leetcode-hot-100(双指针)
1. 移动零
题目链接:移动 0
题目描述:给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
解答
类似于签到题,比较容易。
class Solution {
public:void moveZeroes(vector<int>& nums) {for (int i = 0, j = 0; i < nums.size(); ++i) {if (nums[i] != 0) {swap(nums[i], nums[j]);j++;}}}
};
上述代码和官方的差不多,官方如下:
class Solution {
public:void moveZeroes(vector<int>& nums) {int len = nums.size(), left = 0, right = 0;while (right < len) {if (nums[right]) {swap(nums[left], nums[right]);left++;}right++;}}
};
主要就是需要看右边是啥样的,也就是说,要是右指针指向的位置不为零,则交换左右指针。我一开始编写的代码如下,查看的是左指针,于是出现了很多错误:
class Solution {
public:void moveZeroes(vector<int>& nums) {int len = nums.size(), left = 0, right = 1;while (right < len) {// 问题 1: 这里只跳过右边是 0 的情况,没有意义。// 它只是让 right 跳过连续的 0,但 left 依然可能是 0。while (right < len && nums[right] == 0)right++;// 问题 2: 如果 nums[left] 不是 0,就不交换,但是 left 永远不会越过这个位置,// 导致后面即使有非零数字也无法向前移动。if (nums[left] == 0 && right < len) {swap(nums[left], nums[right]);}left++;right++;}}
};
要是实在是想这样写的话,GPT给的答案不错:
class Solution {
public:void moveZeroes(vector<int>& nums) {int len = nums.size(), left = 0, right = 1;// 确保 right 不会越界while (right < len && left < len) {// 移动 left 直到找到一个 0while (left < len && nums[left] != 0) {left++;// 确保 right 始终在 left 右边或与之相同if (right < left) right = left + 1;}// 如果 left 已经到达数组末尾,退出循环if (left >= len) break;// 移动 right 直到找到一个非 0 元素while (right < len && nums[right] == 0) {right++;}// 如果 right 到达数组末尾,退出循环if (right >= len) break;// 交换 left 和 right 所指的元素swap(nums[left], nums[right]);// 交换后移动 left 和 right 指针left++;right++;}}
};
2. 盛最多水的容器
题目链接:盛最多水的容器
题目描述:给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。
解答
我觉得这个大佬写的不错,放在这里供大家欣赏,这道题目主要是需要弄懂为啥使用双指针是正确的,以及为啥设置双指针可以全部遍历所有的情况。
大佬解答
要是思想弄懂,代码其实都是差不多的:
class Solution {
public:int maxArea(vector<int>& height) {int left = 0, right = height.size() - 1;int ans = 0;while (left < right) {int temp = min(height[left], height[right]) * (right - left);ans = max(ans, temp);if (height[left] >= height[right])right--;elseleft++;}return ans;
};
解答那位大佬的博客写的不错,我这里就不详细的论述了,下面主要讨论两个问题。
1.为啥使用双指针是对的?
2.上面的解法(两端指针向中间移动)不会遗漏情况吗?
下面就这两个问题简要说明一下。
说实话,一开始我的想法是:使用两个指针,两个for,从前向后一直遍历,直到找到最优解,代码如下:
class Solution {
public:int maxArea(vector<int>& height) {int len = height.size();int ans = 0;for (int left = 0; left < len; left++) {for (int right = left + 1; right < len; right++) {int temp = min(height[left], height[right]) * (right - left);ans = max(ans, temp);}}return ans;}
};
但是很不幸的是,这段代码超出了时间限制。

因此上述这样使用双指针的话,就不对。因为两个for的时间复杂度实在是太高了。那么可不可以将时间复杂度降低呢?排序肯定没法用,于是只能想到还是使用两个双指针,但是这次一个左指针在开始位置,一个右指针在结尾的位置,然后一次向中间移动。这样的话,底层是贪心的思想,永远找最高的和最远的,局部最优推出全局最优。上述解法肯定存在遗漏(不然就更for嵌套一样慢了)但是遗漏的都是非局部最优解,所以对全局最优解没有影响。
3. 三数之和
题目链接:三数之和
题目描述:给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
解答
好,看到此题的第一想法,就是上循环,毕竟用 for 是真的香。也就是上三重循环,遍历整个数组,然后得到满足条件的数组,当然,由于题目要求不含有重复的三元组,因此还需要使用哈希表进行去重,于是代码编写如下:
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {int n = nums.size();vector<vector<int>> ans;unordered_set<string> seen;for (int i = 0; i < n; ++i) {for (int j = i + 1; j < n; ++j) {for (int k = j + 1; k < n; ++k) {if (nums[i] + nums[j] + nums[k] == 0) {// 去重:先排序再转成字符串判断是否重复vector<int> triplet = {nums[i], nums[j], nums[k]};sort(triplet.begin(), triplet.end());string key = to_string(triplet[0]) + "," + to_string(triplet[1]) + "," + to_string(triplet[2]); if (seen.find(key) == seen.end()) {ans.push_back(triplet);seen.insert(key);}}}}}return ans;}
};
过测试用例没有问题,然后提交,发现:

其实这也好理解,如果我们直接使用三重循环枚举三元组,会得到 O ( N 3 ) O(N^3) O(N3) 个满足题目要求的三元组(其中 N N N 是数组的长度)时间复杂度至少为 O ( N 3 ) O(N^3) O(N3)。在这之后,我们还需要使用哈希表进行去重操作,得到不包含重复三元组的最终答案,又消耗了大量的空间。这个做法的时间复杂度和空间复杂度都很高,肯定是有些测试用例过不了的。
上述代码不行的话,就需要另想方法了。
既然题目需要不重复,那么就只需要保证如下的性质即可:
- 第二重循环枚举到的元素不小于当前第一重循环枚举到的元素;
- 第三重循环枚举到的元素不小于当前第二重循环枚举到的元素。
也就是说,我们枚举的三元组 ( a , b , c ) (a,b,c) (a,b,c) 满足 a ≤ b ≤ c a≤b≤c a≤b≤c,保证了只有 ( a , b , c ) (a,b,c) (a,b,c) 这个顺序会被枚举到,而 ( b , a , c ) (b,a,c) (b,a,c)、 ( c , b , a ) (c,b,a) (c,b,a) 等等这些不会,这样就减少了重复。要实现这一点,我们可以将数组中的元素从小到大进行排序,随后使用普通的三重循环就可以满足上面的要求。
代码如下:
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {vector<vector<int>> ans;int n = nums.size(); // 排序以便去重sort(nums.begin(), nums.end()); for (int first = 0; first < n; ++first) {// 跳过重复的 firstif (first > 0 && nums[first] == nums[first - 1]) continue; for (int second = first + 1; second < n; ++second) {// 跳过重复的 secondif (second > first + 1 && nums[second] == nums[second - 1]) continue; for (int third = second + 1; third < n; ++third) {// 跳过重复的 thirdif (third > second + 1 && nums[third] == nums[third - 1]) continue; // 判断三数之和是否为 0if (nums[first] + nums[second] + nums[third] == 0) {ans.push_back({nums[first], nums[second], nums[third]});}}}} return ans;}
};
但是时间复杂度还是 O ( N 3 ) O(N^3) O(N3),因此还是可以继续进行优化的,因为上述循环还是没有改变三个 for 的情况。于是还需要继续进行优化:
可以发现,如果我们固定了前两重循环枚举到的元素 a 和 b,那么只有唯一的 c 满足 a + b + c = 0。当第二重循环往后枚举一个元素 b' 时,由于 b' > b,那么满足 a + b' + c' = 0 的 c' 一定有 c' < c,即 c' 在数组中一定出现在 c 的左侧。也就是说,我们可以从小到大枚举 b,同时从大到小枚举 c,即第二重循环和第三重循环实际上是并列的关系。
由于之前将数组进行了排序,因此就可以保持第二重循环不变,而将第三重循环变成一个从数组最右端开始向左移动的指针。
官方给出的伪代码如下:
nums.sort()
for first = 0 .. n-1if first == 0 or nums[first] != nums[first-1] then// 第三重循环对应的指针third = n-1for second = first+1 .. n-1if second == first+1 or nums[second] != nums[second-1] then// 向左移动指针,直到 a+b+c 不大于 0while nums[first]+nums[second]+nums[third] > 0third = third-1// 判断是否有 a+b+c==0check(first, second, third)
基于上述思想和伪代码可以编写正确代码如下:
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {vector<vector<int>> ans;int n = nums.size(); // 排序数组,便于去重和双指针操作sort(nums.begin(), nums.end()); for (int first = 0; first < n; ++first) {// 跳过重复的 first 元素if (first > 0 && nums[first] == nums[first - 1]) continue; // third 初始化为最右边的元素int third = n - 1; for (int second = first + 1; second < n; ++second) {// 跳过重复的 second 元素if (second > first + 1 && nums[second] == nums[second - 1]) continue; // 将 third 指针向左移动到合适的位置while (second < third && nums[first] + nums[second] + nums[third] > 0) {--third;} // 检查是否找到满足条件的三元组if (second < third && nums[first] + nums[second] + nums[third] == 0) {ans.push_back({nums[first], nums[second], nums[third]});}}} return ans;}
};
还是需要多做多看,才能顿悟啊!!!
4. 接雨水
题目链接:接雨水
题目描述:给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
解答
方法一:单调栈
使用一个单调栈来记录柱子的索引,栈中元素保持递减顺序。当遇到一个比栈顶高的柱子时,说明可以形成凹槽接雨水。此时弹出栈顶元素,计算其能接的雨水量。
关键点:
- 栈保存的是索引。
- 每次计算的是中间凹陷部分的高度差和宽度。
- 只有在左右两边都有更高柱子的情况下才能接到水。
class Solution {
public:int trap(vector<int>& height) {int n = height.size();stack<int> stk; // 存储索引int ans = 0;for (int i = 0; i < n; ++i) {while (!stk.empty() && height[i] > height[stk.top()]) {int top = stk.top(); // 当前要计算的底部位置stk.pop();if (stk.empty()) break; // 没有左边的墙,无法接水int distance = i - stk.top() - 1; // 这里不能使用 int distance = i - top; // 因为top和stk.top()不一定相邻。int bounded_height = min(height[i], height[stk.top()]) - height[top];ans += distance * bounded_height;}stk.push(i);}return ans;}
};
上述结果提交发现前面还有很多人的算法的时间复杂度和空间复杂度都比上述算法的好,因此说明上述代码还是可以继续进行优化的。
这里的部分贴上的标签就是双指针,那么是否可以使用双指针进行求解呢。
方法二:双指针
双指针的大致思想如下:
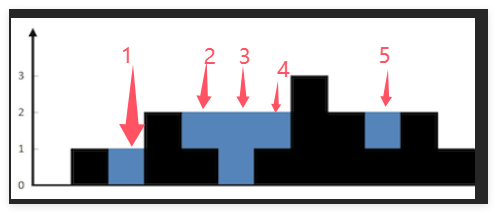
维护两个指针 left 和 right,分别从左右两端向中间移动。同时,我们也会维护两个变量 leftMax 和 rightMax,分别表示当前左侧和右侧的最大高度。
以某个位置(例如图中的值为 1 的位置)为例:此时左边的最大高度是 1,右边的最大高度是 3。根据木桶原理,能接到的雨水量取决于左右两边最大值中较小的那个。
也就是说,该位置能接的雨水量等于 min(leftMax, rightMax) - height[i]。
因此,只要 leftMax < rightMax,我们就可以确定当前位置的储水量由 leftMax 决定,无需等到完全遍历整个数组。同理,如果 rightMax <= leftMax,则由 rightMax 决定。
这种方法的核心思想是:通过双指针动态判断当前哪一侧的高度受限于局部最大值,从而逐步计算出每个位置的储水量。
一句话:就是分析某一个位置的雨水量,就看其左边(包含自己)最大和右边最大的两者的最小值是谁,然后减去自己位置的高度,最优对每一个位置累加即可。
class Solution {
public:int trap(vector<int>& height) {int ans = 0;int left = 0, right = height.size() - 1;int leftMax = 0, rightMax = 0;while (left < right) {leftMax = max(leftMax, height[left]);rightMax = max(rightMax, height[right]);if (height[left] < height[right]) {ans += leftMax - height[left];++left;} else {ans += rightMax - height[right];--right;}}return ans;}
};
评论区还有一些我觉得不错的答案,复制过来分析一下。
FIRST:
试想被水填满后的情况,最高柱子左侧水位必然是递增的,右侧水位必然是递减的,不可能出现中间有凹的情况(凹会被水填满)。于是只要找到最高柱子的位置,左侧一次正向遍历,右侧一次反向遍历,即可实时计算水位并累计水位高度差作为积水量。
class Solution {
public:int trap(vector<int>& height) {int maxHeight = 0;int maxHeightPos = -1;for (int i=0;i<height.size();i++) {if (height[i] > maxHeight) {maxHeight = height[i];maxHeightPos = i;}}if (maxHeightPos == -1) return 0;int waterHeight = 0;int waterSum = 0;for (int i=0;i<maxHeightPos;i++) {// 左侧水位if (height[i] > waterHeight) waterHeight = height[i];waterSum += waterHeight - height[i];}waterHeight = 0;for (int i=height.size()-1;i>maxHeightPos;i--) {// 右侧水位if (height[i] > waterHeight) waterHeight = height[i];waterSum += waterHeight - height[i];}return waterSum;}
};
SECOND:
按行求,按列求
相关文章:
)
leetcode-hot-100(双指针)
1. 移动零 题目链接:移动 0 题目描述:给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 解答 类似于签到题&#x…...

力扣HOT100之二叉树:101. 对称二叉树
这道题我本来想着挑战一下自己,尝试着用迭代的方法来做,然后就是用层序遍历,将每一层的元素收集到一个临时的一维向量中,然后再逐层判断每一层是否都是轴对称的,一旦发现某一层不是轴对称的,就直接return f…...

深入解读tcpdump:原理、数据结构与操作手册
一、tcpdump 核心原理 tcpdump 是基于 libpcap 库实现的网络数据包捕获与分析工具,其工作原理可分解为以下层次: 数据包捕获机制 底层依赖:通过操作系统的 数据链路层接口(如 Linux 的 PF_PACKET 套接字或 AF_PACKET 类型&#x…...

HTML5 中实现盒子水平垂直居中的方法
在 HTML5 中,有几种方法可以让一个定位的盒子在父容器中水平垂直居中。以下是几种常用的方法: 使用 Flexbox 布局 <div class"parent"><div class"child">居中内容</div> </div><style>.parent {di…...

个人博客系统测试报告
目录 1 项目背景 2 项目功能 3 项目测试 3.1 测试用例 3.2 登录页面测试 3.3 博客列表页面测试 3.4 博客详情页面测试 3.5 自动化测试 3.5.1 Utils类 3.5.2 登录测试页面类 3.5.3 博客列表页测试类 3.5.4 博客详情页测试类 3.5.5 博客修改页测试类 3.5.6 未登录…...

适配WIN7的最高版本Chrome谷歌浏览器109版本下载
本仓库提供了一个适用于Windows 操作系统的谷歌浏览器109版本的离线安装包。 点击下面链接下载 WIN7的最高版本Chrome谷歌浏览器109版本下载...

从规划到完善,原型标注图全流程设计
一、原型标注图:设计到开发的精准翻译器 1. 设计意图的精准传递 消除模糊性:将设计师的视觉、交互逻辑转化为可量化的数据(尺寸、颜色、动效参数),避免开发“凭感觉还原”。 统一理解标准:通过标注建立团…...

极狐GitLab 通用软件包存储库功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 极狐GitLab 通用软件包存储库 (BASIC ALL) 在项目的软件包库中发布通用文件,如发布二进制文件。然后,…...

系统架构-嵌入式系统架构
原理与特征 嵌入式系统的典型架构可概括为两种模式,即层次化模式架构和递归模式架构 层次化模式架构,位于高层的抽象概念与低层的更加具体的概念之间存在着依赖关系,封闭型层次架构指的是,高层的对象只能调用同一层或下一层对象…...

hive两个表不同数据类型字段关联引发的数据倾斜
不同数据类型引发的Hive数据倾斜解决方案 #### 一、原因分析 当两个表的关联字段存在数据类型不一致时(如int vs string、bigint vs decimal),Hive会触发隐式类型转换引发以下问题: Key值的精度损失:若关联字…...

制作一款打飞机游戏45:简单攻击
粒子系统修复 首先,我们要加载cow(可能是某个项目或资源),然后直接处理粒子系统。你们看到在粒子系统中,我们仍然有X滚动。这现在已经没什么意义了,因为我们正在使用一个奇怪的新系统。所以我们实际上不再…...
 中)
《Vuejs设计与实现》第 5 章(非原始值响应式方案) 中
目录 5.4 合理触发响应 5.5 浅响应与深响应 5.6 只读和浅只读 5.4 合理触发响应 为了合理触发响应,我们需要处理一些问题。 首先,当值没有变化时,我们不应该触发响应: const obj = { foo: 1 } const p = new Proxy(obj, { /* ... */ })effect(() => {console.log(p…...

深入理解 Webpack 核心机制与编译流程
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

okhttp3.Interceptor简介-笔记
1. Interceptor 简介 okhttp3.Interceptor 是 OkHttp 提供的一个核心接口,用于拦截 HTTP 请求和响应,允许开发者在请求发送前和响应接收后插入自定义逻辑。它在构建灵活、可扩展的网络请求逻辑中扮演着重要角色。常见的用途包括: 添加请求头…...

交易流水表的分库分表设计
交易流水表的分库分表设计需要结合业务特点、数据增长趋势和查询模式,以下是常见的分库分表策略及实施建议: 一、分库分表核心目标 解决性能瓶颈:应对高并发写入和查询压力。数据均衡分布:避免单库/单表数据倾斜。简化运维&#…...

《AI大模型应知应会100篇》第59篇:Flowise:无代码搭建大模型应用
第59篇:Flowise:无代码搭建大模型应用 摘要:本文将详细探讨 Flowise 无代码平台的核心特性、使用方法和最佳实践,提供从安装到部署的全流程指南,帮助开发者和非技术用户快速构建复杂的大模型应用。文章结合实战案例与配…...
)
开发环境(Development Environment)
在软件开发与部署过程中,通常会划分 开发环境(Development)、测试环境(Testing)、生产环境(Production) 这三个核心环境,以确保代码在不同阶段的质量和稳定性。以下是它们的详细介绍…...

MySQL的sql_mode详解:从优雅草分发平台故障谈数据库模式配置-优雅草卓伊凡
MySQL的sql_mode详解:从优雅草分发平台故障谈数据库模式配置-优雅草卓伊凡 引言:优雅草分发平台的故障与解决 近日,优雅草分发平台(youyacaocn)在运行过程中遭遇了一次数据库访问故障。在排查过程中,技术…...

PyCharm 快捷键指南
PyCharm 快捷键指南 常用编辑快捷键 代码完成:Ctrl Space 提供基本的代码完成选项(类、方法、属性)导入类:Ctrl Alt Space 快速导入所需类语句完成:Ctrl Shift Enter 自动结束代码(如添加分号&#…...
)
【数据结构】map_set前传:二叉搜索树(C++)
目录 二叉搜索树K模型的模拟实现 二叉搜索树的结构: Insert()插入: InOrder()中序遍历: Find()查找: Erase()删除: 参考代码: 二叉搜索树K/V模型的模拟实现: K/V模型的简单应用举例&…...

ZYNQ处理器在发热后功耗增加的原因分析及解决方案
Zynq处理器(结合ARM Cortex-A系列CPU和FPGA可编程逻辑)在发热后功耗增大的现象,通常由以下原因导致。以下是系统性分析及解决方案: 1. 根本原因分析 现象物理机制漏电流(Leakage Current)增加温度升高导致…...

Vue学习百日计划-Deepseek版
阶段1:基础夯实(Day 1-30) 目标:掌握HTML/CSS/JavaScript基础,理解Vue核心概念和基础语法。 每日学习内容(2小时): HTML/CSS(Day 1-10) 学习HTML标签语义化…...

DeepSeek-R1-Distill-Qwen-1.5B代表什么含义?
DeepSeek‑R1‑Distill‑Qwen‑1.5B 完整释义与合规须知 一句话先行 这是 DeepSeek‑AI 把自家 R1 大模型 的知识,通过蒸馏压缩进一套 Qwen‑1.5B 架构 的轻量学生网络,并以宽松开源许可证发布的模型权重。 1 | 名字逐段拆解 片段意义备注DeepSee…...

内网服务器之间传输单个大文件最佳解决方案
内网服务器之间传输单个大文件,采用python的http.server模块,结合wget下载文件是最快的传输方案。 笔者在ubuntu与debian之间传输单个单文件进行文件,尝试了scp、sftp、rsync等方案,但传输速度都只有1-3MB/秒;采用pyt…...
:目录与文件操作及拷贝移动命令)
Linux常用命令详解(上):目录与文件操作及拷贝移动命令
Linux系统以其强大的命令行工具著称,无论是日常文件管理还是自动化运维,都离不开基础命令的灵活运用。本文将通过功能说明、语法格式、常用选项和实例演示,系统讲解Linux中目录操作、文件操作及拷贝移动的核心命令。 一、目录操作命令 1. c…...

可灵 AI:开启 AI 视频创作新时代
在当今数字化浪潮中,人工智能(AI)技术正以前所未有的速度渗透到各个领域,尤其是在内容创作领域,AI 的应用正引发一场革命性的变革。可灵 AI 作为快手团队精心打造的一款前沿 AI 视频生成工具,宛如一颗璀璨的…...
实战指南,原理、配置与远程访问,附无公网ip方案)
动态域名解析(DDNS)实战指南,原理、配置与远程访问,附无公网ip方案
本文从实际场景出发,详解如何通过动态域名(DDNS)解决动态IP访问难题,覆盖家庭、企业及IoT场景,并提供动态域名解析、内网端口映射外网远程访问等方案。 一、动态域名(DDNS)是什么?它…...

基于STM32、HAL库的BMP388 气压传感器 驱动程序设计
一、简介: BMP388是Bosch Sensortec推出的一款高精度、低功耗的数字气压传感器,具有以下特点: 压力测量范围:300hPa至1250hPa 相对精度:0.08hPa(相当于0.5米) 温度测量范围:-40C至+85C 工作电压:1.65V至3.6V 低功耗:2μA @1Hz采样率 支持I2C和SPI接口(最高10MHz) …...

window 显示驱动开发-指定 DMA 缓冲区的段
显示微型端口驱动程序可以指定可从中分配 DMA 缓冲区的光圈段。 DMA 缓冲区也可以分配为连续锁定的系统内存。 当应用程序需要 DMA 缓冲区时,视频内存管理器会分配和销毁这些缓冲区。 因此,视频内存管理器需要一组可以分配 DMA 缓冲区的段。 请注意&…...
)
AnaTraf:深度解析网络性能分析(NPM)
目录 一、为什么网络性能分析比你想象的重要? 二、网络性能分析的核心构成 1. 数据采集层 2. 数据分析层 3. 可视化与告警层 三、网络性能分析中关注的关键指标 四、NPM部署策略:选对位置,才能看清全局 1. 边缘部署 2. 核心网络部署…...

安装Python和配置开发环境
用ChatGPT做软件测试 “工欲善其事,必先利其器。” 学习编程,不只是下载安装一个解释器,更是打开一个技术世界的大门。配置开发环境不仅关乎效率,更关乎思维方式、习惯培养与未来技术路线的选择。 一、为什么安装Python不仅仅是“…...

n8n 修改或者智能体用文档知识库创建pdf
以下是对 Nextcloud、OnlyOffice、Seafile、Etherpad、BookStack 和 Confluence 等本地部署文档协作工具的综合评测、对比分析和使用推荐,帮助您根据不同需求选择合适的解决方案。 🧰 工具功能对比 工具名称核心功能本地部署支持适用场景优势与劣势Next…...

Python | Dashboard制作 【待续】
运行环境:jupyter notebook (python 3.12.7)...

Linux 详解inode
目录 一、inode是什么? inode包含的主要信息(inode是一个结构体): 硬链接计数(有多少个文件名指向这个inode) inode的特点: inode编号 二、block区 定义与作用 特点…...
)
Milvus 2.4 使用详解:从零构建向量数据库并实现搜索功能(Python 实战)
文章目录 🌟 引言🧰 环境准备依赖安装 📁 整体代码结构概览🛠️ 核心函数详解1️⃣ 初始化 Milvus 客户端2️⃣ 创建集合 Schema3️⃣ 准备索引参数4️⃣ 删除已存在的集合(可选)5️⃣ 创建集合并建立索引6…...

NY115NY121美光科技芯片NY122NY130
NY115NY121美光科技芯片NY122NY130 美光科技:存储芯片领域的领航者 在全球半导体产业竞争日益激烈的背景下,美光科技(Micron)作为存储技术领域的领先企业,不仅展现了其强大的科技研发力量,更在战略布局上…...

【类拷贝文件的运用】
常用示例 当我们面临将文本文件分成最大大小块的时,我们可能会尝试编写如下代码: public class TestSplit {private static final long maxFileSizeBytes 10 * 1024 * 1024; // 默认10MBpublic void split(Path inputFile, Path outputDir) throws IOException {…...
在算法比赛的应用)
python标准库--heapq - 堆队列算法(优先队列)在算法比赛的应用
目录 一、基本操作 1.构造堆 2.访问堆顶元素(返回堆顶元素) 3.删除堆顶元素(返回堆顶元素) 4.插入新元素,时间复杂度为 O (log n) 5. 插入并删除元素(高效操作) 6. 高级操作- 合并多个有…...

5.12第四次作业
实验要求:完成上图内容,要求五台路由器的环回地址均可以相互访问 AR1 AR2 AR3 AR4 AR5 AS 200 ospf配置 AR2 AR3 AR4 BGP配置 AR1(AS100) AR2(AS200) AR4 AR5(AS300) 结果...

一文读懂如何使用MCP创建服务器
如果你对MCP(模型上下文协议)一窍不通,在阅读本篇文章之前(在获得对MCP深度认识之前),你可以理解为学习MCP就是在学习一个python工具库mcp,类似于其它python工具库一样,如numpy、sys…...

telnetlib源码深入解析
telnetlib 是 Python 标准库中实现 Telnet 客户端协议的模块,其核心是 Telnet 类。以下从 协议实现、核心代码逻辑 和 关键设计思想 三个维度深入解析其源码。 一、Telnet 协议基础 Telnet 协议基于 明文传输,通过 IAC(Interpret As Command…...
)
PID与模糊PID系统设计——基于模糊PID的水下航行器运动控制研究Simulink仿真(包含设计报告)
1.模型简介 本仿真模型基于MATLAB/Simulink(版本MATLAB 2016Rb)软件。建议采用matlab2016 Rb及以上版本打开。(若需要其他版本可联系代为转换) 针对水下航行器控制系统参数变化和海洋环境干扰等影响,研究水下航行器运…...

GPU SIMT架构的极限压榨:PTX汇编指令级并行优化实践
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 一、SIMT架构的调度哲学与寄存器平衡艺术 1.1 Warp Scheduler的调度策略解构 在NVIDIA GPU…...

spark的处理过程-转换算子和行动算子
(一)RDD的处理过程 【老师讲授,画图】 Spark使用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。RDD的处理过程如图所示; RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD…...

设计杂谈-工厂模式
“工厂”模式在各种框架中非常常见,包括 MyBatis,它是一种创建对象的设计模式。使用工厂模式有很多好处,尤其是在复杂的框架中,它可以带来更好的灵活性、可维护性和可配置性。 让我们以 MyBatis 为例,来理解工厂模式及…...

职坐标IT培训:互联网行业核心技能精讲
在互联网行业高速迭代的今天,掌握全链路核心技能已成为职业发展的关键突破口。职坐标IT培训聚焦行业需求,系统拆解从需求分析到系统部署的完整能力模型,助力从业者构建多维竞争力。无论是产品岗的用户调研与原型设计,还是技术岗的…...
使用教程第十二讲)
IBM BAW(原BPM升级版)使用教程第十二讲
续前篇! 一、用户界面:Process Portal和Workplace Process Portal 和 Workplace 都是 IBM Business Automation Workflow (BAW) 中提供的 Web 界面,供用户查看和处理流程任务、监控流程状态等,但它们之间有着不同的历史背景和功…...

2025 年福建省职业院校技能大赛网络建设与运维赛项Linux赛题解析
准备环境:系统安装及网络配置 [!TIP] 接下来将完全按照国赛评分标准进行,过程中需要掌握基础的Linux命令以及理解Linux系统,建议大家在做题前将Linux基础命令熟练运用 网络建设与运维赛项详细教程请联系主页一、X86架构计算机操作系统安装…...

Netty在Java网络编程中的应用:实现高性能的异步通信
Netty在Java网络编程中的应用:实现高性能的异步通信 在当今的分布式系统中,高效、稳定的网络通信是保障系统运行的关键。Java作为一门广泛使用的编程语言,提供了多种网络编程方式,但传统的Socket编程在面对高并发场景时往往显得力…...

[高阶数据结构]二叉树经典面试题
二叉树经典面试题:: 目录 二叉树经典面试题:: 1.根据二叉树创建字符串 2.二叉树的层序遍历 3.二叉树的层序遍历II 4.二叉树的最近公共祖先 5.二叉树与双向链表 6.从前序与中序序列构造二叉树 7.从中序与后序序列构造二叉…...