24/12/9 算法笔记<强化学习> PPO,DPPO
PPO是目前非常流行的增强学习算法,OpenAI把PPO作为目前baseline算法,首选PPO,可想而知,PPO可能不是最强的,但是是最广泛的。
PPO是基于AC架构,因为AC架构有一个好处,就是解决了连续动作空间的问题。
AC输出连续动作
什么是连续动作呢,也就是不仅有动作,而且还有动作的力度大小的概念,就像开车,不仅有方向还要控制油门踩多深,刹车踩多少,转向多少的问题,离散动作是可数的,连续是不可数的。
On-Policy和Off-Policy
例如PG就是一个在线策略,因为PG用于产生数据的策略,和需要更新的策略是一致的。
而DQN是一个离线策略,简而言之就是可以运用之前的数据来更新。
但为什么PG和AC中的Actor更新不能像DQN一样,把数据存起来,更新多次呢?
答案是在一定条件下可以。PPO就是做这个工作的,在了解什么情况下可以的时候,我们先来了解下,为什么不能。

假设我们在一个已知环境下,有两个动作可以选择。现在两个策略,分别是P:[0.5,0.5]和B:[0.1,0.9]
现在我们按照两个策略,进行采样,也就是分别按照这两个策略,以S这套下出发,与环境进行10次互动。获得如图数据,那么,我们可以用B策略下获得的数据,更新P吗?
答案是不行,回顾一下PG算法,PG算法会按照TD-error作为权重,更新策略。权重越大,更新幅度越大,权重越小,更新幅度越小。
Important sampling
那么PPO是怎么做到离线更新策略的呢?答案是Important-sampling,重要性采样技术,如果我们想用策略B抽样出来的数据来更新策略P也不是不可以,但是我们要把TD-error乘以一个重要性权重IW(importance weight)。
IW = P(a) / B(a)
回到我们之前的例子,我们可以计算出,每个动作的重要性权重,P:[0.5,0.5]和B:[0.1,0.9]:
IWa1 = P/B = 0.5/0.1 = 5
IWa2 = P/B = 0.5/0.9 = 0.55
New TD error for a1 = 5 * 1.5 = 7.5
New TD error fot a2 = 0.55 * 1 = 0.55
我们把重要性权重乘以TD-error,我们发现,a1的TD-error大幅度提升,而a2 的TD-error减少了,现在即使我们用P策略:[0.5,0.5]进行更新,a1提升的概率也会比a2 的更多。
PPO应用了importance sampling,使得我们用行为策略获取的数据,能够更新目标策略,把AC从在线策略,变成离线策略。
那么我们为什么可以这样做呢?
回想PG
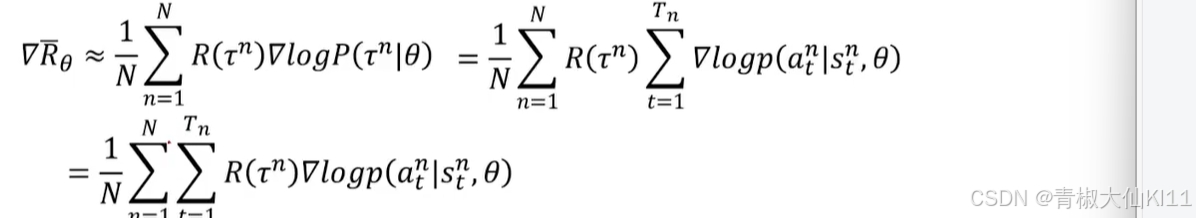
其实可以把它理解为是在求一个期望,通过不断的sample然后求平均去近似期望值

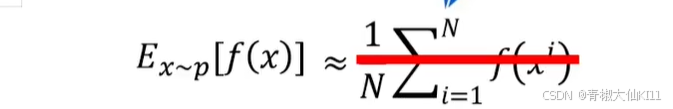
因为我们的经验数据中有很多模型的经验数据,比如B策略的这个经验数据
如果我们不能从p来sample,只能从q来sample,做一下变换。
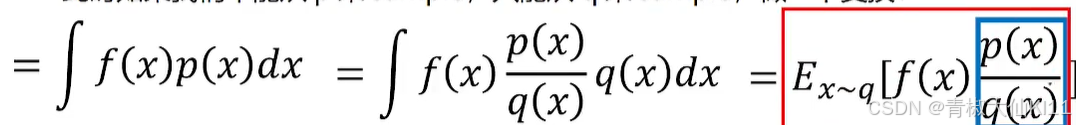
Importance sampling的问题
同学们都清楚,比如两个正态分布的期望一样,但是只要是
不同,就是不一样的正态分布,所以我们上面即使乘上了importance weight对q的期望
进行了修正,但是方差也是不同的
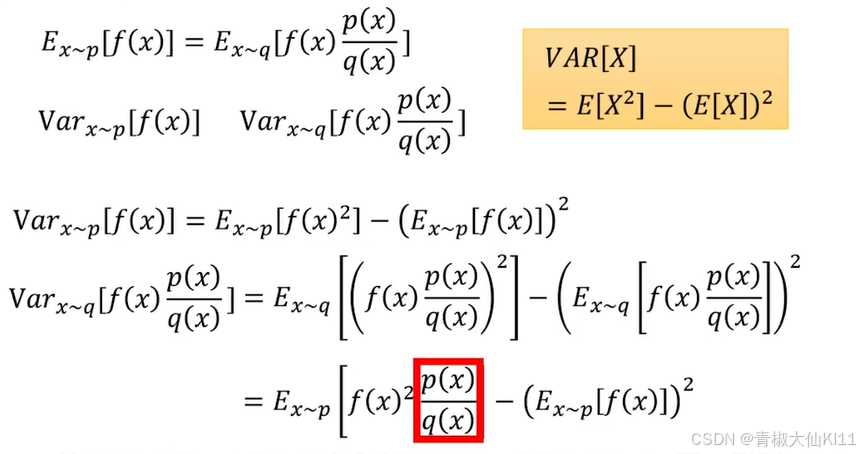
所以结论就是由于修正后期望是一样的,但是方差公式不同,假设我们对p和q采样sample的次数足够多,它们会是一样的,原因是期望;但是当sample次数不够多时,由于方差不一样,方差差距越大,那么sample就有可能得到非常大的差距。
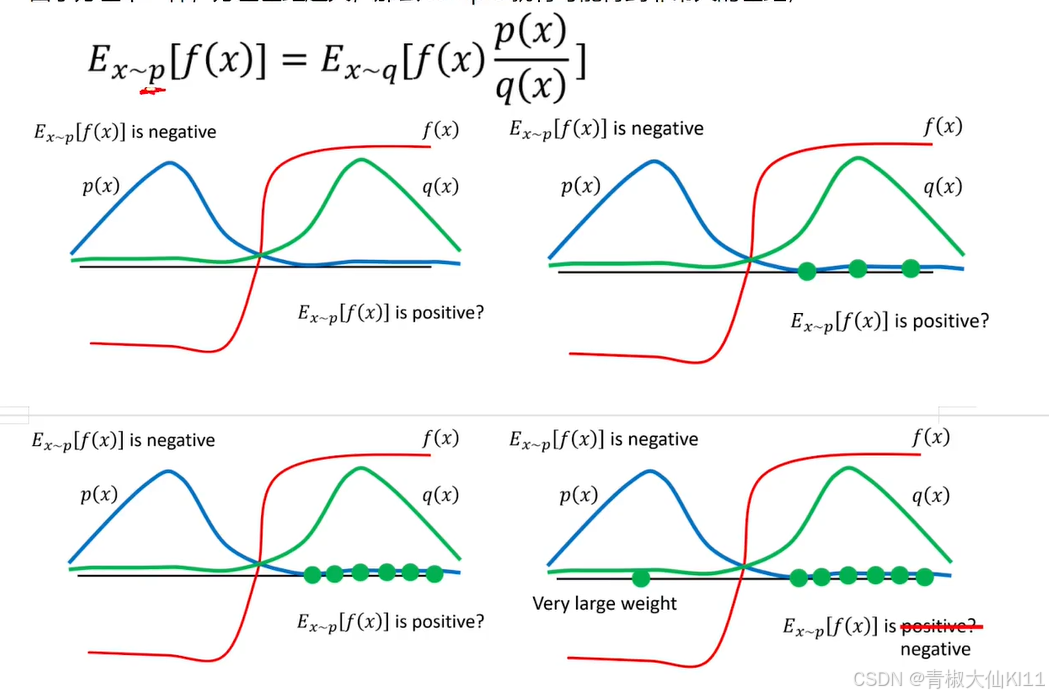
Add Constraint
当两个分布差距太大的时候,就会有问题,于是我们还得限制两个分布差距不能太大

在PPO1里面,用了是KL散度(相对熵)来衡量两个分布的差距,作为一个惩罚项来出现,KL散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。
注意的是,这里KL计算的还真不是参数上面的距离,而是参数使得行为action表现上面的距离,也就是策略的距离。策略就是action上面的几率分布。
是可以动态调整的:

TRPO
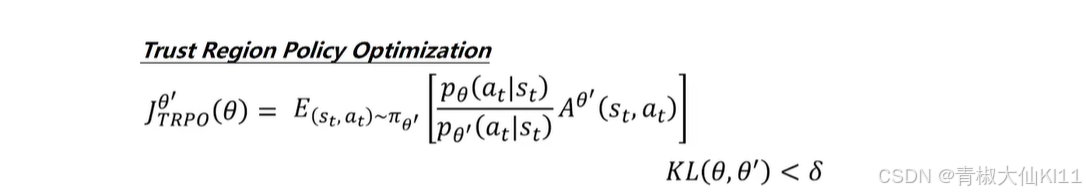
将KL散度当成一个约束条件。
PPO2
PPO2简单粗暴,直接裁剪了更新范围,但是这种方法却出乎意料地好
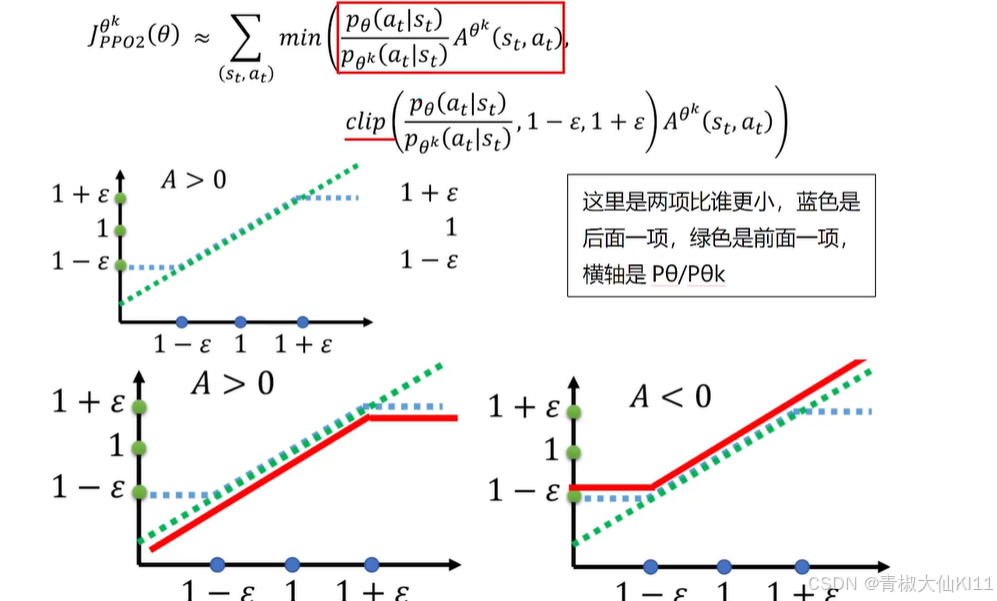
为什么这样限制就ok了呢?因为当A>0时,一定是(st,at)是好的,那么我们就希望P(st,st)变大,回头训练调参就会使得P
/ P
K变大,但是如果不断训练变得太大,他们就不相似了,那么constraint限制住它们的比例不能超过1-
,反而亦然。
代码实现以及核心
动作采样(PPO类的get_action方法)
def get_action(self, state):state = torch.from_numpy(state).float().unsqueeze(0)dist = self.policy(state)action = dist.sample()return action.item(), dist.log_prob(action)将处理后的状态输入到策略网络(self.policy,即 PolicyNetwork 类的实例)中,策略网络输出一个动作的概率分布,然后从这个概率分布中采样出一个动作,同时返回这个动作以及对应的对数概率。对数概率在后续计算策略更新时会用到,它用于衡量当前策略产生这个动作的可能性大小。
优势函数估计(PPO类的update方法中相关部分)
# 计算优势函数估计
returns = []
Gt = 0
for r, d in zip(reversed(rewards), reversed(dones)):Gt = r + self.gamma * Gt * (1 - d)returns.insert(0, Gt)
returns = torch.stack(returns)values = self.value(states)
advantages = returns - values.detach()- 回报(
returns)计算:按照时间步从后往前遍历每一步的即时奖励(rewards)和是否结束(dones)标志。通过动态规划的思想,利用折扣因子(gamma)来累计计算从当前时间步到最终时间步的折扣奖励总和,也就是回报Gt。例如,最后一步的回报就是最后一步的即时奖励,如果不是最后一步,则回报等于当前即时奖励加上下一个时间步回报乘以折扣因子(如果下一个时间步未结束)。最后将计算好的每一步回报组成一个张量returns。
- 优势函数计算:使用价值网络(
self.value,即ValueNetwork类的实例)对每个状态估计其价值(values = self.value(states)),这个估计的价值可以理解为从该状态开始按照当前策略后续能获得的期望奖励。然后用计算得到的回报returns减去价值网络估计的价值(这里要使用detach分离梯度,因为在计算优势函数时不希望价值网络的梯度传播影响到后续对回报的计算等),得到的差值advantages就是优势函数,它反映了在某个状态下采取某个动作相较于平均水平的好坏程度,是后续策略更新的关键依据。
策略更新(PPO类的update方法中相关部分)
dist = self.policy(states)
log_probs = dist.log_prob(actions.squeeze())
ratio = torch.exp(log_probs - old_log_probs.squeeze())
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.clip_eps, 1 + self.clip_eps) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step() 首先将当前收集到的一系列状态(states)再次输入策略网络得到新的动作概率分布(dist),并计算出当前策略下对应之前所采取动作(actions)的对数概率(log_probs),然后和之前记录的旧策略下这些动作的对数概率(old_log_probs)相比较,计算出概率比率 ratio(通过指数运算得到新旧概率的比率)。接着,根据这个比率和优势函数计算出两个替代目标函数 surr1 和 surr2,其中 surr2 是对 ratio 进行了裁剪(clip)操作后的结果,限制策略更新的幅度,避免过大的策略更新导致性能变差,这是 PPO 算法的关键技巧之一。
取 surr1 和 surr2 中的较小值作为最终的策略损失(actor_loss),这样可以保证策略更新朝着让策略更好的方向进行,同时又有一定的约束。然后通过清空梯度(zero_grad)、反向传播(backward)和执行一步优化器更新(step)来更新策略网络的参数,使得策略网络朝着更优的方向调整。
DPPO
DPPO 是在深度确定性策略梯度(DDPG)算法基础上结合 PPO 的一些思想发展而来的。DDPG 主要用于处理连续动作空间的问题,它使用深度神经网络来逼近策略函数和价值函数。
和A3C一样,DPPO是希望多个智能体同时和环境互动,并对全局的PPO网络更新。
在A3C,我们需要跑数据并且计算好梯度,再更新全局网络。这是因为AC是一个在线的算法,所以在更新的时候,产生的数据和更新的策略需要同一个网络,所以我们不能把worker阐述的数据,直接给全局网络计算梯度使用。
但PPO解决了离线更新的问题,所以DPPO的worker只需要提供数据给全局网络,由全局网络从数据中直接学习。
但是这两项工作是不能同时的,当全局网络在学习的时候,workers需要等待全局网络学习完,才能干活,workers在干活的时候,全局网络就需要等待worker提供数据。
关键代码
select_action 方法
def select_action(self, state):state = torch.FloatTensor(state).unsqueeze(0)action = self.actor(state).detach().numpy()[0]return action该方法用于根据当前策略网络(Actor),给定一个状态来选择相应的动作,是智能体与环境交互过程中每次选择动作的关键操作,它将状态转换为网络输入的张量格式,经过策略网络计算后得到动作并转换为 numpy 数组返回,以便能在环境中执行该动作。
update 方法
def update(self):if len(self.memory) < self.batch_size:returnsamples = random.sample(self.memory, self.batch_size)states, actions, rewards, next_states, dones = zip(*samples)states = torch.FloatTensor(states)actions = torch.FloatTensor(actions).unsqueeze(1)rewards = torch.FloatTensor(rewards).unsqueeze(1)next_states = torch.FloatTensor(next_states)dones = torch.FloatTensor(dones).unsqueeze(1)# 计算目标价值target_values = rewards + (1 - dones) * self.gamma * self.critic(next_states)# 更新价值网络values = self.critic(states)critic_loss = nn.MSELoss()(values, target_values.detach())self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 计算优势函数估计值advantages = target_values - values.detach()# 计算旧策略的动作概率old_action_probs = self.actor(states).gather(1, actions.long())# 计算新策略的动作概率new_action_probs = self.actor(states)ratio = (new_action_probs / (old_action_probs + 1e-10)).gather(1, actions.long())# 计算PPO的裁剪损失surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1 - self.eps_clip, 1 + self.eps_clip) * advantagesactor_loss = -torch.min(surr1, surr2).mean()# 更新策略网络self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()update方法是整个DPPO算法的核心训练逻辑所在。它从经验回放缓冲区(memory)中采样一批数据,先基于这批数据计算目标价值来更新价值网络(Critic),然后通过计算优势函数估计值、新旧策略的动作概率等,进而计算策略网络(Actor)的裁剪损失,最终实现对策略网络和价值网络的更新优化,使得智能体能够不断改进其策略以获得更多奖励。
DDPO和PPO的区别
基本区别
PPO: 它主要是为了解决传统策略梯度方法(如 A2C、A3C)在更新策略时样本效率较低和训练不稳定的问题,通过限制新策略和旧策略之间的差异来提高训练效率。
DPPO: 它更像是深度确定性策略梯度(DDPG)算法与 PPO 思想的结合。DPPO 主要用于连续动作空间的强化学习问题,而 PPO 可以用于离散和连续动作空间。
动作空间适用性差异
PPO: 通用性较强,能够很好地处理离散动作空间问题。
DPPO: 主要是为连续动作空间设计的。
策略更新方式差异
PPO: 最常见的是PPO-clip。它通过裁剪目标函数中的概率比(新旧策略下动作概率的比值)来限制新策略和旧策略的差异。具体来说,定义一个裁剪参数,计算新旧策略的概率比
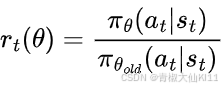 ,然后通过
,然后通过
来更新策略,其中![]() 是优势函数估计值。
是优势函数估计值。
DPPO: 策略更新结合了 DDPG 的一些特点。在 DDPG 中,策略网络(Actor)的更新是基于策略梯度定理,通过最大化累计奖励的期望来更新。DPPO 在这个基础上,类似于 PPO,会采取措施保证策略更新的稳定性。例如,它会利用经验回放等机制,在更新 Actor 网络时,考虑 Critic 网络评估的状态价值变化以及策略网络输出动作的变化,同时限制策略变化的幅度。
网络架构差异
PPO采用A-C架构
DPPO继承了DPPG的网络架构特点,有一个Actor网络用于输出连续动作,一个Critic网络用于评估状态价值。
相关文章:

24/12/9 算法笔记<强化学习> PPO,DPPO
PPO是目前非常流行的增强学习算法,OpenAI把PPO作为目前baseline算法,首选PPO,可想而知,PPO可能不是最强的,但是是最广泛的。 PPO是基于AC架构,因为AC架构有一个好处,就是解决了连续动作空间的问…...

spring boot通过连接池的方式连接时序库IotDB
1、maven依赖 <dependency><groupId>org.apache.iotdb</groupId><artifactId>iotdb-session</artifactId><version>1.3.2</version></dependency>2、配置文件 iotdb:server:url: localhostport: 6667name: rootpwd: rootmax…...

maven多模块开发
目录 聚合 可选依赖 排除依赖 属性 打包 聚合 聚合就是将多个模块组成一个整体,进行项目构建。聚合工程(也称为多模块项目)是 Maven 的一种项目结构,它允许将一个大型项目拆分为多个较小的、更易于管理的子模块。每个子模块…...

Kubernetes Nginx-Ingress | 禁用HSTS/禁止重定向到https
目录 前言禁用HSTS禁止重定向到https关闭 HSTS 和设置 ssl-redirect 为 false 的区别 前言 客户请求经过ingress到服务后,默认加上了strict-transport-security,导致客户服务跨域请求失败,具体Response Headers信息如下; 分析 n…...

华为eNSP:VRRP
一、VRRP背景概述 在现代网络环境中,主机通常通过默认网关进行网络通信。当默认网关出现故障时,网络通信会中断,影响业务连续性和稳定性。为了提高网络的可靠性和冗余性,采用虚拟路由冗余协议(VRRP)是一种…...

linux 安装composer
下载composer curl -sS https://getcomposer.org/installer | php下载后设置环境变量,直接通过命令composer -v mv composer.phar /usr/local/bin/composer查看版本看是否安装成功 composer -v...
)
ESP32-S3模组上跑通ES8388(24)
接前一篇文章:ESP32-S3模组上跑通ES8388(23) 二、利用ESP-ADF操作ES8388 2. 详细解析 上一回解析完了es8388_init函数中的第8段代码,本回继续往下解析。为了便于理解和回顾,再次贴出es8388_init函数源码,在components\audio_hal\driver\es8388\es8388.c中,如下: …...

类文件具有错误的版本 61.0, 应为 55.0 请删除该文件或确保该文件位于正确的类路径子目录中。
类文件具有错误的版本 61.0, 应为 55.0 请删除该文件或确保该文件位于正确的类路径子目录中。 这个错误表明你的项目尝试加载的 .class 文件(编译好的 Java 类)是用比你的运行环境支持更高版本的 Java 编译的。具体来说: 版本 61.0 对应 Ja…...

AI 的时代,新科技和新技术如何推动跨学科的整合?
在当前AI的发展中,我们面临的一个主要挑战就是融合的问题,这实际上不仅是技术上的融合,还有更深层次的哲学层面的思考。 或许在中国这方面的讨论较少,但在西方哲学和神学的语境中,探讨万物的根本和不同学科之间的联系…...

12.9-12.16学习周报
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract一、SNN与传统ANN的比较1.SNN概述2.SNN神经元和ANN的比较结构3.spikingjelly1.数据格式2.状态的保存和重置3.传播模式4.神经元 二、图数据库1.图数据库…...
)
CanFestival移植到STM32 F4芯片(基于HAL库)
本文讲述如何通过简单操作就可以把CanFestival库移植到STM32 F4芯片上,作为Slave设备。使用启明欣欣的工控板来做实验。 一 硬件连接 观察CAN报文需要专门的设备,本人从某宝上买了一个兼容PCAN的开源小板子,二十几块钱,通过USB接…...

构建安全的数据库环境:群晖NAS安装MySQL和phpMyAdmin详细步骤
文章目录 前言1. 安装MySQL2. 安装phpMyAdmin3. 修改User表4. 本地测试连接MySQL5. 安装cpolar内网穿透6. 配置MySQL公网访问地址7. 配置MySQL固定公网地址8. 配置phpMyAdmin公网地址9. 配置phpmyadmin固定公网地址 前言 本文将详细讲解如何在群晖NAS上安装MySQL及其数据库管理…...
硬件组成详解)
相机(Camera)硬件组成详解
简介:个人学习分享,如有错误,欢迎批评指正。 写在前面:可以去B站观看一些相机原理的视频来配合学习,这里推荐:推荐1,推荐2,推荐3 相机(Camera)是一种复杂的光…...

【Linux———基础IO】
每一滴眼泪,每一次心碎,什么爱能无疚无悔.......................................................................... 文章目录 前言 一、【认识文件I/O】 1.1、【回顾C语言文件I/O】 1.2、【操作系统文件I/O】 1.2.1、【open函数】 1、【open函数的三…...
- RTCP协议)
WebRTC服务质量(03)- RTCP协议
一、前言: RTCP(RTP Control Protocol)是一种控制协议,与RTP(Real-time Transport Protocol)一起用于实时通信中的控制和反馈。RTCP负责监控和调节实时媒体流。通过不断交换RTCP信息,WebRTC应用…...

[python SQLAlchemy数据库操作入门]-10.性能优化:提升 SQLAlchemy 在股票数据处理中的速度
哈喽,大家好,我是木头左! 当处理大量数据时,如股票数据,默认的ORM操作可能会显得效率低下。本文将探讨如何通过一些技巧和策略来优化SQLAlchemy ORM的性能,从而提升其在股票数据处理中的速度。 1. 选择合适的数据类型 在定义模型时,选择合适的数据类型对于性能至关重要…...

23种设计模式之中介者模式
目录 1. 简介2. 代码2.1 Mediator (中介者接口)2.2 ChatRoom (具体中介者类)2.3 User (同事接口)2.4 ChatUser (具体同事类)2.5 Test (测试)2.6 运行结果 3. …...

MySQL:GROUP_CONCAT分组合并
目录 一、概述二、用法三、分组去重 一、概述 GROUP_CONCAT函数要配合group by才能发挥作用,主要用于分组之后合并某一字段。 二、用法 SELECT GROUP_CONCAT(age) FROM tb_user GROUP BY banner;三、分组去重 SELECT GROUP_CONCAT(DISTINCT age) FROM tb_user GRO…...

递归方式渲染嵌套的菜单项
1. 递归组件 递归方式渲染嵌套的菜单项,这个是非常好的做法。为了避免在每个子菜单上都渲染一个新的 <ul> 标签,可以使用 v-if 来判断是否有子菜单,再决定是否渲染子菜单的部分。 2. 提高性能 对于递归渲染组件,Vue 可能…...

常用Vim操作
vimrc配置 ctags -R * 生成tags文件 set number set ts4 set sw4 set autoindent set cindent set tag~/tmp/log/help/tags 自动补全: ctrln:自动补全 输入: a:从当前文字后插入i:从当前文字前插入s: 删除当前字…...

spark3 sql优化:同一个表关联多次,优化方案
目录 1.合并查询2.使用 JOIN 条件的过滤优化3.使用 Map-side Join 或 Broadcast Join4.使用 Partitioning 和 Bucketing5.利用 DataFrame API 进行优化假设 A 和 B 已经加载为 DataFramePerform left joins with specific conditions6.使用缓存或持久化7.避免笛卡尔积总结 1.合…...

XML 在线格式化 - 加菲工具
XML 在线格式化 打开网站 加菲工具 选择“XML 在线格式化” 输入XML,点击左上角的“格式化”按钮 得到格式化后的结果...

陪玩系统小程序源码/游戏陪玩APP系统用户端有哪些功能?游戏陪玩小程序APP源码开发
多客陪玩系统-游戏陪玩线下预约上门服务等陪玩圈子陪玩社区系统源码 陪玩系统源码,高质量的陪玩系统源码,游戏陪玩APP源码开发,语音陪玩源码搭建: 线上陪玩活动组局与线下家政服务系统的部署需要综合考虑技术选型、开发流程、部署流程、功能实…...

力扣-图论-9【算法学习day.59】
前言 ###我做这类文章一个重要的目的还是给正在学习的大家提供方向和记录学习过程(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非…...
ViT学习笔记(三) RepViT和TransNext简介
标准ViT的其他模块的功能以及源码解读,在CSDN上有很多优秀文章,参考文章将代码大致过一遍。像我这种只做工程不写论文的,个人认为大致明白就好,用不着特别细究。下面跟踪两个ViT比较新的变种继续深入学习一下:RepViT和…...

大华DSS数字监控系统 attachment_downloadAtt.action 任意文件下载漏洞复现
0x01 产品描述: 大华 DSS 数字监控系统是大华开发的一款安防视频监控系统,拥有实时监视、云台操作、录像回放、报警处理、设备管理等功能。0x02 漏洞描述: 大华DSS数字监控系统 attachment_downloadAtt.action接口存在任意文件读取漏洞,未经身份验证攻击者可通过该漏洞读取…...

Dockerfile容器镜像构建技术
文章目录 1、容器回顾1_容器与容器镜像之间的关系2_容器镜像分类3_容器镜像获取的方法 2、其他容器镜像获取方法演示1_在DockerHub直接下载2_把操作系统的文件系统打包为容器镜像3_把正在运行的容器打包为容器镜像 3、Dockerfile介绍4、Dockerfile指令1_FROM2_RUN3_CMD4_EXPOSE…...

LabVIEW实现MQTT通信
目录 1、MQTT通信原理 2、硬件环境部署 3、云端环境部署 4、程序架构 5、前面板设计 6、程序框图设计 7、测试验证 本专栏以LabVIEW为开发平台,讲解物联网通信组网原理与开发方法,覆盖RS232、TCP、MQTT、蓝牙、Wi-Fi、NB-IoT等协议。 结合实际案例,展示如何利用LabVIEW和常用…...

分布式事物XA、BASE、TCC、SAGA、AT
分布式事务——Seata 一、Seata的架构: 1、什么是Seata: 它是一款分布式事务解决方案。官网查看:Seata 2.执行过程 在分布式事务中,会有一个入口方法去调用各个微服务,每一个微服务都有一个分支事务,因…...

[创业之路-182]:《华为战略管理法-DSTE实战体系》-1-华为的发展历程和战略管理演变
目录 前言、华为在战略管理上做对了什么? 1、前瞻性的战略眼光 2、有效的战略解码 3、灵活的战略调整 4、注重创新和研发 5、以客户为中心的战略导向 6、完善的内部管理体系 一、华为不同时期的战略选择 1.1 华为不同时期的战略选择 1、创业初期ÿ…...

python爬虫--小白篇【爬取B站视频】
目录 一、任务分析 二、网页分析 三、任务实现 一、任务分析 将B站视频爬取并保存到本地,经过分析可知可以分为四个步骤,分别是: 爬取视频页的网页源代码;提取视频和音频的播放地址;下载并保存视频和音频&#x…...

web 自动化 selenium
1、下载Chrome对应的driver版本 我的chrome是 131.0.6778.109,我下载的driver是131.0.6778.69(想找一模一样的,但是没有) https://googlechromelabs.github.io/chrome-for-testing/ chromedriver下载 2、配置Chrome deriver及 …...

【OpenCV】Canny边缘检测
理论 Canny 边缘检测是一种流行的边缘检测算法。它是由 John F. Canny 在 1986 年提出。 这是一个多阶段算法,我们将介绍算法的每一个步骤。 降噪 由于边缘检测易受图像中的噪声影响,因此第一步是使用 5x5 高斯滤波器去除图像中的噪声。我们在前面的章…...

D94【python 接口自动化学习】- pytest进阶之fixture用法
day94 pytest的fixture详解 学习日期:20241210 学习目标:pytest基础用法 -- pytest的fixture详解 学习笔记: fixture的介绍 fixture是 pytest 用于将测试前后进行预备、清理工作的代码处理机制。 fixture相对于setup和teardown来说有以…...

关于idea-Java-servlet-Tomcat-Web开发中出现404NOT FOUND问题的解决
在做web项目时,第一次使用servlet开发链接前端和后端的操作,果不其然,遇到了诸多问题,而遇到最多的就是运行项目打开页面时出现404NOT FOUND的情况。因为这个问题我也是鼓捣了好久,上网查了许多资料才最终解决…...

SpringBoot Maven快速上手
文章目录 一、Maven 1.1 Maven 简介:1.2 Maven 的核心功能: 1.2.1 项目构建:1.2.2 依赖管理: 1.3 Maven 仓库: 1.3.1 本地仓库:1.3.2 中央仓库:1.3.3 私服: 二、第一个 SpringBoot…...

全面解析MySQL底层概念
mysql的概念 (1)mysql的架构 客户端请求--->连接器(验证用户身份,给予权限)--->查询缓存(存在则直接返回,不存在则执行后续操作 --->分析器(对SQL进行词法分析和语法分析…...

【C++】string类
一、C 标准库中的string类 1、string类 string类的文档介绍 首先string并不是STL中的,而是一个类string比STL出现的早 从上面可以看出string是从一个类模板中实例化出来的一个对象 在使用string类是必须要包头文件#include< string > 又因为是std中的类…...

《Python制作动态爱心粒子特效》
一、实现思路 粒子效果: – 使用Pygame模拟粒子运动,粒子会以爱心的轨迹分布并运动。爱心公式: 爱心的数学公式: x16sin 3 (t),y13cos(t)−5cos(2t)−2cos(3t)−cos(4t) 参数 t t 的范围决定爱心形状。 动态效果: 粒子…...

ssd202d-badblock-坏块检测
这边文章讲述的是坏快检测功能 思路: 1.第一次烧录固件会实现跳坏块,但是后续使用会导致坏块的产生; 于是我在uboot环境变量添加了两个变量来控制坏快 lb_badnum = //坏块个数 lb_badoff = //坏块所在位置 2.第一次开机会根据lb_badnum是否存在判断,如果不存在则保存上…...

使用html 和javascript 实现微信界面功能1
1.功能说明: 搜索模块: 提供一个搜索框,但目前没有实现具体的搜索功能。 好友模块: 在左侧的“好友”部分有一个“查看好友”按钮。点击左侧的“查看好友”按钮时,会在右侧显示所有好友的列表。列表中每个好友可以点击查看详情,包…...

趣味编程:猜拳小游戏
1.简介 这个系列的第一篇以猜拳小游戏开始,这是源于我们生活的灵感,在忙碌的时代中,我们每个人都在为自己的生活各自忙碌着,奔赴着自己所走向的那条路上,即使遍体鳞伤。 但是,生活虽然很苦,也不…...
(超级详细))
图形化界面MySQL(MySQL)(超级详细)
目录 1.官网地址 1.1在Linux直接点击NO thanks..... 1.2任何远端登录,再把jj数据库给授权 1.3建立新用户 优点和好处 示例代码(MySQL Workbench) 示例代码(phpMyAdmin) 总结 图形化界面 MySQL 工具大全及其功…...

JavaScript技巧方法总结
技巧总结 字符串字符串首字母大写翻转字符串字符串过滤 数字十进制转换二进制、八进制、十六进制获取随机数字符串转数字指数幂运算 数组从数组中过滤出虚假值数组查找检测是否为一个安全数组数组清空实现并集、交集、和差集 对象检查对象是否为空从对象中选择指定数据动态属性…...

【Web】2023安洵杯第六届网络安全挑战赛 WP
目录 Whats my name easy_unserialize signal Swagger docs 赛题链接:GitHub - D0g3-Lab/i-SOON_CTF_2023: 2023 第六届安洵杯 题目环境/源码 Whats my name 第一段正则用于匹配以 include 结尾的字符串,并且在 include 之前,可以有任…...

【VUE2】纯前端播放海康视频录像回放,视频格式为rtsp格式,插件使用海康视频插件[1.5.4版本]
一、需求 1、后端从海康平台拉流视频回放数据,前端进行页面渲染播放,视频格式为rtsp eg: 基本格式:rtsp://<username>:<password><ip_addr>:<port>/<path>参数说明: usernameÿ…...
,命令介绍(查看,部分命令),从sql文件执行sql语句的两种方法)
mysql程序介绍,选项介绍(常用选项,指定选项的方式,特性),命令介绍(查看,部分命令),从sql文件执行sql语句的两种方法
目录 mysql程序 介绍 选项 介绍 常用选项 指定选项的方式 编辑配置文件 环境变量 选项特性 指定选项 选项名 选项值 命令 介绍 查看客户端命令 tee/notee prompt source system help contents 从.sql文件执行sql语句 介绍 方式 source 从外部直接导入…...

3D 生成重建032-Find3D去找到它身上的每一份碎片吧
3D 生成重建032-Find3D去找到它身上的每一份碎片吧 文章目录 0 论文工作1 论文方法2 实验结果 0 论文工作 该论文研究三维开放世界部件分割问题:基于任何文本查询分割任何物体中的任何部件。以往的方法在物体类别或部件词汇方面存在局限性。最近人工智能的进步在二…...

树莓派4B android 系统添加led灯 Hal 层
本文内容需要用到我上一篇文章做的驱动,可以先看文章https://blog.csdn.net/ange_li/article/details/136759249 一、Hal 层的实现 1.Hal 层的实现一般放在 vendor 目录下,我们在 vendor 目录下创建如下的目录 aosp/vendor/arpi/hardware/interfaces/…...

LLama系列模型简要概述
LLama-1(7B, 13B, 33B, 65B参数量;1.4T tokens训练数据量) 要做真正Open的AI Efficient:同等预算下,增大训练数据,比增大模型参数量,效果要更好 训练数据: 书、Wiki这种量少、质量高…...