数据治理域——数据同步设计
摘要
本文主要介绍了数据同步的多种方式,包括直连同步、数据文件同步和数据库日志解析同步。每种方式都有其适用场景、技术特点、优缺点以及适用的数据类型和实时性要求。文章还详细探讨了数据直连同步的特点、工作原理、优点、缺点、适用场景等,并对数据文件同步和数据库日志解析同步进行了类似的分析。此外,还涉及了阿里数据仓库同步解决方案以及数据同步过程中面临的挑战与解决方案。

1. 数据同步实现方案
业务系统数据类型多元源,涵盖关系型数据库结构化数据、非关系型数据库非结构化数据及文件系统的结构化或非结构化数据。对应数据同步方式有直连同步、数据文件同步和数据库日志解析同步三种,需依不同数据类型和业务场景选择。
| 同步方式 | 适用场景 | 技术特点 | 优缺点 | 数据类型 | 实时性 | 适用数据库/存储类型 |
| 直连同步 | 关系型数据库准实时同步;非关系型数据库批量查询;低频迁移 | JDBC/ODBC直连,通过SQL查询全量/增量数据;依赖数据库驱动 | 优点:简单易用,支持异构迁移; | 结构化(关系型、非关系型) | 分钟级延迟 | MySQL、Oracle、MongoDB、OceanBase 等 |
| 数据文件同步 | 文件系统数据迁移;非结构化数据处理(日志、图片);跨云/跨地域归档 | 周期性导出文件(CSV/Parquet/JSON),通过OSS/FTP传输;依赖文件协议 | 优点:对源系统无侵入,支持海量文件; | 结构化/非结构化(文件形式) | 小时级或天级 | OSS、NAS、HDFS、本地文件系统 |
| 数据库日志解析同步 | 高实时性需求(如金融交易);全量+增量一体化同步;实时数仓ETL | 解析数据库日志(Binlog/Redo Log),捕获DML/DDL变更;支持秒级延迟 | 优点:零侵入,支持双向同步; | 结构化(日志解析) | 秒级~分钟级 | MySQL、Oracle(需开放日志);不支持HBase等 |
1.1. 数据直连同步
数据直连同步是指通过标准化的数据库接口(如ODBC/JDBC)直接连接业务数据库,执行SQL查询或调用API实现数据读取和传输的方式。其核心特点是直接依赖数据库驱动和协议,无需中间件或文件中转,适用于操作型业务系统的实时或准实时数据同步。

数据直连同步是指通过标准化的数据库接口(如ODBC/JDBC)直接连接业务数据库,执行SQL查询或调用API实现数据读取和传输的方式。其核心特点是直接依赖数据库驱动和协议,无需中间件或文件中转,适用于操作型业务系统的实时或准实时数据同步。
1.1.1. 数据直连同步特点
| 维度 | 描述 |
| 连接方式 | 通过ODBC/JDBC等标准接口,使用数据库驱动直接连接源数据库。 |
| 数据读取 | 基于SQL查询(全量/增量)或存储过程获取数据,支持事务控制。 |
| 实时性 | 准实时或分钟级延迟(依赖同步频率)。 |
| 侵入性 | 对源系统无代码改造,但需开放数据库连接权限。 |
1.1.2. 数据直连工作原理
- 接口调用:通过标准化接口(如JDBC的
DriverManager.getConnection())建立数据库连接。 - SQL执行:发送查询语句(如
SELECT * FROM table WHERE update_time > last_timestamp)拉取增量数据。 - 数据传输:将查询结果集转换为中间格式(如JSON/CSV),推送至目标系统(如数据仓库、消息队列)。
- 断点续传:记录同步位点(如最后更新时间戳或日志偏移量),支持异常中断后恢复。
1.1.3. 数据直连优点
- 配置简单:仅需数据库连接信息和SQL语句,无需复杂开发。
- 实时性较高:支持增量同步,适合准实时场景(如小时级报表)。
- 兼容性强:适配所有支持标准接口的关系型和非关系型数据库(如MySQL、MongoDB)。
1.1.4. 数据直连缺点
| 问题 | 原因 |
| 性能开销大 | 全表扫描或频繁查询会占用源库CPU/IO资源,可能拖垮业务系统。 |
| 锁竞争风险 | 大批量数据读取可能导致表锁或行锁,阻塞业务写操作。 |
| 扩展性差 | 数据量激增时,单线程同步效率低,需依赖分片或并行优化。 |
| 一致性挑战 | 增量同步依赖时间戳/自增ID,可能遗漏中间状态变更(如事务回滚)。 |
1.1.5. 数据直连适用场景
- 操作型业务系统同步:示例:将电商订单系统的最新订单同步到BI工具生成实时看板。
- 中小规模数据迁移:示例:每日凌晨从MySQL同步用户表到Hive数仓。
- 异构数据库间查询:示例:通过ODBC将Oracle数据直接映射到PostgreSQL供分析使用。
1.1.6. 数据直连不适用场景
- 海量数据同步(如TB级历史数据迁移):原因:全表扫描效率低,易导致源库性能瓶颈。
- 高并发实时同步(如金融交易流水):原因:单线程查询无法支撑毫秒级延迟,且事务一致性难保障。
- 数据仓库ETL:原因:频繁查询可能干扰业务库,推荐使用日志解析(如Binlog)或文件同步。
1.1.7. 数据直连优化方案
- 读备库:从主从架构的备库拉取数据,避免影响主库性能。
- 分片查询:按时间范围或主键分片并行拉取(如
WHERE id BETWEEN 1-1000)。 - 增量优化:结合时间戳+自增ID双重条件,减少全量扫描频率。
- 限流机制:通过数据库连接池限制并发数(如HikariCP配置最大连接数)。
数据直连同步是轻量级、低门槛的同步方式,适合中小规模、低频次的数据拉取,但对源库性能敏感,需谨慎设计同步策略(如分片、读备库)。在数据量大或实时性要求极高的场景下,应优先考虑日志解析或文件同步。
1.2. 数据文件同步
数据文件同步是指通过生成约定格式的文本文件(如CSV、Parquet、JSON等),利用文件服务器(如FTP、OSS)传输到目标系统,再加载到目标数据库的异步数据传输方式。其核心是通过文件作为中间载体,实现跨系统、跨平台的数据迁移或同步。
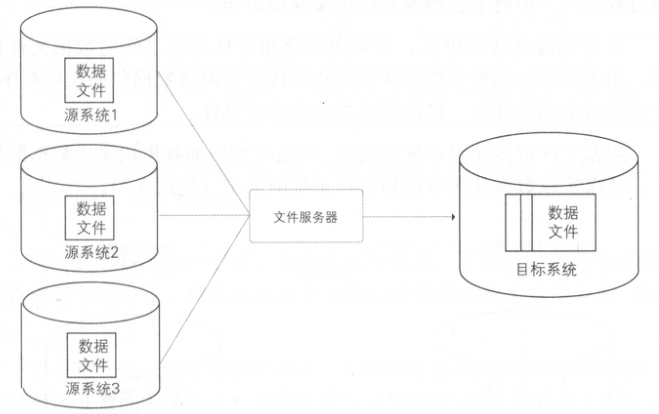
1.2.1. 文件同步核心定义
本质:以文件为媒介,将源系统数据导出为结构化文件,传输后加载到目标系统。
适用场景:多异构数据库迁移、互联网日志处理、跨云/跨地域数据归档等。
典型流程:数据生成(源系统)→ 文件压缩/加密 → 传输(FTP/OSS)→ 校验 → 加载(目标系统)
1.2.2. 文件同步工作原理
- 数据生成:源系统按约定格式(如CSV)导出数据文件,附加校验文件(记录数据量、大小、MD5值)。示例:MySQL导出订单表为
orders_2023.csv,生成校验文件orders_2023.md5。 - 文件传输:通过FTP、OSS、S3等协议上传文件至文件服务器,支持断点续传和并行传输。压缩(如ZIP/GZIP)和加密(如AES)提升传输效率与安全性。
- 数据加载:目标系统下载文件后,校验完整性(如MD5比对),再解析并导入数据库(如Hive、BigQuery)。
1.2.3. 文件同步技术特点
| 维度 | 描述 |
| 数据格式 | 支持结构化(CSV/JSON)和非结构化数据(日志、图片)。 |
| 传输协议 | FTP、SFTP、OSS、HDFS等,适配跨云或跨地域场景。 |
| 完整性保障 | 校验文件(MD5/Checksum)防止传输丢包或损坏。 |
| 安全性 | 支持压缩(减少体积)和加密(防泄露)。 |
| 实时性 | 小时级或按天同步,延迟较高。 |
1.2.4. 文件同步优点
- 对源系统无侵入:无需改造业务代码,仅需配置导出任务。
- 跨系统兼容性:适配异构数据库(如MySQL→Hive)、非结构化数据(日志文件)。
- 海量数据支持:适合TB/PB级数据迁移,可通过分片并行传输加速。
- 容灾友好:断点续传和校验机制降低传输失败风险。
1.2.5. 文件同步缺点
| 问题 | 原因 |
| 实时性差 | 依赖文件生成和传输,难以满足分钟级或秒级延迟需求。 |
| 一致性风险 | 文件生成与传输期间若源数据变更,可能导致数据不一致。 |
| 资源消耗大 | 大文件压缩/加密耗时,且目标系统需额外处理加载和解析。 |
| 管理复杂度高 | 需维护文件命名规则、存储路径、校验逻辑等。 |
1.2.6. 文件同步适用场景
- 多数据库异构迁移,示例:将Oracle用户数据导出为CSV,同步到Hive数仓。
- 日志归档处理,示例:Nginx日志按天生成
access.log,压缩后上传至OSS供ELK分析。 - 跨云数据迁移,示例:从AWS S3下载数据文件,加载到阿里云MaxCompute。
- 冷数据备份,示例:历史订单表导出为Parquet文件,归档至HDFS长期存储。
1.2.7. 文件同步不适用场景
- 实时数仓同步(如Flink实时计算):原因:文件同步延迟高,无法支持流式数据处理。
- 高频事务数据(如支付流水):原因:文件生成周期长,易丢失中间状态变更。
- 数据一致性要求极高:原因:文件传输期间源数据可能变更,需额外对账机制。
1.2.8. 文件同步优化方案
- 增量同步:通过文件名或目录按时间分片(如
data_20231001.csv),仅同步新增文件。 - 并行传输:使用多线程或工具(如Rclone)加速大文件传输。
- 自动校验:目标系统加载前自动校验MD5,失败则触发重传。
- 元数据管理:记录文件生成时间、偏移量,便于追踪和恢复。
数据文件同步是高可靠、低成本的离线数据传输方式,适合多系统间批量数据迁移或归档,但对实时性和一致性要求高的场景需谨慎选择。在实践中常与日志解析(实时层)、直连同步(兜底层)结合,构建混合数据管道。
1.3. 数据库日志解析同步
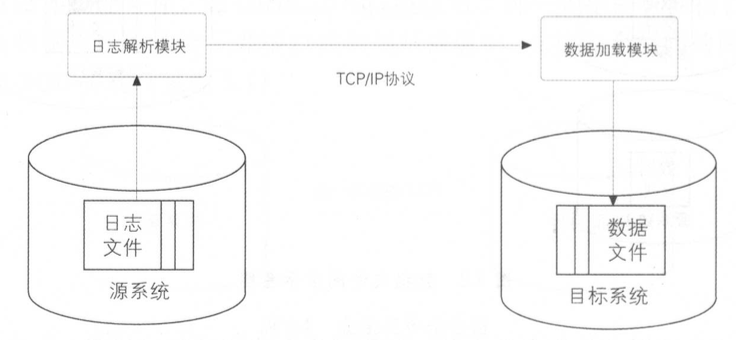
数据库日志解析同步是一种高效、低侵入式的增量数据同步方法,其核心原理是通过解析数据库的变更日志捕获数据变动,实现实时或准实时的数据同步。以下是对该技术的系统化解析及关键问题说明:
1.3.1. 日志解析核心流程
日志捕获阶段
- Oracle实现:通过后台进程(如
ARCH生成归档日志,LGWR写入在线重做日志)持续捕获Redo Log和Archive Log。 - 日志解析:解析二进制日志格式(如Oracle的
Redo Log需通过LogMiner或第三方工具解析),提取DML/DDL操作的详细信息(SQL语句、行数据、事务时间戳等)。 - 过滤与路由:根据预定义规则(如表名、主键范围)筛选目标数据,避免全量解析带来的资源浪费。
数据传输阶段
- 零拷贝传输:直接读取操作系统层面的日志文件(如Oracle的
V$LOGMNR_CONTENTS视图),无需通过数据库实例,降低锁竞争和性能损耗。 - 网络可靠性:采用TCP协议保证顺序性,结合校验和、重传机制(如Kafka的acks=all)确保数据完整性。
目标端加载
- 数据去重:基于主键或唯一索引,按日志时间倒序处理,保留最新状态(如
UPSERT操作:先删除旧记录,再插入新值)。 - 删除处理策略:
-
- 逻辑删除:插入标记字段(如
is_deleted=1),保留历史数据。 - 物理删除:直接同步
DELETE操作,需目标端支持级联删除。 - 软删除+回收站:将删除记录迁移至历史表,保留审计追溯能力。
- 逻辑删除:插入标记字段(如
1.3.2. 日志解析场景与优势
典型应用场景:
- 数据仓库/湖的增量ETL(如Hive/BigQuery同步)
- 主从数据库容灾(Active-Passive架构)
- 实时数据分析(如Flink+Kafka流处理)
| 优势 | 说明 |
| 低延迟(毫秒级) | 日志实时解析,适用于金融交易、实时风控等场景。 |
| 资源消耗低 | 无业务SQL介入,避免触发索引更新、触发器执行等额外开销。 |
| 数据一致性高 | 基于事务日志,保证事务原子性和顺序性。 |
| 兼容性强 | 支持跨版本、跨平台同步(需注意日志格式差异,如MySQL的Binlog与Oracle Redo Log)。 |
1.3.3. 日志解析挑战与解决方案
- 日志解析性能瓶颈:优化方案:并行解析(如Oracle的
DBMS_PARALLEL_EXECUTE)、内存映射文件(Memory-Mapped Files)减少I/O开销。 - 目标端数据冲突:冲突解决:采用
Last Write Wins(基于时间戳)或业务层幂等性设计(如唯一业务主键)。 - 跨数据库异构同步:Schema映射:使用数据管道工具(如Debezium+Debezium Connect)自动转换数据类型和DDL变更。
- 断点续传与故障恢复:检查点机制:记录已解析的日志位置(如Oracle的
V$LOG_HISTORY),崩溃后从断点恢复。
1.3.4. 日志数据删除策略
我们以具体的实例进行说明。如表 3.1 所示为源业务系统中某表变更日志流水表。其含义是:存在 5 条变更日志,其中主键为 1 的记录有3 条变更日志,主键为 2 的记录有 2 条变更日志 。
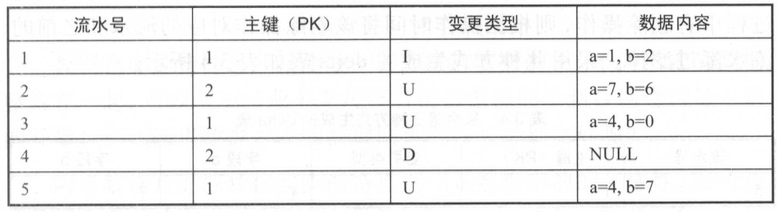
备注:
- 变更类型中的I表示新增(NSERT),U表示更新(UPDATE)、D表示删除(DELETE)。
- 数据内容中的a、b为此表的字段。
针对删除数据这种变更,主要有三种方式,下面以实例进行说明。假设根据主键去重,按照流水倒序获取记录最后状态生成的表为delta表。
第一种方式,不过滤删除流水。
不管是否是删除操作,都获取同一主键最后变更的那条流水。采用此种方式生成的delta表如表所示。

第二种方式,过滤最后一条删除流水。
如果同一主键最后变更的那条流水是删除操作,就获取倒数第二条流水。采用此种方式生成的delta表如表所示。

第三种方式,过滤删除流水和之前的流水。
如果在同一主键变更的过程中有删除操作,则根据操作时间将该删除操作对应的流水和之前的流水都过滤掉。采用此种方式生成的delta表如表所示。

对于采用哪种方式处理删除数据,要看前端是如何删除无效数据的。前端业务系统删除数据的方式一般有两种:正常业务数据删除和手工批量删除。
手工批量删除通常针对类似的场景,业务系统只做逻辑删除,不做物理删除,DBA定期将部分历史数据直接删除或者备份到备份库。 一般情况下,可以采用不过滤的方式来处理,下游通过是否删除记录的标识来判断记录是否有效。如果明确业务数据不存在业务上的删除,但是存在批量手工删除或备份数据删除,例如淘宝商品、会员等,则可以采用只过滤最后一条删除流水的方式,通过状态字段来标识删除记录是否有效。 通过数据库日志解析进行同步的方式性能好、效率高,对业务系统的影响较小。但是它也存在如下一些问题:
- 数据延迟。例如,业务系统做批量补录可能会使数据更新量超出系统处理峰值,导致数据延迟。
- 投人较大。采用数据库日志抽取的方式投入较大,需要在源数据库与目标数据库之间部署一个系统实时抽取数据。
- 数据漂移和遗漏,数据漂移, 一般是对增量表而言的,通常是指该表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。
| 业务场景 | 推荐方案 | 示例 |
| 审计合规要求严格 | 逻辑删除 + 归档表 | 将删除记录插入 |
| 数据频繁更新 | 物理删除 + 时间分区 | 按日分区,定期清理历史分区 |
| 数据恢复需求 | 软删除 + 回滚日志 | 保留删除记录,支持事务回滚 |
| 数据湖场景 | 写入单独 | Kafka流中分离删除事件,下游按需处理 |
2. 阿里数据仓库同步解方案
阿里数据仓库的数据同步在应对多源异构数据和海量数据场景时,形成了独特的架构和技术策略。其核心特点不仅体现在数据规模的量级差异上,更在于对多样性数据源的整合能力、实时性/批量混合处理的灵活性,以及大规模数据高吞吐的优化设计。以下是具体分析与技术实现:
| 挑战 | 传统数据仓库方案 | 阿里数据仓库方案 |
| 数据源多样性 | 仅支持结构化数据(MySQL/Oracle等) | 多模态数据融合:支持关系型数据库、日志文件(如Nginx日志)、NoSQL(HBase)、图数据、视频/图片(OSS存储)等多类型数据源。 |
| 数据量级差异 | 每日同步量在百GB级 | PB级数据同步:通过分布式计算框架(如MaxCompute)和流批一体引擎(如Flink),支持每天PB级数据的高效吞吐。 |
| 时效性要求 | 以离线批量同步为主(T+1) | 实时与离线混合:通过DataWorks实现分钟级延迟的准实时同步,结合MaxCompute的离线能力覆盖全场景。 |
2.1. 批量数据同步
阿里巴巴的DataX作为一款高效的异构数据同步工具,在离线数据仓库场景中解决了多源异构数据的双向批量同步难题。其核心设计理念和技术实现体现了对数据类型统一转换、高性能传输和灵活扩展性的深度优化
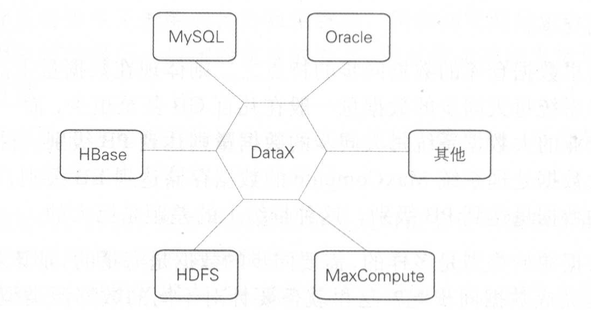
2.1.1. DataX核心设计架构
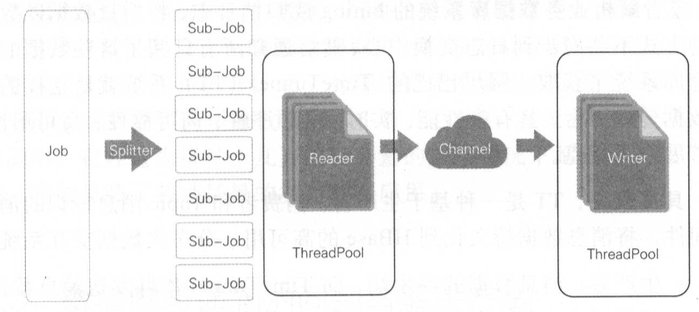
Framework+Plugin架构:
- Framework(框架层)功能:负责数据传输的全流程管理,包括任务调度、并发控制、内存管理、错误重试等。全内存操作:数据在传输过程中不落磁盘,通过内存队列(如环形缓冲区)实现进程间通信,极大提升吞吐量。无锁化设计:采用多进程并行模式(而非多线程),避免锁竞争,充分利用多核CPU资源。动态负载均衡:根据数据源和目标端的压力自动分配任务分片,避免单点瓶颈。
- Plugin(插件层):功能:提供对不同数据源(如MySQL、Oracle、HDFS、Hive、Kafka等)的读写适配。开发者仅需实现
Reader(数据源读取)和Writer(目标写入)接口,即可支持新数据源。标准化接口:所有插件遵循统一的数据格式(中间状态),屏蔽底层数据源差异。 - 不同数据库的数据类型差异显著直接映射会导致兼容性问题。DataX将所有数据类型转换为字符串类型(如
VARCHAR),并在目标端根据元数据描述还原为对应类型。规避复杂类型转换逻辑(如二进制、JSON嵌套结构)。兼容所有支持标准SQL的数据源。数据源侧:读取时通过JDBC驱动或文件解析器将数据转为字符串。目标侧:写入前根据目标表的Schema将字符串解析为目标类型(如将"2023-10-01"转为DATE)。
2.1.2. DataX高效同步机制
分布式并行处理
- 任务分片:将大表按主键或哈希值拆分为多个分片(如按
user_id % 100),每个分片由独立进程处理。 - 动态扩容:支持横向扩展Worker节点,通过增加进程数线性提升吞吐量(如从10进程扩展到100进程)。
- 案例:某电商平台每日同步2PB数据时,通过200个Worker节点并行处理,耗时约2.5小时。
内存优化与零磁盘I/O
- 全内存传输:数据从源端读取后直接存入内存缓冲区,经转换后写入目标端,全程无磁盘落盘。
- 双缓冲机制:使用双缓冲队列交替读写,避免读写冲突,提升CPU利用率。
容错与一致性保障
- 断点续传:记录每个分片的进度(如偏移量或行号),任务失败后从断点恢复,避免全量重跑。
- 数据校验:同步完成后,自动对比源端和目标端的记录数、主键冲突率等指标,确保数据一致性。
2.2. 准实时数据同步
阿里巴巴的TimeTunnel(TT)系统是实时数据传输领域的核心基础设施,专为解决海量日志类数据的实时同步与处理问题而设计。其架构和机制在高吞吐、低延迟、强一致性的场景中表现尤为突出,例如支撑天猫“双11”实时大屏的秒级数据刷新。
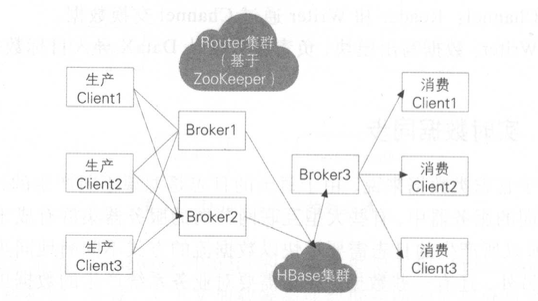
2.2.1. TT系统核心技术机制
高性能与低延迟保障
- 内存队列与零拷贝技术:数据在Broker节点通过内存队列(如Disruptor环形缓冲区)流转,避免磁盘I/O瓶颈,端到端延迟可控制在毫秒级。
- 批量压缩传输:生产者将多条消息合并为批次发送,结合Snappy压缩算法减少网络带宽占用。
顺序性保证
- 分区内严格有序:每个Topic按业务键(如用户ID、订单ID)分片,同一分片内的消息按生产顺序投递,确保下游处理顺序性。
- 全局时间窗口:通过HBase的时间戳索引,支持按事件时间(Event Time)对齐数据流,适用于窗口聚合(如滑动窗口统计)。
高可靠性与容错
- 数据持久化:消息写入HBase时采用WAL(Write-Ahead Log)+ 多副本机制,即使Broker宕机,数据仍可从HBase恢复。
- ACK确认机制:消费者处理完成后需向Broker发送ACK确认,未确认的消息会重试投递,防止数据丢失。
水平扩展能力
- 动态分片(Sharding):Topic可根据数据量动态扩容分片,例如将单Topic从10个分片扩展到100个分片,提升吞吐量。
- 无状态Broker设计:Broker节点仅负责消息路由,状态由HBase统一管理,支持热插拔扩容。
2.2.2. TT系统与同类技术的对比
| 特性 | TimeTunnel(TT) | Apache Kafka | RocketMQ |
| 定位 | 实时数据管道,强依赖HBase持久化 | 分布式消息队列,独立存储 | 金融级消息中间件,支持事务消息 |
| 数据持久化 | 直接写入HBase | 本地磁盘存储 | 分布式CommitLog存储 |
| 顺序性 | 分区内严格有序 | 分区内有序 | 分区内有序 |
| 适用场景 | 日志实时同步、CDC数据分发 | 高吞吐场景(如日志收集)、微服务解耦 | 金融交易、订单状态同步 |
| 生态集成 | 深度整合阿里云MaxCompute、DataWorks | 开源生态丰富(如Flink、Spark) | 阿里云内部生态为主 |
3. 数据同步挑战与解决方案
3.1. 分库分表处理
阿里巴巴的TDDL(Taobao Distributed Data Layer)作为分布式数据库访问引擎,通过逻辑表抽象和规则引擎,有效解决了分库分表场景下的数据同步复杂性问题。其核心设计目标是屏蔽底层分片细节,使下游应用像访问单库单表一样操作分布式数据库,同时保障数据一致性和高可用性。以下从技术原理、核心功能、应用场景及挑战解决方案展开分析:
3.1.1. TDDL架构与核心原理
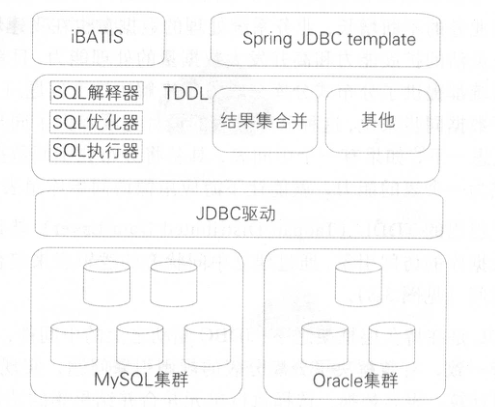
架构分层
TDDL位于持久层框架与JDBC驱动之间,基于JDBC规范实现,其核心模块包括:
- 规则引擎:解析分库分表规则(如按用户ID哈希分片),将SQL路由到对应的物理表。
- SQL解析器:解析SQL语句,识别分片键(Sharding Key),生成分片执行计划。
- 数据源代理:动态选择物理数据库连接,合并结果集并返回给应用层。
逻辑表与物理表映射
- 逻辑表(Virtual Table):如
order,对应用透明,隐藏分片细节。 - 物理表(Physical Table):如
order_0001、order_0002,实际存储数据的物理分片。 - 分片规则:定义逻辑表到物理表的映射逻辑(如按
user_id % 10分片)。
阿里巴巴的TDDL(Taobao Distributed Data Layer)与开源项目 ShardingSphere 在功能定位和架构设计上最为相似。两者均致力于解决分库分表场景下的数据访问复杂性,通过中间件层屏蔽底层分片细节,使应用可以像操作单库单表一样透明地访问分布式数据库。
| 特性 | TDDL | ShardingSphere |
| 定位 | 阿里巴巴内部使用的分布式数据库访问中间件 | Apache顶级开源项目,面向全行业的分布式数据库解决方案 |
| 核心功能 | 逻辑表抽象、分片规则管理、SQL解析与改写 | 分库分表、读写分离、分布式事务、弹性伸缩 |
| 架构层级 | JDBC驱动层中间件 | 数据库代理层中间件 |
| 透明化访问 | 对应用透明,无需改造SQL | 对应用透明,支持标准SQL |
| 分片策略 | 支持哈希、范围、复合分片 | 支持范围、哈希、复合分片及自定义策略 |
| 读写分离 | 内置主从同步与故障转移 | 支持动态读写分离,集成多种负载均衡策略 |
3.1.2. TDDL核心功能与实现
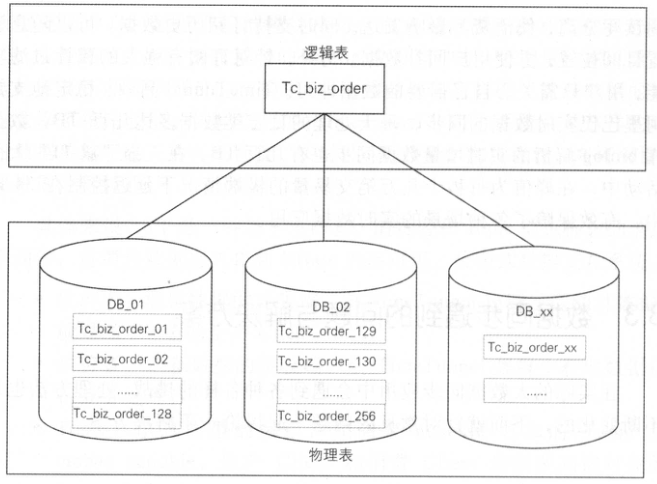
分片规则管理
- 动态规则加载:支持从配置中心(如ZooKeeper)实时同步分片规则变更,无需重启服务。
- 多维度分片策略:支持范围分片(如按时间)、哈希分片、复合分片(如
user_id + order_date)。
SQL解析与改写
- 自动识别分片键:若SQL包含分片键(如
WHERE user_id=123),精确路由到对应分片;若无分片键,则广播查询所有分片并合并结果。 - 语法兼容性:支持标准SQL及常见函数,自动改写跨分片查询(如
UNION ALL)。
读写分离与高可用
- 主从同步:自动识别读/写操作,写请求路由到主库,读请求负载均衡到从库。
- 故障转移:主库宕机时,自动切换至备库,并通过数据校验保证一致性。
结果集合并与聚合
- 跨分片查询:对广播查询(如
SELECT COUNT(*) FROM order)自动合并各分片结果。 - 聚合函数支持:在中间件层完成
SUM、AVG等聚合计算,减少数据传输量。
3.2. 增量和全量同步
在大数据场景下,面对海量数据的增量同步与全量合并需求,传统基于UPDATE的MERGE操作因性能瓶颈难以适用。阿里巴巴提出的全外连接(Full Outer Join)+ 全量覆盖重载(Insert Overwrite)方案,通过重新生成全量数据的方式实现高效合并,尤其适用于PB级数据场景(如淘宝订单表每日增量数亿条、历史累计数百亿条)。传统方案的局限性:MERGE操作的瓶颈:逐行UPDATE在大数据平台(如Hive、Spark)中效率极低,需频繁加锁、写日志,且不支持事务回滚。全量同步的不可行性:每日全量同步几百亿条数据会占用大量计算和存储资源,耗时过长(可能数小时至天级)。
3.2.1. 全外连接+全量覆盖技术方案
输入数据:
- 前一天的全量数据(如
orders_20231001)。 - 当天的增量数据(如
orders_increment_20231002,包含新增、更新、删除录)。
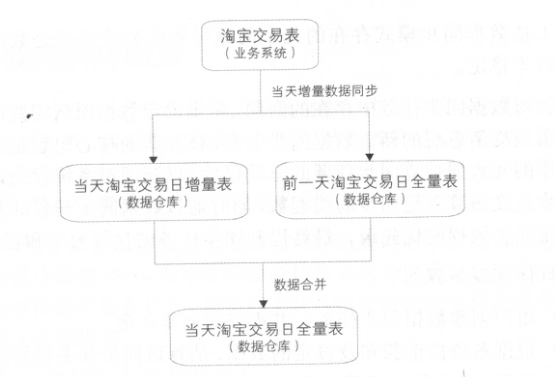
处理逻辑:
- 全外连接(Full Outer Join):以主键(如
order_id)为关联条件,将增量数据与全量数据合并。 - 数据覆盖策略:
-
- 若增量数据中存在相同主键,则覆盖全量数据中的旧记录。
- 若增量数据中无对应主键,则保留全量数据中的旧记录。
- 若增量数据中标记为删除(如
is_deleted=1),则删除全量数据中的对应记录。
- 写入新全量:将合并结果覆盖写入新一天的全量表(如
orders_20231002)。
3.2.2. 性能与场景对比
| 维度 | 传统MERGE方案 | 全外连接+Insert Overwrite方案 |
| 数据量支持 | 百万级以下 | PB级(如淘宝订单每日增量数亿条) |
| 执行时间 | 小时级(逐行更新效率低) | 分钟级(全量覆盖并行计算) |
| 资源消耗 | 高(频繁读写、锁竞争) | 中(仅需两次表写入) |
| 删除处理 | 需额外逻辑标记删除 | 天然支持(通过 |
| 适用平台 | 传统OLTP数据库(MySQL) | 大数据平台(Hive、Spark、Flink) |
3.2.3. 分区与生命周期管理
分区策略
- 按日期分区:每天生成一个独立分区(如
dt=20231002),避免全表扫描。 - 冷热分层:
-
- 热数据:保留最近3天分区,存储于SSD加速查询。
- 冷数据:归档至HDFS或OSS,按需加载。
数据保留策略
- 短周期覆盖:仅保留最近7天全量分区,自动清理旧分区(通过Hive生命周期配置)。
- 长期归档:将历史分区转存至低成本存储(如OSS),保留审计需求。
容错与一致性
- 数据校验:合并后对比增量与全量数据的行数差异,确保无丢失。
- 回滚机制:若合并失败,自动回退到前一天的全量版本。
3.3. 同步性能处理
阿里巴巴提出的基于负载均衡的数据同步优化方案,通过动态资源估算、优先级调度和弹性线程管理,有效解决了传统数据同步模式中的资源浪费、效率低下及任务不稳定问题。以下是该方案的技术解析与实现细节:
3.3.1. 传统数据同步模式的痛点
线程数设置不合理:用户依赖固定值设置首轮线程数,无法适应不同任务的实际需求(如数据量差异、源数据库性能差异)。后果:线程过多导致CPU争抢,线程过少导致资源闲置,同步速度波动大。
资源分配不均衡:同步控制器未考虑机器负载差异,将线程随机分配到高负载节点,导致任务执行效率低下。示例:高优先级任务被分配到CPU繁忙的机器,实际速度远低于预期。
任务优先级缺失:所有任务被平等对待,关键业务(如金融交易同步)无法优先获得资源,影响业务连续性。
3.3.2. 阿里负载均衡方案设计
动态资源估算
- 数据量预估:基于历史元数据(如表行数、增量日志量)预测本次同步所需处理的数据总量。
- 速度预估:根据源数据库类型(如MySQL/Oracle)和网络带宽,计算单线程平均同步速度。
- 线程数计算:
-
- 首轮期望线程数:根据目标数据库的承载能力(如CPU核数、IO阈值)动态设定。
- 总线程数:由数据量与单线程速度反推,确保任务在合理时间内完成。
优先级感知调度
- 任务分级:根据业务重要性定义优先级(如P0-紧急、P1-高、P2-普通)。
- 资源抢占:高优先级任务可抢占低优先级任务的资源,确保关键任务先执行。
弹性线程管理
- 虚拟线程机制:当物理线程不足时,创建虚拟线程占位,避免首轮线程数未达预期的性能损失。
- 多机协同:跨机器分配线程,平衡负载,避免单点资源瓶颈。
3.3.3. 技术实现步骤详解
任务初始化与参数估算
- 输入:用户提交的同步任务(源数据库类型、表结构、目标地址)。
- 处理:元数据查询:获取源表数据量、增量日志大小、历史同步耗时等。速度预估公式:
单线程速度 = 历史平均速度 * (当前网络带宽 / 历史带宽) * (目标数据库负载因子)
总线程数 = ceil(总数据量 / (单线程速度 * 预期完成时间))- 首轮线程数设定:根据目标数据库的CPU核数、内存阈值动态调整(如不超过CPU核数的80%)。
数据分块与线程分配
- 数据分块策略:哈希分片:按主键哈希(如
user_id % 总线程数)拆分数据,保证分片均匀。范围分片:按时间戳或自增ID范围划分,适用于有序数据(如日志表)。 - 线程分配规则:优先将高优先级任务的线程分配到低负载机器。同一任务的线程尽量集中到同一机器(减少跨机通信开销)。
虚拟线程与弹性调度
- 虚拟线程作用:
-
- 当实际线程数未达首轮期望值时,虚拟线程占用调度队列位置,确保后续扩容线程能快速启动。示例:预期首轮线程数为100,但实际分配了80个,虚拟线程补充至100,后续动态扩容。
- 资源探测机制:实时监控各机器的CPU、内存、磁盘IO,优先选择剩余资源充足的节点。
3.4. 数据漂移解决方案
阿里巴巴在处理ODS(Operational Data Store)层数据漂移问题时,通过多维度时间戳字段交叉验证和冗余数据策略,结合业务逻辑设计了一套精准的数据同步方案。以下是针对数据漂移问题的系统性解决方案及技术实践:
3.4.1. 数据漂移的根源分类
数据漂移的定义
数据漂移指ODS表中同一业务日期的数据包含非当日的变更记录(如前一天的延迟数据或次日凌晨的提前数据),或丢失当日变更数据。例如:
- 数据遗漏:凌晨生成的订单因系统延迟未被当日ODS捕获。
- 数据冗余:次日凌晨的更新记录被错误纳入当日ODS。
时间戳字段分类与冲突
| 时间戳类型 | 定义 | 典型问题场景 |
| modified_time | 数据库表中记录最后更新时间(业务侧控制) | 手工订正数据未更新该字段 |
| log_time | 数据库日志记录的操作时间(系统侧生成) | 网络延迟导致日志写入滞后 |
| proc_time | 业务过程发生时间(如订单支付时间) | 多业务过程时间不一致 (如下单→支付延迟) |
| extract_time | 数据抽取到ODS的时间(ETL系统生成) | ETL任务执行延迟导致时间戳偏移 |
时间戳不一致的典型原因
- ETL延迟:
extract_time晚于实际业务时间(如凌晨数据同步耗时)。 - 业务逻辑缺陷:手工修改数据未同步更新
modified_time。 - 系统故障:网络抖动或高负载导致
log_time与proc_time不同步。
3.4.2. 阿里数据漂移处理方案实践
核心思路
- 多时间戳交叉验证:结合
log_time、modified_time、proc_time定义数据时间边界。 - 冗余数据缓冲:通过前后15分钟数据冗余覆盖边界问题。
- 动态去重与排序:按业务主键和时间戳字段去重,保留最新有效状态。
具体实现步骤(以淘宝订单为例)
步骤1:数据冗余与初步过滤
- 前向冗余:获取前一日最后15分钟数据(如
2023-11-11 23:45:00至23:59:59)。 - 后向冗余:获取次日凌晨15分钟数据(如
2023-11-12 00:00:00至00:15:00)。 - 过滤非当日数据:通过
modified_time排除非目标日期数据(如proc_time不在2023-11-11的记录)。
步骤2:多维度时间戳排序与去重
- 按
log_time降序排序:
保留每条订单的最后一次变更记录(覆盖后续更新)。
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY log_time DESC) AS rnFROM ods_orderWHERE modified_time BETWEEN '2023-11-11 00:00:00' AND '2023-11-12 00:15:00'
) t WHERE rn = 1;- 按
proc_time升序排序:
获取订单首次变更记录(如支付成功时间)。
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY proc_time ASC) AS rnFROM ods_orderWHERE modified_time BETWEEN '2023-11-11 00:00:00' AND '2023-11-12 00:15:00'
) t WHERE rn = 1;步骤3:全外连接与数据回补
- 全外连接条件:以
order_id为键,合并前向冗余和后向冗余数据。 - 时间窗口修正:通过
proc_time限制最终数据范围(仅保留proc_time在2023-11-11的记录)。
INSERT OVERWRITE TABLE ods_order_corrected
SELECT COALESCE(a.order_id, b.order_id) AS order_id,a.proc_time AS corrected_proc_time,a.modified_time,a.log_time
FROM (/* 后向冗余数据 */) a
FULL OUTER JOIN (/* 前向冗余数据 */) b
ON a.order_id = b.order_id
WHERE COALESCE(a.proc_time, b.proc_time) BETWEEN '2023-11-11 00:00:00' AND '2023-11-11 23:59:59';3.4.3. 淘宝“双11”订单漂移案例效果
问题场景:大量订单因支付接口延迟,log_time和modified_time跨天(如实际支付时间在23:59:59,日志记录在00:01:00)。
解决方案:
- 冗余前后15分钟数据覆盖边界。
- 按
proc_time(支付时间)过滤,确保仅保留当日交易。 - 通过全外连接合并冗余数据,修正主键状态。
结果:数据准确率提升至99.9%,避免订单状态统计错误。
3.4.4. 其他优化策略与工具支持
动态时间窗口调整
- 自适应冗余窗口:根据历史数据延迟分布动态调整冗余时间(如大促期间延长至30分钟)。
- 实时监控告警:检测
log_time与proc_time偏差,自动触发数据校验任务。
数据质量校验
- 端到端一致性验证:对比源系统与ODS表的主键状态变更一致性。
- 血缘追踪:记录每条数据的来源时间戳字段,支持溯源分析。
工具链支持
- DataX增强配置:在同步任务中嵌入多时间戳过滤逻辑。
- Flink实时修正:通过流处理实时检测并回补漂移数据。
博文参考
《阿里巴巴大数据实战》
相关文章:

数据治理域——数据同步设计
摘要 本文主要介绍了数据同步的多种方式,包括直连同步、数据文件同步和数据库日志解析同步。每种方式都有其适用场景、技术特点、优缺点以及适用的数据类型和实时性要求。文章还详细探讨了数据直连同步的特点、工作原理、优点、缺点、适用场景等,并对数…...

系统架构设计师案例分析题——web篇
软考高项系统架构设计师,其中的科二案例分析题为5选3,总分75达到45分即合格。本贴来归纳web设计题目中常见的知识点即细节: 目录 一.核心知识 1.常见英文名词 2.私有云 3.面向对象三模型 4.计网相关——TCP和UDP的差异 5.MQTT和AMQP协…...

FC7300 SPI MCAL配置引导
一、MCU 组件 - 配置SPI时钟 MCU中配置的SPI输入时钟频率至少应大于2倍的SPI组件中配置的外设波特率。SPI时钟配置为30MHz 二、SPI 组件 - General Spi Level Delivered: 0 级:仅简单同步行为1 级:基本异步行为,通过中断实现2 级:增强型行为,通过轮询实现根据AUTOSAR SPI…...

【记录】Windows|竖屏怎么调整分辨率使横竖双屏互动鼠标丝滑
本文版本:Windows11,记录一下,我最后调整的比较舒适的分辨率是800*1280。 文章目录 第一步 回到桌面第二步 右键桌面第三步 设置横屏为主显示器第四步 调整分辨率使之符合你的需求第五步 勾选轻松在显示器之间移动光标第六步 拖动屏幕符合物理…...

hghac和hgproxy版本升级相关操作和注意事项
文章目录 环境文档用途详细信息 环境 系统平台:N/A 版本:4.5.6,4.5.7,4.5.8 文档用途 本文档用于高可用集群环境中hghac组件和hgproxy组件替换和升级操作 详细信息 1.关闭服务 所有数据节点都执行 1、关闭hgproxy服务 [roothgdb01 tools]# system…...

【超分辨率专题】一种考量视频编码比特率优化能力的超分辨率基准
这是一个Benchmark,超分辨率视频编码(2024) 专题介绍一、研究背景二、相关工作2.1 SR的发展2.2 SR benchmark的发展 三、Benchmark细节3.1 数据集制作3.2 模型选择3.3 编解码器和压缩标准选择3.4 Benchmark pipeline3.5 质量评估和主观评价研…...

操作系统之进程和线程听课笔记
计算机的上电运行就是构建进程树,进程调度就是在进程树节点进程进行切换 进程间通信的好处 经典模型 生产者和消费者 进程和线程的区别 线程引入带来的问题线程的优势 由于unix70年代产生,90年代有线程,当时数据库系统操作需要线程,操作系统没有来得及重造,出现了用户态线…...

Mac安装Navicat16
我的电脑用的是M3芯片,然后在安装的时候也踩了很多的坑 先分享一下链接 通过网盘分享的文件:Navicat Premium v16.2.dmg 链接: https://pan.baidu.com/s/1ENLtU7VLCvzntLKqSyFiqg?pwd1234 提取码: 1234 其实按理说用navicat17也是可以的 首先下载完成后…...

表的设计、聚合函数
目录 1、表的设计 1.1、一对一 1.2、一对多 1.3、多对多 2、插入查询结果 3、聚合查询 3.1、聚合函数 3.2、GROUP BY子句 1、表的设计 根据实际的需求场景,明确当前要创建几个表,每个表什么样子,这些表之间是否存在一定联系 1. 梳理…...

React学习———React Router
React Router React Router 是 React 应用中用于管理路由的流行库,它允许你在单页应用(SPA)中实现导航和页面切换而无需重新加载页面。 安装 npm install react-router-dom核心组件 <BrowserRouter> 使用HTML5的历史记录API&#…...

【前端】[vue3] [uni-app]使用 vantUI 框架
npm 安装: npm i vant/weapp -S --productionmain.js 中挂载 App.vue 引入 vantUI 样式 完成:...

upload-labs通关笔记-第8关 文件上传之点绕过
目录 一、点绕过原理 二、deldot()函数 三、源码分析 四、渗透实战 1、构建脚本test8.php 2、打开靶场 3、bp开启拦截 4、点击上传 5、bp拦截 6、后缀名增加点 7、发包并获取脚本地址 8、访问脚本 本文通过《upload-labs靶场通关笔记系列》来进行upload-labs靶场的渗…...

XML简要介绍
实际上现在的Java Web项目中更多的是基于springboot开发的,所以很少再使用xml去配置项目。所以我们的目的就是尽可能快速的去了解如何读懂和使用xml文件,对于DTD,XMLSchema这类约束的学习可以放松,主要是确保自己知道这里面的大致…...

我设计的一个安全的 web 系统用户密码管理流程
作为一名有多年经验的前端,在刚开始学习web后端的时候,就对如何设计一个安全的 web 系统用户密码管理流程有很多疑问。之前自己也实践过几种方法,但一直觉得不是十分安全。 我们知道,用户在注册或登录界面填写的密码是明文的&…...

事件驱动架构:从传统服务到实时响应的IT新风潮
文章目录 事件驱动架构的本质:从请求到事件的范式转变在EDA中: 事件驱动架构的演进:从消息队列到云原生标配核心技术:事件驱动架构的基石与工具链1. 消息队列:事件传递的枢纽2. 消费者:异步处理3. 事件总线…...

YOLOv11改进 | Neck篇 | 轻量化跨尺度跨通道融合颈部CCFM助力YOLOv11有效涨点
YOLOv11改进 | Neck篇 | 轻量化跨尺度跨通道融合颈部CCFM助力YOLOv11有效涨点 引言 在目标检测领域,YOLO系列算法因其卓越的速度-精度平衡而广受欢迎。YOLOv11作为该系列的最新演进版本,在Neck部分引入了创新的跨尺度跨通道融合模块(CCFM, Cross-scale…...

Unity:场景管理系统 —— SceneManagement 模块
目录 🎬 什么是 Scene(场景)? Unity 项目中的 Scene 通常负责什么? 🌍 一个 Scene 包含哪些元素? Scene 的切换与管理 📁 如何创建与管理 Scenes? 什么是Scene Man…...

官方 Elasticsearch SQL NLPChina Elasticsearch SQL
官方的可以在kibana 控制台上进行查询: POST /_sql { “query”: “SELECT client_ip, status FROM logs-2024-05 WHERE status 500” } NLPChina Elasticsearch SQL就无法以在kibana 控制台上进行查询,但是可以使用postman接口进行查询:...

Kubernetes 1.28 无 Docker 运行时环境下的容器化构建实践:Kaniko + Jenkins 全链路详解
背景说明 随着 Kubernetes 1.28 正式弃用 Docker 作为默认容器运行时(CRI 规范演进),传统的 docker build 方式已无法直接在集群内运行。Kaniko 作为 Google 开源的容器镜像构建工具,凭借其无需特权容器、兼容 OCI 标准的特性&am…...

【Linux】序列化与反序列化、会话与进程组、守护进程
一.序列化和反序列化 协议其实就是结构化的数据。但是再网络通信中,我们不直接发送结构化的数据给对方。我们一般会将结构化的数据序列化成字符串/字节流,然后通过网络在发送出去。而接收方收到之后,要对收到的字符串/流式数据进行反序列化&…...
)
Python机器学习笔记(二十五、算法链与管道)
对于许多机器学习算法,特定数据表示非常重要。首先对数据进行缩放,然后手动合并特征,再利用无监督机器学习来学习特征。因此,大多数机器学习应用不仅需要应用单个算法,而且还需要将许多不同的处理步骤和机器学习模型链接在一起。Pipeline类可以用来简化构建变换和模型链的…...

自媒体工作室如何矩阵?自媒体矩阵养号策略
一、自媒体工作室矩阵搭建方法 1.纵向矩阵:在主流平台都开设账号,覆盖不同用户触达场景。 短视频:抖音、快手、视频号(侧重私域沉淀) 2.主账号导流:通过关联账号、评论区跳转链接实现流量互通 本地生活…...

Pywinauto:轻松实现Windows桌面自动化实战
你是否厌倦了每天重复点击软件界面的枯燥操作?是否希望能像自动化网页那样,轻松控制桌面程序?在自动化测试逐渐扩展到客户端桌面的今天,你还不知道 pywinauto,就真的落后了! 手动测试Windows桌面应用&…...

告别传统的防抖机制,提交按钮的新时代来临
目录 背景 目标 核心代码 样式定义:让图标居中、响应父级颜色 SVG 图标:轻量、无依赖的 loading 图标 指令注册:全局注册 v-bLoading DOM 操作:添加与清除 loading 图标 1. 添加 loading 图标 2. 清除 loading 图标 动画…...

【Linux】Linux安装并配置MongoDB
目录 1.添加仓库 2.安装 MongoDB 包 3.启动 MongoDB 服务 4. 验证安装 5.配置 5.1.进入无认证模式 5.2.1创建用户 5.2.2.开启认证 5.2.3重启 5.2.4.登录 6.端口变更 7.卸载 7.1.停止 MongoDB 服务 7.2.禁用 MongoDB 开机自启动 7.3.卸载 MongoDB 包 7.4.删除数…...

PT2031K单触控单输出触摸IC
1.产品概述 ● PT2031K是一款电容式触摸控制ASIC,支持单通道触摸输入和单路同步开关输出。适用于雾化器、车载用品、电子玩具、消费类电子产品等领域,具有低功耗、高抗干扰、宽工作电压范围的突出优势。 2.主要特性 ● 工作电压范围:2.4~5.5…...

MySQL 与 FastAPI 交互教程
目录 1. 使用 Docker 启动 MySQL2. 创建 FastAPI 应用安装必要的依赖创建项目结构创建数据库连接模块创建数据模型创建 Pydantic 模型(用于请求和响应)创建主应用 3. 运行和测试应用启动应用访问 API 文档 4. 测试 API 端点创建用户获取所有用户获取特定…...

分布式 ID 生成的五种方法:优缺点与适用场景
0.简介 在分布式系统中,生成全局唯一的id是一个常见的需求。由于分布式系统的特性(多节点,网络分区,时钟不同步等),传统的单机ID生成方式不再适用,所以一些分布式生成方式应运而生,…...
的应用与代码示例)
ES(Elasticsearch)的应用与代码示例
Elasticsearch应用与代码示例技术文章大纲 一、引言 Elasticsearch在现代化应用中的核心作用典型应用场景分析(日志分析/全文检索/数据聚合) 二、环境准备(前提条件) Elasticsearch 8.x集群部署要点IK中文分词插件配置指南Ingest Attachment插件安装…...

MinIO 开源的分布式文件服务器
如下是java代码调用MinIO的SDK实现文件的上传,并获取url <dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>4.9.3</version> <!-- 你可以选择4.8.1或更高版本 --></dependenc…...

蓝牙AVRCP协议概述
AVRCP(Audio/Video Remote Control Profile)定义了蓝牙设备和 audio/video 控制功能通信的特 点和过程,另用于远程控制音视频设备,底层传输基于 AVCTP 传输协议。该 Profile 定义了AV/C 数字命令控制集。命令和信息通过 AVCTP(Audio/Video Control Trans…...

【全网首发】解决coze工作流批量上传excel数据文档数据重复的问题
注意:目前方法将基于前一章批量数据库导入的修改!!!!请先阅读上篇文章的操作。抄袭注明来源 背景 上一节说的方法可以批量导入文件到数据库,但是无法解决已经上传的条目更新问题。简单来说,不…...

Hue面试内容整理-Hue 架构与前后端通信
Cloudera Hue 是一个基于 Web 的 SQL 助手,旨在为数据分析师和工程师提供统一的界面,以便与 Hadoop 生态系统中的各个组件(如 Hive、Impala、HDFS 等)进行交互。其架构设计强调前后端的分离与高效通信,确保系统的可扩展性和可维护性。以下是 Hue 架构及其前后端通信机制的…...

【八股战神篇】Java高频基础面试题
1 面向对象编程有哪些特性? 面向对象编程(Object-Oriented Programming,简称 OOP)是一种以对象为核心的编程范式,它通过模拟现实世界中的事物及其关系来组织代码。OOP 具有三大核心特性:封装、继承、多态。…...

matlab建立整车模型,求汽车的平顺性
在MATLAB中建立整车模型评估汽车平顺性,通常采用多自由度振动模型。以下是基于四分之一车模型的详细步骤和代码示例,可扩展至整车模型。 1. 四分之一车模型(简化版) 模型描述 自由度:2个(车身垂直位移 z2…...

在Linux服务器上部署Jupyter Notebook并实现ssh无密码远程访问
Jupyter notebook版本7.4.2(这个版本AI提示我Jupyter7(底层是 jupyter_server 2.x) 服务器开启服务 安装Jupyter notebook 7.4.2成功后,终端输入 jupyter notebook --generate-config 这将在 ~/.jupyter/ 目录下生成 jupyter_…...

C#数组与集合
🧠 一、数组(Array) 1. 定义和初始化数组 // 定义并初始化数组 int[] numbers new int[5]; // 默认值为 0// 声明并赋值 string[] names { "Tom", "Jerry", "Bob" };// 使用 new 初始化 double[] scores …...

服务器内部可以访问外部网络,docker内部无法访问外部网络,只能docker内部访问
要通过 iptables 将容器中的特定端口请求转发到特定服务器,你需要设置 DNAT(目标地址转换)规则。以下是详细步骤: 假设场景 容器端口: 8080(容器内服务监听的端口)目标服务器: 192.168.1.100(请…...

mathematics-2024《Graph Convolutional Network for Image Restoration: A Survey》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...

ssti刷刷刷
[NewStarCTF 公开赛赛道]BabySSTI_One 测试发现过滤关键字,但是特殊符号中括号、双引号、点都能用 可以考虑拼接或者编码,这里使用拼接 ?name{{()["__cla"~"ss__"]}}?name{{()["__cla"~"ss__"]["__ba&…...

Zephyr OS Nordic芯片的Flash 操作
目录 概述 1. 软硬件环境 1.1 软件开发环境 1.2 硬件环境 2 Flash操作库函数 2.1 nRF52832的Flash 2.2 Nordic 特有的 Flash 操作 2.2.1 nrfx_nvmc_bytes_write 函数 2.2.2 nrfx_nvmc_page_erase函数 2.2.3 nrfx_nvmc_write_done_check 函数 3 操作Flash的接口函数…...

傅里叶变换实战:图像去噪与边缘提取
傅里叶变换在图像处理中的应用与实践详解(超详细教程实战代码) 🚀 本文从零开始详解傅里叶变换在图像处理中的应用,手把手教你实现图像去噪与边缘提取!全文配套Python代码,新手也能轻松上手! 一…...

go-中间件的使用
中间件介绍 Gin框架允许开发者在处理请求的过程中加入用户自己的钩子(Hook)函数这个钩子函数就是中间件,中间件适合处理一些公共的业务逻辑比如登录认证,权限校验,数据分页,记录日志,耗时统计 1.定义全局中间件 pac…...

昇腾NPU环境搭建
如果进入服务器输入npu-smi info可以看到npu情况,请直接跳转第三步 STEP1: 服务器安装依赖 sudo yum install -y gcc gcc-c make cmake unzip zlib-devel libffi-devel openssl-devel pciutils net-tools sqlite-devel lapack-devel gcc-gfortran python3-develyu…...
)
【HTML5学习笔记2】html标签(下)
1表格标签 1.1表格作用 显示数据 1.2基本语法 <table><tr> 一行<td>单元格1</td></tr> </table> 1.3表头单元格标签 表头单元格会加粗并且居中 <table><tr> 一行<th>单元格1</th></tr> </table&g…...

开源轻量级地图解决方案leaflet
Leaflet 地图:开源轻量级地图解决方案 Leaflet 是一个开源的 JavaScript 库,用于在网页中嵌入交互式地图。它以轻量级、灵活性和易用性著称,适用于需要快速集成地图功能的项目。以下是关于 Leaflet 的详细介绍和使用指南。 1. Leaflet 的核心…...
线性代数)
LLM学习笔记(六)线性代数
公式速查表 1. 向量与矩阵:表示、转换与知识存储的基础 向量表示 (Vectors): 语义的载体 在LLM中,向量 x ∈ R d \mathbf{x}\in\mathbb{R}^d x∈Rd 是信息的基本单元,承载着丰富的语义信息: 词嵌入向量 (Word Embeddings)&am…...

Vue 3.0双向数据绑定实现原理
Vue3 的数据双向绑定是通过响应式系统来实现的。相比于 Vue2,Vue3 在响应式系统上做了很多改进,主要使用了 Proxy 对象来替代原来的 Object.defineProperty。本文将介绍 Vue3 数据双向绑定的主要特点和实现方式。 1. 响应式系统 1.1. Proxy对象 Vue3 …...

Quasar组件 Carousel走马灯
通过对比两个q-carousel组件来,了解该组件的属性 官方文档请参阅:Carousel 预览 源代码 <template><div class"q-pa-md"><div class"q-gutter-md"><q-carouselv-model"slide"transition-prev&quo…...

Vue 2.0学习
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言&…...