计算机网络 网络层:控制平面
在本章中,包含网络层的控制平面组件。控制平面作为一种网络范围的逻辑,不仅控制沿着从源主机到目的主机的端到端路径间的路由器如何转发数据报,而且控制网络层组件和服务如何配置和管理。5.2节,传统的计算图中最低开销路径的路由选择算法。5.3和5.4节,因特网路由选择协议 OSPF 和 BGP 的基础。OSPF 是一种运行在单一 ISP 的网络中的路由选择算法,BGP 是一种在因特网中用于互联所有网络的路由选择算法,常被称为因特网的“ 粘合剂 ”。
5.5 节,SDN 控制器,软件定义网络(SDN)在数据平面和控制平面之间做了明确分割,在一台分离的“ 控制器 ”服务中实现了控制z平面功能,该控制器服务于他所控制的路由器的转发组件完全分开并远离。 5.6 和 5.7节,涉及管理 IP 网络的某些具体细节:ICMP(互联网控制报文协议)和 SNMP(简单网络管理协议)。
5.1 概述
通过回顾图 4-2 和图 4-3 ,迅速建立起学习网络控制平面的环境。在这里,转发表(在基于目的地转发的场景中)和流表(在通用转发的场景中)是链接网络层的数据平面和控制平面的首要元素。我们知道这些表定义了一台路由器的本地数据平面转发行为。看到在通用转发的场景下,所采取的动作(4.4.2 节)不仅包括转发一个分组到达路由器的每个输出端口,而且能够丢弃一个分组 、复制一个分组和/或重写第 2 ,3 或 4 层分组首部字段。
本章中,学习这些转发表和流表是如何计算、维护和安装的。在 4.1 节的网络层概述中,学习路完成这些工作有两种可能的方法。
① 每路由器控制 。图 5-1 显示了在每台路由器中运行一种路由选择算法的情况,每台路由器中都包含转发和路由选择功能。每台路由器有一个路由选择组件,用于与其他路由器中的路由选择组件通信,以计算其转发表的值。这种每路由器控制的方法在因特网中已经使用了几十年。将在 5.3 节和 5.4 节中学习的 OSPF 和 BGP 协议都是基于这种每路由器的方法进行控制的。
② 逻辑集中式控制。图 5-2 显示了逻辑集中式控制器计算并分发转发表以供每台路由器使用的情况。如在 4.4 节中所见,通用的" 匹配加动作 "抽象允许执行传统的 IP 转发以及其他功能(负载共享、防火墙功能和 NAT)的丰富集合,而这些功能先前是在单独的中间盒中实现的。
该控制器经一种定义良好的协议与每台路由器中的一个控制代理(CA)进行交互,以配置和管理该路由器的转发表。CA 一般具有最少的功能,其任务是与控制器通信并且按控制器命令行事。与图 5-1 中的路由选择算法不同,这些 CA 既不能直接相互交互,也不能主动参与计算转发表。这是每路由器控制和逻辑集中式控制之间的关键差异。


逻辑集中式控制意味着就像路由选择控制服务位于单一的集中服务点那样获取它们,即使该服务处于容错和性能扩展的原因,可能经由多个服务器实现。正如 5.5 节所见,SDN 采用了逻辑集中式控制器的概念,而这种方法在生产部署中得到越来越多的应用。
5.2 路由选择算法
路由选择算法 (routing algorithm) ,其目的是从发送方到接收方的过程中确定一条通过路由器网络的好的路径(等价于路由)。通常, 一条好路径指具有最低开销的路径。然而我们将看到,实践中现实世界还关心诸如策略之类的问题(例如,有一个规则是" 属于组织Y 的路由器X 不应转发任何来源于组织 Z 所属网络的分组")。我们注意到无论网络控制平面采用每路由器控制方法,还是采用逻辑集中式控制方法,必定总是存在一条定义良好的一连串路由器,使得分组从发送主机到接收主机跨越网络"旅行" 。
可以用图来形式化描述路由选择问题。图( graph ) G = (N, E) 是一个 N 个节点和 E 条边的集合,其中每条边是取自 N的 一对节点。在网络层路由选择的环境中,图中的节点表示路由器,这是做出分组转发决定的点;连接这些节点的边表示这些路由器之间的物理链路。这样一个计算机网络的图抽象显示在图 5-3。

如图 5-3 所示,一条边还有一个值表示它的开销。通常,一条边的开销可反映出对应链路的物理长度(例如一条越洋链路的开销可能比一条短途陆地链路的开销高) ,它的链路速度,或与该链路相关的金钱上的开销。为了我们的目的,只将这些链路开销看成是给定的,而不必操心这些值是如何确定的。对于 E 中的任一条边(x,y),用 c(x,y) 表示节点 x 和 节点 y 间边的开销。如果节点对(x,y)不属于 E,则置 c(x,y)=∞。此外,这里考虑的都是无向图(图的边没有方向),因此边(x,y)与边(y,x)是相同的并且 c(x,y) = c(y,x)。然而,学习的算法能够很容易扩展到在每个方向有不同开销的有向链路组合。同时,如果(x,y)属于 E,节点 y 也被称为节点 x 的邻居。
在图抽象中为各条边指派了开销后,路由选择算法的天然目标是找出从源到目的地间的最低开销路径。为了使问题更为精确,回想在图 G= (N, E) 中的一条路径 (path)是一个节点序列(x1,x2,…,xp) ,这样每一个对 (x1 ,x2 ), (x2,x3) ,…, (xp-1,xp)是 E中的边。路径(x1,x2 …,xp)的开销只是沿着路径所有边的开销的总和,即c(x1,x2) + c( x2,x3) +… +C(xp-1,xp)。给定任何两个节点 x 和 y ,通常在这两个节点之间有许多条路径,每条路径都有一个开销。这些路径中的一条或多条是最低开销路径。最低开销路径问题是清楚的:找出源和目的地之间具有最低开销的一条路。例如,在图5-3中,源节点 u 和目的节点 w 之间的最低开销路径是(u,x,y,w),具有的路径开销是3。注意到若在图中的所有边具有相同的开销,则最低开销路径也就是最短路径,即在源和目的地之间的具有最少链路数量的路径。
路由选择算法的一种分类方式是根据该算法是集中式还是分散式来划分。
① 集中式路由选择算法用完整的、全局性的网络知识计算出从源到目的地之间的最低开销路径。也就是说,该算法以所有节点之间的连通性及所有链路的开销为输入。这就要求该算法在真正开始计算以前,要以某种方式获得这些信息。计算本身可在某个场点(例如,图 5-2 中所示的逻辑集中式控制器)进行,或在每台路由器的路由选择组件中重复进行(例如在图 5- 1 中) 然而,这里的主要区别在于,集中式算法具有关于连通性和链路开销方面的完整信息。具有全局状态信息的算法常被称作链路状态 (Link State , LS) 算法,因为该算法必须知道网络中每条链路的开销。我们将在 5.2.1 节中学习 LS 算法。
② 在分散式路由选择算法 (deeentralized routing algorithm) 中,路由器以迭代、分布式的方式计算出最低开销路径。没有节点拥有关于所有网络链路开销的完整信息。相反,每个节点仅有与其直接相连链路的开销知识即可开始工作。然后,通过迭代计算过程以及与相邻节点的信息交换,一个节点逐渐计算出到达某目的节点或一组目的节点的最低开销路径。我们将在后面的 5.2.2 节学习一个称为距离向量( Distance-Vector, DV) 算法的分散式路由选择算法。之所以叫作 DV 算法,是因为每个节点维护到网络中所有其他节点的开销(距离)估计的向量。 这种分散式算法,通过相邻路由器之间的交互式报文交换,也许更为天然地适合那些路由器直接交互的控制平面,就像在图 5-1 中那样。
路由选择算法的第二种广义分类方式是根据算法是静态的还是动态的进行分类。在静态路由选择算法(static routing algorithm) 中,路由随时间的变化非常缓慢,通常是人工进行调整(如人为手工编辑一条链路开销)。动态路由选择算法 (dynamic routi algorithm)随着网络流量负载或拓扑发生变化而改变路由选择路径。一个动态算法可周期性地运行或直接响应拓扑或链路开销的变化而运行。虽然动态算法易于对网络的变化做出反应,但也更容易受诸如路由选择循环、路由振荡之类问题的影响。
路由选择算法的第三种分类方式是根据它是负载敏感的还是负载迟钝的进行划分。在负载敏感算法(load -sensitive algorithm) 中,链路开销会动态地变化以反映出底层链路的当前拥塞水平。如果当前拥塞的一条链路与高开销相联系,则路由选择算法趋向于绕开该拥塞链路来选择路由。当今的因特网路由选择算法(如 RIPOSPF BGP) 都是负载迟钝的( 10ad -insensitive) ,因为某条链路的开销不明确地反映其当前(或最近)的拥塞水平。
5.2.1 链路状态路由选择算法
前面讲过, 在链路状态算法中,网络拓扑和所有的链路开销都是已知的,也就是说可用作 LS 算法的输入。实践中这是通过让每个节点向网络中所有其他节点广播链路状态分组来完成的,其中每个链路状态分组包含它所连接的链路的标识和开销。在实践中(例如使用因特网的 OSPF 路由选择协议,讨论见 5.3 节) ,这经常由链路状态广播(link state broadcast)算法来完成。节点广播的结果是所有节点都具有该网络的统一、完整的视图。于是每个节点都能够像其他节点一样,运行 LS 算法并计算出相同的最低开销路径集合。
下面给出的链路状态路由选择算法叫做 Dijkstra 算法。一个密切相关的算法是 prim 算法。Dijkstra 算法计算从某节点(源节点 称之为 u)到网络中所有其他节点的最低开销路径。Dijkstra 是迭代算法,其性质是经算法的第 k 次迭代后,可知道到 k 个目的节点的最低开销路径,在到所有目的节点的最低开销路径中,着 k 条路径具有 k 个最低开销。定义下列符号。

举一个例子,考虑图 5-3 中的网络,计算从 u 到所有可能目的地的最低开销路径算法的计算过程以表格方式总结于表5-1 中,表中的每一行给出了迭代结束时该算法的变量的值。详细地考虑前几个步骤。

① 在初始化步骤,从 u 到与其直接相连的邻居v 、x、w 的当前已知最低开销路径分别初始化为 2,1,5。特别值得注意的是,到 w 的开销被设为 5(尽管我们很快就会看见确实存在一条开销更小的路径),因为这是从 u 到 w 的直接(一跳)链路开销。到 y 与 z的开销被设为无穷大,因为它们不直接与 u 连接。
② 在第一次迭代中,观察那些还未加到集合 N' 中的节点,并且找出在前一次迭代结束时具有最低开销的节点。那个节点便是 x ,其开销是 1,因此 x 被加到集合 N'。于是 LS 算法中的第 12 行中的程序被执行,以更新所有节点 v 的 D(v),产生表 5-1 中第 2 行( 步骤 )所示的结果。到 v 的路径开销未变。经过节点 x 到 w(在初始化结束时其开销为 5)的路径开销被发现为 4。因此这条具有更低开销的路径被选中,且沿从 u 开始的最短路径上 w' 的前一节点被设为 x。类似地,到 y (经过 x)的开销被计算为 2,且该表也被相应地更新。
③ 在第二次迭代时,节点 v 与 y 被发现具有最低开销路径 (2) ,并且我们任意改变次序将 y 加到集合 N' 中,使得 N' 中含有 u,x 和 y。到仍不在 N' 中的其余节点(即节点 v w 和 z)的开销通过 LS 算法中的第 12 行进行更新,产生如表 5-1 中第 3 行所示的结果。
④ 如此等等。
当 LS 算法终止时,对于每个节点,我们都得到从源节点沿着它的最低开销路径的前一节点。对于每个前一节点,我们又有它的前一节点,以此方式我们可以构建从源节点到所有目的节点的完整路径。通过对每个目的节点存放从 u 到目的地的最低开销路径上的下一跳节点,在一个节点(如节点 u)中的转发表能够根据此信息而构建。图 5-4 显示了对于图 5-3 中的网络产生的最低开销路径和 u 中的转发表。

该算法的计算复杂性是什么?即给定 n 个节点(不算源节点),在最坏情况下要经过多少次计算,才能找到从源节点到所有目的节点的最低开销路径?在第一次迭代中,我们需要搜索所有的 n 个节点以确定出不在 N' 中且具有最低开销的节点 w。 在第二次迭代时,我们需要检查 n-1 个节点以确定最低开销。第三次对 n-2 个节点迭代,依次类推。总之,我们在所有迭代中需要搜寻的节点总数为 n(n+1 )/2 ,因此我们说前面实现的链路状态,算法在最差情况下复杂性 O(n^2)。(该算法的一种更复杂的实现是使用一种称为堆的数据结构,能用对数时间而不是线性时间得到第 9 行的最小值,因而减少其复杂性)。
在完成 LS 算法的讨论之前,考虑一下可能出现的问题。图 5-5 显示了一个简单的网络拓扑,图中的链路开销等于链路上承载的负载,例如反映要历经的时延。在该例中,链路开销是非对称的,即仅当在链路 (u,v) 两个方向所承载的负载相同时 c(u,v) 和 c(v,u) 才相等。在该例中,节点 z 产生发往 w 的一个单元的流量,节点 x 也产生发往w 的一个单元的流量,并且节点 y 也产生发往 w 的一个数量为 e 的流量。初始路由选择情况如图 5-5a 所示,其链路开销对应于承载的流量。
当 LS 算法再次运行时,节点 y 确定(基于图 5-5a 所示的链路开销)顺时针到 w 的路径开销为 1,而逆时针到 w 的路径开销(一直使用的)是 1+e。因此,y 到 w 的最低开销路径现在是顺时针的。类似的,x 确定其到 w 的新的最低开销路径也是顺时针的,产生如图 5-5b 中所示的开销。当 LS 算法下次运行时,节点 x、y 和 z 都检测到一条至 w 的逆时针方向零开销路径,他们都将其流量引导到逆时针方向的路由上。下次 LS 算法运行时,x、y和 z 都将其流量引导到顺时针方向的路由上。

如何才能防止这样的振荡(它不只是出现在链路状态算法中,而且也可能出现在任何使用拥塞或基于时延的链路测度的算法中)。一种解决方案可能强制链路开销不依赖于所承载的流量,但那是一种不可接受的解决方案,因为路由选择的目标之一就是要避开高度拥塞(如高时延)的链路。另一种解决方案就是确保并非所有的路由器都同时运行 LS 算法。这似乎是一个更合理的方案,因为我们希望即使路由器以相同周期运行 LS 算法,在每个节点上算法执行的时机也将是不同的。有趣的是,研究人员近来已注意到了因特网上的路由器能在它们之间进行自同步。 这就是说,即使它们初始时以同一周期但在不同时刻执行算法,算法执行时机最终会在路由器上变为同步并保持之 。避免这种自同步的一种方法是,让每台路由器发送链路通告的时间随机化。
5.2.2 距离向量路由选择算法
距离向量(Distance-Vector DV)算法是一种迭代的、异步的和分布式的算法,而 LS 算法是一种使用全局信息的算法。说它是分布式的,是因为每个节点都要从一个或者多个直接相连邻居接收某些信息,执行计算,然后将其计算结果分发给邻居。说他是迭代的,是因为此过程一直要持续到邻居之间无更多信息要交换为止。(有趣的是,此算法是自我终止的,即没有计算应该停止的信号,它就停止了)。说它是异步的,是因为它不要求所有节点相互之间步伐一致地操作。我们将看到一个异步的、迭代的、自我终止的、分布式的算法。
给出 DV 算法之前,讨论存在于最低开销路径的开销之间的一种重要关系。令 dx(y)是从节点 x 到 y 的最低开销路径的开销。则该最低开销于 Bellman-Ford 方程相关,即

检查在图5-3 中的源节点 u 和目的节点 z。源节点有 3 个邻居:v、x 和 w。通过遍历该图中的各条路径,容易看出 dv(z)=5 dx(z)=3 dw(z)=3。连通开销 c(u,v)=2、c(u,x)=1 c(u,w)=5 带入方程。得出 du(z)=min{2+5,5+3,1+3}=4。显然是正确的。



在该 DV 算法中,当节点 x 发现它的直接相连的链路开销变化或从某个邻居接收到一个距离向量的更新时,它就更新其距离向量估计值。但是为了一个给定的目的地 y 而更新它的转发表,节点 x 真正需要知道的不是到 y 的最短路径距离,而是沿着最短路径到下一跳路由器邻居节点 v*(y) 。如你可能期望的那样,下一跳路由器 v*(y) 是在 DV 算法第14 行中取得最小值的邻居 v 。(如果有多个取得最小值的邻居 v*(y) 能够是其中任何一个有最小值的邻居。)因此,对于每个目的地 y,在第 13 -14 行中,节点 x 也决定v*(y) 并更新它对目的地 y 的转发表。
前面讲过 LS 算法是一种全局算法,在于它要求每个节点在运行 Dìjkstra 算法之前,首先获得该网络的完整信息。DV 算法是分布式的,它不使用这样的全局信息。实际上,节点具有的唯一信息是它到直接相连邻居的链路开销和它从这些邻居接收到的信息。每个节点等待来自任何邻居的更新(第 10 -11 行) ,当接收到一个更新时计算它的新距离向量(第 14 行)并向它的邻居分布其新距离向量(第 16 -17 行)。在实践中许多类似 DV 的算法被用于多种路由选择协议中,包括因特网的 RIP 和 BGP、ISO IDRP等。
图 5-6 举例说明了 DV 算法的运行,应用场合是该图顶部有三个节点的简单网络。算法的运行以同步的方式显示出来,其中所有节点同时从其邻居接收报文,计算其新距离向量,如果距离向量发生了变化则通知其邻居。学习完这个例子后,你应当确信该算法以异步方式也能正确运行,异步方式中可在任意时刻出现节点计算与更新的产生/接收。
该图最左边一列显示了这 3 个节点各自的初始路由选择表( routlng table)。例如,位于左上角的表是节点 x 的初始路由选择表。在一张特定的路由选择表中,每行是一个距离向量一一特别是每个节点的路由选择表包括了它的距离向量和它的每个邻居的距离向量。因此,在节点 x 的初始路由选择表中的第一行 Dx=[Dx(x),Dx(y),Dx(z)]=[0,2,7]。在该表的第二和第三行是分别从节点 y 和 z 收到的距离向量。因为在初始化时节点 x 还没有从节点 y 和z 收到任何东西,所以第二行和第三行的表项被初始化为无穷大。
初始化后,每个节点向它的两个邻居发送其距离向量。图 5-6 中用从表的第一列到表的第二列的箭头说明了情况。例如,节点 x 向两个节点 y 和 z 发送了它的距离向量 Dx=[0,2,7]。在接收到更新后,每个节点重新计算它自己的距离向量。例如,节点 x 计算 
第二列因此为每个节点显示了节点的新距离向量连同刚从它的邻居接收到的距离向量。注意到,例如节点 x 到节点 z 的最低开销估计 Dx(z) 已经从 7 变成 3 了。还应注意到,对于节点 x,节点 y 在该 DV 算法的第 14 行中取得了最小值;因此在该算法的这个阶段,在节点 x 得到了 v*(y)=y 和 v*(z)=y。

在节点重新计算它们的距离向量之后,它们再次向其邻居发送它们的更新距离向量(如果它们已经改变的话)。图 5-6 中由从表第二列到表第三列的箭头说明了这一情况。注意到仅有节点 x 和节点 z 发送了更新:节点 y 的距离向量没有发生变化,因此节点 y 没有发送更新。在接收到这些更新后,这些节点则重新计算它们的距离向量并更新它们的路由选择表,这些显示在第三列中。
从邻居接收更新距离向量、重新计算路由选择表项和通知邻居到目的地的最低开销路径的开销已经变化的过程继续下去,直到无更新报文发送为止。在这个时候,因为无更新报文发送,将不会出现进一步的路由选择表计算,该算法将进入静止状态,即所有的节点将执行 DV 算法的第 10 -11 行中的等待。该算法停留在静止状态,直到一条链路开销发生改变,如下面所讨论的那样。
1. 距离向量算法:链路开销改变与链路故障
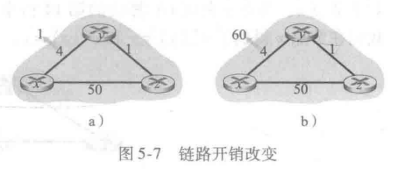
当一个运行 DV 算法的节点检测到从它自己到邻居的链路开销发生变化时(第 10 --11 行) ,它就更新其距离向量(第13-14 行) ,并且如果最低开销路径的开销发生了变化,向邻居通知其新的距离向量(第16-17行)。图 5-7a 图示了从 y 到 x 的链路开销从 4 变为 1 的情况。我们在此只关注 y 与 z 到目的地 x 的距离表中的有关表项。该 DV 算法导致下列事件序列的出现:
① 在 t0 时刻,y 检测到链路开销变化(开销从 4 变为 1) ,更新其距离向量,并通知其邻居这个变化,因为最低开销路径的开销已改变。
② 在 t1 时刻,收到来自 y 的更新报文并更新了其距离表。它计算出到 x 的新最低开销(从开销 5 减为开销 2),它向其邻居发送了它的新距离向量。
③ 在 t2时刻,y 收到来自 z 的更新并更新其距离表。y 的最低开销未变,因此 y 不发送任何报文给 z。该算法进入静止状态。
因此,对于该 DV 算法只需要两次迭代就到达了静止状态。在 x 与 y 之间开销减少的好消息通过网络得到了迅速传播。
现在考虑一下某链路开销增加的情况。假设 x 与 y 之间的链路开销从 4 增加到 60,如图 5-7b

该过程将要继续多久呢?你应认识到该循环将持续 44 次迭代(在 y 与 z 之间交换报文) ,即直到 z 最终算出它经由 y 的路径开销大于 50 为止。此时 z 将(最终)确定它到的最低开销路径是经过它到 x 的直接连接。y 将经由 z 路由选择到 x 。关于链路开销增加的坏消息的确传播得很慢!如果链路开销 c(y,x) 从 4 变为 10000 且开销 c(z x) 为 9999时将发生什么样的现象呢?由于这种情况,我们所见的问题有时被称为无穷计数( count-to-infinity)问题。
2. 距离向量算法:增加毒性逆转
刚才描述的特定循环的场景可以通过使用一种称为毒性逆转 (poisoned reverse) 的技术而加以避免。其思想较为简单:如果 z 通过 y 路由选择到目的地 x,则 z 将通告 y,它(即 z) 到 x 的距离是无穷大,也就是 z 将向 y 通告 Dz(x)=∞(即使 z 实际上知道Dz (x) = 5)。只要 z 经 y 路由选择到 x,z 就持续地向 y 讲述这个善意的小谎言。因为 y 相信 z 没有到 x 的路径,故只要 z 继续经 y 路由选择到 x(并这样去撒谎),y 将永远不会试图经由 z 路由选择到 x。
现在看一下毒性逆转如何解决我们前面在图 5-7b 中遇到的特定环路问题。作为毒性逆转的结果,y 的距离表指示了 Dz(x)=∞。当(x,y) 链路的开销在 t0 时刻从 4 变为60 更新其表,虽然开销高达 60 ,仍继续直接路由选择到 x,并将到 x 的新开销通知z,即 Dy(x) =60。z在 t1 时刻收到更新后,便立即将其到 x 的路由切换到经过开销为 50的直接 (z x) 链路 肉为这是一条新的到坏的最低开销路径,且因为路径不再经过 y,z 就在 t2 时刻通知 y 现在 Dz(x) = 50。在收到来自 z 的更新后,y 便用 Dy(x) =51 更新其距离表.另外,因为 z 此时位于 y到 x 的最低开销路径上,所以 y 通过在 t3 时刻通知 z 其 Dy(x)=∞(即使 y 实际上知道 Dy(x) = 51)毒化从 z 到 x 坏的逆向路径。
毒性逆转解决了一般的无穷计数问题吗?没有。你应认识到涉及 3 个或更多节点(而不只是两个直接相连的邻居节点)的环路将无法用毒性逆转技术检测到。
3. LS 与 DV 路由选择算法的比较
DV 和 LS 算法采用互补的方法来解决路由选择计算问题。在 DV 算法中,每个节点仅与它的直接相连的邻居交谈,但它为其邻居提供了从它自己到网络中(它所知道的)所有其他节点的最低开销估计。LS 算法需要全局信息。因此,当在每台路由器中实现时,例如像在图 4-2 和图 5-1 中那样,每个节点(经广播)与所有其他节点通信,但仅告诉它们与它直接相连链路的开销。通过快速比较它们各自的属性来总结所学的链路状态与距离向量算法。记住 N 是节点(路由器)的集合,而 E 是边(链路)的集合。
① 报文复杂性。LS 算法要求每个节点都知道网络中每条链路的开销。这就要求要发送 O(|N||E|)个报文。而且无论何时一条链路的开销改变时,必须向所有节点发送新的链路开销。DV 算法要求在每次迭代时,在两个直接相连邻居之间交换报文。我们已经看到,算法收敛所需时间依赖于许多因素。当链路开销改变时, DV 算法仅当在新的链路开销导致与该链路相连节点的最低开销路径发生改变时,才传播已改变的链路开销。
② 收敛速度。LS 算法的实现是一个要求 O(|N||E|)个报文的 O(|N|^2)算法。DV 算法收敛较慢,且在收敛时会遇到路由选择环路。DV 算法还会遭遇无穷计数问题。
③ 健壮性。如果一台路由器发生故障、行为错乱或收到蓄意破坏时情况会怎样呢?对于 LS 算法,路由器能够向其连接的链路(而不是其他链路)广播不正确的开销。作为 LS 广播的一部分,一个节点也可损坏或丢弃它收到的任何 LS 广播分组。但是一个 LS 节点仅计算自己的转发表;其他节点也自行执行类似的计算。这就意味着LS 算法下,路由计算在某种程度上是分离的,提供了一定程度的健壮性。DV算法下,一个节点可向任意或所有目的节点通告其不正确的最低开销路径。(在1997 年, 一个小 ISP 的一台有故障的路由器的确向美国的主干路由器提供了错误的路由选择信息。这引起了其他路由器将大量流量引向该故障路由器,并导致因特网的大部分中断连接达数小时)一般地,我们会注意到每次迭代时,在 DV 算法中一个节点的计算会传递给它的邻居,然后在下次迭代时再间接地传递给邻居的邻居。在此情况下, DV 算法中一个不正确的节点计算值会扩散到整个网络。
总之,两个算法没有一个是明显的赢家,它们的确都在因特网中得到了应用。
5.3 因特网中自治系统内部的路由选择:OSPF
在目前为止的算法研究中,将网络只看作一个互联路由器的集合。从所有路由器执行相同的路由选择算法以计算穿越整个网络的路由选择路径的意义上说,一台路由器很难同另一台路由器区别开来。 在实践中,该模型和这种一组执行同样路径选择算法的同质路由器集合的观点有一点简单化。以下两个重要原因:
① 规模。随着路由器数目变得很大,涉及路由选择信息的通信、计算和存储的开销将高得不可实现。当今的因特网由数亿台主机组成。在这些主机中存储的路由选择信息显然需要巨大容量的内存。在所有路由器之间广播连通性和链路开销更新所要求的负担将是巨大的!在如此大量的路由器中迭代的距离向量算法将肯定永远无法收敛!显然,必须采取一些措施以减少像因特网这种大型网络中的路由计算的复杂性。
② 管理自治。如在1.3 节描述的那样,因特网是 ISP 的网络,其中每个 ISP 都有它自己的路由器网络。 ISP 通常希望按自己的意愿运行路由器(如在自己的网络中运行它所选择的某种路由选择算法),或对外部隐藏其网络的内部组织面貌。在理想情况下,一个组织应当能够按自己的愿望运行和管理其网络,还要能将其网络与其他外部网络连接起来。
这两个问题都可以通过将路由器组织进自治系统 (Autonomous System, AS) 来解决,其中每个 AS 由一组通常处在相同管理控制下的路由器组成,通常在一个 ISP 中的路由器以及互联它们的链路构成一个 AS。然而,某些 ISP 将它们的网络划分为多个 AS 。特别是,某些一级 ISP 在其整个网络中使用一个庞大的 AS,而其他 ISP 则将它们的 ISP 拆分为数十个互联的 AS。一个自治系统由其全局唯一 AS号 (ASN) 所标识。就像 IP地址那样, AS 号由 ICANN 区域注册机构所分配
在相同 AS 中的路由器都运行相同的路由选择算法并且有彼此的信息。在一个自治系统内运行的路由选择算法叫做自治系统内部路由选择协议。
开放最短路优先(OSPF)
OSPF 路由选择及其关系密切的协议 IS-IS 都被广泛用于因特网的 AS 内部路由选择。
OSPF 是一种链路状态协议,它使用洪泛链路状态信息和 Dijkstra 最低开销路径算法。使用 OSPF,一台路由器构建了一幅关于整个自治系统的完整拓扑图(即一幅图)。于是,每台路由器在本地运行 Dijkstra 的最短路径算法,以确定一个以自身为根节点到所有子网的最短路径树。各条链路开销是由网络管理员配置的(参见"实践原则:设置 OSPF 链路权值")。管理员也许会选择将所有链路开销设为 1,因而实现了最少跳数路由选择,或者可能会选择将链路权值按与链路容量成反比来设置,从而不鼓励流量使用低带宽链路。OSPF 不强制使用设置链路权值的策略,而是提供了一种机制(协议) ,为给定链路权值集合确定最低开销路径的路由选择 。
使用 OSPF 时,路由器向自治系统内所有其他路由器广播路由选择信息,而不仅仅是向其相邻路由器广播。每当一条链路的状态发生变化时(如开销的变化或连接/中断状态的变化) ,路由器就会广播链路状态信息。即使链路状态未发生变化,它也要周期性地(至少每隔 30 min 一次)广播链路状态。RFC 2328 中有这样的说明:"链路状态通告的这种周期性更新增加了链路状态算法的健壮性"。OSPF 通告包含在 OSPF 报文中,该 OSPF报文直接由 IP 承载,对 OSPF 其上层协议的值为 89。因此 OSPF 协议必须自己实现诸如可靠报文传输、链路状态广播等功能。OSPF 协议还要检查链路正在运行(通过向相连的邻居发送 HELLO 报文) ,并允许 OSPF 路由器获得相邻路由器的网络范围链路状态的数据库。


相关文章:

计算机网络 网络层:控制平面
在本章中,包含网络层的控制平面组件。控制平面作为一种网络范围的逻辑,不仅控制沿着从源主机到目的主机的端到端路径间的路由器如何转发数据报,而且控制网络层组件和服务如何配置和管理。5.2节,传统的计算图中最低开销路径的路由选…...

探索阿里云智能媒体管理IMM:解锁媒体处理新境界
一、引言:开启智能媒体管理新时代 在数字化浪潮的席卷下,媒体行业正经历着前所未有的变革。从传统媒体到新媒体的转型,从内容生产到传播分发,每一个环节都在寻求更高效、更智能的解决方案。而云计算,作为推动这一变革…...

微信点餐小程序—美食物
本项目是基于WAMP Server 和PHP 动态网页技术构建的微信小程序点餐系统,该系统主要分为前端(微信小程序)和后端(基于PHPMySQL服务器端) 整体架构流程 1、前端部分 用户界面:展示菜品、处理用户点餐操作、…...

Python零基础入门到高手8.5节: 实现选择排序算法
目录 8.5.1 排序算法简介 8.5.2 选择排序算法 8.5.3 好好学习,天天向上 8.5.1 排序算法简介 所谓排序,是指将数据集合中的元素按从小到大的顺序进行排列,或按从大到小的顺序进行排列。前者称为升序排序,后者称为降序排序。在数…...
)
JavaEE初阶第四期:解锁多线程,从 “单车道” 到 “高速公路” 的编程升级(二)
专栏:JavaEE初阶起飞计划 个人主页:手握风云 目录 一、Thread类及常用方法 2.1. Thread的常见构造方法 2.2. Thread的常见属性 2.3. 启动一个线程 2.4. 中断一个线程 2.5. 等待一个线程 2.6. 休眠当前线程 一、Thread类及常用方法 2.1. Thread的…...

Metasploit常用命令详解
一、Metasploit 概述 Metasploit是一款开源的渗透测试框架,由 H.D. Moore 于 2003 年首次发布,目前由 rapid7 公司维护。它整合了大量漏洞利用模块、后渗透工具和漏洞扫描功能,已成为网络安全工程师、红队 / 蓝队成员及安全研究人员的核心工…...

2025.6.24总结
今天发生了两件事,这每件事情都足以影响我的工作状态。 1.团队中有人要转岗 这算是最让我有些小震惊的事件了。我不明白,那个同事干得好好的,为啥会转岗,为啥会被调到其他团队。虽然团队有正编,有od,但我自始自终觉得…...

2023年全国青少年信息素养大赛Python 复赛真题——玩石头游戏
今日python每日练习题为——玩石头游戏,大家记得坚持刷题哦,闯入国赛~ 每轮可拿 1-3 块石头,双方均采取最优策略。若石头数 n 为 4 的倍数,无论先手取 k 块(1≤k≤3),后手总能取 4-k 块…...

MySQL之SQL性能优化策略
MySQL之SQL性能优化策略 一、主键优化策略1.1 主键的核心作用1.2 主键设计原则1.3 主键优化实践 二、ORDER BY优化策略2.1 ORDER BY执行原理2.2 ORDER BY优化技巧2.3 处理大结果集排序 三、GROUP BY优化策略3.1 GROUP BY执行原理3.2 GROUP BY优化方法 四、LIMIT优化策略4.1 LIM…...

AI时代工具:AIGC导航——AI工具集合
大家好!AIGC导航是一个汇集多种AIGC工具的平台,提供了丰富的工具和资源。 工具功能: 该平台整合了多样的AIGC工具,涵盖了绘画创作、写作辅助以及视频制作等多个领域。绘画工具能够生成高质量的图像作品;写作工具支持从构思到润色的全流程写…...

性能测试-jmeter实战4
课程:B站大学 记录软件测试-性能测试学习历程、掌握前端性能测试、后端性能测试、服务端性能测试的你才是一个专业的软件测试工程师 性能测试-jmeter实战4 jmeter环境搭建1. 安装Java环境(必需) JMeter环境搭建完整指南1. 安装Java࿰…...

C++字符串的行输入
1、字符串的输入 下面用一个真实的示例来进行演示: #include<iostream> #include<string>int main() {using namespace std;const int ArSize 20;char name[ArSize];char dessert[ArSize];cout << "Enter your name:\n";cin >>…...

【Linux网络与网络编程】15.DNS与ICMP协议
1. DNS 1.1 DNS介绍 TCP/IP 中使用 IP 地址和端口号来确定网络上的一台主机的一个程序,但是 IP 地址不方便记忆,于是人们发明了一种叫主机名的字符串,并使用 hosts 文件来描述主机名和 IP 地址的关系。最初, 通过互连网信息中心(SRI-NIC)来…...

Python训练营-Day40-训练和测试的规范写法
1.单通道图片训练 # import torch # import torch.nn as nn # import torch.optim as optim # from torchvision import datasets, transforms # from torch.utils.data import DataLoader # import matplotlib.pyplot as plt # import numpy as np# # 设置中文字体支持 # plt…...

【Python-Day 29】万物皆对象:详解 Python 类的定义、实例化与 `__init__` 方法
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

内存泄漏和内存溢出的区别
内存泄漏(Memory Leak)和内存溢出(Memory Overflow / Out Of Memory, OOM)是软件开发中两个密切相关但又本质不同的内存问题: 核心区别一句话概括: 内存泄漏: 有垃圾对象占用内存却无法被回收&…...

Linux系统---Nginx配置nginx状态统计
配置Nignx状态统计 1、下载vts模块 https://github.com/vozlt/nginx-module-vts [rootclient ~]# nginx -s stop [rootclient ~]# ls anaconda-ks.cfg nginx-1.27.3 ceph-release-1-1.el7.noarch.rpm nginx-1.27.3.tar.gz info.sh …...

linux操作系统的软件架构分析
一、linux操作系统的层次结构 1.内核的主要功能 1)进程管理 2)内存管理 3)文件系统 4)进程间通信、I/O系统、网络通信协议等 2.系统程序 1)系统接口函数库,比如libc 2)shell程序 3)编译器、编辑…...
:FastMCP的核心组件-构建MCP服务的关键技术实现)
快速手搓一个MCP服务指南(三):FastMCP的核心组件-构建MCP服务的关键技术实现
FastMCP 是一套面向 LLM 应用开发的工具框架,通过标准化协议衔接大语言模型与外部功能组件,构建「LLM工具」的闭环交互体系。其核心技术体系包含四大模块:工具系统将 Python 函数转化为 LLM 可调用的能力单元,通过类型注解实现参数…...

创建首个 Spring Boot 登录项目
📌 摘要 在 Java Web 开发中,登录功能是最基础也是最重要的模块之一。本文将手把手带你使用 IntelliJ IDEA 和 Maven 构建一个基于 Spring Boot 的简单登录系统,涵盖: 使用 IDEA 创建 Spring Boot 项目配置 Maven 依赖ÿ…...
)
order、sort、distribute和cluster by(Spark/Hive)
1. abstract ORDER BY:完整查询结果的全局行排序。与SORT BY、CLUSTER BY、DISTRIBUTE BY互斥,不能同时使用。 示例SELECT * FROM table_name ORDER BY column_name;SORT BY:只在每个分区内排序,局部排序结果不是全局有序。与ORD…...

# Python中等于号的使用
# Python中等于号的使用 ## 1. 问题的分析与思考 在Python中,等于号()是一个赋值运算符,用于将右侧的值或表达式的结果赋给左侧的变量。这是Python(以及许多其他编程语言)中非常基础且核心的一个概念。理…...

无人机神经网络模块运行与技术难点
一、神经网络模块的运行方式 1. 分层处理架构 感知层 多模态数据融合:通过八元数卷积网络(OCNN)统一处理LiDAR、摄像头、IMU等异构传感器数据,将点云坐标(x/y/z)、图像RGB与光流信息编码至8维虚部&#…...
)
宝塔服务器调优工具 1.1(Opcache优化)
第一步:宝塔服务器调优工具 1.1(按照下面的参数填写) 第二步:路径/www/server/php/80/etc/php.ini 搜索jit jit1235 其中1235根据服务器情况修改 第三步:路径/www/server/php/80/etc/php-cli.ini 搜索 jit1235 其中…...

day041-web集群架构搭建
文章目录 0. 老男孩思想-高薪四板斧1. web集群架构图2. 搭建异地备份服务2.1 服务端-阿里云服务器2.1.1 查看rsync软件包2.1.2 添加rsync配置文件2.1.3 添加虚拟用户2.1.4 创建校验用户密码文件2.1.5 创建备份目录2.1.6 启动服务2.1.7 开放安全组端口2.1.8 发送检查邮件 2.2 客…...
)
国产化条码类库Spire.Barcode教程:如何使用 C# 读取 PDF 中的条码(两种方法轻松实现)
在 PDF 文档的 .NET 平台处理流程中,使用 C# 读取 PDF 条码 是一项常见需求,特别适用于处理扫描件或电子表单。无论是物流、金融、医疗还是制造行业,PDF 文档中经常包含用于追踪或识别的条码。这些条码可能是嵌入图像,也可能是矢量…...

vue 3 计算器
效果: <template><div class"calculator-container"><div class"calculator"><!-- 显示区域 --><div class"display">{{ formattedDisplay }}</div><!-- 按钮区域 --><div class"…...

CRMEB PHP多门店版v3.2.1系统全开源+Uniapp前端+搭建教程
一.介绍 CRMEB多店版是一款为品牌连锁门店打造的私域电商解决方案,以三大运营模式为核心,助力品牌连锁门店轻松构建全渠道、一体化的私域电商生态,促进“线上电商”与“线下门店”销售运营融合,加速品牌数字化转型,为…...

主机复制文字和文件到 Ubuntu 虚拟机
在 VMware Workstation Pro 16 中复制文字和文件到 Ubuntu 虚拟机,方法如下: Open-VM-Tools 禁用 Wayland 解决 。 1.安装 VMware Tools(推荐)或 open-vm-tools: sudo apt update sudo apt install open-vm-tools…...

性能测试 —— 数据库的连接池和主从同步和分表分区
一、数据库的调优(库层面) 1、数据库连接池 1、介绍:数据库连接池(Database Connection Pool)是一种用于管理数据库连接的技术,它通过预先创建并维护一组数据库连接来提高应用程序的性能和可扩展性。 2、创建、管理、关闭 数据…...

猿人学js逆向比赛第一届第十二题
一、分析请求 看到这里只有一个m的密文参数,没有cookie,请求头等其他的参数,那么这里跟一堆栈信息。 很顺利地锁定了m的加密位置。看到是字符串拼接然后使用btoa函数进行编码,那么这里尝试使用Python复现一下。顺利拿到结果。 复现…...

第十节 新特性与趋势-CSS层叠规则升级
以下是关于 CSS层叠规则升级 的全面解析,结合最新规范(如级联层layer)和传统层叠机制的演进,从核心原理、应用场景到实践策略的系统性总结: 一、传统层叠规则的三大支柱 CSS层叠规则的传统机制基于以下三个维…...

关键领域软件工厂的安全中枢如何全面升级供应链检测能力
随着软件供应链安全体系在互联网、金融等领域逐步成熟,关键领域正加速迈向以 MLOps、软件工厂为核心的新型研发生态。在这一过程中,面对代码安全、依赖合规、系统可信等多重挑战,传统人工审查模式已难以满足国家级高安全性要求。 Gitee Scan…...

西门子G120XA变频器:数据中心能效革命的核心引擎
在数字经济爆发式增长的今天,数据中心已成为支撑社会运转的"数字心脏"。然而,其庞大的能耗需求与绿色低碳目标之间的矛盾日益凸显——尤其是冷却系统作为数据中心第二大能耗单元(占比约35%),正成为能效提升的…...
)
从零开始学习Spring Cloud Alibaba (一)
人狠话不多,直接开始少点屁话本着共同学习进步的目的和大家交流如有不对的地方望铁子们多多谅解 准备工具 开发工具 idea Java环境 jdk17 容器: docker Maven 3.8.6 仓库镜像阿里云 <mirror><id>alimaven</id><name>aliyun maven</name><…...

【C/C++】C++ 编程规范:101条规则准则与最佳实践
C 编程规范:101条规则准则与最佳实践 引言 C 是一门强大而复杂的语言,能高效控制硬件,也能写出优雅抽象。然而,正因其复杂性,项目中若缺乏统一规范,极易陷入混乱、难维护、易出错的泥潭。 本文总结了 10…...
 用法详解:取最大值)
PyTorch topk() 用法详解:取最大值
torch.topk(input, k) 返回张量中最大的 k 个元素以及它们在原张量中的 索引。 函数原型 torch.topk(input, k, dimNone, largestTrue, sortedTrue)参数说明: 参数说明input输入张量k要取出的前 k 个值dim指定沿哪个维度取值(默认是最后一维ÿ…...

毕业论文查重原理及降重方法
【30%的重复率有那么重要吗?】 老师说论文重读率必须低于30%,否则无法毕业! 如果您在专科或者普通本科学生,我只能这样一句话告诉你:你想多了~, 真的想多了~~~,一篇论文还不至于让你不能毕…...
)
Golang Kratos 系列:业务分层的若干思考(二)
上一篇文章简单讨论了领域层在Kratos中的使用,主要涉及引入领域层,将数据层和业务层之间的解耦,接下来讨论一个稍微全面一点的例子,在此基础上引入外部Api(主要是易变部分)的领域层下的情况。 我们同样可以…...

技术伦理之争:OpenAI陷抄袭风波,法院强制下架宣传视频
在AI巨头OpenAI宣布以65亿美元天价收购苹果前设计总监Jony Ive的硬件公司IO仅一个月后,一场抄袭指控将这家科技明星企业推上风口浪尖。 源自谷歌X实验室的初创企业IYO将OpenAI告上法庭,指控其窃取智能耳塞核心技术,并通过巨额收购试图掩盖抄袭…...

烟花爆竹生产企业库房存储安全风险预警系统
烟花爆竹生产企业库房存储安全风险预警系统是保障库房物资安全、规范作业流程、防范安全事故的重要技术手段,涵盖多个关键预警功能。 温湿度预警 在库房内安装温湿度传感器,这些传感器如同敏锐的“环境感知员”,能够实时监测库房内环境变…...

Jenkins+Jmeter+Ant接口持续集成
2025最新Jmeter接口测试从入门到精通(全套项目实战教程) 前言: 为什么要用Jmeter做接口测试: 当选择这套方案的时候,很多人会问,为什么选择Jmeter做Case管理?为什么不自己写框架?说…...

基于STM32的寻迹小车设计
标题:基于STM32的寻迹小车设计 内容:1.摘要 本文围绕基于STM32的寻迹小车设计展开。背景是随着自动化技术的发展,寻迹小车在工业巡检、物流运输等领域有广泛应用前景。目的是设计一款能稳定、准确寻迹的小车。方法上,以STM32微控制器为核心,…...
)
【150】基于SSM+Vue实现的小说阅读小程序(有文档)
系统介绍 基于SSMVue实现的小说阅读小程序采用前后端分离的架构方式,系统设计了管理员、用户两种角色,系统分为管理端、小程序端,管理端实现了管理员登录、个人中心、管理员管理、帮助中心管理、基础数据管理、论坛中心管理、公告资讯管理、…...

ValKey中使用SIMD指令优化bitcount命令
一、AVX/AVX2 的历史演进 随着计算机技术的飞速发展,数据处理需求呈指数级增长,SIMD(单指令多数据)技术应运而生。它通过一条指令同时处理多个数据元素,大幅提升计算效率,从早期的 MMX 技术起步࿰…...

leetcode114-二叉树展开为链表
leetcode 114 思路 用简单例子推导规律 不要一开始就看复杂的树,先从最简单的情况入手 案例一:只有一个节点 输入:1 输出:1不需要任何操作,直接返回 案例二:有两个节点 输入: 1/2输出&a…...

第七章 习题
1.给出下面表达式的逆波兰表示(后缀式): 3请将表达式-(ab)* (cd)-(abc)分别表示成三元式,间接三元式和四元式序列 四元式(Op,arg1,arg2,result) (,a,b,T1) (,c,d,T2) (*,T1,T2,T3) (uminus,T3,-,T4) (,a,b,T5) (,T5,c,T6) (-,T4,T6,r) 三元式 (op,arg1,arg2) (0) (,…...

Spring Ai Alibaba Graph实现五大工作流模式
Spring Ai Alibaba Graph实现五大工作流模式 概述 在 building-effective-agents 一文中,Anthropic将"智能体系统"(agentic systems),从架构层面分为 “工作流”(workflows)和 “智能体”(agents): 工作流…...
)
基于单片机的语音控制设计(论文)
摘要 自然语音作为人机交互在目前得以广泛的应用以及极大的发展前景。该设计介绍了基于非指定人语音芯片LD3320的语音控制器结构及其实现语音控制的方法。该语音控制器利用STM32F103C8T6单片机作为主要控制器,控制芯片对输入的进行语音识别并处理,根据语…...

【网络安全】从IP头部看网络通信:IPv4、IPv6与抓包工具 Wireshark 实战
从IP头部看网络通信:IPv4、IPv6与抓包工具 Wireshark实战 在网络安全分析和数据通信的世界中,一切都始于“数据包”。数据包是网络上传输的基本单位,而数据包的结构与内容,正是我们理解网络行为的核心。本文将带你深入了解 IP 协…...