缓存之美:万文详解 Caffeine 实现原理(下)
上篇文章:缓存之美:万文详解 Caffeine 实现原理(上)
getIfPresent
现在我们对 put 方法有了基本了解,现在我们继续深入 getIfPresent 方法:
public class TestReadSourceCode {@Testpublic void doRead() {// read constructorCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).build();// read putcache.put("key", "value");// read getcache.getIfPresent("key");}}
对应源码如下,关注注释信息:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {final ConcurrentHashMap<Object, Node<K, V>> data;final Buffer<Node<K, V>> readBuffer;@Overridepublic @Nullable V getIfPresent(Object key, boolean recordStats) {// 直接由 ConcurrentHashMap 获取元素Node<K, V> node = data.get(nodeFactory.newLookupKey(key));if (node == null) {// 更新统计未命中if (recordStats) {statsCounter().recordMisses(1);}// 当前 drainStatus 为 REQUIRED 表示有任务需要处理则调度处理if (drainStatusOpaque() == REQUIRED) {// 这个方法在上文中介绍过,它会提交 PerformCleanupTask 执行维护方法 maintenancescheduleDrainBuffers();}return null;}V value = node.getValue();long now = expirationTicker().read();// 判断是否过期或者需要被回收且value对应的值为nullif (hasExpired(node, now) || (collectValues() && (value == null))) {// 更新统计未命中if (recordStats) {statsCounter().recordMisses(1);}scheduleDrainBuffers();return null;}// 检查节点没有在进行异步计算if (!isComputingAsync(node)) {@SuppressWarnings("unchecked")K castedKey = (K) key;// 更新访问时间setAccessTime(node, now);// 更新读后过期时间tryExpireAfterRead(node, castedKey, value, expiry(), now);}// 处理读取后操作(主要关注)V refreshed = afterRead(node, now, recordStats);return (refreshed == null) ? value : refreshed;}
}
getIfPresent 方法中,部分内容我们已经在上文中介绍过,比如 scheduleDrainBuffers 方法。最后一步 afterRead 方法是我们本次关注的重点,从命名来看它表示“读后操作”接下来看看它的具体流程:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {final Buffer<Node<K, V>> readBuffer;@NullableV afterRead(Node<K, V> node, long now, boolean recordHit) {// 更新统计命中if (recordHit) {statsCounter().recordHits(1);}// 注意这里如果 skipReadBuffer 为 false,那么它会执行 readBuffer.offer(node) 逻辑,向 ReadBuffer 中添加待处理元素boolean delayable = skipReadBuffer() || (readBuffer.offer(node) != Buffer.FULL);// 判断是否需要延迟处理维护任务if (shouldDrainBuffers(delayable)) {scheduleDrainBuffers();}// 处理必要的刷新操作return refreshIfNeeded(node, now);}boolean skipReadBuffer() {// fastpath 方法访问元素是否可以跳过“通知”驱逐策略,true 表示跳过// 第二个判断条件判断频率草图是否初始化,如果“未初始化”则返回 truereturn fastpath() && frequencySketch().isNotInitialized();}// 状态流转,没有满 delayable 为 true 表示延迟执行维护任务boolean shouldDrainBuffers(boolean delayable) {switch (drainStatusOpaque()) {case IDLE:return !delayable;// 当前有任务需要处理则调度维护任务执行,否则均延迟执行 case REQUIRED:return true;case PROCESSING_TO_IDLE:case PROCESSING_TO_REQUIRED:return false;default:throw new IllegalStateException("Invalid drain status: " + drainStatus);}}
}
该方法非常简单,都是熟悉的内容,只有数据结构 ReadBuffer 还没深入了解过,它也是在 Caffeine 的构造方法中完成初始化的。
ReadBuffer
以下为 ReadBuffer 在 Caffeine 缓存中完成初始化的逻辑:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRefimplements LocalCache<K, V> {final Buffer<Node<K, V>> readBuffer;protected BoundedLocalCache(Caffeine<K, V> builder,@Nullable AsyncCacheLoader<K, V> cacheLoader, boolean isAsync) {// ...// 如果指定了过期策略或 key 定义了 week refenence value 定义了 week or soft reference 或定义了访问后过期策略 则 创建 BoundBufferreadBuffer = evicts() || collectKeys() || collectValues() || expiresAfterAccess()? new BoundedBuffer<>(): Buffer.disabled();}
}
Buffer.disabled() 会创建如下枚举来表示 DisabledBuffer:
enum DisabledBuffer implements Buffer<Object> {INSTANCE;@Overridepublic int offer(Object e) {return Buffer.SUCCESS;}@Overridepublic void drainTo(Consumer<Object> consumer) {}@Overridepublic long size() {return 0;}@Overridepublic long reads() {return 0;}@Overridepublic long writes() {return 0;}
}
满足其中条件判断时,ReadBuffer 的实际类型为 BoundedBuffer,它的类关系图如下:
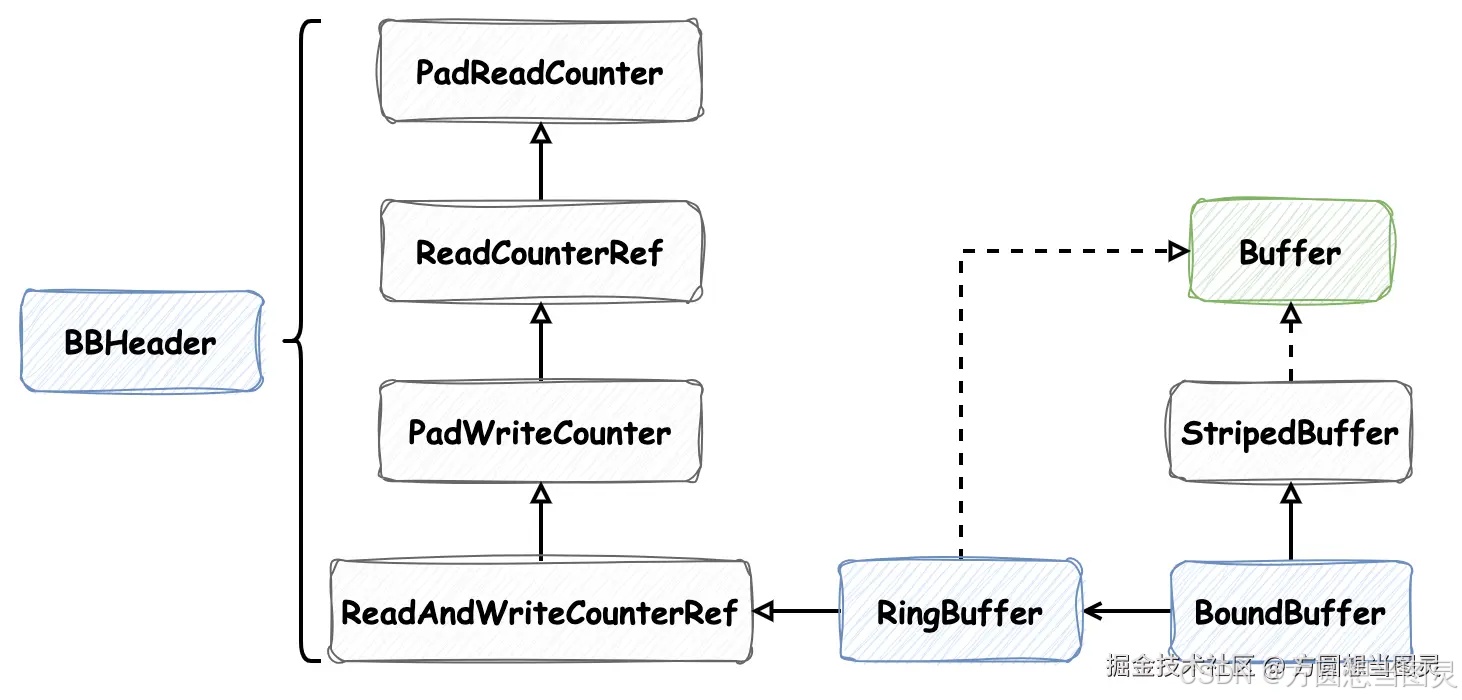
在 Buffer 接口的注释声明中,能获取很多有效信息:它同样也是 多生产者单消费者(MPSC) 缓冲区,上文我们在介绍 WriteBuffer 时,它的单消费者实现方式是加同步锁,ReadBuffer 的实现单消费者的方式一样,因为它们都是在维护方法 maintenance 中加同步锁对元素进行消费。不同的是,如果 ReadBuffer 缓冲区满了或者发生争抢则会拒绝添加新元素,而且它不像队列或栈,不保证 FIFO 或 LIFO。
A multiple-producer / single-consumer buffer that rejects new elements if it is full or fails spuriously due to contention. Unlike a queue and stack, a buffer does not guarantee an ordering of elements in either FIFO or LIFO order.
Beware that it is the responsibility of the caller to ensure that a consumer has exclusive read access to the buffer. This implementation does not include fail-fast behavior to guard against incorrect consumer usage.
在类关系图中,抽象类 StripedBuffer 的实现最值得学习,它采用了分段设计(Striped)和CAS操作实现高效并发写入。分段是将缓冲区分成多个“段”,根据线程的探针值将它们哈希到不同的“段”,减少竞争,接下来我们看一下它具体的实现逻辑,首先是 StripedBuffer#offer 方法:
abstract class StripedBuffer<E> implements Buffer<E> {volatile Buffer<E> @Nullable[] table;@Overridepublic int offer(E e) {// 扰动函数计算 64位 线程探针值long z = mix64(Thread.currentThread().getId());// 取高 32 位值,位或 1 保证它为奇数int increment = ((int) (z >>> 32)) | 1;// 转换为 int 32 位int h = (int) z;// 掩码值为已分段的缓冲区数量-1int mask;int result;// 线程哈希到的具体缓冲区Buffer<E> buffer;// 未竞争标志位boolean uncontended = true;Buffer<E>[] buffers = table;if ((buffers == null)|| ((mask = buffers.length - 1) < 0)// 位与运算获取缓冲区|| ((buffer = buffers[h & mask]) == null)// 向缓冲区中添加元素|| !(uncontended = ((result = buffer.offer(e)) != Buffer.FAILED))) {// 扩容或重试操作return expandOrRetry(e, h, increment, uncontended);}return result;}
}
在 StripedBuffer 中我们能发现定义了 volatile Buffer<E> @Nullable[] table 是数组的形式,这便对应了它“分段”的思想,将元素保存在多个缓冲区中。通过线程探针值哈希获取对应的缓冲区,逻辑并不复杂。expandOrRetry 方法我们稍后再介绍,我们先假设线程哈希到的具体缓冲区 Buffer<E> buffer 对象已经被创建,那么它会执行 buffer.offer(e) 方法。Buffer<E> buffer 对应的实现类为定义在 BoundedBuffer 的静态内部类 RingBuffer,它也实现了 Buffer 接口,源码如下:
final class BoundedBuffer<E> extends StripedBuffer<E> {static final int BUFFER_SIZE = 16;static final int MASK = BUFFER_SIZE - 1;static final class RingBuffer<E> extends BBHeader.ReadAndWriteCounterRef implements Buffer<E> {static final VarHandle BUFFER = MethodHandles.arrayElementVarHandle(Object[].class);final Object[] buffer;// 有参构造,这里表示缓冲区是被延迟创建的,创建时第一个元素便为 epublic RingBuffer(E e) {buffer = new Object[BUFFER_SIZE];BUFFER.set(buffer, 0, e);WRITE.set(this, 1);}@Overridepublic int offer(E e) {// ReadCounterRef#readCounterlong head = readCounter;// ReadAndWriteCounterRef#writeCounterlong tail = writeCounterOpaque();// 计算可操作容量 sizelong size = (tail - head);// 超过缓存大小则证明它已经满了if (size >= BUFFER_SIZE) {return Buffer.FULL;}// CAS 更新 writeCounter 为 writeCounter+1if (casWriteCounter(tail, tail + 1)) {// 位与掩码值获取缓冲区中的索引int index = (int) (tail & MASK);// 将元素 e 更新在指定索引处BUFFER.setRelease(buffer, index, e);return Buffer.SUCCESS;}return Buffer.FAILED;}@Overridepublic void drainTo(Consumer<E> consumer) {// ReadCounterRef#readCounterlong head = readCounter;// ReadAndWriteCounterRef#writeCounterlong tail = writeCounterOpaque();// 计算可操作容量 sizelong size = (tail - head);// size 为 0 表示无元素可操作if (size == 0) {return;}// 循环遍历消费缓冲区中所有元素do {// 计算具体的索引int index = (int) (head & MASK);@SuppressWarnings("unchecked")E e = (E) BUFFER.getAcquire(buffer, index);// 索引处元素为空表示无元素可消费if (e == null) {break;}// 获取到具体元素后将缓冲区该元素位置更新成 nullBUFFER.setRelease(buffer, index, null);// 执行消费逻辑consumer.accept(e);// head累加head++;} while (head != tail);// 更新读索引的值setReadCounterOpaque(head);}}
}final class BBHeader {@SuppressWarnings("PMD.AbstractClassWithoutAbstractMethod")abstract static class PadReadCounter {byte p000, /*省略118字节占位符...*/ p119;}abstract static class ReadCounterRef extends PadReadCounter {volatile long readCounter;}abstract static class PadWriteCounter extends ReadCounterRef {byte p120, /*省略118字节占位符...*/ p239;}abstract static class ReadAndWriteCounterRef extends PadWriteCounter {static final VarHandle READ, WRITE;volatile long writeCounter;// ...}
}
在 BBHeader 类中又看到了熟悉的 120 字节内存占位,在上文中我们详细介绍过,这样能够保证 readCounter 和 writeCounter 分布在不同内存行,避免了内存伪共享问题,保证不同线程读取这两个字段时互不影响。在添加元素的 offer 方法和消费元素的 drainTo 方法中,都能看见它使用了“读索引readCounter”和“写索引writeCounter”,这也对应了它命名中的 Ring。Ring 表示环形,读、写索引在操作过程中会不断累加,但是它会执行位与运算保证索引值一直落在缓冲区长度的有效范围内,也就是说这两个索引值会不断在有效索引范围内“转圈”,则形成一个“环形”缓冲区。
RingBuffer 通过 CAS 操作来确保并发添加元素操作的安全,如果 CAS 操作失败则返回 Buffer.FAILED,这时便会执行 StripedBuffer#expandOrRetry 方法,我们先来看一下它的方法注释内容,它说:这个方法用于处理写过程中发生的初始化、扩容、创建新缓存或竞争写情况。
Handles cases of updates involving initialization, resizing, creating new Buffers, and/ or contention.
具体源码如下:
abstract class StripedBuffer<E> implements Buffer<E> {// 最大尝试 3 次static final int ATTEMPTS = 3;// table 的最大大小static final int MAXIMUM_TABLE_SIZE = 4 * ceilingPowerOfTwo(NCPU);// 1 表示忙碌(扩容或正在创建)0 表示缓冲区无操作,通过 CAS 操作进行更新volatile int tableBusy;volatile Buffer<E> @Nullable[] table;/*** 扩展或重试* * @param e 元素* @param h 调用该方法时为线程探针值高 32 位,但在方法中会变更* @param increment 线程探针值高 32 位* @param wasUncontended true 未发生竞争 false 发生竞争*/final int expandOrRetry(E e, int h, int increment, boolean wasUncontended) {int result = Buffer.FAILED;// true 标志缓冲区中最后一个槽位非空 false 表示为空boolean collide = false;for (int attempt = 0; attempt < ATTEMPTS; attempt++) {Buffer<E>[] buffers;Buffer<E> buffer;int n;// 如果缓冲区数组已经被创建if (((buffers = table) != null) && ((n = buffers.length) > 0)) {// 检查具体的缓冲区是否为空if ((buffer = buffers[(n - 1) & h]) == null) {// 准备创建缓冲区,并更新 tableBusy 标志为 1if ((tableBusy == 0) && casTableBusy()) {boolean created = false;try { Buffer<E>[] rs;int mask, j;if (((rs = table) != null) && ((mask = rs.length) > 0)&& (rs[j = (mask - 1) & h] == null)) {// 创建缓冲区 return new RingBuffer<>(e);rs[j] = create(e);created = true;}} finally {tableBusy = 0;}// 如果创建成功if (created) {result = Buffer.SUCCESS;break;}// 缓冲区已经被其他线程创建了,重新循环重试continue;}collide = false;}// 如果发生竞争,表示向缓冲区中CAS添加元素失败else if (!wasUncontended) {wasUncontended = true;} // 如果重试添加元素成功,结束循环else if ((result = buffer.offer(e)) != Buffer.FAILED) {break;}// table 超过最大大小或已完成扩容但未变更引用(stale)else if ((n >= MAXIMUM_TABLE_SIZE) || (table != buffers)) {collide = false;} else if (!collide) {collide = true;}// 扩容操作,将缓冲区数组扩容为原来的两倍大小// 扩容条件:未超过最大 table 限制且重试添加元素依然失败else if ((tableBusy == 0) && casTableBusy()) {try {if (table == buffers) {table = Arrays.copyOf(buffers, n << 1);}} finally {tableBusy = 0;}collide = false;continue;}// 变更探针哈希值,尝试下一个索引位置h += increment;}// 缓冲区数组的初始化逻辑else if ((tableBusy == 0) && (table == buffers) && casTableBusy()) {boolean init = false;try {if (table == buffers) {// 初始大小为 1,会随着扩容不断将容量扩大两倍@SuppressWarnings({"rawtypes", "unchecked"})Buffer<E>[] rs = new Buffer[1];rs[0] = create(e);table = rs;init = true;}} finally {tableBusy = 0;}// 完成初始化,元素添加成功if (init) {result = Buffer.SUCCESS;break;}}}return result;}
}
根据注释信息了解该方法的逻辑并不难,接下来我们再看一下它的消费方法 drainTo,非常简单:
abstract class StripedBuffer<E> implements Buffer<E> {volatile Buffer<E> @Nullable[] table;@Overridepublic void drainTo(Consumer<E> consumer) {Buffer<E>[] buffers = table;if (buffers == null) {return;}// 循环遍历消费所有缓冲区for (Buffer<E> buffer : buffers) {if (buffer != null) {buffer.drainTo(consumer);}}}
}
总结一下,ReadBuffer 是一个 MPSC 的缓冲区,采用了分段的设计,将缓冲区划分为多份,根据线程的探针值哈希到不同的缓冲区,减少竞争的发生,并使用CAS操作来保证多线程下写入操作高效执行。因为它没有记录元素的写入顺序,所以它并不会像栈或队列一样保证 FIFO 或 LIFO。随着写入竞争发生会不断对缓冲区数组扩容,每次扩容为原来大小的两倍,每个缓冲区为环形缓冲区,通过位与运算计算元素实际的索引,将被消费的元素标记为 null 实现缓冲区中槽位的重用。
现在读写方法已经了解差不多了,需要我们再次回到维护方法 maintenance 中,看一看消费读缓冲区和其他逻辑。
maintenance
维护方法 maintenance 如下所示,第 2 步中处理写缓冲区任务的逻辑已在上文中介绍过,接下来我们会关注第 1 步的处理读缓冲区任务,第 4 步驱逐策略和第 5 步的 “增值(climb)”操作。
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {@GuardedBy("evictionLock")void maintenance(@Nullable Runnable task) {// 更新状态为执行中setDrainStatusRelease(PROCESSING_TO_IDLE);try {// 1. 处理读缓冲区中的任务drainReadBuffer();// 2. 处理写缓冲区中的任务drainWriteBuffer();if (task != null) {task.run();}// 3. 处理 key 和 value 的引用drainKeyReferences();drainValueReferences();// 4. 过期和驱逐策略expireEntries();evictEntries();// 5. “增值” 操作climb();} finally {// 状态不是 PROCESSING_TO_IDLE 或者无法 CAS 更新为 IDLE 状态的话,需要更新状态为 REQUIRED,该状态会再次执行维护任务if ((drainStatusOpaque() != PROCESSING_TO_IDLE) || !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {setDrainStatusOpaque(REQUIRED);}}}
}
drainReadBuffer
首先我们来看处理读缓冲区的逻辑,源码如下:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {final Buffer<Node<K, V>> readBuffer;final Consumer<Node<K, V>> accessPolicy;@GuardedBy("evictionLock")void drainReadBuffer() {if (!skipReadBuffer()) {readBuffer.drainTo(accessPolicy);}}}
它会执行到 StripedBuffer#drainTo 方法,并且入参了 Consumer<Node<K, V>> accessPolicy 消费者。前者会遍历所有缓冲区中对象进行消费;后者在 caffeine 构造方法中完成初始化:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {final Buffer<Node<K, V>> readBuffer;final Consumer<Node<K, V>> accessPolicy;protected BoundedLocalCache(Caffeine<K, V> builder,@Nullable AsyncCacheLoader<K, V> cacheLoader, boolean isAsync) {accessPolicy = (evicts() || expiresAfterAccess()) ? this::onAccess : e -> {};}}
onAccess 方法在上文中也提到过,具体逻辑我们在这里赘述下:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {@GuardedBy("evictionLock")void onAccess(Node<K, V> node) {if (evicts()) {K key = node.getKey();if (key == null) {return;}// 更新访问频率frequencySketch().increment(key);// 如果节点在窗口区,则将其移动到尾节点if (node.inWindow()) {reorder(accessOrderWindowDeque(), node);}// 在试用区的节点执行 reorderProbation 方法,可能会将该节点从试用区晋升到保护区else if (node.inMainProbation()) {reorderProbation(node);}// 否则移动到保护区的尾结点else {reorder(accessOrderProtectedDeque(), node);}// 更新命中量setHitsInSample(hitsInSample() + 1);}// 配置了访问过期策略else if (expiresAfterAccess()) {reorder(accessOrderWindowDeque(), node);}// 配置了自定义时间过期策略if (expiresVariable()) {timerWheel().reschedule(node);}}
}
简单概括来说:ReadBuffer 中所有的元素都会被执行 onAccess 的逻辑,频率草图会被更新,窗口区元素会被移动到该区的尾结点,试用区元素在满足条件的情况下会被晋升到保护区。在原理图中补充 ReadBuffer 相关逻辑,相比于原有 put 方法的逻辑,ReadBuffer 的消费并没有引入特别“新颖”的内容:
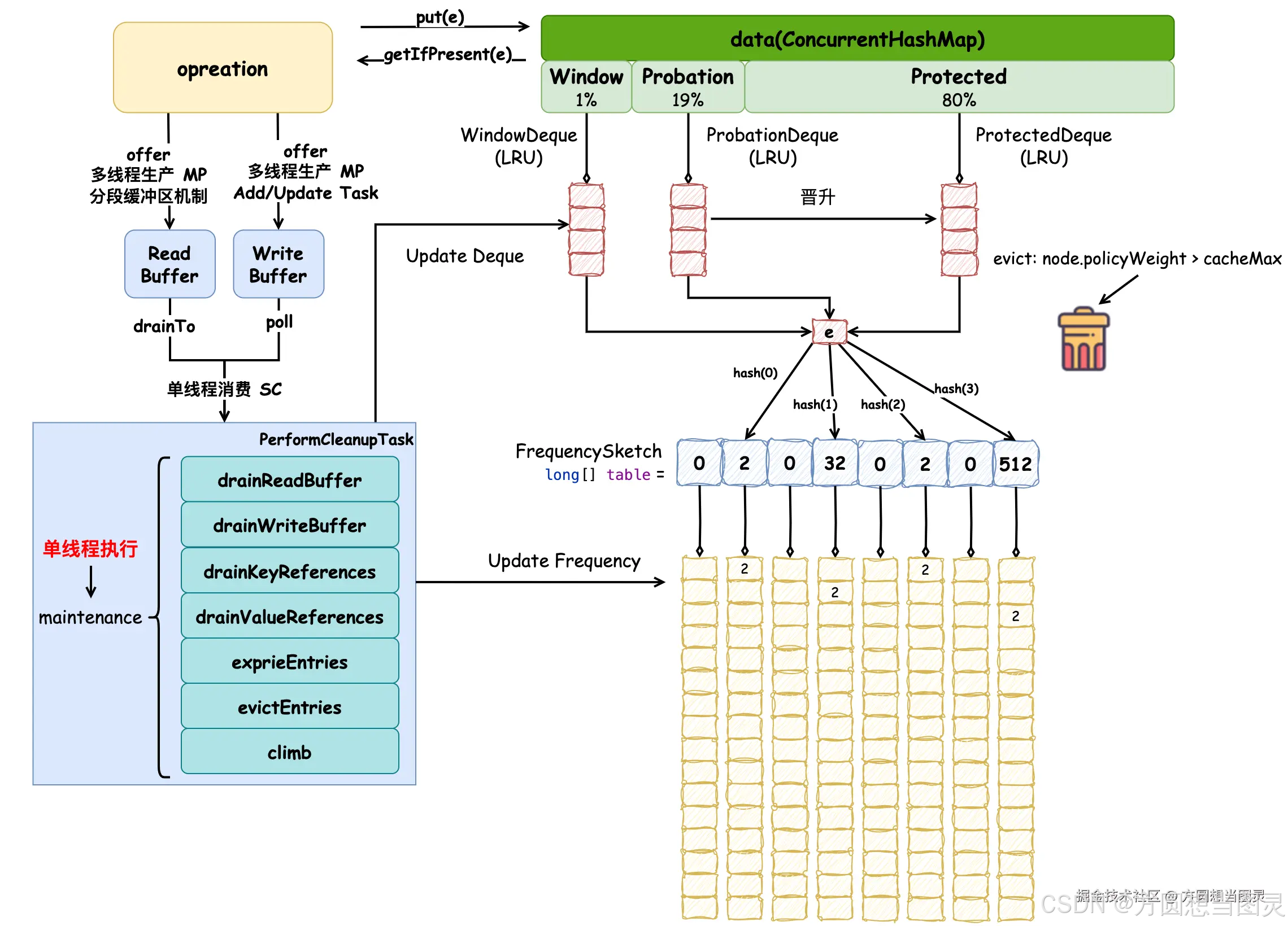
在 reorderProbation 方法中有一段注释比较有意思,它说:如果保护区空间超过它的最大值,它会将其中的元素降级到试用区。但是这个操作被推迟到 maintenance 方法的最后执行,也就是后续我们会介绍的 climb 方法,相当于是对缓存元素的移动做了剧透。
If the protected space exceeds its maximum, the LRU items are demoted to the probation space.
This is deferred to the adaption phase at the end of the maintenance cycle.
evictEntries
evictEntries 方法注释这么描述:如果缓存超过最大值则将元素驱逐。
Evicts entries if the cache exceeds the maximum
它的主方法逻辑非常简单:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {@GuardedBy("evictionLock")void evictEntries() {if (!evicts()) {return;}// 从窗口区“驱逐”var candidate = evictFromWindow();// 从候选区或保护区进行驱逐evictFromMain(candidate);}
}
首先,先来看从窗口区“驱逐”的方法 evictFromWindow:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {@GuardedBy("evictionLock")@NullableNode<K, V> evictFromWindow() {Node<K, V> first = null;// 获取队首元素Node<K, V> node = accessOrderWindowDeque().peekFirst();// 循环操作,直到窗口区权重小于窗口区权重最大限制while (windowWeightedSize() > windowMaximum()) {if (node == null) {break;}// 获取队首节点的下一个节点Node<K, V> next = node.getNextInAccessOrder();// 如果队首节点权重不为 0if (node.getPolicyWeight() != 0) {// 标记为试用区节点并移动到试用区尾节点node.makeMainProbation();accessOrderWindowDeque().remove(node);accessOrderProbationDeque().offerLast(node);// 记录队首节点引用if (first == null) {first = node;}// 更新窗口区权重setWindowWeightedSize(windowWeightedSize() - node.getPolicyWeight());}// node 记录操作完成后的下一个头节点node = next;}// 返回此时的头节点return first;}
}
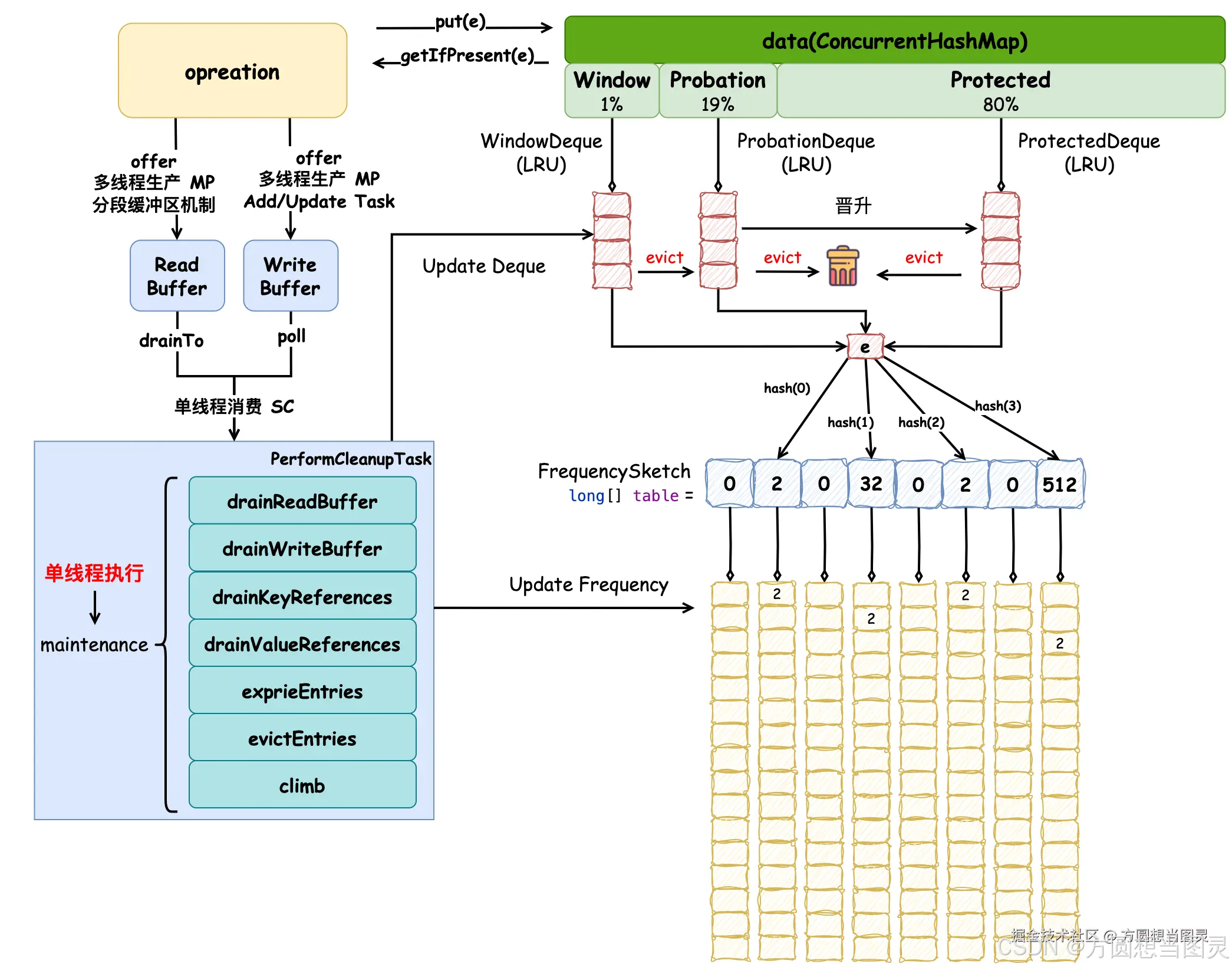
该方法会根据窗口区最大权重限制 将节点由窗口区移动到试用区,直到窗口区内元素小于最大值限制,并不是直接调用 evictEntry 方法真正地将元素驱逐。如果已经在窗口区中将元素移动到试用区,那么接下来会以窗口区头节点会作为入参执行 evictFromMain 方法,它有非常详细的注释内容:
如果缓存超过最大容量限制,则将元素从主空间中移除。主空间通过频率草图决定从窗口区来的元素是被驱逐还是被保留,以便将使用频率最低的元素移除。
窗口区的元素被提升到试用区尾节点(MRU 位置),驱逐策略驱逐的元素从试用区头节点(LRU 位置)开始。在需要执行驱逐策略时,元素会按照由头节点到尾节点的顺序进行评估,如果评估完试用区和保护区仍然需要驱逐元素,那么则会从窗口区驱逐。相似地,如果试用区驱逐完元素后仍然不够,则需要从保护区检查元素进行驱逐。队列按照从头节点到尾节点的顺序消费,使用频率相对较低的元素先被驱逐,在相同频率的情况下,优先保留主空间中的元素而不是窗口区元素。
Evicts entries from the main space if the cache exceeds the maximum capacity. The main space determines whether admitting an entry (coming from the window space) is preferable to retaining the eviction policy’s victim. This decision is made using a frequency filter so that the least frequently used entry is removed.
The window space’s candidates were previously promoted to the probation space at its MRU position and the eviction policy’s victim starts at the LRU position. The candidates are evaluated in promotion order while an eviction is required, and if exhausted then additional entries are retrieved from the window space. Likewise, if the victim selection exhausts the probation space then additional entries are retrieved the protected space. The queues are consumed in LRU order and the evicted entry is the one with a lower relative frequency, where the preference is to retain the main space’s victims versus the window space’s candidates on a tie.
接下来我们看下源码的具体实现:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {public static final int WINDOW = 0;public static final int PROBATION = 1;public static final int PROTECTED = 2;static final int ADMIT_HASHDOS_THRESHOLD = 6;// 为了方便理解,定义 victim 为驱逐区,candidate 为候选驱逐区,实际上它们不对应区域,而是对应某个区域中的节点元素@GuardedBy("evictionLock")void evictFromMain(@Nullable Node<K, V> candidate) {int victimQueue = PROBATION;int candidateQueue = PROBATION;// 首先获取试用区头节点作为首先要被驱逐的区域Node<K, V> victim = accessOrderProbationDeque().peekFirst();// 如果权重大小超过最大值,不断地执行驱逐策略,直到满足条件while (weightedSize() > maximum()) {// 如果候选驱逐区为空且候选驱逐区为试用区,则指定候选驱逐区为窗口区if ((candidate == null) && (candidateQueue == PROBATION)) {// 指定候选驱逐区为窗口区candidate = accessOrderWindowDeque().peekFirst();candidateQueue = WINDOW;}// 候选驱逐区和驱逐区都为空if ((candidate == null) && (victim == null)) {// 当前驱逐区为试用区,指定保护区为驱逐区if (victimQueue == PROBATION) {victim = accessOrderProtectedDeque().peekFirst();victimQueue = PROTECTED;continue;}// 当前驱逐区为保护区,指定驱逐区为窗口区else if (victimQueue == PROTECTED) {victim = accessOrderWindowDeque().peekFirst();victimQueue = WINDOW;continue;}// 没有更多元素供驱逐,则退出循环break;}// 跳过权重为 0 的元素,权重为 0 表示无需驱逐if ((victim != null) && (victim.getPolicyWeight() == 0)) {victim = victim.getNextInAccessOrder();continue;} else if ((candidate != null) && (candidate.getPolicyWeight() == 0)) {candidate = candidate.getNextInAccessOrder();continue;}// 如果要驱逐区为空,则从候选驱逐区中进行驱逐if (victim == null) {// 驱逐当前节点并将指针指向下一个节点 Node<K, V> previous = candidate.getNextInAccessOrder();Node<K, V> evict = candidate;candidate = previous;evictEntry(evict, RemovalCause.SIZE, 0L);continue;}// 候选驱逐区为空,在驱逐区中驱逐元素else if (candidate == null) {Node<K, V> evict = victim;victim = victim.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);continue;}// 驱逐区和候选驱逐区是同一个区的元素if (candidate == victim) {victim = victim.getNextInAccessOrder();evictEntry(candidate, RemovalCause.SIZE, 0L);candidate = null;continue;}// 如果元素已经被垃圾回收,则驱逐K victimKey = victim.getKey();K candidateKey = candidate.getKey();if (victimKey == null) {Node<K, V> evict = victim;victim = victim.getNextInAccessOrder();evictEntry(evict, RemovalCause.COLLECTED, 0L);continue;} else if (candidateKey == null) {Node<K, V> evict = candidate;candidate = candidate.getNextInAccessOrder();evictEntry(evict, RemovalCause.COLLECTED, 0L);continue;}// 如果元素已经被标记为删除,驱逐它们if (!victim.isAlive()) {Node<K, V> evict = victim;victim = victim.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);continue;} else if (!candidate.isAlive()) {Node<K, V> evict = candidate;candidate = candidate.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);continue;}// 如果候选区节点元素超过最大权重,直接驱逐if (candidate.getPolicyWeight() > maximum()) {Node<K, V> evict = candidate;candidate = candidate.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);continue;}// 驱逐频率较低的元素if (admit(candidateKey, victimKey)) {Node<K, V> evict = victim;victim = victim.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);// 变更候选区元素引用candidate = candidate.getNextInAccessOrder();} else {Node<K, V> evict = candidate;candidate = candidate.getNextInAccessOrder();evictEntry(evict, RemovalCause.SIZE, 0L);}}}@GuardedBy("evictionLock")boolean admit(K candidateKey, K victimKey) {// 获取候选驱逐区中元素频率int victimFreq = frequencySketch().frequency(victimKey);int candidateFreq = frequencySketch().frequency(candidateKey);// 候选区元素频率大于驱逐区中元素返回 trueif (candidateFreq > victimFreq) {return true;}// 如果候选区元素频率大于 6else if (candidateFreq >= ADMIT_HASHDOS_THRESHOLD) {// 计算随机值来决定两元素之间的去留int random = ThreadLocalRandom.current().nextInt();return ((random & 127) == 0);// 使用计算随机值的方法来防止 HASH DOS 攻击,攻击者可能人为地将某些不被常用的缓存访问频率提高,如果不计算随机性那么会将真正有价值的元素驱逐,添加这种随机性计算可能减少这种攻击带来的影响,保证缓存的有效命中率}// 候选驱逐区元素小于驱逐区元素频率return false;}
}
方法虽然很长,但是逻辑清晰明了,元素的驱逐流程根据注释可以很明确的了解。窗口区中元素会优先被晋升到试用区,在试用区和保护区中不断的驱逐节点直到满足条件,如果驱逐完成之后还不满足条件则会从窗口区中驱逐元素,此外,在逻辑中使用随机驱逐的方式来减少 HASH DOS 攻击带来的影响也很值得学习,更新原理图如下:
climb
现在我们来到了维护方法的最后一个步骤 climb 方法,看看它是如何为缓存“增值(climb)”的,源码如下:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef implements LocalCache<K, V> {static final double HILL_CLIMBER_RESTART_THRESHOLD = 0.05d;static final double HILL_CLIMBER_STEP_PERCENT = 0.0625d;// 步长值衰减比率static final double HILL_CLIMBER_STEP_DECAY_RATE = 0.98d;static final int QUEUE_TRANSFER_THRESHOLD = 1_000;@GuardedBy("evictionLock")void climb() {if (!evicts()) {return;}// 确定要调整的量determineAdjustment();// 将保护区中的元素降级到试用区demoteFromMainProtected();// 获取第一步计算完毕的调整大小long amount = adjustment();// 不调整则结束,否则根据正负增大或减小窗口大小if (amount == 0) {return;} else if (amount > 0) {increaseWindow();} else {decreaseWindow();}}@GuardedBy("evictionLock")void determineAdjustment() {// 检查频率草图是否被初始化if (frequencySketch().isNotInitialized()) {// 没有被初始化则重置命中率、命中和未命中样本数setPreviousSampleHitRate(0.0);setMissesInSample(0);setHitsInSample(0);return;}// 请求总数 = 命中样本数 + 未命中样本数int requestCount = hitsInSample() + missesInSample();if (requestCount < frequencySketch().sampleSize) {return;}// 计算命中率、命中率变化double hitRate = (double) hitsInSample() / requestCount;double hitRateChange = hitRate - previousSampleHitRate();// 计算调整量,如果命中率增加获取正的步长值,否则获取负的步长值double amount = (hitRateChange >= 0) ? stepSize() : -stepSize();// 计算下一个步长值,如果变化量超过阈值,那么重新计算步长,否则按照固定衰减率计算double nextStepSize = (Math.abs(hitRateChange) >= HILL_CLIMBER_RESTART_THRESHOLD)? HILL_CLIMBER_STEP_PERCENT * maximum() * (amount >= 0 ? 1 : -1): HILL_CLIMBER_STEP_DECAY_RATE * amount;// 记录本次命中率作为下一次计算的依据setPreviousSampleHitRate(hitRate);// 记录要调整的量setAdjustment((long) amount);// 记录步长值setStepSize(nextStepSize);// 重置未命中和命中数量setMissesInSample(0);setHitsInSample(0);}@GuardedBy("evictionLock")void demoteFromMainProtected() {// 获取保护区的最大值和当前值long mainProtectedMaximum = mainProtectedMaximum();long mainProtectedWeightedSize = mainProtectedWeightedSize();// 当前值没有超过最大值则不处理if (mainProtectedWeightedSize <= mainProtectedMaximum) {return;}// 每次从保护区转换到试用区有 1000 个最大限制for (int i = 0; i < QUEUE_TRANSFER_THRESHOLD; i++) {// 一旦不超过最大阈值则停止if (mainProtectedWeightedSize <= mainProtectedMaximum) {break;}// 在保护区取出头节点Node<K, V> demoted = accessOrderProtectedDeque().poll();if (demoted == null) {break;}// 标记为试用区demoted.makeMainProbation();// 加入到试用区尾节点accessOrderProbationDeque().offerLast(demoted);// 计算变更后保护区权重大小mainProtectedWeightedSize -= demoted.getPolicyWeight();}// 更新保护区权重setMainProtectedWeightedSize(mainProtectedWeightedSize);}@GuardedBy("evictionLock")void increaseWindow() {// 保护区最大容量为 0 则没有可调整的空间if (mainProtectedMaximum() == 0) {return;}// 窗口调整的变化量由保护区贡献,取能够变化额度 quota 为 调整量adjustment 和 保护区最大值 中的小值long quota = Math.min(adjustment(), mainProtectedMaximum());// 减小保护区大小增加窗口区大小setMainProtectedMaximum(mainProtectedMaximum() - quota);setWindowMaximum(windowMaximum() + quota);// 保护区大小变动后,需要操作元素由保护区降级到试用区demoteFromMainProtected();// 窗口区增加容量之后,需要优先从试用区获取元素将增加的容量填满,如果试用区元素不够,则从保护区获取元素来填for (int i = 0; i < QUEUE_TRANSFER_THRESHOLD; i++) {// 获取试用区头节点为“候选节点”Node<K, V> candidate = accessOrderProbationDeque().peekFirst();boolean probation = true;// 如果试用区元素为空或者窗口调整的变化量要比该节点所占的权重小,那么尝试从保护区获取节点if ((candidate == null) || (quota < candidate.getPolicyWeight())) {candidate = accessOrderProtectedDeque().peekFirst();probation = false;}// 试用区和保护区均无节点,则无需处理,结束循环if (candidate == null) {break;}// 获取该候选节点的权重,如果可变化额度比候选权重小,那么无需处理int weight = candidate.getPolicyWeight();if (quota < weight) {break;}// 每移除一个节点更新需要可变化额度quota -= weight;// 如果是试用区节点,则直接在试用区移除if (probation) {accessOrderProbationDeque().remove(candidate);}// 如果是保护区节点,需要更新保护区权重大小,再将其从保护区中移除else {setMainProtectedWeightedSize(mainProtectedWeightedSize() - weight);accessOrderProtectedDeque().remove(candidate);}// 增加窗口区大小setWindowWeightedSize(windowWeightedSize() + weight);// 将被移除的“候选节点”添加到窗口区中accessOrderWindowDeque().offerLast(candidate);// 标记为窗口区节点candidate.makeWindow();}// 可能存在 quota 小于 节点权重 的情况,那么这些量无法再调整,需要重新累加到保护区,并在窗口区中减掉setMainProtectedMaximum(mainProtectedMaximum() + quota);setWindowMaximum(windowMaximum() - quota);// 将未完成调整的 quota 记录在调整值中setAdjustment(quota);}@GuardedBy("evictionLock")void decreaseWindow() {// 如果窗口区大小小于等于 1 则无法再减少了if (windowMaximum() <= 1) {return;}// 获取变化量的额度(正整数),取调整值和窗口最大值减一中较小的值long quota = Math.min(-adjustment(), Math.max(0, windowMaximum() - 1));// 更新保护区和窗口区大小setMainProtectedMaximum(mainProtectedMaximum() + quota);setWindowMaximum(windowMaximum() - quota);for (int i = 0; i < QUEUE_TRANSFER_THRESHOLD; i++) {// 从窗口区获取“候选节点”Node<K, V> candidate = accessOrderWindowDeque().peekFirst();// 未获取到说明窗口区已经没有元素了,不能再减小了,结束循环操作if (candidate == null) {break;}// 获取候选节点的权重int weight = candidate.getPolicyWeight();// 可变化的额度小于权重,则不支持变化,结束循环if (quota < weight) {break;}// 随着节点的移动,变更可变化额度quota -= weight;// 更新窗口区大小并将元素从窗口区移除setWindowWeightedSize(windowWeightedSize() - weight);accessOrderWindowDeque().remove(candidate);// 将从窗口区中移除的元素添加到试用区accessOrderProbationDeque().offerLast(candidate);// 将节点标记为试用区元素candidate.makeMainProbation();}// 此时 quote 为剩余无法变更的额度,需要在保护区中减去在窗口区中加上setMainProtectedMaximum(mainProtectedMaximum() - quota);setWindowMaximum(windowMaximum() + quota);// 记录未变更完的额度在调整值中setAdjustment(-quota);}}
现在我们了解了 climb 方法的逻辑,正如它的注释所述 Adapts the eviction policy to towards the optimal recency / frequency configuration.,它会根据访问情况动态调整最佳的分区配置以适应驱逐策略。元素被添加时会优先被放在窗口区,窗口区越大则意味着短期内有大量缓存被添加,或元素添加后被再次访问,缓存命中率提高,需要更大的窗口区来承接这部分新晋的元素。根据 climb 中的逻辑,窗口区增大也会有试用区/保护区的元素不断被移动到窗口区;如果保护区越大意味着缓存中维护的元素都是访问频率较高的元素,命中率降低,并趋于某稳定值附近;试用区元素由窗口区元素晋升得来,再被访问时会被晋升到保护区,它更像是 JVM 分区的 survivor 区。缓冲区不同分区的动态调整可以适应不同的访问模式,优化缓存的性能。接下来我们在原理图中补充上各个分区间元素的变换路径(元素也可由保护区直接降级到窗口区,但在图中未标出),并根据图示对 Caffeine 的实现原理进行概括:

在图示(1)中,put 方法会直接将元素添加到 ConcurrentHashMap 中,并在 WriteBuffer 中添加任务,由单线程异步调用维护方法对任务进行消费,元素访问频率会被更新,试用区元素可能会被晋升到保护区;在图示(2)调用 getIfPresent 方法会直接从 ConcurrentHashMap 中获取元素,并添加任务到 ReadBuffer 中由单线程异步消费,它相比于(1)并没有什么额外操作,两个缓冲区均采用 MPSC 的设计模式,这种设计参考了 WAL(Write-Ahead Logging)思想;图示(3)和图示(4)均发生在维护方法逻辑中,图示(3)驱逐元素时,窗口区元素会被“驱逐”到试用区,而试用区和保护区元素可能被直接驱逐;图示(4)“增值(climb)”操作会根据命中率调整窗口区和保护区的大小,合理分配分区间的元素。
在文中提到过每个分区的双端队列使用了 LRU 算法,被访问过的元素会被放在尾节点,但对元素进行驱逐时并不以 LRU 的顺序为准,而是会参考频率草图中记录的元素频率,保证使用频率高的被保留,低的被驱逐。这和 LFU 算法很像,区别于 LFU 算法的是它采用了 Count-Min Sketch 数据结构来记录频率,能够在较小的内存开销下实现对频率较为精准(93.75%)的估计,这种算法实际被称为 TinyLFU 算法,它结合了两者的有点,在内存和计算开销上达到更好的平衡。
技术选型
现在我们已经对 Caffeine 缓存有了一定的了解,那么究竟什么时候适合选择使用它呢?那就要根据它的特点来了:首先,它是线程安全的,适合在多线程环境下使用;其次它的性能很好,使用了 TinyLFU 算法并采用了高性能缓存的设计;再就是它提供了多种缓存管理机制,除了基于最大容量的驱逐策略,还支持基于时间、软/虚引用等驱逐策略。所以 它适合在高并发环境并且需要高性能、支持多种缓存管理策略的场景下使用。
如果要在多种缓存中选取,可以以如下表格为参考:
| 缓存 | 是否线程安全 | 性能 | 缓存管理机制 |
|---|---|---|---|
| HashMap | 否 | 高 | 无 |
| ConcurrentHashMap | 是 | 高 | 无 |
| Guava | 是 | 中 | 提供基于最大容量、时间、软/虚引用等驱逐策略 |
| Caffeine | 是 | 高 | 提供基于最大容量、时间、软/虚引用等驱逐策略 |
巨人的肩膀
- Github - caffeine
- 并发编程网 - 现代化的缓存设计方案
- 博客园 - CPU Cache与缓存行
相关文章:
)
缓存之美:万文详解 Caffeine 实现原理(下)
上篇文章:缓存之美:万文详解 Caffeine 实现原理(上) getIfPresent 现在我们对 put 方法有了基本了解,现在我们继续深入 getIfPresent 方法: public class TestReadSourceCode {Testpublic void doRead() …...

PHP防伪溯源一体化管理系统小程序
🔍 防伪溯源一体化管理系统,品质之光,根源之锁 🚀 引领防伪技术革命,重塑品牌信任基石 我们自豪地站在防伪技术的前沿,为您呈现基于ThinkPHP和Uniapp精心锻造的多平台(微信小程序、H5网页&…...

STM32——LCD
一、引脚配置 查看引脚 将上述引脚都设置为GPIO_Output 二、导入驱动文件 将 LCD 驱动的 Inc 以及 Src 中的 fonts.h,lcd.h 和 lcd.c 导入到自己工程的驱动文件中。 当然,后面 lcd 的驱动学习可以和 IMX6U 一块学。 三、LCD函数 void LCD_Clear(u16 Color); 功能…...

洛谷刷题1-3
比较巧妙,求最小公倍数,看多少个数一次循环,直接求解就好了,N的数量级比较大,一层循环也会超时,也用了点双指针的想法(归并排序) 这里很大的问题,主要是cin输入的时候遇到…...

Facebook 元宇宙与全球文化交流的新趋势
随着科技的快速发展,虚拟现实与增强现实技术逐渐成为全球社交平台的重要组成部分。Facebook(现改名为 Meta)率先将目光投向了元宇宙这一新兴领域,致力于打造一个超越传统社交媒体的虚拟空间,成为全球文化交流的新平台。…...

结构化布线系统分为六个子系统
文章目录 前言系统介绍1. 工作区子系统 (Work Area Subsystem)2. 水平布线子系统 (Horizontal Cabling Subsystem)3. 管理子系统 (Administration Subsystem)4. 干线(垂直)子系统 (Backbone Cabling Subsystem)5. 设备间子系统 (Equipment Room Subsyste…...

亿坊软件前端命名规范
在前端开发中,文件命名的重要性不言而喻。由于历史原因和个人习惯,不同的开发者在命名DOM结构、图片和CSS文件时,可能会产生不一致的情况。这不仅会导致维护成本增加,还会降低团队协作效率。因此,制定一套统一的命名规…...
(十一))
单片机-STM32 IIC通信(OLED屏幕)(十一)
一、屏幕的分类 1、LED屏幕: 由无数个发光的LED灯珠按照一定的顺序排列而成,当需要显示内容的时候,点亮相关的LED灯即可,市场占有率很高,主要是用于户外,广告屏幕,成本低。 LED屏是一种用发光…...

【Qt】: QPointer详解
考古: 《Qt智能指针之QScopedPointer》 QPointer是Qt框架中的一个智能指针类,用于安全地管理QObject派生对象的指针。它的主要功能是自动将指针置为nullptr,当它所指向的QObject对象被销毁时。这在Qt应用程序中非常有用,因为QObj…...

15_业务系统基类
创建脚本 SystemRoot.cs 因为 业务系统基类的子类 会涉及资源加载服务层ResSvc.cs 和 音乐播放服务层AudioSvc.cs 所以在业务系统基类 提取引用资源加载服务层ResSvc.cs 和 音乐播放服务层AudioSvc.cs 并调用单例初始化 using UnityEngine; // 功能 : 业务系统基类 public c…...

C++中explicit关键字的介绍和使用详解
某一天突然发现Qt自动生成的类文件的构造函数前边都有explicit关键字,但是explicit关键字什么意思呐? 在C中,explicit是一个关键字,主要用于修饰构造函数或转换运算符,其作用是防止隐式类型转换或隐式构造行为。 下面…...

动态内存管理
本章重点 1.为什么存在动态内存分配 2.动态内存函数的介绍 3.malloc free calloc realloc 4.常见的动态内存错误 一.为什么存在动态内存分配 二.动态内存函数的介绍 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #include &…...

Java 中的各种锁详解
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

进制之间转换
「 一、十进制 二进制 」 1.十进制转二进制:一直除以2直到商为0,再反向取余数。 例:13(十进制)转1101(二进制) 2.二进制转十进制:最后一位数开始是2^0,然后一直按照指数递增的方式…...

微信小程序获取位置服务
wx.getLocation({type: gcj02,success(res) {wx.log(定位成功);},fail(err) {wx.log(定位失败, err);wx.showModal({content: 请打开手机和小程序中的定位服务,success: (modRes) > {if (modRes.confirm) {wx.openSetting({success(setRes) {if (setRes.authSetting[scope.u…...

数据结构——实验八·学生管理系统
嗨~~欢迎来到Tubishu的博客🌸如果你也是一名在校大学生,正在寻找各种编程资源,那么你就来对地方啦🌟 Tubishu是一名计算机本科生,会不定期整理和分享学习中的优质资源,希望能为你的编程之路添砖加瓦⭐&…...
USB应用开发-libusb库)
Linux应用编程(五)USB应用开发-libusb库
一、基础知识 1. USB接口是什么? USB接口(Universal Serial Bus)是一种通用串行总线,广泛使用的接口标准,主要用于连接计算机与外围设备(如键盘、鼠标、打印机、存储设备等)之间的数据传输和电…...

Swift语言探索:Sequence与Collection的详细解读
在Swift编程语言中,Sequence和Collection是两个非常重要的协议,它们定义了遍历和访问元素集合的方式。理解这两个协议不仅有助于我们更好地掌握Swift的集合类型,还能让我们在编写代码时更加灵活和高效。本文将详细解读Sequence与Collection&a…...

解锁C# EF/EF Core:从入门到进阶的技术飞跃
一、EF/EF Core 初相识 在.NET 开发的广阔天地中,Entity Framework (EF) 及其轻量级、可扩展、跨平台的版本 Entity Framework Core (EF Core),犹如两颗璀璨的明星,照亮了数据访问层开发的道路。它们是开源的对象关系映射器(ORM&…...

大模型搜广推?对算法工作的影响
大模型与传统应用结合的性质 长期看是一种范式革新。算力和模型定义的边界发生变化,选择生成式AI或大模型发展方向时,会不断发现新的增长曲线,目前在不断被验证。 现阶段大模型确实带来了增量信息,但推荐过程仍在原有流程基础上…...

【教程】最好的pytorch教程
文章目录 Materials for the Learn PyTorch for Deep Learning: Zero to Mastery course from: https://github.com/mrdbourke/pytorch-deep-learning/blob/main/01_pytorch_workflow.ipynb...

基于java线程池和EasyExcel实现异步导出
基于java线程池和EasyExcel实现异步导出 1.controller层 GetMapping("export") public void exportExcel(HttpServletResponse response) throws IOException, InterruptedException {exportService.exportExcel(response); }2. service public void exportExcel(H…...

vue3组件传值具体使用
问: left.vue文件调用接口获取了后端返回的urlLink字段,我该怎么传递给总的父组件index.vue中,我需要点击父组件的一个按钮来触发跳转? 回答: 在 Vue 3 中使用 TypeScript 和 setup 语法糖时,可以通过 e…...

《CPython Internals》阅读笔记:p336-p352
《CPython Internals》学习第 17天,p336-p352 总结,总计 17 页。 一、技术总结 1.GDB GDB 是 GNU Dbugger 的缩写。 (1)安装 sudo apt install gdb(2)创建 .gdbinit 文件 touch ~/.gdbinitvim ~/.gdbinit(3)配置 .gdbinit 文件 add-auto-load-saf…...

WPF基础 | WPF 常用控件实战:Button、TextBox 等的基础应用
WPF基础 | WPF 常用控件实战:Button、TextBox 等的基础应用 一、前言二、Button 控件基础2.1 Button 的基本定义与显示2.2 按钮样式设置2.3 按钮大小与布局 三、Button 的交互功能3.1 点击事件处理3.2 鼠标悬停与离开效果3.3 按钮禁用与启用 四、TextBox 控件基础4.…...

Langchain+讯飞星火大模型Spark Max调用
1、安装langchain #安装langchain环境 pip install langchain0.3.3 openai -i https://mirrors.aliyun.com/pypi/simple #灵积模型服务 pip install dashscope -i https://mirrors.aliyun.com/pypi/simple #安装第三方集成,就是各种大语言模型 pip install langchain-comm…...

2025年华为云一键快速部署幻兽帕鲁联机服务器教程
华为云如何快速部署幻兽帕鲁联机服务器?为了方便新手玩家搭建专属游戏联机服务器,华为云推出了云游戏专场,无需专业技术,新手小白也能一键快速部署幻兽帕鲁联机服务器! 华为云快速部署幻兽帕鲁联机服务器教程如下&…...

Langchain+文心一言调用
import osfrom langchain_community.llms import QianfanLLMEndpointos.environ["QIANFAN_AK"] "" os.environ["QIANFAN_SK"] ""llm_wenxin QianfanLLMEndpoint()res llm_wenxin.invoke("中国国庆日是哪一天?") print(…...
详解)
C++AVL树(一)详解
文章目录 AVL树概念AVL树的插入平衡因子的更新旋转的规则左单旋右单旋抽象的情况h0h1h 2h 3 AVL树 概念 AVL树是一棵平衡二叉查找树,AVL树是空树,保证左右子树都是AVL树,AVL树要求高度差的绝对值不超过1,因为最好情况是1&#…...
)
ceph新增节点,OSD设备,标签管理(二)
一、访问客户端集群方式 方式一: 使用cephadm shell交互式配置 [rootceph141 ~]# cephadm shell # 注意,此命令会启动一个新的容器,运行玩后会退出! Inferring fsid c153209c-d8a0-11ef-a0ed-bdb84668ed01 Inferring config /var/lib/ce…...

c++学习第七天
创作过程中难免有不足,若您发现本文内容有误,恳请不吝赐教。 提示:以下是本篇文章正文内容,下面案例可供参考。 一、const成员函数 //Date.h#pragma once#include<iostream> using namespace std;class Date { public:Date…...

F/V/F/I频率脉冲信号转换器
F/V/F/I频率脉冲信号转换器 概述:捷晟达科技的JSD TFA-1001系列是一进一出频率脉冲信号转换器(F/V转换器),该频率转换器是将频率脉冲信号(方波、正弦波、锯齿波)转换成国际标准的模拟量电压(电流)信号,并远距离无失真传送到控制室(如:PLC,DCS,AD,PC采集系统)产品的输…...

SQLServer中DBCC INPUTBUFFER显示从客户端发送到 SQL Server 实例的最后一个语句
SQLServer中DBCC INPUTBUFFER显示从客户端发送到 SQL Server 实例的最后一个语句 1、本文内容 语法参数结果集权限示例 适用于: SQL ServerAzure SQL 数据库Azure SQL 托管实例 显示从客户端发送到 SQL Server 实例的最后一个语句。 2、语法 DBCC INPUTBUFFE…...

Mysql面试题----MySQL中CHAR和VARCHAR的区别
存储方式 CHAR:是一种固定长度的字符串类型。它会按照定义的长度来分配存储空间,无论实际存储的字符串长度是多少。例如,定义一个 CHAR (10) 的列,如果存储的值是 ‘ab’,那么它仍然会占用 10 个字符的存储空间&#…...

github汉化
本文主要讲述了github如何汉化的方法。 目录 问题描述汉化步骤1.打开github,搜索github-chinese2.打开项目,打开README.md3.下载安装脚本管理器3.1 在README.md中往下滑动,找到浏览器与脚本管理器3.2 选择浏览器对应的脚本管理器3.2.1 点击去…...
)
探索JavaScript前端开发:开启交互之门的神奇钥匙(二)
目录 引言 四、事件处理 4.1 事件类型 4.2 事件监听器 五、实战案例:打造简易待办事项列表 5.1 HTML 结构搭建 5.2 JavaScript 功能实现 六、进阶拓展:异步编程与 Ajax 6.1 异步编程概念 6.2 Ajax 原理与使用 七、前沿框架:Vue.js …...

什么是网络爬虫?Python爬虫到底怎么学?
最近我在研究 Python 网络爬虫,发现这玩意儿真是有趣,干脆和大家聊聊我的心得吧!咱们都知道,网络上的信息多得就像大海里的水,而网络爬虫就像一个勤劳的小矿工,能帮我们从这片浩瀚的信息海洋中挖掘出需要的…...

React 中hooks之 React.memo 和 useMemo用法总结
1. React.memo 基础 React.memo 是一个高阶组件(HOC),用于优化函数组件的性能,通过记忆组件渲染结果来避免不必要的重新渲染。 1.1 基本用法 const MemoizedComponent React.memo(function MyComponent(props) {/* 渲染逻辑 *…...

springboot基于微信小程序的手机银行系统
Spring Boot基于微信小程序的手机银行系统是一种结合现代Web技术和移动应用优势的创新金融服务平台。 一、系统背景与意义 随着信息技术的快速发展和用户对便捷金融服务需求的日益增长,传统手机银行系统的人工管理方法已逐渐显露出效率低下、安全性低以及信息传输…...

Kafka后台启动命令
#保存日志 nohup ./kafka-server-start.sh ../config/server.properties > /path/to/logfile.log 2>&1 &#不保存日志 nohup ./kafka-server-start.sh ../config/server.properties >/dev/null 2>&1 & nohup: 是一个Unix/Linux命令,用于…...

面试题目1
文章目录 C语言函数调用详细过程C语言中const与C中const的区别关系运算符有哪些互斥锁与读写锁的区别gcc的编译过程 C语言函数调用详细过程 调用函数:当程序执行到函数调用语句时,会将当前函数的返回地址、参数列表等信息压入栈中,然后跳转到…...

Android AutoMotive --CarService
1、AAOS概述 Android AutoMotive OS是谷歌针对车机使用场景打造的操作系统,它是基于现有Android系统的基础上增加了新特性,最主要的就是增加了CarService(汽车服务)模块。我们很容易把Android AutoMotive和Android Auto搞混&…...

CSDN 博客之星 2024:默语的技术进阶与社区耕耘之旅
CSDN 博客之星 2024:默语的技术进阶与社区耕耘之旅 🌟 默语,是一位在技术分享与社区建设中坚持深耕的博客作者。今年,我有幸再次入围成为 CSDN 博客之星TOP300 的一员,这既是对过往努力的肯定,也是对未来探…...
)
【Vim Masterclass 笔记24】S10L43 + L44:同步练习10 —— 基于 Vim 缓冲区的各类基础操作练习(含点评课)
文章目录 S10L43 Exercise 12 - Vim Buffers1 训练目标2 操作指令2.1. 打开 buf* 文件2.2. 查看缓冲区 View the buffers2.3. 切换缓冲区 Switch buffers2.4. 同时编辑多个缓冲区 Edit multiple buffers at once2.5. 缓冲区的增删操作 Add and delete buffers2.6. 练习 Vim 内置…...

python如何使得pdf加水印后的大小尽可能小
在 Python 中为 PDF 添加水印并尽可能减少文件大小,可以采取以下优化策略: 1. 使用合适的库 常用的 PDF 处理库: PyMuPDF(fitz):高效且优化的 PDF 处理reportlab pdfrw:可实现水印合并&#…...

Leetcode 3429. Paint House IV
Leetcode 3429. Paint House IV 1. 解题思路2. 代码实现 题目链接:3429. Paint House IV 1. 解题思路 这一题解法上就是一个动态规划的思路,由于题目有两个限制条件,即相邻不可以同色,以及前后同位置不可以同色,因此…...

ASP.NET Core 实战:JWT 身份验证
一、引言 在当今数字化时代,Web 应用的安全性至关重要。ASP.NET Core 作为一种广泛应用的开发框架,为开发者提供了强大的工具来构建安全可靠的应用程序。而 JWT(JSON Web Token)身份验证则是保障应用安全的关键环节之一。 JWT 身…...

【学习笔记15】如何在非root服务器中,安装属于自己的redis
一、下载安装包 官网下载黑马程序员给的安装包(redis-6.2.6) 二、将安装包上传至服务器 我将安装包上传在我的文件夹/home/XXX,指定路径中/src/local/redis/,绝对路径为/home/XXX/src/local/redis/解压安装包 XXXomega:~$ cd …...

基于深度学习的微出血自动检测及解剖尺度定位|文献速递-视觉大模型医疗图像应用
Title 题目 Toward automated detection of microbleeds with anatomical scale localization using deep learning 基于深度学习的微出血自动检测及解剖尺度定位 01 文献速递介绍 基于深度学习的脑微出血(CMBs)检测与解剖定位 脑微出血ÿ…...

Couchbase UI: Dashboard
以下是 Couchbase UI Dashboard 页面详细介绍,包括页面布局和功能说明,帮助你更好地理解和使用。 1. 首页(Overview) 功能:提供集群的整体健康状态和性能摘要 集群状态 节点健康状况:绿色(正…...