021年;Juan等人,2020年)。最近,自监督(Chen等人,2020b;Tian等人,2020年;He等人,2020年;Misra & Maaten,2020年;Li等人,2021年;Grill等人,2020年;Caron等人,2020年)和半监督学习(Yalniz等人,2019年;Xie等人,2020年;Pham等人,2020年)被研究作为替代范式。然而,迄今为止,通过这些方法训练的模型在下游任务的迁移能力有限(Zoph等人,2020年)。
利用图像和自然语言字幕是学习视觉表示的另一个方向。Joulin等人(2015年)、Li等人(2017年)、Desai & Johnson(2020年)、Sariyildiz等人(2020年)、Zhang等人(2020年)表明,通过从图像预测字幕可以学习到良好的视觉表示,这启发了我们的工作。然而,这些工作仅限于Flickr(Joulin等人,2015年;Li等人,2017年)和COCO Captions(Desai & Johnson,2020年;Sariyildiz等人,2020年)等小型数据集,并且产生的模型不产生所需的视觉-语言表示,以用于跨模态检索等任务。
在视觉-语言表示学习领域,已经提出了视觉-语义嵌入(VSE)(Frome等人,2013年;Faghri等人,2018年)及其改进版本(例如,利用目标检测器、密集特征图或多注意力层)(Socher等人,2014年;Karpathy等人,2014年;Kiros等人;Nam等人,2017年;Li等人,2019年;Messina等人,2020年;Chen等人,2020a)。最近,更先进的模型出现了,它们具有跨模态注意力层(Liu等人,2019a;Lu等人,2019年;Chen等人,2020c;Huang等人,2020b),在图像-文本匹配任务中表现出色。然而,它们的运行速度要慢得多,因此在现实世界中的图像-文本检索系统中不切实际。相比之下,我们的模型继承了最简单的VSE形式,但在图像-文本匹配基准测试中仍然优于所有以前的跨注意力模型。
与我们的工作密切相关的是CLIP(Radford等人,2021年),它提出了一种通过自然语言监督在类似的对比学习设置中学习视觉表示的方法。除了使用不同的视觉和语言编码器架构外,关键的区别在于训练数据:ALIGN遵循原始alt-text数据中图像-文本对的自然分布,而CLIP首先从英语维基百科中构建一个高频视觉概念的允许列表来收集数据集。我们证明,可以使用不需要专家知识策划的数据集学习强大的视觉和视觉-语言表示。
3 A Large-Scale Noisy Image-Text Dataset
我们工作的重点是扩大视觉和视觉-语言表示学习。为此,我们采用了比现有数据集大得多的数据集。具体来说,我们遵循构建Conceptual Captions数据集(Sharma等人,2018年)的方法,获得了原始英文alt-text数据(图像和alt-text对)的一个版本。Conceptual Captions数据集通过严格的过滤和后处理进行了清洗。在这里,为了扩大规模,我们通过放宽原始工作中的大部分清洗步骤,以质量换取规模。相反,我们只应用了下面详细说明的最小频率基础过滤。结果是,我们得到了一个更大(18亿图像-文本对)但噪声更多的数据集。图2显示了数据集中的一些样本图像-文本对。

-
1. 基于图像的过滤
-
移除色情图像:
-
目的:避免包含不当内容的图像。
-
方法:使用自动检测工具或手动标注来识别并移除色情图像。
-
-
尺寸和宽高比过滤:
-
保留条件:保留较短维度大于200像素且宽高比小于3的图像。
-
目的:确保图像具有足够的分辨率和合理的宽高比,以便模型能够有效提取特征。
-
例子:如果一张图像的宽度为250像素,高度为150像素,则保留;但如果宽度为250像素,高度为50像素,则不保留。
-
-
去除重复图像:
-
目的:避免在训练集中包含测试集中的图像,防止数据泄露。
-
方法:使用图像哈希或相似度检测技术,移除与下游评估数据集(如ILSVRC-2012、Flickr30K和MSCOCO)中的测试图像重复或近似重复的图像。
-
-
去除高频alt-text关联的图像:
-
条件:与超过1000个相关alt-texts关联的图像被丢弃。
-
目的:避免过于通用或重复的图像,这些图像可能不具有代表性。
-
例子:如果一张图像被1000个不同的alt-texts描述,可能是因为它是常见的背景图像或广告图像,这些图像对训练模型帮助不大。
-
-
过滤标准
-
-
2. 基于文本的过滤
-
过滤标准
-
排除共享的alt-texts:
-
条件:被超过10个图像共享的alt-texts被排除。
-
目的:避免使用与图像内容无关的通用或重复的alt-texts。
-
例子:常见的alt-texts如“1920x1080”、“alt img”和“cristina”通常与图像内容无关,应被排除。
-
-
去除包含稀有标记的alt-texts:
-
条件:包含任何稀有标记的alt-texts(在原始数据集中100百万最频繁的单字和双字之外)被丢弃。
-
目的:避免噪声文本,这些文本可能包含拼写错误、特殊字符或不常见的词汇。
-
例子:包含“image tid 25&id mggqpuwe-qdpd&cache 0&lan code 0”这样的文本应被排除。
-
-
长度过滤:
-
条件:太短(少于3个单字)或太长(超过20个单字)的alt-texts被丢弃。
-
目的:确保alt-texts具有足够的信息量且不过于冗长。
-
例子:太短的文本如“img”或“pic”可能缺乏描述性;太长的文本可能包含不必要的细节或噪声。
-
-
-
总结
通过上述基于图像和文本的过滤步骤,作者能够显著减少数据集中的噪声,提高数据质量。这有助于模型在训练过程中学习到更有用的特征表示,从而在各种任务上取得更好的性能。这些过滤步骤包括:
-
图像过滤:移除色情图像、尺寸和宽高比不符合要求的图像、与测试集重复的图像,以及与过多alt-texts关联的图像。
-
文本过滤:排除共享的alt-texts、包含稀有标记的alt-texts,以及长度过短或过长的alt-texts。
这些过滤步骤确保了最终数据集的质量,使其更适合用于训练视觉和视觉-语言表示模型。
4 Pre-training and Task Transfer
4.1 Pre-training on Noisy Image-Text Pairs
-
架构
-
双编码器架构:模型包含两个主要部分,即图像编码器和文本编码器。这种设计允许模型分别处理图像和文本数据,然后通过某种方式将两种不同形式的信息结合起来。
-
图像编码器:采用了EfficientNet模型,这是一个高效且性能良好的卷积神经网络(CNN),用于提取图像特征。值得注意的是,EfficientNet在这里没有使用其原始的分类头部(即最后的1x1卷积层),而是采用全局池化层来生成图像的固定长度向量表示。
-
文本编码器:基于BERT模型,这是一种基于Transformer的预训练语言模型,特别擅长捕捉文本中的语义信息。文本编码器利用了BERT中的[CLS]标记嵌入作为整个输入序列的表示,并在其后添加了一个全连接层,以确保文本表示的维度与图像表示相匹配。
-
-
训练目标
-
归一化Softmax损失:这是用来优化图像和文本编码器的一种损失函数。它鼓励模型学习到的图像和文本嵌入,在正样本(匹配的图像-文本对)之间具有较高的相似度,而在负样本(随机配对的图像-文本对)之间具有较低的相似度。
-
双向损失:模型通过最小化两个方向上的损失来进行训练:
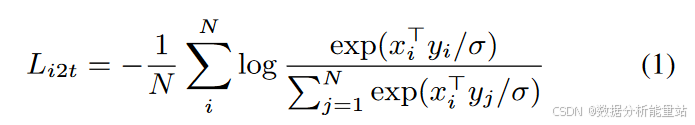
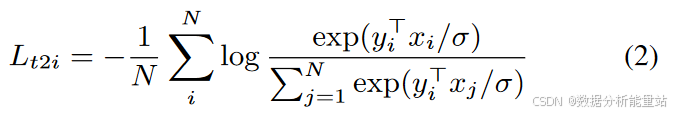
-
图像到文本分类损失 L_{i2t}:衡量给定图像对于正确文本的预测能力。
-
文本到图像分类损失 L_{t2i}:衡量给定文本对于正确图像的预测能力。
-
-
这两个损失函数都使用了余弦相似度来计算配对的图像和文本嵌入之间的相似度,并通过一个温度参数 σ 进行调整。温度参数的作用是控制输出分布的“尖锐”程度,从而影响模型对正样本和负样本区分的能力。
-
批次处理
局部批次:每个计算核心处理的数据批次。例如,如果每个计算核心处理32个样本,则局部批次大小为32。
全局批次:通过将所有计算核心的局部批次合并在一起形成的更大批次。假设使用8个计算核心,每个核心处理32个样本,则全局批次大小为 8×32=256
-
在训练过程中,为了提高负样本的有效性,不仅考虑了当前批次内的所有可能的负样本,还结合了来自其他计算核心的嵌入,形成了一个更大的逻辑批次。这样做可以增加负样本的数量,从而更好地训练模型识别真正的正样本。
-
温度参数 σ 不是固定不变的,而是在训练过程中与其他参数一同学习,以找到最有利于模型性能的值。
-
综上所述,ALIGN模型的设计目的是通过有效的双编码器架构和精心设计的损失函数,促进图像和文本之间的跨模态理解,从而实现高质量的图像-文本匹配。
4.2 Transferring to Image-Text Matching & Retrieval
-
评估任务
-
图像到文本检索:给定一张图像,模型需要从一组候选文本中找到最相关的描述。
-
文本到图像检索:给定一段文本描述,模型需要从一组候选图像中找到最相关的图像。
-
-
基准数据集
-
Flickr30K:
-
来源:Plummer等人,2015年。
-
描述:Flickr30K是一个广泛使用的多模态数据集,包含30,000张图像,每张图像有5个对应的文本描述。这些描述通常是由人类编写的,用于描述图像内容。
-
-
MSCOCO:
-
来源:Chen等人,2015年。
-
描述:MSCOCO(Microsoft Common Objects in Context)是一个大型多模态数据集,包含超过120,000张图像,每张图像有5个文本描述。这个数据集不仅用于图像描述任务,还广泛用于对象检测、分割等任务。
-
-
-
Crisscrossed Captions (CxC) 数据集
-
来源:Parekh等人,2021年。
-
描述:CxC是MSCOCO的一个扩展,除了原有的图像和文本描述外,还包括了额外的人类语义相似性判断。这些判断提供了更丰富的标注信息,支持多种检索和相似性任务。
-
-
CxC 支持的任务
-
内部和跨模态检索任务:
-
图像到文本检索:给定一张图像,从候选文本中找到最相关的描述。
-
文本到图像检索:给定一段文本,从候选图像中找到最相关的图像。
-
文本到文本检索:给定一段文本,从候选文本中找到最相似的描述。
-
图像到图像检索:给定一张图像,从候选图像中找到最相似的图像。
-
-
语义相似性任务:
-
语义文本相似性(STS):评估两段文本之间的语义相似度。
-
语义图像相似性(SIS):评估两张图像之间的语义相似度。
-
语义图像-文本相似性(SITS):评估一张图像和一段文本之间的语义相似度。
-
-
-
评估方法
-
有无微调:评估模型在未经过特定任务微调的情况下(即仅使用预训练模型)和经过微调后的性能。
-
直接评估:由于CxC数据集的训练集与原始MSCOCO相同,可以直接在CxC的注释上评估经过MSCOCO微调后的ALIGN模型。
-
-
总结
-
数据集:使用Flickr30K和MSCOCO作为主要的基准数据集,同时使用CxC数据集来评估更复杂的任务。
-
任务:评估模型在图像到文本、文本到图像、文本到文本、图像到图像检索以及语义相似性任务上的表现。
-
方法:比较模型在有无微调情况下的性能,以评估预训练模型的通用性和特定任务的适应性。
-
通过这些评估,可以全面了解ALIGN模型在多模态任务中的性能,特别是其在不同数据集和任务上的泛化能力和微调后的改进效果。
4.3 Transferring to Visual Classification
-
零样本迁移
-
ImageNet ILSVRC-2012:
-
来源:Deng等人,2009年。
-
描述:ImageNet ILSVRC-2012是一个大规模的图像分类基准,包含约120万张训练图像和1000个类别。预训练的ALIGN模型在没有进一步微调的情况下直接应用于这个基准,评估其零样本迁移能力。
-
-
-
ImageNet变体:
-
ImageNet-R:
-
来源:Hendrycks等人,2020年。
-
描述:包含非自然图像,如艺术作品、卡通和素描。这些图像不属于常见的自然图像分布,用于评估模型对不同类型图像的泛化能力。
-
-
ImageNet-A:
-
来源:Hendrycks等人,2021年。
-
描述:包含对机器学习模型更具挑战性的图像,用于评估模型在困难条件下的性能。
-
-
ImageNet-V2:
-
来源:Recht等人,2019年。
-
描述:是ImageNet的一个变体,用于评估模型在新数据上的性能,确保模型不仅仅是过拟合于训练集。
-
-
-
下游任务的微调
-
图像编码器迁移:
-
ImageNet:
-
设置1:仅训练顶部分类层(冻结ALIGN图像编码器)。
-
设置2:完全微调(包括图像编码器和顶部分类层)。
-
-
细粒度分类数据集:
-
牛津花102(Nilsback和Zisserman,2008年):包含102种不同类型的花朵图像。
-
牛津-IIIT宠物(Parkhi等人,2012年):包含37种不同种类的宠物图像。
-
斯坦福汽车(Krause等人,2013年):包含196种不同型号的汽车图像。
-
食品101(Bossard等人,2014年):包含101种不同类型的食品图像。
-
-
细粒度分类基准测试:只报告了完全微调的设置。
-
-
-
视觉任务适应基准(VTAB)
-
来源:Zhai等人,2019年。
-
描述:VTAB是一个包含19个多样化视觉分类任务的基准,涵盖了自然、专业和结构化图像分类任务。每个任务只有1000个训练样本,用于评估模型在小数据集上的泛化能力和鲁棒性。
-
-
评估方法
-
零样本迁移:直接将预训练的ALIGN模型应用于新的任务,不进行任何微调,评估其在未见过的数据上的表现。
-
微调:在特定任务上对预训练的图像编码器进行微调,以提高其在该任务上的性能。
-
冻结编码器:仅训练顶部分类层,保持预训练的图像编码器权重不变。
-
完全微调:同时微调图像编码器和顶部分类层。
-
-
VTAB评估:遵循Kolesnikov等人(2020年)的做法,评估模型在19个多样化任务上的性能,每个任务只有1000个训练样本。
-
-
总结
-
零样本迁移:评估预训练模型在未见过的数据上的泛化能力。
-
微调:评估预训练模型在特定任务上的适应能力,包括冻结编码器和完全微调两种设置。
-
细粒度分类:评估模型在细粒度分类任务上的性能。
-
VTAB:评估模型在小数据集上的泛化能力和鲁棒性。
-
通过这些评估,可以全面了解ALIGN模型在不同任务和数据集上的性能,特别是其在零样本迁移、微调和小数据集上的表现。
5 Experiments and Results
-
模型架构
-
图像编码器:使用EfficientNet-L2(除非在消融研究中使用其他变体)。EfficientNet-L2是一个非常深且高效的卷积神经网络,适用于图像特征提取。
-
文本编码器:使用BERT-Large。BERT-Large是一个大型的基于Transformer的语言模型,具有24层、1024个隐藏单元和16个注意力头,适用于文本特征提取。
-
-
图像预处理
-
输入分辨率:图像编码器在289×289像素的分辨率下进行训练。
-
数据增强:
-
训练时:首先将输入图像调整到346×346分辨率,然后执行随机裁剪(289×289),并附加随机水平翻转。
-
评估时:执行中心裁剪(289×289)。
-
-
-
文本预处理
-
序列长度:使用最大64个token的wordpiece序列,因为输入文本不超过20个单字。这意味着模型可以处理相对较短的文本描述。
-
-
损失函数
-
归一化Softmax损失:用于优化图像和文本编码器。
-
温度变量:初始化为1.0,这个温度变量在图像到文本损失和文本到图像损失之间共享。
-
标签平滑:在softmax损失中使用0.1作为标签平滑参数,以减少过拟合并提高模型的泛化能力。
-
-
-
优化器
-
LAMB优化器:使用LAMB(Layer-wise Adaptive Moments optimizer for Batch training)优化器,这是一种针对大批次训练的优化算法,特别适合大规模分布式训练。
-
权重衰减:权重衰减比为1e-5,用于防止过拟合。
-
学习率调度:
-
初始阶段:学习率从0线性增加到1e-3,需要10,000步。
-
后续阶段:学习率从1e-3线性衰减到0,需要1.2M步(大约12个周期)。
-
-
-
训练配置
-
硬件资源:在1024个Cloud TPUv3核心上进行训练。
-
批次大小:
-
每个核心:16个正样本对。
-
总的有效批次大小:16384(1024个核心 × 16个正样本对)。
-
-
通过这些详细的配置,可以从头开始有效地训练ALIGN模型,确保其在多模态任务中表现出色。
5.1 Image-Text Matching & Retrieval
评估设置
-
数据集分割
-
Flickr30K:
-
测试集:标准的1K测试集。
-
训练集:30K训练集。
-
-
MSCOCO:
-
测试集:5K测试集。
-
训练集:82K训练集加上30K验证图像(这些图像不在5K验证或5K测试集中)。
-
-
-
微调设置
-
损失函数:使用与预训练相同的归一化Softmax损失。
-
批次大小:从16384减少到2048,以避免假阴性问题。
-
学习率:初始学习率降低到1e-5。
-
训练步数:
-
Flickr30K:3K步。
-
MSCOCO:6K步。
-
-
学习率调度:线性衰减。
-
-
评估结果
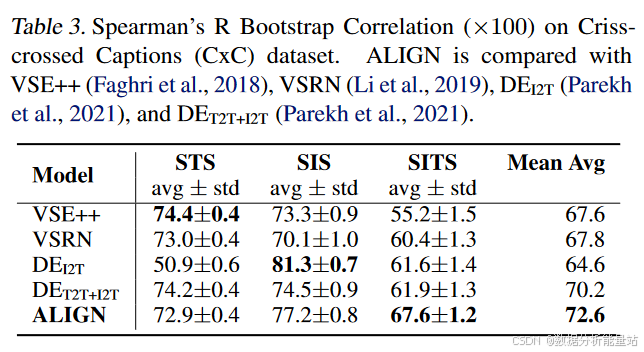
表1:Flickr30K和MSCOCO基准
-
零样本设置:
-
ALIGN在图像检索任务上取得了超过7%的改进,相对于之前的最先进成果CLIP(Radford等人,2021)。
-
-
微调设置:
-
ALIGN以较大的优势超越了所有现有方法,包括那些使用更复杂的跨模态注意力层的方法,如ImageBERT(Qi等人,2020)、UNITER(Chen等人,2020c)、ERNIE-ViL(Yu等人,2020)、VILLA(Gan等人,2020)和Oscar(Li等人,2020)。
-
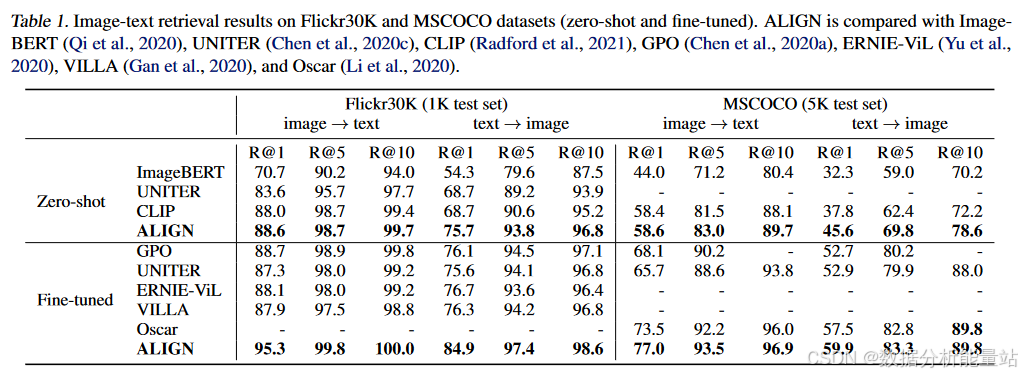
表2:Crisscrossed Captions(CxC)检索任务
-
图像到文本:R@1指标提高了22.2%。
-
文本到图像:R@1指标提高了20.1%。
-
总体表现:在所有指标上都取得了最先进的结果。
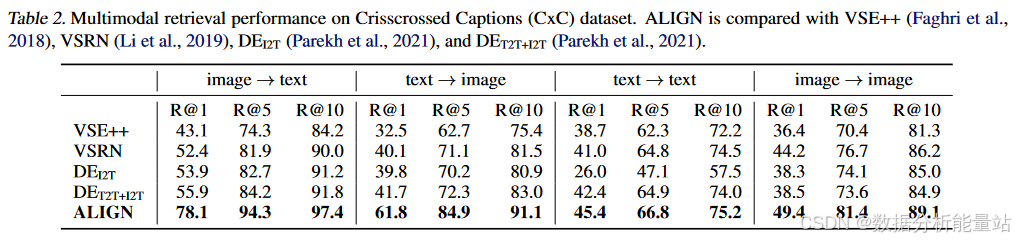
表3:语义相似性任务
-
语义图像-文本相似性(SITS):性能提高了5.7%。
-
观察和讨论
-
跨模态任务 vs 内部模态任务:
-
跨模态任务:ALIGN在图像到文本和文本到图像检索任务上表现出色。
-
内部模态任务:在文本到文本和图像到图像检索任务上的改进相对较小。
-
语义相似性任务:在STS和SIS任务上的性能略逊于VSE++和DEI2T。
-
-
原因分析:
-
ALIGN的训练目标主要集中在跨模态(图像-文本)匹配上,而不是内部模态匹配。
-
Parekh等人(2021)建议多任务学习可能产生更平衡的表示,这将是未来工作的方向。
-
-
尽管在跨模态任务上表现优异,但在内部模态任务上的表现相对较弱,这可能是由于训练目标的不同。未来的工作可以探索多任务学习以平衡不同任务的表现。
5.2 Zero-shot Visual Classification
直接使用类别名称进行图像分类
-
方法:通过将类别名称的文本直接输入到文本编码器中,生成类别嵌入。然后,利用图像-文本检索机制,将图像分类到候选类别中。
-
目的:评估ALIGN模型在不同图像分布上的分类性能,特别是在零样本迁移任务中。
-
数据集
-
ImageNet:标准的图像分类基准,包含1000个类别。
-
ImageNet变体:包括ImageNet-R、ImageNet-A和ImageNet-V2,这些变体包含不同类型的图像,用于评估模型在不同分布上的鲁棒性。
-
-
模型比较
-
ALIGN:本文提出的多模态模型。
-
CLIP:由Radford等人(2021)提出的多模态模型,已经在多个任务上表现出色。
-
-
提示集成方法
-
提示模板:为了进行公平比较,使用了与CLIP相同的提示集成方法。每个类别名称都通过一组预定义的提示模板进行扩展,例如“一张{类别名称}的照片”。
-
类别嵌入:通过平均所有提示模板生成的嵌入,然后进行L2归一化,得到最终的类别嵌入。
-
-
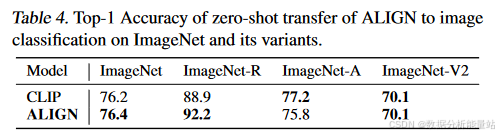
结果
-
表4:比较了ALIGN和CLIP在ImageNet及其变体上的表现。
-
鲁棒性:与CLIP类似,ALIGN在不同图像分布的分类任务上表现出了很好的鲁棒性。
-
性能提升:通过提示集成方法,ALIGN在ImageNet top-1准确率上提高了2.9%。
-
平均所有提示模板的原因?
1. 减少噪声和提高稳定性
单个提示的局限性:每个提示模板生成的嵌入可能会受到特定词语或句子结构的影响,导致某些嵌入不够稳定或存在噪声。
平均嵌入:通过平均多个提示模板生成的嵌入,可以减少个别提示带来的噪声,使最终的类别嵌入更加稳定和可靠。
2. 捕捉多样的语义信息
多角度描述:不同的提示模板可以捕捉到类别名称的不同方面。例如,对于类别“猫”,提示模板“一张猫的照片”和“一只正在玩耍的猫”可能会强调不同的特征。
综合信息:通过平均多个提示模板生成的嵌入,可以综合这些不同方面的信息,使最终的类别嵌入更加丰富和全面。
3. 提高泛化能力
泛化到不同场景:不同的提示模板可以帮助模型更好地泛化到不同的场景和上下文。例如,有些提示可能更适合描述静态的图像,而另一些提示可能更适合描述动态的场景。
鲁棒性:通过平均多个提示模板生成的嵌入,可以使模型在面对不同类型的图像时更加鲁棒,不容易受到特定提示的影响。
4. 增强模型的表达能力
多模态信息融合:提示模板不仅包括类别名称本身,还可以包括其他描述性的词语,这些词语可以提供额外的上下文信息。
丰富嵌入:通过平均多个提示模板生成的嵌入,可以增强模型的表达能力,使其能够更好地理解和表示复杂的类别信息。
具体示例:
示例类别:猫
1. 定义提示模板
假设我们使用以下几个提示模板来生成类别“猫”的嵌入:
“一张{类别名称}的照片”
“一只{类别名称}在睡觉”
“一只{类别名称}在玩耍”
“一只{类别名称}的眼睛”
“一只{类别名称}在吃东西”
将类别名称“猫”代入这些模板,得到:
“一张猫的照片”
“一只猫在睡觉”
“一只猫在玩耍”
“一只猫的眼睛”
“一只猫在吃东西”
2. 生成每个提示的嵌入
使用文本编码器(如BERT)生成每个提示的嵌入。假设生成的嵌入如下(简化为二维向量,实际嵌入通常是高维的):
“一张猫的照片” -> [0.8, 0.2]
“一只猫在睡觉” -> [0.6, 0.4]
“一只猫在玩耍” -> [0.7, 0.3]
“一只猫的眼睛” -> [0.5, 0.5]
“一只猫在吃东西” -> [0.6, 0.4]
3. 平均所有提示的嵌入
将所有提示的嵌入进行平均:
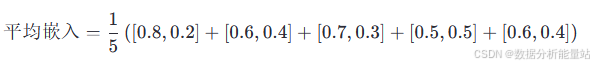
计算平均值:

4. L2归一化
对平均嵌入进行L2归一化,使其长度为1:
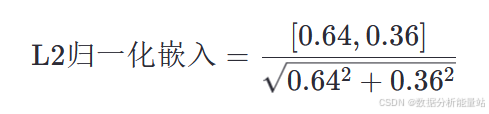
计算归一化因子:
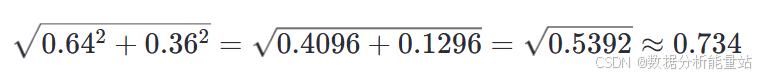
归一化后的嵌入:
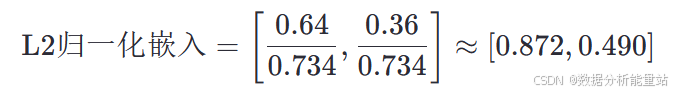
5. 使用归一化嵌入进行分类
图像嵌入:假设我们有一个图像的嵌入 [0.8, 0.5]。
相似度计算:计算图像嵌入与类别嵌入之间的余弦相似度。
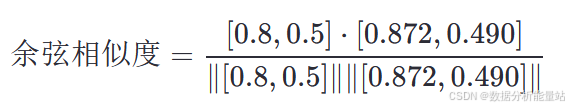
计算点积:
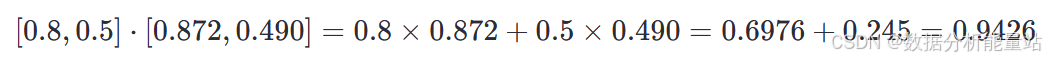
计算范数:
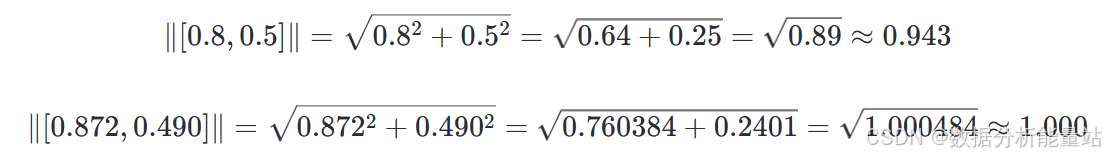
计算余弦相似度:
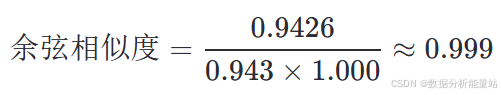
通过平均多个提示模板生成的嵌入,可以减少个别提示带来的噪声,综合多方面的信息,使最终的类别嵌入更加稳定和丰富。这有助于提高模型在分类任务中的性能和鲁棒性。在实际应用中,这种方法确实可以显著提升模型的分类准确率。
5.3 Visual Classification w/ Image Encoder Only
ImageNet基准测试
-
训练策略
-
冻结视觉特征:
-
目标:仅训练分类头部。
-
数据增强:使用随机裁剪(与Szegedy等人(2015年)相同)和水平翻转。
-
评估:应用单一中心裁剪,比例为0.875。
-
分辨率:训练分辨率为289,评估分辨率为360。
-
优化器:使用全局批次大小为1024,动量为0.9的SGD优化器。
-
学习率:初始学习率为0.1,每30个周期衰减0.2,总共100个周期。
-
权重衰减:设置为零。
-
-
微调所有层:
-
目标:微调所有层。
-
分辨率:训练分辨率为475,评估分辨率为600。
-
优化器:使用全局批次大小为1024,动量为0.9的SGD优化器。
-
学习率:初始学习率为0.01,主干网络的学习率比分类头部小10倍。
-
权重衰减:设置为零。
-
学习率调度:每30个周期衰减0.2,总共100个周期。
-
-
-
性能比较
-
冻结特征:ALIGN略优于CLIP,取得了85.5%的top-1准确率,达到最新的结果。
-
微调后:ALIGN的准确率高于BiT和ViT模型,仅次于需要ImageNet训练和大规模未标记数据之间更深层次交互的Meta Pseudo Labels。
-
效率:与同样使用EfficientNet-L2的NoisyStudent和Meta-Pseudo-Labels相比,ALIGN通过使用较小的测试分辨率(600而不是800)节省了44%的FLOPS。
-
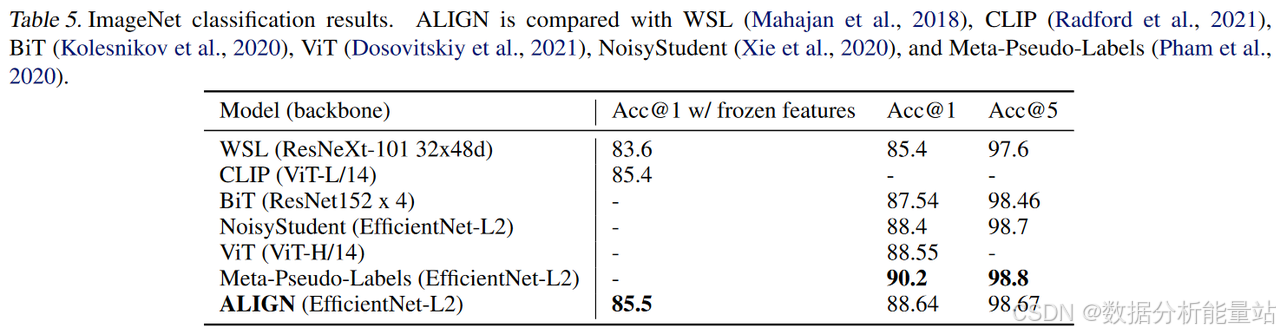
-
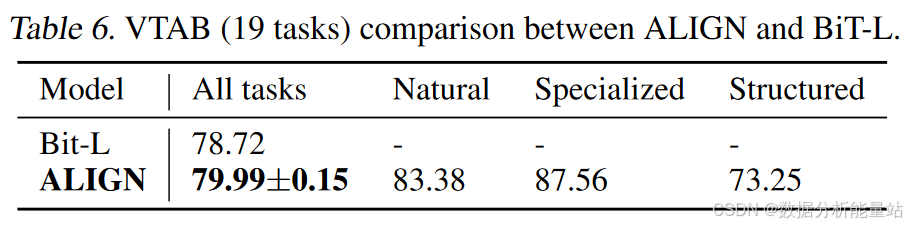
VTAB评估
-
超参数扫描:遵循Zhai等人(2019年)附录I中显示的超参数扫描,每个任务进行50次试验。
-
训练和验证:每个任务在800张图像上训练,使用200张图像的验证集选择超参数。
-
最终训练:扫描后,选定的超参数用于在每个任务的1000张图像的合并训练和验证分割上训练。
-
结果:表6报告了平均准确率(包括每个子组的细分结果)以及三次微调运行的标准差,显示ALIGN优于BiT-L(Kolesnikov等人,2020年),并且应用了类似的超参数选择方法。
-
-
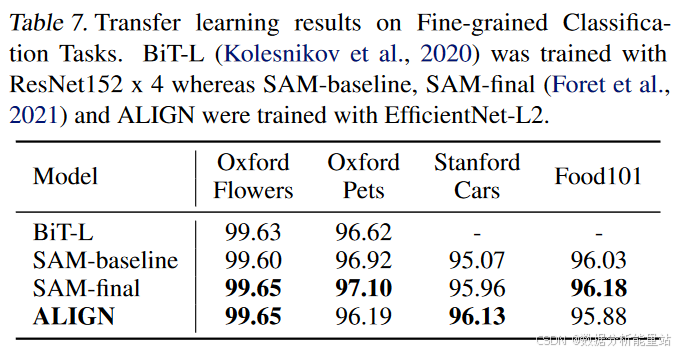
细粒度分类基准
-
微调策略:
-
数据增强和优化器:使用与ImageNet微调相同的数据增和优化器。
-
分辨率:训练/评估分辨率固定在289/360。
-
批次大小:256。
-
权重衰减:1e-5。
-
学习率:初始学习率分别为1e-2(训练分类头部)和1e-3(微调所有层)。
-
学习率调度:在20k步中使用余弦学习率衰减。
-
批量归一化:微调所有层时,冻结批量归一化统计数据。
-
-
性能比较:
-
表7:比较了ALIGN与BiT-L(Kolesnikov等人,2020年)和SAM(Foret等人,2021年),两者都对所有任务应用相同的微调超参数。
-
基线结果:列出了(Foret等人,2021年)中未使用SAM优化的基线结果,以便进行更公平的比较。
-
结果:我们的结果(三次运行的平均值)与不调整优化算法的最新结果相当。
-
-
6 Ablation Study
消融研究(ablation study),用于确定模型中哪些部分对最终性能有重要影响。在这项研究中,作者们主要关注两个任务的性能对比:
-
MSCOCO零样本检索(zero-shot retrieval):这是一个跨模态检索任务,指的是在没有看到特定类别样本的情况下,模型能够识别和检索出与给定文本描述相匹配的图像的能力。
-
ImageNet K最近邻(KNN)任务:这是一个分类任务,其中模型需要识别图像所属的类别。KNN是一种简单的机器学习算法,用于根据特征空间中的最近邻居来预测样本的标签。
作者们选择这两个任务是因为它们能够很好地代表模型的整体性能,并且与其他任务的性能指标有较强的相关性。这意味着,如果一个模型在这两个任务上表现良好,那么它很可能在其他相关任务上也有不错的表现。
6.1 Model Architectures
不同图像和文本主干网络的性能
-
主干网络组合
-
图像编码器:从EfficientNet-B1到EfficientNet-L2。
-
文本编码器:从BERT-Mini到BERT-Large。
-
-
特征维度匹配
-
全连接层:在B1、B3、B5和L2的全局池化特征之上添加了一个额外的全连接层,以线性激活方式匹配B7(640)的输出维度。
-
文本编码器:所有文本编码器也添加了类似的线性层,以确保图像和文本嵌入的维度一致。
-
-
训练设置
-
训练步数:为了节省运行时间,在消融研究中将训练步骤减少到100万步。
-
-
结果
-
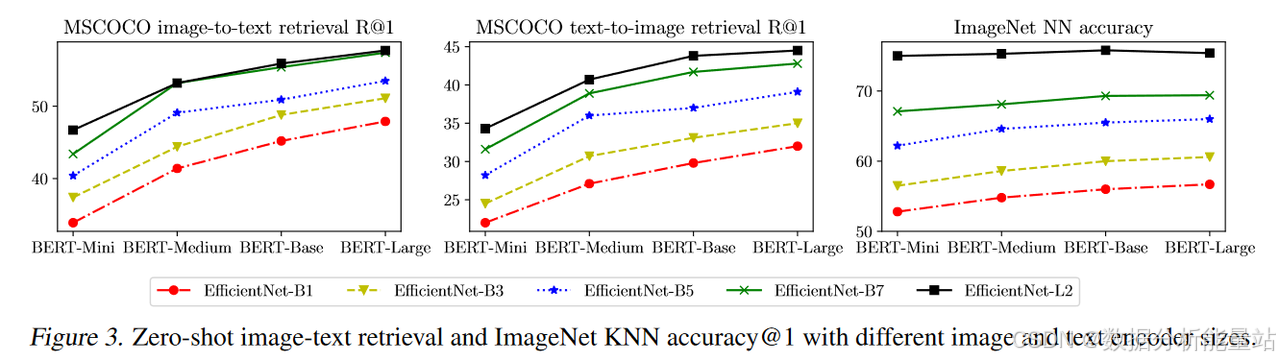
图3:显示了不同图像和文本主干网络组合在MSCOCO零样本检索和ImageNet KNN任务上的性能。
-
模型质量:随着更大的主干网络,模型质量提高,特别是在视觉任务上。
-
饱和现象:从BERT-Base到BERT-Large与EfficientNet-B7和EfficientNet-L2一起,ImageNet KNN指标开始饱和。
-
图像编码器的重要性:扩大图像编码器的容量对视觉任务更为重要,即使使用BERT-Mini文本塔,EfficientNet-L2的性能也优于BERT-Large的B7。
-
图像-文本检索任务:图像和文本编码器的容量同等重要。
-
-
关键架构超参数的研究
-
嵌入维度
-
表8:比较了不同嵌入维度对模型性能的影响。
-
第2-4行:模型性能随着更高的嵌入维度而提高。因此,嵌入维度随着更大的EfficientNet主干(L2使用1376)进行扩展。
-
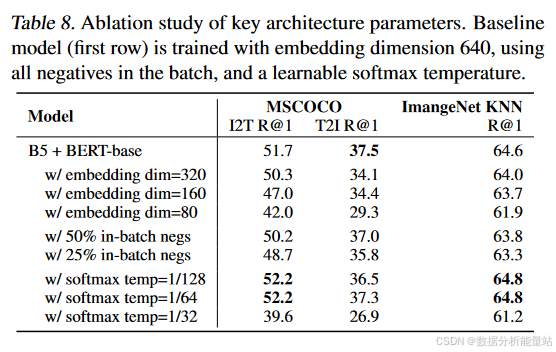
-
批次中随机负样本的数量
-
第5和6行:在softmax损失中使用较少的批次内负样本(50%和25%)会降低性能。使用所有负样本的效果最好。
-
-
-
Softmax温度
-
第7-9行:研究了softmax损失中温度参数的效果。
-
基线模型:使用可学习的温度参数,收敛到大约1/64。
-
固定温度:一些手工选择的固定温度可能稍好一些,但可学习的温度性能具有竞争力,并且使学习更容易。
-
温度变化:温度通常在前100k步迅速下降到仅约为收敛值的1.2倍,然后直到训练结束慢慢收敛。
-
-
通过这些消融研究,可以确定最佳的主干网络组合和关键架构超参数设置,从而在不同任务上优化ALIGN模型的性能。最终,选择EfficientNet-L2 + BERT-Large作为主干网络,并使用可学习的温度参数,以确保模型在各种任务上的最佳表现。
具体如何扩大图像编码器的容量?
增加图像编码器模型的复杂度和参数量,以提高其表示能力和性能。具体来说,这可以通过以下几种方式实现:
1. 使用更深的网络
层数增加:增加网络的层数,使模型能够学习更复杂的特征层次。例如,从EfficientNet-B1到EfficientNet-L2,层数逐渐增加,模型的深度和复杂度也随之增加。
更复杂的模块:使用更复杂的网络模块,如残差块(ResNet)、密集块(DenseNet)等,这些模块可以提高模型的表示能力。
2. 增加宽度
更多的通道:增加每一层的卷积核数量(即通道数),使模型能够捕获更多的特征信息。例如,EfficientNet-L2的通道数比EfficientNet-B1多很多。
更宽的层:增加每一层的宽度,使模型能够在每一层上捕获更多的特征。
3. 增加分辨率
更高的输入分辨率:使用更高分辨率的输入图像,使模型能够捕捉更精细的细节。例如,从224x224增加到384x384或更高。
多尺度特征:在不同尺度上提取特征,然后进行融合,以提高模型的鲁棒性和表示能力。
4. 增加参数量
更多的参数:通过增加网络的层数、宽度或分辨率,模型的参数量也会增加,从而提高其表示能力。例如,EfficientNet-L2的参数量远大于EfficientNet-B1。
5. 更复杂的正则化和优化技术
正则化技术:使用更复杂的正则化技术,如Dropout、Batch Normalization等,以防止过拟合。
优化器:使用更先进的优化器,如Adam、LAMB等,以提高训练效率和模型性能。
具体示例
假设我们从EfficientNet-B1(较浅、较窄的网络)升级到EfficientNet-L2(较深、较宽的网络):
EfficientNet-B1:
层数较少,通道数较少。
参数量较小,表示能力有限。
输入分辨率较低(例如224x224)。
EfficientNet-L2:
层数更多,通道数更多。
参数量更大,表示能力更强。
输入分辨率更高(例如475x475)。
使用更复杂的正则化和优化技术。
影响
性能提升:更大的模型通常在复杂任务上表现更好,因为它们能够学习到更丰富的特征表示。
计算资源需求增加:更大的模型需要更多的计算资源(如GPU内存、训练时间)。
过拟合风险:更大的模型更容易过拟合,因此需要更有效的正则化和数据增强技术。
6.2 Pre-training Datasets
实验设置
模型组合:
EfficientNet-B7 + BERT-base:较大模型。
EfficientNet-B3 + BERT-mini:较小模型。
数据集:
完整ALIGN训练数据:大规模数据集。
随机抽样10%的ALIGN训练数据:中等规模数据集。
概念性字幕(Conceptual Captions,CC-3M):较小规模数据集,约300万张图片。
训练设置:
CC-3M:由于规模较小,训练步数为默认步数的1/10。
所有模型:从头开始训练。
-
实验结果
表9
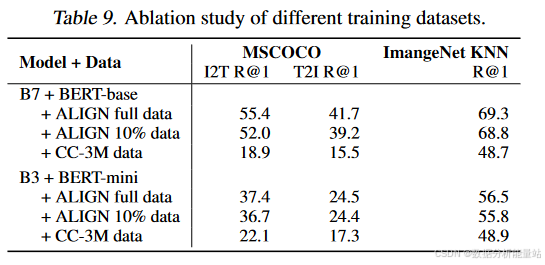
-
大规模数据集(完整ALIGN训练数据):
-
EfficientNet-B7 + BERT-base:表现最好,明显优于其他模型组合。
-
EfficientNet-B3 + BERT-mini:表现良好,但不如EfficientNet-B7 + BERT-base。
-
-
中等规模数据集(随机抽样10%的ALIGN训练数据):
-
EfficientNet-B7 + BERT-base:表现良好,但没有在完整数据集上的改进那么明显。
-
EfficientNet-B3 + BERT-mini:几乎饱和,表明在较小的数据集上,较小的模型已经足够。
-
-
小规模数据集(CC-3M):
-
EfficientNet-B7 + BERT-base:开始过拟合,表现甚至不如EfficientNet-B3 + BERT-mini。
-
EfficientNet-B3 + BERT-mini:表现较好,但不如在完整ALIGN数据集上的表现。
-
-
结论
-
数据集规模的重要性:
-
大规模数据集:对于提高模型性能至关重要。在完整ALIGN数据集上训练的模型明显优于在较小数据集上训练的模型。
-
小规模数据集:可能导致过拟合,特别是在使用较大模型时。例如,在CC-3M上,EfficientNet-B7 + BERT-base开始过拟合,表现甚至不如EfficientNet-B3 + BERT-mini。
-
-
模型容量与数据集规模的关系:
-
需要更大的模型来充分利用更大的数据集:较小的EfficientNet-B3 + BERT-mini在10%的ALIGN数据上几乎饱和,而更大的EfficientNet-B7 + BERT-base在完整ALIGN数据上有明显的改进。
-
较小的数据集适合较小的模型:在CC-3M上,较小的EfficientNet-B3 + BERT-mini表现更好,因为较大的模型容易过拟合。
-
通过这些实验,可以看出数据集的规模对模型性能有显著影响。大规模数据集能够支持更大、更复杂的模型,从而提高性能。而在较小的数据集上,较小的模型更能避免过拟合,表现更好。因此,选择合适的模型容量和数据集规模是优化模型性能的关键。
7 Analysis of Learned Embeddings
图像检索系统
-
数据集:
-
索引:使用了一个包含1.6亿张CC-BY许可的图片的索引,这些图片与训练集是分开的。
-
目的:演示ALIGN模型在图像检索任务中的性能。
-
-
文本到图像检索:
-
图4:显示了一些不在训练数据中的文本查询的前1个文本到图像检索结果。
-
性能:ALIGN能够根据场景的详细描述,或者地标和艺术品等细粒度或实例级概念,检索出精确的图像。
-
示例:例如,输入“埃菲尔铁塔”可以检索到与埃菲尔铁塔相关的图像。
-
结论:这些例子表明,ALIGN模型可以将具有相似语义的图像和文本对齐,并且能够推广到新的复杂概念。
-

嵌入的组合性
-
背景:
-
Word2Vec:Mikolov等人(2013a;b)表明,词向量之间的线性关系是由于训练它们预测句子中相邻的词而出现的。
-
图像和文本嵌入:在ALIGN中,图像和文本嵌入也表现出类似的线性关系。
-
-
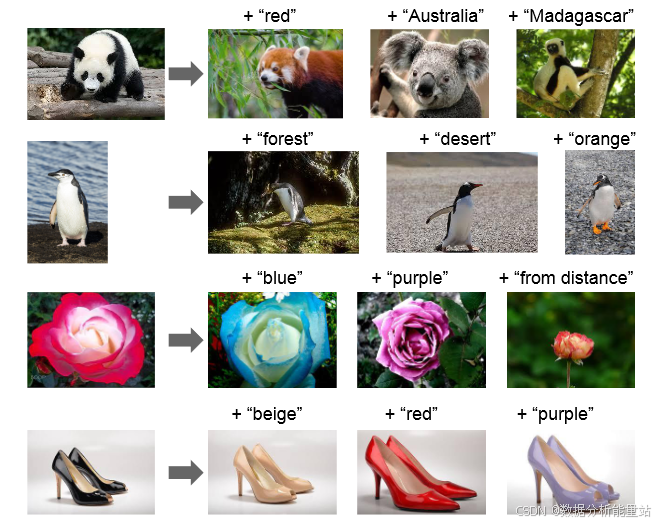
多模态查询:
-
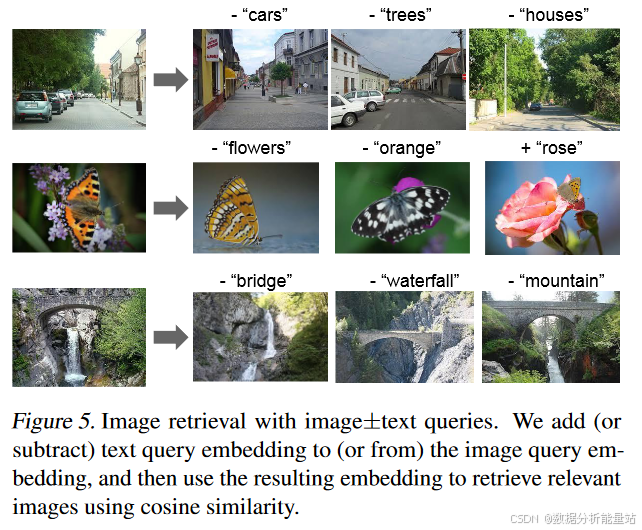
方法:给定一个查询图像和一个文本字符串,将它们的ALIGN嵌入相加,并用它来检索相关图像。
-
图5:显示了各种图像+文本查询的结果。
-
示例:
-
组合查询:例如,输入“熊猫”和“澳大利亚”可以检索到与澳大利亚版熊猫相关的图像。
-
颜色变换:例如,输入“黑色鞋子”和“米色”可以检索到颜色为米色的相似外观的鞋子。
-
-
减法操作:通过在嵌入空间中进行减法,可以移除场景中的对象/属性。例如,输入“海滩”和“-人”可以检索到没有人出现的海滩图像。
-
-
示例解析
图4:文本到图像检索
-
查询:输入文本查询,如“埃菲尔铁塔”、“日落海滩”等。
-
结果:ALIGN模型能够检索出与查询文本高度相关的图像。
-
特点:能够处理细粒度或实例级概念,如地标、艺术品等。
-
图5:多模态查询
-
组合查询:
-
查询:输入图像和文本字符串,如“熊猫”和“澳大利亚”。
-
结果:检索出与澳大利亚版熊猫相关的图像。
-
特点:展示了ALIGN嵌入在视觉和语言领域的组合性。
-
-
颜色变换:
-
查询:输入图像和颜色字符串,如“黑色鞋子”和“米色”。
-
结果:检索出颜色为米色的相似外观的鞋子。
-
特点:展示了通过嵌入相加实现颜色变换的能力。
-
-
减法操作:
-
查询:输入图像和减法字符串,如“海滩”和“-人”。
-
结果:检索出没有人出现的海滩图像。
-
特点:展示了通过嵌入减法移除场景中的对象/属性的能力。
-
通过这些实验,可以看出ALIGN模型不仅在传统的文本到图像检索任务中表现出色,还在多模态查询中展示了强大的组合性和灵活性。这些特性为未来的多模态应用提供了新的可能性。
8 Multilingual ALIGN Model
-
多语言模型ALIGNmling的训练
-
数据集:
-
数据来源:使用带有非常简单过滤条件的嘈杂网络图像文本数据,这些过滤条件并不特定于任何语言。
-
扩展:将概念字幕数据处理流程扩展到多语言(覆盖100多种语言),并将其规模与英文数据集相匹配(18亿图像-文本对)。
-
-
词汇表:
-
多语言wordpiece词汇表:创建了一个新的多语言wordpiece词汇表,大小为25万,以覆盖所有语言。
-
-
训练设置:
-
配置:模型训练遵循与英文配置完全相同的设置。
-
-
多语言模型的评估
-
数据集:
-
Multi30k数据集:这是一个多语言图像文本检索数据集,扩展到德语(de)、法语(fr)和捷克语(cs),基于Flickr30K(Plummer等人,2015年)。
-
内容:包含31,783张图片,每张图片有5个英文和德文的字幕,以及1个法文和捷克文的字幕。
-
分割:训练/开发/测试的分割定义在Young等人(2014年)的研究中。
-
-
评估指标:
-
平均召回率(mR):计算图像到文本检索和文本到图像检索任务中Recall@1、Recall@5和Recall@10的平均得分。
-
-
评估结果:
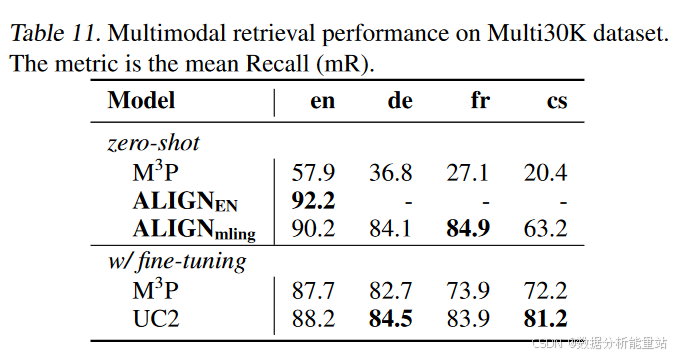
-
表11:显示了ALIGNmling在不同语言上的零样本性能,并与M3P(Huang等人,2020a)和UC2(Zhou等人,2021)进行了比较。
-
性能:
-
德语:ALIGNmling的零样本性能大幅超越M3P。
-
法语:最大绝对mR提高了57.8%。
-
捷克语:性能与经过微调的M3P和UC2相当。
-
英语:性能略逊于其对应的ALIGNEN(仅在英文数据上训练的模型)。
-
-
-
具体示例
-
德语:
-
结果:ALIGNmling的零样本性能大幅超越M3P。
-
示例:输入德语文本“Eine Frau sitzt auf einem Stuhl.”(一个女人坐在椅子上),能够检索到相应的图像。
-
-
法语:
-
结果:最大绝对mR提高了57.8%。
-
示例:输入法语文本“Un homme conduit une voiture.”(一个男人在开车),能够检索到相应的图像。
-
-
捷克语:
-
结果:性能与经过微调的M3P和UC2相当。
-
示例:输入捷克语文本“Muž drží kočku.”(一个男人抱着一只猫),能够检索到相应的图像。
-
-
英语:
-
结果:性能略逊于其对应的ALIGNEN。
-
示例:输入英文文本“A dog is playing with a ball.”(一只狗在玩球),能够检索到相应的图像。
-
-
通过这些实验,可以看出多语言模型ALIGNmling在多语言图像文本检索任务上表现出色,特别是在德语和法语上的零样本性能显著提升。这些结果展示了ALIGNmling在多语言任务中的强大能力和广泛的适用性。
相关文章:

大模型-ALIGN 详细介绍
ALIGN模型(A Large-scale ImaGe and Noisy-text embedding)是一种大规模图像和噪声文本嵌入模型,它通过对比学习的方式将图像和文本嵌入到同一个向量空间中,使得匹配的图像-文本对的嵌入向量接近,不匹配的则远离。这种…...

【C++高并发服务器WebServer】-15:poll、epoll详解及实现
本文目录 一、poll二、epoll2.1 相对poll和select的优点2.2 epoll的api2.3 epoll的demo实现2.5 epoll的工作模式 一、poll poll是对select的一个改进,我们先来看看select的缺点。 我们来看看poll的实现。 struct pollfd {int fd; /* 委托内核检测的文件描述符 */s…...

【算法】动态规划专题⑩ —— 混合背包问题 python
目录 前置知识进入正题总结 前置知识 【算法】动态规划专题⑤ —— 0-1背包问题 滚动数组优化 【算法】动态规划专题⑥ —— 完全背包问题 python 【算法】动态规划专题⑦ —— 多重背包问题 二进制分解优化 python 混合背包结合了三种不同类型的背包问题:0/1背包…...

Java高频面试之SE-20
hello啊,各位观众姥爷们!!!本baby今天又来了!哈哈哈哈哈嗝🐶 Java的泛型是什么? Java 泛型(Generics) 是 Java 5 引入的一项重要特性,用于增强代码的类型安…...

springboot 事务管理
在Spring Boot中,事务管理是通过Spring框架的事务管理模块来实现的。Spring提供了声明式事务管理和编程式事务管理两种方式。通常,我们使用声明式事务管理,因为它更简洁且易于维护。 1. 声明式事务管理 声明式事务管理是通过注解来实现的。…...

opentelemetry-collector 配置elasticsearch
一、修改otelcol-config.yaml receivers:otlp:protocols:grpc:endpoint: 0.0.0.0:4317http:endpoint: 0.0.0.0:4318 exporters:debug:verbosity: detailedotlp/jaeger: # Jaeger supports OTLP directlyendpoint: 192.168.31.161:4317tls:insecure: trueotlphttp/prometheus: …...

IDEA关联Tomcat,部署JavaWeb项目
将IDEA与Tomcat关联 创建JavaWeb项目 创建Demo项目 将Tomcat作为依赖引入到Demo中 添加 Web Application 编写前端和后端代码 配置Tomcat server,并运行...

位图与位运算的深度联系:从图像处理到高效数据结构的C++实现与优化
在学习优选算法课程的时候,博主学习位运算了解到位运算的这个概念,之前没有接触过,就查找了相关的资料,丰富一下自身,当作课外知识来了解一下。 位图(Bitmap): 在计算机科学中有两种…...

运维_Mac环境单体服务Docker部署实战手册
Docker部署 本小节,讲解如何将前端 后端项目,使用 Docker 容器,部署到 dev 开发环境下的一台 Mac 电脑上。 1 环境准备 需要安装如下环境: Docker:容器MySQL:数据库Redis:缓存Nginx&#x…...

DeepSeek-V3 论文解读:大语言模型领域的创新先锋与性能强者
论文链接:DeepSeek-V3 Technical Report 目录 一、引言二、模型架构:创新驱动性能提升(一)基本架构(Basic Architecture)(二)多令牌预测(Multi-Token Prediction…...

react使用if判断
1、第一种 function Dade(req:any){console.log(req)if(req.data.id 1){return <span>66666</span>}return <span style{{color:"red"}}>8888</span>}2、使用 {win.map((req,index) > ( <> <Dade data{req}/>{req.id 1 ?…...
的内窥镜图像去雾)
opencv:基于暗通道先验(DCP)的内窥镜图像去雾
目录 项目大体情况 暗通道先验(Dark Channel Prior, DCP)原理 项目代码解析 该项目是由我和我导师与舟山某医院合作开发的一个基于暗通道先验(Dark Channel Prior,DCP)的内窥镜图像去雾方法。具体来说,…...

2025年物联网相关专业毕业论文选题参考,文末联系,选题相关资料提供
一、智能穿戴解决方案研究方向 序号解决方案论文选题论文研究方向1智能腰带健康监测基于SpringBoot和Vue的智能腰带健康监测数据可视化平台开发研究如何利用SpringBoot和Vue技术栈开发一个数据可视化平台,用于展示智能腰带健康监测采集的数据,如心率、血…...

npm无法加载文件 因为此系统禁止运行脚本
安装nodejs后遇到问题: 在项目里【node -v】可以打印出来,【npm -v】打印不出来,显示npm无法加载文件 因为此系统禁止运行脚本。 但是在winr,cmd里【node -v】,【npm -v】都也可打印出来。 解决方法: cmd里可以打印出…...

使用PyCharm创建项目以及如何注释代码
创建好项目后会出现如下图所示的画面,我们可以通过在项目文件夹上点击鼠标右键,选择“New”菜单下的“Python File”来创建一个 Python 文件,在给文件命名时建议使用英文字母和下划线的组合,创建好的 Python 文件会自动打开&#…...
)
Qt中QFile文件读写操作和QFileInfo文件信息读取方法(详细图文教程)
💪 图像算法工程师,专业从事且热爱图像处理,图像处理专栏更新如下👇: 📝《图像去噪》 📝《超分辨率重建》 📝《语义分割》 📝《风格迁移》 📝《目标检测》 &a…...

CF998A Balloons 构造
Balloons 算法:构造 rating : 1000 思路: 分情况讨论: 1. 当只有一个气球包时,肯定不行 2.当有两个气球包时,若两个气球包的气球个数相同则不行 3.其余的情况都是可以的,题目问给格里高利的气球包数…...

python基础入门:3.5实战:词频统计工具
Python词频统计终极指南:字典与排序的完美结合 import re from collections import defaultdictdef word_frequency_analysis(file_path, top_n10):"""完整的词频统计解决方案:param file_path: 文本文件路径:param top_n: 显示前N个高频词:return:…...

面试准备——Java理论高级【笔试,面试的核心重点】
集合框架 Java集合框架是面试中的重中之重,尤其是对List、Set、Map的实现类及其底层原理的考察。 1. List ArrayList: 底层是动态数组,支持随机访问(通过索引),时间复杂度为O(1)。插入和删除元素时&#…...

Docker 部署 verdaccio 搭建 npm 私服
一、镜像获取 # 获取 verdaccio 镜像 docker pull verdaccio/verdaccio 二、修改配置文件 cd /wwwroot/opt/docker/verdaccio/conf vim config.yaml config.yaml 配置文件如下,可以根据自己的需要进行修改 # # This is the default configuration file. It all…...

每日一题--数组中只出现一次的两个数字
数组中只出现一次的两个数字 题目描述数据范围提示 示例示例1示例2 题解解题思路位运算方法步骤: 代码实现代码解析时间与空间复杂度按位与操作获取最小位1的原理为什么选择最低有效的 1 位而不是其他位? 题目描述 一个整型数组里除了两个数字只出现一次…...

蓝耘智算平台与DeepSeek R1模型:推动深度学习发展
公主请阅 前言何为DeepSeek R1DeepSeek R1 的特点DeepSeek R1 的应用领域DeepSeek R1 与其他模型的对比 何为蓝耘智算平台使用蓝耘智算平台深度使用DeepSeek R1代码解释:处理示例输入:输出结果: 前言 在深度学习领域,创新迭代日新…...

数据中台是什么?:架构演进、业务整合、方向演进
文章目录 1. 引言2. 数据中台的概念与沿革2.1 概念定义2.2 历史沿革 3. 数据中台的架构组成与关键技术要素解析3.1 架构组成3.2 关键技术要素 4. 数据中台与其他平台的对比详细解析 5. 综合案例:金融行业数据中台落地实践5.1 背景5.2 解决方案5.3 成果与价值 6. 方向…...

告别2023~2024
时间过得真快,距离上次写作2年多了。2023年~2024年的这两年时光里经历太多人生大事: 房贷,提前还贷买车,全款拿下租房搬家媳妇怀孕,独自照顾,……老人离世开盲盒喜提千金,百岁宴&am…...

PMO项目管理规范标准
这份文档是一份关于 PMO 项目管理规范标准的 V3.0 版本。以下是该文档的主要内容: 1. 立项管理 - 立项标准、级别划分和管理:定义了立项管理的标准、级别划分和管理,包括立项的审批流程、产品可行性分析、立项建议书、产品需求文档等。 - 立项…...

通过类加载和初始化的一些题目理解Java类加载过程
通过题目重点理解:Class加载流程和运行时区域 目录 子类和父类static变量父子类加载顺序2class.forName初始化 子类和父类static变量 class Parent {static int a 1;static int b 2;static int c;static {c 3;System.out.println("parent static block&quo…...

【人工智能】解码语言之谜:使用Python构建神经机器翻译系统
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 神经机器翻译(NMT)是近年来机器翻译领域的一项重大突破。它利用深度学习模型,特别是循环神经网络(RNN)和Transformer网络,以端到端的…...

瑞芯微 Rockchip 系列 RK3588 主流深度学习框架模型转成 rknn 模型教程
前言 在瑞芯微 Rockchip 芯片上进行 NPU 推理,需要先将模型文件转换成 rknn 模型文件,才能执行各种推理任务。本文将介绍如何安装各种工具,并最终实现将各种深度学习框架的模型文件转换成 rknn 文件。 本教程不仅适合 RK3588 平台ÿ…...

51单片机俄罗斯方块计分函数
/************************************************************************************************************** * 名称:scoring * 功能:计分 * 参数:NULL * 返回:NULL * 备注:采用非阻塞延时 ****************…...

C++线程池
使用线程情况比较频繁的地方,由于线程的创建及销毁都会产生对资源的占用及性能的损耗。为了优化性能,提升效率,在这种场景中,就应该使用线程池来处理任务。 线程池创建的关键点: 装载线程的容器,在C中使用…...

Golang GORM系列:定义GORM模型及关系指南
使用GORM进行数据库管理的核心是定义模型的技能。模型是程序的面向对象结构和数据库的关系世界之间的纽带。本文深入研究了在GORM中创建成功模型的艺术,研究了如何设计结构化的Go结构,用标记注释字段,以及开发跨模型的链接,以便最…...

ssm校园二手交易平台小程序
博主介绍:✌程序猿徐师兄、8年大厂程序员经历。全网粉丝15w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

【虚幻引擎UE】AOI算法介绍与实现案例
【虚幻引擎UE】AOI算法介绍与实现 一、AOI算法介绍AOI算法的典型应用场景二、AOI相关算法1. 边界框法(Bounding Box Method)2. 动态AOI算法3. 布尔运算(Boolean Operations)4. 四叉树(Quadtree)5. R树(R-Tree)6. 圆形AOI算法7. 网格分割(Grid Partitioning)8. 多边形…...

JavaScript 基础语法:变量、数据类型、运算符、条件语句、循环
JavaScript 是一种动态类型的脚本语言,广泛用于前端开发。以下是 JavaScript 基础语法的核心内容,包括变量、数据类型、运算符、条件语句和循环。 --- ### 1. 变量 变量用于存储数据。JavaScript 中有三种声明变量的方式: - **var**&…...

ASP.NET Core 如何使用 C# 从端点发出 GET 请求
使用 C#,从 REST API 端点获取 JSON;如何从 REST API 接收 JSON 数据。 本文需要 ASP .NET Core,并兼容 .NET Core 3.1、.NET 6和.NET 8。 要将数据发布到端点,请参阅本文。 使用 . 从端点发布 GET 数据非常容易HttpClient&…...

Docker 部署 MinIO | 国内阿里镜像
一、导读 Minio 是个基于 Golang 编写的开源对象存储套件,基于Apache License v2.0开源协议,虽然轻量,却拥有着不错的性能。它兼容亚马逊S3云存储服务接口。可以很简单的和其他应用结合使用,例如 NodeJS、Redis、MySQL等。 二、…...

量化交易数据获取:xtquant库的高效应用
量化交易数据获取:xtquant库的高效应用 在量化交易领域,历史行情数据的重要性不言而喻。它不仅为策略回测提供基础,也是实时交易决策的重要参考。本文将介绍如何使用xtquant库来高效获取和处理历史行情数据。 技术背景与应用场景 对于量化…...

Mysql中存储引擎各种介绍以及应用场景、优缺点
概述 MySQL 提供了多种存储引擎,每种引擎有不同的特点和适用场景。以下是几种常见的 MySQL 存储引擎的详细介绍,包括它们的底层工作原理、优缺点,以及为什么 MySQL 默认选择某种引擎。 1. InnoDB 底层工作原理: 事务支持&#…...

面试题整理:Java虚拟机 JVM 内存区域、垃圾回收、类加载器
文章目录 JVM虚拟机内存区域1. ⭐JVM的内存区域有哪些?每个区域的作用是什么?2. 堆和栈的区别是什么?3. 堆内存是如何划分的?4. 永久代和元空间是什么关系?5. 对JVM常量池的理解?6. ⭐Java 对象的创建过程&…...

ASP.NET Core 使用 WebClient 从 URL 下载
本文使用 ASP .NET Core 3.1,但它在.NET 5、 .NET 6和.NET 8上也同样适用。如果使用较旧的.NET Framework,请参阅本文,不过,变化不大。 如果想要从 URL 下载任何数据类型,请参阅本文:HttpClient 使用WebC…...

第六届MathorCup高校数学建模挑战赛-A题:淡水养殖池塘水华发生及池水自净化研究
目录 摘要 1 问题的重述 2 问题的分析 2.1 问题一的分析 2.2 问题二的分析 2.3 问题三的分析 2.4 问题四的分析 2.5 问题五的分析 3. 问题的假设 4. 符号说明 5. 模型的建立与求解 5.1 问题一的建模与求解 5.1.1 分析对象与指标的选取 5.1.2 折线图分析 5.1.3 相关性分析 5.1.4…...

GnuTLS: 在 pull 函数中出错。 无法建立 SSL 连接。
提示信息 [root@localhost ~]# wget https://download.docker.com/linux/static/stable/x86_64/docker-27.5.1.tgz --2025-02-06 12:45:34-- https://download.docker.com/linux/static/stable/x86_64/docker-27.5.1.tgz 正在解析主机 download.docker.com (download.docker.…...
)
OpenAI 实战进阶教程 - 第十二节 : 多模态任务开发(文本、图像、音频)
适用读者与目标 适用读者:已经熟悉基础的 OpenAI API 调用方式,对文本生成或数据处理有一定经验的计算机从业人员。目标:在本节中,你将学会如何使用 OpenAI 提供的多模态接口(图像生成、语音转录等)开发更…...

《qt easy3d中添加孔洞填充》
《qt easy3d中添加孔洞填充》 效果展示一、创建流程二、核心代码效果展示 参考链接Easy3D开发——点云孔洞填充 一、创建流程 创建动作,并转到槽函数,并将动作放置菜单栏,可以参考前文 其中,槽函数on_actionHoleFill_triggered实现如下:...

windows蓝牙驱动开发-蓝牙常见问题解答
Windows 可以支持多少个蓝牙无线电? Windows 中的蓝牙堆栈仅支持一个蓝牙无线电。 此无线电必须符合蓝牙规范和最新的 Windows 硬件认证计划要求。 蓝牙和 Wi-Fi 无线电如何有效共存? 蓝牙和 Wi-Fi 无线电都在 2.4 GHz 频率范围内运行,因此…...

Ubuntu 下 nginx-1.24.0 源码分析 - ngx_ssl_version 函数
定义 event\ngx_event_openssl.h 中: #if (OPENSSL_VERSION_NUMBER > 0x10100001L)#define ngx_ssl_version() OpenSSL_version(OPENSSL_VERSION)#else#define ngx_ssl_version() SSLeay_version(SSLEAY_VERSION)#endif #if (OPENSSL_VERSION_NUMBER…...
)
提示工程:少样本提示(Few-shot Prompting)
少样本提示(Few-shot Prompting)是一种利用大语言模型从少量示例样本中学习并处理任务的方法。它的核心思想是利用大语言模型的上下文学习能力,通过在提示中增加“示例样本”来启发大语言模型达到举一反三的效果。这种方法避免了重新训练或者…...

从量化投资到AI大模型:DeepSeek创始人梁文锋的创新之路
一、学术的启蒙:学霸的崭露头角 梁文锋的成长故事始于1985年,他出生在广东省湛江市的一个普通家庭。从小,梁文锋就展现出对知识的强烈渴望和非凡的学习能力,尤其在数学领域,他总是能够轻松解决复杂的难题,成为学校里备受瞩目的“学霸”。 2002年,年仅17岁的梁文锋以吴川…...
基于lstm+gru+transformer的电池寿命预测健康状态预测-完整数据代码
项目视频讲解: 毕业设计:基于lstm+gru+transformer的电池寿命预测 健康状态预测_哔哩哔哩_bilibili 数据: 实验结果:...

物品匹配问题-25寒假牛客C
登录—专业IT笔试面试备考平台_牛客网 这道题看似是在考察位运算,实则考察的是n个物品,每个物品有ai个,最多能够得到多少个物品的配对.观察题目可以得到,只有100,111,010,001(第一位是ci,第二位是ai,第三位是bi)需要进行操作,其它都是已经满足条件的对,可以假设对其中两个不同…...