知识蒸馏实战:用PyTorch和预训练模型提升小模型性能
在深度学习的浪潮中,我们常常追求更大、更深、更复杂的模型以达到最先进的性能。然而,这些“庞然大物”般的模型往往伴随着高昂的计算成本和缓慢的推理速度,使得它们难以部署在资源受限的环境中,如移动设备或边缘计算平台。知识蒸馏(Knowledge Distillation)技术为此提供了一个优雅的解决方案:将一个大型、高性能的“教师模型”所学习到的“知识”迁移到一个小巧、高效的“学生模型”中。
本篇将一步步使用 PyTorch 实现一个知识蒸馏的案例,其中教师模型将采用预训练模型。
什么是知识蒸馏?
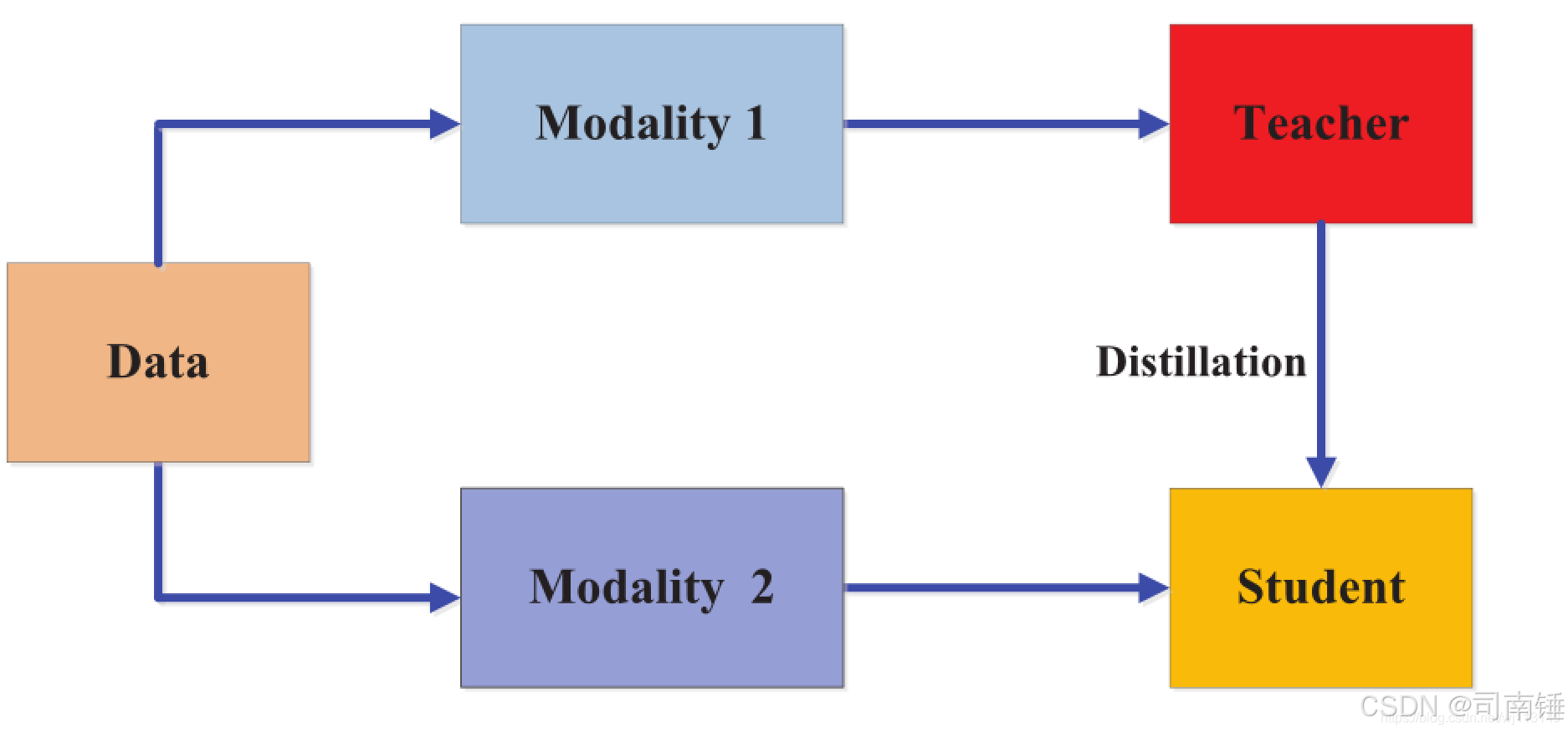
知识蒸馏的核心思想是,训练一个小型学生模型 (Student Model) 来模仿一个大型教师模型 (Teacher Model) 的行为。这种模仿不仅仅是学习教师模型对“硬标签”(即真实标签)的预测,更重要的是学习教师模型输出的“软标签”(Soft Targets)。
- 教师模型 (Teacher Model): 通常是一个已经训练好的、性能优越的大型模型。例如,在计算机视觉领域,可以是 ImageNet 上预训练的 ResNet、VGG 等。
- 学生模型 (Student Model): 一个参数量较小、计算更高效的轻量级模型,我们希望它能达到接近教师模型的性能。
- 软标签 (Soft Targets): 教师模型在输出层(softmax之前,即logits)经过一个较高的“温度”(Temperature, T)调整后的概率分布。高温会使概率分布更平滑,从而揭示类别间的相似性信息,这些被称为“暗知识”(Dark Knowledge)。
- 硬标签 (Hard Targets): 数据集的真实标签。
- 蒸馏损失 (Distillation Loss): 通常由两部分组成:
- 学生模型在真实标签上的损失(例如交叉熵损失)。
- 学生模型与教师模型软标签之间的损失(例如KL散度或均方误差)。
这两部分损失通过一个超参数 a l p h a \\alpha alpha 来加权平衡。
PyTorch 实现步骤
接下来,我们将通过一个图像分类的例子来演示如何实现知识蒸馏。假设我们的任务是对一个包含10个类别的图像数据集进行分类。
1. 准备工作:导入库和设置设备
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.models as models
import torchvision.transforms as transforms # 用于数据预处理# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
2. 定义教师模型 (Pre-trained ResNet18)
我们将使用 torchvision.models 中预训练的 ResNet18 作为教师模型。为了适应我们自定义的分类任务(例如10分类),我们需要替换其原始的1000类全连接层。
class PretrainedTeacherModel(nn.Module):def __init__(self, num_classes, pretrained=True):super(PretrainedTeacherModel, self).__init__()# 加载预训练的 ResNet18 模型# PyTorch 1.9+ 推荐使用 weights 参数if pretrained:self.resnet = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)else:self.resnet = models.resnet18(weights=None) # 或者 models.resnet18(pretrained=False) for older versions# 获取 ResNet18 原本的输出特征数num_ftrs = self.resnet.fc.in_features# 替换最后的全连接层以适应我们的任务类别数self.resnet.fc = nn.Linear(num_ftrs, num_classes)def forward(self, x):return self.resnet(x)
在蒸馏过程中,教师模型的参数通常是固定的,不参与训练。
3. 定义学生模型
学生模型应该是一个比教师模型更小、更轻量的网络。这里我们定义一个简单的卷积神经网络 (CNN)。
class StudentCNNModel(nn.Module):def __init__(self, num_classes):super(StudentCNNModel, self).__init__()# 输入通道数为3 (RGB图像), 假设输入图像大小为 32x32self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 32x32 -> 16x16self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 16x16 -> 8x8# 展平后的特征数: 32 channels * 8 * 8self.fc = nn.Linear(32 * 8 * 8, num_classes)def forward(self, x):out = self.pool1(self.relu1(self.conv1(x)))out = self.pool2(self.relu2(self.conv2(x)))out = out.view(out.size(0), -1) # 展平out = self.fc(out)return out
4. 定义蒸馏损失函数
这是知识蒸馏的核心。损失函数结合了学生模型在硬标签上的性能和与教师模型软标签的匹配程度。
- L _ h a r d L\_{hard} L_hard: 学生模型输出与真实标签之间的交叉熵损失。
- L _ s o f t L\_{soft} L_soft: 学生模型的软化输出与教师模型的软化输出之间的KL散度。
- 总损失 L = a l p h a c d o t L _ h a r d + ( 1 − a l p h a ) c d o t L _ s o f t c d o t T 2 L = \\alpha \\cdot L\_{hard} + (1 - \\alpha) \\cdot L\_{soft} \\cdot T^2 L=alphacdotL_hard+(1−alpha)cdotL_softcdotT2
- T T T 是温度参数。较高的 T T T 会使概率分布更平滑。
- a l p h a \\alpha alpha 是平衡两个损失项的权重。
- L _ s o f t L\_{soft} L_soft 乘以 T 2 T^2 T2 是为了确保软标签损失的梯度与硬标签损失的梯度在量级上大致相当。
class DistillationLoss(nn.Module):def __init__(self, alpha, temperature):super(DistillationLoss, self).__init__()self.alpha = alphaself.temperature = temperatureself.criterion_hard = nn.CrossEntropyLoss() # 硬标签损失# reduction='batchmean' 会将KL散度在batch维度上取平均,这在很多实现中是常见的self.criterion_soft = nn.KLDivLoss(reduction='batchmean') # 软标签损失def forward(self, student_logits, teacher_logits, labels):# 硬标签损失loss_hard = self.criterion_hard(student_logits, labels)# 软标签损失# 使用 softmax 和 temperature 来计算软标签和软预测# 注意:KLDivLoss期望的输入是 (log_probs, probs)soft_teacher_probs = F.softmax(teacher_logits / self.temperature, dim=1)soft_student_log_probs = F.log_softmax(student_logits / self.temperature, dim=1)# 计算KL散度损失loss_soft = self.criterion_soft(soft_student_log_probs, soft_teacher_probs) * (self.temperature ** 2)# 总损失loss = self.alpha * loss_hard + (1 - self.alpha) * loss_softreturn loss
5. 训练流程
现在我们将所有部分组合起来进行训练。
# --- 示例参数 ---
num_classes = 10 # 假设我们的任务是10分类
img_channels = 3
img_height = 32
img_width = 32learning_rate = 0.001
num_epochs = 20 # 实际应用中需要更多 epochs 和真实数据
batch_size = 32
temperature = 4.0 # 蒸馏温度
alpha = 0.3 # 硬标签损失的权重# --- 实例化模型 ---
teacher_model = PretrainedTeacherModel(num_classes=num_classes, pretrained=True).to(device)
teacher_model.eval() # 教师模型设为评估模式,不更新其权重student_model = StudentCNNModel(num_classes=num_classes).to(device)# --- 准备优化器和损失函数 ---
optimizer = optim.Adam(student_model.parameters(), lr=learning_rate) # 只优化学生模型的参数
distillation_criterion = DistillationLoss(alpha=alpha, temperature=temperature).to(device)# --- 生成一些虚拟图像数据进行演示 ---
# !!! 警告: 实际应用中必须使用真实数据加载器 (DataLoader) 和正确的预处理 !!!
# 预训练模型通常对输入有特定的归一化要求。
# 例如,ImageNet预训练模型通常使用:
# normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 并且输入尺寸也需要匹配,或进行适当调整。
# 本例中学生模型接收 32x32 输入,教师模型(ResNet)通常处理更大图像如 224x224。
# 为简化,我们假设教师模型能处理学生模型的输入尺寸,或者在教师模型前对输入进行适配。
dummy_inputs = torch.randn(batch_size, img_channels, img_height, img_width).to(device)
dummy_labels = torch.randint(0, num_classes, (batch_size,)).to(device)print("开始训练学生模型...")
# --- 训练学生模型 ---
for epoch in range(num_epochs):student_model.train() # 学生模型设为训练模式# 获取教师模型的输出 (logits)with torch.no_grad(): # 教师模型的权重不更新# 如果教师模型和学生模型期望的输入尺寸不同,需要适配# teacher_input_adjusted = F.interpolate(dummy_inputs, size=(224, 224), mode='bilinear', align_corners=False) # 示例调整# teacher_logits = teacher_model(teacher_input_adjusted)teacher_logits = teacher_model(dummy_inputs) # 假设教师模型可以处理此尺寸或已适配# 前向传播 - 学生模型student_logits = student_model(dummy_inputs)# 计算蒸馏损失loss = distillation_criterion(student_logits, teacher_logits, dummy_labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 5 == 0 or epoch == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')print("学生模型训练完成!")# (可选) 保存学生模型
# torch.save(student_model.state_dict(), 'student_cnn_distilled.pth')
# print("蒸馏后的学生CNN模型已保存。")
关键点与最佳实践
- 数据预处理: 对于预训练的教师模型,其输入数据必须经过与预训练时相同的预处理(如归一化、尺寸调整)。这是确保教师模型发挥其最佳性能并传递有效知识的关键。
- 输入兼容性: 确保教师模型和学生模型接收的输入在语义上是一致的。如果它们的网络结构原生接受不同尺寸的输入,你可能需要调整输入数据(例如,通过插值
F.interpolate)以适应教师模型,或者确保两个模型都能处理相同的输入。 - 超参数调优:
alpha,temperature,learning_rate等超参数对蒸馏效果至关重要。通常需要通过实验来找到最佳组合。较高的temperature可以让学生学习到更多类别间的细微差别,但过高可能会导致信息模糊。 - 教师模型的选择: 教师模型越强大,通常能传递的知识越多。但也要考虑其推理成本(即使只在训练时)。
- 学生模型的设计: 学生模型不应过于简单,以至于无法吸收教师的知识;也不应过于复杂,从而失去蒸馏的意义。
- 训练时长: 知识蒸馏通常需要足够的训练轮次才能让学生模型充分学习。
- 不仅仅是 Logits: 本文介绍的是最常见的基于 Logits 的蒸馏。还有其他蒸馏方法,例如匹配教师模型和学生模型中间层的特征表示(Feature Distillation),这有时能带来更好的效果。
相关文章:

知识蒸馏实战:用PyTorch和预训练模型提升小模型性能
在深度学习的浪潮中,我们常常追求更大、更深、更复杂的模型以达到最先进的性能。然而,这些“庞然大物”般的模型往往伴随着高昂的计算成本和缓慢的推理速度,使得它们难以部署在资源受限的环境中,如移动设备或边缘计算平台。知识蒸…...

【HTML 全栈进阶】从语义化到现代 Web 开发实战
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...
Transformer 模型与注意力机制
目录 Transformer 模型与注意力机制 一、Transformer 模型的诞生背景 二、Transformer 模型的核心架构 (一)编码器(Encoder) (二)解码器(Decoder) 三、注意力机制的深入剖析 …...

机器学习数据预处理回归预测中标准化和归一化
在机器学习的回归预测任务中,** 标准化(Standardization)和归一化(Normalization)** 是数据预处理的重要步骤,用于消除不同特征量纲和取值范围的影响,提升模型训练效率和预测性能。 一、标准化…...

B2C 商城转型指南:传统企业如何用 ZKmall模板商城实现电商化
在数字化浪潮席卷全球的当下,传统企业向电商转型已不再是选择题,而是关乎生存与发展的必答题。然而,缺乏技术积累、开发成本高、运营经验不足等问题,成为传统企业转型路上的 “拦路虎”。ZKmall模板商城以其低门槛、高灵活、强适配…...

FPGA:Lattice的FPGA产品线以及器件选型建议
本文将详细介绍Lattice Semiconductor的FPGA产品线,帮助你了解各系列的特点和适用场景,以便更好地进行选型。Lattice以低功耗、小尺寸和高性能为核心,产品覆盖低中端市场,广泛应用于通信、计算、工业、汽车、消费电子、嵌入式视觉…...

学习51单片机02
吐血了,板子今天才到,下午才刚开始学的,生气了,害我笔记都断更了一天。。。。 紧接上文...... 如何将HEX程序烧写到程序? Tips:HEX 文件是一种常用于单片机等嵌入式系统的文件格式,它包含了程序的机器码…...

武汉SMT贴片工艺优化与生产效能提升路径
内容概要 随着华中地区电子制造产业集群的快速发展,武汉SMT贴片行业面临工艺升级与效能提升的双重挑战。本文聚焦SMT生产全流程中的关键环节,从钢网印刷精度控制、回流焊温度曲线优化、AOI检测系统迭代三大核心工艺出发,结合区域产业链特点提…...

LineBasicMaterial
LineBasicMaterial 描述 用于绘制纯色线条的基础材质,支持颜色、线宽和纹理映射。常用于THREE.Line或THREE.LineSegments几何体。 构造函数 (Constructor) 构造函数参数描述LineBasicMaterial(parameters?: Object)parameters定义材质外观的对象,可…...

虚拟机安装达梦数据库
准备 关闭SELINUX # setenforce 0 # vi /etc/selinux/config 修改SELINUXdisabled 上传达梦ISO 接下下载的达梦安装包,里面包含一个ISO文件,将其上传到CentOS的/tmp路径下安装达梦所需图形类库 # yum install -y gtk2 libXtst xorg-x11-…...

小波变换+注意力机制成为nature收割机
小波变换作为一种新兴的信号分析工具,能够高效地提取信号的局部特征,为复杂数据的处理提供了有力支持。然而,它在捕捉数据中最为关键的部分时仍存在局限性。为了弥补这一不足,我们引入了注意力机制,借助其能够强化关注…...

科技项目验收测试对软件产品和企业分别有哪些好处?
科技项目验收测试是指在项目的开发周期结束后,针对项目成果进行的一系列验证和确认活动。其目的是确保终交付的产品或系统符合预先设定的需求和标准。验收测试通常包括功能测试、性能测试、安全测试等多个方面,帮助企业评估软件在实际应用中的表现。 科…...

ChatGPT到Claude全适配:跨模型Prompt高级设计规范与迁移技巧
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。 一. 迭代优化:基于反馈的Prompt进化策略 1.1 优化闭环设计 初始Prompt → 生成结果 → 人工评估 → 问题分析 → 改进Prompt 代码示例&#x…...

NexBot AI 1.9.3 | 专业AI写作助手,高自由度定制内容,支持中文设置
NexBot AI是一款强大的人工智能助手应用程序,旨在帮助用户快速生成符合其需求的内容。通过高自由度的关键词和短语合并功能,用户可以根据自己的具体要求定制内容。该应用能够迅速生成多种输出结果供用户选择,非常适合需要高效工作流程的专业人…...

foxmail - foxmail 启用超大附件提示密码与帐号不匹配
foxmail 启用超大附件提示密码与帐号不匹配 问题描述 在 foxmail 客户端中,启用超大附件功能,输入了正确的账号(邮箱)与密码,但是提示密码与帐号不匹配 处理策略 找到 foxmail 客户端目录/Global 目录下的 domain.i…...

eVTOL、无人机电机功耗图和电机效率图绘制测试
测功机是测量电机性能的绝佳工具。通过施加可控负载,测功机可表征电机扭矩、转速和功率。但这是获取电机性能全面理解的唯一途径吗?我们想知道,能否仅通过电机-螺旋桨动力测试台(而非传统制动测功机)实现电机性能测绘。…...

React中useMemo和useCallback的作用:
一、useMemo 基本用法: useMemo 是 React 提供的一个 Hook,用于性能优化,它通过"记忆"(memoization)计算结果来避免在每次渲染时进行不必要的复杂计算。 const memoizedValue useMemo(() > computeExpensiveValue…...

【Shell的基本操作】
文章目录 一、实验目的二、实验环境三、实验内容3.1 Shell变量与脚本基础3.2 定制终端提示符(PS1变量)3.3 文件查找与类型确认(find命令)3.4 管道命令实战(用户登录统计)3.5 交互式备份压缩脚本 四、总结4.…...

部署docker上的redis,idea一直显示Failed to connect to any host resolved for DNS name
参考了https://blog.csdn.net/m0_74216612/article/details/144145127 这篇文章,关闭了centos的防火墙,也修改了redis.conf文件,还是一直显示Failed to connect to any host resolved for DNS name。最终发现是腾讯云服务器那一层防火墙没…...
)
Android 中 显示 PDF 文件内容(AndroidPdfViewer 库)
PDFView 是一个用于在 Android 应用中显示 PDF 文档的库。它提供了丰富的功能和灵活的配置选项,使得开发者能够轻松地在应用中嵌入 PDF 阅读器。 一、 添加依赖 在模块的 build.gradle 文件中添加以下依赖: // pdfimplementation("com.github.bar…...

Linux 系统切换国内镜像源教程
在中国大陆使用 Linux 系统时,由于网络环境的原因,连接官方的软件包镜像源速度较慢,甚至可能出现连接失败的情况。此时,将系统配置为使用国内的镜像源可以显著提升软件包下载和更新的速度。 常见的国内镜像源 阿里云镜像站: htt…...

4.2.3 Thymeleaf标准表达式 - 2. 选择表达式
本实战通过 Thymeleaf 的选择表达式(*{})演示了如何在模板中操作和展示对象的属性与方法。首先,在控制器中创建了一个 User 对象,并将其添加到模型中。接着,在 test2.html 模板中,通过 th:object 声明了对象…...

C#学习第23天:面向对象设计模式
什么是设计模式? 定义:设计模式是软件开发中反复出现的特定问题的解决方案。它们提供了问题的抽象描述和解决方案。目的:通过提供成熟的解决方案,设计模式可以加快开发速度并提高代码质量。 常见的设计模式 设计模式通常分为三大…...

【数据结构】二分查找-LeftRightmost
查找: Leftmost(最左侧重复元素) package 二分查找;public class BinarySearch {public static void main(String[] args) {// TODO Auto-generated method stub}public static int binarySearchBasic(int[] a,int target) {int i0,ja.length-1; //设置指针初值in…...

汽车装配又又又升级,ethernetip转profinet进阶跃迁指南
1. 场景描述:汽车装配线中,使用EtherNet/IP协议的机器人与使用PROFINET协议的PLC进行数据交互。 2. 连接设备:EtherNet/IP机器人控制器(如ABB、FANUC)与PROFINET PLC(如西门子S7-1500)。 3. 连…...
)
链表的中间结点数据结构oj题(力扣876)
目录 题目描述: 题目分析: 代码解决: 题目描述: 给你单链表的头结点 head ,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。 题目分析: 寻找中间节点这道题原理…...
概率论)
LLM学习笔记(五)概率论
1. 随机变量与概率分布:模型输出的基础 在LLM中,随机变量最直观的体现就是模型预测的下一个token。每个时刻,模型都会输出一个概率分布,表示词汇表中每个token可能是"下一个词"的概率。 直观理解 想象模型在处理句子…...

归并排序:分治思想的优雅实现
归并排序(Merge Sort)以简洁而高效的分治思想,在众多排序算法中占据着重要的地位。今天,就让我们一同深入探索归并排序的奥秘。 一、归并排序简介 归并排序是一种基于分治策略的排序算法。它的核心思想是将一个大的问题分解成若…...

从小区到商场再到校园,AI智能分析网关V4高空抛物检测方案全场景护航
在城市化进程不断加速的背景下,高层建筑如雨后春笋般涌现,然而,高空抛物这一“悬在城市上空的痛”却严重威胁着人民群众的生命财产安全。传统的监控方式难以对高空抛物行为进行及时、准确地识别与预警,而AI智能分析网关V4搭载高空…...

WEB安全--Java安全--shiro550反序列化漏洞
一、前言 什么是shiro? shiro是一个Apache的Java安全框架 它的作用是什么? Apache Shiro 是一个强大且灵活的 Java 安全框架,用于处理身份验证、授权、密码管理以及会话管理等功能 二、shiro550反序列化原理 1、用户首次登录并勾选记住密码…...
)
现代计算机图形学Games101入门笔记(十一)
致敬两位大佬 面的细分、简化、正则化 Loop 不是循环,是这个算法的发明人家族名称是Loop. 新增点,白点是不更新前通过细分得到的点。通过加权平均4个点坐标,更新坐标就是最后细分点的坐标。 如果细分出新的点刚好在老点上。那一部分相信周围点…...

OAT 初始化时出错?问题可能出在 PAM 配置上|OceanBase 故障排查实践
本文作者:爱可生数据库工程师,任仲禹,擅长故障分析和性能优化。 背景 某客户在使用 OAT 初始化OceanBase 服务器的过程中,进行到 precheck 步骤时,遇到了如下报错信息: ERROR - check current session ha…...

现场血案:Kafka CRC 异常
一、背景 现场童鞋说客户的研发环境突然在近期间歇式的收到了CRC的相关异常,异常内容如下 Record batch for partition skywalking-traces-0 at offset 292107075 is invalid, cause: Record is corrupt (stored crc = 1016021496, compute crc = 1981017560) 报错完全没有…...

实时技术方案对比:SSE vs WebSocket vs Long Polling
早期网站仅展示静态内容,而如今我们更期望:实时更新、即时聊天、通知推送和动态仪表盘。 那么要如何实现实时的用户体验呢?三大经典技术各显神通: SSE(Server-Sent Events):轻量级单向数据流WebSocket:双向全双工通信Long Polling(长轮询):传统过渡方案假设目前有三…...

搭建游戏云服务器的配置要求包括哪些条件?
在游戏行业迅猛发展的背景下,越来越多的游戏团队、独立开发者、企业平台开始将服务器部署转向云端,尤其是在初期测试、公测阶段及全球发布期,云服务器所带来的弹性部署、全球覆盖、成本控制能力成为不可替代的优势。但问题随之而来࿱…...

Go语言八股文之Mysql锁详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 非常期待和您一起在这个小…...

1T 服务器租用价格解析
服务器作为数据存储与处理的核心设备,对于企业和个人开发者而言至关重要。当涉及到租用 1T 服务器时,价格是大家很为关注的要点。然而,1T 服务器租用一个月的费用并非固定不变,而是受到诸多因素的综合影响。 影响 1T 服务器租用…...

面试题:详细分析Arraylist 与 LinkedList 的异同
相同点 都是List接口的实现类: ArrayList和LinkedList都实现了Java集合框架中的List接口,因此它们都提供了对列表元素的操作方法。 都继承了Collection接口: 由于List接口继承了Collection接口,所以ArrayList和LinkedList也都继承…...

6 任务路由与负载均衡
一、任务路由核心机制 1.1 静态路由配置 # celeryconfig.pytask_routes {# 精确匹配任务路径payment.process_order: {queue: priority_payment},# 通配符匹配任务类型report.*: {queue: low_priority_reports},# 正则表达式匹配re.compile(r^video\.(encode|compress)): {q…...

前端精度问题全解析:用“挖掘机”快速“填平精度坑”的完美解决方案
写在前面 “为什么我的计算在 React Native 中总是出现奇怪的精度问题?” —— 这可能是许多开发者在作前端程序猿的朋友们都会遇到的第一个头疼问题。本文将深入探讨前端精度问题的根源,我将以RN为例,并提供一系列实用解决方案,让你的应用告别计算误差。 一、精度问题的…...

探索嵌入式硬件的世界:技术、应用与未来趋势
目录 一、什么是嵌入式硬件? 二、嵌入式硬件的核心组件与架构 1. 微处理器与控制器 2. 存储器设备 3. 输入/输出接口 4. 电源管理模块 5. 时钟芯片与时序控制 三、嵌入式硬件的设计原则与技术难点 1. 低功耗与能耗优化 2. 小型化与高度集成 3. 高可靠性和…...

中级网络工程师知识点3
1.在网络线路施工中应遵循规范: ①缆线的布防应自然平直,不得产生扭绞、打圈接头等现象 ②线缆两端应贴有标签,标签自己清晰、正确,标签应选用不易损坏的材料 ③水平子系统中配线间到工作区信息插座电缆不超过90米 ④工作区子系统中信息插座到网卡不超过10米 ⑤信息插…...

Spring2:应用事务+连接池形成的工具类
工具类 package com.qcby.utils;import com.alibaba.druid.pool.DruidDataSource;import javax.sql.DataSource; import java.sql.Connection; import java.sql.SQLException;/*** 事务的工具类*/ //事务是通过连接开启的,所以要保证是同一个连接 public class TxU…...

CentOS高手之路:从进阶实战到企业级优化
一、系统深度优化与性能调优 1. 内核参数调优 通过修改/etc/sysctl.conf文件调整内核参数,可显著提升服务器性能。例如: net.ipv4.tcp_fin_timeout30(快速释放TCP连接) vm.swappiness10(减少交换分区使用࿰…...

【Android构建系统】如何在Camera Hal的Android.bp中选择性引用某个模块
背景描述 本篇文章是一个Android.bp中选择性引用某个模块的实例。 如果是Android.mk编译时期,在编译阶段通过某个条件判断是不是引用某个模块A, 是比较好实现的。Android15使用Android.bp构建后,要想在Android.bp中通过自定义的一个变量或者条件实现选…...

命令拼接符
Linux多命令顺序执行符号需要记住5个 【|】【||】【 ;】 【&】 【&&】 ,在命令执行里面,如果服务器疏忽大意没做限制,黑客通过高命令拼接符,可以输入很多非法的操作。 ailx10 网络安全优秀回答者 互联网…...
--- Day 5)
学习笔记(C++篇)--- Day 5
1.取地址运算符重载 1.1 const成员函数 ①将 const 修饰的成员函数称为const成员函数,const 修饰成员函数放到成员函数参数列表的后面。 ②const 实际修饰该成员函数隐含的this指针,表明在该成员函数中不能对类的任何成员进行修改。const 修饰 Date 类的…...

排序算法之基础排序:冒泡,选择,插入排序详解
排序算法之基础排序:冒泡、选择、插入排序详解 前言一、冒泡排序(Bubble Sort)1.1 算法原理1.2 代码实现(Python)1.3 性能分析 二、选择排序(Selection Sort)2.1 算法原理2.2 代码实现ÿ…...

mysql集群
mysql双主keepalivedhaproxy 一、集群作用 实现高可用及负载均衡。 二、示例 1.实验环境 101 mysql01102 mysql01103 haproxy01keepalived01104 haproxy02keepalived02105 client2.各主机改名并关闭防火墙 101 mysql01102 mysql02103 haproxy01104 haproxy02105 clientsyst…...

【嵌入式开发-RGB 全彩 LED】
嵌入式开发-RGB 全彩 LED ■ RGB 全彩 LED简介■ 电路设计■ ■ RGB 全彩 LED简介 RGB 全彩 LED 模块显示不同的颜色。 ■ 电路设计 全彩 LED 使用 PA5、 蓝色(B) TIM2_CHN3 PA1、 绿色(G)TIM2_CHN2 PA2、 红色(R&am…...