Python基础之函数
代码仓库地址:git@github.com:Liucc-123/python_learn.git
函数介绍
函数是组织好的、可重复使用的,用来实现单一、或相关功能的代码段。
函数可以提高应用的模块性和代码的可重复性。python 有许多内置的函数比如 print 打印函数,python 也支持用户实现自己的函数,这类函数也称之为自定义函数。
定义一个函数
定义一个函数需要遵循以下规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串 — 用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。

语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):函数体
实例
默认情况下,参数是按照顺序参数进行匹配的。
示例:定义hello() 函数,打印输出“hello world”
#!/usr/bin/python3def hello() :print("Hello World!")hello()
更复杂点儿的示例,函数带参数:
#!/usr/bin/python3def max(a, b):if a > b:return aelse:return ba = 4
b = 5
print(max(a, b))
以上输出结果:
:::color1
5
:::
def area(width, height):return width * heightdef print_welcome(name):print("Welcome", name)print_welcome("李星云")
width=4
height=5
print("面积是:", area(width, height))
以上输出结果:
:::color1
Welcome 李星云
面积是: 20
:::
函数调用
当一个函数定义好之后,可以在另一个函数中调用此函数,或者在 python 命令提示符中调用。
注意:必须有调用方调用函数,这个函数才有作用,否则仅仅定义一个函数是没有任何输出的。
下面例子中,调用了 printme()函数:
#!/usr/bin/python3# 定义函数
def printme( str ):# 打印任何传入的字符串print (str)return# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
以上示例输出结果:
:::color2
我要调用用户自定义函数!
再次调用同一函数
:::
函数调用机制

说明如下:
- python 的内存结构可以粗浅的理解为由数据区、代码区及栈组成
- 代码区:存放 python 代码的地方,python 解释器会将用户代码翻译为指令,然后由 CPU 顺序的执行
- 栈:程序执行的地方,每调用一个新函数就会开辟一个新栈,当函数返回后,这片内存空间就会被释放
- 数据区:存放变量、对象的地方
- 主程序从
result = area(4, 5)开始 - 此时会调用 area()函数,会开辟一个新栈。实参 4, 5 会被分别传递给参数 width 及 height,此时数据区会创建一块区间用来存放变量 width 和 height 的值
- 继续执行函数 area的函数体
width * height得到结果 20,数据区再创建一块空间存放临时变量 值20 - area 函数执行完毕,出栈,将结果
20返回给调用方也就是主栈 result,此时会释放这个栈空间 - 继续执行主程序
print("面积是:", result),主栈空间释放 - 控制台打印输出对应的值
面积是: 20
函数的传参机制
数值和字符串的传参机制
数值传参机制
示例代码:
# 字符串和数值类型传参机制
def f1(a):print(f"f1() a的值:{a} 地址是:{id(a)}")a += 1print(f"f1() a的值:{a} 地址是:{id(a)}")a = 10
print(f"调用f1()前 a的值:{a} 地址是:{id(a)}")
f1(a)
print(f"调用f1()后 a的值:{a} 地址是:{id(a)}")
:::info
以上示例输出结果:
调用f1()前 a的值:10 地址是:4357169600
f1() a的值:10 地址是:4357169600
f1() a的值:11 地址是:4357169632
调用f1()后 a的值:10 地址是:4357169600
:::

:::color2
说明如下:
- 在主栈空间定义了变量 a=10,假设地址值是 0x1122
- 调用函数f1(a),在函数内修改变量 a。因为变量a 是数值类型,python会在数据区创建一块新的空间保存修改后的值 11.所以函数外部的变量 a 并不会受到影响
- 在函数内打印 id(a),会发现变量 a 的地址已发生改变
- 出栈,因为函数内对变量 a 的修改不会影响到外部变量 a,所以打印 id(a),a 的地址值 仍是 0x1122
:::
字符串传参机制
示例代码:
def f2(name):print(f"f2() name:{name} 地址是:{id(name)}")name += "hi"print(f"f2() name的值:{name} 地址是:{id(name)}")name = "tom"
print(f"调用f2()前 name的值:{name} 地址是:{id(name)}")
f2(name)
print(f"调用f2()后 name的值:{name} 地址是:{id(name)}")
:::info
以上示例输出结果:
调用f2()前 name的值:tom 地址是:4307138768
f2() name:tom 地址是:4307138768
f2() name的值:tomhi 地址是:4307139584
调用f2()后 name的值:tom 地址是:4307138768
:::
:::success
总结:数值和字符串类型是不可变数据类型,当该类型的变量的值发生变化时,该变量对应的内存地址也会发生变化。也即不可变类型的数据值如果发生变化,那么这个变量已经不再是原来的那个变量了,即使他们的变量值是一样的。
:::
list、tuple、set 和dict 的传参机制
列表的传参机制
def f1(my_list):print(f"②f1() my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")my_list[0] = "陆林轩"print(f"③f1() my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")print("-" * 30 + "list" + "-" * 30)
my_list = ["李星云", "姬如雪", "张子凡"]
print(f"①my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")
f1(my_list)
print(f"④my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")print("-" * 30 + "tuple" + "-" * 30)
my_tuple = ("hi", "ok", "hello")
print(f"①my_tuple: {my_tuple} 地址:{id(my_tuple)}")
f2(my_tuple)
print(f"④my_tuple: {my_tuple} 地址:{id(my_tuple)}")def f3(my_set):print(f"②f3() my_set: {my_set} 地址:{id(my_set)}")my_set.add("红楼")print(f"③f3() my_set: {my_set} 地址:{id(my_set)}")print("-" * 30 + "set" + "-" * 30)
my_set = {"水浒", "西游", "三国"}
print(f"①my_set: {my_set} 地址:{id(my_set)}")
f3(my_set)
print(f"④my_set: {my_set} 地址:{id(my_set)}")def f4(my_dict):print(f"②f4() my_dict: {my_dict} 地址:{id(my_dict)}")my_dict['address'] = "兰若寺"print(f"③f4() my_dict: {my_dict} 地址:{id(my_dict)}")print("-" * 30 + "dict" + "-" * 30)
my_dict = {"name": "小倩", "age": 18}
print(f"①my_dict: {my_dict} 地址:{id(my_dict)}")
f4(my_dict)
print(f"④my_dict: {my_dict} 地址:{id(my_dict)}")

:::color2
列表传参机制:
创建列表后,会在数据区开辟一块空间存储列表,地址比如为 0x9800,里面存放了三个元素
调用 f1 函数,将列表作为参数传递进去,此时开辟一个新的栈空间,指针my_list和主栈的指针 mylist 指向的是同一块空间
f1 函数修改第一个元素的值,是列表第一个元素指向了新的地址(陆林轩),但列表的自身的地址并未发生更改。
所以最终打印可以发现调用 f1 函数前后,列表的地址不会发生更改,只有第一个元素的地址发生了变化。
因此说,列表是可变数据类型,当列表的元素发生更改时,列表的地址并不会发生更改。“可变数据类型”中的“可变”是指变量地址是否会发生变化。
:::
小结
- python 数据类型主要有整型 int / 浮点型 float / 字符串 str / 布尔值 bool / 元组 tuple / 列表 list / 字典 dict / 集合 set,数据类型分为两个大类,一种是可变数据类型,一种是不可变数据类型。
- 可变数据类型和不可变数据类型。
- 可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址不变,那么这个数据类型就是可变数据类型。
- 不可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址改变了,那么这个数据类型就是不可变数据类型。
- python 的数据类型。
- 不可变数据类型:数值类型(int、float)、bool(布尔)、string(字符串)、tuple(元组)。
- 可变数据类型:list(列表)、set(集合)、dict(字典)。
递归机制
定义
递归函数,简单来说,就是自己调用自己的函数,它将问题分解为更小的同类子问题,通过不断的自我调用来解决复杂问题。
递归函数的核心特点:
- 自我调用:函数内部直接或间接调用自身
- 基准条件:递归函数必须具备终止递归的条件
- 逐步推进:每次调用都使问题规模向基准条件方向靠拢
递归能解决什么问题?
- 各种数学问题:汉诺塔、八皇后、阶乘问题、迷宫问题等
- 一些算法中也会用到递归:快排、归并排序、二分查找、分支算法等
- 需要用栈数据结构解决的问题
递归举例
1、分析下面代码的执行流程:
def test(n):if n > 2:test(n - 1)print("n =", n)
test(4)
上面代码的执行流程分析如下:
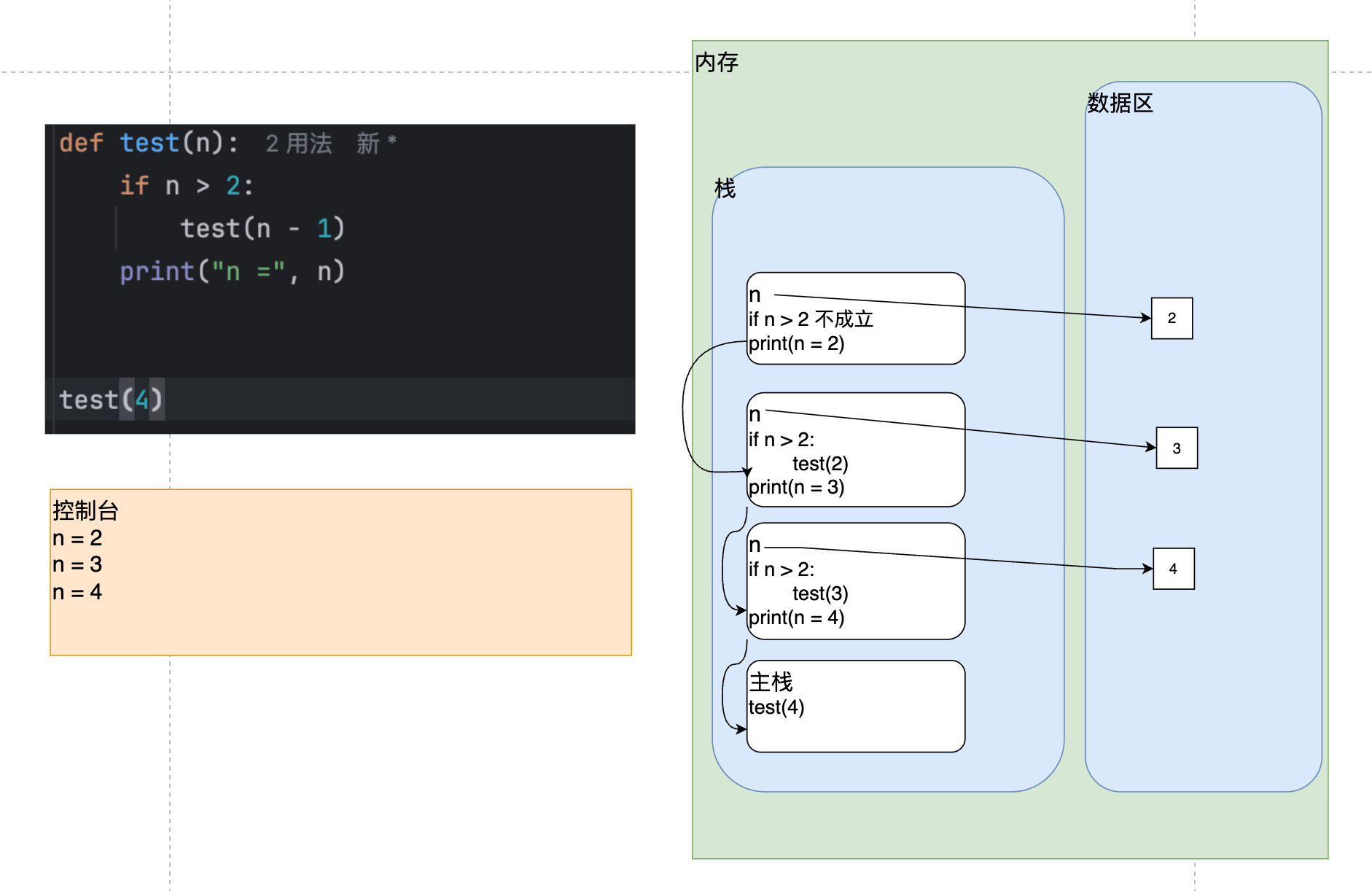
2、阶乘问题
# 阶乘问题
def factorial(n):if n == 1:return 1else:return n * factorial(n - 1)
print(factorial(4))
上面代码的执行流程分析如下:

递归重要规则
- 执行一个函数时,就会开辟一个新的栈空间
- 函数的变量是独立的,比如每个栈空间的变量 n 都是互相独立的
- 递归的走向必须是向递归的基准条件逐渐逼近的,否则就是无限递归了
- 当函数执行完毕,或遇到 return 语句,这个函数对应的栈空间和数据区就会被释放,且遵循谁调用,就将结果返回给谁
练习题
- 斐波那契问题
## 题目一:请使用递归的方式,求出斐波那契数 1,1,2,3,5,8,13… 给你一个整数 n,求出它的值是多少?
# 斐波那契数列 1,1,2,3,5,8,13…
# f(0)=1, f(1) = 1, f(n) = f(n-1) + f(n-2) (n >= 2)
def fibonacci(n):if n == 0:return 1elif n == 1:return 1else:return fibonacci(n - 1) + fibonacci(n - 2)
print(fibonacci(5))
- 猴子吃桃
## 题目二:猴子吃桃问题:有一堆桃子,猴子第一天吃了其中的一半,并再多吃了一个。以后每天猴子都吃其中的一半,然后再多吃一个。
# 当到第 10 天时,想再吃时(即还没吃),发现只有 1 个桃子了。问最初共多少个桃子?
"""
第 10天还有 1 个桃子
第9天还有:(1 + 1) * 2 = 4 个
第 8 天还有:(4 + 1) * 2 = 10 个
第 7 天还有:(10 + 1) * 2 = 22 个
...
"""
def eatPeach(day: int) -> int:"""查询这一天还剩多少个桃子:param day: 第几天:return: 这天还剩下几个桃子"""if day == 10:return 1return (eatPeach(day + 1) + 1) * 2# 第一天还有多少个桃子,也即最初有多少个桃子
print(eatPeach(1))
- 求函数值
## 题目三:求函数值,已知 f(1) = 3; f(n)= 2*f(n-1)+1;请使用递归的思想,求出 f(n)的值?
def f(n: int) -> int:if n == 1:return 3return 2 * f(n - 1) + 1
print(f(2))
- 汉诺塔
## 题目四:汉诺塔: 给定盘子的数量 num,有三个塔 a, b, c,打印出 num 个盘子从 a 塔移动到 c 塔的移动顺序
def hanoi_tower(num, a, b, c):"""打印指定数量 num 个盘子的移动顺序:param num: 盘子的数量:param a: 原始位置:param b: 中间借助位置:param c: 目标移动位置:return:"""if num == 1:# 只有一个盘,将其移动到 C 塔print(f"第1个盘:{a} -> {c}")else:# 多个盘情况:我们认为两个盘,即最下面的盘和上面所有盘# 1.先将上面所有盘移动到 B 塔,这时需要借助 C 塔来完成移动hanoi_tower(num - 1, a, c, b)# 2.然后移动最底下的盘print(f"第{num}个盘:{a} -> {c}")# 3.最后把剩余盘从 B 塔移动到 C 塔,这时需要借助 A 塔来完成移动hanoi_tower(num - 1, b, a, c)# 3个汉诺塔的移动顺序
hanoi_tower(3, "A", "B", "C")
以上示例输出结果如下:
:::success
第1个盘:A -> C
第2个盘:A -> B
第1个盘:C -> B
第3个盘:A -> C
第1个盘:B -> A
第2个盘:B -> C
第1个盘:A -> C
:::
函数作为参数传递
作用
将一个函数作为参数传递给另一个函数使用,提高了代码的复用性。
示例代码如下:
# 定义一个函数,可以返回两个数的最大值
def get_max_val(num1, num2):max_val = num1 if num1 > num2 else num2return max_valdef f1(fun, num1, num2):"""功能:调用fun返回num1和num2的最大值:param fun: 表示接收一个函数:param num1: 传入一个数:param num2: 传入一个数:return: 返回最大值"""return fun(num1, num2)def f2(fun, num1, num2):"""功能:调用fun返回num1和num2的最大值,同时返回两个数的和:param fun::param num1::param num2::return:"""return num1 + num2, fun(num1, num2)print(f1(get_max_val, 10, 20))
print(f2(get_max_val, 10, 20))
sum, max = f2(get_max_val, 10, 20)
print(f"sum: {sum}, max: {max}")
以上示例代码运行结果如下:
:::info
20
(30, 20)
sum: 30, max: 20
:::
示例二:计算器函数
# 定义运算函数
def add(a, b):return a + bdef subtract(a, b):return a - b# 高阶函数:接受运算函数作为参数
def calculate(operation, x, y):return operation(x, y) # 调用传入的函数# 传递函数作为参数
print(calculate(add, 5, 3)) # 输出: 8
print(calculate(subtract, 10, 4)) # 输出: 6
注意事项
- 函数作为参数传递,传递的不是数据,而是业务处理逻辑
- 传递函数时使用函数名而非函数调用(不带括号)
- 被传递的函数需满足目标函数的参数签名
lambda匿名参数
lambda函数定义
Python使用 lambda 关键字来创建函数。
lambda 函数是一种小型的、匿名的函数,可以有任意数量的参数,但只能有一个表达式。这种特性也决定了 lambda 函数只适合编写简单的函数。
lambda 函数不需要使用 def 关键字来定义函数
常用的场景:以函数的形式传参给其他函数使用,例如在 map()、filter()、reduce()等函数中
lambda 函数特点:
- lambda 函数是匿名的,它们没有函数名称,只能通过赋值给变量或作为参数传递给其他函数来使用。
- lambda 函数通常只包含一行代码,这使得它们适用于编写简单的函数。
lambda 函数语法:
lambda arguments: expression
- lambda是 python 的关键字,用于定义匿名函数
- arguments 是匿名函数的参数列表,可以为空,也可以有多个
- expression是一个表达式,用于计算并返回结果
以下示例的 lambda 函数没有参数列表:
f = lambda: print("你好,这是一个无参函数")
f()
输出结果为:
:::color2
你好,这是一个无参函数
:::
以下 lambda 函数用于计算参数 a和 10 的求和结果,并返回:
var = lambda a: a + 10
print(f"结果为{var(15)}")
输出结果为:
:::color2
结果为25
:::
lambda 函数也可以设置多个参数,用逗号隔开。
以下示例用于计算矩形(a,b)的面积:
area = lambda a, b: a * b
print(f"矩形面积为{area(10, 5)}")
输出结果为:
:::color2
矩形面积为50
:::
lambda 函数通常与内置函数如 map()、filter() 和 reduce() 一起使用,以便在集合上执行操作。例如:
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 输出: [1, 4, 9, 16, 25]
使用 lambda 函数与 filter() 一起,筛选偶数:
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 输出:[2, 4, 6, 8]
使用 reduce() 和 lambda 表达式计算一个序列的累积乘积:
from functools import reducenumbers = [1, 2, 3, 4, 5]# 使用 reduce() 和 lambda 函数计算乘积
product = reduce(lambda x, y: x * y, numbers)print(product) # 输出:120
return 语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的 return 语句返回 None。
:::color2
需要说明的是,None 虽然是空,但也是一个有效的数据,通过内置函数 id()也是有对应的值的。
:::
示例代码:
def getStr():print("hello")res = getStr()
print(res)
print(id(res))
以上输出结果:
:::color2
hello
None
4358644536
:::
全局变量和局部变量
基本介绍
- 全局变量:定义在函数外部,在整个程序范围内都可以访问,拥有全局作用域
- 局部变量:定义在函数内部,在函数内部可以访问,拥有局部作用于
代码示例:
# n1 是全局变量
n1 = 100def f1():# n2是局部变量n2 = 200print(n2) # 200# 可以访问全局变量n1print(n1) # 100# 调用
f1()
print(n1) # 100# 不能访问局部变量n2
# print(n2) # NameError: name n2' is not defined.注意事项
- 函数内部修改全局变量 n1,默认是新创建了一个变量n1,全局变量 n1 的值并不会被修改
n1 = 100def f1():# n1 重新定义了n1 = 200print(n1) # 200f1()
print(n1) # 100
- python 通过
global关键字允许函数内直接修改全局变量,这种方式下的修改是真的改变了全局变量的值
n1 = 100def f1():# n1 重新定义了global n1n1 = 200 # 全局变量n1的值被改为200print(n1) # 200f1()
print(n1) # 200
相关文章:

Python基础之函数
代码仓库地址:gitgithub.com:Liucc-123/python_learn.git 函数介绍 函数是组织好的、可重复使用的,用来实现单一、或相关功能的代码段。 函数可以提高应用的模块性和代码的可重复性。python 有许多内置的函数比如 print 打印函数,python 也…...

Python异步爬虫编程技巧:从入门到高级实战指南
Python异步爬虫编程技巧:从入门到高级实战指南 🚀 📚 目录 前言:为什么要学异步爬虫异步编程基础概念异步爬虫核心技术栈入门实战:第一个异步爬虫进阶技巧:并发控制与资源管理高级实战:分布式…...

Redis哨兵模式深度解析与实战部署
Redis哨兵模式深度解析与实战部署 文章目录 Redis哨兵模式深度解析与实战部署一、Redis哨兵模式理论架构详解1.1 哨兵模式的核心架构组成基础架构拓扑图 1.2 哨兵节点的核心功能模块1.2.1 监控模块(Monitoring)1.2.2 决策模块(Decision Makin…...

【软考高级系统架构论文】论边缘计算及其应用
论文真题 边缘计算是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的分布式开放平台(架构),就近提供边缘智能服务。边缘计算与云计算各有所长,云计算擅长全局性、非实时、长周期的大数据处理与分析,能够在长周期维护、业务决策支撑等领域发挥优势;…...
从设备树解析到触摸事件上报)
触摸屏(典型 I2C + Input 子系统设备)从设备树解析到触摸事件上报
触摸屏(典型 I2C Input 子系统设备)从设备树解析到触摸事件上报 以下是架构图,对触摸屏(典型I2C Input子系统设备)从设备树解析到触摸事件上报的全流程详细拆解,包含文字讲解和配套流程图: 注…...
方法的深度解析)
Java中==与equals()方法的深度解析
作为Java后端开发者,我们经常会遇到需要比较两个对象是否相等的情况。在Java中,运算符和equals()方法都可以用于比较,但它们之间存在着本质的区别。 1. 运算符 是一个比较运算符,它的行为取决于比较的类型: 1.1 比较…...

qt常用控件--02
文章目录 qt常用控件--02toolTip属性focusPolicy属性styleSheet属性补充知识点按钮类控件QPushButton 结语 很高兴和大家见面,给生活加点impetus!!开启今天的编程之路!! 今天我们进一步c11中常见的新增表达 作者&…...
)
AI-Sphere-Butler之如何将豆包桌面版对接到AI全能管家~新玩法(一)
环境: AI-Sphere-Butler VBCABLE2.1.58 Win10专业版 豆包桌面版1.47.4 ubuntu22.04 英伟达4070ti 12G python3.10 问题描述: AI-Sphere-Butler之如何将豆包桌面版对接到AI全能管家~新玩法(一) 聊天视频: AI真…...

为什么android要使用Binder机制
1.linux中大多数标准 IPC 场景(如管道、消息队列、ioctl 等)的进程间通信机制 ------------------ ------------------ ------------------ | 用户进程 A | | 内核空间 | | 用户进程 B | | (User Spa…...

Apache SeaTunnel Flink引擎执行流程源码分析
目录 1. 任务启动入口 2. 任务执行命令类:FlinkTaskExecuteCommand 3. FlinkExecution的创建与初始化 3.1 核心组件初始化 3.2 关键对象说明 4. 任务执行:FlinkExecution.execute() 5. Source处理流程 5.1 插件初始化 5.2 数据流生成 6. Transform处理流程 6.1 插…...

XML读取和设置例子
在Qt C中,可以使用Qt的 QDomDocument类来读取、更新和保存XML文件。这个类提供了对XML文档的强大操作能力,支持通过DOM(文档对象模型)对XML进行读取、修改、添加和删除节点等操作。 下面是一个详细的例子,演示如何在Qt…...

数据标注师学习内容
目录 文本标注词性标注实体标注 图像标注语音标注 文本标注 词性标注 第一篇 第二篇 实体标注 点击这里 关系标注 事件标注 意图标注 关键词标注 分类标注 问答标注 对话标注 图像标注 拉框标注 关键点标注 2D标注 3D标注 线标注 目标跟踪标注 OCR标注 图像分类标注 语音…...

如何实现财务自由
如果有人告诉你,普通人也可以在5到10年内,而不是40到50年后实现财务自由、彻底退休,你会不会觉得对方在开玩笑?但这并非天方夜谭,《百万富翁快车道》的作者MJ德马科就是成功案例。他曾和多数人一样做底层工作ÿ…...

一些想法。。。
1.for里面的局部变量这种还是在for里面定义比较好 比如 for(int i 0;i<n;i){ int num; cin>>num; } 实不相瞒,有一次直接cin了i怎么都没看出来哪里错了。。。 2.关于long long 如果发现中间结果大约是10^9,就要考虑int 溢出 即用 long …...

基于分布式部分可观测马尔可夫决策过程与联邦强化学习的低空经济智能协同决策框架
基于分布式部分可观测马尔可夫决策过程与联邦强化学习的低空经济智能协同决策框架 摘要: 低空经济作为新兴战略产业,其核心场景(如无人机物流、城市空中交通、低空监测)普遍面临环境动态性强、个体观测受限、数据隐私敏感及多智能体协同复杂等挑战。本文创新性地提出一种深…...

github常用插件
一,文档辅助阅读系列:自动化wiki处理 1,deepwiki https://deepwiki.com/ 将我们看不懂的官方code文档转换为wiki,更加便于理解。 其实能够翻阅的仓库很有限,比如说: 但是有很多仓库并没有indexÿ…...

python3字典
1 字典简介 字典是一种可变容器模型,且可存储任意类型对象。字典每个基本元素都包括两个部分: 键(key)和键对应的值(value) 每个键值 key>value 对用冒号: 分割,每个对之间用逗号(,)分割&am…...

华为云 Flexus+DeepSeek 征文|增值税发票智能提取小工具:基于大模型的自动化信息解析实践
华为云 FlexusDeepSeek 征文|增值税发票智能提取小工具:基于大模型的自动化信息解析实践 前言背景 企业财务处理中,增值税发票信息手动提取存在效率低、易出错等痛点,华为云 Flexus 弹性算力联合 DeepSeek 大模型,通过…...

[特殊字符] OpenCV opencv_world 模块作用及编译实践完整指南
📌 什么是 opencv_world 模块? opencv_world 是 OpenCV 官方提供的一个 大型集成动态库。它将 OpenCV 所有启用的模块(例如 core, imgproc, highgui, videoio, dnn, photo 等)打包到一个单一的动态库文件(如 Linux 的…...

目标检测之YOLOv5到YOLOv11——从架构设计和损失函数的变化分析
YOLO(You Only Look Once)系列作为实时目标检测领域的标杆性框架,自2016年YOLOv1问世以来,已历经十余年迭代。本文将聚焦YOLOv5(2020年发布)到YOLOv11(2024年前后)的核心技术演进&am…...

Java的SpringAI+Deepseek大模型实战【二】
文章目录 背景交互方式1、等待式问答2、流式问答 设置角色环绕增强1)修改controller2)修改配置日志级别 处理跨域 背景 上篇【Java的SpringAIDeepseek大模型实战【一】】搭建起浏览器交互的环境,如何进行流式问答,控制台打印日志…...

OpenCV——霍夫变换
霍夫变换 一、霍夫变换原理二、霍夫线检测2.1、标准霍夫变换2.2、概率霍夫变换 三、霍夫圆检测3.1、霍夫圆检测的原理3.2、霍夫梯度法 一、霍夫变换原理 霍夫变换(Hough TRansform)是从图像中识别几何图形的基本方法,由Paul Hough于1962年提…...

线程池 JMM 内存模型
线程池 & JMM 内存模型 文章目录 线程池 & JMM 内存模型线程池线程池的创建ThreadPoolExecutor 七大参数饱和策略ExecutorService 提交线程任务对象执行的方法:ExecutorService 关闭线程池的方法:线程池最大线程数如何确定? volatile…...

PillarNet: Real-Time and High-PerformancePillar-based 3D Object Detection
ECCV 2022 paper:[2205.07403] PillarNet: Real-Time and High-Performance Pillar-based 3D Object Detection code:https://github.com/VISION-SJTU/PillarNet-LTS 纯点云基于pillar3D检测模型 网络比较 SECOND 基于vo…...

配电抢修场景案例
以配电抢修场景为例来展示关键业务活动。配电抢修愿景分成业务逻辑、业务活动、业务特征、技术支撑、KPI五个层次,分别从策略、执行、评价、资源、协同5个方面描述配电抢修愿景的关键业务活动。...

H5新增属性
✅ 一、表单相关新增属性(Form Attributes) 这些属性增强了表单功能,提升用户体验和前端验证能力。 1. placeholder 描述:在输入框为空时显示提示文本。示例: <input type"text" placeholder"请输…...
)
C# Task 模式实现 Demo(含运行、暂停、结束状态)
下面是一个完整的 C# Task 实现示例,包含运行(Running)、暂停(Paused)和结束(Completed)状态控制: 1. 基本实现(使用 CancellationToken 控制) using System; using System.Threading; using System.Threading.Tasks;public cla…...

Docker健康检查
目录 1.命令 2.验证 1.命令 docker run -itd --name nginx -v data:/etc/nginx/ -v log:/var/log/ -p 8080:80 \ --health-cmd"curl http://127.0.0.1:80" \ --health-interval30s \ --health-timeout5s \ --health-retries3 \ --health-start-period18s \ nginx:…...

Linux笔记---线程控制
1. 线程创建:pthread_create() pthread_create() 是 POSIX 线程库(pthread)中用于创建新线程的函数。调用该函数后系统就会启动一个与主线程并发的线程,并使其跳转到入口函数处执行。 #include <pthread.h>int pthread_cr…...
智能体在测试时的计算量)
【AI论文】扩展大型语言模型(LLM)智能体在测试时的计算量
摘要:扩展测试时的计算量在提升大型语言模型(LLMs)的推理能力方面已展现出显著成效。在本研究中,我们首次系统地探索了将测试时扩展方法应用于语言智能体,并研究了该方法在多大程度上能提高其有效性。具体而言…...

Spring--IOC容器的一些扩展属性
一、BeanFactoryPostProcessor和BeanPostProcessor BeanFactoryPostProcessor的作用是在实例化前修改BeanDefinition的属性 BeanPostProcessor的作用是在bean完成创建实例、填充属性之后,初始化阶段的前后都会对bean进行操作,使用postProcessBeforeIni…...

WebClient 功能介绍,使用场景,完整使用示例演示
WebClient 功能介绍 WebClient 是 Spring 5 中引入的响应式 HTTP 客户端,用于替代已弃用的 RestTemplate,专为异步非阻塞编程设计,基于 Reactor 框架实现。其核心功能包括: 异步与非阻塞 通过 Mono 和 Flux 处理请求与响应&#…...

[Java 基础]ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制。 ArrayList 的示意可以看 VCR:https://visualgo.net/en/array 创建 ArrayList 对象 final ArrayList<String> strings new ArrayList<>();这里创建 …...

用无人机和AI守护高原净土:高海拔自然保护区的垃圾检测新方法
这篇题为《Automatic Detection of Scattered Garbage Regions Using Small Unmanned Aerial Vehicle Low-Altitude Remote Sensing Images for High-Altitude Natural Reserve Environmental Protection》的论文,发表于 Environmental Science & Technology&am…...

《Redis高并发优化策略与规范清单:从开发到运维的全流程指南》
Redis高并发优化策略与规范清单:从开发到运维的全流程指南 在互联网应用的后端架构中,Redis凭借其高性能、高并发的特性,成为缓存和数据存储的首选方案。无论是电商抢购、社交平台的点赞计数,还是在线旅游平台的实时数据查询&…...

Linux基本指令篇 —— man指令
man命令是Linux系统中最重要的命令之一,它是"manual"(手册)的缩写,用于查看Linux系统中命令、函数、配置文件等的详细说明文档。man命令是Linux系统管理员和开发者的必备工具,熟练掌握man命令可以大大提高工…...

Spring Boot使用MCP服务器
1、JDK版本17 2、pom文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apac…...

学习Linux进程冻结技术
原文:蜗窝科技Linux进程冻结技术 功耗中经常需要用到,但是linux这块了解甚少,看到这个文章还蛮适合我阅读的 1 什么是进程冻结 进程冻结技术(freezing of tasks)是指在系统hibernate或者suspend的时候,将…...

Docker基本概念——AI教你学Docker
1.1 Docker 概念详解 1. Docker 是什么? Docker 是一个开源的应用容器引擎,它让开发者可以将应用及其依赖打包到一个可移植的容器(Container)中,并在任何支持 Docker 的 Linux、Windows 或 macOS 系统上运行。这样做…...

第十六届蓝桥杯C/C++程序设计研究生组国赛 国二
应该是最后一次参加蓝桥杯比赛了,很遗憾,还是没有拿到国一。 大二第一次参加蓝桥杯,印象最深刻的是居然不知道1s是1000ms,花了很多时间在这题,后面节奏都乱了,抗压能力也不行,身体也不适。最后…...
)
Python 数据分析与可视化 Day 5 - 数据可视化入门(Matplotlib Seaborn)
🎯 今日目标 掌握 Matplotlib 的基本绘图方法(折线图、柱状图、饼图)掌握 Seaborn 的高级绘图方法(分类图、分布图、箱线图)熟悉图像美化(标题、标签、颜色、风格)完成一组学生成绩数据的可视化…...
:SDP)
WebRTC(八):SDP
SDP 概念 SDP 是一种描述多媒体通信会话的文本格式(基于 MIME,RFC 4566)。本身 不传输数据,仅用于在会话建立阶段传递信息。常与 SIP(VoIP)、RTSP、WebRTC 等协议配合使用。 用途 描述媒体类型…...
)
《哈希表》K倍区间(解题报告)
文章目录 零、题目描述一、算法概述二、算法思路三、代码实现四、算法解释五、复杂度分析 零、题目描述 题目链接:K倍区间 一、算法概述 计算子数组和能被k整除的子数组数量的算法。通过前缀和与哈希表的结合,高效地统计满足条件的子数组。 需要注…...

牛津大学开源视频中的开放世界目标计数!
视频中的开放世界目标计数 GitHub PaPer Niki Amini-Naieni nikianrobots.ox.ac.uk Andrew Zisserman azrobots.ox.ac.uk 视觉几何组(VGG),牛津大学,英国 图 1:视频中的目标计数:给定顶行的视频&#…...

1.2、CAN总线帧格式
1、帧类型 2、帧类型介绍 (1)数据帧 扩展格式是为了扩展ID,ID号每4位一个字节(11位最大ID号为0x7FF) (2)遥控帧 遥控帧由于没有Data,所以DLC可能没有意义,可给任意值&am…...

DeepSeek今天喝什么随机奶茶推荐器
用DeepSeek生成了一个随机奶茶推荐器-今天喝什么,效果非常棒!UI界面美观。 提示词prompt如下 用html5帮我生成一个今天喝什么的网页 点击按钮随机生成奶茶品牌等,要包括中国常见的知名的奶茶品牌 如果不满意还可以随机再次生成 ui界面要好看 …...

词编码模型怎么进行训练的,输出输入是什么,标签是什么
词编码模型怎么进行训练的,输出输入是什么,标签是什么 词编码模型的训练本质是通过数据驱动的方式,将离散的文本符号映射为连续的语义向量。 一、训练机制:从符号到向量的映射逻辑 1. 核心目标 将单词/子词(Token)映射为低维向量,使语义相关的词在向量空间中距离更近…...
LSTM、GRU 与 Transformer网络模型参数计算
参数计算公式对比 模型类型参数计算公式关键组成部分LSTM4 (embed_dim hidden_size hidden_size hidden_size)4个门控结构GRU3 (embed_dim hidden_size hidden_size hidden_size)3个门控结构Transformer (Encoder)12 embed_dim 9 embed_dim ff_dim 14 embed_dim…...

nnv开源神经网络验证软件工具
一、软件介绍 文末提供程序和源码下载 用于神经网络验证的 Matlab 工具箱,该工具箱实现了可访问性方法,用于分析自主信息物理系统 (CPS) 领域中带有神经网络控制器的神经网络和控制系统。 二、相关工具和软件 该工具箱利用神经…...

SQLite3 在嵌入式系统中的应用指南
SQLite3 在嵌入式系统中的应用指南 一、嵌入式系统中 SQLite3 的优势 SQLite3 是嵌入式系统的理想数据库解决方案,具有以下核心优势: 特性嵌入式系统价值典型指标轻量级适合资源受限环境库大小:500-700KB零配置无需数据库管理员开箱即用无…...