C++ 数据结构
- 数组
- 链表
- 队列
- 堆
- 树
- map/set
- hash
mysql 索引
索引就像是数据的目录。索引的好处就是可以提高查询速度,但是会占用物理空间,而且创建和维护索引要耗费时间,每次进行增删改操作都需要动态维护。
- 索引的分类
-
数据结构:B+ 树索引,hash,full-text
-
物理存储:聚簇索引,二级索引
-
字段特性:主键索引,唯一索引,普通索引,前缀索引
-
字段个数:联合索引,单列索引
主键索引最好是自增的
使用自增主键,每次插入新数据就会按照顺序添加到当前索引的位置,不需要移动已经有的数据,每次都是追加操作。
非自增主键,如果插入的数据在数据中间,这个时候就需要移动后面的数据,如果当前页数据满了,就会出现数据从一个页复制到另一个页的情况,造成页分裂问题,会产生大量内存碎片。
虚拟内存 分段分页 页面置换
线程和进程
-
进程是资源分配的基本单位,线程是调度的基本单位。
-
进程拥有的资源多,内存资源,文件资源,PCB,寄存器等。一个进程内的线程共享进程的地址空间,全局变量,线程拥有自己的寄存器上下文和栈
-
进程上下文切换开销大,包含了虚拟内存,栈,全局变量,内核资源都要切换。一个进程的的线程切换只需要切换寄存器上下文和栈就可以,开销小。
上下文切换的场景
-
进程被挂起(时间片用完了,内存资源不足,被阻塞,高优先级)
-
中断
介绍遇到过印象比较深的bug
给微信发图片设计测试用例
get 和 post 区别
-
Get: 向服务器请求数据(幂等), 请求页面中的资源,图片视频等;
Post 向服务器提交数据(不幂等):提交表单,上传文件。 -
参数传递:
get 在URL 中传递,浏览器地址栏能看到,不安全,传递数据量少
Post:在请求体中传递参数,相对安全(抓包),对数据格式大小没有限制。 -
缓存机制
Get:有缓存机制,如果请求的资源在缓存中存在。就可以直接使用缓存
Post:因为要对服务器内容做修改,没有缓存
接口测试
MySql 的事务
- 事务的四大特性: 原子性,一致性,隔离性,持久性
-
原子性:一个事务中的所有操作,要么全都完成,要么全都不完成,如果由一个操作没完成,数据库就会回滚到事务来之前的状态
-
一致性:事务前后满足完整性约束,数据库保持一致的状态。
-
隔离性:Mysql 支持并发操作,可以防止多个事务交叉进行导致的数据不一致的问题。
-
持久性:事务处理后对数据库的修改是永久的。
- 事务并发执行会引发什么问题?
隔离级别:读未提交,读提交,可重复读,串行化
脏读,不可重复读,幻读()
Linux 查看倒数第n行的数据,超大文件怎么查看指定行数?查看占用端口号
tail -n a.txt
// 查 o
grep -i o // 忽略 o 的大小写
grep -n o // 显示 o 所在行号
grep -c o// o出现次数//端口号
netstat -tulnp // 所有正在监听的端口
ss -tuln // 正在监听的端口
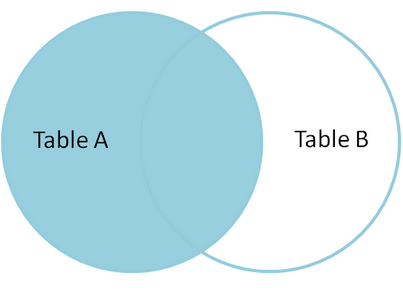
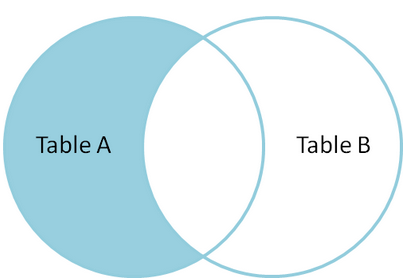
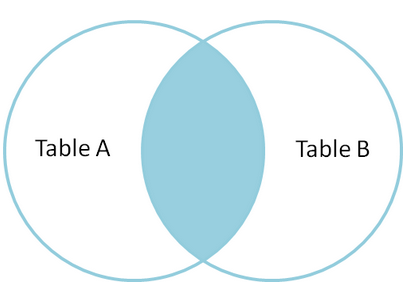
left join 、 right join、 inner join
- 左连接:左表中取所有记录,关联右表中匹配的记录,关联不上,对应的值就是null
- 右连接:右表中所有记录,关联左表中匹配记录
- 内连接:等值连接,取两个表中连接匹配的记录
![image]()
![image]()
Jmeter 测并发
测试前后端是谁的问题
并发测试会注重什么方面
并发:并发容易产生死锁,或者多个资源访问共享资源由于执行的顺序不确定性,产生不可预计的效果
多线程并发的时候如何保证稳定性
线程间正常协作,避免死锁,竞态状态(多个进程或线程同时访问共享资源,由于执行顺序的不确定性,产生不可预测的行为)
- 线程同步/互斥:
互斥:锁, 条件变量(PV)
同步:PV
- 锁:进入临界资源, 必须加锁.加锁成功就可以访问, 访问结束解锁。
- 避免使用共享数据
- 原子操作:保证操作执行的时候不会被中断
同步,互斥
- 同步,并发进程/线程在某一些关键节点,一个进程需要等待另一个进程的结束才可以执行,有依赖关系;
- 互斥:不能在同一时间执行
抽象类
封装,继承,多态
析构函数定义为虚函数
如果一个基类的析构函数没有设置为虚函数,那么如果有一个基类类型的指针指向派生类,通过基类的析构函数析构,编译器不知道实际删除的对象是派生类,可能会造成内存泄漏的问题。
死锁的产生
数据库事务的特性
索引失效的场景
-
左模糊
-
联合索引不遵循最左匹配原则
-
对索引使用函数或者计算
Redis三个缓存问题
-
缓存雪崩:大量数据同时过期
-
缓存穿透:热点数据过期
-
缓存击穿:业务误操作,黑客攻击
- API 对非法请求限制
- 对不存在的数据设置返回值0 或者 null
- 布隆过滤器
Redis 的五种数据类型
-
string : key-value,计算次数(访问次数,点赞次数)
分布式锁:key 不存在就可以加锁,解锁就删掉key -
hash:三要素{key, key, value} :购物车
-
list:双向链表:消息队列
-
set:存储不重复元素的集合,无序:点赞(一个用户只能点一个赞)
-
zset:有序集合:排行榜
测试分类?
性能测试关注哪些指标?
- 客户端的响应时间
- 吞吐量:QPS(请求次数),TPS(每秒处理事务数量:客户端向服务器发请求到服务器作出反应返回给客户端的过程),并发数(系统同时处理的请求次数),响应时间(平均响应时间)
数据包的结构
get post
get : 在浏览器地址栏就可以看到,信息传输格式是明文。,幂等,长度有限制
post 请求在报文中,但是抓包可以看到,不幂等,长度无限制,格式任意
系统设计
tcp/ip
dns解析过程
cookie和session机制
深拷贝浅拷贝
深拷贝:开辟一块新的内存空间,将被复制的对象的内容复制一份放到新的内存中
浅拷贝:只拷贝指针,多一个指针指向这块地址
ai了解吗
索引的优缺点,常见的索引
为什么做性能测试
什么是数据库的事务
什么是数据库的索引
coocike和seesion?
4.HTTP报文格式
请求报文:请求行(方法、URL、协议版本)、请求头部(关键词-值对,每行一对,用冒号隔开)、空行、请求数据。
响应报文:状态行、消息报头、响应正文
设计购买系统
-
明确业务需求和目标,了解用户需求,还要考虑系统的可扩展性。
-
选择合适的架构:根据不同的目标选择不同的架构,可扩展性高的场景选择服务化架构。
服务化架构:强调对业务垂直拆分成多个服务模块。各个模块通过适当的协议进行通信,侧重点在服务的集成、交互、数据传输
微服务架构:每一项核心功能都独立运行,开发团队可以构建更新新的组件,满足不同的业务需求。
3. 设计关键组件,高内聚低耦合,用户界面,业务逻辑,数据存储,缓存,队列等中间件提高系统的性能和稳定性。
系统的容错设计
出现故障时最小化影响。
-
隔离:确保故障不会再系统传播
-
降级策略:再部分功能不可用的时候,系统可以自动降级到有限功能模式
-
重试机制:再操作失败的时候自动进行重试,
-
超时时间:为操作设置超时时间,避免无限等待
秒杀系统
-
高性能:设计大量并发的读写操作,支持高并发访问
-
一致性:秒杀系统在大量并发更新的过程中保证系统数据的一致性
-
高可用:避免大量流量将进入,系统宕机,做好流量限制
- 后端优化:将请求尽量拦截在上游
-
限流:屏蔽无用流量,比如库存为 10, 购买请求为 1000, 只有 10 个是有效请求,其他都是无效请求
-
负载均衡:使用多个服务器处理并发请求,减少单个服务器的压力
-
缓存:创建订单时,每次都要先查询判断库存,可以将商品信息放到缓存中,减少数据库的查询
在活动开始前,可以将商品信息提前缓存到 Redis ,活动开始后就直接从 Redis 中获取。
对热点数据提前进行保护,
- 前端:
-
限流:答题或者验证码,分散用户请求
-
禁止重复提交:每个用户成功执行一次操作后,等待一定时间才能发送下一次请求
-
标记:将提交按钮置灰,禁止重复提交
- 防作弊:
-
隐藏秒杀接口:避免活动开始前,被恶意刷接口。
-
检测IP 的请求频率,如果一个 IP 的请求频率频繁,可以弹出验证码进行身份验证



)



)

















)























