Med-R2:基于循证医学的检索推理框架:提升大语言模型医疗问答能力的新方法
Med-R2 : Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
- Med-R2框架
- Why - 这个研究要解决什么现实问题
- What - 核心发现或论点是什么
- How - 1. 前人研究的局限性
- How - 2. 你的创新方法/视角
- How - 3. 关键数据支持
- How - 4. 可能的反驳及应对
- How good - 研究的理论贡献和实践意义
- 作者设计思路
- 1. 确认最终目标
- 2. 层层分解问题
- 3. 实现步骤
- 对比 RAG算法 与 Med-R2框架
- 1. 背景和目标
- 2. 知识获取和处理
- 3. 查询处理
- 4. 检索精度与效率
- 5. 生成与答案提取
- 6. 效果评估
- 7. 计算成本与训练效率
- 8. 应用场景
- 总结:
- 数据分析
- 第一步:收集所需数据
- 第二步:处理与挖掘数据
- 第三步:探索数据维度相关性
- 第四步:建立数学模型
- 结论
- 解法拆解
- 1. 逻辑关系拆解
- 2. 逻辑链分析
- 3. 隐性方法分析
- 4. 隐性特征分析
- 5. 潜在局限性
- 全流程
- 1. 整体架构(从左到右)
- 2. 各模块详细功能
- 输入层
- 查询优化模块
- 证据处理模块
- 推理应用模块
- 输出层
- 3. 关键信息流
- 4. 重点节点(粗线标注)
- 1. 双重分类
- 2. 双路检索
- 3. 两级评估
- 4. 查询重构
- 5. 循环优化
- 证据等级
- 1. 最高等级证据 [Level 1]
- 2. 随机对照试验(RCTs) [Level 2]
- 3. 队列研究 [Level 3]
- 4. 病例对照研究 [Level 4]
- 5. 横断面研究 [Level 5]
- 6. 病例系列/报道 [Level 6-7]
- 7. 专家意见 [Level 8-9]
- 6. 评分重要特性
论文:Med-R2 : Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
代码:https://github.com/8023looker/Med-RR
Med-R2框架
├── Med-R2框架的研究与应用【研究主题】
│ ├── 背景与挑战【问题阐述】
│ │ ├── 医学大语言模型的潜力【背景介绍】
│ │ │ ├── 临床决策支持【应用场景】
│ │ │ ├── 医学研究【应用场景】
│ │ │ └── 医疗问答系统【应用场景】
│ │ └── 现有方法的局限性【问题描述】
│ │ ├── C1:知识获取低效【具体挑战】
│ │ │ ├── 高计算成本【表现】
│ │ │ └── 数据更新滞后【表现】
│ │ ├── C2:医学检索精度差【具体挑战】
│ │ │ └── 专业性不足【表现】
│ │ └── C3:答案提取低效【具体挑战】
│ │ └── 证据评估不足【表现】
│ │
│ ├── Med-R2框架的创新与解决方案【解决方案】
│ │ ├── 循证医学(EBM)理念【框架基础】
│ │ │ ├── 问题构建【模块功能】
│ │ │ │ ├── 查询分类器【组件】
│ │ │ │ └── 查询重构器【组件】
│ │ │ ├── 证据检索与评估【模块功能】
│ │ │ │ ├── 证据检索器【组件】
│ │ │ │ └── 证据重排序【组件】
│ │ │ └── 证据应用【模块功能】
│ │ │ └── CoT生成器【组件】
│ │ ├── 专业化查询重构与证据排序【创新方法】
│ │ │ ├── 针对医学问题的查询重构【方法】
│ │ │ └── 精细化证据评估与排序【方法】
│ │ └── 证据驱动的推理过程【创新方法】
│ │ └── CoT生成与推理【方法】
│ │
│ ├── 实验结果与验证【评估结果】
│ │ ├── 性能提升【效果】
│ │ │ ├── 相比传统RAG提升14.87%【数据】
│ │ │ └── 相比微调方法提升3.59%【数据】
│ │ └── 规模分析【效果】
│ │ ├── 上下文窗口的影响【分析维度】
│ │ └── 模型参数规模的影响【分析维度】
│ │
│ └── 反思与局限性【反思与应对】
│ ├── 计算资源消耗【局限性】
│ ├── 数据覆盖面有限【局限性】
│ └── 对小规模模型的适应性差【局限性】Why - 这个研究要解决什么现实问题
该研究要解决的现实问题是如何提升大语言模型(LLM)在医学领域应用的效果,特别是在临床决策和医疗问题解答中。现有的LLM方法面临三个主要挑战:
- 知识获取低效:传统LLM依赖预训练数据,且随着时间的推移,这些数据可能已经过时,导致模型无法有效应对医学领域中的快速变化。
- 医学领域检索精度差:现有的检索增强生成(RAG)系统在医学领域的应用中,检索精度常常不足,影响生成答案的准确性和可靠性。
- 答案提取低效:现有方法未能充分考虑医学问题的复杂性,导致生成的答案缺乏专业性和应用价值,难以为医生和患者提供切实的帮助。
What - 核心发现或论点是什么
本文的核心发现是,Med-R2框架通过结合**循证医学(EBM)原则和检索增强生成(RAG)**策略,能够显著提升LLM在医学问题解答中的性能,尤其是在:
- 提高医学领域的检索精度,通过针对医学问题的查询重组和证据排序策略,获得更相关的医学信息。
- 增强答案生成的专业性和可信度,通过将医学证据整合进生成模型的推理过程中,确保模型输出符合循证医学的标准。
How - 1. 前人研究的局限性
前人研究的局限性包括:
- 知识更新滞后:传统的LLM方法依赖预训练的医学数据集,无法适应医学领域的快速发展和最新研究成果,导致模型回答可能已经过时。
- 医学检索精度不足:RAG虽然结合了检索机制,但医学领域的知识具有高度的专业性,传统RAG在医学领域应用时,未能针对医学查询进行足够的精细调整,导致检索结果不够精准,影响答案质量。
- 缺乏循证医学框架的应用:医学问题不仅需要准确的信息,还需要进行合理的推理和判断,传统方法在医学问题的推理和证据评估中存在不足,缺少与医学决策制定相符合的严格框架。
How - 2. 你的创新方法/视角
本文提出的创新方法是Med-R2框架,其主要创新点包括:
- 结合循证医学原则:Med-R2框架遵循循证医学(EBM)的五个步骤(问题制定、证据检索、证据评估、证据应用和效果评估),专门为医学领域定制了查询分类和证据评估策略。
- 查询重组与证据排序:针对医学问题的特点,Med-R2采用了细粒度的查询重组和证据排序机制,使得检索到的医学文献和数据更加相关且精准。
- 引入链式推理(CoT)生成:通过将链式思维生成模块(CoT)与检索的证据结合,使得生成的答案不仅依赖检索结果,还能够进行多轮推理,提供更有深度的医疗决策支持。
How - 3. 关键数据支持
研究通过对多个公开医学数据集(如MedQA-USMLE、MedQA-MCMLE、PubMedQA等)的实验验证,证明了Med-R2框架相较于传统RAG方法在医学任务中的表现优势:
- 准确率提升:Med-R2在检索精度上有显著提升,能够为医学决策提供更相关的证据支持。
- 跨数据集泛化能力:在跨数据集训练下,Med-R2能够成功应用于不同来源的数据集,展现出更强的泛化能力和应用潜力。
How - 4. 可能的反驳及应对
可能的反驳:Med-R2框架复杂的检索和推理过程可能导致计算成本增加,尤其是在医学数据庞大的情况下,是否能保证高效性?
应对方法:通过细粒度的证据评估和排序,Med-R2能够在有限的计算资源下实现高效的检索和推理,实验结果也表明,在不同规模的模型上,Med-R2依然保持较好的性能,并且与传统的基于知识库的训练方法相比,Med-R2能够在不增加额外训练成本的情况下获得较好的性能提升。
How good - 研究的理论贡献和实践意义
理论贡献:
- 提升LLM在医学领域的应用:Med-R2框架将循证医学原则与大语言模型结合,推动了LLM在医学决策支持中的应用,提出了医学问题求解的新思路。
- 完善RAG模型在专业领域的应用:通过提出针对医学领域的检索优化策略和推理机制,Med-R2为RAG算法提供了在专业领域应用的可行性和有效性示范。
实践意义:
- 增强医学临床决策支持:Med-R2能够帮助医生从海量的医学文献中精准地检索相关信息,增强临床决策的支持,特别是在紧急和复杂的医疗情境下。
- 优化患者咨询和医疗问答系统:Med-R2为医疗领域的自动化问答系统提供了可靠的支持,能够为患者提供更专业、更准确的医疗咨询。
作者设计思路
1. 确认最终目标
问句形式:如何提高大语言模型(LLMs)在医学领域中的准确性、效率和专业性,以便更好地支持医学决策和患者护理?
2. 层层分解问题
-
问题1:如何提高医学领域的知识获取效率?
- 解决手段:通过外部知识库的集成,结合**循证医学(EBM)的框架,将医学知识库与LLM结合,利用检索增强生成(RAG)**的方式,减轻模型训练时对大量医学数据的依赖。
-
问题2:如何提升医学检索的精度?
- 解决手段:设计针对医学问题的查询重构器,对医学查询进行专业化处理;同时,结合精细化的证据排序机制,使得检索到的医学信息更加相关和精准。
-
问题3:如何提高模型在医学场景中的推理能力和答案提取效率?
- 解决手段:利用链式推理(CoT)生成模块,在检索到的医学证据基础上进行多轮推理,确保生成的答案更加符合临床需求和循证医学的标准。
-
问题4:如何优化现有RAG方法以适应医学领域的专业需求?
- 解决手段:在RAG的基础上,集成循证医学的五个步骤(问题制定、证据检索、证据评估、证据应用、效果评估),并通过细粒度证据评估和推理过程改进,提升医学领域中的答案生成效果和可靠性。
-
问题5:如何平衡模型的计算效率和答案质量?
- 解决手段:设计精细化的证据评估与排序策略,使得在有限的计算资源下,模型依然能够准确检索到与问题最相关的医学证据,同时保持生成答案的质量。
3. 实现步骤
-
集成外部知识库:通过构建一个覆盖医学领域的外部知识库,提供检索支持。这一步骤可以有效缓解大语言模型在医学领域的知识获取低效问题。
-
查询重构与分类:开发专业化的查询重构器,将用户的医学问题分解为不同类别(例如诊断、治疗、预后等),并根据不同类别调整检索策略,提高检索的精度。
-
证据检索与排序:使用RAG算法进行医学证据的检索,并对检索结果进行精细化排序,选择最相关和最具权威性的医学文献,以提高生成答案的质量。
-
推理与答案生成:在检索到的证据基础上,采用链式推理生成模型(CoT生成器),通过多轮推理确保生成的答案不仅符合问题需求,还能进行复杂的医学推理。
-
效果评估与优化:在生成过程中,通过循证医学的五个阶段来对生成的答案进行评估,确保每一步推理的有效性,最终输出符合循证医学标准的答案。
-
评估与验证:进行多轮实验,利用不同的医学数据集(如MedQA-USMLE、MedQA-MCMLE等)来验证Med-R2框架的效果,并通过对比传统RAG方法,展示该方法在医学领域中的优势。
通过这种目标-手段分析法,作者逐步设计并优化了Med-R2框架,解决了医学领域大语言模型应用中的主要问题,使得框架在医学场景中更加专业、高效,能够有效支撑临床决策和医学研究。
对比 RAG算法 与 Med-R2框架
传统RAG框架直接进行单轮检索和生成,而Med-R2框架通过多轮迭代和细粒度评估,结合循证医学流程进行优化,提升了答案的质量和可信度。
Med-R2通过CoT生成器创建清晰的推理链,并在检索过程中进行多轮迭代优化,确保推理过程在医疗场景中既高效又可靠。
三大创新:
- 基于循证医学(EBM)流程的医疗问答框架
- 多维度证据评估系统(证据等级+文档类型+有用性)
- 迭代优化的检索推理机制(通过CoT反馈优化检索)
1. 背景和目标
- RAG算法(Retrieval-Augmented Generation):RAG是一种结合了外部知识检索和生成式语言模型的框架,旨在提高模型在知识密集型任务中的表现。它的目标是通过检索与任务相关的信息来辅助生成任务的答案,尤其适用于处理开放式问题和需要大规模外部知识支持的任务。
- Med-R2框架:Med-R2是一个为医学领域设计的RAG变体,特别结合了**循证医学(EBM)**的流程,旨在提高医学问题解答的可靠性和精准性。它通过增强医学领域的检索和推理机制,解决了传统RAG在医学领域应用时遇到的知识获取低效、检索精度差以及答案提取不足的问题。
2. 知识获取和处理
- RAG算法:RAG使用外部知识库通过检索与任务相关的文档,生成答案。它通过将检索到的文档与查询合并,然后利用语言模型生成相关答案。这种方法的效率取决于检索系统的性能和知识库的质量。
- Med-R2框架:Med-R2在RAG的基础上进一步增强了医学领域特定的需求。它不仅使用外部知识库,还特别考虑了循证医学的五个阶段(问题制定、证据检索、证据评估、证据应用和效果评估)。Med-R2引入了专业的医学查询分类、查询重组和细粒度的证据排序策略,从而提高了医学领域的检索精度和答案的相关性。
3. 查询处理
- RAG算法:RAG处理查询时,通常使用原始查询直接进行文档检索,未进行太多领域特定的专业化处理。查询的重组和修正通常比较简化,主要依赖检索系统的直接性能。
- Med-R2框架:Med-R2在查询处理上更为复杂,采用了循证医学的分类体系,将查询划分为诊断、治疗、预后等不同类别,并根据医学需求对查询进行专业化重组。这种做法提升了检索精度,确保获取的证据与查询更加相关和准确。
4. 检索精度与效率
- RAG算法:RAG的检索精度和效率取决于外部知识库的质量和检索模型的能力,通常通过稀疏检索和密集检索相结合来提升检索的多样性和精度。RAG能够在多个知识库中进行检索,但其精准度在高度专业化的领域(如医学)上往往有限。
- Med-R2框架:Med-R2专门设计了针对医学问题的检索增强方法,包括精细的证据评估与排序机制。通过引入细粒度的证据重排名和检索后的证据审查(如冲突内容过滤和多轮检索),Med-R2显著提高了检索的精准度,并能在有限的计算资源下获取最相关的信息。
5. 生成与答案提取
- RAG算法:RAG的生成阶段将检索到的相关文档与原始查询合并,进行生成性回答。生成模型的质量影响答案的准确性,RAG系统往往在开放领域问题中表现良好,但在需要高度专业知识的领域(如医学)时,可能会出现不准确或缺乏专业性的回答。
- Med-R2框架:Med-R2引入了**链式思维(CoT)**生成模块,确保生成的答案不仅依赖于检索的文档,还能进行多轮的推理。它结合了医疗文献的层级证据标准,从而生成更加符合循证医学标准的答案。
6. 效果评估
- RAG算法:RAG的评估通常依赖于检索质量和生成内容的相关性,但缺乏系统性的评估机制来考察模型生成的答案是否符合实际的医学需求或准确度。
- Med-R2框架:Med-R2采用了更为严格的效果评估机制,通过循证医学中的效果评估步骤,评估模型生成的答案的实用性和准确性。这种评估不仅关注模型输出的准确性,还关注模型对实际医学决策的支持能力。
7. 计算成本与训练效率
- RAG算法:RAG在训练和推理时依赖于外部知识库的检索系统,这可能带来一定的计算开销,尤其是在知识库庞大时。然而,RAG的优点是可以减少训练时对大型医学数据集的依赖,降低计算成本。
- Med-R2框架:Med-R2不仅在检索过程中依赖外部知识库,还加入了多个处理步骤,如查询重组、证据评估和CoT生成,这些都需要额外的计算资源。尽管如此,Med-R2通过高效的知识检索和专业化的处理方法,优化了计算成本,使其在实际医学应用中具有较高的计算效率。
8. 应用场景
- RAG算法:RAG广泛应用于各种知识密集型领域,特别是开放域问答、信息抽取等任务,适用于需要从大规模知识库中提取信息的任务。
- Med-R2框架:Med-R2专为医学领域设计,能够在医疗决策支持、医学问题解答、患者咨询等场景中提供高质量、符合循证医学标准的解答。它特别适用于医院、诊所、医疗研究等环境中的实际应用。
总结:
- RAG算法是一个通用的框架,能够在多种领域中提升生成模型的性能,尤其是在知识密集型任务中。而Med-R2框架则是专为医学领域设计,通过集成循证医学的流程和优化的检索与推理策略,能够大幅提升医学任务中的准确性和专业性。
- Med-R2在查询处理、检索精度、答案生成与提取方面都比传统的RAG算法更有针对性,尤其是在医学领域,能够更好地满足复杂的专业要求和高标准的答案生成需求。
数据分析
第一步:收集所需数据
数据收集设计:
-
医疗知识库构建
- 学术论文:600万条
- 医学词条:47万条
- 医学书籍:1万本
- 医疗指南:1万份
这些数据涵盖了医学领域的多个方面,为后续的检索和问答任务提供了丰富的知识资源。
-
评估数据集选择
- MedQA-USMLE:用于美国医学执照考试的数据集,包含多种医学领域的问题。
- MedQA-MCMLE:用于中国医学执照考试的数据集,确保跨地区和语言的评估。
- MedMCQA:多选题医学问答数据,帮助评估模型的多选题解答能力。
- PubMedQA:生物医学问答数据,源自PubMed数据库。
- MMLU-Med:医学综合评估数据集,涵盖广泛的医学领域,帮助综合评估模型的多维度能力。
通过收集不同类型的医疗数据,确保数据的全面性与代表性,为模型的训练与验证提供了丰富且真实的医学背景。
第二步:处理与挖掘数据
数据处理策略:
-
文本分段处理
- 设定10000 tokens阈值:为了确保每个输入的处理量合理,避免过长文本带来的计算负担。
- 优先按自然章节划分:通过按自然章节进行分割,使得文本结构更加合理,并确保每个文档在语义上有清晰的层次。
- 超限时进行截断处理:确保输入数据量不会超过模型的最大输入限制,保证处理效率。
-
问题分类体系
- EBM分类:将问题按循证医学(EBM)分类为诊断、治疗、预后等6类,确保问题处理时遵循医学决策流程。
- 通用问题分类:如事实型、参考型、定义型等12类问题,用以细化问题类型,提升模型的精确回答能力。
- 建立问题-文档映射关系:通过对问题的分类与文档内容的关联,保证检索到的文档能够高效解答对应问题。
数据处理阶段确保了数据的结构化,使得后续的分析和建模工作能够顺利进行,并通过有效的分类和映射关系提升了模型的精确度。
第三步:探索数据维度相关性
维度关联分析:
-
模型规模与性能关系
- 轻量级模型(7B-8B):这些模型对外部知识的依赖较高,因为它们的内在知识储备有限,需要通过外部知识库进行补充。
- 中型模型(14B):这些模型的知识获取效率较高,能够较好地平衡内在知识与外部知识的结合。
- 大型模型(32B-70B):由于内置了大量知识,它们对外部知识的依赖较小,性能提升较为有限。
-
上下文窗口影响
- 8B模型:4K窗口最优,适合处理较为简单的问题。
- 14B模型:8K窗口最优,适应较为复杂的医学问题。
- 32B/70B模型:16K窗口最优,能够处理大规模的文献并进行复杂的推理。
通过对不同规模模型的评估,揭示了模型规模与外部知识依赖的关系以及上下文窗口长度对模型性能的影响,为优化模型架构提供了重要的依据。
第四步:建立数学模型
模型构建方案:
-
证据重排序评分模型
公式:F(x) = fh(x)·fg(x)(1+α·fu(x))其中:
- fh(x):证据等级评分,反映证据的可靠性和权威性。
- fg(x):文档类型匹配度,表示文档与问题类型的相关性。
- fu(x):文档有用性评分,衡量文档在解答问题中的实际效用。
- α:权重控制参数,用于调节各项评分的影响力。
-
验证结果:
- 传统RAG提升:14.87%
- 微调方法提升:3.59%
- 证据评估准确率:>85%
通过建立证据重排序评分模型,成功实现了证据的高效筛选和排序,从而显著提升了模型的回答质量,验证了循证医学框架在提升医学问答系统中的有效性。
结论
- 证实了循证医学流程的有效性:Med-R2框架通过引入循证医学的五个阶段,显著提高了医疗LLM的准确性和可靠性。
- 揭示了模型规模与知识依赖的关系规律:小规模模型依赖外部知识更多,而大模型内建知识较为丰富,对外部知识的依赖较低。
解法拆解
Med-R2 = 查询优化模块 + 证据处理模块 + 推理应用模块1. 查询优化模块
├── 查询分类器
│ ├── EBM专业分类
│ │ ├── 诊断类问题映射
│ │ ├── 治疗类问题映射
│ │ ├── 预后类问题映射
│ │ ├── 病因类问题映射
│ │ ├── 预防类问题映射
│ │ └── 成本类问题映射
│ └── 通用问题分类
│ ├── 事实型问题处理
│ ├── 解释型问题处理
│ ├── 比较型问题处理
│ └── 其他9类问题处理
└── 查询重构器├── 专业术语标准化├── 症状描述规范化└── 查询模板填充2. 证据处理模块
├── 混合检索器
│ ├── 密集检索
│ │ ├── 向量索引构建
│ │ └── 语义相似度计算
│ └── 稀疏检索
│ ├── 关键词匹配
│ └── BM25打分
├── 粗粒度重排序器
│ ├── 语义相关度评分
│ └── Top-k文档筛选
└── 细粒度评估器├── 证据等级评分(EL)│ ├── 元分析/系统综述(最高)│ ├── 随机对照试验│ ├── 队列研究│ └── 专家意见(最低)├── 文档类型匹配(DT)│ ├── 问题-文档类型映射│ └── 匹配度计算├── 有用性评分(U)│ ├── 代理模型评估│ └── Loss差值计算└── 综合评分├── F(x) = fh(x)·fg(x)(1+α·fu(x))└── 权重参数优化3. 推理应用模块
├── CoT生成器
│ ├── 问题分析
│ ├── 证据提取
│ ├── 推理链构建
│ └── 答案生成
└── 迭代优化器├── 语义稳定性评估├── 答案准确性评估└── 检索策略调整
1. 逻辑关系拆解
- 技术:Med-R2 = 查询重构 + 证据检索评估 + 证据应用
- 问题:医疗LLM面临知识获取效率低、检索精度有限、答案提取效率低三大挑战
- 主要区别:传统RAG直接检索 vs 基于EBM流程的多维度优化
子解法拆解:
- 查询重构模块(因为医疗查询专业性强)
- EBM分类:根据诊断、治疗等6类进行专业化重构
- 通用问题分类:基于12类问题类型优化检索策略
之所以用查询重构,是因为医疗查询需要专业化处理以提高检索精度。
根据论文内容,我来详细列出所有12类通用问题分类:
-
事实型(Factual):询问具体和客观事实或数据
示例:"马尔堡病毒的潜伏期是多长?" -
参考型(Referential):寻找特定文档或资源的引用
示例:"有哪些关于马尔堡病毒的最新研究文献?" -
定义型(Definition):询问概念或术语的定义
示例:"什么是病毒性出血热?" -
解释型(Explanatory):寻求现象或过程的解释
示例:"为什么马尔堡病毒会导致出血症状?" -
描述型(Descriptive):请求对特征或属性的描述
示例:"马尔堡病毒感染的典型症状有哪些?" -
指导型(Directive):寻求建议或推荐
示例:"如何预防马尔堡病毒感染?" -
意见型(Opinion):征询个人观点或态度
示例:"目前哪种治疗方案最有效?" -
程序型(Procedural):询问具体步骤或流程
示例:"疑似病例如何进行隔离?" -
比较型(Comparative):要求对多个实体进行比较
示例:"马尔堡病毒和埃博拉病毒有什么区别?" -
评估型(Evaluative):评价某个说法或观点
示例:"这种新疗法的效果如何?" -
验证型(Verification):确认信息的准确性
示例:"是否确实没有特效药?" -
假设型(Hypothetical):探讨假设情况
示例:"如果发现疑似病例,应该怎么处理?"
这12类问题分类帮助系统:
-
更准确地理解用户意图
-
选择合适的文档类型进行检索
-
优化答案生成的格式和内容
-
提供更有针对性的回答
-
证据检索评估模块(因为医疗证据有严格等级体系)
- 粗粒度重排:基于语义相关性
- 细粒度评估:证据等级 + 文档类型 + 有用性评分
之所以用分层评估,是因为医疗证据需要严格的质量控制。
-
证据应用模块(因为需要专业推理)
- CoT生成:基于检索证据构建推理链
- 证据迭代:通过CoT序列优化检索
之所以用CoT生成,是因为医疗问题需要清晰的推理过程。
2. 逻辑链分析
Med-R2
├── 查询重构【入口】
│ ├── EBM分类【专业化】
│ └── 通用分类【通用化】
├── 证据检索评估【核心】
│ ├── 粗粒度重排【效率】
│ └── 细粒度评估【质量】
└── 证据应用【输出】├── CoT生成【推理】└── 证据迭代【优化】
该逻辑链展示了Med-R2框架的分步流程:从查询重构到证据检索,再到证据应用,每个步骤针对医疗问题的特定需求进行专业化处理。
3. 隐性方法分析
-
证据冲突处理:当检索到的证据存在矛盾时,基于证据等级进行筛选
- 处理冲突的隐性方法是通过对证据的等级评估来筛选矛盾证据,这确保了最终的推理与高质量的证据一致。
-
上下文窗口动态调整:根据模型规模自适应调整窗口大小
- 在不同规模的模型上调整上下文窗口大小,确保模型在处理不同规模问题时效率和准确性平衡。
-
CoT序列质量评估:通过loss差值评估CoT序列对检索的影响
- 隐性方法之一是评估生成的CoT序列的质量,确保它们对检索到的证据进行了有效的推理,而不会引入无关或错误的结论。
4. 隐性特征分析
-
模型知识依赖度:不同规模模型对外部知识的依赖程度存在显著差异
- 小规模模型依赖更多的外部知识库,尤其在医疗场景中,推理可能不如大模型那么充足。
-
证据完备性:检索证据需要覆盖问题的多个维度
- 检索到的证据必须具备多角度、多层次的覆盖,以确保解答的全面性。
-
推理链一致性:CoT序列需要与医学专业知识保持一致
- CoT生成器在生成推理链时要保证其与医学领域的标准推理一致,确保推理过程中不偏离专业路径。
5. 潜在局限性
-
知识库覆盖:医学知识库可能存在覆盖不完整的问题
- 由于医学知识库的构建和更新需要大量的资源,可能会出现某些医学领域的知识未完全覆盖,影响模型的表现。
-
分类准确性:查询分类器依赖高级语言模型,可能存在分类偏差
- 高级语言模型的分类能力可能受到输入语言差异或模型本身理解能力的影响,导致某些类别的错误分类。
-
证据评估:使用轻量级代理模型可能影响评估准确性
- 代理模型的评估结果可能不如全规模模型精准,导致证据重排序时的误差。
-
CoT生成:对于轻量级模型,生成的CoT序列可能影响检索效果
- 小模型可能在生成推理链时表现较差,这可能影响最终答案的准确性和可靠性。
-
计算开销:多轮迭代和细粒度评估增加了计算复杂度
- 多轮检索和细粒度评估虽然提升了答案质量,但增加了计算量和时间成本,对于大规模数据集和复杂问题可能产生较大负担。
全流程

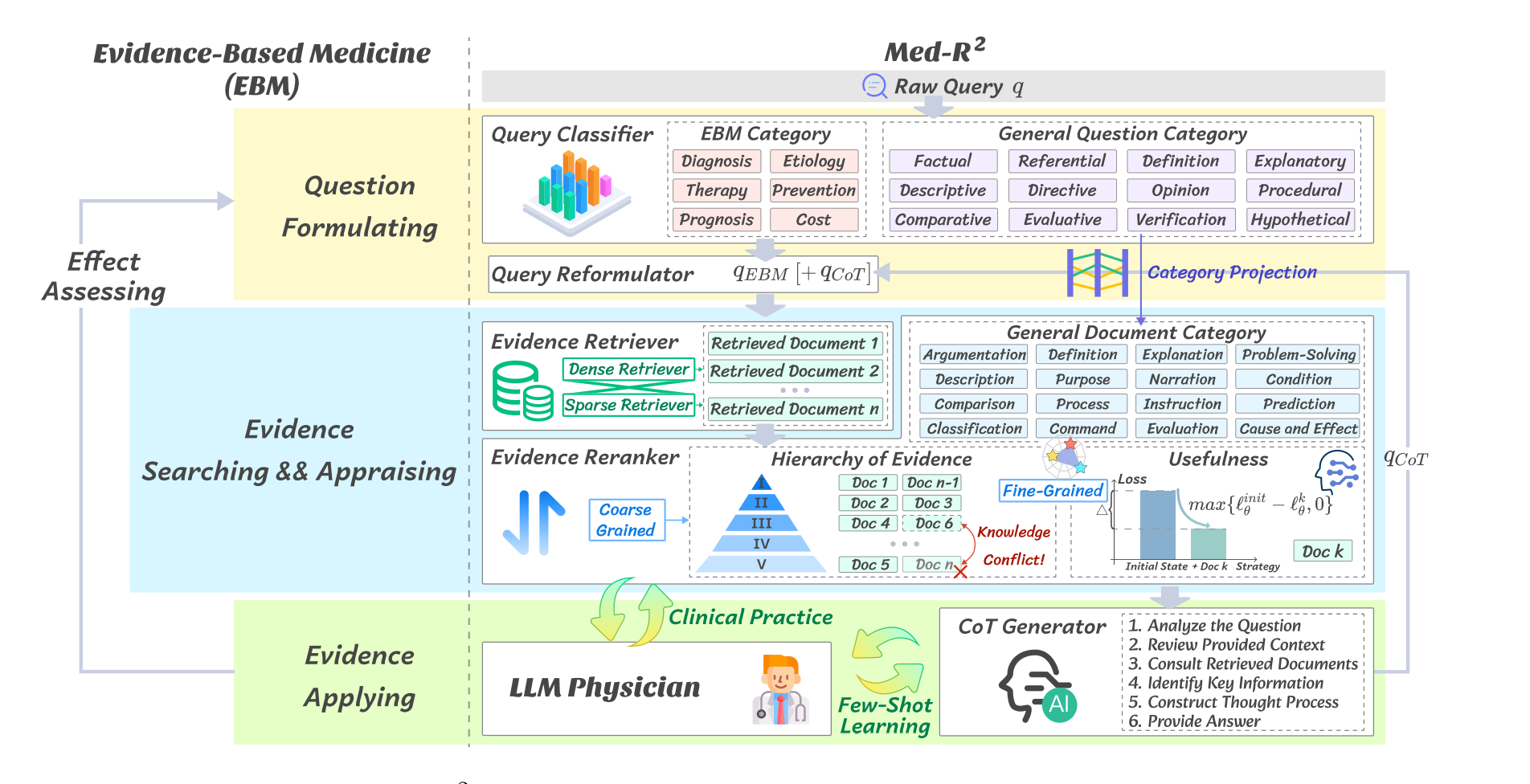
1. 整体架构(从左到右)
该图展示了Med-R2框架的5个主要模块:
- 输入层:原始数据输入
- 查询优化模块:查询预处理
- 证据处理模块:知识检索与评估
- 推理应用模块:答案生成
- 输出层:最终答案
2. 各模块详细功能
输入层
- 医疗查询:用户输入的原始医疗问题
- 知识库:包含医学论文、指南等资源的数据库
查询优化模块
- EBM分类器:将查询分类为诊断、治疗等专业类别
- 通用分类器:识别查询的一般问题类型(如事实型、解释型等)
- 查询重构器:基于分类结果重构优化查询
证据处理模块
- 密集检索:基于语义相似度的深度检索
- 稀疏检索:基于关键词的传统检索
- 粗粒度重排:初步筛选相关文档
- 细粒度评估:多维度详细评估文档质量
推理应用模块
- CoT生成器:构建推理链和答案
- 迭代优化器:优化检索和推理过程
输出层
- 医疗答案:最终生成的专业医疗回答
3. 关键信息流
- 查询处理流:
医疗查询 -> 双重分类(EBM专业分类+通用问题分类双重优化) -> 查询重构 -> 检索
- 知识检索流:
知识库 -> 双路检索(密集检索+稀疏检索并行) -> 两级评估(粗粒度重排+细粒度多维评估)
- 答案生成流:
细粒度评估 -> CoT生成 -> 迭代优化 -> 医疗答案
- 反馈优化流:
迭代优化器 -> 密集/稀疏检索(循环优化)
4. 重点节点(粗线标注)
- 查询重构器:查询优化的关键
- 细粒度评估:证据质量控制的核心
- CoT生成器:专业推理的重要组件
这个架构设计体现了该框架的三个主要特点:
- 多层次的查询理解和优化
- 双路并行的知识检索策略
- 迭代优化的推理生成机制
输入查询:
"患者出现持续发热39度,伴有剧烈头痛和肌肉疼痛,有非洲旅行史,如何判断是否感染马尔堡病毒?"
- 查询优化模块处理:
a) 查询分类
- EBM类别:诊断类
- 通用类别:程序性问题
b) 查询重构
专业查询:
"请提供马尔堡病毒感染的诊断标准,包括:
1. 主要临床表现(发热、头痛、肌肉疼痛等症状特点)
2. 流行病学依据(非洲旅行史)
3. 实验室检查指标
4. 鉴别诊断要点"
- 证据处理模块处理:
a) 混合检索
- 密集检索:基于语义相似度查找相关医学文献
- 稀疏检索:基于关键词匹配查找诊疗指南
b) 证据评估
粗粒度评分:
- 文档1:WHO马尔堡病毒诊疗指南(相关度0.92)
- 文档2:马尔堡病毒临床研究(相关度0.85)
- 文档3:病毒性出血热鉴别诊断(相关度0.78)细粒度评分:
F(x) = 证据等级 * 文档类型匹配度 * (1 + 有用性评分)
- 文档1:9.8(指南最高级)
- 文档2:8.5(临床研究)
- 文档3:7.2(综述)
- 推理应用模块处理:
a) CoT生成
推理步骤:
1. 分析临床症状匹配度- 持续高热:符合(典型体温>38.3度)- 头痛和肌肉疼痛:符合(早期典型症状)2. 评估流行病学证据- 非洲旅行史:重要流行病学依据3. 建议实验室检查- RT-PCR检测- 血常规- 生化指标4. 应急处置方案- 隔离措施- 报告程序
b) 迭代优化
- 检查答案完整性
- 评估推理链合理性
- 补充缺失信息
最终输出:
基于您提供的症状和流行病学史,建议:1. 临床症状分析:- 持续高热(39度)、剧烈头痛和肌肉疼痛符合马尔堡病毒早期表现- 非洲旅行史提供重要流行病学依据2. 建议立即进行:- 马尔堡病毒RT-PCR检测- 血常规、凝血功能、肝肾功能检查3. 紧急措施:- 立即实施隔离- 报告当地疾控中心- 对密切接触者进行追踪4. 注意事项:- 需要排除登革热、黄热病等其他病毒性出血热- 病情监测重点:出血倾向、器官功能
让我详细解释这几个关键机制:
1. 双重分类
将一个医疗问题从两个维度同时进行分类:
输入: "如何判断是否感染了马尔堡病毒?"EBM专业分类:
- 类别:诊断类问题
- 目标:确定疾病诊断标准和方法通用问题分类:
- 类别:程序型问题
- 目标:需要明确的步骤说明
2. 双路检索
同时使用两种不同策略检索医学知识:
密集检索:
- 方法:使用向量相似度计算
- 优势:能捕获深层语义关联
- 示例:即使用词不同,也能找到相关文献稀疏检索:
- 方法:关键词匹配和BM25算法
- 优势:精确匹配关键医学术语
- 示例:准确定位包含特定疾病名称的文档
3. 两级评估
分两个层次评估检索到的文档:
粗粒度评估:
- 计算文档与查询的语义相关性
- 选出Top-k相关文档细粒度评估:
- 证据等级评分:如元分析>随机对照试验>专家意见
- 文档类型匹配:问题类型与文档类型的匹配度
- 有用性评分:内容对回答问题的帮助程度
4. 查询重构
基于双重分类结果优化原始查询:
原始查询:
"如何判断是否感染了马尔堡病毒?"重构后查询:
{专业维度: "马尔堡病毒感染的诊断标准、临床表现和实验室检查指标是什么?"+ 通用维度: "请列出判断马尔堡病毒感染的具体步骤和关键点"
}
5. 循环优化
迭代优化器会根据中间结果不断改进检索过程:
第1轮:
- 检索原始医学文献
- 生成初步推理链第2轮:
- 基于推理链发现需要补充的信息
- 调整检索策略,查找特定细节第3轮:
- 评估信息完整性
- 如有缺失,继续优化检索终止条件:
- 达到预设迭代次数
- 或检索结果趋于稳定
比如对于马尔堡病毒的例子:
第1轮:获取基本诊断标准
第2轮:发现需要补充鉴别诊断信息,调整检索
第3轮:发现需要最新治疗方案,再次检索
...直到信息完整
这种多层次、迭代式的设计确保了答案的专业性和完整性。
证据等级

根据论文中的证据等级评估体系(Hierarchy of Evidence),从高到低详细划分如下:
1. 最高等级证据 [Level 1]
- 系统性综述(Systematic Reviews)
- 荟萃分析(Meta-Analyses)
特点: - 综合多项研究结果
- 使用严格的方法学评估
- 提供最全面的证据汇总
2. 随机对照试验(RCTs) [Level 2]
- 大型多中心RCTs
- 设计良好的单中心RCTs
特点: - 随机分配受试者
- 有对照组设计
- 降低偏倚风险
3. 队列研究 [Level 3]
- 前瞻性队列研究
- 回顾性队列研究
特点: - 追踪特定人群
- 观察暴露和结局关系
- 可识别因果关系
4. 病例对照研究 [Level 4]
特点:
- 比较病例组和对照组
- 回溯性研究设计
- 可能存在选择偏倚
5. 横断面研究 [Level 5]
特点:
- 某一时间点的调查
- 可研究疾病分布
- 难以确定因果关系
6. 病例系列/报道 [Level 6-7]
- 病例系列
- 个案报道
特点: - 描述性研究
- 生成研究假设
- 证据级别较低
7. 专家意见 [Level 8-9]
- 专家共识
- 个人经验
特点: - 基于临床经验
- 缺乏系统研究
- 可能存在主观偏见
在Med-R2系统中,这个分级体系用于证据评分计算:
F(x) = fh(x) * fg(x) * (1 + α * fu(x))
其中:
- fh(x):证据等级评分
- fg(x):文档类型匹配度
- fu(x):有用性评分
- α:权重控制参数(论文中设为1)
# 假设一个医学指南文档的评分过程
doc = {'evidence_level': 1, # 系统综述'doc_type': 'guideline','initial_loss': 0.8,'doc_loss': 0.3
}# 1. 计算证据等级分
h_score = 9 - (1 - 1) = 9# 2. 计算类型匹配度
# 假设问题期望指南类型文档,匹配概率0.95
g_score = 0.95# 3. 计算有用性分
u_score = 0.8 - 0.3 = 0.5# 4. 最终综合评分
final_score = 9 * 0.95 * (1 + 1 * 0.5) = 12.825
6. 评分重要特性
- 证据等级是基础分
- 类型匹配作为乘数调整
- 有用性分作为额外奖励
- 高质量文档的特征:
- 高等级证据(系统综述/元分析)
- 与问题类型高度匹配
- 能显著降低回答loss
这种多维度的评分机制确保了:
- 优先使用高质量证据
- 文档内容与问题相关
- 信息对回答有实际帮助
相关文章:

Med-R2:基于循证医学的检索推理框架:提升大语言模型医疗问答能力的新方法
Med-R2 : Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine Med-R2框架Why - 这个研究要解决什么现实问题What - 核心发现或论点是什么How - 1. 前人研究的局限性How - 2. 你的创新方法/视角How - 3. 关键数据支持How - 4. 可…...
)
Docker入门篇(Docker基础概念与Linux安装教程)
目录 一、什么是Docker、有什么作用 二、Docker与虚拟机(对比) 三、Docker基础概念 四、CentOS安装Docker 一、从零认识Docker、有什么作用 1.项目部署可能的问题: 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题࿱…...

完美世界C++游戏开发面试题及参考答案
堆栈数据结构有什么区别,举例说明 栈(Stack)和堆(Heap)是两种不同的数据结构,它们在多个方面存在显著区别: 存储方式 栈:栈是一种后进先出(LIFO)的数据结构,它的存储空间是连续的。栈由系统自动分配和释放,用于存储函数调用时的局部变量、函数参数、返回地址等信息…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.21 随机数生成:梅森旋转算法的工程实现
2.21 随机数生成:梅森旋转算法的工程实现 目录 #mermaid-svg-J92AWLtQsj9ys1z6 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-J92AWLtQsj9ys1z6 .error-icon{fill:#552222;}#mermaid-svg-J92AWLtQsj9y…...
空间复杂度-一次遍历双指针)
LeetCode 0922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针
【LetMeFly】922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针 力扣题目链接:https://leetcode.cn/problems/sort-array-by-parity-ii/ 给定一个非负整数数组 nums, nums 中一半整数是 奇数 ,一半整数是 偶数 。 对数组进…...

VSCode设置内容字体大小
1、打开VSCode软件,点击左下角的“图标”,选择“Setting”。 在命令面板中的Font Size处选择适合自己的字体大小。 2、对比Font Size值为14与20下的字体大小。...

【蓝桥杯】日志统计
日志统计(编程题)https://dashoj.com/d/lqbproblem/p/53https://dashoj.com/d/lqbproblem/p/53https://dashoj.com/d/lqbproblem/p/53 题目 日志统计(编程题) 讲解 这个讲解感觉比较通俗易懂。 蓝桥杯2018年省赛B组08(c/c)日…...
)
九. Redis 持久化-AOF(详细讲解说明,一个配置一个说明分析,步步讲解到位 2)
九. Redis 持久化-AOF(详细讲解说明,一个配置一个说明分析,步步讲解到位 2) 文章目录 九. Redis 持久化-AOF(详细讲解说明,一个配置一个说明分析,步步讲解到位 2)1. Redis 持久化 AOF 概述2. AOF 持久化流程3. AOF 的配置4. AOF 启…...
)
蓝桥杯备赛题目练习(一)
一. 口算练习题 ## 题目描述 王老师正在教简单算术运算。细心的王老师收集了 i 道学生经常做错的口算题,并且想整理编写成一份练习。 编排这些题目是一件繁琐的事情,为此他想用计算机程序来提高工作效率。王老师希望尽量减少输入的工作量,比…...
:信号在内核中的处理及信号捕捉详解)
【Linux探索学习】第二十八弹——信号(下):信号在内核中的处理及信号捕捉详解
Linux学习笔记: https://blog.csdn.net/2301_80220607/category_12805278.html?spm1001.2014.3001.5482 前言: 在前面我们已经学习了有关信号的一些基本的知识点,包括:信号的概念、信号产生和信号处理等,今天我们重…...

AI与SEO关键词的完美结合如何提升网站流量与排名策略
内容概要 在当今数字营销环境中,内容的成功不仅依赖于高质量的创作,还包括高效的关键词策略。AI与SEO关键词的结合,正是这一趋势的重要体现。 AI技术在SEO中的重要性 在数字营销领域,AI技术的引入为SEO策略带来了前所未有的变革。…...

《运维:技术的基石,服务的保障》
1. LVS(Linux Virtual Server):基于Linux内核的四层负载均衡解决方案 2. Bonding(链路聚合):物理网卡冗余与带宽叠加技术 3. RHEL(Red Hat Enterprise Linux):企业级Li…...

CSS Display属性完全指南
CSS Display属性完全指南 引言核心概念常用display值详解1. block(块级元素)2. inline(行内元素)3. inline-block(行内块级元素)4. flex(弹性布局)5. grid(网格布局&…...

【C++】STL——vector底层实现
目录 💕 1.vector三个核心 💕2.begin函数,end函数的实现(简单略讲) 💕3.size函数,capacity函数的实现 (简单略讲) 💕4.reserve函数实现 (细节…...

Docker Compose的使用
文章首发于我的博客:https://blog.liuzijian.com/post/docker-compose.html 目录 Docker Compose是什么Docker Compose安装Docker Compose文件Docker Compose常用命令案例:部署WordPress博客系统 Docker Compose是什么 Docker Compose是Docker官方的开源…...
11 3D变换模块(transform3d.rs)
transform3d.rs代码定义了一个名为 Transform3D 的 Rust 结构体,它用于表示一个3D变换矩阵。这个结构体是泛型的,包含三个类型参数:T、Src 和 Dst。其中,T 用于矩阵元素的数据类型,Src 和 Dst 用于表示变换的源和目标类…...

昆仑万维Java开发面试题及参考答案
进程和线程的区别是什么? 进程和线程都是操作系统中非常重要的概念,它们在多个方面存在显著的区别。 从定义上看,进程是操作系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间,包括代码段、数据段、堆栈段等。例如,当你在电脑上同时打开浏览器和音乐播放…...

vscode命令面板输入 CMake:build不执行提示输入
CMake:build或rebuild不编译了,弹出:> [Add a new preset] , 提示输入发现settings.jsons设置有问题 { "workbench.colorTheme": "Default Light", "cmake.pinnedCommands": [ "workbench.action.tasks.configu…...

Fastdds学习分享_xtpes_发布订阅模式及rpc模式
在之前的博客中我们介绍了dds的大致功能,与组成结构。本篇博文主要介绍的是xtypes.分为理论和实际运用两部分.理论主要用于梳理hzy大佬的知识,对于某些一带而过的部分作出更为详细的阐释,并在之后通过实际案例便于理解。案例分为普通发布订阅…...

什么叫DeepSeek-V3,以及与GPT-4o的区别
1. DeepSeek 的故事 1.1 DeepSeek 是什么? DeepSeek 是一家专注于人工智能技术研发的公司,致力于打造高性能、低成本的 AI 模型。它的目标是让 AI 技术更加普惠,让更多人能够用上强大的 AI 工具。 1.2 DeepSeek-V3 的问世 DeepSeek-V3 是…...

【C#】Process、ProcessStartInfo启动外部exe
在C#中使用 Process 和 ProcessStartInfo 类启动外部 .exe 文件,可以按照以下步骤进行: 创建 ProcessStartInfo 实例:配置进程启动信息,包括可执行文件的路径、传递给该程序的参数等。 设置启动选项:根据需要配置 Pro…...

android 音视频系列引导
音视频这块的知识点自己工作中有用到,一直没有好好做一个总结,原因有客观和主观的。 客观是工作太忙,没有成段时间做总结。 主观自己懒。 趁着这次主动离职拿了n1的钱,休息一下,对自己的人生做一下总结,…...

Mac电脑上最新的好用邮件软件比较
在Mac电脑上,选择一款好用的邮件软件需要根据个人需求、功能偏好以及与系统生态的兼容性来决定。以下是基于我搜索到的资料,对当前市场上一些优秀的邮件客户端进行比较和推荐: 1. Apple Mail Apple Mail是Mac系统自带的邮件客户端ÿ…...
——枚举(Enum)的基础知识和高级应用)
C#,入门教程(11)——枚举(Enum)的基础知识和高级应用
上一篇: C#,入门教程(10)——常量、变量与命名规则的基础知识https://blog.csdn.net/beijinghorn/article/details/123913570 不会枚举,就不会编程! 枚举 一个有组织的常量系列 比如:一个星期每一天的名字…...

Spring 实现注入的方式
一、XML配置文件注入 概念:这是一种传统的依赖注入方式,通过在XML文件中配置bean的相关信息来实现依赖注入。在Spring框架中,需要在applicationContext.xml或spring-config.xml等配置文件中定义bean,并通过<property>标签或…...

【论文复现】粘菌算法在最优经济排放调度中的发展与应用
目录 1.摘要2.黏菌算法SMA原理3.改进策略4.结果展示5.参考文献6.代码获取 1.摘要 本文提出了一种改进粘菌算法(ISMA),并将其应用于考虑阀点效应的单目标和双目标经济与排放调度(EED)问题。为提升传统粘菌算法…...
构建教程编写智能体)
【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...
))
04树 + 堆 + 优先队列 + 图(D1_树(D10_决策树))
目录 一、引言 二、算法原理 三、算法实现 四、知识小结 一、引言 决策树算法是一种常用的机器学习算法,可用于分类和回归问题。它基于特征之间的条件判断来构 建一棵树,树的每个节点代表一个特征,每个叶节点代表一个类别或回归值。决策…...

JavaScript模块化
什么是JavaScript的模块化? JavaScript的模块化是指将代码分割成独立的、可重用的模块,每个模块具有自己的功能和作用,可以单独进行开发、测试和维护。不同的目的是提升代码的可维护性、可复用性和可扩展性,同时避免不同模块间的…...

排序算法--插入排序
插入排序是一种简单且稳定的排序算法,适合小规模数据或部分有序数据。 // 插入排序函数 void insertionSort(int arr[], int n) {for (int i 1; i < n; i) { // 从第二个元素开始int key arr[i]; // 当前需要插入的元素int j i - 1;// 将比 key 大的元素向后移…...

【C语言篇】“三子棋”
一、游戏介绍 三子棋,英文名为 Tic - Tac - Toe,是一款简单而经典的棋类游戏。游戏在一个 33 的棋盘上进行,两名玩家轮流在棋盘的空位上放置自己的棋子(通常用 * 和 # 表示),率先在横、竖或斜方向上连成三个…...

【大模型理论篇】DeepSeek-R1:引入冷启动的强化学习
1. 背景 首先给出DeepSeek-V3、DeepSeek-R1-Zero、DeepSeek-R1的关系图【1】。 虽然DeepSeek-R1-Zero推理能力很强,但它也面临一些问题。例如,DeepSeek-R1-Zero存在可读性差和语言混杂等问题。为了使推理过程更具可读性,进而推出了DeepSee…...

Linux基础 ——tmux vim 以及基本的shell语法
Linux 基础 ACWING y总的Linux基础课,看讲义作作笔记。 tmux tmux 可以干嘛? tmux可以分屏多开窗口,可以进行多个任务,断线,不会自动杀掉正在进行的进程。 tmux – session(会话,多个) – window(多个…...

使用 Kotlin 将 Vertx 和 Springboot 整合
本篇文章目的是将 Springboot 和 Vertx 进行简单整合。整合目的仅仅是为了整活,因为两个不同的东西整合在一起提升的性能并没有只使用 Vertx 性能高,因此追求高性能的话这是在我来说不推荐。而且他们不仅没有提高很多性能甚至增加了学习成本 一、整合流…...
)
【单层神经网络】softmax回归的从零开始实现(图像分类)
softmax回归 该回归分析为后续的多层感知机做铺垫 基本概念 softmax回归用于离散模型预测(分类问题,含标签) softmax运算本质上是对网络的多个输出进行了归一化,使结果有一个统一的判断标准,不必纠结为什么要这么算…...

课题推荐——基于自适应滤波技术的多传感器融合在无人机组合导航中的应用研究
无人机在现代航空、农业和监测等领域的应用日益广泛。为了提高导航精度,通常采用多传感器融合技术,将来自GPS、惯性测量单元(IMU)、磁力计等不同传感器的数据整合。然而,传感器的量测偏差、环境干扰以及非线性特性使得…...

【基于SprintBoot+Mybatis+Mysql】电脑商城项目之用户登录
🧸安清h:个人主页 🎥个人专栏:【Spring篇】【计算机网络】【Mybatis篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🎯1.登录-持久层 &…...

Mono里运行C#脚本40—mono_magic_trampoline函数的参数设置
前面介绍过跳板代码,它是用来切换托管代码与非托管的代码,以及运行时与C#代码的交互。实现从运行时切换到C#代码来运行,再从C#代码返回运行时。 要想理解整个切换的细节,那么就需要理解mono_magic_trampoline函数, 而要理解此函数,就必须了解这个函数的参数来源。 要理…...
:过程)
Verilog基础(三):过程
过程(Procedures) - Always块 – 组合逻辑 (Always blocks – Combinational) 由于数字电路是由电线相连的逻辑门组成的,所以任何电路都可以表示为模块和赋值语句的某种组合. 然而,有时这不是描述电路最方便的方法. 两种always block是十分有用的: 组合逻辑: always @(…...

实际操作 检测缺陷刀片
号he 找到目标图像的缺陷位置,首先思路为对图像进行预处理,灰度-二值化-针对图像进行轮廓分析 //定义结构元素 Mat se getStructuringElement(MORPH_RECT, Size(3, 3), Point(-1, -1)); morphologyEx(thre, tc, MORPH_OPEN, se, Point(-1, -1), 1); …...

DeepSeek 阐述 2025年前端发展趋势
预测2025年前端的发展趋势。首先,我需要考虑当前的前端 技术发展情况,以及近几年的变化趋势。比如,框架方面,React、Vue、Angular这些主流框架的更新方向和社区活跃度。可能用户想知道未来哪些技术会更流行,或者需要学…...

Elasticsearch基本使用详解
文章目录 Elasticsearch基本使用详解一、引言二、环境搭建1、安装 Elasticsearch2、安装 Kibana(可选) 三、索引操作1、创建索引2、查看索引3、删除索引 四、数据操作1、插入数据2、查询数据(1)简单查询(2)…...

【Rust自学】17.3. 实现面向对象的设计模式
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 17.3.1. 状态模式 状态模式(state pattern) 是一种面向对象设计模式,指的是一个值拥有的内部状态由数个状态对象(…...

司库建设-融资需求分析与计划制定
当企业现金流紧张时,企业需要考虑外部融资,从财务营运角度来考虑和分析如何确定输入和输出,进行整体解决方案设计。 融资需求分析与计划制定 功能点: 现金流预测工具:集成历史数据和业务计划,自动生成未来1…...

2. 【.NET Aspire 从入门到实战】--理论入门与环境搭建--.NET Aspire 概览
在当今快速发展的软件开发领域,构建高效、可靠且易于维护的云原生应用程序已成为开发者和企业的核心需求。.NET Aspire 作为一款专为云原生应用设计的开发框架,旨在简化分布式系统的构建和管理,提供了一整套工具、模板和集成包,帮…...

【Elasticsearch】allow_no_indices
- **allow_no_indices 参数的作用**: 该参数用于控制当请求的目标索引(通过通配符、别名或 _all 指定)不存在或已关闭时,Elasticsearch 的行为。 - **默认行为**: 如果未显式设置该参数,默认值为 …...

26.useScript
在 Web 应用开发中,动态加载外部脚本是一个常见需求,特别是在需要集成第三方库或服务时。然而,在 React 应用中管理脚本加载可能会变得复杂。useScript 钩子提供了一种优雅的方式来处理外部脚本的加载、错误处理和清理,使得在 Rea…...

跨域问题和解决方案
跨域问题及解决方案 同源策略及跨域问题 同源策略是一套浏览器安全机制,当一个源的文档和脚本,与另一个源的资源进行通信时,同源策略就会对这个通信做出不同程度的限制。 简单来说,同源策略对 同源资源 放行,对 异源…...

springboot中路径默认配置与重定向/转发所存在的域对象
Spring Boot 是一种简化 Spring 应用开发的框架,它提供了多种默认配置和方便的开发特性。在 Web 开发中,路径配置和请求的重定向/转发是常见操作。本文将详细介绍 Spring Boot 中的路径默认配置,并解释重定向和转发过程中存在的域对象。 一、…...
)
【OS】AUTOSAR架构下的Interrupt详解(下篇)
目录 3.代码分析 3.1中断配置代码 3.2 OS如何找到中断处理函数 3.3 Os_InitialEnableInterruptSources实现 3.4 Os_EnableInterruptSource 3.5 DisableAllInterrupts 3.5.1Os_IntSuspendCat1 3.5.2 Os_InterruptDisableAllEnter 3.5.3 Disable二类中断 3.5.4 Disable一…...