《Python星球日记》 第72天:问答系统与信息检索
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、问答系统概述
- 1.问答系统的工作原理
- 2. 问答系统的典型应用场景
- 二、问答系统分类
- 1. 基于检索的问答系统
- 2. 基于生成的问答系统
- 3. 两种方法的对比
- 三、使用BERT构建问答系统
- 1. SQuAD数据集简介
- 2. 微调BERT进行问答任务
- 四、代码练习:实现一个基于BERT的问答系统
- 1. 环境准备
- 2. 构建基本问答模型
- 3. 使用预训练模型测试问答系统
- 4. 微调BERT模型用于自定义问答任务
- 5. 构建完整的端到端问答应用
- 五、问答系统的未来发展
- 六、总结与实践建议
- 参考资料
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第71天:命名实体识别(NER)与关系抽取
欢迎回到Python星球🪐日记!今天是我们旅程的第72天。
在前面的日子里,我们深入学习了自然语言处理的基础知识,包括文本预处理、词向量、Transformer架构和各种预训练模型。今天,我们将探索问答系统这一NLP的重要应用,以及如何结合信息检索技术构建智能问答系统。
一、问答系统概述
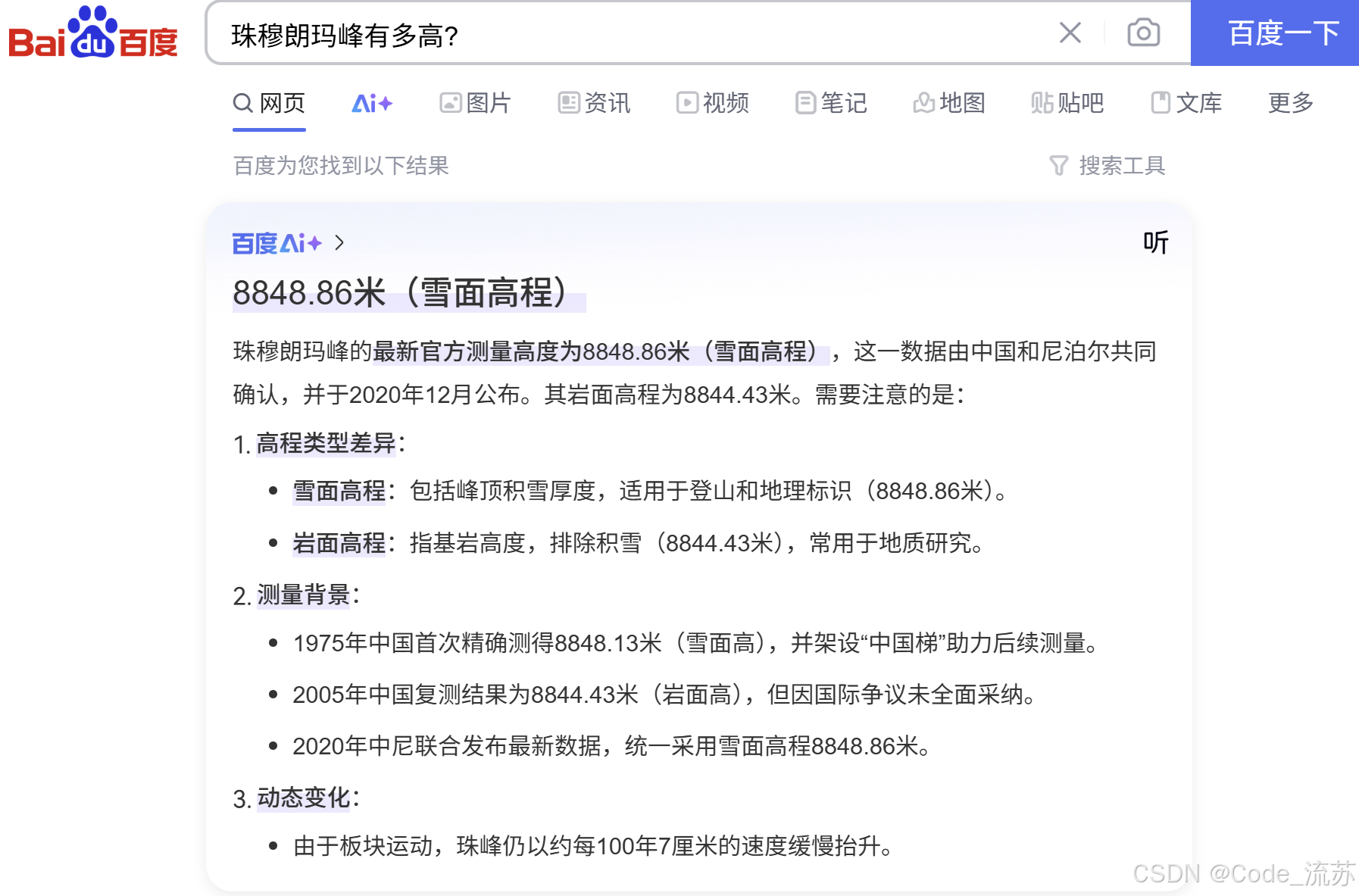
问答系统(Question Answering System)是一种能够理解用户的自然语言问题并给出准确答案的人工智能系统。从早期的规则型系统到如今基于深度学习的系统,问答技术已经取得了飞跃性的进步。
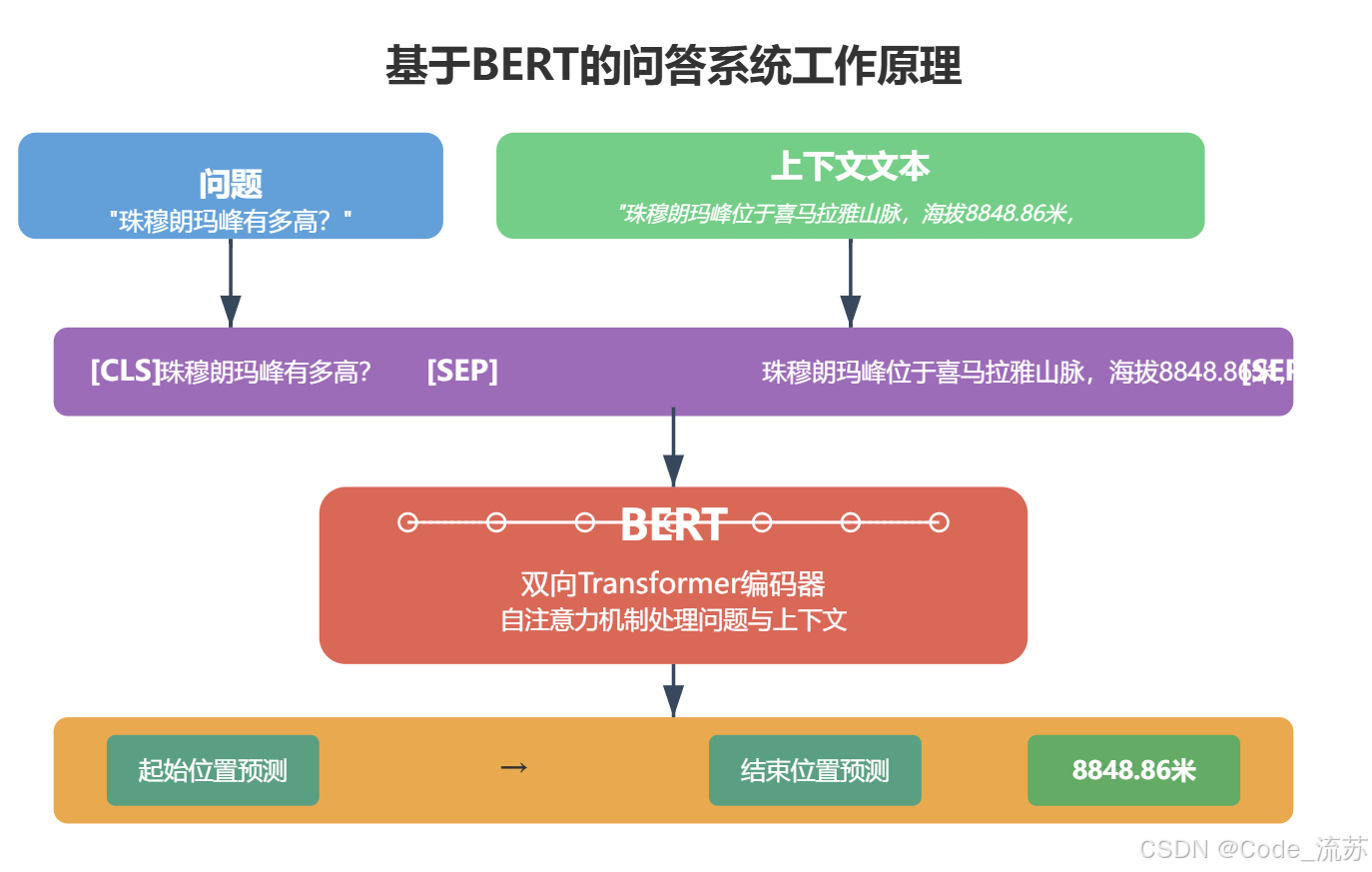
当你使用搜索引擎查询"珠穆朗玛峰有多高?"时,不再需要翻阅多个网页,而是直接得到"8848.86米"的精准答案,这就是问答系统的魅力所在。
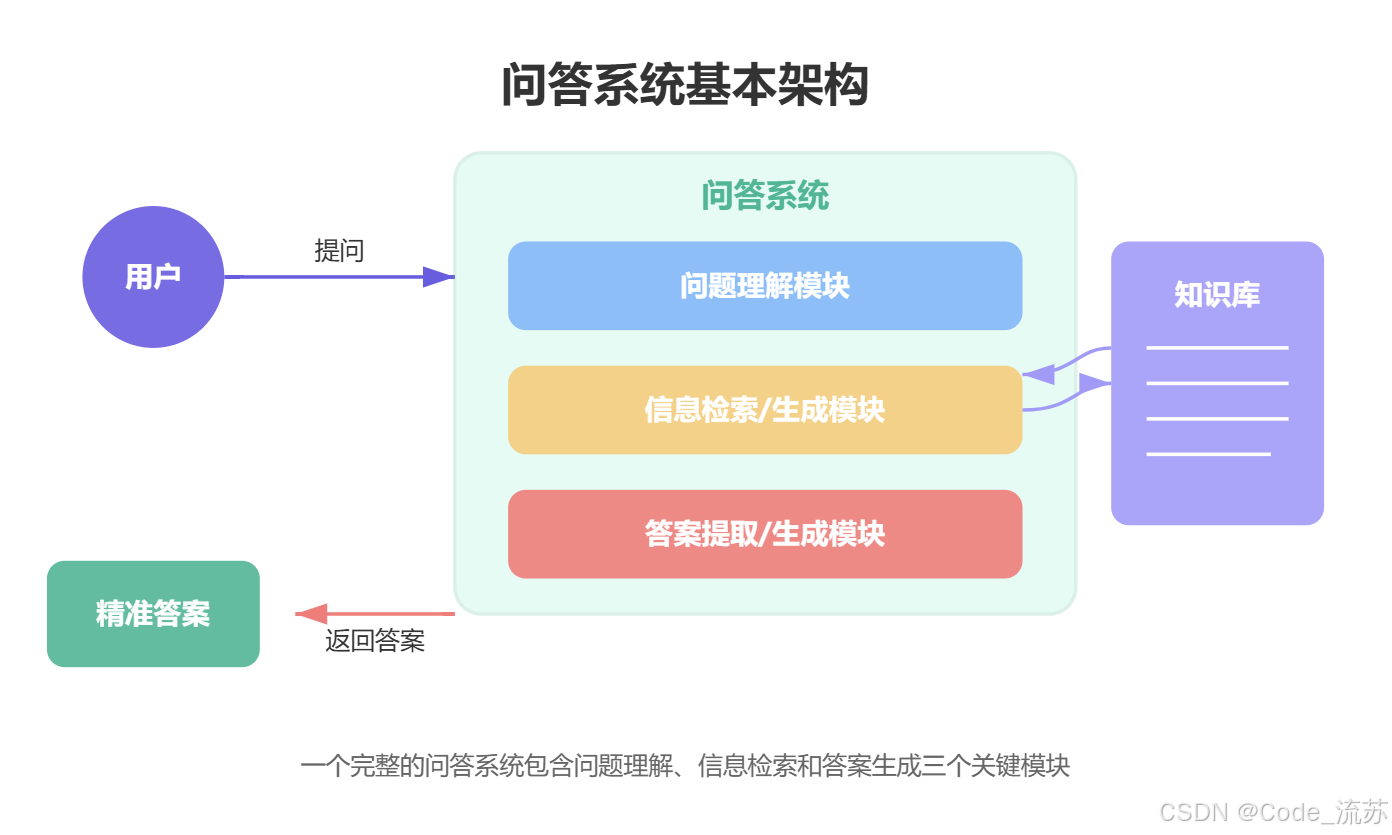
1.问答系统的工作原理
问答系统通常包含三个核心组件:问题理解、信息检索/生成和答案提取/生成。系统通过分析用户问题的语义,从知识库中检索相关信息,然后提取或生成最终答案。
2. 问答系统的典型应用场景
- 客服机器人:自动回答用户常见问题
- 智能搜索引擎:直接给出问题答案,而非仅列出网页链接
- 个人助手:Siri、Alexa等智能助手中的问答功能
- 医疗诊断辅助:回答医疗相关问题,辅助临床决策
- 教育辅导:回答学生的学习问题,提供个性化辅导
二、问答系统分类
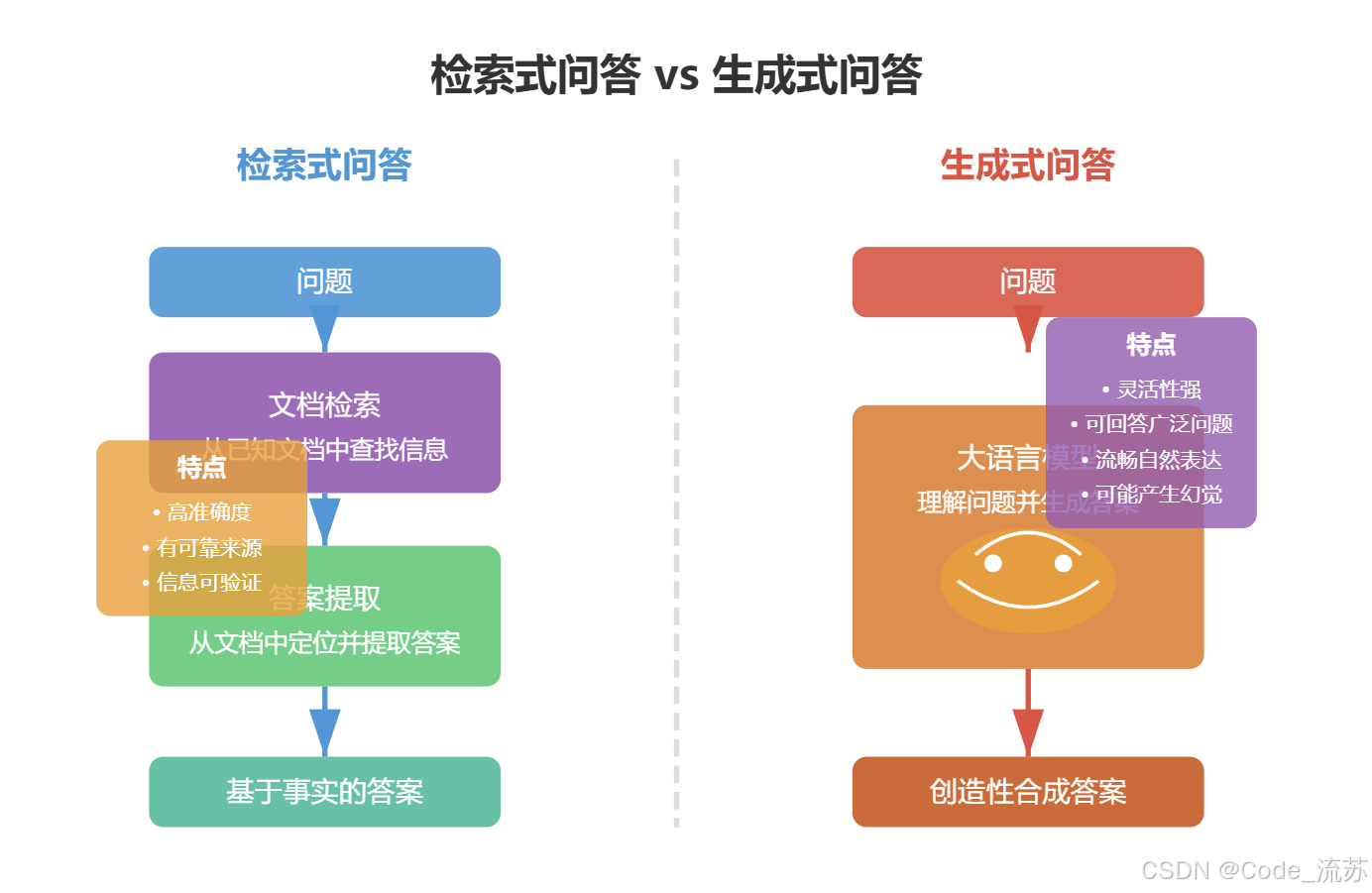
根据答案生成方式的不同,问答系统主要分为两类:基于检索的问答系统和基于生成的问答系统。
1. 基于检索的问答系统
基于检索的问答系统(Retrieval-based QA)工作原理是从大量已有文档中检索并提取答案。这种方法确保答案有明确的来源依据,也称为抽取式问答。
工作流程主要包含三个步骤:
- 问题处理:分析用户问题,确定问题类型和关键词
- 文档检索:使用信息检索技术找到相关文档
- 答案提取:从检索到的文档中精确定位并提取答案片段
这类系统的关键在于两项核心技术:
- 信息检索(IR):使用BM25、TF-IDF等算法检索相关文档
- 阅读理解(MRC):从检索文档中精确定位答案位置
# 基于检索的问答系统简化示例
def retrieval_based_qa(question, documents):# 步骤1:检索相关文档relevant_docs = retrieve_documents(question, documents)# 步骤2:从相关文档中提取答案answer = extract_answer(question, relevant_docs)return answer
2. 基于生成的问答系统
基于生成的问答系统(Generation-based QA)通过生成模型直接创建答案文本,而不是从已有文档中提取。这类系统通常基于大型语言模型(LLM),如GPT系列、LLaMA等。
生成式问答的优势在于:
- 灵活性强:可以回答开放性问题,生成流畅自然的答案
- 知识融合:能结合训练数据中的广泛知识
- 处理复杂问题:能回答假设性问题或需要推理的问题
但也存在一些挑战:
- 幻觉问题:可能生成看似合理但实际不准确的内容
- 控制困难:难以精确控制答案的范围和内容
- 缺乏透明度:难以追溯答案来源
# 基于生成的问答系统简化示例
def generation_based_qa(question, model):# 构建提示prompt = f"问题: {question}\n回答: "# 使用预训练模型生成答案answer = model.generate(prompt)return answer
3. 两种方法的对比
| 特性 | 基于检索的问答 | 基于生成的问答 |
|---|---|---|
| 答案来源 | 从文档中提取 | 模型生成 |
| 答案范围 | 受限于已有文档 | 开放性生成 |
| 准确性 | 高(有明确来源) | 可能出现幻觉 |
| 灵活性 | 受限 | 灵活 |
| 可追溯性 | 强 | 弱 |
| 适用场景 | 事实型问题、领域专业问题 | 开放性问题、推理问题 |
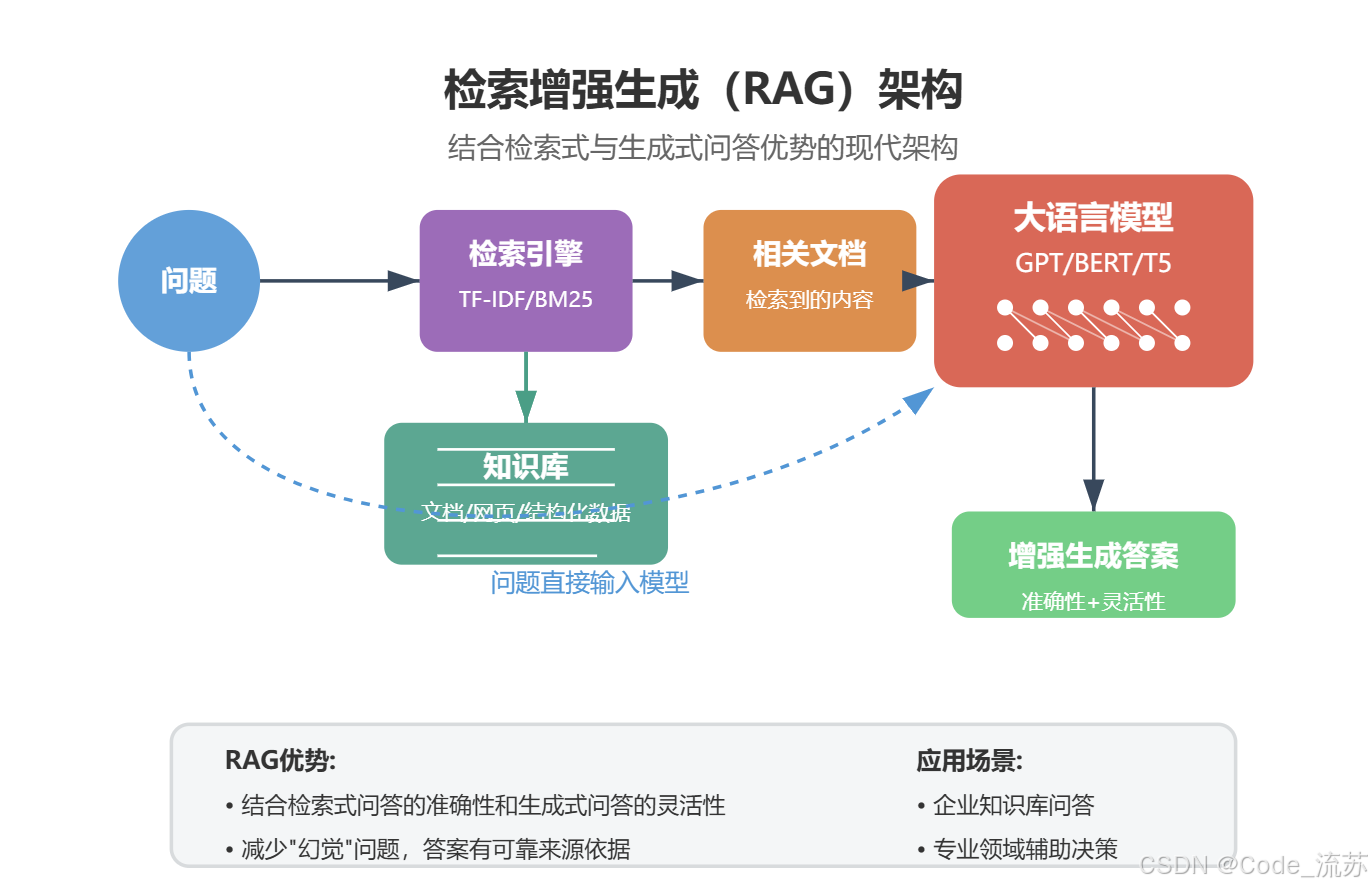
现代问答系统通常会结合这两种方法的优势,形成检索增强生成(RAG)架构,既保证答案的准确性,又提供灵活的表达能力。
三、使用BERT构建问答系统
1. SQuAD数据集简介
SQuAD(Stanford Question Answering Dataset)是构建和评估问答系统的标准数据集。它包含了从维基百科文章中提取的10万多个问题-答案对。
SQuAD的特点:
- 篇章式问答:每个问题都基于一段文本,答案是文本中的一个片段
- 人工标注:由人类标注者创建高质量的问答对
- 开放获取:公开可用,便于研究和比较不同模型
示例:
{"data": [{"title": "Super_Bowl_50","paragraphs": [{"context": "Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title.","qas": [{"question": "Which NFL team won Super Bowl 50?","id": "56be4db0acb8001400a502ec","answers": [{"text": "Denver Broncos","answer_start": 177}]},{"question": "What was the score of Super Bowl 50?","id": "56be4db0acb8001400a502ed","answers": [{"text": "24–10","answer_start": 249}]}]}]}]
}
2. 微调BERT进行问答任务
BERT (Bidirectional Encoder Representations from Transformers)模型因其强大的上下文理解能力,成为构建问答系统的绝佳选择。通过在SQuAD数据集上微调BERT,我们可以创建一个高性能的问答系统。
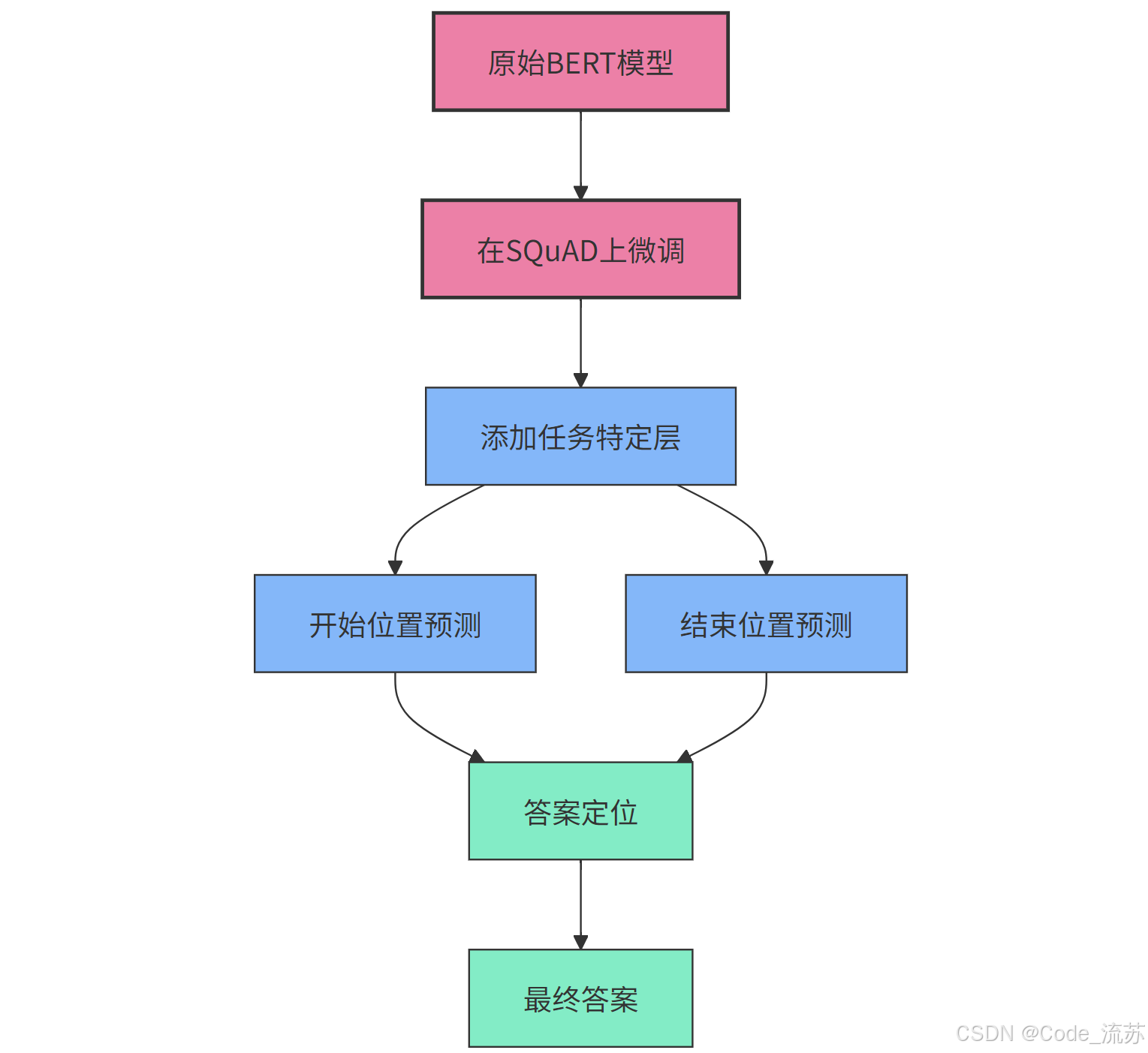
BERT模型针对问答任务的微调过程包括:
- 输入格式化:将问题和上下文拼接成单一序列
[CLS] 问题 [SEP] 上下文 [SEP] - 添加任务特定层:在BERT顶层添加两个全连接层,分别用于预测答案的开始位置和结束位置
- 训练目标:最大化正确答案跨度的概率
- 推理过程:对所有可能的答案跨度计算概率,选择概率最高的作为最终答案
微调BERT进行问答任务的关键技术细节:
- 注意力机制:使BERT能够捕捉问题与上下文之间的复杂关系
- 上下文嵌入:每个单词的表示包含了整个序列的上下文信息
- 跨度预测:不是生成答案,而是预测答案在文本中的起始和结束位置
四、代码练习:实现一个基于BERT的问答系统
下面我们将通过实际代码,实现一个基于BERT的问答系统。我们将使用Hugging Face的Transformers库,它提供了丰富的预训练模型和便捷的API。
1. 环境准备
首先安装必要的库:
# 安装必要的库
!pip install transformers datasets torch pandas matplotlib
2. 构建基本问答模型
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
import numpy as npclass BertQASystem:def __init__(self, model_name="bert-base-uncased"):"""初始化BERT问答系统参数:model_name: 使用的预训练模型名称"""# 加载预训练的tokenizerself.tokenizer = BertTokenizer.from_pretrained(model_name)# 加载预训练的问答模型self.model = BertForQuestionAnswering.from_pretrained(model_name)# 将模型设置为评估模式self.model.eval()# 如果有GPU,则使用GPUself.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.model.to(self.device)def answer_question(self, question, context, max_length=512):"""回答基于上下文的问题参数:question: 问题文本context: 包含答案的上下文文本max_length: 输入序列的最大长度返回:answer: 从上下文中提取的答案start_score: 开始位置的得分end_score: 结束位置的得分"""# 准备输入inputs = self.tokenizer.encode_plus(question,context,add_special_tokens=True,max_length=max_length,truncation="only_second",padding="max_length",return_tensors="pt")# 将输入移动到正确的设备上input_ids = inputs["input_ids"].to(self.device)attention_mask = inputs["attention_mask"].to(self.device)token_type_ids = inputs["token_type_ids"].to(self.device)# 获取模型预测with torch.no_grad():outputs = self.model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 获取开始和结束位置的预测分数start_scores = outputs.start_logitsend_scores = outputs.end_logits# 找到最可能的答案# 忽略[CLS]和[SEP]等特殊标记answer_start = torch.argmax(start_scores) answer_end = torch.argmax(end_scores)# 确保答案是有效的(开始位置在结束位置之前)if answer_start > answer_end:answer_start, answer_end = answer_end, answer_start# 将token IDs转换回文本tokens = self.tokenizer.convert_ids_to_tokens(input_ids[0])# 获取答案文本answer = self.tokenizer.convert_tokens_to_string(tokens[answer_start:answer_end+1])# 移除特殊标记和填充标记answer = answer.replace("[CLS]", "").replace("[SEP]", "").replace("[PAD]", "").strip()return {"answer": answer,"start_position": answer_start.item(),"end_position": answer_end.item(),"start_score": start_scores[0][answer_start].item(),"end_score": end_scores[0][answer_end].item()}
让我解释一下这段代码的核心部分。上面的BertQASystem类创建了一个问答系统,它使用预训练的BERT模型来从上下文中找出问题的答案。
这个系统的工作原理是:首先,我们使用tokenizer将问题和上下文文本转换成BERT模型能理解的数字序列。这些数字代表了词汇表中的标记(tokens),并且会添加特殊标记如[CLS](表示序列开始)和[SEP](用于分隔问题和上下文)。
当我们将这些数据输入BERT模型时,模型会输出两组分数:一组表示答案开始位置的可能性,另一组表示答案结束位置的可能性。通过找出这两组分数中的最大值,我们可以确定模型认为最可能的答案跨度(从开始位置到结束位置的文本片段)。
最后,我们将这些数字标记转换回文本,并进行一些清理工作,如移除特殊标记,就得到了我们的答案。
3. 使用预训练模型测试问答系统
# 使用预训练模型进行测试
def test_qa_system():# 初始化问答系统,使用预训练的QA模型qa_system = BertQASystem(model_name="deepset/bert-base-cased-squad2")# 测试用例contexts = ["Python是一种广泛使用的解释型、高级和通用的编程语言。Python支持多种编程范式,包括结构化、面向对象和函数式编程。它拥有动态类型系统和垃圾回收功能,能够自动管理内存使用。Python由吉多·范罗苏姆创建,第一版发布于1991年。","自然语言处理(NLP)是人工智能的一个子领域,专注于使计算机能够理解、解释和生成人类语言。NLP结合了计算语言学、统计学、机器学习和深度学习等多个领域的技术。近年来,基于Transformer架构的模型如BERT、GPT和T5在NLP任务上取得了突破性进展。"]questions = ["Python是谁创建的?","NLP是什么的子领域?"]for i, (context, question) in enumerate(zip(contexts, questions)):print(f"\n测试 {i+1}:")print(f"问题: {question}")print(f"上下文: {context[:100]}...")# 获取答案result = qa_system.answer_question(question, context)print(f"答案: {result['answer']}")print(f"开始位置得分: {result['start_score']:.4f}")print(f"结束位置得分: {result['end_score']:.4f}")# 运行测试
if __name__ == "__main__":test_qa_system()
这部分代码展示了如何使用我们刚刚创建的问答系统。我们使用了一个已经在SQuAD数据集上微调过的BERT模型(“deepset/bert-base-cased-squad2”),并给它提供了两个测试用例:一个关于Python的创建者,另一个关于NLP的分类。
当运行这段代码时,系统会尝试从给定的上下文中找出问题的答案。例如,对于"Python是谁创建的?"这个问题,系统应该能够从上下文中找出"吉多·范罗苏姆"这个答案。同样,对于"NLP是什么的子领域?“,系统应该能够识别出"人工智能”。
输出结果不仅包括答案本身,还包括模型对这个答案的置信度(通过开始位置和结束位置的得分表示)。这可以帮助我们评估模型的预测有多可靠。
4. 微调BERT模型用于自定义问答任务
对于特定领域的问答任务,我们可能需要在自己的数据集上微调BERT模型。这个过程包括准备符合SQuAD格式的训练数据,然后进行模型训练。
微调过程的主要步骤包括:
- 数据准备:将数据转换为SQuAD格式,包含上下文、问题和答案位置
- 模型初始化:加载预训练的BERT模型
- 训练配置:设置优化器、学习率等超参数
- 训练循环:在训练数据上迭代,更新模型参数
- 模型保存:保存微调后的模型以供后续使用
5. 构建完整的端到端问答应用
现在让我们将前面的功能整合起来,构建一个完整的问答应用程序,该程序能够加载文档、预处理文本、检索相关内容,并使用BERT模型提取答案。
这个端到端系统实现了以下关键功能:
- 文档管理:添加和处理多个文档
- 文档检索:使用TF-IDF向量化和余弦相似度找到与问题最相关的文档
- 答案提取:使用BERT模型从检索到的文档中定位并提取答案
- 结果评估:计算答案的置信度和相关度得分
这个系统代表了一个典型的检索增强问答系统,它首先使用传统的信息检索技术找到相关文档,然后使用深度学习模型(BERT)提取精确答案。这种结合方法既能处理大量文档,又能提供精确的答案,是现代问答系统的标准架构。
五、问答系统的未来发展
问答系统技术正在快速发展,未来趋势包括:
- 多模态问答:结合图像、视频等多种模态的问答系统
- 对话式问答:能够维持多轮对话上下文的问答系统
- 知识图谱增强:利用结构化知识增强问答能力
- 更强的推理能力:能够进行复杂逻辑推理的问答系统
- 领域适应:更容易适应特定领域的问答系统
六、总结与实践建议
今天我们学习了问答系统的基础知识,包括:
- 问答系统的基本概念和分类
- 基于检索和基于生成的问答系统各自的优缺点
- 使用BERT模型构建问答系统的技术细节
- 端到端问答系统的实现方法
构建优秀问答系统的实践建议:
- 选择合适的架构:根据应用场景选择检索式、生成式或混合架构
- 数据质量至关重要:确保训练数据的质量和覆盖范围
- 进行充分的评估:使用多种指标评估系统性能
- 考虑实际部署限制:在实际应用中需要考虑延迟、资源消耗等因素
- 不断迭代改进:根据用户反馈持续优化系统
问答系统是NLP技术的重要应用,也是人工智能与人类交互的关键接口。随着技术的不断进步,问答系统将变得越来越智能,为我们提供更加精准、自然的信息获取体验。
参考资料
- SQuAD数据集:https://rajpurkar.github.io/SQuAD-explorer/
- Hugging Face Transformers文档:https://huggingface.co/docs/transformers/
- BERT论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 斯坦福CS224N课程:自然语言处理与深度学习
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第72天:问答系统与信息检索
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、问答系统概述1.问答系统的工作原理2. 问答系统的典型应用场景 二、问答系统…...
)
VUE3 -综合实践(Mock+Axios+ElementPlus)
目录 前言 目标 1.工程创建 2.Mock 2.1 配置Mock 扩 展 2.2 定义模拟数据 2.3 创建Mock服务器 3.导入ElementPlus 4.表格页面搭建 5.动态路由跳转 6.详情页面的制作 前言 基于前文 VUE3详细入门,我们对VUE3的基本使用有了初步的了解,下…...

Qt原型模式实现与应用
在Qt中实现原型模式(Prototype Pattern)可以通过以下步骤完成。该模式的核心是通过克隆现有对象来创建新对象,而非通过传统的构造函数。以下是详细说明和示例: 1. 原型模式的核心概念 目的:避免重复初始化对象的高成本…...

语音识别-2
上一篇关于语音识别, 虽然能用,但在系统适配,机器适配方面,速度,性能等还是有优化的地方.所以这篇是关于这些的. 1.蓝牙优化 A2DP:是一种单向的高品质音频数据传输链路,通常用于播放立体声音乐;SCO: 则是一种双向的音频数据的传输链路,该链路只支持8K及16K单声道的音频数据…...
:聚合——分桶聚合、指标聚合、管道子聚合)
ElasticSearch深入解析(十二):聚合——分桶聚合、指标聚合、管道子聚合
文章目录 一、分桶聚合1. 分桶聚合的核心逻辑与核心类型2. 分桶聚合的高级特性 二、指标聚合1. 指标聚合的核心逻辑与基础类型(1)基础统计指标(单值输出)(2)复合统计指标(多值输出) …...

互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化
互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化 场景背景: 郑薪苦是一名经验丰富的Java开发者,他正在参加一家匿名互联网大厂的技术总监面试。这家公司专注于基于AI的内容生成平台,支持大规模用户请求和复杂…...

论MCU如何在Fatfs中使用Flash接口的方法
前提: MCU移植了FS,如FATFSOSFMount工具 OSFMount或者其他磁盘工具用于挂载.img镜像,可格式化文件系统打开并放入实际使用的文件 步骤 1. cmd命令建立空.img镜像,以下为12MB fsutil file createnew fat.img 120000002. OSFMo…...

Python+Selenium爬虫:豆瓣登录反反爬策略解析
1. 引言 在当今互联网时代,数据抓取(爬虫)技术广泛应用于数据分析、市场调研、自动化测试等领域。然而,许多网站采用动态加载技术(如Ajax、React、Vue.js等框架)来渲染页面,传统的**<font s…...

nt!MiDispatchFault函数分析之第一次循环前后的变化
第一部分:nt!MiDispatchFault函数分析之第一次循环之前 1: kd> !pte 0x002bf810 VA 002bf810 PDE at C0300000 PTE at C0000AFC contains 7B314867 contains 00000000 pfn 7b314 ---DA--UWEV not valid 1: kd> dd C0000AFC…...

JMeter性能测试工具使用
JMeter是一款强大的性能测试工具,由Java编写,小巧轻便,最关键的是开源免费,现在已经成了主流的性能测试工具。 下面介绍一下基本的安装使用、高级功能及可视化实时图表展示,带你们感受一下JMeter的世界~ 1、安装 1.…...

Windows 环境下安装 Node 和 npm
安装 Node.js 和 npm https://nodejs.org/zh-cn/download 执行 fnm install 22 之后,执行 node 或 npm 提示找不到命令 fnm env 看环境变量 找到 node 和 npm 命令在 C:\Users\HUAWEI\AppData\Roaming\fnm\node-versions\v22.15.0\installation 目录下࿰…...

开发指南112-样式的优先级别
在前端样式设置里,界面元素一般会多个地方进行定义和影响。一般而言,CSS样式的优先级如下: 1、内联样式:style属性中定义的样式,具有最高的优先级。 2、ID选择器:通过ID选择器指定的样式ÿ…...

单向通信机制EventSource
EventSource 是浏览器提供的一种实现服务器推送 简称 SSE 基于 HTTP 协议的单向通信机制 可以通过服务器将实时数据推送到客户端 而不需要客户端不断发起请求EventSource 和 WebSocket 都可以实现服务器向客户端的实时数据推送,但它们有不同的适用场景:E…...
的深度解析)
PyTorch中mean(dim=1)的深度解析
mean(dim=1) 是什么意思 在自然语言处理中,文本经过分词器处理后会转换为token序列,每个token对应一个向量表示。mean(dim=1) 的作用是在序列维度上对这些向量取平均,将整个序列压缩为单个向量。下面我用具体例子解释: 1. 张量的维度结构 假设我们有一个输入文本:"…...

Xcode报错:“Set `maskView` to `nil` before adding it as a subview of ZFMaskView
Assertion failure in -[ZFMaskView _addSubview:positioned:relativeTo:] 嗯,坑爹的IOS18,当你基于UIView实现的自己的子类中定义一个属性并初始化时就会出现崩溃! /// 遮罩property (nonatomic, strong) UIView *maskView; 因为UIVIEW本…...

uniapp -- 验证码倒计时按钮组件
jia-countdown-verify 验证码倒计时按钮组件 一个用于发送短信验证码的倒计时按钮组件,支持自定义样式、倒计时时间和文本内容。适用于各种需要验证码功能的表单场景。 代码已经 发布到插件市场 可以自行下载 下载地址 特性 支持自定义按钮样式(颜色、…...

e.g. ‘django.db.models.BigAutoField‘.
在Django框架中,django.db.models.BigAutoField 是一个用于数据库模型的字段类型,它用于自动增长的ID字段。这个字段类型特别适用于需要处理大量数据的应用,比如在大型网站或应用中,普通的 AutoField 可能不足以存储增长的ID值&am…...

【HTTPS基础概念与原理】对称加密与非对称加密在HTTPS中的协作
在HTTPS通信中,对称加密和非对称加密协同工作,共同保障数据的机密性和密钥交换的安全性。以下是两者的协作机制及RSA、ECDHE等算法的核心作用: 一、对称加密与非对称加密的分工 1. 对称加密(如AES、ChaCha20) • 作用&…...

ESP系列单片机选择指南:结合实际场景的最优选择方案
前言 在物联网(IoT)快速发展的今天,ESP系列单片机凭借其优异的无线连接能力和丰富的功能特性,已成为智能家居、智慧农业、工业自动化等领域的首选方案。本文将深入分析各款ESP芯片的特点,结合典型应用场景,帮助开发者做出最优选择…...

使用Thrust库实现异步操作与回调函数
使用Thrust库实现异步操作与回调函数 在Thrust库中,你可以通过CUDA流(stream)来实现异步操作,并在适当的位置插入回调函数。以下是如何实现的详细说明: 基本异步操作 Thrust本身并不直接暴露CUDA流接口,但你可以通过以下方式使…...

【Python 异常处理】
Python 的异常处理机制是构建健壮程序的核心工具,通过 try-except 结构实现优雅的错误管理。以下是系统化指南: 一、基础异常处理结构 try:# 可能出错的代码result 10 / 0 except ZeroDivisionError:# 异常处理逻辑print("错误:除数不…...

40:相机与镜头选型
第一章 相机 1.1 理论基础 1.1.1 相机分类 1 )按照芯片类型: CCD 相机、 CMOS 相机 2 )按照传感器的结构特性:线阵相机、面阵相机 3 )按照扫描方式:隔行扫描相机、逐行扫描相机 4 )按…...

【ESP32-S3】Guru Meditation Error 崩溃分析实战:使用 addr2line 工具 + bat 脚本自动解析 Backtrace
【ESP32-S3】Guru Meditation Error 崩溃分析实战:使用 addr2line 工具 bat 脚本自动解析 Backtrace 在使用 ESP32-S3 进行开发时,我们常常遇到串口报错,例如: Guru Meditation Error: Core 1 paniced (LoadProhibited). Exce…...

win11 VSCode 强制弹窗微软登录
今天在一台新电脑上配置VSCode同步的时候,用了微软账号,因为这台电脑比较特殊,不方便科学上网,所以一开始用的微软账户登录,导致和GitHub账号登录的配置、扩展等等不同步。 后面准备改用GitHub账号登录发现不行&#…...

Thrust库中的Gather和Scatter操作
Thrust库中的Gather和Scatter操作 Thrust是CUDA提供的一个类似于C STL的并行算法库,其中包含两个重要的数据操作:gather(聚集)和scatter(散开)。 Gather操作 Gather操作从一个源数组中按照指定的索引收集元素到目标数组中。 函数原型: t…...

springboot + mysql8降低版本到 mysql5.7
springboot mysql8降低版本到 mysql5.7 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency>spring:datasource:driverClassName: com.mysql.jdbc.D…...

在 Windows 中配置使用 WSL 来运行 Linux 环境,主要有以下步骤:
一、安装 WSL 方法一:使用 wsl --install 命令 :以管理员身份运行 PowerShell 或 Windows 命令提示符,输入 wsl --install 命令,该命令将自动启用运行 WSL 所需的功能,并安装默认的 Linux 发行版 Ubuntu。 方法二&…...

TypeScript泛型:从入门到精通的全方位指南
TypeScript泛型:从入门到精通的全方位指南 前言 最近在社区看到很多小伙伴对TypeScript的泛型概念感到困惑。作为一名从Java转战前端的老兵,我想用最接地气的方式,带大家彻底搞懂这个看似高深实则简单的重要特性。 一、什么是泛型…...

DA14531如何在固件中生成与时间相关的mac和版本号
一. 蓝牙device information service显示固件编译时间 这里我是用序列号的characteristic来显示。 只需要把序列号的characteristic value用宏的方式: #define APP_DIS_SERIAL_NB_STR (__DATE__" "__TIME__) #define APP_DIS_SERIAL_NB_STR…...

内存安全设计方案
内存安全设计方案 1. 内存问题分析 1.1 常见内存问题 内存泄漏: 单例对象持有过多引用缓存未及时清理线程池资源未释放内存溢出: 大对象频繁创建队列积压并发处理不当GC频繁: 对象创建过多内存碎片化大对象分配1.2 问题场景 #mermaid-svg-uPgkoDPv6GNGT28v {font-family:&…...

免费Ollama大模型集成系统——Golang
Ollama Free V2 Web 功能实现:界面交互与后端逻辑 一、Web 界面概述 Ollama Free V2 的 Web 界面提供了丰富的交互功能,包括模型选择、图片上传、历史记录查看等。界面使用 Bootstrap 进行布局,结合 JavaScript 实现动态交互。 二、前端界…...

工具学习_模糊测试
定义:模糊测试(fuzz testing, fuzzing)是一种软件测试技术。其核心思想是将自动或半自动生成的随机数据输入到一个程序中,并监视程序异常,如崩溃、断言失败,以发现可能的程序错误,比如内存泄漏。…...

AI智能分析网关V4周界入侵检测算法精准监测与智能分析,筑牢周界安全防线
一、方案背景 随着安全防范需求的不断提升,传统周界安防系统存在误报率高、响应迟缓、智能化程度低等问题,难以满足现代化安全管理的要求。AI智能分析网关V4集成先进的人工智能算法与高性能计算能力,能够实现对周界区域的精准监测与智能分…...

ubuntu20.04系统搭建k8s1.28集群-docker作为容器运行时
ubuntu系统搭建 ubuntu-22.04.5-desktop-amd64.iso映像文件--->实际却是20.4focal版本。 【安装过程没有特别指出的默认回车下一步】 【用户和密码设置】 【网络连接】 【在vmware上安装的话,网络配置如下】【在vm里配置选择nat或者桥接即可】 【国内源配置】&…...

安全合规检查开源项目ComplianceAsCode/content详解及操作系统新产品开发适配指南
I. ComplianceAsCode/content简介 A. 项目使命及其在自动化合规中的重要性 ComplianceAsCode/content项目致力于为各类操作系统发行版和产品提供安全与合规内容。该项目的核心目标是促进自动化安全扫描和配置验证,从而取代传统的手动审计方法,这与日益增长的“合规即代码”…...

Jmeter -- JDBC驱动连接数据库超详细指南
数据库性能决定应用成败!高峰期,慢查询拖垮系统?并发用户激增导致连接超时?这些问题让开发者头疼不已。Apache JMeter作为性能测试神器,不仅能测试Web应用,还能直连数据库,模拟多用户负载&#…...

R利用spaa包计算植物/微生物的生态位宽度和重叠指数
一、生态位宽度 生态位宽度指数包括shannon生态位指数和levins生态位指数。下面是采用levins方法计算生态位宽度。method也可以选择“shannon”。 二、生态位重叠指数 生态位重叠指数,包括levins生态位重叠指数、schoener生态位重叠指数、petrai…...

《AI大模型应知应会100篇》第62篇:TypeChat——类型安全的大模型编程框架
第62篇:TypeChat——类型安全的大模型编程框架 摘要 在构建 AI 应用时,一个常见的痛点是大语言模型(LLM)输出的不确定性与格式不一致问题。开发者往往需要手动解析、校验和处理模型返回的内容,这不仅增加了开发成本&a…...

STM32 片上资源之串口
STM32 片上资源之串口 1 串口介绍1.1 初步介绍1.2 主要特性1.2.1 USART特性1.2.2 UART特性 1.3 主要寄存器1.4 波特率计算1.5 常用工作模式1.5.1 轮询模式:1.5.2 中断模式:1.5.3 DMA模式: 1.6 常见应用1.7 注意事项 2 软件层面协议2.1 基本概…...

全球首个投影机息屏显示专利授权:九天画芯重新定义设备交互与节能显示新范式
一、从 “功能闲置” 到 “持续交互”—— 投影机专利授权开启显示技术新纪元 在智能设备高速发展的今天,投影机作为重要的显示终端,长期面临 “非观影时段功能闲置” 的行业痛点。2025 年,一项名为 “投影机息屏显示” 的核心基础专利获得授…...

音频分类的学习
1.深度学习PyTorch入门-语音分类 https://blog.csdn.net/sinat_41787040/article/details/129795496 https://github.com/musikalkemist/pytorchforaudio https://github1s.com/musikalkemist/pytorchforaudio/blob/main/04%20Creating%20a%20custom%20dataset/urbansoundda…...

Java—— 可变参数、集合工具类、集合嵌套
可变参数 说明 1. 可变参数本质上就是一个数组 2. 作用:在形参中接收多个数据 3. 格式:数据类型...参数名称 举例:int...a 4. 注意事项: 形参列表中可变参数只能有一个 可变参数必须放在形参列表的最后面 案例演示 …...
:向量检索之调用ollama向量数据库)
AGI大模型(15):向量检索之调用ollama向量数据库
这里介绍将向量模型下载到本地,这里使用ollama,现在本地安装ollama,这里就不过多结束了。直接从下载开始。 1 下载模型 首先搜索模型,这里使用bge-large模型,你可以根据自己的需要修改。 点击进入,复制命令到命令行工具中执行。 安装后查看: 2 代码实现 先下载ollama…...

“强强联手,智启未来”凯创未来与绿算技术共筑高端智能家居及智能照明领域新生态
近日,北京凯创未来科技有限公司总经理赵健凯先生莅临广东省绿算技术有限公司北京运营中心,双方正式签订战略合作协议,标志着绿算技术在高端智能家居及智能照明领域的技术实力与产业布局获得智能家居行业认可,同时也为凯创未来在高…...

【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权
【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权 文章目录 【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权[toc]一:Kerberos 委派攻击原理之 S4U2利用1.1原理1.2两种扩展协议**S4U2Self (Service for User to Self)****S4U2Proxy (Service for User to Proxy)*…...

Linux grep -r 查找依赖包是否存在依赖类 Class
方法一:通过 Linux ,grep -r ClassPath 命令 grep -f org.apache.kafka.connect.source.SourceRecord在 jar 包所在 lib 或者 lib/plugins 目录下执行,grep -r, flink-sql-connector-sqlserver-cdc-3.3.0.jar 中此 kafka Source…...

Qt笔记---》.pro中配置
文章目录 1、概要1.1、修改qt项目的中间文件输出路径和部署路径1.2、Qt 项目模块配置1.3、外部库文件引用配置 1、概要 1.1、修改qt项目的中间文件输出路径和部署路径 (1)、为解决 “ 输出文件 ” 和 “ 中间输出文件 ”全部在同一个文件夹下的问题&am…...
】)
D. Eating【Codeforces Round 1005 (Div. 2)】
D. Eating 题意 有 n n n 个史莱姆排成一行,第 i i i 个史莱姆的权重为 w i w_i wi。若史莱姆 i i i 的权重满足 w i ≥ w j w_i \geq w_j wi≥wj,则它可以吃掉史莱姆 j j j;之后,史莱姆 j j j 会消失,…...

猫眼浏览器:简约安全,极速浏览
猫眼浏览器是一款以简约安全为目标的Chrome内核增强版浏览器,基于最新的Chromium开源内核进行二次优化开发。它不仅继承了Chrome浏览器的高速浏览体验,还通过增强的隐私保护设置,让用户远离被追踪和广告的烦恼。无论是日常浏览、信息查询还是…...

安全扫描之 Linux 杀毒软件 Clamav 安装
文章目录 背景Clamav 简介安装使用1、安装epel-release2、Clamav安装3、成功安装4、更新病毒库5、执行扫描6、结果分析7、常见问题 背景 最近在做HVV准备工作,应要求需要在 Linux 服务器上安装杀毒软件,以此文记录下Clamav 安装过程。 Clamav 简介 Cl…...