深度学习中的正则化方法与卷积神经网络基础
笔记
1 正则化方法
1.1 什么是正则化
-
防止模型过拟合(训练集效果好, 测试集效果差), 提高模型泛化能力
-
一种防止过拟合, 提高模型泛化能力的策略
-
L1正则: 需要通过手动写代码实现
-
L2正则: SGD(weight_decay=)
-
dropout
-
BN
-
1.2 Dropout正则化
-
让神经元以p概率随机死亡, 每批次样本训练模型时, 死亡的神经元都是随机, 防止预测结果受某个神经元影响(防止过拟合)
-
p概率->[0.2, 0.5], 简单模型概率低, 复杂模型概率高
-
不失活的神经元计算结果除以(1-p), 让训练时输出结果和测试时(dropout不生效)结果一致
-
训练模型 -> model.train()
-
测试模型 -> model.eval()
-
-
dropout是在激活层后使用
import torch import torch.nn as nn # dropout随机失活: 每批次样本训练时,随机让一部分神经元死亡,防止一些特征对结果影响大(防止过拟合) def dm01():# todo:1-创建隐藏层输出结果# float(): 转换成浮点类型张量t1 = torch.randint(low=0, high=10, size=(1, 4)).float()print('t1->', t1)# todo:2-进行下一层加权求和计算linear1 = nn.Linear(in_features=4, out_features=4)l1 = linear1(t1)print('l1->', l1)# todo:3-进行激活值计算output = torch.sigmoid(l1)print('output->', output)# todo:4-对激活值进行dropout处理 训练阶段# p: 失活概率dropout = nn.Dropout(p=0.4)d1 = dropout(output)print('d1->', d1) if __name__ == '__main__':dm01()
1.3 批量归一正则化(Batch Normalization)
-
计算每个batch样本的均值和标准差, 利用均值和标准差计算出标准化的值
-
每个batch的均值和标准差都不一样, 会引入噪声样本数据, 降低训练模型效果(防止过拟合)
-
引入两个自学习的γ和β参数, 让每层的样本分布不一样(每层的激活函数可以不一样)
-
加速模型训练效果, 数据分布越均匀, 加权求和结果落入到合理区间(导数最大)
-
训练时进行标准化, 测试时不进行标准化
""" 正则化: 每批样本的均值和方差不一样, 引入噪声样本 加快模型收敛: 样本标准化后, 落入激活函数的合理区间, 导数尽可能最大 """ import torch import torch.nn as nn # nn.BatchNorm1d(): 处理一维样本, 每批样本数最少是2个, 否则无法计算均值和标准差 # nn.BatchNorm2d(): 处理二维样本, 图像(每个通道由二维矩阵组成), 计算二维矩阵每列均值和标准差 # nn.BatchNorm3d(): 处理三维样本, 视频 # 处理二维数据 def dm01():# todo:1-创建图像样本数据集 2个通道,每个通道3*4列特征图, 卷积层处理的特征图样本# 数据集只有一张图像, 图像是由2个通道组成, 每个通道由3*4像素矩阵input_2d = torch.randn(size=(1, 2, 3, 4))print('input_2d->', input_2d)# todo:2-创建BN层, 标准化 ->一定是在激活函数前进行标准化# num_features: 输入样本的通道数# eps: 小常数, 避免除0# momentum: 指数移动加权平均值# affine: 默认True, 引入可学习的γ和β参数bn2d = nn.BatchNorm2d(num_features=2, eps=1e-5, momentum=0.1, affine=True)ouput_2d = bn2d(input_2d)print('ouput_2d->', ouput_2d) # 处理一维数据 def dm02():# 创建样本数据集input_1d = torch.randn(size=(2, 2))# 创建线性层linear1 = nn.Linear(in_features=2, out_features=4)l1 = linear1(input_1d)print('l1->', l1)# 创建BN层bn1d = nn.BatchNorm1d(num_features=4)# 对线性层的结果进行标准化处理output_1d = bn1d(l1)print('output_1d->', output_1d) if __name__ == '__main__':# dm01()dm02()
2 手机价格分类案例
2.1 案例需求
-
分类问题 0,1,2,3 四个类别
-
实现步骤
-
准备数据集 -> 数据集分割, 转换成张量数据集
-
构建神经网络模型 -> 继承nn.module
-
模型训练
-
模型评估
-
2.2 构建张量数据集
# 导入相关模块
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.nn as nn
from torchsummary import summary
import torch.optim as optim
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import time
# todo:1-构建数据集
def create_dataset():print('===========================构建张量数据集对象===========================')# todo:1-1 加载csv文件数据集data = pd.read_csv('data/手机价格预测.csv')print('data.head()->', data.head())print('data.shape->', data.shape)# todo:1-2 获取x特征列数据集和y目标列数据集# iloc属性 下标取值x, y = data.iloc[:, :-1], data.iloc[:, -1]# 将特征列转换成浮点类型x = x.astype(np.float32)print('x->', x.head())print('y->', y.head())# todo:1-3 数据集分割 8:2x_train, x_valid, y_train, y_valid = train_test_split(x, y, train_size=0.8, random_state=88)# todo:1-4 数据集转换成张量数据集# x_train,y_train类型是df对象, df不能直接转换成张量对象# x_train.values():获取df对象的数据值, 得到numpy数组# torch.tensor(): numpy数组对象转换成张量对象train_dataset = TensorDataset(torch.tensor(data=x_train.values), torch.tensor(data=y_train.values))valid_dataset = TensorDataset(torch.tensor(data=x_valid.values), torch.tensor(data=y_valid.values))# todo:1-5 返回训练数据集, 测试数据集, 特征数, 类别数# shape->(行数, 列数) [1]->元组下标取值# np.unique()->去重 len()->去重后的长度 类别数print('x.shape[1]->', x.shape[1])print('len(np.unique(y)->', len(np.unique(y)))return train_dataset, valid_dataset, x.shape[1], len(np.unique(y))
if __name__ == '__main__':train_dataset, valid_dataset, input_dim, class_num = create_dataset()2.3 构建分类神经网络模型
# todo:2-构建神经网络分类模型
class PhonePriceModel(nn.Module):print('===========================构建神经网络分类模型===========================')# todo:2-1 构建神经网络 __init__()def __init__(self, input_dim, output_dim):# 继承父类的构造方法super().__init__()# 第一层隐藏层self.linear1 = nn.Linear(in_features=input_dim, out_features=128)# 第二层隐藏层self.linear2 = nn.Linear(in_features=128, out_features=256)# 输出层self.output = nn.Linear(in_features=256, out_features=output_dim)# todo:2-2 前向传播方法 forward()def forward(self, x):# 第一层隐藏层计算x = torch.relu(input=self.linear1(x))# 第二层隐藏层计算x = torch.relu(input=self.linear2(x))# 输出层计算# 没有进行softmax激活计算, 后续创建损失函数时CrossEntropyLoss=softmax+损失计算output = self.output(x)return output
# todo:3-模型训练
# todo:4-模型评估
if __name__ == '__main__':# 创建张量数据集对象train_dataset, valid_dataset, input_dim, class_num = create_dataset()# 创建模型对象model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)# 计算模型参数# input_size: 输入层样本形状summary(model, input_size=(16, input_dim))2.4 模型训练
# todo:3-模型训练
def train(train_dataset, input_dim, class_num):print('===========================模型训练===========================')# todo:3-1 创建数据加载器 批量训练dataloader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)# todo:3-2 创建神经网络分类模型对象, 初始化w和bmodel = PhonePriceModel(input_dim=input_dim, output_dim=class_num)print("======查看模型参数w和b======")for name, parameter in model.named_parameters():print(name, parameter)# todo:3-3 创建损失函数对象 多分类交叉熵损失=softmax+损失计算criterion = nn.CrossEntropyLoss()# todo:3-4 创建优化器对象 SGDoptimizer = optim.SGD(params=model.parameters(), lr=1e-3)# todo:3-5 模型训练 min-batch 随机梯度下降# 训练轮数num_epoch = 50for epoch in range(num_epoch):# 定义变量统计每次训练的损失值, 训练batch数total_loss = 0.0batch_num = 0# 训练开始的时间start = time.time()# 批次训练for x, y in dataloader:# 切换模型模式model.train()# 模型预测 y预测值y_pred = model(x)# print('y_pred->', y_pred)# 计算损失值loss = criterion(y_pred, y)# print('loss->', loss)# 梯度清零optimizer.zero_grad()# 计算梯度loss.backward()# 更新参数 梯度下降法optimizer.step()# 统计每次训练的所有batch的平均损失值和和batch数# item(): 获取标量张量的数值total_loss += loss.item()batch_num += 1# 打印损失变换结果print('epoch: %4s loss: %.2f, time: %.2fs' % (epoch + 1, total_loss / batch_num, time.time() - start))# todo:3-6 模型保存, 将模型参数保存到字典, 再将字典保存到文件torch.save(model.state_dict(), 'model/phone.pth')
if __name__ == '__main__':# 创建张量数据集对象train_dataset, valid_dataset, input_dim, class_num = create_dataset()# 创建模型对象# model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)# 计算模型参数# input_size: 输入层样本形状# summary(model, input_size=(16, input_dim))# 模型训练train(train_dataset=train_dataset, input_dim=input_dim, class_num=class_num)2.5 模型评估
# todo:4-模型评估
def test(valid_dataset, input_dim, class_num):# todo:4-1 创建神经网络分类模型对象model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)# todo:4-2 加载训练模型的参数字典model.load_state_dict(torch.load(f='model/phone.pth'))# todo:4-3 创建测试集数据加载器# shuffle: 不需要为True, 预测, 不是训练dataloader = DataLoader(dataset=valid_dataset, batch_size=8, shuffle=False)# todo:4-4 定义变量, 初始值为0, 统计预测正确的样本个数correct = 0# todo:4-5 按batch进行预测for x, y in dataloader:print('y->', y)# 切换模型模式为预测模式model.eval()# 模型预测 y预测值 -> 输出层的加权求和值output = model(x)print('output->', output)# 根据加权求和值得到类别, argmax() 获取最大值对应的下标就是类别 y->0,1,2,3# dim=1:一行一行处理, 一个样本一个样本y_pred = torch.argmax(input=output, dim=1)print('y_pred->', y_pred)# 统计预测正确的样本个数print(y_pred == y)# 对布尔值求和, True->1 False->0print((y_pred == y).sum())correct += (y_pred == y).sum()print('correct->', correct)# 计算预测精度 准确率print('Acc: %.5f' % (correct.item() / len(valid_dataset)))
if __name__ == '__main__':# 创建张量数据集对象train_dataset, valid_dataset, input_dim, class_num = create_dataset()# 创建模型对象# model = PhonePriceModel(input_dim=input_dim, output_dim=class_num)# 计算模型参数# input_size: 输入层样本形状# summary(model, input_size=(16, input_dim))# 模型训练# train(train_dataset=train_dataset, input_dim=input_dim, class_num=class_num)# 模型评估test(valid_dataset=valid_dataset, input_dim=input_dim, class_num=class_num)2.6 网络性能优化
-
输入层数据进行标准化
-
神经网络层数增加, 神经元个数增加
-
梯度下降优化方法由SGD调整为Aam
-
学习率由1e-3调整为1e-4
-
正则化
-
增加训练轮数
-
...
3 图像基础知识
3.1 图像概念
-
计算机中图像分类表示
-
二值图像 1通道(1个二维矩阵) 像素值:0或1
-
灰度图像 1通道 像素值:0-255
-
索引图像 1通道 索引值->RGB二维矩阵行下标 彩色图像 像素值:0-255
-
RGB真彩色图像(最常用) 3通道(3个二维矩阵) R G B三个二维矩阵 像素值:0-255
-
3.2 图像加载
import numpy as np
import matplotlib.pyplot as plt
import torch
# 创建全黑和全白图片
def dm01():# 全黑图片# 创建3通道二维矩阵, 黑色 0像素点# H W C: 200, 200, 3# 高 宽 通道img1 = np.zeros(shape=(200, 200, 3))print('img1->', img1)print('img1.shape->', img1.shape)# 展示图像plt.imshow(img1)plt.show()
# 全白图片# 放到全连接层就是 200*200*3=120000个特征值的一维向量img2 = torch.full(size=(200, 200, 3), fill_value=255)print('img2->', img2)print('img2.shape->', img2.shape)# 展示图像plt.imshow(img2)plt.show()
def dm02():# 加载图片img1 = plt.imread(fname='data/img.jpg')print('img1->', img1)print('img1.shape->', img1.shape)# 保存图像plt.imsave(fname='data/img1.png', arr=img1)# 展示图像plt.imshow(img1)plt.show()
if __name__ == '__main__':# dm01()dm02()4 卷积神经网络(CNN)介绍
4.1 什么是CNN
-
包含卷积层,池化层以及全连接层的神经网络计算模型
-
组成
-
卷积层: 提取图像特征图
-
池化层: 降维, 减少特征图的特征值, 减少模型参数
-
全连接层: 进行预测, 只能接受二维数据集, 1个样本就是1维向量
-
将池化层的特征图(1张图像)转换成一维
200*200*3->120000个特征值
-
-
4.2 CNN应用场景
-
图像分类
-
目标检测
-
面部解锁
-
自动驾驶
-
...
5 卷积层
作用: 提取特征图
5.1 卷积计算
卷积计算等同于线性层加权求和计算
-
通过带有权重的卷积核和图像的特征值进行点乘运算, 得到新特征图上的一个特征值
-
卷积核/滤波器 -> 带有权重参数的神经元
-
w1x1 + w2x2 + .... + b
-
w1->卷积核一个权重参数
-
x1->特征图的一个特征值(像素点)
-
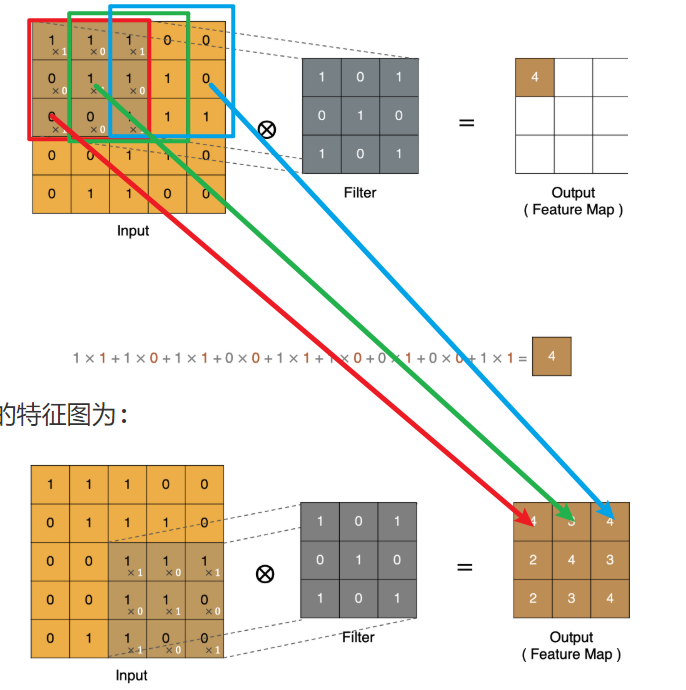
-
5.2 Padding(填充)
-
在原图像特征图周围补充特征值(默认补0)
-
作用
-
使新特征图和原特征图形状保持一致
-
减少边缘特征值信息丢失问题
-
未padding, 边缘特征值只参与一次计算, 经过padding后, 边缘特征值参与多次计算
-
-
-
实现方式
-
不进行padding处理: 新特征图比原图像特征图小
-
same padding: 原图像特征图形状和新特征图形状一致
-
full padding: 新特征图形状比原图像特征图大, 新增特征
-
5.3 Stride(步长)
-
stride指卷积核(神经元)在特征图上滑动的步伐 默认1
-
作用:
-
减少计算量
-
减少特征, 新特征图特征值减少(降维)
-
-
一般默认1, 可以设置2或4
-
原图像特征图
5*5, stride=1->新特征图3*3, stride=2->新特征图2*2
5.4 多通道卷积计算
-
RGB彩色图像是由3个通道组成 -> 3个二维矩阵, 每个矩阵分别代表R/G/B
-
卷积核通道数和原图像通道数一致
-
卷积计算 -> 对应通道二维矩阵进行卷积计算, 将每个通道卷积计算的结果加到一起, 得到新特征图的一个特征值
-
新特征图是1个二维矩阵, 不是3个二维矩阵
5.5 多卷积核卷积计算
-
有多少个卷积核就是有多少个神经元, 就会提取到多少个二维的特征图
5.6 特征图大小计算
-
N = (W-F+2P)/S + 1
-
N: 新特征图高或宽
-
W: 原特征图高或宽
-
F: 卷积核高或宽
-
P: padding值
-
S: stride值
-
N如果为小数, 向下取整, 内部封装floor函数
5.7 卷积层API使用
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
"""
in_channels:原图像的通道数,RGB彩色图像是3
out_channels:卷积核/神经元个数 输出的新图像是由n个通道的二维矩阵组成
kernel_size:卷积核形状 (3,3) (3,5)
stride:步长 默认为1
padding:填充圈数 默认为0 1 same->stride=1 2,3...
nn.Conv2d(in_channels=,out_channels=,kernel_size=,stride=,padding=)
"""
def dm01():# todo:1-加载RGB彩色图像 (H,W,C)img = plt.imread(fname='data/img.jpg')print('img->', img)print('img.shape->', img.shape)# todo:2-将图像的形状(H,W,C)转换成(C,H,W) permute()方法img2 = torch.tensor(data=img, dtype=torch.float32).permute(dims=(2, 0, 1))print('img2->', img2)print('img2.shape->', img2.shape)# todo:3-将这张图像保存到数据集中 (batch_size,C,H,W) unsqueeze()方法# 数据集只有一个样本img3 = img2.unsqueeze(dim=0)print('img3->', img3)print('img3.shape->', img3.shape)# todo:4-创建卷积层对象, 提取特征图conv = nn.Conv2d(in_channels=3,out_channels=4,kernel_size=(3, 3),stride=2,padding=0)conv_img = conv(img3)print('conv_img->', conv_img)print('conv_img.shape->', conv_img.shape)
# 查看提取到的4个特征图# 获取数据集中第一张图像img4 = conv_img[0]# 转换形状 (H,W,C)img5 = img4.permute(1, 2, 0)print('img5->', img5)print('img5.shape->', img5.shape)# img5->(H,W,C)# img5[:, :, 0]->第1个通道的二维矩阵特征图 第一个特征图feature1 = img5[:, :, 0].detach().numpy()plt.imshow(feature1)plt.show()
if __name__ == '__main__':dm01()6 池化层
池化层没有神经元参与, 只是实现降维, 不进行特征提取
6.1 池化计算
-
卷积层提取到的特征图进行降维操作
-
最大池化 -> 二维矩阵中最大的特征作为输出特征
-
平均池化 -> 二维矩阵中平均特征值作为输出特征
6.2 多通道池化计算
-
池化只在高和宽维度计算, 通道维度不参与池化
-
卷积层提取到的特征图像有多少通道, 经过池化后还是多少通道
6.3 池化层API使用
import torch
import torch.nn as nn
"""
最大池化
kernel_size:窗口形状大小, 不是神经元形状大小, 池化层没有神经元参与
nn.MaxPool2d(kernel_size=, stride=, padding=)
平均池化
nn.AVGPool2d(kernel_size=, stride=, padding=)
"""
# 单通道卷积层特征图池化
def dm01():# 创建1通道的3*3二维矩阵, 一张特征图inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]]], dtype=torch.float)print('inputs->', inputs)print('inputs.shape->', inputs.shape)# 创建池化层# kernel_size: 窗口的形状大小pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=1, padding=0)outputs = pool1(inputs)print('outputs->', outputs)print('outputs.shape->', outputs.shape)pool2 = nn.AvgPool2d(kernel_size=(2, 2), stride=1, padding=0)outputs = pool2(inputs)print('outputs->', outputs)print('outputs.shape->', outputs.shape)
# 多通道卷积层特征图池化
def dm02():# size(3,3,3)inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],[[10, 20, 30], [40, 50, 60], [70, 80, 90]],[[11, 22, 33], [44, 55, 66], [77, 88, 99]]], dtype=torch.float)# 创建池化层# kernel_size: 窗口的形状大小pool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=1, padding=0)outputs = pool1(inputs)print('outputs->', outputs)print('outputs.shape->', outputs.shape)pool2 = nn.AvgPool2d(kernel_size=(2, 2), stride=1, padding=0)outputs = pool2(inputs)print('outputs->', outputs)print('outputs.shape->', outputs.shape)
if __name__ == '__main__':# dm01()dm02()相关文章:

深度学习中的正则化方法与卷积神经网络基础
笔记 1 正则化方法 1.1 什么是正则化 防止模型过拟合(训练集效果好, 测试集效果差), 提高模型泛化能力 一种防止过拟合, 提高模型泛化能力的策略 L1正则: 需要通过手动写代码实现 L2正则: SGD(weight_decay) dropout BN 1.2 Dropout正则化 让神经元以p概率随机死亡, 每…...

pg_dump
以下是 PostgreSQL 中 pg_dump 命令的 核心参数 及 使用示例 的详细说明: 一、核心参数分类及说明 pg_dump 主要用于备份单个数据库,支持多种格式和灵活的控制选项。以下是其关键参数分类: 1. 连接参数 参数说明-h, --hostHOST数据库服务器…...

css使用clip-path属性切割显示可见内容
1. 需求 想要实现一个渐变的箭头Dom,不想使用svg、canvas去画,可以考虑使用css的clip-path属性切割显示内容。 2. 实现 <div class"arrow">箭头 </div>.arrow{width: 200px;height: 60px;background-image: linear-gradient(45…...

系统设计——项目设计经验总结1
摘要 在系统设计的时候,注意域的区分,功能区分、类的区分、方法区分范围和定义。在系统设计的时候的,需要思考类、方法在什么情况下会涉及到修改,遵循记住:一个类应该只有一个原因被修改! 当不满足&#x…...

如何在WordPress网站上添加即时聊天功能
在 WordPress 网站上添加即时聊天功能既简单又有益。近年来,即时聊天已经有了长足的发展,融入了强大的交流和自动化功能,类似于流行的人工智能聊天机器人。无论您是想提高销售转化率还是将人工智能整合到客户服务流程中,在 WordPr…...

[luogu12542] [APIO2025] 排列游戏 - 交互 - 博弈 - 分类讨论 - 构造
传送门:https://www.luogu.com.cn/problem/P12542 题目大意:给定一个长为 n n n 的排列和一张 m m m 个点 e e e 条边的简单连通图。每次你可以在图上每个点设置一个 0 ∼ n − 1 0\sim n-1 0∼n−1、两两不同的权值发给交互库,交互库会…...

图像处理基础知识
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 信息是自然界物质运动总体的一个重要方面,人们认识世界和改造世界就是要获得各种各样的图像信息,这些信息是人类获得外界信息的主要来源。大约有70%的信息是通过人眼获得的。近代科学研…...

使用MybatisPlus实现sql日志打印优化
背景: 在排查无忧行后台服务日志时,一个请求可能会包含多个执行的sql,经常会遇到SQL语句与对应参数不连续显示,或者参数较多需要逐个匹配的情况。这种情况下,如果需要还原完整SQL语句就会比较耗时。因此,我…...

HarmonyOS5云服务技术分享--ArkTS开发Node环境
✨ 你好呀,开发者小伙伴们!今天我们来聊聊如何在HarmonyOS(ArkTS API 9及以上)中玩转云函数,特别是结合Node.js和HTTP触发器的开发技巧。文章会手把手带你从零开始,用最接地气的方式探索这个功能࿰…...

水利数据采集MCU水资源的智能守护者
水利数据采集仪MCU,堪称水资源的智能守护者,其重要性不言而喻。在水利工程建设和水资源管理领域,MCU数据采集仪扮演着不可或缺的角色。它通过高精度的传感器和先进的微控制器技术,实时监测和采集水流量、水位、水质等关键数据&…...

深度学习之用CelebA_Spoof数据集搭建一个活体检测-用MNN来推理时候如何利用Conan对软件包进行管理
我为什么用Conan 前面的文章:深度学习之用CelebA_Spoof数据集搭建一个活体检测-训练好的模型用MNN来推理有提到怎么使用MNN对训练好的模型进行推理,里面并没有提到我是怎么编译和进行代码依赖包的管理的详细步骤,在这里我是用的是Conan:一个…...

深入解剖 G1 收集器的分区模型与调优策略
JVM 垃圾收集系列之三 | 高并发低延迟系统的首选 GC 解法! 一、为什么我们需要 G1 垃圾收集器? 在传统 GC(如 CMS)中,我们常常面临的问题是: GC 停顿不可预测(Stop-The-World)内存…...

兰亭妙微・UI/UX 设计・全链路开发
【遇见专业设计,共筑卓越产品】 在数字化浪潮中,界面是产品与用户对话的第一窗口。 兰亭妙微(蓝蓝设计),自 2008 年深耕 UI/UX 领域,以清华团队为核心,16 年专注软件与互联网产品的界面设计开…...

Babylon.js学习之路《六、材质与纹理:为模型赋予真实的表面效果》
文章目录 1. 引言:材质与纹理的重要性1.1 材质与纹理的核心作用 2. 基础材质:StandardMaterial2.1 材质属性详解2.2 实战:创建金属材质 3. 纹理贴图:从基础到高级3.1 基础纹理映射3.2 多纹理混合技术 4. 高级材质:PBRM…...

飞致云旗下开源项目GitHub Star总数突破150,000个
2025年5月19日,中国领先的开源软件提供商飞致云宣布,其旗下开源项目在代码托管平台GitHub上所获得的Star总数已经超过150,000个。基于在开源领域的长期耕耘和探索,飞致云的开源势能不断增强,获得第一个五万GitHub Star用时89个月&…...
场)
萌新联赛第(三)场
C题 这道题用暴力去写想都不要想,一定超时,于是我们需要优化,下面是思路过程: 如图,本题只需找到x的因数个数和(n-x)的因数个数,这两个相乘,得到的就是对于这个x来说组合的个数,且x…...

cplex12.9 安装教程以及下载
cplex 感觉不是很好找,尤其是教育版,我这里提供一个版本,在下面的图可以看到,不仅可以配置matlab,也可以配置vs,现在拿vs2017来测试一下,具体文件的文件有需要的可以复制下面的链接获取 我用网盘分享了「c…...

Pycharm-jupyternotebook不渲染
解决方案: https://youtrack.jetbrains.com/issue/PY-54244 import plotly.io as pio pio.renderers.default "vscode"...

layui 介绍
layui(谐音:类 UI) 是一套开源的 Web UI 解决方案,采用自身经典的模块化规范,并遵循原生 HTML/CSS/JS 的开发方式,极易上手,拿来即用。其风格简约轻盈,而组件优雅丰盈,从源代码到使用…...

大数据相关操作
大数据相关操作 一、环境配置 1、修改主机名 #修改主机名 hostnamectl set-hostname master2、固定IP地址 # 进入修改 sudo vim /etc/netplan/01-network-manager-all.yaml# 修改配置文件 # Let NetworkManager manage all devices on this system network:version: 2rend…...

谷歌宣布推出 Android 的新安全功能,以防止诈骗和盗窃
在上周二的 Android Show 上,也就是Google I/O 开发者大会之前,谷歌宣布了 Android 的全新安全和隐私功能。这些新功能包括对通话、屏幕共享、消息、设备访问和系统级权限的全新保护。谷歌希望通过这些功能保护用户免遭诈骗,在设备被盗或被攻…...
)
WSL虚拟机整体迁移教程(如何将WSL从C盘迁移到其他盘)
文章目录 WSL虚拟机迁移教程一、查看当前主机的子系统二、导出 WSL 子系统三、将打包好的文件发送给另一个人四、在另一台机器导入并恢复子系统五、附加命令六、注意事项和导出文件信息6.1 注意事项6.2 导出文件信息使用 wsl --export 命令导出整个 WSL 子系统时,它…...
的统一)
汽车区域电子电气架构(Zonal E/E)的统一
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界…...

开源一个记账软件,支持docker一键部署
欢迎来到我的博客,代码的世界里,每一行都是一个故事 🎏:你只管努力,剩下的交给时间 🏠 :小破站 开源一个记账软件,支持docker一键部署 项目简介功能特性技术栈快速开始环境要求运行步…...

新能源汽车焊接智能节气阀
在新能源汽车产业迅猛发展的浪潮中,制造工艺的优劣直接关系到车辆的性能、安全与市场竞争力。焊接,作为新能源汽车生产流程里的关键一环,无论是构建车身框架,还是连接电池模组,其质量的好坏都起着决定性作用。而在焊接…...

React 第四十四节Router中 usefetcher的使用详解及注意事项
前言 useFetcher 是 React Router 中一个强大的钩子,用于在不触发页面导航的情况下执行数据加载(GET)或提交(POST)。 一、useFetcher 应用场景: 1、后台数据预加载(如鼠标悬停时加载数据&…...

33、魔法防御术——React 19 安全攻防实战
一、奥术护盾(基础防御) 1. 敏感数据加密术 // cryptoUtils.js - 数据加密工具export const encrypt (data) > {// 实际项目应使用Web Crypto API或crypto-jsreturn btoa(encodeURIComponent(data));};export const decrypt (data) > {try {…...

NVM 安装与配置指南
简介 Node Version Manager(NVM)是一个常用的 Node.js 版本管理工具,可用于在开发过程中方便地切换不同版本的 Node.js。通过 NVM,用户可以根据项目需求选择不同的 Node.js 版本,而无需手动安装和卸载多个版本的 Node…...
)
SpringMVC04所有注解按照使用位置划分| 按照使用层级划分(业务层、视图层、控制层)
目录 一、所有注解按照使用位置划分(类、方法、参数) 1. 类级别注解 2. 方法级别注解 3. 参数级别注解 4. 字段/返回值注解 二、按照使用层级划分(业务层、视图层、控制层) 1、控制层(Controller Layer&#x…...

【数据库】-1 mysql 的安装
文章目录 1、mysql数据库1.1 mysql数据库的简要介绍 2、mysql数据库的安装2.1 centos安装2.2 ubuntu安装 1、mysql数据库 1.1 mysql数据库的简要介绍 MySQL是一种开源的关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,目前…...

MySQL与Redis一致性问题分析
一、一致性问题概述 1.1 什么是一致性问题? 在数据库-缓存架构中,当MySQL中的数据(最新值)与Redis缓存中的数据(缓存旧值)出现差异时,由于程序总是优先读取Redis缓存,就会导致应用…...

Xshell传输文件
新建文件 点击新建 完善主机地址 然后输入我们的远端服务器的SSH协议 一般的是这样的ssh -p 44562 rootregion-1.autodl.com 由于Xshell比较特殊我们输入ssh rootregion-1.autodl.com 44562这样的形式 然后输入服务器的密码即可...

怎样用 esProc 为大主子表关联提速
类似订单和明细表这样的主子表关联比较常见,在 SQL 中,这种关联用 JOIN 实现,在两个表都很大的情况下,常常出现计算速度非常慢的现象。 如果预先将主子表都按照主键有序存储,就可以使用归并算法实现关联。这种算法只需…...

打卡day31
文件的规范拆分和写法 知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 作业:尝试针对之前的心脏病项目,准备拆分的项目文件,思考下哪些部分可以未来复用。 导入依赖库 # 忽视警告 import warnings warn…...

编译原理的部分概念
解释程序:边解释边执行:不断读取源程序的语句,解释语句,读取此语句需要的数据,根据执行结果读取下一条语句,继续解释执行,直到返回结果。 编译程序:将源程序完整地转换成机器语言程…...
的常用方法)
Java中字符串(String类)的常用方法
以下是Java中字符串(String类)的常用方法分类详解,包含核心方法说明和示例代码: 一、字符串基础信息 方法说明示例输出length()返回字符串长度"Hello".length()5isEmpty()判断字符串是否为空(长度是否为0&a…...

什么是 ERP,中国企业如何科学应用 ERP
中国企业在引入 ERP 系统过程中,常因盲目跟风大型企业选型、忽视自身业务适配性,导致系统功能过剩、实施成本高企、员工接受度低等问题,最终造成项目成功率不足 10%。因此,理性认知 ERP 的价值定位与本土化实施路径,成…...

使用SQLite Expert个人版VACUUM功能修复数据库
使用SQLite Expert个人版VACUUM功能修复数据库 一、SQLite Expert工具简介 SQLite Expert 是一款功能强大的SQLite数据库管理工具,分为免费的个人版(Personal Edition)和收费的专业版(Professional Edition)。其核心功…...
)
同源策略深度防御指南:CSP 高级应用与企业微信全场景适配(含 report-uri 实战)
一、CSP 核心指令权威解析与企业微信适配 内容安全策略(CSP)通过Content-Security-Policy响应头实现资源加载的细粒度控制,其核心指令与企业微信场景强相关: 1.1 frame-ancestors:iframe 嵌入源控制 权威规范&#…...

【AGI】大模型微调技术-四大微调框架
【AGI】大模型微调技术-四大微调框架 (1)微调基础概念介绍1.1 微调基本概念1.2 全量微调与高效微调1.3 模型微调的优劣势分析1.4 高效微调与LoRA、QLoRA (2)高效微调的应用场景(3)流微调工具介绍3.1 unslot…...

小白编程学习之巧解「消失的数字」
一、引言:一个看似简单的「找不同」问题 今天遇到一道有趣的算法题:给定一个含 n 个整数的数组 nums,其中每个元素都在 [1, n] 范围内,要求找出所有在 [1, n] 中但未出现在数组中的数字。 这让我想起小时候玩的「找错题」游戏 —…...
的详细步骤)
在 Git 中添加子模块(submodule)的详细步骤
在 Git 中添加子模块(submodule)的详细步骤如下: 1. 添加子模块 命令格式: git submodule add <仓库URL> [目标路径]仓库URL:子模块的 Git 仓库地址(HTTP/SSH 均可)。目标路径ÿ…...

瑞萨单片机笔记
1.CS for CC map文件中显示变量地址 Link Option->List->Output Symbol information 2.FDL库函数 pfdl_status_t R_FDL_Write(pfdl_u16 index, __near pfdl_u08* buffer, pfdl_u16 bytecount) pfdl_status_t R_FDL_Read(pfdl_u16 index, __near pfdl_u08* buffer, pfdl_…...

单片机复用功能重映射Remap功能
目录 一、查看“DS5319 stm32f10x中等密度mcu数据手册(英文)”手册 二、查看“RM0008 STM32F10xxx参考手册(中文)”手册 三、重映射(Remap)功能程序编写 自己学习过程中容易遗忘的知识点,记录…...

小白入门FPGA设计,如何快速学习?
很多刚入门的小伙伴,初次听说FPGA(现场可编程门阵列),脑子里只有一个字:玄! 什么“时序逻辑”“Verilog”“Vivado”,仿佛一夜之间掉进了电子黑魔法的深坑。 但真相是—— FPGA,其实…...

友思特应用 | LCD显示屏等玻璃行业的OCT检测应用
导读 光学相干层析成像(OCT)是一种非侵入式光学成像方法,提供微米尺度的空间分辨率,能够生成内部结构截面图像。自20世纪90年代初发明第一台OCT以来,它在眼科领域得到了广泛应用,并成为临床诊断的黄金标准之一。除了在生物医学领…...

Python的sys模块:系统交互的关键纽带
Python的sys模块:系统交互的关键纽带 对话实录 小白:(挠头)我知道 Python 能做很多事,可怎么让它和计算机系统‘交流’呢,比如获取系统信息、处理命令行参数? 专家:(微…...

若依项目集成sentinel、seata和shardingSphere
集成组件包括MySQL分库分表及读写分离、seata以及Sentinel 若依项目文档连接 代码下载地址 需要结合ruoyi代码配合看,前提是熟悉基本代码结构,熟悉feign调用和基础网关配置等。 采用的版本信息 <java.version>1.8</java.version> <spr…...

张 推进对话式心理治疗:SOULSPEAK的聊天机器人
SOULSPEAK的聊天机器人 利用大语言模型(LLM)来提供低成本的心理治疗服务,旨在解决传统心理咨询在隐私、成本和可及性方面的不足。以下是核心内容的通俗解读: 1. 研究背景:传统心理治疗的困境 问题:全球心理健康问题日益严重(如焦虑、抑郁人数激增),但传统心理咨询受…...

java中的Filter使用详解
Filter(过滤器)是 Java Web 开发的核心组件之一,用于在请求到达 Servlet 或响应返回客户端之前进行拦截和处理。以下是其核心功能、使用方法和实际场景的详细解析: 一、Filter 的作用与原理 核心作用 Filter 充当请求与响应之间的…...