c++11特性——可变参数模板及emplace系列接口
文章目录
- 可变参数模板
- 基本语法和使用
- sizeof...运算符
- 从语法角度理解可变参数模板
- 包扩展
- 通过编译时递归解析参数包
- 直接对解析行为展开
- emplace系列接口
- 举例讲解
- emplace_back的实现
可变参数模板
可变参数模板是c++11新特性中极其重要的一节。前文我们提到过,c++11中对于个别容器引入了emplace系列的接口。可以在一定程度上提高一些效率。而emplace系列的接口又必须依靠可变参数模板来实现。
本篇文章将重点讲解关于可变参数模板这一个部分的内容。
基本语法和使用
先不看基本的语法。我们先来试着想一下,可变参数模板是变什么?参数可以变的东西也不多,无非就是类型,个数,顺序等。
但是我们已经学过模板了,模板在一定程度上就是泛化了参数的数据类型。模板就是为了泛化编程出现的。以往学的模板已经是做到了数据类型和顺序的泛化。现在进一步的泛化只能是泛化模板参数的个数了。这是非常有意义的,在了解意义之前,我们还是得先了解一下可变参数模板的基础语法和其底层原理。
首先我们先来看一下c++11引入的这个可变参数模板的基本语法:
C++11支持可变参数模板,也就是说支持可变数量参数的函数模板和类模板,可变数目的参数被称为参数包,存在两种参数包:模板参数包,表示零或多个模板参数;函数参数包:表示零或多个函数参数。
下面是可变参数模板的声名和定义:
template <class …Args> void Func(Args… args) {}
template <class …Args> void Func(Args&… args) {}
template <class …Args> void Func(Args&&… args) {}
这里和以往不同了。以往我们写模板参数的时候,是需要多少写多少。但是现在我们想要把模板参数的个数进行泛化,也就是说,在编写模板的时候并不知道有多少个。所以c++11引入了一个新的概念叫参数包。
写在模板参数声名的位置的叫做模板参数包。模板参数都被泛化成模板参数包了,那么函数参数列表也自然被泛化成了函数参数包。
我们用省略号…来指出一个模板参数或函数参数表示的一个包,在模板参数列表中,class…或typename…指出接下来的参数表示零或多个类型列表;在函数参数列表中,类型名后面跟…指出接下来表示零或多个形参对象列表;函数参数包可以用左值引用或右值引用表示,跟前面普通模板一样,每个参数实例化时遵循引用折叠规则。
这里的Args其实是参数英文arguments的缩写。本质上就是给传入的一系列不知道具体类型和个数的参数列表(可能有int,string,char,其他自定义类型,数量不知)取一个名字罢了。喜欢什么用什么。只不过大部分情况下更倾向于使用Args这个名字。
所以在这里我们可以浅显的认为,符号…代表的就是一个参数包。
sizeof…运算符
我们来试用一下可变参数模板并且讲解一下一个新的操作符sizeof…。
先来看下面一段代码:
//声名可变参数模板
template<class... Args>
void func(Args&&... args) {cout << sizeof...(args) << endl;
}#include<vector>int main() {func(2);func(1.1, string("123"));func(2, 2.2, 'a');int a = 10;func(&a, 10, 10.5, string("adab"));func(&a, 10, 30.5, string("abcd"), vector<int>());return 0;
}
我们先给出结论,操作符sizeof…是专门用来计算一个参数包有几个参数的。
比如上面的代码,我们将函数参数包args传给操作符sizeof…,就可以计算出args这个参数包内有几个参数。
我们试着验证一下,既然说可变参数模板是即可变参数类型,又可以变参数个数,我们就按照上面的测试方法进行参数的传递。
这里注意一下,我们采用的是万能引用去接收,对于深拷贝类型是可以调用移动构造从而不调用拷贝构造,节省效率。为什么这里可以使用左值引用和万能引用等一下讲解可变参数模板的原理的时候会细细道来。
我们来看一下上面那一段代码输出的结果是什么:

结果正好和上面说的一样。操作符sizeof…接收一个参数包,计算的是参数包里面参数的个数。注意这里的sizeof…和我们以前学的sizeof其实是两个不同的操作符。从功能上看确实是这样。因为sizeof计算的是数据类型占用的空间。
而且我们也可可看见,对于可变参数模板声名的函数,我们是可以传入任意类型和任意个数的参数进去的,最终都是被参数包接收了。
从语法角度理解可变参数模板
这种多可变参数的形式我们其实很早就接触过,就是在学习c语言时候学习的printf和scanf函数,我们称前面" "包起来的,以%开头的东西叫做占位符,如%d %f %c
而且在使用这两个函数的时候,前面占位符的个数是可以自己手动确定的。只需要后面传参数的时候一一对应就可以了。
可变参数模板其实就感觉和这个原理有点像。我们应该怎么去理解这个内容呢?
我们一步步推导,我们以一个实例来举例:
假设我们现在要写一个Print函数,功能是打印出函数参数列表中的每个参数
double x = 2.2;
Print();
Print(1);
Print(1, string("xxxxx"));
Print(1.1, string("xxxxx"), x);
在学习了函数重载的内容后,我们知道,函数名相同,参数不一样就可以构成函数的重载。在没有学习任何的模板的相关知识前,我们需要像下面这样写代码:
void Print() {cout << "" << endl;}
void Print(int x) {cout << x << endl;}
void Print(int x, const string& str) {cout << x << " " << str << endl;}
void Print(int x, const string& str, double y)
{cout << x << " " << str << " " << y << endl;}
是需要根据具体的传入的参数去写不同版本的Print函数的。
但是这样写是很麻烦的,所以c++引入了一个叫模板的概念,也就是在确定参数个数的情况下,泛化数据的类型,这样子就可以针对于不同的参数做出处理了,只不过说参数数据个数是确定的,于是可以写出下面这样的代码:
void Print() {cout << "" << endl;}template <class T1>
void Print(T1&& arg1) {cout << arg1 << endl;}template <class T1, class T2>
void Print(T1&& arg1, T2&& arg2) {cout << arg1 << " " << arg2 << endl;}template <class T1, class T2, class T3>
void Print(T1&& arg1, T2&& arg2, T3&& arg3)
{cout << arg1 << " " << arg2 << " " << arg3 << endl;}
这里使用了万能引用,这个需要注意一下。
使用了模板后,我们发现,针对于数据个数确定的情况下,类型是可以随意传的。只要数据类型有对应实现流插入提取运算符(能打印)就不会报错。
但是这个还是不够泛化。所以c++11引入了新的语法——可变参数模板。把模板参数和函数参数都泛化成了一个参数包。这个参数包可能由(0 ~ N)个不知道具体类型的参数集组成的。从语法的角度上来理解:
//可变参数模板写法
template <class ...Args>
void Print(Args&&... args)
{cout << sizeof...(args) << endl;}
假设当前调用了这个可变参数模板,把一系列的参数集传给这个函数参数包args,我们可以这样理解:

我们就以前面0个参数、1个参数、2个参数的来进行讲解。
首先,我们可以这么认为,之前的普通模板就是在参数个数确定的情况下,把数据类型泛化了。可变参数模板就是在参数类型已经泛化的前提下,再把参数个数进行泛化操作。
其次,当传入某个参数集的时候,在语法角度上,我们可以理解为,编译器先判断当前有几个参数。然后就会先生成一个对应的数据个数的函数模板。比如传入10个参数给可变参数模板的函数,那么我们可以认为编译器会自动生成带有10个模板参数的函数模板。
最后,传入的数据集每个参数的类型是确定的,所以又可以认为,编译器生成函数模板后,就会根据传入的参数集来自动推导每个模板参数的类型,实例化出对应的版本。
如果从上面的角度去理解的话,其实和以前学的函数模板差不多。只不过可以认为是再原有的函数模板的基础上又针对数量又套了一层函数模板。导致可变参数模板的步骤要多一步生成对应函数模板后再来推导。
但是需要注意的是,上面的阐述只是我们从语法角度去理解的。其实编译器可能并不是这样做的,很有可能编译器经过特殊处理后可以直接一步到位的。但是着并不妨碍我们从语法角度去理解它。就像引用和指针的关系一样,语法角度理解引用就是取别名。但是本质是一个指针。但是为了能够更好的掌握知识,有时候语法和底层实现是相背离的,需要我们灵活地去理解。
包扩展
但是细心的朋友们肯定发现了,前一个部分代码中定义的func函数中好像没有涉及到使用参数包里面的各个参数呢。以往在使用函数的,哪怕是模板函数,因为知道参数的名称的,所以可以直接使用参数。但是现在变成了一个参数包,应该怎么样通过这个参数包进行使用各个参数呢?这是需要我们进行思考的。
这个问题需要通过本部分讲的内容——包扩展来解决。包扩展其实就是将参数包中的参数解析出来,包的扩展十分重要。
我们先来讲一个很多人觉得可行的用法,但实际却不行:
假设我们想打印出参数包中的每一个参数(假设均已实现流插入和提取运算符):
template<class... Args>
void f(Args... args) {for (size_t i = 0; i < sizeof...(args); ++i) {cout << args[i] << endl;}
}int main() {int a = 10;f(1, 2.2, 'a', string("123"), &a);return 0;
}
很多人会觉得这样子是可以把每个参数取出来的。其实我也觉得这样子写很爽,特别好用。但是实际上不是这样的,编译会报错:

编译器是不支持这样子做的。报错的原因是args这个参数包必须要扩展。其实就是包扩展。c++在处理这种问题的时候是采取包扩展的方式,将参数包中的参数一个个解析出来的。至于怎么对包进行扩展,这是我们等一下要重点讲的内容。
现在我们来试着理解一下为什么c++不支持像图中那个用法。如果要这样子使用的话,有一个最大的问题是,每个参数的数据类型很可能是不同的。要支持上面那样解析参数包,就要把每个参数存起来。但是c++中支持的容器是只在后面新的版本才支持每个数据类型不一样。在c++11的时候,STL库中的所有容器中所有的数据类型都是一样的。而且上面那种方式用起来是很简单,但是也要考虑到对编译器的要求。也可能是这种解析方式对于编译器来讲实现难度太大了。很可能是这些原因导致c++不支持这种解析方式。
接下来将重点讲解两种包扩展的方式。
通过编译时递归解析参数包
第一种方法是通过编译时递归的方法进行参数包的解析。为什么需要特意强调是编译时的递归呢,这点我们先不讲,先来直接看用法:
//编译时递归终止条件
void Show() {cout << endl;
}//递归函数
template<class T, class... Args>
void Show(T x, Args&&... args) {cout << x << endl;Show(args...);
}template<class... Args>
void func(Args&&... args) {Show(args...);
}int main() {int a = 10;func(1, 2.2, 'a', string("123"), &a);return 0;
}
我们来看看结果:

发现输出结果是我们想要的,但是我们发现,这种方式其实很奇怪。但是别着急,我们一起来分析一下这个过程是如何进行的。
- 首先我们得知道这个是编译时递归
为什么说是编译时递归,难道以前用的递归不是编译时递归吗?
是的,以前我们使用的递归是运行时递归,是一个动态过程。而这里是一个静态过程。怎么样来判断呢?很简单,我们尝试着把递归终止条件删除看看:

这里报错了。但是以往的递归中,如果在没有语法错误的情况下,不写终止条件是编译是不会报错的。因为编译检查的是语法。但是运行的时候就会发现程序会因为栈溢出的问题崩溃了。所以正常来说,这里不应该报错。
但是在取消了终止条件后,编译器报错了。说明编译器做了一件事情:就是在编译的时候将递归展开了,但是没有终止条件,所以最后报错了。所以这里足以证明这里的包解析方式是通过编译时的递归进行展开包的。
- 了解编译时递归是如何进行的
首先,对于解析参数而言,要将参数包展开进行解析。然后需要通过另外一个函数来帮忙的。这个函数就是上面的Show函数(当然可以是其它的名字)。然后通过这个Show函数和对应的终止条件进行编译时的递归。
我们先来看看Show函数的声名,这也是一个函数模板,只不过模板参数比较特殊:
是一个模板参数T和可变模板参数的参数包。然后func函数中调用这个Show函数。
然后我们直接开始讲具体的流程:
首先,func函数调用Show函数,把参数包args传给Show函数的参数部分。但是需要注意一下这里的传参,会发现args后面加了…。这是为什么?因为要将参数包展开。我们可以理解在参数包名后面加…,这个行为就是告诉编译器要将这个包进行展开。
因为一个包肯定是没办法直接赋值给一个参数列表的。在Show函数中,参数列表是一个T类型和一个参数包。func中的args这个参数包肯定是没办法传给T x,Args…组成的参数列表的。所以在包后面加…就是告诉编译器,按照接收参数的部分进行包展开,以便能够匹配参数。不这样做编译器是会报错的:

然后我们就得知道,这里是如何做到递归的:
递归最重要的就是理解子进程和终止条件。我们发现上面的终止条件是参数列表为空的时候。我们大致就可以猜测,这种编译时递归的包扩展应该就是靠参数控制的。
实际确实是这样:首先main函数调用func函数的时候,传入了五个参数,这五个参数包会在func函数中展开传给Show函数。这里我们就得知道,将参数包展开传给子函数的时候是怎么展开的。
展开方式是:将参数包中的第一个参数给到参数T x,然后剩余的参数组成一个新的包。那么子进程的args包就会变成4个。然后再继续调用,那么又是重复上面的过程,把包中第一个参数给T x,然后再把剩余的3个参数组成一个包给子进程的args包。以此类推,直到编译器发现,参数包变成空的时候,就会调用参数列表为空的那个Show函数。这样子就停止这个递归展开的过程了。
可以画个图进行理解,为了画图方便,只画出三个参数二段情况。其实参数多少个原理都一样,只不过递归展开次数有变化而已:

就是在调用Show函数的时候,参数包展开。只不过需要匹配一下Show函数的参数列表。匹配的方式就是将第一个参数给Show的第一个参数,剩下的给到参数包。然后再将新的参数包展开传入调用,直到参数包为空就停止这个过程。
这就是第一种方式进行包的展开。
直接对解析行为展开
上面那种方法属于是编译时递归,现在这个方法我认为可以称为对解析行为的展开。
我们来直接看代码怎么写的:
template<class T>
const T& GetArg(const T& arg) {cout << arg << endl;return arg;
}template<class... Args>
void Argment(Args... args) {cout << "Hello" << endl;
}template<class... Args>
void Print(Args... args) {Argment(GetArg(args)...);
}int main() {Print(1, 2.5, string("123"));return 0;
}
在Print函数中,如果想要将参数包args进行参数的解析,还可以使用这种方法。
假设想要在Print调用Argment这个函数,正常来讲是可以直接这么调用的:

直接在Print中将args展开传给Argment函数就可以了。但是现在想要把args中的参数一个个解析出来,用到的方法就是使用语句:Argment(GetArg(args)…)
我们发现,这个展开符号…放在了GetArg这个调用的后面。我管这种行为叫:对解析行为的展开。因为我们发现,解析函数GetArg的参数列表中仅仅只有一个参数。我们是万万不能直接将args…传给它的参数列表进行接收的。因为GetArg函数的参数没有参数包,将args展开至少得参数包去接收。
假设外界调用Print(1, 2.5, string(“123”));,传给Print的函数包args就有三个参数。但是对于GetArg来说,一次只能接收一个参数。而Argment这个函数的参数部分是参数包,也就是说,想要通过GetArg解析出来的参数传给Argment函数,势必要对GetArg这个行为进行展开,要不然是匹配不上参数形式的。
传给Print函数的参数有三个,那么再把args传给GetArg函数,并对这个行为展开,也就是说,GetArg(args)…其实要调用三次。才能得出Print中参数包args的样子。
我们画个图来理解一下:

再说一次:因为Print参数包里面有三个参数,如果将这个参数包传给GetArg然后并且对这个行为进行展开,本质上就是args里有多少个参数,GetArg就会调用多少次,然后将这些解析出来的返回值传给下一层函数Argment。
当然这个GetArg的返回值也可以是其他,比如返回一个int。因为Argment的参数是一个参数包,可以随便接收。具体返回什么取决于使用场景,我们看看上面那段代码的输出结果:
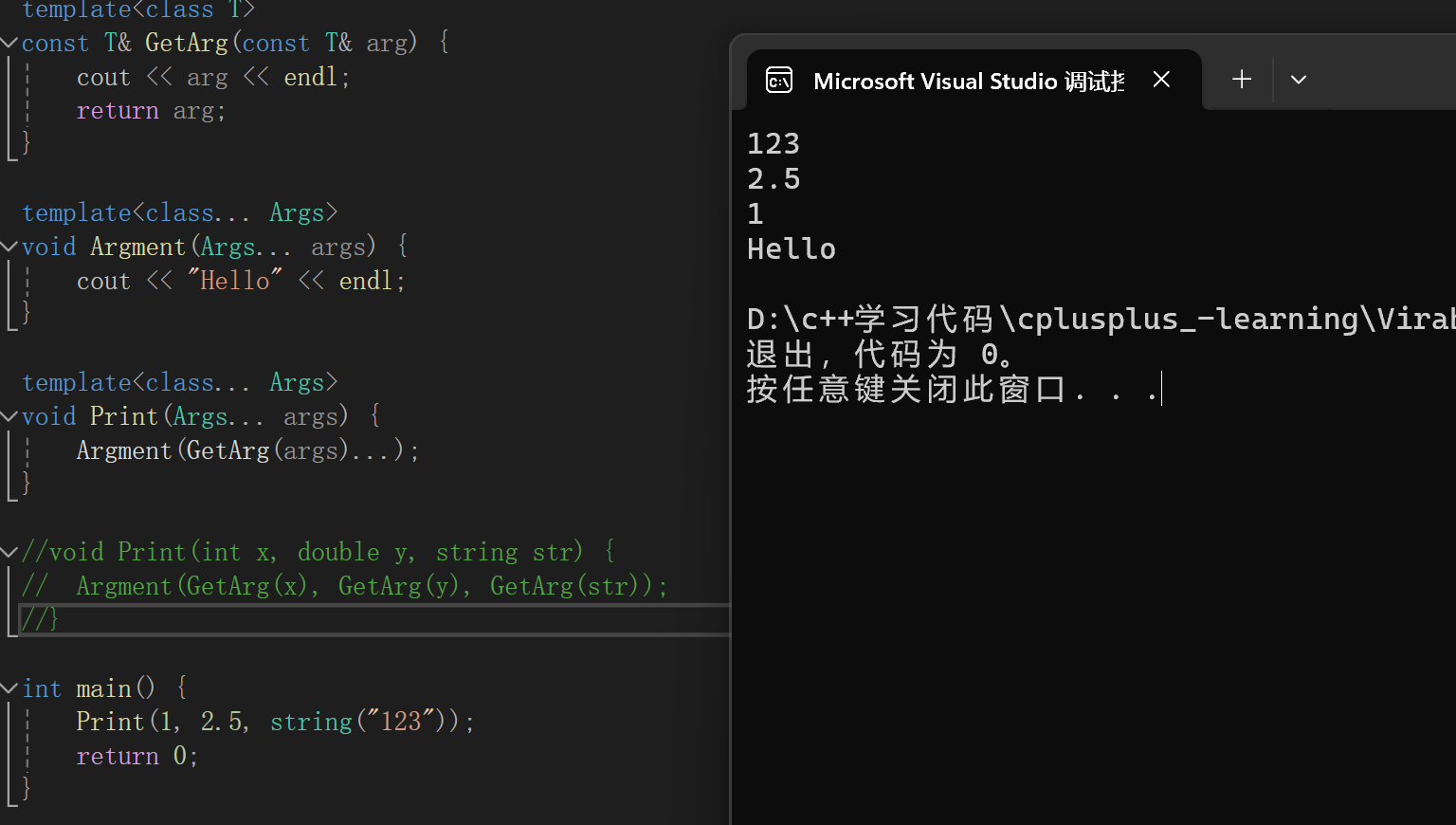
我们发现是可以正常解析出来的。但是解析出来的顺序是反过来的。这点注意一下就可以了。
emplace系列接口
c++11后,有些容器(如list)引入了一个新的系列的接口:


在刚开始学习STL容器的时候,我们就说过,对于emplace系列的接口,其实和push_back和push_front两个插入接口基本上是一样的。只不过说对于某些场景下,emplace系列的接口可以更加高效一点。今天我们一起来探讨以下为什么emplace系列的接口会高效,且看看为什么c++11引入这个接口后很多人更倾向于使用emplace系列的接口。
举例讲解
我们就以自行实现的list< myspace::string >容器进行讲解。但是emplace系列接口涉及我们以前讲到的移动构造和移动赋值等知识,所以我们得改进一下以往实现的list和string:
改进的string
#include<iostream>
#include<assert.h>
#include<string.h>
using namespace std;namespace my {class string{
public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)-构造" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}string(const string& s):_str(nullptr){cout << "string(const string& s) -- 拷贝构造" << endl;reserve(s._capacity);for (auto ch : s){push_back(ch);}}// 移动构造string(string&& s){cout << "string(string&& s) -- 移动构造" << endl;swap(s);}string& operator=(const string& s){cout << "string& operator=(const string& s) -- 拷贝赋值" <<endl;if (this != &s){_str[0] = '\0';_size = 0;reserve(s._capacity);for (auto ch : s){push_back(ch);}}return *this;}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动赋值" << endl;swap(s);return *this;}~string(){//cout << "~string() -- 析构" << endl;delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str){strcpy(tmp, _str);delete[] _str;}_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}size_t size() const{return _size;}
private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;
};
}
对于string来讲,加多了几个接口。即移动构造和移动赋值。加上这两个接口是为了减少拷贝构造的调用。这点我们在上一篇文章就已经讲过的。
改进后的List:
namespace my{
#pragma once
#include<iostream>
#include<assert.h>
#include<string>
#include<vector>
#include<initializer_list>
using namespace std; namespace MyList {template<class T>struct list_node {T _data;list_node<T>* _prev = nullptr;list_node<T>* _next = nullptr;list_node(const T& Val = T()):_data(Val),_prev(nullptr),_next(nullptr){}list_node(T&& Val):_data(std::forward<T>(Val)),_prev(nullptr),_next(nullptr){}template<class... Args>list_node(Args... args) : _data(std::forward<Args>(args)...),_prev(nullptr),_next(nullptr){}};//模仿源码中写的方式 写迭代器template<class T, class Ref, class Ptr> //T代表数据类型(节点中存储的数据 Ref代表对数据的引用 区分const和非const Ptr为指向数据的指针 也是区分const和非conststruct list_iterator{typedef list_node<T> Node;typedef list_iterator<T, Ref, Ptr> Self;list_iterator(Node* node = nullptr){_node = node;}Ref& operator*() {return _node->_data;}Ptr operator->() {return &(_node->_data);}Self& operator++() {_node = _node->_next;return *this;}Self& operator--() {_node = _node->_prev;return *this;}Self operator++(int) {list_iterator tmp(*this);_node = _node->_next;return tmp;}Self operator--(int) {list_iterator tmp(*this);_node = _node->_prev;return tmp;}bool operator==(const Self& x) {return _node == x._node;}bool operator!=(const Self& x) {return _node != x._node;}Node* _node;};template<class T>class list {public:typedef list_node<T> Node; typedef list_iterator<T, T&, T*> iterator;typedef list_iterator<T, const T&, const T*> const_iterator;//创建哨兵位节点void HeadNode() {_head = new Node(T());_head->_prev = _head;_head->_next = _head;_size = 0;}list(int n, const T& value = T()) {HeadNode();for (int i = 0; i < n; ++i) {push_back(value);}}template <class T>list(const initializer_list<T>& x) {HeadNode();typename initializer_list<T>::iterator it = x.begin();while (it != x.end()) {push_back(*it);++it;}}template <class PushIterator>list(PushIterator first, PushIterator last) { HeadNode(); PushIterator it = first; while (it != last) { push_back(*it); ++it; }}list() {cout << "list() 构造" << endl;HeadNode();}list(list<T>& l) { //cout << "拷贝构造" << endl; HeadNode(); typename list<T>::iterator it = l.begin(); while (it != l.end()) { push_back(*it); ++it; }}list(list<T>&& l) {//cout << "移动构造" << endl;swap(l);}list<T>& operator=(list<T>& tmp) {//cout << "拷贝赋值" << endl;HeadNode();typename list<T>::const_iterator it = tmp.begin();while (it != tmp.end()) { push_back(*it); ++it; }return *this;}list<T>& operator=(list<T>&& tmp) {//cout << "移动赋值" << endl;swap(tmp);return *this;}//析构~list() {clear();delete _head;_head = nullptr;}void push_back(const T& x) {insert(end(), x);}void push_back(T&& x){insert(end(), forward<T>(x));}template<class... Args>void emplace_back(Args&&... args) {insert(end(), std::forward<Args>(args)...);}//iterator//iterator begin() {return _head->_next;}iterator end() {return _head;}const_iterator begin() const{return _head->_next;}const_iterator end() const{return _head;}////capacitysize_t size() {return _size;}bool empty() {return _size == 0;}////access//T& front() {assert(!empty());return _head->_next->_data;}T& back() {assert(!empty());return _head->_prev->_data;}const T& front() const{assert(!empty());return _head->_next->_data;}const T& back() const{ assert(!empty());return _head->_prev->_data;}////operation///void swap(list& lt) {std::swap(_head, lt._head);std::swap(_size, lt._size);}iterator insert(iterator pos, const T& x) {Node* newnode = new Node(x);Node* prev = (pos._node)->_prev, *next = pos._node;prev->_next = newnode;newnode->_prev = prev;newnode->_next = next;next->_prev = newnode;++_size;return newnode;//隐式类型转换返回}iterator insert(iterator pos, T&& x){Node* cur = pos._node;Node* newnode = new Node(forward<T>(x));Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}template<class... Args>iterator insert(iterator pos, Args&&... args){Node* cur = pos._node;Node* newnode = new Node(std::forward<Args>(args)...);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}iterator erase(iterator pos) {assert(pos != end());Node* POS = pos._node;Node* prev = (pos._node)->_prev, *next = (pos._node)->_next;prev->_next = next;next->_prev = prev;delete POS; return next;}void clear() {list<T>::iterator it = begin();while (it != end()) {it = erase(it);}_size = 0;}void push_front(const T& val) {insert(begin(), val);}void pop_front(){erase(begin()); }private:Node* _head;size_t _size; };
}注意:这里我直接实现了list对应的emplace_back接口。至于具体原理是什么等一下会说。这里就以尾插的方式来测试就好了。主要是理解原理,并能够较为熟练地使用这个系列的接口。
我们先来看第一个:在只使用push_back接口的情况下:
#include"List.h"
#include"String.h"
using namespace std;
int main() {//先调用list的默认构造//然后生成头结点的时候得生成一个string,所以调用构造//然后因为给的是右值进行构造 所以是再调用一次移动构造MyList::list<my::string> lt1;cout << "--------------------------------------------" << endl;//这个s1先调用构造生成s1 然后s1已存在 是个左值 所以再调用push_back就是走的拷贝构造my::string s1("123456");lt1.push_back(s1);cout << "--------------------------------------------" << endl;//这个是先生成临时变量 然后调用移动构造lt1.push_back("123456");cout << "--------------------------------------------" << endl;//构造临时对象 然后是个右值 还是走移动构造lt1.push_back(my::string("123456"));cout << "--------------------------------------------" << endl;return 0;
}
这些其实在上一节课已经讲过。但是为了和后面调用emplace_back的时候做对比,所以就再来回顾一下,我们一起看看结果:

事实确实是如此。
现在再来看一下emplace系列的接口的使用,我们先看结果,再来讲实现:
int main() {//先调用list的默认构造//然后生成头结点的时候得生成一个string,所以调用构造//然后因为给的是右值进行构造 所以是再调用一次移动构造MyList::list<my::string> lt2;cout << "--------------------------------------------" << endl;//会直接调用构造lt2.emplace_back("123456789");cout << "--------------------------------------------" << endl;//调用构造后再移动构造lt2.emplace_back(my::string("123456"));cout << "--------------------------------------------" << endl;//先构造出s 然后调用拷贝构造my::string s("hello");lt2.emplace_back(s);cout << "--------------------------------------------" << endl;return 0;
}
我们来看看输出:

结果和分析的一样。
调用emplace的接口,如果传入的是左值,那么就和push_back一样走的拷贝构造。但是传入右值的时候,就发现有一些区别了。如果传入的是匿名对象,那逻辑和尾插也差不多。但是如果只传字符串,emplace系列的接口优势就来了。直接就构造就好了,都不需要再调用任何的移动构造和拷贝构造。这效率肯定是高一点点的,但不会很多。
我们再来看一个例子:
int main() {MyList::list<pair<my::string, int>> lt3;cout << "--------------------------------------------" << endl;//这里先通过隐式类型转化 构造出一个pair的临时对象//然后再调用移动构造lt3.push_back({ "string1", 1 });cout << "--------------------------------------------" << endl;//先调用构造 构造出p1//然后p1是左值 所以调用push_back的时候还需要调用拷贝构造pair<my::string, int> p1("string2", 2);lt3.push_back(p1);cout << "--------------------------------------------" << endl;//p1是左值//所以和push_back的行为是一样的lt3.emplace_back(p1);cout << "--------------------------------------------" << endl;//要小心move左值 会把左值的内容掠夺走//右值 最后直接进行移动构造lt3.emplace_back(move(p1));cout << "--------------------------------------------" << endl;return 0;
}

总的来说,经过几个测试用例发现,其实emplace和push两个方式用法其实差不多。都可以接收左值和右值。区别就是在于,对于push系列,左值右值是分开实现的。但是emplace系列是通过可变参数模板进行接收的。对于emplace系列,如果接收左值,行为其实和push_back的左值调用差不多。
但是在右值的处理上就有一些差别了。对于某些情况下,emplace不需要进行移动构造,所以效率会略高一点。但是这限于需要深拷贝的数据类型。因为不需要深拷贝的类型没有移动构造这一说法。所以效率也差不多。
emplace_back的实现
我们先来看一个例子:

其实就是刚才的测试用例,发现当list内存的是一个pair<my::string, int>的时候,当我们想走隐式转换构造一个pair,然后再去调用移动构造的时候发现,emplace_back这个接口不支持这么干。反倒是把这个pair里面的内容分开来传进去倒是可以正常使用:

而且,分开来写效率还更高一点。这是为什么?这也太奇怪了。
别急,这关系到emplace_back底层的实现原理,我们先来讲emplace_back的实现:
实现emplace_back其实很简单,就是把参数变成可变模板参数的万能引用版本:
//迭代器是已经实现的了。
template<class... Args>
void emplace_back(Args&&... args) {//注意这里参数包的展开有点特别 先完美转发 再展开insert(end(), std::forward<Args>(args)...);
}
emplace_back其实就是尾插。所以直接调用insert接口,通过迭代器插入就好了。
前面我们讲过,插入的数据如果是一个参数包,就需要将其展开。而且接收这个展开参数包的接口的形参必须也是参数包。还有个问题就是,如果参数包中有传右值的,我们最好保持其特性。因为对于传右值的,是一些临时变量、匿名对象而已。肯定要去匹配右值版本的接口会更好。因为右值会调用移动构造和移动赋值。效率是比拷贝的高很多的。
但是传入左值的,我们也应该是希望保持其特性。因为左值一般是长期存储在内存中的值。如果让它变成右值就很危险了,很容易把它的资源给掠夺了。但是大部分情况下,传左值是不希望被修改的,所以也要保持左值的特性。
但是无论是左值引用还是右值引用本身,都是左值。所以在前面我们讲过,为了保持特性,应该使用完美转发,一直保持类型即可。
这里不需要对参数包解析。可以这么理解:把整个参数包当成一个参数进行插入。解析出来没用,我们又不需要使用里面的参数。
这里我们没有实现有参数包的insert接口,实现一个就好了。
template<class... Args>
iterator insert(iterator pos, Args&&... args)
{Node* cur = pos._node;Node* newnode = new Node(std::forward<Args>(args)...);Node* prev = cur->_prev;// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);
}
这里也要使用完美转发。为什么?
一样的道理,new Node的时候会调用节点的构造函数。现在是要把参数包当成数据插入。所以还是要把参数包展开传给Node的构造函数。还是要完美转发。因为虽然前面完美转发过一次,但是在这个函数里面,右值引用的本身又是左值。所以还是得完美转发一次。
但是Node的构造函数里面又没有参数包版本的,所以又得实现一个参数包版本的:
template<class... Args>
list_node(Args... args) : _data(std::forward<Args>(args)...),_prev(nullptr),_next(nullptr)
{}
这里也是一样的,直接完美转发再展开。到这里就实现完了。
因为到了这一层,这个_data其实就是要插入的数据的类型。前面要一直不停的传是因为没有停止的条件。到这里就不一样了。这里参数包展开后,我们可以理解为在参数列表那变成了一个个的参数,这些参数其实就是这个数据类型_data所需要的构造条件。
就以刚刚的pair举例:
lt3.emplace_back(“12345678910”, 1);
这样子写,参数包里面第一个参数是const char*,第二个是int。
调用emplace_back接口,把参数包展开传给insert接口。由于insert接口没有匹配的,所以要实现一个对应的版本。
insert接口里面又调用Node的构造函数。Node的构造函数又是没有匹配的版本,所以得实现以恶搞版本。
所以前面一直只是把参数包展开,然后往下传。但是到了Node的构造这一层就不一样了,比如这个pair,展开后应该是这样的:
list_node(class... Args){
//相当于list_node(const char* pstr, int x): _data(std::forward<Args>(args)...),//相当于这个_data(pstr, x);_prev(nullptr),_next(nullptr)
}
这不正好是调用pair的构造吗?如果只有一个pstr在这,不正好构成了string用字符串来构造的默认构造函数吗?
所以传到最后一层发现,直接调用构造了。这也就是为什么emplace系列效率高的原因。因为传参数包进来直接调用构造了,而且写起来还很方便。
但是如果是调用push_back的接口,会先构造再来移动构造。所以差别就在这里。
现在再来回过头看开头提出的问题就很好理解了。:
因为lt3.emplace_back的时候,emplace_back的那个模板参数包Args还是没有确定的。emplace_back其实套了两层模板参数。第一层是T,也就是存储的数据类型。第二层是这个参数包Args。但是push_back并没有多套一层模板参数,push_back的参数列表中,数据类型是T。这个早在实例化出list的时候就被确定了。
所以在调用push_back的时候,就可以确认,插入的数据是一个pair。然后将{ }括起来的东西走隐式转化变成pair类再插入。
但是emplace_back在调用的时候,这个Args并不确定的,只是用来接收参数包的。但是直接写成这样{“12345678910”, 1} 传给参数包。参数包都不知道这个是什么。这个不是pair,不要给花括号隐式类型转化成pair搞迷糊了。这个也不是initializer_list,因为initializer_list要求里面每个数据的数据类型是一样的。所以这里这样子写是一定会报错的。
所以我们在这里总结:
emplace系列的接口在插入右值的时候效率确实高一些。而且在通过emplace系列操作的时候,都不需要走隐式转化呢,也不需要提前构造。直接准备好需要的参数就可以了。这写起来简单又明了。emplace接收左值的行为又基本和push系列的行为差不多。所以以后可以多使用以下这个系列的接口,确实高效一点,还好用。
相关文章:

c++11特性——可变参数模板及emplace系列接口
文章目录 可变参数模板基本语法和使用sizeof...运算符 从语法角度理解可变参数模板包扩展通过编译时递归解析参数包直接对解析行为展开 emplace系列接口举例讲解emplace_back的实现 可变参数模板 可变参数模板是c11新特性中极其重要的一节。前文我们提到过,c11中对…...
深入理解 Pre-LayerNorm :让 Transformer 训练更稳
摘要 在超深 Transformer 与大语言模型(LLM)时代,归一化策略直接决定了模型能否稳定收敛、推理性能能否最大化。把归一化层从 “残差之后” 挪到 “子层之前”(Pre-LayerNorm,Pre-LN),再将传统…...

vue3:十三、分类管理-表格--分页功能
一、实现效果 实现分页功能,并且可对分页功能和搜索框功能能动态显示 1、显示分页 2、分页功能和搜索栏隐藏 二、基础搭建 1、官网参考 Pagination 分页 | Element Plus 使用分页的附加功能 2、表格中底部写入分页 (1)样式class 在全局js中写入顶部外边距样式margin-t…...

工商总局可视化模版-Echarts的纯HTML源码
概述 基于ECharts的工商总局数据可视化HTML模版,帮助开发者快速搭建专业级工商广告数据展示平台。这款模版设计规范,功能完善,适合各类工商监管场景使用。 主要内容 本套模版采用现代化设计风格,主要包含以下核心功能模块&…...

8.2 线性变换的矩阵
一、线性变换的矩阵 本节将对每个线性变换 T T T 都指定一个矩阵 A A A. 对于一般的列向量,输入 v \boldsymbol v v 在空间 V R n \pmb{\textrm V}\pmb{\textrm R}^n VRn 中,输出 T ( v ) T(\boldsymbol v) T(v) 在空间 W R m \textrm{\pmb W}\…...

工业路由器WiFi6+5G的作用与使用指南,和普通路由器对比
工业路由器的技术优势 在现代工业环境中,网络连接的可靠性与效率直接影响生产效率和数据处理能力。WiFi 6(即802.11ax)和5G技术的结合,为工业路由器注入了强大的性能,使其成为智能制造、物联网和边缘计算的理想选择。…...

Nginx核心服务
一.正向代理 正向代理(Forward Proxy)是一种位于客户端和原始服务器之间的代理服务器,其主要作用是将客户端的请求转发给目标服务器,并将响应返回给客户端 Nginx 的 正向代理 充当客户端的“中间人”,代…...
 原理及其在语义分割中的应用)
条件随机场 (CRF) 原理及其在语义分割中的应用
条件随机场 (CRF) 原理及其在语义分割中的应用 一、条件随机场的原理 条件随机场 (Conditional Random Fields, CRF) 是一种判别式概率无向图模型。它用于在给定观测序列 (如图像中的像素) 的条件下,对另一组序列 (如像素的语义标签) 进行建模和预测。 与生成式模…...

2025年Y2大型游乐设施操作证备考练习题
Y2 大型游乐设施操作证备考练习题 单选题 1、《游乐设施安全技术监察规程(试行)》规定:对操作控制人员无法观察到游乐设施的运行情况,在可能发生危险的地方应( ),或者采取其他必要的安全措施。…...

L53.【LeetCode题解】二分法习题集2
目录 1.162. 寻找峰值 分析 代码 提交结果 2.153. 寻找旋转排序数组中的最小值 分析 图像的增长趋势可以分这样几类 逐个击破 比较明显的 先增后减再增 用二段性给出left和right的更新算法 代码 提交结果 其他做法 提交结果 3.LCR 173. 点名(同剑指offer 53:0~…...
)
趣味编程:抽象图(椭圆组成)
概述:本篇博客主要讲解由椭圆图案组合而成的抽象图形。 1.效果展示 该程序的实际运行是一个动态的效果,因此实际运行相较于博客图片更加灵动。 2.源码展示 // 程序名称:椭圆组合而成的抽象图案// #include <graphics.h> #include <…...

RPA浪潮来袭,职业竞争的新风口已至?
1. RPA职业定义与范畴 1.1 RPA核心概念 RPA(Robotic Process Automation,机器人流程自动化)是一种通过软件机器人模拟人类操作,实现重复性、规律性任务自动化的技术。它能够自动执行诸如数据输入、文件处理、系统操作等任务&…...

【Elasticsearch】字段别名
在 Elasticsearch 中,字段别名(Field Alias)主要用于查询和检索阶段,而不是直接用于写入数据。 为什么不能通过字段别名写入数据? 字段别名本质上是一个映射关系,它将别名指向实际的字段。Elasticsearch …...
)
【Linux笔记】防火墙firewall与相关实验(iptables、firewall-cmd、firewalld)
一、概念 1、防火墙firewall Linux 防火墙用于控制进出系统的网络流量,保护系统免受未授权访问。常见的防火墙工具包括 iptables、nftables、UFW 和 firewalld。 防火墙类型 包过滤防火墙:基于网络层(IP、端口、协议)过滤流量&a…...

人工智能解析:技术革命下的认知重构
当生成式AI能够自主创作内容、设计方案甚至编写代码时,我们面对的不仅是工具革新,更是一场关于智能本质的认知革命。人工智能解析的核心,在于理解技术如何重塑人类解决问题和创造价值的底层逻辑——这种思维方式的转变,正成为数字…...

Neo4j实现向量检索
最近因为Dify、RagFlow这样的智能体的镜像拉取的速度实在太麻烦,一狠心想实现自己的最简单的RAG。 因为之前图数据库使用到了neo4j,查阅资料才发现Neo4j从5.11版本开始支持向量索引,提供一个真实可用的单元测试案例。 Neo4j建向量索引表…...

SpringBoot外部化配置
外部化配置(Externalized Configuration)是指将应用的配置从代码中剥离出来,放在外部文件或环境中进行管理的一种机制。 通俗地说,就是你不需要在代码里写死配置信息(比如数据库账号、端口号、日志级别等)…...
|深度多组学破局肝癌免疫联合治疗耐药的空间微环境图谱)
Gut(IF: 23.1)|深度多组学破局肝癌免疫联合治疗耐药的空间微环境图谱
肝细胞癌(HCC)是癌症相关死亡的主要原因之一,晚期患者预后极差。近年来,免疫检查点抑制剂(ICI)联合治疗(如抗CTLA-4的tremelimumab和抗PD-L1的durvalumab)已成为晚期HCC的一线治疗方…...

2025年保姆级教程:Powershell命令补全、主题美化、文件夹美化及Git扩展
文章目录 1. 美化 Powershell 缘起2. 安装 oh-my-posh 和 posh-git3. 安装文件夹美化主题【可选】 1. 美化 Powershell 缘起 背景:用了 N 年的 Windows 系统突然觉得命令行实在太难用了,没有补全功能、界面也不美观。所以,我决定改变它。但是…...

LeetCode-链表-合并两个有序链表
LeetCode-链表-合并两个有序链表 ✏️ 关于专栏:专栏用于记录 prepare for the coding test。 文章目录 LeetCode-链表-合并两个有序链表📝 合并两个有序链表🎯题目描述🔍 输入输出示例🧩题目提示🧪AC递归&…...
-前端基本页面配置-登录界面编写-Axios请求封装-后端跨越请求错误)
SpringBoot3+Vue3(2)-前端基本页面配置-登录界面编写-Axios请求封装-后端跨越请求错误
前端: 清理文件 main.js 刷新后页面上什么都没有了 App.vue就留这 1.基本页面配置 新建Vue组件 单页面,考路由才操作。 1.前端根目录下安装路由 2.创建路由文件夹 main.js中添加路由配置 App.vue 添加上路由 welcomeView.vue 浏览器刷新&…...

Android Framework学习八:SystemServer及startService原理
文章目录 SystemServer、SystemServiceManger、SystemService、serviceManager的关系SystemServer进程的执行包含的ServiceSystemServer启动服务的流程startService Framework学习系列文章 SystemServer、SystemServiceManger、SystemService、serviceManager的关系 管理机制&a…...

远程访问家里的路由器:异地访问内网设备或指定端口网址
在一些情况下,我们可能需要远程访问家里的路由器,以便进行设置调整或查看网络状态等,我们看看怎么操作? 1.开启远程访问 在路由本地电脑或手机,登录浏览器访问路由管理后台,并设置开启WEB远程访问。 2.内…...

大语言模型 17 - MCP Model Context Protocol 介绍对比分析 基本环境配置
MCP 基本介绍 官方地址: https://modelcontextprotocol.io/introduction “MCP 是一种开放协议,旨在标准化应用程序向大型语言模型(LLM)提供上下文的方式。可以把 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 提供了一种…...

python生成requirements.txt文件
方法一:只生成项目所用到的python包(常用) 首先安装pipreqs pip install pipreqs 然后进入到你所在的项目根目录,运行以下命令: pipreqs ./ --encodingutf-8 方法二:把本地所有安装包写入文件 pip freeze > requirements.txt …...

如何在PyCharm2025中设置conda的多个Python版本
前言 体验的最新版本的PyCharm(Community)2025.1.1,发现和以前的版本有所不同。特别是使用Anaconda中的多个版本的Python的时候。 关于基于Anaconda中多个Python版本的使用,以及对应的Pycharm(2023版)的使用,可以参考…...

StepX-Edit:一个通用图像编辑框架——论文阅读笔记
一. 前言 代码:https://github.com/stepfun-ai/Step1X-Edit 论文:https://arxiv.org/abs/2504.17761 近年来,图像编辑技术发展迅速,GPT- 4o、Gemini2 Flash等前沿多模态模型的推出,展现了图像编辑能力的巨大潜力。 这…...

vue原生table表格实现动态添加列,一行添加完换行继续添加。el-select输入框背景颜色根据所选内容不同而改变
效果如下 动态添加列 代码如下 <template><div class"table-container"><button click"addColumn">添加列</button><div class"scroll-container"><div class"table-grid"><div v-for"(r…...

maven之pom.xml
MAVEN 1、基础配置2、项目信息3、依赖管理4、构建配置5、继承与聚合6、仓库与SCM7、其他高级配置 Maven的pom.xml文件是项目的核心配置文件,用于定义项目结构、依赖关系和构建过程 https://www.runoob.com/maven/maven-pom.html 1、基础配置 **<…...

深度学习Y8周:yolov8.yaml文件解读
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 本周任务:根据yolov8n、yolov8s模型的结构输出,手写出yolov8l的模型输出、 文件位置:./ultralytics/cfg/models/v8/yolov8.…...

充电桩APP的数据分析:如何用大数据优化运营?
随着新能源汽车的普及,充电桩作为基础设施的核心环节,其运营效率直接影响用户体验和行业可持续发展。充电桩APP积累了海量用户行为、充电记录、设备状态等数据,如何利用这些数据优化运营成为关键课题。大数据分析能够帮助运营商精准定位问题、…...

shell脚本之函数详细解释及运用
什么是函数 通俗地讲,所谓函数就是将一组功能相对独立的代码集中起来,形成一个代码块,这个代码可 以完成某个具体的功能。从上面的定义可以看出,Shell中的函数的概念与其他语言的函数的 概念并没有太大的区别。从本质上讲&#…...

校平机的原理、应用及发展趋势
一、校平机的定义与作用 校平机(Leveling Machine)是一种用于矫正金属板材、带材或卷材表面平整度的工业设备。其核心功能是通过机械作用消除材料内部残余应力,修正材料在加工、运输或存储过程中产生的弯曲、波浪形、翘曲等缺陷,…...

NFM算法解析:如何用神经网络增强因子分解机的特征交互能力?
在推荐系统和广告点击率预测等场景中,特征交叉(Feature Interaction)是提升模型效果的关键。传统的因子分解机(FM)通过二阶特征交互取得了显著效果,但其线性建模方式和有限阶数限制了模型的表达能力。今天&…...

Python人工智能算法 模拟退火算法:原理、实现与应用
模拟退火算法:从物理启发到全局优化的深度解析 一、算法起源与物理隐喻 模拟退火算法(Simulated Annealing, SA)起源于20世纪50年代的固体退火理论,其核心思想可追溯至Metropolis等人提出的蒙特卡罗模拟方法。1983年,…...
)
服务器网络配置 netplan一个网口配置两个ip(双ip、辅助ip、别名IP别名)
文章目录 问答 问 # This is the network config written by subiquity network:ethernets:enp125s0f0:dhcp4: noaddresses: [192.168.90.180/24]gateway4: 192.168.90.1nameservers:addresses:- 172.0.0.207- 172.0.0.208enp125s0f1:dhcp4: trueenp125s0f2:dhcp4: trueenp125…...

FTP与NFS服务详解
一、FTP服务 (一)Linux下FTP客户端管理工具 1. ftp工具 安装命令:yum install ftp -y连接服务器:ftp 服务器IP,输入账号密码登录。常用命令: 命令说明ls查看远程目录文件put上传单个文件到远程服务器get…...

算法中的数学:欧拉函数
1.相关定义 互质:a与b的最大公约数为1 欧拉函数:在1~n中,与n互质的数的个数就是欧拉函数的值 eg: n1时,欧拉函数的值为1,因为1和1是互质的 n2是,值为2,因为1和2都是互质的 积性函数&…...

如果有三个服务实例部署在三台不同的服务器上,这三个服务实例的本地缓存,是存储一模一样的数据?还是各自只存一部分?
✅ 答案是:通常每个服务实例都会独立地缓存它自己访问过的数据,这些数据可能是相同的,也可能是不同的,取决于请求的内容。 📌 举个例子说明 假设你有一个商品详情页的服务,部署了 3 个服务实例(…...

Coze工作流-选择器的用法
上集回顾 上集教程我们学习了什么是变量以及变量类型的用法。即什么时候用什么变量类型 教程简介 本教程将带大家学习工作流的选择和问答模块 工作流类型选择 在Coze中,工作流是智能体的核心逻辑单元。根据任务复杂度,可选择两种模式: 类…...

《AI工程技术栈》:三层结构解析,AI工程如何区别于ML工程与全栈工程
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

uni-app使用大集
1、手动修改页面标题 uni.setNavigationBarTitle({title: 修改标题 }); 2、单选 不止有 radio-group,还有 uni-data-checkbox 数据选择器 <!-- html部分 --> <uni-data-checkbox v-model"sex" :localdata"checkboxList"></u…...

链表day3
链表定义 struct ListNode{int val;ListNode *next; //next是一个指针变量,存储的是地址,是ListNode类型的地址ListNode(int x) : val(x),next(nullptr){} //也就是说ListNode必须接受一个int x,next指针默认为nullptr,值由外部指…...
介绍)
C++23关联容器的异质擦除重载 (P2077R2)介绍
文章目录 一、基本概念二、原理重载机制类型转换 三、优势提高查找效率提升程序整体性能避免不必要的初始化确保系统实时性 四、应用场景高性能计算大型对象管理实时系统 五、代码示例六、相关图片材料结构与微观图像半导体研究图示与图表科学图表芯片与电路板 一、基本概念 在…...

Flink架构概览,Flink DataStream API 的使用,FlinkCDC的使用
一、Flink与其他组件的协同 Flink 是一个分布式、高性能、始终可用、准确一次(Exactly-Once)语义的流处理引擎,广泛应用于大数据实时处理场景中。它与 Hadoop 生态系统中的组件可以深度集成,形成完整的大数据处理链路。下面我们从…...

AI加速芯片全景图:主流架构和应用场景详解
目录 一、为什么AI芯片如此重要? 二、主流AI芯片架构盘点 三、不同芯片在训练与推理中的部署逻辑 四、真实应用案例解读 五、AI芯片发展趋势预测 AI芯片的选择,是AI系统能否高效运行的关键。今天笔者就从架构角度出发,带你系统了解主流AI加速芯片的种类、优劣对比及实际…...

Ubuntu22.04 系统安装Docker教程
1.更新系统软件包 #确保您的系统软件包是最新的。这有助于避免安装过程中可能遇到的问题 sudo apt update sudo apt upgrade -y 2.安装必要的依赖 sudo apt install apt-transport-https ca-certificates curl software-properties-common -y 3.替换软件源 原来/etc/apt/s…...

更新ubuntu软件源遇到GPG error
BUG背景 执行sudo apt update后遇到类似下列报错: E: The repository https://download.docker.com/linux/ubuntu bionic Release no longer has a Release file. N: Updating from such a repository cant be done securely, and is therefore disabled by defau…...

vue调后台接口
1.1 什么是 axios Axios 是一个基于 promise 的 HTTP 库,可以用来发送网络请求。它可以在浏览器和 node.js 中使用,本质上是对原生 XMLHttpRequest 的封装,符合最新的 ES 规范,支持 Promise API,能够拦截请求和响应&am…...

Ubuntu学习记录
冷知识补充 1.VMware官网安装后,会有两个软件,一个收费(pro)(功能更多,可以一次运行多个虚拟机)(尽管2024年最新版本的也免费了)一个免费(player)。 2.ubuntu打开终端快捷键:ctrlal…...