CPU cache基本原理
CPU cache基本原理
- 存储器层次结构
- 存储器层次结构中的缓存
- 高速缓存存储器
- 直接映射高速缓存
- 组相联高速缓存
- 全相联高速缓存
- 多核 CPU 下缓存问题
- 内存的读写操作流程
- 数据一致性与并发控制
高速缓存(cache)是一个小而快速地存储设备,它作为存储在更大,也更慢的设备中的数据对象的缓冲区域。
存储器层次结构
存储技术作为一项复杂的技术,针对于不同的存储技术,它的访问时间差异很大,速度较快的技术每字节的成本要比速度较慢的技术高,而且容量较小,CPU 与主存之间的速度差距在增大,所以为了了解决 CPU 与内存之间的速度不匹配问题,就出现了高速缓存,也就是我们平时所说的 cache 。
现代计算机系统当中都会依赖存储器层次结构,如下图所示,就展示了一个典型的存储器结构层次,一般而言,从高层往低层次走,存储设备变得更慢,更便宜和更大,最高层(L0)是少量快速地 CPU 寄存器,CPU 可以再一个时钟周期访问它们,接下来就是一个或者是多个小型或者是中型的基于 SRAM 的高速缓存存储器,可以再几个 CPU 时钟周期访问它们,然后是一个更大的基于 DRAM 的主存,可以再几十个或者是几百个 CPU 时钟周期访问它们,最后,有些系统包含了一层附加的远程服务器上附加的磁盘,要通过网络来访问他们。
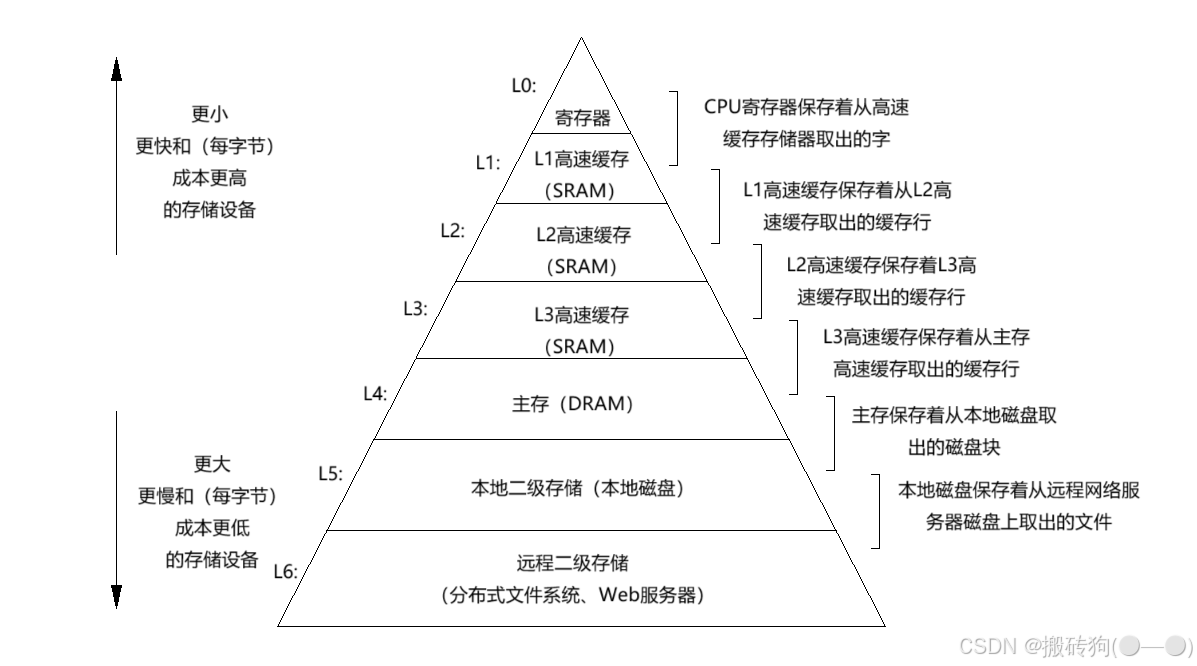
存储器层次结构中的缓存
存储器结构的中心思想就是,对于每个 k ,位于 k 层的更快更小的存储设备作为位于 k + 1 层的更大更慢的存储设备的缓存,也就是说,层次结构每一层都还缓存着来自低一层的数据对象,如下图所示,第 k + 1 层存储器被划分为连续的数据对象组块(block),每一个块都有一个唯一的地址或名字区分于其他的块。
第 k 层的存储器被划分为较少块的集合,每个块的大小与 k + 1 层块的大小一致,也就是说第 k 层的缓存包含第 k + 1 层块的一个子集的副本。同时,数据总是以块的大小为传递单元在第 k 层到 k + 1 层之间来回进行复制的,我们可以理解为相邻的两个结构层次之间的块的大小是一致的,但是其他层次之间又可以是不同的,比如 L0 和 L1 之间是以一个字节块为大小,L1 和 L1 之间又可以是以几十个字节为块的大小进行传递。
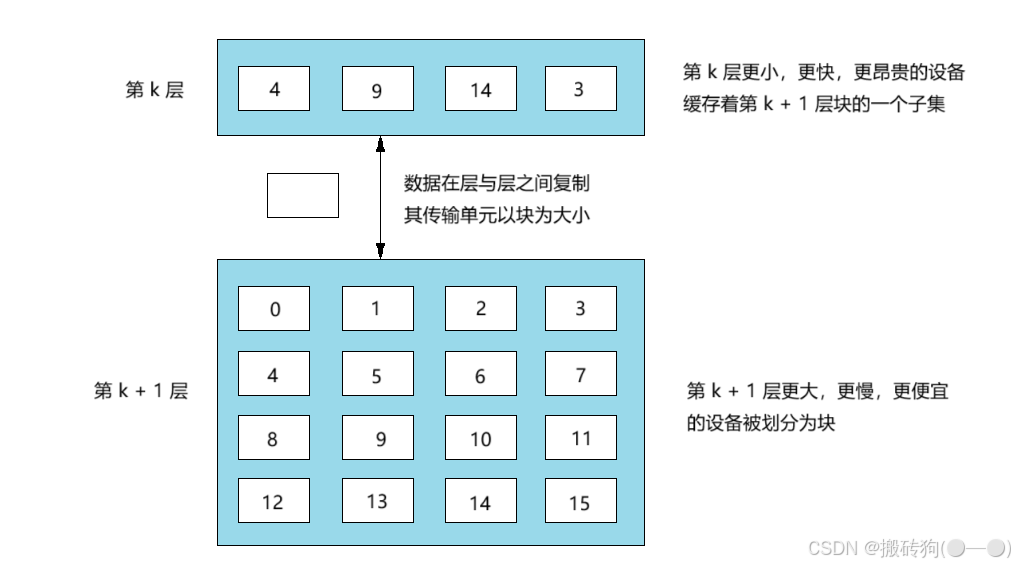
缓存命中
当程序需要第 k + 1 的某个数据对象 d 时,它首先会在当前存储的第 k 层的一个块中查找 d ,如果 d 刚好缓存在第 k 层中,这就是我们所说的缓存命中。
缓存不命中
与之相反,如果第 k 层没有缓存数据对象 d ,这就称之为缓存不命中。
当缓存不命中发生以后,第 k 层的缓存从第 k + 1 层的缓存中取出包含 d 的那个块,如果第 k 层的缓存已经满了,可能就会覆盖现存的一个块,这个覆盖的过程我们称之为替换或者是驱逐,被驱逐的这个块可以称之为牺牲块(victim block),决定怎么去替换哪个块是有缓存的替换策略来进行控制的。
高速缓存存储器
在一个计算机系统当中,其中每个每个存储器的地址有 m 位,形成 M = 2 m 2^{m} 2m 个不同的地址。如下图所示,这样的机器被组织成为一个有 S = 2 s 2^{s} 2s 个高速缓存组(cache set)的数组,每个组包含 E 个高速缓存行(cache line),每行是由一个 B = 2 b 2^{b} 2b 字节的数据块组成的。有效位(valid bit)指明这个行是否包含有意义的信息,还有 t=m-(b+s)个标记位,唯一的标识存储在这个高速缓存行中的块。
我们可以简单理解一下,当一条加载指令指示 CPU 从主存地址 A 中读取一个字时,是如何进行工作的:
参数 S 和 B 将 m 个地址分成了3个字段,A 中 s 个组索引位是一个到 S 个组的数组的索引,如下图所示,第一个组时组0,第二个是组1,以此类推,组索引告诉我们这个字必须存储在哪个组当中,当我们知道这个字必须存放在哪个组当中以后,A 中的 t 个标记位就告诉我们这个组的哪一行包含这个字(如果存在的话)。当且仅当设置了有效位并且该行的标记位与地址 A 中标记位匹配时,组中的这一行才包含这个字,一旦定位完成以后,b 个块偏移就会给出在 B 个字节的数据块中的字偏移。
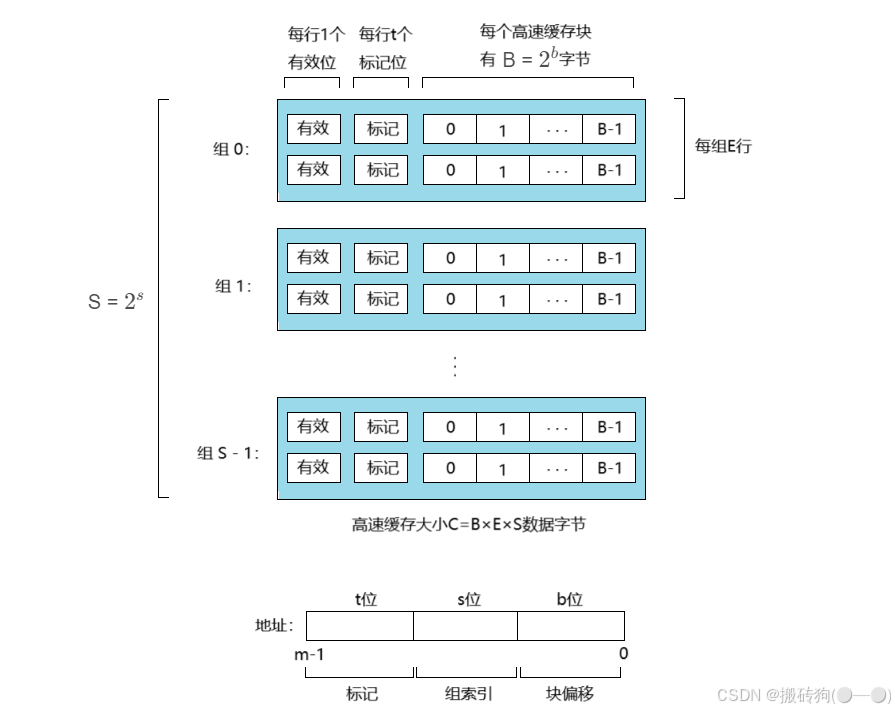
根据每个组的高速缓存行数 E ,高速缓存被分为不同的类,主要为直接映射高速缓存、组相联高速缓存和全相联高速缓存,接下会简单的一 一介绍:
直接映射高速缓存
每个组只有一行(E = 1)的高速缓存称为直接映射高速缓存,这种也是最容易理解和实现的,如下图所示:
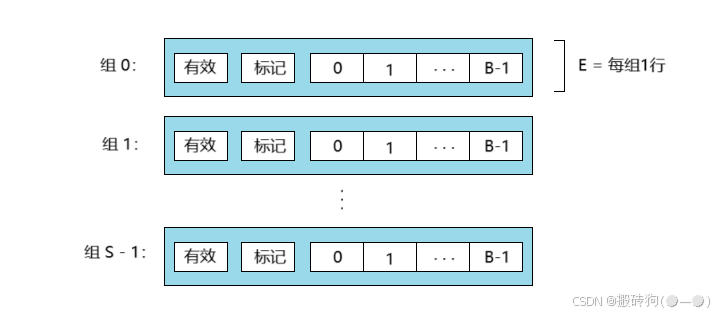
我们假设当前存在这样一个系统,它有一个 CPU,一个寄存器文件,一个L1高速缓存,一个主存,当 CPU 执行一条读取内存字 w 指令,他会向 L1 高速缓存请求这个字,如果 L1 高速缓存存在 w 字的一个副本,那么就会得到 L1 高速缓向命中,高速缓存就会很快抽取出这个 w ,返回给 CPU 。否则就是我们的缓存不命中, L1 高速缓存会向主存请求 w 这个字段,在这期间 CPU 就会进行等待,当请求的块最终从内存到达时,L1 高速缓存就会将这个块存到一个高速缓存行当中,然后从被存储的块中抽取出字 w ,最终返还给 CPU ,高速缓存确定一个请求是否命中,在抽取出对应我们所需要的字的过程分为三步:组选择->行匹配->字抽取。
直接映射高速缓存的组选择
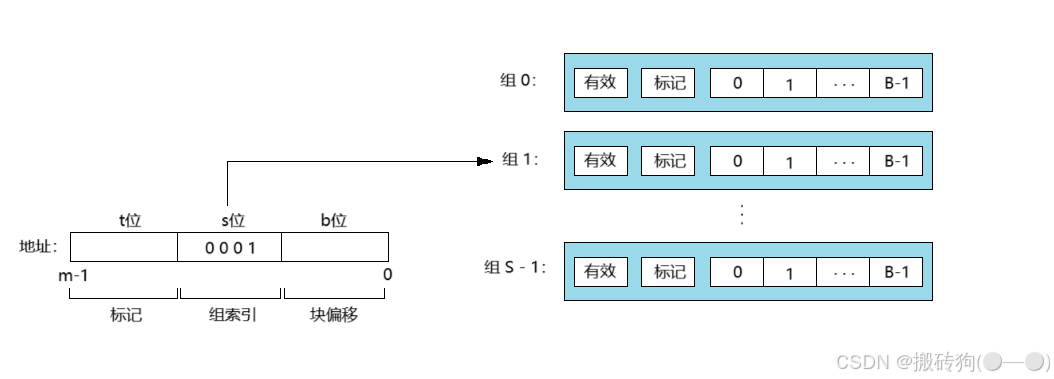
当前步骤,高速缓存会从 w 的地址中间抽取 s 个组索引位,这些位被解释成为一个对应组号的无符号整数,也就是说,上图中的0 0 0 1被解释成为一个选择组 1 的整数索引,这也就完成了对应的组选择这一步流程。
直接映射高速缓存的行匹配
当我们选择了组以后,接下来就需要确认是否有 w 字的副本存在于当前组的高速缓存行中,在直接映射高速缓存中很容易,因为就只有一行,所以只需保证当且仅当设置了有效位,而且高速缓存行中的标记位跟地址中的标记位匹配时,就证明这一行中包含 w 的副本。
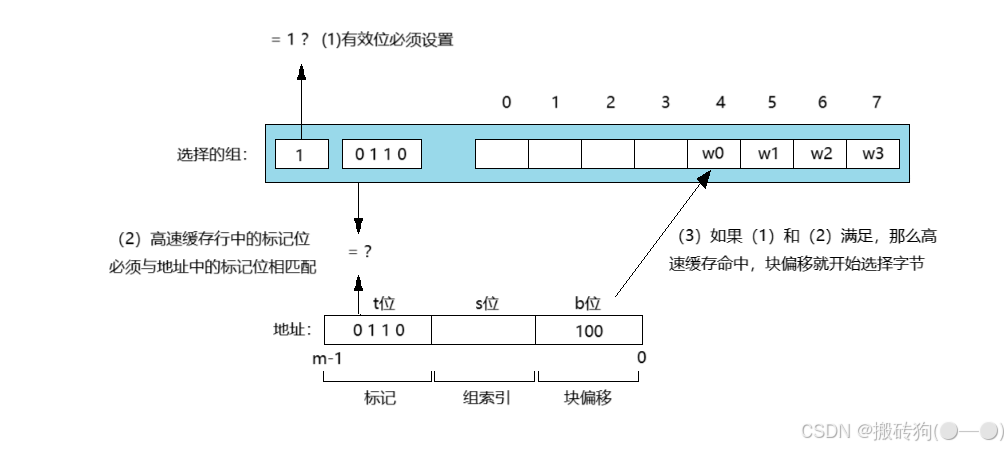
直接映射高速缓存的字选择
一旦缓存命中,我们就知道 w 就在这个块中的某个地方,最后一步就是确定这个所需要的字是从块中的哪
一块位置开始的,块偏移提供的所需字的第一个字节的偏移,就如上图所示一样,把高速缓存看成一个行的数组一样。
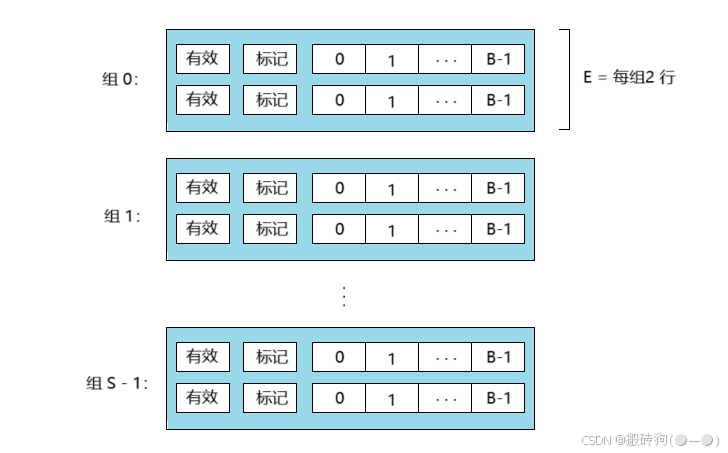
组相联高速缓存
直接映射高速缓存冲突不命中造成的问题就是源于每个组只有一行这个限制,对于组相联高速缓存来说,就放松了这个限制,每个组保存了多余一个的高速缓存行,一个 1 < E < C / B 的高速缓存通常称为 E 路组相联高速缓存,如下图所示:
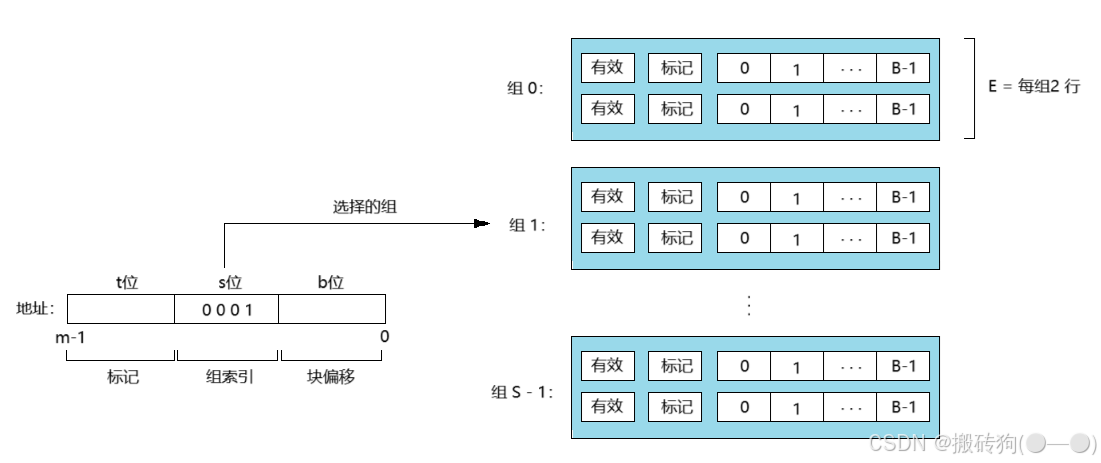
组相联高速缓存的组选择
组相联高速缓存中的组选择其实跟直接映射高速缓存中的组选择一样,都是以组索引位标识组,如下图所示:
组相联高速缓存的行匹配和字选择
组相联高速缓存的行匹配相对于直接高速缓存的行匹配就会复杂许多了,这在于他会检查多个行的标记位和有效位,以确定请求的字是否会出现在某个组当中,我们可以理解相联存储器就是一个(key,value)对的数组,以 key 为输入,返回与输入的 key 相匹配的 value 值。我们可以把组相联高速缓存中的每个组都看做是一个小的相联存储器, key 是标记和有效位,而 value 就是块的内容。
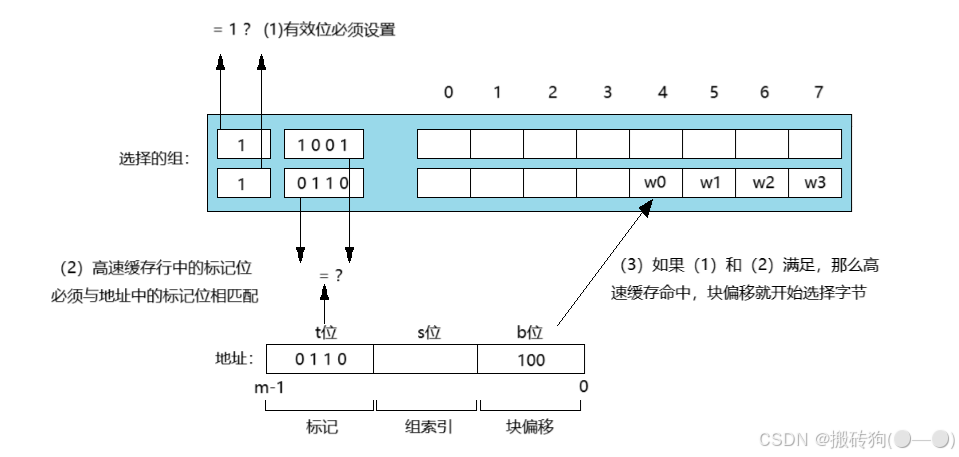
全相联高速缓存
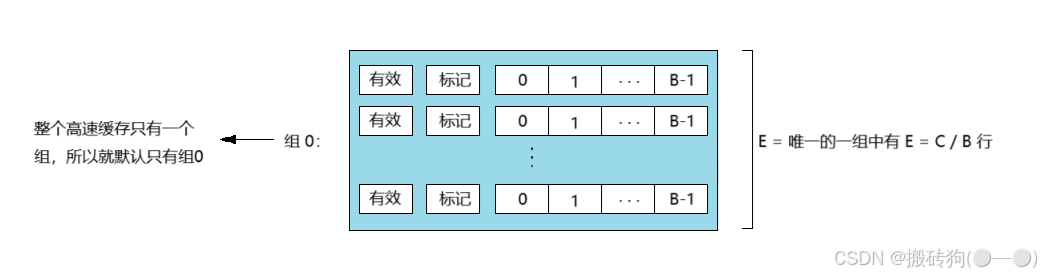
全相联高速缓存是由一个包含所有高速缓存行的组(即 E = C / B)组成的如下图所示:
全相联高速缓存的组选择
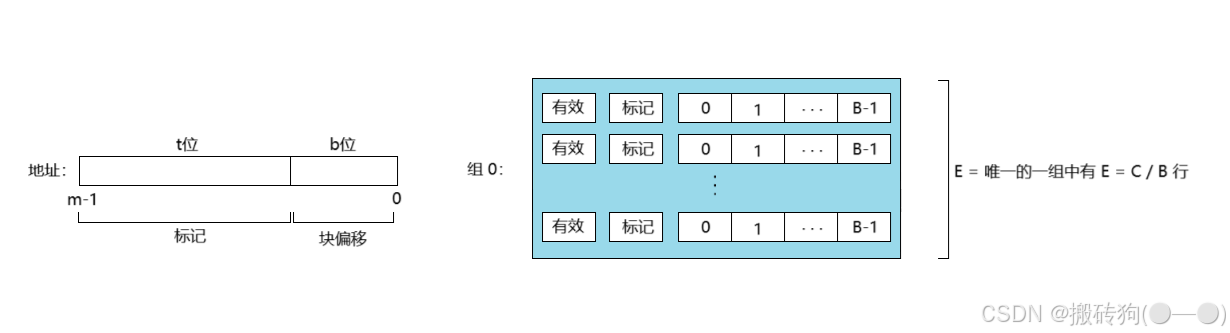
因为默认就一个组,所以地址中就没有组索引,只被划分为一个标记和一个块偏移。
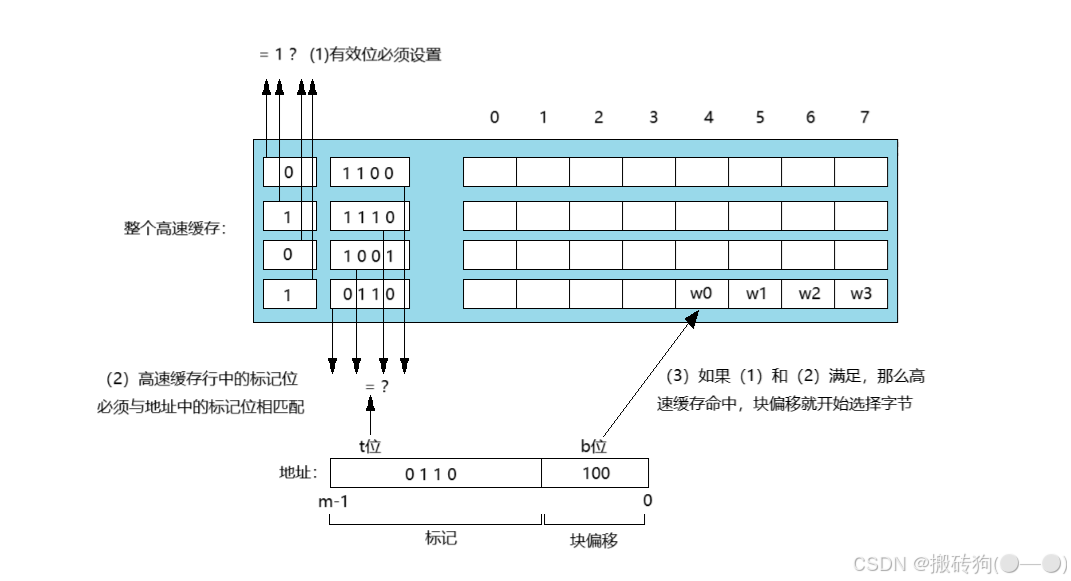
全相联高速缓存的行匹配和字选择
全相联高速缓存的行匹配和字选择跟组相联高速缓存是一致的,他们之间的区别就在于规模的大小。
通过上述所讲知识,我们对高速缓存有了一个系统的了解,缓存出现的原因就是由于硬盘的内部数据传输速度和外界介面传输速度不同,缓存在其中起到一个缓冲的作用。缓存的大小与速度是直接关系到硬盘的传输速度的重要因素,能够大幅度地提高硬盘整体性能。当硬盘存取零碎数据时需要不断地在硬盘与内存之间交换数据,如果有大缓存,则可以将那些零碎数据暂存在缓存中,减小外系统的负荷,也提高了数据的传输速度。
而缓存主要作用可以总结为以下三点:
- 预读取:当硬盘受到CPU指令控制开始读取数据时,硬盘上的控制芯片会控制磁头把正在读取的簇的下一个或者几个簇中的数据读到缓存中(由于硬盘上数据存储时是比较连续的,所以读取命中率较高),当需要读取下一个或者几个簇中的数据的时候,硬盘则不需要再次读取数据,直接把缓存中的数据传输到内存中就可以了,由于缓存的速度远远高于磁头读写的速度,所以能够达到明显改善性能的目的。
- 对写入动作进行缓存:当硬盘接到写入数据的指令之后,并不会马上将数据写入到盘片上,而是先暂时存储在缓存里,然后发送一个“数据已写入”的信号给系统,这时系统就会认为数据已经写入,并继续执行下面的工作,而硬盘则在空闲(不进行读取或写入的时候)时再将缓存中的数据写入到盘片上。虽然对于写入数据的性能有一定提升,但也不可避免地带来了安全隐患——如果数据还在缓存里的时候突然掉电,那么这些数据就会丢失。如果突然掉电,磁头会借助惯性将缓存中的数据写入零磁道以外的暂存区域,等到下次启动时再将这些数据写入目的地。
- 临时存储最近访问过的数据:硬盘内部的缓存会将读取比较频繁的一些数据存储在缓存中,再次读取时就可以直接从缓存中直接传输。
多核 CPU 下缓存问题
内存的读写操作流程
- 读操作:当CPU需要读取数据时,它会通过地址总线发送出内存地址,然后通过数据总线接收内存返回的数据。
- 写操作:当CPU需要写数据时,它会通过地址总线发送出内存地址,并在数据总线上发送要写入的数据。
CPU 与内存的关系如下图所示:
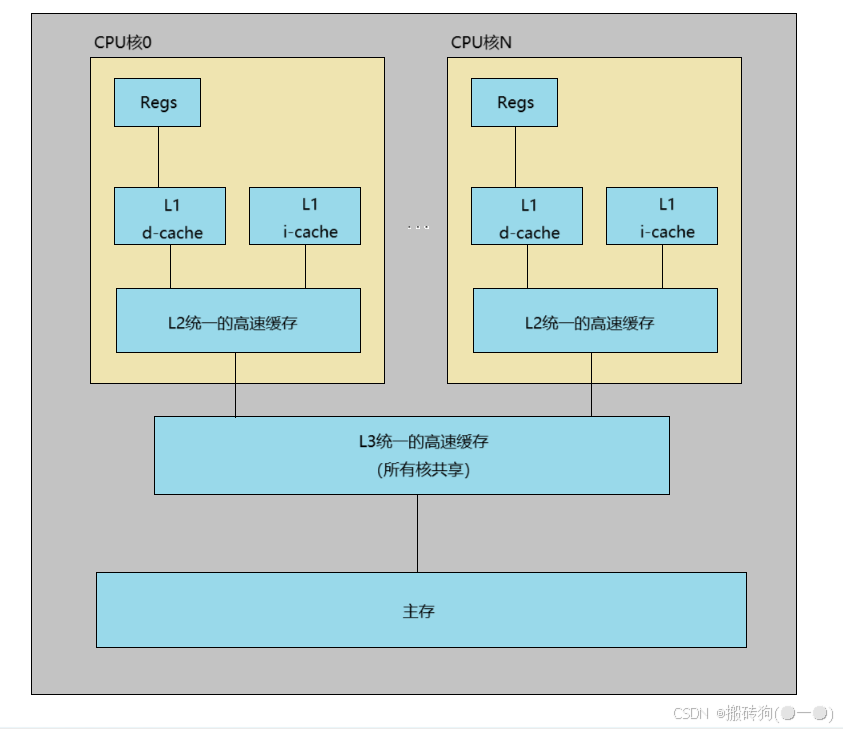
实际上,高速缓存既保存数据,也保存指令。只保存指令的高速缓存称为i-cache,只保存程序数据的高速缓存称为d-cache,既保存指令又保存数据的高速缓存称之为统一的高速缓存。就如上图所示,每个核有自己私有的 L1 i-cache、L1 d-cache 和 L2 统一高速缓存,所有核共享 L3 统一的高速缓存。
CPU如何读取磁盘中的一个数据 ?
- 请求阶段:当程序需要数据时,CPU 发出指令要求读取磁盘数据,这个请求被送到 I/O 控制器;
- 寻址阶段:I/O 控制器根据 CPU 提供的地址信息,控制磁盘的机械臂移动读 / 写磁头到相应磁道,并等待目标扇区旋转到读写位置;
- 数据传输阶段:利用 DMA(直接存储器访问)技术,磁盘将数据直接传输至内存的缓冲区中;
- 完成通知:数据传输完成后,I/O 控制器向 CPU 发送中断信号,告知操作已完成;
- 数据处理:CPU 收到中断信号后,将数据从内存缓冲区拷贝到 CPU 缓存,再从缓存中读取数据到寄存器进行处理。
数据一致性与并发控制
对于多核心 CPU,每个核心都有自己的缓存。当不同核心同时访问和修改同一内存变量时,可能会出现缓存不一致的情况。例如,一个核心更新了其缓存中的变量值,但其他核心的缓存中仍保留着旧值。为了解决这个问题,需要采用缓存一致性协议,确保当一个核心更新了缓存中的数据时,其他核心能够及时得知并更新自己的缓存,以保证数据的一致性。
当CPU 对 Cache进行写操作时,为了确保 Cache 和内存之间的数据一致性以及提高系统性能,会采用不同的数据写入策略,其中最常见的是直写(Write Through)和写回(Write Back)策略 。
直写
直写,也被称为写直通或写穿透 。其操作逻辑非常直观:当 CPU 要写入数据时,数据会同时被写入 Cache 和内存 。也就是说,只要有写操作发生,Cache 和内存中的数据都会立即被更新 。这就好比你在两个笔记本上同时记录同一件事情,一个笔记本是 Cache,另一个笔记本是内存 。
写回
写回策略的工作机制与直写策略有很大不同 。在写回策略中,当 CPU 进行写操作时,数据首先被写入 Cache,并不会立即写入内存 。只有当被修改的 Cache Line(缓存行,是 Cache 与内存之间数据交换的最小单位)要被替换出 Cache 时(比如 Cache 已满,需要腾出空间来存放新的数据),才会将其写回到内存中 。
为了实现这种延迟写入的机制,每个 Cache Line 都有一个脏标记位(Dirty Bit) 。当数据被写入 Cache 时,脏标记位会被设置,表示该 Cache Line 中的数据已经被修改,与内存中的数据不一致 。当 Cache Line 需要被替换时,系统会检查其脏标记位 。如果脏标记位被设置,说明该 Cache Line 中的数据是最新的,需要先将其写回到内存中,然后再进行替换操作;如果脏标记位未被设置,说明该 Cache Line 中的数据与内存中的数据一致,直接进行替换即可 。
缓存一致性问题的产生
在多核 CPU 的时代,每个 CPU 核心都拥有自己独立的缓存,这虽然进一步提高了数据访问的速度,但也带来了一个新的棘手问题 —— 缓存一致性问题 。
想象一下,有一个多核心的 CPU,其中核心 A 和核心 B 都需要访问内存中的同一个数据 X 。一开始,数据 X 被加载到核心 A 和核心 B 各自的缓存中 。当核心 A 对缓存中的数据 X 进行修改时,此时核心 A 缓存中的数据 X 已经更新,但核心 B 缓存中的数据 X 仍然是旧的 。如果在这个时候,核心 B 读取自己缓存中的数据 X,就会得到一个错误的、过时的值,这就导致了数据不一致的情况 。
以一个简单的银行转账程序为例,假设有两个线程分别在不同的 CPU 核心上执行转账操作 。这两个线程都需要读取账户余额,然后进行相应的加减操作 。如果存在缓存一致性问题,就可能出现这样的情况:第一个线程读取了账户余额为 1000 元,然后在自己的缓存中进行了减 100 元的操作,但还没有将更新后的数据写回内存 。此时,第二个线程从自己的缓存中读取账户余额,由于其缓存中的数据没有更新,仍然是 1000 元,然后也进行了减 100 元的操作 。最后,两个线程都将各自缓存中的数据写回内存,结果账户余额就变成了 800 元,而实际上应该是 900 元 。这种数据不一致的情况会对程序的正确性产生严重影响,尤其是在涉及到金融、数据库等对数据准确性要求极高的领域 。
缓存一致性解决方案
要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案呢,叫作总线嗅探——总线嗅探是一种解决缓存一致性问题的基本机制 。在这种机制下,每个CPU核心都通过总线与内存相连,并且每个核心都可以 “嗅探” 总线上的通信 。当一个CPU核心对自己缓存中的数据进行写操作时,它会向总线发送一个写请求,这个请求包含了被修改数据的地址等信息 。
总线上的其他 CPU 核心会监听这个请求,当它们发现请求中的地址与自己缓存中某数据的地址相同时,就会根据请求的类型(例如是写操作还是使缓存失效的操作),对自己缓存中的数据进行相应的处理 。如果是写操作,其他核心可能会选择将自己缓存中的该数据标记为无效,这样下次访问时就会从内存中重新读取最新的数据;如果是使缓存失效的操作,直接将对应缓存数据标记为无效即可 。
总线嗅探的优点是实现相对简单,不需要复杂的目录结构来记录缓存状态 。它能够快速地检测到其他核心对共享数据的修改,从而及时更新自己的缓存,保证数据的一致性 。然而,它也存在一些明显的缺点 。随着 CPU 核心数量的增加,总线上的通信量会大幅增加,因为每次写操作都要通过总线广播通知其他核心,这会导致总线带宽成为瓶颈,降低系统的整体性能 。而且,总线嗅探机制在处理复杂的多处理器系统时,可能会出现一些一致性问题,例如在多个核心同时进行读写操作时,可能会出现数据更新顺序不一致的情况 。
并发控制手段
锁机制是一种极为常见的并发控制手段,主要涵盖以下几种类型:
- 互斥锁(Mutex):用于保护共享资源在同一时刻只能被一个线程访问,适用于需要对共享资源进行独占访问的场景。
- 读写锁(Read - Write Lock):允许多个线程同时对共享资源进行读操作,但只允许一个线程进行写操作,适用于读操作频繁、写操作较少的场景。
- 自旋锁(Spinlock):当线程尝试获取锁时,如果锁已被其他线程占用,该线程会一直循环等待,直到获取到锁为止,适用于保护临界区较小且期望临界区锁定时间较短的场景。
- 递归锁(Reentrant Lock):允许同一个线程多次获取同一个锁,而不会导致死锁,适用于需要在同一线程中多次获取锁的场景,如递归函数调用。
- 条件变量(Condition Variable):一种线程间通信的机制,通常与互斥锁配合使用,当某个条件不满足时,线程可以通过条件变量进入等待状态,直到条件满足时被唤醒。
- 乐观锁(Optimistic Locking):基于假设并发冲突不常发生,在更新数据时检查数据是否已被其他事务修改,适用于读多写少的场景,通过版本号或时间戳等方式实现。
- 悲观锁(Pessimistic Locking):假设并发冲突可能频繁发生,因此在访问数据前加锁,确保数据在访问期间不会被其他事务修改,适用于写多读少的场景,如数据库的行锁、表锁等。
原子操作是一种不需要显式锁的同步机制,它通过硬件支持的原子操作指令来确保对共享资源的原子访问。虽然原子操作与锁机制都用于解决并发访问的问题,但严格来说原子操作不属于锁机制,不过在实现某些锁(如自旋锁)时通常会使用原子操作来更新锁的状态,以确保在多线程环境下的原子性。
除了锁机制和原子操作,常见的并发控制手段还有信号量、互斥量等。信号量可以控制多个进程或线程对有限资源的访问,通过 wait () 和 signal () 操作来实现资源的申请和释放。互斥量是更接近底层实现的锁机制,一般一次只能被一个线程获取所有权,锁定后的状态也只能被该线程释放
相关文章:

CPU cache基本原理
CPU cache基本原理 存储器层次结构存储器层次结构中的缓存高速缓存存储器直接映射高速缓存组相联高速缓存全相联高速缓存 多核 CPU 下缓存问题内存的读写操作流程数据一致性与并发控制 高速缓存(cache)是一个小而快速地存储设备,它作为存储在…...
)
【Java学习笔记】【第一阶段项目实践】零钱通(面向过程版本)
零钱通(面向过程版本) 需求分析 1. 需要实现的功能 (1) 收益入账 (2) 消费 (3 )查看明细 (4 )退出系统 2. 代码优化部分 (1) 对用户输入 4 退出时,给出提示 “你确定要退出吗?y/n”,必须输入正确的 y/n,…...

Cursor无法使用C/C++调试的解决办法
背景 这几天在二开ffmpeg,发现用cursor无法使用cppdbg进行调试,只能上机gdb,比较麻烦。 配置文件 // launch.json {// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// Fo…...
Excel开发进阶2:操作图片 改变大小 滚动到可视区)
VSTO(C#)Excel开发进阶2:操作图片 改变大小 滚动到可视区
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 入…...
)
嵌入式自学第二十二天(5.15)
顺序表和链表 优缺点 存储方式: 顺序表是一段连续的存储单元 链表是逻辑结构连续物理结构(在内存中的表现形式)不连续 时间性能, 查找顺序表O(1):下标直接查找 链表 O(n):从头指针往后遍历才能找到 插入和…...

高云FPGA-新增输出管脚约束
module led (input sys_clk, // clk inputinput sys_rst_n, // reset inputoutput reg [5:0] led, // 6 LEDS pinoutput reg gpio // 1 GPIO pin 25 ); 在原来的代码基础上新增加一个gpio输出,绑定到25管脚上 打开工程文件夹中的cts文件…...
原因排查)
Nginx 返回 504 状态码表示 网关超时(Gateway Timeout)原因排查
Nginx 返回 504 状态码表示 网关超时(Gateway Timeout),这意味着 Nginx 作为反向代理服务器,在等待上游服务器(如后端应用服务器、数据库服务器等)响应时,超过了预设的时间限制,最终…...

单片机 | 基于STM32的智能马桶设计
基于STM32的智能马桶设计结合了传感器技术、嵌入式控制及物联网功能,旨在提升用户体验并实现健康监测。以下是其设计原理、功能模块及代码框架的详细解析: 一、系统架构与核心功能 智能马桶的系统架构通常分为主控模块、传感器模块、执行器模块、通信模块及用户交互模块,主…...

2900. 最长相邻不相等子序列 I
2900. 最长相邻不相等子序列 I class Solution:def getLongestSubsequence(self, words: List[str], groups: List[int]) -> List[str]:n len(groups) # 获取 groups 列表的长度ans [] # 初始化一个空列表,用于存储结果for i, g in enumerate(groups): # 遍…...

欧姆龙 CJ/CP 系列 PLC 串口转网口模块:工业通信升级的智能之选
在工业自动化领域,欧姆龙 CJ/CP 系列 PLC 凭借高可靠性和灵活扩展性,广泛应用于汽车制造、食品加工、能源化工等关键行业。然而,传统串口通信的局限性(如距离受限、协议兼容性差、难以实现远程监控)却成为企业智能化升…...

BGP选路实验
一.需求 1.使用PreVal策略,确保R4通过R2到达192.168.10.0/24 2.使用As_Path策略,确保R4通过R3到达192.168.11.0/24 3.配置MED策略,确保R4通过R3到达192.168.12.0/24 4.使用Local Preference策略,确保R1通过R2到达192.168.1.0/2…...

Linux服务之lvs+keepalived nginx+keepalived负载均衡实例解析
目录 一.LVSKeepAlived高可用负载均衡集群的部署 二.NginxKeepAlived高可用负载均衡集群的部署 一.LVSKeepAlived高可用负载均衡集群的部署 实验环境 主keepalived:192.168.181.10 lvs (7-1) 备keepalived:192.168.181.10…...

idea整合maven环境配置
idea整合maven 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是springboot的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码…...

pytest框架 - 第二集 allure报告
一、断言assert 二、Pytest 结合 allure-pytest 插件生成美观的 Allure 报告 (1) 安装 allure 环境 安装 allure-pytest 插件:pip install allure-pytest在 github 下载 allure 报告文件 地址:Releases allure-framework/allure2 GitHub下载&#x…...

互联网大厂Java求职面试:构建高并发直播平台的架构设计与优化
标题:互联网大厂Java求职面试:构建高并发直播平台的架构设计与优化 引言 在互联网大厂的Java求职面试中,技术总监级别的面试官通常会提出一系列复杂且前沿的技术问题,以评估候选人的真实技术水平。本篇文章将围绕构建一个千万级…...

Ruby 循环与迭代器
Ruby 循环与迭代器 循环迭代器timesuptostep 循环 。。。。 迭代器 迭代器本质上可以理解为是循环的一种类型 times 3.times do print "Ho! " end begin Ho! Ho! Ho! end上述代码表示我们对当前 block 部分中的内容循环三次。最终,我们打印出了三个…...
)
pyenv简单的Python版本管理器(macOS版)
问题 python版本是真的多,需要用一个版本管理器管理Python多版本安装在同一台机器的问题。接下来,我们就尝试使用pyenv来管理。 安装pyenv brew update brew install pyenv配置Zsh echo export PYENV_ROOT"$HOME/.pyenv" >> ~/.zshr…...

Automatic Recovery of the Atmospheric Light in Hazy Images论文阅读
Automatic Recovery of the Atmospheric Light in Hazy Images 1. 论文的研究目标与实际意义1.1 研究目标1.2 实际问题与产业意义2. 论文的创新方法、模型与公式2.1 方法框架2.1.1 方向估计(Orientation Estimation)2.1.2 幅值估计(Magnitude Estimation)2.2 与传统方法的对…...

Vuex和Vue的区别
Vue和Vuex有着不同的功能和定位,主要区别如下: 概念与功能 - Vue:是一个构建用户界面的JavaScript框架,专注于视图层的开发,采用组件化的方式构建应用程序,通过数据绑定和指令系统,能方便地…...

全国青少年信息素养大赛 Python编程挑战赛初赛 内部集训模拟试卷八及详细答案解析
信息素养大赛初赛Python编程模拟试卷八 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...
)
RabbitMQ 消息模式实战:从简单队列到复杂路由(二)
进阶探索:工作队列模式 工作队列模式剖析 工作队列模式,也被称为任务队列模式,是对简单队列模式的一种扩展和优化,旨在解决当任务量较大时,单个消费者无法快速处理所有任务的问题 。在工作队列模式中,依然…...

崩坏星穹铁道风堇前瞻养成攻略 崩坏星穹铁道风堇配队推荐
风堇是崩坏星穹铁道3.3上半版本即将登场的一名全新五星角色,她的机制和强度都还不错,今天就给大家一些养成攻略。 一、突破材料准备 1.基础材料:旅情见闻 3 个冒险记录 3 个漫游指南 289 个命运的足迹 8 个 2.特供材料:思量的种…...

如何利用 Python 爬虫按关键字搜索京东商品:实战指南
在电商领域,京东作为国内知名的电商平台,拥有海量的商品数据。通过 Python 爬虫技术,我们可以高效地按关键字搜索京东商品,并获取其详细信息。这些信息对于市场分析、选品上架、库存管理和价格策略制定等方面具有重要价值。本文将…...

阿里云的网络有哪些
阿里云的网络类型丰富,主要包括以下几种: 专有网络 VPC(Virtual Private Cloud)1:是用户基于阿里云创建的自定义私有网络。不同的专有网络之间二层逻辑隔离,用户可在自己创建的专有网络内创建和管理云产品…...

【微信小程序】webp资源上传失败
正文 快速开发了一个小程序,图片资源占比较多,于是从 png 到 jpg 压缩,勉强满足了 2MB 的限制,不用另外准备 cdn。 但这样肯定不适合,进一步更新时,空间便会爆表。 于是花了点时间,将所有的…...

鸿蒙 ArkUI - ArkTS 组件 官方 UI组件 合集
ArkUI 组件速查表 鸿蒙应用开发页面上需要实现的 UI 功能组件如果在这 100 多个组件里都找不到,那就需要组合造轮子了 使用技巧:先判断需要实现的组件大方向,比如“选择”、“文本”、“信息”等,或者是某种形状比如“块”、“图…...

科学养生指南:解锁健康生活的密码
健康是人生最宝贵的财富,科学养生则是守护这笔财富的关键。即使抛开传统中医理论,现代科学也为我们提供了诸多实用的养生方法。 合理饮食是健康养生的基石。人体需要碳水化合物、蛋白质、脂肪、维生素和矿物质等多种营养物质维持运转。日常饮食应遵循…...

Linux的进程管理和用户管理
gcc与g的区别 比如有两个文件:main.c mainc.cpp(分别是用C语言和C语言写的)如果要用gcc编译: gcc -o mainc main.c gcc -o mainc mainc.cpp -lstdc表明使用C标准库; 区别一: gcc默认只链接C库&#x…...

数据科学和机器学习的“看家兵器”——pandas模块 之五
目录 4.5 pandas 高级数据处理与分析 一、课程目标 二、对数据表格进行处理 (一)行列转置 (二)将数据表转换为树形结构 三、数据表的拼接 (一)merge () 函数的运用 (二)concat () 函数的运用 (三)append () 函数的运用 四、对数据表格的同级运算 五、计算数据表格中数…...

轻量级Web画板Paint Board如何本地部署与随时随地在线绘画分享
文章目录 前言1.关于Paint Board2.本地部署paint-board3.使用Paint Board4.cpolar内网穿透工具安装5.创建远程连接公网地址6.固定Paint Board公网地址 前言 今天我要给大家介绍一款超级轻便、好玩到飞起的Web画板Paint Board!这可是创意人手中的秘密武器。无论是刚…...

攻击溯源技术体系:从理论架构到工程化实践的深度剖析
一、攻击溯源的理论基石与模型构建 1.1 形式化理论框架 攻击溯源本质上是基于离散数学与图论的演绎推理过程。通过构建攻击事件有向图(AEDG, Attack Event Directed Graph),将网络空间中的每个事件抽象为节点,事件间的因果关系…...

fpga系列 HDL : Microchip FPGA开发软件 Libero Soc 安装 license申请
启动 注册账号:https://login.microchip.com/申请免费许可:https://www.microchipdirect.com/fpga-software-products C:\Windows\System32>vol驱动器 C 中的卷是 Windows卷的序列号是 ****-****为“D:\Microsemi\License.dat”创建环境变量“LM_LICE…...

海康立体相机3DMVS软件使用不同工作模式介绍
文章目录 1. Sensor Calibration(传感器标定模式)2. Depth(深度模式)3. RGB-D(彩色深度融合模式)4. Depalletizing(拆垛模式)5. Debug(调试模式)6. Point Clo…...

深度学习、机器学习及强化学习的联系与区别
联系 深度学习与机器学习 :深度学习是机器学习的一个分支。机器学习涵盖众多方法,如决策树、支持向量机等,而深度学习基于神经网络构建多层结构来学习数据特征。深度学习利用反向传播算法和梯度下降等优化方法来训练神经网络模型,…...

75.xilinx复数乘法器IP核调试
(83*j)*(57j) 935j 正确的是 1971j 分析出现的原因:(abj)* (cdj) (ac-bd)j(adbc) 其中a,b,c,d都是16bit的有符号数,乘积的结果为保证不溢出需要32bit存储,最终的复数乘法结果是两个32b…...

【笔记】CosyVoice 模型下载小记:简单易懂的两种方法对比
#工作记录 笔记标签:#CosyVoice 模型 #模型下载 #ModelScope #Git LFS #语音合成开发 一、强烈推荐:用 ModelScope SDK 下载(简单又靠谱) 1.1 好处多多 不容易出错:能自动把模型需要的所有东西都下载好,…...

本地部署 私有云网盘 Nextcloud 并实现外部访问
Nextcloud 是一款开源免费的私有云盘系统,可以快速地搭建一套属于自己的云同步网盘,从而实现跨设备的文件同步、文件共享、以及团队协作等功能。Nextcloud 功能强大且完全开源,拥有庞大的开源社区支持。 本文将详细的介绍如何利用 Docker 在…...

黑马程序员C++2024版笔记 第0章 C++入门
1.C代码的基础结构 以hello_world代码为例: 预处理指令 #include<iostream> using namespace std; 代码前2行是预处理指令,即代码编译前的准备工作。(编译是将源代码转化为可执行程序.exe文件的过程) 主函数 主函数是…...

D3485:一款高性能RS-485收发器解析
D3485是一款5V供电、半双工RS-485收发器,广泛应用于智能电表、工业控制和安防监控等领域。它内部包含一路驱动器和一路接收器,采用限摆率驱动器设计,能有效减少电磁干扰(EMI)和反射,支持高达10Mbps的无差错…...

std::deque和std::vector对比
std::deque和std::vector都是 C标准库中非常重要的容器,但它们的设计目标和优化方向不同,因此各有适用场景。std::deque并没有取代std::vector,原因主要在于以下几个方面: 1.性能特点不同 1.1std::vector的优势 • 连续存储&am…...

【蓝桥杯省赛真题49】python偶数 第十五届蓝桥杯青少组Python编程省赛真题解析
python偶数 第十五届蓝桥杯青少组python比赛省赛真题详细解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...

15分钟决胜项目管理:碎片时间的高效拆解术
作为项目经理,你是否经常觉得一天像打仗?会议连轴转、消息轰炸、计划赶不上变化……时间总是不够用。但真相是:高效的人并不是时间更多,而是更会“切分时间”。试试“15分钟法则”——每天用几段碎片时间,就能让工作从…...

计算机网络:什么是电磁波以及有什么危害?
电磁波详解 电磁波(Electromagnetic Wave)是由电场和磁场相互激发、在空间中传播的能量形式。它既是现代通信的基石(如手机、Wi-Fi、卫星信号),也是自然界中光、热辐射等现象的本质。以下从定义、产生、特性、分类及应用全面解析: 一、电磁波的本质 1. 核心定义 电场与…...

Docker部署单节点Elasticsearch
1.Docker部署单节点ES 1.前置条件 配置内核参数 echo "vm.max_map_count262144" >> /etc/sysctl.conf sysctl -w vm.max_map_count262144准备密码 本文所有涉及密码的配置,均使用通用密码 Zzwl2024。 生产环境,请用密码生成器生成20…...

Docker构建Nginx、PHP、MySQL及WordPress部署及解释
目录 一、构建Nginx 二、构建PHP 三、构建MySQL 四、启动容器 五、测试 六、部署网站 一、构建Nginx 创建目录并进入目录 bash 复制 mkdir /opt/nginx cd /opt/nginx mkdir /opt/nginx:在 /opt 目录下创建一个名为 nginx 的目录。 cd /opt/nginx&#x…...

计算机网络:蜂窝网络和WiFi网络使用的射频信号有什么区别?
— 频段设计,蜂窝网络,比如4G LTE或5G,使用的频段通常由各国政府机构分配,例如在Sub-6GHz范围内,还有一些高频的毫米波。而WiFi主要使用的是2.4GHz和5GHz的ISM(工业、科学、医疗)免许可频段。这说明两者的频段不同,可能带来不同的传播特性和干扰情况。 —调制方式,蜂窝…...

今日行情明日机会——20250515
上证指数缩量收阴线,个股跌多涨少,上涨波段4月9日以来已有24个交易日,时间周期上处于上涨末端,注意风险。 深证指数缩量收阴线,日线上涨结束的概率在增大,注意风险。 2025年5月15日涨停股主要行业方向分…...

康复训练:VR 老年虚拟仿真,趣味助力恢复
对于那些因身体机能衰退、疾病或者意外而急需康复训练的老人而言,传统的康复方式通常显得极为枯燥乏味。例如,只是在康复师的指导下机械地重复抬腿、伸手等简单动作,日复一日,毫无新意,这样的模式使得老人很难长期坚持…...

【美团】后端一面复盘|项目驱动 + 手撕 + JVM + 数据库全面覆盖
【美团】后端一面复盘|项目驱动 手撕 JVM 数据库全面覆盖 📍 面试公司:美团 🎯 面试岗位:后端开发工程师 📞 面试形式:电话面(OC) 🕒 面试时长࿱…...

3DVR制作的工具或平台
3DVR(三维虚拟现实)是利用三维图像技术和虚拟现实技术,将真实场景进行三维扫描并转换成计算机可识别的三维模型,使用户能够在虚拟空间中自由漫游,体验身临其境的感觉。3DVR技术结合了全景拍摄和虚拟现实,提…...