Pydantic数据验证实战指南:让Python应用更健壮与智能
导读:在日益复杂的数据驱动开发环境中,如何高效、安全地处理和验证数据成为每位Python开发者面临的关键挑战。本文全面解析了Pydantic这一革命性数据验证库,展示了它如何通过声明式API和类型提示系统,彻底改变Python数据处理模式。
从基础的字段验证到复杂的嵌套模型,从传统的错误处理到与大语言模型的深度集成,文章层层深入,为读者揭示了Pydantic的核心优势:自动类型转换、详细的错误报告、基于类型提示的验证以及卓越的性能表现。通过与传统验证方法的对比,您将看到Pydantic如何显著减少样板代码,提高代码可读性。
文章还探讨了一个引人注目的前沿应用:Pydantic与LLM的结合如何构建更可靠的AI应用?PydanticOutputParser如何确保非结构化LLM输出转为可靠的结构化数据?
无论您是构建Web API、处理复杂配置还是开发AI应用,这篇指南都将帮助您掌握现代Python数据验证的最佳实践。
引言:数据验证的重要性
在当今数据驱动的软件开发环境中,处理外部数据已成为每个应用程序的核心挑战。无论是来自API的响应、用户输入还是配置文件,数据验证都是确保系统稳定性和安全性的关键环节。正如开发界的经典格言所言:“永远不要相信用户的输入”。
Pydantic作为Python生态系统中的明星库,彻底改变了我们处理数据验证和解析的方式。本文将深入探讨Pydantic的核心功能、实践应用以及与大语言模型(LLM)结合的高级用例,帮助开发者构建更加健壮、可靠的Python应用。
一、Pydantic基础:重新定义Python数据验证
1.1 Pydantic的本质与价值
Pydantic是Python生态系统中的数据验证与解析库,通过声明式的方式定义数据模型,并结合Python的类型提示系统提供强大的验证功能。它的核心价值在于:
- 自动类型转换:智能地将输入数据转换为预期类型
- 详细的错误报告:提供清晰的错误信息,便于调试
- 基于类型提示:利用Python的类型注解系统,代码即文档
- 高性能:核心验证逻辑用Rust实现,性能卓越
与传统的数据验证方法相比,Pydantic显著减少了样板代码,提高了代码可读性和可维护性。
1.2 传统验证方法的痛点
在Pydantic出现之前,开发者通常需要编写大量的验证代码。以下对比展示了传统方法与Pydantic的差异:
Java传统方式:
public class User {private String name;private int age;// 需要手写校验方法public void validate() throws IllegalArgumentException {if (name == null || name.isEmpty()) {throw new IllegalArgumentException("姓名不能为空");}if (age > 150) {throw new IllegalArgumentException("年龄不合法");}}
}
传统Python方式:
class User:def __init__(self, name: str, age: int):if not isinstance(name, str):raise TypeError("name必须是字符串")if not isinstance(age, int):raise TypeError("age必须是整数")if age > 150:raise ValueError("年龄必须在0-150之间")self.name = nameself.age = age
Pydantic方式:
from pydantic import BaseModel, Fieldclass User(BaseModel):name: str = Field(min_length=1, max_length=50) # 内置字符串长度验证age: int = Field(ge=0, le=150) # 数值范围验证
Pydantic方式不仅代码量减少,更重要的是将验证规则与数据定义紧密结合,提高了代码的表达力和可维护性。
1.3 安装与基本使用
Pydantic V2是当前的生产版本,需要Python 3.10+:
pip install pydantic==2.7.4
基本使用示例:
from pydantic import BaseModelclass UserProfile(BaseModel):username: str # 必须字段age: int = 18 # 带默认值的字段email: str | None = None # 可选字段# 创建实例
user1 = UserProfile(username="Alice")
print(user1) # username='Alice' age=18 email=None# 自动类型转换
user2 = UserProfile(username="Bob", age="20")
print(user2.age) # 20 (int类型)# 验证失败示例
try:UserProfile(username=123) # 触发验证错误
except ValueError as e:print(e.errors())
二、深入Pydantic字段验证
2.1 Field函数:字段验证的核心
Field函数是Pydantic中为字段添加元数据和验证规则的主要工具。它提供了丰富的参数来定义字段的特性和约束:
from pydantic import BaseModel, Fieldclass Product(BaseModel):name: str = Field(..., # 表示必填字段title="产品名称",description="产品的显示名称",min_length=2,max_length=50)price: float = Field(...,gt=0, # 大于0description="产品价格(元)")tags: list[str] = Field(default_factory=list, # 默认空列表max_length=10 # 最多10个标签)
Field函数的常用参数包括:
| 参数 | 描述 | 适用类型 |
|---|---|---|
| default | 默认值 | 所有类型 |
| title | 字段标题 | 所有类型 |
| description | 详细描述 | 所有类型 |
| min_length/max_length | 长度限制 | 字符串、列表 |
| gt/ge/lt/le | 数值范围 | 数值类型 |
| regex | 正则表达式 | 字符串 |
| example | 示例值 | 所有类型 |
2.2 必填与可选字段
在Pydantic中,字段的必填性由是否提供默认值决定:
from pydantic import BaseModel, Fieldclass User(BaseModel):# 必填字段 (使用...)name: str = Field(..., title="用户名", min_length=2)# 可选字段 (有默认值)age: int = Field(18, ge=0, le=150)# 可为None的字段email: str | None = Field(None, title="电子邮箱")
...是Python中的特殊对象,在Pydantic中表示"无默认值",即该字段必须由用户提供。
2.3 复杂验证场景
嵌套模型验证
Pydantic支持模型嵌套,实现复杂数据结构的验证:
from pydantic import BaseModel, Fieldclass Address(BaseModel):city: str = Field(..., min_length=1)street: strpostal_code: str = Field(..., pattern=r'^\d{5,6}$')class User(BaseModel):name: str = Field(...)address: Address # 嵌套模型# 使用嵌套字典初始化
user = User(name="Alice", address={"city": "Shanghai", "street": "Main St", "postal_code": "200001"}
)
混合类型字段
Pydantic支持联合类型,允许字段接受多种类型的值:
from pydantic import BaseModel
from typing import Unionclass Item(BaseModel):# 可以是整数或字符串id: Union[int, str] # Python 3.10前的写法# 或使用新语法 (Python 3.10+)quantity: int | float # 可以是整数或浮点数
三、自定义验证器:超越基本约束
3.1 field_validator装饰器
当Field参数无法满足复杂验证需求时,可以使用field_validator装饰器实现自定义验证逻辑:
from pydantic import BaseModel, Field, field_validatorclass User(BaseModel):username: strpassword: str@field_validator("username")def validate_username(cls, value: str) -> str:if len(value) < 3:raise ValueError("用户名至少需要3个字符")if not value.isalnum():raise ValueError("用户名只能包含字母和数字")return value@field_validator("password")def validate_password(cls, value: str) -> str:errors = []if len(value) < 8:errors.append("密码至少需要8个字符")if not any(c.isupper() for c in value):errors.append("密码需要至少一个大写字母")if not any(c.isdigit() for c in value):errors.append("密码需要至少一个数字")if errors:raise ValueError("; ".join(errors))return value
3.2 多字段验证器
验证器可以同时应用于多个字段:
from pydantic import BaseModel, field_validatorclass Product(BaseModel):price: floatcost: float@field_validator("price", "cost")def check_positive(cls, v):if v <= 0:raise ValueError("金额必须大于0")return v
3.3 高级验证技巧
依赖其他字段的验证
在某些情况下,一个字段的验证可能依赖于其他字段的值:
from pydantic import BaseModel, field_validatorclass Discount(BaseModel):original_price: floatdiscounted_price: float@field_validator("discounted_price")def validate_discount(cls, v, info):# 获取原始价格original = info.data.get("original_price")if original is not None and v > original:raise ValueError("折扣价不能高于原价")return v
格式化与清理数据
验证器不仅可以验证数据,还可以格式化或清理数据:
from pydantic import BaseModel, field_validatorclass User(BaseModel):email: str@field_validator("email")def normalize_email(cls, v):# 转换为小写并去除空白return v.lower().strip()
四、Pydantic与大语言模型的结合:高级解析器
4.1 为什么需要Pydantic解析器
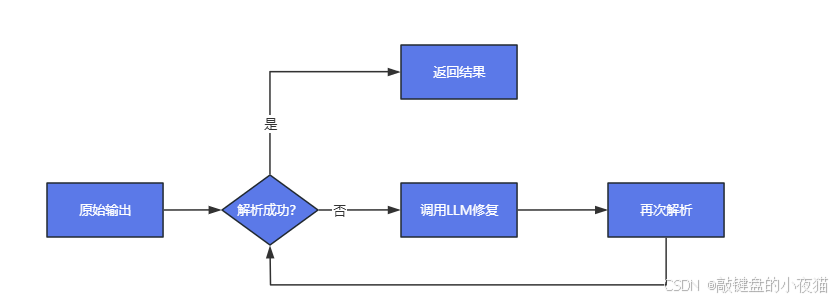
在与大语言模型(LLM)交互时,我们经常需要将其自然语言输出转换为结构化数据。Pydantic解析器提供了以下优势:
- 结构化输出:将非结构化文本转换为可编程对象
- 数据验证:自动验证字段类型和约束条件
- 开发效率:减少手动解析代码
- 错误处理:内置异常捕获与修复机制
4.2 PydanticOutputParser实战
PydanticOutputParser是LangChain库中的一个组件,用于将LLM输出解析为Pydantic模型实例:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate# 定义Pydantic模型
class UserInfo(BaseModel):name: str = Field(description="用户姓名")age: int = Field(description="用户年龄", gt=0)hobbies: list[str] = Field(description="兴趣爱好列表")# 创建解析器
parser = PydanticOutputParser(pydantic_object=UserInfo)# 定义大模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 构建提示模板
prompt = ChatPromptTemplate.from_template("""
提取用户信息,严格按格式输出:
{format_instructions}用户信息:{input}
""")# 注入格式指令
prompt = prompt.partial(format_instructions=parser.get_format_instructions()
)# 组合处理链
chain = prompt | model | parser# 执行解析
result = chain.invoke({"input": "我的名称是张三,年龄是18岁。兴趣爱好有打篮球、看电影。"
})print(type(result)) # <class '__main__.UserInfo'>
print(result) # name='张三' age=18 hobbies=['打篮球', '看电影']
4.3 JsonOutputParser与Pydantic结合
JsonOutputParser是另一个常用的解析器,它与Pydantic结合使用可以实现更灵活的解析:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser# 定义JSON结构
class SentimentResult(BaseModel):sentiment: strconfidence: floatkeywords: list[str]# 定义大模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 构建处理链
parser = JsonOutputParser(pydantic_object=SentimentResult)prompt = ChatPromptTemplate.from_template("""
分析评论情感:
{input}
按照JSON格式返回:
{format_instructions}
""")chain = prompt | model | parser# 执行分析
result = chain.invoke({"input": "物流很慢,包装破损严重"})
print(result)
# 输出: sentiment='negative' confidence=0.85 keywords=['物流慢', '包装破损']
JsonOutputParser的一个重要优势是支持流式处理,适用于大型响应:
# 流式调用
for chunk in chain.stream({"input": "物流很慢, 包装破损严重"}):print(chunk) # 逐步输出结果
五、OutputFixingParser:提升解析鲁棒性
5.1 LLM输出修复机制
大语言模型的输出有时会存在格式问题,如JSON语法错误、字段缺失等。OutputFixingParser提供了自动修复这些问题的机制:
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List# 定义模型
class Actor(BaseModel):name: str = Field(description="演员姓名")film_names: List[str] = Field(description="参演电影列表")# 创建基础解析器
parser = PydanticOutputParser(pydantic_object=Actor)# 定义LLM
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 包装为修复解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
5.2 修复常见格式错误
以下示例展示了如何修复常见的JSON格式错误:
# 模拟格式错误的输出 (使用单引号而非双引号)
misformatted_output = "{'name': '成龙', 'film_names': ['宝贝计划','十二生肖','警察故事']}"# 直接解析会失败
try:parsed_data = parser.parse(misformatted_output)
except Exception as e:print(f"解析失败: {e}") # 输出: 解析失败: JSONDecodeError...# 使用修复解析器
fixed_data = fixing_parser.parse(misformatted_output)
print(type(fixed_data)) # <class '__main__.Actor'>
print(fixed_data.model_dump()) # {'name': '成龙', 'film_names': ['宝贝计划', '十二生肖', '警察故事']}
OutputFixingParser的工作原理是:
- 检测到错误后,将错误信息与原始输入传递给LLM
- LLM根据提示生成符合Pydantic模型的修正结果
- 返回修正后的结构化数据
5.3 提高解析成功率的最佳实践
为了最大限度地提高解析成功率,可以采取以下措施:
- 明确的格式说明:在提示中提供详细的输出格式指南
- 示例驱动:提供正确格式的示例,帮助模型理解期望输出
- 降低模型温度:对于结构化输出,使用较低的temperature值(0.0-0.3)
- 多次重试:设置适当的重试次数
- 错误处理:实现优雅的错误处理机制
# 增强修复解析器配置
enhanced_fixing_parser = OutputFixingParser.from_llm(parser=parser,llm=model,max_retries=2 # 最多重试2次
)# 错误处理示例
try:result = enhanced_fixing_parser.parse(problematic_output)# 成功解析process_valid_data(result)
except Exception as e:# 即使修复也失败handle_parsing_failure(e, problematic_output)
六、实际应用场景与最佳实践
6.1 API请求/响应验证
Pydantic在FastAPI等现代Web框架中广泛用于API请求和响应验证:
from fastapi import FastAPI
from pydantic import BaseModel, Fieldapp = FastAPI()class CreateUserRequest(BaseModel):username: str = Field(..., min_length=3)email: strpassword: str = Field(..., min_length=8)class UserResponse(BaseModel):id: intusername: stremail: str@app.post("/users/", response_model=UserResponse)
async def create_user(user: CreateUserRequest):# FastAPI自动验证请求体# 并将响应序列化为UserResponse格式db_user = await database.create_user(user.username, user.email, user.password)return db_user
6.2 配置管理
Pydantic非常适合处理应用程序配置:
from pydantic import BaseModel, Field
from pydantic_settings import BaseSettings
import osclass DatabaseSettings(BaseModel):host: str = "localhost"port: int = 5432username: strpassword: strdatabase: strclass AppSettings(BaseSettings):app_name: str = "MyApp"debug: bool = Field(default=False, description="启用调试模式")database: DatabaseSettings# 从环境变量加载配置class Config:env_prefix = "MYAPP_"env_nested_delimiter = "__"# 使用
settings = AppSettings(database=DatabaseSettings(username=os.getenv("DB_USER"),password=os.getenv("DB_PASS"),database="myapp")
)
6.3 LLM应用中的结构化输出
在构建LLM应用时,Pydantic可以确保输出符合预期格式:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, field_validator
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate# 定义产品推荐模型
class ProductRecommendation(BaseModel):product_name: str = Field(description="推荐产品名称")price_range: str = Field(description="价格范围,例如'100-200元'")reasons: list[str] = Field(description="推荐理由列表,至少3条")@field_validator("reasons")def validate_reasons(cls, v):if len(v) < 3:raise ValueError("推荐理由至少需要3条")return v# 创建解析器和链
parser = PydanticOutputParser(pydantic_object=ProductRecommendation)
model = ChatOpenAI(temperature=0.2)prompt = ChatPromptTemplate.from_template("""
根据用户需求推荐一款产品:
{user_needs}{format_instructions}
""")chain = (prompt.partial(format_instructions=parser.get_format_instructions())| model| parser
)# 使用
recommendation = chain.invoke({"user_needs": "我需要一款性价比高的笔记本电脑,主要用于办公和轻度设计"
})print(f"推荐产品: {recommendation.product_name}")
print(f"价格范围: {recommendation.price_range}")
print("推荐理由:")
for i, reason in enumerate(recommendation.reasons, 1):print(f"{i}. {reason}")
6.4 性能优化建议
在处理大量数据时,可以考虑以下性能优化建议:
- 使用model_construct:对于已知有效的数据,使用
model_construct跳过验证 - 延迟验证:使用
validate=False创建模型,在需要时手动调用model_validate - 自定义验证器优化:避免在验证器中执行耗时操作
- 批量处理:处理大量数据时使用批量验证
# 性能优化示例
from pydantic import BaseModel
import timeclass Item(BaseModel):name: strprice: float# 标准方法
start = time.time()
items1 = [Item(name=f"item{i}", price=i*1.5) for i in range(10000)]
print(f"标准方法: {time.time() - start:.4f}秒")# 优化方法 - 使用model_construct
start = time.time()
items2 = [Item.model_construct(name=f"item{i}", price=i*1.5) for i in range(10000)]
print(f"使用model_construct: {time.time() - start:.4f}秒")
七、Pydantic V2的新特性与迁移指南
7.1 V1与V2的主要区别
Pydantic V2是对库的重大重写,带来了许多改进和API变化:
| 功能 | Pydantic V1 | Pydantic V2 |
|---|---|---|
| 性能 | 纯Python实现 | 核心验证逻辑用Rust实现,性能提升5-50倍 |
| 类型系统 | 有限支持 | 更全面的类型支持,包括TypedDict |
| API | 原始API | 更一致的命名约定 |
| 验证器 | @validator | @field_validator 和 @model_validator |
| 序列化 | dict() | model_dump() |
| JSON解析 | parse_raw() | model_validate_json() |
7.2 API变更对照表
以下是V1到V2的主要API变更:
| Pydantic V1 | Pydantic V2 |
|---|---|
| fields | model_fields |
| private_attributes | pydantic_private |
| validators | pydantic_validator |
| construct() | model_construct() |
| copy() | model_copy() |
| dict() | model_dump() |
| json_schema() | model_json_schema() |
| json() | model_dump_json() |
| parse_obj() | model_validate() |
| update_forward_refs() | model_rebuild() |
7.3 迁移策略
从V1迁移到V2的建议步骤:
- 更新依赖:确保Python版本≥3.10,更新pydantic到最新版本
- API调整:使用新的方法名称(如
model_dump替代dict) - 验证器更新:将
@validator替换为@field_validator - 类型注解检查:确保类型注解与V2兼容
- 测试覆盖:确保充分的测试覆盖,验证迁移后的功能正确性
# Pydantic V1
from pydantic import BaseModel, validatorclass UserV1(BaseModel):name: strage: int@validator('age')def check_age(cls, v):if v < 0:raise ValueError('年龄不能为负数')return vdef to_dict(self):return self.dict()# Pydantic V2
from pydantic import BaseModel, field_validatorclass UserV2(BaseModel):name: strage: int@field_validator('age')def check_age(cls, v):if v < 0:raise ValueError('年龄不能为负数')return vdef to_dict(self):return self.model_dump()
八、结论与展望
Pydantic已经成为Python生态系统中数据验证和解析的标准工具,其声明式API和强大的验证功能使其在Web开发、数据处理和AI应用中不可或缺。
随着AI和大语言模型的兴起,Pydantic与LangChain等框架的结合为构建可靠的AI应用提供了坚实基础。通过PydanticOutputParser和OutputFixingParser等工具,开发者可以轻松地将非结构化的LLM输出转换为结构化数据,实现更复杂的应用场景。
未来,随着Pydantic继续发展,我们可以期待:
- 更深入的AI集成:与更多AI框架的无缝集成
- 更高的性能:进一步优化Rust核心,提供更快的验证速度
- 更丰富的生态系统:更多基于Pydantic的工具和扩展
对于Python开发者来说,掌握Pydantic不仅能提高日常开发效率,还能为构建下一代AI应用打下坚实基础。无论是构建API、处理配置还是与大语言模型交互,Pydantic都是不可或缺的工具。
参考资源
- Pydantic官方文档
- LangChain文档
- FastAPI与Pydantic
- Pydantic V2迁移指南
相关文章:

Pydantic数据验证实战指南:让Python应用更健壮与智能
导读:在日益复杂的数据驱动开发环境中,如何高效、安全地处理和验证数据成为每位Python开发者面临的关键挑战。本文全面解析了Pydantic这一革命性数据验证库,展示了它如何通过声明式API和类型提示系统,彻底改变Python数据处理模式。…...

深度解析 HDFS与Hive的关系
1. HDFS 和 Hive 如何协同 我们将从 HDFS(Hadoop Distributed File System) 的架构入手,深入剖析其核心组成、工作机制、内部流程与高可用机制。然后详细阐述 Hive 与 HDFS 的关系,从执行流程、元数据管理、文件读写、计算耦合等…...

ArrayList源码分析
1. ArrayList默认初始化容量 首先编写一个简单的初始化ArrayList的代码 List<String> li new ArrayList<>();然后进入ArrayList中,在无参数构造方法中可以查看到上面的绿色注释中写了构造一个空的集合并且初始化容量为10。接下来继续查看源码&#x…...

文件操作和IO-2 使用Java操作文件
Java操作文件的API 1、针对文件系统的操作。包括但不限于:创建文件、删除文件、重命名文件、列出目录内容…… 2、针对文件内容的操作。读文件/写文件 Java中针对文件的操作,使用File类来进行操作,这个类被存储在java.io这个包里面。 i&a…...

day 31
文件的拆分 1. 项目核心代码组织 src/(source的缩写):存放项目的核心源代码。 2. 配置文件管理 config/ 目录:集中存放项目的配置文件,方便管理和切换不同环境(开发、测试、生产)的配置。 …...

基于Python批量删除文件和批量增加文件
一、为什么写这么一个程序 其实原因也是很简单的,我去网上下载了一个文件夹,里面太多别人的文件了,我不喜欢,所以我就写了这么一个代码。 二、安装Python和vscode 先安装Python在安装vscode Python安装 vscode的安装 三、源码…...

【信息系统项目管理师】第12章:项目质量管理 - 26个经典题目及详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...
)
ShenNiusModularity项目源码学习(27:ShenNius.Admin.Mvc项目分析-12)
订单列表页面用于浏览、检索、维护商城模块的订单信息。订单列表页面的后台控制器类OrderController位于ShenNius.Admin.Mvc项目的Areas\Shop\Controllers内,页面文件位于同项目的Areas\Shop\Views\Order内,其中Index.cshtml页面为主页面,Det…...
,不小心删掉RabbitMQ配置文件数据库及如何恢复)
(T_T),不小心删掉RabbitMQ配置文件数据库及如何恢复
一、不小心删除 今天是2025年5月15日,非常沉重的一天,就在今早8点左右的时候我打算继续做我的毕业设计,由于开机的过程十分缓慢(之前没有),加上刚开机电脑有卡死的迹象,再加上昨天晚上关电脑前…...

【Python装饰器深度解析】从语法糖到元编程实战
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选型对比🛠️ 二、实战演示⚙️ 环境配置要求💻 核心代码实现案例1:基础计时装饰器案…...
)
操作系统学习笔记第5章 (竟成)
目录 第 5 章 输入 / 输出 (I/O) 管理 5.1 I/O 管理基础 5.1.1 I/O 设备 1.I/O 设备的基本概念 2.I/O 设备的分类 3.I/O 接口 4.I/O 端口 (1) I/O 端口的概念 (2) I/O 端口的编址 ① 独立编址方式 ② 统一编址方式 5.1.2 I/O 控制方式 1. 程序查询方式 2. 程序中断方式 3. DMA …...
)
【DCGMI专题1】---DCGMI 在 Ubuntu 22.04 上的深度安装指南与原理分析(含架构图解)
目录 一、DCGMI 概述与应用场景 二、Ubuntu 22.04 系统准备 2.1 系统要求 2.2 环境清理(可选) 三、DCGMI 安装步骤(详细图解) 3.1 安装流程总览 3.2 分步操作指南 3.2.1 系统更新与依赖安装 3.2.2 添加 NVIDIA 官方仓库 3.2.3 安装数据中心驱动与 DCGM 3.2.4 服务…...

C# 使用 OpenCV 基础
一、C#安装OpenCV 安装上面两个模块 二、使用 导入 using OpenCvSharp;加载图片 // 导入图片 Mat image Cv2.ImRead("C:\x5.bmp"); // 拷贝 Mat image2 image.Clone();// 打开窗口 Cv2.NamedWindow("image", WindowFlags.AutoSize); // 显示图片 Cv2…...

如何解决全局或静态变量被修改的bug
问题卡死 程序原来设置Firware name 时N32G475,在程序运行时,程序崩溃,发现输出的固件名称没有了,这里说明固件名称被程序修改了 程序在开机时都是对的 打开map文件查找fw_name的内存地址,他的值被更改,就…...
)
[Java实战]Spring Boot整合Sentinel:流量控制与熔断降级实战(二十九)
[Java实战]Spring Boot整合Sentinel:流量控制与熔断降级实战(二十九) 一、Sentinel简介 Sentinel是阿里开源的分布式系统流量防卫组件,核心功能包括: 流量控制:根据QPS、线程数等指标限制资源访问熔断降…...

Linux系统中,Ctrl+C的运行过程是什么?
文章目录 前言1.终端驱动捕获键盘输入2.信号发送到前台进程组3. 进程处理信号4. 信号传递的详细流程5. Shell 的后续处理关键机制说明扩展:其他相关信号总结 前言 今天看到有个小伙伴面试问到这个问题,感觉挺有意思,我们后端开发者相信都用过…...

101个α因子#9
((0 < ts_min(delta(close, 1), 5)) ? delta(close, 1) : ((ts_max(delta(close, 1), 5) < 0) ? delta(close, 1) : (-1 * delta(close, 1))))worldquant brain平台上调整后的语法: ((0 < min(close-ts_delay(close, 1), ts_delay(close, 1)-ts_delay(c…...

DAY28 超大力王爱学Python
知识点回顾: 类的定义pass占位语句类的初始化方法类的普通方法类的继承:属性的继承、方法的继承 作业 题目1:定义圆(Circle)类 import mathclass Circle:def __init__(self, radius1):self.radius radius # 半径属性…...

【C++算法】70.队列+宽搜_N 叉树的层序遍历
文章目录 题目链接:题目描述:解法C 算法代码: 题目链接: 429. N 叉树的层序遍历 题目描述: 解法 使用队列层序遍历就可以了。 先入根节点1。queue:1 然后出根节点1,入孩子节点2,3&a…...

常用UI自动化测试框架
🔍 常用UI自动化测试框架全览(Web / 移动 / 桌面 / AI驱动) UI(用户界面)测试框架是一类用于自动化测试应用图形界面的工具,帮助开发者和测试人员验证界面元素的功能性、交互性和视觉一致性。本文系统梳理了…...
:回调函数、qsort函数)
C语言指针深入详解(五):回调函数、qsort函数
目录 一、回调函数 1、使用回调函数改造前 2、使用回到函数改造后 二、qsort使用举例 1、使用qsort函数排序整型数据 2、使用qsort排序结构数据 三、qsort函数模拟实现 结语 🔥个人主页:艾莉丝努力练剑 🍓专栏传送门:《…...

# YOLOv5:目标检测的新里程碑
YOLOv5:目标检测的新里程碑 在计算机视觉领域,目标检测一直是研究的热点和难点之一。近年来,随着深度学习技术的飞速发展,目标检测算法也取得了显著的进步。YOLO(You Only Look Once)系列算法以其高效的实…...
消息删除)
beanstalk一直被重新保留(reserved 状态)消息删除
说明:wallet是我的tube 完整流程示例 暂停 tube(防止任务被重新保留)pause-tube wallet 300踢回并删除任务kick 100000 # 踢回所有 reserved 任务 delete 183723 # 删除目标任务恢复 tube(取消暂停)pause-tu…...
: 概率论与统计学(贝叶斯定理、概率分布等))
NLP学习路线图(二): 概率论与统计学(贝叶斯定理、概率分布等)
引言 自然语言处理(NLP)作为人工智能的重要分支,致力于让机器理解、生成和操作人类语言。无论是机器翻译、情感分析还是聊天机器人,其底层逻辑都离不开数学工具的支持。概率论与统计学是NLP的核心数学基础之一,它们为…...

塔能智能照明方案——贵州某地区市政照明改造实践
在城市市政建设中,照明系统作为城市基础设施的重要组成部分,其能耗问题日益凸显。传统市政照明设备能耗高、运维效率低,成为城市绿色发展的阻碍。塔能科技针对这一痛点,为贵州某地区量身打造智能照明改造方案,通过技术…...

Mybatis的逆向工程Generator
Mybatis的逆向工程 什么是逆向工程 generator 简单点说,就是通过数据库中的单表,自动生成java代码。 Mybatis官方提供了逆向工程,可以针对单表自动生成mybatis代码(mapper.java\mapper.xml\po类) 企业开发中&#…...

Runtime Suspend 专项训练
Q1. 什么是 Runtime PM?与 System Suspend 有什么区别? 答: Runtime PM(运行时电源管理)是 Linux 内核为单个设备提供的自动挂起机制。其核心思想是在设备空闲期间,关闭其时钟、电源、总线连接等资源&…...
智能制造理学硕士招生宣讲会——深圳大学专场)
香港科技大学(广州)智能制造理学硕士招生宣讲会——深圳大学专场
深圳大学专场宣讲会 时间:5月22日(星期四)19:00-20:00 地点:深圳大学沧海校区致原楼1101 🎓主讲嘉宾: 汤凯 教授 https://facultyprofiles.hkust-gz.edu.cn/faculty-personal-page/TANG-Kai/mektang …...

使用MacPro 安装flutter开发环境 详细教程
Mac 有 英特尔芯片 和 苹果芯片,故安装路径可能略有不同,但是思路 大致一样,以下内容仅供小伙伴们参考: 首先下载环境安装的软件,并推荐使用稳定版本。 gralde 8.5 点击下载 android studio 点击下载 jdk 点击下载…...

常见的 API 及相关知识总结
常见的 API 及相关知识总结 一、Math 类 Math 类提供了许多用于数学计算的静态方法和常量。 常见方法总结 方法描述Math.abs()返回一个数的绝对值Math.ceil()返回大于或等于给定数字的最小整数Math.floor()返回小于或等于给定数字的最大整数Math.round()对一个数进行四舍五…...

7-Zip软件下载与使用攻略:如何使用7z格式解压缩更高效?
在数字化文件管理中,压缩与解压缩工具的选择至关重要。7-Zip是一款广受欢迎的开源软件,以其高效的压缩率和多种格式支持而备受推崇。然而,解压专家作为另一款优秀的解压缩软件,同样值得关注。本文将为您推荐7-Zip的下载渠道&#…...

第 84 场周赛:翻转图像、字符串中的查找与替换、图像重叠、树中距离之和
Q1、[简单] 翻转图像 1、题目描述 给定一个 n x n 的二进制矩阵 image ,先 水平 翻转图像,然后 反转 图像并返回 结果 。 水平翻转图片就是将图片的每一行都进行翻转,即逆序。 例如,水平翻转 [1,1,0] 的结果是 [0,1,1]。 反转…...

SkyReels-V2:开启无限时长电影生成新时代
AI 在视频生成领域的突破尤为引人注目,为内容创作带来了全新的可能性。而 SkyReels-V2 的问世,更是如同一场革命,彻底颠覆了人们对视频生成技术的认知,开启了无限时长电影生成的新时代。 一、背景与挑战 回顾视频生成技术的发展…...

教师可用的申报书——基于GAI的小学数学课堂跨学科支架设计与实践
课题申报书:基于GAI的小学数学课堂跨学科支架设计与实践 (一)立项依据与研究内容 1. 项目的立项依据 1.1 研究意义 2025年《教育强国建设规划纲要》明确提出“推动学科融合发展”,《信息化标准建设行动计划(2024-2027年)》强调技术赋能教育创新。小学数学作为基础学科,…...

79、modelsim单独仿真altera带IP核的文件
1.编译 quartus 仿真库(如果有就不用编译了) 编译完成后 sim 文件夹中产生一个 verilog_libs 文件夹,打开文件夹 以上便是编译产生的库,将库添加到 modelsim 中也就是观察此文件中的 modelsim.ini 与 modelsim 安装目录下此…...

将 Workbook 输出流直接上传到云盘
如果不想将 Excel 文件保存到本地,而是希望直接将输出流上传到云存储(如阿里云OSS、腾讯云COS、七牛云等),可以采用以下方法: 文章目录 1. 创建内存中的 Excel 输出流2. 上传到云存储的通用方法3. 具体云服务实现示例…...

【LINUX操作系统】日志系统——自己实现一个简易的日志系统
经过一段时间的操作系统的学习,现在是时候让读者朋友们利用学过的技术知识自己完成一个简单的日志系统。认识、了解日志系统既是对已有多线程知识的运用,也是进一步提升项目技术能力的必须步骤。 1. 什么是日志 ⽇志认识 计算机中的⽇志是记录系统和软件…...

HTML页面渲染过程
前言 文章很长,凡是我觉得好的东西统统都塞进来了。看了很多的文章,有些说法甚至都不统一,所以还动用了AI搜索。总之希望这篇文章能有点用,如有错误,欢迎指正。 浏览器介绍 浏览器的主要组件包括: 界面…...
高频面试题)
【八股战神篇】Java虚拟机(JVM)高频面试题
目录 专栏简介 一 请解释Java虚拟机(JVM)及其主要功能 延伸 1. JVM的基本概念 2. JVM的主要功能 二 对象创建的过程了解吗 延伸 1.Java 创建对象的四种常见方式 三 什么是双亲委派模型 延伸 1.双亲委派机制的作用: 2.双亲委派模型…...

微店商品详情接口开发指南
接口概述 微店商品详情接口(/api/v1/product/detail)用于获取商品的完整信息,包括标题、价格、库存、SKU、主图等数据,支持OAuth2.0鉴权。 点击获取key和secret 请求方式 GET https://open.weidian.com/api/v1/product/detail …...
,补偿重试)
拦截指定注解(FeignClient),补偿重试
拦截指定注解(FeignClient),补偿重试;对代码无入侵 避免正常调用和重试逻辑调用重复插入; 根据自己的业务需求 插入新数据时 是否需要删除之前的旧数据,防止数据覆盖 import cn.hutool.core.util.ObjectUti…...

使用 GitHub Pages 部署单页面应用教程
## 简介 GitHub Pages 是 GitHub 提供的一个静态网站托管服务,可以免费托管个人、项目或组织页面。本教程将指导您如何部署一个单页面应用到 GitHub Pages。 ## 前提条件 - 拥有 GitHub 账号 - 已安装 Git - 已安装 Node.js(如果使用前端框架&#x…...

day16-17-磁盘管理
1. 磁盘分类 磁盘接口 硬盘 大小 sata接口 机械硬盘、固态硬盘 机械:4tb 10k性能要求不高 sas接口 机械硬盘、固态硬盘 机械:900G 15k性能好,容量低 pcie-e接口 固态硬盘 tb级别 4tb 8tb 性能要求高,数据库,…...

【神经网络与深度学习】扩散模型之通俗易懂的解释
引言: 扩散模型(Diffusion Models)是近年来深度学习领域的一项重要突破,尤其在生成式人工智能(Generative AI)中展现了惊人的能力。它的核心思想类似于一个孩子学习搭建乐高城堡的过程——先拆散࿰…...

Linux Bash 中 $? 的详细用法
Bash (Bourne Again SHell) 是使用最广泛的 SHell 脚本语言之一,因为它与 Unix 和 Linux 系统兼容。它提供了许多内置函数和变量,使脚本编写更高效,更不容易出错。其中一个变量是 $?, 它是 Bash 脚本错误处理的一个组成部分。这个…...
标准IO、文件操作)
嵌入式培训之系统编程(一)标准IO、文件操作
目录 一、系统编程概述 二、标准IO (一)(以计算机为中心)标准IO (二)io的分类 (三)man命令 三、文件读写操作 (一)文件操作步骤 (二&#…...

NVIDIA Earth-2 AI 天气模型 DLI 课程:解锁全球风云的未来之匙
电影闲聊引发思索之言: 曾几何时,当我们闲聊起那些描绘美国气候的大电影时(龙卷风-后天等美国大片),仿佛被带入了一个个奇幻而真实的气象世界。从狂风暴雨到烈日炎炎最后到冰天雪地,电影里的场景让我们对气…...
代码详解(ai辅助整理))
至此(day1-day4)代码详解(ai辅助整理)
至此(day1-day4)代码详解 ipl10.nas ; 第一阶段引导程序 ; 功能:读取磁盘数据并跳转到第二阶段加载程序 ; 编译参数:nask -o ipl10.bin ipl10.nasCYLS EQU 10 ; 预设读取柱面数(实际值由BIOS决定)ORG…...

STM32F103_LL库+寄存器学习笔记12.2 - 串口DMA高效收发实战2:进一步提高串口接收的效率
导言 通过优化代码算法,在串口空闲中断回调里不需要暂时关闭DMA接收,达到提高串口接收的效率。在IDLE接收中断里关闭DMA接收会导致接收过程中有数据丢失风险(关DMA的瞬间如果有数据到来,会丢帧!)。 回顾一…...

conda 设置env后,环境还是安装在c盘的解决方式:
1|设置 envs 文件夹权限 右键【envs】文件夹,选择【属性】 选择【安全】,点击【编辑】 选中【Users(用户名\Users)】,选中运行所有权限,如图所示 点击【确认】,确保修改被保存 2、环境变量path设置 选择【高级系统设置…...