【Linux】进程通信 管道
🌻个人主页:路飞雪吖~
🌠专栏:Linux
目录
一、👑进程间通信分类
二、👑管道
🌟什么是管道?
🌟匿名管道
🎉原理:
🔥站在文件描述符角度 ----- 深入理解管道:
🔥验证接口:
🌟管道IO出现的四种现象:
🔥匿名管道的5大特性:
🔥管道原则:原子性
🔥管道通信的场景:进程池
🌟命名管道
✨例子
🌠匿名管道与命名管道的区别:
✨命名管道的原理(理解)
🌠小贴士UID --- 记录特定的用户:
🌠命名管道的打开规则:
如若对你有帮助,记得关注、收藏、点赞哦~ 您的支持是我最大的动力🌹🌹🌹🌹!!!
若有误,望各位,在评论区留言或者私信我 指点迷津!!!谢谢 ヾ(≧▽≦*)o \( •̀ ω •́ )/
进程具有独立性,进程之间最亲密的关系就是父子关系。
🐳进程之间为什么需要通信呢?
数据传输、资源共享、通知事件、进程控制。(传递信息)
🐳那进程之间是如何进行通信的呢?
前提:先得让不同得进程,看到同一份资源!
• 同一份资源:以某种形式得内存空间;
• 提供资源得人:只能是操作系统!
若共享资源是以文件的形式提供就为 管道;
若共享资源是以内存块的形式进行提供就为 共享内存;
若共享资源是以队列的形式提供一块一块的数据块就为 消息队列;
若共享资源是以计数器的形式提供就为 信号量。
一、👑进程间通信分类
<1> 管道
• 匿名管道pipe • 命名管道
<2> SystemV IPC
• System V 消息队列 • System V 共享内存 • System V 信号量
<3> POSIX IPC
• 消息队列 • 共享内存
• 信号量 • 互斥量
• 条件变量 • 读写锁
二、👑管道
🌟什么是管道?
• 管道是Unix中最古⽼的进程间通信的形式。
• 我们把从⼀个进程连接到另⼀个进程的⼀个数据流称为⼀个“管道”
• 在命令行中用管道级联【sleep 2000 | sleep 3000 &】,& 在后端执行,【sleep 2000】和 【sleep 3000】是两个进程,他们表示兄弟关系。
• 【who】和 【wc --- 统计文件行数】是两个命令,在管道【|】的加持之下,瞬间就会变成两个进程,经过管道的通信,本质上是属于进程间通信。


🌟匿名管道
🎉原理:
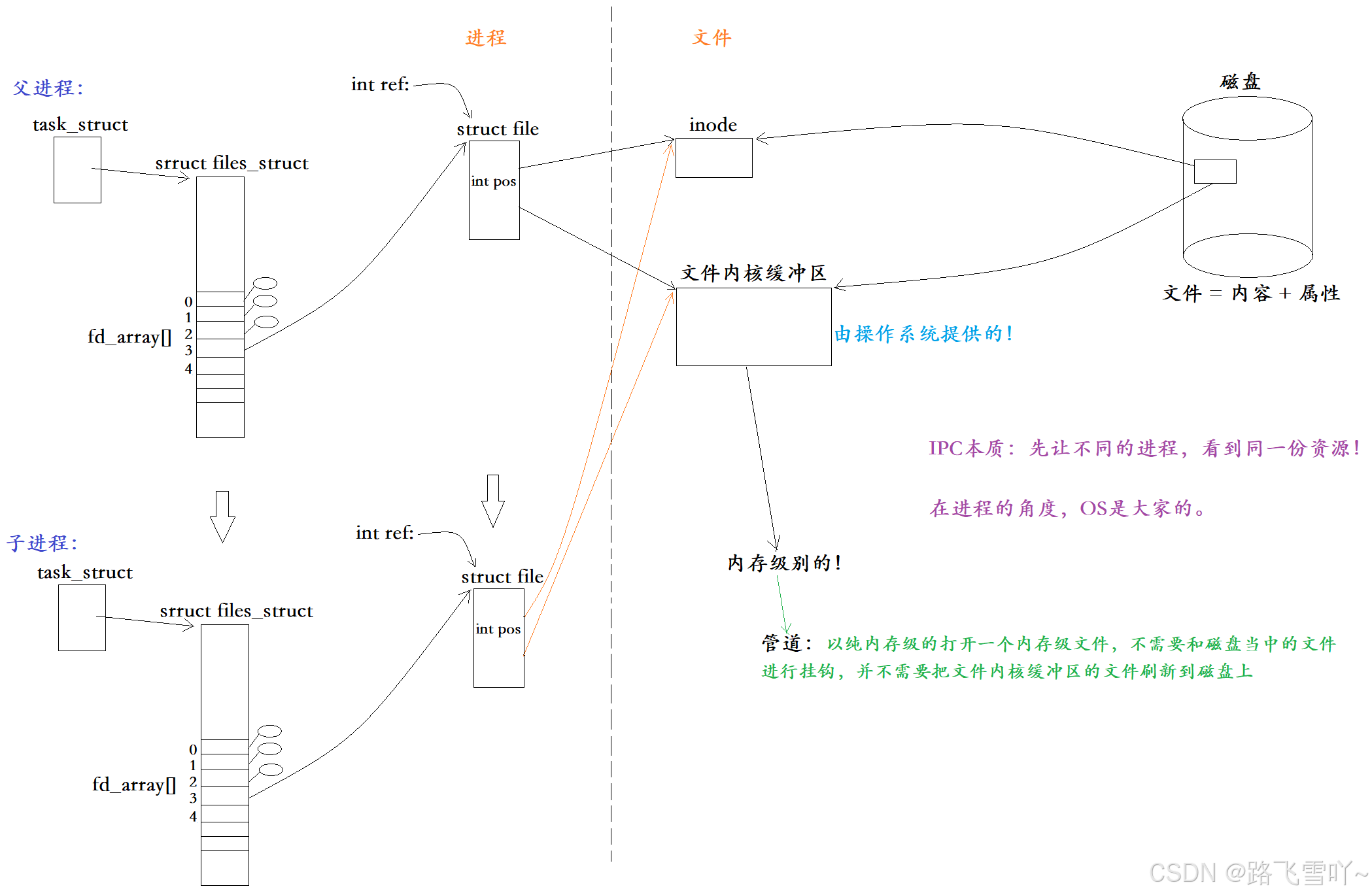
每一个进程都有自己对应的文件描述符表,【struct files_struct 进程和文件所对应的映射关系,严格来讲属于偏进程方面的,若要创建子进程就要创建它】里面有一个数组【fd_array[]】数组对应都有自己的下标,在进程的内部有指针指向自己的文件描述符表,当进程打开磁盘文件【文件 = 内容 + 属性】,找到inode和文件的映射关系,在内核当中就可以创建一个所对应的内核数据结构【struct file 】,里面包含有文件相关的属性集【inode 和 文件内核缓冲区】,文件的属性就可以放到inode里面,内容放到文件缓冲区里面做预读【想读数据就从文件内核缓冲区里面读数据;想写就在文件内核缓冲区里面写,写完就刷新到外设里面,刷新的过程又是访问磁盘的过程】,把文件直接打开之后,当前进程就可以在没有被分配的文件描述符当中分配一个对应的文件下标,就可以把对应文件的指针填下来,接着给上层返回对应的文件描述符【3】,最终上层就可通过文件描述符【3】去访问文件了,当改进程【父进程】创建了子进程,子进程就会独立创建【task_struct、struct files_struct、struct file】没必要让子进程再重新拷贝一份 文件属性inode、文件内核缓冲区,在概念上不统一,【task_struct、struct files_struct】属于进程方面,inode 和 文件内核缓冲区 属于文件部分,子进程创建的是进程,和文件部分无关,在操作系统上不需要重复的打开同一个文件 【即 inode 和 文件内核缓冲区 不需要重复出现】,在操作系统上维护一份 inode 和 文件内核缓冲区 就够了,一个文件的读写位置记录在 struct flie 当中,每个进程在读写文件时的读写位置都是独立的【当父子进程读到相同的文件时,是独立读取的,并不是说父进程读到开头,子进程也一起读到开头】,所以子进程才会独立创建struct file,父子进程有各自的读写位置,又因为文件部分是独立的,所以子进程的 struct file 指向父进程打开的 文件属性inode 和 文件内核缓冲区 ,此时父子进程都可以通过文件描述符【3】在各自的文件读写位置,在同一个文件内核缓冲区【操作系统提供的】当中进行操作,IPC本质:先让不同的进程,看到同一份资源! 父子进程通过同一个文件内核缓冲区看到了同一份资源,父子进程都有各自的读写位置,使得父子进程就可以做到并行的读写。
打开文件是系统进行调用创建的,
对于父子进程什么叫做我自己内部创建的【创建之后让 子进程 父进程 看不见】?父/子进程自己 new / malloc 出来的,根据进程地址空间 new / malloc 申请的地址空间是在堆区上的,堆区叫做用户空间,自己 new / malloc 出来的空间能释放,这个空间就属于进程自己的,所以创建子进程,子进程看不见父进程 new / malloc 出来的空间。 但是用系统调用在操作系统内部创建的空间属于大家都能看见的,在进程的角度,OS是大家的。所以文件内核缓冲区在进程打开属于操作系统,这就是为什么我们把一个进程关掉,文件也会被释放的根本原因。在操作系统当中,里面的很多数据结构【struct file 、inode、文件内核缓冲区】都会存在引用计数 [ int ref ],即有多少个指针指向它,它都是知道的,当有数据结构被释放引用计数就会被减1,只要引用计数被减到0,这个数据结构才会被释放。
如果两个进程在同一个文件里面去写,刷新到磁盘上的这个文件里面的文件一定是乱的,进程间通信的文件不需要刷新到磁盘上,进程间通信不需要和磁盘产生关系,只需要把父进程的数据给子进程 或者 子进程把数据给父进程。为此设计了一种 纯内存级的文件 以及 匹配有对应的系统调用的接口,让它可以纯内存级的打开一个内存级文件,不需要和磁盘当中的文件进行挂钩,并不需要把文件内核缓冲区的文件刷新到磁盘上,用它专门在两个进程之间实现通信,在内存级实现数据拷贝。---- 管道【只能进行单向通信】。
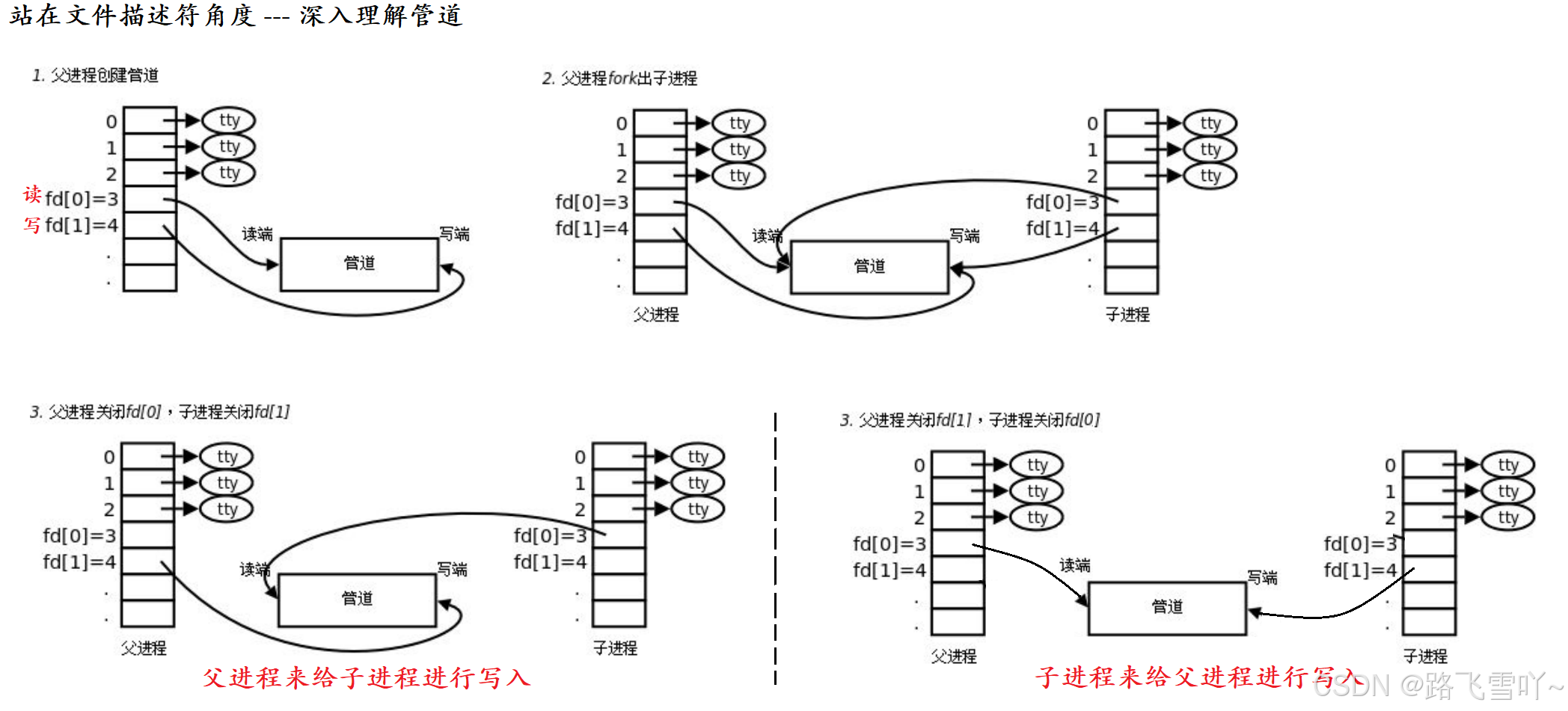
🔥站在文件描述符角度 ----- 深入理解管道:
1、进程间通信,设计了一种文件级的对象,父进程创建完了,直接同时以读和写的方式,打开对应的同一个文件【fd[0] = 3, fd[1] = 4】,即在内存当中 创建进程的两个 struct file 一个表示读,一个表示写 这两文件指向同一个 inode、文件内核缓冲区 。
2、父进程fork出子进程,创建出来的子进程,与父进程看到的是同样的文件描述符表,此时父子进程分别有对应的读写位置;
3、父进程关闭读fd[0],子进程关闭写fd[1]【父子进程关闭不需要的读写端】,此时就是父进程来给子进程进行写入,至此父子进程看到的是基于内存的文件【特定的文件内核级缓冲区】,使得父子进程看的是同一份资源。
父进程读写打开就有两个struct file,指向同一个文件内核级缓冲区,创建子进程后就共有四个 struct file 指向同一个文件内核级缓冲区,当最后要关掉的时候,把对应的读写关闭掉【struct file】即可,使得父子进程可以进行通信。
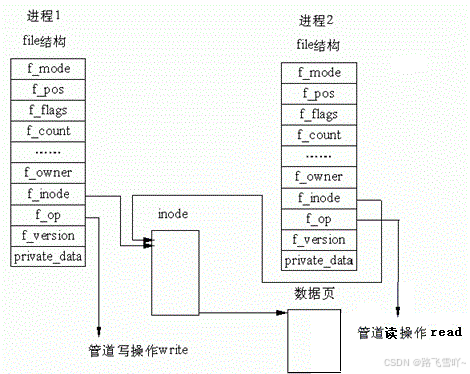
🐳• 若不关闭对应的读写端,会发生什么?
照样可以进行通信,但是会造成文件描述符泄露【文件描述符是数组下标,是有限的,有用的就是资源,造成资源浪费】,和 误操作【当父进程不关闭读写端,父进程只想使用读端,当不小心把父进程的fd[1] = 4,直接去写入,就会破坏管道结构,进而影响通信】;
🐳• 父进程为什么 RW 同时打开?
不可以先把子进程创建出来再打开文件,不然父子进程看不到同一个文件【子进程创建时会继承父进程相关资源】,因此 必须先创建管道,再创建进程,父进程不能单独以读方式打开文件,struct file 里面有【int flag】标记了当前的文件是读还是写,若只以读的方式打开,子进程继承的也都是读的方式,此时父子进程都是读端,只能读文件,不能进行通信。所以只能以读写的方式进行打开,先继承,再关闭。
• 为什么叫管道?只能单向通信?
【为了简化代码】最开始的需求是只要进行单向通信,只想简单的进行通信,才命名为管道。
• 为什么叫做匿名管道?
不会在磁盘上进行刷新,打开这个管道时,不需要创建磁盘级的路径【管道跟磁盘没有关系】,不需要指定管道的文件名,不需要通过路径来标识管道的唯一性,在内核直接创建,所以叫匿名管道。
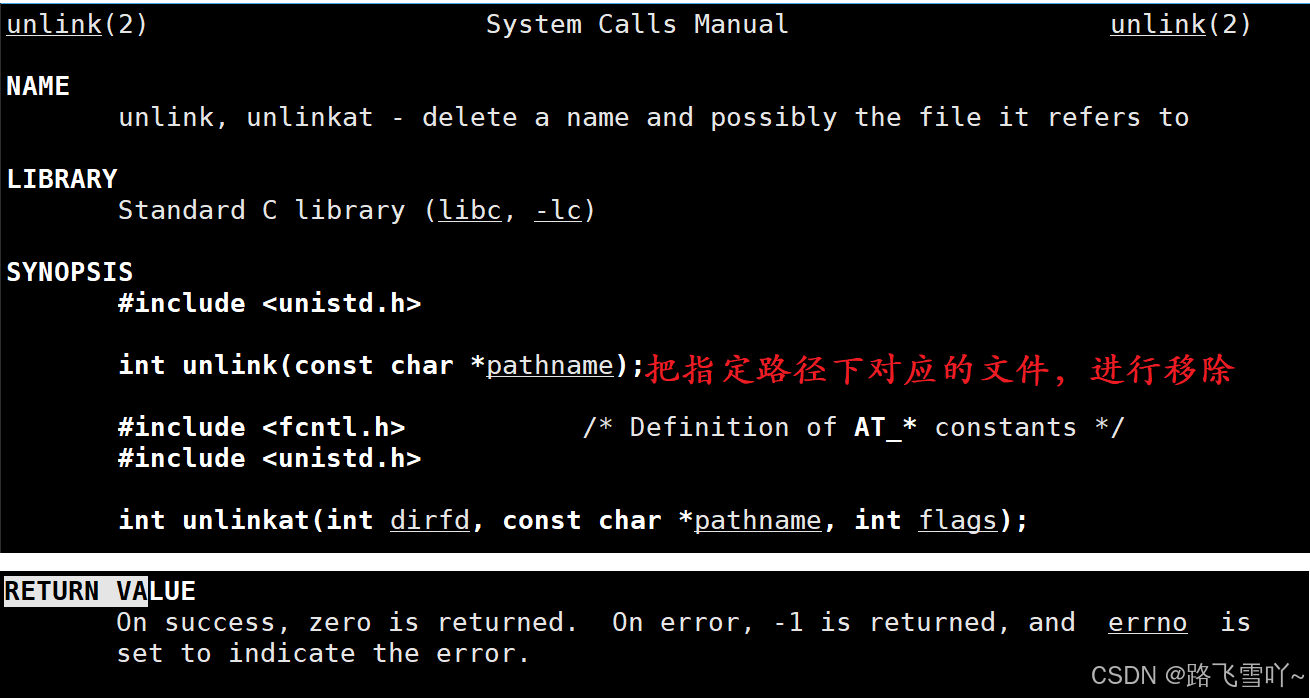
🔥验证接口:
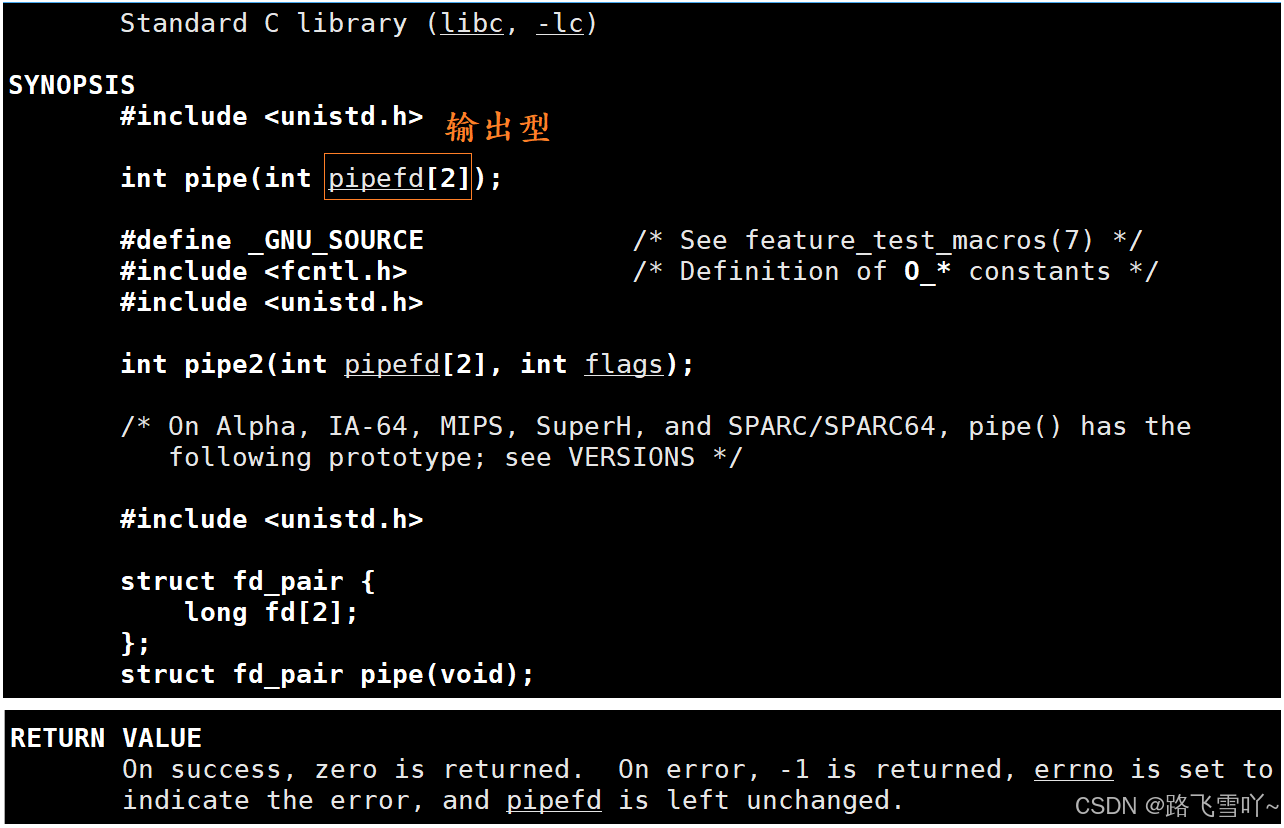
// Makefilemypipe:mypipe.ccg++ -o $@ $^ -std=c++11
.PHONY:clean
clean:rm -f mypipe
// mypipe.cc#include <iostream>
#include <unistd.h>int main()
{int fds[2] = {0};int n = pipe(fds); // 输出型参数if(n == 0)// 创建成功{std::cout << "fds[0]:" << fds[0] << std::endl; // 3std::cout << "fds[0]:" << fds[1] << std::endl; // 4}return 0;
}
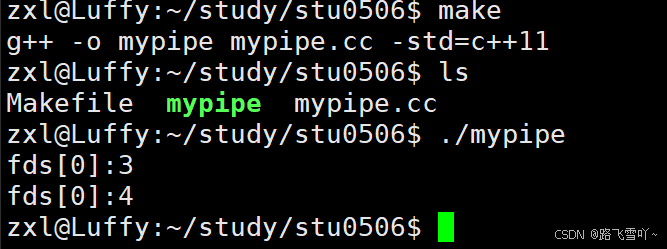
🌠小贴士:
为什么不会重定向到文件里面?
#include <iostream> #include <unistd.h>int main() {int fds[2] = {0};int n = pipe(fds); // 输出型参数if(n != 0){std::cerr << "pipe error" << std::endl;return 1;}std::cerr << "pipe error" << std::endl;std::cerr << "pipe error" << std::endl;std::cerr << "pipe error" << std::endl;return 0; }
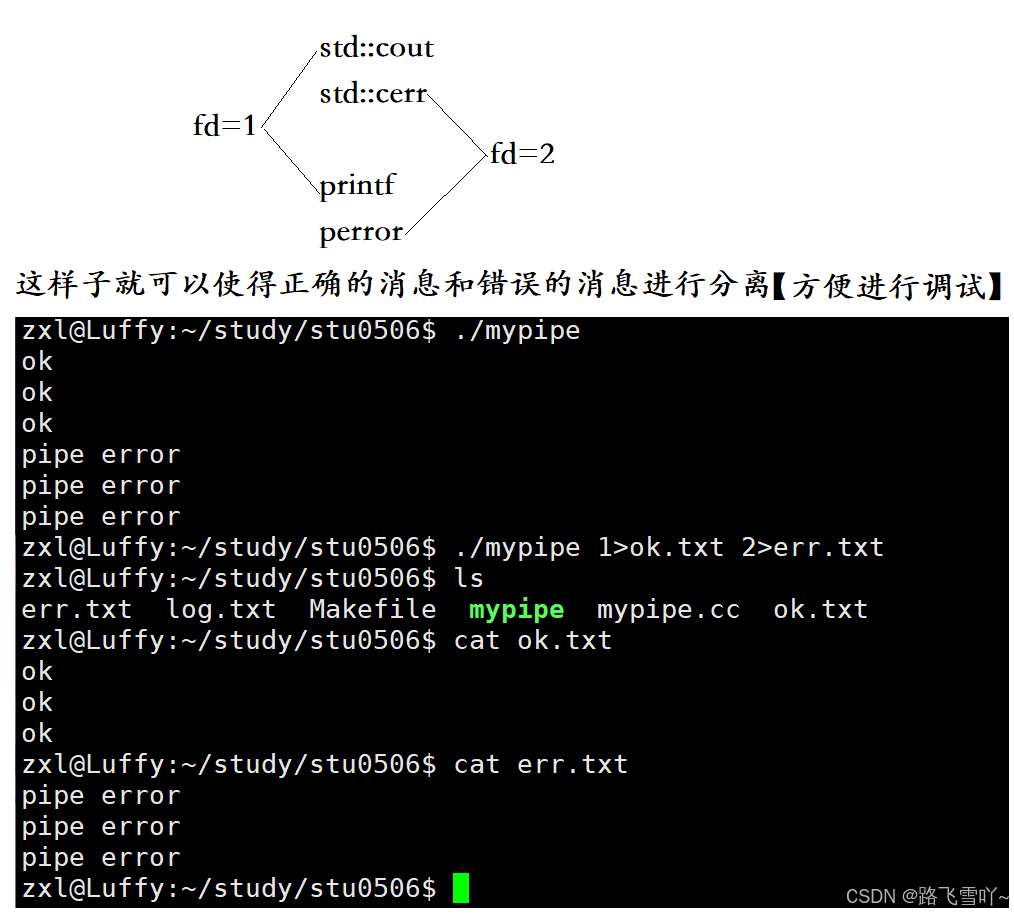
在系统当中的文件里,标准输入【fd = 0】、标准输出【fd = 1】、标准错误【fd = 2】都是文件,我们要打开对应的文件才能写入!
#include <iostream> #include <unistd.h>int main() {int fds[2] = {0};int n = pipe(fds); // 输出型参数if(n != 0){std::cerr << "pipe error" << std::endl;return 1;}std::cout << "ok" << std::endl;std::cout << "ok" << std::endl;std::cout << "ok" << std::endl;std::cerr << "pipe error" << std::endl;std::cerr << "pipe error" << std::endl;std::cerr << "pipe error" << std::endl;return 0; }
指定是哪一个文件描述符的重定向:
【&1】让fd = 1里面的内容放到 fd = 2 里面【fd = 1 拷贝到 fd = 2】:

进程具有独立性,必须通过系统调用才能进行通信。
• int fds[2] = {0};
• int n = pipe(fds);
子进程写,父进程读,此时在子进程的角度上父进程就是一个文件【管道技术的诞生:可以简化通讯模型
】。
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>// father process --> read
// child process ---> writeint main()
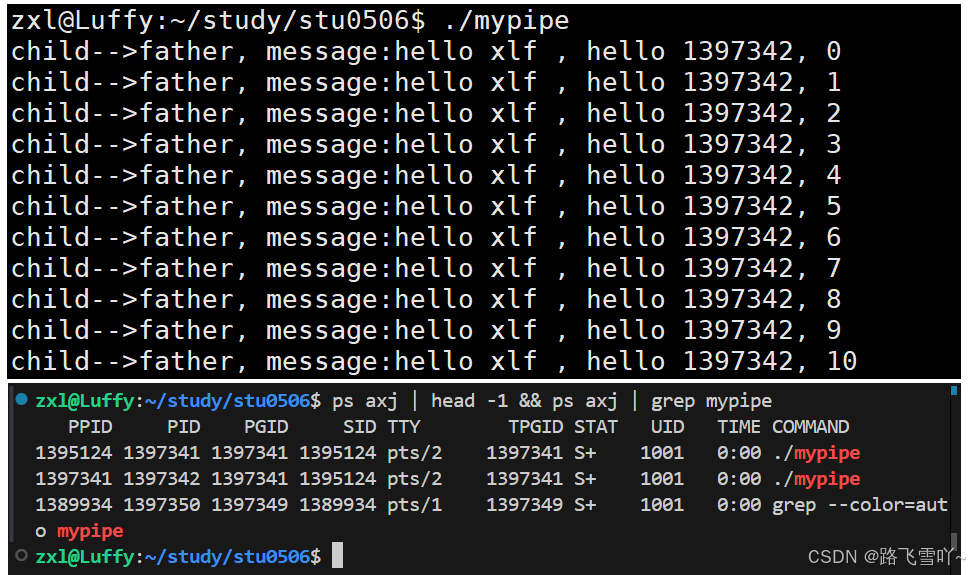
{// 1、创建管道int fds[2] = {0};int n = pipe(fds); // 输出型参数if (n != 0){std::cerr << "pipe error" << std::endl;return 1;}// 2、fork创建子进程pid_t id = fork();if(id < 0){std::cerr << "fork error" << std::endl;}else if(id == 0) // 子进程 进行写入{// 3、关闭不需要的fd, 关闭 read// :: 表示全局的命名空间(系统调用)::close(fds[0]);int cnt = 0;while(true){std::string message = "hello xlf , hello ";message += std::to_string(getpid());// 进程号message += ", ";message += std::to_string(cnt);// 写的次数// fds[1] 向父进程进行写入[向管道进行写入],管道技术:简化通讯模型::write(fds[1], message.c_str(), message.size());cnt++;sleep(1);}//::close(fds[1]);// 文件关不关都没有问题,当一个进程退出之后,struct files_struct 和 struct file也会被关闭exit(0);}else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){// 此时意味着子进程把数据交给了父进程ssize_t n = ::read(fds[0], buffer, 1024);if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}}//::close(fds[0]);// 文件关不关都没有问题,当一个进程退出之后,struct files_struct 和 struct file也会被关闭pid_t rid = waitpid(id, nullptr, 0);std::cout << "father wait child success:" << rid << std::endl;}return 0;
}
• [ cnt++ ]为了表示子进程给父进程发送的消息是一个变化的消息,若定义的是全局的字符串,fork后父子进程都能看见,但是这个全局的字符串不能进行修改,一旦修改就会发生写时拷贝,根本不是通信,且这个全局字符串只能重父到子,不能从子到父;
🌟管道IO出现的四种现象:
☄️情况一: 当管道为空【子进程】在sleep()时,【父进程】读端在阻塞;
IPC本质:先让不同的进程,看到同一份资源【共享资源】,即这一个文件所对应的文件内核缓冲区是被两个执行流【进程】同时看到的,会出现写一半就被读了 或 读一半就被写入了 ,出现数据不一致的问题。
else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){// 此时意味着子进程把数据交给了父进程// 一次读5个字符ssize_t n = ::read(fds[0], buffer, 5);if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}std::cout << std::endl;}//::close(fds[0]);// 文件关不关都没有问题,当一个进程退出之后,struct files_struct 和 struct file也会被关闭pid_t rid = waitpid(id, nullptr, 0);std::cout << "father wait child success:" << rid << std::endl;}
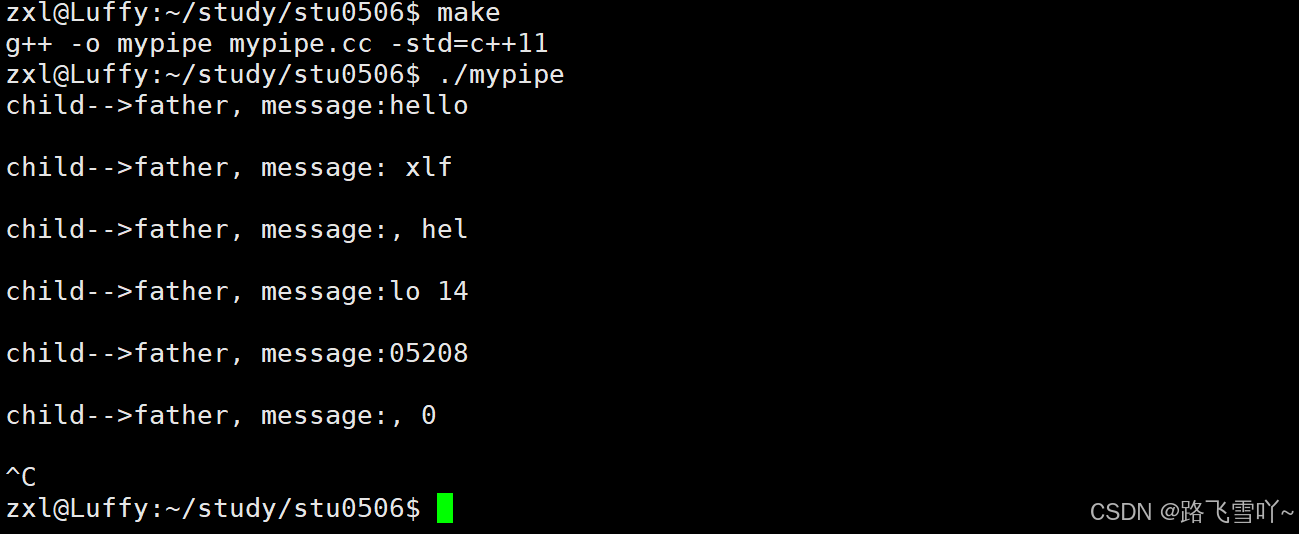 当共享资源进行数据共享的时候,我们需要保护共享资源,在管道内部就做保护了 --- 临界资源。所以父进程在没有数据的时候会进行阻塞,即操作系统把父进程的R状态变为S状态,把父进程的PCB列入到管道的文件【struct file】等待队列里面,当管道里面有数据父进程才会去读,就不会把已经为空的管道继续去读,此时就可以保证管道数据内读取数据的安全。
当共享资源进行数据共享的时候,我们需要保护共享资源,在管道内部就做保护了 --- 临界资源。所以父进程在没有数据的时候会进行阻塞,即操作系统把父进程的R状态变为S状态,把父进程的PCB列入到管道的文件【struct file】等待队列里面,当管道里面有数据父进程才会去读,就不会把已经为空的管道继续去读,此时就可以保证管道数据内读取数据的安全。
☄️情况二:【管道为满】父进程【读端】sleep(100),子进程【写端】不休眠,此时子进程在干嘛?子进程【写端】会进行阻塞。
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>// father process --> read
// child process ---> writeint main()
{// 1、创建管道int fds[2] = {0};int n = pipe(fds); // 输出型参数if (n != 0){std::cerr << "pipe error" << std::endl;return 1;}// 2、fork创建子进程pid_t id = fork();if(id < 0){std::cerr << "fork error" << std::endl;}else if(id == 0) // 子进程 进行写入{// 3、关闭不需要的fd, 关闭 read// :: 表示全局的命名空间(系统调用)::close(fds[0]);int cnt = 0;int total = 0;while(true){std::string message = "h";// 一次写入一个字节total += ::write(fds[1], message.c_str(), message.size());cnt++;std::cout << "total:" << total << std::endl;}exit(0);}else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){sleep(100);// 此时意味着子进程把数据交给了父进程ssize_t n = ::read(fds[0], buffer, 1024);if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}std::cout << std::endl;}pid_t rid = waitpid(id, nullptr, 0);std::cout << "father wait child success:" << rid << std::endl;}return 0;
}
此时就说明了管道有上限,Ubuntu 的大小是64KB;管道内部自带同步【两个进程间执行时,在一定的程度上具有顺序性】,当管道被写满了,就不能继续写了,该到读端进行读了;当管道被读完了,就不能继续读了,该到写端进行写了【保证管道数据的安全】,因此读写它们之间时可以同步的。否则就会覆盖前面写过的内容,此时就会出现数据不一致的问题。
当进程进行 read(),并不会看 write() 写入了多少就读多少,而是按照 read() 最大的期望值来进行一下子读出。所以在读写双方看来,使用管道通信的时候,根本不关心管道里面写的是什么,管道曾经被写入多少次,只关系要读多少个数据 ---- 面向字节流。
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>// father process --> read
// child process ---> writeint main()
{// 1、创建管道int fds[2] = {0};int n = pipe(fds); // 输出型参数if (n != 0){std::cerr << "pipe error" << std::endl;return 1;}// 2、fork创建子进程pid_t id = fork();if(id < 0){std::cerr << "fork error" << std::endl;}else if(id == 0) // 子进程 进行写入{// 3、关闭不需要的fd, 关闭 read// :: 表示全局的命名空间(系统调用)::close(fds[0]);int cnt = 0;int total = 0;while(true){std::string message = "hx";total += ::write(fds[1], message.c_str(), message.size());cnt++;std::cout << "total:" << total << std::endl;}exit(0);}else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){sleep(1);// 此时意味着子进程把数据交给了父进程ssize_t n = ::read(fds[0], buffer, 1024);// 直接在文件中读取1024个字节if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}std::cout << std::endl;}pid_t rid = waitpid(id, nullptr, 0);std::cout << "father wait child success:" << rid << std::endl;}return 0;
}
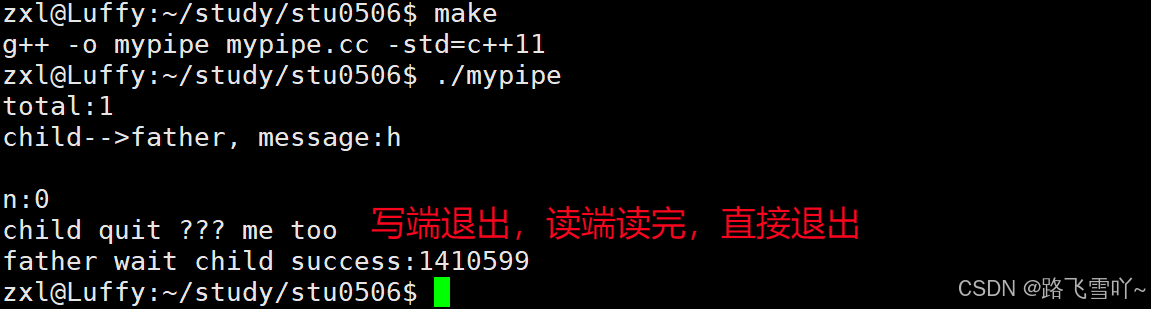
☄️情况三:若写端关闭【write()】写入一条消息后直接退出,读端 是会阻塞还是继续 读呢?读端读完管道内部的数据,在读取的时候,就会读取到返回值0,表示对端关闭,也表示读到文件结尾。此时就直接退出,waitpid() 进程等待成功。
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>// father process --> read
// child process ---> writeint main()
{// 1、创建管道int fds[2] = {0};int n = pipe(fds); // 输出型参数if (n != 0){std::cerr << "pipe error" << std::endl;return 1;}// 2、fork创建子进程pid_t id = fork();if(id < 0){std::cerr << "fork error" << std::endl;}else if(id == 0) // 子进程 进行写入{// 3、关闭不需要的fd, 关闭 read// :: 表示全局的命名空间(系统调用)::close(fds[0]);int cnt = 0;int total = 0;while(true){std::string message = "h";total += ::write(fds[1], message.c_str(), message.size());cnt++;std::cout << "total:" << total << std::endl;sleep(1);// 此时父进程就会阻塞break;// 子进程写入完成之后,直接退出}exit(0);}else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){sleep(1);// 此时意味着子进程把数据交给了父进程ssize_t n = ::read(fds[0], buffer, 1024);if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}else if(n == 0){// 如果写端关闭// 读端读完管道内部的数据,在读取的时候,// 就会读取到返回值0,表示对端关闭,也表示读到文件结尾std::cout << "n:" << n << std::endl;std::cout << "child quit ??? me too" << std::endl;break;// 读到文件结尾直接退出}std::cout << std::endl;}pid_t rid = waitpid(id, nullptr, 0);std::cout << "father wait child success:" << rid << std::endl;}return 0;
}
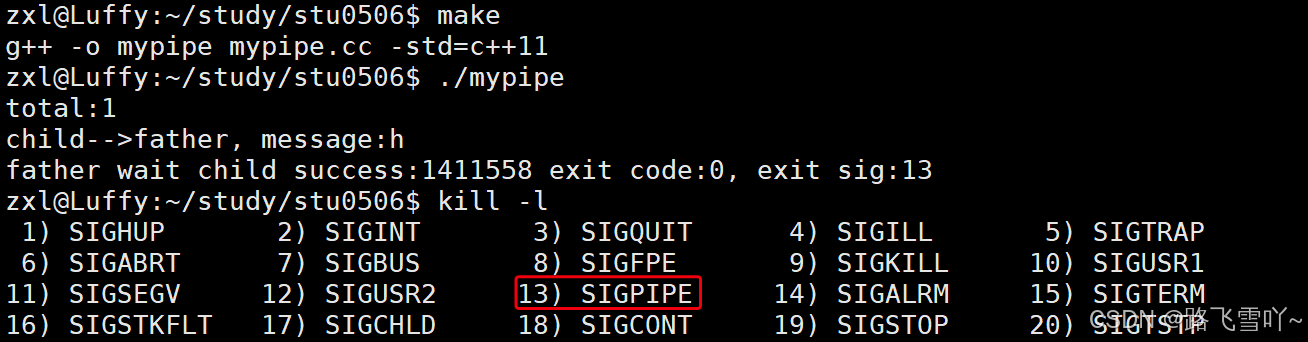
☄️情况四:当【子进程】写端一直在写入,【父进程】读端已经关闭了,就会触发 SIGPIPE,写端就会被操作系统杀掉,子进程就会退出,父进程就会拿到子进程的退出信息【包括子进程的退出信号】。
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>// father process --> read
// child process ---> writeint main()
{// 1、创建管道int fds[2] = {0};int n = pipe(fds); // 输出型参数if (n != 0){std::cerr << "pipe error" << std::endl;return 1;}// 2、fork创建子进程pid_t id = fork();if(id < 0){std::cerr << "fork error" << std::endl;}else if(id == 0) // 子进程 进行写入{// 3、关闭不需要的fd, 关闭 read// :: 表示全局的命名空间(系统调用)::close(fds[0]);int cnt = 0;int total = 0;while(true){std::string message = "h";total += ::write(fds[1], message.c_str(), message.size());cnt++;std::cout << "total:" << total << std::endl;sleep(2);// 此时父进程就会阻塞// 写端一直在写}exit(0);}else // 父进程 进行读取{// 3、关闭不需要的fd, 关闭 write// :: 表示全局的命名空间::close(fds[1]);char buffer[1024];while(true){sleep(1);// 此时意味着子进程把数据交给了父进程ssize_t n = ::read(fds[0], buffer, 1024);if(n > 0){buffer[n] = 0;std::cout << "child-->father, message:" << buffer << std::endl;}else if(n == 0){// 如果写端关闭// 读端读完管道内部的数据,在读取的时候,// 就会读取到返回值0,表示对端关闭,也表示读到文件结尾std::cout << "n:" << n << std::endl;std::cout << "child quit ??? me too" << std::endl;}close(fds[0]);// 直接关掉读端break;// 读端直接退出std::cout << std::endl;}int status = 0;pid_t rid = waitpid(id, &status, 0);std::cout << "father wait child success:" << rid << " exit code:" << ((status<<8)&0xFF) << ", exit sig:" << (status & 0x7F) << std::endl;}return 0;
}
🔥管道IO出现的四种现象:
• 管道为空 && 管道正常,read 会阻塞【read 是一个系统调用】;
• 管道为满 && 管道正常, write 会阻塞【write 也是一个系统调用】;
• 管道写端关闭 && 读端继续,读端读到0,表示读到文件结尾;
• 管道写端正常 && 读端关闭,OS会直接杀掉写入的进程【OS会给目标进程发送信号13) SIGPIPE】。
🔥匿名管道的5大特性:
• 面向字节流;
• 用来进行具有血缘关系的进程,进行IPC,常用于父子;
• 文件的生命周期,随进程!管道也是!【进程里自己malloc/new,也随着进程的关闭而释放】
• 单向数据通信;【要双向通信,就弄两个管道】
• 管道自带同步互斥等保护机制【两个执行流或多个执行流,任何一个时刻只允许一个执行流正在访问一份公共资源[ATM机取钱只能一个一个人排队取]】。
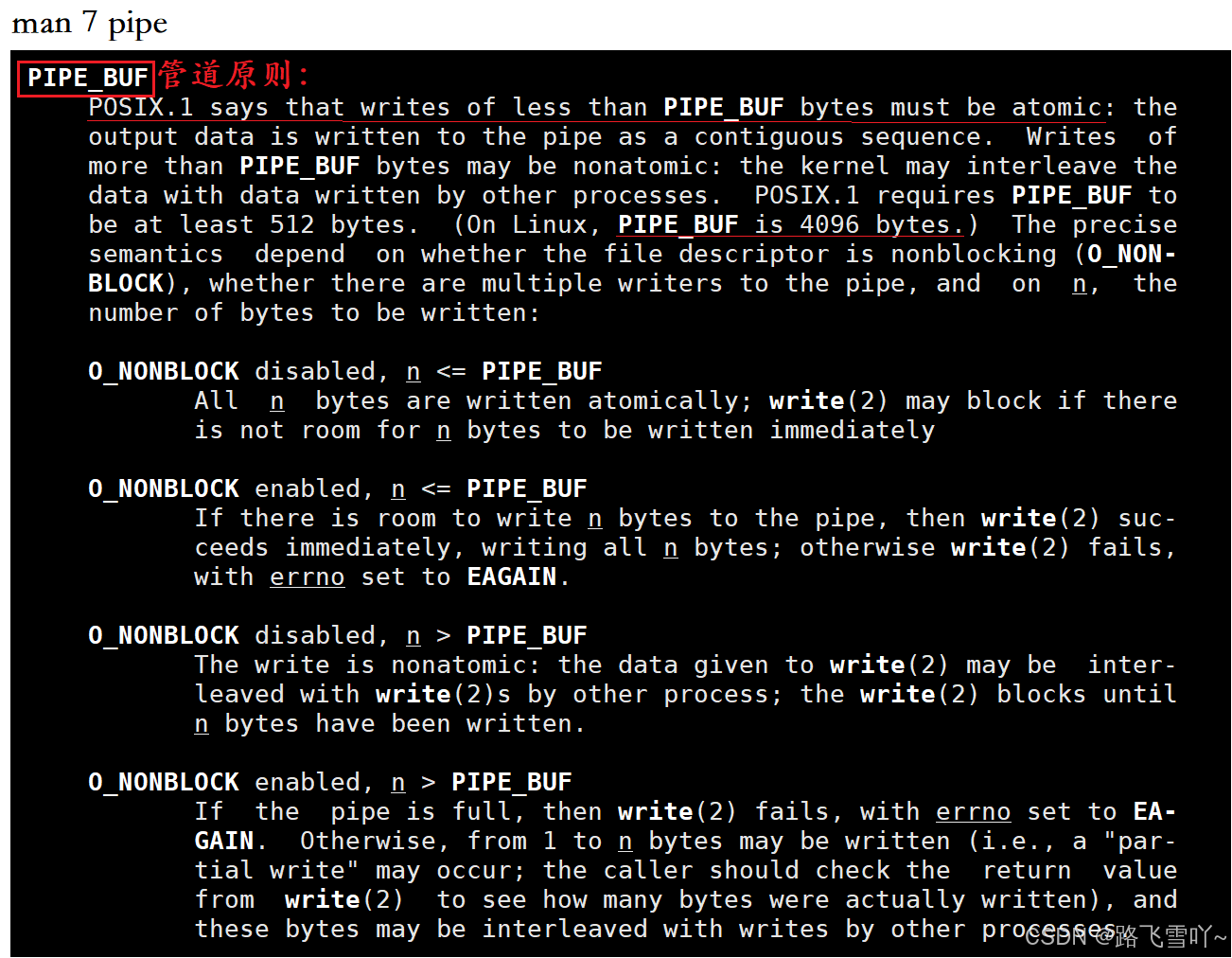
🔥管道原则:原子性
当使用管道,调用write去写入的时候,若向管道写入的数据 单次写入的数据小于宏值【PIPE_BUF】这个写入操作就必须是原子的【要么不做,要么全部做完,没有中间状态】。
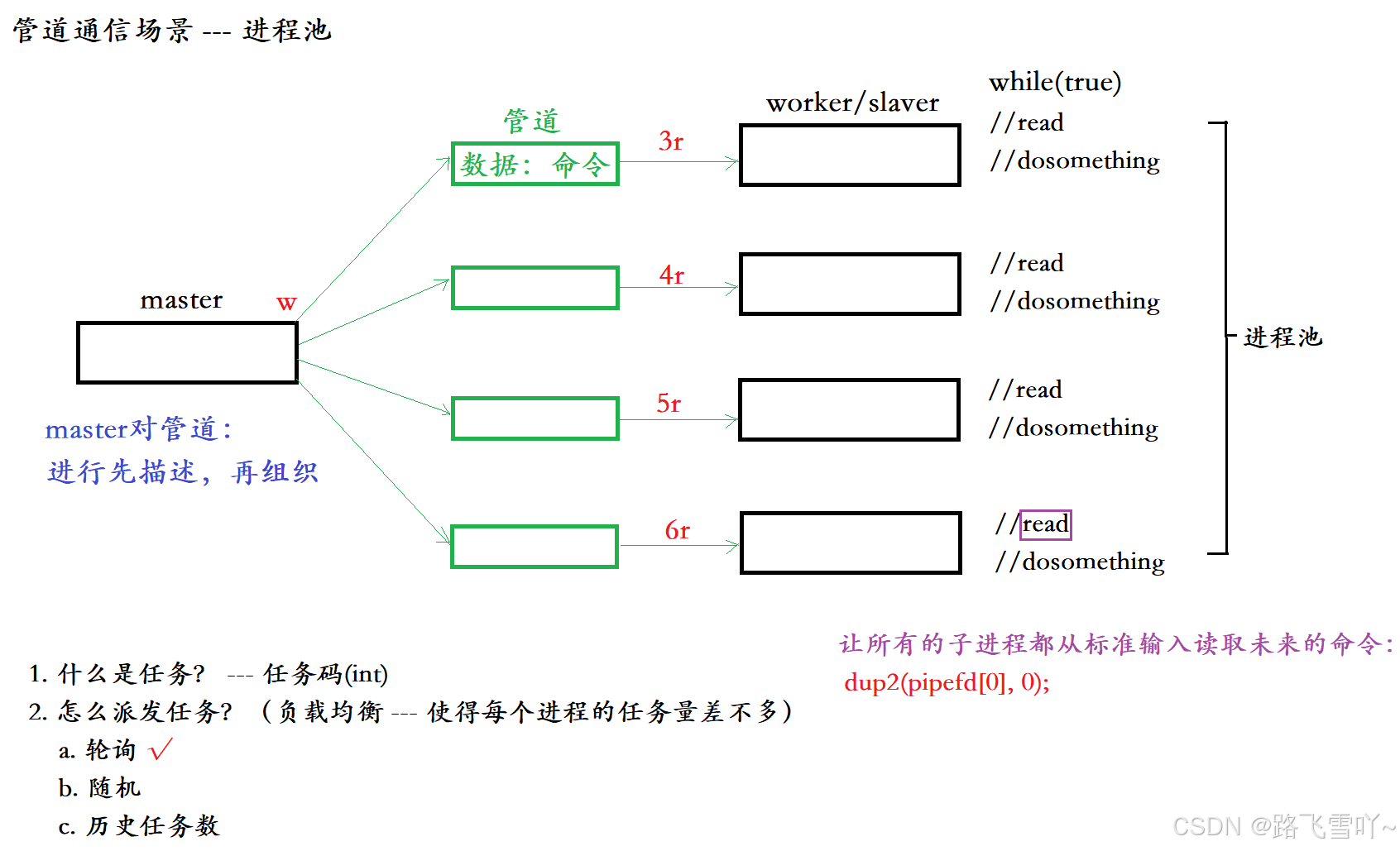
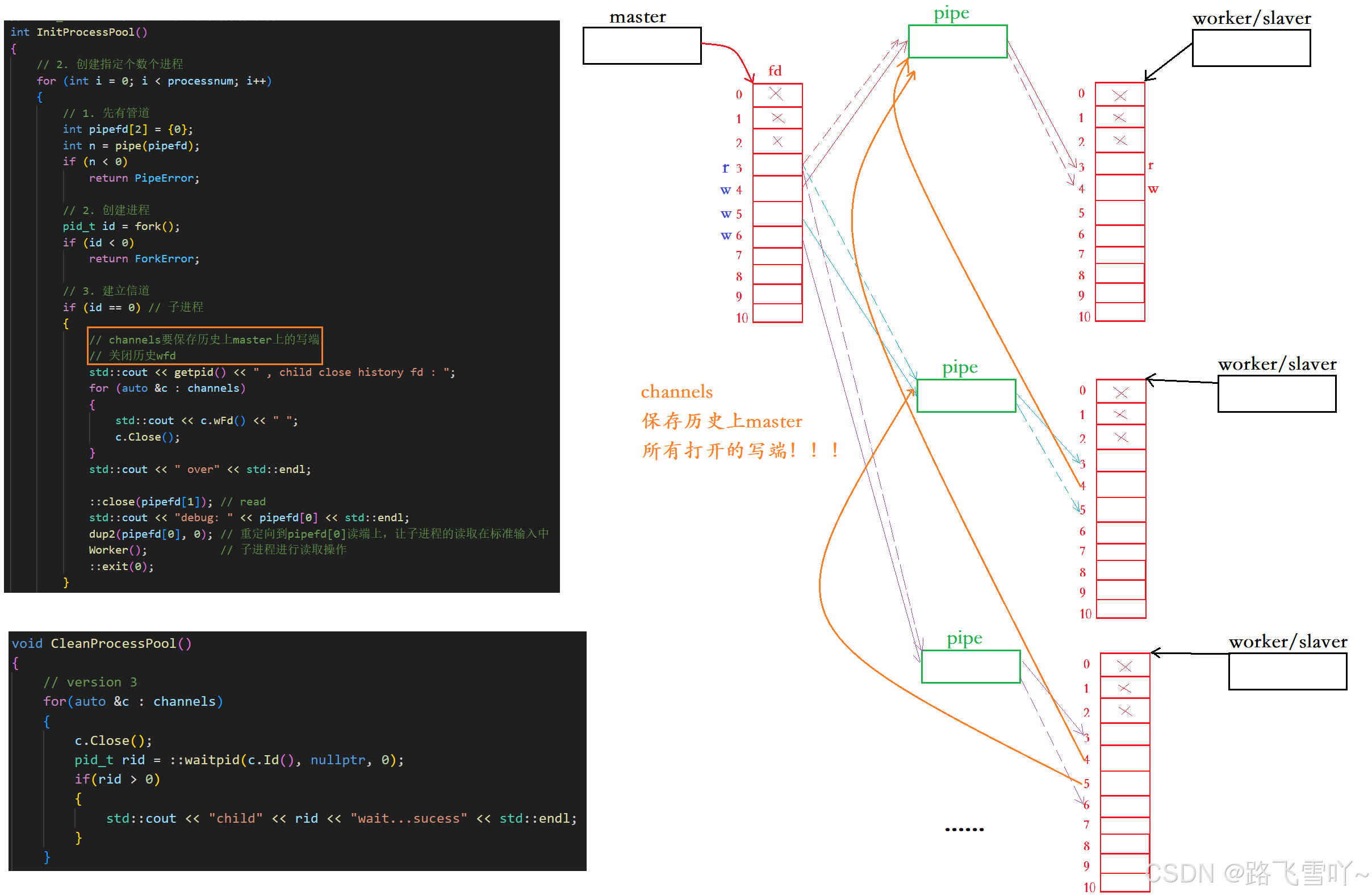
🔥管道通信的场景:进程池
让一个进程可以向其他进程派发任务,指定任务式的把多进程协同起来。
父进程创建对应的四个子进程,也创建了对应的管道,父进程向管道统一进行写入,子进程通过管道统一进行读取。父进程通过向管道当中写入数据,来控制对应的子进程,其中这些子进程是预先创建出来的,即当我们要完成某个任务的时候,要预先创建一批进程,一旦父进程派发任务子进程就去完成任务。此时这些预先创建的子进程就是 --- 进程池。
Makefile:
BIN=processpool
CC=g++
FLAGS=-c -Wall -std=c++11
LDFLAGS=-o
# SRC=$(shell ls *.cc)
SRC=$(wildcard *.cc)
OBJ=$(SRC:.cc=.o)$(BIN):$(OBJ)$(CC) $(LDFLAGS) $@ $^
%.o:%.cc$(CC) $(FLAGS) $<.PHONY:clean
clean:rm -f $(BIN) $(OBJ).PHONY:test
test:@echo $(SRC)@echo $(OBJ)Main.cc:
#include "ProcessPool.hpp"void Usage(std::string pro)
{std::cout << "Usage: " << pro << "process-num" << std::endl;
}// 我们自己就是master
// 父进程 wirte
// 子进程 read
int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);return UsageError;}int num = std::stoi(argv[1]);ProcessPool *pp = new ProcessPool(num, Worker);// 1. 初始化进程池pp->InitProcessPool();// 2. 派发任务pp->DispatchTask();// 3. 退出进程池pp->CleanProcessPool();// std::vector<Channel> channels;// 管道对象// // 1. 初始化进程池// InitProcessPool(num, channels, Worker);// //DebugPrint(channels);// // 2. 派发任务// DispatchTask(channels);// // 3. 退出进程池// CleanProcessPool(channels);// sleep(100);delete pp;return 0;
}ProcessPool.hpp :
#include <iostream>
#include <string>
#include <vector>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <functional>
#include "Task.hpp"
#include "Channel.hpp"// typedef std::function<void()> work_t;
using work_t = std::function<void()>; // 定义函数对象类型
// 包装器 --- 保存任何可调用的对象enum
{OK = 0,UsageError,PipeError,ForkError
};class ProcessPool
{
public:ProcessPool(int n, work_t w): processnum(n), work(w){}// channels: 输出型参数// work_t work : 回调 让子进程执行其他任务int InitProcessPool(){// 2. 创建指定个数个进程for (int i = 0; i < processnum; i++){// 1. 先有管道int pipefd[2] = {0};int n = pipe(pipefd);if (n < 0)return PipeError;// 2. 创建进程pid_t id = fork();if (id < 0)return ForkError;// 3. 建立信道if (id == 0) // 子进程{// channels要保存历史上master上的写端// 关闭历史wfdstd::cout << getpid() << " , child close history fd : ";for (auto &c : channels){std::cout << c.wFd() << " ";c.Close(); }std::cout << " over" << std::endl;::close(pipefd[1]); // readstd::cout << "debug: " << pipefd[0] << std::endl;dup2(pipefd[0], 0); // 重定向到pipefd[0]读端上,让子进程的读取在标准输入中Worker(); // 子进程进行读取操作::exit(0);}// 父进程执行::close(pipefd[0]); // wirtechannels.emplace_back(pipefd[1], id);// Channel ch(pipefd[1], id);// 向子进程写入// channels.push_back(ch);// 循环num次,就维护了num个管道}return OK;}void DispatchTask(){int who = 0;// 2. 派发任务int num = 20;while (num--){// a. 选择一个任务,整数int task = tm.SelectTask();// b. 选择一个子进程channelChannel &curr = channels[who++];who %= channels.size();std::cout << "##################" << std::endl;std::cout << "send " << task << " to " << curr.Name() << "任务还剩:" << num << std::endl;std::cout << "##################" << std::endl;// c. 派发任务curr.Send(task);sleep(2);}}void CleanProcessPool(){// version 3for(auto &c : channels){c.Close();pid_t rid = ::waitpid(c.Id(), nullptr, 0);if(rid > 0){std::cout << "child" << rid << "wait...sucess" << std::endl;}}// version 2// 关闭管道// for (auto &c : channels)// for (int i = channels.size() - 1; i >= 0; i--) // 倒着关闭子进程// {// channels[i].Close();// pid_t rid = ::waitpid(channels[i].Id(), nullptr, 0); // 阻塞了!// if (rid > 0)// {// std::cout << "child " << rid << "wait ... success" << std::endl;// }// }// version 1// // 关闭管道// for (auto &c : channels)// {// c.Close();// }// // 回收子进程// for (auto &c : channels)// {// pid_t rid = ::waitpid(c.Id(), nullptr, 0);// if (rid > 0)// {// std::cout << "child " << rid << "wait ... success" << std::endl;// }// }}void DebugPrint(){for (auto &c : channels){std::cout << c.Name() << std::endl;}}private:std::vector<Channel> channels;int processnum;work_t work;
};
Channel.hpp :
#ifndef __CHANNEL_HPP__
#define __CHANNEL_HPP__#include <iostream>
#include <string>
#include <unistd.h>// 对管道进行: 先描述,再组织
class Channel
{
public:Channel(int wfd, pid_t who) : _wfd(wfd), _who(who){// Channel-3-1234_name = "Channel-" + std::to_string(wfd) + "-" + std::to_string(who);}std::string Name() { return _name; };void Send(int cmd) { ::write(_wfd, &cmd, sizeof(cmd));}void Close(){ ::close(_wfd);}pid_t Id() { return _who;}int wFd() { return _wfd; }~Channel(){}private:int _wfd;std::string _name;pid_t _who;
};#endifTask.hpp:
#pragma once#include <iostream>
#include <functional>
#include <unordered_map>
#include <ctime>
#include <sys/types.h>
#include <unistd.h>using task_t = std::function<void()>;void Download()
{std::cout << "我是下载任务..., pid:" << getpid() << std::endl;
}void Log()
{std::cout << "我是日志任务..., pid:" << getpid() << std::endl;
}void Sql()
{std::cout << "我是数据库同步任务..., pid:" << getpid() << std::endl;
}static int number = 0;
class TaskManger
{
public:TaskManger(){InsertTask(Download);InsertTask(Log);InsertTask(Sql);}// 插入任务void InsertTask(task_t t){tasks[number++] = t;}// 选择任务int SelectTask(){return rand() % number;}// 执行任务void Excute(int number){if (tasks.find(number) == tasks.end())return;tasks[number]();}~TaskManger() {}private:std::unordered_map<int, task_t> tasks;
};TaskManger tm;void Worker()
{// read -> 0 子进程从标准输入上读取数据while (true){int cmd = 0;int n = ::read(0, &cmd, sizeof(cmd));if (n == sizeof(cmd)){tm.Excute(cmd);}else if (n == 0){std::cout << "pid: " << getpid() << "quit..." << std::endl;break;}else{}}
}🌟命名管道
匿名管道,是如何让父子进程看到的呢?--- 子进程继承父进程资源。
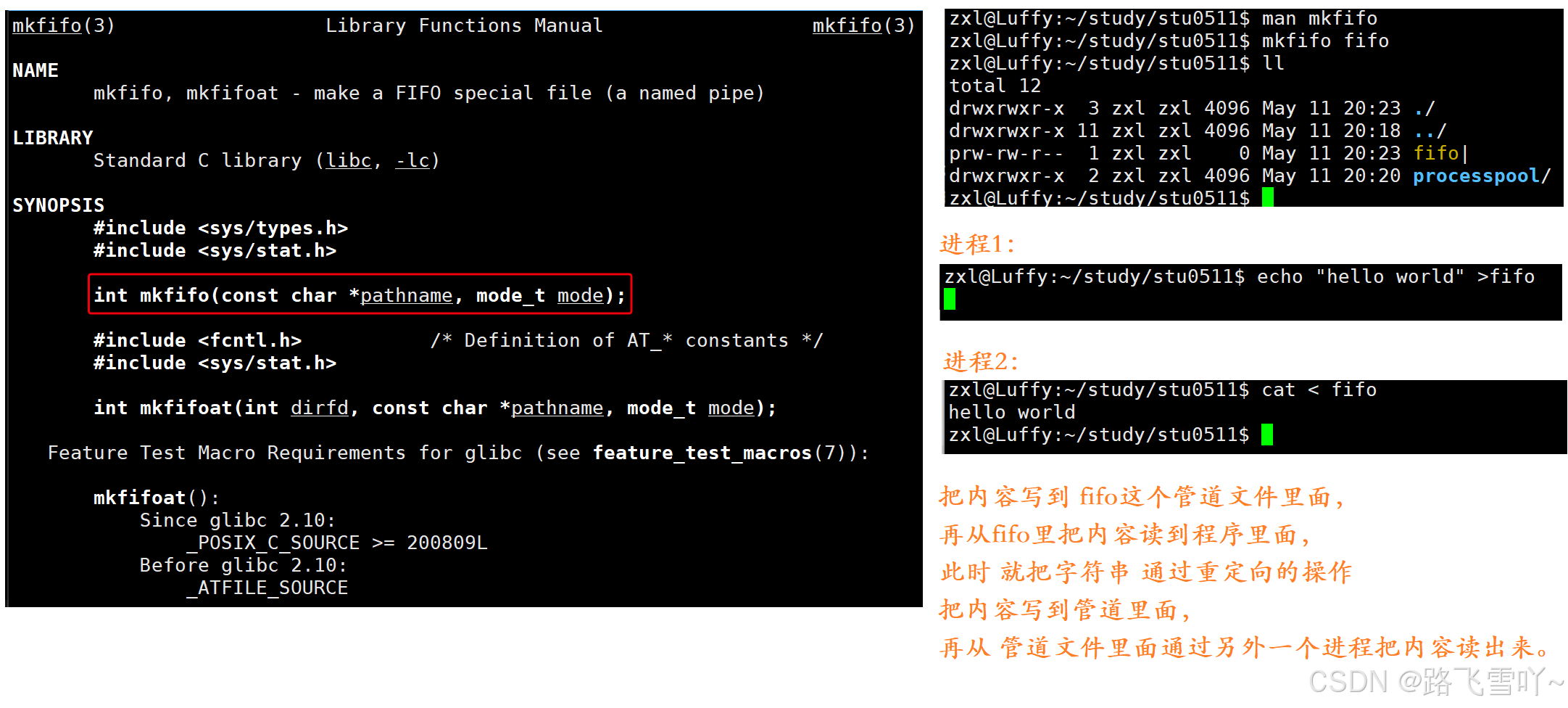
如果我们想在不相关的进程之间交换数据,可以使⽤FIFO⽂件来做这项⼯作,它经常被称为命名 管道。
命名管道是⼀种特殊类型的⽂件。
✨例子
🌠匿名管道与命名管道的区别:
• 匿名管道由pipe函数创建并打开;
• 命名管道由mkfifo函数创建,打开⽤open;
• FIFO(命名管道)与pipe(匿名管道)之间唯⼀的区别在它们创建与打开的⽅式不同,⼀但这些 ⼯作完成之后,它们具有相同的语义。
✨命名管道的原理(理解)
为什么叫做命名管道?--- 是正真存在的文件(就有 路径 + 文件名 --> 具有唯一性)。
进程间通信本质:先让不同的进程,看到同一份资源。 ---> 命名管道就是让不同的进程,用同一个文件系统路径标识同一个资源。
当有一个进程打开了 命名管道【加载到内存上】, 另一个进程的inode和文件内核缓冲区就不需要在磁盘上重新加载了,Linux文件系统要保证文件内部的属性和数据的唯一性。所以两个进程打开同一个 命名管道文件 在底层实现的是同一个inode和同一个文件内核缓冲区。
若是自己创建一个 xxx.txt 文件 让两个进程都打开,基于文件进行通信,也是可以进行通信的,但是普通文件要把数据刷新到磁盘中,而且普通文件对于文件缓冲区是没有做管理的,当别人写满了,一个进程在写,一个进程再读,当把文件删除了,就不能写了,再继续创建普通文件,再写,再读 --- 普通文件是没有任何的保护的,管道写满了还有满的概念,写满了就不能再写了,最重要的是普通文件是要把数据刷新到磁盘上的。
所以在操作系统中,文件是以p开头的,就只使用内核文件缓冲区,不做磁盘级刷新。
文件系统为什么还要构建 fifo 这个文件符号呢? ---- 在磁盘上建立 fifo 仅仅是用来做一个占位符在磁盘里真实存在,因为我们需要使用这个文件名来标识路径的唯一性。
✨没有联系的两个进程进行通信 --- 命名管道
【fifo】公共资源:一般要让指定的一个进程先行创建。通信双方,一个是创建并使用资源,一个是获取并使用资源。
🌠小贴士UID --- 记录特定的用户:
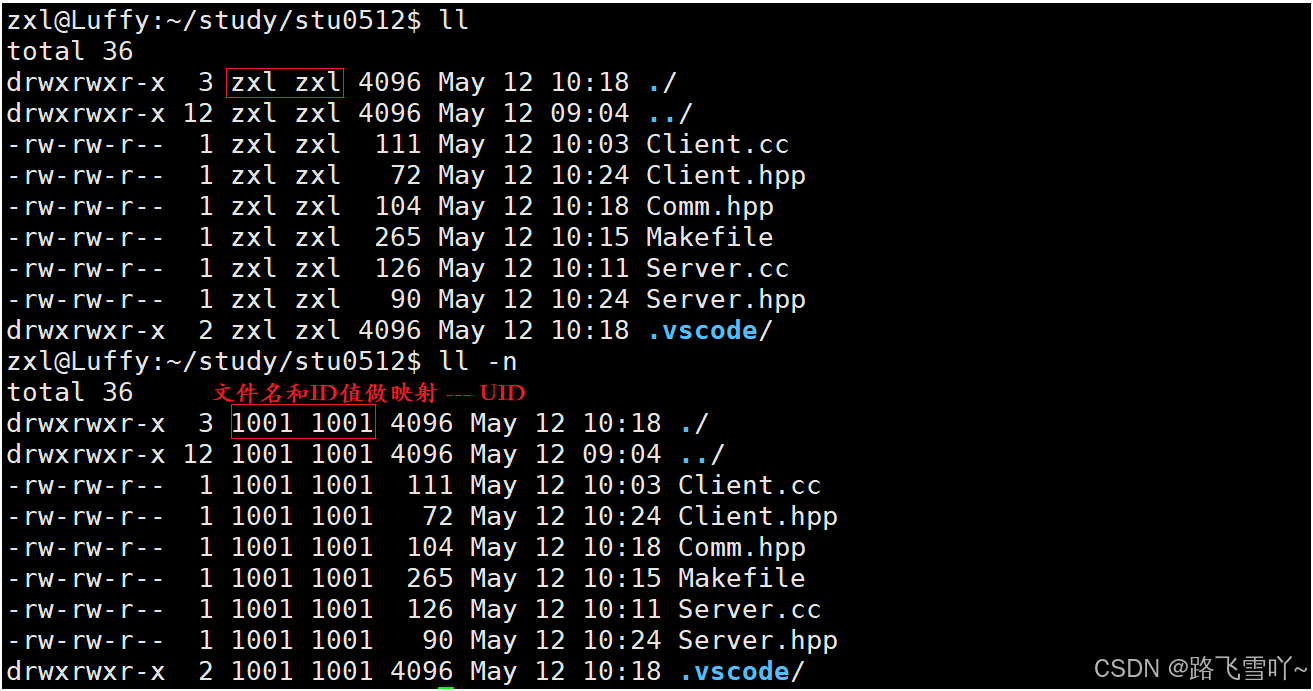
在Linux当中进行操作时,所有的用户行为都会转化为进程,而权限限制的是文件,【例:通过读写来限制哪些进程不允许使用这个管道来进行通信】,但进程都是人启动的,两个人在同一台机器启用不同的进程,在进程的PCB当中包含UID,用来记录特定的用户。
文件会记录用户UID,当每个用户启动的时候,就会为当前用户创建进程,进程的 task_struct 里面也包含有UID是谁启动的,系统通过UID来判断,一个进程是否有权限访问这个用户,进程通过对比 UID 来知道 是 拥有者、所属组、other,进而查看文件的权限。
命名管道打开文件有先有后,server【读端】,client【写端】,当刚开始启动【./server】时,不一个是属于 管道写端关闭&&读端继续 --- 读端到0,表示读到文件结尾 正常情况下 server 应该退出,为什么 server 没有退出呢?管道手册以读的方式打开,这个管道曾经没有被打开过,就会被阻塞住【如果读端打开文件时,写端还没有打开,读端对应的 OpenPipeForRead() 就会阻塞】,当 ./client 启动时【还没写内容】,server 就会从 OpenPipeForRead() 返回;客户端和服务器,可能是在不同的时间点打开文件,但是 server 和 client 会在 OpenPipeForRead() 这里会进行互相等待,保证这两个在一定程度上同时进入IO函数。
Makefile:
SERVER=server
CLIENT=client
cc=g++
SERVER_SRC=Server.cc
Client_SRC=Client.cc.PHONY:all
all: $(SERVER) $(CLIENT)$(SERVER):$(SERVER_SRC)$(cc) -o $@ $^ -std=c++11
$(CLIENT):$(Client_SRC)$(cc) -o $@ $^ -std=c++11.PHONY:clean
clean:rm -f $(SERVER) $(CLIENT)Comm.hpp:
#pragma once#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>const std::string gpipeFile = "./fifo"; // 公共文件
const mode_t gmode = 0600;
const int gdefault = -1;
const int gsize = 1024;
const int gForRead = O_RDONLY;
const int gForWrite = O_WRONLY;int OpenPipe(int flag)
{// 如果读端打开文件时,写端还没有打开,读端对应的open就会阻塞int fd = ::open(gpipeFile.c_str(), flag);if (fd < 0){std::cerr << "open error" << std::endl;}return fd;
}void ClosePipeHelper(int fd)
{if (fd >= 0)::close(fd);
}
Server.hpp:
#pragma once
#include <iostream>
#include "Comm.hpp"class Init
{
public:Init(){umask(0);int n = ::mkfifo(gpipeFile.c_str(), gmode);if (n < 0){std::cerr << "mkfifo error" << std::endl;return;}std::cout << "mkfifo success" << std::endl;//sleep(10);}~Init(){int n = ::unlink(gpipeFile.c_str());if (n < 0){std::cerr << "unlink error" << std::endl;return;}std::cout << "unlink success" << std::endl;}
};Init init;// 创建&&使用
class Server
{
public:Server(): _fd(gdefault){}bool OpenPipeForRead(){_fd = OpenPipe(gForRead);if (_fd < 0) return false;return true;}// std::string * : 输出型参数// const std::string & : 输入型参数// std::string & : 输入输出型参数int RecvPipe(std::string *out){char buffer[gsize];ssize_t n = ::read(_fd, buffer, sizeof(buffer) - 1);if (n > 0){buffer[n] = 0;*out = buffer;}return n;}void ClosePipe(){ClosePipeHelper(_fd);}~Server(){}private:int _fd;
};Server.cc:
#include "Server.hpp"
#include <iostream>int main()
{Server server;std::cout << "pos 1" << std::endl;server.OpenPipeForRead();std::cout << "pos 2" << std::endl;std::string message;while (true){if (server.RecvPipe(&message) > 0)std::cout << "client Say# " << message << std::endl;elsebreak;std::cout << "pos 3" << std::endl;}std::cout << "client quit, me too" << std::endl;server.ClosePipe();return 0;
}Client.hpp:
#pragma once
#include <iostream>
#include "Comm.hpp"class Client
{
public:Client(): _fd(gdefault){}bool OpenPipeForwrite(){_fd = OpenPipe(gForWrite);if (_fd < 0) return false;return true;}// std::string * : 输出型参数// const std::string & : 输入型参数// std::string & : 输入输出型参数int SendPipe(std::string &in){return ::write(_fd, in.c_str(), in.size());}void ClosePipe(){ClosePipeHelper(_fd);}~Client(){}private:int _fd;
};Client.cc:
#include "Client.hpp"
#include <iostream>int main()
{Client client;client.OpenPipeForwrite();std::string message;while(true){std::cout << "Please Enter# ";std::getline(std::cin, message);client.SendPipe(message);}client.ClosePipe();return 0;
}🌠命名管道的打开规则:
• 如果当前打开操作是为读而打开FIFO时:
◦ O_NONBLOCK disable:阻塞直到有相应进程为写而打开FIFO;
◦ O_NONBLOCK enable:立刻返回成功;
• 如果当前打开操作是为写而打开FIFO时 :
◦ O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO;
◦ O_NONBLOCK enable:立刻返回失败,错误码为ENXIO;
如若对你有帮助,记得关注、收藏、点赞哦~ 您的支持是我最大的动力🌹🌹🌹🌹!!!
若有误,望各位,在评论区留言或者私信我 指点迷津!!!谢谢 ヾ(≧▽≦*)o \( •̀ ω •́ )/

相关文章:

【Linux】进程通信 管道
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、👑进程间通信分类 二、👑管道 🌟什么是管道? 🌟匿名管道 🎉原理: 🔥站在文件描述…...

基于智能家居项目 解析DHT11温湿度传感器
一、模块简介 DHT11 是一款数字式温湿度传感器,内部集成了温度传感元件、湿度传感元件以及一个 8 位单片机芯片,用于采集数据和通信。。 测量范围:湿度 20%~90% RH,温度 0~50℃ 精度:湿度 5% …...

3.1 泰勒公式出发点
第一步:引入背景与动机 首先,泰勒公式(Taylor Series)是数学分析中的一个重要工具,它允许我们将复杂的函数近似为多项式形式。这不仅简化了计算,还帮助我们更好地理解函数的行为。那么为什么我们需要这样一…...

裸机开发的核心技术:轮询、中断与DMA
一、裸机开发的核心技术:轮询、中断与DMA 1. 轮询(Polling) 定义:程序主动、周期性地检查硬件状态或数据。应用场景:适用于简单、实时性要求不高的任务。示例: C while (1) { if (GPIO_ReadPin(SENSOR_P…...

从零开始:使用 Vue-ECharts 实现数据可视化图表功能
目录 前言为什么选择 Vue-ECharts案例:Vue-Echart开发一个分组柱状图 安装依赖 引入 全局引入 按需引入编写组件总结 前言 你好,小二!很高兴你愿意分享关于 Vue-ECharts 的使用经验。 📊 Vue-ECharts:让你在 Vue 项…...

Antd中Form详解:
1.获取Form表单值的方式: ① 使用Form.useForm()钩子(推荐方式) const [form] Form.useForm();const getFormValues () > {const values form.getFieldsValue();};<Form form{form}>...<Form.Item label{null}><Button onClick{ge…...
python开发经验)
(2)python开发经验
文章目录 1 pyside6加载ui文件2 使用pyinstaller打包 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 pyside6加载ui文件 方法1: 直接加载ui文件 from PySide6.QtWidgets import QAp…...

Landsat 5介绍
USGS Landsat 5 Level 2, Collection 2, Tier 1 数据集可用性:1984-03-16T16:18:01Z–2012-05-05T17:54:06Z 数据集提供程序 USGS Earth Engine 代码段 ee.ImageCollection("LANDSAT/LT05/C02/T1_L2") open_in_new 重新访问间隔:16 天 说…...

PowerShell 实现 conda 懒加载
问题 执行命令conda init powershell会在 profile.ps1中添加conda初始化的命令。 即使用户不需要用到conda,也会初始化conda环境,拖慢PowerShell的启动速度。 解决方案 本文展示了如何实现conda的懒加载,默认不加载conda环境,只…...

解锁ozon运营新路径:自养号测评技术如何实现降本增效
OZON测评自养号技术在跨境电商运营中具有显著的技术优势,主要体现在环境安全、账号控制、成本效率及风险规避等方面。以下是具体分析: 一:安全可控的测评环境搭建通过模拟俄罗斯本地物理环境和家庭住宅IP,自养号测评可规避平台风…...

算法第十七天|654. 最大二叉树、617.合并二叉树、700.二叉搜索树中的搜索、98.验证二叉搜索树
654. 最大二叉树 题目 思路与解法 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def constructMaximumB…...

Spring Boot 的自动配置为 Spring MVC 做了哪些事情?
Spring Boot 的自动配置为 Spring MVC 做了大量的工作,极大的简化了我们开发时的配置负担,我们可以快速启动并运行一个基于 Spring MVC 的 Web 应用。以下是 Spring Boot 自动配置为 Spring MVC 所做的主要事情: DispatcherServlet 的自动注册…...

【python】—conda新建python3.11的环境报错
1.报错 conda create -n py3.11 python3.11 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ Collecting package metadata: done Solving environment: failed PackagesNotFoundError: The following packages are not available from current channel…...

桑德拉精神与开源链动2+1模式AI智能名片S2B2C商城小程序的协同价值研究
摘要:本文深入剖析桑德拉无私奉献精神在商业领域的映射价值,结合开源链动21模式、AI智能名片及S2B2C商城小程序的技术特性,系统探讨其在用户赋能、资源协同与价值共创中的协同效应。研究表明,该技术组合通过去中心化激励、智能需求…...

JavaEE--初识网络
目录 一、IP地址 二、端口号 三、认识协议 四、五元组 五、协议分层 1. OSI七层模型 2. TCP/IP五层(或四层)模型 3. 网络设备所在分层 4. 封装和分用 一、IP地址 IP地址(Internet Protocol Address)是用于标识设备在网络…...

2.7/Q2,Charls最新文章解读
文章题目:Climate risks, multi-tier medical insurance systems, and health inequality: evidence from Chinas middle-aged and elderly populations DOI:10.1186/s12913-025-12648-2 中文标题:气候风险、多层次医疗保险制度和健康不平等—…...

Mac显卡的工作原理及特殊之处
目录 🧠 一、显卡的基本工作原理(适用于所有平台) 🍏 二、Mac 显卡的工作机制 1. Mac 使用的显卡类型 Intel 架构时代(Intel CPU Intel/AMD 显卡) Apple Silicon 时代(M1/M2/M3 芯片&…...

MUSE Pi Pro 编译kernel内核及创建自动化脚本进行环境配置
视频讲解: MUSE Pi Pro 编译kernel内核及创建自动化脚本进行环境配置 今天分享的主题为创建自动化脚本编译MUSE Pi Pro的kernel内核,脚本已经上传到中 GitHub - LitchiCheng/MUSE-Pi-Pro-Learning: MUSE-Pi-Pro-Learning ,有需要可以自行clon…...

flink的TaskManager 内存模型
Flink TaskManager 的内存模型是一个多层管理体系,从 JVM 进程到具体任务的内存分配均有明确的逻辑划分和配置策略。以下是其核心构成及运行机制: 一、内存模型总览 TaskManager 内存整体分为 JVM 特有内存 和 Flink 管理内存 两大层级&…...

【NLP 72、Prompt、Agent、MCP、function calling】
命运把我们带到哪里,就是哪里 —— 25.5.13 一、Prompt 1.User Prompt 用户提示词 当我们与大模型进行对话时,我们向大模型发送的消息,称作User Prompt,也就是用户提示词,一般就是我们提出的问题或者想说的话 但是我们…...

无人机俯视风光摄影Lr调色预设,手机滤镜PS+Lightroom预设下载!
调色详情 无人机俯视风光摄影 Lr 调色是利用 Adobe Lightroom 软件,对无人机从俯视角度拍摄的风光照片进行后期处理的调色方式。通过调整色彩、对比度、光影等多种参数,能够充分挖掘并强化画面独特视角下的壮美与细节之美,让原本平凡的航拍风…...

【HTML5】【AJAX的几种封装方法详解】
【HTML5】【AJAX的几种封装方法详解】 AJAX (Asynchronous JavaScript and XML) 封装是为了简化重复的异步请求代码,提高开发效率和代码复用性。下面我将介绍几种常见的 AJAX 封装方式。 方法1. 基于原生 XMLHttpRequest 的封装 XMLHttpRequest。其主要特点如下…...

STM32 __rt_entry
STM32中__rt_entry函数的深度解析 在STM32的启动流程中,__rt_entry是一个由ARM C库提供的核心函数,负责在__main完成基础初始化后,搭建完整的C语言运行环境。以下是其核心功能及工作机制的详细分析: 一、__rt_entry的核心作用 …...

YOLOv11融合[AAAI2025]的PConv模块
YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程 YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总 《Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection》 一、 模块介绍 论文链接:https://…...

point3d 视野朝向设置
这里写自定义目录标题 point3d 视野朝向设置三维相机朝向的直观理解 point3d 视野朝向设置 open3d.visualization.Visualizer 中的 get_view_control() 方法返回一个 ViewControl 对象,用来控制 3D 可视化窗口中的相机视角。通过这个对象可以设置视角朝向ÿ…...

基于大模型的腰椎管狭窄术前、术中、术后全流程预测与治疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、腰椎管狭窄概述 2.1 定义与分类 2.2 发病原因与机制 2.3 临床表现与诊断方法 三、大模型技术原理与应用现状 3.1 大模型的基本原理 3.2 在医疗领域的应用案例 3.3 选择大模型预测腰椎管狭窄的依据 四、…...

Matlab基于SSA-MVMD麻雀算法优化多元变分模态分解
Matlab基于SSA-MVMD麻雀算法优化多元变分模态分解 目录 Matlab基于SSA-MVMD麻雀算法优化多元变分模态分解效果一览基本介绍程序设计参考资料效果一览 基本介绍 Matlab基于SSA-MVMD麻雀算法优化多元变分模态分解 可直接运行 分解效果好 适合作为创新点(Matlab完整源码和数据),…...

工程师必读! 3 个最常被忽略的 TDR 测试关键细节与原理
TDR真的是一个用来看阻抗跟Delay的好工具,通过一个Port的测试就可以看到通道各个位置的阻抗变化。 可是使用上其实没这么单纯,有很多细节需要非常地小心,才可以真正地看到您想看的信息! 就让我们整理3个极为重要的TDR使用小细节&…...

Spring Boot 项目中什么时候会抛出 FeignException?
在 Spring Boot 项目中使用 Feign 时,FeignException 是 Feign 客户端在执行 HTTP 请求过程中可能抛出的基础异常。它有很多子类,分别对应不同类型的错误。以下是一些常见的会抛出 FeignException (或其子类) 的情况: 网络连接问题 (Network …...

Spring Boot Swagger 安全防护全解析:从旧版实践到官方规范
摘要 本文系统梳理 Swagger 安全防护的核心方案,涵盖旧版 Swagger(SpringFox)的swagger.basic配置实践、官方推荐的 Spring Security 方案,以及多环境管理、反向代理过滤等全链路技术。结合权威文档,明确不同方案的适…...

基于 PLC 的轮式服务机器人研究
标题:基于 PLC 的轮式服务机器人研究 内容:1.摘要 本文以轮式服务机器人为研究对象,探讨基于可编程逻辑控制器(PLC)的设计与实现。在智能化服务需求不断增长的背景下,旨在开发一种具备稳定运动控制和高效服务功能的轮式服务机器人…...
)
emed64_20.9.2.msi 安装步骤(超简单版)
找到安装包 首先,先下载安装包链接:https://pan.quark.cn/s/2efb908815a4(可能在下载文件夹或者别人发给你的位置),双击它就行。如果双击没反应,就右键点它,选“安装”。 弹出安装向导 这时候会…...

HTML、CSS 和 JavaScript 基础知识点
HTML、CSS 和 JavaScript 基础知识点 一、HTML 基础 1. HTML 文档结构 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.…...

直接在Excel中用Python Matplotlib/Seaborn/Plotly......
本次分享如何利用pyxll包,实现直接在Excel中使用Python Matplotlib/Seaborn/Plotly等强大可视化工具。 pyxll配置 pyxll安装 pip install pyxll pyxll install pyxll自定义方法 例如,自定义一个计算斐波那契数的方法fib,并使用pyxll装饰器…...

互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-5
互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-5 第一轮面试:业务场景切入 面试官(技术总监): 欢迎郑薪苦参与今天的面试。我们先从一个实际业务场景谈起——假设你正在设计一个电商平台的优惠券服务系统&…...

KV cache 缓存与量化:加速大型语言模型推理的关键技术
引言 在大型语言模型(LLM)的推理过程中,KV 缓存(Key-Value Cache) 是一项至关重要的优化技术。自回归生成(如逐 token 生成文本)的特性决定了模型需要反复利用历史token的注意力计算结果&#…...

[250512] Node.js 24 发布:ClangCL 构建,升级 V8 引擎、集成 npm 11
目录 Node.js 24 版本发布:Windows 平台构建工具链转向 ClangCL Node.js 24 版本发布:Windows 平台构建工具链转向 ClangCL 流行的开源跨平台 JavaScript 运行时环境 Node.js 近日发布了 24.0 版本。此版本带来了多项性能提升、安全增强和开发体验的改进…...

Linux常用命令39——free显示系统内存使用量情况
在使用Linux或macOS日常开发中,熟悉一些基本的命令有助于提高工作效率,free命令的功能是显示系统内存使用量情况,包含物理内存和交换内存的总量、使用量、空闲量情况。本篇学习记录free命令的基本使用。 首先查看帮助文档: 语法格…...

4. 文字效果/2D-3D转换 - 3D翻转卡片
4. 文字效果/2D-3D转换 - 3D翻转卡片 案例:3D产品展示卡片 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><style type"text/css">.scene {width: 300px;height…...

游戏引擎学习第276天:调整身体动画
运行游戏,演示我们遇到的拉伸问题,看起来不太好,并考虑切换到更顶视角的视角 我们开始讨论游戏开发中的一些美学决策,特别是在处理动画方面。虽然我们是游戏程序员,通常不负责设计或艺术部分,但因为这是一…...

Java线程池性能优化全解析:从配置到实践
一、线程池配置原则 1.1 核心参数设定 线程池的性能优化始于合理配置,关键参数包括: 核心线程数(corePoolSize) CPU密集型任务:设为Runtime.getRuntime().availableProcessors()(通常为CPU核心数)IO密集型任务:设为CPU核心数 * 2(或更高,根据IO等待时间调整)最大线…...

【入门】歌德巴赫猜想
描述 任一个大于等于4的偶数都可以拆分为两个素数之和。 输入描述 一个整数n( 4 < n < 200 ) 输出描述 将小于等于n的偶数拆分为2个质数之和,列出所有方案! 用例输入 1 10 用例输出 1 422 633 835 1037 1055 #include<b…...

kafka----初步安装与配置
目录标题 ⭐kafka 与 zookeeper间的关系一.集群部署二.修改配置文件三.分发安装包四.启动与关闭 kafka 与 zookeeper 相同,是以集群的形式使用 ⭐kafka 与 zookeeper间的关系 kafka 的使用 要在 zookeeper 集群配置好的基础上 使用要想启动kafka 要先启动 zookeep…...

如何通过 Windows 图形界面找到 WSL 主目录
WSL(Windows Subsystem for Linux)是微软开发的一个软件层,用于在 Windows 11 或 10 上原生运行 Linux 二进制可执行文件。当你在 WSL 上安装一个 Linux 发行版时,它会在 Windows 内创建一个 Linux 环境,包括自己的文件系统和主目录。但是,如何通过 Windows 的图形文件资…...

Cursor 编辑器 的 高级使用技巧与创意玩法
以下是针对 Cursor 编辑器 的 高级使用技巧与创意玩法 深度解析,涵盖代码生成优化、工作流定制、隐藏功能等层面,助你将 AI 辅助编程效率提升至新高度: 一、代码生成进阶技巧 1. 精准控制生成粒度 行级控制: 在代码行内用 // > 指定生成方向(替代模糊注释)def merge_…...

element-ui 源码调用接口跨域问题
今天在看 upload 组件源码时,在组件源码当中调用的本地启动的 nodejs 服务写的上传接口,遇到跨域问题: 问题一、在 upload.md 中调用 nodejs 服务中的 上传接口,控制台报跨域报错。 解决方法1:在根目录增加 vue.conf…...

Docker与PostgreSQL
1. 背景介绍 Docker是一种开源的容器化技术,它通过使用容器来隔离应用程序及其运行环境,使得开发人员能够快速、可靠地构建、部署和运行应用程序。Docker容器是轻量级的虚拟化单元,能够在任何支持Docker的操作系统上运行,从而消除…...

iVX 研发基座:大型系统开发的协作与安全架构实践
通过图形化开发、组件化封装和多厂商协作机制,iVX 解决了传统开发模式在效率、安全和扩展性上的痛点。文章结合政务、教育、企业等行业案例,展示其在数据治理、权限控制和 DevOps 等方面的创新实践,为大型系统开发提供完整的技术参考。 一、…...

Vxe UI vue vxe-table 实现表格数据分组功能,不是使用树结构,直接数据分组
Vxe UI vue vxe-table 实现表格数据分组功能,不是使用树结构,直接数据分组 查看官网:https://vxetable.cn gitbub:https://github.com/x-extends/vxe-table gitee:https://gitee.com/x-extends/vxe-table 代码 通过…...

基于TI AM6442+FPGA解决方案,支持6网口,4路CAN,8个串口
TI AM6442FPGA解决方案具有以下技术优势及适用领域: 一、技术优势 异构多核架构:AM6442处理器集成7个内核(2xCortex-A534xCortex-R5F1xCortex-M4F),可实现应用处理、实时控制和独立任务分核协同,满足…...