解析在OceanBase创建分区的常见问题|OceanBase 用户问题精粹
在《分区策略和管理分区计划的实践方案》这篇文章中,我们介绍了在ODC中制定分区策略及有效管理分区计划的经验。有不少用户在该帖下提出了使用中的问题,其中一个关于创建分区的限制条件的问题,也是很多用户遭遇的老问题。因此本文以其为切入,将创建分区的几个问题进行解析,与大家共同探讨分享。
为什么主键必须包含全部分区键?
用户问:“有一张订单流水表,数据很大,想考虑按年份对数据进行分区。现在只有 ID 列是主键。尝试了一下好像无法按日期进行分区。是必须要把日期做成和 ID 的联合主键才可以分区么?”
答案是对的,主键必须包含所有分区键。因为主键的唯一性检查是在各个分区内部进行的,如果主键不包含全部分区键,这个检查就会失效,所以 MySQL 及其他数据库,也一样会有这个要求。
-- 如果主键不包含全部分区键,建表就会失败报错,报错信息也挺明确的。
create table t1(c1 int, c2 int,c3 int,primary key (c1))
partition by range (c2) (partition p1 values less than(3),partition p1 values less than(6));ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function下面举个例子:
create table t1(c1 int, c2 int,c3 int,primary key (c1, c2))
partition by range (c2) (partition p0 values less than(3),partition p1 values less than(6));
Query OK, 0 rows affected (0.146 sec)obclient [test]> insert into t1 values(1, 2, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> insert into t1 values(1, 5, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> select * from t1;
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
| 1 | 5 | 3 |
+----+----+------+
2 rows in set (0.032 sec)我们创建了一张表,主键是 c1 和 c2,分区键是 c2,小于 3 的值在 p0 分区,大于等于 3 且小于 6 的值在 p1 分区。然后插入了两个行,第一行在 p0 分区,第二行在 p1 分区。
obclient [test]> select * from t1 PARTITION(p0);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
+----+----+------+
1 row in set (0.033 sec)obclient [test]> select * from t1 PARTITION(p1);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 5 | 3 |
+----+----+------+
1 row in set (0.034 sec)如果主键只有 c1 而没有 c2,那么在 p0 和 p1 分区内对 c1 列的唯一性检测都会成功,因为在各个分区内 c1 列的值都不重复,然后就会判定插入的数据符合主键约束。但实际上在分区间会有重复值,数据并不符合主键约束,所以所有数据库在分区时,都要求主键包含全部分区键。
为什么分区能让查询变快?
用户另外一个问题:“按日期分区是否能达到让查询变快的目的?”
个人理解,分区除了可以让一张超级大表的数据比较被均衡地被负载在不同的数据库节点上,另外一个目的就是加速查询。因为查询时会利用过滤条件里面的分区键进行分区裁剪。例如下面这两个例子:
如果过滤条件里有分区键,计划中可以看到 partitions(p0),说明只扫描了 p0 这一个分区的数据。
obclient [test]> explain select * from t1 where c2 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.034 sec)如果过滤条件里没有分区键,计划中可以看到 partitions(p[0-1]),说明扫描了 p0 和 p1 全部所有分区的数据。其中 PX PARTITION ITERATOR 算子就是用来循环扫描所有分区的迭代器。
obclient [test]> explain select * from t1 where c3 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |6 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |6 | |
| |2 | └─PX PARTITION ITERATOR| |1 |5 | |
| |3 | └─TABLE FULL SCAN |t1 |1 |5 | |
| ============================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| force partition granule |
| 3 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c3 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p[0-1]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
19 rows in set (0.038 sec)range 分区不支持 datetime 类型咋办?
用户的另另外一个问题:“range 分区不支持 datetime 类型咋办?”。
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE(UNIX_TIMESTAMP(a))(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 1486 (HY000): Constant or random or timezone-dependent expressions in (sub)partitioning function are not allowed试了下,OB 的 MySQL 模式,为了兼容 MySQL 行为,会和 MySQL 对 random expressions 进行一些限制。我第一时间想到的是用生成列绕过,不过很快发现,为了兼容 MySQL 行为,OB 对生成列的使用也进行了限制,生成列里也不允许出现 UNIX_TIMESTAMP 这个特殊的表达式,所以并没什么卵用:
CREATE TABLE ff01 (a datetime , b timestamp as (UNIX_TIMESTAMP(a)))
PARTITION BY RANGE(b)(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 3102 (HY000): Expression of generated column contains a disallowed function至于为啥 UNIX_TIMESTAMP 在生成列里属于 disallowed function,猜测大概率是因为它是个非 deterministic 的系统函数。非 deterministic 简单来说就是这个 UNIX_TIMESTAMP() 函数在前一秒执行,和在后一秒执行,可能会返回不同的结果。像分区表达式、生成列表达式、check 约束里面的表达式,都不允许出现这种非确定性的函数。
下面举个简单的例子,解释一下上面 ERROR 1486 这个报错里 random 一词,以及非 deterministic 的含义:
obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008180 |
+------------------+
1 row in set (0.042 sec)obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008419 |
+------------------+
1 row in set (0.041 sec)-- 是不是一下子就明白,为啥 UNIX_TIMESTAMP 这么特殊,在哪里都不受待见了吧?不过不得不说,OB 的 MySQL 兼容性做的还挺好的,不仅是兼容了 MySQL 各种使用上的限制,甚至是一些 MySQL 的 bug 都给兼容了,虽然给使用带来了一些不便,不过迁移 MySQL 大概会变得比较轻松。
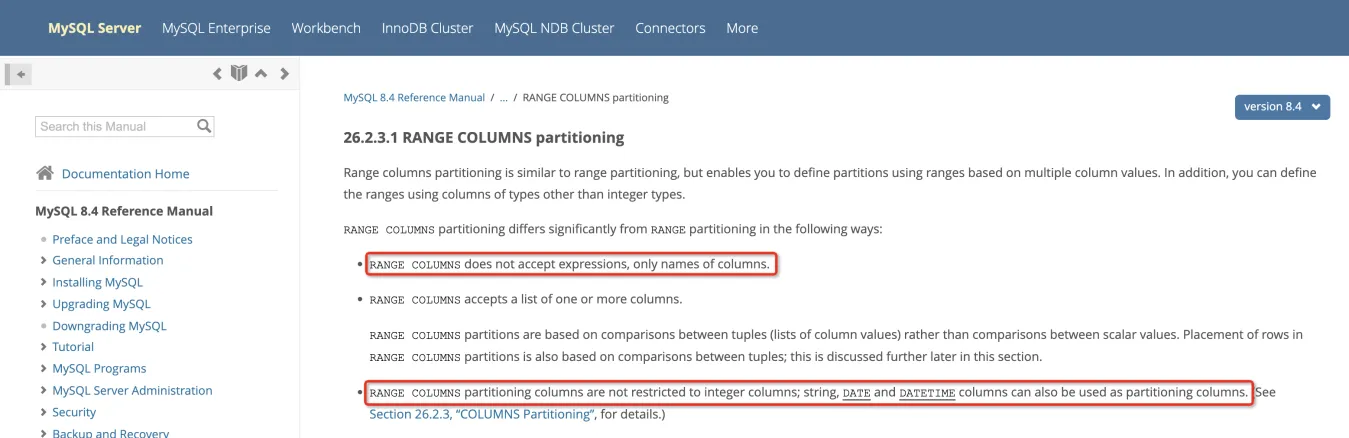
扯远了,回归正题,后面查了下 OB 官网,发现有一种分区方式叫 Range Columns,和 Range 分区十分类似,优点是相比 Range 分区可以支持更多的数据类型,例如用户需要的 datetime 类型,缺点是分区定义不支持表达式。
因为 Range 不支持 UNIX_TIMESTAMP 这类特殊的非 deterministic 表达式,所以个人理解这里可以通过 Range Columns 解决用户的问题。例如:
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE COLUMNS(a)(PARTITION p0 VALUES less than ('2023-01-01'),PARTITION p1 VALUES less than ('2023-01-02'),PARTITION pn VALUES less than MAXVALUE);Query OK, 0 rows affected (0.101 sec)说来惭愧,我之前也一直没注意过 Range 分区和 Range Columns 分区的区别,一直是把他们等价的,今天也算是学习到了,哈哈~
最后附上一个 MySQL 的官网文档链接,感觉它对 RANGE COLUMNS partitioning 的介绍比 OB 的官网要更清楚些,在这里推荐给对分区方式感兴趣的朋友阅读~
What else?
有同学提出还可以通过利用 to_days 函数代替 UNIX_TIMESTAMP 函数的方式解决第三个问题,这样就不需要更改 range 分区为 range columns 分区了。例如:
##创建range分区表
-- 分区字段是start_time,类型datetime
CREATE TABLE dba_test_range_1 (id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) NOT NULL COMMENT 'name',start_time datetime NOT NULL COMMENT '开始时间',
PRIMARY KEY (id,start_time)
)AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = 'test range'
PARTITION BY RANGE(to_days(start_time))(PARTITION M202301 VALUES LESS THAN(to_days('2023-02-01')),PARTITION M202302 VALUES LESS THAN(to_days('2023-03-01')),PARTITION M202303 VALUES LESS THAN(to_days('2023-04-01')));相关文章:

解析在OceanBase创建分区的常见问题|OceanBase 用户问题精粹
在《分区策略和管理分区计划的实践方案》这篇文章中,我们介绍了在ODC中制定分区策略及有效管理分区计划的经验。有不少用户在该帖下提出了使用中的问题,其中一个关于创建分区的限制条件的问题,也是很多用户遭遇的老问题。因此本文以其为切入&…...
)
python学习路径(一)
学习 Python 的完整大纲应该从基础知识到高级应用层层递进,并以构建自己的项目为目标,最终形成自己的知识体系。以下是一个完整、详细且逻辑清晰的学习路径: 第一部分:Python 基础 1. 环境配置与工具 Python 安装与版本管理&…...

【Nginx-5】Nginx 限流配置指南:保护你的服务器免受流量洪峰冲击
在现代互联网应用中,流量波动是常态。无论是突发的用户访问高峰,还是恶意攻击,都可能导致服务器资源耗尽,进而影响服务的可用性。为了应对这种情况,限流(Rate Limiting)成为了一种常见的保护措施…...
从入门到精通——运算操作)
OpenCV(python)从入门到精通——运算操作
加法减法操作 import cv2 as cv import numpy as npx np.uint8([250]) y np.uint8([10])x_1 np.uint8([10]) y_1 np.uint8([20])# 加法,相加最大只能为255 print(cv.add(x,y))# 减法,相互减最小值只能为0 print(cv.subtract(x_1,y_1))图像加法 import cv2 as…...

MFC 自定义网格控件
一、什么是 Custom Control? Custom Control(自定义控件) 是 MFC(Microsoft Foundation Classes)框架中提供的一种控件类型,用于实现自定义的外观和功能。当标准控件(例如 CEdit、CButton、CLi…...

什么是卷积?卷积的意义
卷积是一种在数学和信号处理中广泛应用的运算方法,它通常被用于描述两个函数之间的关系。在信号处理中,卷积可以将两个信号进行组合,以得到一个新的信号,该信号反映了这两个原始信号之间的关系。 具体来说,假设有两个…...
---软件定时器)
μC/OS-Ⅱ源码学习(7)---软件定时器
快速回顾 μC/OS-Ⅱ中的多任务 μC/OS-Ⅱ源码学习(1)---多任务系统的实现 μC/OS-Ⅱ源码学习(2)---多任务系统的实现(下) μC/OS-Ⅱ源码学习(3)---事件模型 μC/OS-Ⅱ源码学习(4)---信号量 μC/OS-Ⅱ源码学习(5)---消息队列 μC/OS-Ⅱ源码学习(6)---事件标志组 本文进一…...

3D和AR技术在电商行业的应用有哪些?
3D展示和AR技术在电商行业的应用为消费者带来了更为直观、沉浸式的购物体验,显著提升了商品展示效果和销售转化率。以下是3D和AR技术在电商行业的具体应用: 1、商品3D展示: 通过3D技术,商品可以在电商平台上以三维形式呈现&…...

数据增强的几大方式
1. 随机擦除(Random Erasing) 说明 随机在图像中选取一个矩形区域,将其像素值随机化或设为零,以增加模型对部分缺失信息的鲁棒性。 import numpy as np import cv2def random_erasing(image, sl0.02, sh0.2, r10.3):h, w, _ image.shapearea h * wta…...

GraphReader: 将长文本结构化为图,并让 agent 自主探索,结合的大模型长文本处理增强方法
GraphReader: 将长文本结构化为图,并让 agent 自主探索,结合的大模型长文本处理增强方法 论文大纲理解为什么大模型和知识图谱不够?还要多智能体 设计思路数据分析解法拆解全流程核心模式提问为什么传统的长文本处理方法会随着文本长度增加而…...

VTK 模型封闭 closeSurface 补洞, 网格封闭性检测
网格封闭性检测 见: vtk Edges 特征边 提取 网格封闭性检测_vtkfeatureedges-CSDN博客 由于以前做过3D打印模型,要求模型必须是封闭的,原来对模型封闭有研究过,不过没有记录;现在又遇到,整理一下ÿ…...

【译】仅有 Text2SQL 是不够的: 用 TAG 统一人工智能和数据库
原文地址:Text2SQL is Not Enough: Unifying AI and Databases with TAG 摘要 通过数据库为自然语言问题提供服务的人工智能系统有望释放出巨大的价值。此类系统可让用户利用语言模型(LM)的强大推理和知识能力,以及数据管理系统…...

Java:链接redis报错:NoSuchElementException: Unable to validate object
目录 前言报错信息排查1、确认redis密码设置是否有效2、确认程序配置文件,是否配置了正确的redis登录密码3、检测是否是redis持久化的问题4、确认程序读取到的redis密码没有乱码 原因解决 前言 一个已经上线的项目,生产环境的redis居然没有设置密码&…...

每日一题 334. 递增的三元子序列
334. 递增的三元子序列 使用贪心来找到三个数字 class Solution { public:bool increasingTriplet(vector<int>& nums) {int first INT_MAX;int second INT_MAX;for(int num : nums){if(num < first){first num;}else if(num < second){second num;}els…...

金仓 Kingbase 日常运维 SQL 汇总
金仓 Kingbase 日常运维 SQL 汇总 1 单机启停 sys_ctl start|stop|restart 或指定data路径和端口等 sys_ctl start|stop|restart -D /data/kingbase/data -p 543222 集群启停 sys_monitor start|stop|restart3 修改配置后重新加载 sys_ctl reload4 初始化实例 initdb -E ut…...

JAVA开发ERP时在 PurchaseOrderServiceImpl.java 中添加日志记录进行调试
在 PurchaseOrderServiceImpl.java 中添加日志记录,以便在保存订单时输出参数进行调试。可以使用 Spring 的日志框架(SLF4J 和 Logback)来实现这一点。 添加日志记录 引入 SLF4J 依赖: 确保项目中已经包含了 SLF4J 和 Logback 的依赖。通常在…...

36.3 grafana-dashboard看图分析
kube-prometheus中的grafana总结 db使用 sqlit,volume类型为emptydir 无法持久化,pod扩缩就重新创建通过configMap设置的prometheus DataSource 通过 prometheus-k8s svc对应的 域名访问下面对应两个prometheus容器,有HA 各个dashboard通过 …...

面试题整理5----进程、线程、协程区别及僵尸进程处理
面试题整理5----进程、线程、协程区别及僵尸进程处理 1. 进程、线程与协程的区别1.1 进程(Process)1.2 线程(Thread)1.3 协程(Coroutine)2. 总结对比 3. 僵尸进程3.1 什么是僵尸进程?3.2 僵尸进…...
【合集】)
【C语言程序设计——基础】顺序结构程序设计(头歌实践教学平台习题)【合集】
目录😋 <第1关:顺序结构的应用> 任务描述 相关知识 编程要求 测试说明 我的通关代码: 测试结果: <第2关:交换变量值> 任务描述 相关知识 编程要求 测试说明 我的通关代码: 测试结果: <第…...

LLM大语言模型私有化部署-OpenEuler22.03SP3上容器化部署Dify与Qwen2.5
背景 Dify 是一款开源的大语言模型(LLM) 应用开发平台。其直观的界面结合了 AI 工作流、 RAG 管道、 Agent 、模型管理、可观测性功能等,让您可以快速从原型到生产。相比 LangChain 这类有着锤子、钉子的工具箱开发库, Dify 提供了更接近生产需要的完整…...

C语言中的转义字符
C语言中的转义字符 常见字符ASCII码表...

ilqr算法原理推导及代码实践
目录 一. ilqr原理推导1.1 ilqr问题描述1.2 ilqr算法原理1.3 ilqr算法迭代过程 二. ilqr实践代码 一. ilqr原理推导 1.1 ilqr问题描述 本文参考知乎博主: LQR与iLQR:从理论到实践【详细】 基础LQR只能处理线性系统 (指可以使用 x ( k 1 ) A x ( k ) B u ( k )…...
)
系列1:基于Centos-8.6部署Kubernetes (1.24-1.30)
每日禅语 “木末芙蓉花,山中发红萼,涧户寂无人,纷纷开自落。”这是王维的一首诗,名叫《辛夷坞》。这首诗写的是在辛夷坞这个幽深的山谷里,辛夷花自开自落,平淡得很,既没有生的喜悦ÿ…...

finereport新的数据工厂插件使用场景一 通过accessToken获取数据
1 有两个接口,一个接口获取一个accessToken,一个接口根据accessToken来获取数据。代码示例为: @RequestMapping(value = {"df_test/getAccessToken"},method = {RequestMethod.GET})@ResponseBodypublic String getAccessToken(HttpServletRequest req, HttpServ…...

matlab绘图时设置左、右坐标轴为不同颜色
目录 一、需求描述 二、实现方法 一、需求描述 当图中存在两条曲线,需要对两条曲线进行分别描述时,应设置左、右坐标轴为不同颜色,并设置刻度线,且坐标轴颜色需要和曲线颜色相同。 二、实现方法 1.1、可以实现: 1…...

魏裕雄的JAVA学习总结
JAVA学习总结 Java面向对象程序设计知识总结第1章 初识Java与面向对象程序设计JAVA概述面向对象程序设计思想JAVA开发环境搭建第一个JAVA程序JAVA常用开发工具 第2章 Java编程基础变量与常量运算符与表达式选择结构循环结构方法数组JVM中的堆内存与栈内存 第3章 面向对象程序设…...

深度学习从入门到精通——图像分割实战DeeplabV3
DeeplabV3算法 参数配置关于数据集的配置训练集参数 数据预处理模块DataSet构建模块测试一下数据集去正则化模型加载模块DeepLABV3 参数配置 关于数据集的配置 parser argparse.ArgumentParser()# Datset Optionsparser.add_argument("--data_root", typestr, defa…...

SAP抓取外部https报错SSL handshake处理方法
一、问题描述 SAP执行报表抓取https第三方数据,数据获取失败。 报错消息: SSL handshake with XXX.COM:449 failed: SSSLERR_SSL_READ (-58)#SAPCRYPTO:SSL_read() failed##SapSSLSessionStartNB()==SSSLERR_SSL_READ# SSL:SSL_read() failed (536875120/0x20001070)# …...

Electron-Vue 开发下 dev/prod/webpack server各种路径设置汇总
背景 在实际开发中,我发现团队对于这几个路径的设置上是纯靠猜的,通过一点点地尝试来找到可行的路径,这是不应该的,我们应该很清晰地了解这几个概念,以下通过截图和代码进行细节讲解。 npm run dev 下的路径如何处理&…...

穷举vs暴搜vs深搜vs回溯vs剪枝专题一>全排列II
题目: 解析: 这题设计递归函数,主要把看如何剪枝 代码: class Solution {private List<List<Integer>> ret;private List<Integer> path;private boolean[] check;public List<List<Integer>> p…...

Nginx中Server块配置的详细解析
Nginx中Server块配置的详细解析 一、Server块简介 在Nginx配置文件中,server块是非常关键的部分。它用于定义虚拟主机,一个server块就代表一个虚拟主机。这使得我们可以在一台Nginx服务器上通过不同的配置来处理多个域名或者基于不同端口的服务请求。 …...

【后端面试总结】Redis的三种模式原理介绍及优缺点
Redis作为一款高性能的键值对数据库,提供了多种模式以满足不同场景下的需求。本文将详细介绍Redis的三种主要模式:主从复制模式、哨兵模式(Sentinel)和集群模式(Cluster),包括它们的原理、配置、…...

TCP协议详解
目录 一. TCP协议概述 1. 概念 2. 特点 (1) 面向连接 (2) 可靠传输 (3) 面向字节流 (4) 全双工通信 (5) 流量控制和拥塞控制 二. TCP协议报文格式 1. 源端口号 和 目的端口号 (16位) 2. 序号 和 确认序号 (32位) 3. 首部长度 (4位) 4. 保留位 (6位) 7. 控制位 8.…...
)
Webpack学习笔记(2)
1.什么是loader? 上图是Webpack打包简易流程,webpack本身只能理解js和json这样的文件,loader可以让webpack解析其他类型文件,并且将文件转换成模块供我们使用。 test识别出那些文件被转换,use定义转换时使用哪个loader转换 上图…...
)
【漏洞复现】Grafana 安全漏洞(CVE-2024-9264)
🏘️个人主页: 点燃银河尽头的篝火(●’◡’●) 如果文章有帮到你的话记得点赞👍+收藏💗支持一下哦 一、漏洞概述 1.1漏洞简介 漏洞名称:Grafana 安全漏洞 (CVE-2024-9264)漏洞编号:CVE-2024-9264 | CNNVD-202410-1891漏洞类型:命令注入、本地文件包含漏洞威胁等级:…...

C++实现最大字段和
又是一道非常基础且经典的动态规划题目:假设有一个整数序列,我们将连续的几个元素组成的序列称为子段,要求我们得出所有子段和中最大的一个~ 例如:{-2,11,-4,13,-5,-2},这一序列中&a…...

当我用影刀AI Power做了一个旅游攻略小助手
在线体验地址:旅游攻略小助手https://power.yingdao.com/assistant/ca1dfe1c-9451-450e-a5f1-d270e938a3ad/share 运行效果图展示: 话不多说一起看下效果图: 智能体的截图: 工作流截图: 搭建逻辑: 其实这…...

K8s HPA的常用功能介绍
Kubernetes 的 Horizontal Pod Autoscaler (HPA) 是一种自动扩展功能,用于根据资源使用情况(如 CPU、内存等)或自定义指标,动态调整 Pod 的副本数量,从而保证应用的性能和资源利用率。 以下是 HPA 的常用功能介绍&…...

web3跨链预言机协议-BandProtocol
项目简介 Band Protocol 项目最初于 2017年成立并建立在 ETH 之上。后于2020年转移到了 Cosmos 网络上,基于 Cosmos SDK 搭建了一条 Band Chain 。这是一条 oracle-specific chain,主要功能是提供跨链预言机服务。Cosmos生态上第一个,也是目…...
)
Python如何正确解决reCaptcha验证码(9)
前言 本文是该专栏的第73篇,后面会持续分享python爬虫干货知识,记得关注。 我们在处理某些国内外平台项目的时候,相信很多同学或多或少都见过,如下图所示的reCaptcha验证码。 而本文,笔者将重点来介绍在实战项目中,遇到上述中的“reCaptcha验证码”,如何正确去处理并解…...

电商数据采集电商,行业数据分析,平台数据获取|稳定的API接口数据
电商数据采集可以通过多种方式完成,其中包括人工采集、使用电商平台提供的API接口、以及利用爬虫技术等自动化工具。以下是一些常用的电商数据采集方法: 人工采集:人工采集主要是通过基本的“复制粘贴”的方式在电商平台上进行数据的收集&am…...

【java】Executor框架的组成部分
目录 1. 任务(Task)2. 执行器(Executor)3. 任务结果(Future)4. 线程池(ThreadPool)5. 任务队列(Work Queue)6. 线程工厂(Thread Factoryÿ…...

KMP算法基础
文章一览 前言一、核心思想二、实现步骤三、图解实现四、next数组的实现总结 前言 本栏目将讲解在学习过程中遇到的各种常用算法,深入浅出的讲解算法的用法与使用场景。 那么话不多说,让我们进入第一个算法KMP算法吧! 一、核心思想 KMP&am…...

C语言——实现百分制换算为等级分
问题描述:百分制换算为等级分 //百分制换算为等级分#include<stdio.h>void my_function(int x) {if(x>95 && x<100){printf("A");}else if(x>81 && x<94){printf("B");}else if(x>70 && x<8…...
 跟 @pytest.fixture有区别吗?)
@pytest.fixture() 跟 @pytest.fixture有区别吗?
在iOS UI 自动化工程里面最早我用的是pytest.fixture(),因为在pycharm中联想出来的fixture是带()的,后来偶然一次我没有带()发现也没有问题,于是详细查了一下pytest.fixture() 和 pytest.fixtur…...

docker run命令大全
docker run命令大全 基本语法常用选项基础选项资源限制网络配置存储卷和挂载环境变量重启策略其他高级选项示例总结docker run 命令是 Docker 中最常用和强大的命令之一,用于创建并启动一个新的容器。该命令支持多种选项和参数,可以满足各种使用场景的需求。以下是 docker ru…...

BootAnimation源码流程分析
BootAnimation流程 bootanimation源码位于frameworks/base/cmds/bootanimation,正如其名,主要功能是加载播放开机动画,是一个C程序,编译生成的可执行文件位于/system/bin 主要逻辑:解析系统路径下的bootanimation.zi…...

Vue前端开发-数据缓存
完成全局性的axios实例对象配置后,则可以在任意一个组件中直接调用这个对象,发送异步请求,获取服务端返回的数据,同时,针对那些不经常变化的数据,可以在请求过程中,进行数据缓存,并根…...

唯品会Android面试题及参考答案
HTTP 和 HTTPS 的区别是什么?你的项目使用的是 HTTP 还是 HTTPS? HTTP 和 HTTPS 主要有以下区别。 首先是安全性。HTTP 是超文本传输协议,数据传输是明文的,这意味着在数据传输过程中,信息很容易被窃取或者篡改。比如&…...

ARM CCA机密计算安全模型之固件启动
安全之安全(security)博客目录导读 目录 1、安全启动(Verified boot) 2、镜像格式和签名方案 3、防回滚 4、离线启动(Off-line boot) 5、CCA HES固件启动流程 6、CCA系统安全域启动过程 7、应用程序PE启动过程 8、稳健性 本节定义了将CCA固件引导至可证明状态的要…...