深度学习模型部署——基于Onnx Runtime的深度学习模型CPU与GPU部署(C++实现)
1.概述
许多机器学习和深度学习模型都是在基于 Python 的框架中开发和训练的,例如 PyTorch 和 TensorFlow 等。但是,当需要将这些训练好模型部署到生产环境中时,通常会希望将模型集成到生产流程中,而这些流程大多是用 C++ 编写的,因为 C++ 可以提供更快的实时性能。
目前有许多工具和框架可以帮助我们将预训练模型部署到 C++ 应用程序中。例如,ONNX Runtime 可用于边缘计算和服务器环境,NCNN 和 MNN 适用于移动设备,而 TensorRT 则适用于 Nvidia 的嵌入式平台。这里,通过一个完整的端到端示例来讨论如何利用 ONNX Runtime(GPU 版本)将一个预训练的 PyTorch 模型部署到 C++ 应用程序中。
这种部署方式不仅可以帮助开发者利用 C++ 的高效性能,还可以通过 ONNX Runtime 灵活地使用不同的硬件加速器,如 CPU、CUDA 或 TensorRT 等。通过这种方式,可以在保持应用程序性能的同时,快速集成和部署机器学习和深度学习模型。
2.onnx介绍
ONNX是一个为机器学习设计的开放文件格式,它被用来存储预训练的模型。ONNX 的主要目的是促进不同人工智能框架之间的互操作性,使得模型可以在这些框架之间轻松迁移和部署。这种格式支持统一的模型表示,因此,不同的训练框架,比如 Caffe2、PyTorch、TensorFlow 等,都可以使用相同的格式来存储模型数据,进而实现数据的交互和共享。
ONNX 的规范和代码主要由一些科技巨头公司开发,包括但不限于 Microsoft(微软)、Amazon(亚马逊)、Facebook(脸书)和 IBM。这些公司的贡献确保了 ONNX 作为一个开放标准能够持续发展,并且得到了业界的广泛支持和应用。
通过使用 ONNX,开发者可以更加灵活地选择适合自己项目的 AI 框架,而不必担心框架间的兼容性问题。此外,ONNX 也为模型的优化和加速提供了可能,因为它可以与各种硬件后端(如 CPU、GPU、TPU 等)配合工作,从而提高模型运行的效率。
3. ONNX Runtime介绍
ONNX Runtime 是一个跨平台的机器学习模型加速器,它提供了一个灵活的接口,允许集成针对特定硬件优化的库。这意味着 ONNX Runtime 可以适配多种硬件环境,并且能够充分利用硬件的特性来加速模型的执行。
ONNX Runtime 支持多种执行提供者,包括:
- CPU:作为通用处理器,CPU 是执行机器学习模型的一个常见选择。
- CUDA:NVIDIA 的 CUDA 为使用 NVIDIA GPU 加速提供了接口,可以显著提升模型在支持 CUDA 的 GPU 上运行的性能。
除了能够利用不同的执行提供者外,ONNX Runtime 还能够与多个框架训练的模型一起使用,这些框架包括但不限于:
- PyTorch:一个流行的开源机器学习库,广泛用于计算机视觉和自然语言处理任务。
- TensorFlow/Keras:Google 开发的 TensorFlow 是一个强大的机器学习平台,Keras 是其上的高级神经网络 API。
- TFLite:TensorFlow 的轻量级解决方案,专门用于移动和嵌入式设备。
- scikit-learn:一个简单高效的 Python 编程库,用于数据挖掘和数据分析。
通过 ONNX Runtime 的推理功能,开发者可以轻松地将预训练的 PyTorch 模型部署到 C++ 应用程序中。这使得在需要高性能和实时处理的生产环境中,利用机器学习模型成为可能。通过这种方式,开发者可以享受到 C++ 的性能优势,同时又能通过 ONNX Runtime 灵活地部署和运行各种机器学习模型。
4. 模型转换与依赖安装
Pytorch模型转onnx并推理的步骤如下:
模型转换:首先,需要将 PyTorch 预训练模型文件(可以是 .pth 或 .pt 格式)转换成 ONNX 格式的文件(.onnx 格式)。这一转换过程在 PyTorch 环境中进行。
使用 ONNX Runtime:转换得到的 .onnx 文件随后作为输入,被用于 C++ 应用程序中。在这个应用程序中,调用 ONNX Runtime 的 C++ API 来执行模型的推理。
这个流程允许开发者利用 PyTorch 强大的训练能力来训练模型,并将训练好的模型通过 ONNX 这一开放格式,部署到 C++ 环境中,从而在多种不同的平台上实现高性能的推理计算。通过这种方式,开发者可以兼顾模型的开发效率和部署时的性能要求。
4.1 PyTorch 模型转换到 ONNX
为了演示方便,这里使用Yolov8的一个人脸检测的模型进行演示,首先安装ultralytics框架:
conda create --name yolov8 python==3.10
conda activate yolov8
pip install ultralytics
然后把模型好的.pt模型转成onnx模型,转换代码如下:
from ultralytics import YOLO
model = YOLO("yolov8n_face.pt")
success = model.export(format="onnx", simplify=True) # export the model to onnx format
assert success
print("转换成功")
运行之后之后成功一个同名的onnx模型。
4.2 安装GPU依赖库
A: 我这里的测试环境是Win10,IDE 是VS2019,显卡是NVIDIA GeForce RTX 2070 SUPER ,8G的显存,cuda 是11.7,cudnn是8.5。
首先要安装cuda 11.7,从官网下载cudu 11.7 win10对应的版本:


B: 安装的时候按指示下一步下一步就可以了:

C: 指示安装,安装完成之后,在所先的安装路径上可以看到:

D: 并且它会自动把需要的路径加到系统环境变量:

E: 下载cudnn:
可以从官方下载到所指定的cudnn版本:

F: 下载完成之后,解压出三个目录,把三个目录复制一份放到上面C图所在的路径,该路径原本就存有相同的目录,直接粘贴就可以:

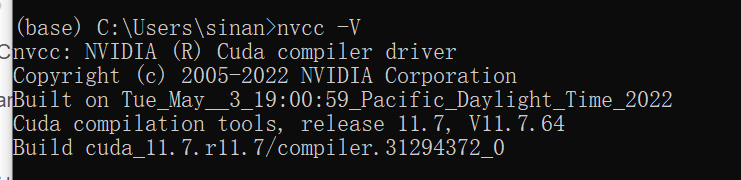
G: 启动命令行,输入nvcc -V,检查是否安装成功,如出现下面的提示表示安装成功,否则请重新检查以上的步骤是否正确:
4.3 安装编程所需的依赖库
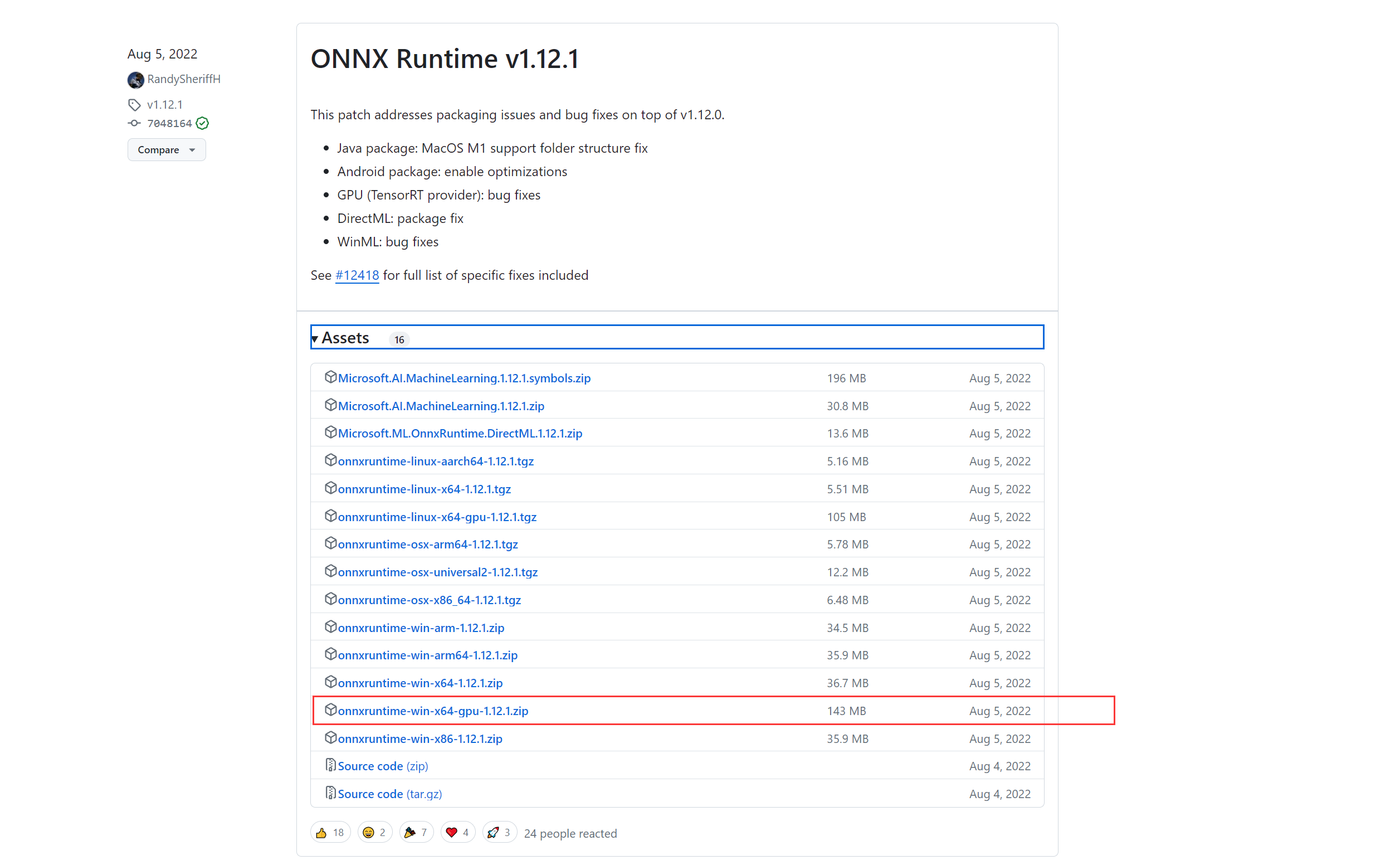
4.3.1 ONNX Runtime下载
可以从https://github.com/microsoft/onnxruntime/releases下载到编译好的依赖库,这里的演示环境是Win10, IDE是vs2019,我下载v1.12.1 GPU这个版本。
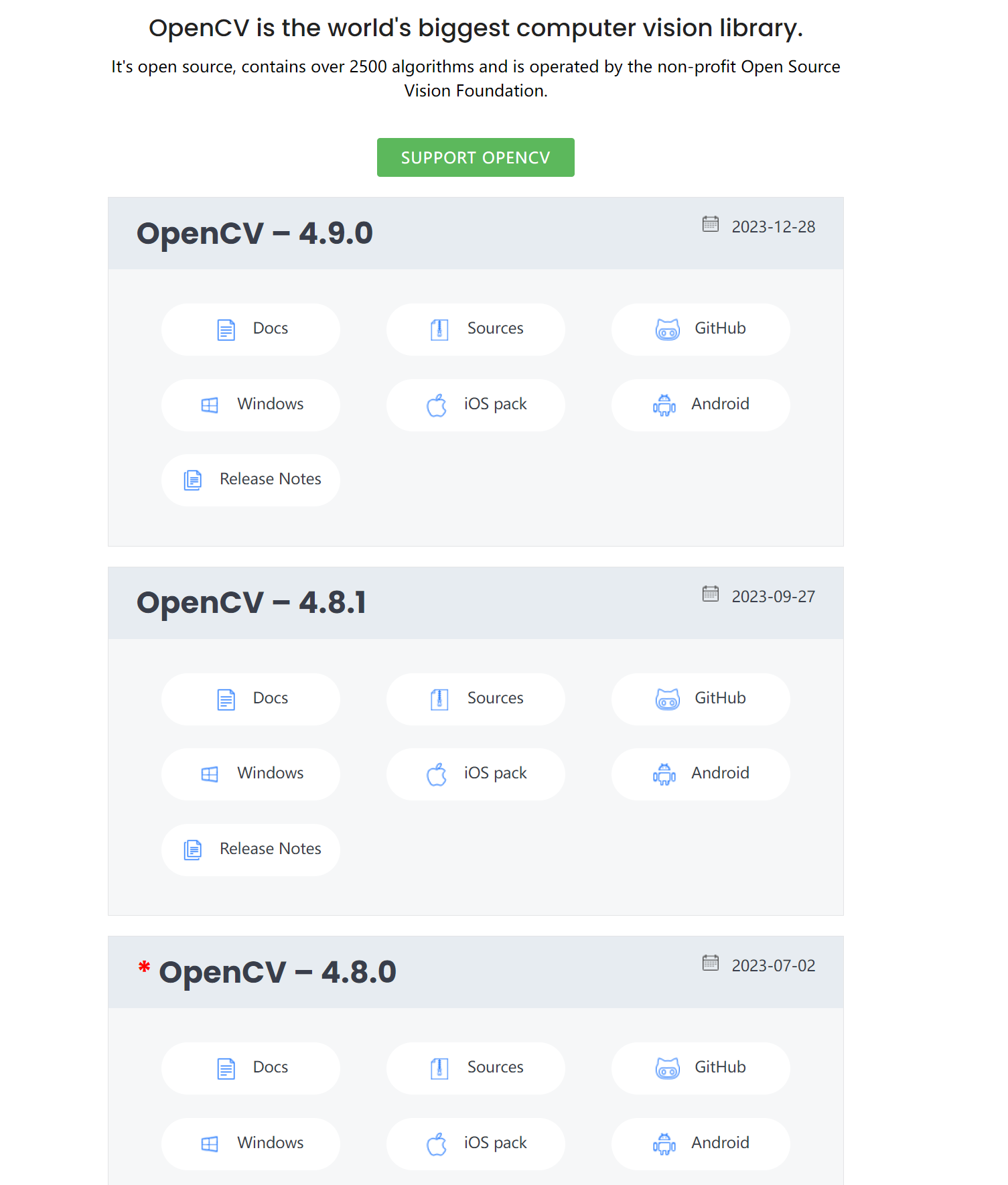
4.3.2 OpenCV库
因为使用的模型需要显示出效果图,这里使用OpenCV来做图像预处理相关的操作,可以从OpenCV官网下载到所需的库:
5.使用 ONNX Runtime 进行推理
5.1 创建工程
A: 使用vs2019创建一个C++工程,然后把OnnxRuntime和OpenCV加到工程里面:

B: 把OnnxRuntime和OpenCV加入到工程包含路径,路径里面包含OnnxRuntime和OpenCV的头文件:

添加到目录:
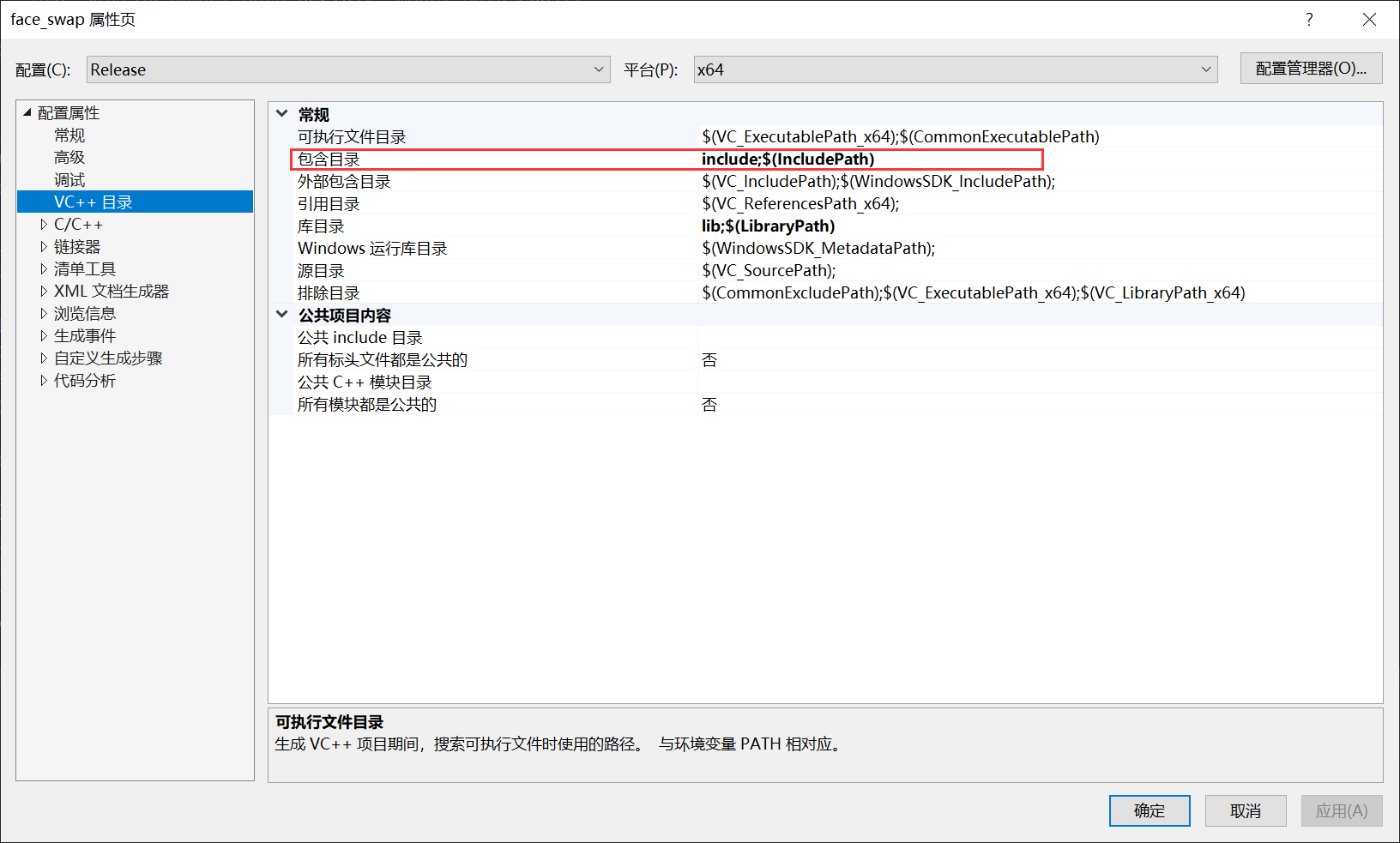
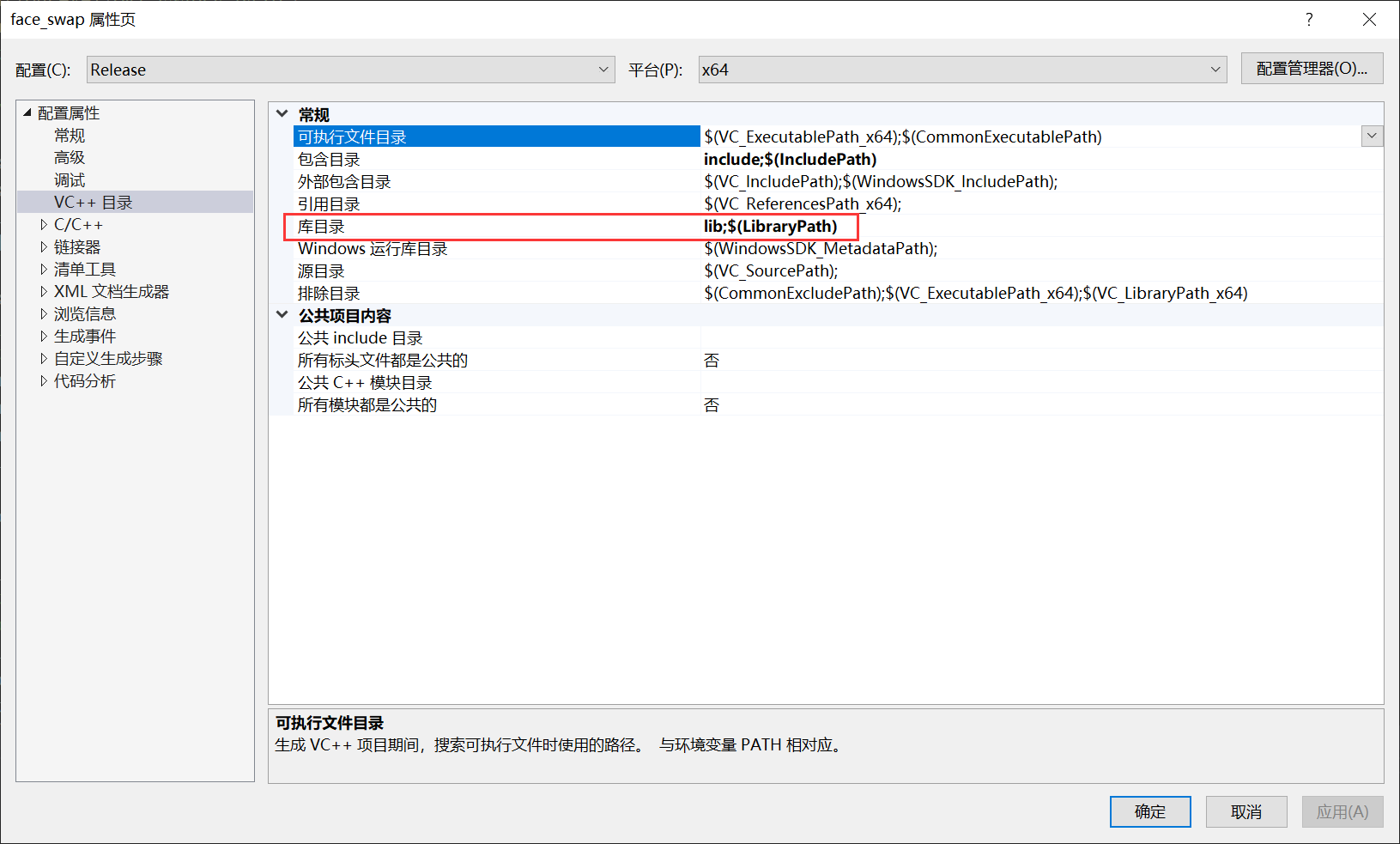
C: 把lib添加到库目录,lib包含到OnnxRuntime和OpenCV 的lib文件:
把lib路径加到库目录:
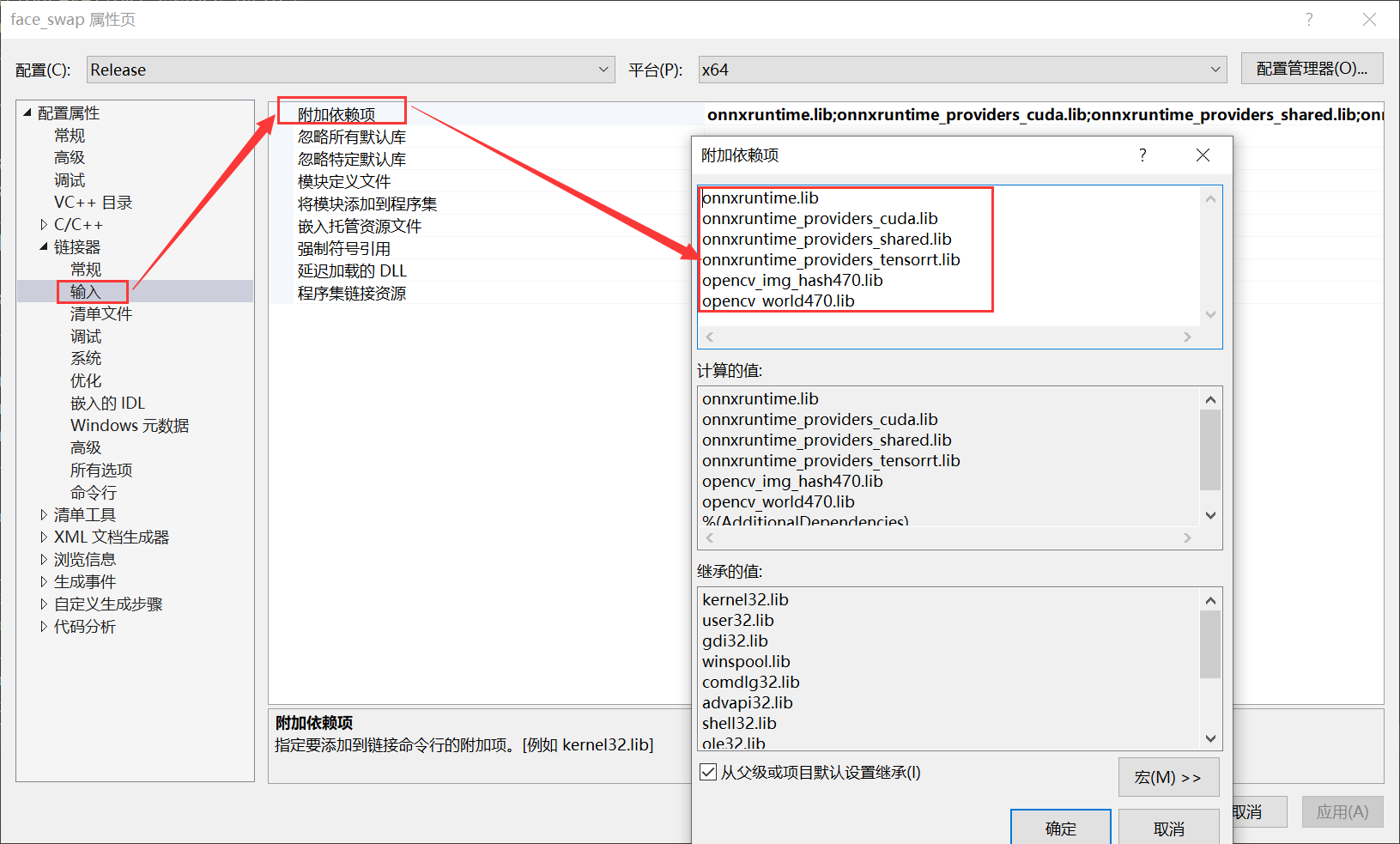
把lib文件名添加到链接器:
5.2 ONNX Runtime推理流程
5.2.1 推理流程:
初始化 ONNX Runtime 环境:
- 首先,你需要初始化 ONNX Runtime 的运行时环境。这通常涉及到创建一个
Ort::Env对象,它包含了线程池和其他运行时设置。 - 设置会话选项:
- 接着,设置 ONNX Runtime 会话的选项。这可能包括配置 GPU 使用、优化器级别、执行模式等。
- 加载模型并创建会话:
- 加载预训练的 ONNX 模型文件。
- 使用运行时环境、会话选项和模型创建一个
Ort::Session对象。 - 获取模型输入输出信息:
- 从
Ort::Session对象中获取模型输入和输出的详细信息,包括数量、名称、类型和形状。 - 推理准备:
- 创建输入和输出张量,这些张量是用于存储推理数据的内存块。
- 分配内存给这些张量,以准备数据输入。
- 执行推理:
- 调用
Ort::Session::Run方法,传入输入张量、输出张量和其他必要的参数,执行推理。 - 后处理推理结果:
- 推理完成后,从输出张量中获取结果数据。
- 根据需要对结果进行后处理,比如解码、格式化等,以获得最终的预测结果。
5.2 ONNX Runtime推理代码
类的头文件:
# ifndef YOLOV8FACE
# define YOLOV8FACE
#include <fstream>
#include <sstream>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#include <provider_options.h>
#include <onnxruntime_cxx_api.h>
#include "utils.h"class Yolov8Face
{
public:Yolov8Face(std::string modelpath, const float conf_thres=0.5, const float iou_thresh=0.4);void detect(cv::Mat srcimg, std::vector<Bbox> &boxes);
private:void preprocess(cv::Mat img);std::vector<float> input_image;int input_height;int input_width;float ratio_height;float ratio_width;float conf_threshold;float iou_threshold;Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "Face Detect");Ort::Session *ort_session = nullptr;Ort::SessionOptions sessionOptions = Ort::SessionOptions();std::vector<char*> input_names;std::vector<char*> output_names;std::vector<std::vector<int64_t>> input_node_dims; // >=1 outputsstd::vector<std::vector<int64_t>> output_node_dims; // >=1 outputsOrt::MemoryInfo memory_info_handler = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
};
#endif
类的实现文件:
// 构造函数,用于初始化 YOLOv8Face 类的实例
Yolov8Face::Yolov8Face(string model_path, const float conf_thres, const float iou_thresh)
{// 设置执行提供者为 CUDA,并添加到会话选项中OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); // 设置图优化级别为最高级别sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);// 将字符串路径转换为宽字符串,用于创建会话std::wstring widestr = std::wstring(model_path.begin(), model_path.end());ort_session = new Session(env, widestr.c_str(), sessionOptions);// 如果是Linux,则用以下的方式// ort_session = new Session(env, model_path.c_str(), sessionOptions); // 获取输入和输出节点的数量size_t numInputNodes = ort_session->GetInputCount();size_t numOutputNodes = ort_session->GetOutputCount();// 创建默认分配器AllocatorWithDefaultOptions allocator;// 获取输入节点的名称和维度信息for (int i = 0; i < numInputNodes; i++){input_names.push_back(ort_session->GetInputName(i, allocator)); // 新版本的Onnx Runtime使用的接口// AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator);// input_names.push_back(input_name_Ptr.get()); Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();auto input_dims = input_tensor_info.GetShape();input_node_dims.push_back(input_dims);}// 获取输出节点的名称和维度信息for (int i = 0; i < numOutputNodes; i++){output_names.push_back(ort_session->GetOutputName(i, allocator));// 新版本的Onnx Runtime使用的接口// AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);// output_names.push_back(output_name_Ptr.get()); Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();auto output_dims = output_tensor_info.GetShape();output_node_dims.push_back(output_dims);}// 从输入节点维度中获取输入图像的高度和宽度this->input_height = input_node_dims[0][2];this->input_width = input_node_dims[0][3];// 设置置信度阈值和 IOU 阈值this->conf_threshold = conf_thres;this->iou_threshold = iou_thresh;
}// 对输入图像进行预处理
void Yolov8Face::preprocess(Mat srcimg)
{// 获取原始图像的高度和宽度const int height = srcimg.rows;const int width = srcimg.cols;// 创建临时图像副本Mat temp_image = srcimg.clone();// 如果图像的高度或宽度大于输入尺寸,则进行缩放if (height > this->input_height || width > this->input_width){const float scale = std::min((float)this->input_height / height, (float)this->input_width / width);Size new_size = Size(int(width * scale), int(height * scale));resize(srcimg, temp_image, new_size);}// 计算比例因子,用于将检测框映射回原始图像尺寸this->ratio_height = (float)height / temp_image.rows;this->ratio_width = (float)width / temp_image.cols;// 创建输入图像,如果必要的话,使用 copyMakeBorder 来填充边缘Mat input_img;copyMakeBorder(temp_image, input_img, 0, this->input_height - temp_image.rows, 0, this->input_width - temp_image.cols, BORDER_CONSTANT, 0);// 分离图像的 BGR 通道vector<cv::Mat> bgrChannels(3);split(input_img, bgrChannels);// 将每个通道的数据类型转换为 float,并进行归一化for (int c = 0; c < 3; c++){bgrChannels[c].convertTo(bgrChannels[c], CV_32FC1, 1 / 128.0, -127.5 / 128.0);}// 将所有通道的数据复制到一个连续的数组中const int image_area = this->input_height * this->input_width;this->input_image.resize(3 * image_area);size_t single_chn_size = image_area * sizeof(float);memcpy(this->input_image.data(), (float *)bgrChannels[0].data, single_chn_size);memcpy(this->input_image.data() + image_area, (float *)bgrChannels[1].data, single_chn_size);memcpy(this->input_image.data() + image_area * 2, (float *)bgrChannels[2].data, single_chn_size);
}// 执行目标检测
void Yolov8Face::detect(Mat srcimg, std::vector<Bbox> &boxes)
{// 对输入图像进行预处理this->preprocess(srcimg);// 设置输入张量的形状std::vector<int64_t> input_img_shape = {1, 3, this->input_height, this->input_width};// 创建输入张量,并分配内存Value input_tensor_ = Value::CreateTensor<float>(memory_info_handler, this->input_image.data(), this->input_image.size(), input_img_shape.data(), input_img_shape.size());// 设置运行选项Ort::RunOptions runOptions;// 运行推理,获取输出结果vector<Value> ort_outputs = this->ort_session->Run(runOptions, this->input_names.data(), &input_tensor_, 1, this->output_names.data(), output_names.size());// 获取第一个输出张量的数据指针float *pdata = ort_outputs[0].GetTensorMutableData<float>(); // 获取输出张量中的检测框数量const int num_box = ort_outputs[0].GetTensorTypeAndShapeInfo().GetShape()[2];// 存储原始检测框和得分vector<Bbox> bounding_box_raw;vector<float> score_raw;for (int i = 0; i < num_box; i++){const float score = pdata[4 * num_box + i];if (score > this->conf_threshold){// 将检测框的坐标从归一化映射到原始图像尺寸float xmin = (pdata[i] - 0.5 * pdata[2 * num_box + i]) * this->ratio_width; float ymin = (pdata[num_box + i] - 0.5 * pdata[3 * num_box + i]) * this->ratio_height; float xmax = (pdata[i] + 0.5 * pdata[2 * num_box + i]) * this->ratio_width; float ymax = (pdata[num_box + i] + 0.5 * pdata[3 * num_box + i]) * this->ratio_height;bounding_box_raw.emplace_back(Bbox{xmin, ymin, xmax, ymax});score_raw.emplace_back(score);}}// 使用非极大值抑制(NMS)算法去除重叠的检测框vector<int> keep_inds = nms(bounding_box_raw, score_raw, this->iou_threshold);// 获取保留的检测框数量const int keep_num = keep_inds.size();// 清空输出向量并设置为保留的检测框数量boxes.clear();boxes.resize(keep_num);// 将保留的检测框复制到输出向量中for (int i = 0; i < keep_num; i++){const int ind = keep_inds[i];boxes[i] = bounding_box_raw[ind];}
}
5.3 代码解释
5.3.1 选择GPU推理
// 设置执行提供者为 CUDA,并添加到会话选项中,这里选择第一块GPUOrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); // 设置图优化级别为最高级别,这里使用最大优化sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);sessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
5.3.2 获取输入层
// 获取输入节点的名称和维度信息for (int i = 0; i < numInputNodes; i++){input_names.push_back(ort_session->GetInputName(i, allocator)); // 新版本的Onnx Runtime使用的接口// AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator);// input_names.push_back(input_name_Ptr.get()); Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();auto input_dims = input_tensor_info.GetShape();input_node_dims.push_back(input_dims);}
可以使用可视化看到模型输入层:

5.3.3 获取输出层
// 获取输出节点的名称和维度信息for (int i = 0; i < numOutputNodes; i++){output_names.push_back(ort_session->GetOutputName(i, allocator));// 新版本的Onnx Runtime使用的接口// AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);// output_names.push_back(output_name_Ptr.get()); Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();auto output_dims = output_tensor_info.GetShape();output_node_dims.push_back(output_dims);}
可以使用可视化看到模型输出层:

5.4 使用CPU进行推理
注释掉调用GPU部分,运行代码,计算运行时间,可以看到每张图运行速度如下:

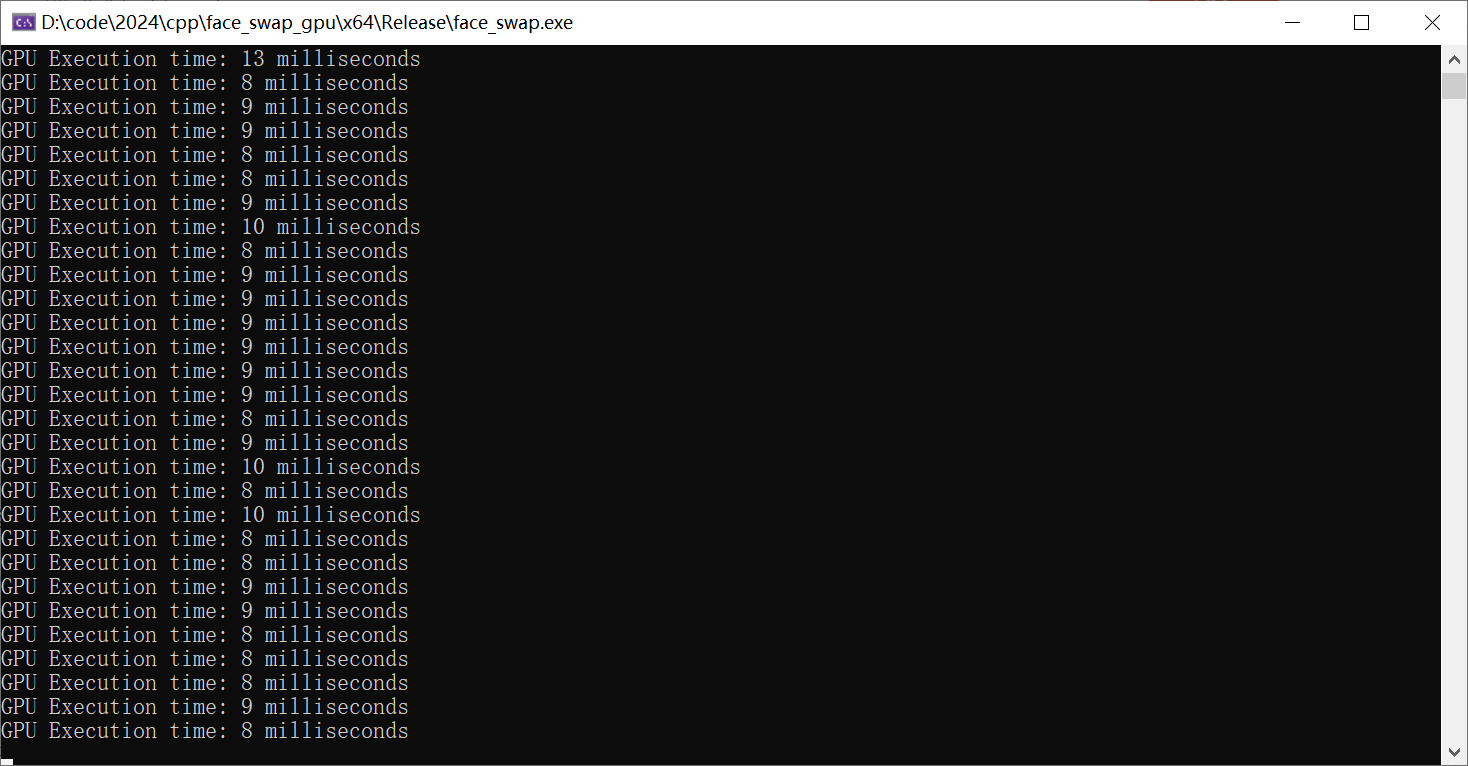
5.5 使用GPU进行推理
作用GPU推理设置参数如下:
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);- ORT_DISABLE_ALL:禁用所有图优化。
- ORT_ENABLE_BASIC:启用基本的图优化。
- ORT_ENABLE_EXTENDED:启用扩展的图优化,这通常包括基本优化加上一些更激进的优化策略,可能会提高模型的执行速度,但也可
能需要更多的时间来优化图。
使用GPU推理,运行代码,计算运行时间,可以看到每张图运行速度如下:
可以打开资源管理器看GPU的使用情况:

6.总结
以上就是在win 10下使用Onnx Runtime用CPU与GPU来对onnx模型进行推理部署的对比,可以明显的看出来,使用GPU之后的推理速度,但在正式的大型项目中,在win下使用GPU部署模型是不建议,一般都会选择Linux,那样对GPU的利用率会高出不少,毕竟蚊腿肉也是肉。
相关文章:
)
深度学习模型部署——基于Onnx Runtime的深度学习模型CPU与GPU部署(C++实现)
1.概述 许多机器学习和深度学习模型都是在基于 Python 的框架中开发和训练的,例如 PyTorch 和 TensorFlow 等。但是,当需要将这些训练好模型部署到生产环境中时,通常会希望将模型集成到生产流程中,而这些流程大多是用 C 编写的&a…...

Selenium 的四种等待方式及使用场景
Selenium 的四种等待方式及使用场景 隐式等待(Implicit Wait)显式等待(Explicit Wait)自定义等待(Custom Wait)固定等待(Sleep) 1. 隐式等待 定义: 隐式等待是为 WebD…...

攻防世界 ics-07
点击之后发现有个项目管理能进,点进去,点击看到源码,如下三段 <?php session_start(); if (!isset($_GET[page])) { show_source(__FILE__); die(); } if (isset($_GET[page]) && $_GET[page] ! index.php) { include(flag.php);…...

一文读懂「LoRA」:大型语言模型的低秩适应
LoRA: Low-Rank Adaptation of Large Language Models 前言 LoRA作为大模型的微调框架十分实用,在LoRA出现以前本人都是通过手动修改参数、优化器或者层数来“炼丹”的,具有极大的盲目性,但是LoRA技术能够快速微调参数,如果LoRA…...

新车月交付突破2万辆!小鹏汽车“激活”智驾之困待解
首次突破月交付2万辆规模的小鹏汽车,稳吗? 本周,高工智能汽车研究院发布的最新监测数据显示,2024年11月,小鹏汽车在国内市场(不含出口)交付量(上险口径,下同)…...
)
dockerfile 中 #(nop)
在 Dockerfile 中,#(nop) 通常出现在 docker history 命令的输出中。以下是对它的详细解释: 背景 当你使用 docker history <image_name> 命令查看 Docker 镜像的构建历史时,你可能会看到 #(nop) 这样的标记。这是因为 Docker 镜像由…...

升级 Spring Boot 3 配置讲解 —— 为何 SpringBoot3 淘汰了 JDK8?
学会这款 🔥全新设计的 Java 脚手架 ,从此面试不再怕! 随着 Spring Boot 3 的发布,许多开发者发现了一个重要的变化:Spring Boot 3 不再支持 JDK 8。这一变化引发了不少讨论,尤其是对于那些仍然在使用 JDK …...
)
IT面试求职系列主题-人工智能(一)
想成功求职,必要的IT技能一样不能少,再从人工智能基础知识来一波吧。 1)您对人工智能的理解是什么? 人工智能是计算机科学技术,强调创造能够模仿人类行为的智能机器。这里智能机器可以定义为能够像人一样行动、像人一…...

JVM 优化指南
JVM 优化指南 1. JVM 参数配置 1.1 基础参数配置 设置堆内存大小 -Xms2048m -Xmx2048m 设置新生代大小 -Xmn1024m 设置元空间大小 -XX:MetaspaceSize256m -XX:MaxMetaspaceSize256m 设置线程栈大小 -Xss512k1.2 垃圾回收器配置 使用 G1 垃圾回收器 -XX:UseG1GC 设置期望停顿…...

windows下编写的shell脚本在Linux下执行有问题解决方法
前言: 这个问题在实际工作中经常会遇到(非语法错误),脚本来源有些是自己在windows系统编写的、有些是从别人那里copy来的,还有些原本是好的被别人拿到windows下修改了一些内容,总之各种场景,但是如果是一个内容比较多的…...
—将指定目录下的 CSV 或 Excel 文件导入 SQLite 数据库)
使用 SQL 和表格数据进行问答和 RAG(6)—将指定目录下的 CSV 或 Excel 文件导入 SQLite 数据库
将指定目录下的 CSV 或 Excel 文件导入 SQLite 数据库。以下是详细代码逻辑: 1. 类结构 该类包含三个主要方法: _prepare_db:负责将文件夹中的 CSV 和 XLSX 文件转换为 SQL 表。_validate_db:用于验证 SQL 数据库中创建的表是否…...

【算法】算法大纲
这篇文章介绍计算机算法的各个思维模式。 包括 计数原理、数组、树型结构、链表递归栈、查找排序、管窥算法、图论、贪心法和动态规划、以及概率论:概率分治和机器学习。没有办法逐个说明,算法本身错综复杂,不同的算法对应着不同的实用场景,也需要根据具体情况设计与调整。…...
, react (16及以上)开发者工具资源)
vue(2,3), react (16及以上)开发者工具资源
在前端开发的广阔领域中,Vue.js 和 React.js 作为两大主流框架,各自拥有庞大的用户群体和丰富的生态系统。为了帮助开发者更高效地进行调试和开发,Vue Devtools 和 React 开发者工具应运而生,成为这两个框架不可或缺的辅助工具。本…...
)
系统编程(网络,文件基础)
网络链接 虚拟机和主机之间网络连接的主要模式有三种,分别是桥接模式(Bridged)、网络地址转换模式(NAT)以及主机模式(Host-Only)。以下是这三种模式的详细解释: 一、桥接模式&…...

重温设计模式--13、策略模式
策略模式介绍 文章目录 策略模式介绍C 代码示例 策略模式是一种行为设计模式,它允许在运行时选择算法的行为。该模式将算法的定义和使用分离开来,使得算法可以独立于使用它的客户端而变化,提高了代码的灵活性和可维护性。 其主要包含以下几个…...

数字IC设计高频面试题
在数字IC设计领域,面试是评估候选人技术能力和问题解决能力的重要环节。数字IC设计的复杂性和要求在不断提高。面试官通常会提出一系列面试题,以考察应聘者在数字设计、验证、时钟管理、功耗优化等方面的专业知识和实践经验。 这些题目不仅涉及理论知识…...

C#异步多线程——ThreadPool线程池
C#实现异步多线程的方式有多种,以下总结的是ThreadPool的用法。 线程池的特点 线程池受CLR管理,线程的生命周期,任务调度等细节都不需要我们操心了,我们只需要专注于任务实现,使用ThreadPool提供的静态方法把我们的任…...
)
矩母函数(MGF)
矩母函数(MGF)简介 矩母函数(Moment Generating Function,MGF)是概率统计中描述随机变量分布特征的重要工具。MGF的主要用途是通过导数来计算随机变量的矩(比如均值、方差等),同时它…...

【技术支持】安卓无线adb调试连接方式
Android 10 及更低版本,需要借助 USB 手机和电脑需连接在同一 WiFi 下;手机开启开发者选项和 USB 调试模式,并通过 USB 连接电脑(即adb devices可以查看到手机);设置手机的监听adb tcpip 5555;拔掉 USB 线…...
将三维空间中的点投影到二维图像平面上函数projectPoints()的使用)
OpenCV相机标定与3D重建(46)将三维空间中的点投影到二维图像平面上函数projectPoints()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将3D点投影到图像平面上。 cv::projectPoints 是 OpenCV 库中的一个函数,用于将三维空间中的点投影到二维图像平面上。这个过程涉及到…...

Android wifi常见问题及分析
参考 Android Network/WiFi 那些事儿 前言 本文将讨论几个有意思的网络问题,同时介绍 Android 上常见WiFi 问题的分析思路。 网络基础Q & A 一. 网络分层缘由 分层想必大家很熟悉,是否想过为何需要这样分层? 网上大多都是介绍每一层…...

如何用 ESP32-CAM 做一个实时视频流服务器
文章目录 ESP32-CAM 概述ESP32-S 处理器内存Camera 模块MicroSD 卡槽天线板载 LED 和闪光灯其他数据手册和原理图ESP32-CAM 功耗 ESP32-CAM 引脚参考引脚排列GPIO 引脚哪些 GPIO 可以安全使用?GPIO 0 引脚MicroSD 卡引脚 ESP32-CAM 的烧录方式使用 ESP32-CAM-MB 编程…...

编译与汇编
本文来自《程序员的自我修养》 编译过程是把预处理完的文件进行一系列词法分析,语法分析,语义分析以及优化后生成相应的汇编文件代码。 现在版本的GCC把预编译和编译两个步骤合并为一个步骤。 gcc -S HelloWorld.c HelloWorld.sint main() {//test/* …...

Linux入门攻坚——43、keepalived入门-1
Linux Cluster(Linux集群的类型):LB、HA、HPC,分别是负载均衡集群、高可用性集群、高性能集群。 LB:lvs,nginx HA:keepalived,heartbeat,corosync,cman HP&am…...

备考蓝桥杯:顺序表相关算法题
目录 询问学号 寄包柜 移动0 颜色分类 合并两个有序数组 物品移动 询问学号 我们的思路:创建一个顺序表存储从1开始依次存放进入教室的学生学号,然后查询 #include <iostream> #include <vector> using namespace std; const int N 2…...
)
【STM32+QT项目】基于STM32与QT的智慧粮仓环境监测与管理系统设计(完整工程资料源码)
视频演示: 基于STM32与QT的智慧粮仓环境监测与管理系统设计 目录: 目录 视频演示: 目录: 前言:...

Vue3 自定义hook
文章目录 Vue3 自定义hook概述用法 Vue3 自定义hook 概述 Vue3推荐利用Vue的组合式API函数进行代码封装,这种封装方式统称为自定义hook。 用法 定义 hook/countHook.js: import {computed, ref, watch} from "vue";export default (initC…...

【VBA】【EXCEL】将某列内容横向粘贴到指定行
Sub CopyRowToColumn()On Error GoTo ErrorHandler 添加错误处理Application.ScreenUpdating FalseApplication.Calculation xlCalculationManualApplication.EnableEvents False 禁用事件处理Dim lastCol As LongDim lastRow As LongDim i As Long, colCount As LongDim …...

使用Llama 3.1创建合成数据集以调优你的大型语言模型
使用Llama 3.1创建合成数据集以调优你的大型语言模型 在数据驱动的人工智能领域,数据是核心资产。开发高质量数据集既复杂又昂贵,因此很多实验室和开发者选择使用合成数据集。本文将介绍如何利用大型语言模型Llama 3.1 405B创建合成数据集,并…...

【Ubuntu22.04】VMware虚拟机硬盘扩容
1.首先打开虚拟机设置 2.根据需要对硬盘扩展 这边提示我们还需要进入虚拟机在内部分区 3.安装界面化磁盘管理工具 # 安装 sudo apt install gparted# 启动 sudo gparted调整硬盘大小 调整的时候会提示我们硬盘是只读的,因此还要进行操作 新建终端重新挂载文件系…...

初学stm32 --- DMA直接存储器
目录 DMA介绍 STM32F1 DMA框图 DMA处理过程 DMA通道 DMA优先级 DMA相关寄存器介绍 F1 DMA通道x配置寄存器(DMA_CCRx) DMA中断状态寄存器(DMA_ISR) DMA中断标志清除寄存器(DMA_IFCR) DMA通道x传输…...

reactor中的并发
1. reactor中的并发有两种方式 1.1 flatmap,底层是多线程并发处理。在reactor的演讲中,flatmap对于io类型的并发效果较好. flamap有两个参数: int concurrency, int prefetch。分别代表并发的线程数和缓存大小 注意凡是参数中有prefetch的,都…...

HTML - <script>,<noscript>
<script>标签用于在网页插入脚本,<noscript>标签用于指定浏览器不支持脚本时的显示内容。 1.<script> <script>用于加载脚本代码,目前主要是加载 JavaScript 代码。 <script> console.log(hello world); </script&g…...

C#语言的函数实现
C#语言的函数实现 在现代编程语言中,函数(Function)是最基本也是最重要的组成部分之一。函数不仅提高了代码的复用性,还使得程序结构更清晰。C#作为一种多用途的编程语言,函数的知识是程序员必备的基本技能之一。本文…...

JAVA I/O流练习1
往D盘中的JAVA复习文件夹中写数据: 数据改了一下哈: import java.io.*; import java.util.Scanner; public class Test {public static void main(String[] args) throws IOException {String fileName"D:JAVA复习\\grade.txt";FileWriter w…...

HTML——75. 内联框架
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>内联框架</title><style type"text/css">iframe{width: 100%;height: 500px;}</style></head><body><!--iframe元素会创建包含…...

js获取当前浏览器地址,ip,端口号等等
前言: js获取当前浏览器地址,ip,端口号等等 window.location属性查询 具体属性: 1、获取他的ip地址 window.location.hostname 2、获取他的端口号 window.location.port 3、获取他的全路径 window.location.origin 4、获取…...
)
C++虚函数(八股总结)
什么是虚函数 虚函数是在父类中定义的一种特殊类型的函数,允许子类重写该函数以适应其自身需求。虚函数的调用取决于对象的实际类型,而不是指针或引用类型。通过将函数声明为虚函数,可以使继承层次结构中的每个子类都能够使用其自己的实现&a…...

【每日学点鸿蒙知识】跳转三方地图、getStringSync性能、键盘避让模式等
1、跳转三方地图导航页 类似于Android 跳转到地图APP 导航页面: // 目标地点的经纬度和名称 double destinationLat 36.547901; double destinationLon 104.258354; String destinationName "目的地名称"; // 构建URI Uri uri Uri.parse("…...

【线性代数】通俗理解特征向量与特征值
这一块在线性代数中属于重点且较难理解的内容,下面仅个人学习过程中的体会,错误之处欢迎指出,有更简洁易懂的理解方式也欢迎留言学习。 文章目录 概念计算几何直观理解意义 概念 矩阵本身就是一个线性变换,对一个空间中的向量应用…...
:备忘录模式,时光倒流的魔法)
C#设计模式(行为型模式):备忘录模式,时光倒流的魔法
C#设计模式:备忘录模式,时光倒流的魔法 在软件开发中,我们经常会遇到需要保存对象状态,并在未来某个时刻恢复的场景。例如: 撤销操作: 文本编辑器中的撤销功能,游戏中的回退操作。事务回滚&am…...

服务器信息整理:用途、操作系统安装日期、设备序列化、IP、MAC地址、BIOS时间、系统
文章目录 引言I BIOS时间Windows查看BIOS版本安装日期linux查看BIOS时间II 操作系统安装日期LinuxWindowsIII MAC 地址IV 设备序列号Linux 查看主板信息知识扩展Linux常用命令引言 信息内容:重点信息:用途、操作系统安装日期、设备序列化、IP、MAC地址、BIOS时间、系统 Linux…...

用OpenCV实现UVC视频分屏
分屏 OpencvUVC代码验证后话 用OpenCV实现UVC摄像头的视频分屏。 Opencv opencv里有很多视频图像的处理功能。 UVC Usb 视频类,免驱动的。视频流格式有MJPG和YUY2。MJPG是RGB三色通道的。要对三通道进行分屏显示。 代码 import cv2 import numpy as np video …...

【C#学习】基类的静态变量 派生类会如何处理
来源GPT,仅记录学习 在C#中,子类继承父类的public static变量时,父类的静态变量对所有类(包括子类)都是共享的。子类并不会重新创建父类静态变量,而是共享父类的静态成员。 具体行为: 静态变量…...

Unity3D仿星露谷物语开发19之库存栏丢弃及交互道具
1、目标 从库存栏中把道具拖到游戏场景中,库存栏中道具数相应做减法或者删除道具。同时在库存栏中可以交换两个道具的位置。 2、UIInventorySlot设置Raycast属性 在UIInventorySlot中,我们只希望最外层的UIInventorySlot响应Raycast,他下面…...

SQL进阶实战技巧:如何利用 Oracle SQL计算线性回归置信区间?
目录 1 置信区间计算方法 步骤1:计算回归系数 步骤2:计算标准误差 步骤3:计算置信区间 2 数据准备 <...

计算机网络——网络层—IP数据报与分片
一、IP 数据报的格式 • 一个 IP 数据报由首部和数据两部分组成。 • 首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。 • 在首部的固定部分的后面是一些可选字段,其长度是可变的。 IP 数据报首部的固定部分中的各字段 版…...

高山旅游景区有效降低成本,无人机山下到山上物资吊运技术详解
在高山旅游景区,传统的物资运输方式往往面临人力成本高昂、效率低下等问题,而无人机技术的引入为这一难题提供了新的解决方案。以下是对无人机从山下到山上进行物资吊运技术的详细解析: 一、无人机物资吊运技术的优势 1. 降低人力成本&#…...

Linux 注册线程化的中断处理程序
1. 注册线程化中断处理函数 devmem_request_threaded_irq 是 Linux 内核中的一个函数,用于请求并注册一个线程化的中断处理程序。这个函数允许开发者注册一个中断处理函数,这个函数会在中断发生时被调用,从而实现相应的中断处理逻辑。它通过…...

【狂热算法篇】解锁数据潜能:探秘前沿 LIS 算法
嘿,各位编程爱好者们!今天带来的 LIS 算法简直太赞啦 无论你是刚入门的小白,还是经验丰富的大神,都能从这里找到算法的奇妙之处哦!这里不仅有清晰易懂的 C 代码实现,还有超详细的算法讲解,让你轻…...