时间序列分析ARIMA(AutoRegressive Integrated Moving Average,自回归积分滑动平均)模型:中英双语
ARIMA模型:时间序列分析中的强大工具
在时间序列分析中,ARIMA(AutoRegressive Integrated Moving Average,自回归积分滑动平均)模型是一种广泛使用的模型。它通过结合自回归、差分和滑动平均三种方法来对时间序列进行建模和预测。本文将详细介绍ARIMA模型的基本原理、数学公式以及如何在Python中实现ARIMA模型,并通过数值模拟示例来展示其应用。
1. ARIMA模型的基本原理
ARIMA模型的核心思想是将一个非平稳的时间序列转化为平稳序列,然后利用自回归(AR)、差分(I)和滑动平均(MA)三种技术进行建模。具体来说,ARIMA模型包含三个重要部分:
1.1 自回归(AR)
自回归(AutoRegressive)部分表示当前值与前几个时间点的值之间的关系。自回归过程假设时间序列的当前值是其前几期值的线性组合。自回归模型的阶数(即使用多少个过去值)由参数p决定。
数学公式为:
Y t = ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + ⋯ + ϕ p Y t − p + ϵ t Y_t = \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \dots + \phi_p Y_{t-p} + \epsilon_t Yt=ϕ1Yt−1+ϕ2Yt−2+⋯+ϕpYt−p+ϵt
其中,( Y t Y_t Yt)是时间点t的观测值,( ϕ 1 , ϕ 2 , … , ϕ p \phi_1, \phi_2, \dots, \phi_p ϕ1,ϕ2,…,ϕp)是回归系数,( ϵ t \epsilon_t ϵt)是误差项。
1.2 差分(I)
差分(Integrated)部分用于使非平稳的时间序列变得平稳。通过计算连续时间点之间的差值,消除趋势性波动。差分的次数由参数d决定。
差分操作的数学公式为:
Δ Y t = Y t − Y t − 1 \Delta Y_t = Y_t - Y_{t-1} ΔYt=Yt−Yt−1
这里的( Δ Y t \Delta Y_t ΔYt)是差分后的时间序列。
1.3 滑动平均(MA)
滑动平均(Moving Average)部分表示当前的观测值是前几期的误差项的线性组合。MA部分的阶数由参数q决定。
数学公式为:
Y t = μ + ϵ t + θ 1 ϵ t − 1 + θ 2 ϵ t − 2 + ⋯ + θ q ϵ t − q Y_t = \mu + \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + \dots + \theta_q \epsilon_{t-q} Yt=μ+ϵt+θ1ϵt−1+θ2ϵt−2+⋯+θqϵt−q
其中,( ϵ t \epsilon_t ϵt)是当前的误差项,( θ 1 , θ 2 , … , θ q \theta_1, \theta_2, \dots, \theta_q θ1,θ2,…,θq)是滑动平均系数。
1.4 ARIMA模型的数学公式
ARIMA模型的总的数学公式可以写作:
Y t = μ + ϕ 1 Y t − 1 + ⋯ + ϕ p Y t − p + θ 1 ϵ t − 1 + ⋯ + θ q ϵ t − q + ϵ t Y_t = \mu + \phi_1 Y_{t-1} + \dots + \phi_p Y_{t-p} + \theta_1 \epsilon_{t-1} + \dots + \theta_q \epsilon_{t-q} + \epsilon_t Yt=μ+ϕ1Yt−1+⋯+ϕpYt−p+θ1ϵt−1+⋯+θqϵt−q+ϵt
其中,( μ \mu μ)是常数项,( ϕ \phi ϕ)和( θ \theta θ)分别是AR和MA部分的系数,( ϵ t \epsilon_t ϵt)是误差项。
2. ARIMA模型的参数选择
ARIMA模型的参数选择需要根据数据的性质进行调整。通常,我们根据以下几个步骤来确定最合适的参数:
- 平稳性检查:首先检查时间序列的平稳性。如果时间序列不平稳,我们需要进行差分操作(I部分)。
- ACF和PACF图分析:通过分析自相关函数(ACF)和偏自相关函数(PACF)图,选择AR和MA部分的阶数。
- ACF图主要用于确定MA部分的阶数。
- PACF图主要用于确定AR部分的阶数。
- 模型拟合与评估:根据上述步骤选择的参数,拟合ARIMA模型,并使用AIC(赤池信息准则)、BIC(贝叶斯信息准则)等指标评估模型的优劣。
3. Python代码实现ARIMA模型
下面是使用Python中的statsmodels库实现ARIMA模型的代码示例,包含了数据生成、ARIMA模型拟合和预测过程。
3.1 安装所需库
首先,确保你安装了statsmodels和matplotlib库:
pip install statsmodels matplotlib
3.2 代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA# 生成模拟时间序列数据
np.random.seed(0)
n = 100
t = np.arange(n)
data = 0.5 * t + np.random.normal(0, 10, n) # 生成带有趋势的时间序列数据# 将数据转换为pandas的Series格式
series = pd.Series(data)# 可视化原始数据
plt.figure(figsize=(10, 6))
plt.plot(t, series)
plt.title('Generated Time Series Data')
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()# 拟合ARIMA(1,1,1)模型,p=1, d=1, q=1
model = ARIMA(series, order=(1, 1, 1))
model_fit = model.fit()# 打印模型的概况
print(model_fit.summary())# 做出预测
forecast = model_fit.forecast(steps=10)# 可视化结果
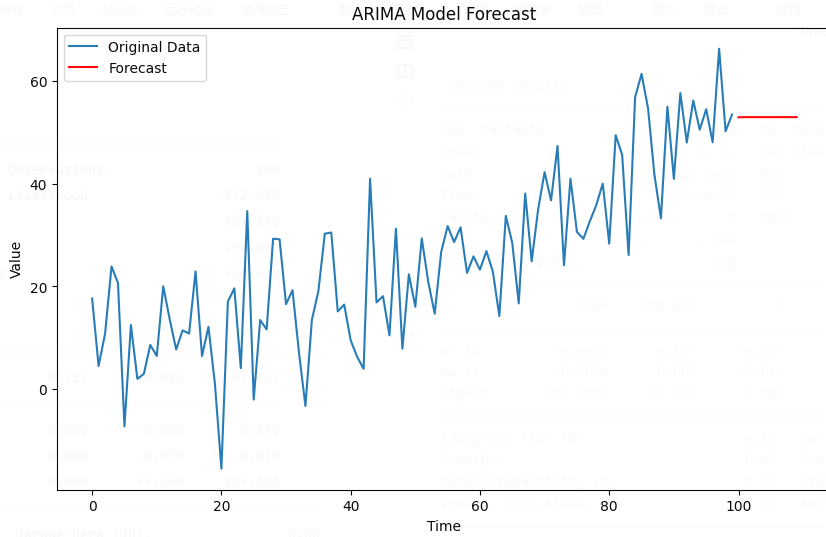
plt.figure(figsize=(10, 6))
plt.plot(t, series, label='Original Data')
plt.plot(t[-1] + np.arange(1, 11), forecast, label='Forecast', color='red')
plt.title('ARIMA Model Forecast')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
3.3 代码解释
- 数据生成:我们首先生成一个具有趋势的时间序列数据,其中包含一定的噪声。
- 模型拟合:通过
ARIMA模型拟合数据,指定模型的阶数(这里是(1, 1, 1),表示AR部分的阶数为1,差分次数为1,MA部分的阶数为1)。 - 模型预测:使用拟合好的模型进行未来10个时间点的预测,并绘制预测结果。
3.4 输出结果
通过上面的代码,我们可以得到模型的拟合结果和未来数据点的预测,通常结果会包括系数的估计值、标准误差、AIC/BIC等评估指标。
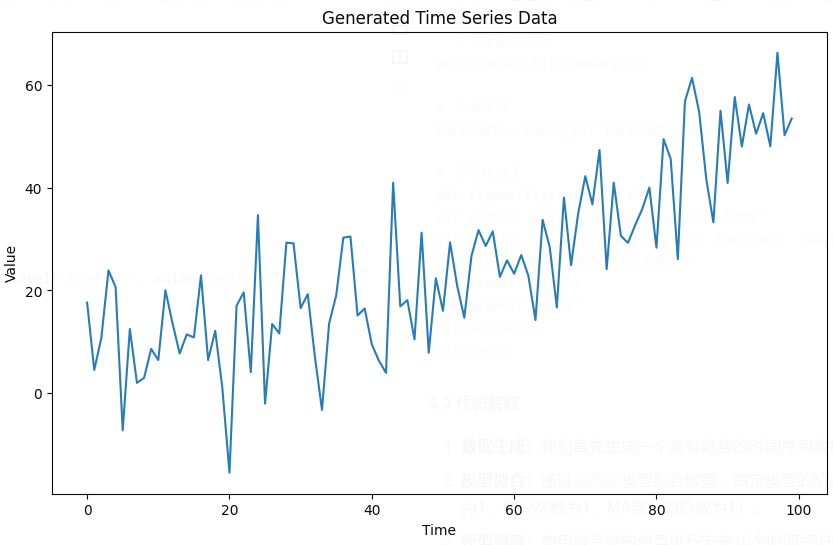
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: ARIMA(1, 1, 1) Log Likelihood -372.639
Date: Fri, 17 Jan 2025 AIC 751.278
Time: 07:16:37 BIC 759.063
Sample: 0 HQIC 754.428- 100
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.0656 0.124 -0.527 0.598 -0.309 0.178
ma.L1 -0.7876 0.087 -9.011 0.000 -0.959 -0.616
sigma2 107.6992 15.377 7.004 0.000 77.560 137.838
===================================================================================
Ljung-Box (L1) (Q): 0.18 Jarque-Bera (JB): 0.00
Prob(Q): 0.67 Prob(JB): 1.00
Heteroskedasticity (H): 0.78 Skew: 0.01
Prob(H) (two-sided): 0.48 Kurtosis: 2.99
===================================================================================Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
4. ARIMA模型的应用
ARIMA模型在经济、金融、气象等领域得到了广泛应用。以下是几个典型的应用场景:
4.1 股票市场预测
ARIMA模型广泛用于股票市场的价格预测。通过分析股票历史数据,ARIMA模型能够识别股票价格的趋势和周期性波动,进而预测未来的股价走势。
4.2 需求预测
在零售和供应链管理中,ARIMA模型常用于产品需求预测。通过对历史销售数据进行建模,企业可以预测未来的需求,帮助调整库存和生产计划。
4.3 经济数据分析
ARIMA模型也被广泛用于宏观经济数据的分析,例如GDP、失业率、通货膨胀等。通过对这些经济指标的时间序列进行分析,ARIMA模型能够揭示经济活动中的潜在趋势和波动。
5. 总结
ARIMA模型是一种强大的时间序列预测工具,适用于平稳和非平稳数据的建模。通过自回归(AR)、差分(I)和滑动平均(MA)三种方法,ARIMA能够帮助分析人员理解时间序列中的趋势和季节性,并进行有效的预测。在Python中,我们可以通过statsmodels库轻松实现ARIMA模型,并进行预测和模型评估。
ARIMA Model: A Powerful Tool for Time Series Analysis
The ARIMA (AutoRegressive Integrated Moving Average) model is a widely used model in time series analysis. By combining autoregression, differencing, and moving average techniques, it models and predicts time series data. This blog will give a detailed introduction to the ARIMA model’s basic principles, mathematical formulas, and Python implementation, as well as provide a numerical simulation example to showcase its application.
1. Basic Principles of the ARIMA Model
The core idea of the ARIMA model is to transform a non-stationary time series into a stationary series, and then model it using the three components: Autoregression (AR), Differencing (I), and Moving Average (MA). Specifically, the ARIMA model consists of three key components:
1.1 Autoregression (AR)
Autoregression (AR) refers to the relationship between the current value and its previous values. The AR process assumes that the current value is a linear combination of its past values. The order of autoregression (i.e., how many past values to use) is denoted by the parameter ( p p p ).
The mathematical formula for AR is:
Y t = ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + ⋯ + ϕ p Y t − p + ϵ t Y_t = \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \dots + \phi_p Y_{t-p} + \epsilon_t Yt=ϕ1Yt−1+ϕ2Yt−2+⋯+ϕpYt−p+ϵt
where ( Y t Y_t Yt ) is the observed value at time ( t t t ), ( ϕ 1 , ϕ 2 , … , ϕ p \phi_1, \phi_2, \dots, \phi_p ϕ1,ϕ2,…,ϕp ) are the regression coefficients, and ( ϵ t \epsilon_t ϵt ) is the error term.
1.2 Differencing (I)
Differencing (Integrated) is used to make a non-stationary time series stationary. By calculating the difference between consecutive time points, trends in the data can be removed. The order of differencing is denoted by ( d d d ).
The differencing operation can be written as:
Δ Y t = Y t − Y t − 1 \Delta Y_t = Y_t - Y_{t-1} ΔYt=Yt−Yt−1
Here, ( Δ Y t \Delta Y_t ΔYt ) represents the differenced time series.
1.3 Moving Average (MA)
Moving Average (MA) refers to modeling the current value as a linear combination of past error terms. The order of MA is denoted by ( q q q ).
The mathematical formula for MA is:
Y t = μ + ϵ t + θ 1 ϵ t − 1 + θ 2 ϵ t − 2 + ⋯ + θ q ϵ t − q Y_t = \mu + \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + \dots + \theta_q \epsilon_{t-q} Yt=μ+ϵt+θ1ϵt−1+θ2ϵt−2+⋯+θqϵt−q
where ( ϵ t \epsilon_t ϵt ) is the error term at time ( t t t ), and ( θ 1 , θ 2 , … , θ q \theta_1, \theta_2, \dots, \theta_q θ1,θ2,…,θq ) are the moving average coefficients.
1.4 ARIMA Model Formula
The overall mathematical formula of the ARIMA model can be written as:
Y t = μ + ϕ 1 Y t − 1 + ⋯ + ϕ p Y t − p + θ 1 ϵ t − 1 + ⋯ + θ q ϵ t − q + ϵ t Y_t = \mu + \phi_1 Y_{t-1} + \dots + \phi_p Y_{t-p} + \theta_1 \epsilon_{t-1} + \dots + \theta_q \epsilon_{t-q} + \epsilon_t Yt=μ+ϕ1Yt−1+⋯+ϕpYt−p+θ1ϵt−1+⋯+θqϵt−q+ϵt
where ( μ \mu μ ) is the constant term, ( ϕ \phi ϕ ) and ( θ \theta θ ) are the coefficients of the AR and MA components, and ( ϵ t \epsilon_t ϵt ) is the error term.
2. ARIMA Model Parameter Selection
Choosing the right parameters for the ARIMA model depends on the characteristics of the data. Typically, the following steps are followed to determine the best parameters:
- Stationarity Check: First, check whether the time series is stationary. If the series is non-stationary, differencing (I) is needed.
- ACF and PACF Analysis: Analyze the Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) plots to determine the order of AR and MA.
- ACF plot is mainly used to determine the order of MA.
- PACF plot is used to determine the order of AR.
- Model Fitting and Evaluation: After selecting the parameters, fit the ARIMA model and evaluate it using criteria like AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion).
3. Python Code Implementation of ARIMA
Below is an example Python code that implements the ARIMA model using the statsmodels library. It includes data generation, ARIMA model fitting, and prediction.
3.1 Install Required Libraries
First, make sure to install the required libraries: statsmodels and matplotlib.
pip install statsmodels matplotlib
3.2 Code Implementation
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA# Generate synthetic time series data
np.random.seed(0)
n = 100
t = np.arange(n)
data = 0.5 * t + np.random.normal(0, 10, n) # Generate time series data with trend# Convert to pandas Series
series = pd.Series(data)# Plot the original data
plt.figure(figsize=(10, 6))
plt.plot(t, series)
plt.title('Generated Time Series Data')
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()# Fit ARIMA(1,1,1) model, p=1, d=1, q=1
model = ARIMA(series, order=(1, 1, 1))
model_fit = model.fit()# Print model summary
print(model_fit.summary())# Make predictions
forecast = model_fit.forecast(steps=10)# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(t, series, label='Original Data')
plt.plot(t[-1] + np.arange(1, 11), forecast, label='Forecast', color='red')
plt.title('ARIMA Model Forecast')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
3.3 Code Explanation
- Data Generation: First, we generate synthetic time series data with a trend, adding some noise.
- Model Fitting: We fit the ARIMA model with the specified order ( ( 1 , 1 , 1 ) (1, 1, 1) (1,1,1) ), meaning 1 autoregressive term, 1 differencing, and 1 moving average term.
- Prediction: The
forecast()method is used to predict the next 10 time points. The results are plotted alongside the original data for comparison.
3.4 Output
Running the code will give the summary of the ARIMA model’s fit and plot the original time series alongside the forecasted values. The model summary will include parameter estimates, standard errors, and evaluation criteria such as AIC and BIC.
4. Applications of the ARIMA Model
ARIMA is a powerful tool for time series forecasting and is applied in various fields such as economics, finance, and meteorology. Here are a few typical applications:
4.1 Stock Market Prediction
ARIMA is widely used for stock market price prediction. By analyzing historical stock data, ARIMA can identify trends and cyclical patterns, which helps in predicting future stock prices.
4.2 Demand Forecasting
In retail and supply chain management, ARIMA models are used for demand forecasting. By modeling past sales data, businesses can predict future demand, which helps in inventory management and production planning.
4.3 Economic Data Analysis
ARIMA is also extensively used for analyzing macroeconomic data such as GDP, unemployment rates, and inflation. By modeling these economic indicators, ARIMA can uncover underlying trends and fluctuations in economic activity.
5. Conclusion
The ARIMA model is a powerful tool for time series forecasting, suitable for both stationary and non-stationary data. By using autoregression (AR), differencing (I), and moving average (MA), ARIMA helps uncover trends and seasonality in time series data. In Python, the statsmodels library provides an easy-to-use implementation for fitting ARIMA models and making predictions.
后记
2025年1月17日15点16分于上海,在GPT4o大模型辅助下完成。
相关文章:
模型:中英双语)
时间序列分析ARIMA(AutoRegressive Integrated Moving Average,自回归积分滑动平均)模型:中英双语
ARIMA模型:时间序列分析中的强大工具 在时间序列分析中,ARIMA(AutoRegressive Integrated Moving Average,自回归积分滑动平均)模型是一种广泛使用的模型。它通过结合自回归、差分和滑动平均三种方法来对时间序列进行…...

青少年编程与数学 02-007 PostgreSQL数据库应用 02课题、PostgreSQL数据库安装
青少年编程与数学 02-007 PostgreSQL数据库应用 02课题、PostgreSQL数据库安装 一、安装Windows系统安装PostgreSQL 17Linux系统安装PostgreSQL 17 二、配置Windows系统Linux系统 三、启动(一)Windows系统使用服务管理器(services.msc&#x…...

群发邮件适合外贸行业吗
一、群发邮件契合外贸行业的市场拓展需求 外贸业务的本质在于跨越地域限制,与全球各地的潜在客户建立联系。群发邮件能够突破时空限制,瞬间将产品或服务信息传递到世界各地。通过精准的市场调研与客户数据整理,企业可以针对不同国家和地区的…...

面试之《new关键字》
一问:new关键字做了什么操作,手写一个new方法,实现new关键字的作用 二问: // 第一题 / function Test(){this.name 1;return {name: 2} } const a new Test(); console.log(a.name) // 打印什么/// 第二题 / function Test2()…...
降维)
《机器学习》——SVD(奇异分解)降维
文章目录 SVD基本定义SVD降维的步骤SVD降维使用场景SVD 降维的优缺点SVD降维实例导入所需库定义SVD降维函数导入图像处理图像处理图像打印降维结果并显示处理后两个图像的对比图 SVD基本定义 简单来说就是,通过SVD(奇异值分解)对矩阵数据进行…...

【MySQL实战】mysql_exporter+Prometheus+Grafana
要在Prometheus和Grafana中监控MySQL数据库,如下图: 可以使用mysql_exporter。 以下是一些步骤来设置和配置这个监控环境: 1. 安装和配置Prometheus: - 下载和安装Prometheus。 - 在prometheus.yml中配置MySQL通过添加以下内…...

业务架构、数据架构、应用架构和技术架构
TOGAF(The Open Group Architecture Framework)是一个广泛应用的企业架构框架,旨在帮助组织高效地进行架构设计和管理。 TOGAF 的核心就是由我们熟知的四大架构领域组成:业务架构、数据架构、应用架构和技术架构。 企业数字化架构设计中的最常见要素是4A 架构。 4…...

mysql-5.7.18保姆级详细安装教程
本文主要讲解如何安装mysql-5.7.18数据库: 将绿色版安装包mysql-5.7.18-winx64解压后目录中内容如下图,该例是安装在D盘根目录。 在mysql安装目录中新建my.ini文件,文件内容及各配置项内容如下图,需要先将配置项【skip-grant-tab…...

Linux测试处理fps为30、1920*1080、一分钟的视频性能
前置条件 模拟fps为30、1920*1080、一分钟的视频 项目CMakeLists.txt cmake_minimum_required(VERSION 3.30) project(testOpenGl)set(CMAKE_CXX_STANDARD 11)add_executable(testOpenGl main.cpptestOpenCl.cpptestOpenCl.hTestCpp.cppTestCpp.hTestCppThread.cppTestCppTh…...

kubeneters-循序渐进Ingress
文章目录 overviewIngress 是什么?为什么使用 Ingress?我们会在这里做些什么?HTTP 服务器(Nginx)还能做什么?Kubernetes 中的简单示例:A) 使用 Service ClusterIPB) 手动配置 Nginx 服务作为代理…...

Shell控监Kafka积压
1、获取Kafka消息堆积情况 vi check-kafka-lag.sh #!/bin/bashTOPIC"total_random" GROUP_ID"etl-dw" BOOTSTRAP_SERVER"node-01:9092,node-02:9092,node-03:9092"# 检查第一个参数是否为数字 if ! [[ $1 ~ ^[0-9]$ ]]; thenecho &…...

USB3020任意波形发生器4路16位同步模拟量输出卡1MS/s频率 阿尔泰科技
信息社会的发展,在很大程度上取决于信息与信号处理技术的先进性。数字信号处理技术的出现改变了信息 与信号处理技术的整个面貌,而数据采集作为数字信号处理的必不可少的前期工作在整个数字系统中起到关键 性、乃至决定性的作用,其应用已经深…...

MongoDB 学习指南与资料分享
MongoDB学习资料 MongoDB学习资料 MongoDB学习资料 在数据爆炸的当下,MongoDB 作为非关系型数据库的佼佼者,以其独特优势在各领域发光发热。无论是海量数据的存储,还是复杂数据结构的处理,MongoDB 都能轻松应对。接下来…...
)
Web端实时播放RTSP视频流(监控)
一、安装ffmpeg: 1、官网下载FFmpeg: Download FFmpeg 2、点击Windows图标,选第一个:Windows builds from gyan.dev 3、跳转到下载页面: 4、下载后放到合适的位置,不用安装,解压即可: 5、配置path 复制解压后的\bin路径,配置环境变量如图: <...

23- TIME-LLM: TIME SERIES FORECASTING BY REPRO- GRAMMING LARGE LANGUAGE MODELS
解决问题 用LLM来解决时序预测问题,并且能够将时序数据映射(reprogramming)为NLP token,并且保持backbone的大模型是不变的。解决了时序序列数据用于大模型训练数据稀疏性的问题。 方法 Input Embedding 输入: X …...

【Go】Go数据类型详解—数组与切片
1. 前言 今天需要学习的是Go语言当中的数组与切片数据类型。很多编程语言当中都有数组这样的数据类型,Go当中的切片类型本质上也是对 数组的引用。但是在了解如何定义使用数组与切片之前,我们需要思考为什么要引入数组这样的数据结构。 1.1 为什么需要…...

微服务中引入消息队列的利弊
微服务中引入消息队列的利弊 1、微服务架构中引入消息队列(Message Queue)的主要优势: 1.1 解耦(Decoupling) 服务之间不需要直接调用,通过消息队列实现松耦合 生产者和消费者可以独立扩展和维护 降低系统间的依赖性 1.2 异步处理(Asynchronous Proc…...

如何使用策略模式并让spring管理
1、策略模式公共接口类 BankFileStrategy public interface BankFileStrategy {String getBankFile(String bankType) throws Exception; } 2、策略模式业务实现类 Slf4j Component public class ConcreteStrategy implements BankFileStrategy {Overridepublic String ge…...
-可编程渲染管线Shader编程)
骑砍2霸主MOD开发(11)-可编程渲染管线Shader编程
一.固定渲染管线&可编程渲染管线 固定渲染管线:GPU常规渲染算法,将3D模型经过四大变换计算得到2D屏幕图像 可编程渲染管线:定制化GPU渲染算法,需要提交Shader至GPU中,GPU根据定制化算法得到2D屏幕图像 二.CoreShader&TerrainShader CoreShader:游戏中使用的静态shader…...

【PowerQuery专栏】PowerQuery 函数之CSV文件处理函数
CSV.Document 函数是进行CSV文件解析功能的函数,函数目前包含4个参数: 参数1为文件的数据源,数据类型为二进制类型,值为需要读取的文本数据参数2为列名称,数据类型为字符串类型,值为分割后的列名称参数3为分隔符,数据类型为任意类型,值为分割数据的分隔符参数4为文件编…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Map Kit(4)
1.问题描述: 添加了很多的marker点,每个marker点都设置了customInfoWindow,但是每次只能显示一个customInfoWindow吗? 解决方案: Marker的InfoWindow每次只能显示一个。 2.问题描述: 在地图选型中&…...

通过ffmpeg将FLV文件转换为MP4
使用 ffmpeg 将 FLV 文件转换为 MP4 文件是一个常见的操作。ffmpeg 是一个强大的多媒体处理工具,支持多种格式的转换、剪辑、合并等操作。以下是详细的步骤和命令示例,帮助你完成这一任务。 安装 FFmpeg 如果你还没有安装 ffmpeg,可以根据你…...

深入分析Java中的重载与重写:理解多态的两个面向
深入分析Java中的重载与重写:理解多态的两个面向 之前其实写过一篇文章来探讨Java当中的方法重载与方法重写但当时学的还不够通透,分析有点片面,这次我从多态的角度对其进行分析,有问题欢迎大家来评论区一起探讨 在Java编程中&a…...

STM32的集成开发环境STM32CubeIDE安装
STM32CubeIDE - STM32的集成开发环境 - 意法半导体STMicroelectronics...
)
【狂热算法篇】探秘图论之 Floyd 算法:解锁最短路径的神秘密码(通俗易懂版)
: 羑悻的小杀马特.-CSDN博客羑悻的小杀马特.擅长C/C题海汇总,AI学习,c的不归之路,等方面的知识,羑悻的小杀马特.关注算法,c,c语言,青少年编程领域.https://blog.csdn.net/2401_82648291?spm1010.2135.3001.5343 在本篇文章中,博主将带大家去学习所谓的…...

25/1/13 嵌入式笔记 继续学习Esp32
PWM(Pulse Width Modulation,脉宽调制) 是一种通过快速切换高低电平来模拟中间电压值的技术。它广泛应用于控制 LED 亮度、电机速度、音频生成等场景。 analogWrite函数:用于在微控制器(如 Arduino)上生成模拟信号。 …...

C语言的语法糖
C语言的语法糖 引言 在程序开发的过程中,语言的设计和编写风格往往会直接影响开发效率和代码可读性。C语言作为一种广泛应用于系统编程和嵌入式开发的编程语言,其设计虽然追求简洁与高效,但在某些方面同样存在可以提高编程体验的“语法糖”…...

客户案例:致远OA与携程商旅集成方案
一、前言 本项目原型客户公司创建于1992年,主要生产并销售包括糖果系列、巧克力系列、烘焙系列、卤制品系列4大类,200多款产品。公司具有行业领先的生产能力,拥有各类生产线100条,年产能超过10万吨。同时,经过30年的发展,公司积累了完善的销售网络,核心经销商已经超过1200个,超…...

浔川 AI 翻译已修复,可正常使用
浔川 AI 翻译已修复,可正常使用 亲爱的用户们: 大家好!经过技术团队的不懈努力,浔川 AI 翻译平台已完成修复,目前各项功能均已恢复正常,可流畅使用。在此,我们向一直以来关心和支持浔川 AI 翻译…...

【Python】深入探讨Python中的单例模式:元类与装饰器实现方式分析与代码示例
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 单例模式(Singleton Pattern)是一种常见的设计模式,它确保一个类只有一个实例&…...

D. Paint the Tree
https://codeforces.com/problemset/problem/1975/D 分析: 观察样例可以发现,对于PB第一次在位置 r 接触到红点之后,接下来的怎么走完全可以有PB说了算,情况不会更差。同时还能发现,大部分边都是需要走两遍的ÿ…...

ScratchLLMStepByStep:训练自己的Tokenizer
1. 引言 分词器是每个大语言模型必不可少的组件,但每个大语言模型的分词器几乎都不相同。如果要训练自己的分词器,可以使用huggingface的tokenizers框架,tokenizers包含以下主要组件: Tokenizer: 分词器的核心组件,定…...

【Linux】Socket编程-TCP构建自己的C++服务器
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 Socket 编程 TCP 🦋 TCP socket API 详解🦋 多线程远程命令执行🦋 网络版计算器(应用层自定义协议与序列化…...

数据结构——线性表和顺序表
1、线性表的基本概念 1.1 定义 线性结构是简单且常用的数据结构,而线性表则是一种典型的线性结构 存储数据,最简单,最有效的方法是吧它们存储在一个线性表中 一个线性表是n个元素的有限序列。每个元素在不同的情况下有不同的含义,…...

FunASR 在Linux/Unix 平台编译
第一步拉取镜像并生成容器: ### 镜像启动 通过下述命令拉取并启动FunASR软件包的docker镜像: shell sudo docker pull \ registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-online-cpu-0.1.12 mkdir -p ./funasr-runtime-…...

AIP-200 先例
编号200原文链接AIP-200: Precedent状态批准创建日期2018-06-28更新日期2018-06-28 很多时候,API的编写方式会违反新的指导原则。此外,有时出于特定原因也需要打破标准,例如与现有系统保持一致、满足严格的性能要求或其他因素。最后…...

SAP五大核心模块:塑造企业数字化未来
在数字化转型的浪潮中,SAP(Systems, Applications and Products in Data Processing)以其强大的企业资源规划(ERP)系统,成为众多企业信赖的伙伴。SAP系统通过五大核心模块,即财务管理࿰…...

【UE5.3】fix DONET报错
新的机器 4070 gpu 运行ue项目, 可能是epic 启动器是vs安装的, vs安装的epic 启动器自己更新了一波,导致了.NET的问题? ue项目是拷贝远程的windows的电脑里面的,应该不会导致ue源码里的cs出问题? 【UE5.3】UnrealLink 安装:fix Detected compiler newer than Visual Stu…...

【0393】Postgres内核 checkpointer process ③ 构建 WAL records 工作缓存区
1. 初始化 ThisTimeLineID、RedoRecPtr 函数 InitXLOGAccess() 内部会初始化 ThisTimeLineID、wal_segment_size、doPageWrites 和 RedoRecPtr 等全局变量。 下面是这四个变量初始化前的值: (gdb) p ThisTimeLineID $125 = 0 (gdb) p wal_segment_size $126 = 16777216 (gdb…...

pc 端 TensorRT API 实现 YOLOv11 的 C++ 小白部署经验
标题1 模型转化 python 先下载项目 https://github.com/ultralytics/ultralytics 同时下载模型 https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt pythonconda虚拟环境,主要是以下三个,其余缺什么直接pip anaconda…...
)
LLM - 大模型 ScallingLaws 的 C=6ND 公式推导 教程(1)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145185794 Scaling Laws (缩放法则) 是大模型领域中,用于描述 模型性能(Loss) 与 模型规模N、数据量D、计算资源C 之间关系的经验规律…...
解决欺诈数据中正负样本极度不平衡问题)
【机器学习实战】kaggle 欺诈检测---使用生成对抗网络(GAN)解决欺诈数据中正负样本极度不平衡问题
【机器学习实战】kaggle 欺诈检测---如何解决欺诈数据中正负样本极度不平衡问题https://blog.csdn.net/2302_79308082/article/details/145177242 本篇文章是基于上次文章中提到的对抗生成网络,通过对抗生成网络生成少数类样本,平衡欺诈数据中正类样本极…...

C++ 之多线程相关总结
C 之多线程相关总结 1.多线程相关基础知识 1.1 线程的创建和管理 1. std::thread 类: 用于创建和管理线程。通过将可调用对象(如函数、函数对象、lambda 表达式)作为参数传递给 std::thread 的构造函数,可以创建一个新的线程。…...

基于机器学习随机森林算法的个人职业预测研究
1.背景调研 随着信息技术的飞速发展,特别是大数据和云计算技术的广泛应用,各行各业都积累了大量的数据。这些数据中蕴含着丰富的信息和模式,为利用机器学习进行职业预测提供了可能。机器学习算法的不断进步,如深度学习、强化学习等…...

性能测试 - Locust WebSocket client
Max.Bai 2024.10 0. 背景 Locust 是性能测试工具,但是默认只支持http协议,就是默认只有http的client,需要其他协议的测试必须自己扩展对于的client,比如下面的WebSocket client。 1. WebSocket test Client “”“ Max.Bai W…...

量子计算将彻底改变商业分析
虽然量子计算听起来颇具未来感,但这项技术正迅速走向成熟 —— 就如同 ChatGPT 这类人工智能(AI)工具一样。我相信,量子计算技术所产生的连锁反应很快就会对业务分析领域产生巨大影响。 什么是量子计算? 尽管名字听起…...

爬山算法与模拟退火算法的全方面比较
一、基本概念与原理 1. 爬山算法 爬山算法是一种基于启发式的局部搜索算法,通过不断地向当前解的邻域中搜索更优解来逼近全局最优解。它的核心思想是,从当前解出发,在邻域内找到一个使目标函数值更大(或更小)的解作为新的当前解,直到找不到更优的解为止。 2.模拟退火算…...

【深度学习】用RML2018训练好模型去识别RML2016的数据会遇到输入维度不匹配的问题,如何解决?
文章目录 问题解决办法1. 调整输入数据长度2. 修改模型结构(我个人比较推崇的方法)3. 迁移学习4. 重新训练模型5. 数据增强6. 其他差异问题 经常会有人问的一个问题: 我用RML2018跑的调制识别模型,用RML2016数据集能直接识别吗?(2018数据集信号样本的长度是1024,2016数据集…...
)
2025年1月17日(点亮一个 LED)
系统信息: Raspberry Pi Zero 2W 系统版本: 2024-10-22-raspios-bullseye-armhf Python 版本:Python 3.9.2 已安装 pip3 支持拍摄 1080p 30 (1092*1080), 720p 60 (1280*720), 60/90 (640*480) 已安装 vim 已安装 git 学习目标:…...
—辐射抗干扰(ALSE)和便携式发射机抗干扰(HPT))
商用车电子电气零部件电磁兼容条件和试验(8)—辐射抗干扰(ALSE)和便携式发射机抗干扰(HPT)
写在前面 本系列文章主要讲解商用车电子/电气零部件或系统的传导抗干扰、传导发射和辐射抗干扰、电场辐射发射以及静电放电等试验内容及要求,高压试验项目内容及要求。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) 目录 商用车电子电气零部件电磁兼容条件和试验—目录…...