【Java基础笔记vlog】Java中常见的几种数组排序算法汇总详解
Java中常见的几种排序算法:
- 冒泡排序(Bubble Sort)
- 选择排序(Selection Sort)
- 插入排序(Insertion Sort)
- 希尔排序(Shell Sort)
- 归并排序(Merge Sort)
- 快速排序(Quick Sort)
- 堆排序(Heap Sort)
- 计数排序(Counting Sort)
- 桶排序(Bucket Sort)
- 基数排序(Radix Sort)
其中冒泡、选择、插入等是最常用的几种排序算法(必须要掌握)
算法复杂度
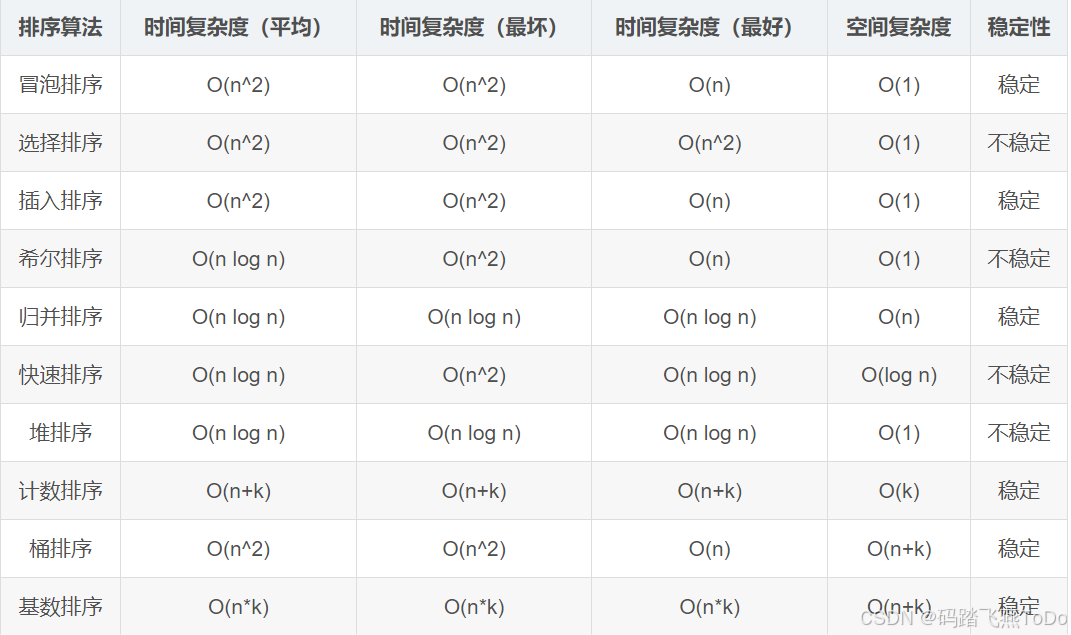
其中,n表示输入元素的数量,k表示元素的取值范围大小。
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机 内执行时所需存储空间的度量,它也是数据规模n的函数。
1.冒泡排序(Bubble Sort)
冒泡排序的基本思想是对比相邻的元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把较大的元素移动到数组后面(也就是交换元素的位置),这样较小的元素就像气泡一样从底部升到顶部。

算法示例
//排序实现public void sort(int[] arry) {for(int i=1;i<arry.length;i++) {for(int j=0;j<arry.length-i;j++) {//如果数组元素第一位比第二位大 就创建temp把第一位赋值于他 //然后第二位向前移,temp存储的第一位的值到第二位上 完成一次排序if(arry[j]>arry[j+1]) { int temp = arry[j];arry[j] = arry[j+1];arry[j+1] = temp;}}}showArry(arry);//遍历}public void showArry(int[] arry) {for(int i:arry) {System.out.print(">"+i);}}2.选择排序(Selection Sort)
基本思想:选择排序的基本思想是每次从待排序的元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的元素排完。

public class SelectionSort {public static void sort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {int minIndex = i;for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}int temp = arr[minIndex];arr[minIndex] = arr[i];arr[i] = temp;}}
}3.插入排序(Insertion Sort)
基本思想:将未排序数据插入到已排序序列的合适位置

public class InsertionSort {public static void sort(int[] arr) {int n = arr.length;for (int i = 1; i < n; i++) {int key = arr[i];int j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}}
}4.希尔排序(Quick Sort)
基本思想:将待排序的数组按照一定的间隔进行分组,对每组使用插入排序算法进行排序,然后缩小间隔,再对分组进行排序,直到间隔为1为止。逐渐减小间隔大小的方法有助于提高排序过程的效率,可以减少比较和交换的次数。这是希尔排序算法的一个关键特点。

import org.junit.jupiter.api.Assertions;
import java.util.Arrays;public class Shell {public static void shellSort(int[] arr) {int n = arr.length;// 初始化间隔(gap)的值,它决定了每次迭代中子数组的大小// 从数组长度的一半开始作为初始间隔值,gap就是分割的子数组数量for (int gap = n / 2; gap > 0; gap /= 2) {// 循环从间隔值开始,遍历数组直到数组的末尾;代表循环所有的子数组for (int i = gap; i < n; i++) {int temp = arr[i];int j = i;// 将当前元素 arr[j] 的值替换为前一个元素 arr[j - gap] 的值。// 通过这个操作,将较大的元素向后移动,为当前元素腾出位置while (j >= gap && arr[j - gap] > temp) {arr[j] = arr[j - gap];j -= gap;}arr[j] = temp;}}}public static void main(String[] args) {int[] arr = {5, 2, 8, 3, 1, 6};int[] expectedArr = {1, 2, 3, 5, 6, 8};Shell.shellSort(arr);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}
}
5.归并排序(Merge Sort)
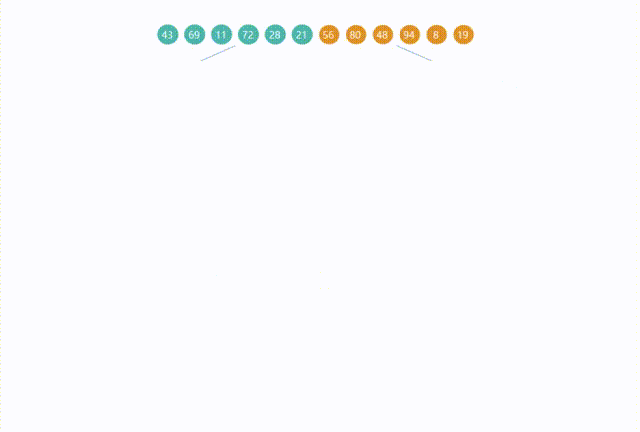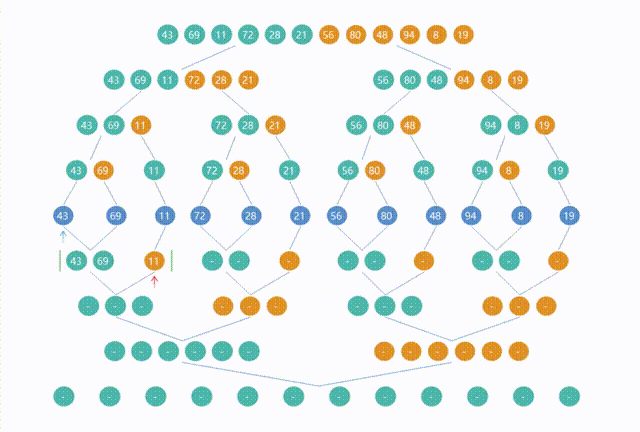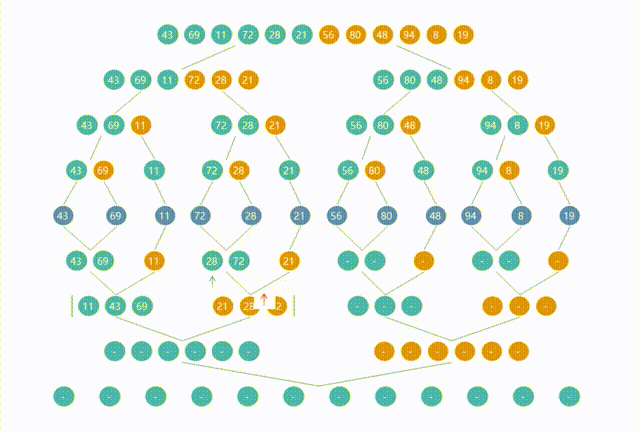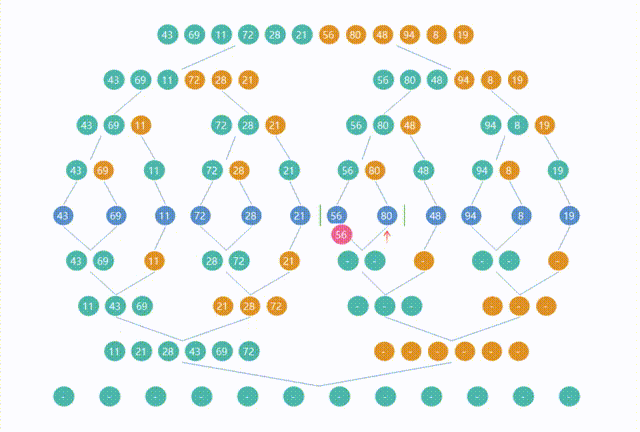
import org.junit.jupiter.api.Assertions;
import java.util.Arrays;public class Merge {public static void main(String[] args) {int[] arr = {5, 2, 8, 3, 1, 6};int[] expectedArr = {1, 2, 3, 5, 6, 8};Merge.mergeSort(arr, 0, arr.length - 1);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}public static void mergeSort(int[] arr, int left, int right) {if (left < right) {int mid = (left + right) / 2;mergeSort(arr, left, mid);mergeSort(arr, mid + 1, right);merge(arr, left, mid, right);}}public static void merge(int[] arr, int left, int mid, int right) {// 子数组 L 的大小int n1 = mid - left + 1;// 右子数组 R 的大小int n2 = right - mid;// 创建两个临时数组 L 和 R ,分别用来存储左子数组和右子数组的元素int[] L = new int[n1];int[] R = new int[n2];// 使用 for 循环将原始数组 arr 中的元素复制到临时数组 L 和 R 中,分别从 left 和 mid + 1 开始for (int i = 0; i < n1; i++) {L[i] = arr[left + i];}for (int j = 0; j < n2; j++) {R[j] = arr[mid + 1 + j];}// 初始化三个变量 i、j和k,分别指向数组 L 、R 和原始数组 arr 的起始位置int i = 0, j = 0, k = left;// 使用 while 循环,比较 L 和 R 的元素,并将较小的元素放回原始数组 arr 中while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 当 L 或 R 中的元素用完时,将剩余的元素依次放回原始数组 arr 中while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}// merge 方法执行完毕后,两个子数组范围内的元素已经按照从小到大的顺序合并到了原始数组 arr 中}
}
6. 快速排序(Quick Sort)

import org.junit.jupiter.api.Assertions;
import java.util.Arrays;public class Quick {public static void main(String[] args) {int[] arr = {5, 2, 8, 6, 1, 3};int[] expectedArr = {1, 2, 3, 5, 6, 8};Quick.quickSort(arr, 0, arr.length - 1);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}// 接收一个数组 arr,一个低索引 low ,和一个高索引 high 作为参数public static void quickSort(int[] arr, int low, int high) {// 检查 low 是否小于 high。如果不是,则意味着数组只有一个元素或为空,因此不需要排序if (low < high) {int pivot = partition(arr, low, high);quickSort(arr, low, pivot - 1);quickSort(arr, pivot + 1, high);}}/*** 取最后一个元素作为枢轴元素,将较小的元素放在左边,较大的元素放在右边* @param arr 输入数组* @param low 低位索引* @param high 高位索引* @return 枢轴所在位置*/private static int partition(int[] arr, int low, int high) {// 将最后一个元素作为枢轴元素( arr[high] )int pivot = arr[high];// 将 i 初始化为 low - 1,用于跟踪较小元素的索引int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] < pivot) {// 如果当前元素 arr[j] 小于枢轴元素,则增加 i 并交换 arr[i] 和 arr[j]// 较小元素索引+1i++;// 将当前元素 arr[j] 放在较小元素索引位置// 将较小元素放在前面swap(arr, i, j);}// 其他情况,则较小元素索引没有增加,说明当前元素应该放在右边}// 将枢轴元素( arr[high] )与索引 i + 1 处的元素交换。// 确保枢轴元素左边是较小元素,右边是较大元素swap(arr, i + 1, high);// 将 i + 1 作为枢轴索引返回return i + 1;}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
7. 堆排序(Heap Sort)

public class Heap {// 堆排序方法public static void heapSort(int[] arr) {int n = arr.length;// 构建大根堆,// 这段代码是构建大根堆的过程,它的循环次数为n/2-1次,是因为在完全二叉树中,叶子节点不需要进行堆化操作,// 所以只需要对非叶子节点进行堆化,而非叶子节点的数量为n/2-1个。因此,只需要循环n/2-1次即可完成大根堆的构建。// 非叶子节点在一维数组中就是前面 n/2-1for (int i = n / 2 - 1; i >= 0; i--) {// 从最底层的根节点开始堆化,每次执行完成后,都找出最大值,并放在根节点位置// 逐层往上找,循环结束后,第一个元素肯定是最大值heapify(arr, n, i);}// 依次取出堆顶元素,并将余下元素继续堆化,得到有序序列for (int i = n - 1; i >= 0; i--) {// 第一个for循环已经找出最大值,所以先做交货,把最大值换到最后一个位置// 把最大值交换到最后一个位置,下一次循环最后一个位置就不比较了swap(arr, 0, i);// 继续找出最大值,放在第一个位置heapify(arr, i, 0);}}private static void heapify(int[] arr, int heapSize, int i) {int largest = i; // 初始化假设最大值为根节点int left = 2 * i + 1; // 相对于索引i的左节点索引int right = 2 * i + 2; // 相对于索引i的右节点索引// 找到左右子节点中的最大值if (left < heapSize && arr[left] > arr[largest]) {// 如果有左节点,且左节点大于根节点,则记录左节点为最大值largest = left;}if (right < heapSize && arr[right] > arr[largest]) {// 如果有右节点,且右节点大于最大值,则记录右节点为最大值largest = right;}// 上面两个if之后,肯定找到最大值if (largest != i) {// i 是根节点下标// 如果最大值不是根节点,则交换根节点与最大值节点,// 并递归地对最大值节点进行堆化swap(arr, i, largest);heapify(arr, heapSize, largest);}}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {int[] arr = {5, 2, 8, 3, 12, 35, 57, 1, 6};int[] expectedArr = {1, 2, 3, 5, 6, 8, 12, 35, 57};Heap.heapSort(arr);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}
}
8. 计数排序(Counting Sort)
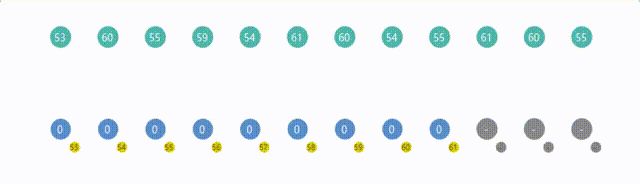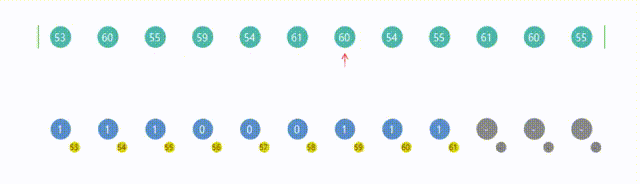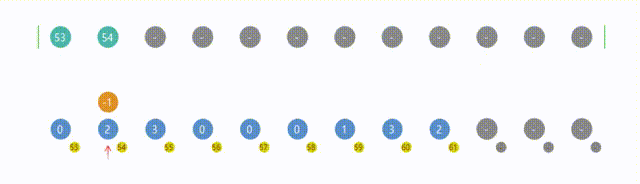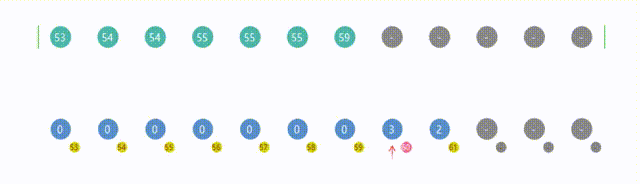
import org.junit.jupiter.api.Assertions;
import java.util.Arrays;public class Counting {public static void countingSort(int[] arr) {int n = arr.length;// 取出数组中最大值int max = getMax(arr);int[] count = new int[max + 1];// 统计每个元素出现的次数for (int i = 0; i < n; i++) {count[arr[i]]++;}// 计算每个元素在有序序列中的位置for (int i = 1; i <= max; i++) {// 因为count包含了每个数据出现的次数,所以从小到大,// 逐个往前加得到就是原数组中每个元素在有序序列中应有的位置count[i] += count[i - 1];}// 输出有序序列int[] sortedArr = new int[n];for (int i = n - 1; i >= 0; i--) {int item = arr[i];//元素int itemPos = count[item];// 元素在有序数组中的位置sortedArr[itemPos - 1] = item; // 将元素填入有序数组count[item]--;}// 将有序序列复制回原数组System.arraycopy(sortedArr, 0, arr, 0, n);}private static int getMax(int[] arr) {int max = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}return max;}public static void main(String[] args) {int[] arr = {5, 2, 6, 8, 3, 1, 6, 5, 12};int[] expectedArr = {1, 2, 3, 5, 5, 6, 6, 8, 12};Counting.countingSort(arr);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}
}
9. 桶排序(Bucket Sort)
import org.junit.jupiter.api.Assertions;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;public class Bucket {public static void main(String[] args) {int[] arr = {5, 2, 8, 3, 12, 35, 57, 1, 6};int[] expectedArr = {1, 2, 3, 5, 6, 8, 12, 35, 57};Bucket.bucketSort(arr, 20);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}/*** 桶排序* @param arr 待排序数组* @param bucketSize 桶大小,数据不宜过大,桶越大,后续对桶内数据排序越耗时*/public static void bucketSort(int[] arr, int bucketSize) {if (arr.length == 0) {return;}// 循环数组,先找到最小值和最大值int minValue = arr[0];int maxValue = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] < minValue) {minValue = arr[i];} else if (arr[i] > maxValue) {maxValue = arr[i];}}// 根据桶的大小,计算桶个数,并初始化桶int bucketCount = (maxValue - minValue) / bucketSize + 1;List<List<Integer>> buckets = new ArrayList<>(bucketCount);for (int i = 0; i < bucketCount; i++) {buckets.add(new ArrayList<>());}for (int i = 0; i < arr.length; i++) {int bucketIndex = (arr[i] - minValue) / bucketSize;buckets.get(bucketIndex).add(arr[i]);}int currentIndex = 0;for (int i = 0; i < bucketCount; i++) {List<Integer> bucket = buckets.get(i);// 对桶内数据进行排序Collections.sort(bucket);// 将数据逐个从桶内取出,并存入数组for (int j = 0; j < bucket.size(); j++) {arr[currentIndex++] = bucket.get(j);}}}}
10. 基数排序(Radix Sort)
基数排序的时间复杂度为O(d(n+k)),其中d为最大元素的位数,n为待排序元素的个数,k为桶的个数。
public class Radix {public static void radixSort(int[] arr) {if (arr.length == 0) {return;}// 循环取得数组中的最大值int maxNum = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] > maxNum) {maxNum = arr[i];}}// 根据最大值算出数组中的最大位数,个位、十位、百位、千位等int maxDigit = 0;while (maxNum != 0) {maxNum /= 10;maxDigit++;}// 初始化10个list,分别存放位数是0-9的10组数字List<List<Integer>> buckets = new ArrayList<>(10);for (int i = 0; i < 10; i++) {buckets.add(new ArrayList<>());}int mod = 10; // 初始10,用于数据个位数取模int div = 1; // 桶序号除数// 按位数循环数组,个位循环1次,十位循环2次,百位循环3次,以此类推!for (int i = 0; i < maxDigit; i++, mod *= 10, div *= 10) {// 循环数组,将数据分别存入桶中// 第一次循环,桶里面的个位数顺序排序完成// 第二次循环,个位、十位都排序完成// 第三次循环,个位、十位、百位都排序完成for (int j = 0; j < arr.length; j++) {// 计算当前位数的桶序号int bucketIndex = (arr[j] % mod) / div;buckets.get(bucketIndex).add(arr[j]);}// 循环桶列表,将当前位数已排序的数据放入数组中int currentIndex = 0;for (int j = 0; j < 10; j++) {List<Integer> bucket = buckets.get(j);for (int k = 0; k < bucket.size(); k++) {arr[currentIndex++] = bucket.get(k);}bucket.clear();}}}public static void main(String[] args) {int[] arr = {5, 2, 8, 3, 12, 35, 57, 1, 6};int[] expectedArr = {1, 2, 3, 5, 6, 8, 12, 35, 57};Radix.radixSort(arr);System.out.println("arr = " + Arrays.toString(arr));Assertions.assertArrayEquals(expectedArr, arr);}
}
相关文章:

【Java基础笔记vlog】Java中常见的几种数组排序算法汇总详解
Java中常见的几种排序算法: 冒泡排序(Bubble Sort)选择排序(Selection Sort)插入排序(Insertion Sort)希尔排序(Shell Sort)归并排序(Merge Sort)…...

flink 提交流程
flink 提交流程 基础架构并行度算子链任务槽 基础架构 上图是普通的 standalone 架构,就是独立模式,会话模式部署,客户端在接受 job 时,会生成逻辑流图,这里只是按照业务生成对应的执行图,到了 JobManager …...

使用Pandoc实现Markdown和Word文档的双向转换
前言 Word文档是老牌的文档工具,Markdown是新兴的势力。Csdn发文章就是支持Markdown文件的导入,而并不支持Word文件的导入。相反的,今日头天发文章就是支持Word文件的导入,而不支持Markdown文件的导入。 所以,这两种…...

【Python零基础入门系列】第3篇:什么是 Python 的变量、数据类型和输入输出?
欢迎来到【Python 零基础入门系列】第3篇! 前两篇我们已经学会了如何安装 Python 使用编程工具 IDE,并写出了人生第一个程序 print("Hello, world!"),是不是有点成就感了?今天我们就继续深入一点点,来聊聊编程的“灵魂三问”: 什么是变量?什么是数据类型?如…...

破解充电安全难题:智能终端的多重防护体系构建
随着智能终端的普及,充电安全问题日益凸显。从电池过热到短路起火,充电过程中的安全隐患不仅威胁用户的生命财产安全,也制约了行业的发展。如何构建一套高效、可靠的多重防护体系,成为破解充电安全难题的关键。通过技术创新和系统…...

无人机桥梁巡检
无人机桥梁巡检 防护墙巡查 路面巡查 主梁巡查 桥墩路基巡查 支座巡查 周边环境检查...
Android Binder线程池饥饿与TransactionException:从零到企业级解决方案(含实战代码+调试技巧)
简介 在Android系统中,Binder作为进程间通信(IPC)的核心机制,承载着大量跨进程调用任务。然而,当Binder线程池资源耗尽时,可能导致严重的线程饥饿问题,最终引发TransactionException异常,甚至导致应用崩溃或系统卡顿。本文将从零开始,系统讲解Binder线程池的工作原理…...

138. Copy List with Random Pointer
目录 题目描述 方法一、使用哈希表 方法二、不使用哈希表 题目描述 问题的关键是,random指针指向的是原链表的结点,这个原链表的结点对应哪一个新链表的结点呢?有两种办法。一是用哈希表。另一种是复制原链表的每一个结点,并将…...

Java面试问题基础篇
面向对象 面向对象编程:拿东西过来做对应的事情 特征: 封装:对象代表什么,就要封装对应的数据,并提供数据对应的行为 继承:Java中提供一个关键字extends,用这个关键字可以让一个类和另一个类…...

ILRuntime中实现OSA
什么是ILRuntime? ILRuntime项⽬为基于C#的平台(例如Unity)提供了⼀个 纯 C# 实现 , 快速 、 ⽅便 且 可靠 的IL 运⾏时,使得能够在不⽀持JIT的硬件环境(如iOS)能够实现代码的热更新。具体可以学习: http://http s://ourpalm.github.io/ILRuntime/public/v1/guide/ind…...

总结一个编程的学习方式~
目录 学习开发 一切从简 代码风格 学习工具 总结 学习开发 一切从简 在学习写代码的时候,一定要快速的写起来,不要在开发工具上浪费太多的时间。比如说萌新学习C/C,上来直接使用Visual Studio 2019开始把代码写起来,不要追…...

ABC 353
目录 C. Sigma Problem D. Another Sigma Problem C. Sigma Problem 容斥。所有都先不取模,每个数出现 n - 1次,先算出不取模的答案。 接下来找出哪些对之和超出了 1e8,统计这样的对的个数,再拿之前的答案减掉 个数 * 1e8 只需要…...
APC注入)
【免杀】C2免杀技术(八)APC注入
本文主要写点自己的理解,如有问题,请诸位指出! 概念和流程 “APC注入”(APC Injection)是免杀与恶意代码注入技术中的一种典型方法,主要用于在目标进程中远程执行代码,常见于后门、远控、植入型…...

集星云推“碰一碰源码”开发思路解析
在当今数字化营销的浪潮中,集星云推的“碰一碰发视频”工具脱颖而出,为实体商家带来了全新的发展机遇。 AI 视频生成引擎: 集星云推的“碰一碰发视频”工具,在AI视频生成方面下足了功夫。它精心挑选合适的AI视频生成算法…...

容器网络中的 veth pair 技术详解
什么是 veth pair? 在 Linux 容器网络中,veth pair(Virtual Ethernet Pair)是一种虚拟网络设备,用于在不同的网络命名空间(Network Namespace)之间建立通信。它本质上是一对虚拟网卡࿰…...

PCB 横截面几何形状
PCB 横截面几何形状描述了 PCB 堆叠中介电基板、走线和参考平面的细节。然后,它们彼此之间的物理关系可用于预测相应走线的特性阻抗。只有三个通用的横截面几何,每个几何内部都有变化。他们是: 共面 微带线 带状线 共面: 共面几何,有时也称为共面波导 (CPW),是夹在两个…...

面向高温工业场景的EtherCAT/CANopen协议转换系统设计与应用
在金属冶炼行业,高效稳定的通信系统是保障生产流程顺畅、提升生产效率的关键。从矿石预处理、高温熔炼,到精炼成型,各个环节的设备紧密协作,而JH-ECT009疆鸿智能EtherCAT转CANopen协议网关,作为连接不同通信协议设备的…...

Redis语法大全
一、String(字符串) 特点:单键值存储,值可为字符串、数字,支持原子操作。 常用命令 SET 语法:SET key value [EX seconds] [PX milliseconds] [NX|XX]说明:设置键值对,可指定过期时…...

【项目管理】项目管理中的”三边、六拍、四没和只谈“
三边、六拍、四没和只谈总结 中国特色项目管理的“三边、六拍、四没和只谈”,你知道多少? “三边”是指:边计划、边实施、边修改 “六拍”是指:拍脑袋、拍肩膀、拍胸口、拍桌子、拍屁股、拍大腿 "四没"是指:没问题、没关系、没办法、没资源 “只谈”是指:项目初…...

Python训练Day30
模块和库的导入 知识点 回顾 : 导入官方库的三种手段导入自定义库/模块的方式导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 1.1标准导入:导入整个库 # 方式1:导入整个模块 imp…...

面试相关的知识点
1 vllm 1.1常用概念 1 vllm:是一种大模型推理的框架,使用了张量并行原理,把大型矩阵分割成低秩矩阵,分散到不同的GPU上运行。 2 模型推理与训练:模型训练是指利用pytorch进行对大模型进行预训练。 模型推理是指用训…...

【notepad++如何设置成中文界面呢?】
“Notepad”是一款非常强大的文本编辑软件,将其界面设置成中文的方法如下: 一、工具/原料: 华为 Matebook 15、Windows 10、Notepad 8.4.6。 二 、具体步骤: 1、找到任意一个文本文件,比如 txt 格式的文…...

从版本控制到协同开发:深度解析 Git、SVN 及现代工具链
前言:在当今软件开发的浪潮中,版本控制与协同开发无疑扮演着举足轻重的角色。从最初的单兵作战到如今大规模团队的高效协作,一套成熟且得力的版本控制系统以及围绕其构建的现代工具链,已然成为推动软件项目稳步前行的关键引擎。今…...

十一、xlib绘制编辑框-续
系列文章目录 本系列文章记录在Linux操作系统下,如何在不依赖QT、GTK等开源GUI库的情况下,基于x11窗口系统(xlib)图形界面应用程序开发。之所以使用x11进行窗口开发,是在开发一个基于duilib跨平台的界面库项目&#x…...

PyTorch进阶实战指南:02分布式训练深度优化
PyTorch进阶实战指南:02分布式训练深度优化 前言 在大模型时代,分布式训练已成为突破单机算力瓶颈的核心技术。本文深入解析PyTorch分布式训练的技术实现,从单机多卡并行到万卡集群协同,系统揭示现代深度学习规模化训练的核心机制…...

使用Vite创建一个动态网页的前端项目
1. 引言 虽然现在的前端更新换代的速度很快,IDE和工具一批批的换,但是我们始终要理解一点基本的程序构建的思维,这些环境和工具都是为了帮助我们更快的发布程序。笔者还记得以前写前端代码的时候,只使用文本编辑器,然…...

常见的LLM
常见的 LLM(大语言模型,Large Language Models)可以按照开源/闭源、机构/公司、用途等维度分类。以下是一些主流和常见的 LLM 及其简介: 一、开源 LLM Meta(Facebook) 名称参数量特点LLaMA 1 / 2 / 37B /…...

助力 FPGA 国产化,ALINX 携多款方案亮相深圳、广州“紫光同创 FPGA 技术研讨会”
5 月中旬,一年一度的紫光同创技术研讨会系列活动正式拉开帷幕,相继在深圳、广州带来 FPGA 技术交流盛宴。 ALINX 作为紫光同创官方合作伙伴,长期助力推动 FPGA 国产化应用发展,此次携多款基于 Kosmo-2 系列产品开发的方案 demo 亮…...

深入浅出IIC协议 - 从总线原理到FPGA实战开发 --第四篇:I2C工业级优化实践
第四篇:I2C工业级优化实践 副标题 :从实验室到产线——I2C控制器的高可靠设计秘籍 1. 时序收敛技巧 1.1 关键路径识别与优化 Vivado时序报告解析 : Slack (MET): 0.152ns (要求≥0) Data Path Delay: 3.821ns (逻辑布线) Cell Delay: i…...

【leetcode】70. 爬楼梯
文章目录 1. 数组2. 优化空间 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1 阶 1…...

【web全栈】若依框架B站学习视频
文章目录 基础篇-01 AI若依导学视频基础篇02 若依搭建基础篇03 入门案例基础篇04 功能详解-权限控制 基础篇-01 AI若依导学视频 基础篇02 若依搭建 基础篇03 入门案例 基础篇04 功能详解-权限控制...

MFC 捕捉桌面存成jpg案例代码
下面是关于截屏并保存成jpg文件的代码。由主函数OnCapScreenJpg()、DDBToDIB()、JpegFromDib()、DibToSamps()以及QuadFromWord()函数组成。这些函数的功能包括截取屏幕、将截取的屏幕转成设备无关bmp、再进一步压缩成jpeg格式。这些代码是从网上得到的,得到的代码没…...

2.4.4-死锁的处理策略-检测和解除
知识总览 死锁的检测 用资源分配图这种数据结构来检测是否产生了死锁,资源分配图上有2种节点,进程节点用圆圈表示,一个圆圈代表一个进程,还有资源节点,一个矩形代表一类资源,用矩形中的圆圈表示当前类型的…...

豪越智能仓储:为消防应急物资管理“上锁”
在城市的繁华街角,一场突如其来的大火无情地肆虐着一栋商业大楼。火焰在楼内疯狂蔓延,滚滚浓烟迅速弥漫,人们的生命财产安全受到了严重威胁。消防警报声骤然响起,消防队员们迅速出动,争分夺秒赶赴火灾现场。然而&#…...
数字化转型之质量管理:遵循PDCA规范的全流程避险指南)
(06)数字化转型之质量管理:遵循PDCA规范的全流程避险指南
在全球化竞争和消费升级的双重驱动下,质量管理已从单纯的产品检验演变为企业核心竞争力的重要组成部分。一个完善的质量管理体系不仅能降低质量成本、提升客户满意度,更能成为品牌差异化的战略武器。本文将系统性地介绍现代企业质量管理的完整框架&#…...
:从基础到高频面试题)
图论算法精解(Java 实现):从基础到高频面试题
一、图的基础表示方法 1.1 邻接矩阵(Adjacency Matrix) 邻接矩阵是表示图的一种直观方式,它使用一个二维数组来存储节点之间的连接关系。对于一个有 n 个节点的图,邻接矩阵是一个 nn 的矩阵,其中 matrix [i][j] 表示…...
)
[Linux] Linux信号量深度解析与实践(代码示例)
Linux信号量深度解析与实践 文章目录 Linux信号量深度解析与实践一、什么是信号量1. 信号量的核心概念2. 信号量的分类3. 信号量的操作机制 二、怎么用信号量1. 信号量API的深度解析(1)无名信号量API(2)有名信号量API(…...
正式发布 替代Yuzu模拟器)
Switch最新 模拟器 Eden(伊甸)正式发布 替代Yuzu模拟器
Switch最新 模拟器 Eden(伊甸)正式发布 替代Yuzu模拟器 100 帧跑满《塞尔达传说:旷野之息》 这款模拟器基于 Yuzu 框架开发,但团队强调它并非…...

[cg] [ds]深度缓冲z与线性z推导
4. GLSL 代码实现 在着色器中,将深度缓冲值转换为线性深度: float LinearizeDepth(float depth, float near, float far) {// OpenGL 的 NDC 深度范围是 [-1, 1],需转换float z_ndc 2.0 * depth - 1.0;// 计算线性深度return (2.0 * near …...

clock的时钟频率check代码
在芯片验证中,经常遇到需要check时钟频率的场景,由于时钟数量有很多,手动写代码得到后年马月,所以我这边写了一个宏define,可以通过输入参数的形式验证需要check的时钟频率,大大提升了验证效率和准确率&…...

企业数字化转型是否已由信息化+自动化向智能化迈进?
DeepSeek引发的AI热潮迅速蔓延到了各个行业,目前接入DeepSeek的企业,涵盖了科技互联网、云服务、电信、金融、能源、汽车、手机等热门领域,甚至全国各地政府机构也纷纷引入。 在 DeepSeek 等国产 AI 技术的推动下,众多企业已经敏锐…...

PT5F2307触摸A/D型8-Bit MCU
1. 产品概述 ● PT5F2307是一款51内核的触控A/D型8位MCU,内置16K*8bit FLASH、内部256*8bit SRAM、外部512*8bit SRAM、触控检测、12位高精度ADC、RTC、PWM等功能,抗干扰能力强,适用于滑条遥控器、智能门锁、消费类电子产品等电子应用领域。 …...
)
嵌入式STM32学习——串口USART 2.0(printf重定义及串口发送)
printf重定义: C语言里面的printf函数默认输出设备是显示器,如果要实现printf函数输出正在串口或者LCD显示屏上,必须要重定义标准库函数里调用的与输出设备相关的函数,比如printf输出到串口,需要将fputc里面的输出指向…...
【Linux操作系统】)
进程信号(上)【Linux操作系统】
文章目录 进程信号信号引入进程要如何识别信号?进程接收到信号的时候,不一定马上处理信号进程处理信号的情况 信号相关概念信号产生键盘产生通过指令向进程发送信号系统调用向进程发送信号软件条件异常错误 操作系统如何知道进程出现了异常错误ÿ…...
)
全方位详解微服务架构中的Service Mesh(服务网格)
一、引言 随着微服务架构的广泛应用,微服务之间的通信管理、流量控制、安全保障等问题变得日益复杂。服务网格(Service Mesh)作为一种新兴的技术,为解决这些问题提供了有效的方案。它将服务间通信的管理从微服务代码中分离出来&a…...

bi工具是什么意思?bi工具的主要功能有哪些?
目录 一、BI 工具是什么意思? 1. 基本概念 2. 发展历程 编辑二、BI 工具的主要功能 1. 数据连接与整合 2. 数据存储与管理 3. 数据分析与挖掘 4. 可视化呈现 5. 报表生成与分享 6. 实时监控与预警 三、BI 工具的应用场景 1. 销售与营销 2. 财务与会计…...

cocos creator使用jenkins打包微信小游戏,自动上传资源到cdn,windows版运行jenkins
cocos 版本2.4.11 在windows上jenkins的具体配置和部署,可参考上一篇文章cocos creator使用jenkins打包流程,打包webmobile_jenkins打包,发布,部署cocoscreator-CSDN博客 特别注意,windows上运行jenkins需要关闭windows自己的jenkins服务&a…...

PaddleOCR的Pytorch推理模块
概述 在项目中,遇到文字识别OCR的使用场景。 然而,目前效果最好的PaddleOCR只能用百度的PaddlePaddle框架运行。 常见项目中,往往使用更普遍的Pytorch框架,单独安装PaddlePaddle不仅会让项目过于臃肿,而且可能存在冲…...
)
操作系统期末复习(一)
一、选择 1.从用户的观点看,操作系统是() A.用户与计算机之间的接口 B.控制和管理计算机资源的软件 C.合理地组织计算机工作流程的软件 由若干层次的程序按一定的结构组成的有机体 答案:A 2.操作系统在计算机系统中位于&#x…...

今日行情明日机会——20250521
上证指数缩量收阳线,个股跌多涨少,整体处于日线上涨末端,注意风险。 深证指数,出现60分钟的顶分型,需要观察方向的选择。 2025年5月21日涨停股主要行业方向分析 并购重组 涨停家数:9家。 代表标的&am…...