【模型】RNN模型详解
1. 模型架构
RNN(Recurrent Neural Network)是一种具有循环结构的神经网络,它能够处理序列数据。与传统的前馈神经网络不同,RNN通过将当前时刻的输出与前一时刻的状态(或隐藏层)作为输入传递到下一个时刻,使得它能够保留之前的信息并用于当前的决策。

- 输入层:输入数据的每一时刻(如时间序列数据的每个时间步)都会传递到网络。
- 隐藏层:RNN的核心是循环结构,它将先前的隐藏状态与当前的输入结合,生成当前的隐藏状态。通常,RNN的隐藏层包含多个神经元,且它们的状态是由上一时刻的输出状态递归计算得来的。
- 输出层:基于隐藏层的输出,生成预测结果。
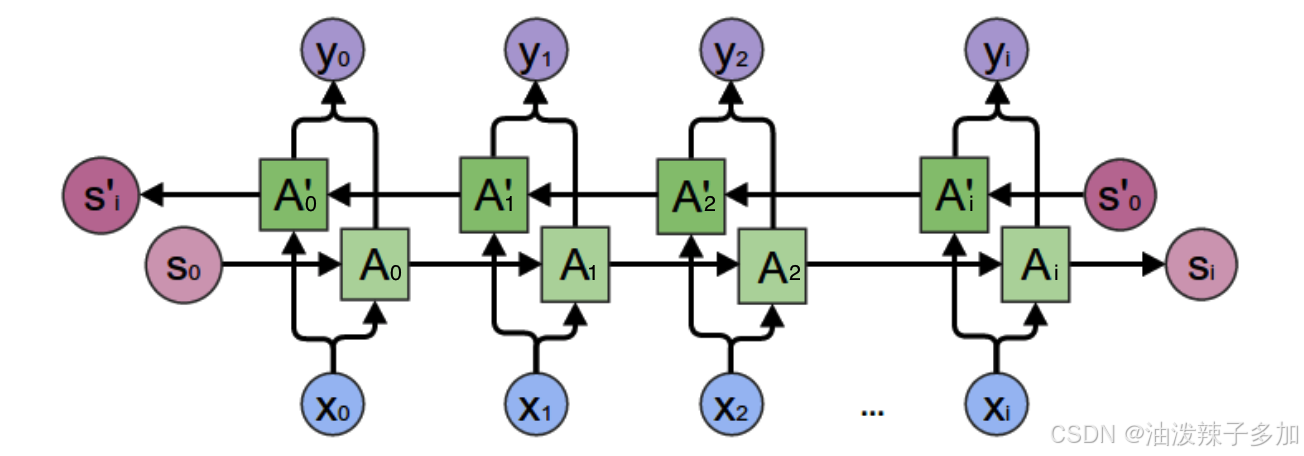
RNN通过共享参数和权重来处理任意长度的序列输入,能够用于语言模型、时间序列预测等任务。
2. 算法实现(PyTorch)
在PyTorch中实现一个简单的RNN模型,通常需要以下几个步骤:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# 定义RNN模型类
class RNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, forecast_horizon):super(RNN, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.forecast_horizon = forecast_horizon# 定义RNN层self.rnn = nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size,num_layers=self.num_layers, batch_first=True)# 定义全连接层self.fc1 = nn.Linear(self.hidden_size, 64)self.fc2 = nn.Linear(64, self.forecast_horizon) # 输出5步的数据# Dropout层,防止过拟合self.dropout = nn.Dropout(0.2)def forward(self, x):# 初始化隐藏状态h_0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)# 通过RNN层进行前向传播out, _ = self.rnn(x, h_0)# 只取最后一个时间步的输出out = F.relu(self.fc1(out[:, -1, :])) # 输出通过全连接层1并激活out = self.fc2(out) # 输出通过全连接层2,预测未来5步的数据return out# 准备训练数据
# 假设你已经准备好了数据,X_train, X_test, y_train, y_test等
# 并且 X_train, X_test 是形状为 (samples, time_steps, features) 的三维数组# 设置设备,使用GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')# 将数据转换为torch tensors,并转移到设备(GPU/CPU)
X_train_tensor = torch.Tensor(X_train).to(device)
X_test_tensor = torch.Tensor(X_test).to(device)# 将y_train和y_test调整形状为(batch_size, forecast_horizon),即去掉最后一维
y_train_tensor = torch.Tensor(y_train).squeeze(-1).to(device) # 将 y_train.shape 从 (batch_size, forecast_horizon, 1) -> (batch_size, forecast_horizon)
y_test_tensor = torch.Tensor(y_test).squeeze(-1).to(device) # 将 y_test.shape 从 (batch_size, forecast_horizon, 1) -> (batch_size, forecast_horizon)# 初始化RNN模型
input_size = X_train.shape[2] # 特征数量
hidden_size = 64 # 隐藏层神经元数量
num_layers = 2 # RNN层数
forecast_horizon = 5 # 预测的目标步数model = RNN(input_size, hidden_size, num_layers, forecast_horizon).to(device)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
def train_model(model, X_train, y_train, X_test, y_test, epochs=2000, batch_size=1024):train_loss = []val_loss = []for epoch in range(epochs):model.train()optimizer.zero_grad()# 前向传播output_train = model(X_train)# 计算损失loss = criterion(output_train, y_train)loss.backward()optimizer.step()train_loss.append(loss.item())# 计算验证集损失model.eval()with torch.no_grad():output_val = model(X_test)val_loss_value = criterion(output_val, y_test)val_loss.append(val_loss_value.item())if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{epochs}], Train Loss: {loss.item():.4f}, Validation Loss: {val_loss_value.item():.4f}')# 绘制训练损失和验证损失曲线plt.plot(train_loss, label='Train Loss')plt.plot(val_loss, label='Validation Loss')plt.title('Loss vs Epochs')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()plt.show()# 训练模型
train_model(model, X_train_tensor, y_train_tensor, X_test_tensor, y_test_tensor, epochs=2000)# 评估模型
def evaluate_model(model, X_test, y_test):model.eval()with torch.no_grad():y_pred = model(X_test)y_pred_rescaled = y_pred.cpu().numpy()y_test_rescaled = y_test.cpu().numpy()# 计算均方误差mse = mean_squared_error(y_test_rescaled, y_pred_rescaled)print(f'Mean Squared Error: {mse:.4f}')return y_pred_rescaled, y_test_rescaled# 评估模型性能
y_pred_rescaled, y_test_rescaled = evaluate_model(model, X_test_tensor, y_test_tensor)# 保存模型
def save_model(model, path='./model_files/multisteos_rnn_model.pth'):torch.save(model.state_dict(), path)print(f'Model saved to {path}')# 保存训练好的模型
save_model(model)1.代码解析
(1)反向传播
def forward(self, x):# 初始化隐藏状态h_0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)# 通过RNN层进行前向传播out, _ = self.rnn(x, h_0)# 只取最后一个时间步的输出out = F.relu(self.fc1(out[:, -1, :])) # 输出通过全连接层1并激活out = self.fc2(out) # 输出通过全连接层2,预测未来5步的数据return out
- 此处
h_0是RNN的初始隐藏状态,形状为(num_layers, batch_size, hidden_size),它存储了每一层在时间步t=0的初始隐藏状态; out中存储的是 最后一层的所有时间步的隐藏状态,PyTorch 的nn.RNN系列实现中,out始终返回的是 最后一层 的隐藏状态;例如,3层的 RNN,out中的数据是第3层的隐藏状态,前两层的状态不会在out中;out[:, -1, :]取的是最后一层并且最后一个时间步的隐藏状态,这是因为在许多任务中(如预测未来值),最后时间步的隐藏状态通常包含了整个序列的信息,因此可以作为最终的特征表示;_是 所有层 的最后一个时间步的隐藏状态,通常会有多个层(即num_layers > 1时),其形状为(num_layers, batch_size, hidden_size);
3. 训练使用方式
- 数据准备:通常RNN处理时间序列数据。数据需要转换成合适的格式,即将每个数据点按时间顺序组织成序列样本。
- 损失函数:对于回归任务,通常使用均方误差(MSE),而分类任务则使用交叉熵损失。
- 优化器:使用Adam或SGD等优化器来更新网络权重。
- 批处理和梯度裁剪:RNN的训练可能遇到梯度爆炸或梯度消失的问题,可以使用梯度裁剪(gradient clipping)来缓解。
4. 模型优缺点
优点:
- 时间序列建模:RNN可以处理具有时序依赖的数据(如语音、文本、股市等)。
- 共享权重:RNN通过在时间步之间共享权重,减少了模型的参数数量。
- 灵活性:RNN可以处理不同长度的输入序列。
缺点:
- 梯度消失/爆炸:在长序列中,RNN容易出现梯度消失或梯度爆炸的问题,导致训练困难。
- 训练效率低:传统的RNN难以捕捉长时间跨度的依赖关系,训练速度较慢。
- 局部依赖:RNN在捕获远程依赖时表现较差,容易受到短期记忆的影响。
5. 模型变种
-
LSTM (Long Short-Term Memory)
- LSTM 是RNN的一种变种,通过引入“记忆单元”来解决标准RNN中的梯度消失问题。它使用了三个门控机制——输入门、遗忘门和输出门,来控制信息的存储与更新,从而能够捕捉长时间跨度的依赖。
-
GRU (Gated Recurrent Unit)
- GRU是LSTM的一个简化版本,具有类似的性能但较少的参数。它合并了LSTM中的遗忘门和输入门为一个“更新门”,使得模型更为简洁。
-
Bidirectional RNN
- 双向RNN在处理序列数据时,通过同时考虑从前向和反向两个方向的信息,能够提高模型的表达能力,尤其在文本处理任务中有较好表现。
-
Attention机制
- Attention机制不仅在NLP任务中广泛使用,还被引入到RNN中,帮助模型关注输入序列中最重要的部分,从而有效处理长时间序列和远程依赖问题。
-
Transformer
- Transformer模型去除了传统RNN中的循环结构,完全基于自注意力机制(self-attention)来建模序列的依赖关系,避免了RNN的梯度消失问题,并能够并行处理序列。
6. 模型特点
- 时序数据建模:RNN特别适用于处理时序数据,可以理解序列中前后时间步之间的依赖关系。
- 状态更新:RNN通过隐藏层的状态传递,实现了对历史信息的持续更新和记忆。
- 参数共享:与传统的前馈神经网络不同,RNN在每个时间步使用相同的权重,因此模型在处理长序列时参数效率较高。
7. 应用场景
- 自然语言处理:
- 语言模型:RNN可以用于生成语言模型,如生成文本或对句子进行语言建模。
- 机器翻译:通过编码器-解码器结构,RNN(尤其是LSTM和GRU)在序列到序列(seq2seq)任务中非常有效。
- 语音识别:将语音信号转化为文字的过程中,RNN用于捕捉语音的时序特性。
- 时间序列预测:
- 股市预测:RNN可以用于基于历史股市数据预测未来价格。
- 天气预测:使用RNN模型预测未来几天的气候变化。
- 销售预测:基于历史销售数据预测未来销售量。
- 生成模型:
- 文本生成:基于RNN的文本生成模型(如char-level语言模型)可以生成与输入数据风格相似的文本。
- 音乐生成:RNN可以用来生成音乐序列,模仿人类作曲的风格。
- 视频分析:
- 视频分类:利用RNN在视频帧序列中的时序特性进行分类。
- 动作识别:RNN可以捕捉视频序列中的动作模式,用于人类行为分析。
相关文章:

【模型】RNN模型详解
1. 模型架构 RNN(Recurrent Neural Network)是一种具有循环结构的神经网络,它能够处理序列数据。与传统的前馈神经网络不同,RNN通过将当前时刻的输出与前一时刻的状态(或隐藏层)作为输入传递到下一个时刻&…...

软件测试压力太大了怎么办?
本文其实是知乎上针对一个问题的回答: 目前在做软件测试,主要负责的是手机端的项目测试,项目迭代很快,每次上线前验正式都会发现一些之前验测试包时候没有发现的问题,压力太大了,应该怎么调整 看过我之前其…...

ES6 类语法:JavaScript 的现代化面向对象编程
Hi,我是布兰妮甜 !ECMAScript 2015,通常被称为 ES6 或 ES2015,是 JavaScript 语言的一次重大更新。它引入了许多新特性,其中最引人注目的就是类(class)语法。尽管 JavaScript 一直以来都支持基于…...
二进制输入输出)
【时时三省】(C语言基础)二进制输入输出
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 二进制输入 用fread可以读取fwrite输入的内容 字符串以文本的形式写进去的时候,和以二进制写进去的内容是一样的 整数和浮点型以二进制写进去是不一样的 二进制输出 fwrite 字…...
- 农场施肥 (JavaScriptJava PythonC/C++))
【2024年华为OD机试】(A卷,200分)- 农场施肥 (JavaScriptJava PythonC/C++)
一、问题描述 题目描述 某农场主管理了一大片果园,fields[i] 表示不同果林的面积,单位:平方米(m)。现在需要为所有的果林施肥,且必须在 n 天之内完成,否则会影响收成。小布是果林的工作人员,他每次选择一片果林进行施肥,且一片果林施肥完后当天不再进行施肥作业。 …...

k8s服务StatefulSet部署模板
java 服务StatefulSet部署模板 vim templates-test.yamlapiVersion: apps/v1 kind: StatefulSet metadata:labels:app: ${app_labels}name: ${app_name}namespace: ${app_namespace} spec:replicas: ${app_replicas_count}selector:matchLabels:app: ${app_labels}template:la…...

跟我学C++中级篇——C++初始化的方式
一、初始化的方式 在前面的初级篇中对C的初始化有过一个说明。但随着新标准的迭代以及新的方式的应用,本篇对初始化再做一次整体的总结。下面把C的初始化按照时间线进行一个划分: 1、早期初始化 这种初始化中,开发者一般在初学时都会遇到&am…...

设计模式的艺术-代理模式
结构性模式的名称、定义、学习难度和使用频率如下表所示: 1.如何理解代理模式 代理模式(Proxy Pattern):给某一个对象提供一个代理,并由代理对象控制对原对象的引用。代理模式是一种对象结构型模式。 代理模式类型较多…...

【Nginx】【SSE】【WebSocket】Nginx配置SSE,WebSocket的转发请求
Nginx 配置 SSE 和 WebSocket 转发 一、配置背景(火狐游览器不支持,建议谷歌游览器开发测试) 在使用 Django 框架开发 Web 应用时,为了实现实时通信,可以选择使用以下两种技术: SSE (Server-Sent Events…...

Gin 应用并注册 pprof
pprof 配置与使用步骤 1. 引言 通过下面操作,你可以顺利集成和使用 pprof 来收集和分析 Gin 应用的性能数据。你可以查看 CPU 使用情况、内存占用、以及其他运行时性能数据,并通过图形化界面进行深度分析。 1. 安装依赖 首先,确保安装了 gi…...

国产编辑器EverEdit - 输出窗口
1 输出窗口 1.1 应用场景 输出窗口可以显示用户执行某些操作的结果,主要包括: 查找类:查找全部,筛选等待操作,可以把查找结果打印到输出窗口中; 程序类:在执行外部程序时(如:命令窗…...

【C++探索之路】STL---string
走进C的世界,也意味着我们对编程世界的认知达到另一个维度,如果你学习过C语言,那你绝对会有不一般的收获,感受到C所带来的码云风暴~ ---------------------------------------begin--------------------------------------- 什么是…...

安装 docker 详解
在平常的开发工作中,我们经常需要部署项目。随着 Docker 容器的出现,大大提高了部署效率。Docker 容器包含了应用程序运行所需的所有依赖,避免了换环境运行问题。可以在短时间内创建、启动和停止容器,大大提高了应用的部署速度&am…...
AR打包命令)
GCC之编译(8)AR打包命令
GCC之(8)AR二进制打包命令 Author: Once Day Date: 2025年1月23日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章请查看专栏: Linux实践记录_Once-Day的博客-C…...
)
自定义命令执行器:C++中命令封装的深度探索(C/C++实现)
在现代软件开发中,执行系统命令是一项常见的需求,无论是自动化脚本、系统管理工具,还是需要调用外部程序的复杂应用程序,都离不开对系统命令的调用。然而,直接使用系统调用(如 execve)虽然简单&…...
,Kotlin(三))
Android BitmapShader简洁实现马赛克/高斯模糊(毛玻璃),Kotlin(三)
Android BitmapShader简洁实现马赛克/高斯模糊(毛玻璃),Kotlin(三) 发现,如果把(二) Android BitmapShader简洁实现马赛克,Kotlin(二)-CSDN博客 …...

7.渲染管线——几何阶段的概述
几何阶段是渲染管线中的一个重要部分,主要负责处理3D模型的几何信息(比如顶点位置、形状、大小等),并将它们转换为屏幕上的2D图像。用通俗易懂的方式来解释: 通俗解释:几何阶段就像把3D模型“拍扁”成2D照片…...

微信小程序实现自定义日历功能
文章目录 1. 创建日历组件实现步骤:2. 代码实现过程3. 实现效果图4. 关于作者其它项目视频教程介绍 1. 创建日历组件实现步骤: 创建日历组件:首先,你需要创建一个日历组件,包含显示日期的逻辑。样式设计:为…...

Vue3 + TS 实现批量拖拽 文件夹和文件 组件封装
一、html 代码: 代码中的表格引入了 vxe-table 插件 <Tag /> 是自己封装的说明组件 表格列表这块我使用了插槽来增加扩展性,可根据自己需求,在组件外部做调整 <template><div class"dragUpload"><el-dial…...

私域流量池构建与转化策略:以开源链动2+1模式AI智能名片S2B2C商城小程序为例
摘要:随着互联网技术的快速发展,流量已成为企业竞争的关键资源。私域流量池,作为提升用户转化率和增强用户粘性的有效手段,正逐渐受到企业的广泛关注。本文旨在深入探讨私域流量池构建的目的、优势及其在实际应用中的策略…...

NFT Insider #166:Nifty Island 推出 AI Agent Playground;Ronin 推出1000万美元资助计划
引言:NFT Insider 由 NFT 收藏组织 WHALE Members、BeepCrypto 联合出品, 浓缩每周 NFT 新闻,为大家带来关于 NFT 最全面、最新鲜、最有价值的讯息。每期周报将从 NFT 市场数据,艺术新闻类,游戏新闻类,虚拟…...

Keepalived实现HAProxy高可用搭建
Keepalived实现HAProxy高可用 文章目录 Keepalived实现HAProxy高可用拓扑表格如下拓扑结构(示例)nginx安装(所有server)HAProxy安装(主备机相同)HAProxy配置(主备机相同) 注释如下内…...

HashTable, HashMap, ConcurrentHashMap 之间的区别
一、HashTable 只是将关键方法加上了锁(synchronized关键字)。 缺点:1.如果多线程访问同一个HashTable就回直接造成锁冲突。 2.HashTable的size属性也是通过 synchronized来控制同步的,效率比较低。 3.在扩容时会涉及大量的拷贝…...

如何确保Spring单例Bean在高并发环境下的安全性?
在Spring中,单例Bean就像是一个“公共的水杯”,整个应用程序中的所有线程都会共享这一个实例。在大部分情况下,这没什么问题,但如果多个线程同时想要修改这个“水杯”里的内容,就可能会出现问题了。 想象一下ÿ…...
- 工单调度策略(JavaScriptJava PythonC/C++))
【2024年华为OD机试】 (A卷,200分)- 工单调度策略(JavaScriptJava PythonC/C++)
一、问题描述 问题描述 华为工单调度系统需要根据不同的策略调度外线工程师(FME)修复工单。每个工单有一个修复时间要求(SLA时间),在SLA时间内完成修复的工单可以获得对应的积分,超过SLA时间完成的工单不获得积分,但必须完成该工单。目标是设计一种调度策略,使得外线…...

Linux 内核中的高效并发处理:深入理解 hlist_add_head_rcu 与 NAPI 接口
在 Linux 内核的开发中,高效处理并发任务和数据结构的管理是提升系统性能的关键。特别是在网络子系统中,处理大量数据包的任务对性能和并发性提出了极高的要求。本文将深入探讨 Linux 内核中的 hlist_add_head_rcu 函数及其在 NAPI(网络接收处理接口)中的应用,揭示这些机制…...

Alibaba Spring Cloud 六 Seata 的核心组件:RM
在 Alibaba Spring Cloud Seata 中,Resource Manager (RM) 是三大核心组件之一。它主要负责管理分支事务中的资源(如数据库、文件等),并与 Transaction Coordinator (TC) 协作完成分支事务的注册、提交和回滚。RM 是分布式事务实际…...

【Linux】列出所有连接的 WiFi 网络的密码
【Linux】列出所有连接的 WiFi 网络的密码 终端输入 sudo grep psk /etc/NetworkManager/system-connections/*会列出所有连接过 Wifi 的信息,格式类似 /etc/NetworkManager/system-connections/AAAAA.nmconnection:pskBBBBBAAAAA 是 SSID,BBBBB 是对…...

snippets router pinia axios mock
文章目录 补充VS Code 代码片段注册自定义组件vue routerpinia删除vite创建项目时默认的文件axiosmock3.0.x版本的 viteMockServe 补充 为文章做补充:https://blog.csdn.net/yavlgloss/article/details/140063387 VS Code 代码片段 为当前项目创建 Snippets {&quo…...
,有什么好的方法可以解决?)
C#常考随笔2:函数中多次使用string的+=处理,为什么会产生大量内存垃圾(垃圾碎片),有什么好的方法可以解决?
在 C# 中,由于string类型是不可变的,当在函数中多次使用操作符来拼接字符串时,每次操作都会创建一个新的string对象,旧的对象则成为垃圾对象,这会导致大量的内存分配和垃圾回收,产生内存垃圾和碎片。 在需…...

GitLab配置免密登录和常用命令
SSH 免密登录 Windows免密登录 删除现有Key 访问目录:C:\Users\Administrator\ .ssh,删除公钥:id_rsa.pub ,私钥:id_rsa 2.生成.ssh 秘钥 运行命令生成.ssh 秘钥目录( ssh-keygen -t rsa -C xxxxxx126.…...

编码器和扩散模型
目录 摘要abstract1.自动编码器2.变分编码器(VAE)3.论文阅读3.1 介绍3.2 方法3.3 结论 4.总结参考文献 摘要 本周学习了自动编码器(AE)和变分自动编码器(VAE)的基本原理与实现,分析其在数据降维…...

three.js用粒子使用canvas生成的中文字符位图材质
three.js用粒子使用canvas生成中文字符材质 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Three.…...
 (Ts版))
数据结构与算法之堆: LeetCode 208. 实现 Trie (前缀树) (Ts版)
实现 Trie (前缀树) https://leetcode.cn/problems/implement-trie-prefix-tree/description/ 描述 Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景&am…...

在 Linux 中使用 nslookup命令
什么是 nslookup? nslookup 命令是名称服务器查找的缩写,是一种网络管理工具,用于获取域名的 IP 地址或其他 DNS 记录信息,通常用于解决 DNS 或名称解析问题 nslookup一般语法,<domain-name>是您要查询的域名,…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.1 从零搭建NumPy环境:安装指南与初体验
1. 从零搭建NumPy环境:安装指南与初体验 NumPy核心能力图解(架构图) NumPy 是 Python 中用于科学计算的核心库,它提供了高效的多维数组对象以及用于处理这些数组的各种操作。NumPy 的核心能力可以概括为以下几个方面:…...

PHP校园助手系统小程序
🔑 校园助手系统 —— 智慧校园生活 📱一款基于ThinkPHPUniapp框架深度定制的校园助手系统,犹如一把智慧之钥,专为校园团队精心打造,解锁智慧校园生活的无限精彩。它独家适配微信小程序,无需繁琐的下载与安…...
申请内存设计)
2_高并发内存池_各层级的框架设计及ThreadCache(线程缓存)申请内存设计
一、高并发内存池框架设计 高并发池框架设计,特别是针对内存池的设计,需要充分考虑多线程环境下: 性能问题锁竞争问题内存碎片问题 高并发内存池的整体框架设计旨在提高内存的申请和释放效率,减少锁竞争和内存碎片。 高并发内存…...

在线可编辑Excel
1. Handsontable 特点: 提供了类似 Excel 的表格编辑体验,包括单元格样式、公式计算、数据验证等功能。 支持多种插件,如筛选、排序、合并单元格等。 轻量级且易于集成到现有项目中。 具备强大的自定义能力,可以调整外观和行为…...

物业管理系统源码优化物业运营模式实现服务智能化与品质飞跃
内容概要 在当今快速发展且竞争激烈的市场环境中,物业管理面临着众多挑战,而“物业管理系统源码”的优化,无疑为解决这些问题提供了有效的途径。这些优化不仅提升了物业管理的效率,还实现了服务智能化,推动了物业运营…...

双足机器人开源项目
双足机器人(也称为人形机器人或仿人机器人)是一个复杂的领域,涉及机械设计、电子工程、控制理论、计算机视觉等多个学科。对于想要探索或开发双足机器人的开发者来说,有许多开源项目可以提供帮助。这些项目通常包括硬件设计文件、…...

第五部分:Linux中的gcc/g++以及gdb和makefile
目录 1、编译器gcc和g 1.1、预处理(进行宏替换) 1.2、编译(生成汇编) 1.3、汇编(生成机器可识别代码) 1.4、连接(生成可执行文件或库文件) 1.5、gcc编译器的使用 2、Linux调试器-gdb使用 2.1、debug…...

decison tree 决策树
熵 信息增益 信息增益描述的是在分叉过程中获得的熵减,信息增益即熵减。 熵减可以用来决定什么时候停止分叉,当熵减很小的时候你只是在不必要的增加树的深度,并且冒着过拟合的风险 决策树训练(构建)过程 离散值特征处理:One-Hot…...
的应用实战教程)
GPU算力平台|在GPU算力平台部署AI虚拟换衣模型(CatVTON)的应用实战教程
文章目录 一、GPU算力服务平台概述智能资源分配优化的Kubernetes架构按需计费安全保障平台特色功能 二、平台账号注册流程AI虚拟换衣模型(CatVTON)的应用实战教程AI虚拟换衣模型(CatVTON)的介绍AI虚拟换衣模型(CatVTON)的部署步骤 一、GPU算力服务平台概述 蓝耘GPU算力平台专为…...

使用云服务器自建Zotero同步的WebDAV服务教程
Zotero 是一款广受欢迎的文献管理软件,其同步功能可以通过 WebDAV 实现文献附件的同步。相比 Zotero 官方提供的300MB免费存储服务,自建 WebDAV 服务具有存储空间大、成本低以及完全控制数据的优势。本文将详细介绍如何使用云服务器自建 WebDAV 服务&…...

单片机基础模块学习——按键
一、按键原理图 当把跳线帽J5放在右侧,属于独立按键模式(BTN模式),放在左侧为矩阵键盘模式(KBD模式) 整体结构是一端接地,一端接控制引脚 之前提到的都是使用了GPIO-准双向口的输出功能&#x…...

FlinkSql使用中rank/dense_rank函数报错空指针
问题描述 在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError) 报错内容如下 该报错没有行号/错误位置,无法排查 现状 目前已经确认为bug,根据github上的PR日…...

WPF基础 | WPF 基础概念全解析:布局、控件与事件
WPF基础 | WPF 基础概念全解析:布局、控件与事件 一、前言二、WPF 布局系统2.1 布局的重要性与基本原理2.2 常见布局面板2.3 布局的测量与排列过程 三、WPF 控件3.1 控件概述与分类3.2 常见控件的属性、方法与事件3.3 自定义控件 四、WPF 事件4.1 路由事件概述4.2 事…...

【AIGC学习笔记】扣子平台——精选有趣应用,探索无限可能
背景介绍: 由于近期业务发展的需求,我开始接触并深入了解了扣子平台的相关知识,并且通过官方教程自学了简易PE工作流搭建的技巧。恰逢周会需要准备与工作相关的分享主题,而我作为一个扣子平台的初学者,也想探索一下这…...

mock可视化生成前端代码
介绍:mock是我们前后端分离的必要一环、ts、axios编写起来也很麻烦。我们就可以使用以下插件,来解决我们的问题。目前支持vite和webpack。(配置超级简单!) 欢迎小伙伴们提issues、我们共建。提升我们的开发体验。 vi…...