基于CNN的猫狗识别(自定义CNN模型)
目录
一,数据集介绍
1.1 数据集下载
1.2 数据集简介
二,模型训练
2.1 用到的模块
2.2 设置随机种子
2.3 图像的预处理
2.4 CNN模型层结构
2.5 初始化
2.6 训练和验证
三,模型测试
3.1 定义相同预处理
3.2 定义相同的层结构
3.3 初始化
3.4 预测
四,测试结果
4.1 训练集结果 编辑
4.2 测试集结果
4.3 总结与改进
五,完整代码
5.1 训练部分代码
5.2 测试部分代码
一,数据集介绍
1.1 数据集下载
本数据集下载自:
Cat and Dog![]() https://www.kaggle.com/datasets/tongpython/cat-and-dog
https://www.kaggle.com/datasets/tongpython/cat-and-dog
1.2 数据集简介
该数据集分为训练集和测试集,其中训练集包含4000张"cat"照片和4000张"dog"照片
测试集包括1000+"cat"照片和1000+"dog"照片


二,模型训练
2.1 用到的模块
import os # 用于文件路径操作
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.optim import lr_scheduler # 学习率调度器
from torch.utils.data import DataLoader, random_split # 数据加载和分割工具
from torchvision import datasets, transforms # 计算机视觉数据集和数据增强工具
import matplotlib.pyplot as plt # 绘图工具
import numpy as np # 数值计算库和之前的实验不同的是加入了学习率调度器这个东西,用于动态调整优化器的学习率,以平衡训练初期的快速收敛和后期的精细调优。合理的学习率调整策略可以显著提升模型性能,避免陷入局部最优或过拟合。学习率调度器可以看作是深度学习训练中的 “自动调优助手”,它的核心目标是通过算法自动调整学习率。
2.2 设置随机种子
torch.manual_seed(42) # 设置PyTorch随机种子
np.random.seed(42) # 设置NumPy随机种子确保实验结果可复现
2.3 图像的预处理
# 定义训练集数据预处理流程(包含数据增强)
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 将图像缩放到256x256尺寸transforms.RandomCrop(224), # 随机裁剪到224x224尺寸(增强模型泛化能力)transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)transforms.ToTensor(), # 将图像转换为PyTorch张量# 图像归一化(使用ImageNet数据集的均值和标准差)transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 定义验证集数据预处理流程(无数据增强,仅标准化)
val_transform = transforms.Compose([transforms.Resize((256, 256)), # 缩放到256x256尺寸transforms.CenterCrop(224), # 中心裁剪到224x224尺寸(保持一致性)transforms.ToTensor(), # 转换为张量# 相同的归一化操作,确保和训练集数据分布一致transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 设置数据集路径(需替换为实际路径)
data_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\training_set\training_set'# 创建原始数据集(训练集和验证集使用不同的预处理流程)
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform) # 训练集带增强
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform) # 验证集无增强# 划分数据集为训练集和验证集(80%训练,20%验证)
train_size = int(0.8 * len(train_dataset)) # 计算训练集样本数量
val_size = len(train_dataset) - train_size # 计算验证集样本数量
# 创建随机数生成器(确保分割结果可复现)
generator = torch.Generator().manual_seed(42)
# 按索引随机分割数据集(使用相同的随机种子保证划分一致)
train_indices, val_indices = random_split(range(len(train_dataset)), # 使用数据集索引进行分割[train_size, val_size], # 分割比例generator=generator # 指定随机数生成器
)# 根据索引创建子集(分别对应训练集和验证集)
train_dataset = torch.utils.data.Subset(train_dataset, train_indices) # 训练集子集
val_dataset = torch.utils.data.Subset(val_dataset, val_indices) # 验证集子集验证集的使命是 “真实评估”,而非 “数据增强”。保持其数据分布与测试集一致,是确保模型性能评估可靠的关键。验证集的核心作用就是在训练过程中实时、客观地评估模型性能
2.4 CNN模型层结构
class CatDogCNN(nn.Module):def __init__(self):super(CatDogCNN, self).__init__() # 继承父类初始化# 第一层卷积:输入3通道,输出32通道,卷积核3x3,填充1保持尺寸self.conv1 = nn.Conv2d(3, 32, 3, padding=1)# 第二层卷积:输入32通道,输出64通道,卷积核3x3,填充1self.conv2 = nn.Conv2d(32, 64, 3, padding=1)# 第三层卷积:输入64通道,输出128通道,卷积核3x3,填充1self.conv3 = nn.Conv2d(64, 128, 3, padding=1)# 第四层卷积:输入128通道,输出256通道,卷积核3x3,填充1self.conv4 = nn.Conv2d(128, 256, 3, padding=1)self.pool = nn.MaxPool2d(2, 2) # 最大池化层:尺寸减半# 全连接层1:输入维度由卷积层输出决定(256通道,14x14尺寸)self.fc1 = nn.Linear(256 * 14 * 14, 512)# 全连接层2:输出2类(猫和狗)self.fc2 = nn.Linear(512, 2)self.dropout = nn.Dropout(0.5) # 随机失活层(防止过拟合)self.relu = nn.ReLU() # 激活函数def forward(self, x):# 卷积 -> 激活 -> 池化 的标准流程x = self.pool(self.relu(self.conv1(x)))x = self.pool(self.relu(self.conv2(x)))x = self.pool(self.relu(self.conv3(x)))x = self.pool(self.relu(self.conv4(x)))# 将多维张量展平为一维(用于全连接层输入)x = x.view(-1, 256 * 14 * 14)x = self.dropout(x) # 应用随机失活x = self.relu(self.fc1(x)) # 全连接层+激活函数x = self.dropout(x) # 再次应用随机失活x = self.fc2(x) # 最终分类层(不添加Softmax,由损失函数处理)return x
2.5 初始化
# 初始化设备(优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device) # 将模型移动到指定设备(CPU/GPU)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数(适用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,初始学习率0.001# 创建学习率调度器(当验证损失不再下降时降低学习率)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, # 关联的优化器mode='min', # 监控指标为最小值(验证损失)patience=3, # 连续3个epoch无改善则调整学习率factor=0.5 # 学习率调整因子(乘以0.5)
)2.6 训练和验证
# 定义训练和验证函数
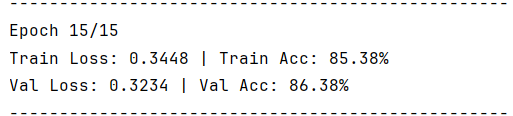
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):best_val_acc = 0.0 # 记录最佳验证准确率history = { # 用于保存训练过程中的指标'train_loss': [],'train_acc': [],'val_loss': [],'val_acc': []}for epoch in range(epochs): # 遍历指定的训练轮数# --------------------------- 训练阶段 ---------------------------model.train() # 设置模型为训练模式(激活Dropout等层)train_loss = 0.0 # 初始化训练损失train_correct = 0 # 初始化正确预测数train_total = 0 # 初始化总样本数# 遍历训练数据加载器for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数# 累加损失和准确率统计train_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1) # 获取最大概率的类别索引train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss = train_loss / len(train_dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------model.eval() # 设置模型为评估模式(关闭Dropout等层)val_loss = 0.0 # 初始化验证损失val_correct = 0 # 初始化正确预测数val_total = 0 # 初始化总样本数with torch.no_grad(): # 不计算梯度(节省内存和计算资源)for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备outputs = model(inputs) # 前向传播(无梯度)loss = criterion(outputs, labels) # 计算损失# 累加验证损失和准确率统计val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss = val_loss / len(val_dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整 ---------------------------scheduler.step(val_loss) # 根据验证损失调整学习率# --------------------------- 模型保存 ---------------------------if val_acc > best_val_acc: # 如果当前验证准确率更高best_val_acc = val_acc # 更新最佳准确率# 保存模型参数到文件torch.save(model.state_dict(), 'best_cat_dog_model.pth')# --------------------------- 结果记录 ---------------------------history['train_loss'].append(train_loss) # 记录训练损失history['train_acc'].append(train_acc) # 记录训练准确率history['val_loss'].append(val_loss) # 记录验证损失history['val_acc'].append(val_acc) # 记录验证准确率# 打印当前epoch的训练结果print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50) # 分隔线return model, history # 返回训练好的模型和训练历史三,模型测试
3.1 定义相同预处理
# 定义预处理流程(与验证集一致)
test_transform = transforms.Compose([transforms.Resize((256, 256)),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])3.2 定义相同的层结构
class CatDogCNN(nn.Module):def __init__(self):super(CatDogCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.conv4 = nn.Conv2d(128, 256, 3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(256 * 14 * 14, 512)self.fc2 = nn.Linear(512, 2)self.dropout = nn.Dropout(0.5)self.relu = nn.ReLU()def forward(self, x):x = self.pool(self.relu(self.conv1(x)))x = self.pool(self.relu(self.conv2(x)))x = self.pool(self.relu(self.conv3(x)))x = self.pool(self.relu(self.conv4(x)))x = x.view(-1, 256 * 14 * 14)x = self.dropout(x)x = self.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x3.3 初始化
# 初始化模型和设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device)
model.load_state_dict(torch.load('best_cat_dog_model.pth', map_location=device))
model.eval() # 设置为评估模式3.4 预测
def test_on_dataset(test_dir):"""对整个测试数据集进行预测并计算准确率:param test_dir: 测试集路径(需包含'cat'和'dog'子文件夹):return: 测试集准确率"""try:# 检查路径是否存在if not os.path.exists(test_dir):raise FileNotFoundError(f"错误:测试集路径不存在 - {test_dir}")# 加载数据集test_dataset = datasets.ImageFolder(test_dir,transform=test_transform)test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=32,shuffle=False,num_workers=0 # 避免多线程冲突)correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalprint(f"测试集准确率:{accuracy:.2f}%")return accuracyexcept Exception as e:print(f"批量预测失败:{e}")return None四,测试结果
4.1 训练集结果 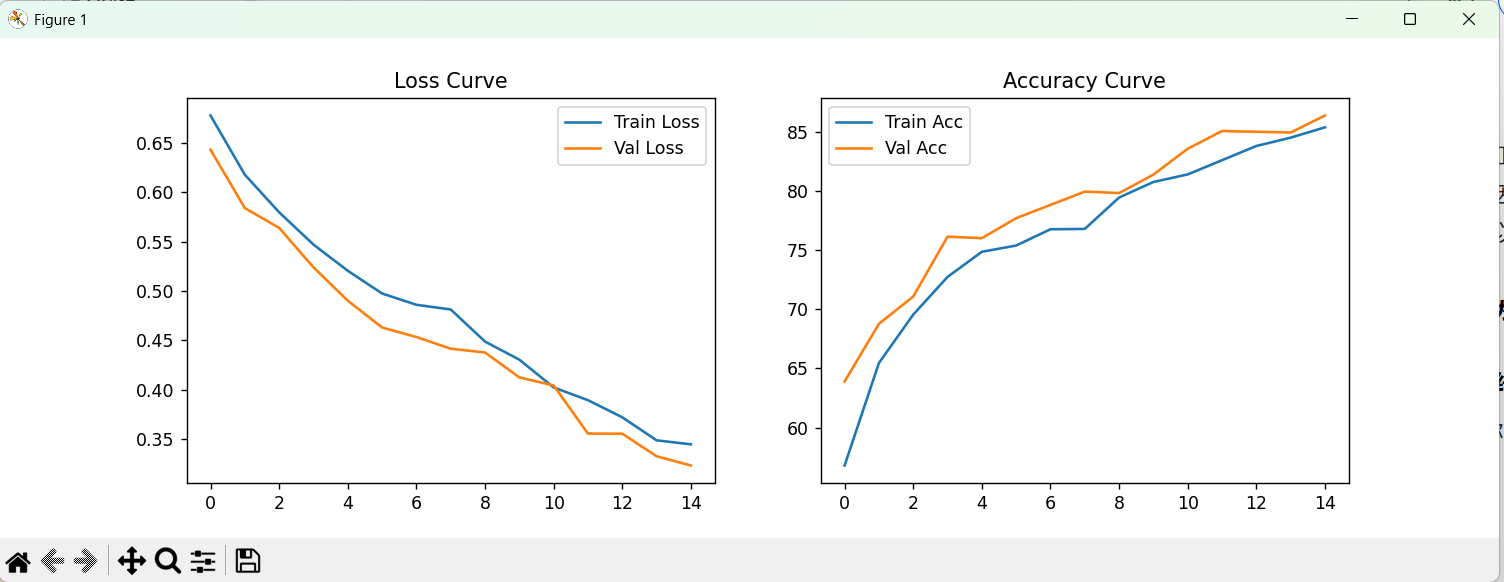
4.2 测试集结果

4.3 总结与改进
该模型使用到最基本的CNN模型,由于参数设置的问题以及模型本身的问题,导致识别的准确率不高,相比相对比较成熟的模型如:resnet,Inception,EfficientNet等还存在较大差距,下次实验将利用效果更好的模型进行训练。但是就优点来说,该模型并没有发生过拟合的情况,测试集与训练集以及验证集的识别率都高度一致。
五,完整代码
5.1 训练部分代码
# 导入必要的库
import os # 用于文件路径操作
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.optim import lr_scheduler # 学习率调度器
from torch.utils.data import DataLoader, random_split # 数据加载和分割工具
from torchvision import datasets, transforms # 计算机视觉数据集和数据增强工具
import matplotlib.pyplot as plt # 绘图工具
import numpy as np # 数值计算库
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 添加在此处
# 设置随机种子,确保实验结果可复现
torch.manual_seed(42) # 设置PyTorch随机种子
np.random.seed(42) # 设置NumPy随机种子# 定义训练集数据预处理流程(包含数据增强)
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 将图像缩放到256x256尺寸transforms.RandomCrop(224), # 随机裁剪到224x224尺寸(增强模型泛化能力)transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)transforms.ToTensor(), # 将图像转换为PyTorch张量# 图像归一化(使用ImageNet数据集的均值和标准差)transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 定义验证集数据预处理流程(无数据增强,仅标准化)
val_transform = transforms.Compose([transforms.Resize((256, 256)), # 缩放到256x256尺寸transforms.CenterCrop(224), # 中心裁剪到224x224尺寸(保持一致性)transforms.ToTensor(), # 转换为张量# 相同的归一化操作,确保和训练集数据分布一致transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 设置数据集路径(需替换为实际路径)
data_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\training_set\training_set'# 创建原始数据集(训练集和验证集使用不同的预处理流程)
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform) # 训练集带增强
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform) # 验证集无增强# 划分数据集为训练集和验证集(80%训练,20%验证)
train_size = int(0.8 * len(train_dataset)) # 计算训练集样本数量
val_size = len(train_dataset) - train_size # 计算验证集样本数量
# 创建随机数生成器(确保分割结果可复现)
generator = torch.Generator().manual_seed(42)
# 按索引随机分割数据集(使用相同的随机种子保证划分一致)
train_indices, val_indices = random_split(range(len(train_dataset)), # 使用数据集索引进行分割[train_size, val_size], # 分割比例generator=generator # 指定随机数生成器
)# 根据索引创建子集(分别对应训练集和验证集)
train_dataset = torch.utils.data.Subset(train_dataset, train_indices) # 训练集子集
val_dataset = torch.utils.data.Subset(val_dataset, val_indices) # 验证集子集# 创建数据加载器(用于批量加载数据)
train_loader = DataLoader(train_dataset, # 训练集数据集batch_size=32, # 批量大小shuffle=True # 训练时打乱数据顺序
)
val_loader = DataLoader(val_dataset, # 验证集数据集batch_size=32, # 批量大小shuffle=False # 验证时不打乱数据
)# 定义改进的CNN模型(猫狗分类任务)
class CatDogCNN(nn.Module):def __init__(self):super(CatDogCNN, self).__init__() # 继承父类初始化# 第一层卷积:输入3通道,输出32通道,卷积核3x3,填充1保持尺寸self.conv1 = nn.Conv2d(3, 32, 3, padding=1)# 第二层卷积:输入32通道,输出64通道,卷积核3x3,填充1self.conv2 = nn.Conv2d(32, 64, 3, padding=1)# 第三层卷积:输入64通道,输出128通道,卷积核3x3,填充1self.conv3 = nn.Conv2d(64, 128, 3, padding=1)# 第四层卷积:输入128通道,输出256通道,卷积核3x3,填充1self.conv4 = nn.Conv2d(128, 256, 3, padding=1)self.pool = nn.MaxPool2d(2, 2) # 最大池化层:尺寸减半# 全连接层1:输入维度由卷积层输出决定(256通道,14x14尺寸)self.fc1 = nn.Linear(256 * 14 * 14, 512)# 全连接层2:输出2类(猫和狗)self.fc2 = nn.Linear(512, 2)self.dropout = nn.Dropout(0.5) # 随机失活层(防止过拟合)self.relu = nn.ReLU() # 激活函数def forward(self, x):# 卷积 -> 激活 -> 池化 的标准流程x = self.pool(self.relu(self.conv1(x)))x = self.pool(self.relu(self.conv2(x)))x = self.pool(self.relu(self.conv3(x)))x = self.pool(self.relu(self.conv4(x)))# 将多维张量展平为一维(用于全连接层输入)x = x.view(-1, 256 * 14 * 14)x = self.dropout(x) # 应用随机失活x = self.relu(self.fc1(x)) # 全连接层+激活函数x = self.dropout(x) # 再次应用随机失活x = self.fc2(x) # 最终分类层(不添加Softmax,由损失函数处理)return x# 初始化设备(优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device) # 将模型移动到指定设备(CPU/GPU)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数(适用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,初始学习率0.001# 创建学习率调度器(当验证损失不再下降时降低学习率)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, # 关联的优化器mode='min', # 监控指标为最小值(验证损失)patience=3, # 连续3个epoch无改善则调整学习率factor=0.5 # 学习率调整因子(乘以0.5)
)# 定义训练和验证函数
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):best_val_acc = 0.0 # 记录最佳验证准确率history = { # 用于保存训练过程中的指标'train_loss': [],'train_acc': [],'val_loss': [],'val_acc': []}for epoch in range(epochs): # 遍历指定的训练轮数# --------------------------- 训练阶段 ---------------------------model.train() # 设置模型为训练模式(激活Dropout等层)train_loss = 0.0 # 初始化训练损失train_correct = 0 # 初始化正确预测数train_total = 0 # 初始化总样本数# 遍历训练数据加载器for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数# 累加损失和准确率统计train_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1) # 获取最大概率的类别索引train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss = train_loss / len(train_dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------model.eval() # 设置模型为评估模式(关闭Dropout等层)val_loss = 0.0 # 初始化验证损失val_correct = 0 # 初始化正确预测数val_total = 0 # 初始化总样本数with torch.no_grad(): # 不计算梯度(节省内存和计算资源)for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备outputs = model(inputs) # 前向传播(无梯度)loss = criterion(outputs, labels) # 计算损失# 累加验证损失和准确率统计val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss = val_loss / len(val_dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整 ---------------------------scheduler.step(val_loss) # 根据验证损失调整学习率# --------------------------- 模型保存 ---------------------------if val_acc > best_val_acc: # 如果当前验证准确率更高best_val_acc = val_acc # 更新最佳准确率# 保存模型参数到文件torch.save(model.state_dict(), 'best_cat_dog_model.pth')# --------------------------- 结果记录 ---------------------------history['train_loss'].append(train_loss) # 记录训练损失history['train_acc'].append(train_acc) # 记录训练准确率history['val_loss'].append(val_loss) # 记录验证损失history['val_acc'].append(val_acc) # 记录验证准确率# 打印当前epoch的训练结果print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50) # 分隔线return model, history # 返回训练好的模型和训练历史# 开始训练模型
print("开始训练模型...")
model, history = train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs=15
)# --------------------------- 结果可视化 ---------------------------
plt.figure(figsize=(12, 4)) # 创建绘图窗口# 绘制损失曲线
plt.subplot(1, 2, 1) # 子图1(左)
plt.plot(history['train_loss'], label='Train Loss') # 训练损失
plt.plot(history['val_loss'], label='Val Loss') # 验证损失
plt.legend() # 显示图例
plt.title('Loss Curve') # 设置标题# 绘制准确率曲线
plt.subplot(1, 2, 2) # 子图2(右)
plt.plot(history['train_acc'], label='Train Acc') # 训练准确率
plt.plot(history['val_acc'], label='Val Acc') # 验证准确率
plt.legend() # 显示图例
plt.title('Accuracy Curve') # 设置标题plt.show() # 显示图像# 打印最佳验证集准确率
print(f"最佳验证集准确率: {max(history['val_acc']):.2f}%")5.2 测试部分代码
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from PIL import Image
import os# 定义模型类(与训练代码完全一致)
class CatDogCNN(nn.Module):def __init__(self):super(CatDogCNN, self).__init__()# 四层卷积+池化结构,逐步提取图像特征self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 输入3通道,输出32通道,3x3卷积核self.conv2 = nn.Conv2d(32, 64, 3, padding=1) # 通道数翻倍self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.conv4 = nn.Conv2d(128, 256, 3, padding=1)self.pool = nn.MaxPool2d(2, 2) # 2x2最大池化,每次尺寸减半# 全连接分类器self.fc1 = nn.Linear(256 * 14 * 14, 512) # 卷积输出展平后的维度 -> 512self.fc2 = nn.Linear(512, 2) # 512 -> 2类(猫/狗)self.dropout = nn.Dropout(0.5) # 防止过拟合self.relu = nn.ReLU() # 激活函数def forward(self, x):# 前向传播过程:卷积+ReLU+池化的四层结构x = self.pool(self.relu(self.conv1(x))) # 输入:224x224 -> 输出:112x112x = self.pool(self.relu(self.conv2(x))) # 112x112 -> 56x56x = self.pool(self.relu(self.conv3(x))) # 56x56 -> 28x28x = self.pool(self.relu(self.conv4(x))) # 28x28 -> 14x14x = x.view(-1, 256 * 14 * 14) # 展平为一维向量x = self.dropout(x) # 训练时随机丢弃神经元x = self.relu(self.fc1(x)) # 全连接+激活x = self.dropout(x)x = self.fc2(x) # 输出最终分类得分return x# 初始化模型和设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断是否可用GPU
model = CatDogCNN().to(device) # 创建模型并移至GPU/CPU
model.load_state_dict(torch.load('best_cat_dog_model.pth', map_location=device)) # 加载预训练权重
model.eval() # 设置为评估模式(关闭Dropout等)# 定义预处理流程(与验证集一致)
test_transform = transforms.Compose([transforms.Resize((256, 256)), # 图像缩放到256x256transforms.CenterCrop(224), # 中心裁剪到224x224(模型输入尺寸)transforms.ToTensor(), # 转换为Tensor并归一化到[0,1]# 使用ImageNet数据集的均值和标准差进行归一化transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])### 测试集批量预测函数 ###
def test_on_dataset(test_dir):"""对整个测试数据集进行预测并计算准确率:param test_dir: 测试集路径(需包含'cat'和'dog'子文件夹):return: 测试集准确率"""try:# 检查路径是否存在if not os.path.exists(test_dir):raise FileNotFoundError(f"错误:测试集路径不存在 - {test_dir}")# 加载数据集(假设目录结构:test_dir/cat/*.jpg 和 test_dir/dog/*.jpg)test_dataset = datasets.ImageFolder(test_dir,transform=test_transform # 应用预处理)test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=32, # 每批处理32张图像shuffle=False, # 不打乱顺序num_workers=0 # 单线程加载(避免多线程冲突))# 批量预测并计算准确率correct = 0 # 预测正确的样本数total = 0 # 总样本数with torch.no_grad(): # 禁用梯度计算,节省内存和加速for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device) # 数据移至设备outputs = model(inputs) # 模型预测_, predicted = torch.max(outputs.data, 1) # 获取预测类别(最大值索引)total += labels.size(0) # 累加总样本数correct += (predicted == labels).sum().item() # 累加正确预测数accuracy = 100 * correct / total # 计算准确率百分比print(f"测试集准确率:{accuracy:.2f}%")return accuracyexcept Exception as e:print(f"批量预测失败:{e}")return None### 主函数(执行预测) ###
if __name__ == "__main__":# ---------------------- 配置路径 ----------------------# 测试集路径(替换为你的测试集根目录)test_dataset_path = r"C:\Users\10532\Desktop\Study\Test\Data\catordog\test_set\test_set"# ---------------------- 执行测试集批量预测 ----------------------print("\n----------------------")print(f"正在测试数据集:{test_dataset_path}")test_on_dataset(test_dataset_path)相关文章:
)
基于CNN的猫狗识别(自定义CNN模型)
目录 一,数据集介绍 1.1 数据集下载 1.2 数据集简介 二,模型训练 2.1 用到的模块 2.2 设置随机种子 2.3 图像的预处理 2.4 CNN模型层结构 2.5 初始化 2.6 训练和验证 三,模型测试 3.1 定义相同预处理 3.2 定义相同的层结构 3.3…...

互联网大厂Java面试场景:从Spring Boot到分布式缓存技术的探讨
互联网大厂Java面试场景:从Spring Boot到分布式缓存技术的探讨 场景描述 互联网大厂某次Java开发岗面试,主考官是一位严肃的技术专家,而应聘者则是搞笑的程序员“码农明哥”。面试围绕音视频场景的技术解决方案展开,探讨从Sprin…...

linux本地部署ollama+deepseek过程
1.Tags ollama/ollama GitHub 选择一个版本下载,我下的是0.5.12 2.tar解压该文件 3.尝试启动ollama ollama serve 4.查看ollama的版本 ollama -v 5.创建一个系统用户 ollama,不允许登录 shell,拥有一个主目录,并且用…...

【数据结构与算法】ArrayList 与顺序表的实现
目录 一、List 接口 1.1 List 接口的简单介绍 1.1 常用方法 二、顺序表 2.1 线性表的介绍 2.2 顺序表的介绍 2.3 顺序表的实现 2.3.1 前置条件:自定义异常 2.3.2 顺序表的初始化 2.3.2 顺序表的实现 三、ArrayList 实现类 3.1 ArrayList 的两种使用方式 3.2 Array…...

Vue 3.0 中的slot及使用场景
1. 基本概念 在 Vue 中, slot 用于定义组件中的插槽位置,外部的内容会被插入到组件内部的这个位置。插槽的内容是动态的,可以根据需要进行传递和渲染。它允许开发者在组件外部传递任意内容,并在组件内部进行渲染,主要…...

go语言协程调度器 GPM 模型
go语言协程调度器 GPM 模型 下面的文章将以几个问题展开,其中可能会有扩展处: 什么是调度器?为什么需要调度器? 多进程/多线程时cpu怎么工作? 进程/线程的数量多多少?太多行不行?为什么不行&…...

Python打卡 DAY 29
知识点回顾 1. 类的装饰器 2. 装饰器思想的进一步理解:外部修改、动态 3. 类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工…...
)
C++控制结构详解:if-else、switch、循环(for/while/do-while)
1. 引言 在C编程中,控制结构用于控制程序的执行流程。它们决定了代码在什么条件下执行、如何重复执行某段代码,以及如何选择不同的执行路径。C提供了多种控制结构,主要包括: 条件语句:if-else、switch-case循环语句&…...

APP手机端测试覆盖点
通过上图,我们覆盖了完整的一个APP,需要进行哪些测试...

C++:⾯向对象的三⼤特性
面向对象的三大特性: 继承:允许一个类(子类 / 派生类)继承另一个类(父类 / 基类)的属性和方法,实现代码复用和层次化设计。 封装:将数据(成员变量)和操作数据…...

三、高级攻击工具与框架
高级工具与框架是红队渗透的核心利器,能够实现自动化攻击、权限维持和隐蔽渗透。本节聚焦Metasploit、Cobalt Strike及企业级漏洞利用链,结合实战演示如何高效利用工具突破防御并控制目标。 1. Metasploit框架深度解析 定位:渗透测试的“瑞…...

玄机-第二章日志分析-redis应急响应
前言 记录记录 关于redis的一些手法 redis未授权访问漏洞利用redis写webshell利用“公私钥” 认证获取root权限利用crontab反弹shellredis日志: /var/log/redis.log 1. 通过本地 PC SSH到服务器并且分析黑客攻击成功的 IP 为多少,将黑客 IP 作为 FLAG 提交; cd /var/log 查看…...

MoodDrop:打造一款温柔的心情打卡单页应用
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起心动念:我想做一款温柔的情绪应用 「今天的你,心情如何?」 有时候&#x…...

Web开发-JavaEE应用SpringBoot栈SnakeYaml反序列化链JARWAR构建打包
知识点: 1、安全开发-JavaEE-WAR&JAR打包&反编译 2、安全开发-JavaEE-SnakeYaml反序列化&链 一、演示案例-WEB开发-JavaEE-项目-SnakeYaml序列化 常见的创建的序列化和反序列化协议 • (已讲)JAVA内置的writeObject()/readObje…...

RISC-V 开发板 MUSE Pi Pro V2D图像加速器测试,踩坑介绍
视频讲解: RISC-V 开发板 MUSE Pi Pro V2D图像加速器测试,踩坑介绍 今天测试下V2D,这是K1特有的硬件级别的2D图像加速器,参考如下文档,但文档中描述的部分有不少问题,后面会讲下 https://bianbu-linux.spa…...

学习!FastAPI
目录 FastAPI简介快速开始安装FastApiFastAPI CLI自动化文档 Reqeust路径参数Enum 类用于路径参数路径参数和数值校验 查询参数查询参数和字符串校验 请求体多个请求体参数嵌入单个请求体参数 CookieHeader表单文件直接使用请求 ResponseResponse Model多个关联模型 响应状态码…...

【Python 算法零基础 4.排序 ① 选择排序】
就算经历各番碰撞,幸运也将一直站在我这边 —— 25.5.18 一、引言 选择排序(Selection Sort) 是一种简单直观的排序算法。它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小…...

05 部署Nginx反向代理
01 服务器基本信息 名称IP地址真实Web服务器172.2.25.10Proxy服务器172.2.25.11 02 Proxy基本设置 [rootlikexy-nginx-01 conf.d]# pwd /etc/nginx/conf.d [rootlikexy-nginx-01 conf.d]# cat proxy.conf server {listen 80;server_name www.wp.proxy.com;location / {prox…...
通俗解释Transformer在处理序列问题高效的原因(个人理解)
Transformer出现的背景 CNN 的全局关联缺陷卷积神经网络(CNN)通过多层堆叠扩大感受野,但在自然语言处理中存在本质局限: 局部操作的语义割裂:每个卷积核仅处理固定窗口(如 3-5 词),…...

【Vue】路由1——路由的引入 以及 路由的传参
目录 一、什么是路由 ! 1.1 一个完整的前端路由规则编辑 1.2 后端路由 1.3 安装路由插件 1.4 嵌套(多级)路由 二、路由的query传参 2.1 传参 2.2 取值 三、命名路由 四、 路由的params参数 五、路由的props配置 第一种写法&…...
?)
大模型为什么学新忘旧(大模型为什么会有灾难性遗忘)?
字数:2500字 一、前言:当学霸变成“金鱼” 假设你班上有个学霸,数学考满分,英语拿第一,物理称霸全校。某天,他突然宣布:“我要全面发展!从今天起学打篮球!” 一周后&am…...

07 负载均衡
01 面试题 面试题: 说一下如何实现的负载均衡 1.使用的proxy_pass模块 2.通过proxy_pass模块转发给upstream模块定义的地址池 3.使用的是默认的rr轮训算法分发到后端的服务器02 负载均衡配置 # 写一个简单的配置 [rootlikexy-nginx-01 conf.d]# cat lb.conf server {listen …...

谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。 此外还…...
)
【深度学习】残差网络(ResNet)
如果按照李沐老师书上来,学完 VGG 后还有 NiN 和 GoogLeNet 要学,但是这两个我之前听都没听过,而且我看到我导师有发过 ResNet 相关的论文,就想跳过它们直接看后面的内容。 现在看来这不算是不踏实,因为李沐老师说如果…...

最新最热门的特征提取方式:CVOCA光学高速复值卷积
目录 一、问题背景与核心挑战 二、CVOCA核心原理与数学建模 1. 复杂值卷积的数学表达 2. CVOCA的三大光学映射策略 三、关键创新点详解 1. 合成波长技术(Synthetic Wavelength) 2. 复杂值电光调制器(CVEOM) 3. 时间-波长交织卷积计算 四、代码实现与仿真验证 1. …...

获取Class的方式有哪些?
在Java中,获取Class对象是进行反射操作的基础,以下是几种常见方式及其详细说明,以及记忆方法: 1. 使用 .class 语法 语法:类名.class(如 String.class)。特点: 编译时确定ÿ…...

STM32八股【9】-----volatile关键字
一句话: 主要是为了防止编译器优化导致无法得到最新的值。主要用于以下三处: 1.在中断中修改访问的变量。 2.多任务(线程)共享的变量。 3.硬件寄存器变量 问题 嵌入式程序中常出现变量值改变但代码未正确响应的现象 原因 编译…...

【android bluetooth 协议分析 01】【HCI 层介绍 4】【LeSetEventMask命令介绍】
在蓝牙协议栈中,HCI_LE_Set_Event_Mask 是一个主机控制接口(HCI)层的命令,属于 LE(Low Energy)控制指令集。该命令用于 配置控制器向主机报告哪些 LE 事件,以便主机能够根据需求控制被中断的事件…...

关于文件分片的介绍和应用
文件分片,顾名思义,就是将一个大文件分割成多个小的文件块(chunk)。每个文件块都是原始文件的一部分,并可以通过特定的方式将这些小文件块重新组装成原始文件。 1. 基本原理: 文件分片从底层来看,主要是对…...
)
tauri2项目动态添加 Sidecar可行性方案(运行时配置)
tauri2官方文档:Embedding External Binaries | Tauri Tauri 的 Sidecar 功能允许你将外部二进制文件(External Binaries)与你的 Tauri 应用程序捆绑在一起,并在运行时调用它们。根据你提供的链接和 Tauri 的文档,以下…...

20倍云台球机是一种高性能的监控设备
20倍云台球机是一种高性能的监控设备,其主要特点包括20倍光学变焦能力和云台旋转功能。以下是对20倍云台球机的详细分析: 一、主要特点 20倍光学变焦 : 摄像机镜头能够在保持图像清晰度的前提下,将监控目标放大20倍。 这一功能…...

利用html制作简历网页和求职信息网页
前言 大家好,我是maybe。今天下午初步学习了html的基础知识。做了两个小网页,一个网页是简历网页,一个网页是求职信息填写网页。跟大家分享一波~ 说明:我不打算上传图片。所以如果有朋友按照我的代码运行网页,会出现一个没有图片…...

三:操作系统线程管理之线程概念
揭秘幕后英雄:理解线程的奥秘与优势 在当今软件应用的世界里,流畅的用户体验、高效的后台处理以及强大的并发能力已经成为必备的要求。你有没有想过,一个看似简单的程序是如何在同一时间处理多个任务的?或者为什么一个复杂的应用…...
)
学习黑客Active Directory 入门指南(一)
Active Directory 入门指南(一):初识AD与核心概念 🔑 大家好!欢迎来到 “Active Directory 入门指南” 系列的第一篇。在本系列中,我们将逐步深入探索 Windows Active Directory (AD)——微软推出的目录服…...

单列集合——ArrayList,LinkedList,迭代器的底层原理和源码
ArrayList 底层原理 空参构造创建集合时候,创建长度为零的数组名叫elementData,还有个成员变量size用来记录元素的个数,第一次空参,size长度是0。 添加第一个元素时,底层创建新的长度尾10的数组,数组中默认…...

C++模板进阶使用技巧
非类型模板参数缺省模板参数类模板特化全特化偏特化 模板的分离编译 我们在前面已经初识了 模板并且在各种数据结构的实现中,熟练掌握了模板的一些基础功能。 至于为什么是基础功能,因为模板还有一些进阶的功能,像非类型模板参数,…...
与 正常表格进行高度同步)
jqGrid冻结列错行问题,将冻结表格(悬浮表格)与 正常表格进行高度同步
在使用jqGrid时,如果你遇到了冻结列(也称为冻结表格或悬浮表格)与正常表格高度不同步的问题,这通常是由于CSS样式或者布局管理不当所导致的。下面是一些解决此问题的步骤和建议: 1. 确保CSS样式正确 首先,确…...
:搜索迭代器、使用分区密钥)
Milvus(25):搜索迭代器、使用分区密钥
1 搜索迭代器 ANN Search 对单次查询可调用的实体数量有最大限制,因此仅使用基本 ANN Search 可能无法满足大规模检索的需求。对于 topK 超过 16,384 的 ANN Search 请求,建议考虑使用 SearchIterator。 1.1 概述 Search 请求返回搜索结果,而…...

深入探索PointNet:点云处理的革命性算法
深入探索PointNet:点云处理的革命性算法 在计算机视觉和三维图形处理领域,点云数据的处理一直是一个极具挑战性的任务。点云数据由一系列三维坐标点组成,这些点通常来源于激光雷达(LiDAR)、三维扫描仪等设备。与图像数…...

四品种交易策略
策略概述 策略思路: 交易品种:同时交易四个品种,每个品种使用总资金的10%。 合约选择:使用连续合约(data0)发出交易信号,实际交易 主力合约(data1)和下一个主力合约(data2)。 资金管理:总资金用A_CurrentEquity表示,交易手数据此计算。 止损执行:盘中达到止损…...

NC61 两数之和【牛客网】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路3.1 排序双指针3.1 散列 四、参考代码4.1 排序双指针4.2 散列 零、原题链接 NC61 两数之和 一、题目描述 二、测试用例 三、解题思路 3.1 排序双指针 基本思路: 先对序列进行排序,然后…...

电子电路:什么是电流离散性特征?
关于电荷的量子化,即电荷的最小单位是电子的电荷量e。在宏观电路中,由于电子数量极大,电流看起来是连续的。但在微观层面,比如纳米器件或单电子晶体管中,单个电子的移动就会引起可观测的离散电流。 还要提到散粒噪声,这是电流离散性的表现之一。当电流非常小时,例如在二…...

如何完美安装GPU版本的torch、torchvision----解决torch安装慢 无法安装 需要翻墙安装 安装的是GPU版本但无法使用的GPU的错误
声明: 本视频灵感来自b站 如何解决所述问题 如何安装对应版本的torch、torchvison 进入pytorch官网 进入历史版本 这里以cuda11.8 torch 2.1.0为例演示 根据文档找到要安装的torch、torchvison版本 但不是使用命令行直接安装 命令行直接安装可能面临着 安装慢…...

Fine-Tuning Llama2 with LoRA
Fine-Tuning Llama2 with LoRA 1. What is LoRA?2. How does LoRA work?3. Applying LoRA to Llama2 models4. LoRA finetuning recipe in torchtune5. Trading off memory and model performance with LoRAModel ArgumentsReferences https://docs.pytorch.org/torchtune/ma…...
--Brush)
Compose笔记(二十五)--Brush
这一节主要了解一下Compose中Brush,在Jetpack Compose里,Brush是一个重要的 API,它用于定义填充图形的颜色渐变或图案,能够为界面元素添加丰富的视觉效果。简单总结如下: 1 常见场景 填充形状(圆形、矩形等) 创建渐变…...
)
访问共享打印机提示错误0x00000709多种解决方法(支持win10和win11)
在日常办公和生活中,打印机是不可或缺的重要设备。然而,有时在连接打印机的过程中,我们可能会遇到错误代码0x00000709的提示。有更新补丁导致的、有访问共享打印机服务异常、有访问共享打印机驱动异常等问题导致的,针对访问共享打…...
;)
【Mini 型 http 服务器】—— int get_line(int sock, char *buf, int size);
作用: 逐行读取并返回读取的内容长度,取出读取的内容保存在 buf 数组中 输入: int sock:需要读取的 sock 套接字 char *buf:用于记录保存读取的内容 int size:buf 的大小 返回值: -1 表示 读取…...

Window远程连接Linux桌面版
Window远程连接Linux桌面版 卸载RealVNC Server 一、确认是否安装了 VNC Server 先检查是否已安装: which vncserver # 或 dpkg -l | grep vnc # 或 rpm -qa | grep vnc二、在 Debian / Ubuntu 上卸载(.deb 安装) 1. 卸载 RealVNC Serve…...
)
计算机系统---TPU(张量处理单元)
一、定义与定位 TPU(Tensor Processing Unit) 是由Google开发的专用AI加速芯片,专为深度学习中的张量运算(如矩阵乘法、卷积)设计,属于ASIC(专用集成电路)范畴。其核心目标是在算力…...

5.18 day24
知识点回顾: 元组可迭代对象os模块 作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径。 元组 元组的特点: 有序,可以重复,这一点和列表一样 元组中的元素不能修改,这一点…...