
资源
- NJU Compiler 课程
- 中科大 Compiler 课程
- LLVM IR Github book教程
- Koopa IR 框架
- PKU 讲义本体
- Github仓库
Lv0 环境配置
Docker
获取编译实践的镜像:
sudo docker pull maxxing/compiler-dev
-
docker安装
-
配置docker镜像
-
vim /etc/docker/daemon.json -
{"registry-mirrors": ["xxx","xxx"] } -
docker 存活的镜像
-
Docker 基本使用方法
- 官方文档
// 启动容器
docker run maxxing/compiler-dev// 查看目前 Docker 中所有的容器:
docker ps -a// 删除 容器
docker rm CONTAINER ID
// -it 参数, 这个参数会开启容器的 stdin 以便我们输入 (-i), 同时 Docker 会为容器分配一个终端 (-t).
docker run -it maxxing/compiler-dev bash
在许多情况下, 我们需要让 Docker 容器访问宿主系统中的文件. 比如你的编译器存放在宿主机的 /home/max/compiler 目录下, 你希望 Docker 容器也能访问到这个目录里的内容, 这样你就可以使用容器中的测试脚本测试你的编译器了. 你可以执行:
docker run -it --rm -v /home/max/compiler:/root/compiler maxxing/compiler-dev bash
-v /home/max/compiler:/root/compiler选项, 这个选项代表: 我希望把宿主机的/home/max/compiler目录, 挂载 (mount) 到容器的/root/compiler目录. 这样, 在进入容器之后, 我们就可以通过访问/root/compiler来访问宿主机的/home/max/compiler目录了.- --rm: Docker 会在退出后删除刚刚的容器
- 因为Docker只是测试我们在宿主机上实现的代码,所以测完直接可以丢掉了
maxxing/compiler-dev 实验环境
实验环境中已经配置了如下工具:
- 必要的工具:
git,flex,bison,python3. - 构建工具:
make,cmake. - 运行工具:
qemu-user-static. - 编译工具链: Rust 工具链, LLVM 工具链.
- Koopa IR 相关工具:
libkoopa(Koopa 的 C/C++ 库),koopac(Koopa IR 到 LLVM IR 转换器). - 测试脚本:
autotest.
我们要做的事情就是在宿主机上编写我们的compiler代码,然后将我们代码目录挂载到docker的某个目录下,在docker maxxing/compiler-dev的实验环境中运行测试我们的程序
具体查看
项目模板
Github
Lv1 main函数
编译原理基础知识
语法分析树
二义性
所谓的二义性可以理解为对于一个文法,可以构造出多个语法分析树
因为语法分析树是对语义的解释,则说对于一个文法我们有多个语义
案例:
-
因最短/最长匹配导致的二义性

如上图中的文法和语句,我们有多个方式解释
if a then if b then c else d这个语句,即在执行时,其有多个语义:if (a) then { if b then c else d}if (a) then { if b then c } else { d }
我们可以通过更改文法/规定匹配来避免二义性,例如这里我们规定else匹配距离其最近的if,则最终我们只会得到
if (a) then { if b then c else d}, 其语法树: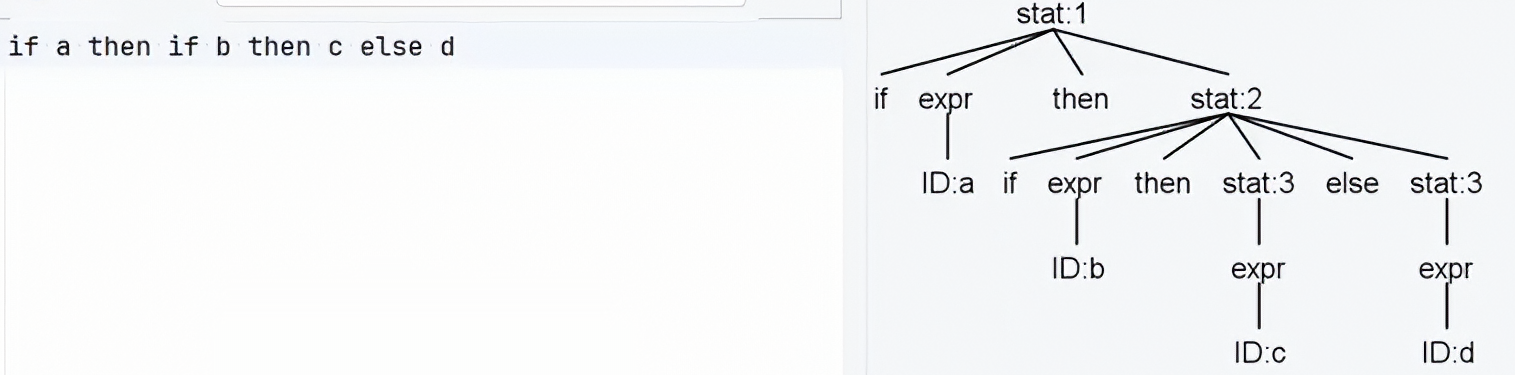
-
因运算符的结合性/优先级导致的二义性
例如运算符优先级导致的二义性,我们可以通过规定运算符优先级(更常见)或者更改文法避免。如
a - b * c语义可以为:a - (b * c)(a - b) * c

我们通过如上方式避免(ANTLR 4 中规定越在上的优先级越高)
抽象语法树
抽象语法树的前身--语法分析树
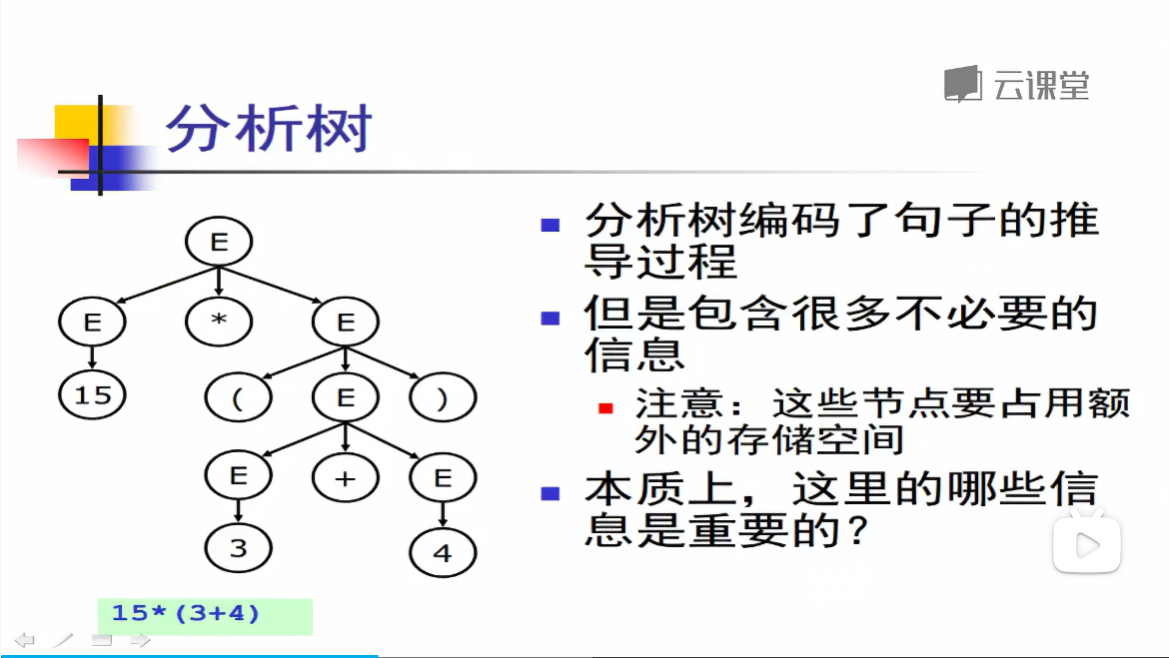
上图中例如"(" 和 ")"这些信息是不重要的,同时3,4这两个叶子结点的父节点也是没有必要的
对于表达式而言,编译只需要知道运算符和运算数
优先级、结合性等已经在语法分析部分处理掉了
对于语句、函数等语言其他构造而言也一样
例如,编译器不关心赋值符号是=还是:=或其它
抽象语法树
为了节省内存,压缩信息,得到更加紧凑的表示,我们对语法分析树进行浓缩:
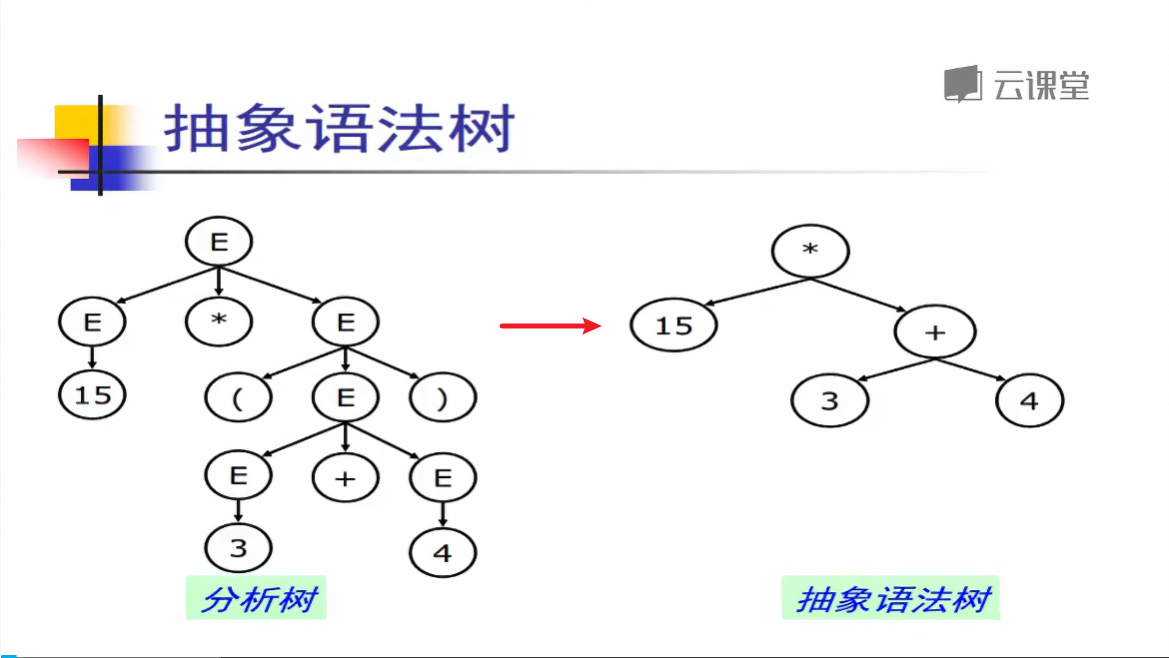
- 具体语法是语法分析器使用的语法
- 必须适合于语法分析,如各种分隔符、消除左递归、提取左公因子,等等
- 抽象语法是用来表达语法结构的内部表示
- 现代编译器一般都采用抽象语法作为前端(词法语法分析)和后端(代码生成)的接口
在编译器中,为了定义抽象语法树,需要使用实现语言(C++/C/java...)来定义一组数据结构
例如在课中以简单的实例说明的:

其给每个终结符和非终结符定义了结构体,并定义构造函数在生成抽象语法树时使用:


抽象语法树的自动生成
在语法动作中,加入生成语法树的代码片段。
- 片段一般是语法树的“构造函数’
在产生式归约的时候,会自底向上构造整棵树
- 从叶子到根
上述内容说的就是Bison中的写法,例如:
FuncDef: FuncType IDENT '(' ')' Block {auto ast = new ast::FuncDefAST();ast->func_type = unique_ptr<ast::BaseAST>($1);ast->ident = *unique_ptr<std::string>($2);ast->block = unique_ptr<ast::BaseAST>($5);$$ = ast;}
若想要表示位置信息,则可以在数据结构中完善更多的信息:
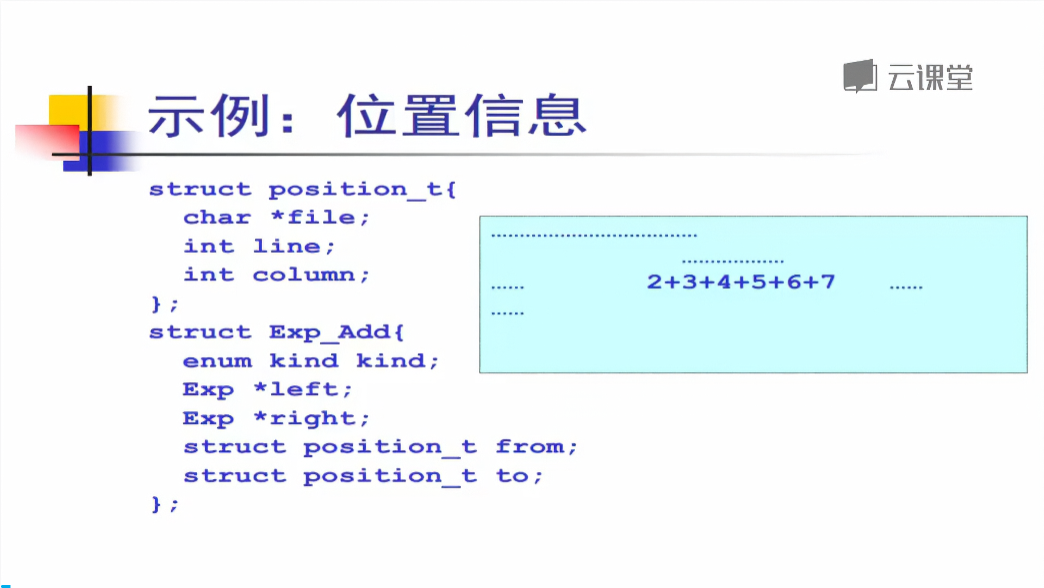
中间代码生成
语义分析
- 语义分析也称为类型检查、上下文相关分析
- 负责检查程序(抽象语法树)的上下文相关的属性:
- 这是具体语言相关的,典型的情况包括:
- 变量在使用前先进行声明
- 每个表达式都有合适的类型
- 函数调用和函数的定义一致
- ...
- 这是具体语言相关的,典型的情况包括:
在Flex/Bison中已经做到了一部分语义分析,例如类型检查
例如我们在Bison中通过%union和%token定义终结符和非终结符语义的类型:
%union {std::string *str_val;int int_val;ast::BaseAST *ast_val;
}// 终结符的类型定义
%token INT RETURN
%token <str_val> IDENT
%token <int_val> INT_CONST// 非终结符的类型定义
%type <ast_val> FuncDef FuncType Block Stmt
%type <int_val> Number
符号表
若要我们自己实现语义分析中的类型检查,变量声明检查等内容,符号表不可或缺
P -> D E
D -> T id;|
T -> int| bool
E -> n| id| true| false| E + E| E && E
我们以上述简单的语法为例:
-
P : program
-
D : declare
-
T : type
-
E : express
-
id: 终结符
-
n: 终结符
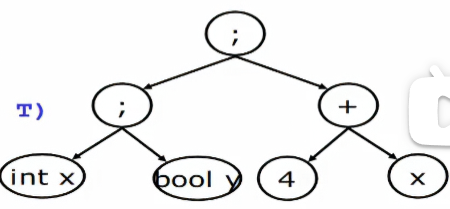
我们对语句:
int x;
bool y;
4 + x;
进行语法检查和语义检查:
抽象语法树:
类型检查算法
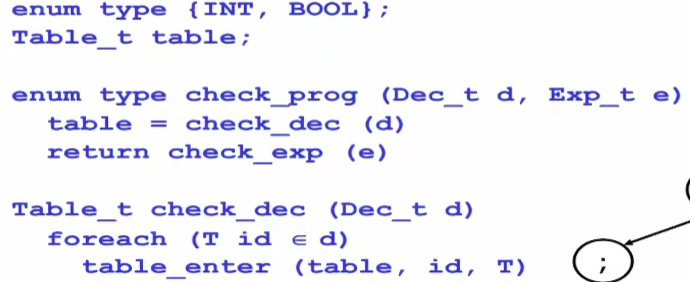
table_enter为插入符号表的操作- 当我们检查声明时,若未在符号表找到相关符号的声明,则插入新元素[key, value],其中key为符号的name, 如
x, value为符号的类型,如int
- 当我们检查声明时,若未在符号表找到相关符号的声明,则插入新元素[key, value],其中key为符号的name, 如

- 在检查表达式时,若表达式中的符号未在符号表中查找到,则说明使用了未声明的符号
符号表的作用域与scope
作用域
int x;int foo() {int x;int y;return x + y;
}
上述代码中在不同作用域下有两个不同的x,符号表需要能够区分:
- 方法#1:一张表的方法
- 进入作用域时,插入元素
- 退出作用域时,删除元素
- 方法#2:采用符号表构成的栈
- 进入作用域时,插入新的符号表
- 退出作用域时,删除栈顶符号表
Scope
struct list{int x;struct list *list;
} *list;void walk(struct list *list) {list:if (list == list->list)goto list;
}
上述代码中list出现了多次,分别为:
-
变量名 (
*list) -
命名 (
struct list) -
标号 (
goto list)
它们被称为不同的scope
每个scope用一个表来处理
中间代码生成
中间代码其实也可以理解为是某种语言,例如LLVM IR,其与汇编语言已经非常相近了,同时也可以作为一门语言进行书写
这里我们以更加简单的例子进行讲解:

我们从之间的语法 --> IR
R_t Gen E(E e) {
switch(e) {case n: r=fresh();emit("movn n,r");return r;case id: r=fresh();emit ("mov id,r');return r;case true: r=fresh();emit("movn 1,r");return r;case false:r=fresh();emit("movn 0,r");return r;case e1 + e2: r1 = Gen_E(e1);r2 = Gen_E(e2);r = fresh();emit("add r1, r2, r3");return r;case e1 && e2: r1 = Gen_E(e1);r2 = Gen_E(e2);r = fresh();emit("and r1, r2, r3");return r;
R_t表示一个寄存器类型fresh()表示生成一个新的寄存器emit表示生成对应的IR指令
上述方法也很像我们实现抽象语法树时做的行为
中间代码的形式有很多:
- 树和有向无环图(DAG)
- 高层表示,适用于程序源代码
- 三地址码(3-address code)
- 低层表示,靠近目标机器
- 控制流图(CFG)
- 更精细的三地址码,程序的图状表示适合做程序分析、程序分析等
- 静态单赋值形式(SSA)
- 更精细的控制流图
- 同时编码控制流信息和数据流信息
- 连续传递风格(CPS)
- 更一般的SSA
抽象语法树变体 --DAG 有向无环图
“语法树的变体是有向无环图” 的意思是:编译器里用于表示程序结构的“树状”数据结构可以允许不同父节点指向同一个子节点(即共享子结构),形成一个有向图,而且这个图通常不会包含环(acyclic),因此称为 DAG(Directed Acyclic Graph)。
-
树:每个节点有且只有一个父节点(除了根),不同分支间不会共享子树。
-
有向图:节点间的引用有方向(例如父 → 子)。
-
DAG:有向且无环的图;允许多个父节点共享同一个子节点,但不会有回到自己/循环的路径。
树是最直观的表示法,但在实际编译器中多个位置可能出现相同的子表达式或相同的“值”。为了节省内存、方便优化与比较,常采用共享子节点的做法——这会把结构从树变成 DAG。
例如对于表达式a+a*(b-c)+(b-c)*d, 其抽象语法树为:
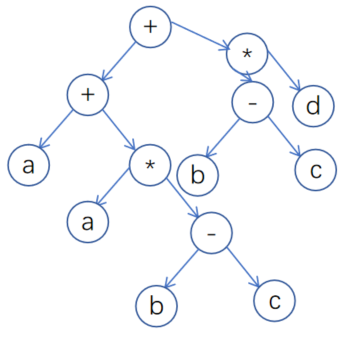
树是最直观的表示法,但在实际编译器中多个位置可能出现相同的子表达式或相同的“值”。为了节省内存、方便优化与比较,常采用共享子节点的做法——这会把结构从树变成 DAG。
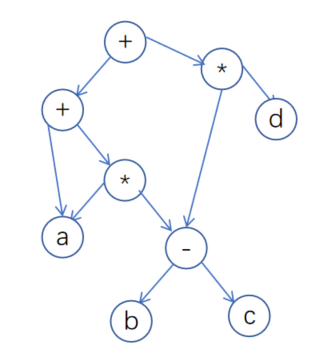
对于重复子表达式, 边从上层节点指向这个共享节点。
于是上述抽象语法树变成如下:
DAG --> 三地址中间表示
语法制导翻译 -- 依赖图
- 依赖图(dependency graph) 是把“某一棵语法树(或某次产生式展开)中每个属性的具体出现”作为节点,属性之间的“谁依赖谁”作为有向边构成的图。
- 求属性的合法计算顺序就是对这个图做 拓扑排序(topological order)。
- 如果图中有环(cycle),说明这些属性不能用单次有向无环评估得到(需要重写规则或使用迭代/固定点技巧)。
- 对于只含合成属性(S-属性)的文法,依赖图天然是自底向上的,直接用后序遍历(reduce 时计算)即可。
- 对于 L-属性(L-attributed),可以在一次自顶向下/左到右的遍历或在解析时用语义动作按顺序求到属性值(能在线计算)。
- 依赖图的正式定义(简洁)
给定:一棵 解析树(parse tree) T 和一个 SDD(syntax-directed definition,给出每条产生式的属性计算规则)。
- 节点集合 V = “T 中所有属性的出现”(每个语法树结点对于每个属性出现一个节点,例:对某个语法树结点 A,如果 A 有属性
A.inh和A.s,就有两个依赖图节点)。 - 有向边 (u → v) 当且仅当:v 的计算公式使用了 u 的值。
举例:如果规则写A.s = B.s + C.s,那么在语法树的对应位置就会有边B.s → A.s和C.s → A.s。
目标:找到一个节点序列,使得每条边 u→v 都满足 u 在 v 之前被计算——这就是拓扑序。
- 怎么构造依赖图(步骤)
- 在解析树的每个树结点(一个非终结符或终结符)上列出它的所有属性实例(合成/继承/其他)。这些属性实例就是依赖图的节点。
- 对照你为每条产生式写的语义规则(例如
A.s = B.s + C.s,C.inh = A.inh等),为每个语义等式加入有向边:从被使用的属性指向被定义的属性。- 例如在产生式
A -> B C中,规则C.inh = f(B.inh, B.s)会产生B.inh → C.inh和B.s → C.inh。
- 例如在产生式
- 做完语法树上所有出现的产生式和对应规则,得到完整的依赖图。
- 对该有向图做拓扑排序(比如 Kahn 算法或 DFS)。若能得到排序,则按此顺序依次计算属性;若不能(存在环),则说明不能单次评估。
命令
启动docker环境
docker run -it --rm -v /home/cilinmengye/Github/PKU_Compiler:/root/compiler maxxing/compiler-dev bash
Cmake编译命令
cd 项目目录
cmake -DCMAKE_BUILD_TYPE=Debug -B build
cmake --build build
执行命令
build/compiler -koopa debug/hello.c -o debug/hello.koopa
Flex and Bison 初见
- vscode 下载 Yash插件,提供flex 和 bison 高亮
Flex注释问题
Flex 推荐用 C 风格注释:
/* 这是注释 */
Flex 把 .l 文件分为三段:
%{ ... %}:直接拷贝到生成的.c%% ... %%:规则区(正则表达式 + 动作)%% ...之后:C 代码区
Flex 确实允许 C 风格注释,但是要注意:
- 注释只能写在 C 代码区 或 动作
{...}里面。 - 直接把一大段
/* ... */放在规则区开头,有些版本的 Flex 会误判,把它当成“正则模式”
Lv2 初试目标代码生成
目的:
- AST --> in-memory Koopa IR
- in-memory Koopa IR --> Text form Koopa IR
建立内存形式的 Koopa IR
我想要通过如下方法实现:
-
遍历 AST, 直接建立 (某种) 内存形式的 Koopa IR, 再将其转换为文本形式输出.
-
遍历 AST, 输出文本形式的 Koopa IR 程序,再使用
libkoopa中的接口将文本形式 Koopa IR 转换为 raw program
好吧1方法实在是太有难度了,我还是选择方法2进行实现吧。
In-memory Koopa IR --> Riscv assembly code
在 SysY 程序中, 我们定义了一个 main 函数, 这个函数什么也没做, 只是返回了一个整数, 之后就退出了. RISC-V 程序所做的事情与之一致:
- 定义了
main函数. - 将作为返回值的整数加载到了存放返回值的寄存器中.
- 执行返回指令.
命令
// 测试
build/compiler -riscv debug/hello.c -o debug/hello.S
clang debug/hello.S -c -o debug/hello.o -target riscv32-unknown-linux-elf -march=rv32im -mabi=ilp32
ld.lld debug/hello.o -L$CDE_LIBRARY_PATH/riscv32 -lsysy -o debug/hello
qemu-riscv32-static debug/helloecho $?
附录 参考资料
- LLVM IR
- Koopa IR 接口
- Koopa IR 文档
- Koopa IR 相关博客
- Koopa IR 人话版
Lv3 表达式
编译原理基础知识
三地址码
我们的Koopa IR也是一种三地址码:
- 我们需要给每个中间变量和计算结果命名
- 只有最基本的控制流(call,jump等),没有各种控制结构(if, while, for等)
控制流图
控制流图也是一种中间表示
我们将三地址码划分为基本块,基本块与基本块之间的跳转我们用->表示
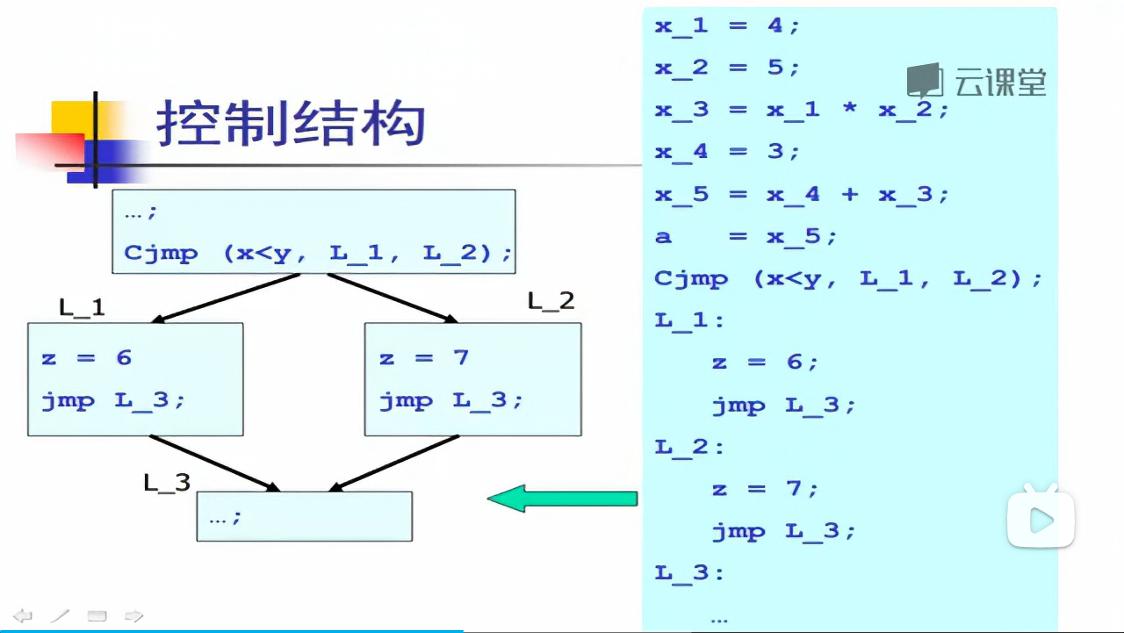
基于控制流图的数据流分析:
- 例如永远到达不了的基本块节点,我们可以将这个基本块删除(死基本块删除)
- 例如变量的值随控制流图传播发现值不会改变,则可以将变量直接变成常量(常量传播)


语法制导 实现抽象语法树-->IR
生成临时变量

- E.code: 综合属性,表示中间代码
- 综合属性则说明从语法分析树自下而上,步步传递给父节点的综合属性
- E.addr: 综合属性,表示变量名(临时变量/常量)
- top: 表示当前scope下的符号表
- top.get(id.lexeme) 表示取出 当前scope下符号表最上一个变量名
- gen(xxx): 表示生成代码xxx
- new Temp():表示生成临时变量
- 如右边的t1, t2等为生成的临时变量
S → id = E ;
S.code = E.code || gen(top.get(id.lexeme) '=' E.addr)
含义:- 先生成
E的代码 - 再生成一条赋值语句,把
E的值存入id对应的地址 top.get(id.lexeme)就是符号表里取出这个id的位置
- 先生成
IR --> RISCV
IR --> RISCV 这个过程例如 LLVM IR反而是最顶层的IR,我们在将LLVM IR --> RISCV时需要转化为多次更底层的IR,IR --> 更底层IR 这个过程被称为 pass
每次pass的过程都在依据IR进行优化
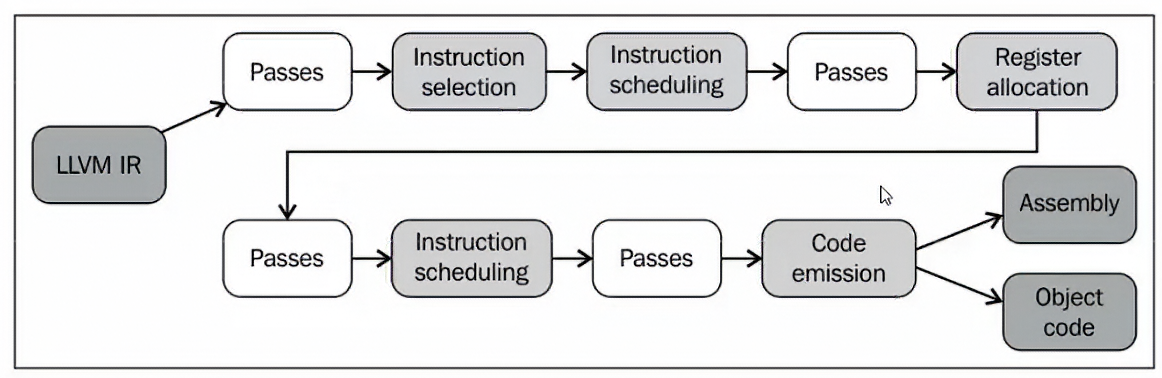
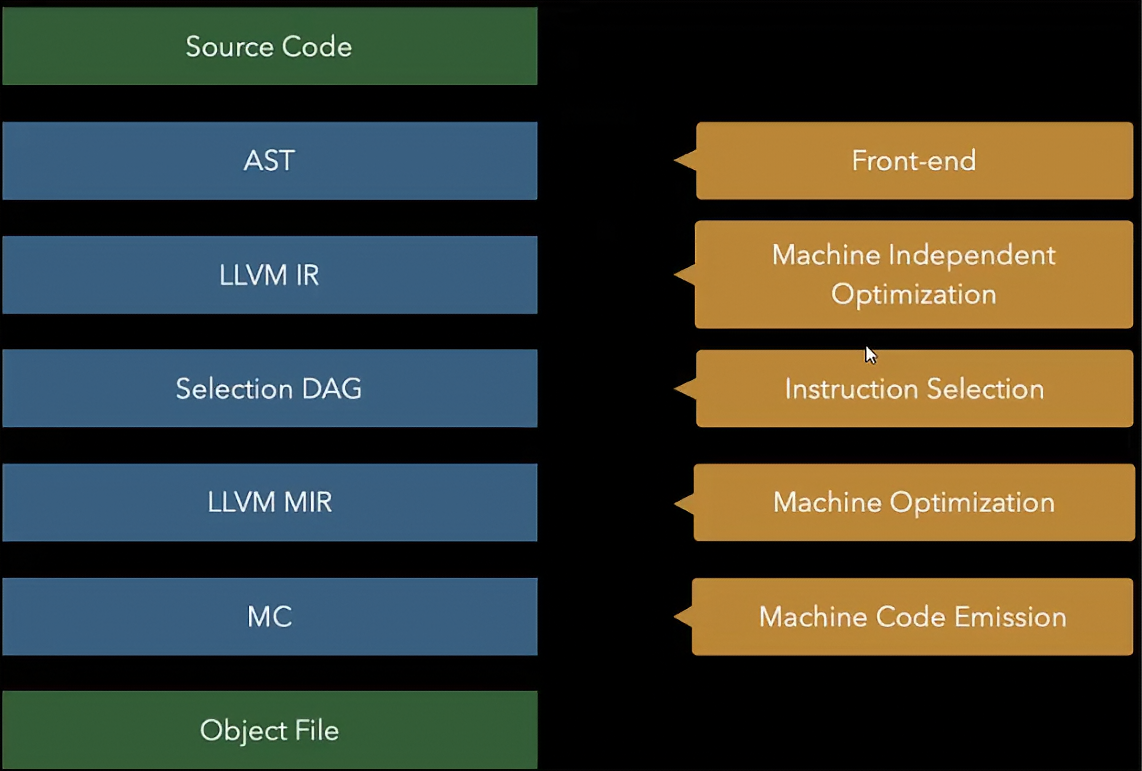
- LLVM IR --> DAG,DAG也是一种中间表示,即IR
- 在DAG的基础上进行指令选择,指令调度,寄存器分配等过程变为更底层的LLVM MIR,这个时候LLVM MIR已经是与架构相关的了
- 最后成为Machine Code
总结
- Flex: 我们在其中编写的是词法分析
- Bison: 我们在其中编写的是语法分析(产生式规则),同时我们以
{}动作 编写了遍历语法树的过程 - 我们还需要编写 语义分析(语义规则),这点需要我们独自创建
.hpp和.cpp进行编写了,在我的实现中ast.hpp做的正是这点
Lv3.1. 一元表达式
命令
build/compiler -koopa debug/unaryop.c -o debug/unaryop.koopa
Koopa IR
Koopa IR 程序的in-memory raw Koopa IR结构:
-
最上层是
koopa_raw_program_t, 也就是Program.// https://github.com/pku-minic/koopa/blob/master/crates/libkoopa/include/koopa.htypedef const void *koopa_program_t;typedef struct {const void **buffer; // Buffer of slice items.uint32_t len; // Length of slice.koopa_raw_slice_item_kind_t kind; // 其为enum类型: Unknown. Type. Function. Basic block. Value. } koopa_raw_slice_t;typedef struct {koopa_raw_slice_t values; // Global values (global allocations only).koopa_raw_slice_t funcs; // Function definitions. } koopa_raw_program_t; -
之下是全局变量定义列表和函数定义列表.
- 在 raw program 中, 列表的类型是
koopa_raw_slice_t. - 本质上这是一个指针数组, 其中的
buffer字段记录了指针数组的地址 (类型是const void **),len字段记录了指针数组的长度,kind字段记录了数组元素是何种类型的指针 - 在访问时, 你可以通过
slice.buffer[i]拿到列表元素的指针, 然后通过判断kind来决定把这个指针转换成什么类型.
- 在 raw program 中, 列表的类型是
-
koopa_raw_function_t代表函数, 其中是基本块列表.typedef struct {koopa_raw_type_t ty; // Type of function.const char *name; // Name of function.koopa_raw_slice_t params; // Parameters.koopa_raw_slice_t bbs; // Basic blocks, empty if is a function declaration. } koopa_raw_function_data_t; typedef const koopa_raw_function_data_t *koopa_raw_function_t; -
koopa_raw_basic_block_t代表基本块, 其中是指令列表.typedef struct {const char *name; // Name of basic block, null if no name.koopa_raw_slice_t params; // Parameters.koopa_raw_slice_t used_by; // Values that this basic block is used by.koopa_raw_slice_t insts; // Instructions in this basic block. } koopa_raw_basic_block_data_t; typedef const koopa_raw_basic_block_data_t *koopa_raw_basic_block_t; -
koopa_raw_value_t代表全局变量, 或者基本块中的指令.struct koopa_raw_value_data {koopa_raw_type_t ty; // Type of value.const char *name; // Name of value, null if no name.koopa_raw_slice_t used_by; // Values that this value is used by.koopa_raw_value_kind_t kind; // Kind of value. }; typedef struct koopa_raw_value_data koopa_raw_value_data_t; typedef const koopa_raw_value_data_t *koopa_raw_value_t;
相关类型定义:
///
/// Tag of raw Koopa type.
///
typedef enum {/// 32-bit integer.KOOPA_RTT_INT32,/// Unit (void).KOOPA_RTT_UNIT,/// Array (with base type and length).KOOPA_RTT_ARRAY,/// Pointer (with base type).KOOPA_RTT_POINTER,/// Function (with parameter types and return type).KOOPA_RTT_FUNCTION,
} koopa_raw_type_tag_t;///
/// Tag of raw Koopa value.
///
typedef enum {/// Integer constant.KOOPA_RVT_INTEGER,/// Zero initializer.KOOPA_RVT_ZERO_INIT,/// Undefined value.KOOPA_RVT_UNDEF,/// Aggregate constant.KOOPA_RVT_AGGREGATE,/// Function argument reference.KOOPA_RVT_FUNC_ARG_REF,/// Basic block argument reference.KOOPA_RVT_BLOCK_ARG_REF,/// Local memory allocation.KOOPA_RVT_ALLOC,/// Global memory allocation.KOOPA_RVT_GLOBAL_ALLOC,/// Memory load.KOOPA_RVT_LOAD,/// Memory store.KOOPA_RVT_STORE,/// Pointer calculation.KOOPA_RVT_GET_PTR,/// Element pointer calculation.KOOPA_RVT_GET_ELEM_PTR,/// Binary operation.KOOPA_RVT_BINARY,/// Conditional branch.KOOPA_RVT_BRANCH,/// Unconditional jump.KOOPA_RVT_JUMP,/// Function call.KOOPA_RVT_CALL,/// Function return.KOOPA_RVT_RETURN,
} koopa_raw_value_tag_t;///
/// Kind of raw Koopa value.
///
typedef struct {koopa_raw_value_tag_t tag;union {koopa_raw_integer_t integer;koopa_raw_aggregate_t aggregate;koopa_raw_func_arg_ref_t func_arg_ref;koopa_raw_block_arg_ref_t block_arg_ref;koopa_raw_global_alloc_t global_alloc;koopa_raw_load_t load;koopa_raw_store_t store;koopa_raw_get_ptr_t get_ptr;koopa_raw_get_elem_ptr_t get_elem_ptr;koopa_raw_binary_t binary;koopa_raw_branch_t branch;koopa_raw_jump_t jump;koopa_raw_call_t call;koopa_raw_return_t ret;} data;
} koopa_raw_value_kind_t;
后续
我认为后续实验的内容都是整体核心思想不变,全部都是工程量,所以接下来我也就没有兴趣继续写下去了
不过作者的Koopa IR框架值得学习
CMake
Outline
- 视频
- 教程
- 案例
基础
Message
message(STATUS "...")
在 CMake 脚本里,message() 用来打印信息。
STATUS表示这是普通提示信息(在配置时会显示)。- 常见级别有:
STATUS:提示信息WARNING:警告FATAL_ERROR:致命错误(立刻终止 CMake)
例如:
message(STATUS "Hello, CMake")
运行 cmake .. 时会看到:
-- Hello, CMake
(前面的 -- 是 CMake 自动加的。)
"Include directory: ${INC_DIR}"
这里 ${INC_DIR} 表示变量替换。
- 在 CMake 里,变量用
${...}来取值。 - 所以这行代码的效果是:打印字符串 +
INC_DIR的值。
例如:
set(INC_DIR /usr/include/mylib)
message(STATUS "Include directory: ${INC_DIR}")
输出:
-- Include directory: /usr/include/mylib
Include directory
“加头文件目录”的写法:
| 写法 | 影响范围 | 推荐度 |
|---|---|---|
include_directories() |
全局(当前目录及子目录所有 target) | ❌ 老式,不推荐 |
target_include_directories() |
只影响指定 target,且能控制传递性(PUBLIC/PRIVATE/INTERFACE) | ✅ 现代 CMake 推荐 |
C++
C++ 命名规范
- 类/类型:大驼峰
KoopaParser - 函数:小驼峰
parseFunction() - 变量:小驼峰
lineNumber,成员变量加_或m_ - 常量/宏:全大写
MAX_BUFFER_SIZE - 命名空间:小写
koopa_ir - 文件:小写下划线
koopa_parser.cpp
智能指针
| 语法 | 作用 |
|---|---|
auto |
自动推导类型 |
make_unique<T>() |
创建智能指针,避免手动 new |
unique_ptr<T> |
独占所有权智能指针,自动释放内存 |
move() |
移动语义,转移所有权,避免拷贝 |
例如:
std::string* name = new std::string("hello");std::unique_ptr<std::string> func_name = std::unique_ptr<std::string>(name);
- 注意:
std::unique_ptr<T>()中需要传入的是T的原始指针T*, 而不能是T这个对象 - 当我们要输出
name的值时需要使用*name, 因为func_nane是个指针
make_uniqueC++14 引入的一个 工厂函数,作用就是简化上面的写法:
std::unique_ptr<std::string> func_name = std::make_ptr<std::string>("hello");
move:
move() 是 C++11 的 移动语义。
unique_ptr不能被拷贝(拷贝构造被删除),只能 移动。
std::unique_ptr<std::string> func_Name = move(func_name);
移动后,func_name 为空(指针被置为 nullptr),func_Name 成为新的所有者。
运算
强制类型转换运算符
reinterpret_cast<新类型>(指针)
reinterpret_cast是 C++ 里最“原始”的转换,它会直接把一块内存的比特位重新解释成另一种类型。- 它不会检查类型是否兼容,只要编译器认为语法合法,它就会“硬转”。
int x = 0x12345678;
char* p = reinterpret_cast<char*>(&x);
// p 现在指向 int 的内存,但把它解释成了 char*
类
类的创建
好问题 👍 我们一步步来。
在 C++ 里,创建类实例有两种主要方式:栈上创建 和 堆上创建。
1. 栈上创建(自动存储)
最常见、最推荐的方式:
#include <iostream>
#include <string>class Person {
public:std::string name;int age;Person(const std::string& n, int a) : name(n), age(a) {}void introduce() {std::cout << "Hi, I'm " << name << ", age " << age << std::endl;}
};int main() {Person p("Alice", 20); // 栈上实例化p.introduce();return 0;
}
这里 p 会在 main 结束时自动销毁,不需要手动释放。
2. 堆上创建(动态存储)
用 new,需要手动释放:
int main() {Person* p = new Person("Bob", 25); // 堆上实例化p->introduce();delete p; // 必须释放,否则内存泄漏return 0;
}
3. 使用智能指针(推荐替代 new)
避免手动 delete,更现代安全:
#include <memory>int main() {auto p = std::make_unique<Person>("Charlie", 30);p->introduce();// 离开作用域时自动释放
}
我想确认下,你现在是想在 函数里直接用一个对象(栈上更合适),还是想把对象传来传去/长期保存(那就用 std::unique_ptr 比较安全)?
Kernel Debugging && Logging
Kernel Debugging
QEMU + kernel image
可以参考XV6实验中的做法,将XV6 OS的镜像放入QEMU中运行,在QEMU中开启gdb,调试kernel
Logging
debugfs -- 开发者调试内核
Linux debugfs(Debug Filesystem)概述
debugfs 是内核提供的一个专用于调试的虚拟文件系统。它用于暴露内核或模块的调试信息与控制接口 —— 开发者和内核调试工具常用它来查看/修改内核内部状态。它不是稳定的用户接口(ABI/行为可变),因此不应在面向用户的生产工具中当作稳定接口依赖。
如何挂载 / 检查
# 检查是否已经挂载
mount | grep /sys/kernel/debug# 如果未挂载,root 下挂载:
mount -t debugfs none /sys/kernel/debug# 安全检查(systemd 常会自动挂载)
ls -la /sys/kernel/debug
要确认内核是否启用了 debugfs,查看内核配置(例如 /boot/config-$(uname -r) 中 CONFIG_DEBUG_FS=y),或在编译内核时确认该选项被打开。
常见用途与例子
- ftrace / tracing:
/sys/kernel/debug/tracing/提供函数追踪、trace_pipe、set_ftrace_pid 等接口。
例:echo function > /sys/kernel/debug/tracing/current_tracer,然后cat /sys/kernel/debug/tracing/trace或cat trace_pipe实时查看。 - kmemleak:
/sys/kernel/debug/kmemleak用于内存泄露检测(scan、show 等)。 - slab / slabinfo:查看 slab 分配器内部信息:
cat /sys/kernel/debug/slab。 - lockdep:死锁检测、锁依赖关系检查信息通常在 debugfs 中。
- 自定义模块的调试接口:模块可以把内部状态、控制开关、统计信息暴露到 debugfs,便于开发和调试。
常用 shell 操作示例:
# 读取调试信息
cat /sys/kernel/debug/some_debug_file# 改变内核调试选项(写入)
echo 1 > /sys/kernel/debug/some_debug_control
与 procfs / sysfs 的区别
- debugfs:专为调试设计,接口不稳定、权限通常需要 root、用于开发者调试。
- sysfs:稳定的设备与驱动用户空间接口(表示内核对象属性),用于正式的用户空间 API。
- procfs:暴露进程与部分内核信息(例如
/proc),部分接口较正式但也有历史包袱。
原则:用于长期、稳定暴露的接口应使用 sysfs 或 netlink,而不是 debugfs。
demesg
很好——下面用简明扼要的方式解释 dmesg 是什么、它从哪里来、常见用法和注意点。
什么是 dmesg
dmesg(display message)是一个查看 内核环形缓冲区(kernel ring buffer) 中消息的用户命令。内核和内核驱动(以及用 printk() 打印日志的代码)会把运行时信息、引导信息、设备驱动加载/卸载、错误、oops/panic 等写到这个缓冲区。dmesg 就是把这些内核日志输出到终端,便于调试与排错。
常见输出示例(典型行)
[ 12.345678] usb 1-1: new high-speed USB device number 2 using xhci_hcd
方括号内通常是自系统启动以来的秒数(相对时间),后面是内核消息内容。
常用命令与选项
dmesg:打印全部内核缓冲区(顺序从旧到新)。dmesg -T:把时间戳转为可读时间(注意:转换是近似的,内核时间与系统墙钟可能不完全精确)。dmesg -H:漂亮输出(带颜色与分页,类似 human)。dmesg -w:实时跟随(像tail -f),会持续打印新产生的内核消息。sudo dmesg -C:清空内核缓冲区(需要 root)。dmesg --level=err,warn:只显示错误/警告等级的消息。dmesg | grep -i usb:按关键词筛选(常用于定位硬件/驱动问题)。
内核日志来源和持久化
- 内核的消息最终写入内核缓冲区(kernel ring buffer),也可以被
klogd/rsyslog/systemd-journald等守护进程采集并写入持久日志文件(比如/var/log/kern.log、/var/log/messages或 systemd 的journal)。 - 在 systemd 系统上,推荐使用
journalctl -k(或journalctl -b)来查看内核消息的持久记录。
用途(为什么要用 dmesg)
- 查看启动过程中的内核/驱动加载信息(设备识别、驱动绑定等)。
- 排查硬件问题(USB、SCSI、PCI 设备错误)、查看驱动报错、查看内核 panic/oops 信息。
- 调试内核模块或驱动:模块中的
printk()输出会出现在这里。 - 查看内核检测到的硬件事件(比如磁盘掉线、I/O 错误、网络设备重置等)。
权限与隐私
- 有些系统限制非 root 用户读取全部内核缓冲区(因为可能泄露敏感信息,如内存地址)。
- 内核日志可能包含敏感信息(如内存地址、设备序列号等),在公开或贴出日志前注意脱敏。
小贴士
- 如果你想在出现问题的瞬间抓取内核日志,
dmesg -w很方便用于实时监控。 - 内核环形缓冲区大小有限,老日志会被新日志覆盖 —— 因此长期诊断应查看持久化日志(
journalctl或/var/log)。 - 常见问题排查命令:
dmesg | tail -n 50(看最近 50 行)
dmesg | grep -i error/dmesg --level=err(查看错误)









)



































)


