《DEADiff:一种具有解耦表示高效的风格化扩散模型》
paper:2403.06951
GitHub:bytedance/DEADiff: [CVPR 2024] Official implementation of "DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations"
目录
摘要
1、介绍
2、相关工作
2.1 扩散模型在文本到图像生成中的应用
2.2 使用T2I模型生成风格化图像
3、方法
3.1 初步概念
3.2 双重解耦表示提取
3.3 解耦条件机制(DCM)
3.4 配对数据集构建
3.5 训练与推理
4、实验
4.1 实验设置
4.2 与现有方法的比较
4.3 消融研究
4.4 应用
摘要
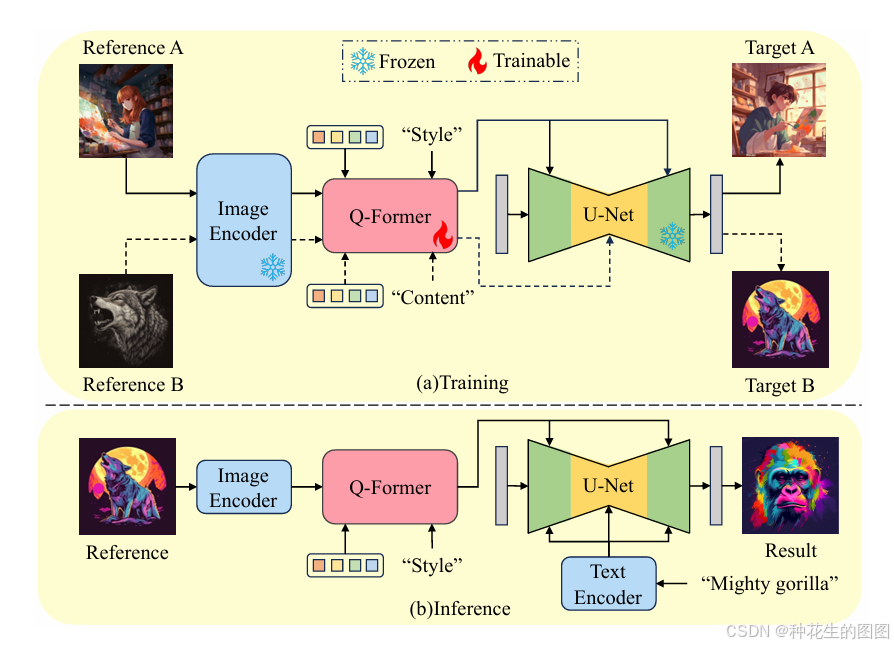
基于扩散的文本到图像模型在传递参考风格方面具有巨大的潜力。然而,当前基于编码器的方法在转换风格时显著削弱了文本到图像模型的文本可控性。本文提出了DEADiff来解决这个问题,采用了以下两种策略:
1)一种解耦参考图像风格与语义的机制。首先通过Q-Former提取解耦的特征表示,Q-Former根据不同的文本描述进行指导。然后,这些表示被注入到交叉注意力层的互斥子集,以实现更好的解耦。
2)一种非重建学习方法。Q-Former使用配对图像进行训练,而不是使用相同的目标,其中参考图像与真实图像具有相同的风格或语义。
我们展示了DEADiff在视觉风格化结果上取得了最佳表现,并在文本可控性和风格相似性之间达到了最佳平衡,既在定量上也在定性上都有显著的表现。
1、介绍
最近,基于扩散的文本到图像生成模型由于其惊人的表现,引发了广泛的研究。由于扩散模型普遍缺乏增强的可控性,因此如何稳定可靠地引导它们遵循由参考图像定义的预定风格成为一个难题。
考虑到效果和效率,风格迁移的普遍方法是基于额外编码器的方式。基于编码器的方法通常训练一个编码器,将参考图像编码为有用的特征,这些特征随后被注入到扩散模型中,作为其引导条件。值得注意的是,基于编码器的方法由于单次计算,通常比需要多次迭代学习的优化方法更高效。
通过这样的编码器,可以提取高度抽象的特征,有效地描述参考图像的风格。这些丰富的风格特征使扩散模型能够准确理解它需要合成的参考图像的风格,正如图1左侧所示,典型方法(如T2I-Adapter)能够生成自然且忠实的参考风格。

然而,这种方法也带来了一个特别棘手的问题:虽然它使得模型能够遵循参考图像的风格,但却显著削弱了模型理解文本条件语义的能力。
文本可控性的丧失主要来源于两个方面。一方面,编码器提取的是将风格与语义耦合的信息,而不是纯粹的风格特征。具体来说,之前的方法缺乏有效机制来区分图像风格和图像语义。因此,提取的图像特征不可避免地包含了风格和语义信息。这些图像语义与文本条件中的语义发生冲突,导致对基于文本的条件的控制能力减弱。
另一方面,之前的方法将编码器的学习过程视为重建任务,其中参考图像的 ground-truth 就是图像本身。与训练一个文本到图像模型遵循文本描述相比,从参考图像的重建学习通常更容易。因此,在重建任务下,模型倾向于关注参考图像,而忽视文本到图像模型中的原始文本条件。
针对上述问题,我们提出了DEADiff,以高效地将参考风格迁移到合成图像中,而不失去文本条件的可控性。DEADiff由两个部分组成。
首先,我们从特征提取和特征注入方面解耦参考图像中的风格和语义。对于特征提取,我们提出了一种双解耦表示提取机制(DDRE),利用 Q-Former 从参考图像中获取风格和语义表示。Q-Former通过‘风格’和‘内容’条件来指导选择性地提取与给定指令一致的特征。
对于特征注入,我们引入了一种解耦条件机制,将解耦的表示注入到交叉注意力层的互斥子集,以实现更好的解耦,这受到扩散U-Net中不同交叉注意力层对风格和语义表达不同响应的启发。
其次,我们提出了一种非重建训练范式,使用配对合成图像进行训练。具体而言,Q-Former通过‘风格’条件指导,使用具有与参考图像和真实图像相同风格的配对图像进行训练。与此同时,Q-Former通过‘内容’条件指导,使用具有相同语义但风格不同的图像进行训练。
通过风格和语义解耦机制及非重建训练目标,DEADiff够成功模仿参考图像的风格,并忠实于各种文本提示。如图1(b)所示,DEADiff与基于优化的方法相比,更高效,同时保持了出色的风格迁移能力。
与传统的基于编码器的方法相比,我们的方法能够有效地保留文本控制能力。此外,DEADiff消除了手动调整通常需要的微调参数(如特征融合权重),这是之前方法(例如T2I-Adapter)所要求的。
总之,我们的贡献有三点:
- 我们提出了一个双解耦表示提取机制,从参考图像中分别获取风格和语义表示,从学习任务的角度缓解了文本与参考图像语义冲突的问题。
- 我们引入了解耦条件机制,允许交叉注意力层的不同部分分别负责注入图像风格/语义表示,从模型结构的角度进一步减少语义冲突。
- 我们建立了两个配对数据集,以帮助DDRE机制使用非重建训练范式。
2、相关工作
2.1 扩散模型在文本到图像生成中的应用
近年来,扩散模型在图像生成中取得了巨大的成功。扩散概率模型(DPMs)[26] 被提出用于学习恢复通过前向扩散过程破坏的目标数据分布。自从初期的扩散图像生成工作[4, 8, 28]证明了其强大的生成能力以来,DPMs在图像合成领域引起了越来越多的关注。最新的扩散模型[21, 22, 25]通过大规模预训练在文本到图像生成中进一步实现了最先进的性能。这些方法使用U-Net[23]作为扩散模型,其中交叉注意力层用于注入从预训练编码器[19, 20]中提取的文本特征。尤其是潜在扩散模型(LDMs)[22],也被称为稳定扩散(SD)模型,通过预训练的自动编码器将扩散过程转移到低分辨率的潜在空间,从而实现高效的高分辨率文本到图像生成。考虑到扩散模型在文本到图像(T2I)生成中的巨大成功,许多最近的扩散方法[14, 34, 35]都专注于利用更多来自参考图像的条件。其中一个典型代表就是风格,这也是本文的主要关注点。
2.2 使用T2I模型生成风格化图像
基于预训练的深度卷积或基于Transformer的神经网络,风格化图像生成已经得到了广泛的研究[1–3, 6, 12, 18, 33],并且取得了显著的进展,推动了众多实际应用的实现。在大型文本到图像模型的强大功能的推动下,如何利用这些模型来生成具有更好质量和更高灵活性的风格化图像,是一个值得探索的激动人心的话题。基于文本逆转的方法[5, 37]将风格图像映射到文本令牌空间中的可学习嵌入。然而,由于从视觉到文本模态的映射存在信息丢失问题,这对学习到的嵌入在准确呈现参考图像的风格时提出了重大挑战。相比之下,DreamBooth [24] 和 Custom Diffusion [13] 通过优化扩散模型的所有或部分参数,能够合成出更好地捕捉参考图像风格的图像。然而,这种方法的代价是由于严重的过拟合导致文本提示的忠实度下降。目前,参数高效的微调提供了风格化图像生成的更有效方法,而不会影响扩散模型对文本提示的忠实度,如InST [37]、LoRA [9]和StyleDrop [27]。然而,尽管这些基于优化的方法能够定制风格,它们仍然需要几分钟到几个小时的时间来微调每个输入参考图像的模型。这些额外的计算和存储开销阻碍了这些方法在实际生产中的可行性。
因此,一些无优化的方法[10, 17, 32]被提出,通过设计的图像编码器从参考图像中提取风格特征。其中,T2I Adapter-Style [17]和IP-Adapter [34]使用Transformer [30]作为图像编码器,输入CLIP [19]图像嵌入,并通过U-Net交叉注意力层利用提取的图像特征。BLIP-Diffusion [14]构建了一个Q-Former [15],将图像嵌入转换为文本嵌入空间,并将其输入扩散模型的文本编码器。这些方法使用整体图像重建[17, 34]或对象重建[14]作为训练目标,从而导致从参考图像中提取内容和风格信息。为了使图像编码器专注于提取风格特征,StyleAdapter [32]和ControlNet-shuffle [35]通过洗牌参考图像的图像块或像素,从而能够生成具有目标风格的各种内容。
3、方法
3.1 初步概念
SD是一种潜在扩散模型(Latent Diffusion Model,LDM)[22],它在潜在空间内执行一系列渐进的去噪操作,并将去噪后的潜在编码重新映射回像素空间,从而生成最终的输出图像。在训练过程中,SD最初通过变分自编码器(Variational Auto-Encoder,VAE)[11]将输入图像 x 转换为潜在编码 z。在随后的阶段,时间步 t 上的有噪潜在 作为去噪 U-Net
的输入,U-Net通过交叉注意力与文本提示 c 进行交互。该过程的监督通过以下目标来确保:
其中, 代表从标准高斯分布中采样的随机噪声。
3.2 双重解耦表示提取
受到BLIP-Diffusion [14] 的启发,BLIP-Diffusion通过使用具有不同背景的合成图像对来学习主体表示,以避免出现平凡的解决方案,我们将两个辅助任务集成到一个非重构范式中,利用Q-Former作为表示过滤器嵌套在其中。这使我们能够隐式地辨别图像中风格和内容的解耦表示。
一方面,我们采样一对不同的图像,这两张图像保持相同的风格,但分别作为Stable Diffusion(SD)生成过程中的参考图像和目标图像,如图2(a)中的A对所示。参考图像被输入到CLIP图像编码器中,输出通过交叉注意力与Q-Former的可学习查询标记和输入文本进行交互。对于这一过程,我们选择将“style”作为输入文本,期望生成与文本对齐的图像特征作为输出。该输出封装了风格信息,然后与描述目标图像内容的标题结合,提供给去噪U-Net进行条件输入。此提示组合策略的动力是更好地将风格与内容标题解耦,允许Q-Former更专注于风格中心表示的提取。此学习任务定义为风格表示提取,简称STRE。
另一方面,我们引入了一个对应的、对称的内容表示提取任务,称为SERE。如图2(a)中的B对所示,我们选择两张共享相同主题但呈现不同风格的图像,分别作为参考图像和目标图像。重要的是,我们将Q-Former的输入文本替换为“content”一词,以提取与内容相关的表示。为了获取纯粹的内容表示,我们将Q-Former查询标记的输出与目标图像的文本风格词一起,作为去噪U-Net的条件输入。在这种方法中,Q-Former会筛选掉嵌套在CLIP图像嵌入中的与内容无关的信息,同时生成目标图像。
同时,我们将一个重构任务整合到整个管道中。这个学习任务的条件提示由“style”Q-Former和“content”Q-Former处理后的查询标记组成。通过这种方式,我们可以确保Q-Former不会忽视重要的图像信息,考虑到内容和风格之间的互补关系。
3.3 解耦条件机制(DCM)
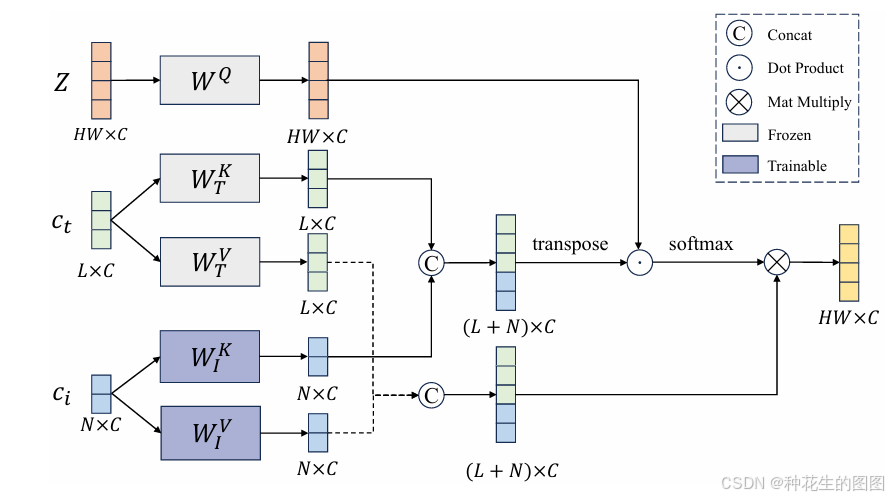
受到文献 [31] 中观察到的启发,去噪U-Net中的不同交叉注意力层主导了合成图像的不同属性,我们引入了一种创新的解耦条件机制(Disentangled Conditioning Mechanism,DCM)。本质上,DCM采用了一种策略,即用语义条件对低空间分辨率的粗层进行条件化,而用风格条件对高空间分辨率的细层进行条件化。如图2(a)所示,我们仅将Q-Former输出的带有“style”条件的查询注入细层,这些层响应的是局部区域特征,而不是全局语义特征。这种结构适应促使Q-Former在输入“style”条件时提取更多面向风格的特征,如图像的笔画、纹理和颜色,同时减弱其对全局语义的关注。因此,这一策略实现了风格和语义特征的更有效解耦。
同时,为了使去噪U-Net支持图像特征作为条件,我们设计了一个联合的文本-图像交叉注意力层,如图3所示。与IP-Adapter [34] 类似,我们包括了两个可训练的线性投影层 、
来处理图像特征
,同时保持文本特征
的冻结投影
、
。然而,我们没有分别独立地执行图像和文本特征的交叉注意力,而是将文本和图像特征的键和值矩阵连接起来,然后与U-Net的查询特征 Z进行一次交叉注意力操作。具体的公式可以表示为:
3.4 配对数据集构建
准备具有相同风格或主题的图像对,如第3.2节所述,是一项复杂的工作。幸运的是,现有的最先进的文本到图像模型已经展现出对给定文本提示的高度保真度。因此,我们手动创建了一个文本提示列表,通过结合主题词和风格词,并利用预训练模型构建两个配对图像数据集:一个是相同风格的样本,另一个是相同主题的样本。正式来说,配对数据集的构建包括以下三个步骤:
步骤1:文本提示组合
我们列出了近12,000个主题词,涵盖四个主要类别:人物、动物、物体和场景。此外,我们列出了近700个风格词,包括艺术风格、艺术家、笔触、阴影、镜头、分辨率和视觉角度等属性。然后,每个主题词平均分配约14个风格词,并将组合形成最终的文本提示,用于文本到图像模型。
步骤2:图像生成与收集
将文本提示与主题词和风格词结合后,我们获得了超过16万个提示。随后,所有文本提示被送到Midjourney,一个领先的文本到图像生成产品,用于合成相应的图像。根据Midjourney的特点,给定的提示会直接输出4张分辨率为512×512的图像。我们将每张图像上采样到1024×1024,并存储它与给定的提示。由于数据收集的冗余性,我们最终收集了总计106万对图像-文本对。
步骤3:配对图像选择
我们观察到,即使是相同的风格词,使用不同的主题词生成的图像也会存在显著差异。鉴于此,对于风格表示学习任务,我们使用两张通过相同提示合成的图像,这两张图像分别作为参考图像和目标图像,如图2(a)所示。为了实现这一目标,我们将相同提示的图像作为单个项目进行存储,并在每次迭代时随机选择两张图像。对于内容表示学习任务(如图2(b)所示),我们将具有相同主题词但不同风格词的图像配对为一个项目。最终,我们为前者任务得到了一个包含超过16万条数据的数据集,为后者任务得到了一个包含106万条数据的数据集。
3.5 训练与推理
我们采用公式(1)中所示的损失函数来监督上述三个学习任务。在训练过程中,仅优化Q-Former和新增加的线性投影层。推理过程如图2(b)所示。
4、实验
4.1 实验设置
实现细节
我们采用 Stable Diffusion v1.5 作为基础的文本到图像模型,该模型包含总共16个交叉注意力层。我们按照输入到输出的顺序将这些层编号为0到15,并将第4到第8层定义为粗层(coarse layers),用于注入图像内容表示。因此,其他层被定义为细层(fine layers),用于注入图像风格表示。我们使用 CLIP [19] 中的 ViT-L/14 作为图像编码器,并保持 Q-Former 的可学习查询令牌数量与 BLIP-Diffusion 中的一致,即16个。我们采用两个 Q-Former,分别提取语义和风格表示,以鼓励它们专注于各自的任务。为了加速收敛,我们将 Q-Former 的初始化设为使用 HuggingFace 上提供的 BLIP-Diffusion 预训练模型 [14]。至于额外的投影层 、
,我们将其初始化为
、
的参数。在训练过程中,我们将三项学习任务的采样比例设置为1:1:1,如第3.2节所述,目的是让风格 Q-Former 和内容 Q-Former 得到均衡训练。我们固定图像编码器、文本编码器和原始 U-Net [23] 的参数,仅更新 Q-Former、16个可学习查询和额外的投影层
、
的参数。模型使用16个 A100-80G GPU 训练,批量大小为512。我们采用 AdamW [16] 作为优化器,学习率为
,并训练100000次迭代。对于推理过程,我们使用DDIM [28] 采样器,步数为50,分类无关引导 [7] 的引导比例为8。
数据集
我们使用第3.4节中介绍的自构建数据集来训练我们的模型。初始数据集包含106万对图像-文本对,用于重建任务。风格表示学习任务使用16万个相同风格的图像对进行训练,而语义表示学习任务则使用106万对具有相同语义的图像对进行训练。为了评估 DEADiff 的有效性,我们构建了一个评估集,包括从 WikiArt 数据集 [29] 和 Civitai 平台收集的32张风格图像。我们排除了在 StyleAdapter [32] 中发布的冗余主题的文本提示,最终从原始的52个文本提示中筛选出35个。我们遵循 StyleAdapter 的做法,使用 Stable Diffusion v1.5 生成与这些35个文本提示相对应的内容图像,从而与风格迁移方法(如 CAST [36] 和 StyleTR2 [3])进行比较。
评估指标
由于缺乏精确且合适的风格相似性(SS)度量,我们提出了一种更合理的方法,如第6.1节中所述。此外,我们还确定了在 CLIP 文本-图像嵌入空间中,文本提示与其相应生成图像之间的余弦相似度,作为文本对齐能力(TA)的指标。我们还报告了每种方法的图像质量(IQ)结果。最后,为了消除随机性对目标指标计算的干扰,我们进行了用户研究,以反映对结果的主观偏好(SP)。
4.2 与现有方法的比较
在本节中,我们将我们的方法与当前的最先进方法进行比较,包括无需优化的方法,如 CAST [36]、StyleTr2 [3]、T2I-Adapter [17]、IP Adapter [34] 和 StyleAdapter [32],以及基于优化的方法,如 InST [37]。需要注意的是,由于 StyleAdapter 没有开源,我们直接使用其发布论文中的结果进行展示。
定性比较
图4展示了与现有方法的比较结果。从该图中,我们可以观察到几条值得注意的结论。首先,基于内容图像的风格迁移方法,如 CAST [36] 和 StyleTr2 [3],由于没有使用扩散模型,避免了文本控制的减弱问题。然而,这些方法只是简单地执行颜色转移,而没有更多地借用参考图像中的独特特征,如笔触和纹理,导致每个合成结果中都有明显的伪影。因此,当这些方法遇到具有复杂风格参考和较大内容图像结构复杂性的场景时,它们的风格迁移能力显著下降。其次,对于使用扩散模型进行训练的重建目标方法,无论是基于优化的(如 InST [37])还是无需优化的(如 T2I-Adapter [17]),它们通常在生成结果中会受到风格图像的语义干扰,如图4中的第一行和第四行所示。这与我们之前对语义冲突问题的分析一致。第三,尽管后续改进的工作 StyleAdapter [32] 有效解决了语义冲突问题,但它学习到的风格仍不理想。它丧失了参考图像中的细节笔触和纹理,而且颜色也有明显的差异。最后,IP Adapter [34] 通过为每个参考图像精细调节权重能够获得不错的结果,但其生成的输出要么引入了参考图像的部分语义,要么遭遇了风格退化。相反,我们的方法不仅更好地遵循了文本提示,而且显著保留了参考图像的整体风格和细节纹理,颜色色调的差异非常小。

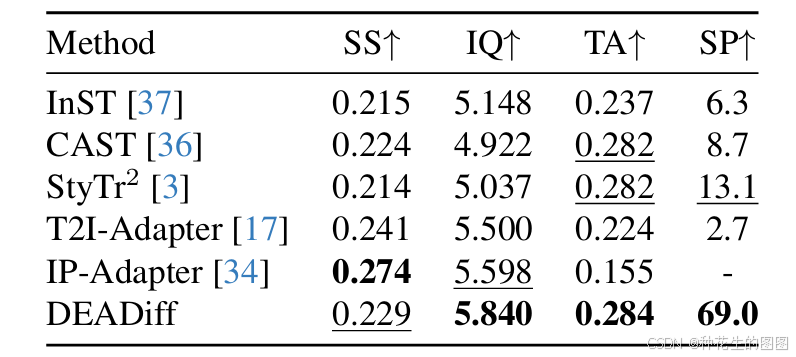
定量比较
表1展示了我们的方法与现有最先进方法在我们构建的评估集上的风格相似性、图像质量、文本对齐度以及总体主观偏好的比较结果。我们从表中得出以下结论。首先,除了 T2I-Adapter [17] 和 IP-Adapter [34](由于缺乏精细的权重调节,其生成的结果通常是参考图像的重新组织,文本对齐度得分较低)外,我们在风格相似性上取得了最高的成绩,证明我们的方法确实有效地捕捉到了参考图像的整体风格。其次,我们的方法在文本对齐度上与两个基于 SD 的方法 CAST [36] 和 StyleTr2 [3] 相当。这表明我们的方法在学习参考图像风格的同时,并没有妥协 SD 的原始文本控制能力。第三,我们的方法在图像质量指标上相较于所有其他方法具有显著的优势,这进一步证明了我们方法的实用性。此外,如表1右侧最后一列所示,用户对我们方法的偏好明显高于其他所有方法。总的来说,DEADiff 在文本忠实性和图像相似性之间取得了最佳的平衡,并且具有最令人愉悦的图像质量。
与 StyleDrop [27] 的比较
另外,图5展示了我们的方法与 StyleDrop 之间的视觉比较。总体来说,尽管 DEADiff 在颜色准确度方面略逊于基于优化的 StyleDrop,但在艺术风格和对文本的忠实度方面,它达到了相当或甚至更好的效果。DEADiff 生成的船舱、帽子和机器人更加贴切,并且没有遭遇参考图像中固有的语义干扰。这证明了将语义从参考图像中解耦的关键作用。

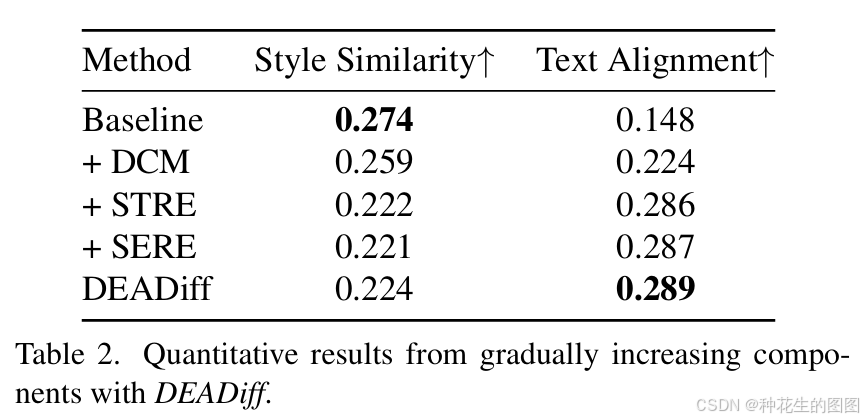
4.3 消融研究
为了理解 DEADiff 中每个组件的作用,我们进行了系列的消融实验。表2展示了在所有配置下的定量结果,而图6列出了代表性的视觉结果。需要注意的是,基准配置是指将 Q-Former 提取的图像特征注入到 U-Net [23] 的所有交叉注意力层中,并且使用重建训练范式进行训练。每个配置在训练 50,000 次迭代后,都会在评估集上进行评估。

解耦条件机制 (DCM)
结合表2的前两行和图6的第二、三列,可以明显看出,重建训练范式不可避免地会引入参考图像的语义,掩盖文本提示的控制能力。尽管 DCM 通过利用 U-Net 在不同层次上响应条件的特点来增强控制能力,如视觉结果和更高的文本对齐度所示,但图像特征中的语义成分仍然与文本语义发生冲突。
双重解耦表示提取 (Dual Decoupling Representation Extraction)
参考表2的后三行和图6的最右三列,我们观察到与前述的 DCM 相比,文本可编辑性有了显著增强,并且进一步得到了提升。具体而言,STRE(表2的第三行)引入了非重建训练范式,使得 Q-Former 提取的特征能够更多地关注参考图像的风格信息,从而减少了其中包含的语义成分。因此,参考图像的内容立即从生成的结果中消失,如图6第四列所示。此外,尽管引入 SERE(表2的倒数第二行)对结果的影响似乎有限,但将其与 STRE(表2的最后一行)结合用于重建原始图像,确保了提取的两个表示是解耦的,相互补充且没有遗漏。如图6最后一列所示,文本控制能力得到了完美体现,同时完美复制了参考图像的风格,展现了完整的 DEADiff。
4.4 应用
与 ControlNet [35] 的结合
DEADiff 支持所有 SD v1.5 原生的 ControlNet 类型。以深度 ControlNet 为例,图7展示了在保持布局的同时,风格化的出色效果。DEADiff 拥有广泛的应用场景。在本节中,我们列举了其几个典型的应用。
参考语义的风格化
由于 DEADiff 可以提取参考图像的语义表示,它可以通过文本提示对参考图像中的语义对象进行风格化。如图8所示,风格化效果明显优于 IP-Adapter [34]。

风格混合
DEADiff 能够将多个参考图像的风格进行混合。图9展示了在两张参考图像的不同控制下,其逐步变化的效果。

基础 T2I 模型的切换
由于 DEADiff 不对基础 T2I 模型进行优化,它可以直接在不同的基础模型之间切换,从而生成不同的风格化结果,如图10所示。

相关文章:

《DEADiff:一种具有解耦表示高效的风格化扩散模型》
paper:2403.06951 GitHub:bytedance/DEADiff: [CVPR 2024] Official implementation of "DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations" 目录 摘要 1、介绍 2、相关工作 2.1 扩散模型在文本到…...

webpack系统学习
webpack4和webpack5区别1---loader_webpack4与webpack5处理图片的不同-CSDN博客 webpack4和webpack5区别2---代码压缩_webpack4如何使用terser-CSDN博客 webpack4和webpack5区别3---缓存_cacheprune-CSDN博客 webpack4和webpack5区别4---自动清除打包目录_webpack4打包目录清…...

C++11新特性之unique_ptr智能指针
本节继续介绍智能指针,不了解的读者可以先阅读——C11新特性之shared_ptr智能指针-CSDN博客 1.介绍 unique_ptr是C11标准提供的另一种智能指针。与shared_ptr不同的是,unique_ptr指针指向的堆内存无法同其他unique_ptr共享,也就是每一片堆内…...

如何使用python制作一个天气预报系统
制作一个天气预报系统可以通过调用天气 API 来获取实时天气数据,并使用 Python 处理和展示这些数据。以下是一个完整的指南,包括代码实现和注意事项。 1. 选择天气 API 首先,需要选择一个提供天气数据的 API。常见的天气 API 有: OpenWeatherMap API:提供全球范围内的天…...

保姆级教程Docker部署Zookeeper模式的Kafka镜像
目录 一、安装Docker及可视化工具 二、Docker部署Zookeeper 三、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 5、验证生产消费 四、部署可视化工具 1、创建挂载目录 2、Compose运行Kafka-eagle容器 3、查看Kafka-e…...

在阿里云ECS上一键部署DeepSeek-R1
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式。据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理能力,该模型性能对标 OpenAl o1 正式版。DeepSeek-R1 推出…...

P3413 SAC#1 - 萌数
题目背景 本题由世界上最蒟蒻的 SOL 提供。 寂月城网站是完美信息教室的官网。地址:http://191.101.11.174/mgzd。 题目描述 蒟蒻 SOL 居然觉得数很萌! 好在在他眼里,并不是所有数都是萌的。只有满足“存在长度至少为 22 的回文子串”的数是萌的——也就是说,101 是萌…...

DeepSeek-R1系列01——技术报告解读:DeepSeek-R1:通过强化学习激励 LLM 中的推理能力
1.阅读目标 DeepSeek-R1 发布,性能对标 OpenAI o1 正式版 DeepSeek-R1已经发布,并同步开源模型权重。 DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 DeepSeek-R1 上线API,对用户开放思维链输出&a…...
每日小游戏平台系列)
(1/100)每日小游戏平台系列
每日小游戏平台 项目简介以及地址 准备开发一个一百天小游戏平台,使用Flask构建的简单游戏导航网站,无需登录,让大家在返工的同时也可以愉快的摸鱼玩耍。 每天更新一个小游戏上传,看看能不能坚持一百天。 这些小游戏主要使用前端…...

前端布局与交互实现技巧
前端布局与交互实现技巧 1. 保持盒子在中间位置 在网页设计中,经常需要将某个元素居中显示。以下是一种常见的实现方式: HTML 结构 <!doctype html> <html lang"en"> <head><meta charset"UTF-8"><m…...

spark单机版本搭建
spark单机版本搭建 服务器配置 CPU内存磁盘操作系统内核版本2c2g40GCentOS 73.10.0 1.JDK 下载安装 # 列出版本 yum -y list java* # 安装 yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel # 检查 java -version2.spark下载 spark下载地址 本文下载&#x…...

【C++八股】std::atomic —— 原子操作
std::atomic 是 C11 引入的模板类,主要用于多线程编程中的原子操作,确保在多个线程访问或修改共享变量时不会产生数据竞争。 1. std::atomic 的作用 在多线程环境下,普通变量的操作不是原子的,可能被多个线程同时访问和修改&…...

GPU、CUDA 和 cuDNN 学习研究【笔记】
分享自己在入门显存优化时看过的一些关于 GPU 和 CUDA 和 cuDNN 的网络资料。 更多内容见: Ubuntu 22.04 LTS 安装 PyTorch CUDA 深度学习环境-CSDN博客CUDA 计算平台 & CUDA 兼容性【笔记】-CSDN博客 文章目录 GPUCUDACUDA Toolkit都包含什么?NVID…...

AI-学习路线图-PyTorch-我是土堆
1 需求 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili PyTorch 深度学习快速入门教程 配套资源 链接 视频教程 https://www.bilibili.com/video/BV1hE411t7RN/ 文字教程 https://blog.csdn.net/xiaotudui…...

Android Camera API 介绍
一 StreamConfigurationMap 1. StreamConfigurationMap 的作用 StreamConfigurationMap 是 Android Camera2 API 中的一个核心类,用于描述相机设备支持的输出流配置,包含以下信息: 支持的格式与分辨率:例如 YUV_420_888、JPEG、…...

活动预告 |【Part 1】Microsoft 安全在线技术公开课:通过扩展检测和响应抵御威胁
课程介绍 通过 Microsoft Learn 免费参加 Microsoft 安全在线技术公开课,掌握创造新机遇所需的技能,加快对 Microsoft Cloud 技术的了解。参加我们举办的“通过扩展检测和响应抵御威胁”技术公开课活动,了解如何更好地在 Microsoft 365 Defen…...

RabbitMQ 消息顺序性保证
方式一:Consumer设置exclusive 注意条件 作用于basic.consume不支持quorum queue 当同时有A、B两个消费者调用basic.consume方法消费,并将exclusive设置为true时,第二个消费者会抛出异常: com.rabbitmq.client.AlreadyClosedEx…...

web第二次作业
一.后台管理系统首页代码 1.html代码 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>实验&l…...
 安装)
AI 编程开发插件codeium Windsurf(vscode、editor) 安装
1、vscode中安装: 2、vscode中使用 3、输入注册的账号密码,就可以使用。 4、或者直接下载editor 5、安装editor 下一步,下一步,直到安装成功,中间可以改下安装位置,如果C盘空间不够。 同样提示注册或者登录…...

变压器-000000
最近一个项目是木田12V的充电器,要设计变压器,输出是12V,电压大于1.5A12.6*1.518.9W. 也就是可以将变压器当成初级输入的一个负载。输入端18.9W. 那么功率UI 。因为变压器的输入是线性上升的,所以电压为二份之一,也就是1/2*功率…...

C# OpenCvSharp 部署MOWA:多合一图像扭曲模型
目录 说明 效果 项目 代码 下载 参考 C# OpenCvSharp 部署MOWA:多合一图像扭曲模型 说明 算法模型的paper名称是《MOWA: Multiple-in-One Image Warping Model》 ariv链接 https://arxiv.org/pdf/2404.10716 效果 Stitched Image 翻译成中文意思是&…...
)
Ai无限免费生成高质量ppt教程(deepseek+kimi)
第一步:打开deepseek官网(DeepSeek) 1.如果deepseek官网网络繁忙,解决方案如下: (1)使用easychat官网(EasyChat)使用deepseek模型,如图所示: (2)本地部署&…...

LLMs之DeepSeek r1:Logic-RL的简介、安装和使用方法、案例应用之详细攻略
LLMs之DeepSeek r1:Logic-RL的简介、安装和使用方法、案例应用之详细攻略 目录 Logic-RL的简介 1、Logic-RL的特点 2、性能 Logic-RL 的安装和使用方法 1、安装 2、使用方法 数据准备 基础模型 指令模型 训练执行 实现细节 Logic-RL的案例应用 Logic-RL…...

解决跨域问题
相信大多数的伙伴在第一次通过vue spring 做项目的时候都会遇到这个问题 什么是同源策略和跨域问题 同源策略指的就是,浏览器出于安全考虑,实施的一种策略,即只允许来自同一源(即协议域名端口都相同)的请求访问资源. 否则就会导致跨域问题 例如: http://xxx.com -> http…...
IEEE802标准)
网络工程师 (28)IEEE802标准
前言 IEEE 802标准是由电气和电子工程师协会(IEEE)制定的一组局域网(LAN)和城域网(MAN)标准,定义了网络中的物理层和数据链路层。 一、起源与背景 IEEE 802又称为LMSC(LAN/MAN Stand…...

Playwright 与 Selenium 的关系
Playwright 与 Selenium 的关系 Playwright 和 Selenium 都是流行的浏览器自动化测试工具,它们都可以用于 Web 应用的端到端测试,但它们在设计理念、架构和功能上存在一些差异。 以下是两者的主要关系对比: 特性PlaywrightSelenium开发语言JavaScript (Node.js)多种语言 (…...
)
保研考研机试攻略:python笔记(4)
🐨🐨🐨15各类查找 🐼🐼二分法 在我们写程序之前,我们要定义好边界,主要是考虑区间边界的闭开问题。 🐶1、左闭右闭 # 左闭右闭 def search(li, target): h = len(li) - 1l = 0#因为都是闭区间,h和l都可以取到并且相等while h >= l:mid = l + (h - l) // 2…...
)
Matplotlib基础01( 基本绘图函数/多图布局/图形嵌套/绘图属性)
Matplotlib基础 Matplotlib是一个用于绘制静态、动态和交互式图表的Python库,广泛应用于数据可视化领域。它是Python中最常用的绘图库之一,提供了多种功能,可以生成高质量的图表。 Matplotlib是数据分析、机器学习等领域数据可视化的重要工…...
Spring Boot: 使用 @Transactional 和 TransactionSynchronization 在事务提交后发送消息到 MQ
Spring Boot: 使用 Transactional 和 TransactionSynchronization 在事务提交后发送消息到 MQ 在微服务架构中,确保消息的可靠性和一致性非常重要,尤其是在涉及到分布式事务的场景中。本文将演示如何使用 Spring Boot 的事务机制和 TransactionSynchron…...

解析3DMAX转OBJ
3ds Max 是一款功能强大的三维建模、动画和渲染软件,而 OBJ 是一种常用的三维模型文件格式,以下是关于 3ds Max 转 OBJ 的相关解析: 3ds Max 转 OBJ 的原因 兼容性需求: OBJ 格式被众多三维软件和渲染器所支持,将 3…...

html为<td>添加标注文本
样式说明: /*为td添加相对定位点*/ .td_text {position: relative; }/*为p添加绝对坐标(相对于父元素中的定位点)*/ .td_text p {position: absolute;top: 80%;font-size: 8px; }参考资料:...

AI驱动的智能流程自动化是什么
在当今快速发展的数字化时代,企业正在寻找更高效、更智能的方式来管理日常运营和复杂任务。其中,“AI驱动的智能流程自动化”(Intelligent Process Automation, IPA)成为了一个热门趋势。通过结合人工智能(AIÿ…...

vue动态table 动态表头数据+动态列表数据
效果图: <template><div style"padding: 20px"><el-scrollbar><div class"scrollbar-flex-content"><div class"opt-search"><div style"width: 100px"> </div><div class"opt-b…...

ubuntu下迁移docker文件夹
在 Ubuntu 系统中迁移 Docker 文件夹(如 Docker 数据存储文件夹 /var/lib/docker)到另一个磁盘或目录,通常是为了释放系统盘空间。以下是迁移过程的详细步骤: 1. 停止 Docker 服务 在进行迁移之前,必须停止 Docker 服…...
——SpringBoot整合Neo4j)
Neo4j图数据库学习(二)——SpringBoot整合Neo4j
一. 前言 本文介绍如何通过SpringBoot整合Neo4j的方式,对图数据库进行简单的操作。 Neo4j和SpringBoot的知识不再赘述。关于Neo4j的基础知识,有兴趣可以看看作者上一篇的文章:Neo4j图数据库学习(一)——初识CQL 二. 前置准备 新建SpringBo…...

离散型变量的 PSI-群体稳定性指标计算
文章目录 PSI-群体稳定性指标(离散型)单个指标计算所有指标计算 PSI-群体稳定性指标(离散型) 单个指标计算 代码 import pandas as pddf pd.read_csv(/Users/mengzhichao/Desktop/文件/图表/小微企业用电量数据.csv)X_train df.sample(n7000) X_test df.sample(n3000)计算单…...

docker grafana安装
mkdir /root/grafana-storage chmod 777 -R /root/grafana-storage docker run -d -p 3000:3000 --namedocker-apisix-grafana-1 --network docker-apisix_apisix -v /root/grafana-storage:/var/lib/grafana grafana/grafana:9.1.0 浏览器访问: http://192.…...

NetCore Consul动态伸缩+Ocelot 网关 缓存 自定义缓存 + 限流、熔断、超时 等服务治理 + ids4鉴权
网关 OcelotGeteway 网关 Ocelot配置文件 {//单地址多实例负载均衡Consul 实现动态伸缩"Routes": [{// 上游 》》 接受的请求//上游请求方法,可以设置特定的 HTTP 方法列表或设置空列表以允许其中任何方法"UpstreamHttpMethod": [ "Get", &quo…...

【进度条实现】Python中tqdm使用示例
tqdm 是 Python 中一个非常流行的进度条库,可以快速为循环或长时间运行的任务添加进度提示。以下是 tqdm 的常见用法和示例: 1. 安装 pip install tqdm2. 基本用法 在循环中使用 最简单的用法是用 tqdm 包装一个可迭代对象(如列表、range …...

Chirpy3D:用于创意 3D 鸟类生成的连续部分潜在特征
Chirpy3D框架可以将细粒度的2D图像理解提升至3D生成的全新境界。当前的3D生成方法往往只关注于重构简单的对象,缺乏细致的特征和创造性。Chirpy3D通过结合多视角扩散模型和连续的部件潜在空间,能够生成全新且合理的3D鸟类模型。该系统不仅能够保持细致的…...

李飞飞团队 S1 与 DeepSeek R1 技术对比
李飞飞团队 S1 与 DeepSeek R1 技术对比 李飞飞团队的 S1 模型和 DeepSeek R1 模型都是在 AI 推理领域具有重要影响力的模型,它们在技术原理、性能表现和训练成本等方面存在一些差异。 技术原理 S1 模型:S1 模型采用了监督微调(SFT…...

LeetCode 3444.使数组包含目标值倍数的最小增量
给你两个数组 nums 和 target 。 在一次操作中,你可以将 nums 中的任意一个元素递增 1 。 返回要使 target 中的每个元素在 nums 中 至少 存在一个倍数所需的 最少操作次数 。 示例 1: 输入:nums [1,2,3], target [4] 输出:…...

Node.js 中模块化
随着软件开发项目的规模和复杂性的增加,如何有效地组织代码、提高可维护性和促进团队协作成为了一个重要的课题。Node.js 提供了强大的模块系统,使得开发者能够将代码分割成独立的、可重用的模块,从而简化大型应用的开发过程。本文将详细介绍…...

jdk8新特性
目录 1 lambda表达式 1.1 类型推断 1.2 局部变量限制 2 函数式接口 2.1 Predicate 函数式接口 2.2 Supplier函数式接口 2.3 Consumer函数式接口 2.4 Function函数式接口 2.5 Runnable函数式接口 3 方法引用和构造器引用 3.1 对象方法引用 3.2 静态方法引用 3.3 构造方法引用 4 …...

ZooKeeper 和 Dubbo 的关系:技术体系与实际应用
引言 在现代微服务架构中,服务治理和协调是至关重要的环节。ZooKeeper 和 Dubbo 是两个在分布式系统中常用的技术工具,它们之间有着紧密的联系。本文将详细探讨 ZooKeeper 和 Dubbo 的关系,从基础概念、技术架构、具体实现到实际应用场景&am…...
)
ESP32-S3模组上跑通esp32-camera(43)
接前一篇文章:ESP32-S3模组上跑通esp32-camera(42) 一、OV5640初始化 2. 相机初始化及图像传感器配置 上一回继续对reset函数的后一段代码进行解析。为了便于理解和回顾,再次贴出reset函数源码,在components\esp32-camera\sensors\ov5640.c中,如下: static int reset…...

解决bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException
解决Spring Boot中MySQL数据库报错“Bad SQL Grammar”的问题 目录 解决Spring Boot中MySQL数据库报错“Bad SQL Grammar”的问题 问题描述解决步骤解决方案结论附:MySql常用配置参数及使用场景 在使用Spring Boot连接MySQL数据库时,有时候会遇到“B…...

NCV4275CDT50RKG 车规级LDO线性电压调节器芯片——专为新能源汽车设计的高可靠性电源解决方案
产品概述: NCV4275CDT50RKG 是一款符合 AEC-Q100 车规认证的高性能LDO(低压差线性稳压器),专为新能源汽车的严苛工作环境设计。该芯片支持 输出调节为 5.0 V 或 3.3 V,最大输出电流达 450mA,具备超低静态电流…...

DeepSeek Window本地私有化部署
前言 最近大火的国产AI大模型Deepseek大家应该都不陌生。除了在手机上安装APP或通过官网在线体验,其实我们完全可以在Windows电脑上进行本地部署,从而带来更加便捷的使用体验。 之前也提到过,本地部署AI模型有很多好处,比如&…...

镜头放大倍率和像素之间的关系
相互独立的特性 镜头放大倍率:主要取决于镜头的光学设计和结构,决定了镜头对物体成像时的缩放程度,与镜头的焦距等因素密切相关。比如,微距镜头具有较高的放大倍率,能将微小物体如昆虫、花朵细节等放大成像࿰…...