51c自动驾驶~合集43
我自己的原文哦~ https://blog.51cto.com/whaosoft/12930230
#ChatDyn
上交大最新ChatDyn:一句话操纵三维动态
理解和生成真实的三维虚拟世界是空间智能的核心。所生成的三维虚拟世界能够为自动驾驶、具身智能等AI系统提供高质量闭环仿真训练场,高效提供源源不断的训练数据,并以极低成本合成罕见情景进行测试。目前,虽然我们有了Diffusion,三维虚拟世界的画质呈现大幅提升,但是虚拟世界中前景物体交互行为的一致性、可靠性、可控性仍然很低,限制了这一领域取得实质性突破。
为了突破现有困境,上海交通大学人工智能学院陈思衡团队联合上海人工智能实验室,马普所,苏黎世联邦理工和香港大学的研究者们重磅推出ChatDyn,这是首个实现自然语言驱动的街景多参与者互动与真实动态生成的系统,统筹考虑高层次的规划和低层次执行,一并生成丰富并带有交互信息的交通参与者动态。如样例1所示,输入指令“A person is taking a taxi at the left roadside, and a vehicle overtakes the taxi. Two persons are walking together with one's arm around another's shoulder. A person is chasing another person along the roadside.”即可生成相关动态场景,包括了人与人交互,人与车交互等复杂动态交互。
,时长00:07
,时长00:07
样例 1(上图白膜,下图带蒙皮)包含多种不同交互类型(人车交互,人人交互),并能够依据高层级轨迹控制行人、车辆动态。指令:A person is taking a taxi at the left roadside, and a vehicle overtakes the taxi. Two persons are walking together with one's arm around another's shoulder. A person is chasing another person along the roadside.
ChatDyn的核心理念在于结合高层次规划与低层次控制,以创建一个真实的仿真系统。大型语言模型(LLM)擅长高层次规划,而基于物理的方法则非常适合生成细粒度的低层次控制。基于这一观察,ChatDyn将多LLM代理用于高层次规划,并结合基于物理的执行器进行低层次生成。通过集成高层次和低层次组件,ChatDyn允许用户输入语言指令来指定需求。然后,它会根据指定的场景生成真实的动态,涵盖包括行人和车辆在内的多种交通参与者,并支持参与者之间复杂多样的互动。
主页链接:https://vfishc.github.io/chatdyn/
论文链接:https://arxiv.org/pdf/2412.08685
ChatDyn整体设计
ChatDyn能够解读并分析用户的语言指令,然后生成与之相符的场景动态。ChatDyn采用了两阶段的处理流程:高层次规划阶段负责在复杂和抽象的指令下规划轨迹和行为;低层次生成阶段则负责生成细粒度的真实动态。由于用户指令可能包含许多需要精确控制的具体细节,以及需要理解的抽象语义,ChatDyn利用多LLM-agent角色扮演方法,将每个交通参与者视为一个LLM-agent。该方法充分利用了LLM在理解语义信息和广泛常识上的能力,通过特定的工具和交互过程完成高层次的轨迹和行为规划。每个交通参与者的对应代理还配备了一个执行器作为工具之一。在高层次规划完成后,执行器利用规划结果执行低层次生成过程。执行器基于高层次规划生成细粒度、真实且物理上可行的动态。

图 1 ChatDyn系统结构
基于规划的行人动态生成
行人执行器(PedExecutor),根据高层次规划中规划的轨迹和行为生成低层次的行人动态。行人行为可以细分为由语言直接指定的单一代理行为和多个代理之间发生的互动行为。因此,挑战在于如何同时处理轨迹跟随、单一代理的运动规范以及多代理之间的互动,同时保持类人品质。为此,PedExecutor利用统一的多任务训练,通过单一策略执行LLM规划的轨迹、单一代理行为和多代理互动。PedExecutor采用了多任务统一训练的方式,能够使用一个策略网络实现多种不同控制信号下的生成,并能够完成预先设定的交互行为且结合物理引擎得到相应的物理反馈。为了提升最终行人动态的质量和真实性,动作空间采用了层级控制提供先验信息,而奖励函数使用身体遮蔽的对抗性运动先验(AMP)来鼓励类人的控制行为。最终,PedExecutor返回的动态能够遵循规划轨迹并完成预期行为,从而生成真实的行人动态。

图 2 PedExecutor结构设计
基于规划的车辆动态生成
车辆执行器(VehExecutor),根据高层次规划的轨迹生成最终的真实且物理上可行的车辆动态控制策略,这些轨迹在初始阶段可能会违反某些动态约束。为了引入物理约束并实现精确控制,VehExecutor利用基于物理的过渡环境,并结合历史感知的状态和动作空间设计。最终的动态通过累积车辆的位置和航向信息从环境中获得。

图 3 VehExecutor结构设计
实验结果
系统整体效果
我们在开头展示了系统输出来自两个场景。每个生成的输出都包含了丰富的交通参与者,基于用户的指令进行生成。从系统的输出中,我们可以看到以下几点:(i)互动得到了全面展示,包括人车互动(例如打车、避让、减速)、车与车的互动(例如换道、超车),以及人与人之间的互动(例如推搡、追逐、肩并肩走)。不同类型交通参与者之间的这些互动使得场景动态更加多样化和真实;(ii)系统实现了精确和细致的控制,每个场景描述都较为复杂,可能包含抽象的语义信息。通过多LLM-agents角色扮演的设计,复杂的指令得到了准确分析和执行,抽象的语义信息有效地被分解成可执行的指令,最终生成动态;(iii)生成的结果高度逼真。基于物理的控制策略使行人和车辆的动态表现得既真实又直观,特别是在展现人与人之间的互动时,突出体现了物理反馈。指令:A person pushes another person, and another person is making a phone call, then walks along the roadside. A vehicle turns right at the intersection, and a hurried vehicle overtakes a stationary one.
,时长00:07
,时长00:07
样例2(上图白膜,下图带蒙皮)包含多种交互,能够实现交互的物理反馈,并能够控制行人、车辆进行具体细致的行为。指令:A person pushes another person, and another person is making a phone call, then walks along the roadside. A vehicle turns right at the intersection, and a hurried vehicle overtakes a stationary one.
高层次规划对比
我们将LLM agent生成的规划轨迹与现有的基于语言的交通生成方法进行比较,验证高层级规划的结果是否让用户满意。结果表明,ChatDyn始终生成更准确的规划结果,这些结果更符合描述,且更受用户偏好。我们还提供了视觉示例,其中也展示了ChatDyn在包含行人的场景中的一些规划结果。ChatDyn能够准确满足需求,生成符合规范的高质量输出,即使在涉及行人的场景中也能表现优异。

表 1 高层次规划对比

图 4 高层次规划对比
行人动态生成对比
我们评估了PedExecutor在轨迹跟随和动作模仿任务中的表现。在分层控制和相关训练策略的支持下,PedExecutor生成了更高质量的动态,并在跟随和模仿任务中展示了高度竞争的表现。我们还评估了执行互动任务的过程,以确定每种方法在完成这些任务中的有效性。凭借分层控制和身体遮蔽的AMP,PedExecutor不仅在任务成功率上表现优秀,还能保持高质量、类人的输出。

表 2 PedExecutor模仿与跟随任务对比

表 3 PedExecutor交互任务对比

图 5 PedExecutor交互任务可视化对比
,时长00:34
视频 3. PedExecutor对比视频
车辆动态生成对比
我们通过测量位置误差和速度误差,评估了VehExecutor在不同初始速度下的精度。VehExecutor在所有速度下始终表现出最佳的准确率。

表 4 VehExecutor对比实验结果
,时长00:17
视频 4 VehExecutor对比视频
总结
ChatDyn的突破,标志着我们在模拟真实世界动态方面迈出了重要一步。通过将大型语言模型(LLM)的高层次规划能力与基于物理的方法的低层次控制相结合,ChatDyn能够精确地执行复杂的语言指令,从而生成街道场景中交互式、可控制及真实的参与者动态。这种结合不仅提高了模拟的准确性,还极大地增强了虚拟环境的真实感和沉浸感。ChatDyn能够细致全面地模拟场景物体动态,进而能够作为先验辅助下游方式例如渲染引擎、生成模型等进行成像,助力构建更加真实,可控的世界模型。ChatDyn中的相关方法也能够在特定优化下应用于室内等场景,进行室内场景的动态仿真。
#UniGraspTransformer
各种形状和方向的物体都能抓取!UniGraspTransformer不一般
论文标题:UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
论文链接:https://arxiv.org/pdf/2412.02699
项目链接:https://dexhand.github.io/UniGraspTransformer/
作者单位:微软亚洲研究院 悉尼大学 新加坡国立大学
UniGraspTransformer的出发点
UniGraspTransformer是一种基于Transformer的通用网络,用于灵巧机器人的抓取任务,具有简化训练流程并提升可扩展性与性能的优势。与需要复杂多步骤训练流程的先前方法(如UniDexGrasp++)不同,UniGraspTransformer采用简化的训练过程:首先,通过强化学习为单个物体训练专用策略网络,以生成成功的抓取轨迹;随后,将这些轨迹蒸馏到一个统一的通用网络中。本文的方法使得UniGraspTransformer能够高效扩展,支持多达12个自注意力模块,用于处理数千种具有不同姿态的物体。此外,该模型在理想化输入和现实世界输入中都表现出了良好的泛化能力,适用于基于状态和基于视觉的环境。值得注意的是,UniGraspTransformer可以为各种形状和方向的物体生成更广泛的抓取姿态,从而实现更加多样化的抓取策略。实验结果表明,在多个物体类别上,UniGraspTransformer相比最先进的方法UniDexGrasp++表现出显著的性能提升。在基于视觉的场景中,其抓取成功率分别在以下任务中实现了提升:对于已见物体提高3.5%,对于已见类别的未见物体提高7.7%,对于完全未见的物体提高10.1%。
方法设计
灵巧机器人的抓取任务依然是机器人领域的一大挑战,尤其是在处理形状、尺寸及物理属性多样的物体时更为复杂。灵巧机械手由于其多自由度以及复杂的控制需求,在执行操作任务时面临独特的困难。尽管方法如UniDexGrasp++ 在这一领域取得了显著进展,但当单一网络需要处理大量且多样化的物体时,其性能会显著下降。此外,UniDexGrasp++ 采用了多步骤的训练流程,包括策略学习、基于几何的聚类、课程学习以及策略蒸馏等,这种复杂的训练方式限制了方法的可扩展性并降低了训练效率。
在本研究中,本文简化了通用网络的训练流程,使其能够处理数千种物体,同时提升了性能和泛化能力。本文提出的工作流程清晰简洁:
- 为训练集中每个物体单独训练策略网络:利用强化学习方法,通过精心设计的奖励函数,引导机器人掌握针对特定物体的抓取策略;
- 生成大量成功抓取轨迹:使用这些经过充分训练的策略网络,生成数百万条成功的抓取轨迹;
- 训练通用Transformer网络:基于这些丰富的抓取轨迹集,在监督学习框架下训练一个基于Transformer的通用网络,即UniGraspTransformer,使其能够高效泛化到训练中见过的物体以及全新未见的物体。
本文的架构提供了以下四个主要优势:
- 简洁性:本文直接以离线方式将所有单独的强化学习策略蒸馏到一个通用网络中,无需使用任何额外的技术,例如网络正则化或渐进蒸馏。
- 可扩展性:较大的抓取网络通常能够处理更广泛的物体,并在形状和尺寸的变化中表现出更强的鲁棒性。本文的方法利用离线蒸馏,使得最终网络——UniGraspTransformer——可以设计为更大规模,支持多达12个自注意力模块。与传统的在线蒸馏方法相比,这种方法提供了显著的灵活性和容量,而后者通常依赖于较小的MLP网络以确保收敛,但限制了可扩展性。此外,本文的专用策略网络设计为轻量级,每个网络仅需要处理单个物体,从而在不牺牲性能的前提下确保效率。
- 灵活性:每个专用策略网络在一个受控的、理想化的环境中进行训练,在该环境中,系统的全状态(包括物体表示,如完整的点云;灵巧机械手状态,如手指关节角度;以及它们的交互,如手-物体距离)是完全可观测且高度精确的。本文的架构能够将这种理想环境下的知识蒸馏到更实用的真实世界环境中,即使某些观测可能不完整或不可靠。例如,物体的点云可能存在噪声,或者物体姿态的测量可能不够精确。这些专用策略网络的主要作用是为各种物体生成多样化的成功抓取轨迹。在蒸馏过程中,这些抓取轨迹作为标注数据,使本文能够利用现实环境中的输入(如带噪声的物体点云和估计的物体姿态)训练UniGraspTransformer模型,从而预测出与理想环境中的成功抓取轨迹高度一致的动作序列。
- 多样性:本文的更大规模通用网络结合离线蒸馏策略,不仅能够抓取数千种不同的物体,还展现出为各种方向的物体生成更广泛抓取姿态的能力。这相较于先前的方法(如UniDexGrasp++)有显著提升,后者通常在不同物体间生成重复且单一的抓取姿态。
在本文的实验中,所提出的方法在多个评估环境下相较于现有最先进方法UniDexGrasp++展现了显著的性能提升。具体而言,本文在两种设置下对方法进行了评估:
- 基于状态的设置:在此设置中,物体的观测信息与灵巧机械手的状态由模拟器提供,具有完全的精确性。
- 基于视觉的设置:在此设置中,物体的点云由多视图重建生成。
在多种物体类型上,本文的方法始终优于UniDexGrasp++,包括已见物体、已见类别中的未见物体,以及来自未见类别的完全未见物体,如图1所示。例如,在基于视觉的设置下,本文的方法分别在以下任务中实现了性能提升:对已见物体提高3.5%,对已见类别的未见物体提高7.7%,对完全未见类别的物体提高10.1%。
图1. UniDexGrasp、UniDexGrasp++ 和本文提出的 UniGraspTransformer 在基于状态和基于视觉两种设置下的性能比较。对于每种设置,成功率分别在以下三种任务中进行评估:已见物体、已见类别中的未见物体,以及来自未见类别的完全未见物体。
图2. UniGraspTransformer 概览
(a) 专用策略网络训练:每个单独的强化学习策略网络被训练以抓取特定物体,并适应不同的初始姿态。
(b) 抓取轨迹生成:每个策略网络生成 条成功的抓取轨迹,构成轨迹集合 。
(c) UniGraspTransformer 训练:利用轨迹集合
本文研究了两种设置——基于状态和基于视觉。这两种设置的主要区别体现在物体状态和手-物体距离的输入表示(图中以“*”标注)。S-Encoder 和 V-Encoder 的具体架构请参考图3。
图3. 基于状态的设置中物体点云编码器 S-Encoder 的网络架构示意图
该过程从物体点云中采样 1,024 个点,生成维度为
在推理阶段,仅使用编码器,将物体点云转换为 128 维的物体特征。
表1. 专用策略网络的输入类型
输入被组织为五个组别,每组的具体元素定义详见附录。这些输入类型同样适用于本文的 UniGraspTransformer。
实验结果
图4. 抓取姿态多样性的定量分析
图5. 比较 UniDexGrasp++(上排)和本文提出的 UniGraspTransformer(下排)生成的抓取姿态。每列展示了同一物体在相同初始姿态下的两种不同抓取姿态。
表2. 与现有最先进方法在灵巧机器人抓取任务中的通用模型对比
在基于状态和基于视觉的设置下,通过成功率进行评估。对于已见类别中的未见物体及完全未见类别的物体的评估,反映了模型的泛化能力。标记 † 的结果为 UniDexGrasp++ 中报告的数据。“Obj.” 表示物体,“Cat.” 表示类别。
表3. 不同 值对 UniGraspTransformer 性能的影响分析
针对每个专用策略网络(共 3,200 个),本文生成 条成功的抓取轨迹,并将其蒸馏到 UniGraspTransformer 中。该表分析了随着
表4. UniGraspTransformer 中自注意力模块数量对性能的影响分析
模型由
表5. 不同数量专用策略网络蒸馏到 UniGraspTransformer 的影响分析
表6. 不同输入组件对 UniGraspTransformer 训练的影响
“Prev.”:先前状态;“Obj.”:物体;“Feat.”:特征;“Dist.”:距离;“SR”:成功率。
表7. 使用近似估计(特别是局部物体点云的中心和PCA)对性能的提升
表8. 基于视觉的物体编码器在是否使用蒸馏损失情况下对 UniGraspTransformer 性能的影响
表9. 引入奖励 和两种奖励变体 对专用策略网络性能的影响
总结
本文提出了UniGraspTransformer,一种基于Transformer的通用网络,用于简化灵巧机器人抓取任务的训练流程,同时在抓取策略的可扩展性、灵活性和多样性方面实现显著提升。本文的方法通过专用的强化学习策略网络为单个物体生成抓取轨迹,随后采用高效的离线蒸馏过程,将这些成功的抓取轨迹整合到一个单一的、可扩展的模型中,从而简化了传统复杂的训练管线。UniGraspTransformer 能够处理数千种物体及其多样化的姿态,展现出在基于状态和基于视觉的多种设置中的鲁棒性和适应性。尤其值得注意的是,该模型在已见物体、已见类别的未见物体以及全新类别的未见物体上显著提升了抓取成功率,相较当前最先进方法,在各类评估环境下均实现了大幅性能改进。
#DrivingRecon
港科技最新DrivingRecon:可泛化自动驾驶4D重建新SOTA!
从这一两年发表的论文数量可以看出,自动驾驶街景的重建与仿真备受关注,由此构建的自动驾驶仿真器对corner case的生成以及端到端模型的闭环评估/测试都非常重要,本次分享的是一篇关于自动驾驶场景4D重建的工作DrivingRecon。
- 论文链接: https://arxiv.org/abs/2412.09043
- 开源地址: https://github.com/EnVision-Research/DriveRecon
过去有很多使用3DGS或者Diffusion来做自动驾驶街景重建/生成的工作,比较具有代表性的是StreetGaussian,OmniRe这一类借助3D bbox将静态背景和动态物体解耦的框架,后来又出现了使用4D NeRF学习动态信息的方法,虽然取得了不错的效果,但这些方法都有一个共性,就是需要不断的训练来进行重建,即每个场景训练一个模型,非常耗时。因此作者提出了一种可泛化的自动驾驶4D重建模型DrivingRecon。在模型中,作者引入了PD-Block来更好的融合相邻视角的图像特征,消除重叠区域的高斯;也引入了Temporal Cross-attention来增强时序的信息融合,并且解耦动态和静态物体来更好的学习几何和运动特征。实验结果表明,与现有的视图合成方法相比,DrivingRecon 方法显著提高了场景重建质量和新视图合成。此外,作者还探讨了 DrivingRecon 在模型预训练、车辆自适应和场景编辑中的应用。
相关工作回顾
驾驶场景重建
现有的自动驾驶模拟引擎如 CARLA或 AirSim,在创建虚拟环境时需要花费很多时间,而且生成的数据缺乏现实性。Block-NeRF和 Mega-NeRF提出将场景分割成不同的Block用于单独建模。Urban辐射场利用来自 LiDAR 的几何信息增强了 NeRF 训练,而 DNMP利用预先训练的可变形mesh primitive来表示场景。Streetsurf将场景分为近景、远景和天空类别,获得较好的城市街道表面的重建效果。MARS使用单独的网络对背景和车辆进行建模,建立了一个实例感知的仿真框架。随着3DGS的引入,DrivingGaussian引入了复合动态高斯图和增量静态高斯,而 StreetGaussian优化了动态高斯的跟踪姿态(位姿),并引入了四维球谐函数,用于不同时刻的车辆外观建模。Omnire进一步关注驾驶场景中非刚性对象的建模,例如运动的行人。然而,这些重建算法需要耗时的迭代来建立一个新的场景。
大型重建模型
一些工作提出通过训练神经网络来直接学习完整的重建任务,从而大大提高了重建速度。LRM利用大规模多视图数据集来训练基于Transformer的 NeRF 重建模型,训练完的模型具有更好的泛化性,在单次模型前向传递中,从稀疏姿态图像中重建以物体为中心的3D形状质量更高。类似的工作研究了将场景表示改变为高斯溅射,也有一些方法改变模型的架构以支持更高的分辨率,并将方法扩展到3D 场景。L4GM 利用时间交叉注意力融合多帧信息来预测动态物体的高斯表示。然而,对于自动驾驶,还没有人探索融合多视图的特殊方法。简单的模型会预测相邻视图的重复高斯点,显著降低了重建性能。此外,稀疏的图像监督和大量的动态物体进一步让重建的任务变得更复杂。
文章主要贡献如下:
- DrivingRecon是第一个专门为环绕视图驾驶场景设计的前馈4D 重建模型
- 提出了 PD-Block,学习从不同的视角和背景区域去除冗余的高斯点。该模块还学会了对复杂物体的高斯点进行扩张,提高了重建的质量
- 为静态和动态组件设计了渲染策略,允许渲染图像跨时间序列进行有效监督
- 验证了算法在重建、新视图合成和跨场景泛化方面的性能
- 探索了 DrivingRecon 在预训练、车辆适应性和场景编辑任务中的有效性
方法详解
通常,先看一下论文的框架图有益于对整体的理解,DrivingRecon的整体框架如下:
为了得到一种generalizable的模型,那模型必然不能和数据是一一对应的关系,实现这一步的关键就是提取图像数据特征然后再进行后面的步骤,这个思路很常见,类似的还有GaussianFormer等。首先使用一个共享图像编码器对图像提取特征;接下来使用一个深度估计网络预测对应图像的深度,然后结合相机的内外参得到世界坐标系下的点云(x,y,z),并和图像特征拼接得到具有几何信息的特征。对于4D的任务,Temporal Cross Attention的是很常见且有用的模块,用来融合不同时序的特征,DrivingRecon也有使用到,可以看下文的细节;然后再用一个解码器增强特征的分辨率,最后,高斯适配器将解码的特征转换为高斯点(即scale,alpha等)和分割输出。
以上是DrivingRecon的整体思路,下面看一些细节:
3D Position Encoding
这部分主要是为了融合不同视角和不同时间间隔的特征:首先用DepthNet获得uv坐标下的像素深度d_(u,v),方法也很简单,直接使用Tanh激活函数来处理第一个通道的图像特征,然后再将深度投影到世界坐标系:
![]()
最后结合图像特征一起输入到PD-Block进行多视角特征融合。为了更好的融合,作者在训练时使用lidar得到的稀疏深度进行约束,即lidar点投影到图像上与之对应的深度算loss,具体计算为:
![]()
其中为有效深度的mask。
Temporal Cross Attention
因为视角的稀疏性,精确的街景甚至其他场景的重建是非常困难的。为了获取更多的有用特征,增强场景建模效果,在时间维度或空间维度来融合特征是比较常见的方法。文章中的方法可以简单表示为:

其中x是输入的特征,B表示Batch size, T表示时间维度,V表示视角个数,H,W,C表示特征的高,宽以及通道数。注意,与更为常见的时序交叉注意力不一样的是,这里同时考虑时间空间的信息融合, 从倒数第二维度可以看出。
Gaussian Adapter
由两个卷积blocks构成,输入是时序融合后的特征,输出分割c,深度类别,深度回归修正,RGB颜色rgb,alpha,scale,rotation,UV坐标偏移量[∆u,∆v],optical flow [∆x,∆y,∆z],最后深度的计算方式如下:

这里为啥要预测坐标偏移量?是因为作者使用的方法不是严格的像素对齐的,原因是PD -Block通过将资源从简单场景重新分配到更复杂的物体上,有效的管理空间的计算冗余。此时世界坐标的计算变为:
![]()
这里输出的光流可以用来获得每一个世界坐标下的点在下一帧的位置,即:
![]()
Prune and Dilate Block(PD-Block)
如上图所示,自动驾驶车辆上的相邻相机视野通常会存在重叠部分,就会导致不同视角中的同一个物体会出现重复gaussian预测,叠加后生成的效果会变差,另外在场景表示中,像天空这些区域不需要太多的gaussian来表达,而对于物体边缘处(高频处)则需要更多的gaussian来表示,因此作者提出了一个PD-Block的模块,它可以对复杂实例的高斯点进行扩张,并对相似背景或不同视图的高斯点进行修剪,步骤如下:
(1)将相邻视角的特征图以range view的形式拼接起来,那重叠部分的特征在位置上是比较靠近的,易于融合
(2)然后为了减少内存的使用将range view特征分割成多个区域
(3)在空间中均匀地选择K个中心,中心特征通过平均其Z个最近点来计算
(4)计算区域特征和中心点之间的余弦相似矩阵S
(5)根据阈值生成生成mask
(6)基于mask,可以对长距离特征和局部特征进行聚合,即 。其中,长距离特征e_lt通过大核卷积提取,局部特征e_lc为原始range view特征。
动静解耦
自动驾驶场景的视野非常稀疏,这意味着只有有限数量的摄像机同时捕捉到相同的场景。因此,跨时间视图监督是必不可少的。对于动态目标,该算法不仅可以在 t 时刻预测动态目标的高斯分布,而且可以预测每个高斯分布点的Flow(类似光流)。因此,实验中也会使用下一帧来监督预测的高斯点,即 。对于静态对象,可以使用相邻时间戳的相机参数来渲染场景,并且只监督静态部分,即 。大多数方法只使用静态的物体场景来更好地构建3D高斯,而忽略了对动态物体多视图的监督。注意,当监督跨时间序列的渲染时,阈值小于 α 的渲染图像是不进行监督的,因为这些像素通常不会在整个时间序列中重叠。此外,同样使用 L1重建约束 ,让渲染的图像与GT更接近。
分割
主要有两个作用:一是为了获得动态物体的mask(例如车辆和行人),静态物体的mask,以及天空的mask,另外引入语义监督有利网络对整个场景的理解(建模),作者用的模型是DeepLabv3plus。作者还将3D bbox投影到2D图像上,以此做为prompt通过SAM获得更精确的mask,这里使用一个简单的“或”逻辑合并两种处理的方式,确保所有动态的物体都获得对应的mask,相当于双重保障了。
损失函数
训练中的损失函数为:

- :约束渲染图像
- :约束深度的类别
- :约束修正后的深度
- :约束深度
- :约束动态对象
- :约束静态对象
- :约束分割结果
和 使用分割的标签,这部分不用于预训练实验。其他损失是无监督的,这也使得DrivingRecon 实现良好的性能。这些规则和约束使得 DrivingRecon 能够有效地整合几何和运动信息,提高其跨时间和跨视角的场景重建能力。
实验分析
与现有方法的渲染结果对比:
与现有方法的指标对比:
从表1和表2可以看出,不管是动态还是静态对象,指标提升的还是很大的。
重建结果可视化:
泛化性测试结果如下:
消融实验:
最后,文章最后还讨论几个潜在的应用:
车辆适应性:新车型的引入可能导致摄像机参数的变化,如摄像机类型(内参)和摄像机位置(外参)。所提出的四维重建模型能够用不同的摄像机参数来渲染图像,以减小这些参数的潜在过拟合。实验中作者在 Waymo 上使用随机的内参渲染图像,并以随机的方式渲染新的视角图像作为一种数据增强的形式。渲染的图像也会使用图像检测中的数据增强方式,包括调整大小和裁剪,然后结合原始数据训练BEVDepth,结果如下:
预训练模型:四维重建网络能够理解场景的几何信息、动态物体的运动轨迹和语义信息。这些能力反映在图像编码中,其中这些编码器的权重是共享的。为了利用这些能力进行预训练,作者用 ResNet-50替换了编码器。然后重新训练DrivingRecon,没有使用任何语义注释,属于完全无监督的预训练。随后,用预先训练好的模型替换了 UniAD 的编码器,并在 nuScenes 数据集上对其进行了微调。与 ViDAR 相比,使用新的预训练模型取得了更好的性能。
场景编辑:四维场景重建模型能够获得一个场景的全面的四维几何信息,这允许删除,插入和控制场景中的对象。文中给出了一个例子,在场景中的固定位置添加了带有人脸的广告牌,表示汽车停下的corner case:
结论
文章中提出了一种新的4D重建模型DrivingRecon,输入全景视频(环视)即可快速重建出4D自动驾驶场景。其中关键的创新点是提出了PD-Block,可以删除相邻视角的冗余高斯点,并允许复杂边缘周围进行点扩张,增强了动态和静态物体的重建。另外,文章中也引入了一种使用光流预测的动静态渲染方法,可以更好的监督跨时间序列的动态对象。实验表明,与现有方法对比,DrivingRecon在场景重建和新视角生成方面具有更优越的性能。并通过实验证明了可以用于模型的预训练,车辆自适应,场景编辑等任务。
#Selective Kalman Filter
怼上所有传感器不一定好!Selective Kalman Filter:优雅的融合如何处理个别传感器的退化
为了解决复杂环境中的挑战并提高定位的鲁棒性和环境感知能力,越来越多的研究集中于融合多种传感器的SLAM系统。这些系统通常集成了多种传感器,如LiDAR、视觉、RGB-D相机和IMU,代表性的系统包括R3LIVE、FAST-LIVO、LVIO-Fusion、RIVER等。
现有关于卡尔曼滤波器的研究主要集中在多传感器信息融合方面,这些研究提出了使用扩展卡尔曼滤波器(EKF)和自适应模糊逻辑系统来融合里程计和声纳信号的方案,其核心思想是自适应调整增益。然而,这些工作主要集中于如何利用和融合来自多传感器的信息,而未考虑是否有必要融合或是否需要融合所有可用数据。在非退化条件下,当高精度数据与中等精度数据融合时,精度的提升往往是微小的,甚至可能是负面的,同时还会增加额外的计算开销。我们将这种对所有测量数据不加区分进行融合的方法称为“全包含”(“all-in”)方法。这种方法面临以下两个主要问题:
- 首先,“全包含”方法处理的信息量比单传感器SLAM大得多,通常导致计算负担显著增加,影响实时性能。
- 其次,尽管该方法结合了各种传感器的优势,但也引入了其劣势。例如,视觉SLAM易受运动模糊、剧烈光照变化和动态物体的影响,从而产生较大的误差,甚至导致系统失效。
因此,通过探讨何时以及如何选择性地融合多传感器信息,以LiDAR与视觉融合SLAM系统为例,解决上述两个问题。在多传感器SLAM融合中,单一传感器易出现定位退化,而整合不同类型的传感器可以提供额外的约束,防止SLAM退化。
- 对于“何时”融合,我们的解决方案是仅在更为精确和鲁棒的LiDAR SLAM子系统表现出退化时,才引入视觉信息,否则仅依赖LiDAR子系统进行位姿估计。
- 关于“如何”融合,如果直接融合所有信息,视觉子系统的较低精度可能会降低LiDAR系统的整体精度。因此,我们的解决方案是仅在LiDAR子系统退化的方向上融合视觉信息。
- 解决“何时”问题需要准确判断LiDAR SLAM是否发生退化。现有方法未考虑点面约束中旋转与平移的高耦合性,导致退化方向的评估不准确。
Selective Kalman Filter(选择性卡尔曼滤波器)[1]的解决方案通过准确判断LiDAR SLAM退化的方向,仅在这些退化方向上引入视觉观测数据。相比之下,LION的融合方法在LiDAR退化时停止使用LiDAR里程计,转而依赖其他里程计信息。这种方法较为粗糙,因为在非退化方向上依赖较低精度和鲁棒性的传感器信息可能会降低系统性能。Zhang、Hinduja和X-ICP的方法主张仅在退化方向融合其他传感器信息,这被我们认为是优化的策略。然而,这些优化方法基于优化框架,未能在滤波框架中精确识别退化的具体方向,可能导致实际退化方向未被充分约束。

具体贡献包括:
- 提出了一种新型的多传感器融合方法——选择性卡尔曼滤波器,设计用于解决数据“何时”与“如何”选择性融合的问题。这种方法仅在LiDAR数据退化时引入必要的视觉信息,大幅提升实时性能,同时确保鲁棒性和精度。
- 提出了一种创新高效的LiDAR里程计退化检测方法,可同时确定退化方向。该方法充分考虑了旋转与平移约束之间的耦合关系。
- 通过实验验证了所提退化检测方法的精确性以及选择性卡尔曼滤波器的效率。
- 开源了代码以促进社区参与和广泛应用。
系统概述
首先介绍LiDAR-惯性-视觉SLAM的“全包含”方法,该方法由FAST-LIVO和R3LIVE等方法所代表。在没有视觉或LiDAR测量数据的情况下,类似于FAST-LIO2,系统利用IMU的加速度和角速度进行状态传播,作为卡尔曼滤波的预测步骤。当LiDAR或视觉测量数据到达时,系统在卡尔曼滤波中执行数据融合更新。

据我们所知,在没有退化的情况下,与视觉-惯性SLAM(VIO)相比,LiDAR-惯性里程计(LIO)系统通常表现出更高的精度和更强的鲁棒性。在将选择性卡尔曼滤波器集成到LiDAR-惯性-视觉里程计(LIVO)系统中时,我们优先将LIO子系统作为核心,将VIO子系统作为辅助。系统的工作流程如图2所示。与“全包含”方法不同,我们的方法基于LiDAR测量进行退化检测与分析:
- 如果LIO子系统未发生退化,我们选择不融合视觉测量数据。这种方法有助于避免因视觉问题(如运动模糊、过度曝光和错误特征匹配)引入的误差。此外,它还减少了计算负担,从而提高了实时性能。
- 如果LIO子系统发生退化,为了尽量减少引入的视觉信息并防止状态估计恶化,我们分析LiDAR的退化方向,然后选择性地融合与此退化方向相关的视觉数据,并舍弃与非退化方向相关的数据。这有助于防止LiDAR的非退化维度的精度下降。
我们将这种选择性更新信息融合的方法称为“选择性卡尔曼滤波器”(Selective Kalman Filter)。
LiDAR SLAM中的退化检测
首先,我们通过加权线性最小二乘法对LiDAR测量方程(2)进行变换,得到以下形式:
其中,为状态的估计值。为了简化表示,我们做出以下定义:
因此,上述方程可以简化为:。
由于实际场景中的噪声影响,矩阵通常为满秩矩阵,因此是一个6×6的对称正定矩阵。

Hinduja方法通过比较的最小特征值与预设阈值来检测退化。然而需要注意的是,由于的前三维表示旋转,后三维表示平移,其特征值是旋转和平移的耦合值,缺乏明确的物理意义,且单位同时与旋转和平移相关。同一特征值分解中的特征值单位不同,因此难以设定合理的退化检测阈值。此外,与这些特征值对应的特征向量也无法代表实际方向,这使得该方法在实际部署中往往不切实际。
为了解决这一问题,LION提出通过分析的对角元素来确定退化及其方向。首先,将矩阵表示为分块矩阵的形式:
LION分别对和进行特征值分解:
其中,和为对角矩阵,包含旋转和平移部分的特征值。然后通过设定两个阈值,评估旋转和平移是否退化。这种方法有效解决了Hinduja方法中阈值缺乏物理意义的问题,但其忽略了耦合项和,从而忽视了旋转和平移约束之间的相互影响。这种忽略导致在大多数情况下,退化程度及方向的估计不准确。
例如,如图3(a)所示,根据LION的观点,y方向的估计仅依赖于点A在y方向的点面残差雅可比,导致y方向估计较差(如所示)。但实际上,点B的点面残差可以改善旋转的估计,从而增强y方向的估计(如所示)。可以推断,这种考虑了平移和旋转耦合的后者方法,对于不确定的估计具有更高的准确性。
为了解决上述问题,我们提出了一种基于协方差信息的新型、简单且具有物理意义的退化检测方法。我们首先对矩阵求逆,得到状态的协方差矩阵:
需要注意的是:
从以上公式可以看出,我们的方法与LION使用局部Hessian矩阵的方法不同。我们的方法考虑了旋转与平移之间的耦合关系。此外,该方法具有实际的物理意义:协方差矩阵的对角块表示状态的方差,而非对角块表示不同状态之间的相关性。方差可以作为退化程度的直观量度,例如,高方差表示该方向上的估计存在较大的不确定性,从而表明退化。
我们对和进行特征值分解:
其中,和的特征值分别具有物理单位,旋转部分为,平移部分为。对应的特征向量代表退化方向,此时,和分别为旋转矩阵,能够将原始坐标系旋转到这些特征方向。
最后,我们基于实际需求和经验设置两个方差阈值和。如果,则表示发生旋转退化,对应的特征向量表示退化方向;平移部分同理。
综上所述,本节提出了一种具有实际物理意义并考虑耦合约束的退化检测方法,理论上能够更准确地判断退化程度及方向。
视觉测量的选择
我们首先对视觉测量方程 (3) 应用加权线性最小二乘法,得到以下形式:
其中, 为状态 的估计值。为了简化表示,我们定义如下:。
因此,方程可以简化为:。
需要注意的是,根据实际场景中的噪声,矩阵 总是可逆的。因此,可以得到估计状态 为:。
利用协方差矩阵的特征向量矩阵 和 ,我们定义一个新的旋转矩阵 :。
该旋转矩阵能够将 的坐标系旋转至旋转和平移的主分量方向上:。
在已知 LiDAR 子系统退化维度的情况下,我们定义一个选择矩阵 ,以选择视觉测量方程中与退化方向相关的信息,从而滤除无关数据:。
例如,如果 LiDAR 子系统在一个平移方向和一个旋转方向上发生退化,例如 和 ,我们可以将选择矩阵 设置为:
在该矩阵中,设置为1的对角元素对应退化状态的维度,而设置为0的对角元素对应非退化维度。我们将状态恢复到原始坐标系,并同时恢复原始测量方程:
为了保持信息矩阵的对称性,我们进一步处理,得到:
可以简化为:,
其中:
此时,我们已完成对视觉数据的选择,仅保留与 LiDAR 退化方向相关的信息。
选择性卡尔曼滤波器
首先,我们描述传统卡尔曼滤波器的形式。对于视觉子系统,假设已存在先验估计,记为 和协方差 。按照FAST-LIO的方法,卡尔曼增益 的计算公式为:,
得到更新方程为:。
将卡尔曼增益 代入更新方程并进行简化,可以得到:
根据式 (17),可以进一步简化为:
其中, 是后验估计状态。
对于后验协方差 ,其公式为:。
将 的表达式代入并简化,可以得到:。
通过观察视觉信息的测量方程在选择前(式 (18))和选择后(式 (26))的变化,我们只需将 替换为 ,将 替换为 ,即可得到新的选择性卡尔曼滤波器公式:。
备注:在本文中,所有进行特征值分解的矩阵均为实对称矩阵,因此其特征值分解和奇异值分解的结果是等价的。我们的主要目标是确定这些矩阵的主方向,这本质上与奇异值相关的物理含义一致。为了简化表达并减少变量的数量,本文统一采用特征值分解描述整个过程。
LiDAR-惯性-视觉里程计
基于出色的LIVO框架R3LIVE,我们集成了选择性卡尔曼滤波器,构建了SKF-Fusion,其系统框架如图4所示。原始R3LIVE框架包含两个并行子系统:LiDAR-惯性里程计(LIO)和视觉-惯性里程计(VIO)。本文未重复描述R3LIVE中的相同内容。在此基础上,我们对LIO子系统进行退化检测。如果未检测到退化,仅将视觉信息用于上色,同时保存地图的颜色信息,以便在退化状态下使用。如果检测到退化,则在帧与帧之间以及帧与地图之间进行序列更新,专注于退化状态的相关成分。在随后的实验中,我们使用R3LIVE数据集对SKF-Fusion进行了评估。

系统工作流程:
未检测到退化时:
- 系统仅使用LiDAR子系统进行状态估计和更新。
- 视觉信息仅用于地图的颜色渲染,无需进行视觉状态更新。
- 这种方式避免了视觉子系统带来的计算开销,并减少了因视觉特性(如运动模糊、过度曝光等)引起的误差。
- 检测到退化时:
- 系统分析LiDAR的退化方向。
- 针对退化方向,选择性地融合视觉观测数据,仅对退化状态进行更新。
- 非退化方向的数据被舍弃,从而防止引入不必要的误差。
通过引入选择性卡尔曼滤波器,SKF-Fusion实现了高效的退化处理,显著提升了系统的鲁棒性和实时性能。
实验效果








总结一下
基于传统的“全包含”融合SLAM(涉及LiDAR、视觉和IMU),本研究引入了一种基于协方差信息的创新退化检测模块,以及用于退化状态选择性更新的选择性卡尔曼滤波器。与现有退化检测方法相比,实验结果表明,该方法显著提升了退化检测的准确性,从而提高了定位的精度和鲁棒性。此外,与“全包含”方法相比,方法显著提升了视觉子系统的实时性能。需要注意的是,当前的阈值选择未能适应不同体素分辨率下的LIO,这为未来的研究提供了方向。
#某主机厂智驾自研的波澜
今年这家主机厂在智驾业务上的一系列变化,都源自于大BOSS的战略构想。眼看新能源汽车的上半场“电动化”结束,进入下半场的“智能化”,所以大BOSS就想在下半场的“智能化”上占领用户心智。
在大BOOS的战略设想中,智驾会存在技术引领者和技术普及者两种角色。华为是技术引领者的角色,以这家主机厂现阶段的技术能力来说肯定比不了华为。而且,以这家主机厂的销量规模和用户层次来说,现阶段技术普及者的战略定位比较合适。
所以,这家主机厂准备在智驾普及上发动大规模的攻势。
一是尽可能的把智驾做到标配,用标配打响智驾普及的第一枪。以这家主机厂的体量来说足以引起声势浩大的市场反响,这一枪要打好了足以站稳智驾普及者的地位。二是除了部分高阶智驾继续采用头部供应商的方案之外,其他的全部切自研。
压力就来到了自研团队这边。在这家主机厂高层眼里,自研上的钱投入了很多、时间也不短了,到了该拉出来溜溜的时候了。
这家主机厂在重大技术攻坚上喜欢赛马机制,投入了A和B两个自研团队。今年下半年对赛马进行考核,要两个自研团队交考卷,其中一个考核点是谁能先把自研的方案量产上车。
A团队的进度要快于B团队,再加上A团队的负责人是老人,导致B团队的业务和人员被A团队给“吞掉”。B团队的负责人也被调岗,不过最终还是离职走人。
在这一波的赛马PK过程中,A团队的负责人成了大赢家。原本在这家主机厂智驾业务上是智驾负责人、A团队负责人、B团队负责人的三人“斗地主”的局面,A团队不仅PK掉了B团队负责人,而且下半年也不断传出智驾负责人离职的消息。
风光无限的同时,A团队的一些技术中层也在不断的担忧,明年自研方案的量产上车能不能成功?如果量产上车的过程不顺利或者出了岔子,到时候问责,锅是先扣负责人头上还是掉在自己头上?
带着一脑子问号的部分技术中层,谋生了跳槽走人的想法。
#Pi-0: 面向通用机器人控制的VLA Flow 模型
Pi-0 是Physical Intelligence 成立后的第一个论文工作(全公司都署名了,豪华阵容)。这篇论文主要关注如何实现robot foundation model,并聚焦在两个方面:Pre/Post-Training 策略;基于Flow-Matching 的action expert。从结果看,pi-0可以实现比较强的泛化能力,并能实现非常实时的推理。比起之前的OpenVLA 等工作,pi-0 在端到端VLA这条路线上向robot foundation model 迈进了很多。

Motivatio
Pi-0 的核心motivation 是将LLM 和VLM 领域中已经经过考验的Pre/Post-Training 训练范式迁移到机器人具身模型的训练过程中来,即:
- Pre-training:在大规模且非常多样性的互联网语料库上对模型做预训练;
- Post-training:在更精心设计的数据集上fine-tune (or "align") 模型,使模型输出更符合预期;
如何将这个范式迁移到机器人领域呢?Pi-0 的训练,实质上是三步:
- Internet-scale Pre-Training: Pi-0 是基于一个训练好的开源VLM 模型继续训练的,因此这个开源VLM 模型的训练实质上相当于是Pi-0 模型训练的第一个阶段,提供了模型的多模理解能力;
- Pre-Training:基于团队构造的一个10000 小时机器人操作数据集,进行了大规模训练。实质上,Pre-Training 后,Pi-0 模型就已经可以处理见过的任务,并zero-shot泛化到一些不那么难的任务上
- Post-Training:对于一些新的很困难的任务,需要5-100 小时数据进行fine-tune.
作者认为,要获得一个具备良好泛化能力的robot foundation model,主要有三方面挑战:
- 数据的规模要足够大(数据量、本体丰富度、任务丰富度等);
- 模型的架构要合理(支持高频控制,连续action space控制);
- Training recipe 要合理(训练策略,数据配比等);
围绕这几个问题,Pi-0 的核心设计如下节介绍。
The Pi-0 Model模型结构

模型结构如上图所示:
- 模型基于一个Pre-Trained VLM (PaliGemma) 构建,其包含视觉Encoder 部分(SigLIP,400M)和Transformer 部分(Gemma,2.6B);
- 在预训练模型的基础上,Pi-0 通过MoE 混合专家模型的方式引入了一个action expert 来处理动作的输入和输出。这里是指,只有一个Transformer 模型,在处理文本和图像token 时,用的是原模型的参数;在处理action token 时,则用新初始化的action expert 的参数;
- 输入:模型的输入包括3帧最近的图像,文本指令,以及机器人本体信号(即各joint 当前angle)
- 输出:输出是称作action chunk 的形式,即未来一段时间的action 序列,这里的序列长度H 设定为50,对于50HZ 控制的情况,即相当于预测未来一秒钟的动作。这里action 的维度,设定为各个本体中最长的那个(18DoF),不够的本体则pad。(注意,这里action space 都设定在joint space,这有利于模型输出结果直接控制机械臂,避免了IK 解算环节)
Flow Matching as Action Expert
Flow matching 可以看作是diffusion 的一种变体,之前有听说但没仔细学习过,正好这次学习了下(知乎上也有很多不错的介绍文章,比如 笑书神侠:深入解析Flow Matching技术 )。Flow-Matching 主要是学习如何从一个噪声分布数据流形到目标分布数据流形之间的flow。Flow matching 的主要优势主要在于训练/推理方式比较简单、生成路径比较容易控制、稳定性更高等。Flow Matching +简单线性高斯概率路径的方案在生成任务上也获得了比较好的效果。
具体到Pi-0中:在action 预测任务中,在时间t我们要预测一个action chunk, 则优化目标为:

- 是 [0,1] 之间的数值,代表flow-matching 的timestep,0对应噪声分布,1对应目标分布;
- 即所对应的噪声流形到目标流形的中间流形。基于flow matching 的定义,我们可以将后验概率(即已知,来获得)表示为:
![]()
- 具体地,基于线性高斯路径策略,可以表示为(和扩散加噪过程很相似):
![]()
- 而在前面的训练损失函数中,我们实质监督的是,在这个时间点流形的 flow 或者说是速度方向(也因此这种训练方法叫做flow matching)。(,)指网络预测结果,其优化目标为:
![]()
- 因此,diffusion 和flow matching 的训练都是一个去噪过程,但表示形式不同,前者预测的是添加的噪声,后者预测的是噪声到分布的方向。flow matching 可以通过控制优化路径来实现更灵活的生成控制。
- 在训练阶段,从一个beta 分布中采样(为了强调前段/噪声更多阶段的训练)。而在inferece 阶段,Pi-0 使用了10步均等步长(=0.1)的形式来实现flow matching 过程:
Pre-Training and Post-Training

作者认为预训练阶段最重要的就是diversity,用了一个10000小时规模的数据集训练:
- 数据集大部分是自采的(采集方式下一节介绍),仅9.1% 是开源的(Open-emb-x, droid 等)。数据集的自采集部分,包含了903 million timestep。
- 数据集中使用了多种本体,大部分都是双臂数据,基本都是aloha 数据
- 自采任务包含68个任务,但普遍都是比较复杂的符合任务,所以实质上包含的任务更多;
作者认为后训练阶段数据的要点是动作质量高,即动作要完成地一致且高效
- Post-training 阶段的任务选择地和预训练有明显差异;
- 简单的任务,需要5小时数据,最复杂的任务需要100小时甚至更多;
Robot System

Pi-0 构造了一个还算比较丰富的多本体平台,如上图所示。具体信息整理如下:

- 轻型机械臂用的都是Aloha 方案,主要是Trossen,ARX(方舟无限,国产)和AgileX(松灵,国产)
- 非轻型机械臂(UR5e 和Franka)用的不是Aloha 方案,没说啥采集方案。猜测应该是6D 鼠标等遥操设备。
- 这里面的所有任务都是夹爪,没做灵巧手;
Experiment
实验内容比较多,这里主要贴一下两个主要实验
Zero-shot evaluation
这个任务主要是想看Pre-Training 完的模型直接拿来用的效果,和OpenVLA,Octo 等方法比;


- Pi-0 比OpenVLA 等方法效果好很多;
- Pi-0-Parity 是训练步数比较少的模型 160k/700k,表明训练充分对模型效果影响很大
- Pi-0-Small 是没有用Pretrain VLM 的模型,可以看出来效果也差了很多。
Post-Training Evaluation
在新的困难的灵巧任务上进行训练和测试:


部署 & 效率测评
这里补充一下附录里面提到的部署时的推理策略和推理效率。推理策略:
- 模型每次生成H timestep 的action chunk,H一般是50;
- 对于20Hz 控制的机械臂,需要2.5s 执行完;对于50HZ 控制的机械臂,需要1s 的执行完;
- 实质上,并不会等所有action 执行完再进入下一轮执行。对于20Hz 平台,在执行完16步(0.8s)后就会进入下一轮;对于50Hz平台,执行完25步(0.5s)后就会进入下一轮
这个执行策略,其实是每0.5s 做一次重新规划。这是因为Pi-0 并没有把历史决策作为输入,即这个模型并没有维护history 信息。所以这个方案实质上还是应该看作是一个开环方案。

- 速度是在4090 上测试的,可以看出这个3.4B模型的推理还是很快的,应该用上了当前主流的推理加速
- Off-board 指显卡不在设备上,通过wifi 通信,可以看出他们这个通信延迟做的也还行。
- 整体延迟控制在了100ms 内,这意味着他们其实最高可以以10FPS 频率来做重规划。
讨论 & 总结
Pi-0 方案可以看作是OpenVLA 这类VLA 方案的一次系统升级,主要是更好的训练数据 + 更好的Policy Head。而且Policy Head 和VLM 模型连接的方式,可能是一种很好的大小脑系统连接的路径。整个方案系统性很强,值得细读学习,整体读下来感觉也很好。
除了优点,还是有不少槽点和疑惑点的:
- 从预训练的层面,这篇工作似乎并没有带来太多新东西。当前大家对于“具身预训练”这个话题,可能更多还是希望能够减少需要大量人力投入的遥操数据采集环节。所以,这篇文章里面的Pre-Training,可能实质上对应的是我们认为的Post-Training,而Post-Training 对应的则是我们认为的few-shot adaption。
- 文章中提到一个观点:“高质量数据不能教会模型如何从错误中恢复”,那言下之意应该是低质量数据中一下错误后重新尝试的数据对这方面有帮助。这个观点很认同,但文中其实并没有分析训练数据中是否真的有这类数据,也没有做相关的佐证实验。
- Pi-0 的框架没有加入history 我感觉还是比较可惜的,或许是他们的下一步吧;
- 模型部分,不同本体似乎没有加一个区分指示的token,只靠action space 维度区分不太靠谱;同时Pi-0 也没有展示本体层面的泛化能力。
#LiON-合成数据助力自驾点云异常检测新SOTA
论文信息
- 论文题目:LiON: Learning Point-wise Abstaining Penalty for LiDAR Outlier DetectioN Using Diverse Synthetic Data
- 论文发表单位:清华大学, 厦门大学,滴滴出行, 香港中文大学-深圳
- 论文地址:https://arxiv.org/abs/2309.10230
- 项目仓库:https://github.com/Daniellli/LiON
1.Motivation
基于点云的语义场景理解是自动驾驶汽车感知技术栈中的重要模块。然而,由于点云不像图像那样具有丰富的语义信息,在点云中这个识别异常点是一项极具挑战性的任务。本工作从两个方面缓解了点云缺乏语义信息对异常点感知的影响:1) 提出了一种新的学习范式,使模型能够学习更鲁棒的点云表征,增强点与点之间的辨别性;2) 借助额外的数据源,ShapeNet,提出了一套可以生成多样且真实伪异常的方法。实验结果表明,在公开数据集 SemanticKITTI 和 NuScenes 上,本方法显著超越了前 SOTA。
,时长01:29
2.Method
给定一个场景点云,点云语义分割的主要任务是为点云中的每个样本点分配一个预先定义的类别,例如车、树、行人等。本工作将这些属于预先定义类别的样本点称为正常样本点。而 点云异常检测则作为点云语义分割模块的补充,用于识别那些不属于预先定义类别集合的样本点,例如桌子、椅子等无法预料的类别。本工作将这些样本点称为异常样本点。
此前的工作 REAL 将图像异常检测方法直接适配到点云异常检测领域,并通过实验发现,大量异常样本被错误分类为预先定义的类别。为了解决这一问题,REAL 提出了一种新的校正损失,用于校正正常样本的预测。然而,本工作的实验结果表明,尽管该校正损失能够提升异常样本的分类性能,但同时也对正常样本的分类性能造成了显著的负面影响。
本工作将图像异常检测方法在点云异常检测领域表现不佳的原因归结于点云不像图像那样具有丰富的语义信息。比如Figure 1左侧,即使是人类也难以识别道路中央的家具信息。因此,该工作从两个方面缓解点云缺乏丰富语义含义所带来的影响。

Figure 1 点云语义分割模块错误地将家具分类成道路
首先,该工作提出为每个样本点计算一个惩罚项,并通过额外的损失函数保证正常样本点的惩罚较小,而异常样本点的惩罚较大。然后,将该惩罚项嵌入交叉熵损失中,以动态调整模型的优化方向。通过为每个样本点学习额外的惩罚项并改进学习范式,本工作增强了样本点之间的辨别性,缓解了点云缺乏语义信息的问题,从而全面提升了异常检测能力。
此外,该工作提出利用 ShapeNet 数据集生成伪异常。ShapeNet 是一个大规模的三维形状数据集,包含超过 22 万个三维模型,覆盖 55 个主要类别和 200 多个子类别。因此,通过 ShapeNet 生成的伪异常具有较高的多样性。其次,在生成伪异常时,该工作进一步考虑了点云的采样模式,从而使生成的伪异常更加真实。因此,该工作通过生成更加多样且真实的伪异常,更好地估计和模拟了真实异常的分布,缓解了点云缺乏语义信息的问题。
2.1. 模型整体架构
如Figure 2所示,本工作通过伪异常生成方法对输入点云进行编辑生成带有伪异常的输入点云x, 而后该点云通过特征提取器和正常样本分类器f和异常样本分类器g处理, 得到正常类别logit , 以及异常类别logit , 而后通过softmax 处理, 可以拿到正常类别概率和异常类别概率。c表示正常样本类别数量,n表示给定点云的点数量。该处理过程可以形式化表达为:

其中[·]表示拼接操作。

Figure 2 算法处理流程
2.2. 基于逐点惩罚的学习范式
本工作提出对每个样本点用能量函数计算一个额外的惩罚项,惩罚项的计算如下所示:

此外,该工作通过一个额外的逐点惩罚损失函数使得对于所有的正常样本点都有个较小的惩罚,对于所有的异常样本点都有较大的惩罚。该逐点惩罚损失函数的形式化表达如下:

其中,m表示数据集大小;n表示场景点数量;I(.)表示示性函数;{1,...,c,c+1}为样本点类别真值,c+1表示异常类别;max(.)为最大值函数;,为超参数。该损失函数的作用如Figure 3所示,对于所有的正常样本点(逐点惩罚损失函数公式左侧),如果惩罚项大于,损失函数的值就会大于0;反之,损失函数的值等于0。异常样本的情况与此类似。通过优化逐点惩罚损失函数,就可以对所有的正常样本计算得到一个接近甚至小于的惩罚, 对于所有异常样本得到一个接近甚至大于的惩罚。

Figure 3 惩罚项和逐点惩罚损失之间关系
而后,该工作用惩罚项升级交叉熵损失函数,动态调整交叉熵损失的优化重点, 升级后的交叉熵损失函数被叫做逐点拒绝(abstain)损失函数:

对于所有正常样本,该算法会计算得到一个较小的惩罚系数。将其取负后,值会变得较大,而取负后的平方值则会进一步放大。因此将异常类别概率除上该值,异常类别概率对于逐点拒绝损失函数的影响会被抑制,从而逐点拒绝损失函数重点会放在优化正常类别概率上。异常样本的情况与此类似。
因此整个算法的损失函数为:

其中为损失函数的系数。
2.3.合成数据生成点云异常
该工作通过引入额外的数据源, ShapeNet,来生成更加多样且真实的伪异常,从而更好地近似真实异常分布。首先,通过伯努利分布计算插入的伪异常数量G。而后,通过循环G次下面流程来插入伪异常。
如Figure 4所示,该生成方法包括以下步骤:(a)加载物体后,基于均匀分布计算平移距离和旋转角度,并对物体进行(b)平移和(c)旋转,使其有可能放置在场景中的任意角落;(d)基于均匀分布计算的缩放系数,对物体进行缩放;(e) 将物体放置于场景地面; (f)使用被插入物体遮挡住的场景样本点来替换插入物体的样本点。

Figure 4 伪异常生成流程
3.Experiment
实验结果表明,该工作提出的方法在SemanticKITTI和NuScenes两个公开数据集上能够大幅优于之前的SOTA方法。
3.1.实验基准
该工作沿用了之前的实验基准。采用SemanticKITTI和NuScenes作为基准数据集。在SemanticKITTI中,将{other-vehicle}设为异常类别;在NuScenes中,将{barrier,constructive-vehicle,traffic-cone,trailer}设为异常类别。这些异常类别的样本在训练过程是不可见的。
在测试阶段,主要评估算法对这些被设为异常类别的样本的分类精度,采用的评价指标主要包括 AUPR 和 AUROC。此外,对于正常样本分类的评估指标为。该任务的目标是在保证不受影响的前提下,尽可能提升AUPR和AUROC。
3.2.定量结果

Table 1 定量结果对比
该工作沿用之前的实验设置, 选C3D(Cylinder3D)作为分割基座模型。前SOTA方法, APF,没有在NuScenes上开展实验并且没有开源代码, 因此该工作无法在NuScenes上与其进行对比。Table 1实验结果表明,该工作提出的算法在两个公开基准数据集上大幅优于之前SOTA方法。
3.3.定性结果

Figure 5 SemanticKITTI(左)和NuScenes(右)上的定性结果对比
与前SOTA算法对比,该工作提出的算法不管是在64线雷达采集的点云数据上(SemanticKITTI)还是32线雷达采集的点云数据(NuScenes)上都表现出了优越的性能, 不仅能够精确定位异常类别而且能够赋予较高的置信度。
#OpenEMMA
自动驾驶黑科技 | 开源框架 OpenEMMA 正式上线!
今天为大家带来一个自动驾驶领域的重磅消息:OpenEMMA,一个完全开源、端到端的多模态框架,正式发布啦!
这是我们团队在推动自动驾驶技术透明化和普惠化道路上的重要一步,希望通过开源化,赋能更多科研人员和开发者,共同推进这一领域的快速发展。在2024年十月底,谷歌的自动驾驶子公司Waymo发布了第一个基于纯视觉的自动驾驶端到端多模态大模型解决方案EMMA,其Blog如下图所示
Waymo发布了端到端多模态自动驾驶大模型EMMA
我们团队于11月份正式开始计划来进行开源版本的复现,旨在让自动驾驶和交通社区都能用上开源的替代解决方案,推动自动驾驶开源化、透明化。于是呼,OpenEMMA正式诞生了!
什么是 OpenEMMA?OpenEMMA 是一个基于多模态大语言模型(MLLMs)的开源自动驾驶框架,灵感来自 Waymo 的 EMMA 系统。它支持从感知到规划的完整自动驾驶任务链,专为推动行业透明化和技术共享而打造。OpenEMMA 的亮点功能
链式推理(Chain-of-Thought Reasoning)
通过引入链式推理技术,OpenEMMA 让轨迹规划和决策过程更可解释,贴近人类逻辑思维。
增强的 3D 目标检测
集成微调后的 YOLO3D 模型,大幅提升目标检测精度,无论在城市街道还是复杂环境中表现出色。
强大的适应性和鲁棒性
从急转弯到低光环境,OpenEMMA 能轻松应对各种驾驶场景,确保稳定性与安全性。
结果和性能
视频例子
我们测试了OpenEMMA在真实数据集上视频序列上的效果,具体如下图所示
完全开源
框架、数据集、模型权重全都开源,致力于推动学术研究和产业开发的共同进步。为什么 OpenEMMA 很重要?在自动驾驶领域,技术的透明化和普惠化是加速行业发展的关键。OpenEMMA 不仅为开发者提供了一个高性能工具,还让更多人有机会参与其中,推动技术的落地应用。这是我们迈向更安全、更智能交通体系的重要一步!参与我们 | 一起让自动驾驶更安全我们希望 OpenEMMA 成为一个全球化的开源社区,任何意见、建议或者贡献都是极为宝贵的!目前框架还处于初期阶段,我们期待和全世界的开发者、学者们一起完善它。如果你对自动驾驶感兴趣,欢迎 DM 或留言加入我们的社区!
论文链接:arxiv.org/abs/2412.15208
开源地址:https://github.com/taco-group/OpenEMMA
#如何评价deepseek上线的deepseek-V3模型?
国产大模型又信仰充值了
deepseek 找到了一个弯道超车海外 LLM 的方法,作为友商员工我都愿意粉一下,真产业升级
我觉得把刷榜看成是模型能力增强带来的副产品,效果是好于 1. 对着榜去刷过拟合 2.急着用赶超战略复刻新技术的
比方说我们发现 GPT4 某些榜表现好,专门加这类数据并不本质,反而污染了一个原本很好的评价指标
把基模做强就有惊喜!又是 The Bitter Lesson。既想刷榜又不想做预训练,就很容易技术落后
当 OpenAI / Anthropic 有些新现象和新技术出来,要复刻的前提是基础模型够强,不然即使人家把监督微调 / 强化学习的数据开源了,小模型可能学完也没什么变化
研究小模型最怕的也是得到的结论和大模型完全不相关,浪费宝贵人力和时间
从这个角度来说,预训练不做就很难发现新的模型特性和现象,只能等别人喂
等别人开源模型完再动工新产品或者研究,再退一步就是等着 copy huggingface 开源社区 demo 了
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
作为近期必读的技术报告,我也来瞅瞅,当然工程上我有很多不了解的地方,欢迎大家指正
主要贡献
- 架构改进: 在 DeepSeek-V2 的高效架构基础上,我们引入了一种无辅助损失的负载均衡策略,以最小化负载均衡对模型性能的负面影响。
- 多令牌预测: 我们研究了多令牌预测(MTP)目标,并证明了它在模型性能方面的益处。MTP 目标可以用于推测性解码,以加速推理。
- 预训练: 我们设计了一个 FP8 混合精度训练框架(工程好强啊),并首次在极其大规模的模型上验证了其可行性和有效性。通过算法、框架和硬件的联合设计,我们克服了跨节点 MoE 训练的通信瓶颈,实现了近全计算-通信重叠,从而显著提高了训练效率并降低了成本。
- 后训练: 我们引入了一种创新的方法,从 DeepSeek-R1 系列模型中蒸馏推理能力,并将其集成到标准 LLMs 中,特别是 DeepSeek-V3。我们的管道优雅地将 R1 的验证和反射模式集成到 DeepSeek-V3 中,显著提高了其推理性能。同时,我们还保持了对输出样式和长度的控制。
- 核心评估结果总结: DeepSeek-V3 在知识、代码、数学和推理等多个领域表现出色。在教育基准测试(如 MMLU、MMLU-Pro 和 GPQA)上,它超越了所有其他开源模型,并表现出与领先封闭源代码模型(如 GPT-4o 和 Claude-Sonnet-3.5)相当的性能。在数学相关基准测试上,DeepSeek-V3 取得了最先进的性能,甚至在某些基准测试上超过了 o1-preview。在编码相关任务上,DeepSeek-V3 在编码竞赛基准测试(如 LiveCodeBench)上表现出色,成为该领域的领先模型。

预训练
14.8T数据,2048 H卡,训了56天(2.788M GPU hours),算力开销是四千万人民币,很值的感觉。这就能烧一个 GPT4 水平的基础模型,大佬们应该都蠢蠢欲动了。
- 14.8T 训练:
- 完整训练仅需 2.788M H800 GPU 小时。
- 看报告有三十位数据标注员。这版覆盖更多语言,继续增加了数学 / 代码的比例,代码数据中的 10% 用中间补充(FIM)策略来组织(我理解这主要是为了给模型强化一个常用的推理功能)。为了压缩其它语言的内容,调整了分词器。
- 模型架构:
- 700B MoE 模型。
- 256 个总专家,其中 1/8 共享专家,8 top-k,推理激活了 37B 参数。
- 与 DeepSeek v2 的比较:236B MoE,16 个专家,1/8 共享,1 top-k 选择,推理激活了 21B 参数。
- 多头潜在注意力(MLA):
- 类似于 DeepSeek v2 MoE,前三层不是 MoE。
- 其他细节:
- 61 层,宽度 7168。
- 多令牌预测(MTP)作为目标。
- 16 PP(并行)/ 64 EP(专家并行)/ Zero-1 DP(数据并行)#优化了全对全通信内核,而不是昂贵的 TP(张量并行)。
- 在 CPU 上进行 EMA
超参数
- 初始的学习率和优化器配置,都是继承 deepseek v1 的结论,batchsize 也是按缩放定律从 v1 的 3072 到 15,360。
- WSD 学习率调度器:0 → 2.2e-4(2k steps)→ 常数直到 10T → 2.2e-5(在 4.3T tokens 时余弦衰减)→ 2.2e-5(在剩余的 167B tokens 时常数)。
长文本能力
- 用 YaRN 方法 (arXiv:2309.00071)
- 上下文窗口扩展: 每 1000 steps,从 4k 逐步扩展到 32k,然后到 128k。
RLHF 部分
奖励构建:
- 基于规则的奖励机制。对于可以使用特定规则进行验证的问题,我们采用基于规则的奖励系统来确定反馈。例如,某些数学问题有确定的结果,我们要求模型在指定的格式内(例如,在方框中)提供最终答案,以便我们可以应用规则来验证正确性。类似地,对于 LeetCode 问题,我们可以利用编译器根据测试用例生成反馈。通过尽可能利用基于规则的验证,我们确保了更高的可靠性,因为这种方法不易受到操纵或利用。
- 对于具有自由形式真实答案的问题,我们依靠奖励模型来确定响应是否与预期的真实答案匹配。相反,对于没有明确真实答案的问题,例如涉及创意写作的问题,奖励模型的任务是根据问题和相应的答案作为输入提供反馈。奖励模型从 DeepSeek-V3 SFT 检查点进行训练。为了提高其可靠性,我们构建了偏好数据,这些数据不仅提供最终奖励,还包括导致奖励的思维链。这种方法有助于减轻在特定任务中奖励被操纵的风险。
看起来还是客观题用规则方法,主观题用奖励模型,而且是一种 COT 的奖励模型
- 训练了 2epoch,余弦学习率衰减
- 提到了 constitutional AI approach 和 self-rewarding,显然有模型打分造数据的部分了
评测
我圈出了一些比较有亮点的数字
我个人觉得如果一个榜 qwen-dense 也能做得不错,可能就不是做超大 MoE 模型应该关注的点了

比较有亮点的是数学能力,Coding 看这个榜不好说提升是不是非常大,因为 Codeforces 漏题还是比较严重的,从论文字面上没看出来有没有排除相关影响
无所谓,训出来了,自有大儒会讲经的
论文讨论部分
蒸馏好像很重要,但是主要在这部分描述
从 DeepSeek-R1 蒸馏
我们通过基于 DeepSeek-V2.5 的实验来消融从 DeepSeek-R1 蒸馏的贡献。基线模型是在短链数据上训练的,而其竞争对手则使用了由专家检查点生成的数据。
表 9 展示了蒸馏数据的有效性,在 LiveCodeBench 和 MATH-500 基准测试中都取得了显著改进。我们的实验揭示了一个有趣的权衡:蒸馏会导致性能更好,但也会显著增加平均响应长度。为了在模型准确性和计算效率之间保持平衡,我们为 DeepSeek-V3 的蒸馏精心选择了最佳设置。
我们的研究表明,从推理模型中蒸馏知识是一个有前途的后训练优化方向。虽然我们目前的工作重点是蒸馏数学和编码领域的数据,但这种方法在各种任务领域都显示出潜力。这些特定领域的有效性表明,长链蒸馏可能对增强其他需要复杂推理的认知任务的模型性能有价值。对这种方法在其他领域的进一步探索仍然是未来研究的一个重要方向。

推理过程强化,然后筛选和蒸馏反哺,听起来很有搞头
自我奖励
奖励在 RL 中起着至关重要的作用,指导着优化过程。在可以通过外部工具进行验证的领域,如某些编码或数学场景中,RL 显示出了出色的效果。然而,在更一般的场景中,通过硬编码构建反馈机制是不切实际的。在 DeepSeek-V3 的开发过程中,对于这些更广泛的上下文,我们采用了Constitutional AI 方法(Bai et al., 2022),利用 DeepSeek-V3 本身的投票评估结果作为反馈源。这种方法产生了显著的对齐效果,显著提高了 DeepSeek-V3 在主观评估中的表现。
通过将补充信息与 LLM(大型语言模型)作为反馈源相结合,DeepSeek-V3 可以优化到 Constitutional 方向。我们认为这种范式将补充信息与 LLM 作为反馈源相结合,对于推动 LLM 的自我改进至关重要。除了自我奖励外,我们还致力于发现其他一般性和可扩展的奖励方法,以持续推动模型能力在一般场景中的发展。
Constitutional AI 方法简单来说就是,不是所有打标都要人搞,比如有害性标注就可以交给模型负责,然后我们可以在降低有害性,提高有用性两个维度上,做帕累托改进
多令牌预测评估
DeepSeek-V3 通过多令牌预测(MTP)技术预测了下一个 2 个令牌,而不是仅仅预测下一个单个令牌。结合推测性解码框架(Leviathan et al., 2023; Xia et al., 2023),这可以显著加速模型的解码速度。一个自然的问题是,额外预测的令牌的接受率是多少?基于我们的评估,第二个令牌预测的接受率在各种生成主题上都保持在 85% 到 90% 之间,展示了一致的可靠性。这个高接受率使 DeepSeek-V3 能够实现显著改进的解码速度,将 TPS(每秒令牌数)提高了 1.8 倍。
虽然解码速度提升是常数级的,但是对于用户体验非常重要的
#Frenet坐标系 or Cartesian坐标系?
首发于 Frenet坐标系 or Cartesian坐标系?
在智能驾驶领域,轨迹规划问题可以抽象成在满足一定约束条件下寻找最优解的问题,优化变量、状态方程和约束条件是决定优化问题求解复杂性的关键要素。坐标系的选择不仅是解决问题首先要考虑的,而且对优化问题形式和复杂性有着至关重要的影响。
智能驾驶领域中广泛使用的坐标系有Frenet坐标系(sl坐标系)和Cartesian坐标系(xy坐标系),两者最大的区别在于坐标轴是否允许为曲线,Cartesian坐标系即几何中常见的直角坐标系,两条坐标轴是相互正交的直线。而Frenet坐标系允许一条坐标轴为曲线(参考线s),故又称为曲线坐标系。
从定义上可以直觉得出Frenet坐标系特别适合自动驾驶领域的结论,因为车辆的行驶的绝大部分场景都是存在车道线的道路环境下,只要将道路的中心线作为参考线,就可以将复杂的道路环境简化为直线隧道模型,图1显示了Cartesian坐标系向Frenet坐标系的转换。
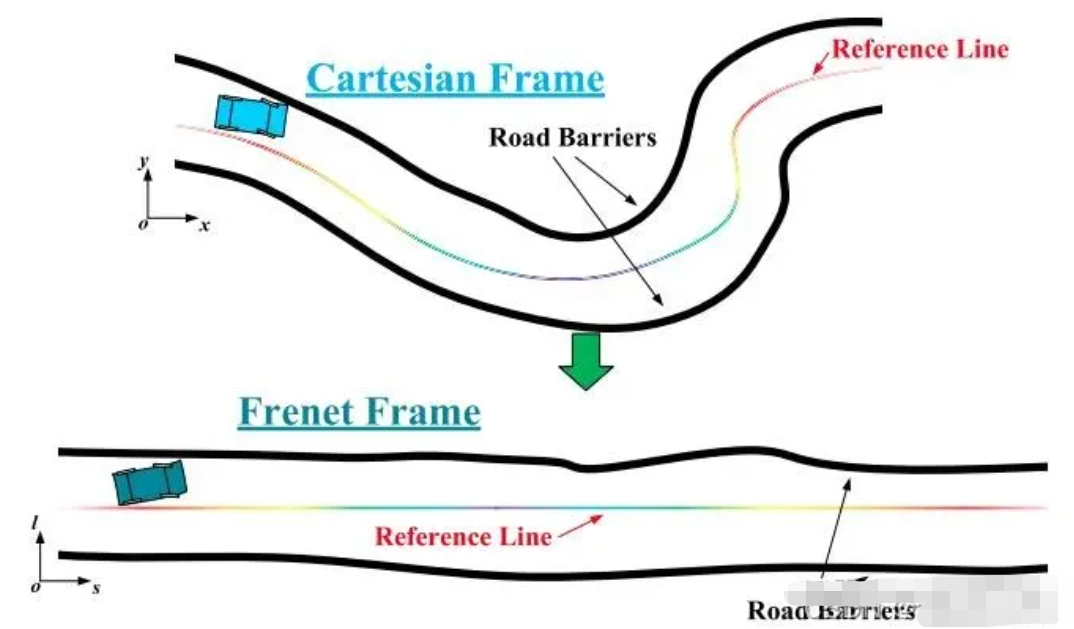
图1 Cartesian坐标系向Frenet坐标系的转换示意图[1]
将弯曲的道路拉直,这是Frenet坐标系最大(也许是唯一)的优点,怎么评估这个优点的大小?在自动驾驶领域,道路边界是一个不得不处理的约束,很多情况下,非线性的道路边界也是最难表示和处理的约束。这种转换直接将非线性的道路边界约束变成了线性的约束,从而大大简化了后续优化问题的求解。此外,现实中的车辆大多数时候都是沿着道路中心线行驶的,所以在Frenet坐标系中,车辆的运动可以直接解耦为纵向运动和横向运动,实现了降维的效果,这是在Cartesian坐标系中是很难实现的。所以,虽然Frenet坐标系有诸多不足之处,它依旧是自动驾驶领域优先考虑的坐标系。
下面主要讨论Frenet坐标系在使用过程中可能出现的问题点:
问题1:xy向sl坐标转换的连续性问题
xy坐标向sl坐标转换的第一步是确定投影点的位置,即在s轴上寻找距离点P最近的投影点,这是一个寻找最优值的过程,没法保证其解的唯一性。如图2所示,参考线上红色区域是曲率为kr的圆弧,圆弧上的任何一点都是其圆心位置P0的投影点。多个投影点的后果是坐标转换困难,如果在多个可行解中随机取值就可能会导致连续的xy轨迹转换成不连续的sl轨迹,这是不连续性的第一个来源。即使能实现处处一对一的转换,xy转换成sl也可能变得不连续,如图2所示,Cartesian坐标系下相距很近的P1、P2的投影点s1、s2也差距巨大。对于曲率越大的参考线,发生这种问题的风险就越高。
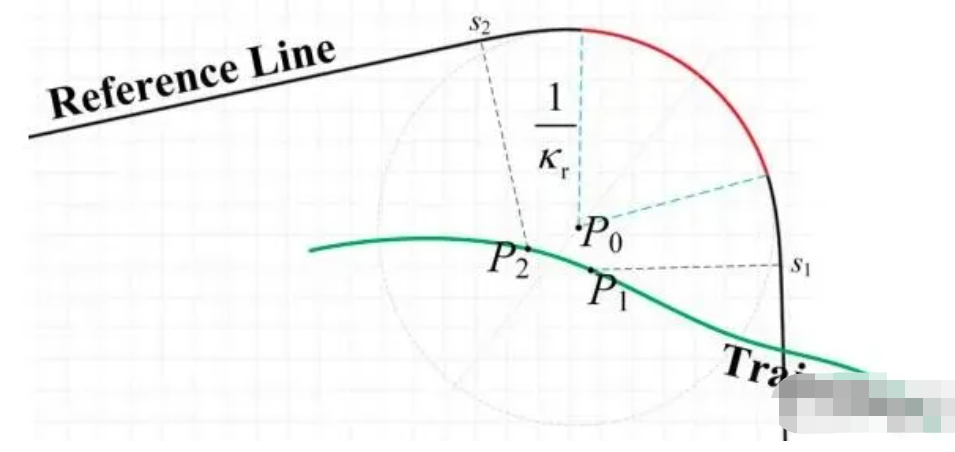
图2 xy向sl坐标转换导致不连续 [1]
问题2:对参考线要求高
参考线直接决定投影点的位置,以及sl曲线。以kx表示xy曲线的曲率,kf表示sl曲线的曲率,两者的转换关系如下:
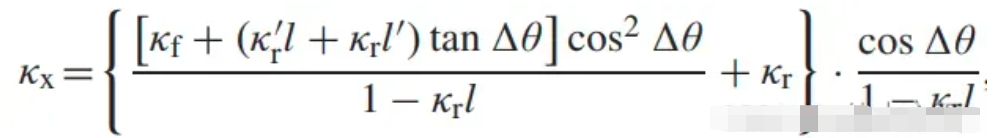
式中kr为参考线曲率,所以要得到曲率连续sl曲线,不仅要求xy曲线的曲率连续,还要求参考线的曲率连续;
问题3:车辆形状扭曲
车辆一般被简化为具有固定尺寸的矩形,用四个顶点来控制其边界,甚至车辆会被抽象成一个点,向四周碰撞一定距离形成边界,在Cartesian坐标系中,这种简化与实际情况完全相符。Frenet坐标系将弯曲道路拉直的同时,也将规则的车辆变得扭曲,如下图3所示。相应地,Frenet中规则的方形实际上代表的是与参考线平行的扭曲形状,如果简单以四个顶点的模型来代表整个车辆边界,就会与真实车辆形状产生偏差,常用的碰撞检测算法就会失效。这种偏差随着参考线曲率和车辆尺寸的变大而变大。
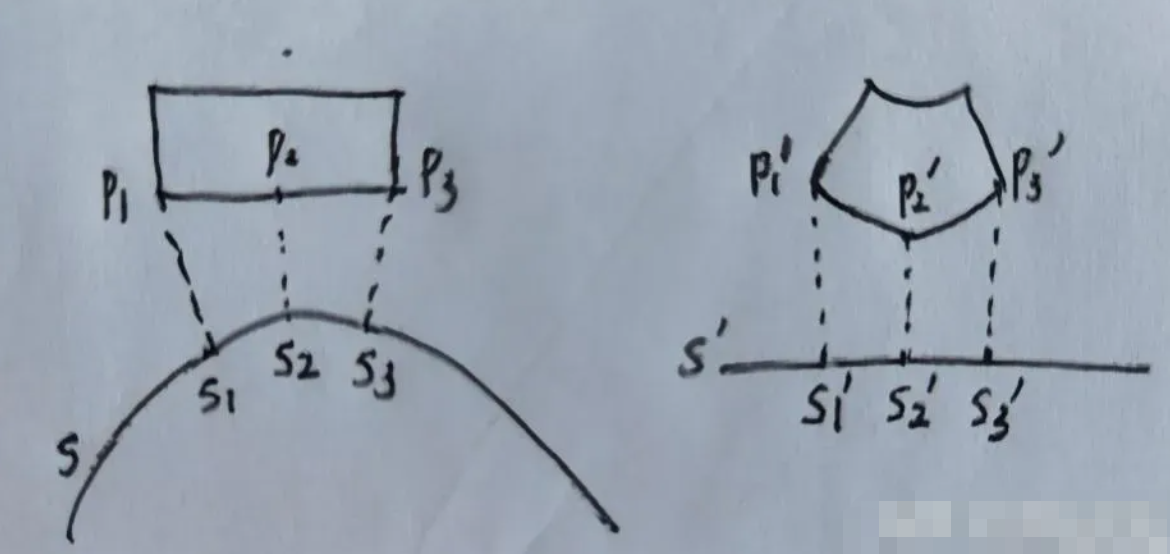
图3 坐标转换导致车辆形状扭曲
问题4:sl和xy的坐标转换误差
工程应用中,参考线通常是以一系列离散坐标点的形式表示的,只有离散点处(x,y)的信息来自传感器,其他的heading/kappa/dkappa信息都是据此推导而来的,这些信息的连续性或平滑性,依赖于相邻参考点之间的连接处理。使用高阶连续曲线处理,可以解决连续性问题,但是会导致投影点的计算量剧增,而坐标转换的计算是个高频行为,有时甚至是算法的性能瓶颈,工程中为了降低计算复杂性,通常有以下假设:
假设1:xy向sl转换时,假设相邻两参考点之间的参考线是直线,heading保持不变。
假设2:sl向xy转换时,假设相邻两参考点之间参考线的heading是线性变化的。
在这两条不一直的假设下,xy和sl之间的来回转换就是不可逆,即(x, y) → (s,l) → (x', y'),(x, y) != (x', y'),如下图4所示。这种差异也会随着参考线曲率和轨迹的采样间隔的增加而增大。
图4 sl和xy的坐标转换误差示意图
有了上面的讨论后,我们再重新思考Frenet坐标系和Cartesian坐标系的选择问题,可以有如下建议:
- 在小曲率的结构化道路中(如高速路或城区快速路),Frenet是首选坐标系。
- Frenet坐标系的问题随着参考线曲率的增加而被放大,所以在大曲率的结构化道路(如城区有引导线的路口)中,选择Frenet就要慎重。
- 对于非结构化的道路,如港口、矿区、停车场,无引导线的路口,建议使用Cartesian坐标系。
#DrivingGPT
中科院最新:利用多模态自回归方法统一驾驶世界模型和规划双任务!
目前,驾驶世界模型已获得了来自工业界和学术界的广泛关注,因为基于模型的搜索和规划被广泛认为是实现人类级智能的重要途径。这些模型有多种用途,包括训练数据增强、稀有场景生成。大多数当前世界模型都是通过微调现有的扩散模型来开发的,利用视频生成基础模型的泛化能力。控制信号(如文本、布局和驾驶操作)通过两种主要方法整合:扩散模型的空间特征与控制信号特征之间的交叉注意,或通道级特征调制技术。
尽管驾驶世界模型取得了非常不错的研究进展,但一个根本挑战仍然存在:在可微分框架中无缝集成世界建模和规划仍未得到很大程度的解决,从而限制了可微分模型规划的全部潜力。世界模型目前主要基于视频扩散架构,限制了它们生成多种模态(如文本和动作序列)的能力。因此,在扩散模型框架内实现驾驶规划和世界建模的真正端到端集成仍然是一项重大的技术挑战。这些限制促使我们探索能够自然处理多模态输入和输出并实现端到端可微分规划的替代架构。
与扩散模型相比,具有下一个Token预测训练目标的自回归Transformer在包括语言建模、视觉问答、图像生成、视频预测、顺序决策和机器人操作在内的广泛任务中表现出卓越的建模能力。自回归Transformer处理顺序数据和多种模态的天生能力使其特别有希望成为基于模型的集成驾驶规划器。
基于上述的讨论,在这项工作中,我们旨在利用自回归Transformer的建模能力来进行驾驶任务中的世界建模和轨迹规划,提出的算法模型称为DrivingGPT。在具有挑战性的 NAVSIM 基准上进行的实验进一步证明了所提出的多模态驾驶语言作为规划训练目标的有效性。我们的 DrivingGPT 在驾驶得分方面优于流行的带有 MLP 轨迹解码器规划器的视觉编码器。
- 论文链接:https://arxiv.org/pdf/2412.18607
网络模型结构&技术细节
经过训练用于下一个Token预测的自回归Transformer已在不同领域展现出卓越的能力。在这项工作中,我们通过结合世界模型和轨迹规划,利用自回归Transformer的强大功能实现自动驾驶。我们的方法将视觉输入和驾驶动作转换为离散驾驶语言,从而通过自回归Transformer实现统一建模,其整体的网络结构图如下图所示。
问题表述
与许多其他任务一样,驾驶问题可以表述为马尔可夫决策过程,这是一种在具有部分随机结果的环境中做出决策的通用数学框架。MDP 包含一个状态空间,它反映了自车和环境的所有状态;一个动作空间;一个随机转换函数,它描述了给定时间的状态和动作的所有可能结果的概率分布;以及一个标量奖励函数,它决定了在特定状态下应采取的最佳动作。在大多数实际应用中,我们只能感知到噪声观测,而无法感知底层状态。因此,引入了观测概率函数,MDP 变为部分可观测的 MDP。预测未来轨迹的端到端策略和模拟驾驶世界动态的观察空间随机转换函数在自动驾驶中都非常重要。我们寻求将这两个挑战统一为一个序列建模任务。
多模态驾驶语言
一般的驾驶序列可以表示为一系列时间同步的观察-行动对,时间范围为。在这里,我们需要将观察和动作标记为离散token,并形成多模态驾驶语言,然后才能利用自回归Transformer进行下一个token预测。
Observation Tokenization
为了简化我们的方法,我们只将前置摄像头图像包含在观察空间中,而将更先进的传感器设置(如周围的 cemaras、LiDAR 和 IMU)留待将来探索。为了将更多帧纳入我们的序列建模,我们利用 VQ-VAE 将图像下采样为图像token。
Action Tokenization
我们的方法与现有的驾驶世界建模方法的不同之处在于,它能够生成未来的驾驶行为。与大多数的端到端驾驶规划器不同,可以预测未来的整个驾驶轨迹。我们的下一个 token 预测公式的因果性质禁止我们构建具有较长动作范围的驱动序列。未来的观察和行动都从历史行动中获取了太多特权信息。
如果我们使用的动作范围,最后的历史动作将包含直到时间戳的所有未来驾驶动作,导致模型只学习复制历史动作,而不是学习基于观察的驾驶。因此,我们不是预测长距离绝对驾驶轨迹,而是预测帧间相对驾驶轨迹,表示时间戳之间的纵向平移、横向平移和偏航旋转。我们将量化为动作token,首先将每个动作组限制在其第1百分位和第99百分位之间。然后,我们通过将限制的动作成分均匀划分为M个格子,获得动作标记。由于的大小和单位不同,我们用不同的词汇量化这三个动作成分,以最大限度地减少信息损失。
Unified Visual Action Sequence Modeling
我们根据token化的驾驶序列构建统一的驾驶语言,然后利用带有因果注意力掩码的自回归Transformer将驾驶建模为下一个token预测。我们将视觉模态和动作模态视为不同的foreign language,并使用统一的词汇表进行驱动。视觉模态的词汇量为,即 VQ-VAE 的codebook大小。动作模态的词汇量为,其中是每个动作组件的bin大小,3表示不同的动作组件。因此,我们的多模态驾驶语言的词汇量为。
我们对图像和动作token应用逐帧一维旋转embedding。然后,自回归Transformer学习使用标准交叉熵损失对统一token序列进行建模。

虽然驾驶语言模型形式看起来很简单,但它明确地将驾驶世界建模和端到端驾驶作为其子任务。
Integrating Action into Trajectory
由于我们在驾驶语言中使用了帧与帧之间的相对动作,因此我们需要将它们整合起来以获得绝对驾驶轨迹。我们首先将预测的动作转换为二维变换矩阵,然后进行整合。
然后,我们通过连续乘以这些相对位姿矩阵来获得绝对位姿,并将其相应地转换回绝对动作。
实验结果&评价指标
视频生成的实验结果
我们对navtest数据集上的几种方法进行了定量比较,相关的实验结果汇总在下表当中。
由于许多视频模型仅发布模型权重,我们将我们的方法与它们公开可用的模型进行比较。我们发现 SVD 和 CogvideoX 都倾向于产生细微的动作,这导致驾驶场景中的表现不佳。为了确保公平比较,我们在 navtrain 集上微调了 SVD 模型。以前的视频模型通常依赖于基于扩散的方法,而我们的方法是自回归视频生成的先驱。值得注意的是,我们从头开始训练的模型在视频生成质量方面超越了以前的方法。
自回归模型的一个关键优势是能够通过有效利用历史信息来生成长时长视频,从而生成更连贯的视频。在这个实验中,我们从 navtest 数据集中选择了 512 个视频片段(每个片段包含超过 64 帧)进行评估。而 SVD 方法在生成较长的序列时很难保持质量,相关的实验结果如下表所示。
通过上表的实验结果可以看出,我们的方法表现出了生成高质量长期序列的卓越能力。SVD的固定帧数训练限制导致较长序列的图像和视频质量显着下降。相比之下,我们的方法始终如一地生成高质量图像并获得较低的 FVD 分数,表明性能更稳定和更优越。
此外,与以往基于扩散的方法相比,我们的方法可以生成更加多样化和合理的场景。如下图所示,SVD 微调方法在生成较长的视频时经常会陷入重复过去内容的困境,例如长时间被困在红灯下。相比之下,自回归方法在生成长视频方面表现出显着的优势,从而显着改善了场景内容和视频质量。
除了长视频生成之外,我们方法的另一个优势在于它能缓解物体幻觉现象。如下图所示,基于扩散的方法由于缺乏历史信息,经常会遭遇物体突然出现(红色框)和逐渐消失(绿色框)的情况。相比之下,我们的自回归方法保持了卓越的一致性。
端到端规划的实验结果
我们的 DrivingGPT 能够联合预测未来图像和驾驶行为,从而实现端到端的规划性能评估。为了严格评估我们的规划器的性能,我们选择了更具挑战性的 NAVSIM 基准,该基准旨在提供比以前的 nuScenes 和 nuPlan 基准更多样化的驾驶操作。此外,鉴于最近关于使用自车状态将为规划者提供过多特权信息的讨论,我们故意选择将其排除在我们的驾驶语言之外。按照 NAVSIM 设置,我们根据过去 2 秒的观察和行动来预测未来 4 秒的轨迹。相关的实验结果如下表所示。
与恒定速度和恒定速度恒定偏航率的基线相比,我们提出的 DrivingGPT 实现了不俗的表现性能。此外,我们的 DrivingGPT 与使用 ResNet-50 视觉编码器和 MLP 轨迹解码器实现的简单但可靠的端到端规划器基线相比更具优势。该基线仅使用前置摄像头图像,也不使用自车状态。考虑到我们提出的 DrivingGPT 只能通过重建驾驶环境的高度压缩图像token来学习表示,结果突出了联合学习世界建模和给定规划的潜力。下图展示了我们提出的DrivingGPT 在具有挑战性的驾驶场景下生成的轨迹。
消融实验分析
如下表所示,视觉标记器的质量显著影响世界模型视觉预测质量的上限。我们在navtest数据集上评估了几种最先进的离散视觉标记器,该数据集包含 12,146 个视频样本。根据我们的评估,我们选择 Llama-Gen 作为我们世界模型的最佳视觉标记器。
此外,自回归Transformer是众所周知的强大拟合机器。因此,我们试图回答一个问题:DrivingGPT 是否真正学会了驾驶,还是只是通过复制或推断历史驾驶动作来偷工减料。我们逐渐用仅从历史动作估计的未来动作替换 DrivingGPT 的预测动作。我们只是复制最后的历史动作,因为一般的驾驶轨迹不涉及任何动作输入变化。相关的实验结果如下表所示。
我们的 DrivingGPT 始终优于所有简单复制横向、纵向和历史动作的变体。可能会注意到,复制之前的纵向动作会产生最差的规划结果,这是因为 NAVSIM 基准包含许多场景,其中自车刚刚开始从停止和启动加速。实验结果表明,我们的 DrivingGPT 真正学会了如何驾驶,而不仅仅是复制历史动作。
同时,我们发现数据质量在语言建模等其他任务上训练自回归Transformer时起着核心作用。因此,我们研究驱动数据质量和数量对端到端规划性能的影响,相关的实验结果如下表所示。
使用NAVSIM等高质量数据训练的模型(仅包含 100k 个驾驶序列)优于使用 650k 个 nuPlan 驾驶序列训练的模型。结果表明,在驾驶语言建模中,数据质量比数据数量更重要。
结论
在本文中,我们提出了一种新颖的多模态驾驶语言,该语言有效地将视觉世界建模和轨迹规划统一到序列建模任务中。我们设计的算法框架称为DrivingGPT,可以联合学习为这两个任务生成图像和动作token。在nuPlan 和 NAVSIM 基准上进行的实验和消融研究证明了所提出的 DrivingGPT 在动作条件视频生成和端到端规划方面的有效性。
相关文章:

51c自动驾驶~合集43
我自己的原文哦~ https://blog.51cto.com/whaosoft/12930230 #ChatDyn 上交大最新ChatDyn:一句话操纵三维动态 理解和生成真实的三维虚拟世界是空间智能的核心。所生成的三维虚拟世界能够为自动驾驶、具身智能等AI系统提供高质量闭环仿真训练场,高效…...

随机变量是一个函数-如何理解
文章目录 一. 随机变量二. 随机变量是一个函数-栗子(一对一)1. 掷骰子的随机变量2. 掷骰子的随机变量(求点数平方)3. 抛硬币的随机变量4. 学生考试得分的随机变量 三. 随机变量是一个函数-理解(多对一) 一. 随机变量 随机变量就是定义在样本空间上的函数…...

云计算在医疗行业的应用
云计算在医疗行业的应用广泛而深入,为医疗服务带来了前所未有的变革。以下是对云计算在医疗行业应用的详细解析: ### 一、医疗数据共享与整合 云计算平台具有强大的数据存储和处理能力,使得医疗数据共享与整合成为可能。通过云计算平台&…...

Cursor提示词
你是一位经验丰富的项目经理,对于用户每一次提出的问题,都不急于编写代码,更多是通过深思熱虑、结构化的推理以产生高质量的回答,探索更多的可能方案,并从中寻找最佳方案。 约束 代码必须可以通过编译回答尽量使用中…...
)
C++ 设计模式:单例模式(Singleton Pattern)
链接:C 设计模式 链接:C 设计模式 - 享元模式 单例模式(Singleton Pattern)是创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问这个实例。单例模式在需要全局共享资源或控制实例数量的…...

C++中生成0到180之间的随机数
在C中生成0到180之间的随机数,可以使用标准库中的和头文件。提供了rand()函数来生成随机数,而提供了time()函数来设置随机数生成的种子。这样每次运行程序时,生成的随机数序列都会不同。 以下是一个简单的示例代码,展示了如何生成…...

[.闲于修.]Autosar_UDS_笔记篇_ISO14229-1
前言:闲来无事,摸鱼无趣,准备细读一下14229,记录一些容易被忽略掉的内容 正文:(以下数字代表章节) 7、Application layer protocol 7.5.6 多个并发请求消息 常见的服务器实现在服务器中只有一…...

如何利用云计算进行灾难恢复?
云计算环境下的灾难恢复实践指南 天有不测风云,企业的IT系统也一样,我见过太多因为没有做好灾备而吃大亏的案例。今天就和大家聊聊如何用云计算来做灾难恢复。 一个惊心动魄的真实案例:某电商平台的主数据中心因为市政施工不小心挖断了光纤…...
)
Redis - 1 ( 7000 字 Redis 入门级教程 )
一: Redis 1.1 Redis 简介 Redis 是一种基于键值对(key-value)的 NoSQL 数据库,与其他键值对数据库不同,Redis 的值可以是多种数据结构和算法的组合,如字符串(string)、哈希&#…...

[羊城杯 2024]不一样的数据库_2
题目描述: 压缩包6 (1).zip需要解压密码: 尝试用ARCHPR工具爆破一下: (字典可自行在github上查找) 解压密码为:753951 解压得到13.png和Kee.kdbx文件: 二维码图片看上去只缺了正常的三个角&…...

租赁系统的数字化转型与高效管理新模式分析
内容概要 在当今瞬息万变的市场环境中,租赁系统的数字化转型显得尤为重要。信息技术的迅猛发展不仅改变了我们的生活方式,也迫使企业重新审视其运营模式。为了顺应这一潮流,租赁系统亟需通过高效管理新模式来提升运营效率,从而保…...
:Jenkins发送邮件报错Not sent to the following valid addresses解决方案)
Selenium+Java(21):Jenkins发送邮件报错Not sent to the following valid addresses解决方案
问题现象 小月妹妹近期在做RobotFrameWork自动化测试,并且使用Jenkins发送测试邮件的时候,发现报错Not sent to the following valid addresses,明明各个配置项看起来都没有问题,但是一到邮件发送环节,就是发送不出去,而且还不提示太多有用的信息,急的妹妹脸都红了,于…...

【每日学点鸿蒙知识】文字识别、快捷登录、输入法按钮监听、IDE自动换行、资产访问等
【每日学点鸿蒙知识】24.09.07 1、API使用: hms.ai.ocr.textRecognition(文字识别)? 需要接入API文档https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/core-vision-text-recognition-api-V5中的文字识别…...

LabVIEW化工实验室设备故障实时监测
化工实验室中,各类设备的运行状态直接影响实验的精度与安全性。特别是重要分析仪器的突发故障,可能导致实验中断或数据失效。为了实现设备运行状态的实时监控与故障快速响应,本文提出了一套基于LabVIEW的解决方案,通过多参数采集、…...

小程序学习05——uniapp路由和菜单配置
目录 一、路由 二、如何管理页面及路由? 三、pages.json 页面路由 四、 tabBar 一、路由 路由:在前端,往往指代用不同地址请求不同页面,决定了用户如何在应用的不同页面之间导航。 菜单:对于每个路径(…...
)
漏洞分析 | Apache Struts文件上传漏洞(CVE-2024-53677)
漏洞概述 Apache Struts是美国阿帕奇(Apache)基金会的一个开源项目,是一套用于创建企业级Java Web应用的开源MVC框架。 近期,网宿安全演武实验室监测到Apache Struts在特定条件下,存在文件上传漏洞(网宿评…...

【VBA】EXCEL - VBA 遍历工作表的 5 种方法,以及注意事项
目录 1. 遍历单列数据并赋值 2. 遍历整个工作表的数据区域并赋值 3. 遍历指定范围的数据并赋值 4. 遍历多列数据并赋值 5. 遍历所有工作表中的数据并赋值 注意事项: 1. 遍历单列数据并赋值 Sub UpdateColumnData()Dim ws As WorksheetSet ws ThisWorkbook.S…...

CSS浮动
浮动 可以让块级元素待在一行,紧挨着,没有空格 float:left 浮动的元素会脱离正常的文档系统,像浮云一样飘起来浮动元素后面的正常元素会自动补位浮动元素会被父元素的宽高所束缚,所以不算完全的脱离文档流当浮动元素…...

gitlab 还原合并请求
事情是这样的: 菜鸡从 test 分支切了个名为 pref-art 的分支出来,发布后一机灵,发现错了,于是在本地用 git branch -d pref-art 将该分支删掉了。之后切到了 prod 分支,再切出了一个相同名称的 pref-art 分支出来&…...

【GPT】Coze使用开放平台接口-【8】创建应用
coze 可以用来创建简单的应用啦,这样测试起来会比原本的 Agent 更加方便,我们来看看如何创建一个“语音Real不Real”的应用。这个应用就是来检测语音是否是伪造的,克隆或者是合成的。先看下原本 Agent 的样子: 深度伪造语音检测&a…...

海外盲盒系统开发,助力企业全球化发展
近几年来,在海外市场中,盲盒已经成为了一种新的时尚单品,深受东南亚等海外消费者的喜爱。同时,泡泡玛特在海外的成功也为国内企业提供了发展机遇,盲盒出海具有广阔的发展前景! 随着信息技术的快速发展&a…...

pytorch 梯度判断函数介绍
PyTorch 提供了一些函数用于判断当前的梯度计算状态以及张量是否需要梯度。这些函数帮助开发者在训练、推理和调试过程中了解和控制梯度计算行为。 PyTorch 梯度判断函数 1. torch.is_grad_enabled() 功能: 判断当前是否启用了全局的梯度计算状态。返回值: 布尔值,True 表…...

每日一题 367. 有效的完全平方数
367. 有效的完全平方数 低效率法 class Solution { public:bool isPerfectSquare(int num) {if(num 1){return true;}long num1 num;for(int i1;i< num/2;i){if((long)(i)*i num){return true;}}return false;} };二分法 class Solution { public:bool isPerfectSquar…...

图像转换 VM与其他格式互转
目录 前言 图像转换 1.相机取流转VM对应类型图像格式 1.1 相机采图转流程输入和Group输入(ImageBaseData_V2) 1.2 相机采图转图像源SDK输入(ImageBaseData) 1.3 相机采图转模块输入(InputImageData) 1.4 相机采图转算子输入(CmvdImage) 2.Bitmap取图与VM对应图像格式互…...

streamlit、shiny、gradio、fastapi四个web APP平台体验
streamlit、shiny、gradio、fastapi四个web APP平台体验 经常被问的问题就是:web APP平台哪个好?该用哪个?刚开始只有用streamlit和shiny,最近体验了一下gradio和fastapi,今天根据自己的体会尝试着回答一下。 使用R语…...

BootstrapTable处理表格
需求背景 历史项目使用 BootstrapTable 作为前端组件 应客户需要调整: 冻结前四列对于大文本文字显示部分内容,鼠标悬浮显示完整内容 冻结列 1、引入相关CSS,JS CSS <link rel"stylesheet" href"/css/bootstrap.min.css"> …...

家政预约小程序04活动管理表结构设计
目录 1 创建活动表2 创建活动规则表3 创建活动参与记录表总结 为了满足我们日常的营销,我们通常需要搞一些活动,比如满减、折扣、团购等。启动活动后,会在首页进行显示,当用户访问小程序的时候,就可以参与活动…...

WPF使用OpenCvSharp4
WPF使用OpenCvSharp4 创建项目安装OpenCvSharp4 创建项目 安装OpenCvSharp4 在解决方案资源管理器中,右键单击项目名称,选择“管理 NuGet 包”。搜索并安装以下包: OpenCvSharp4OpenCvSharp4.ExtensionsOpenCvSharp4.runtime.winSystem.Man…...

STM32-笔记23-超声波传感器HC-SR04
一、简介 HC-SR04 工作参数: • 探测距离:2~600cm • 探测精度:0.1cm1% • 感应角度:<15 • 输出方式:GPIO • 工作电压:DC 3~5.5V • 工作电流:5.3mA • 工作温度:-40~85℃ 怎么…...

4G报警器WT2003H-16S低功耗语音芯片方案开发-实时音频上传
一、引言 在当今社会,安全问题始终是人们关注的重中之重。无论是家庭、企业还是公共场所,都需要一套可靠的安全防护系统来保障人员和财产的安全。随着科技的飞速发展,4G 报警器应运而生,为安全防范领域带来了全新的解决方案。…...

机器学习中的欠拟合
当模型不能够准确地表达输入与输出的关系时,就是欠拟合。它在训练集和未见过的数据都会产生高误差率。过度拟合则在训练集表现出低误差率,只有对未见过的数据表现出高误差率。 当模型太过于简单时,它需要更多的训练时间、更多的输入特征、更…...

数据结构之栈和队列
栈的定义: 我们要记住这8个字,先进后出,后进先出 我们对于栈的操作只有两个,进栈和出栈 栈的顺序结构初始化:(和顺序表差不多) 代码实现: 栈的顺序结构进栈: 代码实现…...

【北京迅为】iTOP-4412全能版使用手册-第六十九章 Linux内核裁剪与定制
iTOP-4412全能版采用四核Cortex-A9,主频为1.4GHz-1.6GHz,配备S5M8767 电源管理,集成USB HUB,选用高品质板对板连接器稳定可靠,大厂生产,做工精良。接口一应俱全,开发更简单,搭载全网通4G、支持WIFI、蓝牙、…...

MF248:复制工作表形状到Word并调整多形状位置
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...

若依框架之简历pdf文档预览功能
一、前端 (1)安装插件vue-pdf:npm install vue-pdf (2)引入方式:import pdf from "vue-pdf"; (3)components注入方式:components:{pdf} (4&…...

常用的数据库类型都有哪些
在Java开发和信息系统架构中,数据库扮演着存储和管理数据的关键角色。数据库种类繁多,各有特色,适用于不同的应用场景。 1. 关系型数据库(RDBMS): • 关系型数据库是最为人熟知的数据库类型,数据…...

使用apisix+oidc+casdoor配置微服务网关
一、服务架构图 二、安装配置 1. 安装配置apisix (1). 快速启动及验证: curl -sL https://run.api7.ai/apisix/quickstart | sh该命令启动 apisix-quickstart 和 etcd 两个容器,APISIX 使用 etcd 保存和同步配置。APISIX 和 etcd 容器使用 Docker 的 …...

【系统分析师】- 案例 -数据库特训
目录 1、规范化与逆规范化 2、数据库视图 3、数据库索引 4、SQL优化 5、数据库分区 6、分布式数据库 7、NoSql 8、读写分离(主从复制) 9、缓存一致性 10、云数据库 11、主题数据库 12、数据同步 1、规范化与逆规范化 规范化: 优点…...

创建型设计模式、结构型设计模式与行为型设计模式 上下文任务通用方案 设计模式 大全
设计模式(Design Pattern)是一种面向对象编程思想,分为创建型模式、结构型模式与行为型模式三大类,提供在特定上下文中解决常见任务通用方案,旨在让程序(软件)具有更好特点,如降低耦…...

2412git,gitdiff与编码
原文 除了git命令行工具外,还有其他工具或服务可让你查看git历史记录中的更改.最有趣的是那些按拉请的一部分更改的情况,因为这些是你正在审查和批准的更改. 但一个常见的问题是,它们给你展示的可能不是实际改变的内容. 我把讨论限制在我有经验的服务和工具上,即它是git命令…...

什么是 Git Hooks?
在团队开发中,当成员提交代码的描述信息不符合约定提交规范的时候,需要阻止当前的提交,而要实现这个目的,我们就需要先来了解一个概念,叫做 Git hooks,即Git 在执行某个事件之前或之后进行一些其他额外的操…...

Android中加载一张图片占用的内存
在安卓(Android)系统中,加载图片占用内存的大小并不是图片本身的大小,比如一张图片大小为100kb,那当他加载到Android上时其占用的内存大小并不是100kb。 加载图片到内存中占用的内存大小取决于多种因素,包括…...

【竞技宝】LOL:IG新赛季分组被质疑
北京时间2024年12月31日,今天已经2024年的最后一天,在进入一月之后,英雄联盟将迎来全新的2025赛季。而目前新赛季第一阶段的抽签结果已经全部出炉,其中人气最高的IG战队在本次抽签中抽到了“绝世好签”引来了网友们的质疑。 首先介…...

智能工厂的设计软件 应用场景的一个例子:为AI聊天工具添加一个知识系统 之12 方案再探之3:特定于领域的模板 之2 首次尝试和遗留问题解决
本文提要 现在就剩下“体”本身的 约定了--这必然是 自律自省的,或者称为“戒律” --即“体”的自我训导discipline。完整表述为: 严格双相的庄严“相” (<head>侧),完全双性的本质“性”(<boot>侧&…...

超融合时间节点同步
1. 执行以下命令停止相关进程。 l 节点为主机,执行: perl /opt/galax/gms/common/config/restartCnaProcess.pl l 节点为VRM,执行: sh /opt/omm/ha/module/hacom/script/stop_ha.sh 2. 执行以下命令修改节…...

【分布式文件存储系统Minio】2024.12保姆级教程
文章目录 1.介绍1.分布式文件系统2.基本概念 2.环境搭建1.访问网址2.账号密码都是minioadmin3.创建一个桶4.**Docker安装miniomc突破7天限制**1.拉取镜像2.运行容器3.进行配置1.格式2.具体配置 4.查看桶5.给桶开放权限 3.搭建minio模块1.创建一个oss模块1.在sun-common下创建2.…...

pycharm pytorch tensor张量可视化,view as array
Evaluate Expression 调试过程中,需要查看比如attn_weight 张量tensor的值。 方法一:attn_weight.detach().numpy(),view as array 方法二:attn_weight.cpu().numpy(),view as array...

LeetCode 3219.切蛋糕的最小总开销 II:贪心——先切贵的
【LetMeFly】3219.切蛋糕的最小总开销 II:贪心——先切贵的 力扣题目链接:https://leetcode.cn/problems/minimum-cost-for-cutting-cake-ii/ 有一个 m x n 大小的矩形蛋糕,需要切成 1 x 1 的小块。 给你整数 m ,n 和两个数组&…...

【PDF物流单据提取明细】批量PDF提取多个区域内容导出表格或用区域内容对文件改名,批量提取PDF物流单据单号及明细导出表格并改名的技术难点及小节
相关阅读及下载: PDF电子物流单据: 批量PDF提取多个区域局部内容重命名PDF或者将PDF多个局部内容导出表格,具体使用步骤教程和实际应用场景的说明演示https://mp.weixin.qq.com/s/uCvqHAzKglfr40YPO_SyNg?token720634989&langzh_CN扫描…...

Redis到底支不支持事务啊?
大家好,我是锋哥。今天分享关于【Redis到底支不支持事务啊?】面试题。希望对大家有帮助; Redis到底支不支持事务啊? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Redis 支持事务,但它的事务模型与传统的…...