# 深度剖析LLM的“大脑”:单层Transformer的思考模式探索
简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。
LLMs 是怎么思考的呢?
开源 LLM 出现之后,研究的方法就变得简单啦,那就是去读它们的架构,因为每个 LLM 都是由神经元组成的嘛。要研究它们,就得弄清楚对于某个特定输入,哪些神经元会被激活。比如说,用户问了一句:“声音的定义是什么呀?”那就可以看看为了回答这个问题,哪些神经元被激活了,这样就能窥探到 LLM 的思考过程啦。
为了回答这个问题,咱们就来训练一个单层 Transformer,这个 Transformer 是基于稀疏自编码器的 LLM,至少能让它说话的时候语法和标点符号都用得对。训练好之后,就可以开始探索它的内部架构,看看对于某些输入文本,哪些神经元会被激活。说不定还能发现一些挺有意思的见解呢。咱们会复制 Anthropic 最新的研究成果,这样就能更清楚地看到 LLM 背后到底是怎么思考的啦。
到底是什么问题呀?
研究 LLMs 是怎么工作的主要问题就是,一个单独的神经元代表多种功能,也就是说,一个神经元可能会在 “对数学方程、诗歌、JSON 代码片段以及跨多种语言的‘尤里卡!’都做出反应”。这就叫 多义性,想象一下,要是用 10 亿参数的 LLMs,那里面有很多神经元都被激活了,而且每个神经元都对应着混合的信息。这可真的让人很难看清思考到底是怎么发生的。
最近研究人员提出了一个技术,不是去看每一个单独的神经元,而是去看那些能捕捉特定概念的神经元的线性组合,这就叫 单义性,而这种技术就叫做 稀疏字典学习。
神经网络快速回顾
神经网络你可能已经很熟悉啦,不过咱还是快速复习一下基础知识吧。对于计算机来说,语言模型不过就是一组矩阵,按照特定的方式相乘相加而已。但是人类更抽象地看待它们,把它们当作由人工神经元组成的网络。它们通常看起来是这样的:
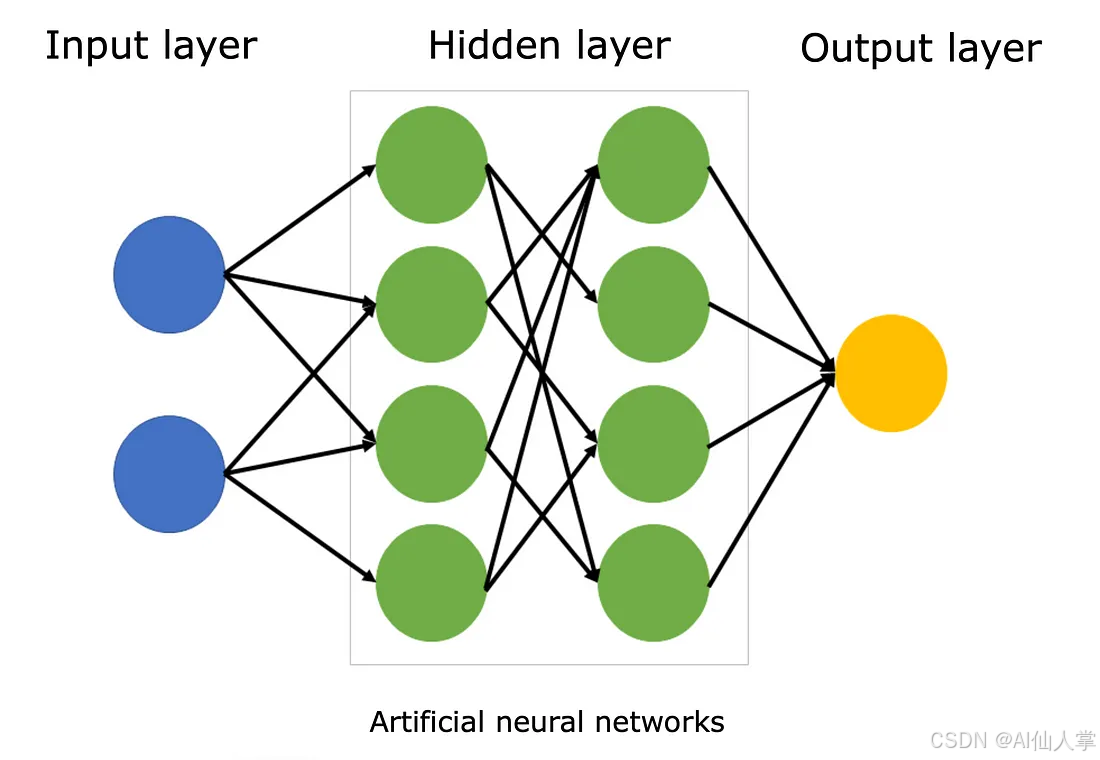
那两列绿色的圆圈就是所谓的“层”。当输入信号从左到右穿过网络的时候,这些层会产生 “激活”,咱们可以把这些激活想象成向量。这些激活向量就代表着模型基于输入的 “思考”,也展示了咱们想要理解的神经元。
准备训练数据
咱们的训练数据集必须得多样化,包含来自不同领域的信息,而 The Pile 就是个不错的选择。虽说它有 825 GB 那么大,但咱就只用其中的 5% 好啦。先来下载数据集,看看它是怎么工作的。我打算下载 HuggingFace 上可用的版本。
# 下载验证数据集!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst# 下载训练数据集的第一部分
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst
下载得花点时间,不过你也可以把训练数据集限制在只用一个文件,比如 00.jsonl.zst,而不是三个。它已经分成了训练集、验证集和测试集啦。下载完之后,记得把文件正确地放在各自的目录里哦。
import os
import shutil
import glob# 定义目录结构
train_dir = "data/train"
val_dir = "data/val"# 如果目录不存在就创建
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)# 把所有训练文件(比如 00.jsonl.zst、01.jsonl.zst 等等)都移动到对应的目录里
train_files = glob.glob("*.jsonl.zst")
for file in train_files:if file.startswith("val"):# 移动验证文件dest = os.path.join(val_dir, file)else:# 移动训练文件dest = os.path.join(train_dir, file)shutil.move(file, dest)
咱们的数据集是 .jsonl.zst 格式的,这是一种常用来存储大型数据集的压缩文件格式。它把 JSON Lines(.jsonl,每一行都是一个有效的 JSON 对象)和 Zstandard(.zst)压缩结合在了一起。咱们来读取一下刚刚下载的文件的一个样本,看看它长啥样。
in_file = "data/val/val.jsonl.zst" # 验证文件的路径with zstd.open(in_file, 'r') as in_f:for i, line in tqdm(enumerate(in_f)): # 读取前 5 行data = json.loads(line)print(f"Line {i}: {data}") # 打印原始数据供检查if i == 2:break
#### 输出结果 ####
Line: 0
{"text": "Effect of sleep quality ... epilepsy.","meta": {"pile_set_name": "PubMed Abstracts"}
}
Line: 1
{"text": "LLMops a new GitHub Repository ...","meta": {"pile_set_name": "Github"}
}
接下来,咱们得对数据集进行编码(也就是分词)。咱们的目标是让 LLM 至少能输出正确的单词。为了做到这一点,咱们得用一个已经有的分词器。咱们会用 OpenAI 的开源分词器 tiktoken,用 r50k_base 分词器,也就是 ChatGPT(GPT-3)模型用的那个,来对数据集进行分词。
咱们得创建一个函数来避免重复劳动,因为咱们要对训练集和验证集都进行分词。
def process_files(input_dir, output_file):"""处理指定输入目录中的所有 .zst 文件,并将编码后的 token 保存到 HDF5 文件中。参数:input_dir (str): 包含输入 .zst 文件的目录。output_file (str): 输出 HDF5 文件的路径。""" with h5py.File(output_file, 'w') as out_f: # 在 HDF5 文件中创建一个可扩展的数据集,名为 'tokens'dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')start_index = 0 # 遍历输入目录中的所有 .zst 文件for filename in sorted(os.listdir(input_dir)):if filename.endswith(".jsonl.zst"):in_file = os.path.join(input_dir, filename)print(f"正在处理:{in_file}") # 打开 .zst 文件进行读取with zstd.open(in_file, 'r') as in_f: # 遍历压缩文件中的每一行for line in tqdm(in_f, desc=f"正在处理 {filename}"): # 将行加载为 JSONdata = json.loads(line) # 在文本末尾添加结束文本标记并进行编码text = data['text'] + "<|endoftext|>"encoded = enc.encode(text, allowed_special={'<|endoftext|>'})encoded_len = len(encoded) # 计算新 token 的结束索引end_index = start_index + encoded_len # 扩展数据集大小并存储编码后的 tokendataset.resize(dataset.shape[0] + encoded_len, axis=0)dataset[start_index:end_index] = encoded # 更新下一批 token 的开始索引start_index = end_index
这个函数有两个重要点需要注意哦:
- 咱们把分词后的数据存储在 HDF5 文件里,这样在训练模型的时候就能更快速地访问数据啦。
- 添加
<|endoftext|>标记是为了标记每个文本序列的结束,告诉模型它已经到达了一个有意义的上下文的结尾,这有助于生成连贯的输出哦。
现在就可以简单地用下面的代码对训练集和验证集进行编码啦:
# 定义分词数据输出目录out_train_file = "data/train/pile_train.h5"
out_val_file = "data/val/pile_dev.h5"# 加载(GPT-3/GPT-2 模型)的分词器
enc = tiktoken.get_encoding('r50k_base')# 处理训练数据
process_files(train_dir, out_train_file)# 处理验证数据
process_files(val_dir, out_val_file)
咱们来看看分词后的数据样本吧:
with h5py.File(out_val_file, 'r') as file: # 访问 'tokens' 数据集
tokens_dataset = file['tokens'] # 打印数据集的 dtype
print(f"'tokens' 数据集的 dtype:{tokens_dataset.dtype}") # 加载并打印数据集的前几个元素
print("‘tokens’ 数据集的前几个元素:")
print(tokens_dataset[:10]) # 前 10 个 token#### 输出结果 ####
Dtype of 'tokens' dataset: int32
First few elements of the 'tokens' dataset:
[ 2725 6557 83 23105 157 119 229 77 5846 2429]
单层 Transformer 概述
现代语言模型几乎总是使用某种 Transformer 架构的变体。虽说没必要深入探究 Transformer 是怎么工作的,但咱还是简单了解一下大概吧:
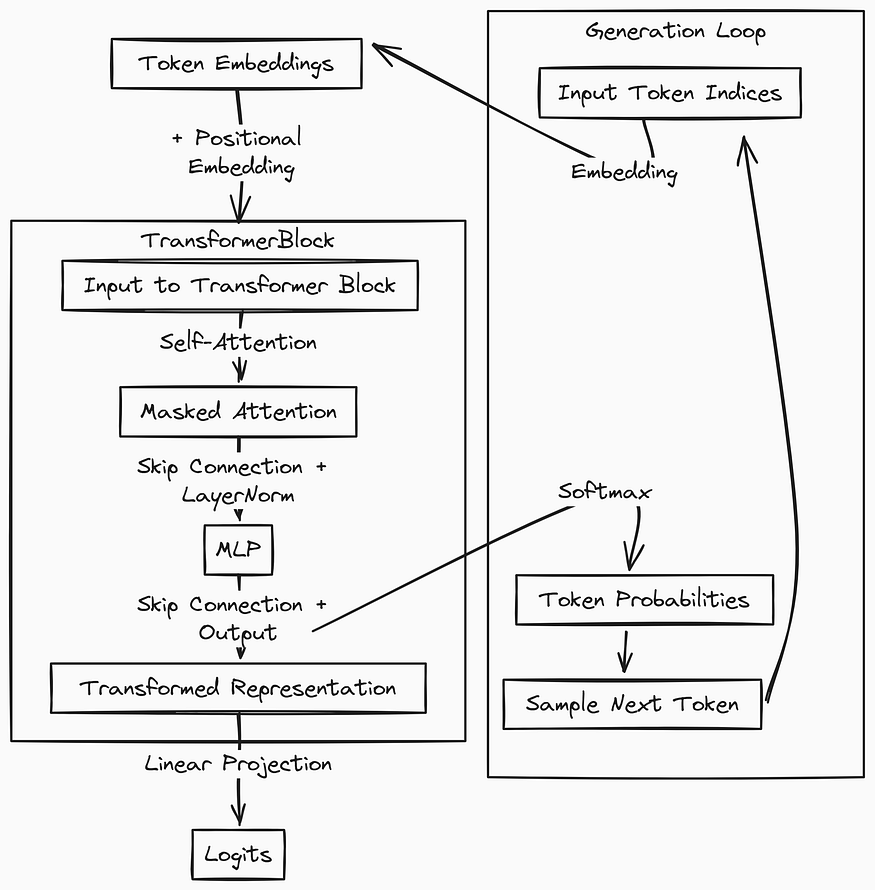
Transformer 架构
对于语言模型来说,Transformer 接收一串文本(编码为 token)作为输入,然后输出每个可能的下一个 token 的概率。Transformer 由多个 Transformer 块组成,最后是一个全连接层。通常情况下,Transformer 有很多这样的块堆叠在一起,但这次研究用的网络只有一块,为了简单起见,这就是 “咱们还搞不懂的最简单的语言模型”。
在 Transformer 块里面,你会找到自注意力头和一个叫做多层感知器(MLP)的组件。你可以这样理解这两个组件:注意力头决定模型应该关注输入的哪些部分,而 MLP 则进行实际的处理或者说“思考”。MLP 本身是一个简单的前馈神经网络,有一个输入(注意力头的输出)、一个隐藏层和一个输出。
这个隐藏层扮演着一个挺有意思的的角色哦,为了简单起见,咱们就关注它,忽略模型的其他部分吧。每次把一串文本输入到 Transformer 里的时候,隐藏层的激活作为向量,就是能告诉我们 LLMs 是怎么思考的答案啦。往后,咱们可以称这些为 “MLP 激活向量” 或者简单地说 “激活向量”。
MLP(多层感知器)
MLP 是 Transformer 前馈网络的关键部分哦。它能帮助模型学习数据中复杂的关系。MLP 有两个主要部分:
- 一个隐藏层,它会增加输入的大小(通常是原来的 4 倍),并且应用 ReLU 激活函数。
- 一个最终层,它会把大小再减回到原来的维度。
这种结构有助于完善注意力机制所学到的数据表示。n_embed 参数定义了输入的大小。
class MLP(nn.Module):def __init__(self, n_embed):super().__init__()# 定义一个简单的 MLP,包含两个线性层和一个 ReLU 激活函数self.net = nn.Sequential(nn.Linear(n_embed, 4 * n_embed), # 第一层将嵌入大小扩展 4 倍nn.ReLU(), # ReLU 激活引入非线性nn.Linear(4 * n_embed, n_embed) # 第二层将大小减回嵌入大小) def forward(self, x):# 将输入传递通过 MLP 网络return self.net(x)
- 首先定义了一个
Sequential网络,包含两个Linear层。 - 第一层将输入大小(
n_embed)扩展到4 * n_embed,为更复杂的转换留出空间。 ReLU激活函数引入非线性,帮助模型捕捉复杂模式。- 第二个
Linear层将大小再减回n_embed,确保输出与 Transformer 兼容。
注意力机制
注意力头专注于输入序列的相关部分。重要的参数包括:
- n_embed:定义了输入到注意力机制的大小。
- context_length:帮助创建一个因果掩码,确保模型只关注过去的 token。
注意力头使用无偏置的线性层来计算键、查询和值。使用下三角矩阵进行因果掩码,确保模型不会关注未来的 token。
class Attention(nn.Module):def __init__(self, n_embed, context_length):super().__init__()# 定义一个线性层来计算查询、键和值矩阵self.qkv = nn.Linear(n_embed, n_embed * 3, bias=False) # 创建一个三角矩阵用于因果掩码,防止关注未来的 tokenself.tril = torch.tril(torch.ones(context_length, context_length)) def forward(self, x):B, T, C = x.shape # B = 批量大小,T = 序列长度,C = 嵌入大小# 将 qkv 线性层的输出分成查询、键和值q, k, v = self.qkv(x).chunk(3, dim=-1) # 使用查询和键的点积计算注意力分数attn = (q @ k.transpose(-2, -1)) / C**0.5 # 应用因果掩码,防止关注序列中未来的位置attn = attn.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # 应用 softmax 将注意力分数转换为概率,然后对值进行加权return (F.softmax(attn, dim=-1) @ v)
qkv是一个单独的线性层,产生三个不同的矩阵:查询(q)、键(k)和值(v)。q和k的点积创建了注意力分数,这些分数通过C**0.5进行缩放。- 因果掩码(
tril)确保我们不会关注未来的 token(对于自回归任务很重要)。 - 应用
softmax将分数转换为概率,然后使用这些概率对值(v)进行加权。
Transformer 块
Transformer 块是注意力层和 MLP 层的组合,用 LayerNorm 和残差连接包裹起来,以帮助稳定训练。既然咱们这次不针对多头注意力,所以也就没必要用 n_block 参数来定义需要多少个块啦!
class TransformerBlock(nn.Module):def __init__(self, n_embed, context_length):super().__init__()# 初始化注意力机制self.attn = Attention(n_embed, context_length) # 初始化 MLP 组件self.mlp = MLP(n_embed) # 用于训练稳定性的层归一化self.ln = nn.LayerNorm(n_embed) def forward(self, x):# 应用 LayerNorm 和注意力,然后加上残差连接x = x + self.attn(self.ln(x)) # 应用 LayerNorm 和 MLP,再加上另一个残差连接return x + self.mlp(self.ln(x))
LayerNorm在应用转换之前对输入进行归一化。- 首先应用注意力机制,其输出通过残差连接加回到输入。
- 然后,应用 MLP 并加上另一个残差连接。
- 这些步骤有助于稳定训练并实现更好的特征学习。
训练单层模型
现在咱们已经有了所有组件,就可以开始训练啦,不过在那之前,咱们得把 token 嵌入和位置嵌入与 Transformer 块结合起来,用于序列到序列的任务。
class Transformer(nn.Module):def __init__(self, n_embed, context_length, vocab_size):super().__init__()# 用于 token 表示的嵌入self.embed = nn.Embedding(vocab_size, n_embed) # 用于位置编码的嵌入self.pos_embed = nn.Embedding(context_length, n_embed) # 定义 Transformer 块(多头注意力 + MLP 层)self.block = TransformerBlock(n_embed, context_length) # 最终的线性层,将隐藏状态映射到词汇大小,用于 token 预测self.lm_head = nn.Linear(n_embed, vocab_size) # 注册位置索引缓冲区,以便在生成过程中进行一致的索引self.register_buffer('pos_idxs', torch.arange(context_length)) def forward(self, idx):# 获取输入 token 及其位置的嵌入x = self.embed(idx) + self.pos_embed(self.pos_idxs[:idx.shape[1]]) # 将嵌入的输入传递通过 Transformer 块x = self.block(x) # 将输出传递通过语言模型头部进行 token 预测return self.lm_head(x) def generate(self, idx, max_new_tokens):# 逐个生成新 token,直到达到 max_new_tokensfor _ in range(max_new_tokens):# 获取序列中最后一个 token 的 logitslogits = self(idx)[:, -1, :] # 通过将 softmax 应用于 logits 来随机抽样下一个 tokenidx_next = torch.multinomial(F.softmax(logits, dim=-1), 1) # 将预测的 token 添加到输入序列中idx = torch.cat((idx, idx_next), dim=1) # 返回生成的 token 序列return idx
现在咱们已经构建了最简单的 Transformer 模型,接下来,咱们需要定义训练配置。
# 定义词汇表大小和 Transformer 配置VOCAB_SIZE = 50304 # 词汇表中唯一 token 的数量
BLOCK_SIZE = 512 # 模型的最大序列长度
N_EMBED = 2048 # 嵌入空间的维度
N_HEAD = 16 # 每个 Transformer 块中的注意力头数量# 训练参数
BATCH_SIZE = 64
MAX_ITER = 100 # 为了快速示例,减少迭代次数
LEARNING_RATE = 3e-4
DEVICE = 'cpu' # 或者 'cuda',如果你有 GPU 的话# 训练和开发数据集的路径
TRAIN_PATH = "data/train/pile_val.h5" # 训练数据集的文件路径
DEV_PATH = "data/val/pile_val.h5" # 验证数据集的文件路径
接下来,咱们来编写一个简单的训练循环,开始训练咱们的单层 Transformer 模型,看看它对于调试有没有用哦。
# 从 HDF5 文件中加载训练数据
train_data = h5py.File(TRAIN_PATH, 'r')['tokens']# 获取训练或验证的批次数据的函数
def get_batch(split):# 为了简单起见,训练和验证都使用相同的数据(`train_data`)data = train_data# 随机选择每个序列在批次中的起始索引ix = torch.randint(0, data.shape[0] - BLOCK_SIZE, (BATCH_SIZE,))# 为批次中的每个元素创建输入(x)和目标(y)序列x = torch.stack([torch.tensor(data[i:i+BLOCK_SIZE], dtype=torch.long) for i in ix])y = torch.stack([torch.tensor(data[i+1:i+BLOCK_SIZE+1], dtype=torch.long) for i in ix])# 将输入和目标批次移动到设备(GPU/CPU)x, y = x.to(DEVICE), y.to(DEVICE)return x, y# 初始化 Transformer 模型、优化器和损失函数
model = Transformer(N_EMBED, CONTEXT_LENGTH, VOCAB_SIZE).to(DEVICE) # 定义模型
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE) # AdamW 优化器
loss_fn = nn.CrossEntropyLoss() # 用于训练的交叉熵损失# 训练循环
for iter in tqdm(range(MAX_ITER)): # 在指定的迭代次数内进行迭代# 获取一批训练数据xb, yb = get_batch('train') # 执行模型的前向传播以获取 logits(预测值)logits = model(xb) # 重塑 logits 以匹配损失计算所需的形状B, T, C = logits.shape # B:批量大小,T:序列长度,C:词汇表大小logits = logits.view(B*T, C) # 展平批量和时间维度yb = yb.view(B*T) # 展平目标标签 # 通过比较 logits 和目标标签计算损失loss = loss_fn(logits, yb) # 将优化器的梯度清零optimizer.zero_grad() # 执行反向传播以计算梯度loss.backward() # 使用优化器更新模型参数optimizer.step() # 每 10 次迭代打印一次损失if iter % 10 == 0:print(f"迭代 {iter}:损失 {loss.item():.4f}")# 将训练好的模型保存到文件中
MODEL_SAVE_PATH = "one_layer_transformer_short.pth" # 定义模型保存路径
torch.save(model.state_dict(), MODEL_SAVE_PATH) # 保存模型的状态字典(权重)
print(f"模型已保存至 {MODEL_SAVE_PATH}")print("训练完成。") # 表明训练已经完成
它将开始咱们的训练,并且每 10 次迭代打印一次损失:
迭代 0:损失 0.1511241
迭代 1:损失 0.1412412
迭代 2:损失 0.1401021
...
生成文本
一旦训练完成 100 个 epoch,咱们就可以看看咱们训练好的模型的输出,看看它对于正确的标点和语法生成有没有用。
# 定义模型路径、输入文本以及其他参数
model_path ='one_layer_transformer_short.pth'
input_text = "|<end_of_text >|"
max_new_tokens = 50
device = 'cuda' # 或者 'cpu'# 加载模型检查点
checkpoint = torch.load(model_path, map_location=torch.device(device))#使用配置文件中的配置初始化模型
model =Transformer( n_head=config['n_head'], n_embed=config['n_embed'],
context_length=config['context_length'], vocab_size=config['vocab_size'],)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval().to(device)# 加载分词器
enc =tiktoken.get_encoding("r50k_base")# 对输入文本进行编码
start_ids =enc.encode_ordinary(input_text)
context = torch.tensor(start_ids,dtype=torch.long, device=device).unsqueeze(0)# 生成过程 withtorch.no_grad(): generated_tokens = model.generate(context,max_new_tokens=max_new_tokens)[0].tolist()# 对生成的 token 进行解码output_text = enc.decode(generated_tokens)# 输出生成的文本print(output_text)
★ "Twisted Roads in Sunset Drive"("I’m aware my partner
heads out next week for business" 的一个变体)山谷的宁静低语,被 Montgomery 观察着。
跨越美洲,各种机构(参考欧洲模式)John Robinson 深入探究了这些转变,如今他的反思正在影响更广阔的格局。
领导者的思绪尚未被完全捕捉。
输出的内容没啥意义,不过咱们感兴趣的是它的语法和标点,而且它在这方面表现得还不错,足够咱们进行下一步啦。
神经元分布
现在,为了大致了解一下咱们训练好的模型中的神经元行为,咱们可以看看神经元密度直方图。
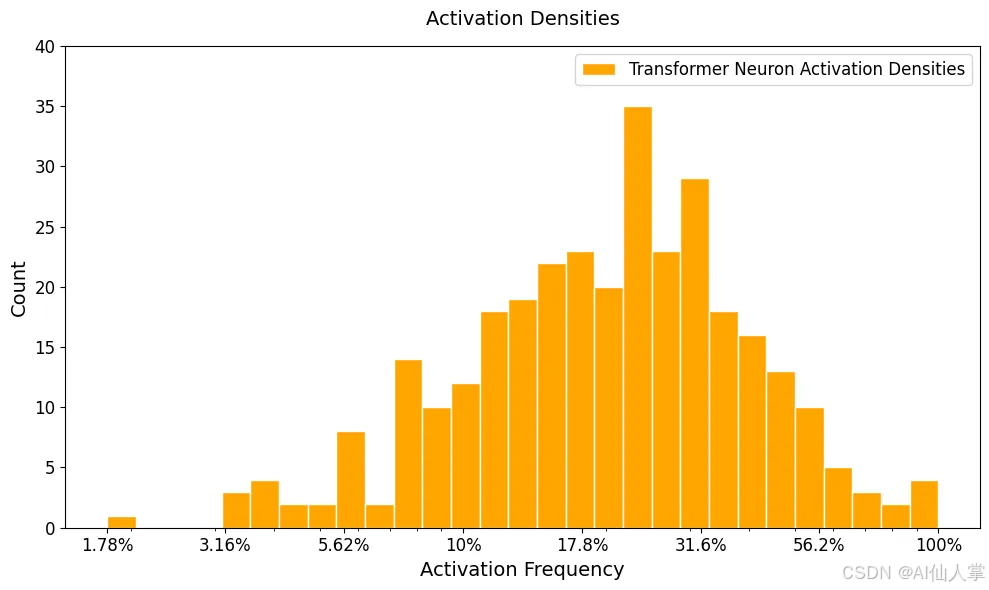
这个直方图展示了当给定来自数据集的输入时,神经元激活的频率。咱们随机采样了很多输入,检查了激活情况,并且记录了每个神经元被激活(也就是有非零激活值)的频率。直方图显示了在所有输入中,每个神经元被激活的比例。
从图中可以看出,大多数神经元的激活频率超过 10%,而且大约有一半的神经元激活频率超过 25%。这对于可解释性来说可不是好事,因为这表明这些神经元要么是为了非常宽泛的想法而激活,要么是为了多个概念。为了更好地进行解释,咱们希望神经元能够对特定的、狭窄的概念做出反应,这意味着咱们需要让它们的激活更加稀疏和 稀疏。
稀疏自编码器
为了让激活变得稀疏,咱们使用稀疏自编码器。这是一个与 Transformer 一起训练的独立网络。自编码器接收 MLP 激活向量,对其进行编码,然后尝试重建它。咱们在隐藏层中强制执行稀疏性,以便对 MLP 激活进行解释。

它的原理如下:
- 自编码器有一个单独的隐藏层。
- 输入和输出的形状与激活向量相同。
- 中间层的大小是固定的(例如,1024 个特征),足够小以高效训练,但又足够大以捕捉有用的特征。
- 为了强制执行稀疏性,在训练过程中向损失函数添加 L1 惩罚(激活值的绝对值之和),除了均方误差(MSE)损失之外。这通过将小激活值推向零来鼓励激活变得稀疏。
稀疏字典学习
Anthropic 的研究人员在训练过程中加入了 稀疏字典学习与自编码器,这进一步促进了稀疏性。它的原理如下:
- 强制解码器权重矩阵的每一行具有单位 L2 范数和零均值。这确保了每个激活方向都是不同的(就像一个“字典”)。
- MLP 激活向量被表示为这些字典条目的线性组合,其中每个隐藏层激活是一个字典条目的系数。
在训练过程中:
- 解码器权重被归一化为零均值,这有助于自编码器学习高效的稀疏表示。
- 最终的损失包括编码表示的 L1 范数,这控制了学习到的特征的稀疏性。咱们可以通过一个超参数来调整稀疏性水平。
接下来,咱们来编写稀疏自编码器以及字典学习的代码,然后就可以检查神经元分布,看看它有没有变得更好啦。
class SparseAutoencoder(nn.Module):def __init__(self, n_features, n_embed):super().__init__() # 编码器:一个全连接层,将输入转换到编码空间。# 输入大小为 n_embed * 4,输出大小为 n_features。self.encoder = nn.Linear(n_embed * 4, n_features) # 解码器:一个全连接层,从编码中重建原始输入。# 输入大小为 n_features,输出大小为 n_embed * 4。self.decoder = nn.Linear(n_features, n_embed * 4) # ReLU 激活函数,在编码后应用。self.relu = nn.ReLU() def encode(self, x_in):# 在编码过程中,从输入中减去解码器的偏差以进行归一化。x = x_in - self.decoder.bias # 应用编码器(线性变换后跟 ReLU 激活)。f = self.relu(self.encoder(x)) return f def forward(self, x_in, compute_loss=False): # 对输入进行编码以获得特征表示。f= self.encode(x_in) # 对特征表示进行解码,将其还原回输入空间x = self.decoder(f) # 如果 compute_loss 为 True,则计算重建损失和正则化损失if compute_loss:# 计算重建输入和原始输入之间的均方误差损失recon_loss = F.mse_loss(x, x_in) # 正则化损失:对编码后的特征施加 L1 惩罚(稀疏性正则化)reg_loss = f.abs().sum(dim=-1).mean()else:# 如果 compute_loss 为 False,则返回 None 作为两种损失recon_loss = Nonereg_loss = None return x, recon_loss, reg_loss def normalize_decoder_weights(self): with torch.no_grad():# 对解码器层的权重进行归一化,使其在特征维度(维度 1)上具有单位范数self.decoder.weight.data = nn.functional.normalize(self.decoder.weight.data, p=2, dim=1)
encode 函数在应用编码器和 ReLU 激活之前,先减去解码器的偏差。forward 函数运行解码器,并计算两种类型的损失:重建损失和正则化损失。
normalize_decoder_weights 函数确保解码器的权重具有单位范数和零均值。
训练循环
对于训练循环,Anthropic 使用了一个大型数据集,其中包含了通过将大部分 The Pile 数据通过 Transformer 并保存激活值所生成的 MLP 激活向量。这些向量占用的空间相当大(因为每个 token 占用 4 个字节,而一个 512 元素的 FP16 向量占用 1024 个字节)。由于存储限制,咱们需要在自编码器的训练过程中以批量的方式进行计算。
# 遍历训练步骤的次数
for _ in range(num_training_steps): # 从批量迭代器中获取一批输入(xb),忽略标签xb, _ = next(batch*iterator) # 禁用梯度计算,因为咱们只是使用模型进行嵌入生成(不进行训练)with torch.no_grad(): # 获取输入批次的嵌入(MLP 激活向量)来自模型x_embedding, * = model.forward_embedding(xb) # 将优化器的梯度清零,为反向传播做准备optimizer.zero_grad() # 将嵌入通过自编码器,并计算重建损失和正则化损失outputs, recon_loss, reg_loss = autoencoder(x_embedding, compute_loss=True) # 应用正则化项,并使用一个缩放因子(lambda_reg)reg_loss = lambda_reg \* reg_loss # 总损失是重建损失和正则化惩罚的组合loss = recon_loss + reg_loss # 执行反向传播以计算梯度loss.backward() # 使用优化器更新模型的权重optimizer.step() # 在每个训练步骤后对解码器权重进行归一化autoencoder.normalize_decoder_weights()
在循环结束时,咱们使用 normalize_decoder_weights。
一旦有了训练好的 Transformer,咱们就可以运行这个训练循环,教自编码器如何创建 Transformer 的 MLP 激活的稀疏表示。然后,对于一个新的 tokenized 输入,咱们可以像这样操作:
# 获取咱们训练好的 LLM 的特征features = autoencoder.encode(transformer.forward_embedding(tokens))
现在,features 将会包含 tokenized 文本的稀疏表示。如果一切顺利的话,features 中的元素应该很容易解释,并且具有明确的含义。
密度直方图
为了确保特征真正稀疏,咱们需要比较 MLP 激活和自编码器的特征激活的密度直方图。这些直方图展示了特征或神经元在输入样本上被激活的频率。通过比较它们,咱们可以验证自编码器是否创建了稀疏特征。
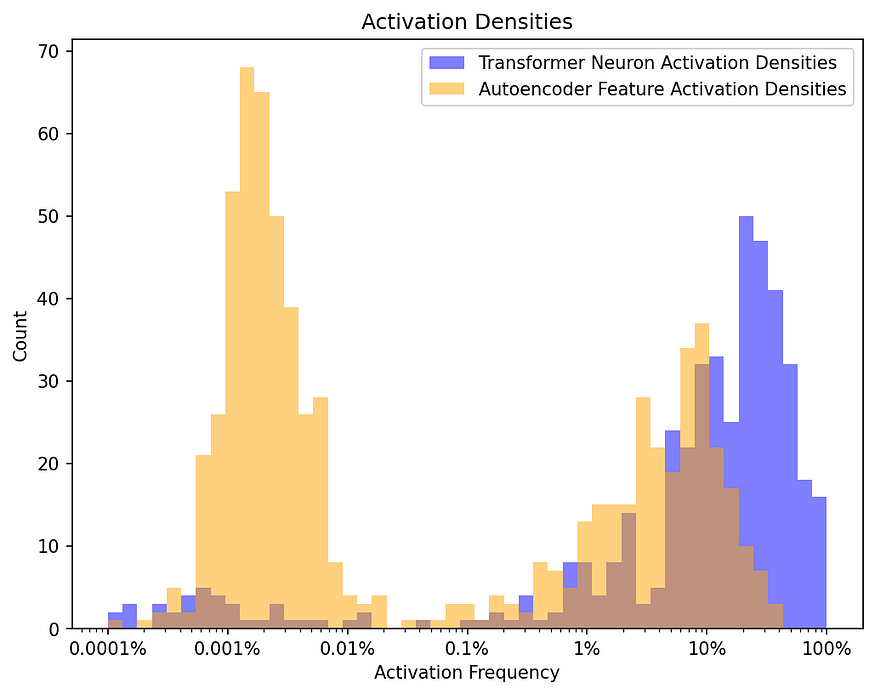
密度直方图(由 Fareed Khan 创建)
自编码器的特征(以浅黄色显示)比 Transformer 神经元(以蓝色显示)被激活的可能性要小得多。这个图是用对数刻度绘制的,意味着每个向左的刻度代表激活可能性减少了 90%。然而,你会注意到,仍然有相当数量的特征被激活的频率超过 10%,这并不理想。这发生是因为在增加稀疏性和避免从不激活的特征(死亡特征)之间需要保持平衡。左侧的大峰值表明有一组特征激活得非常不频繁,Anthropic 的作者们将其称为 “超低密度簇”。
现在,咱们可以为新的输入生成特征向量,并检查这些特征是否真正可解释。
结果与分析
总共有 576 个特征,比自编码器隐藏层中的神经元数量要少。这是因为研究人员识别出了一个 “超低密度簇”,这些特征激活得非常稀少,并且似乎没有有意义的解释。我发现了类似激活值非常低的特征,在特征密度直方图中以最左侧的峰值表示。这些低激活特征对损失的贡献不大,所以我选择将它们从我的分析中排除,以保持清晰。
在排除了激活频率低于每 10K 个 token 一次的特征之后,我最终得到了略多于一半的特征,这仍然比 Transformer 的输入神经元要多,这正是咱们的目标。
特征 169:非英语激活
当西班牙语、法语和葡萄牙语的后缀出现时,这个特征会被激活,这是特定于语言的,并不是任何用这些语言写的文本都会触发它。
这表明某些神经元会针对西班牙语、法语和葡萄牙语的特定词尾激活,而不是任何这些语言的文本。这意味着模型能够识别语言模式,比如词尾,并且以不同的方式处理它们,暗示它理解不同语言中的词的部分,而不仅仅是整个词。
特征 224:高度敏感
当出现十六进制或 base64 等字母数字字符串时,尤其是在技术上下文中,这个特征会被触发。
这表明这个神经元对字母数字模式非常敏感,特别是十六进制和 base64 字符串,这些通常出现在编码、加密和数字标识符中。这表明模型不仅仅是在读取字符,而是在检测结构化数据,几乎就像是在文本中寻找隐藏的代码,这种能力对于技术语言处理来说可能至关重要。
特征 76:可能性
这个特征能够检测到像“could”“might”或“must”这样的情态动词,这些词表示可能性或必要性。
这表明这个神经元能够检测到像“could”这样的情态动词,它们表达可能性或必要性。这意味着模型不仅仅理解单词,还理解单词背后的细微含义,帮助它解释句子中的不确定性以及义务。
特征 44:数学
当出现破折号时,尤其是在减法或否定的上下文中(例如“not good”或“5–3”),这个特征会被激活。
这表明这个神经元会在破折号出现时亮起,尤其是在它表示减法或否定的时候,比如在数学方程中或者像“not good”这样的短语中。这表明模型不仅仅看到的是一个破折号 —— 它能够识别出意义的转变,无论是分解数字还是改变句子的语气。
特征 991:医学
它能够检测到与细胞和分子生物学相关的 token,暗示它专注于特定领域的语言。
这表明这个神经元能够高度识别像“virus”(病毒)、“protein”(蛋白质)和“cell”(细胞)这样的细胞和分子生物学术语,暗示它对科学语言有很强的专注度。这表明模型能够识别并处理复杂的生物概念,使其非常适合理解生命科学领域的技术讨论。
特征 13:“un”
当出现带有“un”前缀的 token 时,例如“undo”(撤销)或“unhappy”(不开心),这个特征会被激活。
这表明这个神经元会针对带有“un”前缀的 token 激活,比如“undo”或“unhappy”。这表明模型对带有否定或反转含义的前缀很敏感,帮助它理解一个词带有否定或对立的含义。
特征 229:LaTeX
当出现 LaTeX 表达式中的 token 时,这个特征会被触发,这些表达式通常被美元符号包围,出现在数学或科学上下文中。
这表明这个神经元在遇到 LaTeX 表达式中的 token 时会变得活跃,比如“ x x x”或“ N N N”,这些通常出现在数学和科学领域。这意味着模型能够识别并理解复杂的公式,几乎就像是在解码数学和科学符号的语言 —— 帮助它轻松处理技术内容。
特征 211:“let”
当出现以“let”开头的数学函数声明中的闭合括号时,这个特征会被激活。
这表明这个神经元会在以“let”开头的数学函数声明(比如“Let f(x) = …”)中的闭合括号出现时激活。这表明模型能够精准地识别数学定义,帮助它识别并理解公式中的函数表达式及其结构。
特征 100:数学 LaTeX
当出现 LaTeX 表达式中的各种 token 时,尤其是使用开括号时,这个特征会被激活。它通常出现在涉及 LaTeX 格式的数学或科学上下文中。
这表明这个神经元会在 LaTeX 表达式中的 token 被激活,尤其是当使用像 { 和 [ 这样的开括号时,这些在数学和科学上下文中很常见。这表明模型能够识别 LaTeX 格式,帮助它识别和解释在技术文档中常见的复杂方程、表达式和引用。
特征 2:决策制定
这个特征比较难以解释。然而,它似乎会在与“说服性论点”或“决策制定”相关的上下文中激活。或许检查更长的上下文有助于明确其目的,或者可能这个特征本身就是难以完全理解的。自编码器的一些特征仍然很难完全弄清楚。
特征 3:逗号
当逗号出现在不同上下文中时,这个特征会被激活。它在文本中起到了结构化的作用,只要句子中出现逗号就会被激活。
特征 5:数学解释
这个特征在数学上下文中激活,尤其是在教学环境中,比如证明或考试题目中。它似乎专注于学术或技术讨论,特别是当讨论数学概念时。
结果说明了啥?
咱们给这个迷你 LLM 的“大脑”安了一个小小的“显微镜”,想看看它是怎么思考的。但一开始看到的不是整齐有序的想法,而是一片混乱,每个神经元似乎并不是只专注于一件事,而是同时在处理多个想法。这就叫 多义性,这使得整个系统感觉就像是试图通过同时聆听成千上万人的喊叫来理解一座城市一样。
为了从混乱中理出头绪,咱们使用了一种巧妙的技术,叫做稀疏自编码器,结果它还真管用!突然之间,一些神经元开始高度专注于某些特定的概念。
例如,有一个神经元只有在模型看到西班牙语后缀时才会亮起来,另一个对十六进制代码的反应特别具体,还有一个会在情态动词像“could”(可能)和“must”(必须)出现时被触发。甚至还有能够识别 LaTeX 数学表达式的神经元,而且,令人兴奋的是,有一个可能与检测“说服性论点”有关 —— 这是对抽象推理的一瞥!
有些发现仍然有点模糊不清,但这已经是一个令人兴奋的进步啦。咱们不再只是看到一个巨大的、神秘的数字矩阵,而是开始发现专门化的功能和模式,几乎就像是 LLM 为不同类型的知识配备了小小的“电路”。这次研究只是针对一个小型模型,但它证明了一件大事:理解LLMs的“思考”并非不可能。这是一个挑战,但咱们可以一步步来,一个神经元接一个神经元地去攻克。说不定,有了像稀疏字典学习这样的技术,咱们最终能绘制出整个LLM的“大脑”地图,揭开AI组织知识的惊人方式呢!
相关文章:
# 深度剖析LLM的“大脑”:单层Transformer的思考模式探索
简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。 LLMs 是怎么思考的呢? 开源 LLM 出现之后…...

Git仓库迁移
前言 前面我讲了GitLab搭建与使用(SSH和Docker)两种方式,那么就会延伸出来一个情况:Git仓库迁移虽然这种情况很少发生,但是我自己公司近期要把 阿里云迁移到华为云,那么放在上面的Git仓库也要全量迁移下面我就写了一个脚本演示&am…...

Windows避坑部署CosyVoice多语言大语言模型
#工作记录 前言 在实际部署与应用过程中,项目的运行环境适配性对其稳定性与功能性的发挥至关重要。CosyVoice 项目虽具备强大的语音处理能力,但受限于开发与测试环境的侧重方向,其对运行环境存在特定要求。 该项目在 Linux 和 Docker 生态…...

《实现模式》以Golang视角解读 价值观和原则 day 1
为什么阅读实现模式? 为什么阅读《实现模式》?Kent Beck 的《实现模式》其核心思想——编写清晰、易于理解且易于维护的代码,对于软件工程的新手而言,直接深入复杂的设计模式或架构理念可能会感到困惑。《实现模式》则弥合了设计…...

解决 PicGo 上传 GitHub图床及Marp中Github图片编译常见难题指南
[目录] 0.行文概述 1.PicGo图片上传失败 2.*关于在Vscode中Marp图片的编译问题* 3.总结与启示行文概述 写作本文的动机是本人看到了Awesome Marp,发现使用 Markdown \texttt{Markdown} Markdown做PPT若加持一些 CSS , JavaScript \texttt{CSS},\texttt{JavaScript} …...

LeetCode 820 单词的压缩编码题解
LeetCode 820 单词的压缩编码题解 题目描述 题目链接 给定一个单词列表,将其编码为一个索引字符串S,格式为"单词1#单词2#…"。要求当某个单词是另一个单词的后缀时,该单词可以被省略。求最终编码字符串的最小长度。 解题思路 逆…...

Windows软件插件-写wav
下载本插件 本插件,将PCM音频流写入WAV音频文件。或将PCM音频流压缩为ALAW格式,写入WAV文件。可以创作大文件(超过4字节所能表示的大小)。插件类型为DLL,可以在win32和MFC程序中使用。使用本插件创建的ALAW格式WAV音频…...
)
基于 Spring Boot 瑞吉外卖系统开发(十五)
基于 Spring Boot 瑞吉外卖系统开发(十五) 前台用户登录 在登录页面输入验证码,单击“登录”按钮,页面会携带输入的手机号和验证码向“/user/login”发起请求。 定义UserMapper接口 Mapper public interface UserMapper exte…...

【Linux高级IO】多路转接之epoll
多路复用之epoll 一,认识epoll二,epoll的相关接口1. epoll_create2. epoll_ctl3. epoll_wait 三,epoll的原理四,epoll的两种工作模式(ET和LT)1. 两种工作模式2. 对比ET和LT 五,总结 在了解到sel…...

Java 性能调优全解析:从设计模式到 JVM 的 7 大核心方向实践
引言 在高并发、低延迟的技术场景中,Java 性能优化需要系统化的方法论支撑。本文基于7 大核心优化方向(复用优化、计算优化、结果集优化、资源冲突优化、算法优化、高效实现、JVM 优化),结合权威框架与真实案例,构建从…...

“海外滴滴”Uber的Arm迁移实录:重构大规模基础设施
云工作负载在性价比上的自然演进路径: Intel ➜ AMD ➜ ARM 不信?来看看 Uber 的做法: 01/Arm架构:云计算新时代 2023 年 2 月,Uber 正式开启了一项战略性迁移:将从本地数据中心迁移至云端,…...

java加强 -File
File类的对象可以代表文件/文件夹,并可以调用其提供的方法对象文件进行操作。 File对象既可以代表文件,也可以代表文件夹。 创建File对象,获取某个文件的信息 语法: File 对象名 new File("需要访问文件的绝对路径&…...

SQL注入 ---04
1 简单的sql注入 要求: 要有sql注入: 1,变量 2,变量要带入数据库进行查询 3,没有对变量进行过滤或者过滤不严谨 mysql> select * from users where id2 limit 0,1; 当我的语句这样写时查寻到的结果 当我修改为&…...
)
MySQL知识点总结(持续更新)
聚合函数通常用于对数据进行统计和聚合操作。以下是一些常见数据库系统(如 MySQL、PostgreSQL、Oracle、SQL Server 等)中常用的聚合函数: 常见的数据库聚合函数: COUNT():计算指定列中非空值的数量 SELECT COUNT(*) …...

数字信号处理-大实验1.1
MATLAB仿真实验目录 验证实验:常见离散信号产生和实现验证实验:离散系统的时域分析应用实验:语音信号的基音周期(频率)测定 目录 一、常见离散信号产生和实现 1.1 实验目的 1.2 实验要求与内容 1.3 实验…...

Qt操作SQLite数据库教程
Qt 中操作 SQLite 数据库的步骤如下: 1. 添加 SQLite 驱动并打开数据库 #include <QSqlDatabase> #include <QSqlError> #include <QSqlQuery>// 创建数据库连接 QSqlDatabase db QSqlDatabase::addDatabase("QSQLITE"); db.setData…...

【PSINS工具箱】基于工具箱的单独GNSS导航、单独INS导航、两者结合组合导航,三种导航的对比程序。附完整的代码
本文给出基于PSINS工具箱的单独GNSS导航、单独INS导航、两者结合组合导航(153EKF)的程序。并提供三者的轨迹对比、误差对比。 文章目录 运行结果MATLAB代码代码的简单介绍简介2. 平均绝对误差 (MAE)主要模块运行结果 三轴轨迹图: 各轴误差曲线: 命令行窗口的结果输出: …...

开发者的测试复盘:架构分层测试策略与工具链闭环设计实战
摘要 针对测试复盘流于形式、覆盖率虚高等行业痛点,本文提出一套结合架构分层与工具链闭环的解决方案: 分层测试策略精准化:通过单元测试精准狙击核心逻辑、契约测试驱动接口稳定性、黄金链路固化端到端场景,实现缺陷拦截率…...

手写CString类
学习和理解字符串处理机制:手写 CString 类是深入学习字符串处理和内存管理的有效方式。通过实现构造函数、析构函数、赋值运算符等,能够理解字符串在内存中的存储方式、动态内存分配和释放的原理,以及如何处理字符串的复制、拼接、查找等操作…...

electron结合vue,直接访问静态文件如何跳转访问路径
在最外的app.vue或者index.vue的js模块编写 let refdade ref(1);//刷新,获得请求// 获取完整的查询字符串(例如: "?dade/myms")const searchParams new URLSearchParams(window.location.search);// 获取 dade 参数的值…...

解读RTOS 第七篇 · 驱动框架与中间件集成
1. 引言 在面向生产环境的 RTOS 系统中,硬件驱动框架与中间件层是连接底层外设与上层应用的桥梁。一个模块化、可扩展的驱动框架能够简化外设管理,提升代码可维护性;而丰富的中间件生态则为网络通信、文件系统、图形界面、安全加密等功能提供开箱即用的支持。本章将从驱动模…...

Java GUI开发全攻略:Swing、JavaFX与AWT
Swing 界面开发 Swing 是 Java 中用于创建图形用户界面(GUI)的库。它提供了丰富的组件,如按钮、文本框、标签等。 import javax.swing.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener;public class SwingExa…...

Cursor 0.5版本发布,新功能介绍
Cursor,这款流行的AI编程平台,刚刚在其v0.50更新中推出了一系列新功能。 首先,请将您的Cursor IDE更新到最新版本。当您打开Cursor时,您应该会在屏幕左下方收到关于最新版本发布的通知。 更多上下文控制: 对上下文的精细可见性,以及最新模型的MAX模式。 聊天升级: 导出…...
)
Android学习总结之Glide自定义三级缓存(实战篇)
一、为什么需要三级缓存 内存缓存(Memory Cache) 内存缓存旨在快速显示刚浏览过的图片,例如在滑动列表时来回切换的图片。在 Glide 中,内存缓存使用 LruCache 算法(最近最少使用),能自动清理长…...

Maven 下载安装与配置教程
## 1. Maven 简介 Maven 是一个项目管理和构建自动化工具,主要用于 Java 项目。Maven 可以帮助开发者管理项目的构建、报告和文档,简化项目依赖管理。 ## 2. 下载 Maven 1. 访问 Maven 官方网站 [https://maven.apache.org/download.cgi](https://maven.…...

一篇解决Redis:持久化机制
目录 认识持久化 持久化方案 RDB(Redis DataBase) 手动触发 自动触发 小结 AOF(Append-Only File) AOF缓冲区刷新机制 AOF重写机制 AOF重写流程 编辑 混合持久化 认识持久化 我们都知道Mysql有四大特征,原子性,持久…...

使用IDEA创建Maven版本的web项目以及lombok的使用
1.新建项目 2.修改pom.xml 3.修改项目结构 4.在main/java下面写一个Servlet测试一下 然后当前页面往下滑 -Dfile.encodingUTF-8编写一句输出语句,测试是否成功部署配置,并选择到正确的位置: 回车以后 再回到idea里面,发现控…...

2025年AI开发者在开发者占比?
AI开发者在全球开发者中的占比目前没有一个统一且精确的数值,但根据行业报告和调研数据,可以给出以下大致的范围和趋势分析: 1. 综合估算范围 全球范围:AI/ML(机器学习)开发者约占开发者总数的 5%-15%&…...

SpringBoot整合MQTT实战:基于EMQX构建高可靠物联网通信,从零到一实现设备云端双向对话
一、引言 随着物联网(IoT)技术的快速发展,MQTT(Message Queuing Telemetry Transport)协议因其轻量级、低功耗和高效的特点,已成为物联网设备通信的事实标准。本文将详细介绍如何使用SpringBoot框架整合MQTT协议,基于开源MQTT代理EMQX实现设…...

Windows更新暂停七天关键注册表
环境:windows10 工具:procmon 下载地址:https://learn.microsoft.com/zh-cn/sysinternals/downloads/procmon 监控截图: 界面截图: 注: 1.北京时间差8小时 2.至少是从第二天恢复,即至少暂停…...
:spring)
小白学习java第18天(上):spring
Spring :是一个轻量级(一个小依赖就可以实现还不是轻量级)的控制反转(IOC)和面向切面编程(AOP)的框架! 优点: 1.Spring 是一个开源免费的框架(容器…...

用Array.from实现创建一个1-100的数组
一、代码实现 let arr Array.from({length: 100}, (_, i) > i 1); 二、代码分析 1、Array.from(arrayLike, mapFn) (1)arrayLike 类数组对象(如 { length: 100 })本身没有索引属性(如 0: undefined, 1: undefi…...

什么是物联网 IoT 平台?
目录 物联网IoT平台的定义 物联网 IoT 平台发展历程 物联网IoT平台数据的特征 物联网IoT平台的处理流程 专为物联网 IoT 平台处理而生的时序数据库 物联网 IoT 平台时序数据处理面临的挑战及解决方案 收益与价值 物联网 IoT 平台企业案例 至数摇光 x TDengine 华自科技…...

PostgREST:无需后端 快速构建RESTful API服务
在现代 Web 开发中,API 已成为连接前后端的核心桥梁,传统的做法是通过后端框架来构建API接口,然后由前后端人员进行联调。 PostgREST是基于无服务器的一种实现方案,允许开发者将PostgreSQL数据库直接暴露为RESTful API࿰…...

3天北京旅游规划
北京 第一天应该集中在故宫和市中心区域,比如天安门、人民广场。这样可以体验到北京的历史和政治文化。午餐推荐烤鸭,因为这可是北京的特色。下午可以安排南锣鼓巷,既有古色古香的胡同,又有丰富的美食选择。 第二天的话࿰…...

MySQL--day1--数据库概述
(以下内容全部来自上述课程) 概述 1. 为什么要用数据库 持久化:内存中的数据断电之后就不存在了,所以需要持久化–>需要相关介质。 其中的一个介质就是数据库:存储数据量大、存储数据类型多 2. 数据库与数据库…...

[思维模式-38]:看透事物的关系:什么是事物的关系?事物之间的关系的种类?什么是因果关系?如何通过数学的方式表达因果关系?
一、什么是事物的关系? 事物的关系是指不同事物之间存在的各种联系和相互作用,它反映了事物之间的相互依存、相互影响、相互制约等特性。以下从不同维度为你详细阐述: 1、关系的类型 因果关系 定义:一个事件(原因&a…...

图像识别与 OCR 应用实践
图像识别是一种让计算机具备“看”与“理解”图像能力的人工智能技术,其目标是从图像或视频中提取有意义的信息,如物体、人物、场景或文字。在现实生活中,这项技术被广泛应用于面部识别、自动驾驶、安防监控、医疗诊断、图像搜索等多个领域。…...

深入理解卷积神经网络:从基础原理到实战应用
在人工智能领域,卷积神经网络(Convolutional Neural Network,简称 CNN)凭借其强大的图像识别、处理能力,成为深度学习中不可或缺的技术。无论是自动驾驶汽车识别道路标志,还是医学影像分析辅助疾病诊断&…...

51单片机——交通指示灯控制器设计
设计目标 1、设计一交通灯控制,控制东西方向的红、黄、绿灯和南北方向的红、黄、绿灯。 2、可手动控制和自动控制,设置两个输入控制开关。 手动/自动开关,通过P11的按键输入控制 3、手动:设置开关P11,两种情况&#x…...

vue2 头像上传+裁剪组件封装
背景:最近在进行公司业务开发时,遇到了头像上传限制尺寸的需求,即限制为一寸证件照(宽295像素,高413像素)。 用到的第三方库: "vue-cropper": "^0.5.5" 完整组件代码&…...

面向对象设计模式之代理模式详解
文章目录 面向对象设计模式之代理模式详解面向对象思想:现代软件开发的基石代理模式:巧妙的中间层设计JavaScript 语法点与代理模式的结合JavaScript 实现代理模式示例代理模式的应用场景 面向对象设计模式之代理模式详解 在现代软件开发的浩瀚领域中&a…...

Leetcode209做题笔记
力扣209 题目分析:想象一个窗口遍历着这个数组,不断扩大右边界,让r。往窗口中添加数字: 此时我们找到了这个窗口,它的和满足了大于等于target的条件,题目让我求最短的,那么我们就尝试来缩短它&…...

SVG 知识详解:从入门到精通
SVG 知识详解:从入门到精通 作为一名前端开发者,我经常会被SVG的魅力所折服。这种基于XML的矢量图形格式,不仅能完美适配各种屏幕分辨率,还能通过CSS和JavaScript进行灵活控制。今天,就让我们一起来深入探索SVG的世界…...

编译openssl源码
openssl版本 1.1.1c windows 安装环境 perl 先安装perl,生成makefile需要 https://strawberryperl.com/releases.html nasm nasm 也是生成makefile需要 https://www.nasm.us/ 安装完perl输入一下nasm,看看能不能找到,找不到的话需要配…...

土壤温湿盐分传感器用于节水农业灌溉引领者三针设计原理便于安装维护
土壤温度部分是由精密铂电阻和高精度变送器两部分组成。变送器部分由电源模块、温度传感模块、变送模块、温度补偿模块及数据处理模块等组成,彻底解决铂电阻因自身特点导入的测量误差,变送器内有零漂电路和温度补偿电路,对使用环境有较高的适…...

Kotlin Compose 与传统 Android UI 开发对比
在移动应用开发领域,Android 开发一直是技术演进的前沿阵地,而 UI 开发作为用户与应用交互的核心环节,其技术体系的变革更是备受瞩目。 技术演进背景 Android UI 开发体系发展脉络 原生 View 体系阶段 在早期的 Android 开发中,原生 View 体系占据了主导地位。开发者通…...

docker-compose——安装redis
文章目录 一、编写docker-compose.yaml文件二、编写redis.conf文件三、启动docker-compose 一、编写docker-compose.yaml文件 version: 3.3 services:redis:image: redis:latestcontainer_name: redisrestart: alwaysports:- 6379:6379volumes:- ./redis/data:/data- ./redis/…...

MFC 调用海康相机进行软触发
初始化相机类文件 #pragma once #include "MvCameraControl.h" class CMvCamera { public:CMvCamera();~CMvCamera();//初始化相机int InitCamera();int SaveCurrentImage(CString filePath);//关闭相机void CloseCamera();//设置int SetEnumValue(IN const char* s…...

第二章 变量和运算符
主要内容 关键字和标识符变量和常量八大基本数据类型Scanner键盘输入基本数据类型的类型转换算术运算符赋值运算符扩展赋值运算符比较运算符逻辑运算符三目运算符运算符的优先级别 学习目标 知识点要求关键字和标识符理解变量和常量掌握八大基本数据类型掌握Scanner键盘输入…...