Python(Pandas)数据分析学习
1.Pandas基本构成
引入Pandas
import pandas as pd1.Series 行
对应Excel中的一行数据,一维数据
定义Series
# 第一个参数是具体数据
# 第二个参数的对应的索引下标
# 第三个参数的行名称
data = pd.Series([1,2,3,4,5], index=['a','b','c','d','e'], name='data')
print(data)
# 输出Series对象的索引
print(data.index)
# 输出Series对象里面索引为 'a'的值
print(data['a'])执行结果:

2.DataFrame 表
对应Excel表,二维数据,类似于二维数组,由Series组成
定义DataFrame
# 定义DataFrame
# 先定义单独的每一行
s1 = pd.Series([1, 2, 3, 4, 5], index=['a','b','c','d','e'], name='A')
s2 = pd.Series([10, 20, 30, 40, 50], index=['a','b','c','d','e'], name='B')
s3 = pd.Series([100, 200, 300, 400, 500], index=['a','b','c','d','e'], name='C')
df = pd.DataFrame([s1, s2, s3])
print(df)
# 字典方式定义
# 输出结果与上方 行列颠倒
df2 = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})
print(df2)执行结果:

2.Pandas基本操作
1.读取写入数据
1.读取数据
import pandas as pd# 读取
# pandas读取时会自动跳过空行
# header参数可以指定跳过哪一行
# 读取时会产生默认的索引
file_path = "test.xlsx"
data = pd.read_excel(file_path, header=2, sheet_name="Sheet1")
print(data)# index_col 指定索引列
# dtype 转换指定列的数据类型
data1 = pd.read_excel(file_path, sheet_name="Sheet1", index_col='name', dtype={"age": int})
print(data1)执行结果

2.写入数据
# 写入
df = pd.DataFrame({"id": [1, 2, 3, 4, 5],"name": ["张三", "李四", "王五", "刘大", "关二"],"age": [10, 20, 30, 40, 50]
})
# 自定义索引
df = df.set_index("id")
df.to_excel("test.xlsx")如果写入时to_excel方法报错,则下载openpyxl解决
from openpyxl import Workbook执行结果:

2.对数据进行排序
import pandas as pd# 读取文件
people = pd.read_excel('test.xlsx', index_col="id")
# by 根据哪一列进行排序
# inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
# ascending 是否按照升序排序,默认升序,False为降序
# na_position 设定缺失值的显示位置 first lase
people.sort_values(by="age", inplace=True, ascending=False, na_position="first")
print(people)# 根据多个列进行排序
peoples = pd.read_excel('test.xlsx', index_col="id")
peoples.sort_values(by=["age", "name"], ascending=[True, False], inplace=True)
print(peoples)3.数据过滤
读取列或行数据时,其索引必须存在,否则报错
import pandas as pdpeople = pd.read_excel("test.xlsx", index_col="id")
# 判断数据行中是否有缺省值
print(people.isnull().any)
# 删除数据中的缺省值
people.dropna(inplace=True)
# 过滤数据中符合条件的数据
# [] 里面直接写条件
result = people[(people["name"] == "张三") & (people["age"] >= 10)]
print(result)# 定义一个函数
def age_10_to_50(a):return 10 <= a <= 50def score_10_to_50(a):return 0 <= a <= 60# loc方法是读取文件行列数据的方法,可以读取指定行,列,区域的数据
result_10_to_50 = people[people["name"] == "张三"].loc[people["age"].apply(age_10_to_50)].loc[people["score"].apply(score_10_to_50)]
print(result_10_to_50)
4.Excel数据拆分
本质还是使用了字符串的split方法
import pandas as pdpeople = pd.read_excel("test.xlsx", index_col="id")# 将name拆分
df = people["name"].str.split(expand=True)
# 保存拆分出来的数据 保存前全部表中有这两列
people["姓氏"] = df[0]
people["名字"] = df[1]
print(people)5.多表联合操作
import pandas as pdstudent = pd.read_excel("test.xlsx")
score = pd.read_excel("test1.xlsx")
age = pd.read_excel("test2.xlsx")# how 指定连接方式,默认inner 内连, left,right,outer 类似数据库多表查询
# on 用于连接的列名,必须同时存在与左右两个DataFrame对象中
# left_on,right_on 左右测用于连接的列
# left_index,right_index 如果为True,则使用左右侧的行索引作为其连接键
# sort 是否按照字典顺序通过连接键对结果DataFrame排序
# suffixes 用于重叠列的字符串后缀元组
# copy 是否总是从传递的DataFrame对象复制数据,默认为True
# indicator 如果为True,则添加一个名为_merge的特殊列,显示每列的合并信息
# fillna() 如果单元格为空,则填充指定数据
table = student.merge(score, how='left', on="id").fillna(0)
table["分数"] = table["分数"].astype(int)table2 = table.merge(age, how='left', on="id").fillna(0)
table2["年龄"] = table2["年龄"].astype(int)print(table2)6.统计运算
import pandas as pddf = pd.DataFrame([[1, 2, 3], [2, 2, 3], [3, 3, 3]], columns=['A', 'B', 'C'])
print(df)# 求某一行平均数或列
# mean 计算平均值方法
# axis 0:按列计算 1:按行计算
# skipna:是否忽略缺失值,默认为True
print(df.mean(axis=1))
# drop 删除指定标签的行或列
# axis 0:删除索引 1:删除列
# inplace False:返回一个副本 True:在原地删除并返回None
print(df.drop("A", axis=1))people = pd.read_excel("test1.xlsx")
columns_name = ["A", "B", "C"]
# 对行求平均值,总和
row_mean = people[columns_name].mean(axis=1)
row_sum = people[columns_name].sum(axis=1)
total = "总分"
average = "平均分"
people[total] = row_sum
people[average] = row_mean
columns_name += [total, average]
# 对列求平均值
col_mean = people[columns_name].mean()
# 给结果行中加个名字
col_mean["名称"] = "Summary"
people = people._append(col_mean, ignore_index=True)
print(people)7.数据可视化
设置字体部分很重要
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt# 设置显示中文字体 黑体 重要
matplotlib.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符合
matplotlib.rcParams["axes.unicode_minus"] = False# 解决matplotlib版本与pandas冲突
matplotlib.use("TkAgg")
# matplotlib 常用绘图工具students = pd.read_excel("test1.xlsx")
name = "名称"
score = "分数"
age = "年龄"
students.sort_values(by=score, inplace=True, ascending=False)
# 绘制图片
plt.bar(students[name], students[score], color="blue")
# 设置标题
plt.title("Student Score", fontsize=16)
# 设置X轴与Y轴的名称
plt.xlabel("Name", fontsize=16)
plt.ylabel("Score", fontsize=16)
# 将指定的列的数据旋转90度
plt.xticks(students[name], rotation=90, fontsize=16)
plt.tight_layout()
# 展示
plt.show()# 绘制折线图 上方为柱状图
students.plot(y=[score, age])
plt.title("学生的分数")
plt.xticks(students.index)
plt.show()# 散点图
students.plot.scatter(x=score, y=age)
plt.title("学生的分数年龄")
plt.ylabel("分数")
plt.xlabel("年龄")
plt.show()输出结果:
柱状图部分

折线图部分

散点图部分

8.读写word文档
from docx import Document# 创建文件
document = Document()
document.save("new.docx")# 读取文件
doc = Document("new.docx")
# 循环段落
for paragraph in doc.paragraphs:print(paragraph.text)# 将文字写入到word文档中
doc1 = Document()
# 添加标题
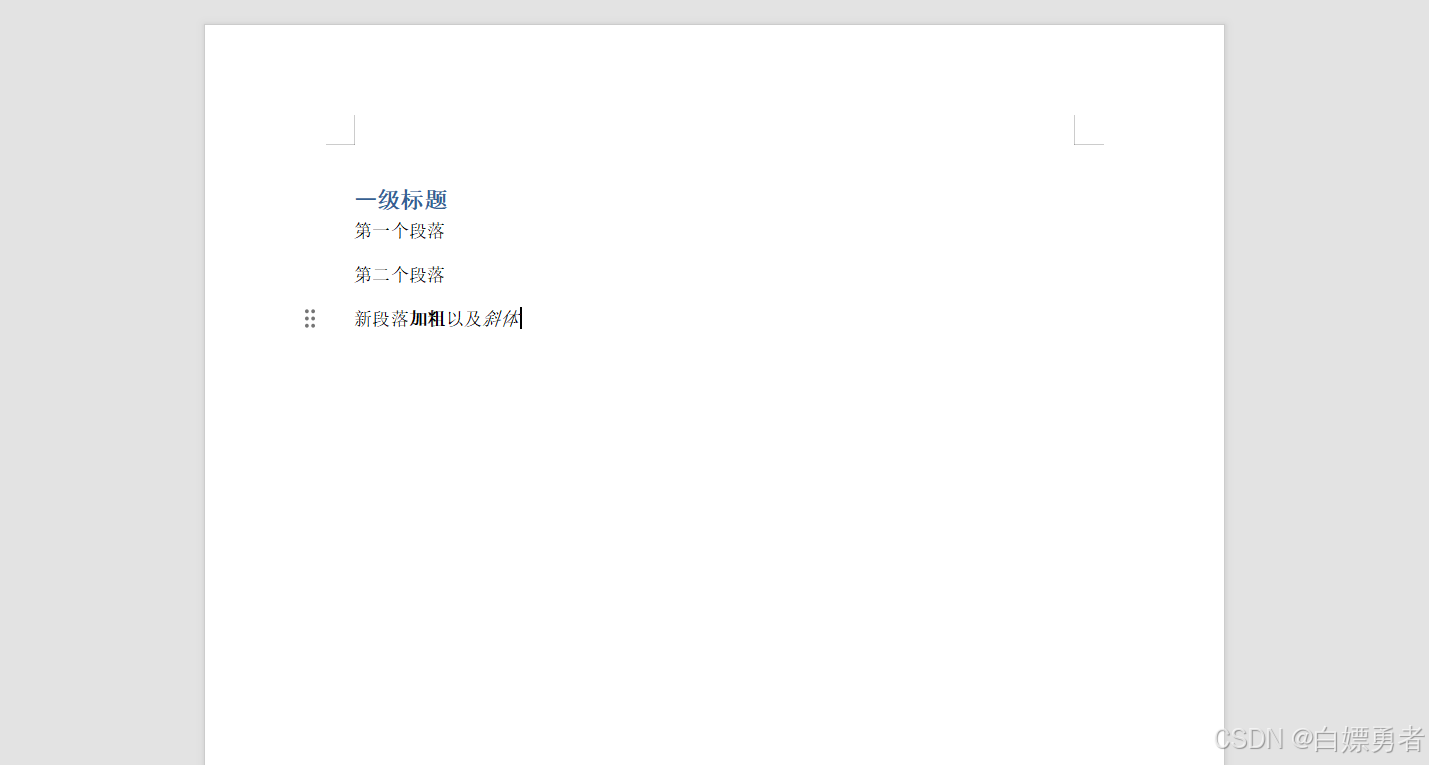
doc1.add_heading("一级标题", level=1)
# 添加段落
p2 = doc1.add_paragraph("第二个段落")
p1 = p2.insert_paragraph_before("第一个段落")
p3 = doc1.add_paragraph("新段落")
# 增加文字内容
p3.add_run("加粗").bold = True
p3.add_run("以及")
p3.add_run("斜体").italic = True
doc1.save("new1.docx")输出结果:
9.word写入图片
from docx import Document
from docx.shared import Inchesdoc = Document()
doc.add_picture("p.png", width=Inches(1.25))
doc.save("new2.docx")10.word写入表格
from docx import Document
from docx.shared import Inchesdoc = Document()
# 创建table 设置行列数量
table = doc.add_table(rows=3, cols=3)
# 设置table的样式
table.style = "Table Grid"
# 获取单元格
cell = table.cell(0, 1)
# 设置单元格文本
cell.text = "第一行第二列"
p = cell.paragraphs[0]
run = p.add_run()
run.add_picture("img.png", width=Inches(2))doc.save("new3.docx")

11.xlrd读取excel表格数据
注意版本使用
import xlrd# xlrd新版本只支持读取xls文件,读取xlsx文件需要降为1.2.0版本
data = xlrd.open_workbook("test1.xlsx")
print(data)# 获取第一个sheet页 三种方法
sheet = data.sheets()[0]
sheet = data.sheet_by_index(0)
sheet = data.sheet_by_name("Sheet1")
print(sheet)相关文章:
数据分析学习)
Python(Pandas)数据分析学习
1.Pandas基本构成 引入Pandas import pandas as pd 1.Series 行 对应Excel中的一行数据,一维数据 定义Series # 第一个参数是具体数据 # 第二个参数的对应的索引下标 # 第三个参数的行名称 data pd.Series([1,2,3,4,5], index[a,b,c,d,e], namedata) print(d…...
--内存管理与垃圾回收机制详解)
JavaScript系列(53)--内存管理与垃圾回收机制详解
JavaScript内存管理与垃圾回收机制详解 🧹 今天,让我们深入探讨JavaScript的内存管理与垃圾回收机制。理解这些机制对于编写高性能、无内存泄漏的JavaScript应用至关重要。 内存管理基础概念 🌟 💡 小知识:JavaScrip…...

每日一题——用两个栈实现队列
用两个栈实现队列 题目描述数据范围示例 代码实现1. 代码思路push 操作:pop 操作: 2. 代码实现3. 代码解析4. 时间复杂度与空间复杂度 总结 题目描述 用两个栈来实现一个队列,使用 n 个元素来完成 n 次在队列尾部插入整数(push)和 n 次在队列…...

DeepSeek与OpenAI:谁是AI领域的更优选择?
在人工智能领域,DeepSeek和OpenAI是两个备受瞩目的玩家。尽管OpenAI凭借其强大的GPT系列模型在全球范围内获得了广泛的认可,但DeepSeek凭借其独特的技术优势和创新理念,正在逐渐成为许多企业和开发者的新选择。本文将对DeepSeek和OpenAI进行详…...

【爬虫】JS逆向解决某药的商品价格加密
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

deepseek v3 搭建个人知识库
目录 deepseek-r1本地部署,这个比较好,推荐 Chatbox连接ollama服务 知乎教程,需要注册: deepseek-r1本地部署,这个比较好,推荐 公司数据不泄露,DeepSeek R1本地化部署web端访问个人知识库搭建…...

ETCD集群证书生成
安装cfssl工具配置CA证书请求文件创建CA证书创建CA证书策略配置etcd证书请求文件生成etcd证书 继续上一篇文章《负载均衡器高可用部署》下面介绍一下etcd证书生成配置。其中涉及到的ip地址和证书基本信息请替换成你自己的信息。 安装cfssl工具 下载cfssl安装包 https://github…...

【软件测试项目实战】淘宝网订单管理功能
一、测试功能模块分析 选择淘宝网订单管理功能进行测试,核心子功能包含: 订单创建(商品结算、地址选择)订单状态变更(待付款、已付款、已发货、已收货、退款中)订单修改(地址修改、商品数量修…...
)
扩散模型(一)
在生成领域,迄今为止有几个主流的模型,分别是 GAN, VAE,Flow 以及 Diffusion 模型。 GAN:GAN 的学习机制是对抗性学习,通过生成器和判别器的对抗博弈来进行学习,这种竞争机制促使生成器不断提升生成能力&a…...

EF Core与ASP.NET Core的集成
目录 分层项目中EF Core的用法 数据库的配置 数据库迁移 步骤汇总 注意: 批量注册上下文 分层项目中EF Core的用法 创建一个.NET类库项目BooksEFCore,放实体等类。NuGet:Microsoft.EntityFrameworkCore.RelationalBooksEFCore中增加实…...
)
深入解析“legit”的地道用法——从俚语到正式表达:Sam Altman用来形容DeepSeek: legit invigorating(真的令人振奋)
深入解析“legit”的地道用法——从俚语到正式表达 一、引言 在社交媒体、科技圈甚至日常对话中,我们经常会看到或听到“legit”这个词。比如最近 Sam Altman 在 X(原 Twitter)上发的一条帖子中写道: we will obviously deliver …...
)
玩转ChatGPT:DeepSeek测评(科研思路梳理)
一、写在前面 DeepSeek-R1出圈了,把OpenAI的o3-mini模型都提前逼上线了(还免费使用)。 都号称擅长深度推理,那么对于科研牛马的帮助有多大呢? 我连夜试一试。 二、科研思路梳理 有时候我们牛马们做了一堆结果以后&…...
)
实验9 JSP访问数据库(二)
实验9 JSP访问数据库(二) 目的: 1、熟悉JDBC的数据库访问模式。 2、掌握预处理语句的使用 实验要求: 1、使用Tomcat作为Web服务器 2、通过JDBC访问数据库,实现增删改查功能的实现 3、要求提交实验报告,将代…...

CMake项目编译与开源项目目录结构
Cmake 使用简单方便,可以跨平台构建项目编译环境,尤其比直接写makefile简单,可以通过简单的Cmake生成负责的Makefile文件。 如果没有使用cmake进行编译,需要如下命令:(以muduo库echo服务器为例)…...

PyCharm中使用Ollama安装和应用Deepseek R1模型:完整指南
引言 人工智能和大型语言模型正在改变我们与技术交互的方式。Deepseek R1是一个强大的AI模型,而Ollama则是一个让我们能够轻松在本地运行这些模型的工具。本文将指导您如何使用Ollama安装Deepseek R1模型,并在PyCharm中创建一个简单的聊天应用。 © ivwdcwso (ID: u0121…...

编程AI深度实战:大模型知识一文打尽
系列文章: 编程AI深度实战:私有模型deep seek r1,必会ollama-CSDN博客 编程AI深度实战:自己的AI,必会LangChain-CSDN博客 编程AI深度实战:给vim装上AI-CSDN博客 编程AI深度实战:火的编程AI&…...

012-51单片机CLD1602显示万年历+闹钟+农历+整点报时
1. 硬件设计 硬件是我自己设计的一个通用的51单片机开发平台,可以根据需要自行焊接模块,这是用立创EDA画的一个双层PCB板,所以模块都是插针式,不是表贴的。电路原理图在文末的链接里,PCB图暂时不选择开源。 B站上传的…...

基于springboot+vue的哈利波特书影音互动科普网站
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

MySQL5.5升级到MySQL5.7
【卸载原来的MySQL】 cmd打开命令提示符窗口(管理员身份)net stop mysql(先停止MySQL服务) 3.卸载 切换到原来5.5版本的bin目录,输入mysqld remove卸载服务 测试mysql -V查看Mysql版本还是5.5 查看了环境变量里的…...
)
列表标签(无序列表、有序列表)
无序列表 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </head><…...
)
【数据结构】_链表经典算法OJ:分割链表(力扣—中等)
目录 1. 题目描述及链接 2. 解题思路 2.1 思路1 2.2 思路2 2.3 思路3(本题采取该解法) 3. 题解程序 1. 题目描述及链接 题目链接:面试题 02.04. 分割链表 - 力扣(LeetCode) 题目描述: 给你一个链表…...

深入核心:一步步手撕Tomcat搭建自己的Web服务器
介绍: servlet:处理 http 请求 tomcat:服务器 Servlet servlet 接口: 定义 Servlet 声明周期初始化:init服务:service销毁:destory 继承链: Tomcat Tomcat 和 servlet 原理&#x…...

ASP.NET Core与配置系统的集成
目录 配置系统 默认添加的配置提供者 加载命令行中的配置。 运行环境 读取方法 User Secrets 注意事项 Zack.AnyDBConfigProvider 案例 配置系统 默认添加的配置提供者 加载现有的IConfiguration。加载项目根目录下的appsettings.json。加载项目根目录下的appsettin…...

在 Ubuntu 上安装 Node.js 23.x
在 Ubuntu 上安装 Node.js 23.x 前提条件安装步骤1. 下载设置脚本2. 运行设置脚本3. 安装 Node.js4. 验证安装 参考链接总结 在现代 web 开发中,Node.js 是一个不可或缺的工具。它提供了一个强大的 JavaScript 运行时环境,使得开发人员可以在服务器端使用…...

《 C++ 点滴漫谈: 二十五 》空指针,隐秘而危险的杀手:程序崩溃的真凶就在你眼前!
摘要 本博客全面解析了 C 中指针与空值的相关知识,从基础概念到现代 C 的改进展开,涵盖了空指针的定义、表示方式、使用场景以及常见注意事项。同时,深入探讨了 nullptr 的引入及智能指针在提升代码安全性和简化内存管理方面的优势。通过实际…...

SpringBoot中Excel表的导入、导出功能的实现
文章目录 一、easyExcel简介二、Excel表的导出2.1 添加 Maven 依赖2.2 创建导出数据的实体类4. 编写导出接口5. 前端代码6. 实现效果 三、excel表的导出1. Excel表导入的整体流程1.1 配置文件存储路径 2. 前端实现2.1 文件上传组件 2.2 文件上传逻辑3. 后端实现3.1 文件上传接口…...

CodeGPT使用本地部署DeepSeek Coder
目前NV和github都托管了DeepSeek,生成Key后可以很方便的用CodeGPT接入。CodeGPT有三种方式使用AI,分别时Agents,Local LLMs(本地部署AI大模型),LLMs Cloud Model(云端大模型,从你自己…...

SpringBoot 整合 SpringMVC:配置嵌入式服务器
修改和 server 相关的配置(ServerProperties): server.port8081 server.context‐path/tx server.tomcat.uri‐encodingUTF‐8 注册 Servlet 三大组件:Servlet、Fileter、Listener SpringBoot 默认是以 jar 包的方式启动嵌入式的 Servlet 容器来启动 Spr…...

浅谈Linux 权限、压缩、进程与服务
概述 放假回家,对Linux系统的一些知识进行重新的整理,做到温故而知新,对用户权限管理、文件赋权、压缩文件、进程与服务的知识进行了一次梳理和总结。 权限管理 Linux最基础的权限是用户和文件,先了解基础的用户权限和文件权限…...

LeetCode 0040.组合总和 II:回溯 + 剪枝
【LetMeFly】40.组合总和 II:回溯 剪枝 力扣题目链接:https://leetcode.cn/problems/combination-sum-ii/ 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates…...

springCload快速入门
原作者:3. SpringCloud - 快速通关 前置知识: Java17及以上、MavenSpringBoot、SpringMVC、MyBatisLinux、Docker 1. 分布式基础 1.1. 微服务 微服务架构风格,就像是把一个单独的应用程序开发为一套小服务,每个小服务运行在自…...

实现使用K210单片机进行猫脸检测,并在检测到猫脸覆盖屏幕50%以上时执行特定操作
要实现使用K210单片机进行猫脸检测,并在检测到猫脸覆盖屏幕50%以上时执行特定操作,以及通过WiFi上传图片到微信小程序,并在微信小程序中上传图片到开发板进行训练,可以按照以下步骤进行: 1. 硬件连接 确保K210开发板…...

FlashAttention v1 论文解读
论文标题:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness 论文地址:https://arxiv.org/pdf/2205.14135 FlashAttention 是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。…...
)
Kafka 副本机制(包含AR、ISR、OSR、HW 和 LEO 介绍)
文章目录 Kafka 副本机制(包含AR、ISR、OSR、HW 和 LEO 介绍)1. 副本的基本概念2. 副本同步和一致性2.1 AR(Assigned Replicas)2.2 ISR(In-Sync Replicas)2.3 OSR(Out-of-Sync Replicas…...

QtCreator在配置Compilers时,有一个叫ABI的选项,那么什么是ABI?
问题提出 QtCreator在配置Compilers时,有一个叫ABI的选项,那么什么是ABI? ABI(Application Binary Interface)介绍 ABI(Application Binary Interface,应用二进制接口)是指应用程序与操作系统或其他程序…...

ResNet--深度学习中的革命性网络架构
一、引言 在深度学习的研究和应用中,网络架构的设计始终是一个关键话题。随着计算能力和大数据的不断提升,深度神经网络逐渐成为解决复杂任务的主流方法。然而,随着网络层数的增加,训练深度神经网络往往面临梯度消失或梯度爆炸的…...

【 软件测试项目实战】 以淘宝网购物车管理功能为例
一、测试功能模块分析 选择淘宝网购物车管理功能进行测试,核心子功能包含: 单商品添加/删除购物车商品数量修改多商品勾选与批量删除失效商品识别与处理 二、测试用例设计方法论应用 1. 等价类划分法(商品添加操作) 分析&…...

Go 中 defer 的机制
文章目录 Go 语言中 defer 的底层机制与实战解析一、defer 的执行顺序:后进先出(LIFO)示例 :多个 defer 的执行顺序 二、defer 的参数预计算:值拷贝的陷阱示例 :参数预计算的影响 三、defer 与闭包…...

智能小区物业管理系统推动数字化转型与提升用户居住体验
内容概要 在当今快速发展的社会中,智能小区物业管理系统的出现正在改变传统的物业管理方式。这种系统不仅仅是一种工具,更是一种推动数字化转型的重要力量。它通过高效的技术手段,将物业管理与用户居住体验紧密结合,无疑为社区带…...

【memgpt】letta 课程4:基于latta框架构建MemGpt代理并与之交互
Lab 3: Building Agents with memory 基于latta框架构建MemGpt代理并与之交互理解代理状态,例如作为系统提示符、工具和agent的内存查看和编辑代理存档内存MemGPT 代理是有状态的 agents的设计思路 每个步骤都要定义代理行为 Letta agents persist information over time and…...

HTML DOM 对象
HTML DOM 对象 引言 HTML DOM(文档对象模型)是现代网页开发的核心技术之一。DOM 将 HTML 或 XML 文档结构化,使其成为可编程的对象。通过 DOM,开发者可以轻松地操作网页内容、样式和结构。本文将详细介绍 HTML DOM 对象的相关知识,包括其概念、结构、操作方法以及在实际…...

高温环境对电机性能的影响与LabVIEW应用
电机在高温环境下的性能可能受到多种因素的影响,尤其是对于持续工作和高负荷条件下的电机。高温会影响电机的效率、寿命以及可靠性,导致设备出现过热、绝缘损坏等问题。因此,在设计电机控制系统时,特别是在高温环境下,…...

【09-电源线布线与覆铜 GND与转孔】
走线 从接触点处走线 TYPEC画线-加铜皮 1.关闭不需要的层(锡膏层和阻焊层和机械层) 紫色阻焊层 L: 顶层锡膏 底层锡膏 顶层阻焊 底层阻焊 2.修改线框或者贴铜 3.顶层走不过去:打四个孔 核心:走线-打孔-贴铜皮 设置孔的参数:大小和人为盖有 挨一下其他才会有网络 4个孔也要贴…...
:反转链表)
算法题(48):反转链表
审题: 需要我们将链表反转并返回头结点地址 思路: 一般在面试中,涉及链表的题会主要考察链表的指向改变,所以一般不会允许我们改变节点val值。 这里是单向链表,如果要把指向反过来则需要同时知道前中后三个节点&#x…...
)
C++ 泛型编程指南02 (模板参数的类型推导)
文章目录 一 深入了解C中的函数模板类型推断什么是类型推断?使用Boost TypeIndex库进行类型推断分析示例代码关键点解析 2. 理解函数模板类型推断2.1 指针或引用类型2.1.1 忽略引用2.1.2 保持const属性2.1.3 处理指针类型 2.2 万能引用类型2.3 传值方式2.4 传值方式…...

穷举vs暴搜vs深搜vs回溯vs剪枝系列一>单词搜索
题解如下 题目:解析决策树:代码设计: 代码: 题目: 解析 决策树: 代码设计: 代码: class Solution {private boolean[][] visit;//标记使用过的数据int m,n;//行,列char…...
)
9 点结构模块(point.rs)
一、point.rs源码 use super::UnknownUnit; use crate::approxeq::ApproxEq; use crate::approxord::{max, min}; use crate::length::Length; use crate::num::*; use crate::scale::Scale; use crate::size::{Size2D, Size3D}; use crate::vector::{vec2, vec3, Vector2D, V…...
)
基于vue船运物流管理系统设计与实现(源码+数据库+文档)
船运物流管理系统目录 目录 基于springboot船运物流管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员登录 2、货运单管理 3、公告管理 4、公告类型管理 5、新闻管理 6、新闻类型管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考…...

海思ISP开发说明
1、概述 ISP(Image Signal Processor)图像信号处理器是专门用于处理图像信号的硬件或处理单元,广泛应用于图像传感器(如 CMOS 或 CCD 传感器)与显示设备之间的信号转换过程中。ISP通过一系列数字图像处理算法完成对数字…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.12 连续数组:为什么contiguous这么重要?
2.12 连续数组:为什么contiguous这么重要? 目录 #mermaid-svg-wxhozKbHdFIldAkj {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-wxhozKbHdFIldAkj .error-icon{fill:#552222;}#mermaid-svg-…...