将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo

本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。
在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器。
我们已经上传了一些 OneLake 文档并将其索引到 Elasticsearch 中以供搜索。但是,这仅适用于一次性上传。如果我们想要同步数据,那么我们需要开发一个更复杂的系统。
幸运的是,Elastic 有一个连接器框架可用于开发满足我们需求的自定义连接器:
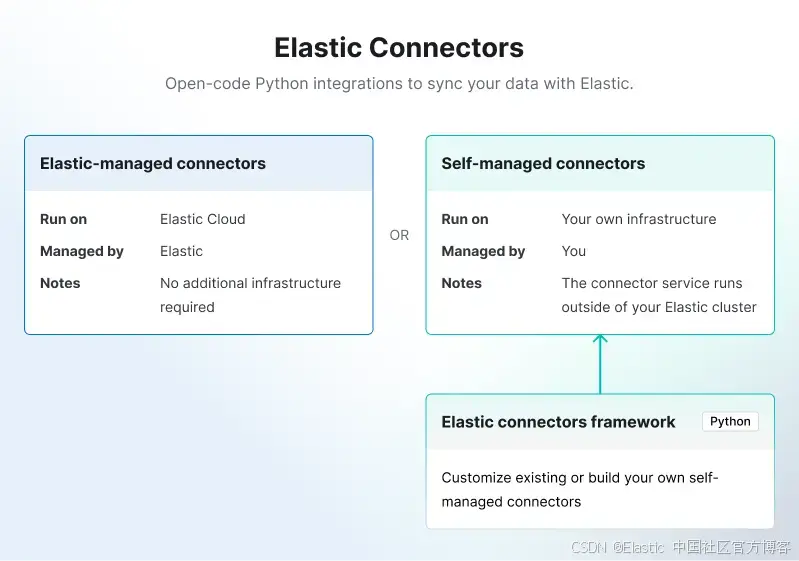
我们现在将根据本文制作一个 OneLake 连接器:如何为 Elasticsearch 创建自定义连接器。
步骤
- 连接器引导
- 实现 BaseDataSource 类
- 身份验证
- 运行连接器
- 配置计划
连接器引导
背景信息:Elastic 连接器分为两种类型:
- Elastic 托管连接器:完全由 Elastic Cloud 托管和运行。
- 自托管连接器:由用户自行托管,必须部署在你的基础设施中。
自定义连接器属于 “连接器客户端” 类别,因此我们需要下载并部署连接器框架。
首先,克隆连接器的代码库:
git clone https://github.com/elastic/connectors现在在 requirements/framework.txt 文件末尾添加你将使用的依赖项。在本例中:
azure-identity==1.19.0
azure-storage-file-datalake==12.17.0这样,存储库就完成了,我们可以开始编码了。
实现 BaseDataSource 类
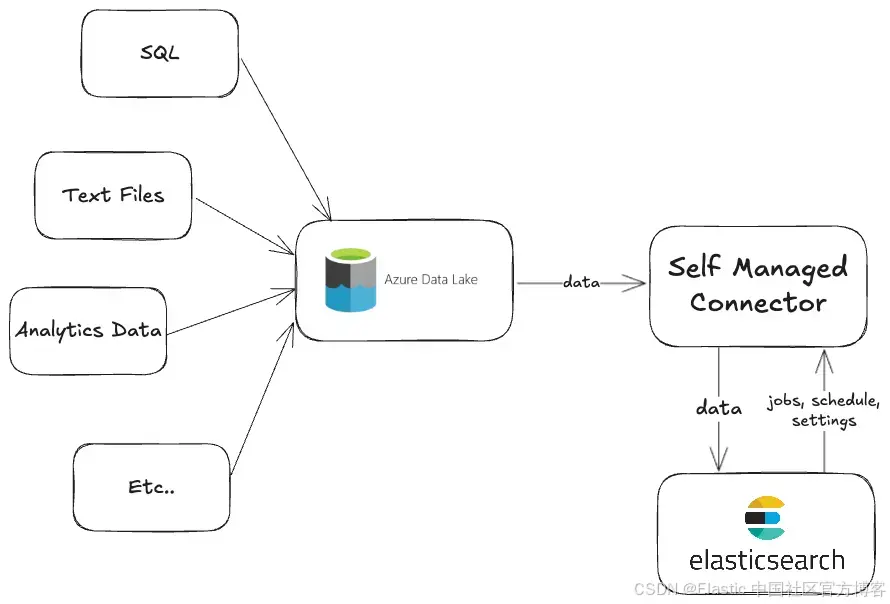
你可以在此存储库中找到完整的工作代码。
我们将介绍 onelake.py 文件中的核心部分。
在导入和类声明之后,我们必须定义将捕获配置参数的 __init__ 方法。
"""OneLake connector to retrieve data from datalakes"""from functools import partialfrom azure.identity import ClientSecretCredential
from azure.storage.filedatalake import DataLakeServiceClientfrom connectors.source import BaseDataSourceACCOUNT_NAME = "onelake"class OneLakeDataSource(BaseDataSource):"""OneLake"""name = "OneLake"service_type = "onelake"incremental_sync_enabled = True# Here we can enter the data that we'll later need to connect our connector to OneLake.def __init__(self, configuration):"""Set up the connection to the azure base clientArgs:configuration (DataSourceConfiguration): Object of DataSourceConfiguration class."""super().__init__(configuration=configuration)self.tenant_id = self.configuration["tenant_id"]self.client_id = self.configuration["client_id"]self.client_secret = self.configuration["client_secret"]self.workspace_name = self.configuration["workspace_name"]self.data_path = self.configuration["data_path"]然后,你可以配置 UI 将显示的表单,使用返回配置字典的 get_default_configuration 方法填充这些参数。
# Method to generate the Enterprise Search UI fields for the variables we need to connect to OneLake.@classmethoddef get_default_configuration(cls):"""Get the default configuration for OneLakeReturns:dictionary: Default configuration"""return {"tenant_id": {"label": "OneLake tenant id","order": 1,"type": "str",},"client_id": {"label": "OneLake client id","order": 2,"type": "str",},"client_secret": {"label": "OneLake client secret","order": 3,"type": "str","sensitive": True, # To hide sensitive data like passwords or secrets},"workspace_name": {"label": "OneLake workspace name","order": 4,"type": "str",},"data_path": {"label": "OneLake data path","tooltip": "Path in format <DataLake>.Lakehouse/files/<Folder path>","order": 5,"type": "str",},"account_name": {"tooltip": "In the most cases is 'onelake'","default_value": ACCOUNT_NAME,"label": "Account name","order": 6,"type": "str",},}然后我们配置下载方法,并从 OneLake 文档中提取内容。
async def download_file(self, file_client):"""Download file from OneLakeArgs:file_client (obj): File clientReturns:generator: File stream"""try:download = file_client.download_file()stream = download.chunks()for chunk in stream:yield chunkexcept Exception as e:self._logger.error(f"Error while downloading file: {e}")raiseasync def get_content(self, file_name, doit=None, timestamp=None):"""Obtains the file content for the specified file in `file_name`.Args:file_name (obj): The file name to process to obtain the content.timestamp (timestamp, optional): Timestamp of blob last modified. Defaults to None.doit (boolean, optional): Boolean value for whether to get content or not. Defaults to None.Returns:str: Content of the file or None if not applicable."""if not doit:returnfile_client = await self._get_file_client(file_name)file_properties = file_client.get_file_properties()file_extension = self.get_file_extension(file_name)doc = {"_id": f"{file_client.file_system_name}_{file_properties.name}", # workspacename_data_path"name": file_properties.name.split("/")[-1],"_timestamp": file_properties.last_modified,"created_at": file_properties.creation_time,}can_be_downloaded = self.can_file_be_downloaded(file_extension=file_extension,filename=file_properties.name,file_size=file_properties.size,)if not can_be_downloaded:return docextracted_doc = await self.download_and_extract_file(doc=doc,source_filename=file_properties.name.split("/")[-1],file_extension=file_extension,download_func=partial(self.download_file, file_client),)return extracted_doc if extracted_doc is not None else doc为了让我们的连接器对框架可见,我们需要在 connectors/config.py 文件中声明它。为此,我们将以下代码添加到源中:
"sources": {..."onelake": "connectors.sources.onelake:OneLakeDataSource",...}身份验证
在测试连接器之前,我们需要获取 client_id, tenant_id 和 client_secret,我们将使用它们从连接器访问工作区。
我们将使用 service principals 作为身份验证方法。
Azure service principal 是为与应用程序、托管服务和自动化工具一起使用以访问 Azure 资源而创建的身份。
步骤如下:
- 创建应用程序并收集 client_id、tenant_id 和 client_secret
- 在工作区中启用 service principal
- 将 service principal 添加到工作区
你可以逐步遵循本教程。
准备好了吗?现在是测试连接器的时候了!
运行连接器
连接器准备好后,我们现在可以连接到我们的 Elasticsearch 实例。
转到: Search > Content > Connectors > New connector 并选择 Customized Connector
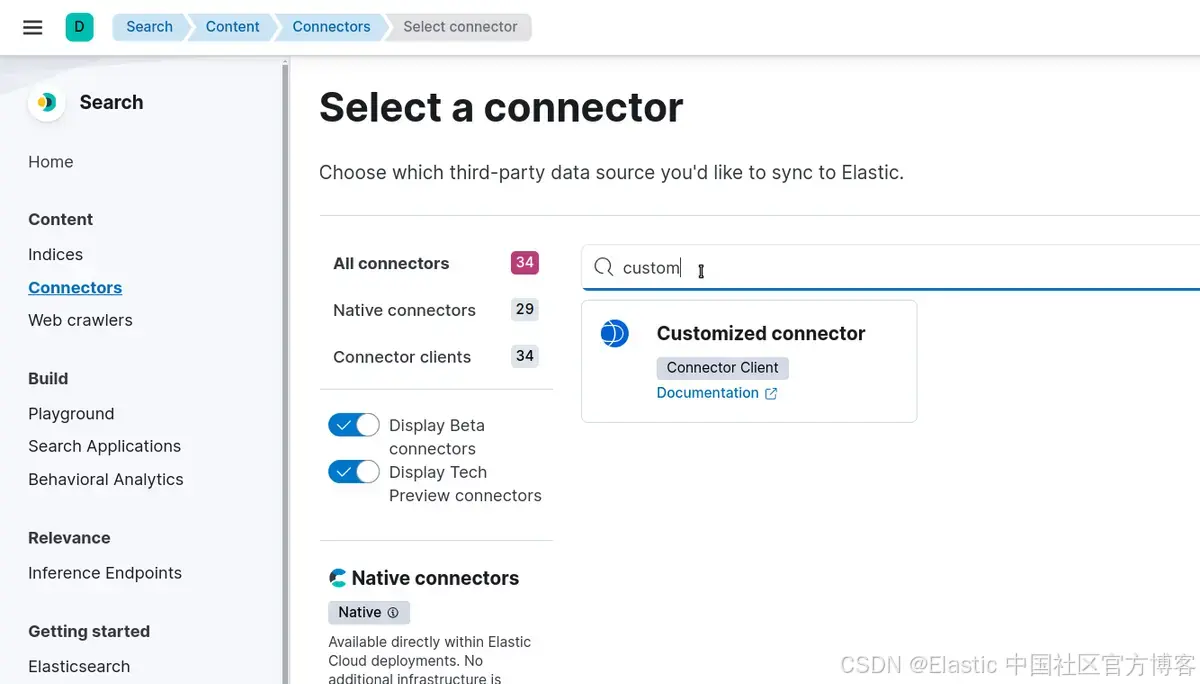
选择要创建的名称,然后选择 “Create and attach an index” 以创建与连接器同名的新索引。
你现在可以使用 Docker 运行它或从源代码运行它。在此示例中,我们将使用 “Run from source”。
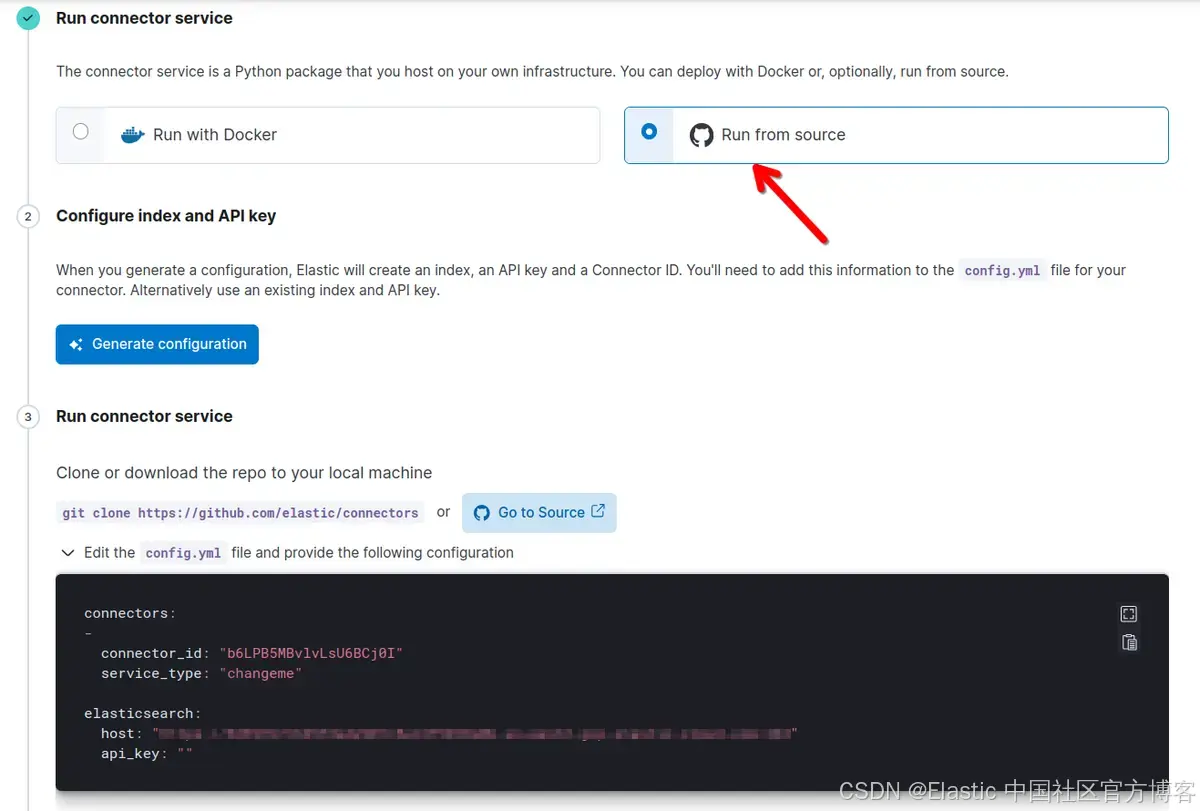
单击 “Generate Configuration”,然后将框中的内容粘贴到项目根目录中的 config.yml 文件中。在字段 service_type 上,你必须匹配 Connectors/config.py 中的连接器名称。在本例中,将 changeme 替换为 onelake。
现在,你可以使用以下命令运行连接器:
make install
make run如果连接器正确初始化,你应该在控制台中看到如下消息:

注意:如果出现兼容性错误,请检查你的连接器/版本文件并与你的 Elasticsearch 集群版本进行比较:与 Elasticsearch 的版本兼容性。我们建议保持连接器版本和 Elasticsearch 版本同步。在本文中,我们使用 Elasticsearch 和连接器版本 8.15。
如果一切顺利,我们的本地连接器将与我们的 Elasticsearch 集群通信,我们将能够使用我们的 OneLake 凭据对其进行配置:
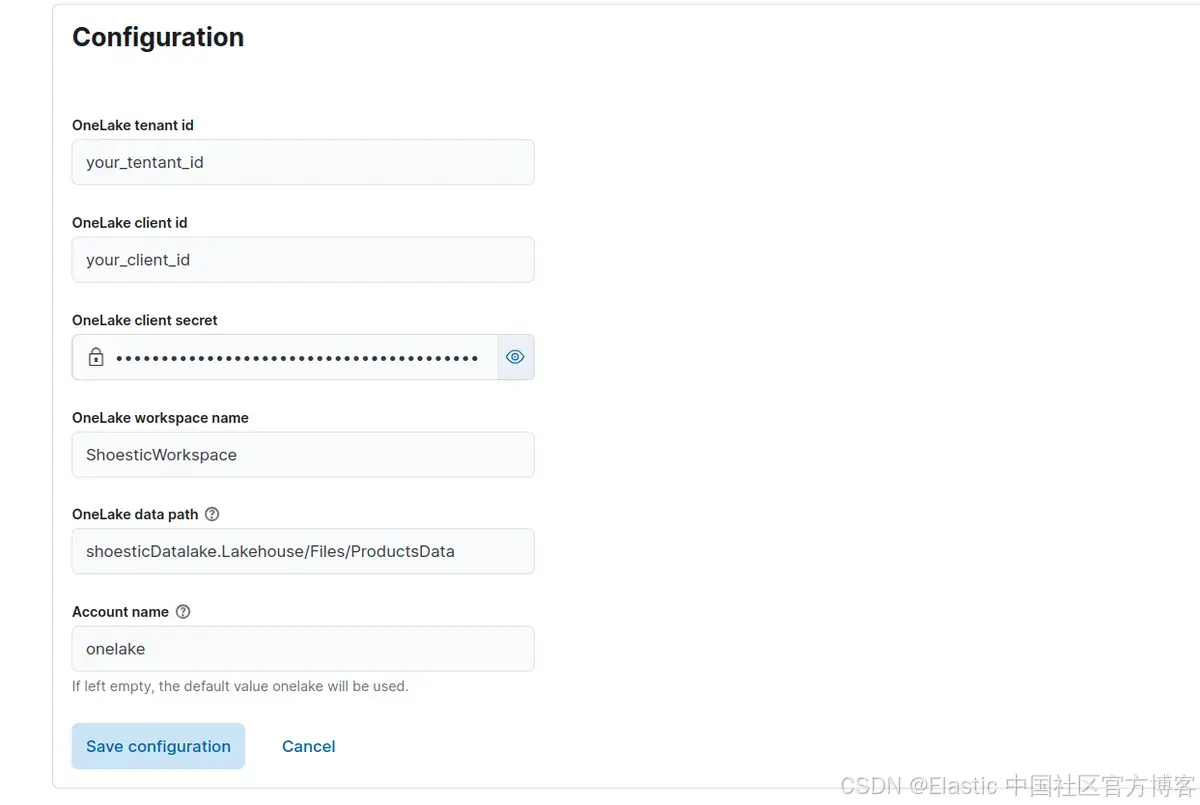
我们现在将索引来自 OneLake 的文档。为此,请单击 Sync > Full Content,运行完整内容同步:
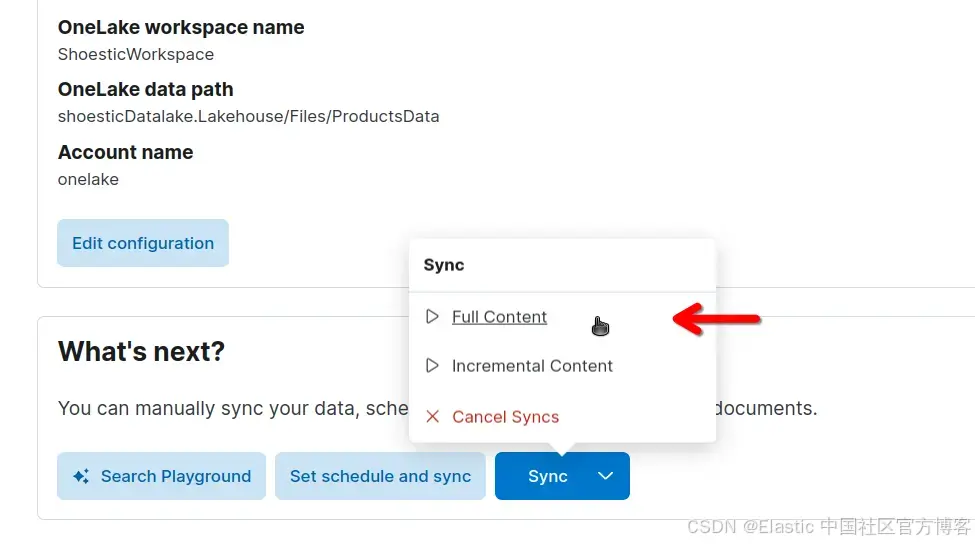
同步完成后,你应该在控制台中看到以下内容:

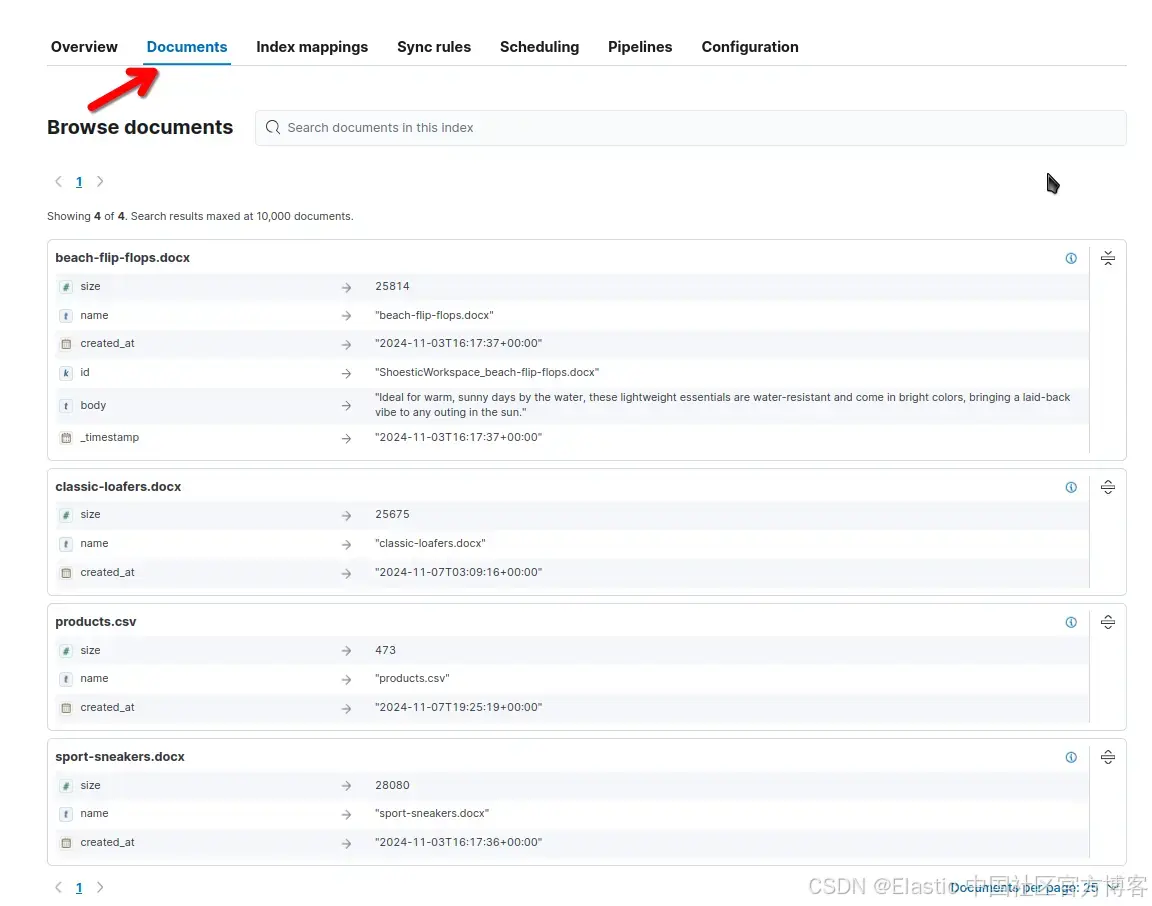
在企业搜索 UI 中,你可以单击 “Documents” 来查看已索引的文档:
配置计划
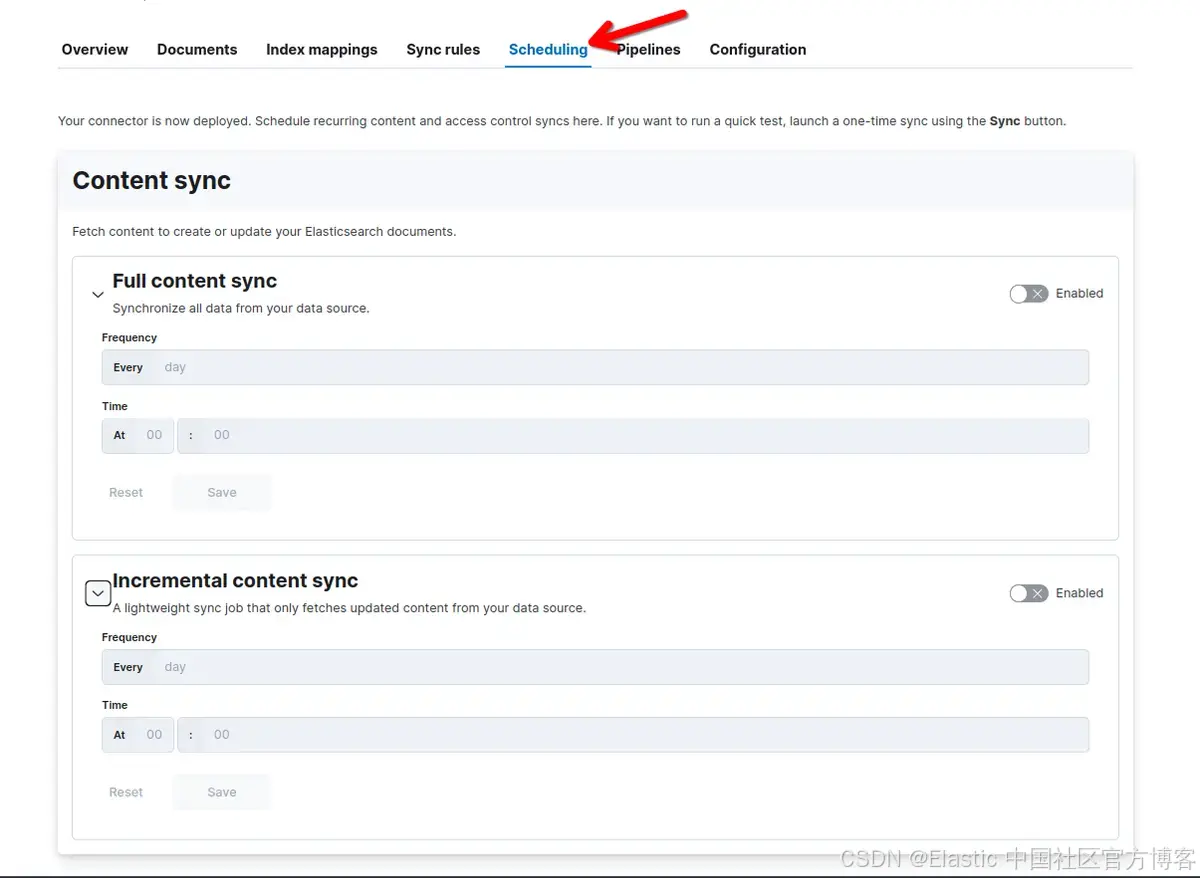
你可以根据需要使用 UI 安排定期内容同步,以使索引保持更新并与 OneLake 同步。
要配置计划同步,请转到 “Search > Content > Connectors,然后选择你的连接器。然后单击 “scheduling”:
或者,你可以使用允许 CRON 表达式的更新连接器调度 API。
结论
在第二部分中,我们通过使用 Elastic 连接器框架并开发我们自己的 OneLake 连接器来轻松与我们的 Elastic Cloud 实例通信,将我们的配置更进一步。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时开始!
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Indexing OneLake data into Elasticsearch - Part II - Elasticsearch Labs
相关文章:

将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

数据密码解锁之DeepSeek 和其他 AI 大模型对比的神秘面纱
本篇将揭露DeepSeek 和其他 AI 大模型差异所在。 目录 编辑 一本篇背景: 二性能对比: 2.1训练效率: 2.2推理速度: 三语言理解与生成能力对比: 3.1语言理解: 3.2语言生成: 四本篇小结…...

安心即美的生活方式
如果你的心是安定的,那么,外界也就安静了。就像陶渊明说的:心远地自偏。不是走到偏远无人的边荒才能得到片刻清净,不需要使用洪荒之力去挣脱生活的枷锁,这是陶渊明式的中国知识分子的雅量。如果你自己是好的男人或女人…...
)
基于深度学习的输电线路缺陷检测算法研究(论文+源码)
输电线路关键部件的缺陷检测对于电网安全运行至关重要,传统方法存在效率低、准确性不高等问题。本研究探讨了利用深度学习技术进行输电线路关键组件的缺陷检测,目的是提升检测的效率与准确度。选用了YOLOv8模型作为基础,并通过加入CA注意力机…...

手写防抖函数、手写节流函数
文章目录 1 手写防抖函数2 手写节流函数 1 手写防抖函数 函数防抖是指在事件被触发n秒后再执行回调,如果在这n秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。 function debou…...

UE 导入sbsar插件
Substance 3D 插件支持直接在 Unreal Engine 5 和 Unreal Engine 4 中使用 Substance 材质。无论您是在处理游戏、可视化,还是在移动设备、桌面或 XR 上进行部署,Substance 都能提供独特的体验,并优化功能以提高生产力。 Substance 资源平台…...

pytorch实现简单的情感分析算法
人工智能例子汇总:AI常见的算法和例子-CSDN博客 在PyTorch中实现中文情感分析算法通常涉及以下几个步骤:数据预处理、模型定义、训练和评估。下面是一个简单的实现示例,使用LSTM模型进行中文情感分析。 1. 数据预处理 首先,我…...

Baklib揭示内容中台实施最佳实践的策略与实战经验
内容概要 在当前数字化转型的浪潮中,内容中台的概念日益受到关注。它不再仅仅是一个内容管理系统,而是企业提升运营效率与灵活应对市场变化的重要支撑平台。内容中台的实施离不开最佳实践的指导,这些实践为企业在建设高效内容中台时提供了宝…...
)
11.[前端开发]Day11-HTML+CSS阶段练习(仿小米和考拉页面)
一、小米穿戴设备(浮动) 完整代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"vie…...
)
设计模式学习(二)
结构型 适配器模式 定义 它允许将一个类的接口转换成客户端期望的另一个接口。适配器模式通常用于使不兼容的接口能够一起工作。 适配器模式的角色 目标接口(Target):客户端期望的接口。适配者(Adaptee)ÿ…...

【Docker】快速部署 Nacos 注册中心
【Docker】快速部署 Nacos 注册中心 引言 Nacos 注册中心是一个用于服务发现和配置管理的开源项目。提供了动态服务发现、服务健康检查、动态配置管理和服务管理等功能,帮助开发者更轻松地构建微服务架构。 仓库地址 https://github.com/alibaba/nacos 步骤 拉取…...

大白话讲清楚embedding原理
Embedding(嵌入)是一种将高维数据(如单词、句子、图像等)映射到低维连续向量的技术,其核心目的是通过向量表示捕捉数据之间的语义或特征关系。以下从原理、方法和应用三个方面详细解释Embedding的工作原理。 一、Embe…...

pandas中的apply方法使用
apply 用于对 DataFrame 或 Series 中的数据进行逐行或逐列的操作。它可以接受一个函数(通常是 lambda 函数或自定义函数),并将该函数应用到每一行或每一列上。apply语法: DataFrame.apply(func, axis0, rawFalse, result_typeNo…...

简单易懂的倒排索引详解
文章目录 简单易懂的倒排索引详解一、引言 简单易懂的倒排索引详解二、倒排索引的基本结构三、倒排索引的构建过程四、使用示例1、Mapper函数2、Reducer函数 五、总结 简单易懂的倒排索引详解 一、引言 倒排索引是一种广泛应用于搜索引擎和大数据处理中的数据结构,…...

Nginx知识
nginx 精简的配置文件 worker_processes 1; # 可以理解为一个内核一个worker # 开多了可能性能不好events {worker_connections 1024; } # 一个 worker 可以创建的连接数 # 1024 代表默认一般不用改http {include mime.types;# 代表引入的配置文件# mime.types 在 ngi…...
:有关于VGG16 的结构展开的问题(1))
CNN的各种知识点(三):有关于VGG16 的结构展开的问题(1)
有关于VGG16 的结构展开的问题(1) 1. VGG16 的原生结构2. model.avgpool 的作用原生 VGG16 中没有 avgpool 层?代码中的 model.avgpool 是什么? 3. model.classifier 的作用原生 VGG16 的 classifier用户代码中的 classifier 4. 为…...

vue3中el-input无法获得焦点的问题
文章目录 现象两次nextTick()加setTimeout()解决结论 现象 el-input被外层div包裹了,设置autofocus不起作用: <el-dialog v-model"visible" :title"title" :append-to-bodytrue width"50%"><el-form v-model&q…...

sqli-labs靶场通关
sqli-las通关 mysql数据库5.0以上版本有一个自带的数据库叫做information_schema,该数据库下面有两个表一个是tables和columns。tables这个表的table_name字段下面是所有数据库存在的表名。table_schema字段下是所有表名对应的数据库名。columns这个表的colum_name字段下是所有…...

深度学习深度解析:从基础到前沿
引言 深度学习作为人工智能的一个重要分支,通过模拟人脑的神经网络结构来进行数据分析和模式识别。它在图像识别、自然语言处理、语音识别等领域取得了显著成果。本文将深入探讨深度学习的基础知识、主要模型架构以及当前的研究热点和发展趋势。 基础概念与数学原理…...

sobel边缘检测算法
人工智能例子汇总:AI常见的算法和例子-CSDN博客 Sobel边缘检测算法是一种用于图像处理中的边缘检测方法,它能够突出图像中灰度变化剧烈的地方,也就是边缘。该算法通过计算图像在水平方向和垂直方向上的梯度来检测边缘,梯度值越大…...

LeetCode 349: 两个数组的交集
LeetCode 349: 两个数组的交集 - C语言 问题描述 给定两个数组 ransomNote 和 magazine,你需要判断 ransomNote 是否可以由 magazine 里的字符构成。每个字符可以使用一次。 解题思路 通过统计 magazine 中每个字符的频次,并与 ransomNote 中字符的需…...

MATLAB的数据类型和各类数据类型转化示例
一、MATLAB的数据类型 在MATLAB中 ,数据类型是非常重要的概念,因为它们决定了如何存储和操作数据。MATLAB支持数值型、字符型、字符串型、逻辑型、结构体、单元数组、数组和矩阵等多种数据类型。MATLAB 是一种动态类型语言,这意味着变量的数…...

c++ list的front和pop_front的概念和使用案例—第2版
在 C 标准库中,std::list 的 front() 和 pop_front() 是与链表头部元素密切相关的两个成员函数。以下是它们的核心概念和具体使用案例: 1. front() 方法 概念: 功能:返回链表中第一个元素的引用(直接访问头部元素&am…...

如何使用SliverList组件
文章目录 1 概念介绍2 使用方法3 示例代码 我们在上一章回中介绍了沉浸式状态栏相关的内容,本章回中将介绍SliverList组件.闲话休提,让我们一起Talk Flutter吧。 1 概念介绍 我们在这里介绍的SliverList组件是一种列表类组件,类似我们之前介…...

DIFY源码解析
偶然发现Github上某位大佬开源的DIFY源码注释和解析,目前还处于陆续不断更新地更新过程中,为大佬的专业和开源贡献精神点赞。先收藏链接,后续慢慢学习。 相关链接如下: DIFY源码解析...

搜索引擎友好:设计快速收录的网站架构
本文来自:百万收录网 原文链接:https://www.baiwanshoulu.com/14.html 为了设计一个搜索引擎友好的网站架构,以实现快速收录,可以从以下几个方面入手: 一、清晰的目录结构与层级 合理划分内容:目录结构应…...

2007-2019年各省科学技术支出数据
2007-2019年各省科学技术支出数据 1、时间:2007-2019年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区名称、年份、科学技术支出 4、范围:31省 5、指标解释:科学技术支出是指为促进科学研究、技术开发…...
)
【数据分析】案例03:当当网近30日热销图书的数据采集与可视化分析(scrapy+openpyxl+matplotlib)
当当网近30日热销图书的数据采集与可视化分析(scrapy+openpyxl+matplotlib) 当当网近30日热销书籍官网写在前面 实验目的:实现当当网近30日热销图书的数据采集与可视化分析。 电脑系统:Windows 使用软件:Visual Studio Code Python版本:python 3.12.4 技术需求:scrapy、…...

DRM系列二:DRM总体介绍
一、简介 DRM,全称Direct Rending Manger。是目前Linux主流的图形显示框架。相比较传统的Framebuffer(FB原生不支持多层合成,不支持VSYNC,不支持DMA-BUF,不支持异步更新,不支持fence机制等等)&…...

步进电机的型号和分类
步进电机的型号和分类通常根据其尺寸、结构、相数、步距角等参数来区分。以下是一些常见的步进电机型号、分类方法以及如何识别它们的指南: 一、常见步进电机型号 步进电机的型号通常由厂家命名,但也有一些通用的命名规则。以下是一些常见的型号系列&am…...

【力扣】15.三数之和
AC截图 题目 思路 这道题如果简单的用暴力三重遍历去做,会超时。所以我们思考假如有三个下标,i,l,r 其中i0(初始),li1 rnums.size()-1 我们固定nums[i]的值,那么就转换为两数之和…...

Redis 基础命令
1. redis 命令官网 https://redis.io/docs/latest/commands/ 2. 在 redis-cli 中使用 help 命令 # 查看 help string 基础命令 keys * # * 代表通配符set key value # 设置键值对del key # 删除键expire key 时间 # 给键设置时间 # -2 代表时间到期了, -1 代表…...

CSES Missing Coin Sum
思路是对数组排序 设 S [ i ] S[i] S[i] 是数组的前缀和 R [ i ] R[i] R[i] 是递增排序后的数组 遍历数组,如果出现 S [ i − 1 ] 1 < R [ i ] S[i - 1] 1 < R[i] S[i−1]1<R[i],就代表S[i - 1] 1是不能被合成出来的数字 因为:…...
:简化类的定义与数据管理)
Python中的数据类(dataclass):简化类的定义与数据管理
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着Python语言的发展,代码的简洁性与可维护性变得愈发重要。Python 3.7引入的dataclass模块为数据类的定义提供了一种简便而高效的方式,…...

Java线程认识和Object的一些方法ObjectMonitor
专栏系列文章地址:https://blog.csdn.net/qq_26437925/article/details/145290162 本文目标: 要对Java线程有整体了解,深入认识到里面的一些方法和Object对象方法的区别。认识到Java对象的ObjectMonitor,这有助于后面的Synchron…...

使用真实 Elasticsearch 进行高级集成测试
作者:来自 Elastic Piotr Przybyl 掌握高级 Elasticsearch 集成测试:更快、更智能、更优化。 在上一篇关于集成测试的文章中,我们介绍了如何通过改变数据初始化策略来缩短依赖于真实 Elasticsearch 的集成测试的执行时间。在本期中࿰…...

统计学中的样本概率论中的样本
不知道当初谁想的把概率论和数理统计合并,作为一门课。这本身是可以合并,完整的一条线,看这里。但是,作为任课老师应该从整体上交代清楚,毕竟是两个学科,不同的学科合并必然会有各种不协调的问题。 举个最…...

SQL 总结
SQL 总结 引言 SQL(Structured Query Language)是一种用于管理关系数据库的计算机语言。自从1970年代被发明以来,SQL已经成为了数据库管理的基础。本文将对SQL的基本概念、常用命令、高级特性以及SQL在数据库管理中的应用进行总结。 SQL基本概念 数据库 数据库是存储数…...

Openfga 授权模型搭建
1.根据项目去启动 配置一个 openfga 服务器 先创建一个 config.yaml文件 cd /opt/openFGA/conf touch ./config.yaml 怎么配置? 根据官网来看 openfga/.config-schema.json at main openfga/openfga GitHub 这里讲述详细的每一个配置每一个类型 这些配置有…...

【Proteus】NE555纯硬件实现LED呼吸灯效果,附源文件,效果展示
本文通过NE555定时器芯片和简单的电容充放电电路,设计了一种纯硬件实现的呼吸灯方案,并借助Proteus仿真软件验证其功能。方案无需编程,成本低且易于实现,适合电子爱好者学习PWM(脉宽调制)和定时器电路原理。 一、呼吸灯原理与NE555功能分析 1. 呼吸灯核心原理 呼吸灯的…...

DRM系列三:drm core模块入口
本系列文章基于linux 5.15 一、drm_core_init 执行一些drm core的初始化工作 static int __init drm_core_init(void) {int ret;drm_connector_ida_init();idr_init(&drm_minors_idr);drm_memcpy_init_early();ret drm_sysfs_init();if (ret < 0) {DRM_ERROR("…...

Clock Controller of RH850/F1KH-D8, RH850/F1KM-S4, RH850/F1KM-S2
&esmp; 时钟控制器由时钟振荡电路、时钟选择电路、和时钟输出电路组成。 RH850/F1KH、RH850/F1KM单片机的时钟控制器具有以下特点: 六个片上时钟振荡器: 主振荡器(MainOSC),振荡频率分别为8、16、20和24 MHz子振荡器(SubOSC),振荡频率为32.768 kHz*1 100针的产品…...

kamailio-auth模块详解【以下内容来源于官网,本文只做翻译】
以下是《Auth 模块》文档的中文翻译: Auth 模块 作者:Jan Janak FhG Fokus janiptel.org Juha Heinanen TutPro Inc jhsong.fi Daniel-Constantin Mierla asipto.com micondagmail.com 版权所有 © 2002, 2003 FhG FOKUS 官网链接: https://kamaili…...

从TypeScript到ArkTS的适配指导
文章目录 一、ArkTS语法适配背景程序稳定性程序性能.ets代码兼容性支持与TS/JS的交互方舟运行时兼容TS/JS二、从TypeScript到ArkTS的适配规则概述强制使用静态类型禁止在运行时变更对象布局限制运算符的语义不支持 structural typing约束说明限制使用标准库一、ArkTS语法适配背…...

Git 版本控制:基础介绍与常用操作
目录 Git 的基本概念 Git 安装与配置 Git 常用命令与操作 1. 初始化本地仓库 2. 版本控制工作流程 3. 分支管理 4. 解决冲突 5. 回退和撤销 6. 查看提交日志 前言 在软件开发过程中,开发者常常需要在现有程序的基础上进行修改和扩展。但如果不加以管理&am…...

【Python】理解Python中的协程和生成器:从yield到async
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在现代编程中,异步编程成为提升程序性能和响应速度的重要手段。Python作为一门功能强大的编程语言,提供了丰富的工具来实现异步操作,其中…...

Unity开发游戏使用XLua的基础
Unity使用Xlua的常用编码方式,做一下记录 1、C#调用lua 1、Lua解析器 private LuaEnv env new LuaEnv();//保持它的唯一性void Start(){env.DoString("print(你好lua)");//env.DoString("require(Main)"); 默认在resources文件夹下面//帮助…...

什么是区块链
区块链是一种去中心化的分布式账本技术,它通过一系列复杂而精密的设计原则和机制来确保数据的安全性、透明性和不可篡改性。在最基础的层面上,区块链是由一系列按照时间顺序链接起来的数据块组成的链式结构。每个数据块中包含了一定数量的交易记录或状态…...
(也称为析构函数))
C++中的析构器(Destructor)(也称为析构函数)
在C中,析构器(Destructor)也称为析构函数,它是一种特殊的成员函数,用于在对象销毁时进行资源清理工作。以下是关于C析构器的详细介绍: 析构函数的特点 名称与类名相同,但前面有一个波浪号 ~&a…...

【ts + java】古玩系统开发总结
src别名的配置 开发中文件和文件的关系会比较复杂,我们需要给src文件夹一个别名吧 vite.config.js import { defineConfig } from vite import vue from vitejs/plugin-vue import path from path// https://vitejs.dev/config/ export default defineConfig({pl…...