TDengine 在新能源领域的价值

能源数据的定义
能源数据是指记录和描述能源产业各个方面的信息,包括能源生产、供应、消费、储备、价格、排放以及相关政策和技术的数据。这些数据可以通过各种途径收集和整理,如能源企业的统计报表、政府部门的调查和监测、国际组织的发布数据等。
能源数据主要包括以下几个类别:
- 能源产量和供应数据:这包括各种能源的产量、进口和出口量、储备量等。能源产量数据反映了能源资源的开采和生产情况,供应数据则反映了能源的供应能力和稳定性。
- 能源消费和需求数据:这包括各个部门和行业的能源消费量、能源消费结构、能源需求预测等。能源消费数据可以用于评估能源利用效率,指导能源节约和优化能源结构。
- 能源价格数据:这包括各种能源的市场价格、价格趋势、价格指数等。能源价格数据对于能源市场的运行和能源企业的经营决策具有重要的参考意义。
- 能源排放数据:这包括各种能源的二氧化碳排放量、污染物排放量等。能源排放数据是衡量能源产业对环境的影响和评估环境政策的重要指标。
- 能源政策和技术数据:这包括各国能源政策和法规、能源技术的研发和应用情况等。能源政策和技术数据可以帮助分析能源市场的政策环境和技术进步的影响。
能源数据的采集、整理和发布需要依靠能源部门、统计机构、研究机构等的协作和合作。同时,为了确保数据的准确性和可比性,还需要建立统一的数据标准和指标体系。
能源数据对于能源领域的决策者、研究人员和企业来说具有重要的意义。通过分析能源数据,可以了解能源市场的发展趋势、评估能源供需状况、制定能源政策和规划等。同时,能源数据也可以帮助评估能源的可持续性和环境影响,指导能源的合理利用和保护。因此,能源数据的准确性、及时性和可靠性是至关重要的。
能源数据发展历程
能源数据的发展历程可以追溯到工业革命以后,随着能源产业的兴起和能源需求的不断增长,人们对能源数据的需求也逐渐增加。以下是能源数据发展的主要阶段:
- 初期数据收集阶段(19 世纪末 – 20 世纪初):在 19 世纪末至 20 世纪初期,随着煤炭、石油和天然气等化石能源的广泛应用,人们开始对能源数据进行收集和整理。最早的能源数据是通过能源生产和销售的统计记录得到的,包括煤炭和石油的产量、进口和出口数据等。
- 国家统计数据阶段(20 世纪 20 年代 – 50 年代):在 20 世纪 20 年代至 50 年代,各国建立了统一的统计体系,并开始对能源数据进行系统的收集和发布。国家统计机构成为能源数据的主要来源,能源产量、消费、进出口、价格等数据得到了较为全面和规范的统计。
- 国际组织数据发布阶段(20 世纪 60 年代 – 90 年代):在 20 世纪 60 年代至 90 年代,随着能源市场的国际化和全球化,国际组织开始发布能源数据,如国际能源署(IEA)和联合国能源组织(UN Energy)等。这些组织通过调查和研究,提供了跨国和全球范围的能源数据,为国际能源合作和政策制定提供了重要的依据。
- 全球能源数据互联网时代(21 世纪至今):随着互联网的快速发展和信息技术的进步,能源数据的获取和分享变得更加便捷和广泛。能源数据的发布逐渐向开放数据平台和在线数据库转移,人们可以通过各种渠道和工具获取和分析能源数据。同时,数据科学和人工智能的发展也为能源数据的分析和应用提供了更多的可能性。
在能源数据的发展过程中,数据的准确性、标准化和可比性成为重要的问题。各国和国际组织致力于制定统一的数据标准和指标体系,以确保数据的质量和可靠性。此外,能源数据的时效性和更新性也变得越来越重要,以满足实时决策和监测能源市场的需求。
总的来说,能源数据的发展历程反映了人们对能源信息的需求和对能源市场的关注程度的提高,也为能源决策和能源管理提供了更多的科学依据。
能源数据的特征
能源数据通常是通过能源设备、传感器和测量仪器等采集和记录的,它包括能源的生产、传输、分配和使用等方面的数据,这些数据通常具有时序数据的特征。时序数据是按照时间顺序排列的数据,能够记录和反映随时间变化的特征和趋势。能源数据的产生往往与时间相关,例如电力的用电量、发电厂的发电量、风力发电机的风速等。
这些数据通常以时间戳作为标识,可以按照时间维度进行分析和处理,既包括历史数据,反映了过去的能源产业和消费情况;也包括实时数据,反映了当前的能源供需状况。同时,能源数据还具有地域性,不同国家和地区的能源数据可能存在差异和特点。
此外,能源数据还具有以下时序数据的特征:
- 时间连续性:能源数据通常以连续的时间序列形式存在,例如每小时、每天或每月的能源用量数据。这种连续性使得能够对能源数据进行时间序列分析和预测。
- 周期性:能源数据往往具有一定的周期性。例如,电力消耗在一天中的不同时间段可能存在显著的波动,太阳能发电的产量可能随着白天和晚上的变化而变化。这种周期性可以通过时序数据分析方法来识别和利用。
- 实时性:能源数据的产生和更新通常是实时的,能够及时反映能源的生产和使用情况。这要求对能源数据进行实时监测、处理和分析,以便及时采取相应的措施。
- 大数据量:能源数据通常涉及到大量的数据量。由于能源是一个庞大而复杂的系统,需要收集和分析大量的数据才能全面了解能源市场的情况和趋势。
综上所述,能源数据是通过采集和记录能源相关设备和仪器产生的,具有时序数据的特征,可以按照时间维度进行分析和处理,以揭示能源的特征和趋势,并支持能源决策和管理。
当下,随着能源行业的发展,能源企业在处理大规模时序数据方面面临着一系列挑战,这些挑战也阻碍了业务发展进程。在这种背景下,在应对时序数据处理上更为专业的时序数据库(Time Series Database,TSDB),如 TDengine,逐渐成为众多能源企业关注的焦点,特别是那些面临数字化转型需求的企业。
能源数据的处理流程
能源数据的处理流程通常包括以下步骤:
- 数据收集:收集能源相关的数据,包括供应量、需求量、价格、消费者行为等各种指标。数据可以来自各个渠道,包括政府部门、能源公司、研究机构等。
- 数据清洗:对收集到的数据进行清洗和整理,包括去除重复数据、处理缺失值、修正错误值等。确保数据的准确性和完整性。
- 数据存储:将清洗后的数据存储到数据库或数据仓库中,以便后续的分析和使用。选择合适的存储方式可以提高数据的访问效率和可靠性。
- 数据分析:使用统计学和机器学习等方法对能源数据进行分析,探索数据之间的关系和趋势。这可以帮助了解能源市场的供需情况、预测未来的能源需求等。
- 数据可视化:将分析结果可视化,以图表、图像等形式展示数据的洞察力。这有助于在决策过程中更好地理解和解释数据。
- 数据应用:将分析和可视化结果应用于实际问题中,例如能源政策制定、市场预测、资源配置等。根据需求,可以采取不同的应用方式,如报告、决策支持系统、智能能源管理系统等。
需要注意的是,能源数据的处理流程可能因数据来源和具体需求而有所不同。不同的数据处理工具和技术也可以根据具体情况进行选择和应用。
能源数据处理面临的挑战
伴随新能源物联网的发展,生产、分配、消耗等各个方面由设备及传感器所产生的时序数据量越来越大,严重挑战传统的以关系型数据库为核心的解决方案,数据处理性能低下、数据架构臃肿、存储成本高昂等问题频发,如何应对大数据量下的数据存储、查询、分析,成为了能源企业目前迫切需要解决的难点,数字化转型升级迫在眉睫。
具体来说,能源数据处理面临的问题主要包括以下几个方面:
- 传统数据库难以应对大规模数据:能源行业的数据量通常非常庞大,传统的关系型数据库在处理大规模数据时性能和扩展性较差,往往无法满足能源企业的需求。这导致数据的存储、查询和分析变得困难和低效。
- 大数据组件复杂,开发运维成本高:针对大规模数据处理,能源企业可能会采用大数据技术组件,如 Hadoop、Spark 等。然而,这些组件的配置和管理相对复杂,需要专业的技术团队进行开发和运维,增加了企业的成本和风险。
- 分析和查询实时性要求难以满足:能源行业需要对数据进行实时分析和查询,以及时发现问题和做出决策。然而,传统的数据处理方法往往无法满足实时性要求,导致分析和查询结果的响应时间较长。
- 能源行业安全要求高,有国产化需求:能源数据的安全性是能源企业关注的重要问题。在国家对数据保护和信息安全要求越来越高的背景下,能源企业对于数据的安全性和控制权有更高的要求,因此需要具备国产化的数据处理解决方案。
- 跨区跨隔离数据同步麻烦,实时性响应差:能源企业通常分布在不同的地理区域,跨区跨隔离的数据同步成为一个挑战。传统的数据同步方法往往需要耗费大量的时间和资源,导致实时性响应较差,无法满足能源企业对于数据的及时性要求。
为应对这些问题,诸多能源企业考虑采用新一代的时序数据库解决方案,如 TDengine。TDengine 具备高性能、高可扩展性和实时处理能力,能够应对大规模能源数据的处理需求;支持多节点部署和数据同步机制,能够实现跨区跨隔离的数据同步,提高数据的实时性响应能力。此外,它还提供了国产化的解决方案,满足能源行业对于数据安全和控制权的要求。
能源数据处理有效的解决方案
以下是一些能源数据处理和分析的挑战和应对方法:
- 数据存储和管理:由于能源数据的大规模,传统的存储和管理方法可能无法满足需求。时序数据库如 TDengine 提供了高效的时序数据存储和管理能力,能够应对大规模能源数据的存储需求。
- 数据清洗和预处理:在时序数据的处理中,经常要对原始数据进行清洗、预处理,再使用时序数据库进行长久的储存。在传统的时序数据解决方案中,常常需要部署 Kafka、Flink 等流处理系统。而流处理系统的复杂性,带来了高昂的开发与运维成本。TDengine 3.0 的流式计算引擎提供了实时处理写入的数据流的能力,还能够支持乱序数据的写入。
- 数据分析和建模:能源数据的分析需要使用高效的算法和工具。例如,时间序列分析、机器学习和人工智能等方法可以应用于能源数据的分析和建模,以提取有价值的信息和进行预测。从时序数据特征出发,TDengine 创新式打造了“超级表”和“一个数据采集点一张表”的建模方式,让数据整合和关联操作更加便捷。
- 可视化和报告:能源数据的可视化和报告对于决策者和利益相关者来说非常重要。通过可视化工具和报告系统,能源数据可以以直观和易于理解的方式呈现,帮助用户更好地理解和利用数据。除了和 Grafana 一类的第三方可视化工具进行集成,TDengine 还打造了自己的可视化监控工具 TDinsight、taosKeeper,为开发者实时监控 TDengine 集群运行状态提供了便利。
当前,TDengine 已经应用在众多能源企业的数据架构改造项目中,它的引入帮助这些能源项目显著减少了组件数量,简化了架构的复杂度,降低存储成本的同时业务响应实时性也有所提升,业务写入、查询和分析的实时性要求也得到了保障。
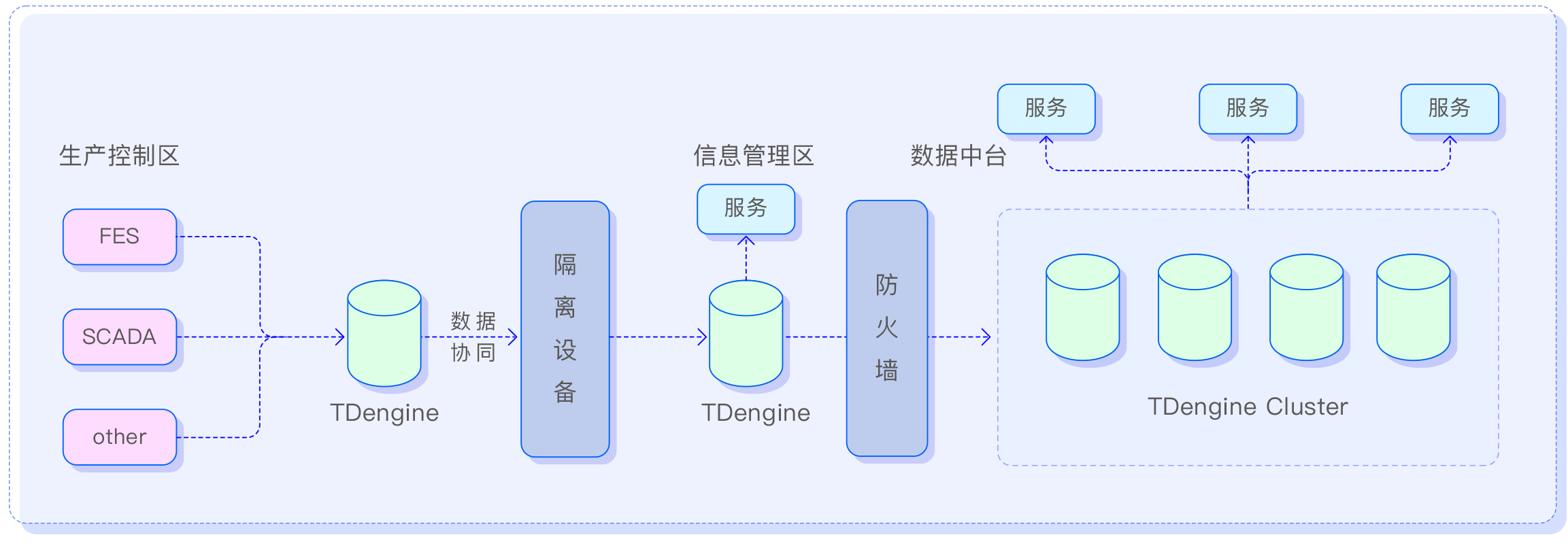
具体来讲,TDengine 提供的极简架构使能源企业在数据处理方面能够轻松进行运维和管理;高效数据存储和即席查询分析功能,让能源企业摆脱了繁琐的中间库和中间表,提高了数据处理的效率。同时,它还提供丰富的接口支持和强大的聚合函数、窗口函数,方便用户进行更加灵活和高级的数据分析。此外,TDengine 还提供了自带的边缘协同组件,使能源企业能够轻松实现跨隔离的数据同步,提高数据的实时性和响应能力。
总而言之,处理和分析大规模和复杂的能源数据需要使用如 TDengine 一般高效的数据库工具。它们可以帮助能源企业克服数据挑战,从而更好地利用能源数据,提高能源效率、优化资源配置和推动能源行业的转型和发展。
能源数据处理相关案例
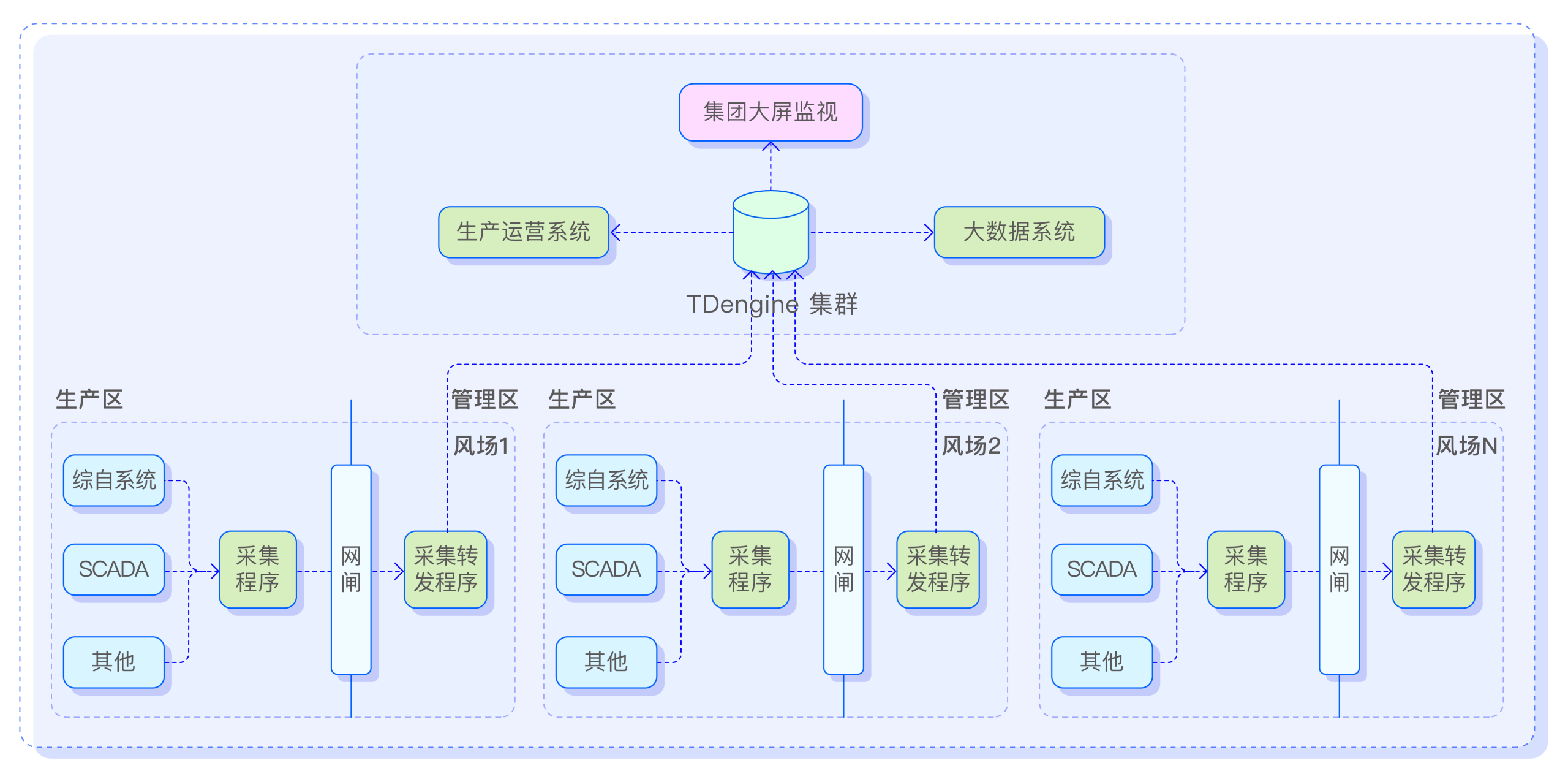
中节能电力发电运维系统 x TDengine
“目前基于 TDengine 我们构建了中节能风电运维平台,使用后数据存储优势明显,整体压缩比在 7-8 倍,数据查询也实现了秒级响应。未来我们考虑在每个风电场站的三区部署一个单节点 TDengine,作用不只是采集和转发,还要起到时序数据质量治理以及实时模型预测的功能;而在集团侧我们会考虑基于 TDengine 构建更多更复杂的计算指标和高级模型;同时还要和任务调度引擎以及风电行业标准集成。”
业务背景
尽管中节能风力发电股份有限公司具备成熟的风电开发和运维经验,但随着在建风场逐步增多以及各类新型传感器的加装,传统运维方式越发吃力,严重限制业务发展。顺应时代潮流,数字化智能化的需求越来越强烈,其迫切需要基于海量时序数据的数据平台来支撑繁杂的运维工作。在选型调研工作中,中节能最初尝试使用传统的工控时序数据库,但随着测点数量的增多,单机版架构已经无力支撑,后期他们尝试了 InfluxDB 和 OpenTSDB 等分布式架构的时序数据库,但性能又达不到要求。经过反复对比测试以及应用适配后,最终其选定 TDengine 作为数据平台的时序数据解决方案。
架构图
查看案例详情
上海电气储能智慧运维系统 x TDengine
“在使用 InfluxDB 一周以后执行查询,内存使用率达到了 80%,并且过了十分钟也没出来结果,已经完全不适合业务使用。而在使用了 TDengine 近 1 个月后,使用相同的 SQL 语句,查询只需要 0.2 秒,表现非常优异。在压缩方面,在采集点数量相同的情况下,压缩后的数据量 TDengine 是 InfluxDB 的 1/3。”
业务背景
围绕“一芯 3S”核心产品链,上海电气着手构建储能核心竞争力,“SmartOPS 储能智慧运维系统”就作为其中的关键组成部分,旨在实现全面监测、预测性维护、热管理分析等高级应用。在本地部署中,该系统需要重点考虑本地硬件资源的限制,如站端系统的内存、CPU 以及读写性能等,选择合适的时序数据库成为破解问题的关键。在对 OpenTSDB、InfluxDB、Apache IoTDB、TDengine、ClickHouse 几款数据库进行对比测试后,其尝试在系统中落地了 TDengine。
查看案例详情
八五信息新能源电力物联网平台 x TDengine
“在应用 TDengine 之后,系统读写性能较原 TimescaleDB 数据库提高 10 倍左右,在数据接入层我们不用再担心数据库的写入性能瓶颈;数据分析查询应用层也较原系统有较大提升,尤其是在时间跨度大的聚合类分析几乎瞬间响应。在软硬件方面,TDengine 帮助我们节省了系统大量的计算资源以及存储资源,较原系统降低了大约 4 倍左右的存储成本。”
平台架构
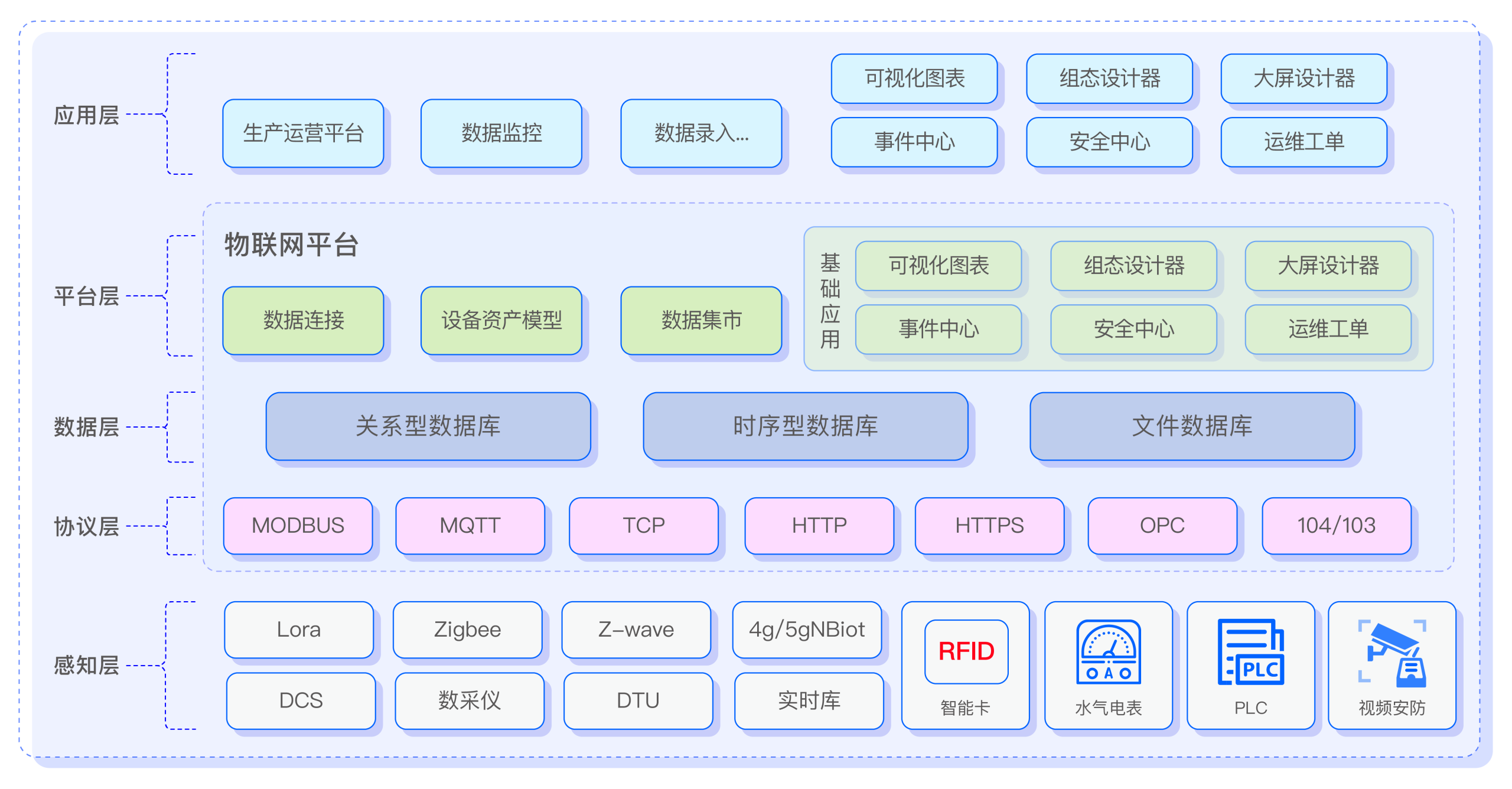
查看案例详情
水电厂畸变波形分析及故障预判系统 x TDengine
“TDengine 在该项目中顺利投入使用,在现场运行环境的表现,如同我们的验证测试一样,拥有优异的写入能力和快速的查询能力,可以有力地支撑系统对原始信号数据进行进一步的分析与应用。”
业务背景
计算机监控系统和机组稳定性监测分析系统,主要是从振动、气隙等状态量对主机设备的运行状态进行监测和评估,其核心需求是将全厂的电力系统各元件纳入系统的监测,并存储高采样率的原始信号数据,初步估算全厂电力系统元件 1 天即可产生 1.7TB 字节数据量,数据存储难题横亘眼前,在经过反复对比测试后,其决定将 TDengine 正式引入该项目。
查看案例详情
时序数据库的设计和优化都是根据时序数据特点而来,在面对具备时序数据特征的海量能源数据处理需求时,时序数据库显然更加有针对性,而以上企业的事实证明,在能源行业中,时序数据库的应用能够有效增加系统的各方面性能,降低研发和运维成本,真正帮助企业实现降本增效。也只有当能源数据得到了高效处理,它才能为能源决策和政策制定提供更具有价值的科学依据。
参考文献
[1] 《新能源发电企业大数据中心提高数据采集质量的方法及其有效性分析》.陈瑞
[2] 《基于大数据云平台的电力能源大数据采集方法及应用探讨》.鲍俊如 金莹 熊亮
[3]《基于电力企业大数据环境下的数据治理》.李方军 宋曦 赵博 袁昊 金铭
[4]《研发了 5 年的时序数据库,到底要解决什么问题?》.陶建辉
[5]《单机每秒百万记录、毫秒级延迟,TDengine 3.0 流处理引擎全面解析》.刘继聪
[6] 能源数据领域案例 —《TDengine 在水电厂畸变波形分析及故障预判系统中的应用》.深圳双合电机监测和故障预测产品研发团队
[7] 能源数据领域案例 —《代替 TimescaleDB,TDengine 接管数据量日增 40 亿条的光伏日电系统》.李良政
[8] 能源数据领域案例 —《TDengine 在上海电气储能智慧运维系统中的应用》.上海电气 SmartOPS团队
[9] 能源数据领域案例 —《TDengine 在中节能风力发电运维系统中的落地实践》.潘文彪
相关文章:

TDengine 在新能源领域的价值
能源数据的定义 能源数据是指记录和描述能源产业各个方面的信息,包括能源生产、供应、消费、储备、价格、排放以及相关政策和技术的数据。这些数据可以通过各种途径收集和整理,如能源企业的统计报表、政府部门的调查和监测、国际组织的发布数据等。 能…...

浅谈Frida 检测与绕过
目录 ptrace 占位与进程名检测端口检测与 D-Bus 协议通信扫描 /proc 目录(maps、task、fd)定位 so 中的 SVC syscall内存动态释放代码 1. ptrace 占位与进程名检测 检测方式 遍历运行进程列表,检查是否存在 frida-server 或相关进程名&…...

WaterStamp —— 一个实用的网页水印生成器开发记
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 最近,我和 CodeBuddy 一起完成了一个名为 WaterStamp 的网页水印生成器项目。这个小工具主要用于给…...

【MySQL】存储过程,存储函数,触发器
目录 准备工作 一. 存储过程 1.1.什么是存储过程 1.2.创建存储过程 1.3.创建只显示大于等于指定值的记录的存储过程 1.4.显示,删除存储过程 二. 存储函数 2.1.什么是存储函数 2.2.使用存储函数 2.2.1.使用存储函数之前 2.2.2.使用存储函数计算标准体重 …...

python打卡第29天
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

vim - v
在 Vim 中,使用 可视模式(Visual Mode) 可以选中文本并进行复制、剪切、粘贴等操作。以下是详细的使用方法: 1. 进入可视模式 命令功能v字符可视模式(按字符选择)V(大写)行可视模式…...
)
Linux 线程(上)
前言:大家早上中午晚上好!!今天来学习一下linux系统下所谓的线程吧!!! 一、重新理解进程,什么是进程? 1.1 图解 其中黑色虚线部分一整块就是进程,注意:一整…...
报错:“没有主清单属性” 的解决方法)
# 终端执行 java -jar example.jar 时(example.jar为项目jar包)报错:“没有主清单属性” 的解决方法
终端执行 java -jar example.jar 时(example.jar为项目jar包)报错:“没有主清单属性” 的解决方法 在Java中,一个JAR文件必须包含一个主清单属性(Main-Class属性)才能在命令行中直接运行。如果你在尝试运行…...

4:OpenCV—保存图像
将图像和视频保存到文件 在许多现实世界的计算机视觉应用中,需要保留图像和视频以供将来参考。最常见的持久化方法是将图像或视频保存到文件中。因此,本教程准备解释如何使用 OpenCV C将图像和视频保存到文件中。 将图像保存到文件 可以学习如何保存从…...

[C++面试] const相关面试题
1、非 const 的引用必须指向一个已存在的变量 int main() {int &a 20; // 错误const int &b 30; } 字面量 20 是临时值(右值),没有明确的内存地址。非常量引用(左值引用)不能直接绑定到右值(如…...
Redis当中的消息队列)
#Redis黑马点评#(六)Redis当中的消息队列
目录 Redis当中的消息队列 一 基于List 二 基于PubSub 三 基于Stream 单消费模式 消费者组 Redis当中的消息队列 消息队列,字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色: 消息队列:存储和管理消息,也称为…...

Git基础原理和使用
Git 初识 一、版本管理痛点 在日常工作和学习中,我们经常遇到以下问题: - 通过不断复制文件来保存历史版本(如报告-v1、报告-最终版等) - 版本数量增多后无法清晰记住每个版本的修改内容 - 项目代码管理存在同样问题 二、版本控…...
)
Java程序员学AI(一)
一、前言 最近刷技术圈,满眼都是 GPT、DeepSeek、QWen 这些 AI 名词。看着同行们在群里聊 AI 写代码、做数据分析,我这个摸了 Java 老程序员突然慌了 —— 再不出手,怕是真要被时代落下了! 作为一个 Java 死忠粉,学 …...
)
《Python星球日记》 第91天:端到端 LLM 应用(综合项目:医疗文档助手)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、项目概述与需求分析1. 项目背景2. 项目目标3. 技术栈概览二、数据准备与处理1. 文档收集策略2. 文本预处理流程3. 向量化与知识库构建三、模…...

目前主流的AI测试工具推荐
以下是目前备受关注的AI测试工具及平台,涵盖功能测试、视觉测试、性能测试及国产化解决方案等多个领域,结合其核心特性与适用场景进行综合推荐: 一、主流AI测试工具推荐 Testim 核心功能:基于AI的动态元素定位技术,…...
)
vscode优化使用体验篇(快捷键)
本文章持续更新中 最新更新时间为2025-5-18 1、方法查看方法 1.1当前标签跳到新标签页查看方法实现 按住ctrl 鼠标左键点击方法。 1.2使用分屏查看方法实现(左右分屏) 按住ctrl alt 鼠标左键点击方法。...

uniprot中PTM数据的下载
首先是PTM的介绍: 参考:https://en.wikipedia.org/wiki/Post-translational_modification 蛋白质的翻译后修饰(PTM)通过改变氨基酸残基的化学结构,显著影响其带电性质,从而调控蛋白质的功能、定位和相互作…...

【QGIS二次开发】地图编辑-04
系列目录: 【QGIS二次开发】地图显示与交互-01_qgis二次开发加载地图案例-CSDN博客 【QGIS二次开发】地图显示与交互-02_setlayerlabeling-CSDN博客 【QGIS二次开发】地图符号与色表-03-CSDN博客 4 地图编辑 4.1 添加点要素 功能演示: 运行程序后…...
)
Qt 信号和槽-核心知识点小结(11)
目录 小结表格索引 disconnect函数 lambda表达式 啥是耦合,啥是内聚 简介:这是Qt信号和槽的最后一篇文章,最主要的是总结该信号和槽的核心知识点。以及该核心知识点的文章索引(表格太长了,手机可能看不完整&#…...

React响应事件中onClick={handleClick} 的结尾有没有小括号的区别
你可以通过在组件中声明 事件处理 函数来响应事件: function MyButton() {function handleClick() {alert(You clicked me!);}return (<button onClick{handleClick}>点我</button>);} 注意,onClick{handleClick} 的结尾没有小括号&#x…...

React-Query使用react-testing-library进行测试
1.测试react-query首先我们必须得拥有queryClient,所以我们初始化queryClient,因为默认是重试三次,这意味着如果想测试错误的查询,测试可能会超时。所以可以在初始化时关闭 const createWrapper () > {const queryClient new…...

软件设计师CISC与RISC考点分析——求三连
一、考点分值占比与趋势分析(CISC与RISC) 综合知识分值统计表 年份考题数量分值分值占比考察重点2018111.33%指令特征对比2019111.33%控制器实现方式2020222.67%寄存器数量/流水线技术2021111.33%寻址方式对比2022222.67%指令复杂度/译码方式2023111.3…...
常用关键字总结)
GO语言(一期)常用关键字总结
GO语言(主题一)常用关键字总结 我们这里列出一些go语言关键字,方便各位友友们检查一下自己的学习效果,也方便友友们学习查询。 break default func interface select case defer go map …...

Ubuntu搭建NFS服务器的方法
0 工具 Ubuntu 18.041 Ubuntu搭建NFS服务器的方法 在Ubuntu下搭建NFS(网络文件系统)服务器可以让我们像访问本地文件一样访问Ubuntu上的文件,例如可以把开发板的根文件系统放到NFS服务器目录下方便调试。 1.1 安装nfs-kernel-server&#…...
)
京东商品详情API接口开发指南(含Java/Python实现)
接口概述 京东开放平台提供了商品详情查询接口,开发者可以通过SKUID获取商品的详细信息,包括标题、价格、图片、促销信息等。该接口需要申请API权限和认证密钥。 点击获取key和secret 接口特点 支持批量查询(最多20个SKU)返回J…...

二叉树构造:从前序、中序与后序遍历序列入手
目录 引言 从前序与中序遍历序列构造二叉树(题目 105) 解题思路 举例说明 从中序与后序遍历序列构造二叉树(题目 106) 解题思路 举例说明 总结 引言 二叉树的遍历与构造是算法领域中的经典问题。LeetCode 上的“从前序与中…...

GEE谷歌地球引擎批量下载逐日ERA5气象数据的方法
本文介绍在谷歌地球引擎(Google Earth Engine,GEE)中,批量下载逐日的ERA5土壤湿度数据(或者是其他气象数据、遥感影像数据等)的方法。 首先,明确一下本文的需求。我们希望在GEE中,下…...
全方位讲解:定义、特性、应用与实践)
C#接口(Interface)全方位讲解:定义、特性、应用与实践
引言 在面向对象编程(OOP)中,接口(Interface)是一种重要的结构,它定义了某一类对象或类应遵循的行为规范。接口强调“做什么(What)”,而非“怎么做(How&…...

索引与数据结构、并行算法
3. 索引与数据结构 索引类比目录:类似于书籍目录,帮助我们快速定位信息。索引的核心目的:提升数据查找效率,优化增删改查性能。实际应用广泛:MySQL、Redis、搜索引擎、分布式系统、中间件等。 3.1. 索引设计中的需求…...

GC全场景分析
GC全场景分析 文章目录 GC全场景分析标记-清除法**标记 - 清除法核心流程与 STW 机制****标记 - 清除法四步流程****1. STW 启动(暂停用户线程)****2. 标记可达对象(从根集合出发)****3. 清除未标记对象(回收堆内存&am…...
)
OSI七层模型和TCP/IP的五层(四层模型)
分层 1.什么是分层 我理解是对同一相同或者相似的事务或者操作功能进行分类,比如我们去餐厅吃饭,就可以分为好多层,客户层,服务员层,前台层,后厨层,每一层都专注自己的事情,客户层…...

MouseDown,MouseUp,LostMouseCapture的先后顺序
本文目标是实现如下功能: 按下一个按钮后置位某变量;鼠标松开后复位某个变量? 看似简单,但是一般来说会存在如下两种现象: 鼠标移出按钮:默认会丢失鼠标事件跟踪,即MouseLeftButtonUp事件并不会被触发。 焦点切换:Tab 键切换焦点会干扰按钮的事件捕获 本文通过几个…...

第8章 常用实用类
8.1 String类 在java.lang包(默认引入)中,可直接使用。 定义为final类,不能扩展String类,不可以继承,不可以有子类。 8.1.1 构造String对象 常量对象: 英文双引号括起来 String常量放入常…...
)
视差场(disparity field)
视差场(disparity field)是立体视觉中的一个重要概念,用于描述两幅立体图像之间像素的对应关系。以下是对视差场的详细解释: 1. 视差(Disparity)的定义 视差是指同一场景点在两幅立体图像中的像素位置差异…...

AI:OpenAI论坛分享—《AI重塑未来:技术、经济与战略》
AI:OpenAI论坛分享—《AI重塑未来:技术、经济与战略》 导读:2025年4月24日,OpenAI论坛全面探讨了 AI 的发展趋势、技术范式、地缘政治影响以及对经济和社会的广泛影响。强调了 AI 的通用性、可扩展性和高级推理能力,以…...

【已经解决诸多问题】Mamba安装
mamba被称为新一代的计算架构,因此在CV和时序领域存在诸多的方案开始采用这一新架构,但是这个架构的安装过程中存在诸多问题!!!!为了更好帮助大家理解我们给出一个统一的安装流程!!&…...

计算机的基本组成与性能
1. 冯诺依曼体系结构:计算机组成的金字塔 1.1. 计算机的基本硬件组成 1.CPU - 中央处理器(Central Processing Unit)。 2.内存(Memory)。 3.主板(Motherboard)。主板的芯片组(Ch…...

“绿色邮政,智能九识”——呼和浩特邮政无人快递车发车,驶向智慧物流新时代!
5月12日,“绿色邮政,智能九识”呼和浩特邮政无人驾驶快递车发车。 此次投运的邮政无人驾驶快递车实力惊人:单车运量超1000件,时速达40公里,通过智能路径规划实现24小时作业,与传统运输相比,运转…...
:通过LangChain的接口来调用OpenAI对话)
AGI大模型(24):通过LangChain的接口来调用OpenAI对话
1 创建对话 使用langchain库中的ChatOpenAI类来创建一个对话模型。 from dotenv import load_dotenvload_dotenv()import os from langchain_openai import ChatOpenAIllm = ChatOpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),base_url="https://api.deepsee…...

大模型中的Token机制深度解析
目录 大模型中的Token机制深度解析 一、Token的本质与核心作用 二、主流分词算法对比 三、GPT-3分词机制详解 四、分词策略对模型性能的影响 五、工程实践建议 六、未来演进方向 一、Token的本质与核心作用 Token是大模型处理文本的最小语义单元,类似于人类语…...

【MySQL】库与表的操作
一、库的操作 1. 查看数据库 语法:show databases;这里的database是要加s的 查看当前自己所处的数据库:select database(); 例如下图,我当前所处的数据库就是在class1数据库 2. 创建数据库 语法:create database [if not e…...

创建指定版本的vite项目
1、获取vite的版本号 npm view create-vite versions 注:4.4.1版本即对应着node16版本的项目 2、创建制定版本的vite项目 npm init vite<version>...

java中的Servlet3.x详解
Servlet 3.x 是 Java Web 开发的重要里程碑,包含 Servlet 3.0(2009年发布)和 Servlet 3.1(2013年发布)两个主要版本。它通过多项革新优化了开发效率、性能及扩展性,成为现代 Java Web 应用的核心技术基础。…...

单目测距和双目测距 bev 3D车道线
单目视觉测距原理 单目视觉测距有两种方式。 第一种,是通过深度神经网络来预测深度,这需要大量的训练数据。训练后的单目视觉摄像头可以认识道路上最典型的参与者——人、汽车、卡车、摩托车,或是其他障碍物(雪糕桶之类…...

weibo_comment_pc_tool | 我于2025.5月用python开发的评论采集软件,根据帖子链接爬取评论的界面工具
本工具仅限学术交流使用,严格遵循相关法律法规,符合平台内容的合法及合规性,禁止用于任何商业用途! 一、背景分析 1.1 开发背景 微博(以下简称wb)是国内极具影响力的社交媒体平台,具有内容形式…...

ubuntu防火墙命令和放行ssh端口
一、关闭UFW防火墙(Ubuntu默认工具) 1. 临时关闭防火墙 sudo ufw disable sudo ufw status # 显示 Status: inactive 表示已关闭 2. 永久禁用防火墙(禁用系统服务) sudo systemctl stop ufw # 立即停止服务 sudo sy…...

PWM讲解+STM32任意频率、占空比、脉宽生成函数介绍
1.PWM讲解 脉冲宽度调制(PWM),是英文“Pulse Width Modulation”的缩写,简称脉宽调制。 脉宽调制 最开始使用PWM时,是做智能车时使用的舵机打角,电机驱动。这都属于比较浅显,普通的应用。下面和大家简单分享一下PWM的…...
)
C++23 范围迭代器作为非范围算法的输入 (P2408R5)
文章目录 一、引言二、C23及范围迭代器的背景知识2.1 C23概述2.2 范围迭代器的概念 三、P2408R5提案的内容3.1 提案背景3.2 提案内容 四、范围迭代器作为非范围算法输入的优势4.1 代码简洁性4.2 提高开发效率4.3 更好的兼容性 五、具体的代码示例5.1 使用范围迭代器进行并行计算…...

CVE-2018-1273 漏洞深度分析
漏洞概述 CVE-2018-1273 是 Spring Data Commons 中的一个高危远程代码执行(RCE)漏洞,影响版本为 Spring Data Commons 1.13–1.13.10 和 2.0–2.0.5。攻击者通过构造包含恶意 SpEL表达式的 HTTP 请求参数,触发表达式注入&#x…...

C++23:修正常量迭代器、哨兵和范围
文章目录 引言C20范围库回顾C23之前常量迭代器的问题视图可能不传播const代理对象的复杂性泛型代码中的一致性 P2278R4提案及C23的改进std::views::as_const的工作原理代码示例 浅const视图(如std::span)的改进总结 引言 在C的发展历程中,每…...