第R5周:天气预测
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
任务说明:该数据集提供了来自澳大利亚许多地点的大约 10 年的每日天气观测数据。你需要做的是根据这些数据对RainTomorrow进行一个预测,这次任务任务与以往的不同,我增加了探索式数据分析(EDA),希望这部分内容可以帮助到大家。
一、导入数据
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation,Dropout
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.layers import Dropout
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error , mean_absolute_percentage_error , mean_squared_error
data = pd.read_csv("/home/aiusers/space_yjl/深度学习训练营/进阶/第R5周:天气预测/weatherAUS.csv")
df = data.copy()
data.head()
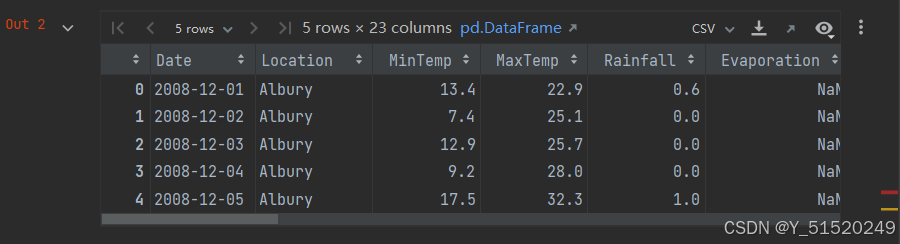
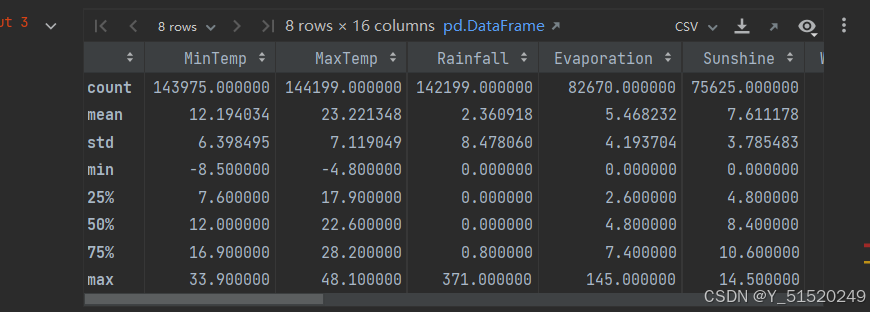
data.describe()
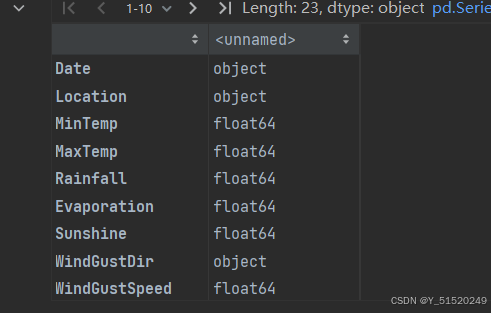
data.dtypes
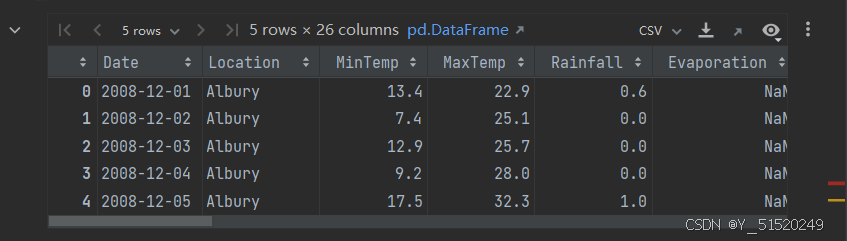
#将数据转换为日期时间格式
data['Date'] = pd.to_datetime(data['Date'])data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.daydata.head()
data.drop('Date',axis=1,inplace=True)
data.columns
二、探索式数据分析(EDA)
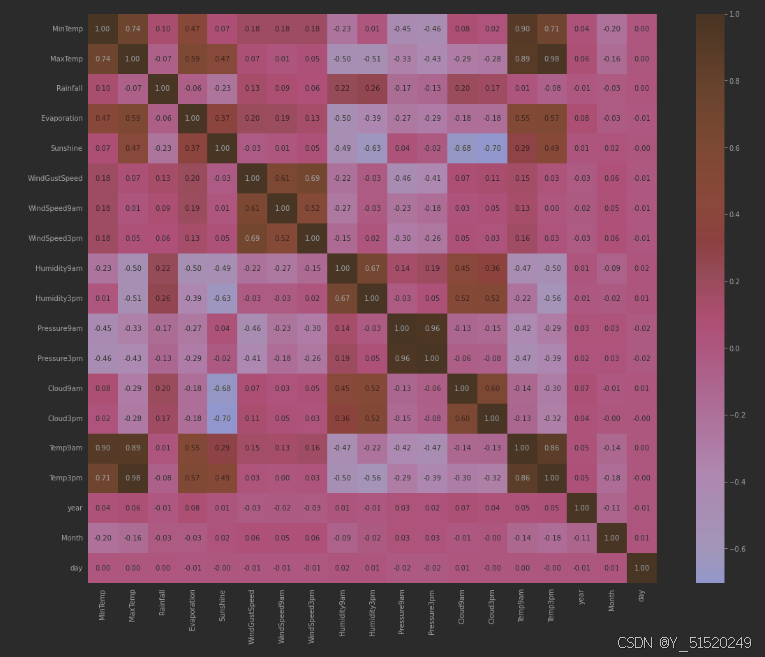
1. 数据相关性探索
# 选择数值型数据
numeric_data=data.select_dtypes(include=[np.number])#计算相关性矩阵
plt.figure(figsize=(20,15))
# data.corr()表示了data中的两个变量之间的相关性
ax=sns.heatmap(numeric_data.corr(),square=True,annot=True,fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(),rotation=90)
plt.show()
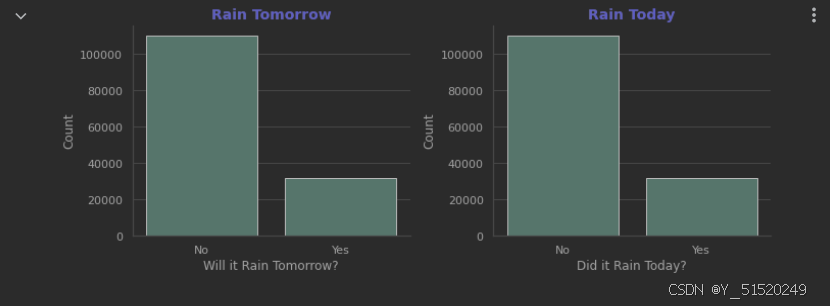
2. 是否会下雨
# 设置样式和调色板
sns.set(style="whitegrid", palette="Set2")# 创建一个 1 行 2 列的图像布局
fig, axes = plt.subplots(1, 2, figsize=(10, 4)) # 图形尺寸调大 (10, 4)# 图表标题样式
title_font = {'fontsize': 14, 'fontweight': 'bold', 'color': 'darkblue'}# 第一张图:RainTomorrow
sns.countplot(x='RainTomorrow', data=data, ax=axes[0], edgecolor='black') # 添加边框
axes[0].set_title('Rain Tomorrow', fontdict=title_font) # 设置标题
axes[0].set_xlabel('Will it Rain Tomorrow?', fontsize=12) # X轴标签
axes[0].set_ylabel('Count', fontsize=12) # Y轴标签
axes[0].tick_params(axis='x', labelsize=11) # X轴刻度字体大小
axes[0].tick_params(axis='y', labelsize=11) # Y轴刻度字体大小# 第二张图:RainToday
sns.countplot(x='RainToday', data=data, ax=axes[1], edgecolor='black') # 添加边框
axes[1].set_title('Rain Today', fontdict=title_font) # 设置标题
axes[1].set_xlabel('Did it Rain Today?', fontsize=12) # X轴标签
axes[1].set_ylabel('Count', fontsize=12) # Y轴标签
axes[1].tick_params(axis='x', labelsize=11) # X轴刻度字体大小
axes[1].tick_params(axis='y', labelsize=11) # Y轴刻度字体大小sns.despine() # 去除图表顶部和右侧的边框
plt.tight_layout() # 调整布局,避免图形之间的重叠
plt.show()
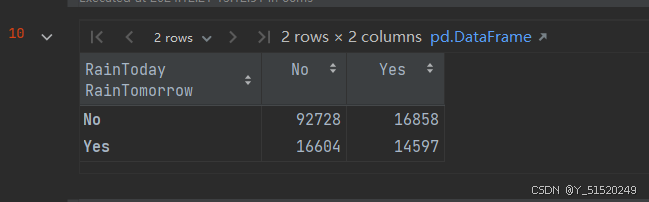
x=pd.crosstab(data['RainTomorrow'],data['RainToday'])
x
y=x/x.transpose().sum().values.reshape(2,1)*100
y
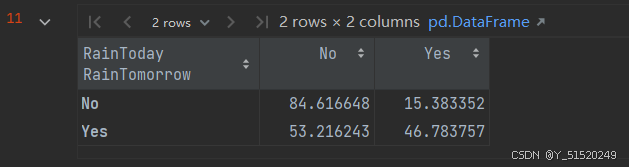
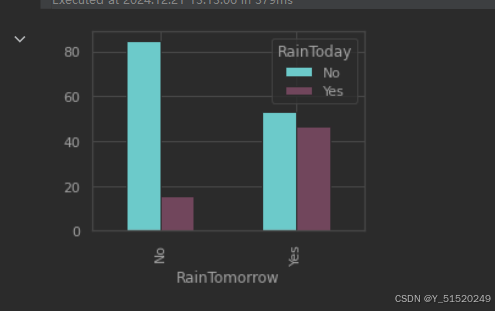
如果今天不下雨,那么明天下雨的机会 = 53.22% ● 如果今天下雨明天下雨的机会 = 46.78%
y.plot(kind="bar",figsize=(4,3),color=['#006666','#d279a6']);
3. 地理位置与下雨的关系
x=pd.crosstab(data['Location'],data['RainToday'])
# 获取每个城市下雨天数和非下雨天数的百分比
y=x/x.transpose().sum().values.reshape((-1, 1))*100
# 按每个城市的雨天百分比排序
y=y.sort_values(by='Yes',ascending=True )color=['#cc6699','#006699','#006666','#862d86','#ff9966' ]
y.Yes.plot(kind="barh",figsize=(15,20),color=color)
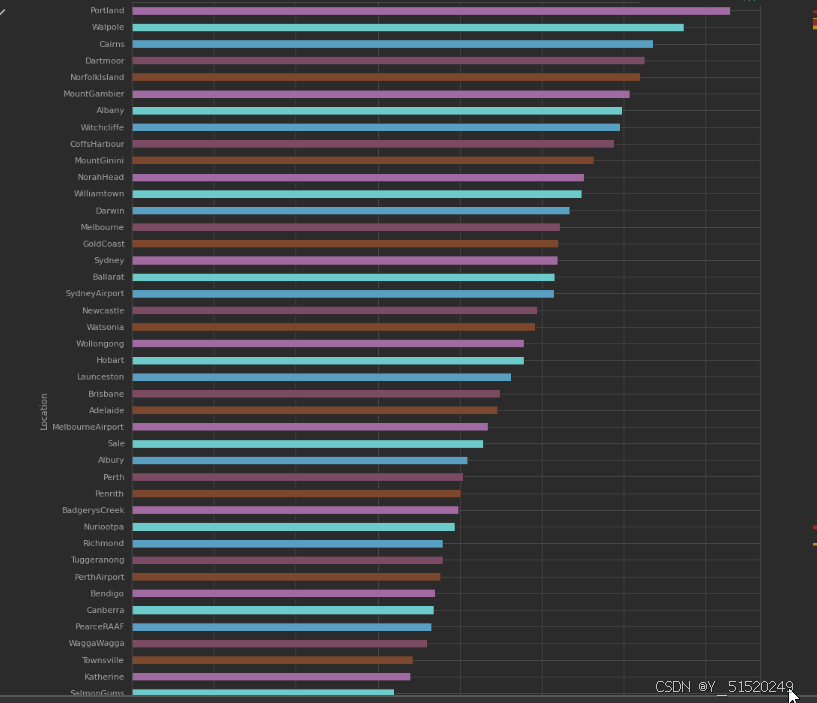
位置影响下雨,对于 Portland 来说,有 36% 的时间在下雨,而对于 Woomers 来说,只有6%的时间在下雨
4. 湿度和压力对下雨的影响
data.columns
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Pressure9am',y='Pressure3pm',hue='RainTomorrow');
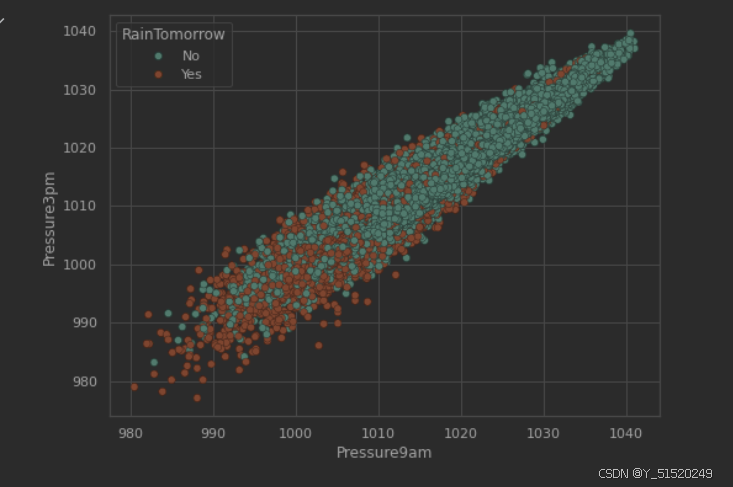
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Humidity9am',y='Humidity3pm',hue='RainTomorrow');
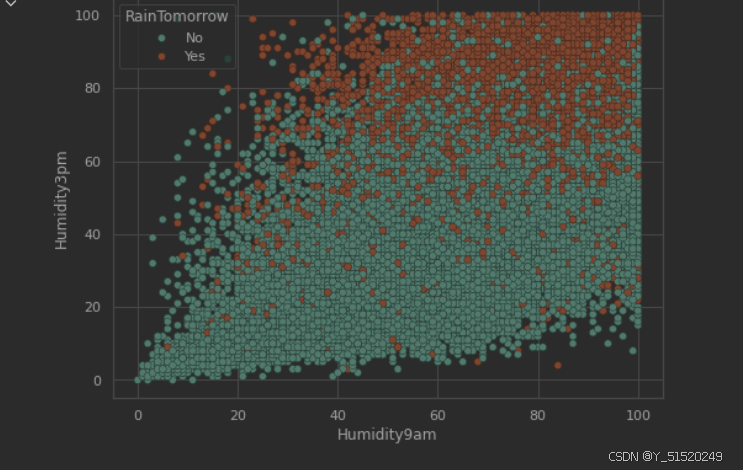
低压与高湿度会增加第二天下雨的概率,尤其是下午 3 点的空气湿度。
5. 气温对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(x='MaxTemp', y='MinTemp', data=data, hue='RainTomorrow');
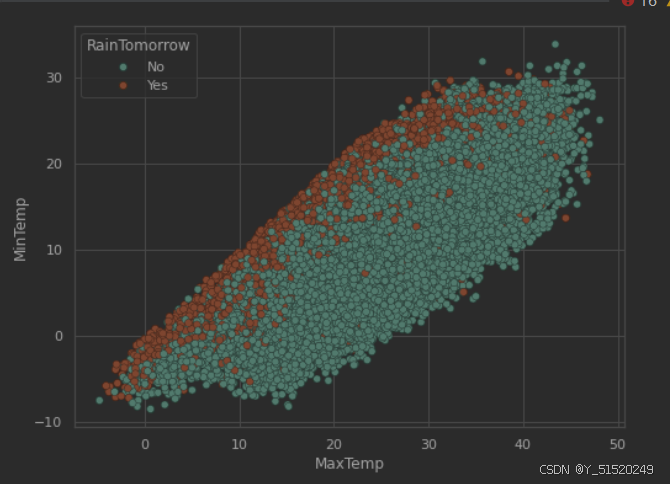
结论:当一天的最高气温和最低气温接近时,第二天下雨的概率会增加。
三、数据预处理
1. 处理缺损值
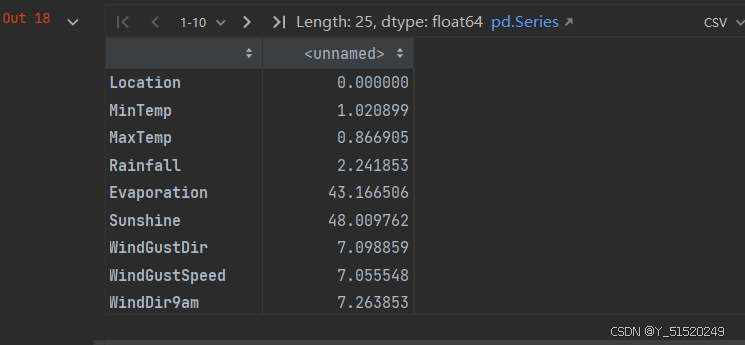
# 每列中缺失数据的百分比
data.isnull().sum()/data.shape[0]*100
# 在该列中随机选择数进行填充
lst=['Evaporation','Sunshine','Cloud9am','Cloud3pm']
for col in lst:fill_list = data[col].dropna()data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list, size=len(data.index))))
s = (data.dtypes == "object")
object_cols = list(s[s].index)
object_cols

# inplace=True:直接修改原对象,不创建副本
# data[i].mode()[0] 返回频率出现最高的选项,众数for i in object_cols:data[i].fillna(data[i].mode()[0], inplace=True)
t = (data.dtypes == "float64")
num_cols = list(t[t].index)
num_cols
# .median(), 中位数
for i in num_cols:data[i].fillna(data[i].median(), inplace=True)
data.isnull().sum()
2. 构建数据集
from sklearn.preprocessing import LabelEncoderlabel_encoder = LabelEncoder()
for i in object_cols:data[i] = label_encoder.fit_transform(data[i])X = data.drop(['RainTomorrow','day'],axis=1).values
y = data['RainTomorrow'].valuesX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25,random_state=101)scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
四、预测是否下雨
1. 搭建神经网络
# from tensorflow.keras.optimizers import Adam
#
# model = Sequential()
# model.add(Dense(units=24,activation='tanh',))
# model.add(Dense(units=18,activation='tanh'))
# model.add(Dense(units=23,activation='tanh'))
# model.add(Dropout(0.5))
# model.add(Dense(units=12,activation='tanh'))
# model.add(Dropout(0.2))
# model.add(Dense(units=1,activation='sigmoid'))
#
# optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
#
# model.compile(loss='binary_crossentropy',
# optimizer=optimizer,
# metrics="accuracy")from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
import tensorflow as tf# 创建模型
model = Sequential()
model.add(Dense(units=24, activation='tanh'))
model.add(Dense(units=18, activation='tanh'))
model.add(Dense(units=23, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(units=12, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=1, activation='sigmoid'))# 创建优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)# 编译模型
model.compile(loss='binary_crossentropy',optimizer=optimizer,metrics=['accuracy']) # 修改这里,metrics 应该是一个列表# 查看模型架构
model.summary()
2.早停
early_stop = EarlyStopping(monitor='val_loss', mode='min',min_delta=0.001, verbose=1, patience=25,restore_best_weights=True)
2. 模型训练
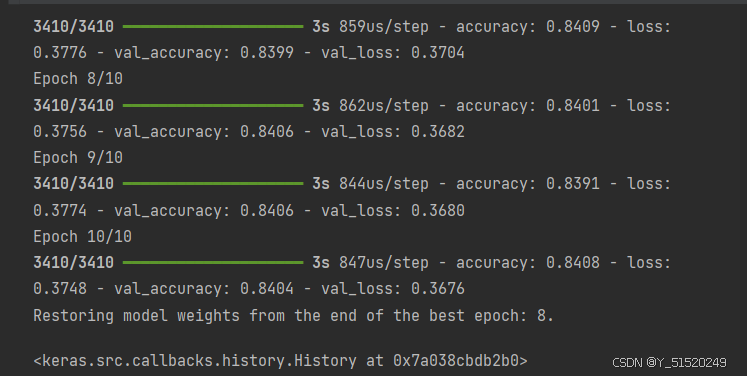
model.fit(x=X_train, y=y_train, validation_data=(X_test, y_test), verbose=1,callbacks=[early_stop],epochs = 10,batch_size = 32
)
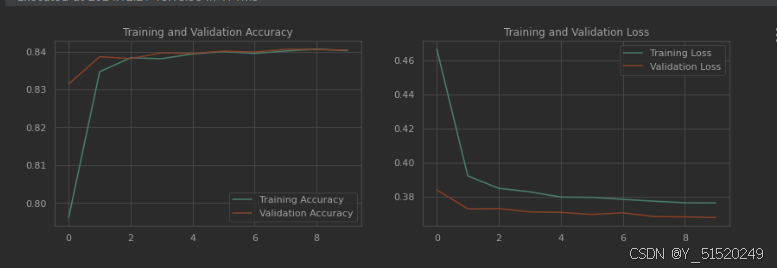
3. 结果可视化
import matplotlib.pyplot as pltacc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']loss = model.history.history['loss']
val_loss = model.history.history['val_loss']epochs_range = range(10)plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
五、总结
探索式数据分析(EDA)是数据分析过程中的关键环节,具有重要意义与诸多特性。
从目的来看,它旨在初步了解数据的整体特征、分布情况、变量间关系等,为后续深入分析、建模提供坚实基础。例如,在研究市场销售数据时,通过 EDA 能快速知晓各产品销量的高低分布、不同地区销售额的差异,以及销售时间与销量的关联趋势。
方法上涵盖多个维度。首先是数据概览,查看数据的基本信息,像数据集的大小、变量的数据类型(是数值型、分类型还是日期型等),对数据全貌心中有数。描述性统计分析也极为常用,计算均值、中位数、标准差、众数等统计量,以此把握数据的集中趋势、离散程度。数据可视化更是 EDA 的 “利器”,利用柱状图展现不同类别数据的数量对比,折线图呈现时间序列数据的变化走势,散点图探索两个变量间的潜在关系,箱线图分析数据的分布区间及异常值情况等,让抽象的数据以直观形式呈现。
相关文章:

第R5周:天气预测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 任务说明:该数据集提供了来自澳大利亚许多地点的大约 10 年的每日天气观测数据。你需要做的是根据这些数据对RainTomorrow进行一个预测,…...

【每日学点鸿蒙知识】ets匿名类、获取控件坐标、Web显示iframe标签、软键盘导致上移、改变Text的背景色
1、HarmonyOS ets不支持匿名类吗? 不支持,需要显式标注对象字面量的类型,可以参考以下文档:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V5/typescript-to-arkts-migration-guide-V5#%E9%9C%80%E8%A6%81%E6%…...

【Vim Masterclass 笔记02】第3章:Vim 核心知识 + L08:Vim 核心浏览命令 + L09:Vim 核心浏览命令同步练习
文章目录 Section 3:Vim Essentials(Vim 核心知识)S03L08 Essential Navigation Commands1 光标的上下左右移动2 上 / 下翻页3 基于单词前移4 基于单词后移5 重新定位视图中的文本(页面重绘)6 定位到所在行的行首7 光标…...

Spring Boot教程之四十:使用 Jasypt 加密 Spring Boot 项目中的密码
如何使用 Jasypt 加密 Spring Boot 项目中的密码 在本文中,我们将学习如何加密 Spring Boot 应用程序配置文件(如 application.properties 或 application.yml)中的数据。在这些文件中,我们可以加密用户名、密码等。 您经常会遇到…...

unity 按钮发送数据到服务器端
1. canvas 明显大于 main camera显示范围 按钮设置 reset 2 设置场景背景图片 2. 如何设置 sense 与背景图大小一致 stretch 没有生效 手动拖拽到 camera 大小 3 将button 按钮拖拽到背景image 中...

【TG\SE二次开发】天工CAD二次开发-c++模板介绍
VS的安装的环境: 1. Visual Studio EnterPrise 2022版本 2. 涉及到的工作负荷: 使用C的桌面开发、通用Windows平台开发 3. 特别要求的单个组件: 适用于最新的v143生成工具的CATL(x86和x64)组件、适用于最新的v143生…...

C语言预处理
预处理 C语言的编译步骤 预处理编译汇编链接 C语言的预处理 预处理就是在源文件编译之前,所进行的一部分预备操作,这部分操作是由预处理程序自动完成;当源文件在编译时,编译器会自动调用预处理程序来完成预处理操作执行的解析…...

DPIN基金会在曼谷发布全球去中心化GPU算力网络计划
12月12日,DPIN基金会在泰国曼谷举行的“DPIN—AIDePIN全球共识发布会”上,展示了其构建全球去中心化GPU算力网络的宏伟蓝图与愿景。DPIN基金会致力于开发一个基于人工智能与去中心化物理基础设施网络(DePIN)的高性能计算平台&…...

ONNX Runtime gpu版本安装
ONNX Runtime版本与cudatoolkit版本对应关系:NVIDIA - CUDA | onnxruntime onnx runtime发的版本:Releases microsoft/onnxruntime onnx runtime 官网:ONNX Runtime | Home onnx和onnx runtime版本对应关系:Compatibility | o…...

深入理解 MVCC 与 BufferPool 缓存机制
深入理解 MVCC 与 BufferPool 缓存机制 在 MySQL 数据库中,MVCC(Multi-Version Concurrency Control)多版本并发控制机制和 BufferPool 缓存机制是非常重要的概念,它们对于保证数据的一致性、并发性以及提升数据库性能起着关键作用…...

RockyLinux介绍及初始化
文章目录 一、背景二、下载 RockyLinux9 镜像三、环境初始化四、安装 Docker 环境 一、背景 这里讲一个小故事: 我们都知道Linux 内核是由芬兰计算机科学家林纳斯托瓦兹 (Linus Torvalds) 于 1991 年首次开发的,随后有一个非常重要的公司RetHat成立&am…...

Python中切片操作符
在Python中,切片是一种操作符,允许你获取序列(如列表、元组、字符串)的一部分。切片操作返回序列的一个子集,这个子集是一个新的对象,与原始序列是独立的。切片操作通常用于列表、元组、字符串等。 切片语…...

python -【es】基本使用
一. 前言 在Python中使用Elasticsearch(ES)通常涉及安装Elasticsearch的Python客户端库,然后通过该库与Elasticsearch集群进行交互。 二. 基本使用 1. 安装Elasticsearch Python客户端库 首先,你需要安装elasticsearch库。你可…...

JVM实战—5.G1垃圾回收器的原理和调优
大纲 1.G1垃圾回收器的工作原理 2.G1分代回收原理—性能为何比传统GC好 3.使用G1垃圾回收器时应如何设置参数 4.如何基于G1垃圾回收器优化性能 5.问题汇总 1.G1垃圾回收器的工作原理 (1)ParNew CMS的组合有哪些痛点 (2)G1垃圾回收器 (3)G1如何实现垃圾回收的停顿时间是…...
从网站获取信息并存入数据库(mysql))
Python爬虫(selenium)从网站获取信息并存入数据库(mysql)
简介: 在本篇博客中,我们将介绍如何使用Python编写一个简单的网络爬虫,从指定网站上获取图书信息,并将这些信息存入数据库。这个项目涉及到Python编程、selenium爬虫技术以及数据库操作等内容,适合对这些领域感兴趣的初…...

spring中使用@Validated,什么是JSR 303数据校验,spring boot中怎么使用数据校验
文章目录 一、JSR 303后台数据校验1.1 什么是 JSR303?1.2 为什么使用 JSR 303? 二、Spring Boot 中使用数据校验2.1 基本注解校验2.1.1 使用步骤2.1.2 举例Valid注解全局统一异常处理 2.2 分组校验2.2.1 使用步骤2.2.2 举例Validated注解Validated和Vali…...

RabbitMQ中的异步Confirm模式:提升消息可靠性的利器
在现代分布式系统中,消息队列(Message Queue)扮演着至关重要的角色,它能够解耦系统组件、提高系统的可扩展性和可靠性。RabbitMQ作为一款广泛使用的消息队列中间件,提供了多种机制来确保消息的可靠传递。其中ÿ…...
)
C++ 设计模式:代理模式(Proxy Pattern)
链接:C 设计模式 链接:C 设计模式 - 门面模式 链接:C 设计模式 - 中介者 链接:C 设计模式 - 适配器 代理模式(Proxy Pattern)是一种结构型设计模式,它为其他对象提供一种代理以控制(…...

41.1 预聚合提速实战项目之需求分析和架构设计
本节重点介绍 : 需求分析架构设计 需求分析 使用预聚合提速查询并且降低高基数查询对后端的压力用户无需变更grafana上的查询语句,后端自动替换效果图 架构设计 架构图 解决方案说明 heavy_query对用户侧表现为查询速度慢在服务端会导致资源占用过多甚至打挂…...
)
学习路之VScode--自定义按键写注释(插件)
1. 安装 "KoroFileHeader" 插件 首先,在 VScode 中搜索并安装名为 "KoroFileHeader" 的插件。你可以通过在扩展商店中搜索插件名称来找到并安装它。 2. 进入 VScode 设置页面 点击 VScode 左下角的设置图标,然后选择 "设置&q…...

Web安全 - “Referrer Policy“ Security 头值不安全
文章目录 概述原因分析风险说明Referrer-Policy 头配置选项1. 不安全的策略no-referrer-when-downgradeunsafe-url 2. 安全的策略no-referreroriginorigin-when-cross-originsame-originstrict-originstrict-origin-when-cross-origin 推荐配置Nginx 配置示例 在 Nginx 中配置 …...

Milvus×EasyAi:如何用java从零搭建人脸识别应用
如何从零搭建一个人脸识别应用?不妨试试原生Java人工智能算法:EasyAi Milvus 的组合拳。 本文将使用到的软件和工具包括: EasyAi:人脸特征向量提取Milvus:向量数据库用于高效存储和检索数据。 01. EasyAi:…...

CGAL windows 安装教程
1.下载源代码 CGAL官网下载https://github.com/CGAL/cgal/releases 2.下载boost库 BOOST官网下载https://www.boost.org/ 3.下载 GMP and MPFR 4.配置VS2022 头文件: 库路径 做完以上步骤,可以使用CGAL了!...

低代码开源项目Joget的研究——Joget8社区版安装部署
大纲 环境准备安装必要软件配置Java配置JAVA_HOME配置Java软链安装三方库 获取源码配置MySql数据库创建用户创建数据库导入初始数据 配置数据库连接配置sessionFactory(非必须,如果后续保存再配置)编译下载tomcat启动下载aspectjweaver移动jw…...

【Ubuntu 20.4安装截图软件 flameshot 】
步骤一: 安装命令: sudo apt-get install flameshot 步骤二: 设置快捷方式: Ubuntu20.4 设置菜单,点击 号 步骤三: 输入软件名称, 软件快捷命令(flameshot gui)&am…...
)
AUTOSAR 平台介绍 (R24-11新标准发布!)
AUTOSAR 平台介绍——R24-11 0引言 随着技术的不断进步和市场需求的变化,AUTOSAR在汽车行业中的重要性日益增强。R24-11版本作为AUTOSAR平台的重要更新,旨在提升系统性能、安全性和用户体验。本文将详细介绍R24-11版本的主要更新内容 1 AUTOSAR介绍 AUTOSAR汽车软件架构,旨…...
之源码下载)
Framework开发入门(一)之源码下载
一、使用Linux操作系统的小伙伴可以跳转到官网链接按提示操作 官网源码地址:下载源代码 | Android Open Source Project 1.创建一个空目录来存放您的工作文件。为其指定一个您喜欢的任意名称: mkdir WORKING_DIRECTORYcdWORKING_DIRECTORY …...

CentOS7下的 OpenSSH 服务器和客户端
目录 1. 在 IP 地址为 192.168.98.11 的 Linux 主机上安装 OpenSSH 服务器; 2. 激活 OpenSSH 服务,并设置开机启动; 3. 在 IP 地址为 192.168.98.22 的 Linux 主机上安装 OpenSSH 客户端,使用客户端命令(ssh、 scp、…...
--broker发送消息给消费者)
rocketmq5--(三)--broker发送消息给消费者
202412/30回过头来记录一下:之前一直找不到在哪里把消息丢给消费者(2024/11/23),找了很久都没找到,就放弃了,然后发现,我靠原来是在poplongpollingservice里。。。。还是乱打断点,偶…...

QComboBox中使用树形控件进行选择
事情是这样的,要在一个ComboBox中通过树形结构进行内容的选择。 默认的QComboBox展开是下拉的列表。因此需要定制一下。 效果就是这样的 实现上面效果的核心代码就是下面这样的 MainWindow::MainWindow(QWidget *parent) : QMainWindow(parent) { treenew…...

单片机中运行多个定时器
在单片机的裸机编程环境中,同时运行多个定时器是完全可行的,但需要注意一些关键点以确保系统的稳定性和效率。以下是一些考虑因素和实现方法: 1. 硬件支持 定时器数量:首先确认您的单片机是否具备足够的定时器资源。大多数现代…...

go 模拟TCP粘包和拆包,及解决方法
1. 什么是 TCP 粘包与拆包? 粘包(Sticky Packet) 粘包是指在发送多个小的数据包时,接收端会将这些数据包合并成一个数据包接收。由于 TCP 是面向流的协议,它并不会在每次数据发送时附加边界信息。所以当多个数据包按顺…...

论文笔记PhotoReg: Photometrically Registering 3D Gaussian Splatting Models
1.abstract 最近推出的3D高斯飞溅(3DGS),它用多达数百万个原始椭球体来描述场景,可以实时渲染。3DGS迅速声名鹊起。然而,一个关键的悬而未决的问题仍然存在:我们如何将多个3DG融合到一个连贯的模型中?解决这个问题将使…...

宝塔服务器安装备份配置
1.服务器下载安装宝塔功能 if [ -f /usr/bin/curl ];then curl -sSO https://download.bt.cn/install/install_panel.sh;else wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh;fi;bash install_panel.sh ed8484bec执行后选择y 等待下载完成会给出…...

ubuntu22 安装CUDA
在Ubuntu系统中,使用nvidia-smi命令可以看到当前GPU信息,在右上角可以看到CUDA Version,意思是最大支持的CUDA版本号。 安装下载 CUDA Toolkit 11.6 Downloads | NVIDIA Developer https://developer.nvidia.com/cuda-downloads?target_osL…...

LabVIEW故障诊断中的无故障数据怎么办
在使用LabVIEW进行故障诊断时,可能会面临“无故障数据”的情况。这种情况下,缺乏明确的故障参考,使得系统难以通过传统对比法进行故障识别。本文将介绍应对无故障数据的关键策略,包括数据模拟、特征提取和基于机器学习的方法&…...

开发模式选择与最佳实践指南20241230
开发模式选择与最佳实践指南 引言 在现代软件开发中,选择合适的开发模式直接影响项目的开发效率和质量。本文将帮助您: 🎯 了解三种主流开发模式的优缺点💡 根据项目特点选择最适合的开发模式🔧 掌握混合开发模式的…...

超详细!一文搞定PID!嵌入式STM32-PID位置环和速度环
本文目录 一、知识点1. PID是什么?2. 积分限幅--用于限制无限累加的积分项3. 输出值限幅--用于任何pid的输出4. PID工程 二、各类PID1. 位置式PID(用于位置环)(1)公式(2)代码使用代码 2. 增量式…...

Redhat7 PCS建立无共享存储浮动地址集群
更新记录 日期版本号内容9/22/2024Ver 1.0重新排版修正 0写在前面 0.1 简述 时间有限使用VMware6.7环境使用Centos7.8最小化安装方式(不用配置本地yum仓库)注意查看主机名(主机双机操作,部分单机操作) 序号HostIPAd…...

爱思唯尔word模板
爱思唯尔word模板 有时候并不一定非得latex https://download.csdn.net/download/qq_38998213/90199214 参考文献书签链接...

交换机Vlan中 tagged和untagged的区别
pvid,tagged与untagged pvid是交换机一个端口上的id,一个端口只能有一个pvid,多个端口可以有相同的pvid。 一:接收数据 Untagged:不管收到的数据帧是否已经有VLAN标记,将数据帧中的vlan标记修改为自己的pvi…...

软件需求分析期末知识点整理
前言:本文为wk学子量身打造,帮助大家少挂科。主要根据ls的会议进行整理。懂得都懂。 重点还是多看看课本 第2章 需求获取的方法 第3章 3.1.2 控制需求(案例*2) 第4章 4.3 范式 第5章 5.2.3 原子功能(案例) 5.2.4 划分功能(案例)5.3.3 工作流图(画图) 第…...

PyAudio使用手册
PyAudio 是一个功能强大的 Python 库,用于在 Python 中进行音频输入和输出操作 1. 安装 在使用 PyAudio 之前,需要先安装它。可以使用 pip 进行安装: pip install pyaudio在某些系统(如 Ubuntu)上,可能还需…...

总结TCP/IP四层模型
总结TCP/IP四层模型 阅读目录(Content) 一、TCP/IP参考模型概述 1.1、TCP/IP参考模型的层次结构二、TCP/IP四层功能概述 2.1、主机到网络层 2.2、网络互连层 2.3、传输层 2.3、应用层 三、TCP/IP报文格式 3.1、IP报文格式3.2、TCP数据段格式3.3、UDP数据段格式3.4、套…...

《深入挖掘Python加解密:自定义加密算法的设计与实现》
利用python实现加解密 在正式编写各种加解密前,我们先写个小案例,如下。 封面在文末呦! 基础加解密-源码 # 加密 def encode():source01 乐茵for c in source01:ascii01 ord(c)ascii01 1print(chr(ascii01), end)# 解密 def decode():…...
:函数)
【前端,TypeScript】TypeScript速成(六):函数
函数 函数的定义 定义一个最简单的加法函数: function add(a: number, b: number): number {return a b }(可以看到 JavaScript/TypeScript 的语法与 Golang 也非常的相似) 调用该函数: console.log(add(2, 3)) // out [LOG…...
内置的数据类型)
Python中元组(tuple)内置的数据类型
在Python中,元组(tuple)是一种内置的数据类型,用于存储不可变的有序元素集合。元组在很多方面与列表(list)相似,但它们之间存在一些关键的区别。以下是关于Python元组的详细解释: 定…...

AI安全的挑战:如何让人工智能变得更加可信
引言 随着人工智能(AI)技术在各个领域的广泛应用,尤其是在医疗、金融、自动驾驶和智能制造等行业,AI正在重塑我们的工作和生活方式。从提高生产效率到实现个性化服务,AI带来了前所未有的便利。然而,在享受这…...

redis用途都有哪些
Redis,作为一个开源的高性能键值对数据库,其用途广泛且功能强大。 1. 缓存(Caching): • Redis常被用作缓存层,存储那些频繁访问但不易改变的数据,如用户会话、商品详情等。 • 通过将这些数据存…...

【Django篇】--动手实现路由模块化与路由反转
一、路由模块化 在一个Django项目中,由于功能类别不同,因此需要将不同功能进行模块化设计。在Django项目中模块化设计则需要将不同模块封装为对应的app模块,每一个模块中涉及到的路由则也需要进行模块化设计,才能更好的让整个项目…...