LLM笔记(十)vLLM(1)PagedAttention论文笔记
文章目录
- PagedAttention论文笔记
- 论文摘要概览
- 1. 引言
- 问题背景
- 提出的解决方案
- 主要贡献和成果
- 2. 背景
- 2.1 基于Transformer的大语言模型
- 2.2 LLM服务与自回归生成
- 2.3 LLM的批处理技术
- 3. LLM服务中的内存挑战
- 3.1 现有系统中的内存管理
- 4. 方法: PagedAttention 和 vLLM
- vLLM 系统概览
- 4.1 PagedAttention 算法
- PagedAttention 算法详解
- 4.2 KV缓存管理器
- 4.3 使用PagedAttention和vLLM进行解码
- 4.4 应用于其他解码场景
- 并行采样
- 束搜索
- 共享前缀(例如系统提示)
- 4.5 调度和抢占
- 4.6 分布式执行
- 5. 实现
- 5.1 PagedAttention的自定义CUDA核心
- 5.2 支持各种解码算法
- 6. 评估
- 6.1 实验设置
- 6.2 基本采样结果(每个请求一个样本)
- 6.3 并行采样和束搜索结果
- 6.4 共享前缀结果
- 6.5 聊天机器人结果
- 7. 消融研究
- 7.1 核心微基准测试
- 7.2 块大小的影响
- 7.3 重计算与交换的比较
- 8. 讨论
- 9. 相关工作
- 10. 结论
- 附录: 核心代码注释
- 基础组件
- 元数据结构
- 内存管理机制
- KV缓存的物理布局
- 内存重组与优化
- 核心操作流程
- 1. 写入新Token的KV到缓存
- 2. 解码阶段的注意力计算
- 3. 预填充阶段的注意力计算
- 4. 物理块管理操作
- 设计亮点与优化
- 参考
PagedAttention论文笔记
vLLM First SF Meetup Slides
论文摘要概览
PageAttention论文提出了一种名为PagedAttention的注意力算法,其灵感来源于操作系统的虚拟内存和分页技术,以及基于此构建的LLM服务系统vLLM。
核心问题是现有LLM服务系统中键值(KV)缓存管理的低效性。由于内存碎片和无法有效共享内存,这种低效性限制了批处理大小,进而影响吞吐量。PagedAttention允许KV缓存块非连续存储并进行灵活管理,实现了近乎零内存浪费,并支持细粒度的内存共享(例如写时复制)。
vLLM利用这一特性,在与FasterTransformer和Orca等最先进系统相似的延迟水平下,实现了2-4倍的吞吐量提升,尤其在处理长序列、大模型和复杂解码算法时效果更显著。
1. 引言
问题背景
- LLM的高吞吐量服务需要同时处理足够多的请求批次
- 现有系统在KV缓存管理上存在困难:
- 每个请求的KV缓存量巨大且动态变化(增长和收缩)
- 低效管理导致内存因碎片(内部和外部)和冗余复制而大量浪费
- 这限制了批处理大小和整体吞吐量
- LLM服务成本高昂(例如,比传统关键字查询贵10倍)
- LLM生成通常受限于内存,导致GPU计算资源未被充分利用
- 约30% GPU内存用于KV缓存,65%用于模型参数
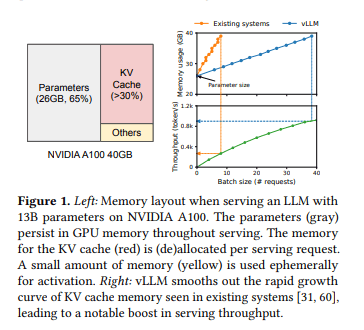
提出的解决方案
- PagedAttention: 一种受经典虚拟内存和分页启发的注意力算法
- 将KV缓存存储在非连续的块中
- 支持在请求内部和请求之间灵活共享KV缓存
- vLLM: 一个基于PagedAttention构建的LLM服务系统
- 在KV缓存内存中实现近乎零浪费
主要贡献和成果
- 识别并量化了LLM服务中的内存分配挑战
- 提出了PagedAttention,用于非连续的分页式KV缓存
- 设计并实现了vLLM,一个使用PagedAttention的分布式LLM服务引擎
- 评估显示,vLLM在相似延迟下,吞吐量比FasterTransformer和Orca提高了2-4倍
- 在长序列、大模型和复杂解码算法下,改进更为明显
- 源代码:
https://github.com/vllm-project/vllm
2. 背景
2.1 基于Transformer的大语言模型
-
自回归分解: P(x) = P(x1) * P(x2|x1) * …
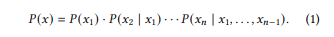
-
自注意力层是关键。查询(q)、键(k)、值(v)向量
-
KV缓存: 已有token的键和值向量被缓存,用于生成未来的token。一个token的KV缓存依赖于其所有先前的token(Decoder推理)
2.2 LLM服务与自回归生成
- 服务接收输入提示,顺序生成输出token
- 提示阶段 (Prompt Phase): 计算所有输入提示token的KV缓存。可并行化(矩阵-矩阵运算)
- 自回归生成阶段 (Autoregressive Generation Phase): 逐个生成输出token。每一步都依赖于先前token的KV缓存。效率较低(矩阵-向量运算),通常受内存限制,是大部分延迟的来源
2.3 LLM的批处理技术
- 通过分摊模型权重加载的开销来提高GPU利用率
- 挑战:请求在不同时间到达;输入/输出长度可变
- 细粒度批处理 (例如,迭代级调度):
- 在迭代级别操作
- 每次迭代后,完成的请求被移除,新的请求被添加
- 减少排队延迟和填充效率低下的问题
3. LLM服务中的内存挑战
- 吞吐量受内存限制,特别是KV缓存空间
- 巨大的KV缓存:
- 例如,OPT 13B模型:每个token 800KB。对于2048个token,每个请求约1.6GB
- GPU内存容量(数十GB)限制了并发请求数
- GPU计算速度的增长快于内存容量的增长
- 复杂的解码算法:
- 并行采样 (Parallel Sampling): 提示的KV缓存可以在多个随机样本之间共享
- 束搜索 (Beam Search): 不同的束可以共享更大部分的KV缓存;共享模式随解码过程演变
- 未知输入输出长度的调度:
- KV缓存所需的内存随着输出的增长而扩展
- 系统需要做出调度决策(例如,逐出/交换KV缓存)
3.1 现有系统中的内存管理
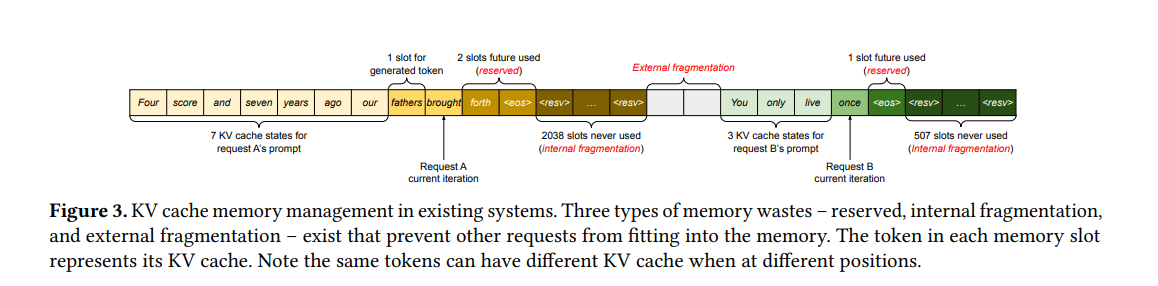
-
将KV缓存存储为连续的张量
-
根据最大可能的序列长度静态分配内存块
-
三种内存浪费来源:
-
预留槽位 (Reserved slots): 为未来token预留,在生成前未使用但占用空间
-
内部碎片 (Internal fragmentation): 为最大长度过度分配,实际长度通常较短
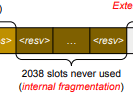
-
外部碎片 (External fragmentation): 来自内存分配器(如伙伴分配器)
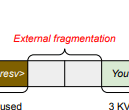
-
-
结果: 以往系统中实际有效内存使用率可能低至20.4%
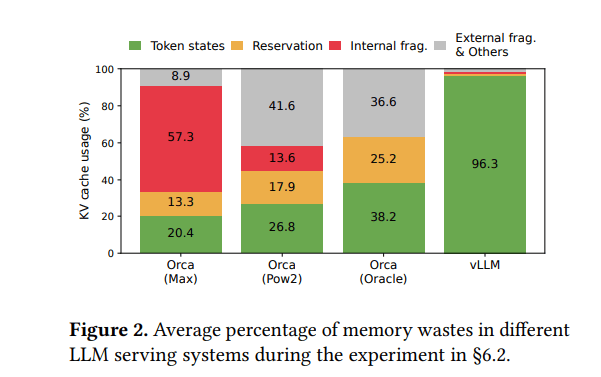
-
由于KV缓存存储在独立的连续空间中,无法利用内存共享机会(例如,用于束搜索)
4. 方法: PagedAttention 和 vLLM
vLLM 系统概览
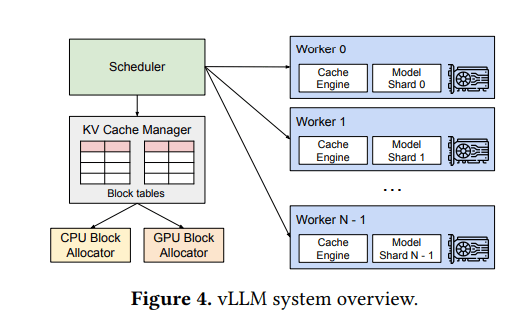
- 中心化调度器协调分布式GPU工作节点
- KV缓存管理器: 通过调度器的指令,以分页方式管理GPU上的物理KV缓存
4.1 PagedAttention 算法
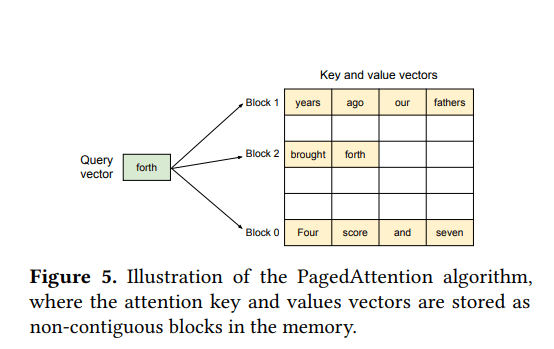
- 将键和值存储在非连续的内存空间中
- 将每个序列的KV缓存划分为固定大小的KV块
- 每个块包含固定数量token的KV(块大小为B)
- 像操作系统虚拟内存一样管理KV缓存(块=页,token=字节,请求=进程)
- 优点:
- 通过使用相对较小的块并按需分配,减轻内部碎片
- 由于所有块大小相同,消除了外部碎片
- 支持块粒度的内存共享
PagedAttention 算法详解
1. 核心思想与动机
- 解决内存挑战: 为了应对内存管理挑战(如碎片化、无法共享等)
- 灵感来源: 受到操作系统中经典的**分页(paging)**思想的启发
- 与传统注意力的区别: 传统注意力算法通常要求Key和Value数据在内存中是连续存储的。PagedAttention允许将连续的逻辑Key和Value数据存储在非连续的物理内存空间中
2. PagedAttention 的工作原理
-
KV缓存分区: 将每个序列的KV缓存分割成多个KV块
-
KV块的内容: 每个KV块包含固定数量token的Key向量和Value向量,这个固定数量称为KV块大小(block size, B)
- 一种设计是将一个token在所有层和所有头上的所有Key和Value向量一起管理在单个KV块中
- 另一种设计是,不同层、不同头的Key和Value向量可以拥有各自独立的KV块,并通过独立的块表进行管理
- 论文选择了第二种设计(即每个层、每个头的KV可以有独立的块)
-
块化计算 (Blockwise Computation):
- 令 K j K_j Kj 表示第 j j j 个Key块,包含从第 ( j − 1 ) B + 1 (j-1)B+1 (j−1)B+1 个token到第 j B jB jB 个token的Key向量
- 令 V j V_j Vj 表示第 j j j 个Value块,包含对应token的Value向量
- 注意力计算如何转化为基于块的计算:
- A i j A_{ij} Aij: 表示查询向量 q i q_i qi 与第 j j j 个Key块 K j K_j Kj 计算得到的注意力得分向量
- 分子: e x p ( q i T K j / d ) exp(q_i^T K_j / \sqrt{d}) exp(qiTKj/d)
- 分母: ∑ t = 1 ⌈ i / B ⌉ e x p ( q i T K t / d ) \sum_{t=1}^{\lceil i/B \rceil} exp(q_i^T K_t / \sqrt{d}) ∑t=1⌈i/B⌉exp(qiTKt/d)
- 注意:这里的公式 (4) 中分母的求和上标 ⌈ i / B ⌉ \lceil i/B \rceil ⌈i/B⌉ 暗示了softmax是在当前查询 q i q_i qi 已经看到的所有历史key上进行的。 A i j A_{ij} Aij 本身似乎是未归一化的得分或局部归一化的得分,最终的 o i o_i oi 才是所有块贡献的加权和。论文原文的公式表达可能需要结合上下文理解其精确的归一化范围。通常注意力计算的softmax是在所有相关的key上进行的。更常见的表达可能是先计算所有 q i K j q_i K_j qiKj 的得分,然后对所有这些得分进行softmax,最后再与 V j V_j Vj 加权求和。此处的块化公式是为了说明PagedAttention如何按块处理。
- o i o_i oi: 最终的注意力输出向量,是所有Value块 V j V_j Vj 根据其对应的注意力得分 A i j T A_{ij}^T AijT 加权求和的结果
- o i = ∑ j = 1 ⌈ i / B ⌉ V j A i j T o_i = \sum_{j=1}^{\lceil i/B \rceil} V_j A_{ij}^T oi=∑j=1⌈i/B⌉VjAijT
- A i j A_{ij} Aij: 表示查询向量 q i q_i qi 与第 j j j 个Key块 K j K_j Kj 计算得到的注意力得分向量
3. PagedAttention 内核的行为
- 独立获取KV块: 在注意力计算过程中,PagedAttention内核能够独立地识别和获取不同的KV块
- 当计算查询token的注意力时:
- 内核会将查询与相关Key向量相乘,计算得到注意力得分
- 然后,内核会将注意力得分与Value向量相乘,得到该块对最终输出的贡献
- 这个过程会对所有相关的KV块重复进行
4. PagedAttention 的核心优势
- 非连续物理内存存储: 允许KV块存储在物理内存的任何可用位置,而不需要大段的连续空间
- 灵活的分页内存管理:
- 减少内存碎片: 由于块是固定大小的,外部碎片几乎被消除;按需分配块也减少了内部碎片
- 动态分配: 只在需要时才为序列分配新的物理块
- 内存共享: 不同序列(或同一序列的不同解码路径)可以共享相同的物理KV块(通过块表映射),并通过写时复制等机制进行管理
简而言之,PagedAttention的核心是将传统注意力计算中对连续KV缓存的依赖,转变为对一系列可能非连续的、固定大小的KV块的操作。这为上层内存管理器提供了极大的灵活性,从而克服了传统LLM服务中的内存管理难题。
4.2 KV缓存管理器
- 将逻辑KV块(请求的视角)映射到物理KV块(在GPU DRAM上)
- 为每个请求维护块表(block tables):记录逻辑块到物理块的映射,以及每个块中已填充token槽位的数量
- 最后一个KV块中未填充的位置为该序列的未来生成保留
- 按需动态分配物理页
4.3 使用PagedAttention和vLLM进行解码
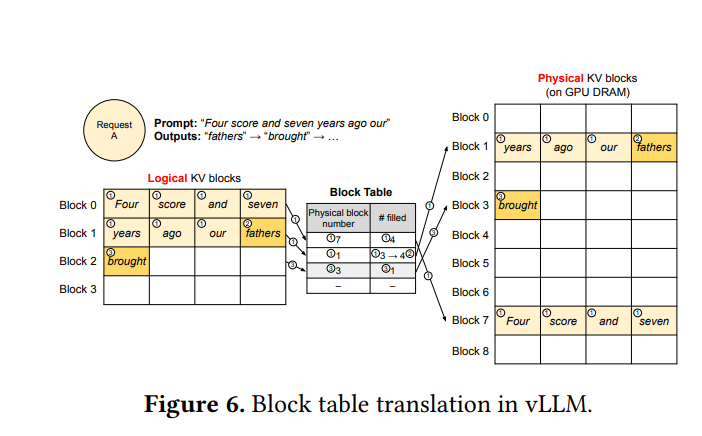
- 初始时,仅为提示分配KV块
- 随着token的生成,如果当前逻辑块已满,则分配一个新的物理块并进行映射
- 一个请求的内存浪费被限制在一个块内
- 允许高效地打包多个请求的KV缓存
4.4 应用于其他解码场景
并行采样
- 场景: 用户提供一个输入提示,希望模型生成多个不同的、随机的输出序列
- 内存共享机会: 所有并行生成的样本共享相同的初始输入提示,因此提示部分的KV缓存可以被所有样本共享
- PagedAttention 的应用:
- 提示阶段: 计算输入提示的KV缓存,存储在一系列物理块中
- 共享映射: 对于所有N个并行样本,它们块表中的初始逻辑块(对应于输入提示的部分)都会被映射到同一组物理块。这些物理块的引用计数会相应增加(例如,如果N个样本共享,则为N)。
- 生成阶段:
- 写时复制(CoW)的触发: 当一个样本生成第一个新token,需要将其KV写入到提示的最后一个(可能部分填充的)物理块时,如果该物理块是共享的(引用计数 > 1),就会触发CoW机制。该样本会获得这个块的一个私有副本。
- 后续生成的token各自分配独立的物理块
- 优势:
- 显著节省内存: 尤其当输入提示很长时,共享提示部分的KV缓存可以节省大量内存,从而允许系统同时处理更多的并行样本或更大的批处理。
- 减少计算: 提示部分的KV缓存只需计算一次
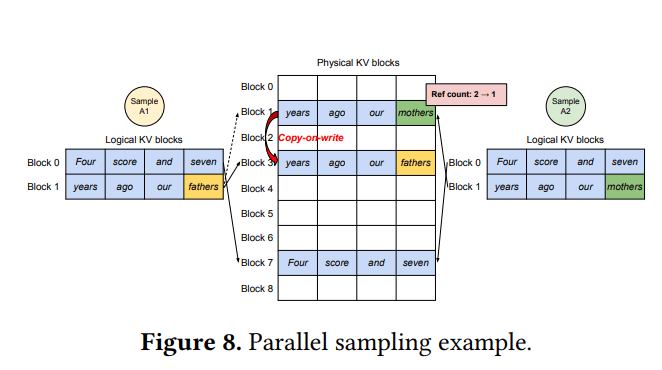
图8 (Parallel sampling example) 的解读:
-
Sample A1 和 Sample A2 共享相同的prompt (“Four score and seven years ago our”)。
-
初始时,它们的逻辑块0和逻辑块1都映射到相同的物理块7和物理块1。物理块7和1的引用计数为2。
-
当Sample A1生成 “fathers” 并需要写入逻辑块1(对应物理块1)时,由于物理块1的引用计数为2,触发CoW。
-
系统分配新的物理块3。
-
物理块1的内容复制到物理块3。
-
Sample A1的逻辑块1现在映射到物理块3。
-
物理块1的引用计数减为1。物理块3的引用计数为1。
-
-
当Sample A2生成 “mothers” 并需要写入其逻辑块1时,它发现其逻辑块1仍然映射到物理块1,且物理块1的引用计数此时已为1。因此,Sample A2可以直接在物理块1上写入,无需再次复制。
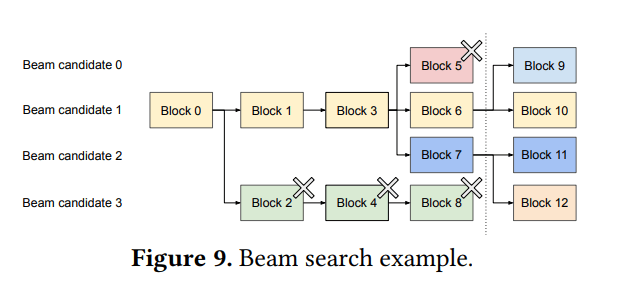
束搜索
- 场景: 保留k个最可能的候选序列(束),而不是只选择最可能的一个token
- 内存共享机会:
- 初始提示共享: 所有束共享相同的输入提示的KV缓存
- 共同前缀共享: 不同束之间可能在多个时间步内共享相同的生成前缀
- 动态共享模式: 随着解码进行,共享模式动态变化
- PagedAttention 的应用:
- 初始化: 所有束共享输入提示的物理KV块
- 扩展与剪枝:
- 当一个束扩展出新的候选token时,可能触发CoW
- 被剪枝的束释放逻辑块,减少物理块引用计数
- 优势:
- 大幅减少内存开销: 利用序列前缀共享
- 高效的动态管理: 有效处理束搜索中的动态关系和生命周期
图9 (Beam search example) 的解读:
-
假设 k=4 (Beam candidate 0, 1, 2, 3)。
-
迭代前:
-
所有候选者共享第一个块0(初始prompt)。
-
候选者0, 1, 2 共享前3个块,在第4个块分化。
-
候选者3 从第二个块开始就与其他候选者不同。
-
-
迭代后:
-
假设新的top-4候选者都源自于旧的候选者1和2。
-
旧的候选者0和3因为不再是top-k而被剪枝,它们引用的逻辑块被释放,对应物理块(2, 4, 5, 8)的引用计数减少,如果减到0则物理块被回收。
-
新的共享结构:
-
所有新的候选者仍然共享块0, 1, 3 (物理块)。
-
新的候选者0和1共享块6。
-
新的候选者2和3共享块7。
-
为新生成的token分配了新的物理块9-12。
-
-
CoW的应用: 如果新生成的token需要写入到一个旧的、仍然被多个新候选者共享的块中,则会发生CoW。例如,如果新的候选者0和1都从旧的候选者1的某个共享块扩展而来,并且它们在新的一步中生成了不同的token,那么这个共享块就会被CoW。
-
共享前缀(例如系统提示)
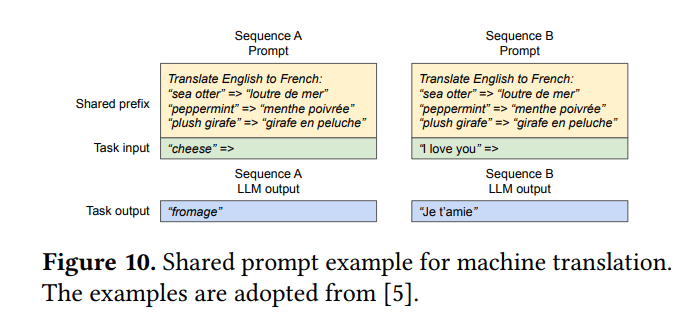
- 通用前缀(如指令)的KV缓存可以预先计算并存储
- 使用此前缀的请求将其初始逻辑块映射到这些缓存的物理块(最后一个块通常是写时复制)
- 混合解码方法: 由于逻辑到物理块映射的抽象层,vLLM可以同时处理具有不同解码方法的请求
4.5 调度和抢占
- FCFS(先来先服务)调度策略
- 如果GPU耗尽物理块以存储新token:
- 驱逐策略: 全有或全无(驱逐一个序列的所有块)。序列组(例如束候选项)被组合调度/抢占
- 恢复被驱逐的块:
- 交换(Swapping): 将被驱逐的块复制到CPU RAM(CPU块分配器)。CPU上的交换空间受GPU KV缓存分配的限制
- 重计算(Recomputation): 为被抢占的序列重新计算KV缓存。将原始提示+已生成的token连接成新的提示;KV缓存在一个提示阶段迭代中生成
4.6 分布式执行
- 支持Megatron-LM风格的张量模型并行
- 中心化调度器中只有一个KV缓存管理器
- 所有GPU工作节点共享逻辑到物理块的映射
- 每个GPU工作节点仅存储其分配的注意力头对应的KV缓存部分
- 调度器向工作节点广播控制消息(token ID,块表)
5. 实现
- 端到端系统:FastAPI前端,基于GPU的推理引擎
- 代码:8.5K行Python(调度器,块管理器),2K行C++/CUDA(核心)
5.1 PagedAttention的自定义CUDA核心
- 融合的reshape和块写入: 新的KV缓存被分割、重塑,并在一个核心中保存到块表指定的位置
- 融合的块读取和注意力计算: 调整FasterTransformer的注意力核心,使其能够即时从块表中读取KV缓存
- 融合的块复制: 将写时复制的多个复制操作批量化到单个核心启动中
5.2 支持各种解码算法
- 使用三个关键方法:
fork(从现有序列创建新序列),append(添加token),free(删除序列)
6. 评估
6.1 实验设置
- 模型: OPT (13B, 66B, 175B), LLaMA (13B)
- 服务器: NVIDIA A100 GPU
- 工作负载:
- 基于ShareGPT (更长、更多变的提示/输出)
- Alpaca (更短的指令跟随)数据集合成
- 泊松请求到达
- 基线系统:
- FasterTransformer: 为延迟高度优化
- Orca: 为吞吐量优化的最先进系统
- Orca (Oracle): 假设确切知道实际生成的输出长度(理论上限)
- Orca (Pow2): 最多按2的幂次方过度预留2倍空间
- Orca (Max): 始终预留到模型的最大序列长度(2048 tokens)
- 指标: 标准化延迟(平均端到端延迟/输出长度),吞吐量(请求速率)
6.2 基本采样结果(每个请求一个样本)
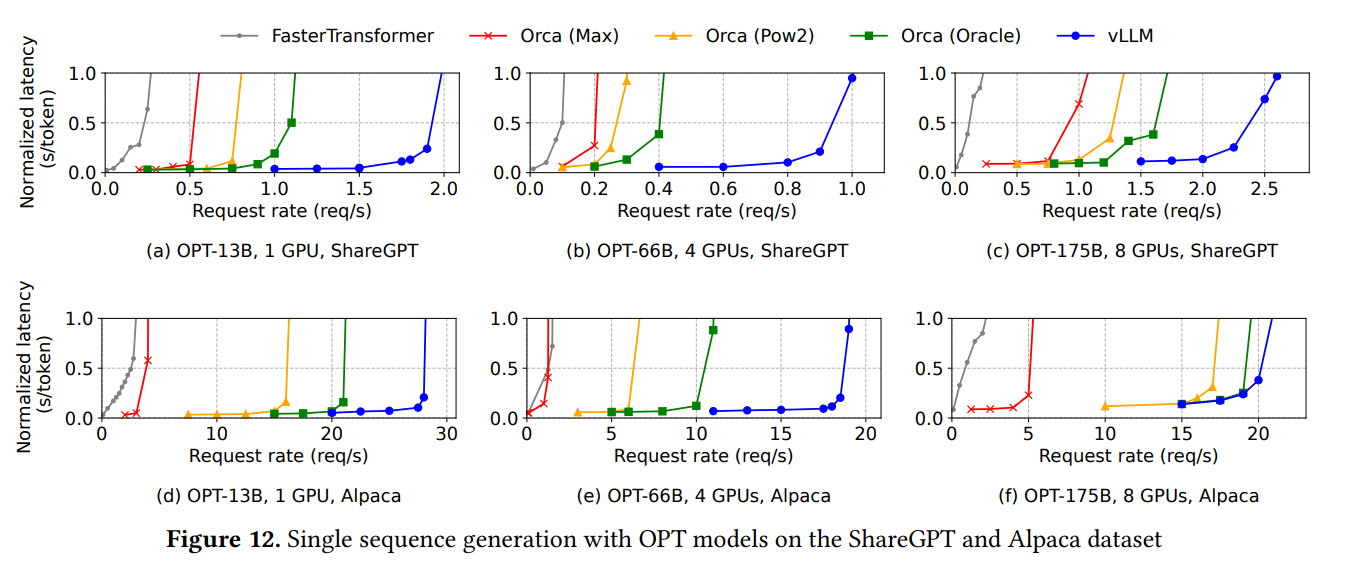
- 在ShareGPT上,vLLM比Orca (Oracle)能维持1.7倍-2.7倍更高的请求速率
- vLLM比Orca (Max)能维持2.7倍-8倍更高的请求速率
- vLLM在一个批次中处理明显更多的请求
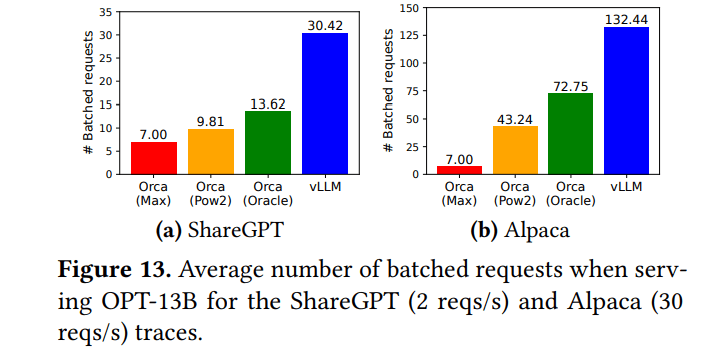
- 比FasterTransformer高出最多22倍的请求速率(得益于更好的批处理和内存管理)
- Alpaca数据集(较短序列)显示类似趋势,尽管对于OPT-175B,当内存对短序列约束较小时,vLLM的优势略微减小
6.3 并行采样和束搜索结果
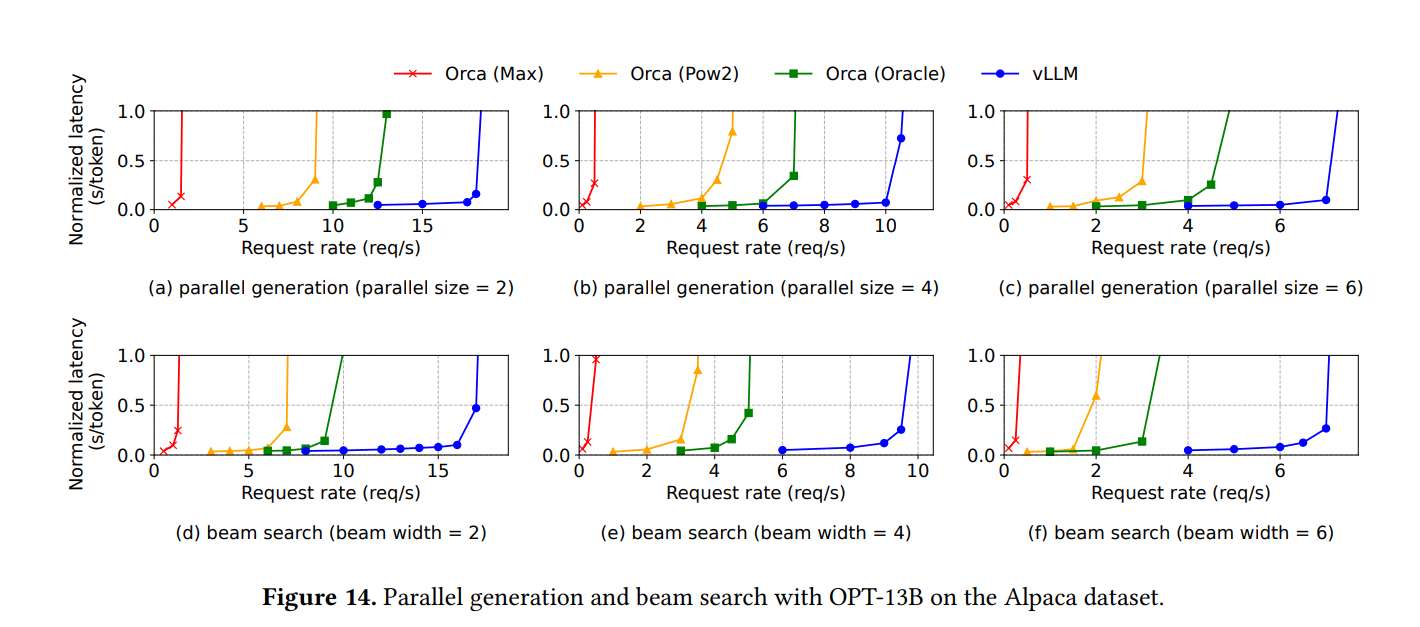
- 随着采样序列数增加或束宽度变宽,vLLM由于共享增加而带来更多改进
- OPT-13B Alpaca,束宽度为6时:vLLM的吞吐量是Orca (Oracle)的2.3倍
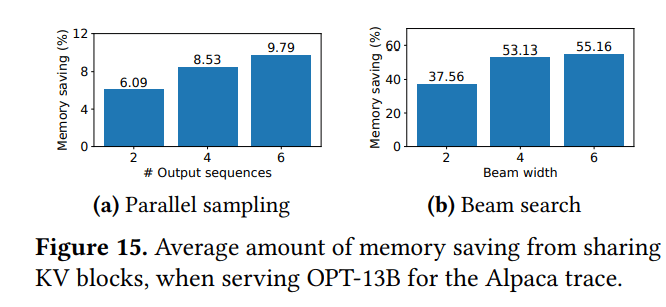
- 内存节省:
- 并行采样: 6.1%-9.8% (Alpaca), 16.2%-30.5% (ShareGPT)
- 束搜索: 37.6%-55.2% (Alpaca), 44.3%-66.3% (ShareGPT)
6.4 共享前缀结果

- 工作负载: WMT16 英德翻译,使用LLaMA-13B
- 1-shot前缀: vLLM吞吐量是Orca (Oracle)的1.67倍
- 5-shot前缀: vLLM吞吐量是Orca (Oracle)的3.58倍
6.5 聊天机器人结果
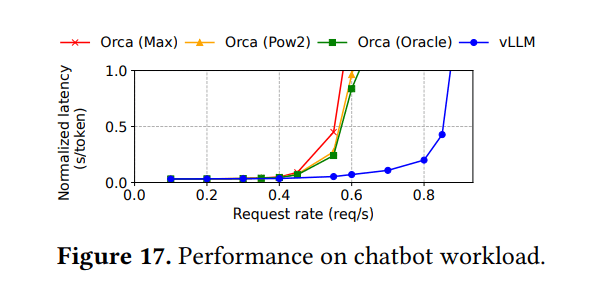
- 工作负载: ShareGPT数据集,提示是聊天历史(最后1024个token)。使用OPT-13B
- vLLM比三个Orca基线能维持2倍更高的请求速率
- Orca基线表现相似,因为长提示迫使其进行最大预留
7. 消融研究
7.1 核心微基准测试
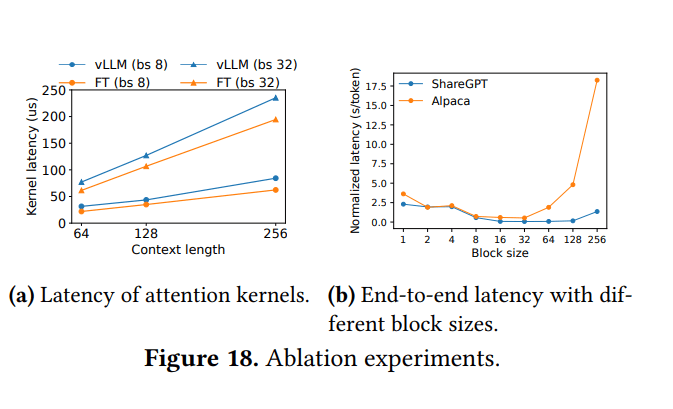
- PagedAttention的注意力核心延迟比FasterTransformer的核心高20-26%(由于块表访问、处理可变序列长度)
- 尽管如此,由于内存管理和批处理的巨大改进,vLLM的端到端性能显著优于FasterTransformer
7.2 块大小的影响
- 最佳块大小是一个权衡:
- 太小:无法充分利用GPU在块读写方面的并行性
- 太大:增加内部碎片,降低共享概率
- vLLM中的默认块大小:16。被认为是一个良好的平衡点
7.3 重计算与交换的比较
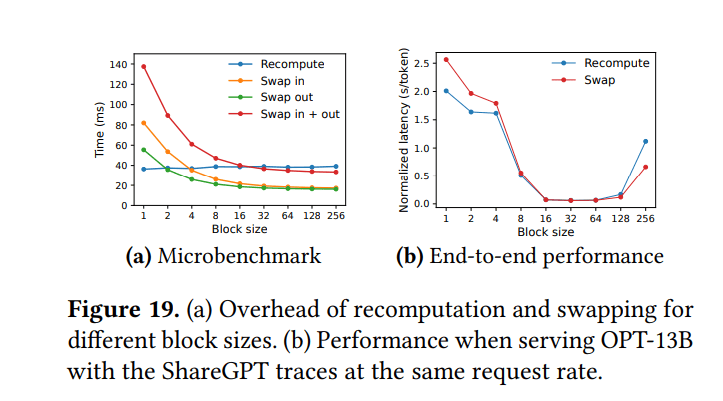
- 交换: 对于小块大小,开销过大(许多小的PCIe传输)。对于大块更有效
- 重计算: 开销在不同块大小间保持不变(不使用KV块)。对于小块更有效。其开销从未超过交换延迟的20%
- 对于中等块大小(16-64),两种方法表现出相当的端到端性能
8. 讨论
- 对其他GPU工作负载的适用性: 虚拟内存/分页技术对于需要动态内存分配且性能受GPU内存限制的工作负载是有益的。并非通用解决方案
- 应用于虚拟内存/分页的LLM特定优化:
- 全有或全无的换出策略(利用序列数据依赖性)
- 通过重计算恢复被驱逐的块(在通用操作系统中不可行)
- 将内存访问的GPU核心与注意力等其他操作的核心融合
9. 相关工作
- 通用模型服务系统: Clipper, TensorFlow Serving, Nexus等,未针对LLM的自回归特性进行优化。
- Transformer专用服务系统:
- Orca: 最相关。专注于迭代级调度。vLLM中的PagedAttention是补充性的:Orca通过交错请求提高GPU利用率;vLLM通过将更多请求装入内存来提高利用率。vLLM的内存技术使得像Orca那样的细粒度调度更加关键。
- 内存优化: 交换/重计算已用于训练。FlexGen研究了在有限GPU内存下为LLM推理交换权重和token状态,但并非针对在线服务。FlashAttention优化了注意力的I/O。
10. 结论
- PagedAttention允许KV缓存使用非连续的分页内存
- vLLM利用PagedAttention,借鉴虚拟内存和写时复制技术,高效管理KV缓存
- 实现了比最先进系统高2-4倍的吞吐量改进
附录: 核心代码注释
基础组件
PagedAttention的实现主要依赖两个核心组件:
- PagedAttentionMetadata - 元数据管理类
- PagedAttention - 主要功能实现类
元数据结构
@dataclass
class PagedAttentionMetadata:# 记录每个序列当前处理了多少个tokenseq_lens_tensor: Optional[torch.Tensor]# 批处理中最长序列的长度max_decode_seq_len: int# 核心数据结构:块表 - 将逻辑块映射到物理块# 形状: (批大小, 每个序列的最大块数)# 例如 [0,1,2] 表示一个序列的tokens存储在物理块0,1,2中block_tables: Optional[torch.Tensor]
块表(block_tables)是实现非连续内存管理的关键。它类似操作系统中的页表,将序列的逻辑视图映射到实际的物理内存位置。
内存管理机制
PagedAttention的核心是将KV缓存存储在非连续的内存块中,并通过映射表管理这些块。
KV缓存的物理布局
@staticmethod
def get_kv_cache_shape(num_blocks, block_size, num_kv_heads, head_size):"""定义KV缓存在物理内存中的布局"""return (2, num_blocks, block_size * num_kv_heads * head_size)
这个函数定义了物理内存中KV缓存的形状:
- 第一维(2):区分Key和Value
- 第二维:物理块的总数
- 第三维:每个块中存储的数据量(block_size个token × 每个token的KV大小)
内存重组与优化
@staticmethod
def split_kv_cache(kv_cache, num_kv_heads, head_size):"""将线性内存重组为结构化的缓存视图"""x = 16 // kv_cache.element_size() # 内存对齐优化num_blocks = kv_cache.shape[1]key_cache = kv_cache[0].view(num_blocks, num_kv_heads, head_size // x, -1, x)value_cache = kv_cache[1].view(num_blocks, num_kv_heads, head_size, -1)return key_cache, value_cache
这个方法将扁平化的物理内存重新组织为更适合GPU处理的结构化视图:
- 对Key缓存进行特殊处理,使其内存访问模式更高效
- 利用张量视图(view)而非复制,避免额外内存开销
- 数据对齐到16字节边界,提高GPU内存访问效率
核心操作流程
PagedAttention实现了两个关键阶段的注意力计算,以及数据块的管理操作。
1. 写入新Token的KV到缓存
@staticmethod
def write_to_paged_cache(key, value, key_cache, value_cache, slot_mapping, kv_cache_dtype, k_scale, v_scale):"""将新生成的token的K和V写入到分页缓存中"""ops.reshape_and_cache(key, value, key_cache, value_cache,slot_mapping.flatten(), kv_cache_dtype, k_scale, v_scale)
key,value: 新计算出的token的K和V向量slot_mapping: 将这些新向量映射到物理内存中具体位置的索引- 使用融合CUDA核心一次性完成重塑和写入,避免多次GPU操作开销
2. 解码阶段的注意力计算
@staticmethod
def forward_decode(query, key_cache, value_cache, block_tables, seq_lens, ...):"""生成阶段的注意力计算"""# 决定使用V1(普通场景)还是V2(超长序列)注意力核心use_v1 = (max_seq_len <= 8192 and (max_num_partitions == 1 or num_seqs * num_heads > 512))if use_v1:# 普通场景的注意力计算ops.paged_attention_v1(...)else:# 超长序列的分区注意力计算ops.paged_attention_v2(...)
解码阶段代表LLM生成文本的过程:
- 每次生成新token时必须计算当前query与所有历史KV的注意力
- 使用
block_tables找到各序列的KV缓存所在的物理块 - V1核心用于普通场景,V2核心专为超长序列优化(将序列分区处理)
3. 预填充阶段的注意力计算
@staticmethod
def forward_prefix(query, key, value, key_cache, value_cache, block_tables, query_start_loc, seq_lens_tensor, ...):"""处理输入提示的并行注意力计算"""context_attention_fwd(query, key, value, output, kv_cache_dtype,key_cache, value_cache, block_tables, query_start_loc, seq_lens_tensor, ...)
预填充阶段代表处理用户输入提示的过程:
- 可以高度并行化,所有提示tokens同时计算
- 同时计算注意力并将KV结果写入分页缓存
- 使用Triton高性能内核提高吞吐量
4. 物理块管理操作
@staticmethod
def swap_blocks(src_kv_cache, dst_kv_cache, src_to_dst):"""在不同内存区域间交换KV缓存块"""ops.swap_blocks(src_kv_cache[0], dst_kv_cache[0], src_to_dst) # Key部分ops.swap_blocks(src_kv_cache[1], dst_kv_cache[1], src_to_dst) # Value部分
@staticmethod
def copy_blocks(kv_caches, src_to_dists):"""实现写时复制(CoW)等高级内存共享机制"""key_caches = [kv_cache[0] for kv_cache in kv_caches]value_caches = [kv_cache[1] for kv_cache in kv_caches]ops.copy_blocks(key_caches, value_caches, src_to_dists)
这两个操作支持了PagedAttention的高级内存管理策略:
swap_blocks:在GPU和CPU内存间移动缓存块(内存不足时)copy_blocks:实现写时复制,允许多个序列共享物理块直到需要修改
设计亮点与优化
PagedAttention的代码实现包含多项精巧的设计和优化:
-
高效的内存结构
- 使用张量视图而非复制重组内存
- 内存对齐优化提高GPU访问效率
-
针对性优化
- 对超长序列使用专门的V2核心
- 融合操作减少GPU核心启动开销
-
灵活的内存管理
- 块表抽象层使物理块可以非连续存储
- 支持细粒度的内存共享和写时复制
-
系统级考量
- 支持GPU与CPU内存交换
- 兼容张量并行等分布式技术
参考
- vllm
- PageAttention论文
- 相关博客
- vLLM内核设计
- vLLM代码逻辑解读
相关文章:
vLLM(1)PagedAttention论文笔记)
LLM笔记(十)vLLM(1)PagedAttention论文笔记
文章目录 PagedAttention论文笔记论文摘要概览1. 引言问题背景提出的解决方案主要贡献和成果 2. 背景2.1 基于Transformer的大语言模型2.2 LLM服务与自回归生成2.3 LLM的批处理技术 3. LLM服务中的内存挑战3.1 现有系统中的内存管理 4. 方法: PagedAttention 和 vLLMvLLM 系统概…...

5.20 note
不用if else实现递归 原代码 class Solution { public: int mechanicalAccumulator(int target) { if (target 0) return 0; // 终止条件:基准情况 return target mechanicalAccumulator(target - 1); // 递归累加 } }; 变形 class Solution { public: int…...

vuejs处理后端返回数字类型精度丢失问题
标题问题描述 后端返回数据有5.00和3.30这种数据,但是前端展示的时候返回对应分别为5和3.0,小数点后0都丢失了。 接口返回数据展示network-Response: 接口返回数据展示network-Preview: 错误数据效果展示 发现问题 浏览器接口…...

指令烧录ORIN NANO操作系统
1 概述 模组为ORIN NANO 4GB版本 Ubuntu系统为18.04虚拟机 说明:刷机过程会有重新连接USB的操作,烧写过程需要注意虚拟机提示,官方不建议使用虚拟机,建议直接使用ubuntu操作系统的机器。 2 下载烧录所需文件 进入到下载网址&am…...

每日算法刷题Day11 5.20:leetcode不定长滑动窗口求最长/最大6道题,结束不定长滑动窗口求最长/最大,用时1h20min
6. 1695.删除子数组的最大得分(中等) 1695. 删除子数组的最大得分 - 力扣(LeetCode) 思想 1.给你一个正整数数组 nums ,请你从中删除一个含有 若干不同元素 的子数组**。**删除子数组的 得分 就是子数组各元素之 和 。 返回 只删除一个 子…...

List介绍
什么是List 在集合框架中,List是一个接口,继承自Collection Collection也是一个接口,该接口中规范了后序容器中常用的一些方法 Iterable也是一个接口,表示实现该接口的类是可以逐个元素进行遍历的,具体如下࿱…...

List更简洁的编码构建
List的链式构建需求 jdk1.8,编码时需要手动构建一个List 传统List构建方式 - 声明列表,依次添加元素; - 利用Arrays.asList方法声明并添加元素 //1 先声明创建 List<String> createList new ArrayList<>();//2 逐个添加元素 c…...

Java 单元测试框架比较:JUnit、TestNG 哪个更适合你?
Java 单元测试框架比较:JUnit、TestNG 哪个更适合你? 在 Java 开发领域,单元测试是保证代码质量的重要环节。而选择一个合适的单元测试框架,对于提升测试效率和代码可靠性至关重要。本文将深入比较 JUnit 和 TestNG 这两个主流的…...

变频器如何通过Profibus DP主站转Modbus RTU/TCP接入到上位机
变频器如何通过Profibus DP主站转Modbus RTU/TCP接入到上位机 在工业自动化领域,Profibus DP和Modbus RTU是两种常见的通信协议。Profibus DP广泛应用于工厂自动化,而Modbus RTU则常用于串行通信。当需要将支持Profibus DP的设备(如变频器&a…...

ElasticSearch性能优化
ES基础概念介绍: 索引:类似于MySQL中的表,它是具有相同特征的一个数据集。文档:格式为JSON格式,类似于MySQL中的一条数据,它是数据存储的基本数据单元,每一条文档都有一个唯一的ID。查询&#x…...

pom.xml中的runtime
在 Maven 的 pom.xml 文件中,<scope> 元素可以指定依赖项的作用范围,而 runtime 是其中的一个作用范围值。以下是 runtime 作用范围的含义: 定义:runtime 作用范围表示该依赖项在编译时不需要,但在运行时需要。…...

第一章走进java世界
第一章 走进 java 世界 1.1 java 语言的特点(小面经) 使用简单、高效 去掉了 C 和 C++中的指针和多重继承技术通过垃圾自动回收机制简化了程序内存管理对于数据类型在不同字长的计算机上实现统一字节数占用完全面向对象 抽象、封装、继承、多态自动内存管理(Auto Garbage C…...

tigase源码学习笔记-事件总线EventBus
前言 最近看到了一些tigase关于异步事件解耦的地方的设计,做一个笔记记录一下。什么是事件总线,我自己对于事件总线的理解是,事件总线是一个对事件(Event)进行集中处理的基于发布订阅模式的一种处理机制。个人拙见&am…...
)
GO语言学习(六)
GO语言学习(六) 各位支持我的友友们我们现在不知不觉的已经进入第六期了,在上一期我们学习了一些简单的HTTP相关知识,还带大家基本的了解了web的深层原理及实现过程,相信大家应该都有自己的收获了,现在我就带领大家学习一下本期的…...

25.5.20学习总结
做题思路 数列分段 Section IIhttps://www.luogu.com.cn/problem/P1182正如题目所说,我们需要得到一个最小的最大段的值,可能有人将注意力放在分段上,事实上,我们更多的应该关注结果。这是一道二分答案的题,你可以先确…...

山东大学软件学院项目实训-基于大模型的模拟面试系统-Vditor编辑器上传图片
Vditor编辑器图片上传功能 使用Vditor进行图片上传时,会返回图片在后端的相对路径,这在前端是无法进行显示的(如下图) 于是为了将图片正常显示,我采取了和头像上传一样的解决方案,使用阿里云图床进行存储…...

在 Kotlin 中,什么是内联函数?有什么作用?
在 Kotlin 中,内联函数是一种通过 inline 关键字声明的函数,其主要目的是优化高阶函数(即以函数作为参数或返回值的函数)的性能。 内联函数的函数体会在编译时直接插入到调用处,从而避免函数调用的开销,并…...
、子串(和为k的子数组、))
leetcode hot100:四、解题思路大全:滑动窗口(无重复字符的最长子串、找到字符串中所有字母异位词)、子串(和为k的子数组、)
滑动窗口 无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 思路 滑动窗口哈希表。 从左到右遍历字符串,以当前字符的下标为右边界,并不断试图往左扩宽左边界。滑动窗口内维护的就是当前字符下标…...
_HTML)
JAVA EE(进阶)_HTML
思如云烟,行若磐石。 ——陳長生. ❀主页:陳長生.-CSDN博客❀ 📕上一篇:JAVA EE(进阶)_进阶的开端-CSDN博客 1.HTML HTML(HyperText Mark…...

【[特殊字符] Vue 3 实现动态加载子组件并缓存状态完整指南】
文章目录 🧩 Vue 3 实现动态加载子组件并缓存状态完整指南💡 需求背景🎯 最终实现效果效果图 🛠️ 技术栈🧱 文件结构示例🔧 实现流程详解1. 定义组件映射关系2. 子组件定义并暴露方法3. 父组件逻辑处理✅ …...
)
从零开始的抽奖系统创作(2)
我们接着进行抽奖系统的完善。 前面我们完成了 1.结构初始化(统一结果返回之类的,还有包的分类) 2.加密(基于Hutool进行的对称与非对称加密) 3.用户注册 接下来我们先完善一下结构(统一异常处理&#…...
)
【计算机方向海外优质会议推荐】第二届图像处理、机器学习与模式识别国际学术会议(IPMLP 2025)
重要信息 大会官网:www.ipmlp.net 会议主页【点击参会/投稿/了解会议详情】:第二届图像处理、机器学习与模式识别国际学术会议(IPMLP 2025)_艾思科蓝_学术一站式服务平台 截稿时间:详见官网 接受/拒稿通知:投稿后1…...

进程之IPC通信二
4.共享内存 共享内存是进程间通信一种方式,多个进程共享一段内存,“ 共享内存 ”。由于多个进程共享了同一段内 存,这个段内存既是你的也是我的。也就是你往这个内存里面写入数据,实际上就相当于往我的内存里 面写入数据。比起其…...

打造高效数据处理利器:用Python实现Excel文件智能合并工具
有时候,我们需要将多个Excel文件按照特定顺序合并成一个文件,这样可以更方便地进行后续的数据处理和分析。今天,我想分享一个使用Python开发的小工具,它可以帮助我们轻松实现Excel文件的智能合并。C:\pythoncode\new\xlsx_merger.…...

使用注解动态映射:根据实体List列表动态生成Excel文件
我们一般通过POI来生成对应的Excel文件,绝大多数情况是需要手动编写单元格内容,然后顺序填充值,今天我们将动态根据实体来生成Excel表头,同时自动填充内容。 文章目录 1. 定义注解2. 实体类应用注解3. 动态导出工具类 1. 定义注解…...

【ISP算法精粹】什么是global tone mapping和local tone mapping?
1. 简介 全局色调映射(Global Tone Mapping)和局部色调映射(Local Tone Mapping)是高动态范围(HDR)图像处理中的两种关键技术,用于将高动态范围图像的亮度值映射到标准动态范围(LDR…...

uniapp生成的app,关于跟其他设备通信的支持和限制
以下内容通过AI生成,这里做一下记录。 蓝牙 移动应用(App)通过蓝牙与其他设备通信,是通过分层协作实现的。 一、通信架构分层 应用层(App) 调用操作系统提供的蓝牙API(如Android的BluetoothA…...
设计思想)
C++ Pimpl(Pointer to Implementation)设计思想
一、C Pimpl(Pointer to Implementation)设计思想 1. 核心思想 Pimpl(Pointer to Implementation)是一种通过将类的实现细节隐藏在一个私有指针背后的设计模式,旨在实现接口与实现的解耦。其核心思想是: …...

便捷的Office批量转PDF工具
软件介绍 本文介绍的软件是一款能实现Office批量转换的工具,名为五五Excel word批量转PDF。 软件小巧 这款五五Excel word批量转PDF软件大小不到2M。 操作步骤一 使用该软件时,只需把软件和需要转换的Word或Excel文件放在同一个文件夹里。 操作步骤…...
)
2025年渗透测试面试题总结-华顺信安[实习]安全服务工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 华顺信安[实习]安全服务工程师 1. 自我介绍 2. 红蓝队经验 3. Shiro漏洞知识体系 4. APP渗透测试方法…...

Mermaid 使用快速入门
使用AI 生成Mermaid 代码,导入Vscode, 安装Mermaid Preview 插件 --- title: config:theme: forest --- graph TDA[开始] --> B{条件判断}B -->|是| C[执行操作1]B -->|否| D[执行操作2] theme可改变主题,可选主题: default - 这是…...

Windows系统下MySQL 8.4.5压缩包安装详细教程
一、MySQL 8.4.5新特性概览 相较于旧版本,MySQL 8.4.5在性能与功能上实现了显著提升: 性能优化:官方测试显示,在高并发场景下,其读写性能较5.7版本提升近2倍,尤其在处理热点数据竞争问题时表现更为出色。…...

机器学习10-随机森林
随机森林学习笔记 一、随机森林简介 随机森林(Random Forest)是一种集成学习算法,基于决策树构建模型。它通过组合多个决策树的结果来提高模型的准确性和稳定性。随机森林的核心思想是利用“集成”的方式,将多个弱学习器组合成一…...

【缺陷】GaN和AlN中的掺杂特性
1997 年 5 月 9 日,北卡罗来纳州立大学的 P. Bogusławski 和 J. Bernholc 等人在《Physical Review B》期刊发表了题为《Doping properties of C, Si, and Ge impurities in GaN and AlN》的文章,基于量子分子动力学方法,研究了碳(C)、硅(Si)和锗(Ge)杂质在氮化镓(G…...

游戏引擎学习第298天:改进排序键 - 第1部分
关于向玩家展示多个房间层所需的两种 Z 值 我们在前一天基本完成了为渲染系统引入分层 Z 值的工作,但还没有完全完成所有细节。我们开始引入图形渲染中的分层概念,即在 Z 轴方向上拥有多个独立图层,每个图层内部再使用一个单独的 Z 值来实现…...

AI大模型从0到1记录学习 大模型技术之数学基础 day26
高等数学 导数 导数的概念 导数(derivative)是微积分中的一个概念。函数在某一点的导数是指这个函数在这一点附近的变化率(即函数在这一点的切线斜率)。导数的本质是通过极限的概念对函数进行局部的线性逼近。 当函数f的自变量在…...
)
计算机视觉与深度学习 | matlab实现ARIMA-WOA-CNN-LSTM时间序列预测(完整源码和数据)
以下是一个基于MATLAB的ARIMA-WOA-CNN-LSTM时间序列预测框架。由于完整代码较长,此处提供核心模块和实现思路,完整源码和数据可通过文末方式获取。 1. 数据准备(示例数据) 使用MATLAB内置的航空乘客数据集: % 加载数据 data = readtable(airline-passengers.csv); data …...


【C++】vector模拟实现
实现以下功能: 构造函数:a.无参默认构造 b.n个val构造 c.迭代器区间构造 d.initializer_list构造,类似于数组 e.拷贝构造 赋值重载 [ ]重载 实现reserve接口 实现size(),capacity()接口 实现push_bakc接口&#…...

门店管理五大痛点解析:如何用数字化系统实现高效运营
实体店竞争白热化,五大管理痛点正悄悄吞噬利润:客户资源流失、数据决策滞后、员工效率模糊、合同风险暗藏、利润核算混乱。本文直击核心问题,拆解数字化系统如何精准破局。 一、传统管理模式的五大核心痛点 1. 客户资源管理粗放化 老…...

双指针法高效解决「移除元素」问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 双指针法高效解决「移除元素」问题 双指针法高效解决「移除元素」问题一、问题描述二、解法解析:双指针法1. 核心思想2. 算法步骤3. 执行过程示例 三、关键点分析…...
)
【Linux笔记】——线程同步信号量与环形队列生产者消费者模型的实现(PV操作)
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】——线程同步条件变量与生产者消费者模型的实现 🔖流水不争,争的是滔滔不…...

武汉科技大学人工智能与演化计算实验室许志伟课题组参加第八届智能优化与调度学术会议
武汉科技大学人工智能与演化计算实验室许志伟课题组参加第八届智能优化与调度学术会议 2025年5月15日至18日,第八届智能优化与调度学术会议在青岛金沙滩希尔顿酒店隆重召开。本次会议由青岛科技大学、湖南省系统仿真学会联合主办,中国仿真学会智能仿真优…...

SparkContext介绍
目录 1. 集群管理接口2. RDD操作中枢3. 任务分发引擎4. 执行环境配置5. 性能监控枢纽 SparkContext是Apache Spark的核心组件,其作用可概括为以下五个关键维度: 1. 集群管理接口 作为与集群管理器(YARN/Mesos/Standalone)通信的唯…...

海外盲盒系统开发:重构全球消费体验的科技引擎
当盲盒文化席卷全球,海外盲盒系统开发已成为重构消费体验的核心赛道。数据显示,2025年全球盲盒市场规模突破120亿,东南亚市场年增长率达4540。我们开发的海外盲盒系统,以技术创新为驱动,打造覆盖全链路的全球化解决方案…...

IP风险画像技术:如何用20+维度数据构建网络安全护城河?
IP风险画像技术作为一种先进的网络安全手段,正逐步成为构建网络安全护城河的重要工具。通过多维度数据的分析和挖掘,IP风险画像技术能够精准识别网络中的潜在威胁,为企业和组织提供更加全面的安全保障。 IP风险画像技术基于IP地址的行为分析…...

Vitest下一代前端单元测试框架
什么是Vitest? Vitest是有vue官方主导开发的下一代测试框架,一个原生支持Vite的测试框架。非常快速。 Vitest 与 Jest 兼容,具有开箱即用的 ESM、Typescript 和 JSX 支持,并且由 esbuild 提供支持。它在测试过程中使用 Vite 开发…...

车道线检测:自动驾驶的“眼睛”
在自动驾驶技术的庞大体系中,车道线检测扮演着至关重要的角色,它就像是自动驾驶汽车的“眼睛”,帮助车辆感知道路边界,从而实现安全、准确的行驶。今天,我们就来深入探讨一下车道线检测的奥秘,看看它是如何…...

基于NLP技术的客户投诉与需求文本分类方法研究
目录 摘要 1. 引言 2. 文本分类基础 2.1 文本分类的定义与类型 2.2 文本分类的评价指标 3. 传统文本分类方法 3.1 基于TF-IDF和SVM的方法 3.2 基于主题模型和词向量的改进方法 4. 深度学习文本分类方法 4.1 TextCNN模型 4.2 BiLSTM模型 4.3 注意力机制与Transformer…...

HarmonyOS5云服务技术分享--自有账号对接AGC认证
✨ 手把手教你:用自有账号玩转华为AGC认证服务 ✨ Hi 各位开发者朋友~👋 今天咱们来聊聊如何将自家已有的账号系统与华为的AppGallery Connect(AGC)认证服务无缝对接。不用重复造轮子,还能享受AGC…...