一、环境准备(centos7.9)
点击查看代码
1、关闭防火墙
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld2、关闭selinux
[root@localhost ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config3、修改主机名
[root@localhost ~]# hostnamectl set-hostname hadoop101
[root@localhost ~]# cat /etc/hostname
hadoop1014、修改hosts
[hadoop@hadoop101(192.168.0.101) ~]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.100 hadoop100
192.168.0.101 hadoop101
192.168.0.102 hadoop102
192.168.0.103 hadoop103
192.168.0.104 hadoop104
192.168.0.105 hadoop105
192.168.0.106 hadoop106
192.168.0.107 hadoop107
192.168.0.108 hadoop1085、新增hadoop用户
[root@localhost ~]# useradd hadoop
[root@localhost ~]# passwd hadoop
[root@localhost ~]# vi /etc/sudoers
hadoop ALL=(ALL) NOPASSWD:ALL6、创建部署目录
[root@localhost ~]# mkdir /opt/module
[root@localhost ~]# mkdir /opt/software
[root@localhost ~]# chown -R hadoop.hadoop /opt/7、修改源下载常用软件
[root@localhost ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
[root@localhost ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
[root@localhost ~]# yum install -y vim net-tools psmisc nc rsync lrzsz ntp libzstd openssl-static tree iotop git8、重启服务器
[root@localhost ~]# reboot
二、SSH无密登录配置
点击查看代码
[hadoop@hadoop101(192.168.0.101) ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:+QTBEPum2MZovt2mHUqlgeKZXqxXkGAKT+U4DGFq7LM hadoop@hadoop101
The key's randomart image is:
+---[RSA 2048]----+
|oo .. o+. |
|=o+o ... |
|oB+.... . |
|+ ..o. . o |
| o. ... S . |
| .o= =.* o |
| E+ *.B . . |
| . =.+ +.. |
| o.o.+oo |
+----[SHA256]-----+[hadoop@hadoop101(192.168.0.101) ~]$ ssh-copy-id hadoop101
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop101 (192.168.0.101)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop101's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop101'"
and check to make sure that only the key(s) you wanted were added.[hadoop@hadoop101(192.168.0.101) ~]$ ssh-copy-id hadoop102
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.0.102)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop102's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop102'"
and check to make sure that only the key(s) you wanted were added.[hadoop@hadoop101(192.168.0.101) ~]$ ssh-copy-id hadoop103
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop103 (192.168.0.103)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop103's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop103'"
and check to make sure that only the key(s) you wanted were added.#拷贝.ssh到其他机器实现互通
[hadoop@hadoop101(192.168.0.101) ~]$ scp -r .ssh/ hadoop102:`pwd`
id_rsa 100% 1675 601.2KB/s 00:00
id_rsa.pub 100% 398 288.2KB/s 00:00
known_hosts 100% 555 465.7KB/s 00:00
authorized_keys 100% 398 176.0KB/s 00:00
[hadoop@hadoop101(192.168.0.101) ~]$ scp -r .ssh/ hadoop103:`pwd`
id_rsa 100% 1675 1.4MB/s 00:00
id_rsa.pub 100% 398 283.8KB/s 00:00
known_hosts 100% 555 206.7KB/s 00:00
authorized_keys 100% 398 322.5KB/s 00:00
[hadoop@hadoop101(192.168.0.101) /opt/module]$ su - root
Password:
Last login: Tue Sep 16 17:59:23 CST 2025 from 192.168.0.1 on pts/0
[root@hadoop101(192.168.0.101) ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:a7R+dZ6FjzCwWW6kI5yas6fKDa5vGqGgZTn1Jl5I2WY root@hadoop101
The key's randomart image is:
+---[RSA 2048]----+
| |
| o |
| + E |
| + = . o |
|. * o +.S. O . |
|o+ + + .+o= * o .|
|o . o o+. + = = |
| +.o+o. . + .|
| o==.+=.. |
+----[SHA256]-----+
[root@hadoop101(192.168.0.101) ~]#
[root@hadoop101(192.168.0.101) ~]# ssh-copy-id hadoop101
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop101 (192.168.0.101)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop101's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop101'"
and check to make sure that only the key(s) you wanted were added.[root@hadoop101(192.168.0.101) ~]# ssh-copy-id hadoop102
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.0.102)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop102's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop102'"
and check to make sure that only the key(s) you wanted were added.[root@hadoop101(192.168.0.101) ~]# ssh-copy-id hadoop103
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop103 (192.168.0.103)' can't be established.
ECDSA key fingerprint is SHA256:GvIGH8BNgOd8kQN6zCNjWqmhOq+BPPdiawWycTRDCuk.
ECDSA key fingerprint is MD5:40:30:ab:8c:62:d3:5f:bd:4d:25:42:21:a1:64:10:c3.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop103's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop103'"
and check to make sure that only the key(s) you wanted were added.三、编写分发脚本
```shell [hadoop@hadoop101(192.168.0.101) ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hadoop/.local/bin:/home/hadoop/bin [hadoop@hadoop101(192.168.0.101) ~]$ mkdir /home/hadoop/bin [hadoop@hadoop101(192.168.0.101) ~]$ cd /home/hadoop/bin [hadoop@hadoop101(192.168.0.101) ~/bin]$ vim myrsync.sh [hadoop@hadoop101(192.168.0.101) ~/bin]$ cat myrsync.sh #!/bin/bash1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
2. 遍历集群所有机器
for host in hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fi
done
done
[hadoop@hadoop101(192.168.0.101) ~/bin]$ chmod +x myrsync.sh
[hadoop@hadoop101(192.168.0.101) ~/bin]$ myrsync.sh
测试脚本
[hadoop@hadoop101(192.168.0.101) ~]$ cd /opt/module/
[hadoop@hadoop101(192.168.0.101) /opt/module]$ ll
total 0
[hadoop@hadoop101(192.168.0.101) /opt/module]$ echo "1111" > test.sh
[hadoop@hadoop101(192.168.0.101) /opt/module]$ myrsync.sh test.sh
==================== hadoop102 ====================
sending incremental file list
test.sh
sent 113 bytes received 35 bytes 296.00 bytes/sec
total size is 5 speedup is 0.03
==================== hadoop103 ====================
sending incremental file list
test.sh
sent 113 bytes received 35 bytes 296.00 bytes/sec
total size is 5 speedup is 0.03
[hadoop@hadoop102(192.168.0.102) ~]$ cd /opt/module/
[hadoop@hadoop102(192.168.0.102) /opt/module]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 5 Sep 16 10:40 test.sh
[hadoop@hadoop103(192.168.0.103) ~]$ cd /opt/module/
[hadoop@hadoop103(192.168.0.103) /opt/module]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 5 Sep 16 10:40 test.sh
<h1 id="G7PZ7">四、安装JDK</h1>
链接: [https://pan.baidu.com/s/1ViOfmFgAIqqVfevSn9-Tnw?pwd=vqmb](https://pan.baidu.com/s/1ViOfmFgAIqqVfevSn9-Tnw?pwd=vqmb) 提取码: vqmb 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v9的分享<font style="background-color:#FFFF00;">注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK</font>```shell
注意:如果你的虚拟机是最小化安装不需要执行这一步。
[root@hadoop101 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e –nodeps:强制卸载软件
#1、上传包
[hadoop@hadoop101(192.168.0.101) /opt/software]$ ll
total 190444
-rw-r--r-- 1 hadoop hadoop 195013152 Sep 16 10:48 jdk-8u212-linux-x64.tar.gz#2、解压包
[hadoop@hadoop101(192.168.0.101) /opt/software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
[hadoop@hadoop101(192.168.0.101) /opt/software]$ ll /opt/module/
total 4
drwxr-xr-x 7 hadoop hadoop 245 Apr 2 2019 jdk1.8.0_212#3、配置JDK环境变量
[hadoop@hadoop101(192.168.0.101) /opt/software]$ sudo vim /etc/profile.d/my_env.sh
[hadoop@hadoop101(192.168.0.101) /opt/software]$ cat /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin[hadoop@hadoop101(192.168.0.101) /opt/software]$ source /etc/profile
[hadoop@hadoop101(192.168.0.101) /opt/software]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
五、安装hadoop
Hadoop下载地址:[https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/](https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/)[hadoop@hadoop101(192.168.0.101) /opt/software]$ ll
total 869604
-rw-r--r-- 1 hadoop hadoop 695457782 Sep 12 11:27 hadoop-3.3.4.tar.gz
-rw-r--r-- 1 hadoop hadoop 195013152 Sep 16 10:48 jdk-8u212-linux-x64.tar.gz
#解压包
[hadoop@hadoop101(192.168.0.101) /opt/software]$ tar xf hadoop-3.3.4.tar.gz -C /opt/module/
[hadoop@hadoop101(192.168.0.101) /opt/software]$ ll /opt/module/
total 4
drwxr-xr-x 10 hadoop hadoop 215 Jul 29 2022 hadoop-3.3.4#添加环境变量
[hadoop@hadoop101(192.168.0.101) /opt/software]$ sudo vim /etc/profile.d/my_env.sh
[hadoop@hadoop101(192.168.0.101) /opt/software]$ cat /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin[hadoop@hadoop101(192.168.0.101) /opt/software]$ source /etc/profile
[hadoop@hadoop101(192.168.0.101) /opt/software]$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:32Z
Compiled with protoc 3.7.1
From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
This command was run using /opt/module/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
**六、 Hadoop目录结构**
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ ll total 92 drwxr-xr-x 2 hadoop hadoop 203 Jul 29 2022 bin drwxr-xr-x 3 hadoop hadoop 20 Jul 29 2022 etc drwxr-xr-x 2 hadoop hadoop 106 Jul 29 2022 include drwxr-xr-x 3 hadoop hadoop 20 Jul 29 2022 lib drwxr-xr-x 4 hadoop hadoop 288 Jul 29 2022 libexec -rw-rw-r-- 1 hadoop hadoop 24707 Jul 29 2022 LICENSE-binary drwxr-xr-x 2 hadoop hadoop 4096 Jul 29 2022 licenses-binary -rw-rw-r-- 1 hadoop hadoop 15217 Jul 17 2022 LICENSE.txt -rw-rw-r-- 1 hadoop hadoop 29473 Jul 17 2022 NOTICE-binary -rw-rw-r-- 1 hadoop hadoop 1541 Apr 22 2022 NOTICE.txt -rw-rw-r-- 1 hadoop hadoop 175 Apr 22 2022 README.txt drwxr-xr-x 3 hadoop hadoop 4096 Jul 29 2022 sbin drwxr-xr-x 4 hadoop hadoop 31 Jul 29 2022 sharebin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本。
etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件。
lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)。
sbin目录:存放启动或停止Hadoop相关服务的脚本。
share目录:存放Hadoop的依赖jar包、文档、和官方案例。
注意:为了方便同步其他服务器,删除/opt/module/hadoop-3.3.4/share/doc
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ cd share/
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/share]$ ll
total 0
drwxr-xr-x 3 hadoop hadoop 20 Jul 29 2022 doc
drwxr-xr-x 8 hadoop hadoop 88 Jul 29 2022 hadoop
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/share]$ rm -rf doc/
<h1 id="OCgQ0">七、完全分布式运行模式</h1>
<h2 id="kO1WI">1、集群部署规划</h2>
<font style="background-color:#FFFF00;">注意:</font>Ø NameNode和SecondaryNameNode不要安装在同一台服务器。Ø ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。| <font style="color:black;"></font> | **<font style="color:black;">hadoop101 </font>** | **<font style="color:black;">hadoop102</font>** | **<font style="color:black;">hadoop103</font>** |
| --- | --- | --- | --- |
| **<font style="color:black;">HDFS</font>**<br/><font style="color:black;"></font> | <font style="color:red;">NameNode</font><br/><font style="color:black;">DataNode</font> | <font style="color:black;"></font><br/><font style="color:black;">DataNode</font> | <font style="color:red;">SecondaryNameNode</font><br/><font style="color:black;">DataNode</font> |
| **<font style="color:black;">YARN</font>** | <font style="color:black;"></font><br/><font style="color:black;">NodeManager</font> | <font style="color:red;">ResourceManager</font><br/><font style="color:black;">NodeManager</font> | <font style="color:black;"></font><br/><font style="color:black;">NodeManager</font> |<h2 id="CdBFu"><font style="color:black;">2、</font>**配置文件说明**</h2>
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。(1)默认配置文件:| **<font style="color:black;">要获取的默认文件</font>** | **<font style="color:black;">文件存放在</font>****<font style="color:black;">Hadoop</font>****<font style="color:black;">的</font>****<font style="color:black;">jar</font>****<font style="color:black;">包中的位置</font>** |
| --- | --- |
| **<font style="color:black;">[core-default.xml]</font>** | <font style="color:black;">hadoop-common-3.3.4.jar/core-default.xml</font> |
| **<font style="color:black;">[hdfs-default.xml]</font>** | <font style="color:black;">hadoop-hdfs-3.3.4.jar/hdfs-default.xml</font> |
| **<font style="color:black;">[yarn-default.xml]</font>** | <font style="color:black;">hadoop-yarn-common-3.3.4.jar/yarn-default.xml</font> |
| **<font style="color:black;">[mapred-default.xml]</font>** | <font style="color:black;">hadoop-mapreduce-client-core-3.3.4.jar/mapred-default.xml</font> |(2)自定义配置文件:**core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml**四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。<h2 id="ns18G">3、配置集群</h2>
<h3 id="ZO0lG">(1)核心配置文件</h3>
```shell
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ cd etc/hadoop
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ ll
total 176
-rw-r--r-- 1 hadoop hadoop 9213 Jul 29 2022 capacity-scheduler.xml
-rw-r--r-- 1 hadoop hadoop 1335 Jul 29 2022 configuration.xsl
-rw-r--r-- 1 hadoop hadoop 2567 Jul 29 2022 container-executor.cfg
-rw-r--r-- 1 hadoop hadoop 774 Jul 29 2022 core-site.xml
-rw-r--r-- 1 hadoop hadoop 3999 Jul 29 2022 hadoop-env.cmd
-rw-r--r-- 1 hadoop hadoop 16654 Jul 29 2022 hadoop-env.sh
-rw-r--r-- 1 hadoop hadoop 3321 Jul 29 2022 hadoop-metrics2.properties
-rw-r--r-- 1 hadoop hadoop 11765 Jul 29 2022 hadoop-policy.xml
-rw-r--r-- 1 hadoop hadoop 3414 Jul 29 2022 hadoop-user-functions.sh.example
-rw-r--r-- 1 hadoop hadoop 683 Jul 29 2022 hdfs-rbf-site.xml
-rw-r--r-- 1 hadoop hadoop 775 Jul 29 2022 hdfs-site.xml
-rw-r--r-- 1 hadoop hadoop 1484 Jul 29 2022 httpfs-env.sh
-rw-r--r-- 1 hadoop hadoop 1657 Jul 29 2022 httpfs-log4j.properties
-rw-r--r-- 1 hadoop hadoop 620 Jul 29 2022 httpfs-site.xml
-rw-r--r-- 1 hadoop hadoop 3518 Jul 29 2022 kms-acls.xml
-rw-r--r-- 1 hadoop hadoop 1351 Jul 29 2022 kms-env.sh
-rw-r--r-- 1 hadoop hadoop 1860 Jul 29 2022 kms-log4j.properties
-rw-r--r-- 1 hadoop hadoop 682 Jul 29 2022 kms-site.xml
-rw-r--r-- 1 hadoop hadoop 13700 Jul 29 2022 log4j.properties
-rw-r--r-- 1 hadoop hadoop 951 Jul 29 2022 mapred-env.cmd
-rw-r--r-- 1 hadoop hadoop 1764 Jul 29 2022 mapred-env.sh
-rw-r--r-- 1 hadoop hadoop 4113 Jul 29 2022 mapred-queues.xml.template
-rw-r--r-- 1 hadoop hadoop 758 Jul 29 2022 mapred-site.xml
drwxr-xr-x 2 hadoop hadoop 24 Jul 29 2022 shellprofile.d
-rw-r--r-- 1 hadoop hadoop 2316 Jul 29 2022 ssl-client.xml.example
-rw-r--r-- 1 hadoop hadoop 2697 Jul 29 2022 ssl-server.xml.example
-rw-r--r-- 1 hadoop hadoop 2681 Jul 29 2022 user_ec_policies.xml.template
-rw-r--r-- 1 hadoop hadoop 10 Jul 29 2022 workers
-rw-r--r-- 1 hadoop hadoop 2250 Jul 29 2022 yarn-env.cmd
-rw-r--r-- 1 hadoop hadoop 6329 Jul 29 2022 yarn-env.sh
-rw-r--r-- 1 hadoop hadoop 2591 Jul 29 2022 yarnservice-log4j.properties
-rw-r--r-- 1 hadoop hadoop 690 Jul 29 2022 yarn-site.xml[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ vim core-site.xml
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ cat core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property>
</configuration>
(2)HDFS配置文件
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ vim hdfs-site.xml [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ cat hdfs-site.xml<!-- nn web端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value>
</property>
(3)YARN配置文件
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ vim yarn-site.xml [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ cat yarn-site.xml<!-- 指定MR走shuffle -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- 指定ResourceManager的地址-->
<property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value>
</property><!-- 环境变量的继承 -->
<property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
(4)MapReduce配置文件
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ vim mapred-site.xml [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ cat mapred-site.xml4、**配置workers**
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ vim workers [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/etc/hadoop]$ cat workers hadoop101 hadoop102 hadoop103注意:
该文件中添加的内容结尾不允许有空格,文件中不允许有空行
把默认的localhost删掉
<h2 id="tT42K">5、分发</h2>
```shell
[hadoop@hadoop101(192.168.0.101) /opt/module]$ myrsync.sh hadoop-3.3.4/ jdk1.8.0_212/[hadoop@hadoop102(192.168.0.102) /opt/module]$ ll
total 4
drwxr-xr-x 12 hadoop hadoop 246 Sep 16 11:13 hadoop-3.3.4
drwxr-xr-x 7 hadoop hadoop 245 Apr 2 2019 jdk1.8.0_212[hadoop@hadoop103(192.168.0.103) /opt/module]$ ll
total 4
drwxr-xr-x 12 hadoop hadoop 246 Sep 16 11:13 hadoop-3.3.4
drwxr-xr-x 7 hadoop hadoop 245 Apr 2 2019 jdk1.8.0_212#分发环境变量
[hadoop@hadoop101(192.168.0.101) /opt/module]$ sudo su -
Last login: Tue Sep 16 10:42:43 CST 2025 on pts/0
[root@hadoop101(192.168.0.101) ~]# cd /home/hadoop/bin/
[root@hadoop101(192.168.0.101) /home/hadoop/bin]# ll
total 4
-rwxrwxr-x 1 hadoop hadoop 729 Sep 16 10:38 myrsync.sh
[root@hadoop101(192.168.0.101) /home/hadoop/bin]# ./myrsync.sh /etc/profile.d/my_env.sh
==================== hadoop102 ====================
sending incremental file list
my_env.shsent 311 bytes received 35 bytes 230.67 bytes/sec
total size is 216 speedup is 0.62
==================== hadoop103 ====================
sending incremental file list
my_env.shsent 311 bytes received 35 bytes 692.00 bytes/sec
total size is 216 speedup is 0.62
6、启动集群
(1)**如果集群是第一次启动**,需要在hadoop101节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)[hadoop@hadoop101(192.168.0.101) /opt/module]$ hdfs namenode -format
WARNING: /opt/module/hadoop-3.3.4/logs does not exist. Creating.
2025-09-16 13:13:15,775 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop101/192.168.0.101
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.4
.....
2025-09-16 13:11:20,465 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop101/192.168.0.101
************************************************************/#生成data和logs目录
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ ll
total 92
drwxr-xr-x 2 hadoop hadoop 203 Jul 29 2022 bin
drwxrwxr-x 3 hadoop hadoop 17 Sep 16 13:13 data
drwxr-xr-x 3 hadoop hadoop 20 Jul 29 2022 etc
drwxr-xr-x 2 hadoop hadoop 106 Jul 29 2022 include
drwxr-xr-x 3 hadoop hadoop 20 Jul 29 2022 lib
drwxr-xr-x 4 hadoop hadoop 288 Jul 29 2022 libexec
-rw-rw-r-- 1 hadoop hadoop 24707 Jul 29 2022 LICENSE-binary
drwxr-xr-x 2 hadoop hadoop 4096 Jul 29 2022 licenses-binary
-rw-rw-r-- 1 hadoop hadoop 15217 Jul 17 2022 LICENSE.txt
drwxrwxr-x 2 hadoop hadoop 39 Sep 16 13:13 logs
-rw-rw-r-- 1 hadoop hadoop 29473 Jul 17 2022 NOTICE-binary
-rw-rw-r-- 1 hadoop hadoop 1541 Apr 22 2022 NOTICE.txt
-rw-rw-r-- 1 hadoop hadoop 175 Apr 22 2022 README.txt
drwxr-xr-x 3 hadoop hadoop 4096 Jul 29 2022 sbin
drwxr-xr-x 3 hadoop hadoop 20 Sep 16 11:04 share
drwxrwxr-x 2 hadoop hadoop 22 Sep 16 11:12 wcinput
drwxr-xr-x 2 hadoop hadoop 88 Sep 16 11:13 wcoutput[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ cd data/dfs/name/current/
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/data/dfs/name/current]$ ll
total 16
-rw-rw-r-- 1 hadoop hadoop 401 Sep 16 13:13 fsimage_0000000000000000000
-rw-rw-r-- 1 hadoop hadoop 62 Sep 16 13:13 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 hadoop hadoop 2 Sep 16 13:13 seen_txid
-rw-rw-r-- 1 hadoop hadoop 218 Sep 16 13:13 VERSION[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/data/dfs/name/current]$ cat VERSION
#Tue Sep 16 13:13:16 CST 2025
namespaceID=1864693907
clusterID=CID-49146e2a-a934-4c55-86e7-204c4f5c2fd3
cTime=1757999596710
storageType=NAME_NODE
blockpoolID=BP-1184537275-192.168.0.101-1757999596710
layoutVersion=-66
(2)启动HDFS
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/data/dfs/name/current]$ cd /opt/module/hadoop-3.3.4/
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ sbin/start-dfs.sh
Starting namenodes on [hadoop101]
Starting datanodes
hadoop103: WARNING: /opt/module/hadoop-3.3.4/logs does not exist. Creating.
hadoop102: WARNING: /opt/module/hadoop-3.3.4/logs does not exist. Creating.
Starting secondary namenodes [hadoop103][hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ jps -l
8529 sun.tools.jps.Jps
8276 org.apache.hadoop.hdfs.server.datanode.DataNode
8155 org.apache.hadoop.hdfs.server.namenode.NameNode[hadoop@hadoop102(192.168.0.102) /opt/module]$ jps -l
7648 org.apache.hadoop.hdfs.server.datanode.DataNode
7737 sun.tools.jps.Jps[hadoop@hadoop103(192.168.0.103) /opt/module]$ jps -l
7634 org.apache.hadoop.hdfs.server.datanode.DataNode
7698 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
7800 sun.tools.jps.Jps
(3)在规划好的ResourceManager的节点(hadoop103)启动YARN。
[hadoop@hadoop102(192.168.0.102) /opt/module/hadoop-3.3.4]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers[hadoop@hadoop102(192.168.0.102) /opt/module/hadoop-3.3.4]$ jps -l
7648 org.apache.hadoop.hdfs.server.datanode.DataNode
7963 org.apache.hadoop.yarn.server.nodemanager.NodeManager
7853 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
8270 sun.tools.jps.Jps
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ jps -l
8276 org.apache.hadoop.hdfs.server.datanode.DataNode
8155 org.apache.hadoop.hdfs.server.namenode.NameNode
8684 sun.tools.jps.Jps
8590 org.apache.hadoop.yarn.server.nodemanager.NodeManager
[hadoop@hadoop103(192.168.0.103) /opt/module]$ jps -l
7634 org.apache.hadoop.hdfs.server.datanode.DataNode
7698 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
7864 org.apache.hadoop.yarn.server.nodemanager.NodeManager
7961 sun.tools.jps.Jps八、浏览器查看
1、Web端查看HDFS的NameNode。
①浏览器中输入:[http://hadoop101:9870](http://hadoop101:9870)②查看HDFS上存储的数据信息。
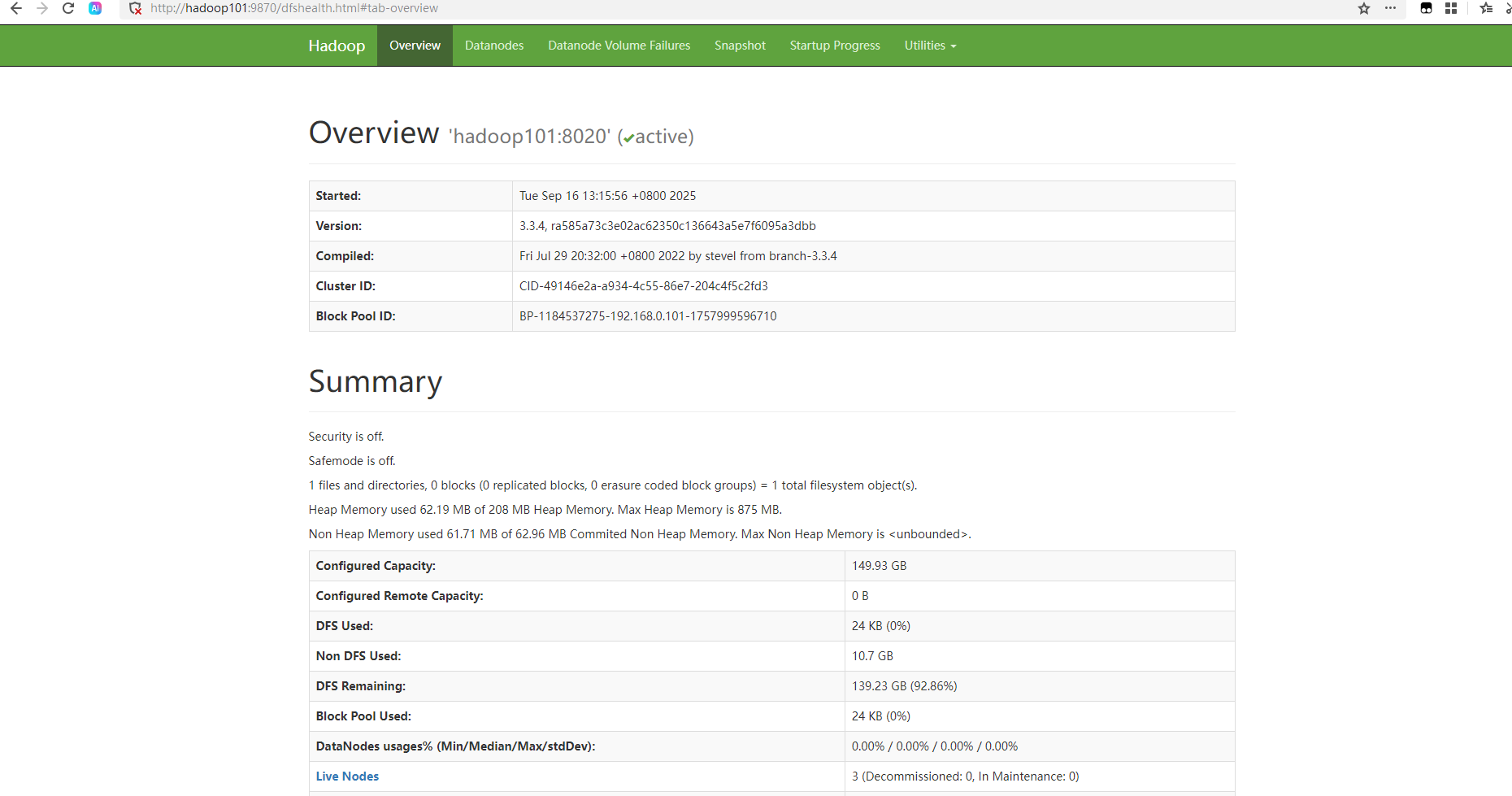
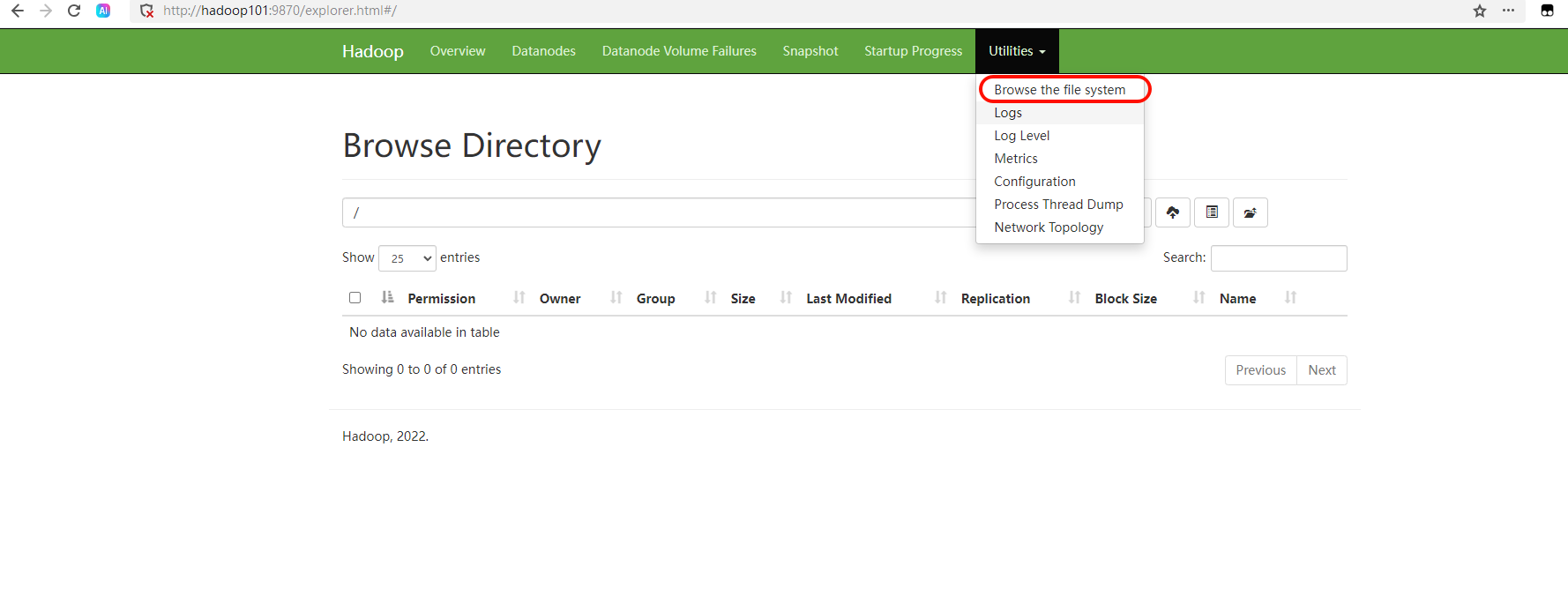
2、Web端查看YARN的ResourceManager。
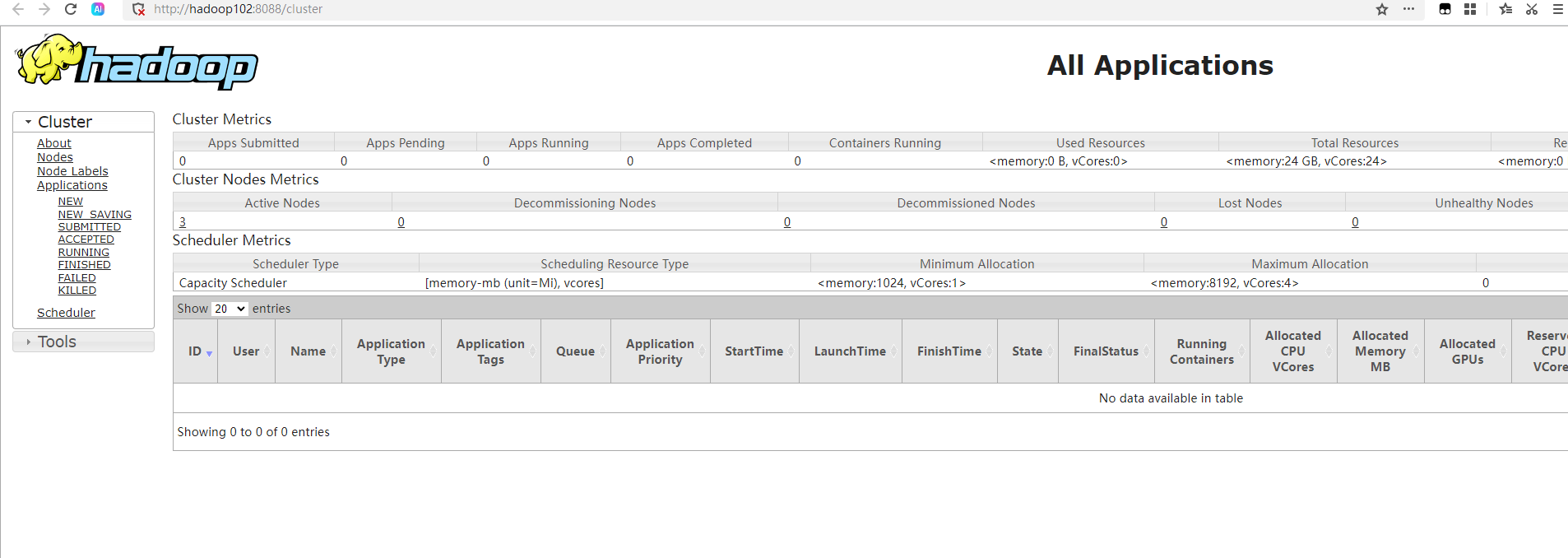
①浏览器中输入:[http://hadoop102:8088](http://hadoop102:8088)②查看YARN上运行的Job信息。
十、测试
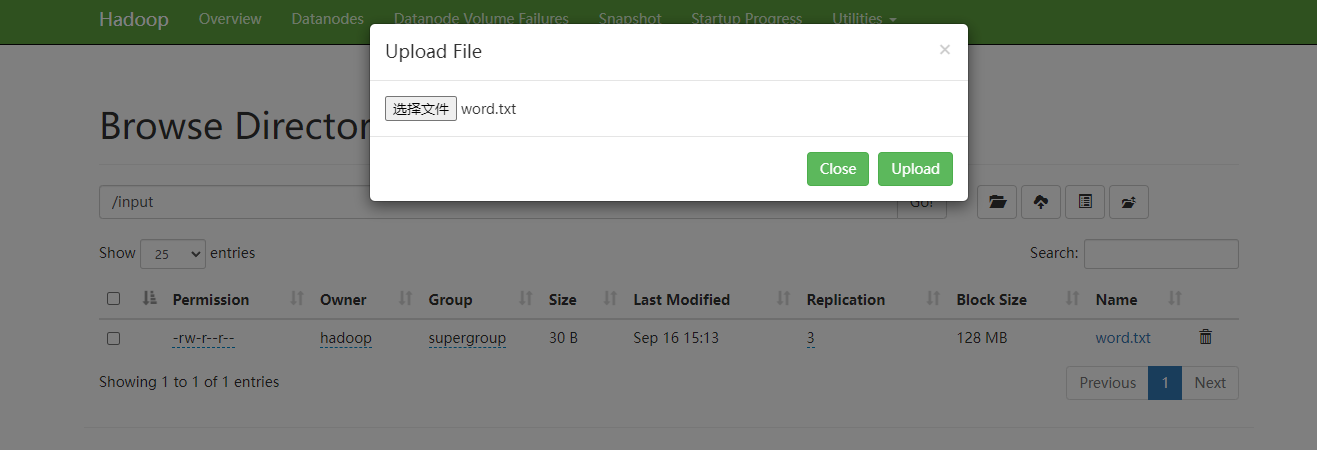
1、浏览器上传
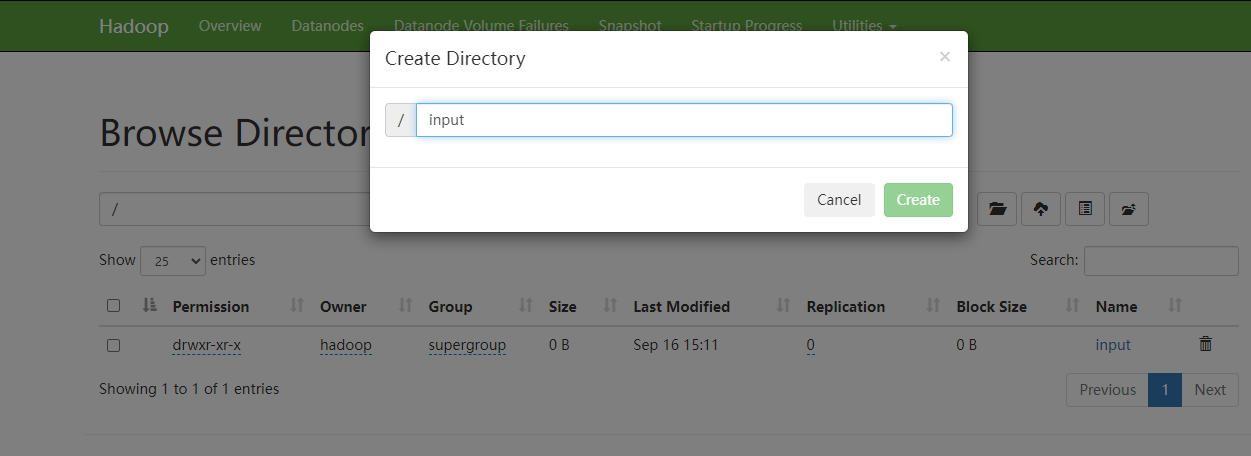
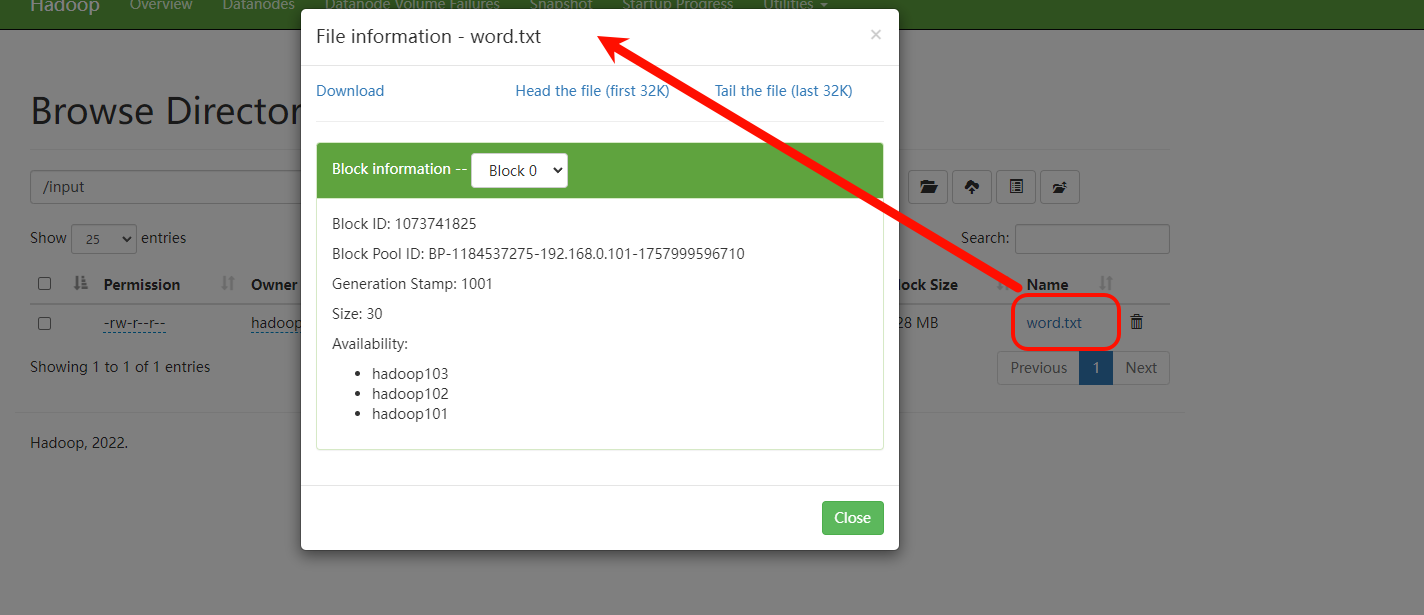
2、代码上传
```shell [hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ hadoop fs -mkdir /inputtest ```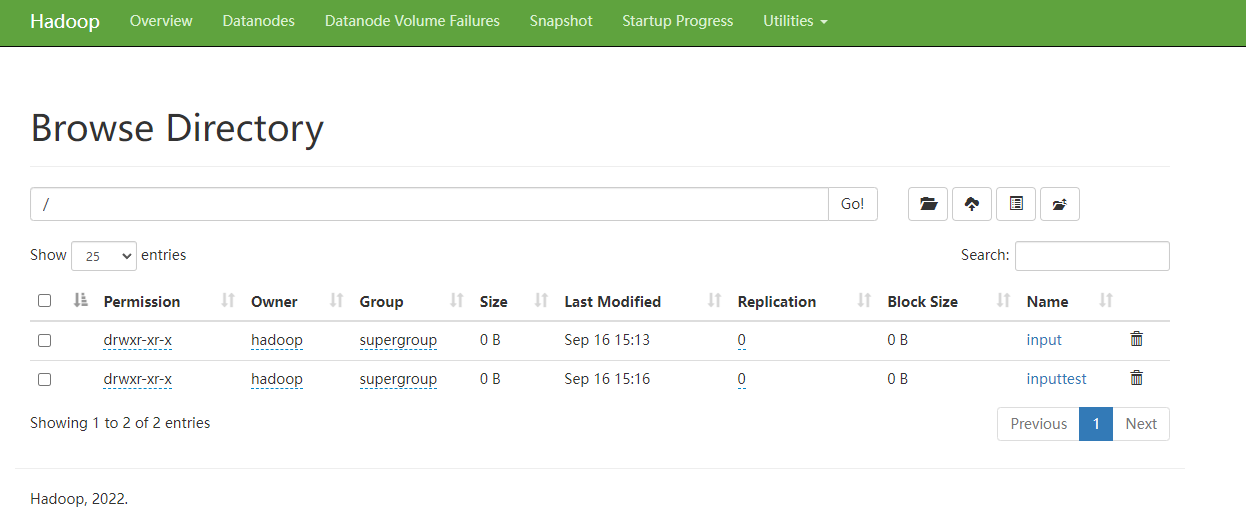
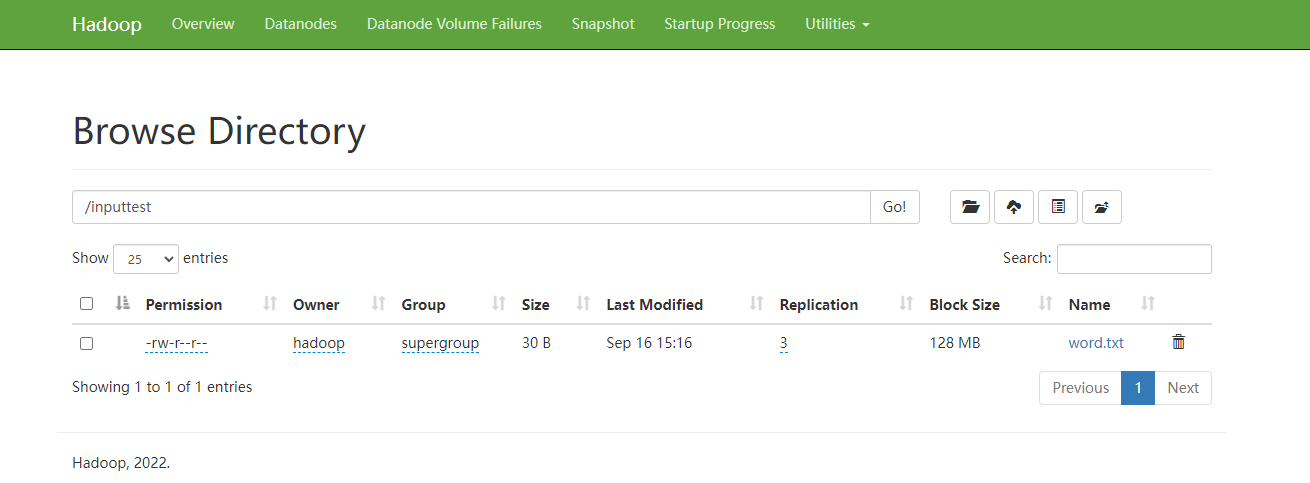
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /inputtest
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/data/dfs/data/current/BP-1184537275-192.168.0.101-1757999596710/current/finalized/subdir0/subdir0]$ ll
total 16
-rw-rw-r-- 1 hadoop hadoop 30 Sep 16 15:13 blk_1073741825
-rw-rw-r-- 1 hadoop hadoop 11 Sep 16 15:13 blk_1073741825_1001.meta
-rw-rw-r-- 1 hadoop hadoop 30 Sep 16 15:16 blk_1073741826
-rw-rw-r-- 1 hadoop hadoop 11 Sep 16 15:16 blk_1073741826_1002.meta
[hadoop@hadoop101(192.168.0.101) /opt/module/hadoop-3.3.4/data/dfs/data/current/BP-1184537275-192.168.0.101-1757999596710/current/finalized/subdir0/subdir0]$ cat blk_1073741826
hadoop yarn
hadoop mapreduce十一、启动方式
1、各个模块分开启动/停止(配置ssh是前提)
```shell (1)整体启动/停止HDFS。 start-dfs.sh/stop-dfs.sh (2)整体启动/停止YARN。 start-yarn.sh/stop-yarn.sh ```2、各个服务组件逐一启动/停止(纯手动启动和停止)
```shell (1)分别启动/停止HDFS组件。 hdfs --daemon start/stop namenode/datanode/secondarynamenode (2)启动/停止YARN。 yarn --daemon start/stop resourcemanager/nodemanager ```3、脚本启动
```shell [hadoop@hadoop101(192.168.0.101) ~/bin]$ cat myhadoop.sh #!/bin/bashif [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " ============= 启动 hadoop集群 ================"
echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.4/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " ============== 关闭 hadoop集群 ================"
echo " --------------- 关闭 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.4/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.3.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
[hadoop@hadoop101(192.168.0.101) ~/bin]$ chmod +x myhadoop.sh
```shell
[hadoop@hadoop101(192.168.0.101) ~/bin]$ cat jpsall.sh
#!/bin/bashfor host in hadoop101 hadoop102 hadoop103
doecho =============== $host ===============ssh $host jps
done
[hadoop@hadoop101(192.168.0.101) ~/bin]$ chmod +x jpsall.sh







)



























 Unit10 TextA 原文以及翻译(仅供学习))











 - pre(l)(1 = l = r = n),以及|pre(r) - pre(l)|)

