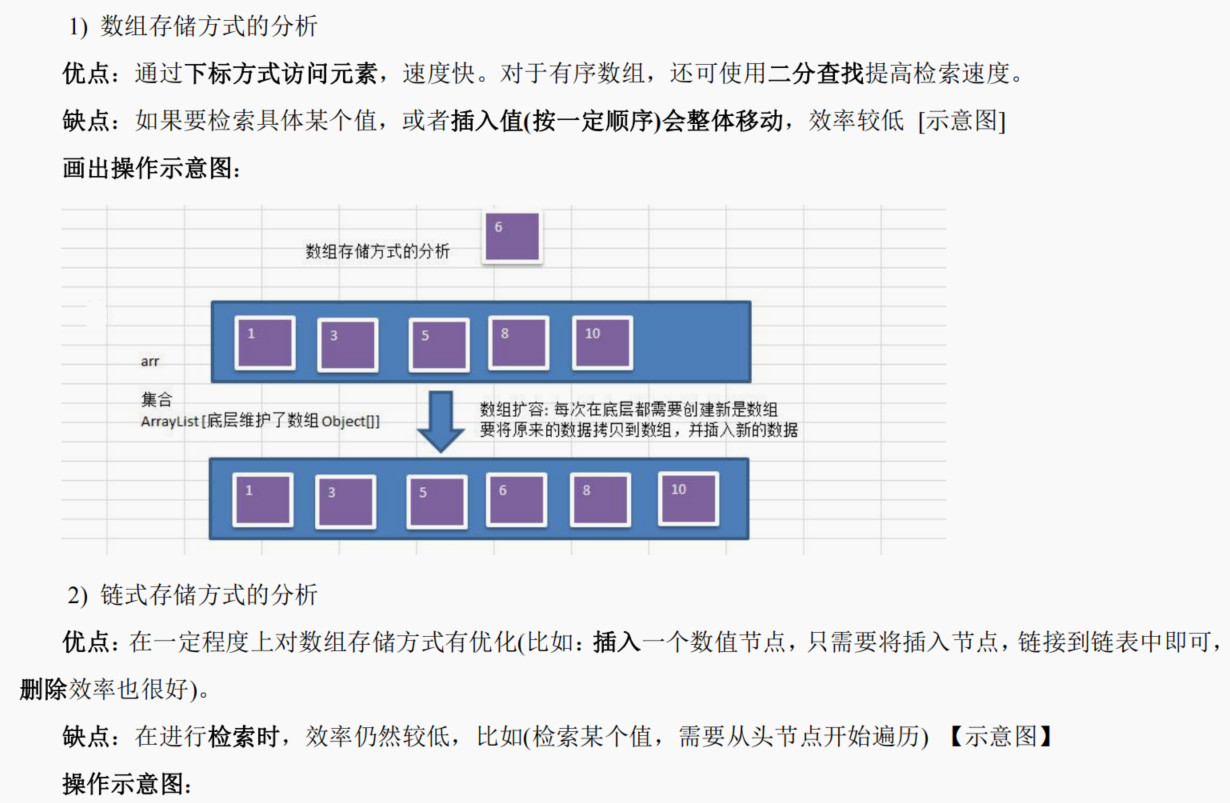
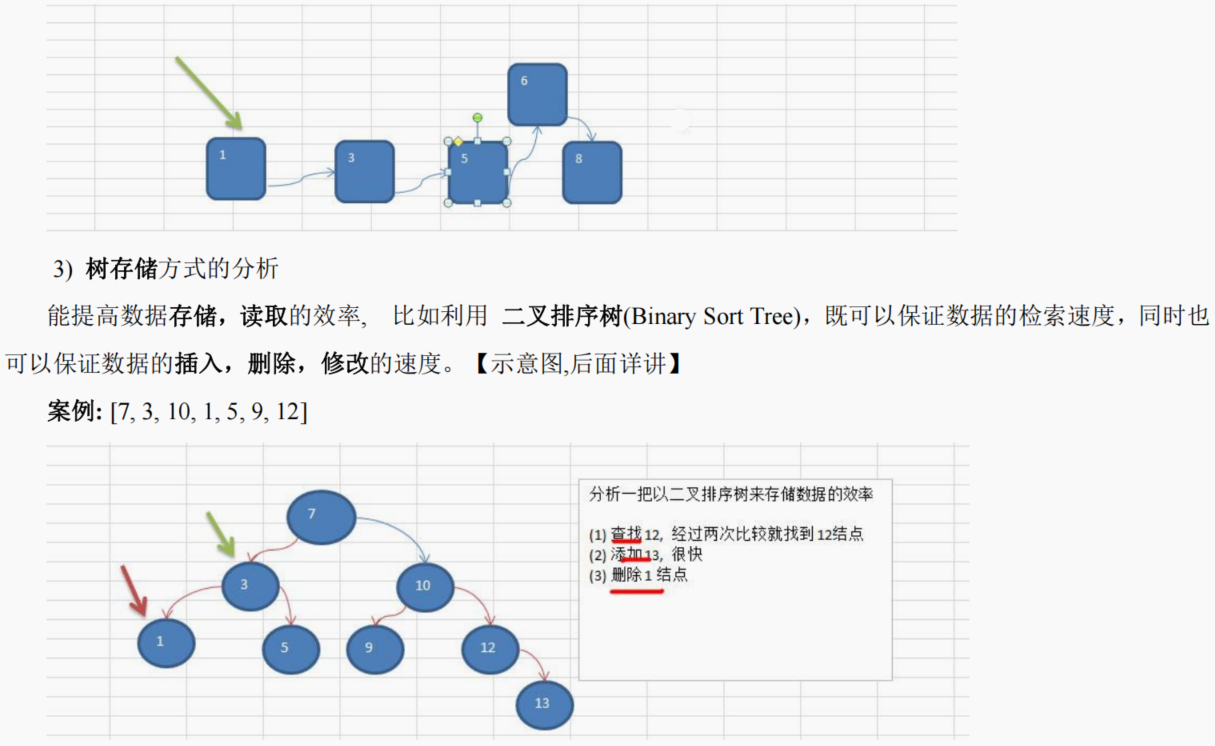
【Java数据结构与算法】第10-14章
第10章 树结构的基础部分
10.1 二叉树
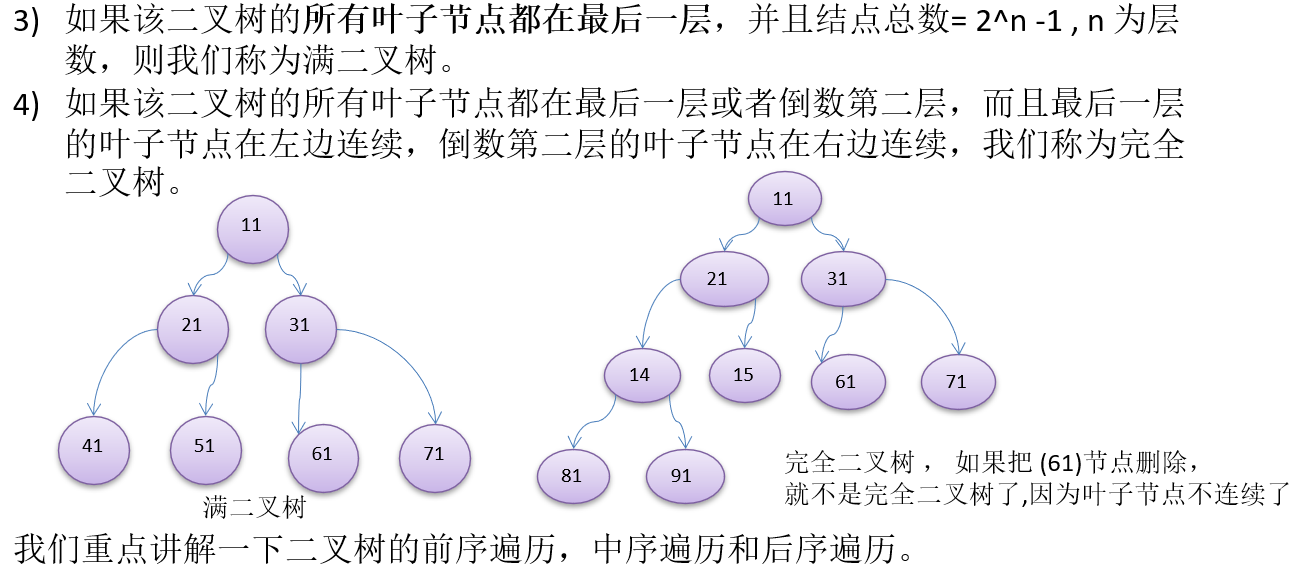
10.1.1 为什么需要树这种数据结构
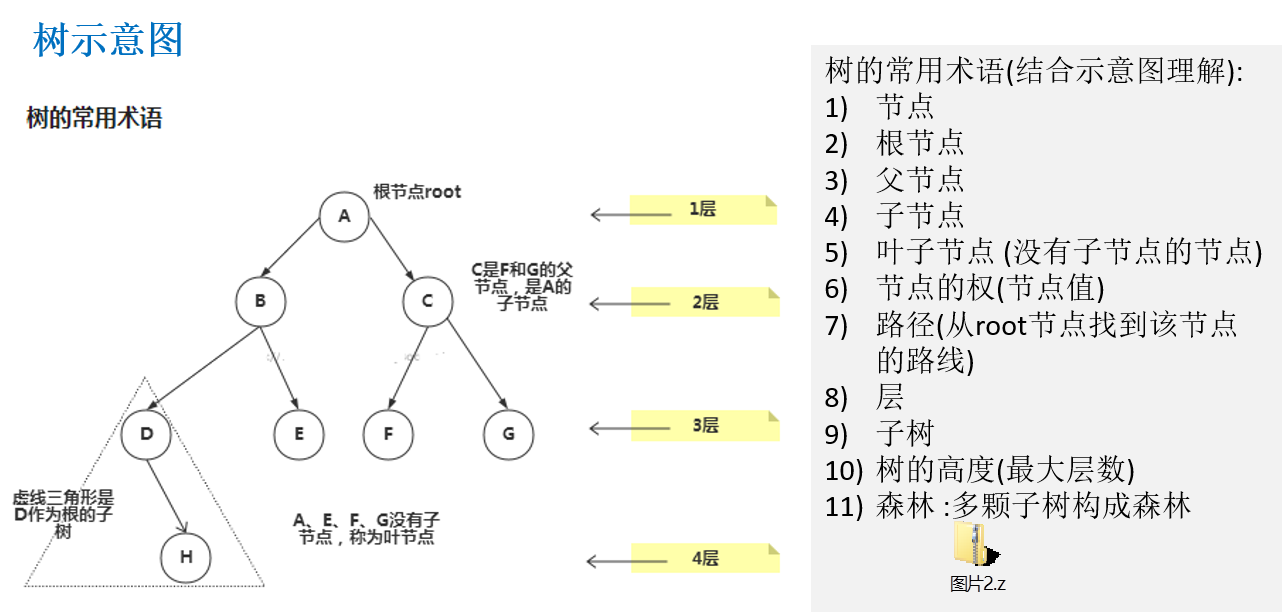
10.1.2 树示意图
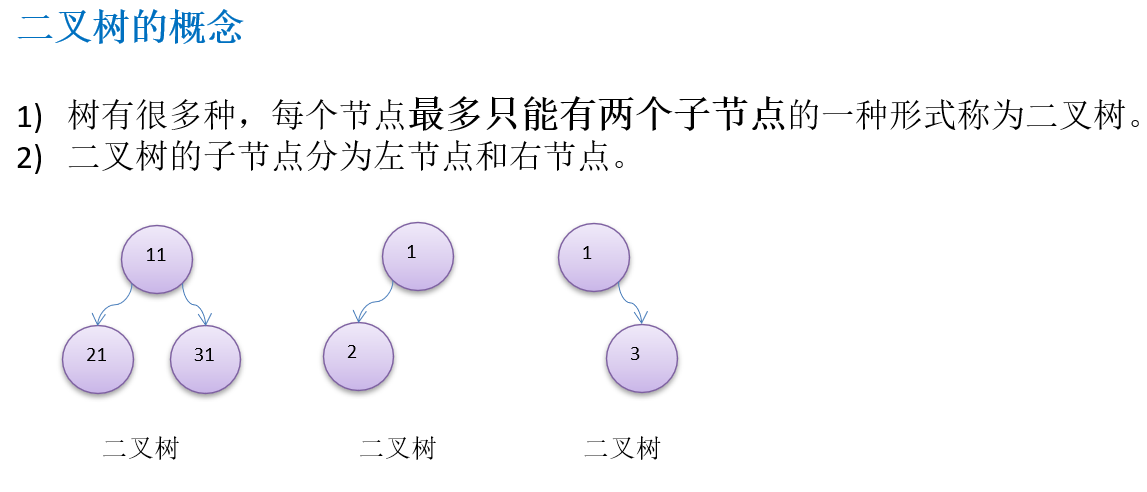
10.1.3 二叉树的概念
10.1.4 二叉树遍历的说明

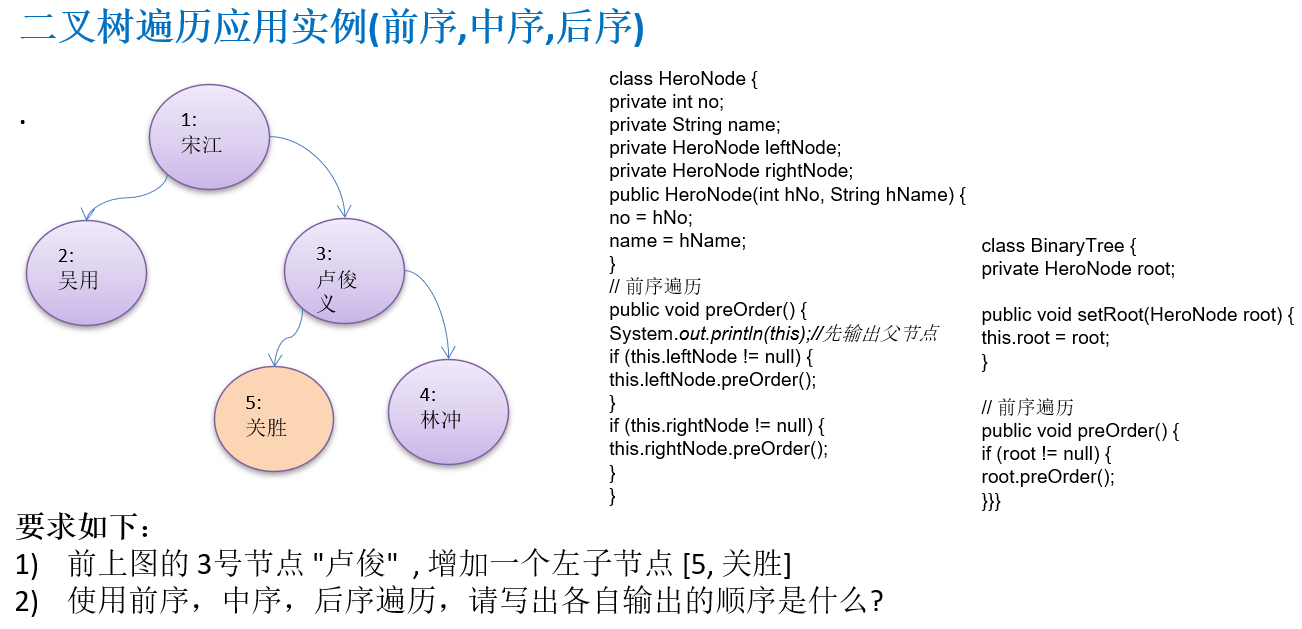
10.1.5 二叉树遍历应用实例(前序,中序,后序)

10.1.6 二叉树-查找指定节点

思路图解

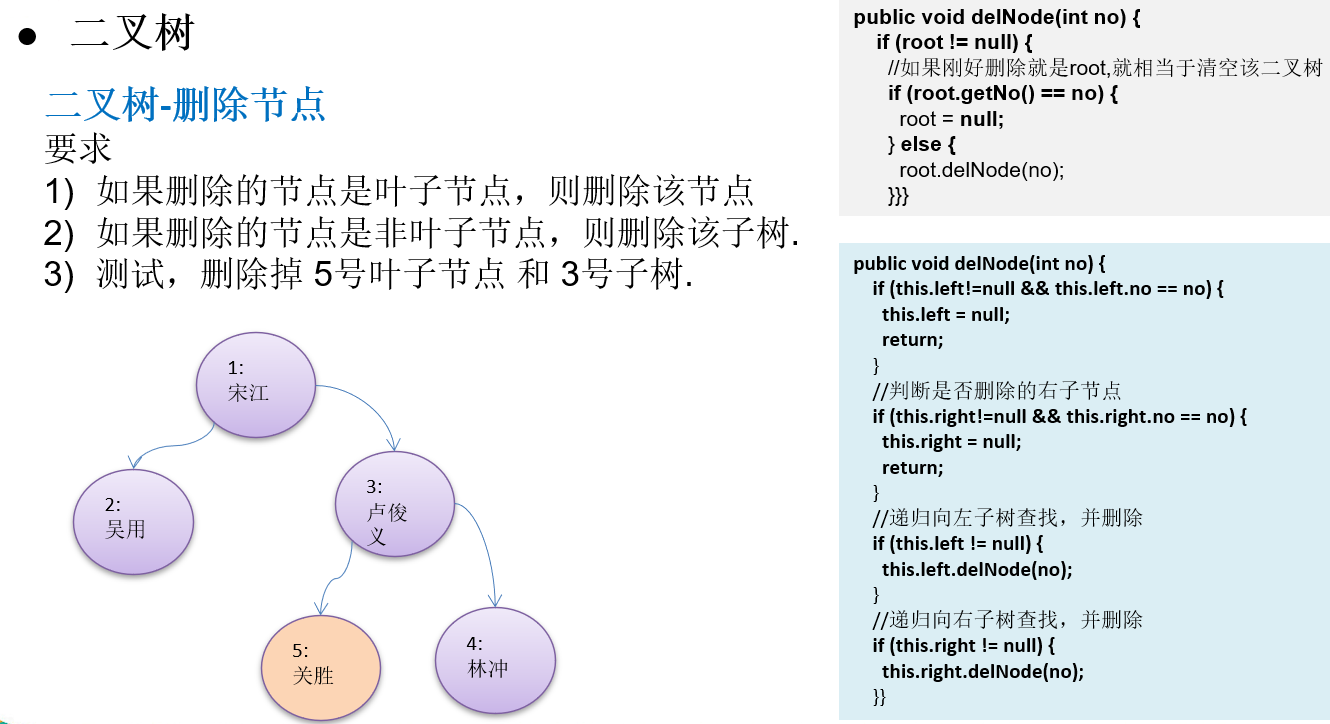
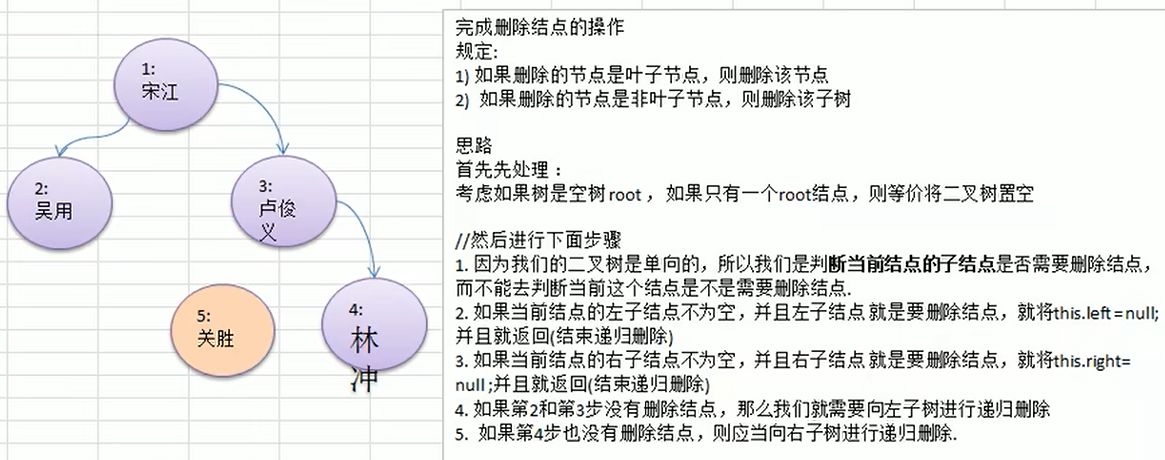
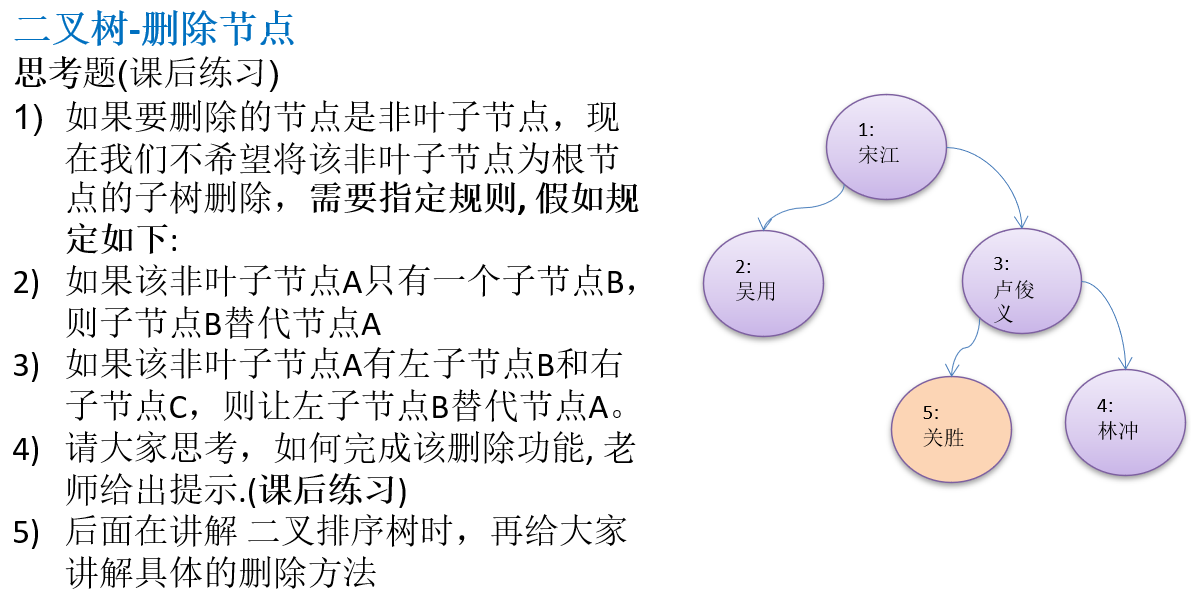
10.1.7 二叉树-删除节点
package com.atguigu.tree;public class BinaryTreeDemo {public static void main(String[] args) {//先需要创建一颗二叉树BinaryTree binaryTree = new BinaryTree();//创建需要的结点HeroNode root = new HeroNode(1, "宋江");HeroNode node2 = new HeroNode(2, "吴用");HeroNode node3 = new HeroNode(3, "卢俊义");HeroNode node4 = new HeroNode(4, "林冲");HeroNode node5 = new HeroNode(5, "关胜");//说明,我们先手动创建该二叉树,后面我们学习递归的方式创建二叉树root.setLeft(node2);root.setRight(node3);node3.setRight(node4);node3.setLeft(node5);binaryTree.setRoot(root);//测试
// System.out.println("前序遍历"); // 1,2,3,5,4
// binaryTree.preOrder();//测试
// System.out.println("中序遍历");
// binaryTree.infixOrder(); // 2,1,5,3,4
//
// System.out.println("后序遍历");
// binaryTree.postOrder(); // 2,5,4,3,1//前序遍历//前序遍历的次数 :4
// System.out.println("前序遍历方式~~~");
// HeroNode resNode = binaryTree.preOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }//中序遍历查找//中序遍历3次
// System.out.println("中序遍历方式~~~");
// HeroNode resNode = binaryTree.infixOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }//后序遍历查找//后序遍历查找的次数 2次
// System.out.println("后序遍历方式~~~");
// HeroNode resNode = binaryTree.postOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }//测试一把删除结点System.out.println("删除前,前序遍历");binaryTree.preOrder(); // 1,2,3,5,4binaryTree.delNode(5);//binaryTree.delNode(3);System.out.println("删除后,前序遍历");binaryTree.preOrder(); // 1,2,3,4}}//定义BinaryTree 二叉树
class BinaryTree {private HeroNode root;public void setRoot(HeroNode root) {this.root = root;}//删除结点public void delNode(int no) {if(root != null) {//如果只有一个root结点, 这里立即判断root是不是就是要删除结点if(root.getNo() == no) {root = null;} else {//递归删除root.delNode(no);}}else{System.out.println("空树,不能删除~");}}//前序遍历public void preOrder() {if(this.root != null) {this.root.preOrder();}else {System.out.println("二叉树为空,无法遍历");}}//中序遍历public void infixOrder() {if(this.root != null) {this.root.infixOrder();}else {System.out.println("二叉树为空,无法遍历");}}//后序遍历public void postOrder() {if(this.root != null) {this.root.postOrder();}else {System.out.println("二叉树为空,无法遍历");}}//前序遍历public HeroNode preOrderSearch(int no) {if(root != null) {return root.preOrderSearch(no);} else {return null;}}//中序遍历public HeroNode infixOrderSearch(int no) {if(root != null) {return root.infixOrderSearch(no);}else {return null;}}//后序遍历public HeroNode postOrderSearch(int no) {if(root != null) {return this.root.postOrderSearch(no);}else {return null;}}
}//先创建HeroNode 结点
class HeroNode {private int no;private String name;private HeroNode left; //默认nullprivate HeroNode right; //默认nullpublic HeroNode(int no, String name) {this.no = no;this.name = name;}public int getNo() {return no;}public void setNo(int no) {this.no = no;}public String getName() {return name;}public void setName(String name) {this.name = name;}public HeroNode getLeft() {return left;}public void setLeft(HeroNode left) {this.left = left;}public HeroNode getRight() {return right;}public void setRight(HeroNode right) {this.right = right;}@Overridepublic String toString() {return "HeroNode [no=" + no + ", name=" + name + "]";}//递归删除结点//1.如果删除的节点是叶子节点,则删除该节点//2.如果删除的节点是非叶子节点,则删除该子树public void delNode(int no) {//思路/** 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点.2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)4. 如果第2和第3步没有删除结点,那么我们就需要向左子树进行递归删除5. 如果第4步也没有删除结点,则应当向右子树进行递归删除.*///2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)if(this.left != null && this.left.no == no) {this.left = null;return;}//3.如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)if(this.right != null && this.right.no == no) {this.right = null;return;}//4.我们就需要向左子树进行递归删除if(this.left != null) {this.left.delNode(no);}//5.则应当向右子树进行递归删除if(this.right != null) {this.right.delNode(no);}}//编写前序遍历的方法public void preOrder() {System.out.println(this); //先输出父结点//递归向左子树前序遍历if(this.left != null) {this.left.preOrder();}//递归向右子树前序遍历if(this.right != null) {this.right.preOrder();}}//中序遍历public void infixOrder() {//递归向左子树中序遍历if(this.left != null) {this.left.infixOrder();}//输出父结点System.out.println(this);//递归向右子树中序遍历if(this.right != null) {this.right.infixOrder();}}//后序遍历public void postOrder() {if(this.left != null) {this.left.postOrder();}if(this.right != null) {this.right.postOrder();}System.out.println(this);}//前序遍历查找/*** * @param no 查找no* @return 如果找到就返回该Node ,如果没有找到返回 null*/public HeroNode preOrderSearch(int no) {System.out.println("进入前序遍历");//比较当前结点是不是if(this.no == no) {return this;}//1.则判断当前结点的左子节点是否为空,如果不为空,则递归前序查找//2.如果左递归前序查找,找到结点,则返回HeroNode resNode = null;if(this.left != null) {resNode = this.left.preOrderSearch(no);}if(resNode != null) {//说明我们左子树找到return resNode;}//1.左递归前序查找,找到结点,则返回,否继续判断,//2.当前的结点的右子节点是否为空,如果不空,则继续向右递归前序查找if(this.right != null) {resNode = this.right.preOrderSearch(no);}return resNode;}//中序遍历查找public HeroNode infixOrderSearch(int no) {//判断当前结点的左子节点是否为空,如果不为空,则递归中序查找HeroNode resNode = null;if(this.left != null) {resNode = this.left.infixOrderSearch(no);}if(resNode != null) {return resNode;}System.out.println("进入中序查找");//如果找到,则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点if(this.no == no) {return this;}//否则继续进行右递归的中序查找if(this.right != null) {resNode = this.right.infixOrderSearch(no);}return resNode;}//后序遍历查找public HeroNode postOrderSearch(int no) {//判断当前结点的左子节点是否为空,如果不为空,则递归后序查找HeroNode resNode = null;if(this.left != null) {resNode = this.left.postOrderSearch(no);}if(resNode != null) {//说明在左子树找到return resNode;}//如果左子树没有找到,则向右子树递归进行后序遍历查找if(this.right != null) {resNode = this.right.postOrderSearch(no);}if(resNode != null) {return resNode;}System.out.println("进入后序查找");//如果左右子树都没有找到,就比较当前结点是不是if(this.no == no) {return this;}return resNode;}}思路图解
10.1.8 二叉树-删除节点(课后练习)
10.2 顺序存储二叉树
10.2.1 顺序存储二叉树的概念
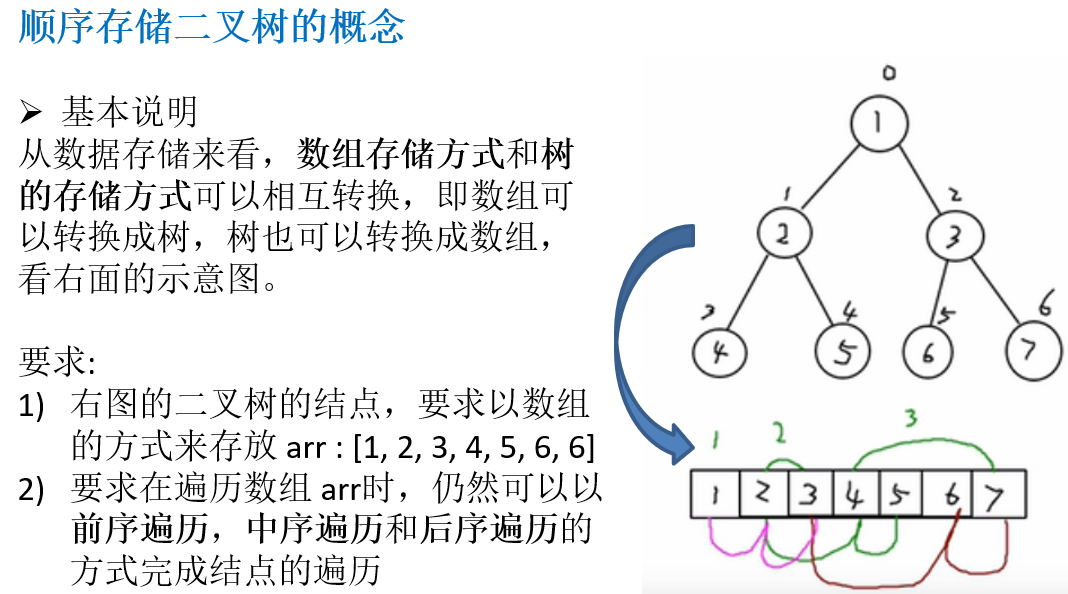

10.2.2 顺序存储二叉树遍历

package com.atguigu.tree;public class ArrBinaryTreeDemo {public static void main(String[] args) {int[] arr = { 1, 2, 3, 4, 5, 6, 7 };//创建一个 ArrBinaryTreeArrBinaryTree arrBinaryTree = new ArrBinaryTree(arr);arrBinaryTree.preOrder(); // 1,2,4,5,3,6,7}}//编写一个ArrayBinaryTree, 实现顺序存储二叉树遍历class ArrBinaryTree {private int[] arr;//存储数据结点的数组public ArrBinaryTree(int[] arr) {this.arr = arr;}//重载preOrderpublic void preOrder() {this.preOrder(0);}//编写一个方法,完成顺序存储二叉树的前序遍历/*** * @param index 数组的下标 */public void preOrder(int index) {//如果数组为空,或者 arr.length = 0if(arr == null || arr.length == 0) {System.out.println("数组为空,不能按照二叉树的前序遍历");}//输出当前这个元素System.out.println(arr[index]); //向左递归遍历if((index * 2 + 1) < arr.length) {preOrder(2 * index + 1 );}//向右递归遍历if((index * 2 + 2) < arr.length) {preOrder(2 * index + 2);}}}
10.2.3 顺序存储二叉树应用实例

10.3 线索化二叉树
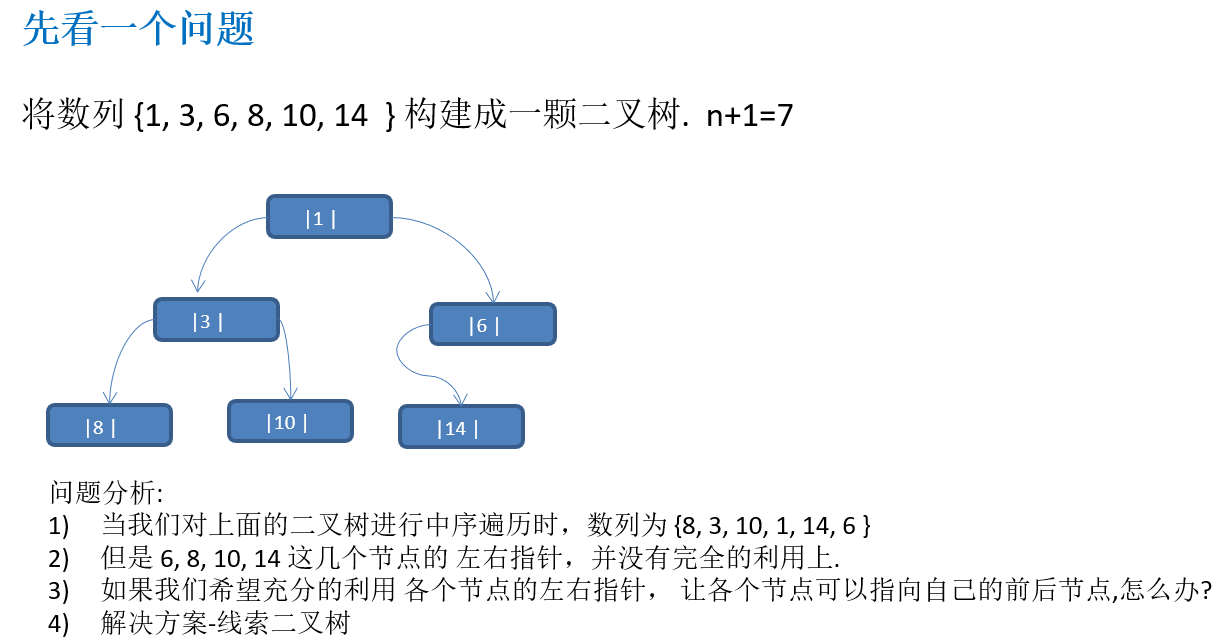
10.3.1 先看一个问题
10.3.2 线索二叉树基本介绍

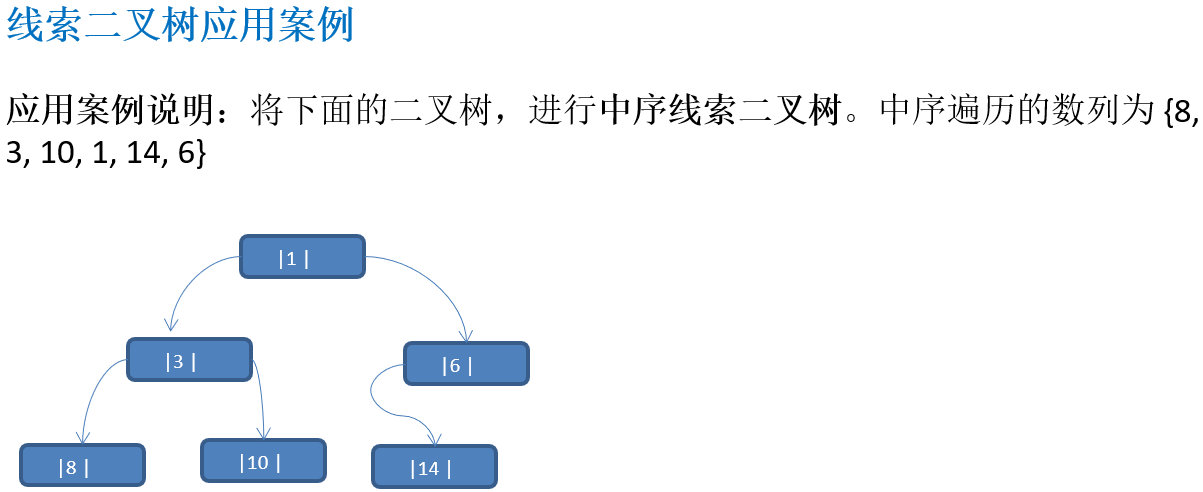
10.3.3 线索二叉树应用案例
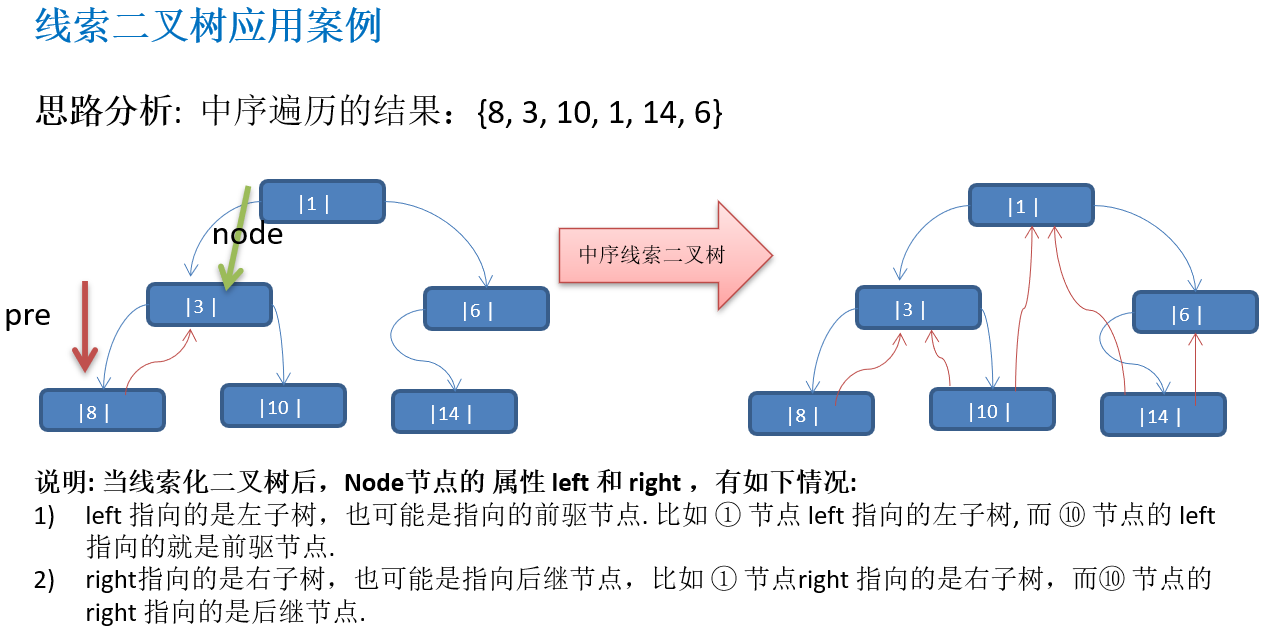

10.3.4 遍历线索化二叉树

package com.atguigu.tree.threadedbinarytree;import java.util.concurrent.SynchronousQueue;public class ThreadedBinaryTreeDemo {public static void main(String[] args) {//测试一把中序线索二叉树的功能HeroNode root = new HeroNode(1, "tom");HeroNode node2 = new HeroNode(3, "jack");HeroNode node3 = new HeroNode(6, "smith");HeroNode node4 = new HeroNode(8, "mary");HeroNode node5 = new HeroNode(10, "king");HeroNode node6 = new HeroNode(14, "dim");//二叉树,后面我们要递归创建, 现在简单处理使用手动创建root.setLeft(node2);root.setRight(node3);node2.setLeft(node4);node2.setRight(node5);node3.setLeft(node6);//测试中序线索化ThreadedBinaryTree threadedBinaryTree = new ThreadedBinaryTree();threadedBinaryTree.setRoot(root);threadedBinaryTree.threadedNodes();//测试: 以10号节点测试HeroNode leftNode = node5.getLeft();HeroNode rightNode = node5.getRight();System.out.println("10号结点的前驱结点是 =" + leftNode); //3System.out.println("10号结点的后继结点是=" + rightNode); //1//当线索化二叉树后,不能再使用原来的遍历方法//threadedBinaryTree.infixOrder();System.out.println("使用线索化的方式遍历 线索化二叉树");threadedBinaryTree.threadedList(); // 8, 3, 10, 1, 14, 6}}//定义ThreadedBinaryTree 实现了线索化功能的二叉树
class ThreadedBinaryTree {private HeroNode root;//为了实现线索化,需要创建一个指向当前结点的前驱结点的指针//在递归进行线索化时,pre 总是保留前一个结点private HeroNode pre = null;public void setRoot(HeroNode root) {this.root = root;}//重载一把threadedNodes方法public void threadedNodes() {this.threadedNodes(root);}//遍历线索化二叉树的方法public void threadedList() {//定义一个变量,存储当前遍历的结点,从root开始HeroNode node = root;while(node != null) {//循环的找到leftType == 1的结点,第一个找到就是8结点//后面随着遍历而变化,因为当leftType==1时,说明该结点是按照线索化//处理后的有效结点while(node.getLeftType() == 0) {node = node.getLeft();}//打印当前这个结点System.out.println(node);//如果当前结点的右指针指向的是后继结点,就一直输出while(node.getRightType() == 1) {//获取到当前结点的后继结点node = node.getRight();System.out.println(node);}//替换这个遍历的结点node = node.getRight();}}//编写对二叉树进行中序线索化的方法/*** * @param node 就是当前需要线索化的结点*/public void threadedNodes(HeroNode node) {//如果node==null, 不能线索化if(node == null) {return;}//(一)先线索化左子树threadedNodes(node.getLeft());//(二)线索化当前结点[有难度]//处理当前结点的前驱结点//以8结点来理解//8结点的.left = null , 8结点的.leftType = 1if(node.getLeft() == null) {//让当前结点的左指针指向前驱结点 node.setLeft(pre); //修改当前结点的左指针的类型,指向前驱结点node.setLeftType(1);}//处理后继结点if (pre != null && pre.getRight() == null) {//让前驱结点的右指针指向当前结点pre.setRight(node);//修改前驱结点的右指针类型pre.setRightType(1);}//!!! 每处理一个结点后,让当前结点是下一个结点的前驱结点pre = node;//(三)在线索化右子树threadedNodes(node.getRight());}//删除结点public void delNode(int no) {if(root != null) {//如果只有一个root结点, 这里立即判断root是不是就是要删除结点if(root.getNo() == no) {root = null;} else {//递归删除root.delNode(no);}}else{System.out.println("空树,不能删除~");}}//前序遍历public void preOrder() {if(this.root != null) {this.root.preOrder();}else {System.out.println("二叉树为空,无法遍历");}}//中序遍历public void infixOrder() {if(this.root != null) {this.root.infixOrder();}else {System.out.println("二叉树为空,无法遍历");}}//后序遍历public void postOrder() {if(this.root != null) {this.root.postOrder();}else {System.out.println("二叉树为空,无法遍历");}}//前序遍历public HeroNode preOrderSearch(int no) {if(root != null) {return root.preOrderSearch(no);} else {return null;}}//中序遍历public HeroNode infixOrderSearch(int no) {if(root != null) {return root.infixOrderSearch(no);}else {return null;}}//后序遍历public HeroNode postOrderSearch(int no) {if(root != null) {return this.root.postOrderSearch(no);}else {return null;}}
}//先创建HeroNode 结点
class HeroNode {private int no;private String name;private HeroNode left; //默认nullprivate HeroNode right; //默认null//说明//1. 如果leftType == 0 表示指向的是左子树, 如果 1 则表示指向前驱结点//2. 如果rightType == 0 表示指向是右子树, 如果 1表示指向后继结点private int leftType;private int rightType;public int getLeftType() {return leftType;}public void setLeftType(int leftType) {this.leftType = leftType;}public int getRightType() {return rightType;}public void setRightType(int rightType) {this.rightType = rightType;}public HeroNode(int no, String name) {this.no = no;this.name = name;}public int getNo() {return no;}public void setNo(int no) {this.no = no;}public String getName() {return name;}public void setName(String name) {this.name = name;}public HeroNode getLeft() {return left;}public void setLeft(HeroNode left) {this.left = left;}public HeroNode getRight() {return right;}public void setRight(HeroNode right) {this.right = right;}@Overridepublic String toString() {return "HeroNode [no=" + no + ", name=" + name + "]";}//递归删除结点//1.如果删除的节点是叶子节点,则删除该节点//2.如果删除的节点是非叶子节点,则删除该子树public void delNode(int no) {//思路/** 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点.2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)4. 如果第2和第3步没有删除结点,那么我们就需要向左子树进行递归删除5. 如果第4步也没有删除结点,则应当向右子树进行递归删除.*///2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)if(this.left != null && this.left.no == no) {this.left = null;return;}//3.如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)if(this.right != null && this.right.no == no) {this.right = null;return;}//4.我们就需要向左子树进行递归删除if(this.left != null) {this.left.delNode(no);}//5.则应当向右子树进行递归删除if(this.right != null) {this.right.delNode(no);}}//编写前序遍历的方法public void preOrder() {System.out.println(this); //先输出父结点//递归向左子树前序遍历if(this.left != null) {this.left.preOrder();}//递归向右子树前序遍历if(this.right != null) {this.right.preOrder();}}//中序遍历public void infixOrder() {//递归向左子树中序遍历if(this.left != null) {this.left.infixOrder();}//输出父结点System.out.println(this);//递归向右子树中序遍历if(this.right != null) {this.right.infixOrder();}}//后序遍历public void postOrder() {if(this.left != null) {this.left.postOrder();}if(this.right != null) {this.right.postOrder();}System.out.println(this);}//前序遍历查找/*** * @param no 查找no* @return 如果找到就返回该Node ,如果没有找到返回 null*/public HeroNode preOrderSearch(int no) {System.out.println("进入前序遍历");//比较当前结点是不是if(this.no == no) {return this;}//1.则判断当前结点的左子节点是否为空,如果不为空,则递归前序查找//2.如果左递归前序查找,找到结点,则返回HeroNode resNode = null;if(this.left != null) {resNode = this.left.preOrderSearch(no);}if(resNode != null) {//说明我们左子树找到return resNode;}//1.左递归前序查找,找到结点,则返回,否继续判断,//2.当前的结点的右子节点是否为空,如果不空,则继续向右递归前序查找if(this.right != null) {resNode = this.right.preOrderSearch(no);}return resNode;}//中序遍历查找public HeroNode infixOrderSearch(int no) {//判断当前结点的左子节点是否为空,如果不为空,则递归中序查找HeroNode resNode = null;if(this.left != null) {resNode = this.left.infixOrderSearch(no);}if(resNode != null) {return resNode;}System.out.println("进入中序查找");//如果找到,则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点if(this.no == no) {return this;}//否则继续进行右递归的中序查找if(this.right != null) {resNode = this.right.infixOrderSearch(no);}return resNode;}//后序遍历查找public HeroNode postOrderSearch(int no) {//判断当前结点的左子节点是否为空,如果不为空,则递归后序查找HeroNode resNode = null;if(this.left != null) {resNode = this.left.postOrderSearch(no);}if(resNode != null) {//说明在左子树找到return resNode;}//如果左子树没有找到,则向右子树递归进行后序遍历查找if(this.right != null) {resNode = this.right.postOrderSearch(no);}if(resNode != null) {return resNode;}System.out.println("进入后序查找");//如果左右子树都没有找到,就比较当前结点是不是if(this.no == no) {return this;}return resNode;}}
10.3.5 线索化二叉树的课后作业
这里讲解了中序线索化二叉树,前序线索化二叉树和后序线索化二叉树的分析思路类似,大家作为课后作业完成
第11章 树结构实际应用
11.1 堆排序★
11.1.1 堆排序基本介绍
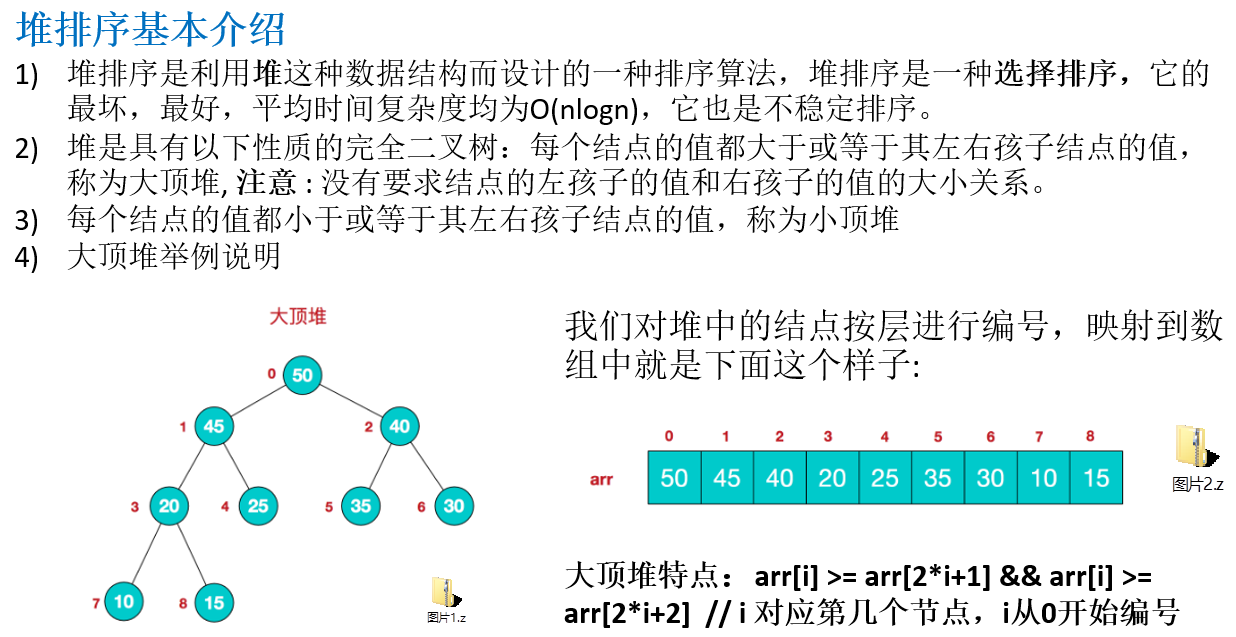
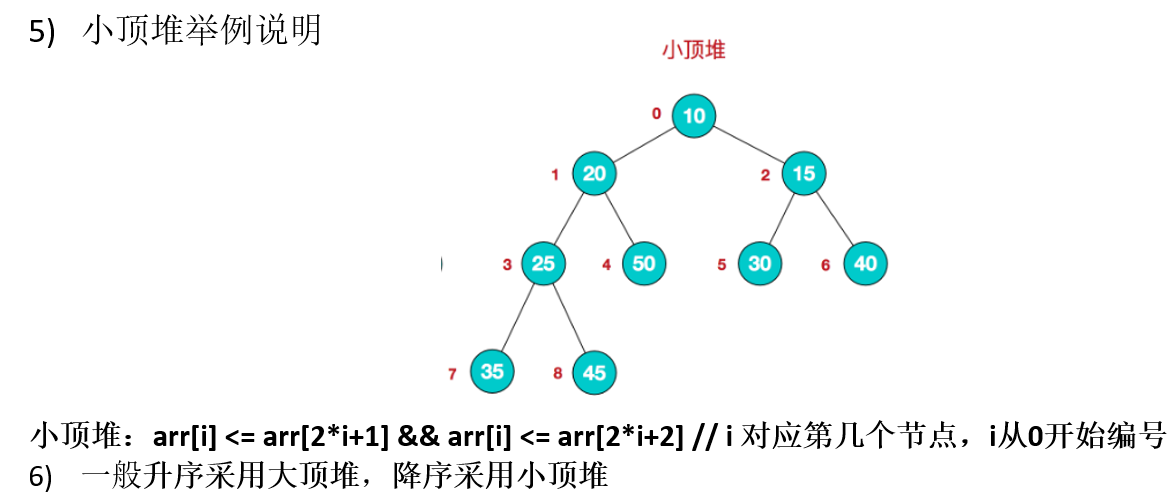
11.1.2 堆排序基本思想

11.1.3 堆排序步骤图解说明

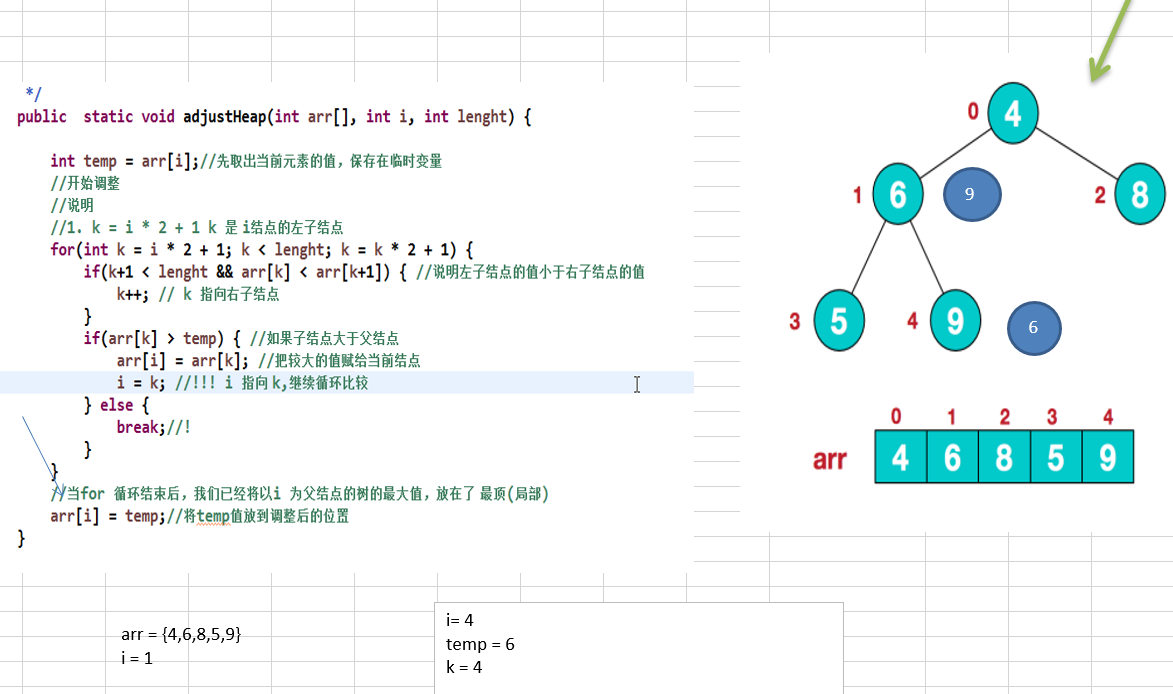
11.1.4 堆排序代码实现

package com.atguigu.tree;import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;public class HeapSort {public static void main(String[] args) {//要求将数组进行升序排序//int arr[] = {4, 6, 8, 5, 9};// 创建要给80000个的随机的数组int[] arr = new int[8000000];for (int i = 0; i < 8000000; i++) {arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数}System.out.println("排序前");Date data1 = new Date();SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String date1Str = simpleDateFormat.format(data1);System.out.println("排序前的时间是=" + date1Str);heapSort(arr);Date data2 = new Date();String date2Str = simpleDateFormat.format(data2);System.out.println("排序前的时间是=" + date2Str);//System.out.println("排序后=" + Arrays.toString(arr));}//编写一个堆排序的方法public static void heapSort(int arr[]) {int temp = 0;System.out.println("堆排序!!");// //分步完成
// adjustHeap(arr, 1, arr.length);
// System.out.println("第一次" + Arrays.toString(arr)); // 4, 9, 8, 5, 6
//
// adjustHeap(arr, 0, arr.length);
// System.out.println("第2次" + Arrays.toString(arr)); // 9,6,8,5,4//完成我们最终代码//将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆for(int i = arr.length / 2 -1; i >=0; i--) {adjustHeap(arr, i, arr.length);}/** 2).将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。*/for(int j = arr.length-1;j >0; j--) {//交换temp = arr[j];arr[j] = arr[0];arr[0] = temp;adjustHeap(arr, 0, j); }//System.out.println("数组=" + Arrays.toString(arr)); }//将一个数组(二叉树), 调整成一个大顶堆/*** 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆* 举例 int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adjustHeap => 得到 {4, 9, 8, 5, 6}* 如果我们再次调用 adjustHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5, 4}* @param arr 待调整的数组* @param i 表示非叶子结点在数组中索引* @param length 表示对多少个元素继续调整, length 是在逐渐的减少*/public static void adjustHeap(int arr[], int i, int length) {int temp = arr[i];//先取出当前元素的值,保存在临时变量//开始调整//说明//1. k = i * 2 + 1 k 是 i结点的左子结点for(int k = i * 2 + 1; k < length; k = k * 2 + 1) {if(k+1 < length && arr[k] < arr[k+1]) { //说明左子结点的值小于右子结点的值k++; // k 指向右子结点}if(arr[k] > temp) { //如果子结点大于父结点arr[i] = arr[k]; //把较大的值赋给当前结点i = k; //!!! i 指向 k,继续循环比较} else {break;//!}}//当for 循环结束后,我们已经将以i 为父结点的树的最大值,放在了 最顶(局部)arr[i] = temp;//将temp值放到调整后的位置}}11.2 赫夫曼树
11.2.1 基本介绍

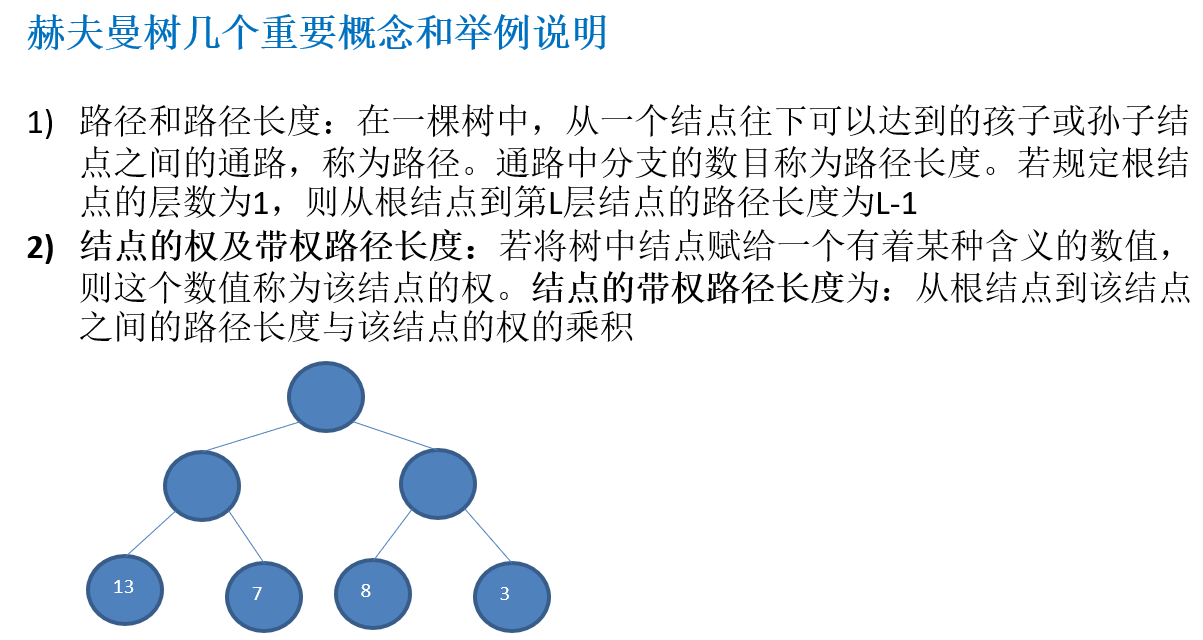
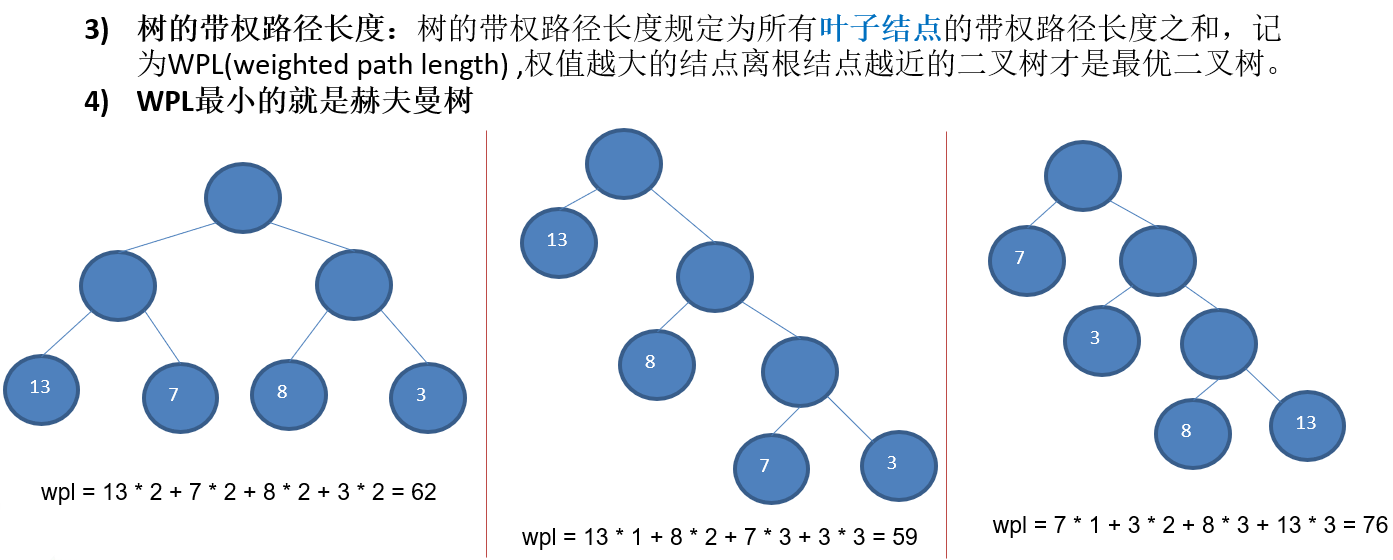
11.2.2 赫夫曼树几个重要概念和举例说明
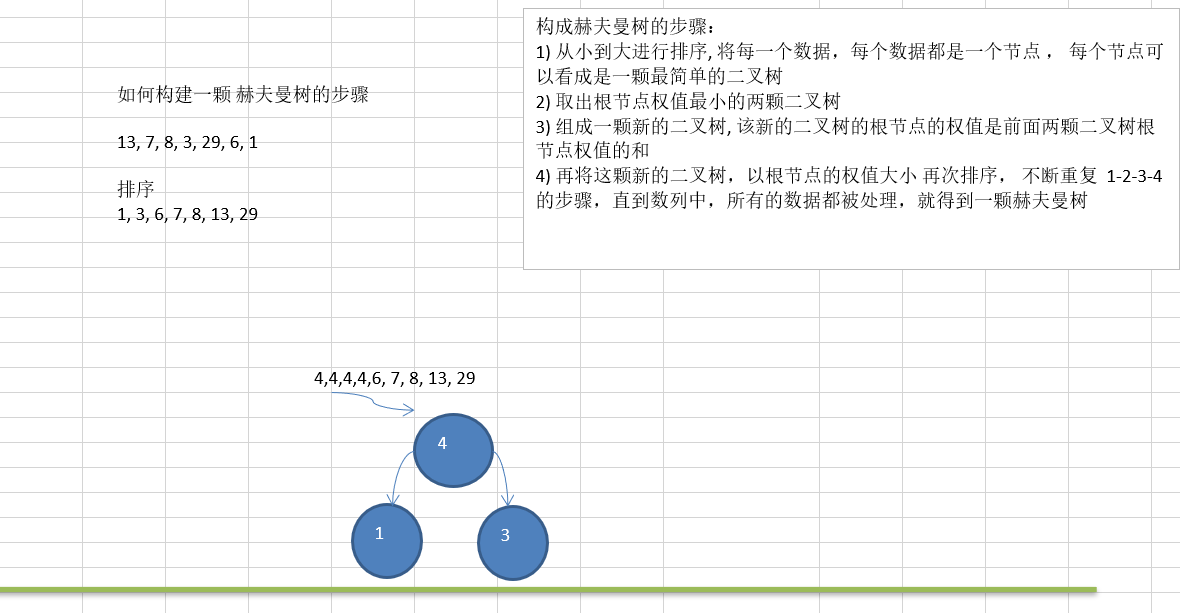
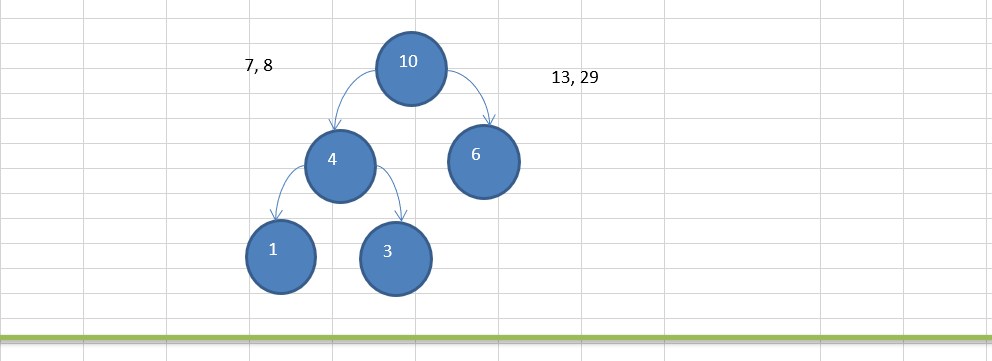
11.2.3 赫夫曼树创建思路图解


11.2.4 赫夫曼树的代码实现
package com.atguigu.huffmantree;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class HuffmanTree {public static void main(String[] args) {int arr[] = { 13, 7, 8, 3, 29, 6, 1 };Node root = createHuffmanTree(arr);//测试一把preOrder(root); //}//编写一个前序遍历的方法public static void preOrder(Node root) {if(root != null) {root.preOrder();}else{System.out.println("是空树,不能遍历~~");}}// 创建赫夫曼树的方法/*** * @param arr 需要创建成哈夫曼树的数组* @return 创建好后的赫夫曼树的root结点*/public static Node createHuffmanTree(int[] arr) {// 第一步为了操作方便// 1. 遍历 arr 数组// 2. 将arr的每个元素构成成一个Node// 3. 将Node 放入到ArrayList中List<Node> nodes = new ArrayList<Node>();for (int value : arr) {nodes.add(new Node(value));}//我们处理的过程是一个循环的过程while(nodes.size() > 1) {//排序 从小到大 Collections.sort(nodes);System.out.println("nodes =" + nodes);//取出根节点权值最小的两颗二叉树 //(1) 取出权值最小的结点(二叉树)Node leftNode = nodes.get(0);//(2) 取出权值第二小的结点(二叉树)Node rightNode = nodes.get(1);//(3)构建一颗新的二叉树Node parent = new Node(leftNode.value + rightNode.value);parent.left = leftNode;parent.right = rightNode;//(4)从ArrayList删除处理过的二叉树nodes.remove(leftNode);nodes.remove(rightNode);//(5)将parent加入到nodesnodes.add(parent);}//返回哈夫曼树的root结点return nodes.get(0);}
}// 创建结点类
// 为了让Node 对象持续排序Collections集合排序
// 让Node 实现Comparable接口
class Node implements Comparable<Node> {int value; // 结点权值char c; //字符Node left; // 指向左子结点Node right; // 指向右子结点//写一个前序遍历public void preOrder() {System.out.println(this);if(this.left != null) {this.left.preOrder();}if(this.right != null) {this.right.preOrder();}}public Node(int value) {this.value = value;}@Overridepublic String toString() {return "Node [value=" + value + "]";}@Overridepublic int compareTo(Node o) {// 表示从小到大排序return this.value - o.value;}}
11.3 赫夫曼编码
11.3.1 基本介绍

11.3.2 原理剖析



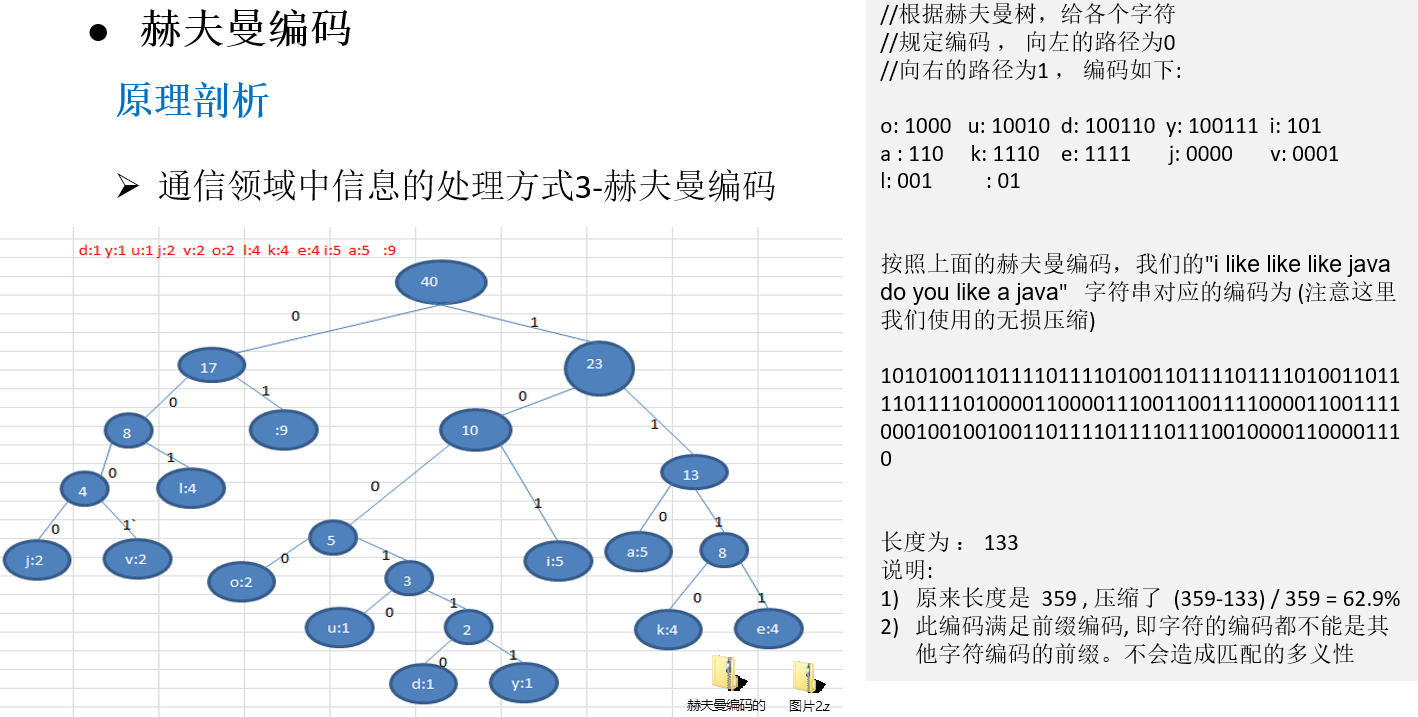
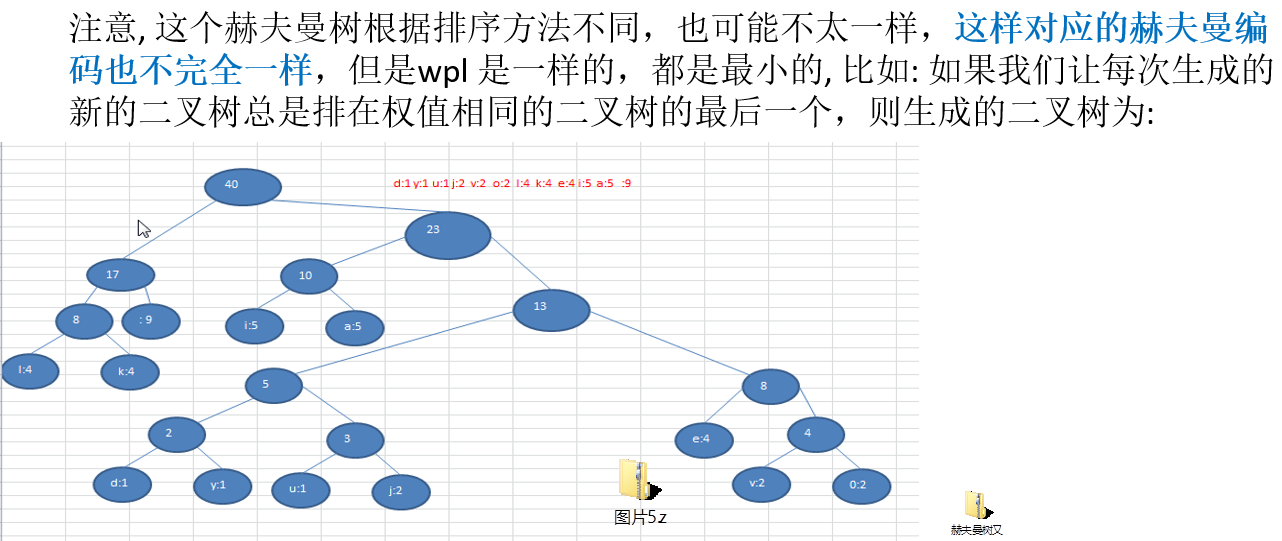
赫夫曼编码的原理剖析

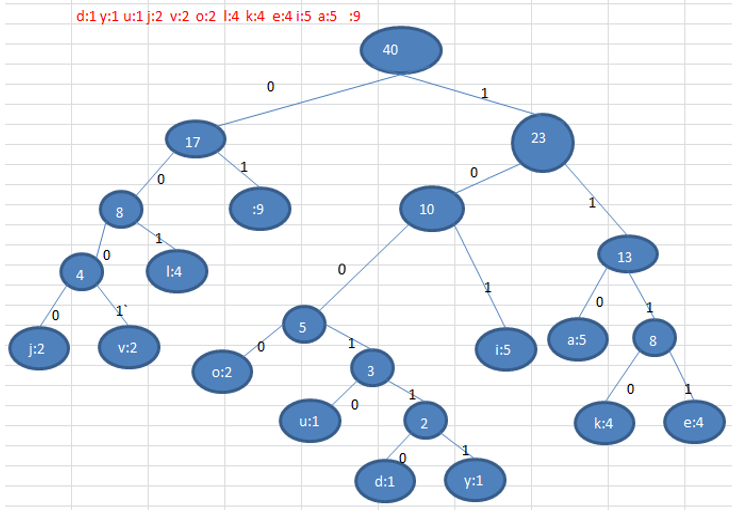

11.3.3 最佳实践-数据压缩(创建赫夫曼树)


11.3.4 最佳实践-数据压缩(生成赫夫曼编码和赫夫曼编码后的数据)

11.3.5 最佳实践-数据解压(使用赫夫曼编码解码)

11.3.6 最佳实践-文件压缩

11.3.7 最佳实践-文件解压(文件恢复)

11.3.8 代码汇总,把前面所有的方法放在一起
package com.atguigu.huffmancode;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class HuffmanCode {public static void main(String[] args) {//测试压缩文件
// String srcFile = "d://Uninstall.xml";
// String dstFile = "d://Uninstall.zip";
//
// zipFile(srcFile, dstFile);
// System.out.println("压缩文件ok~~");//测试解压文件String zipFile = "d://Uninstall.zip";String dstFile = "d://Uninstall2.xml";unZipFile(zipFile, dstFile);System.out.println("解压成功!");/*String content = "i like like like java do you like a java";byte[] contentBytes = content.getBytes();System.out.println(contentBytes.length); //40byte[] huffmanCodesBytes= huffmanZip(contentBytes);System.out.println("压缩后的结果是:" + Arrays.toString(huffmanCodesBytes) + " 长度= " + huffmanCodesBytes.length);//测试一把byteToBitString方法//System.out.println(byteToBitString((byte)1));byte[] sourceBytes = decode(huffmanCodes, huffmanCodesBytes);System.out.println("原来的字符串=" + new String(sourceBytes)); // "i like like like java do you like a java"*///如何将 数据进行解压(解码) //分步过程/*List<Node> nodes = getNodes(contentBytes);System.out.println("nodes=" + nodes);//测试一把,创建的赫夫曼树System.out.println("赫夫曼树");Node huffmanTreeRoot = createHuffmanTree(nodes);System.out.println("前序遍历");huffmanTreeRoot.preOrder();//测试一把是否生成了对应的赫夫曼编码Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);System.out.println("~生成的赫夫曼编码表= " + huffmanCodes);//测试byte[] huffmanCodeBytes = zip(contentBytes, huffmanCodes);System.out.println("huffmanCodeBytes=" + Arrays.toString(huffmanCodeBytes));//17//发送huffmanCodeBytes 数组 */}//编写一个方法,完成对压缩文件的解压/*** * @param zipFile 准备解压的文件* @param dstFile 将文件解压到哪个路径*/public static void unZipFile(String zipFile, String dstFile) {//定义文件输入流InputStream is = null;//定义一个对象输入流ObjectInputStream ois = null;//定义文件的输出流OutputStream os = null;try {//创建文件输入流is = new FileInputStream(zipFile);//创建一个和 is关联的对象输入流ois = new ObjectInputStream(is);//读取byte数组 huffmanBytesbyte[] huffmanBytes = (byte[])ois.readObject();//读取赫夫曼编码表Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();//解码byte[] bytes = decode(huffmanCodes, huffmanBytes);//将bytes 数组写入到目标文件os = new FileOutputStream(dstFile);//写数据到 dstFile 文件os.write(bytes);} catch (Exception e) {System.out.println(e.getMessage());} finally {try {os.close();ois.close();is.close();} catch (Exception e2) {System.out.println(e2.getMessage());}}}//编写方法,将一个文件进行压缩/*** * @param srcFile 你传入的希望压缩的文件的全路径* @param dstFile 我们压缩后将压缩文件放到哪个目录*/public static void zipFile(String srcFile, String dstFile) {//创建输出流OutputStream os = null;ObjectOutputStream oos = null;//创建文件的输入流FileInputStream is = null;try {//创建文件的输入流is = new FileInputStream(srcFile);//创建一个和源文件大小一样的byte[]byte[] b = new byte[is.available()];//读取文件is.read(b);//直接对源文件压缩byte[] huffmanBytes = huffmanZip(b);//创建文件的输出流, 存放压缩文件os = new FileOutputStream(dstFile);//创建一个和文件输出流关联的ObjectOutputStreamoos = new ObjectOutputStream(os);//把 赫夫曼编码后的字节数组写入压缩文件oos.writeObject(huffmanBytes); //我们是把//这里我们以对象流的方式写入 赫夫曼编码,是为了以后我们恢复源文件时使用//注意一定要把赫夫曼编码 写入压缩文件oos.writeObject(huffmanCodes);}catch (Exception e) {System.out.println(e.getMessage());}finally {try {is.close();oos.close();os.close();}catch (Exception e) {System.out.println(e.getMessage());}}}//完成数据的解压//思路//1. 将huffmanCodeBytes [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]// 重写先转成 赫夫曼编码对应的二进制的字符串 "1010100010111..."//2. 赫夫曼编码对应的二进制的字符串 "1010100010111..." =》 对照 赫夫曼编码 =》 "i like like like java do you like a java"//编写一个方法,完成对压缩数据的解码/*** * @param huffmanCodes 赫夫曼编码表 map* @param huffmanBytes 赫夫曼编码得到的字节数组* @return 就是原来的字符串对应的数组*/private static byte[] decode(Map<Byte,String> huffmanCodes, byte[] huffmanBytes) {//1. 先得到 huffmanBytes 对应的 二进制的字符串 , 形式 1010100010111...StringBuilder stringBuilder = new StringBuilder();//将byte数组转成二进制的字符串for(int i = 0; i < huffmanBytes.length; i++) {byte b = huffmanBytes[i];//判断是不是最后一个字节boolean flag = (i == huffmanBytes.length - 1);stringBuilder.append(byteToBitString(!flag, b));}//把字符串安装指定的赫夫曼编码进行解码//把赫夫曼编码表进行调换,因为反向查询 a->100 100->aMap<String, Byte> map = new HashMap<String,Byte>();for(Map.Entry<Byte, String> entry: huffmanCodes.entrySet()) {map.put(entry.getValue(), entry.getKey());}//创建要给集合,存放byteList<Byte> list = new ArrayList<>();//i 可以理解成就是索引,扫描 stringBuilder for(int i = 0; i < stringBuilder.length(); ) {int count = 1; // 小的计数器boolean flag = true;Byte b = null;while(flag) {//1010100010111...//递增的取出 key 1 String key = stringBuilder.substring(i, i+count);//i 不动,让count移动,直到匹配到一个字符b = map.get(key);if(b == null) {//说明没有匹配到count++;}else {//匹配到flag = false;}}list.add(b);i += count;//i 直接移动到 count }//当for循环结束后,我们list中就存放了所有的字符 "i like like like java do you like a java"//把list 中的数据放入到byte[] 并返回byte b[] = new byte[list.size()];for(int i = 0;i < b.length; i++) {b[i] = list.get(i);}return b;}/*** 将一个byte 转成一个二进制的字符串, 如果看不懂,可以参考我讲的Java基础 二进制的原码,反码,补码* @param b 传入的 byte* @param flag 标志是否需要补高位如果是true ,表示需要补高位,如果是false表示不补, 如果是最后一个字节,无需补高位* @return 是该b 对应的二进制的字符串,(注意是按补码返回)*/private static String byteToBitString(boolean flag, byte b) {//使用变量保存 bint temp = b; //将 b 转成 int//如果是正数我们还存在补高位if(flag) {temp |= 256; //按位或 256 1 0000 0000 | 0000 0001 => 1 0000 0001}String str = Integer.toBinaryString(temp); //返回的是temp对应的二进制的补码if(flag) {return str.substring(str.length() - 8);} else {return str;}}//使用一个方法,将前面的方法封装起来,便于我们的调用./*** * @param bytes 原始的字符串对应的字节数组* @return 是经过 赫夫曼编码处理后的字节数组(压缩后的数组)*/private static byte[] huffmanZip(byte[] bytes) {List<Node> nodes = getNodes(bytes);//根据 nodes 创建的赫夫曼树Node huffmanTreeRoot = createHuffmanTree(nodes);//对应的赫夫曼编码(根据 赫夫曼树)Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);//根据生成的赫夫曼编码,压缩得到压缩后的赫夫曼编码字节数组byte[] huffmanCodeBytes = zip(bytes, huffmanCodes);return huffmanCodeBytes;}//编写一个方法,将字符串对应的byte[] 数组,通过生成的赫夫曼编码表,返回一个赫夫曼编码 压缩后的byte[]/*** * @param bytes 这时原始的字符串对应的 byte[]* @param huffmanCodes 生成的赫夫曼编码map* @return 返回赫夫曼编码处理后的 byte[] * 举例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes();* 返回的是 字符串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100"* => 对应的 byte[] huffmanCodeBytes ,即 8位对应一个 byte,放入到 huffmanCodeBytes* huffmanCodeBytes[0] = 10101000(补码) => byte [推导 10101000=> 10101000 - 1 => 10100111(反码)=> 11011000(原码)= -88 ]* huffmanCodeBytes[1] = -88*/private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {//1.利用 huffmanCodes 将 bytes 转成 赫夫曼编码对应的字符串StringBuilder stringBuilder = new StringBuilder();//遍历bytes 数组 for(byte b: bytes) {stringBuilder.append(huffmanCodes.get(b));}//System.out.println("测试 stringBuilder~~~=" + stringBuilder.toString());//将 "1010100010111111110..." 转成 byte[]//统计返回 byte[] huffmanCodeBytes 长度//一句话 int len = (stringBuilder.length() + 7) / 8;int len;if(stringBuilder.length() % 8 == 0) {len = stringBuilder.length() / 8;} else {len = stringBuilder.length() / 8 + 1;}//创建 存储压缩后的 byte数组byte[] huffmanCodeBytes = new byte[len];int index = 0;//记录是第几个bytefor (int i = 0; i < stringBuilder.length(); i += 8) { //因为是每8位对应一个byte,所以步长 +8String strByte;if(i+8 > stringBuilder.length()) {//不够8位strByte = stringBuilder.substring(i);}else{strByte = stringBuilder.substring(i, i + 8);} //将strByte 转成一个byte,放入到 huffmanCodeByteshuffmanCodeBytes[index] = (byte)Integer.parseInt(strByte, 2);index++;}return huffmanCodeBytes;}//生成赫夫曼树对应的赫夫曼编码//思路://1. 将赫夫曼编码表存放在 Map<Byte,String> 形式// 生成的赫夫曼编码表{32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();//2. 在生成赫夫曼编码表示,需要去拼接路径, 定义一个StringBuilder 存储某个叶子结点的路径static StringBuilder stringBuilder = new StringBuilder();//为了调用方便,我们重载 getCodesprivate static Map<Byte, String> getCodes(Node root) {if(root == null) {return null;}//处理root的左子树getCodes(root.left, "0", stringBuilder);//处理root的右子树getCodes(root.right, "1", stringBuilder);return huffmanCodes;}/*** 功能:将传入的node结点的所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合* @param node 传入结点* @param code 路径: 左子结点是 0, 右子结点 1* @param stringBuilder 用于拼接路径*/private static void getCodes(Node node, String code, StringBuilder stringBuilder) {StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);//将code 加入到 stringBuilder2stringBuilder2.append(code);if(node != null) { //如果node == null不处理//判断当前node 是叶子结点还是非叶子结点if(node.data == null) { //非叶子结点//递归处理//向左递归getCodes(node.left, "0", stringBuilder2);//向右递归getCodes(node.right, "1", stringBuilder2);} else { //说明是一个叶子结点//就表示找到某个叶子结点的最后huffmanCodes.put(node.data, stringBuilder2.toString());}}}//前序遍历的方法private static void preOrder(Node root) {if(root != null) {root.preOrder();}else {System.out.println("赫夫曼树为空");}}/*** * @param bytes 接收字节数组* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],*/private static List<Node> getNodes(byte[] bytes) {//1创建一个ArrayListArrayList<Node> nodes = new ArrayList<Node>();//遍历 bytes , 统计 每一个byte出现的次数->map[key,value]Map<Byte, Integer> counts = new HashMap<>();for (byte b : bytes) {Integer count = counts.get(b);if (count == null) { // Map还没有这个字符数据,第一次counts.put(b, 1);} else {counts.put(b, count + 1);}}//把每一个键值对转成一个Node 对象,并加入到nodes集合//遍历mapfor(Map.Entry<Byte, Integer> entry: counts.entrySet()) {nodes.add(new Node(entry.getKey(), entry.getValue()));}return nodes;}//可以通过List 创建对应的赫夫曼树private static Node createHuffmanTree(List<Node> nodes) {while(nodes.size() > 1) {//排序, 从小到大Collections.sort(nodes);//取出第一颗最小的二叉树Node leftNode = nodes.get(0);//取出第二颗最小的二叉树Node rightNode = nodes.get(1);//创建一颗新的二叉树,它的根节点 没有data, 只有权值Node parent = new Node(null, leftNode.weight + rightNode.weight);parent.left = leftNode;parent.right = rightNode;//将已经处理的两颗二叉树从nodes删除nodes.remove(leftNode);nodes.remove(rightNode);//将新的二叉树,加入到nodesnodes.add(parent);}//nodes 最后的结点,就是赫夫曼树的根结点return nodes.get(0);}}//创建Node ,待数据和权值
class Node implements Comparable<Node> {Byte data; // 存放数据(字符)本身,比如'a' => 97 ' ' => 32int weight; //权值, 表示字符出现的次数Node left;//Node right;public Node(Byte data, int weight) {this.data = data;this.weight = weight;}@Overridepublic int compareTo(Node o) {// 从小到大排序return this.weight - o.weight;}public String toString() {return "Node [data = " + data + " weight=" + weight + "]";}//前序遍历public void preOrder() {System.out.println(this);if(this.left != null) {this.left.preOrder();}if(this.right != null) {this.right.preOrder();}}
}
11.3.9 赫夫曼编码压缩文件注意事项

11.4 二叉排序树(Binary Sort(Search) Tree,BST)
11.4.1 先看一个需求

11.4.2 解决方案分析

11.4.3 二叉排序树介绍
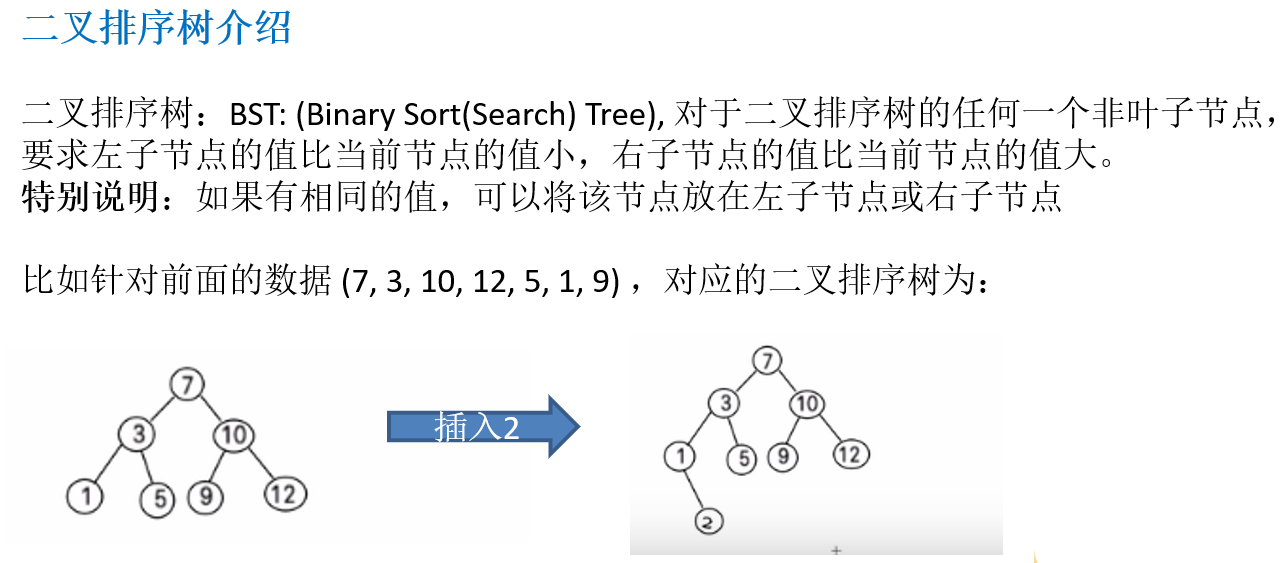
11.4.4 二叉排序树创建和遍历

11.4.5 二叉排序树的删除
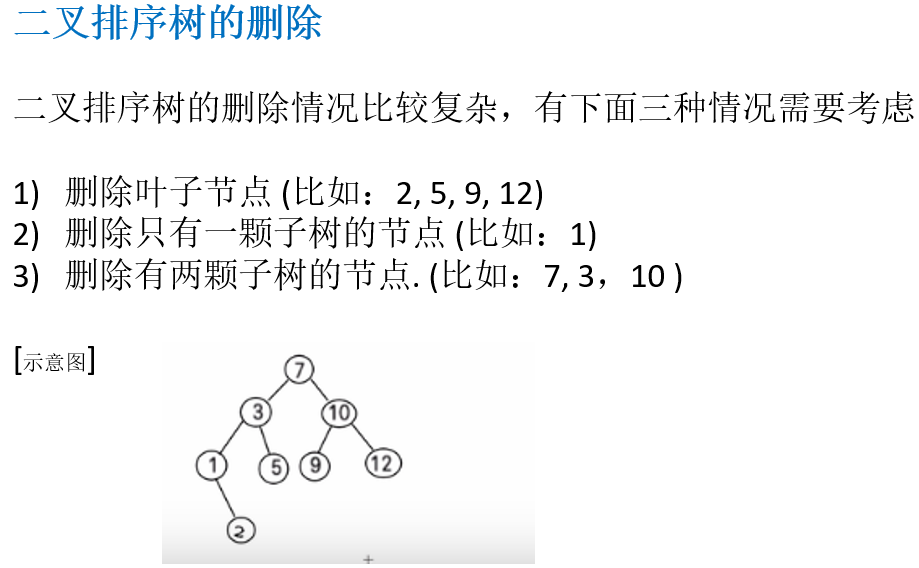


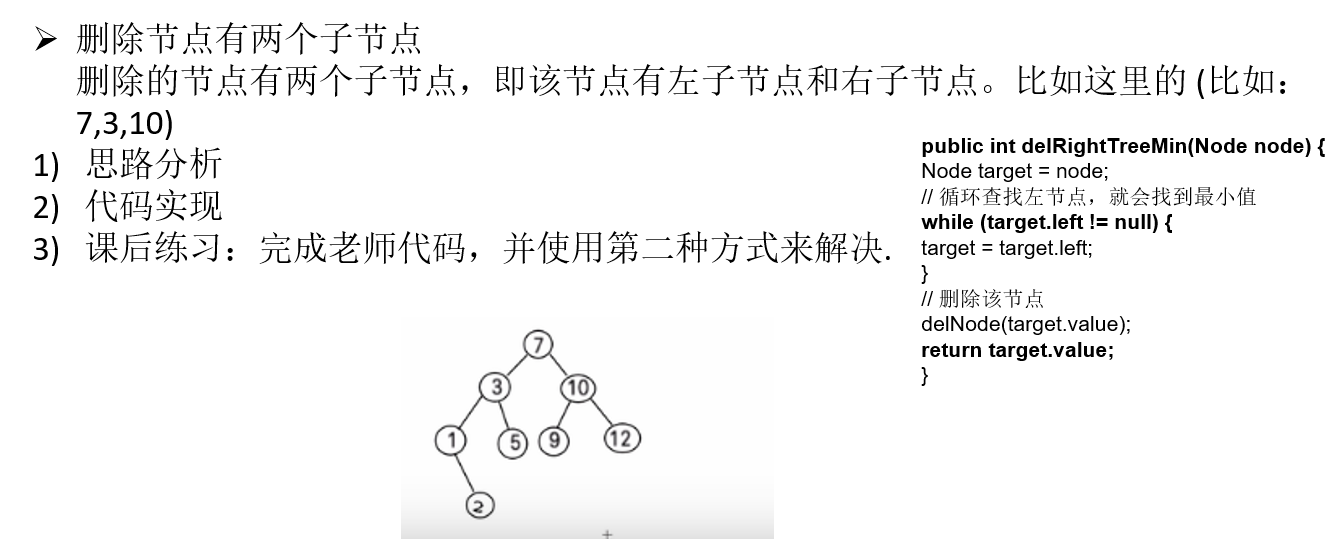

11.4.6 二叉排序树删除节点的代码实现
package com.atguigu.binarysorttree;public class BinarySortTreeDemo {public static void main(String[] args) {int[] arr = {7, 3, 10, 12, 5, 1, 9, 2};BinarySortTree binarySortTree = new BinarySortTree();//循环的添加结点到二叉排序树for(int i = 0; i< arr.length; i++) {binarySortTree.add(new Node(arr[i]));}//中序遍历二叉排序树System.out.println("中序遍历二叉排序树~");binarySortTree.infixOrder(); // 1, 3, 5, 7, 9, 10, 12//测试一下删除叶子结点binarySortTree.delNode(12);binarySortTree.delNode(5);binarySortTree.delNode(10);binarySortTree.delNode(2);binarySortTree.delNode(3);binarySortTree.delNode(9);binarySortTree.delNode(1);binarySortTree.delNode(7);System.out.println("root=" + binarySortTree.getRoot());System.out.println("删除结点后");binarySortTree.infixOrder();}}//创建二叉排序树
class BinarySortTree {private Node root;public Node getRoot() {return root;}//查找要删除的结点public Node search(int value) {if(root == null) {return null;} else {return root.search(value);}}//查找父结点public Node searchParent(int value) {if(root == null) {return null;} else {return root.searchParent(value);}}//编写方法: //1. 返回的 以node 为根结点的二叉排序树的最小结点的值//2. 删除node 为根结点的二叉排序树的最小结点/*** * @param node 传入的结点(当做二叉排序树的根结点)* @return 返回的 以node 为根结点的二叉排序树的最小结点的值*/public int delRightTreeMin(Node node) {Node target = node;//循环的查找左子节点,就会找到最小值while(target.left != null) {target = target.left;}//这时 target就指向了最小结点//删除最小结点delNode(target.value);return target.value;}//删除结点public void delNode(int value) {if(root == null) {return;}else {//1.需求先去找到要删除的结点 targetNodeNode targetNode = search(value);//如果没有找到要删除的结点if(targetNode == null) {return;}//如果我们发现当前这颗二叉排序树只有一个结点if(root.left == null && root.right == null) {root = null;return;}//去找到targetNode的父结点Node parent = searchParent(value);//如果要删除的结点是叶子结点if(targetNode.left == null && targetNode.right == null) {//判断targetNode 是父结点的左子结点,还是右子结点if(parent.left != null && parent.left.value == value) { //是左子结点parent.left = null;} else if (parent.right != null && parent.right.value == value) {//是右子结点parent.right = null;}} else if (targetNode.left != null && targetNode.right != null) { //删除有两颗子树的节点int minVal = delRightTreeMin(targetNode.right);targetNode.value = minVal;} else { // 删除只有一颗子树的结点//如果要删除的结点有左子结点 if(targetNode.left != null) {if(parent != null) {//如果 targetNode 是 parent 的左子结点if(parent.left.value == value) {parent.left = targetNode.left;} else { // targetNode 是 parent 的右子结点parent.right = targetNode.left;} } else {root = targetNode.left;}} else { //如果要删除的结点有右子结点 if(parent != null) {//如果 targetNode 是 parent 的左子结点if(parent.left.value == value) {parent.left = targetNode.right;} else { //如果 targetNode 是 parent 的右子结点parent.right = targetNode.right;}} else {root = targetNode.right;}}}}}//添加结点的方法public void add(Node node) {if(root == null) {root = node;//如果root为空则直接让root指向node} else {root.add(node);}}//中序遍历public void infixOrder() {if(root != null) {root.infixOrder();} else {System.out.println("二叉排序树为空,不能遍历");}}
}//创建Node结点
class Node {int value;Node left;Node right;public Node(int value) {this.value = value;}//查找要删除的结点/*** * @param value 希望删除的结点的值* @return 如果找到返回该结点,否则返回null*/public Node search(int value) {if(value == this.value) { //找到就是该结点return this;} else if(value < this.value) {//如果查找的值小于当前结点,向左子树递归查找//如果左子结点为空if(this.left == null) {return null;}return this.left.search(value);} else { //如果查找的值不小于当前结点,向右子树递归查找if(this.right == null) {return null;}return this.right.search(value);}}//查找要删除结点的父结点/*** * @param value 要找到的结点的值* @return 返回的是要删除的结点的父结点,如果没有就返回null*/public Node searchParent(int value) {//如果当前结点就是要删除的结点的父结点,就返回if((this.left != null && this.left.value == value) || (this.right != null && this.right.value == value)) {return this;} else {//如果查找的值小于当前结点的值, 并且当前结点的左子结点不为空if(value < this.value && this.left != null) {return this.left.searchParent(value); //向左子树递归查找} else if (value >= this.value && this.right != null) {return this.right.searchParent(value); //向右子树递归查找} else {return null; // 没有找到父结点}}}@Overridepublic String toString() {return "Node [value=" + value + "]";}//添加结点的方法//递归的形式添加结点,注意需要满足二叉排序树的要求public void add(Node node) {if(node == null) {return;}//判断传入的结点的值,和当前子树的根结点的值关系if(node.value < this.value) {//如果当前结点左子结点为nullif(this.left == null) {this.left = node;} else {//递归的向左子树添加this.left.add(node);}} else { //添加的结点的值大于 当前结点的值if(this.right == null) {this.right = node;} else {//递归的向右子树添加this.right.add(node);}}}//中序遍历public void infixOrder() {if(this.left != null) {this.left.infixOrder();}System.out.println(this);if(this.right != null) {this.right.infixOrder();}}}
11.4.7 课后练习:完成代码,使用第二种方式解决

11.5 平衡二叉树(AVL树,Adelson-Velsky-Landis)
在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,他们在1962年的论文《An algorithm for the organization of information》中发表了它。
11.5.1 看一个案例(说明二叉排序树可能的问题)

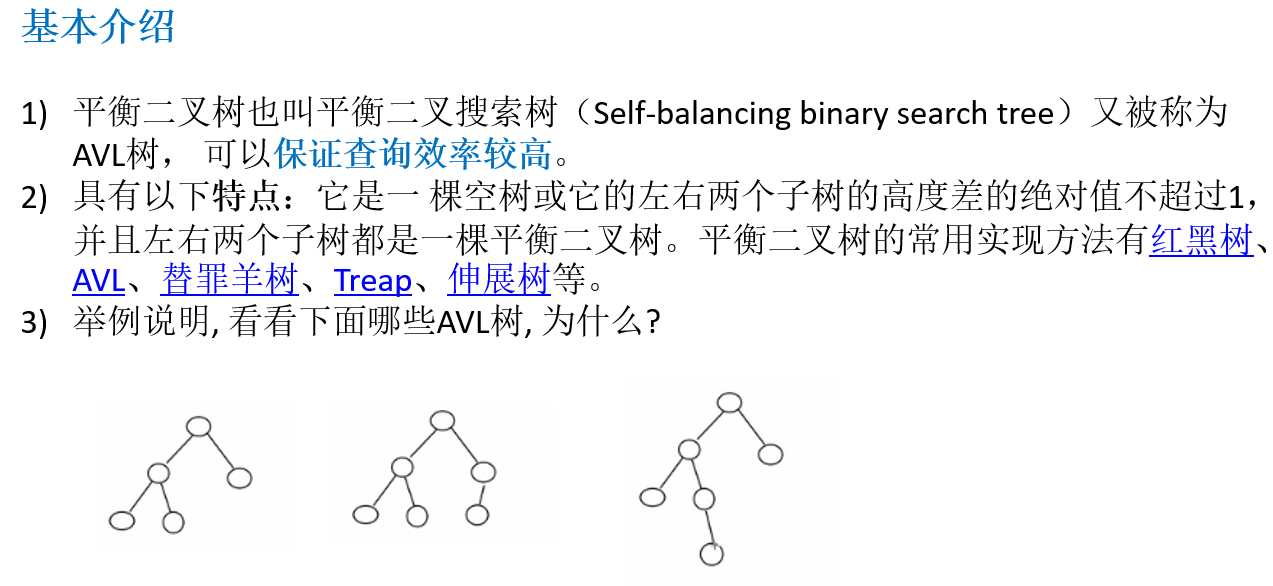
11.5.2 基本介绍
11.5.3 应用案例-单旋转(左旋转)



11.5.4 应用案例-单旋转(右旋转)



11.5.5 应用案例-双旋转

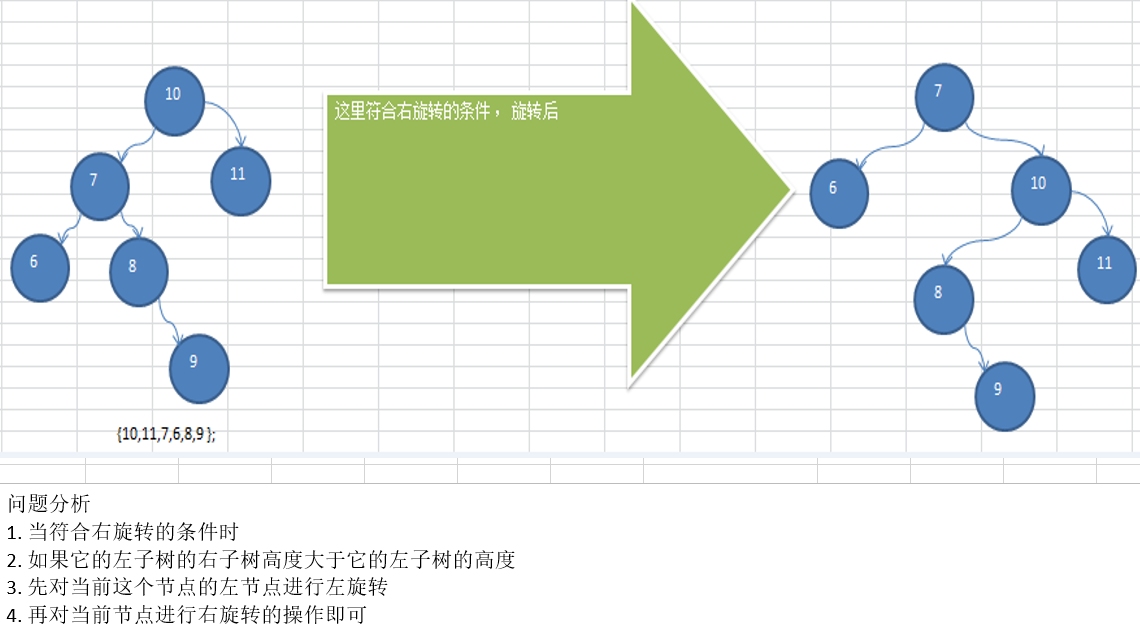
package com.atguigu.avl;public class AVLTreeDemo {public static void main(String[] args) {//int[] arr = {4,3,6,5,7,8};//int[] arr = { 10, 12, 8, 9, 7, 6 };int[] arr = { 10, 11, 7, 6, 8, 9 }; //创建一个 AVLTree对象AVLTree avlTree = new AVLTree();//添加结点for(int i=0; i < arr.length; i++) {avlTree.add(new Node(arr[i]));}//遍历System.out.println("中序遍历");avlTree.infixOrder();System.out.println("在平衡处理~~");System.out.println("树的高度=" + avlTree.getRoot().height()); //3System.out.println("树的左子树高度=" + avlTree.getRoot().leftHeight()); // 2System.out.println("树的右子树高度=" + avlTree.getRoot().rightHeight()); // 2System.out.println("当前的根结点=" + avlTree.getRoot());//8}}// 创建AVLTree
class AVLTree {private Node root;public Node getRoot() {return root;}// 查找要删除的结点public Node search(int value) {if (root == null) {return null;} else {return root.search(value);}}// 查找父结点public Node searchParent(int value) {if (root == null) {return null;} else {return root.searchParent(value);}}// 编写方法:// 1. 返回的 以node 为根结点的二叉排序树的最小结点的值// 2. 删除node 为根结点的二叉排序树的最小结点/*** * @param node* 传入的结点(当做二叉排序树的根结点)* @return 返回的 以node 为根结点的二叉排序树的最小结点的值*/public int delRightTreeMin(Node node) {Node target = node;// 循环的查找左子节点,就会找到最小值while (target.left != null) {target = target.left;}// 这时 target就指向了最小结点// 删除最小结点delNode(target.value);return target.value;}// 删除结点public void delNode(int value) {if (root == null) {return;} else {// 1.需求先去找到要删除的结点 targetNodeNode targetNode = search(value);// 如果没有找到要删除的结点if (targetNode == null) {return;}// 如果我们发现当前这颗二叉排序树只有一个结点if (root.left == null && root.right == null) {root = null;return;}// 去找到targetNode的父结点Node parent = searchParent(value);// 如果要删除的结点是叶子结点if (targetNode.left == null && targetNode.right == null) {// 判断targetNode 是父结点的左子结点,还是右子结点if (parent.left != null && parent.left.value == value) { // 是左子结点parent.left = null;} else if (parent.right != null && parent.right.value == value) {// 是由子结点parent.right = null;}} else if (targetNode.left != null && targetNode.right != null) { // 删除有两颗子树的节点int minVal = delRightTreeMin(targetNode.right);targetNode.value = minVal;} else { // 删除只有一颗子树的结点// 如果要删除的结点有左子结点if (targetNode.left != null) {if (parent != null) {// 如果 targetNode 是 parent 的左子结点if (parent.left.value == value) {parent.left = targetNode.left;} else { // targetNode 是 parent 的右子结点parent.right = targetNode.left;}} else {root = targetNode.left;}} else { // 如果要删除的结点有右子结点if (parent != null) {// 如果 targetNode 是 parent 的左子结点if (parent.left.value == value) {parent.left = targetNode.right;} else { // 如果 targetNode 是 parent 的右子结点parent.right = targetNode.right;}} else {root = targetNode.right;}}}}}// 添加结点的方法public void add(Node node) {if (root == null) {root = node;// 如果root为空则直接让root指向node} else {root.add(node);}}// 中序遍历public void infixOrder() {if (root != null) {root.infixOrder();} else {System.out.println("二叉排序树为空,不能遍历");}}
}// 创建Node结点
class Node {int value;Node left;Node right;public Node(int value) {this.value = value;}// 返回左子树的高度public int leftHeight() {if (left == null) {return 0;}return left.height();}// 返回右子树的高度public int rightHeight() {if (right == null) {return 0;}return right.height();}// 返回 以该结点为根结点的树的高度public int height() {return Math.max(left == null ? 0 : left.height(), right == null ? 0 : right.height()) + 1;}//左旋转方法private void leftRotate() {//创建新的节点,以当前根节点的值Node newNode = new Node(value);//把新的节点的左子树设置成当前节点的左子树newNode.left = left;//把新的节点的右子树设置成当前节点的右子树的左子树newNode.right = right.left;//把当前节点的值替换成右子节点的值value = right.value;//把当前节点的右子树设置成当前节点右子树的右子树right = right.right;//把当前节点的左子树(左子结点)设置成新的节点left = newNode;}//右旋转private void rightRotate() {Node newNode = new Node(value);newNode.right = right;newNode.left = left.right;value = left.value;left = left.left;right = newNode;}// 查找要删除的结点/*** * @param value* 希望删除的结点的值* @return 如果找到返回该结点,否则返回null*/public Node search(int value) {if (value == this.value) { // 找到就是该结点return this;} else if (value < this.value) {// 如果查找的值小于当前结点,向左子树递归查找// 如果左子结点为空if (this.left == null) {return null;}return this.left.search(value);} else { // 如果查找的值不小于当前结点,向右子树递归查找if (this.right == null) {return null;}return this.right.search(value);}}// 查找要删除结点的父结点/*** * @param value* 要找到的结点的值* @return 返回的是要删除的结点的父结点,如果没有就返回null*/public Node searchParent(int value) {// 如果当前结点就是要删除的结点的父结点,就返回if ((this.left != null && this.left.value == value) || (this.right != null && this.right.value == value)) {return this;} else {// 如果查找的值小于当前结点的值, 并且当前结点的左子结点不为空if (value < this.value && this.left != null) {return this.left.searchParent(value); // 向左子树递归查找} else if (value >= this.value && this.right != null) {return this.right.searchParent(value); // 向右子树递归查找} else {return null; // 没有找到父结点}}}@Overridepublic String toString() {return "Node [value=" + value + "]";}// 添加结点的方法// 递归的形式添加结点,注意需要满足二叉排序树的要求public void add(Node node) {if (node == null) {return;}// 判断传入的结点的值,和当前子树的根结点的值关系if (node.value < this.value) {// 如果当前结点左子结点为nullif (this.left == null) {this.left = node;} else {// 递归的向左子树添加this.left.add(node);}} else { // 添加的结点的值大于 当前结点的值if (this.right == null) {this.right = node;} else {// 递归的向右子树添加this.right.add(node);}}//当添加完一个结点后,如果: (右子树的高度-左子树的高度) > 1 , 左旋转if(rightHeight() - leftHeight() > 1) {//如果它的右子树的左子树的高度大于它的右子树的右子树的高度if(right != null && right.leftHeight() > right.rightHeight()) {//先对右子结点进行右旋转right.rightRotate();//然后在对当前结点进行左旋转leftRotate(); //左旋转..} else {//直接进行左旋转即可leftRotate();}return ; //必须要!!!}//当添加完一个结点后,如果 (左子树的高度 - 右子树的高度) > 1, 右旋转if(leftHeight() - rightHeight() > 1) {//如果它的左子树的右子树高度大于它的左子树的高度if(left != null && left.rightHeight() > left.leftHeight()) {//先对当前结点的左结点(左子树)->左旋转left.leftRotate();//再对当前结点进行右旋转rightRotate();} else {//直接进行右旋转即可rightRotate();}}}// 中序遍历public void infixOrder() {if (this.left != null) {this.left.infixOrder();}System.out.println(this);if (this.right != null) {this.right.infixOrder();}}}
第12章 多路查找树
12.1 二叉树与B树
12.1.1 二叉树的问题分析
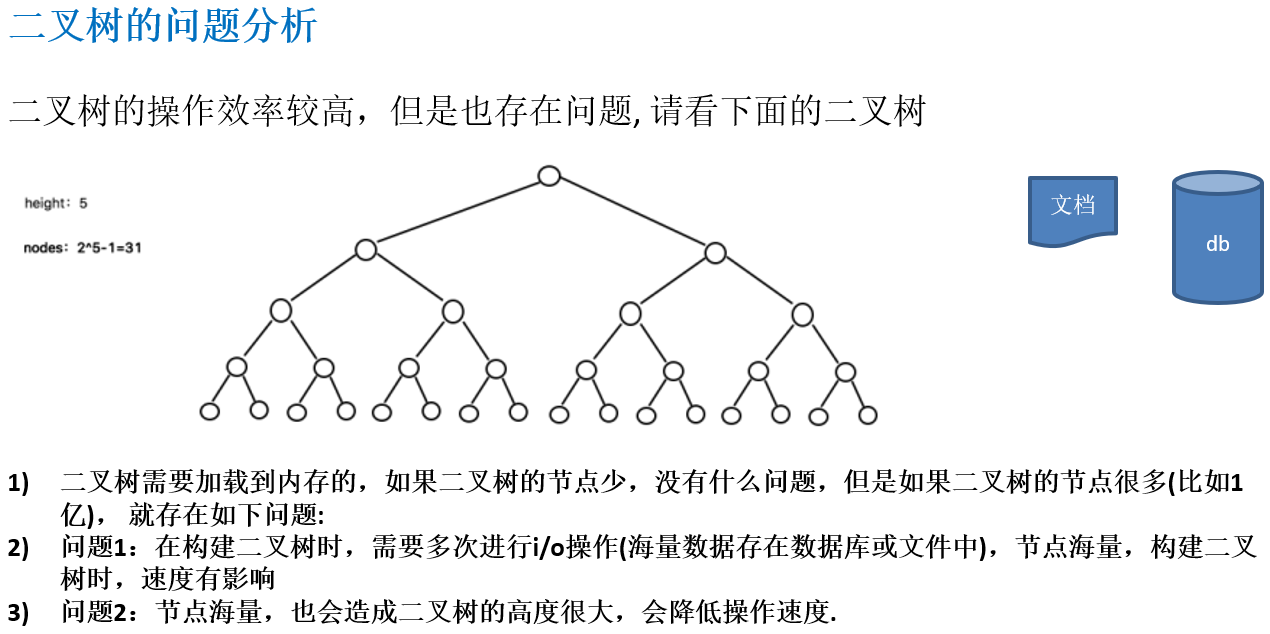
12.1.2 多叉树
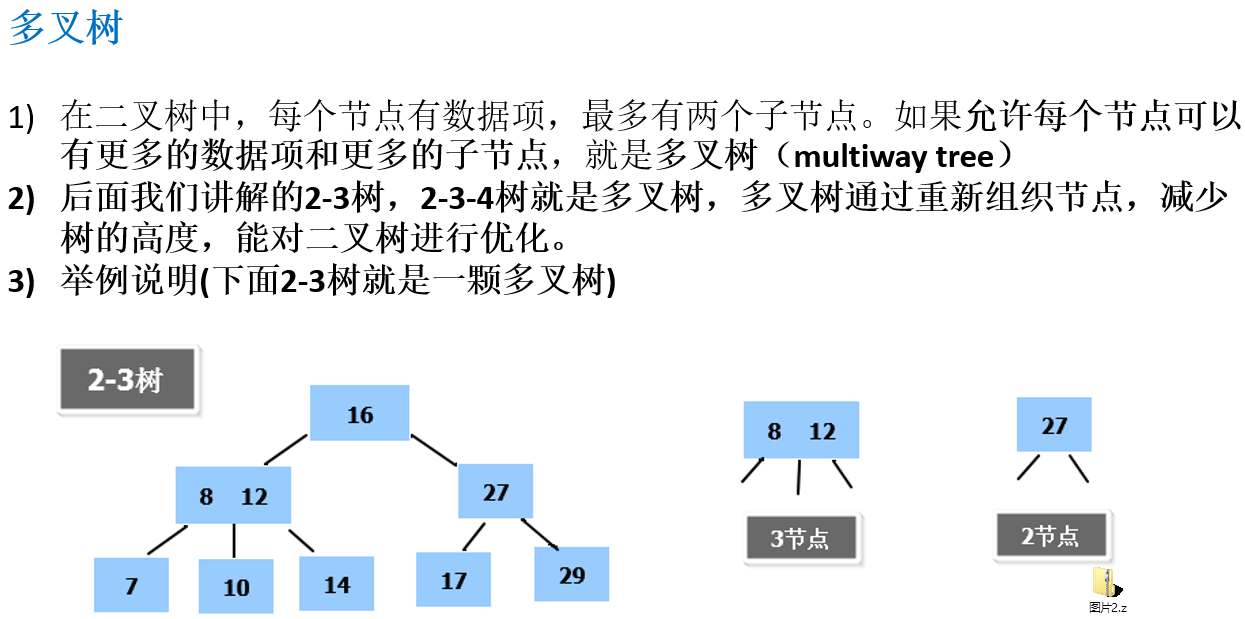
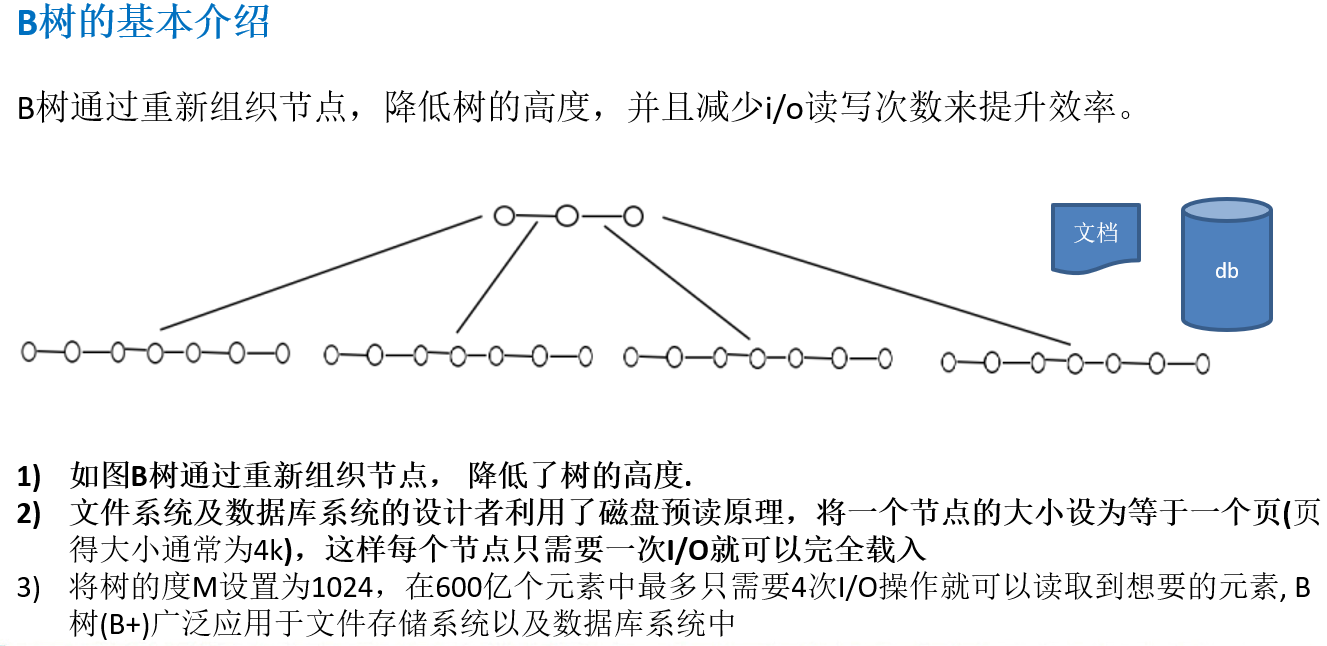
12.1.3 B树的基本介绍
12.2 2-3树
12.2.1 2-3树基本介绍

12.2.2 2-3树应用案例
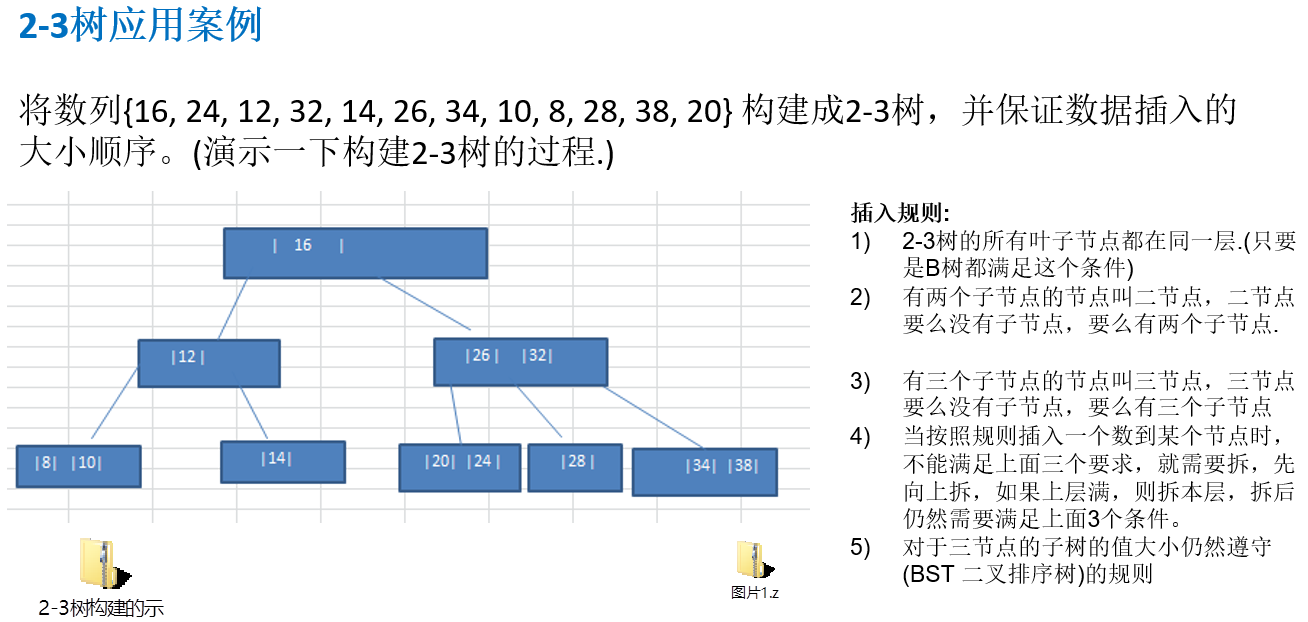
12.2.3 其它说明
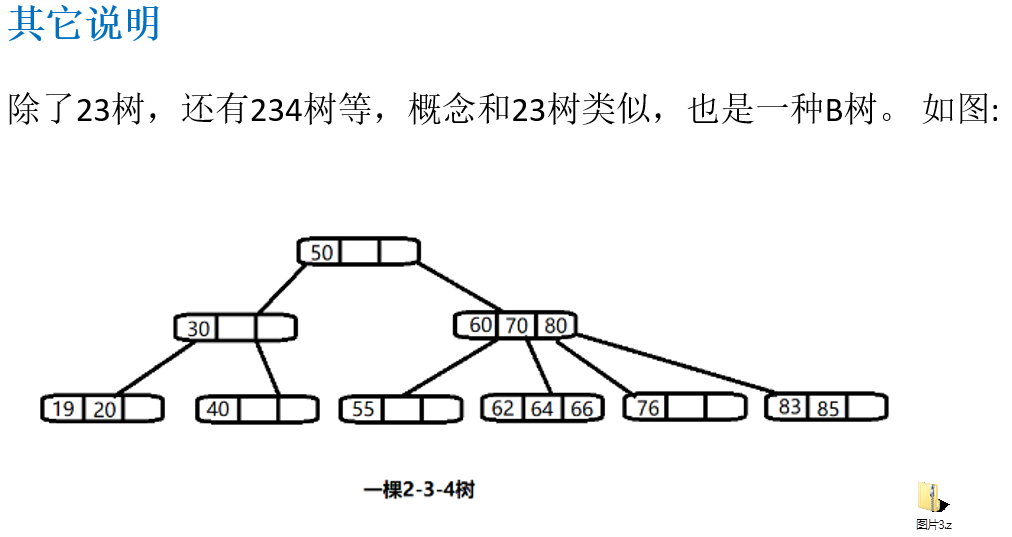
12.3 B树、B+树和B*树(Balanced)★
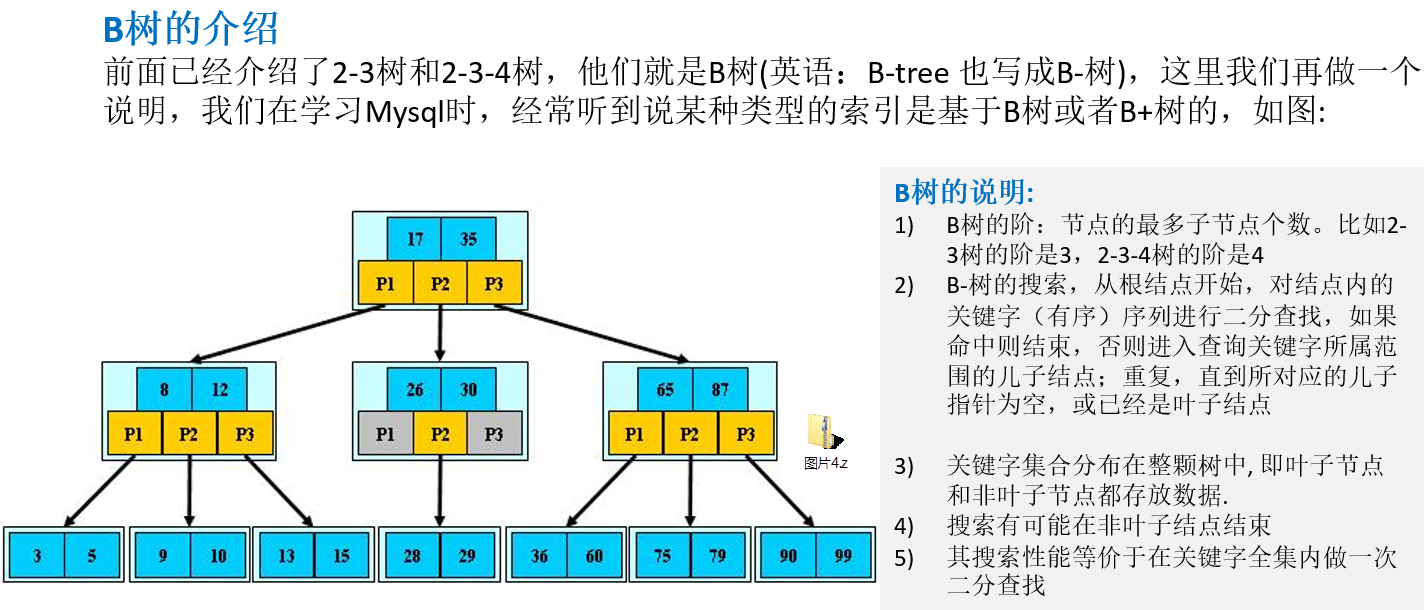
12.3.1 B树的介绍

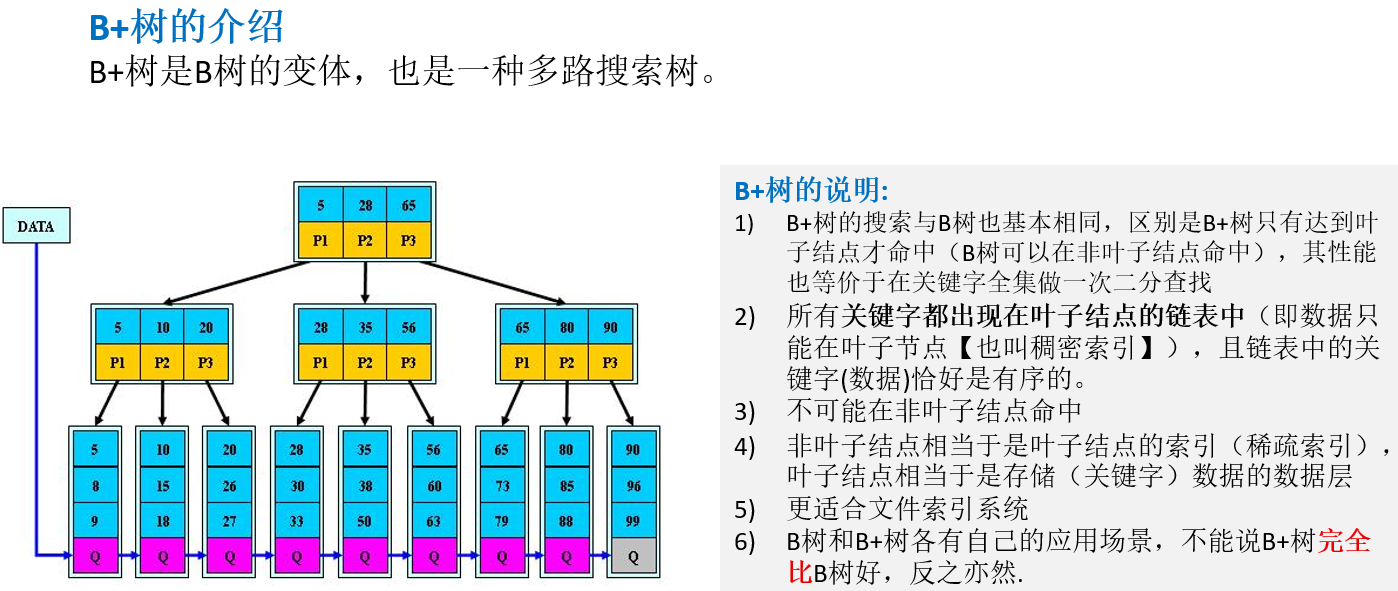
12.3.2 B+树的介绍
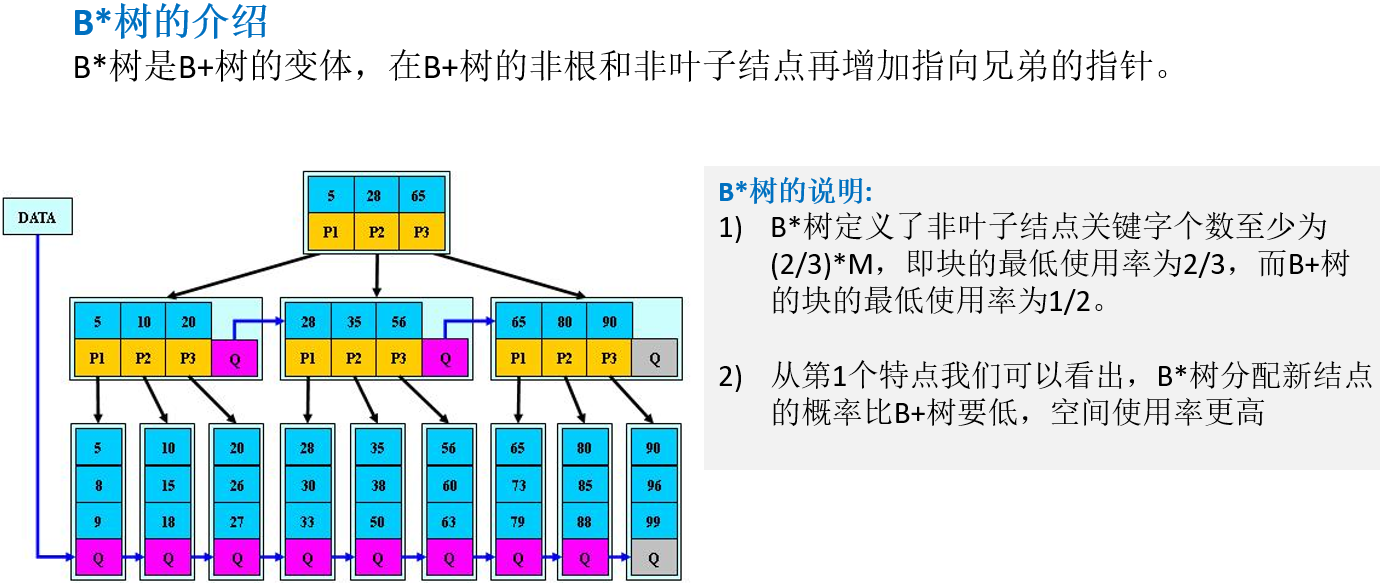
12.3.3 B*树的介绍
第13章 图
13.1 图基本介绍
13.1.1 为什么要有图

13.1.2 图的举例说明

13.1.3 图的常用概念
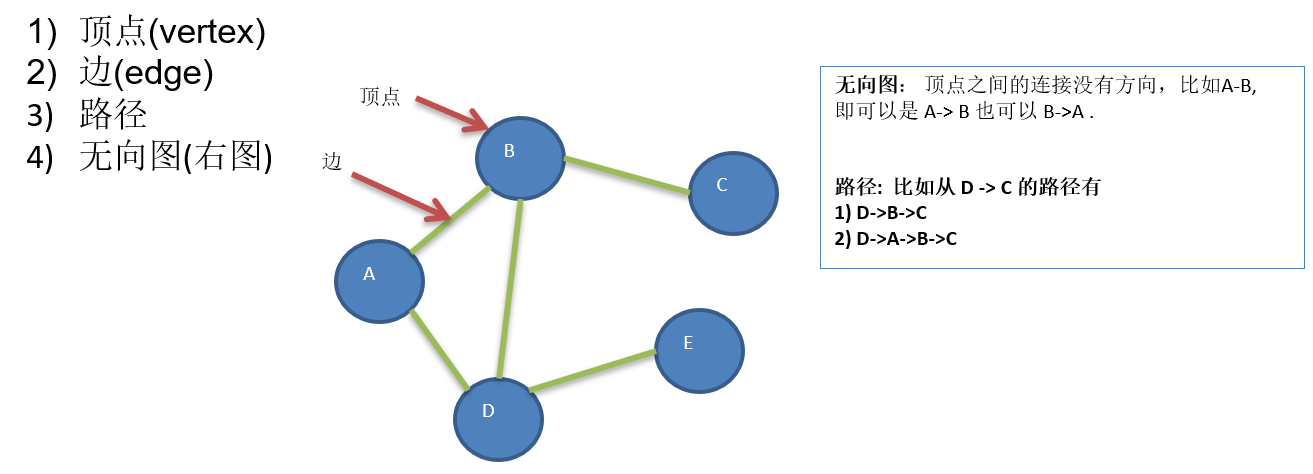
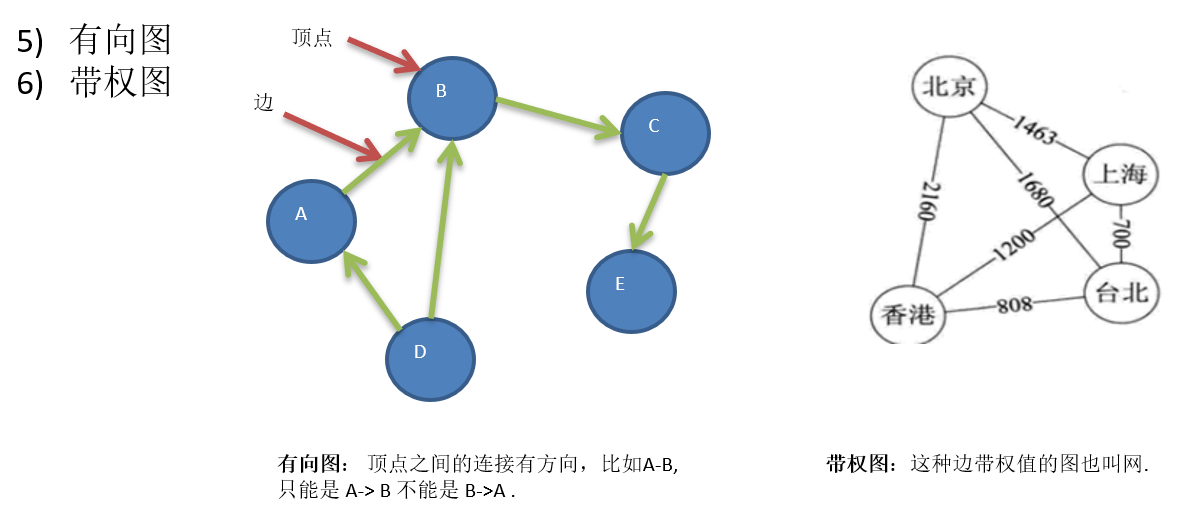
13.2 图的表示方式
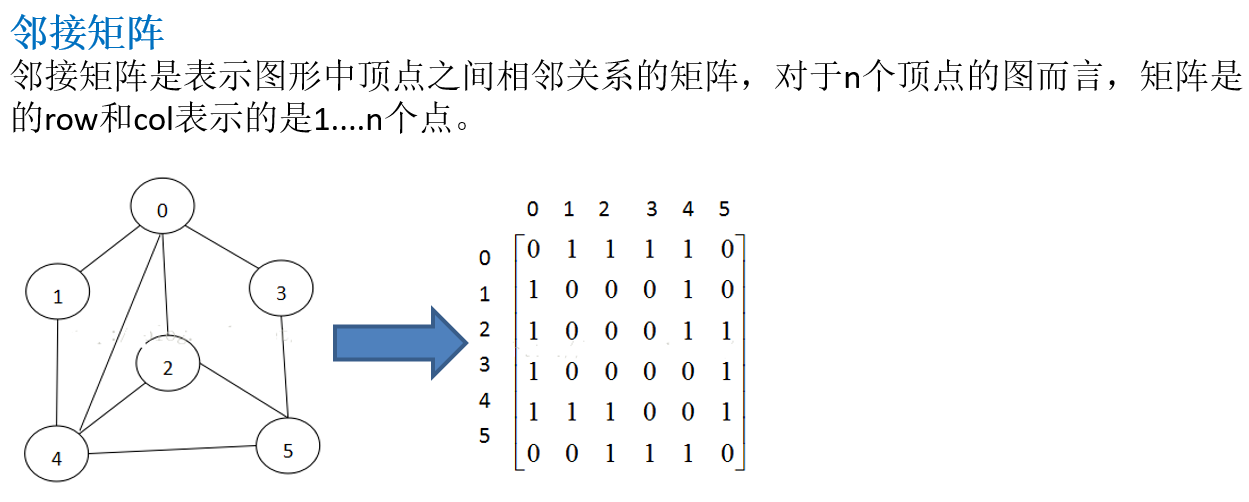
13.2.1 邻接矩阵
13.2.2 邻接表
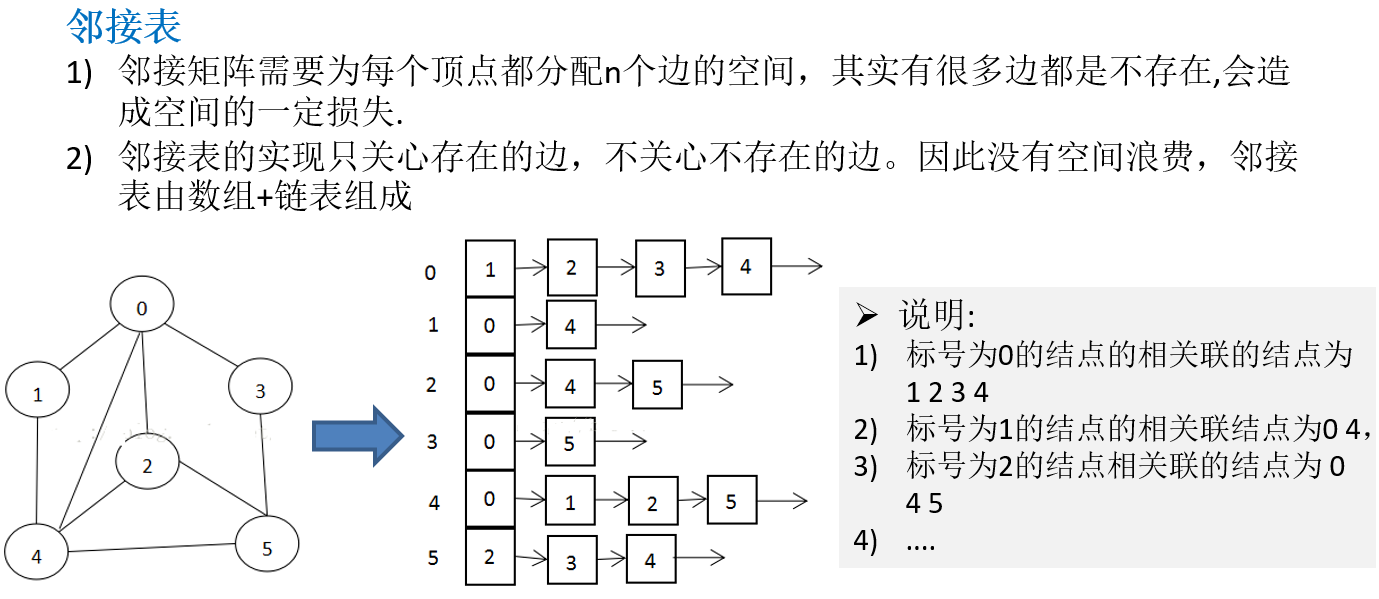
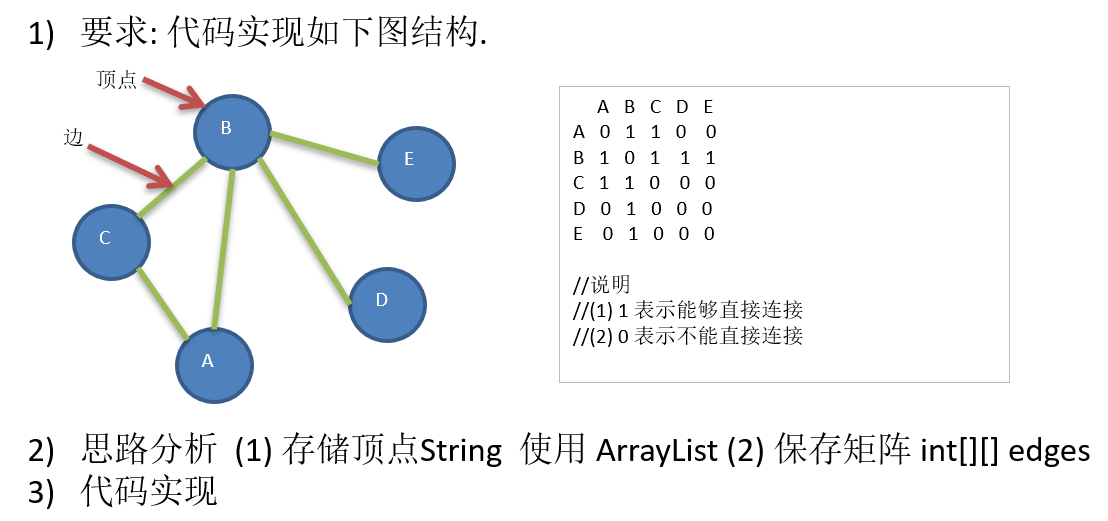
13.3 图的快速入门案例
13.4 图的深度优先遍历介绍(Depth First Search,DFS)
13.4.1 图遍历介绍

13.4.2 深度优先遍历基本思想

13.4.3 深度优先遍历算法步骤
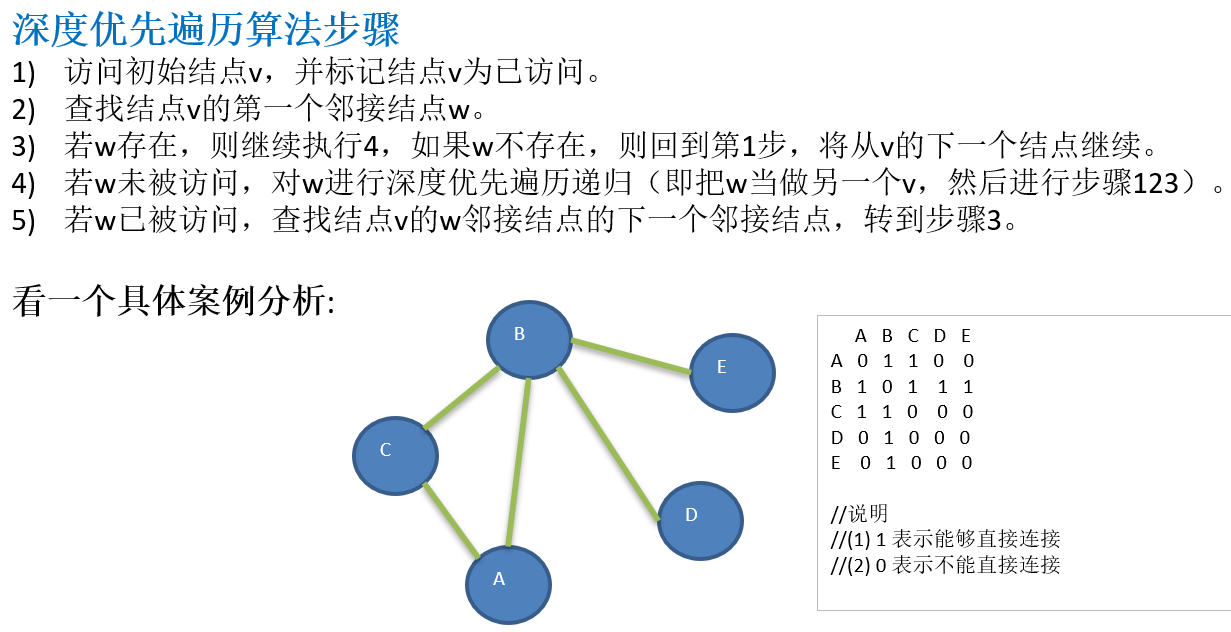
13.4.4 深度优先算法的代码实现
//深度优先遍历算法
//i 第一次就是 0
private void dfs(boolean[] isVisited, int i) {//首先我们访问该结点,输出System.out.print(getValueByIndex(i) + "->");//将结点设置为已经访问isVisited[i] = true;//查找结点i的第一个邻接结点wint w = getFirstNeighbor(i);while(w != -1) {//说明有if(!isVisited[w]) {dfs(isVisited, w);}//如果w结点已经被访问过w = getNextNeighbor(i, w);}}//对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs
public void dfs() {isVisited = new boolean[vertexList.size()];//遍历所有的结点,进行dfs[回溯]for(int i = 0; i < getNumOfVertex(); i++) {if(!isVisited[i]) {dfs(isVisited, i);}}
}13.5 图的广度优先遍历(Broad First Search,BFS)
13.5.1 广度优先遍历基本思想

13.5.2 广度优先遍历算法步骤

13.5.3 广度优先算法的图示
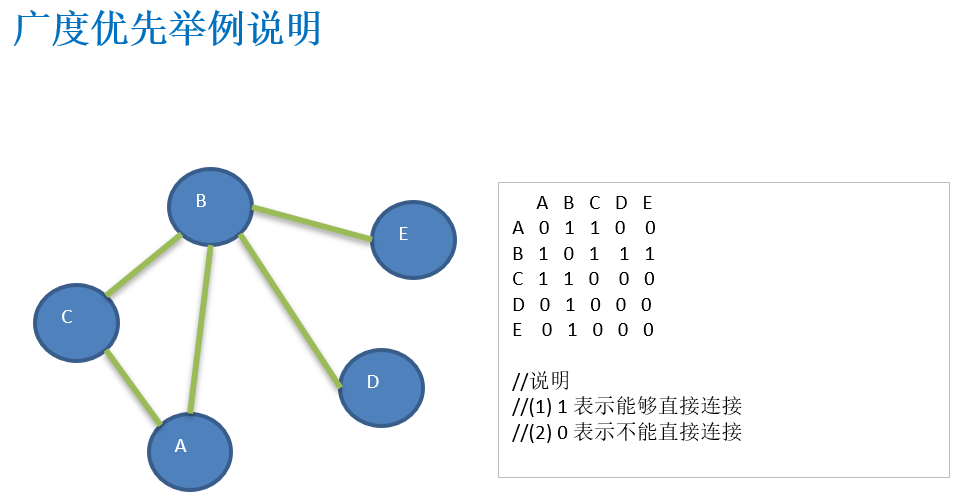
13.5.4 广度优先算法的代码实现
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {int u ; // 表示队列的头结点对应下标int w ; // 邻接结点w//队列,记录结点访问的顺序LinkedList queue = new LinkedList();//访问结点,输出结点信息System.out.print(getValueByIndex(i) + "=>");//标记为已访问isVisited[i] = true;//将结点加入队列queue.addLast(i);while( !queue.isEmpty()) {//取出队列的头结点下标u = (Integer)queue.removeFirst();//得到第一个邻接结点的下标 w w = getFirstNeighbor(u);while(w != -1) {//找到//是否访问过if(!isVisited[w]) {System.out.print(getValueByIndex(w) + "=>");//标记已经访问isVisited[w] = true;//入队queue.addLast(w);}//以u为前驱点,找w后面的下一个邻结点w = getNextNeighbor(u, w); //体现出我们的广度优先}}} //遍历所有的结点,都进行广度优先搜索
public void bfs() {isVisited = new boolean[vertexList.size()];for(int i = 0; i < getNumOfVertex(); i++) {if(!isVisited[i]) {bfs(isVisited, i);}}
}13.6 图的代码汇总
package com.atguigu.graph;import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;public class Graph {private ArrayList<String> vertexList; //存储顶点集合private int[][] edges; //存储图对应的邻结矩阵private int numOfEdges; //表示边的数目//定义一个数组boolean[], 记录某个结点是否被访问private boolean[] isVisited;public static void main(String[] args) {//测试一把图是否创建okint n = 8; //结点的个数//String Vertexs[] = {"A", "B", "C", "D", "E"};String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};//创建图对象Graph graph = new Graph(n);//循环的添加顶点for(String vertex: Vertexs) {graph.insertVertex(vertex);}//添加边//A-B A-C B-C B-D B-E
// graph.insertEdge(0, 1, 1); // A-B
// graph.insertEdge(0, 2, 1); //
// graph.insertEdge(1, 2, 1); //
// graph.insertEdge(1, 3, 1); //
// graph.insertEdge(1, 4, 1); // //更新边的关系graph.insertEdge(0, 1, 1);graph.insertEdge(0, 2, 1);graph.insertEdge(1, 3, 1);graph.insertEdge(1, 4, 1);graph.insertEdge(3, 7, 1);graph.insertEdge(4, 7, 1);graph.insertEdge(2, 5, 1);graph.insertEdge(2, 6, 1);graph.insertEdge(5, 6, 1);//显示一把邻结矩阵graph.showGraph();//测试一把,我们的dfs遍历是否okSystem.out.println("深度遍历");graph.dfs(); // A->B->C->D->E [1->2->4->8->5->3->6->7]
// System.out.println();System.out.println("广度优先!");graph.bfs(); // A->B->C->D-E [1->2->3->4->5->6->7->8]}//构造器public Graph(int n) {//初始化矩阵和vertexListedges = new int[n][n];vertexList = new ArrayList<String>(n);numOfEdges = 0;}//得到第一个邻接结点的下标 w /*** * @param index * @return 如果存在就返回对应的下标,否则返回-1*/public int getFirstNeighbor(int index) {for(int j = 0; j < vertexList.size(); j++) {if(edges[index][j] > 0) {return j;}}return -1;}//根据前一个邻接结点的下标来获取下一个邻接结点public int getNextNeighbor(int v1, int v2) {for(int j = v2 + 1; j < vertexList.size(); j++) {if(edges[v1][j] > 0) {return j;}}return -1;}//深度优先遍历算法//i 第一次就是 0private void dfs(boolean[] isVisited, int i) {//首先我们访问该结点,输出System.out.print(getValueByIndex(i) + "->");//将结点设置为已经访问isVisited[i] = true;//查找结点i的第一个邻接结点wint w = getFirstNeighbor(i);while(w != -1) {//说明有if(!isVisited[w]) {dfs(isVisited, w);}//如果w结点已经被访问过w = getNextNeighbor(i, w);}}//对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfspublic void dfs() {isVisited = new boolean[vertexList.size()];//遍历所有的结点,进行dfs[回溯]for(int i = 0; i < getNumOfVertex(); i++) {if(!isVisited[i]) {dfs(isVisited, i);}}}//对一个结点进行广度优先遍历的方法private void bfs(boolean[] isVisited, int i) {int u ; // 表示队列的头结点对应下标int w ; // 邻接结点w//队列,记录结点访问的顺序LinkedList queue = new LinkedList();//访问结点,输出结点信息System.out.print(getValueByIndex(i) + "=>");//标记为已访问isVisited[i] = true;//将结点加入队列queue.addLast(i);while( !queue.isEmpty()) {//取出队列的头结点下标u = (Integer)queue.removeFirst();//得到第一个邻接结点的下标 w w = getFirstNeighbor(u);while(w != -1) {//找到//是否访问过if(!isVisited[w]) {System.out.print(getValueByIndex(w) + "=>");//标记已经访问isVisited[w] = true;//入队queue.addLast(w);}//以u为前驱点,找w后面的下一个邻结点w = getNextNeighbor(u, w); //体现出我们的广度优先}}} //遍历所有的结点,都进行广度优先搜索public void bfs() {isVisited = new boolean[vertexList.size()];for(int i = 0; i < getNumOfVertex(); i++) {if(!isVisited[i]) {bfs(isVisited, i);}}}//图中常用的方法//返回结点的个数public int getNumOfVertex() {return vertexList.size();}//显示图对应的矩阵public void showGraph() {for(int[] link : edges) {System.err.println(Arrays.toString(link));}}//得到边的数目public int getNumOfEdges() {return numOfEdges;}//返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C"public String getValueByIndex(int i) {return vertexList.get(i);}//返回v1和v2的权值public int getWeight(int v1, int v2) {return edges[v1][v2];}//插入结点public void insertVertex(String vertex) {vertexList.add(vertex);}//添加边/*** * @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1* @param v2 第二个顶点对应的下标* @param weight 表示 */public void insertEdge(int v1, int v2, int weight) {edges[v1][v2] = weight;edges[v2][v1] = weight;numOfEdges++;}
}
13.7 图的深度优先VS广度优先
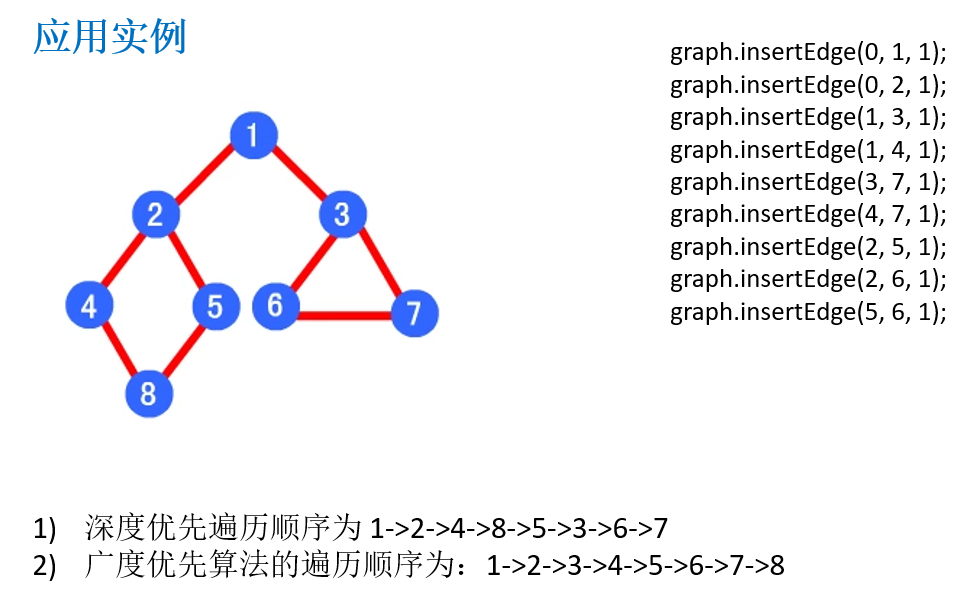
第14章 程序员常用10种算法
14.1 二分查找算法(非递归)
14.1.1 二分查找算法(非递归)介绍

14.1.2 二分查找算法(非递归)代码实现

package com.atguigu.binarysearchnorecursion;public class BinarySearchNoRecur {public static void main(String[] args) {//测试int[] arr = {1,3, 8, 10, 11, 67, 100};int index = binarySearch(arr, 100);System.out.println("index=" + index);//}//二分查找的非递归实现/*** * @param arr 待查找的数组, arr是升序排序* @param target 需要查找的数* @return 返回对应下标,-1表示没有找到*/public static int binarySearch(int[] arr, int target) {int left = 0;int right = arr.length - 1;while(left <= right) { //说明继续查找int mid = (left + right) / 2;if(arr[mid] == target) {return mid;} else if ( arr[mid] > target) {right = mid - 1;//需要向左边查找} else {left = mid + 1; //需要向右边查找}}return -1;}}
14.2 分治算法
14.2.1 分治算法介绍

14.2.2 分治算法的基本步骤

14.2.3 分治(Divide-and-Conquer(P))算法设计模式如下

14.2.4 分治算法最佳实践-汉诺塔


package com.atguigu.dac;public class Hanoitower {public static void main(String[] args) {hanoiTower(64, 'A', 'B', 'C');}//汉诺塔的移动的方法//使用分治算法public static void hanoiTower(int num, char a, char b, char c) {//如果只有一个盘if(num == 1) {System.out.println("第1个盘从 " + a + "->" + c);} else {//如果我们有 n >= 2 情况,我们总是可以看做是两个盘 1.最下边的一个盘 2. 上面的所有盘//1. 先把 最上面的所有盘 A->B, 移动过程会使用到 chanoiTower(num - 1, a, c, b);//2. 把最下边的盘 A->CSystem.out.println("第" + num + "个盘从 " + a + "->" + c);//3. 把B塔的所有盘 从 B->C , 移动过程使用到 a塔 hanoiTower(num - 1, b, a, c);}}
}
14.3 动态规划算法(Dynamic Programming)
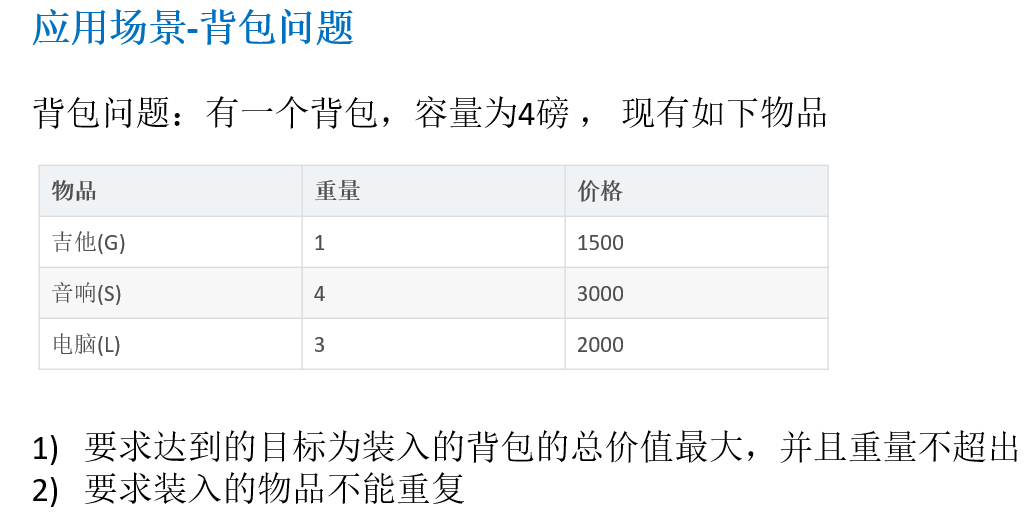
14.3.1 应用场景-背包问题(Knapsack Problem)
14.3.2 动态规划算法介绍

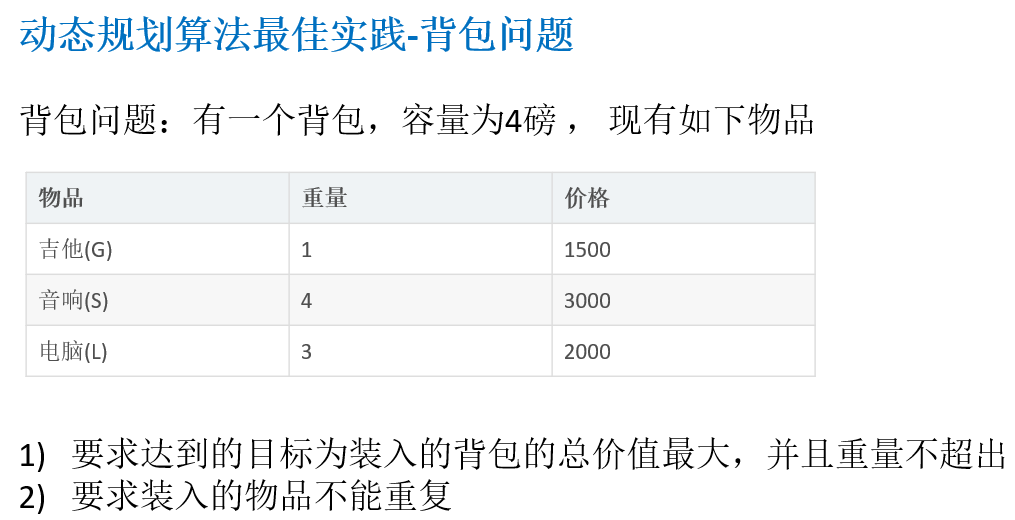
14.3.3 动态规划算法最佳实践-背包问题
思路分析和图解


图解的分析
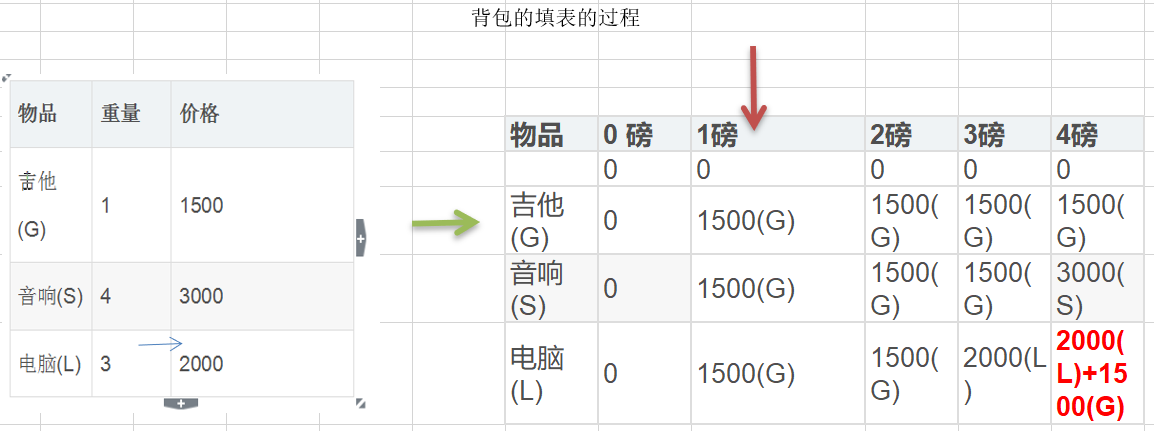

14.3.4 动态规划-背包问题的代码实现
package com.atguigu.dynamic;public class KnapsackProblem {public static void main(String[] args) {int[] w = {1, 4, 3};//物品的重量int[] val = {1500, 3000, 2000}; //物品的价值 这里val[i] 就是前面讲的v[i]int m = 4; //背包的容量int n = val.length; //物品的个数//创建二维数组,//v[i][j] 表示在前i个物品中能够装入容量为j的背包中的最大价值int[][] v = new int[n + 1][m + 1];//为了记录放入商品的情况,我们定一个二维数组int[][] path = new int[n + 1][m + 1];//初始化第一行和第一列, 这里在本程序中,可以不去处理,因为默认就是0for (int i = 0; i < v.length; i++) {v[i][0] = 0; //将第一列设置为0}for (int i = 0; i < v[0].length; i++) {v[0][i] = 0; //将第一行设置0}//根据前面得到公式来动态规划处理for (int i = 1; i < v.length; i++) { //不处理第一行 i是从1开始的for (int j = 1; j < v[0].length; j++) {//不处理第一列, j是从1开始的//公式if (w[i - 1] > j) { // 因为我们程序i 是从1开始的,因此原来公式中的 w[i] 修改成 w[i-1]v[i][j] = v[i - 1][j];} else {//说明://因为我们的i 从1开始的, 因此公式需要调整成//v[i][j]=Math.max(v[i-1][j], val[i-1]+v[i-1][j-w[i-1]]);//v[i][j] = Math.max(v[i - 1][j], val[i - 1] + v[i - 1][j - w[i - 1]]);//为了记录商品存放到背包的情况,我们不能直接的使用上面的公式,需要使用if-else来体现公式if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];//把当前的情况记录到pathpath[i][j] = 1;} else {v[i][j] = v[i - 1][j];}}}}//输出一下v 看看目前的情况for (int i = 0; i < v.length; i++) {for (int j = 0; j < v[i].length; j++) {System.out.print(v[i][j] + " ");}System.out.println();}System.out.println("============================");//输出最后我们是放入的哪些商品//遍历path, 这样输出会把所有的放入情况都得到, 其实我们只需要最后的放入
// for(int i = 0; i < path.length; i++) {
// for(int j=0; j < path[i].length; j++) {
// if(path[i][j] == 1) {
// System.out.printf("第%d个商品放入到背包\n", i);
// }
// }
// }//动脑筋int i = path.length - 1; //行的最大下标int j = path[0].length - 1; //列的最大下标while (i > 0 && j > 0) { //从path的最后开始找if (path[i][j] == 1) {System.out.printf("第%d个商品放入到背包\n", i);j -= w[i - 1]; //w[i-1]}i--;}}}
14.4 KMP算法
14.4.1 应用场景-字符串匹配问题

14.4.2 暴力匹配算法

package com.atguigu.kmp;public class ViolenceMatch {public static void main(String[] args) {//测试暴力匹配算法String str1 = "硅硅谷 尚硅谷你尚硅 尚硅谷你尚硅谷你尚硅你好";String str2 = "尚硅谷你尚硅你~";int index = violenceMatch(str1, str2);System.out.println("index=" + index);}// 暴力匹配算法实现public static int violenceMatch(String str1, String str2) {char[] s1 = str1.toCharArray();char[] s2 = str2.toCharArray();int s1Len = s1.length;int s2Len = s2.length;int i = 0; // i索引指向s1int j = 0; // j索引指向s2while (i < s1Len && j < s2Len) {// 保证匹配时,不越界if(s1[i] == s2[j]) {//匹配oki++;j++;} else { //没有匹配成功//如果失配(即str1[i]! = str2[j]),令i = i - (j - 1),j = 0。i = i - (j - 1);j = 0;}}//判断是否匹配成功if(j == s2Len) {return i - j;} else {return -1;}}}
14.4.3 KMP算法介绍

14.4.4 KMP算法最佳应用-字符串匹配问题



package com.atguigu.kmp;import java.util.Arrays;public class KMPAlgorithm {public static void main(String[] args) {String str1 = "BBC ABCDAB ABCDABCDABDE";String str2 = "ABCDABD";//String str2 = "BBC";int[] next = kmpNext("ABCDABD"); //[0, 1, 2, 0]System.out.println("next=" + Arrays.toString(next));int index = kmpSearch(str1, str2, next);System.out.println("index=" + index); // 15了}//写出我们的kmp搜索算法/*** * @param str1 源字符串* @param str2 子串* @param next 部分匹配表, 是子串对应的部分匹配表* @return 如果是-1就是没有匹配到,否则返回第一个匹配的位置*/public static int kmpSearch(String str1, String str2, int[] next) {//遍历 for(int i = 0, j = 0; i < str1.length(); i++) {//需要处理 str1.charAt(i) != str2.charAt(j), 去调整j的大小//KMP算法核心点, 可以验证...while( j > 0 && str1.charAt(i) != str2.charAt(j)) {j = next[j-1]; }if(str1.charAt(i) == str2.charAt(j)) {j++;} if(j == str2.length()) {//找到了 // j = 3 i return i - j + 1;}}return -1;}//获取到一个字符串(子串) 的部分匹配值表public static int[] kmpNext(String dest) {//创建一个next 数组保存部分匹配值int[] next = new int[dest.length()];next[0] = 0; //如果字符串是长度为1 部分匹配值就是0for(int i = 1, j = 0; i < dest.length(); i++) {//当dest.charAt(i) != dest.charAt(j) ,我们需要从next[j-1]获取新的j//直到我们发现 有 dest.charAt(i) == dest.charAt(j)成立才退出//这是 kmp算法的核心点while(j > 0 && dest.charAt(i) != dest.charAt(j)) {j = next[j-1];}//当dest.charAt(i) == dest.charAt(j) 满足时,部分匹配值就是+1if(dest.charAt(i) == dest.charAt(j)) {j++;}next[i] = j;}return next;}
}
14.5 贪心算法(greedy)
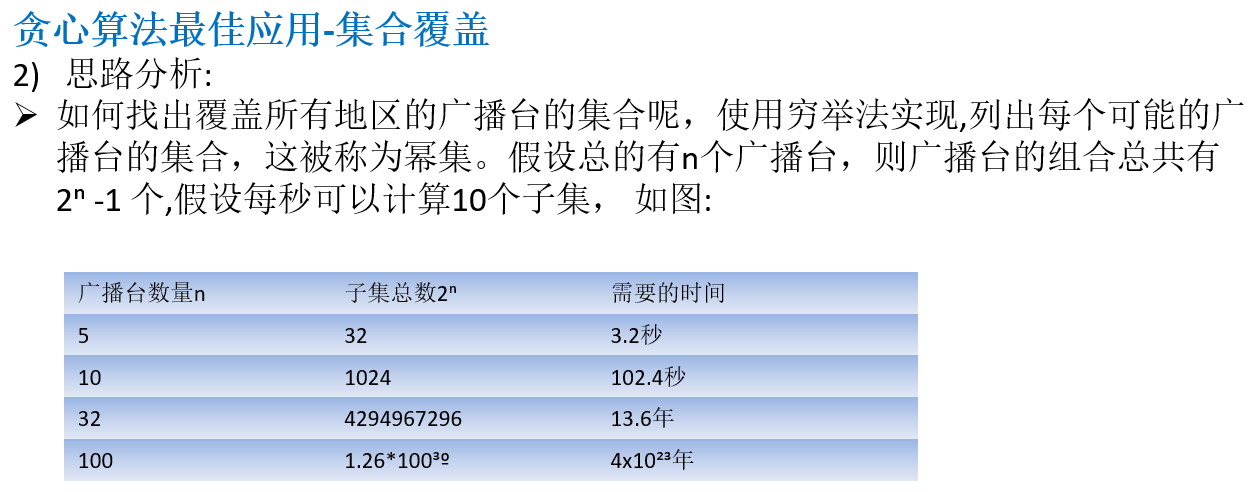
14.5.1 应用场景-集合覆盖问题

14.5.2 贪心算法介绍

14.5.3 贪心算法最佳应用-集合覆盖


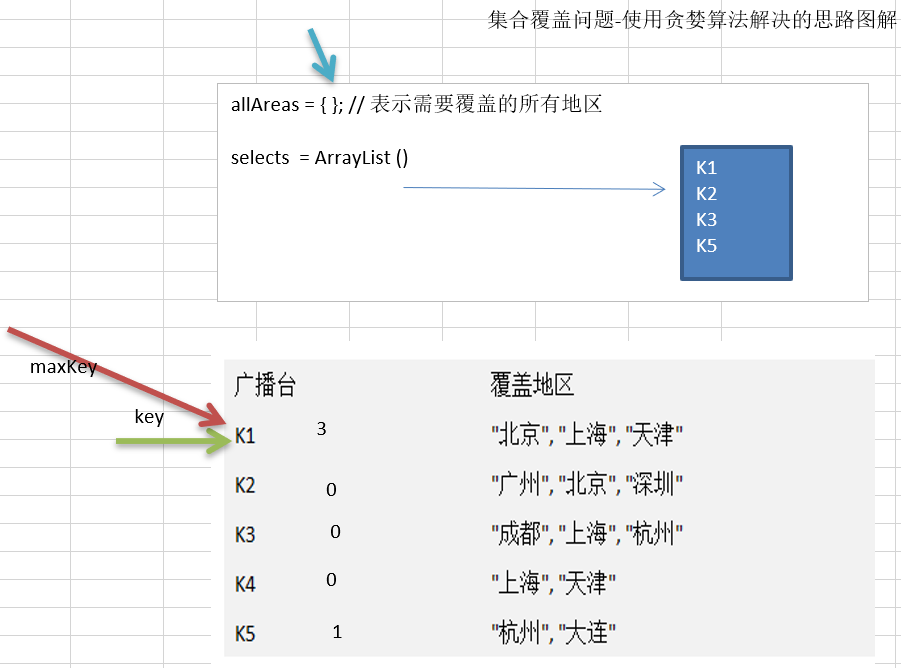
package com.atguigu.greedy;import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;public class GreedyAlgorithm {public static void main(String[] args) {//创建广播电台,放入到MapHashMap<String,HashSet<String>> broadcasts = new HashMap<String, HashSet<String>>();//将各个电台放入到broadcastsHashSet<String> hashSet1 = new HashSet<String>();hashSet1.add("北京");hashSet1.add("上海");hashSet1.add("天津");HashSet<String> hashSet2 = new HashSet<String>();hashSet2.add("广州");hashSet2.add("北京");hashSet2.add("深圳");HashSet<String> hashSet3 = new HashSet<String>();hashSet3.add("成都");hashSet3.add("上海");hashSet3.add("杭州");HashSet<String> hashSet4 = new HashSet<String>();hashSet4.add("上海");hashSet4.add("天津");HashSet<String> hashSet5 = new HashSet<String>();hashSet5.add("杭州");hashSet5.add("大连");//加入到mapbroadcasts.put("K1", hashSet1);broadcasts.put("K2", hashSet2);broadcasts.put("K3", hashSet3);broadcasts.put("K4", hashSet4);broadcasts.put("K5", hashSet5);//allAreas 存放所有的地区HashSet<String> allAreas = new HashSet<String>();allAreas.add("北京");allAreas.add("上海");allAreas.add("天津");allAreas.add("广州");allAreas.add("深圳");allAreas.add("成都");allAreas.add("杭州");allAreas.add("大连");//创建ArrayList, 存放选择的电台集合ArrayList<String> selects = new ArrayList<String>();//定义一个临时的集合, 在遍历的过程中,存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集HashSet<String> tempSet = new HashSet<String>();//定义一个maxKey , 保存在一次遍历过程中,能够覆盖最大未覆盖的地区对应的电台的key//如果maxKey 不为null , 则会加入到 selectsString maxKey = null;while(allAreas.size() != 0) { // 如果allAreas 不为0, 则表示还没有覆盖到所有的地区//每进行一次while,需要maxKey = null;//遍历 broadcasts, 取出对应keyfor(String key : broadcasts.keySet()) {//每进行一次fortempSet.clear();//当前这个key能够覆盖的地区HashSet<String> areas = broadcasts.get(key);tempSet.addAll(areas);//求出tempSet 和 allAreas 集合的交集, 交集会赋给 tempSettempSet.retainAll(allAreas);//如果当前这个集合包含的未覆盖地区的数量,比maxKey指向的集合地区还多//就需要重置maxKey// tempSet.size() >broadcasts.get(maxKey).size()) 体现出贪心算法的特点,每次都选择最优的if(tempSet.size() > 0 && (maxKey == null || tempSet.size() >broadcasts.get(maxKey).size())){maxKey = key;}}//maxKey != null, 就应该将maxKey 加入selectsif(maxKey != null) {selects.add(maxKey);//将maxKey指向的广播电台覆盖的地区,从 allAreas 去掉allAreas.removeAll(broadcasts.get(maxKey));}}System.out.println("得到的选择结果是" + selects);//[K1,K2,K3,K5]}
}
14.5.4 贪心算法注意事项和细节

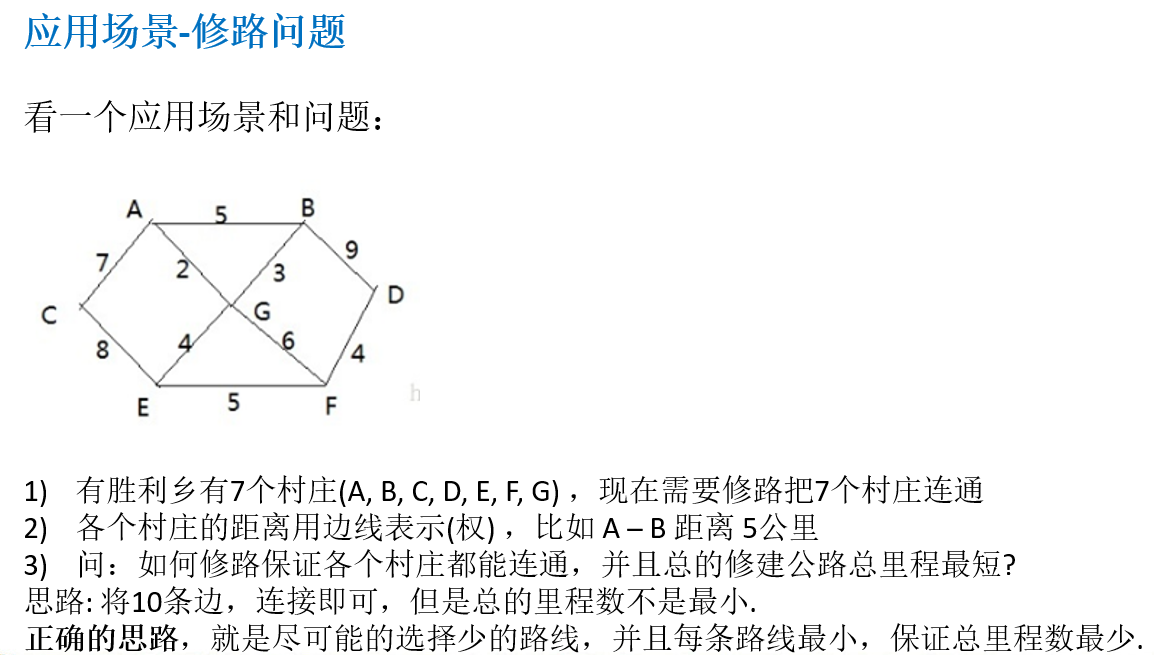
14.6 普里姆算法(Prim)
14.6.1 应用场景-修路问题
14.6.2 最小生成树(Minimum Cost Spanning Tree,MST)
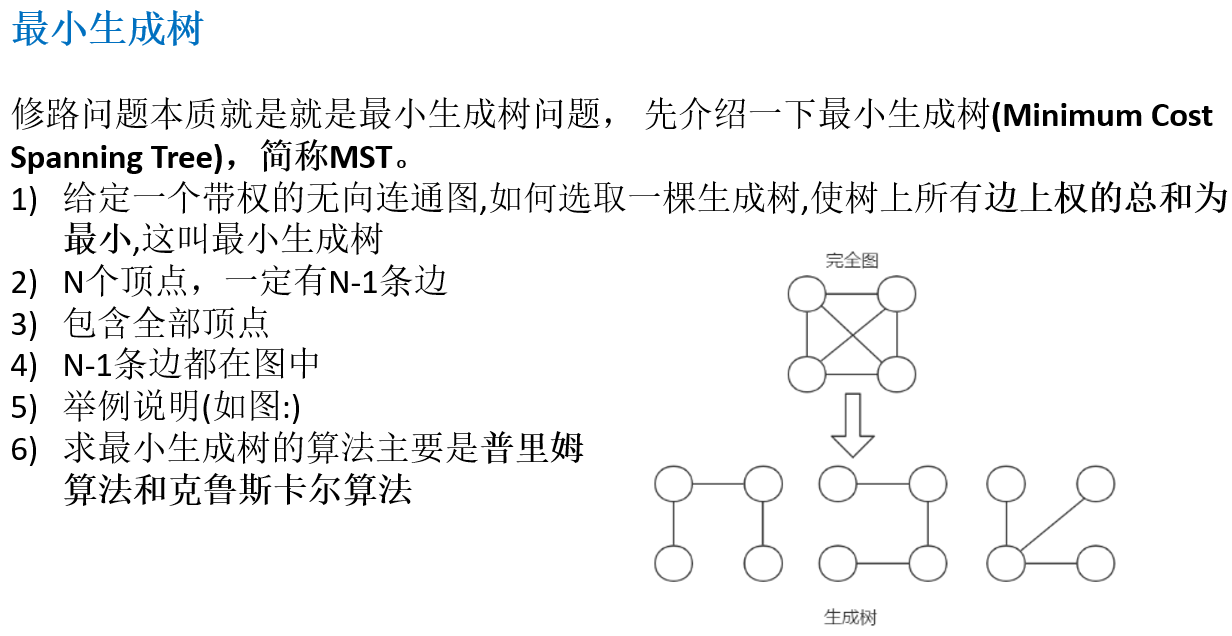
14.6.3 普里姆算法介绍

14.6.4 普里姆算法最佳实践(修路问题)
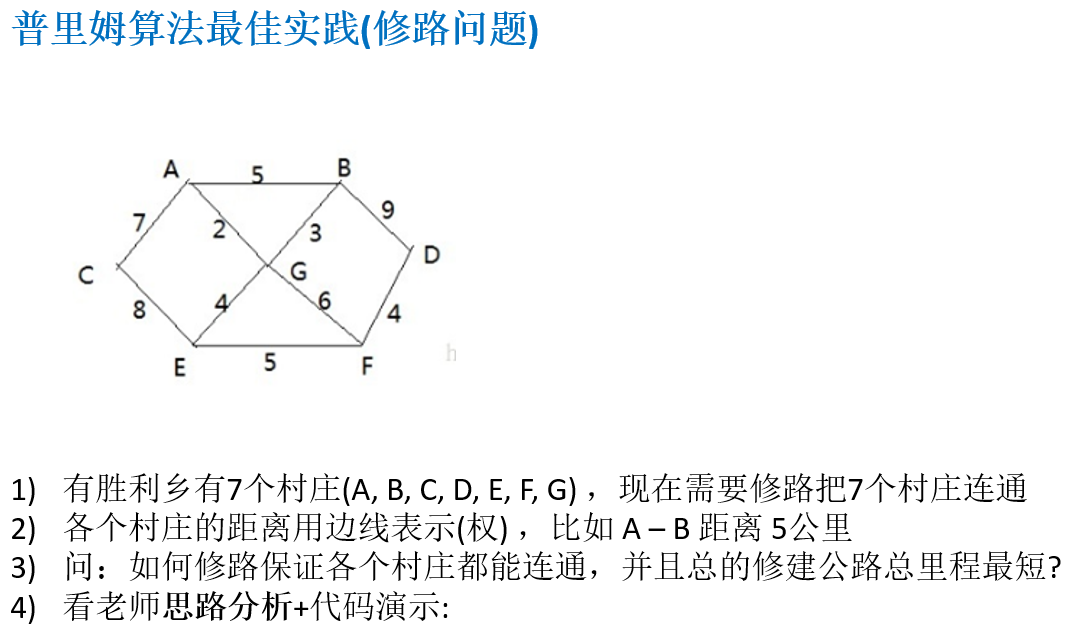

package com.atguigu.prim;import java.util.Arrays;public class PrimAlgorithm {public static void main(String[] args) {//测试看看图是否创建okchar[] data = new char[]{'A','B','C','D','E','F','G'};int verxs = data.length;//邻接矩阵的关系使用二维数组表示,10000这个大数,表示两个点不联通int [][]weight=new int[][]{{10000,5,7,10000,10000,10000,2},{5,10000,10000,9,10000,10000,3},{7,10000,10000,10000,8,10000,10000},{10000,9,10000,10000,10000,4,10000},{10000,10000,8,10000,10000,5,4},{10000,10000,10000,4,5,10000,6},{2,3,10000,10000,4,6,10000},};//创建MGraph对象MGraph graph = new MGraph(verxs);//创建一个MinTree对象MinTree minTree = new MinTree();minTree.createGraph(graph, verxs, data, weight);//输出minTree.showGraph(graph);//测试普利姆算法minTree.prim(graph, 1);// }}//创建最小生成树->村庄的图
class MinTree {//创建图的邻接矩阵/*** * @param graph 图对象* @param verxs 图对应的顶点个数* @param data 图的各个顶点的值* @param weight 图的邻接矩阵*/public void createGraph(MGraph graph, int verxs, char data[], int[][] weight) {int i, j;for(i = 0; i < verxs; i++) {//顶点graph.data[i] = data[i];for(j = 0; j < verxs; j++) {graph.weight[i][j] = weight[i][j];}}}//显示图的邻接矩阵public void showGraph(MGraph graph) {for(int[] link: graph.weight) {System.out.println(Arrays.toString(link));}}//编写prim算法,得到最小生成树/*** * @param graph 图* @param v 表示从图的第几个顶点开始生成'A'->0 'B'->1...*/public void prim(MGraph graph, int v) {//visited[] 标记结点(顶点)是否被访问过int visited[] = new int[graph.verxs];//visited[] 默认元素的值都是0, 表示没有访问过
// for(int i =0; i <graph.verxs; i++) {
// visited[i] = 0;
// }//把当前这个结点标记为已访问visited[v] = 1;//h1 和 h2 记录两个顶点的下标int h1 = -1;int h2 = -1;int minWeight = 10000; //将 minWeight 初始成一个大数,后面在遍历过程中,会被替换for(int k = 1; k < graph.verxs; k++) {//因为有 graph.verxs顶点,普利姆算法结束后,有 graph.verxs-1边//这个是确定每一次生成的子图 ,和哪个结点的距离最近for(int i = 0; i < graph.verxs; i++) {// i结点表示被访问过的结点for(int j = 0; j< graph.verxs;j++) {//j结点表示还没有访问过的结点if(visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {//替换minWeight(寻找已经访问过的结点和未访问过的结点间的权值最小的边)minWeight = graph.weight[i][j];h1 = i;h2 = j;}}}//找到一条边是最小System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);//将当前这个结点标记为已经访问visited[h2] = 1;//minWeight 重新设置为最大值 10000minWeight = 10000;}}
}class MGraph {int verxs; //表示图的节点个数char[] data;//存放结点数据int[][] weight; //存放边,就是我们的邻接矩阵public MGraph(int verxs) {this.verxs = verxs;data = new char[verxs];weight = new int[verxs][verxs];}
}14.7 克鲁斯卡尔算法(Kruskal)
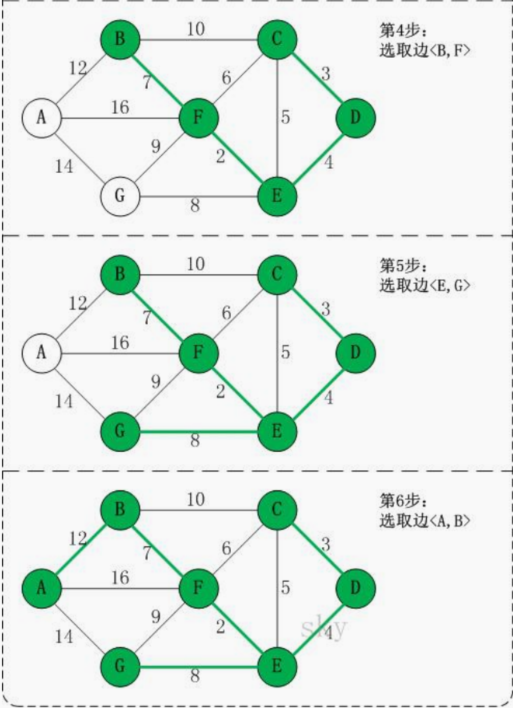
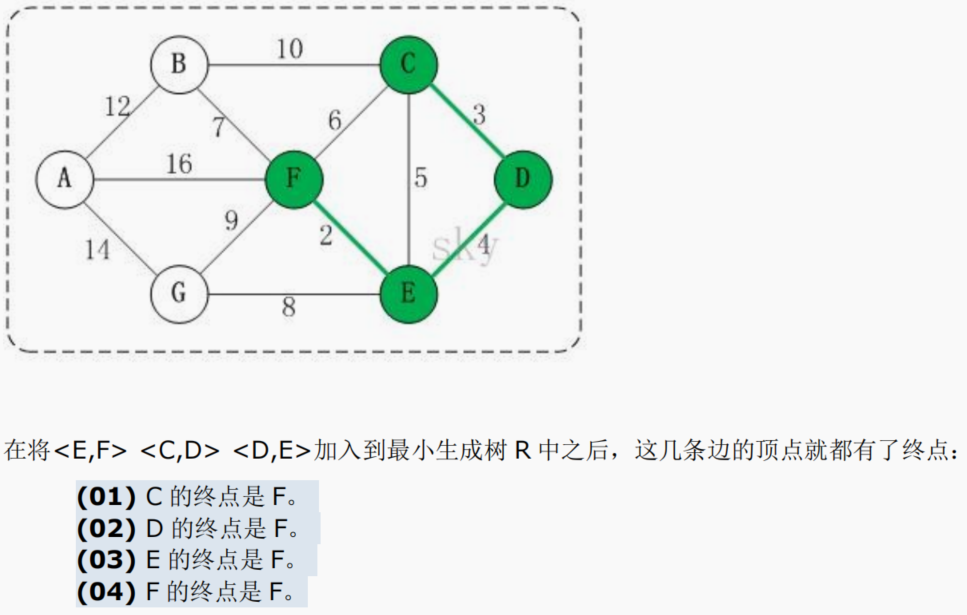
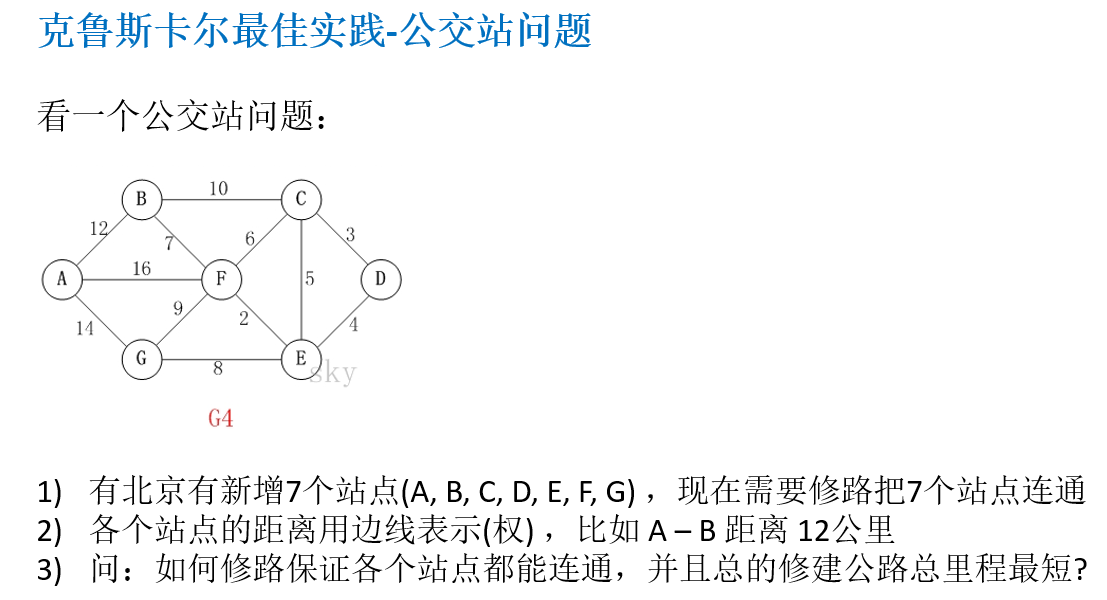
14.7.1 应用场景-公交站问题
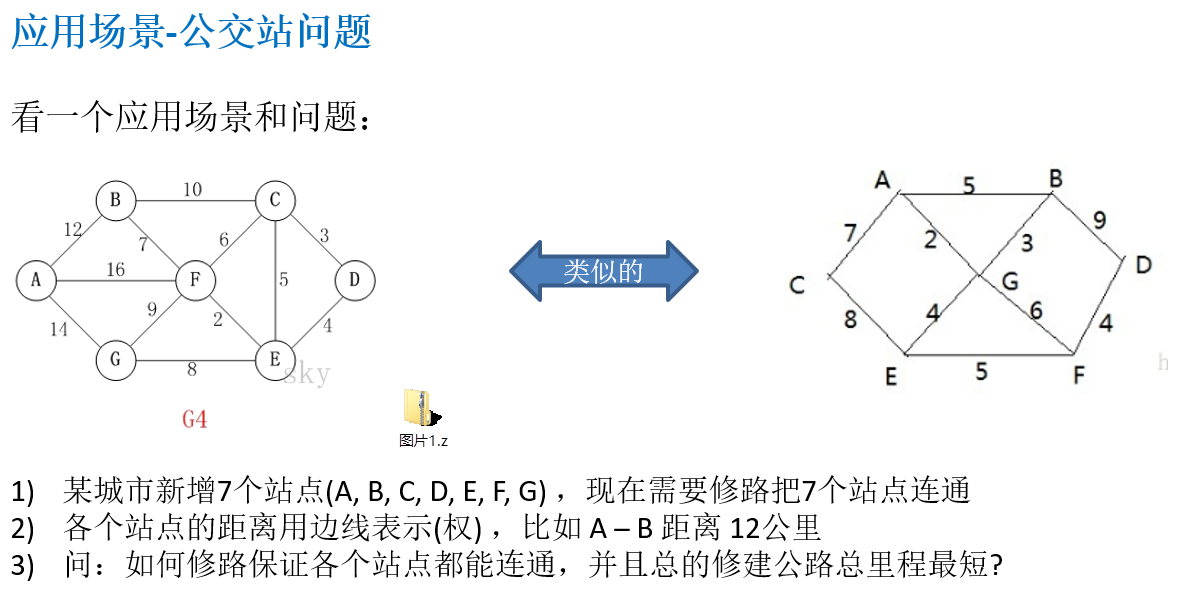
14.7.2 克鲁斯卡尔算法介绍

14.7.3 克鲁斯卡尔算法图解说明
以城市公交站问题来图解说明 克鲁斯卡尔算法的原理和步骤:


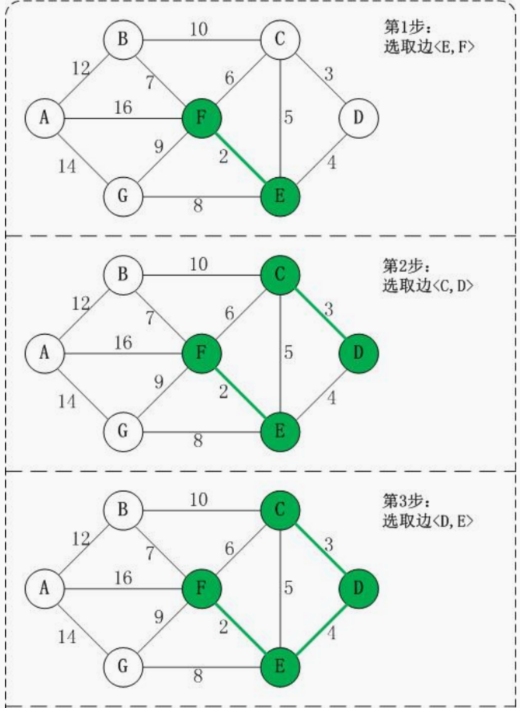




14.7.4 克鲁斯卡尔最佳实践-公交站问题
package com.atguigu.kruskal;import java.util.Arrays;public class KruskalCase {private int edgeNum; //边的个数private char[] vertexs; //顶点数组private int[][] matrix; //邻接矩阵//使用 INF 表示两个顶点不能连通private static final int INF = Integer.MAX_VALUE;public static void main(String[] args) {char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};//克鲁斯卡尔算法的邻接矩阵 int matrix[][] = {/*A*//*B*//*C*//*D*//*E*//*F*//*G*//*A*/ { 0, 12, INF, INF, INF, 16, 14},/*B*/ { 12, 0, 10, INF, INF, 7, INF},/*C*/ { INF, 10, 0, 3, 5, 6, INF},/*D*/ { INF, INF, 3, 0, 4, INF, INF},/*E*/ { INF, INF, 5, 4, 0, 2, 8},/*F*/ { 16, 7, 6, INF, 2, 0, 9},/*G*/ { 14, INF, INF, INF, 8, 9, 0}}; //大家可以再去测试其它的邻接矩阵,结果都可以得到最小生成树.//创建KruskalCase 对象实例KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);//输出构建的kruskalCase.print();kruskalCase.kruskal();}//构造器public KruskalCase(char[] vertexs, int[][] matrix) {//初始化顶点数和边的个数int vlen = vertexs.length;//初始化顶点, 复制拷贝的方式this.vertexs = new char[vlen];for(int i = 0; i < vertexs.length; i++) {this.vertexs[i] = vertexs[i];}//初始化边, 使用的是复制拷贝的方式this.matrix = new int[vlen][vlen];for(int i = 0; i < vlen; i++) {for(int j= 0; j < vlen; j++) {this.matrix[i][j] = matrix[i][j];}}//统计边的条数for(int i =0; i < vlen; i++) {for(int j = i+1; j < vlen; j++) {if(this.matrix[i][j] != INF) {edgeNum++;}}}}public void kruskal() {int index = 0; //表示最后结果数组的索引int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点//创建结果数组, 保存最后的最小生成树EData[] rets = new EData[edgeNum];//获取图中 所有的边的集合 , 一共有12条边EData[] edges = getEdges();System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共"+ edges.length); //12//按照边的权值大小进行排序(从小到大)sortEdges(edges);//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入for(int i=0; i < edgeNum; i++) {//获取到第i条边的第一个顶点(起点)int p1 = getPosition(edges[i].start); //p1=4//获取到第i条边的第2个顶点int p2 = getPosition(edges[i].end); //p2 = 5//获取p1这个顶点在已有最小生成树中的终点int m = getEnd(ends, p1); //m = 4//获取p2这个顶点在已有最小生成树中的终点int n = getEnd(ends, p2); // n = 5//是否构成回路if(m != n) { //没有构成回路ends[m] = n; // 设置m 在"已有最小生成树"中的终点 <E,F> [0,0,0,0,5,0,0,0,0,0,0,0]rets[index++] = edges[i]; //有一条边加入到rets数组}}//<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。//统计并打印 "最小生成树", 输出 retsSystem.out.println("最小生成树为");for(int i = 0; i < index; i++) {System.out.println(rets[i]);}}//打印邻接矩阵public void print() {System.out.println("邻接矩阵为: \n");for(int i = 0; i < vertexs.length; i++) {for(int j=0; j < vertexs.length; j++) {System.out.printf("%12d", matrix[i][j]);}System.out.println();//换行}}/*** 功能:对边进行排序处理, 冒泡排序* @param edges 边的集合*/private void sortEdges(EData[] edges) {for(int i = 0; i < edges.length - 1; i++) {for(int j = 0; j < edges.length - 1 - i; j++) {if(edges[j].weight > edges[j+1].weight) {//交换EData tmp = edges[j];edges[j] = edges[j+1];edges[j+1] = tmp;}}}}/*** * @param ch 顶点的值,比如'A','B'* @return 返回ch顶点对应的下标,如果找不到,返回-1*/private int getPosition(char ch) {for(int i = 0; i < vertexs.length; i++) {if(vertexs[i] == ch) {//找到return i;}}//找不到,返回-1return -1;}/*** 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组* 是通过matrix 邻接矩阵来获取* EData[] 形式 [['A','B', 12], ['B','F',7], .....]* @return*/private EData[] getEdges() {int index = 0;EData[] edges = new EData[edgeNum];for(int i = 0; i < vertexs.length; i++) {for(int j=i+1; j <vertexs.length; j++) {if(matrix[i][j] != INF) {edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);}}}return edges;}/*** 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成* @param i : 表示传入的顶点对应的下标* @return 返回的就是 下标为i的这个顶点对应的终点的下标, 一会回头还要来理解*/private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]while(ends[i] != 0) {i = ends[i];}return i;}}//创建一个类EData ,它的对象实例就表示一条边
class EData {char start; //边的一个点char end; //边的另外一个点int weight; //边的权值//构造器public EData(char start, char end, int weight) {this.start = start;this.end = end;this.weight = weight;}//重写toString, 便于输出边信息@Overridepublic String toString() {return "EData [<" + start + ", " + end + ">= " + weight + "]";}}
14.8 迪杰斯特拉算法(Dijkstra)
14.8.1 应用场景-最短路径问题
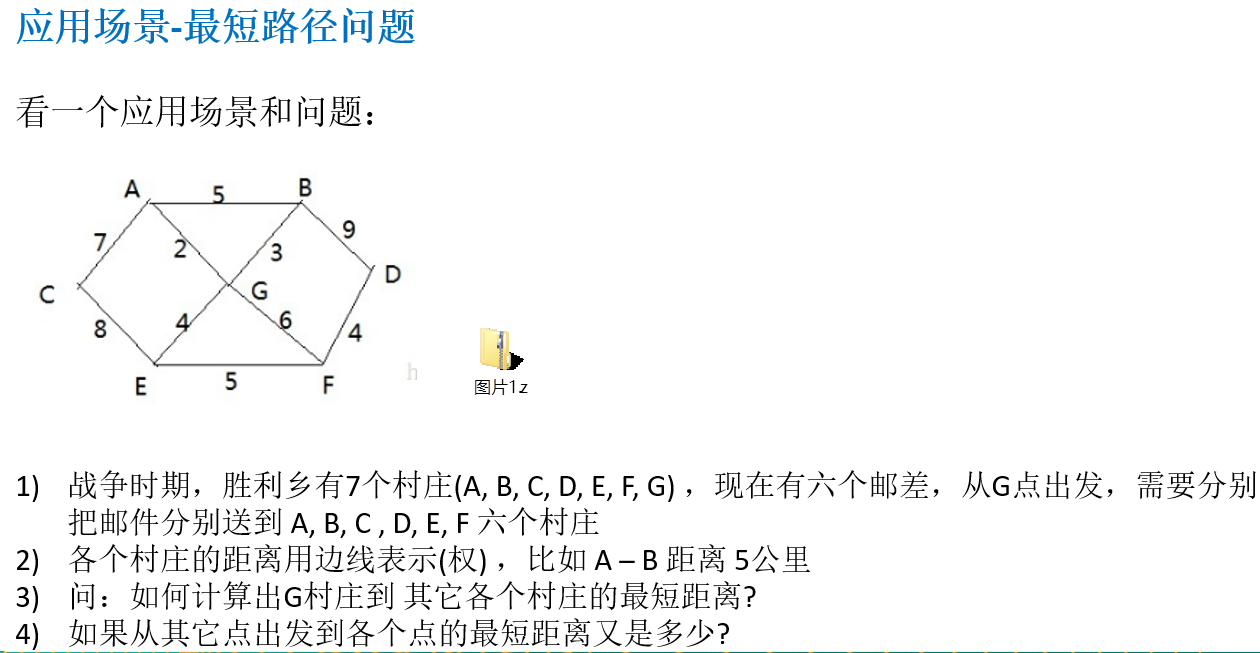
14.8.2 迪杰斯特拉算法介绍

14.8.3 迪杰斯特拉算法过程

14.8.4 迪杰斯特拉算法最佳应用-最短路径
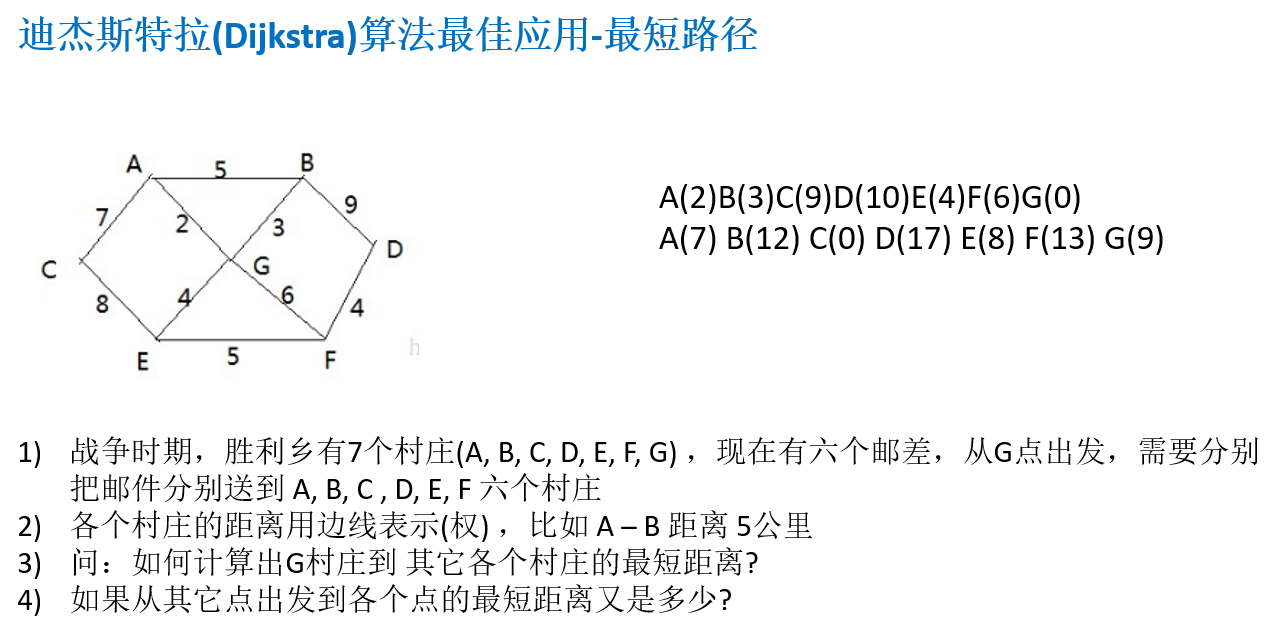
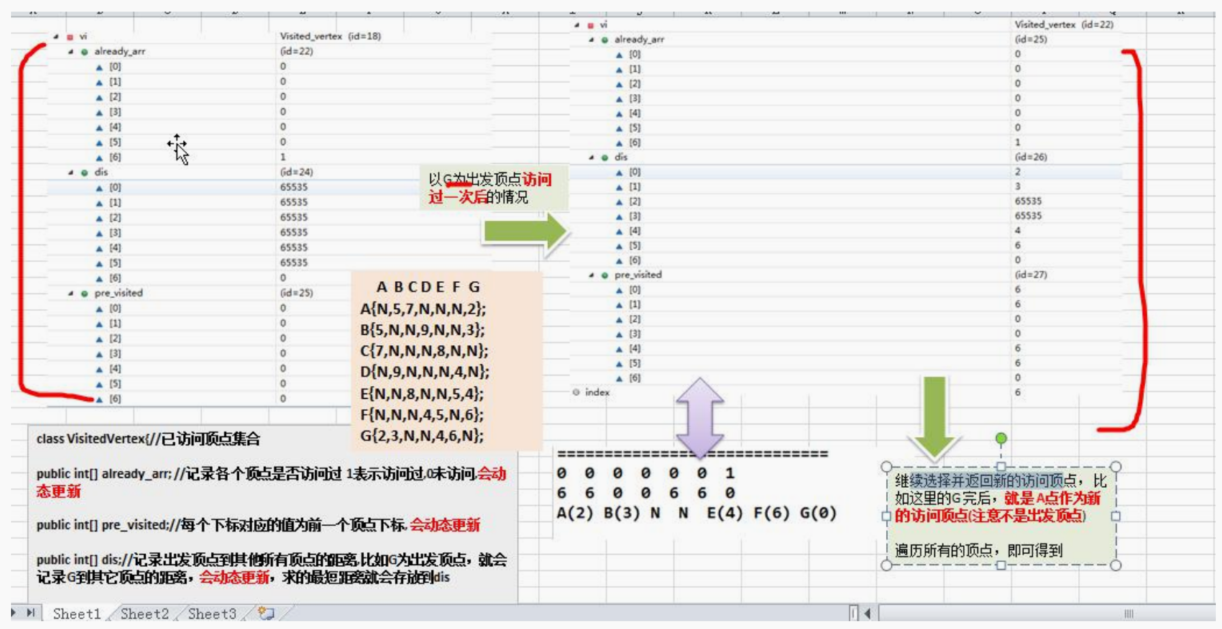
package com.atguigu.dijkstra;import java.util.Arrays;public class DijkstraAlgorithm {public static void main(String[] args) {char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };//邻接矩阵int[][] matrix = new int[vertex.length][vertex.length];final int N = 65535;// 表示不可以连接matrix[0]=new int[]{N,5,7,N,N,N,2}; matrix[1]=new int[]{5,N,N,9,N,N,3}; matrix[2]=new int[]{7,N,N,N,8,N,N}; matrix[3]=new int[]{N,9,N,N,N,4,N}; matrix[4]=new int[]{N,N,8,N,N,5,4}; matrix[5]=new int[]{N,N,N,4,5,N,6}; matrix[6]=new int[]{2,3,N,N,4,6,N};//创建 Graph对象Graph graph = new Graph(vertex, matrix);//测试, 看看图的邻接矩阵是否okgraph.showGraph();//测试迪杰斯特拉算法graph.dsj(2);//Cgraph.showDijkstra();}}class Graph {private char[] vertex; // 顶点数组private int[][] matrix; // 邻接矩阵private VisitedVertex vv; //已经访问的顶点的集合// 构造器public Graph(char[] vertex, int[][] matrix) {this.vertex = vertex;this.matrix = matrix;}//显示结果public void showDijkstra() {vv.show();}// 显示图public void showGraph() {for (int[] link : matrix) {System.out.println(Arrays.toString(link));}}//迪杰斯特拉算法实现/*** * @param index 表示出发顶点对应的下标*/public void dsj(int index) {vv = new VisitedVertex(vertex.length, index);update(index);//更新index顶点到周围顶点的距离和前驱顶点for(int j = 1; j <vertex.length; j++) {index = vv.updateArr();// 选择并返回新的访问顶点update(index); // 更新index顶点到周围顶点的距离和前驱顶点} }//更新index下标顶点到周围顶点的距离和周围顶点的前驱顶点,private void update(int index) {int len = 0;//根据遍历我们的邻接矩阵的 matrix[index]行for(int j = 0; j < matrix[index].length; j++) {// len 含义是 : 出发顶点到index顶点的距离 + 从index顶点到j顶点的距离的和 len = vv.getDis(index) + matrix[index][j];// 如果j顶点没有被访问过,并且 len 小于出发顶点到j顶点的距离,就需要更新if(!vv.in(j) && len < vv.getDis(j)) {vv.updatePre(j, index); //更新j顶点的前驱为index顶点vv.updateDis(j, len); //更新出发顶点到j顶点的距离}}}
}// 已访问顶点集合
class VisitedVertex {// 记录各个顶点是否访问过 1表示访问过,0未访问,会动态更新public int[] already_arr;// 每个下标对应的值为前一个顶点下标, 会动态更新public int[] pre_visited;// 记录出发顶点到其他所有顶点的距离,比如G为出发顶点,就会记录G到其它顶点的距离,会动态更新,求的最短距离就会存放到dispublic int[] dis;//构造器/*** * @param length :表示顶点的个数 * @param index: 出发顶点对应的下标, 比如G顶点,下标就是6*/public VisitedVertex(int length, int index) {this.already_arr = new int[length];this.pre_visited = new int[length];this.dis = new int[length];//初始化 dis数组Arrays.fill(dis, 65535);this.already_arr[index] = 1; //设置出发顶点被访问过this.dis[index] = 0;//设置出发顶点的访问距离为0}/*** 功能: 判断index顶点是否被访问过* @param index* @return 如果访问过,就返回true, 否则访问false*/public boolean in(int index) {return already_arr[index] == 1;}/*** 功能: 更新出发顶点到index顶点的距离* @param index* @param len*/public void updateDis(int index, int len) {dis[index] = len;}/*** 功能: 更新pre这个顶点的前驱顶点为index顶点* @param pre* @param index*/public void updatePre(int pre, int index) {pre_visited[pre] = index;}/*** 功能:返回出发顶点到index顶点的距离* @param index*/public int getDis(int index) {return dis[index];}/*** 继续选择并返回新的访问顶点, 比如这里的G 完后,就是 A点作为新的访问顶点(注意不是出发顶点)* @return*/public int updateArr() {int min = 65535, index = 0;for(int i = 0; i < already_arr.length; i++) {if(already_arr[i] == 0 && dis[i] < min ) {min = dis[i];index = i;}}//更新 index 顶点被访问过already_arr[index] = 1;return index;}//显示最后的结果//即将三个数组的情况输出public void show() {System.out.println("==========================");//输出already_arrfor(int i : already_arr) {System.out.print(i + " ");}System.out.println();//输出pre_visitedfor(int i : pre_visited) {System.out.print(i + " ");}System.out.println();//输出disfor(int i : dis) {System.out.print(i + " ");}System.out.println();//为了好看最后的最短距离,我们处理char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };int count = 0;for (int i : dis) {if (i != 65535) {System.out.print(vertex[count] + "("+i+") ");} else {System.out.println("N ");}count++;}System.out.println();}}14.9 弗洛伊德算法(Floyd)
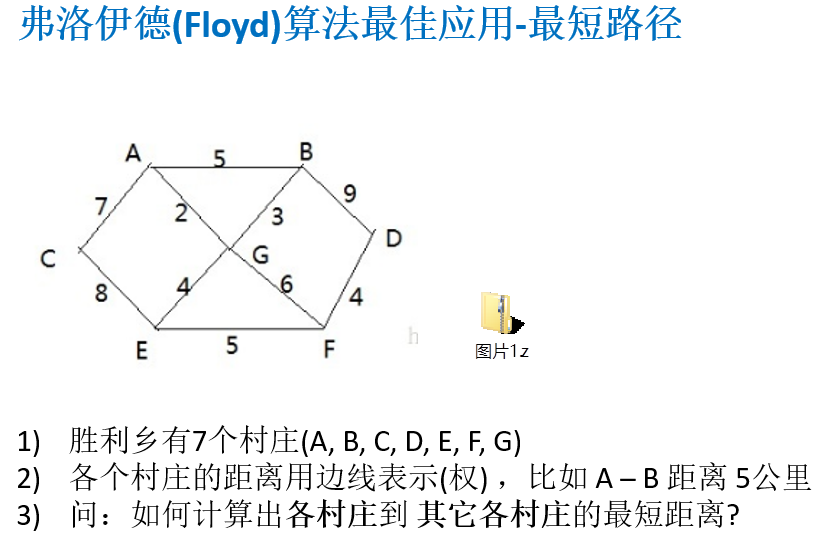
14.9.1 弗洛伊德算法介绍

14.9.2 弗洛伊德算法图解分析

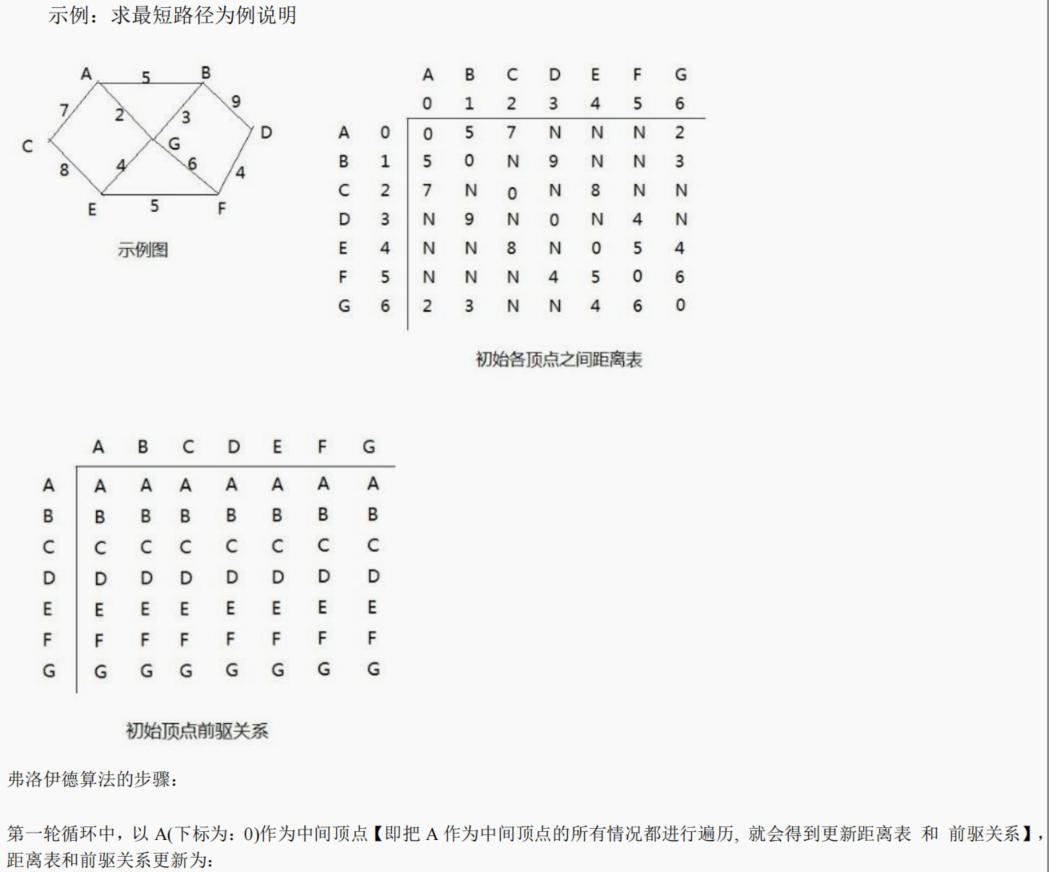

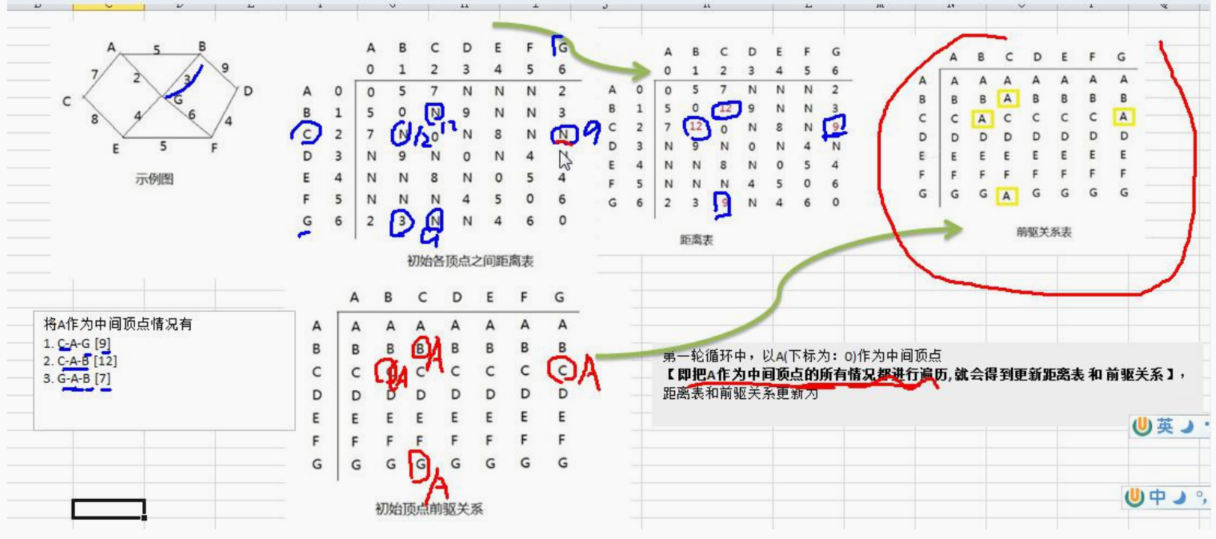
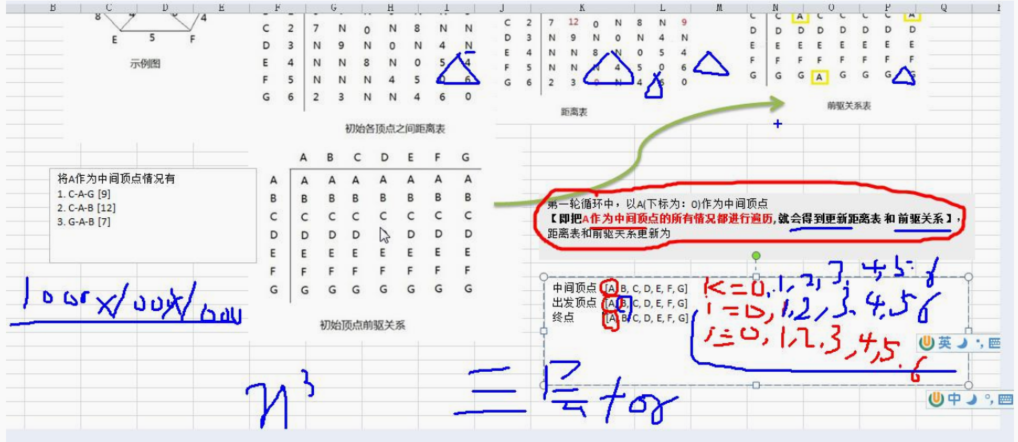
14.9.3 弗洛伊德算法最佳应用-最短路径
package com.atguigu.floyd;import java.util.Arrays;public class FloydAlgorithm {public static void main(String[] args) {// 测试看看图是否创建成功char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };//创建邻接矩阵int[][] matrix = new int[vertex.length][vertex.length];final int N = 65535;matrix[0] = new int[] { 0, 5, 7, N, N, N, 2 };matrix[1] = new int[] { 5, 0, N, 9, N, N, 3 };matrix[2] = new int[] { 7, N, 0, N, 8, N, N };matrix[3] = new int[] { N, 9, N, 0, N, 4, N };matrix[4] = new int[] { N, N, 8, N, 0, 5, 4 };matrix[5] = new int[] { N, N, N, 4, 5, 0, 6 };matrix[6] = new int[] { 2, 3, N, N, 4, 6, 0 };//创建 Graph 对象Graph graph = new Graph(vertex.length, matrix, vertex);//调用弗洛伊德算法graph.floyd();graph.show();}}// 创建图
class Graph {private char[] vertex; // 存放顶点的数组private int[][] dis; // 保存,从各个顶点出发到其它顶点的距离,最后的结果,也是保留在该数组private int[][] pre;// 保存到达目标顶点的前驱顶点// 构造器/*** * @param length* 大小* @param matrix* 邻接矩阵* @param vertex* 顶点数组*/public Graph(int length, int[][] matrix, char[] vertex) {this.vertex = vertex;this.dis = matrix;this.pre = new int[length][length];// 对pre数组初始化, 注意存放的是前驱顶点的下标for (int i = 0; i < length; i++) {Arrays.fill(pre[i], i);}}// 显示pre数组和dis数组public void show() {//为了显示便于阅读,我们优化一下输出char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };for (int k = 0; k < dis.length; k++) {// 先将pre数组输出的一行for (int i = 0; i < dis.length; i++) {System.out.print(vertex[pre[k][i]] + " ");}System.out.println();// 输出dis数组的一行数据for (int i = 0; i < dis.length; i++) {System.out.print("("+vertex[k]+"到"+vertex[i]+"的最短路径是" + dis[k][i] + ") ");}System.out.println();System.out.println();}}//弗洛伊德算法, 比较容易理解,而且容易实现public void floyd() {int len = 0; //变量保存距离//对中间顶点遍历, k 就是中间顶点的下标 [A, B, C, D, E, F, G] for(int k = 0; k < dis.length; k++) { // //从i顶点开始出发 [A, B, C, D, E, F, G]for(int i = 0; i < dis.length; i++) {//到达j顶点 // [A, B, C, D, E, F, G]for(int j = 0; j < dis.length; j++) {len = dis[i][k] + dis[k][j];// => 求出从i 顶点出发,经过 k中间顶点,到达 j 顶点距离if(len < dis[i][j]) {//如果len小于 dis[i][j]dis[i][j] = len;//更新距离pre[i][j] = pre[k][j];//更新前驱顶点}}}}}
}
14.10 马踏棋盘算法(骑士周游回溯算法)
14.10.1 马踏棋盘算法介绍和游戏演示

14.10.2 马踏棋盘游戏代码实现


package com.atguigu.horse;import java.awt.Point;
import java.util.ArrayList;
import java.util.Comparator;public class HorseChessboard {private static int X; // 棋盘的列数private static int Y; // 棋盘的行数//创建一个数组,标记棋盘的各个位置是否被访问过private static boolean visited[];//使用一个属性,标记是否棋盘的所有位置都被访问private static boolean finished; // 如果为true,表示成功public static void main(String[] args) {System.out.println("骑士周游算法,开始运行~~");//测试骑士周游算法是否正确X = 8;Y = 8;int row = 1; //马儿初始位置的行,从1开始编号int column = 1; //马儿初始位置的列,从1开始编号//创建棋盘int[][] chessboard = new int[X][Y];visited = new boolean[X * Y];//初始值都是false//测试一下耗时long start = System.currentTimeMillis();traversalChessboard(chessboard, row - 1, column - 1, 1);long end = System.currentTimeMillis();System.out.println("共耗时: " + (end - start) + " 毫秒");//输出棋盘的最后情况for(int[] rows : chessboard) {for(int step: rows) {System.out.print(step + "\t");}System.out.println();}}/*** 完成骑士周游问题的算法* @param chessboard 棋盘* @param row 马儿当前的位置的行 从0开始 * @param column 马儿当前的位置的列 从0开始* @param step 是第几步 ,初始位置就是第1步 */public static void traversalChessboard(int[][] chessboard, int row, int column, int step) {chessboard[row][column] = step;//row = 4 X = 8 column = 4 = 4 * 8 + 4 = 36visited[row * X + column] = true; //标记该位置已经访问//获取当前位置可以走的下一个位置的集合 ArrayList<Point> ps = next(new Point(column, row));//对ps进行排序,排序的规则就是对ps的所有的Point对象的下一步的位置的数目,进行非递减排序sort(ps);//遍历 pswhile(!ps.isEmpty()) {Point p = ps.remove(0);//取出下一个可以走的位置//判断该点是否已经访问过if(!visited[p.y * X + p.x]) {//说明还没有访问过traversalChessboard(chessboard, p.y, p.x, step + 1);}}//判断马儿是否完成了任务,使用 step 和应该走的步数比较 , //如果没有达到数量,则表示没有完成任务,将整个棋盘置0//说明: step < X * Y 成立的情况有两种//1. 棋盘到目前位置,仍然没有走完//2. 棋盘处于一个回溯过程if(step < X * Y && !finished ) {chessboard[row][column] = 0;visited[row * X + column] = false;} else {finished = true;}}/*** 功能: 根据当前位置(Point对象),计算马儿还能走哪些位置(Point),并放入到一个集合中(ArrayList), 最多有8个位置* @param curPoint* @return*/public static ArrayList<Point> next(Point curPoint) {//创建一个ArrayListArrayList<Point> ps = new ArrayList<Point>();//创建一个PointPoint p1 = new Point();//表示马儿可以走5这个位置if((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y -1) >= 0) {ps.add(new Point(p1));}//判断马儿可以走6这个位置if((p1.x = curPoint.x - 1) >=0 && (p1.y=curPoint.y-2)>=0) {ps.add(new Point(p1));}//判断马儿可以走7这个位置if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {ps.add(new Point(p1));}//判断马儿可以走0这个位置if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {ps.add(new Point(p1));}//判断马儿可以走1这个位置if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {ps.add(new Point(p1));}//判断马儿可以走2这个位置if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {ps.add(new Point(p1));}//判断马儿可以走3这个位置if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {ps.add(new Point(p1));}//判断马儿可以走4这个位置if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {ps.add(new Point(p1));}return ps;}//根据当前这个一步的所有的下一步的选择位置,进行非递减排序, 减少回溯的次数public static void sort(ArrayList<Point> ps) {ps.sort(new Comparator<Point>() {@Overridepublic int compare(Point o1, Point o2) {//获取到o1的下一步的所有位置个数int count1 = next(o1).size();//获取到o2的下一步的所有位置个数int count2 = next(o2).size();if(count1 < count2) {return -1;} else if (count1 == count2) {return 0;} else {return 1;}}});}
}
相关文章:

【Java数据结构与算法】第10-14章
第10章 树结构的基础部分 10.1 二叉树 10.1.1 为什么需要树这种数据结构 10.1.2 树示意图 10.1.3 二叉树的概念 10.1.4 二叉树遍历的说明 10.1.5 二叉树遍历应用实例(前序,中序,后序) 10.1.6 二叉树-查找指定节点 思路图解 10.1.7 二叉树-删除节点 package com.atguigu.tree;…...

MacOS M3源代码编译Qt6.8.1
编译时间过长,如果不想自己编译,可以通过如果网盘进行下载: 链接: https://pan.baidu.com/s/17lvF5jQ-vR6vE-KEchzrVA?pwdts26 提取码: ts26 在macOS上编译Qt 6需要一些前置步骤和工具。以下是编译Qt 6的基本步骤: 安装Xcode和…...

3.银河麒麟V10 离线安装Nginx
1. 下载nginx离线安装包 前往官网下载离线压缩包 2. 下载3个依赖 openssl依赖,前往 官网下载 pcre2依赖下载,前往Git下载 zlib依赖下载,前往Git下载 下载完成后完整的包如下: 如果网速下载不到请使用网盘下载 通过网盘分享的文件…...

实现 QTreeWidget 中子节点勾选状态的递归更新功能只影响跟节点的状态父节点状态不受影响
在 Qt 开发中,QTreeWidget 提供了树形结构的显示和交互功能。为了实现某个子节点勾选或取消勾选时,只影响当前节点及其子节点的状态,同时递归更新父节点的状态以正确显示 Qt::PartiallyChecked 或 Qt::Checked,我们可以借助 Qt 的…...

ubuntu24.04使用opencv4
ubuntu24.04LTS自带opencv4.5代码实例 //opencv_example.cpp #include <opencv2/opencv.hpp> #include <iostream>int main() {// 读取图像cv::Mat img cv::imread("image.jpg", cv::IMREAD_COLOR);if (img.empty()) {std::cerr << "无法读…...

R语言数据分析案例46-不同区域教育情况回归分析和探索
一、研究背景 教育是社会发展的基石,对国家和地区的经济、文化以及社会进步起着至关重要的作用。在全球一体化进程加速的今天,不同区域的教育发展水平呈现出多样化的态势。这种差异不仅体现在教育资源的分配上,还表现在教育成果、教育投入与…...

flink sink doris
接上文:一文说清flink从编码到部署上线 网上关于flink sink drois的例子较多,大部分不太全面,故本文详细说明,且提供完整代码。 flink doris版本对照表 1.添加依赖 <!--doris cdc--><!-- 参考:"https…...

《探索 Apache Spark MLlib 与 Java 结合的卓越之道》
在当今大数据与人工智能蓬勃发展的时代,Apache Spark MLlib 作为强大的机器学习库,与广泛应用的 Java 语言相结合,为数据科学家和开发者们提供了丰富的可能性。那么,Apache Spark MLlib 与 Java 结合的最佳实践究竟是什么呢&#…...

Net9解决Spire.Pdf替换文字后,文件格式乱掉解决方法
官方文档 https://www.e-iceblue.com/Tutorials/Spire.PDF/Program-Guide/Text/Find-and-replace-text-on-PDF-document-in-C.html C# 在 PDF 中查找替换文本 原文件如下图,替换第一行的新编码,把41230441044替换为41230441000 替换代码如下ÿ…...
)
Kafka可视化工具 Offset Explorer (以前叫Kafka Tool)
数据的存储是基于 主题(Topic) 和 分区(Partition) 的 Kafka是一个高可靠性的分布式消息系统,广泛应用于大规模数据处理和实时, 为了更方便地管理和监控Kafka集群,开发人员和运维人员经常需要使用可视化工具…...

青少年编程与数学 02-004 Go语言Web编程 21课题、应用部署
青少年编程与数学 02-004 Go语言Web编程 21课题、应用部署 一、应用部署二、GoWeb部署到WINDOWS系统中1. 安装Go环境2. 创建并编写Go Web应用3. 初始化Go模块4. 编译Go Web应用5. 配置和运行Nginx6. 运行Go Web应用7. 访问应用总结 三、GoWeb部署到LINUX系统中1. 准备Linux服务…...

009-spring-bean的实例化流程
1 spring容器初始化时,将xml配置的bean 信息封装在 beandefinition对象 2 所有的beandefinition存储在 beandefinitionMap的map集合中 3 spring对map进行遍历,使用反射创建bean实例对象 4 创建好的bean存在名为singletonObjects的map集合中 5 调用ge…...

Timsort算法
Timsort算法是一种混合、稳定且高效的排序算法,源自归并排序和插入排序。它通过将已识别的子序列(称为“run”)与现有run合并直到满足某些条件来完成排序。以下是对Timsort算法的详细解释及举例说明: Timsort算法概述 混合性&…...

uniapp+vue 前端防多次点击表单,防误触多次请求方法。
最近项目需求写了个uniappvue前端H5,有个页面提交表单的时候发现会有用户乱点导致数据库多条重复脏数据。故需要优化,多次点击表单只请求一次。 思路: 直接调用uni.showToast,点完按钮跳一个提交成功的提示。然后把防触摸穿透mask设置成true就行&#…...

八、Hbase
Hbase 一、NoSQL非关系型数据库简介1.NoSQL 的起因2.NoSQL 的特点3.NoSQL 面临的挑战4.NoSQL 的分类 二、HBase数据库概述1.HBase数据库简介2.HBase数据模型简介3.HBase数据模型基本概念4.Hbase概念视图(逻辑视图)5.Hbase物理视图6.Hbase主要组件7.Hbase安装8.Hbase的数据读写流…...

ubuntu安装sublime安装与免费使用
1. ubuntu安装sublime 参考官网: Linux Package Manager Repositories 2. 破解过程 打开如下网址,打开/opt/sublime_text/sublime_text https://hexed.it/ 3. 替换在hexed打开的文件中查找并替换: 4180激活方法 使用二进制编辑器 8079 0500 0f94 c2替换为 c641 05…...
)
Onedrive精神分裂怎么办(有变更却不同步)
Onedrive有时候会分裂,你在本地删除文件,并没有同步到云端,但是本地却显示同步成功。 比如删掉了一个目录,在本地看已经删掉,onedrive显示已同步,但是别的电脑并不会同步到这个删除操作,在网页版…...

图像裁剪与批量推理:解决分割和变化检测中的大图处理问题
引言 在分割、变化检测等任务中,我们经常会遇到一个问题:模型的输入尺寸是固定且较小的(如256256或512512)。当需要处理分辨率较高的大图时,直接输入到模型中显然是不切实际的。那么,如何高效地解决这个问…...

第4章 函数
2024年12月25日一稿 4.1 函数的定义 4.1.1 函数和像 4.1.2 函数的性质 4.1.3 常用函数 4.2 复合函数和反函数 4.2.1 复合函数 4.2.2 反函数 4.3 特征函数与模糊子集 4.4 基数的概念 4.4.1 后继与归纳集 4.4.2 自然数,有穷集,无穷集 4.4.3 基数 4.5 可数…...

【JavaEE进阶】Spring传递请求参数
目录 🎍序言 🌴传递单个参数 🍀传递多个参数 🎄传递对象 🌳后端参数重命名(后端参数映射) 🚩ReuqestParam注解 🎍序言 访问不同的路径,就是发送不同的请求.在发送…...

在跨平台开发环境中构建高效的C++项目:从基础到最佳实践20241225
在跨平台开发环境中构建高效的C项目:从基础到最佳实践 引言 在现代软件开发中,跨平台兼容性和高效开发流程是每个工程师追求的目标。尤其是对于 C 开发者,管理代码的跨平台构建以及调试流程可能成为一项棘手的挑战。在本文中,我…...

无人零售及开源 AI 智能名片 S2B2C 商城小程序的深度剖析
摘要:本文聚焦无人零售这一新兴零售模式及其发展浪潮中崛起的开源 AI 智能名片 S2B2C 商城小程序。深入阐述无人零售的发展态势,细致剖析其驱动因素、现存问题,全面详细介绍小程序的功能特性、应用优势以及对无人零售的潜在价值,旨…...
和条件滤波(ConditionalRemoval))
PCL点云库入门——PCL库点云滤波算法之直通滤波(PassThrough)和条件滤波(ConditionalRemoval)
0、滤波算法概述 PCL点云库中的滤波算法是处理点云数据不可或缺的一部分,它们能够有效地去除噪声、提取特征或进行数据降维。例如,使用体素网格滤波(VoxelGrid)可以减少点云数据量,同时保留重要的形状特征。此外&#…...

v语言介绍
V 语言是一种多用途的编程语言,可以用于前端开发、后端开发、系统编程、游戏开发等多个领域。它的设计哲学是提供接近 C 语言的性能,同时简化开发过程并提高代码的安全性和可读性。接下来我会详细介绍 V 在前后端开发中的应用,并给出一个具体…...

GPT-O3:简单介绍
GPT-O3:人工智能领域的重大突破 近日,OpenAI发布了其最新的AI模型GPT-O3,这一模型在AGI评估中取得了惊人的成绩,展现出强大的能力和潜力。GPT-O3的出现标志着人工智能领域的重大进步,预计将在2025年实现更大的突破。 …...

重温设计模式--适配器模式
文章目录 适配器模式(Adapter Pattern)概述适配器模式UML图适配器模式的结构目标接口(Target):适配器(Adapter):被适配者(Adaptee): 作用…...

API部署大模型
由于生产测试环境的服务器配置较低 不能够支撑大模型运行的配置 所以需要将大模型封装部署在A服务器上 在B服务器上进行调用 封装时可以使用FastAPI与Websocket两种通信方式进行通信 Websocket 在A服务器端部署大模型(服务端) import asyncio import …...

Linux -- 同步与条件变量
目录 同步 条件变量 pthread_cond_t pthread_cond_init(初始化条件变量) pthread_cond_destroy(销毁条件变量) pthread_cond_wait(线程等待条件变量) 重要提醒 pthread_cond_boardcast(…...
裸机篇----1.开发环境搭建)
Linux之ARM(MX6U)裸机篇----1.开发环境搭建
下载开启FTP服务 作用:用于电脑与linux系统之前文件传输 如上,编辑完成后重启 Window下FTP客户端安装使用http://www.filezilla.cn/download网址下载 新建网络连接站点 主机后写虚拟机的ip地址,用ifconfig查出ipv4的地址 笔记本电脑中虚拟…...

【C语言】结构体模块化编程
在模块化编程中,结构体作为数据存储的主要方式之一,它不仅用于存储数据,还帮助实现代码的封装与隐私保护。通过将结构体定义放在 .c 文件中并使用 get_ 和 set_ 函数进行访问,我们可以实现对结构体数据的保护,同时降低…...

SpringCloudAlibaba技术栈-Nacos
1、什么是Nacos? Nacos是个服务中心,就是你项目每个功能模块都会有个名字,比如支付模块,我们先给这个模块起个名字就叫paymentService,然后将这个名字和这个模块的配置放到Nacos中,其他模块也是这样的。好处是这样能更好地管理项…...

Windows11家庭版启动Hyper-V
Hyper-V 是微软的硬件虚拟化产品,允许在 Windows 上以虚拟机形式运行多个操作系统。每个虚拟机都在虚拟硬件上运行,可以创建虚拟硬盘驱动器、虚拟交换机等虚拟设备。使用虚拟化可以运行需要较旧版本的 Windows 或非 Windows 操作系统的软件,以…...

《信管通低代码信息管理系统开发平台》Linux环境安装说明
1 简介 信管通低代码信息管理系统应用平台提供多环境软件产品开发服务,包括单机、局域网和互联网。我们专注于适用国产硬件和操作系统应用软件开发应用。为事业单位和企业提供行业软件定制开发,满足其独特需求。无论是简单的应用还是复杂的系统ÿ…...

第一节:电路连接【51单片机-L298N-步进电机教程】
摘要:本节介绍如何搭建一个51单片机L298N步进电机控制电路,所用材料均为常见的模块,简单高效的方式搭建起硬件环境 一、硬件清单 ①51单片机模块 ②恒流模块 ③开关电源 ④L298N模块 ⑤二相四线步进电机 ⑥电线若干 二、接线 三、L298N模…...

YoloDotNet 识别图像中特定关键点的位置
文章目录 1、初始化 Yolo 对象2、加载图像与检测关键点3、处理检测结果4、自定义关键点绘制和处理5、注意事项1、初始化 Yolo 对象 设置 YoloOptions,包括模型路径、模型类型(如果有专门的关键点检测模型类型则指定)、GPU 使用相关参数等。例如: var yoloOptions = new Yo…...
)
山景BP1048增加AT指令,实现单片机串口控制播放音乐(一)
1、设计目的 山景提供的SDK是蓝牙音箱demo,用户使用ADC按键或者IR遥控器,进行人机交互。然而现实很多场景,需要和单片机通信,不管是ADC按键或者IR接口都不适合和单片机通信。这里设计个AT指令用来和BP1048通信。AT指令如下图所示…...

Leetcode3218. 切蛋糕的最小总开销 I
题目描述: 有一个 m x n 大小的矩形蛋糕,需要切成 1 x 1 的小块。 给你整数 m ,n 和两个数组: horizontalCut 的大小为 m - 1 ,其中 horizontalCut[i] 表示沿着水平线 i 切蛋糕的开销。verticalCut 的大小为 n - 1 …...
的智能客服系统)
基于自然语言处理(NLP)的智能客服系统
基于自然语言处理(NLP)的智能客服系统是现代客户服务领域的一项重要技术,它通过模拟人类对话的方式,为用户提供及时、准确和个性化的服务。以下是关于基于NLP的智能客服系统的一些关键要素和功能: 1. 自然语言理解&am…...

RAG实战:构建基于本地大模型的智能问答系统
RAG实战:构建基于本地大模型的智能问答系统 引言 在当今AI快速发展的时代,如何构建一个既智能又可靠的问答系统是一个重要课题。本文将介绍如何使用RAG(检索增强生成)技术,结合本地大模型,构建一个高效的智…...

三维扫描在汽车/航空行业应用
三维扫描技术应用范围广泛,从小型精密零件到大型工业设备,都能实现快速、准确的测量。 通过先进三维扫描技术获取产品和物体的形面三维数据,建立实物的三维图档,满足各种实物3D模型数据获取、三维数字化展示、3D多媒体开发、三维…...

基于AI IDE 打造快速化的游戏LUA脚本的生成系统
前面写了一篇关于使用AI IDE进行C安全开发的博客《使用AI IDE 助力 C 高性能安全开发!》, 得到许多同学们的喜欢,今天我们来继续在游戏开发中扩展一下AI的能力,看看能不能给游戏研发团队一些启发。 在游戏研发中,Lua曾…...

http的访问过程或者访问页面会发生什么
1. 建立连接 客户端与服务器之间需要建立 TCP 连接,常用步骤如下: DNS解析:客户端将目标 URL 转换为服务器的 IP 地址。三次握手:TCP 协议通过三次握手建立可靠连接,确保双方具备通信能力。传输层连接建立࿱…...

Lua 函数
Lua 函数 1. 概述 Lua是一种轻量级的编程语言,常用于游戏开发、脚本编写和嵌入式系统。在Lua中,函数是一等公民,意味着它们可以作为变量传递,也可以作为参数传递给其他函数。本文将详细介绍Lua中的函数,包括函数的定…...

产品升级!Science子刊同款ARGs-HOST分析,get!
凌恩生物明星chanpin 抗性宏基因-宿主分析 Science子刊同款分析 数据挖掘更进一步! 抗生素的大量使用与滥用使微生物体内编码抗生素抗性的基因在环境中选择性富集,致病菌通过基因突变或者水平基因转移获得抗生素抗性基因后,导致抗生素治疗…...

Kubernetes PV及PVC的使用
前提条件 拥有Kubernetes集群环境,可参考:Kubernetes集群搭建理解Kubernetes部署知识,可参考:使用Kubernetes部署第一个应用 、Deloyment控制器拥有NFS服务,可参考:Linux环境搭建NFS服务 概述 Persistent…...

struct udp_sock
这个struct udp_sock结构体是Linux内核网络栈中用于表示一个UDP套接字的数据结构。它继承自struct inet_sock,这意味着它包含了所有IPv4或IPv6套接字共享的基础信息和函数指针。下面是对struct udp_sock中一些关键成员的解释: struct inet_sock inet;:这是udp_sock结构体的第…...

《机器学习》数据预处理简介
目录 1. 数据清洗(Data Cleaning) (1)处理缺失值 (2)处理异常值 (3)处理重复数据 2. 数据转换(Data Transformation) (1)特征缩…...
)
USB接口实现CDC(usb转串口功能)
主控:stm32f429 PHY芯片:usb3320 Cubemx System Core-RCC connectivity-USB_OTG_HS Middleware and Software Packs-USB_DEVICE 时钟配置:根据自己使用的MCU工作频率设置 Generate Code Keil5 打开工程 usbd_cdc_if.c这个文件&…...

ubuntu 网络管理--NetworkManager
ubuntu 网络管理--NetworkManager 1 介绍2 NetworkManager 命令2 nmcli 命令显示可用的wifi AP连接wifi检查网络连接 ?? 如何删除删除网络连接查看设备状态添加一个新的以太网连接设置静态 IP 地址启用并测试连接添加新的wifi连接 3 其他命令参考 1 介绍 NetworkManager 是标…...

FLV视频封装格式详解
目录(?)[-] OverviewFile Structure The FLV headerThe FLV File BodyFLV Tag Definition FLVTAGAudio TagsVideo TagsSCRIPTDATA onMetaDatakeyframes Overview Flash Video(简称FLV),是一种流行的网络格式。目前国内外大部分视频分享网站都是采用的这种格式. File Structure…...