多模态大模型中的视觉分词器(Tokenizer)前沿研究介绍
文章目录
- 引言
- MAETok
- 背景
- 方法介绍
- 高斯混合模型(GMM)分析
- 模型架构
- 实验分析
- 总结
- FlexTok
- 背景
- 方法介绍
- 模型架构
- 实验分析
- 总结
- Emu3
- 背景
- 方法介绍
- 模型架构
- 训练细节
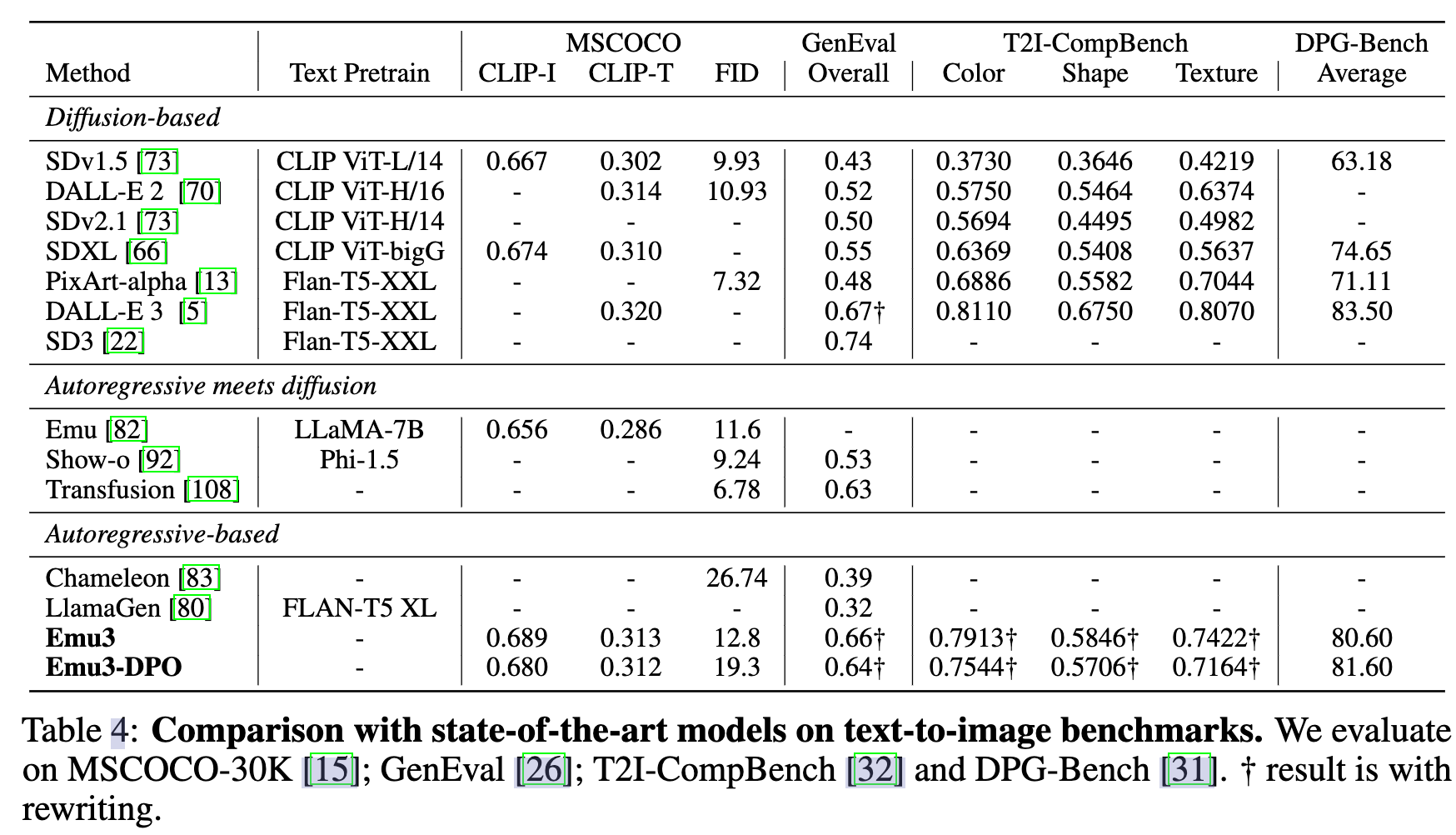
- 实验分析
- 总结
- InternVL2.5
- 背景
- 方法介绍
- 模型架构
- 实验分析
- 总结
- LLAVA-MINI
- 背景
- 方法介绍
- 出发点
- 模型架构
- 实验分析
- 总结
- VideoLLaMA 3
- 背景
- 方法介绍
- 模型架构
- 实验分析
- 总结
- TiTok
- 背景
- 方法介绍
- 模型架构
- 两阶段训练
- 实验分析
- 总结
- LARP
- 背景
- 方法介绍
- 实验分析
- 总结
- Ola
- 背景
- 方法介绍
- 模型架构
- 训练流程
- 训练数据
- 实验分析
- 总结
- 总结
引言
- 多模态大模型中一个核心挑战是视觉分词器(Tokenizer)的设计,即如何将图片、视频转换为 token 供大模型识别、处理
- 本文梳理了 8 篇视觉分词器(Tokenizer)前沿工作,涵盖视觉分词器(Tokenizer)中的潜在空间优化、动态长度分词、全模态对齐等方向。从 MAETok 揭示潜在空间结构对扩散模型的关键作用,到 FlexTok 实现 1-token 极端压缩仍保持语义完整性,再到 Ola 构建支持"看听说写"的全模态模型
MAETok
- 论文名称
- Masked Autoencoders Are Effective Tokenizers for Diffusion Models
- 论文/项目链接
- https://github.com/Hhhhhhao/continuous_tokenizer
- 论文信息
- 作者团队:CMU
背景
- 潜在扩散模型(Latent Diffusion Models, LDMs)在高分辨率图像合成方面展现出了其有效性。然而,用于更好地学习和生成扩散模型的分词器(Tokenizer)的潜在空间特性仍未得到充分探索
- 一个关键问题仍然存在:什么样的潜在空间才是适合扩散模型的“好”潜在空间?
- 变分自编码器(VAE) 通过Kullback-Leibler(KL)约束,确保学习到的潜在编码具有相对平滑的分布。由于正则化的限制,VAE 通常难以在重建时达到高像素保真度。
- 普通自编码器(AE) 可以生成更高保真度的重建结果,但 AE 可能导致潜在空间缺乏组织性,或对下游生成任务过于混杂。也即像素级的高保真度并不一定意味着潜在表征是鲁棒或语义解耦的
- 本文发现生成质量的提升与潜在分布的结构密切相关,例如具有更少的高斯混合模式(Gaussian Mixture Modes)和更具判别性的特征的潜在空间能够提高生成效果
方法介绍
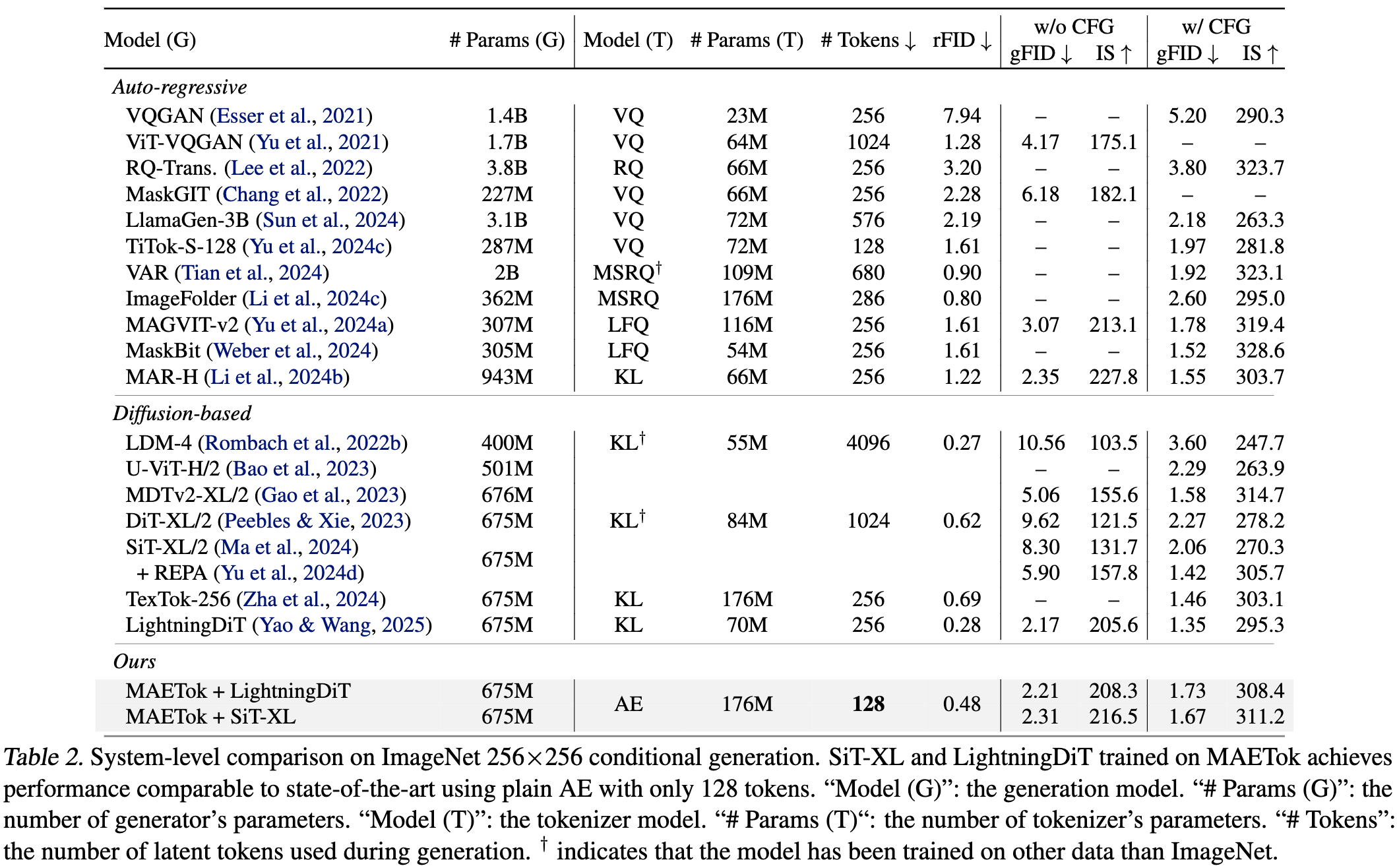
- 提出了 MAETok,这是一种利用掩码建模(Mask Modeling)学习语义丰富的潜在空间,同时保持重建保真度的自编码器(Autoencoder, AE)。大量实验验证了我们的分析,表明变分自编码器(Variational Autoencoders, VAEs)并非必要,仅通过自编码器学习的判别性潜在空间就能够在 ImageNet 生成任务中实现最先进的性能,仅需 128 个 token。
- MAETok 在实践中实现了显著提升,在 512×512 图像生成任务上达到了 gFID 1.69,并且训练速度提升 76 倍,推理吞吐量提高 31 倍。本文研究表明,相较于变分约束,潜在空间的结构对于高效的扩散模型更为关键。
- 揭示了一个有趣的解耦效应(Decoupling Effect):
- 编码器学习判别性和语义丰富的潜在空间的能力,可以与解码器实现高像素保真度的能力分离。
- 在 MAE 训练过程中,较高的掩码比率(40%-60%)通常会降低直接重建的像素级质量。
- 但如果冻结 AE 的编码器(即保持其已组织良好的潜在空间),仅微调解码器,则可以在不牺牲语义表征能力的前提下,恢复高质量的像素重建。
高斯混合模型(GMM)分析
- 在扩散模型参数(例如足够的总时间步数和足够小的离散化步长)最优的情况下,扩散模型的生成质量主要由去噪网络的训练损失决定
- 通过 DDPM(Denoising Diffusion Probabilistic Models)训练扩散模型的有效性,高度依赖于学习潜在空间分布的难度
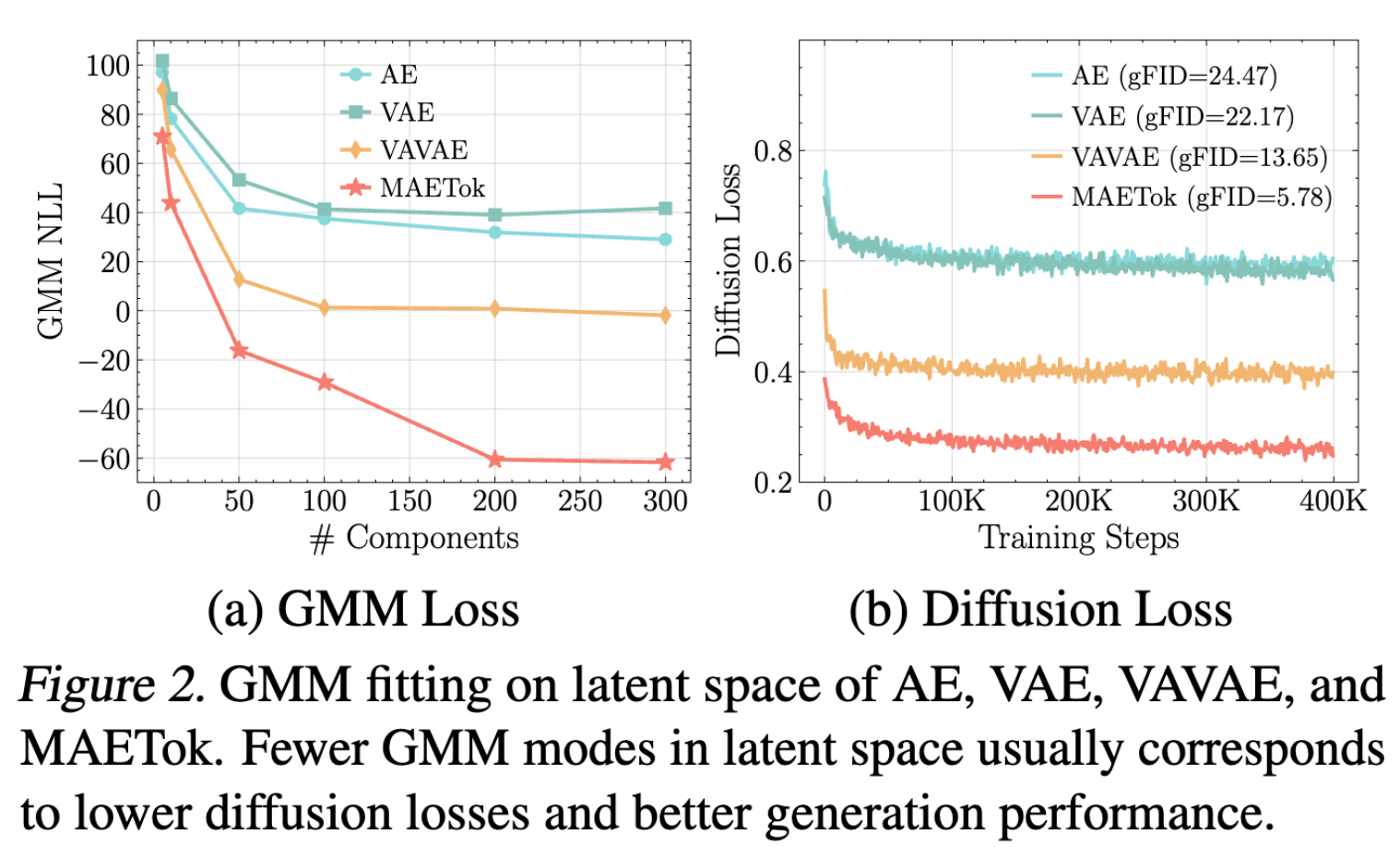
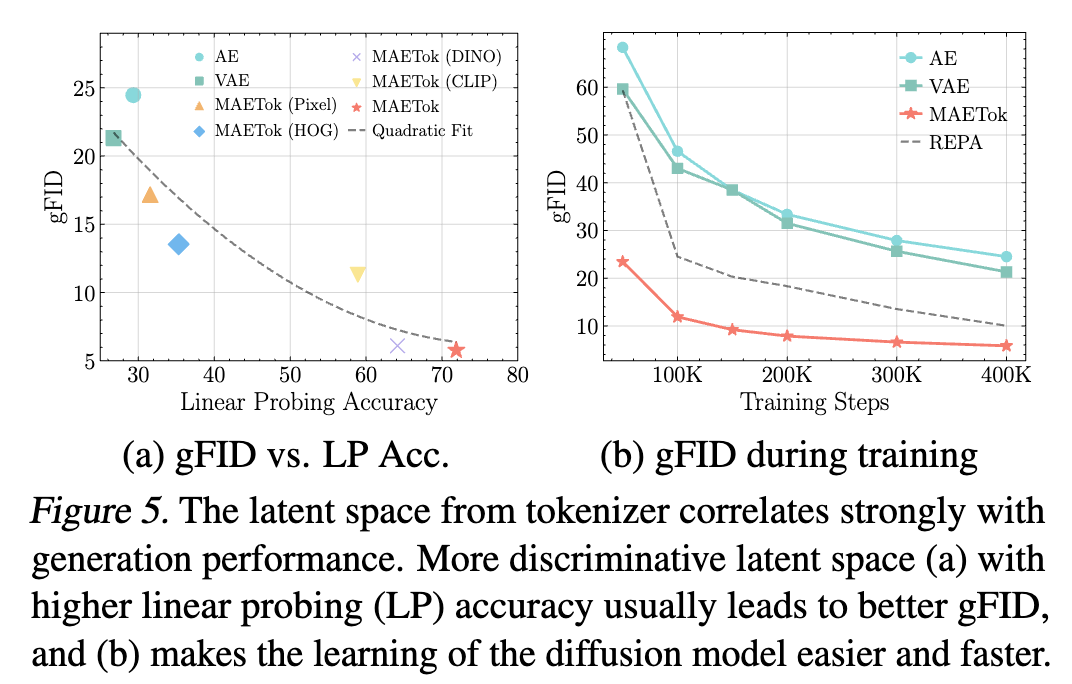
- 使用高斯混合模型(GMM) 来评估不同潜在空间的模态数量(modes)。更多的模态意味着潜在空间的结构更复杂。下图分析了在不同潜在空间上,调整高斯混合成分数目时的负对数似然损失(Negative Log-Likelihood, NLL),NLL 越低,表示拟合质量越好。
- 为了达到相似的 GMM 拟合质量(即 GMM 损失相近),VAVAE 需要的模态数比 VAE 和 AE 更少。说明 VAVAE 的潜在空间结构比 AE 和 VAE 更简单,具有更良好的全局组织性
- 模态数更少的潜在空间(VAVAE)对应于更低的扩散损失和更好的 gFID。更具判别性的潜在空间(模态更少,特征更分离)可以降低学习难度,从而提升扩散模型的生成质量。
模型架构
- MAETok 基于最新的 1D 分词器(Tokenizer)设计
- 编码器(E)和解码器(D)均采用 Vision Transformer(ViT) 结构
- 位置编码(Position Encoding)
- 图像 Patch token(x) 和 解码器中的图像 token(e) 使用 2D 旋转位置编码(RoPE),保持空间信息。
- 潜在 token(z) 及其编码结果(h)使用标准 1D 绝对位置编码,因为它们不映射到特定的空间位置。
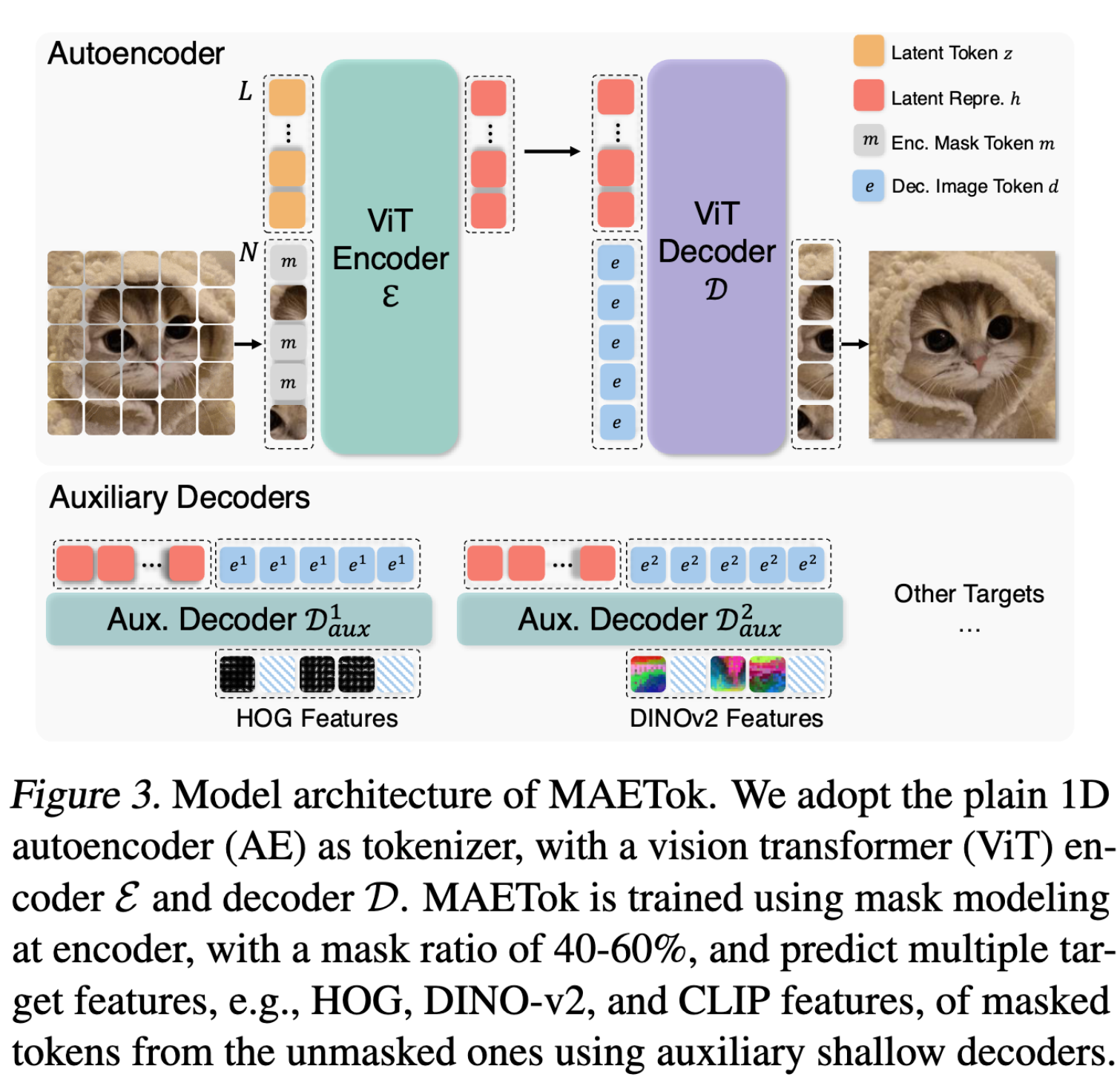
- 训练方式
- loss 使用 MSE + perceptual + GAN
- 掩码建模(Mask Modeling) 学习更具判别性的潜在空间,随机选取 40%-60% 的图像 Patch token 进行 mask。仅对被掩码 token 计算 MSE 损失
- 使用辅助浅解码器(Auxiliary Shallow Decoders)来预测 HOG、DINO-v2、SigCLIP 模型特征
- 像素解码器微调(Pixel Decoder Fine-Tuning): freeze encoder 后对 decoder 进行微调,增加重建质量
实验分析
-
imagenet class condition 生成
-
消融实验
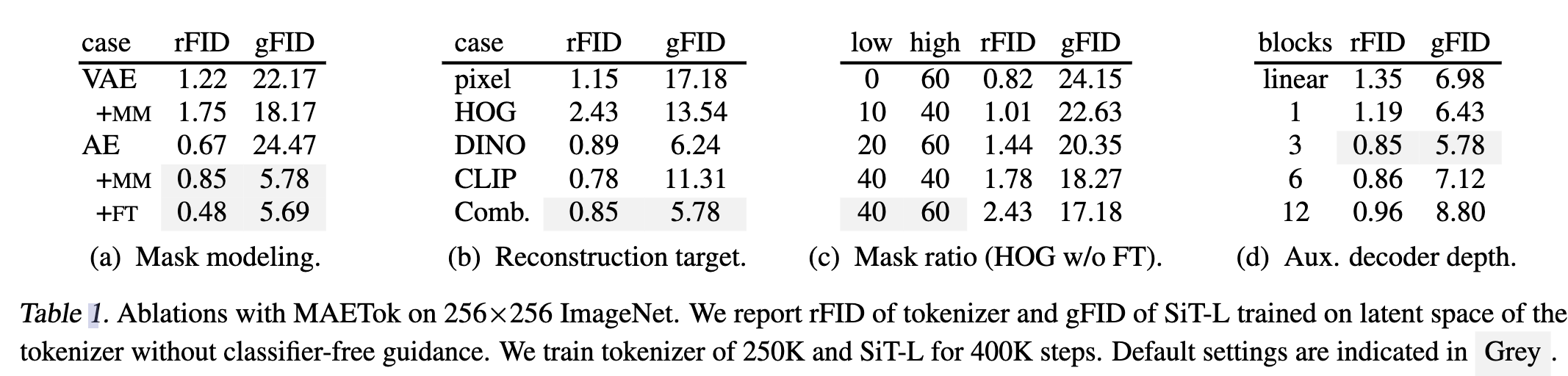
- 掩码建模(Mask Modeling)
- 掩码建模显著改善 gFID
- rFID 略微恶化,但通过 解码器微调 可以恢复
- 重建目标(Reconstruction Target)
- 低级特征(Low-level Features):仅使用像素解码器重建像素值或 HOG 特征,已能学习出较优的潜在空间,使 gFID 下降
- 高级特征(Semantic Features):使用 DINO-v2 和 CLIP 作为教师模型,gFID 显著下降(生成质量提升)
- 组合目标:融合多种重建目标,可以在 重建保真度(rFID)和生成质量(gFID) 之间实现平衡
- 掩码比率(Mask Ratio)大一点生成质量更好
- 掩码建模(Mask Modeling)
-
收敛明显变快
总结
- 在 VA-VAE 上继续优化的工作,主要的改进点应该就是掩码训练和增加更多的视觉编码器监督。
FlexTok
- 论文名称
- FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
- 论文/项目链接
- https://flextok.epfl.ch/
- 论文信息
- 作者团队:Apple + 瑞士联邦理工学院
背景
- image tokenization 提供比原始像素更高效处理的压缩离散表示,使自回归图像生成取得了重大进展
- 最近工作 TiTok 表明,一维 tokenization 可以通过消除网格冗余来实现高质量的图像生成。然而,这些方法通常使用固定数量的 token,因此无法根据图像的固有复杂性进行自适应调整
方法介绍
-
提出 FlexTok,一种可变长度的一维 tokenization 方法,能够将图像编码为有序的、内容依赖的 token 序列
- 将图像压缩为 1 到 256 个 token
- 嵌套 dropout(Nested Dropout) 和 因果注意力掩码(Causal Attention Masking) 结合使用,token 由粗到细排序,使得即使使用极少的 token 也能进行高质量重建,并且随着 token 数量的增加,图像细节逐步增强。
-
与自适应分块方法的对比:为了避免 token 长度依赖于图像尺寸(而非复杂性),近年来出现了自适应分块方法:
- ElasticTok(Yan 等,2024) 的 FSQ 量化器最少使用 256 个 token
- ALIT(Duggal 等,2024) 最少使用 32 个 token
- One-DPiece(Miwa 等,2025) 也采用固定长度的 1D 方案
相比之下,FlexTok 可以将图像压缩至仅 1 个 token,并且其生成能力优于 ElasticTok、ALIT 和 One-DPiece
-
与连续 token 方案对比
- ViLex(Wang 等,2024b) 和 CAT(Shen 等,2025) 关注学习连续 token 以用于扩散模型,而 FlexTok 则专注于 自回归(AR)模型
-
相比于传统二维 tokenization 方法严格栅格扫描(Raster Scan),一维 tokenization 方法支持从粗到细的生成
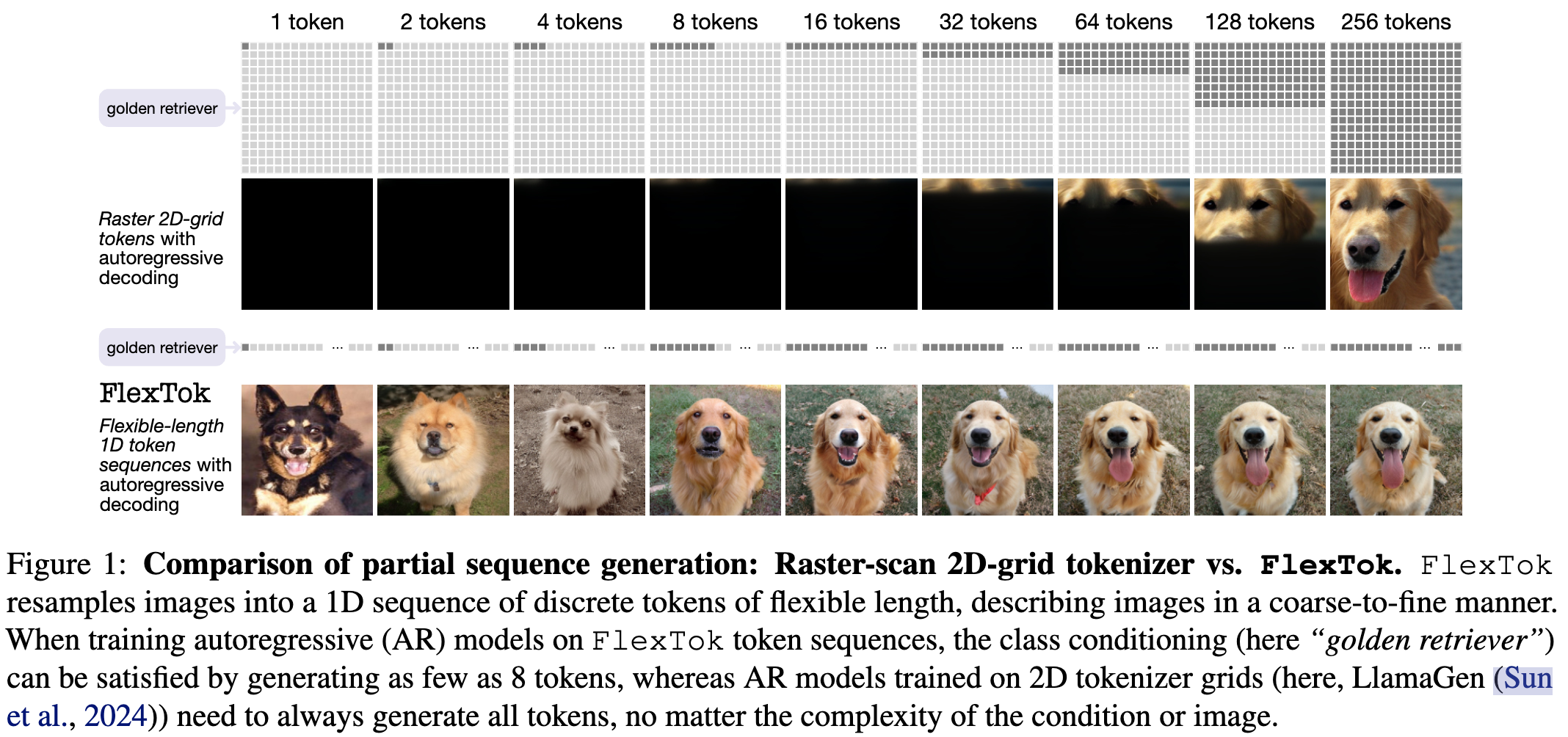
-
较早生成的 token 捕捉高层次的语义和几何信息,额外的 token 逐步添加更精细的细节。

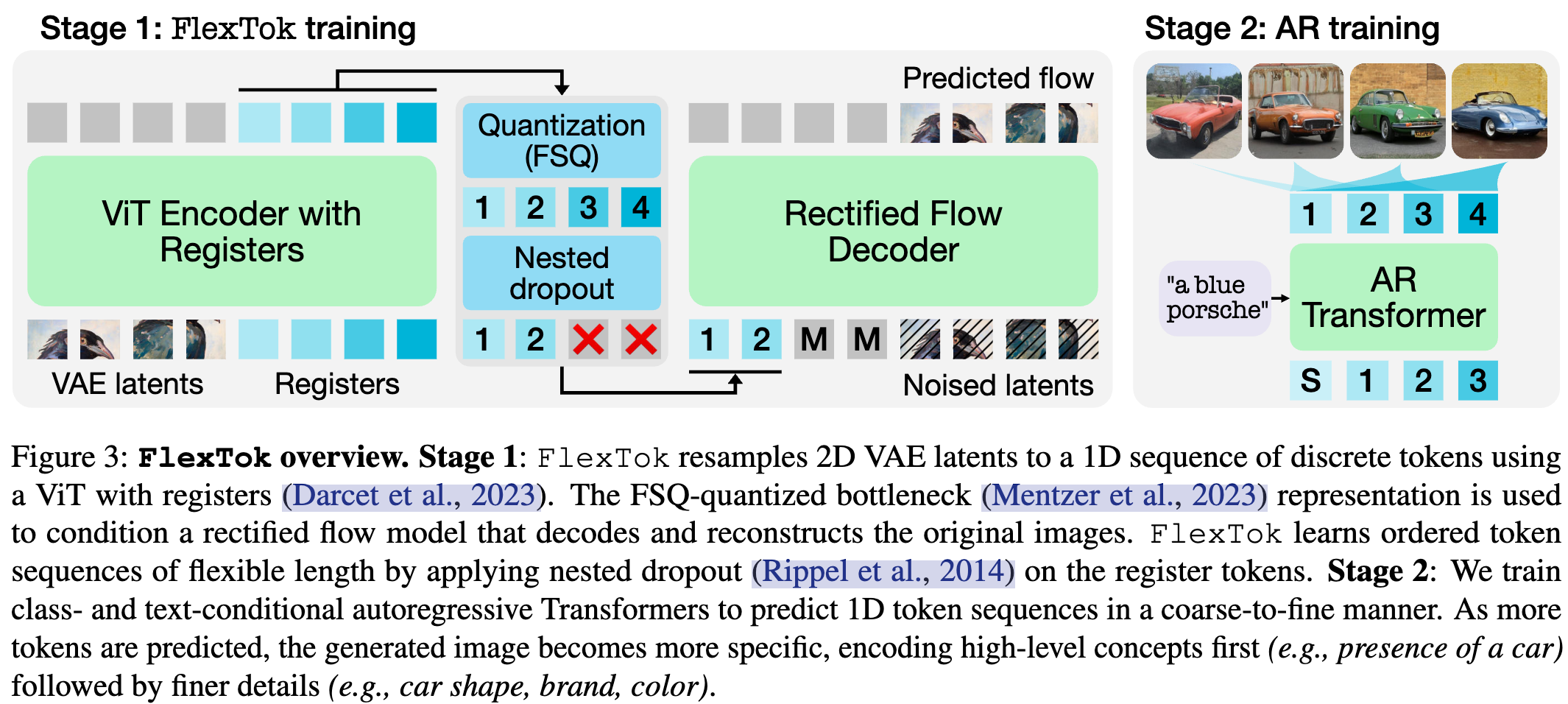
模型架构
- 模型架构
- ViT 编码器将 VAE 生成的 2D 图像 patch 映射为 1D 序列,使用寄存器 token(Register Tokens)
- 寄存器 token 经过 FSQ(Finite Scalar Quantization) 离散化,作为 Rectified Flow Model 的条件输入,重建图像
- 寄存器 token 之间使用 因果注意力(Causal Attention)
- 引入 REPA 归纳偏差损失,并与 DINOv2-L 特征匹配,能够显著提高收敛速度和下游生成性能
- 采用两种技术引入 1D 序列的排序和可变长度:嵌套 Dropout(Nested Dropout),随机丢弃寄存器 token 来学习有序表示。因果注意力掩码(Causal Attention Masks):图像补丁可相互关注,但不能访问寄存器 token,寄存器 token 可访问所有图片补丁,但是寄存器 token 间有 causal 性质,即当前 token 仅可关注到当前以及之前的 token。
- AR 模型用于对 1D image token 进行建模,支持类别条件生成(Class-Conditional Generation)和文本到图像生成(Text-to-Image Generation)
实验分析
-
灵活的 token 长度支持:单 token 也能生成合理的图像,前几个 token 主要捕捉高层语义特征,更多 token 可逐步提高对原始图像的对齐程度

-
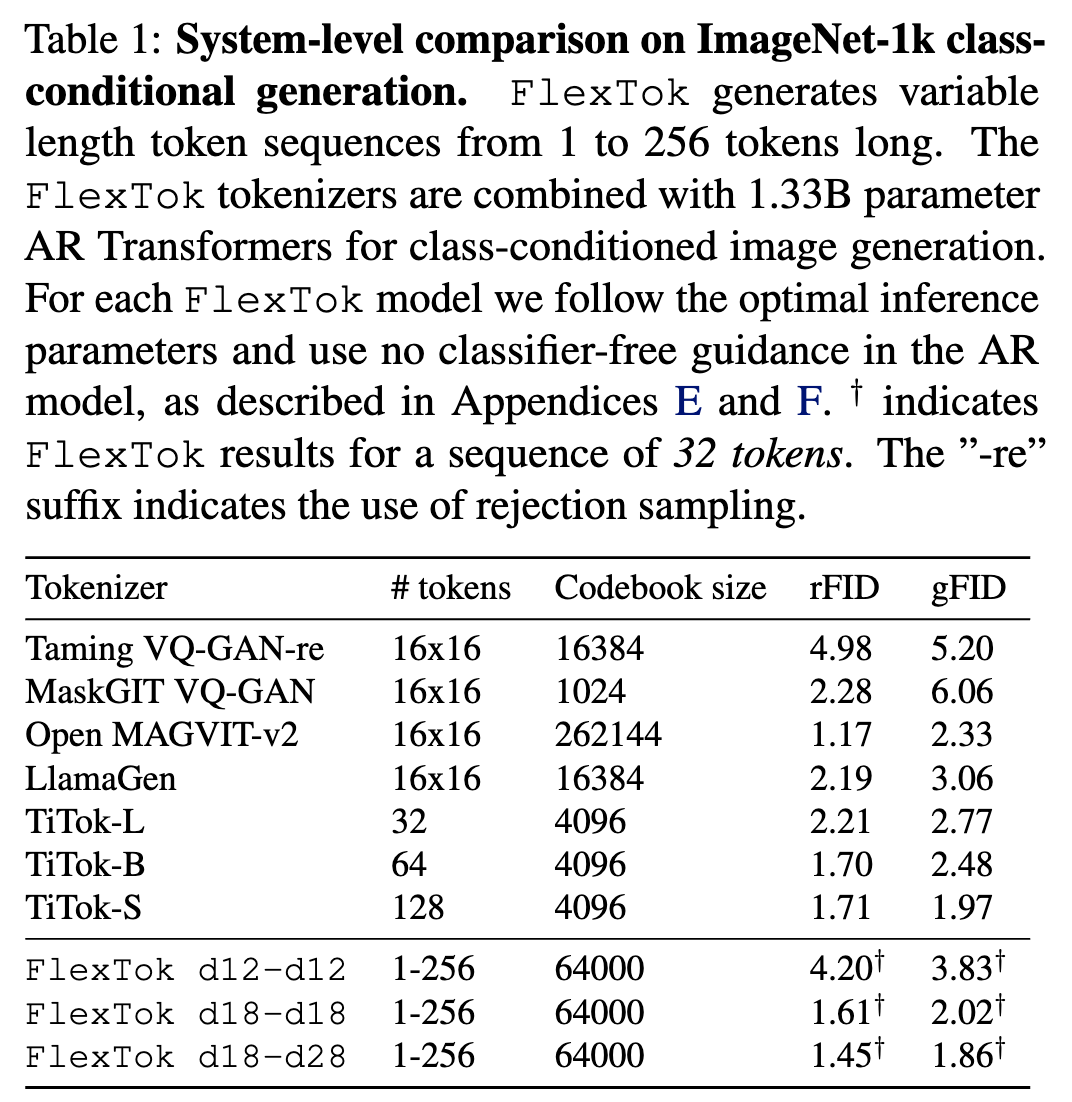
与其他 1D tokenizer 对比,精度最高
-
简单和细节 prompt 的图像生成对比
- 简单提示(如 “a red apple”)在 4-16 token 内即可生成满意图像
- 复杂提示(如 “graffiti of a rocket ship”)需要 完整 256-token 序列
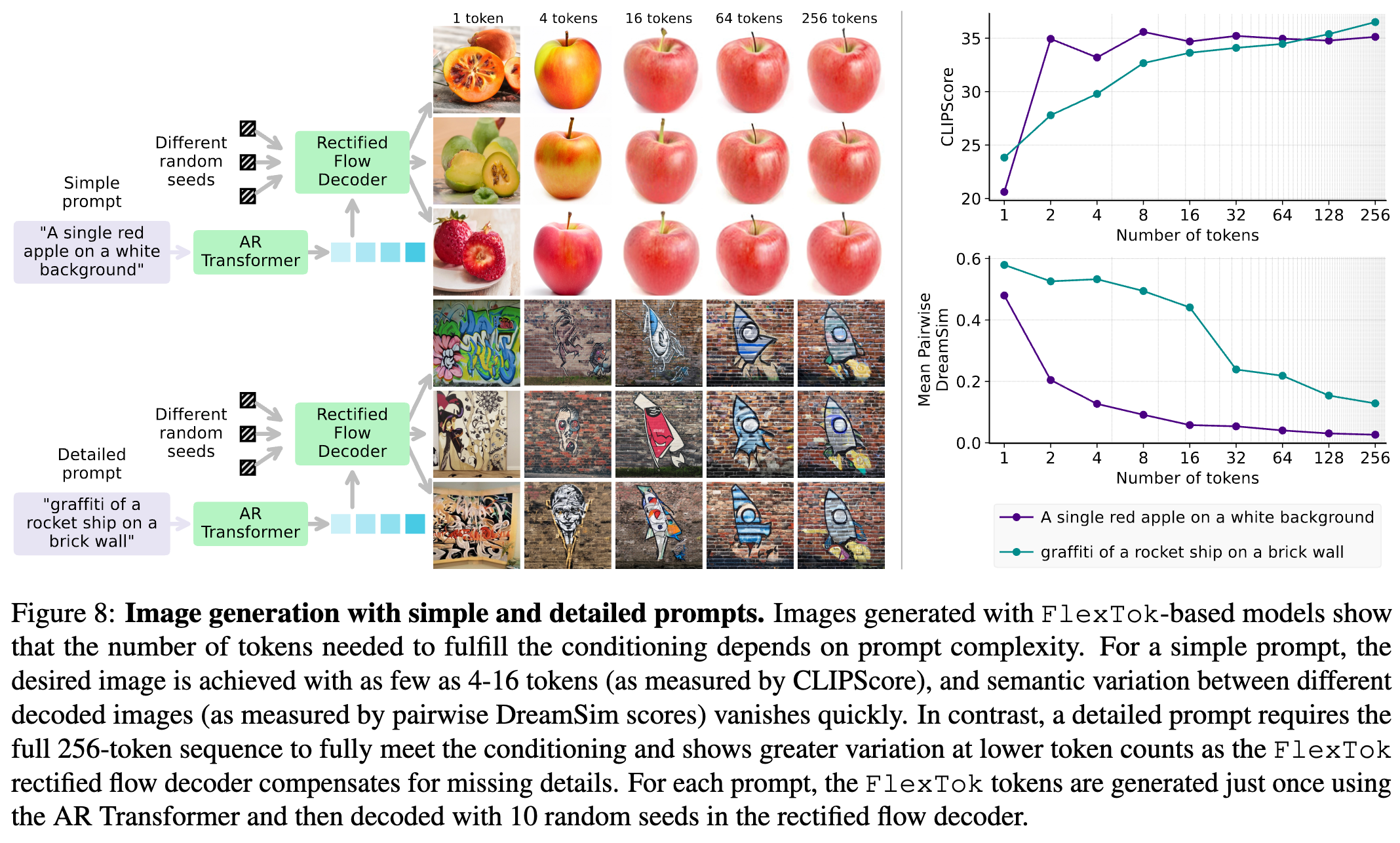
-
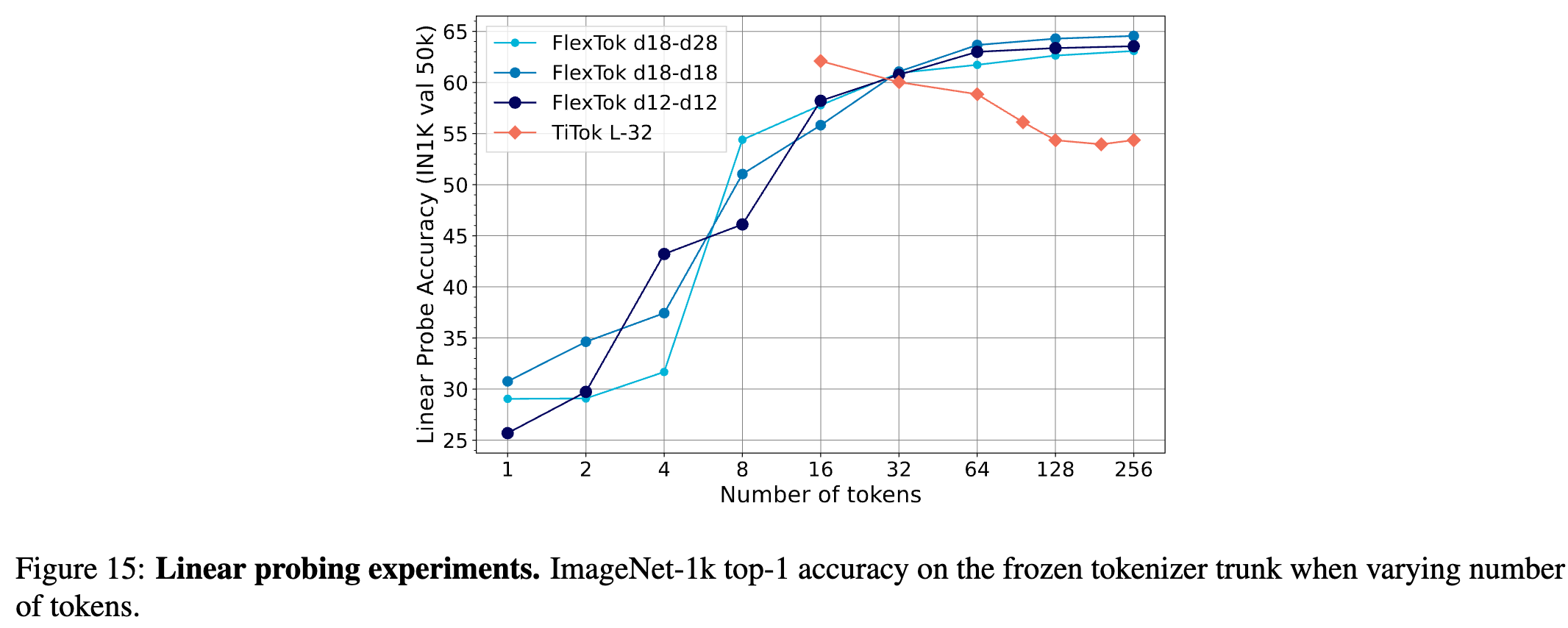
评估 FlexTok 的表征质量:FlexTok 训练的 token 表示具有线性可分性,可用于高效表征学习
- 对 FlexTok 编码器产生的量化寄存器 token 进行线性评估(Linear Evaluation),即这些 token 作为输入传递给流模型(Flow Model),训练线性分类器(Linear Classifier),并在测试集上评估
- 随着 token 数量增加,性能持续提升。与 TiTok 相反,TiTok 的性能随着 token 增加而下降。原因分析
- TiTok 训练时为每个 token 配置单独的模型,导致不同 token 配置的特征空间不同。
- FlexTok 采用统一模型,所有 token 配置共享同一特征空间。
- 更多 token 不会影响已有信息,而是提供更多上下文,最差情况也可以被线性层忽略。
总结
- 提出了一种支持可变序列长度的图像分块方法,实现高保真重建和图像生成。
- FlexTok 可将图像语义压缩至 1 个 token,但高密度内容(如文本)需要更多 token。
- 未来可以探索 FlexTok 是否适用于高冗余领域,如音频、视频。可能在视频上能做到更高的压缩率。
Emu3
- 论文名称
- Emu3: Next-Token Prediction is All You Need
- 论文/项目链接
- https://arxiv.org/pdf/2409.18869
- 论文信息
- 作者团队:BAAI
背景
- 虽然下一token预测被认为是实现人工通用智能(AGI)的一条有前景的路径,但在多模态任务方面却表现不佳,这一领域仍然由扩散模型(如 Stable Diffusion)和组合方法(如 CLIP 与 LLM 结合)主导。
方法介绍
- 介绍了 Emu3,这是一组仅通过下一 token 预测训练的最先进多模态模型。通过将图像、文本和视频离散化为 token
模型架构
- vision tokenizer
- 使用 SBER-MoVQGAN, 4 × 512 × 512 视频片段或 512 × 512 图像编码为 4096 个离散 token,码本大小为 32,768。在时间维度上实现了 4× 压缩,在空间维度上实现了 8×8 压缩,适用于任何时间和空间分辨率
- 在编码器和解码器模块中加入了两个采用 3D 卷积核的时间残差层,以增强视频 tokenization 能力,在 LAION-High-Resolution 和 InternVid 视频数据集上端到端训练。

- Emu3 模型架构
- 使用 Llama2 作为主体架构,扩展嵌入层以适应离散视觉 tokens
- RMSNorm
- GQA
- SwiGLU
- RoPE
- 移除了 qkv 及线性投影层的偏置项,并使用 0.1 的 dropout 率来提高训练稳定性
- 文本 tokenization 采用 QwenTokenizer,支持多语言文本处理
训练细节
-
数据预处理
- 图像/视频在保持纵横比的前提下缩放至接近 512×512 的面积大小
-
通过五个特殊 token 将文本与视觉数据融合,形成类似文档的输入格式:
- [BOS] {caption text} [SOV] {meta text} [SOT] {vision tokens} [EOV] [EOS]
- [BOS] 和 [EOS]:文本 tokenization 的起始和终止标记。
- [SOV]:视觉输入开始标记。
- [SOT]:视觉 tokens 开始标记。
- [EOV]:视觉输入结束标记。
- [EOL] 和 [EOF]:分别用于标识换行符和帧间断点。
- “meta text” 记录图像分辨率信息,而视频的 meta text 额外包含分辨率、帧率和时长等元信息。
- 部分数据集的 “caption text” 字段会被调整到 [EOV] 之后,以增强模型在视觉理解任务中的能力。
- [BOS] {caption text} [SOV] {meta text} [SOT] {vision tokens} [EOV] [EOS]
-
训练目标
- 标准交叉熵损失 进行下一 token 预测任务训练。为了避免视觉 tokens 过度主导学习过程,我们对视觉 token 相关的损失施加 0.5 的权重。
-
训练流程
- 预训练
- 第一阶段(仅包含文本和图像数据):上下文长度设为 5120
- 第二阶段(引入视频数据):上下文长度扩展至 131072
- 视觉生成质量微调
- 继续使用 下一 token 预测 任务训练,但仅对视觉 tokens 进行监督
- DPO
- 数据集构建:
- 每个用户收集的 prompt(p)使用 QFT 模型进行 8-10 次推理,生成初始数据池(x)。
- 三位评审员依据视觉美感和 prompt 贴合度对每个样本评分。
- 选取最高分的样本(xchosen i)和最低分的样本(xrejected i),与 prompt 组成训练 triplet(pi, xchosen i, xrejected i)。
- 采用DPO 损失 + 下一 token 预测交叉熵损失进行微调
- 数据集构建:
- 预训练
实验分析
-
vision tokenizer 重建效果,看起来还行,部分人脸细节有一定失真,小字也有点模糊

-
图片生成精度对比,中文 prompt 下的结果看起来还不错。DPO 对视觉质量和 prompt 对齐有帮助
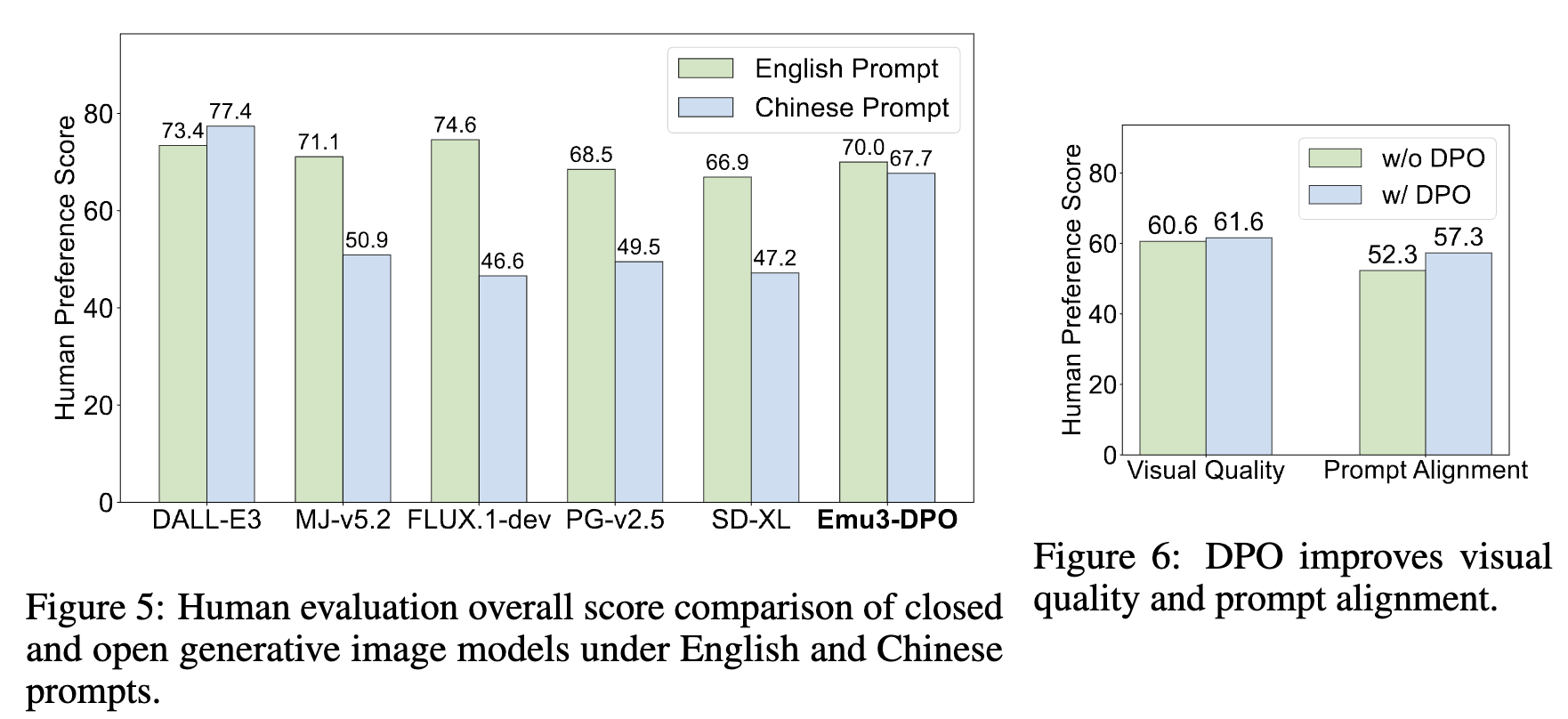
-
文生图效果可视化,看起来还不错

-
视频生成精度对比,和 diffusion 模型精度比起来感觉一般
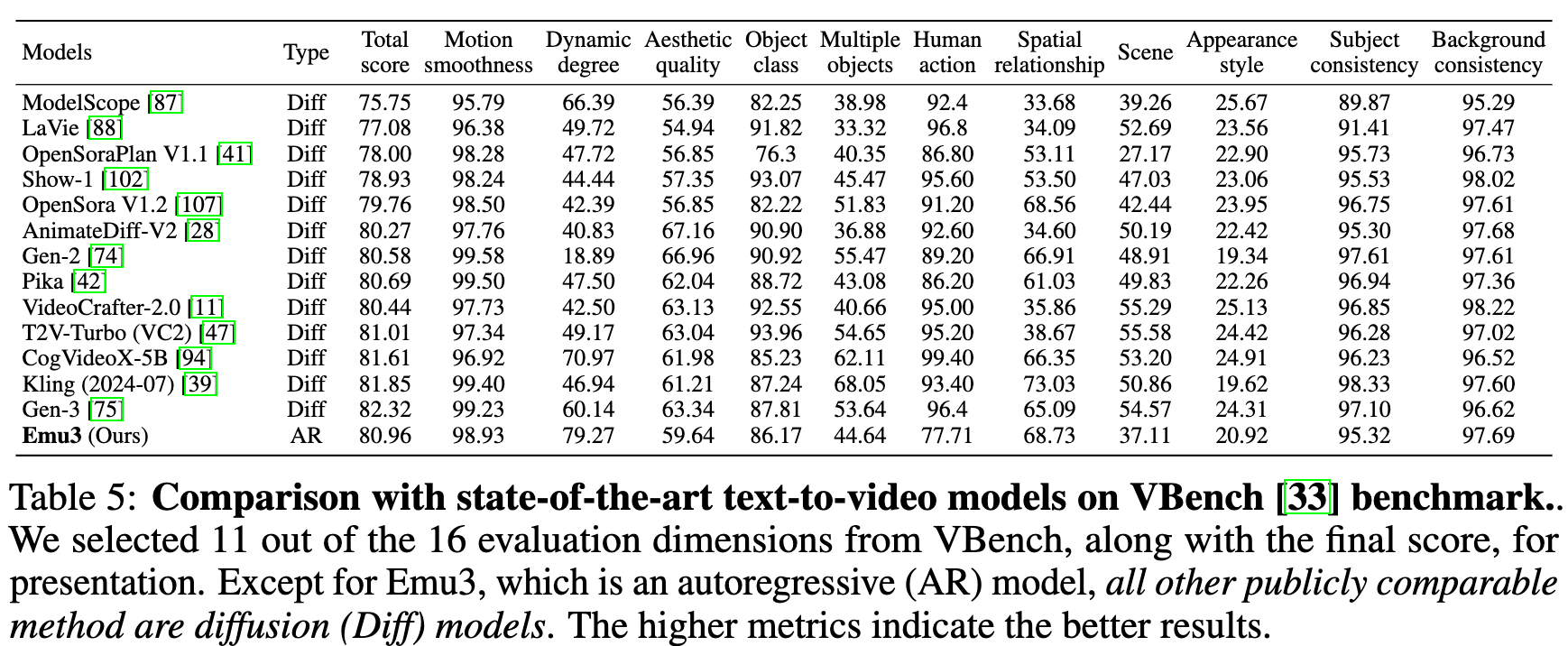
总结
- vision tokenizer 看起来重建精度和可视化效果比较一般,目前应该可以找到更好的替代
- 作为 AR 路线的坚定拥护工作,整体的工作比较扎实,部分效果上与主流模型还有差距,有进一步优化空间
InternVL2.5
- 论文名称
- InternVL2.5: Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 论文/项目链接
- https://internvl.github.io/blog/2024-12-05-InternVL-2.5/
- 论文信息
- 作者团队:Shanghai AI Laboratory
背景
- 开发大规模 MLLMs 仍然面临诸多挑战,包括:
- 巨大的计算资源需求
- 复杂的模型架构设计
- 如何高效整合多模态数据
方法介绍
- 提出 InternVL 2.5,这是一款先进的大规模开源 MLLM,基于 InternVL 2.0 进一步优化。InternVL 系列的目标是缩小开源 MLLMs 与闭源商业模型的性能差距。首个在 MMMU 上超过 70% 的开源模型
- 本文有以下发现:
- 提升视觉编码器规模能有效降低 MLLMs 对训练数据的需求:InternVL 2.5-78B 采用 6B 参数的视觉编码器,仅需 1/10 的训练数据,其性能已超过 Qwen2-VL-72B(600M 视觉编码器)。
- 数据质量比数据规模更重要
- 推理阶段的扩展策略(Test-time Scaling)能显著提升复杂任务的表现,进一步结合 Majority Voting(多数投票),额外带来性能增益
- 训练策略:
- 渐进式扩展策略,先使用较小规模的 LLM 训练视觉编码器,然后再扩展到更大的 LLM,因为发现即使 ViT 和 LLM 通过 NTP(Next Token Prediction)损失联合训练,ViT 提取的视觉特征依然可以泛化,使得其他 LLM 无需重新训练便可理解这些特征。
- 随机 JPEG 压缩(Random JPEG Compression),质量等级范围设定为 75 到 100。
- 损失重加权(Loss Reweighting):Token 平均(Token Averaging):每个 token 贡献相同的梯度。样本平均(Sample Averaging):每个样本贡献相同的梯度。提出平方平均(Square Averaging) 作为统一框架,在 Token Averaging 和 Sample Averaging 之间进行平衡。
模型架构
- InternVL 2.5 继承了其前代 InternVL 1.5 和 InternVL 2.0 的架构,遵循广泛应用于 MLLM 研究的 “ViT-MLP-LLM” 模式
- 视觉编码器:InternViT-6B 或 InternViT-300M,300M 模型通过蒸馏 6B 模型得到
- 视觉 token 通过随机初始化的两层 MLP 投影器(MLP projector) 映射到 LLM 语义空间中
- Pixel Unshuffle 使视觉 token 数量减少至原来的 1/4
- 额外支持了多图和视频输入
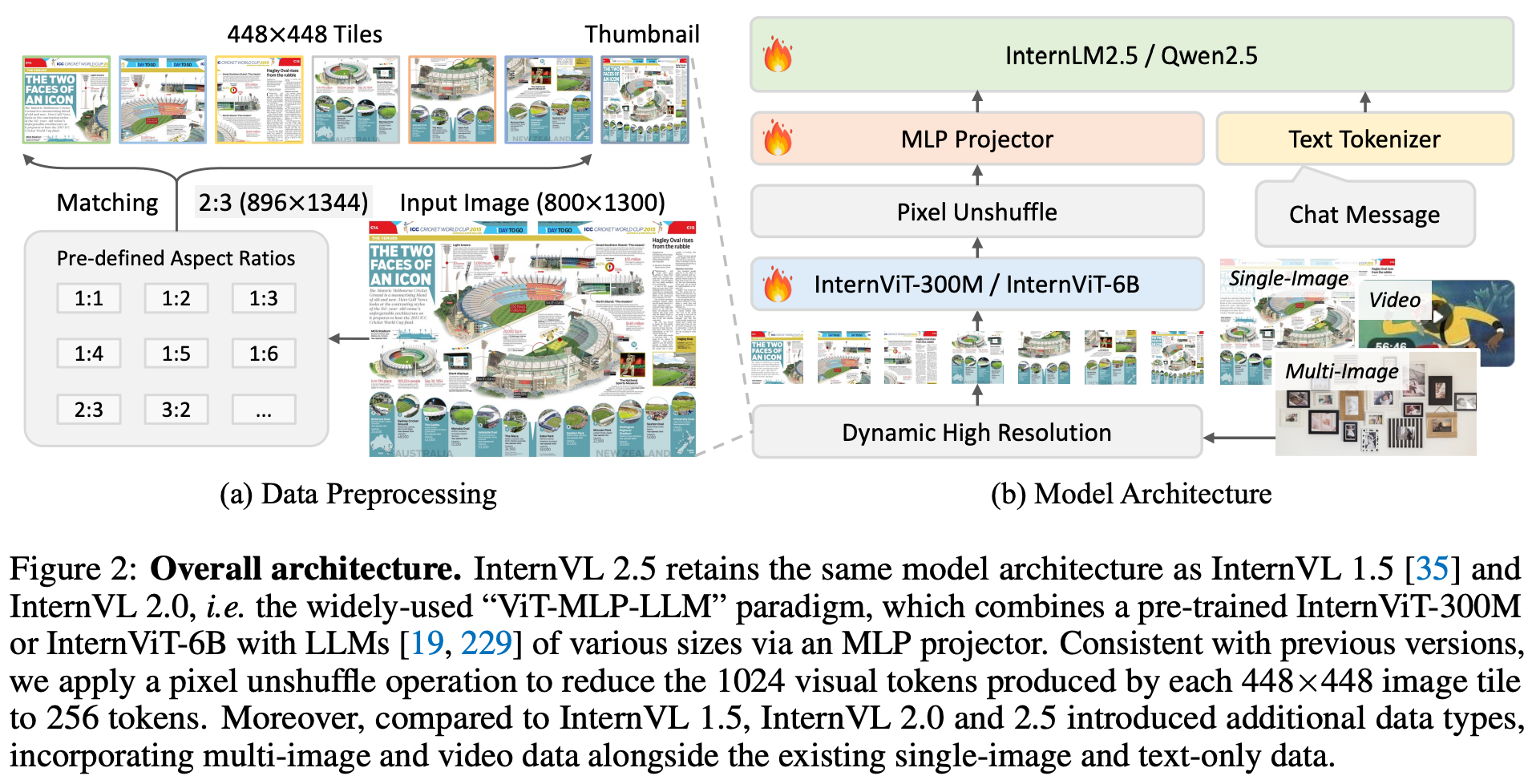
实验分析
- 开源模型里面算是效果最佳的模型了
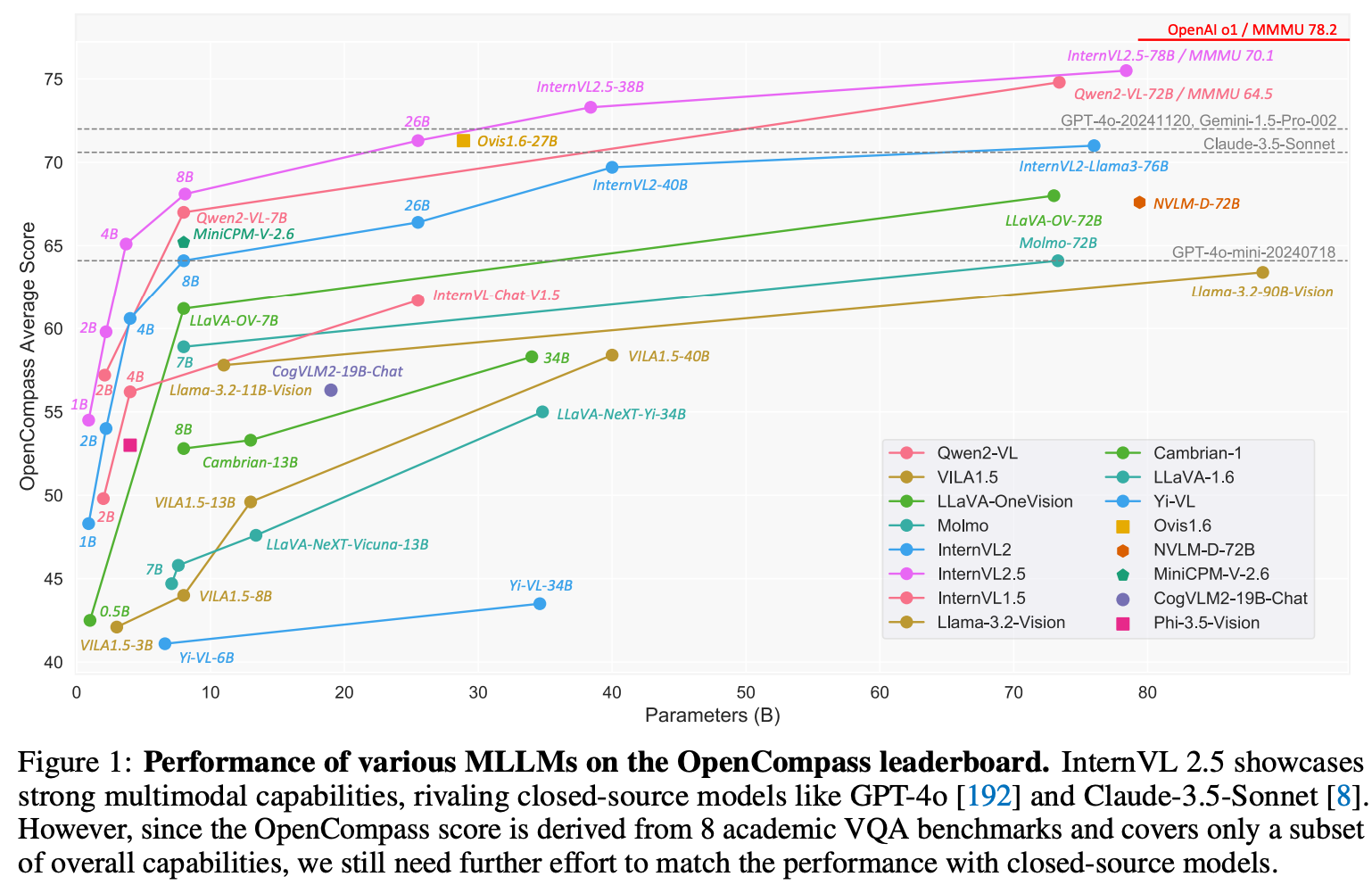
总结
- 开源模型中性能最佳版本,不过这里用了一些 cot + majority voting 的刷榜优化技巧,实际性能提升可能比部分实验中展示的会小一些。
LLAVA-MINI
- 论文名称
- LLAVA-MINI: EFFICIENT IMAGE AND VIDEO LARGEMULTIMODAL MODELS WITH ONE VISION TOKEN
- 论文/项目链接
- https://arxiv.org/pdf/2501.03895
- 论文信息
- 作者团队:中科院计算所
背景
- 此前在高效大多模态模型 (large multimodal models, LMMs) 方面的努力总是集中于用更小的模型替换 LLM 主干,而忽略了 token 数量这一关键问题
- 在广泛使用的视觉编码器 CLIP ViT-L/336px 中,单张图像会被编码为 24 × 24 = 576 个视觉 token,如此大量的视觉 token 带来了巨大的计算开销
- LLaVA-Mini 的目标是通过最小化视觉令牌的数量来开发高效的 LMM,同时保持可比的性能
方法介绍
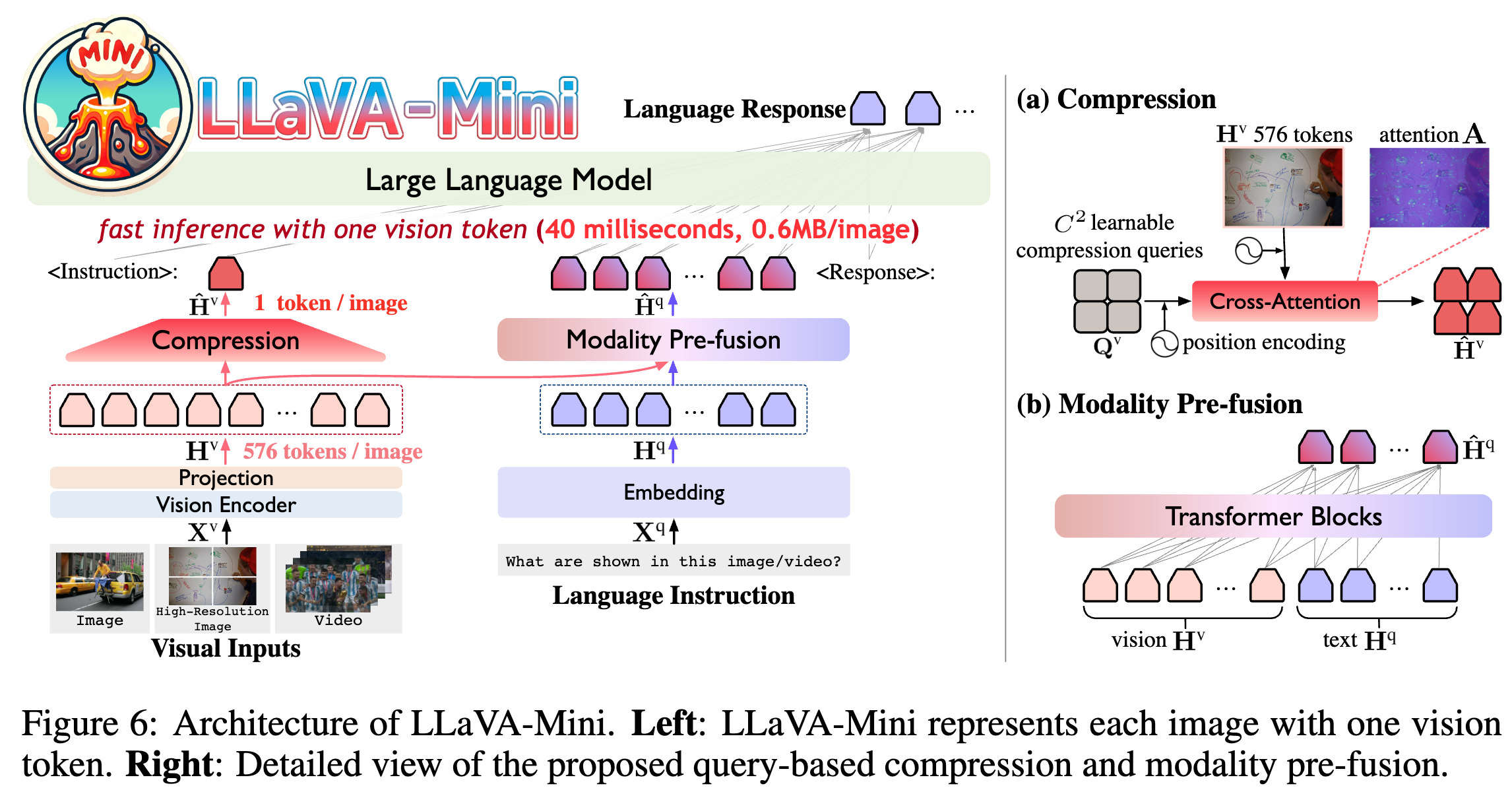
- 提出 LLaVA-Mini:具有极少视觉 token 的高效高质量 LMM。极端情况下仅使用 1 个视觉 token 的高效 LMM
- LLaVA-Mini 在 LLM 之前引入模态预融合(modality pre-fusion)模块,提前将视觉信息融合到指令文本中,并使用压缩模块对视觉 token 进行高度压缩后再输入 LLM
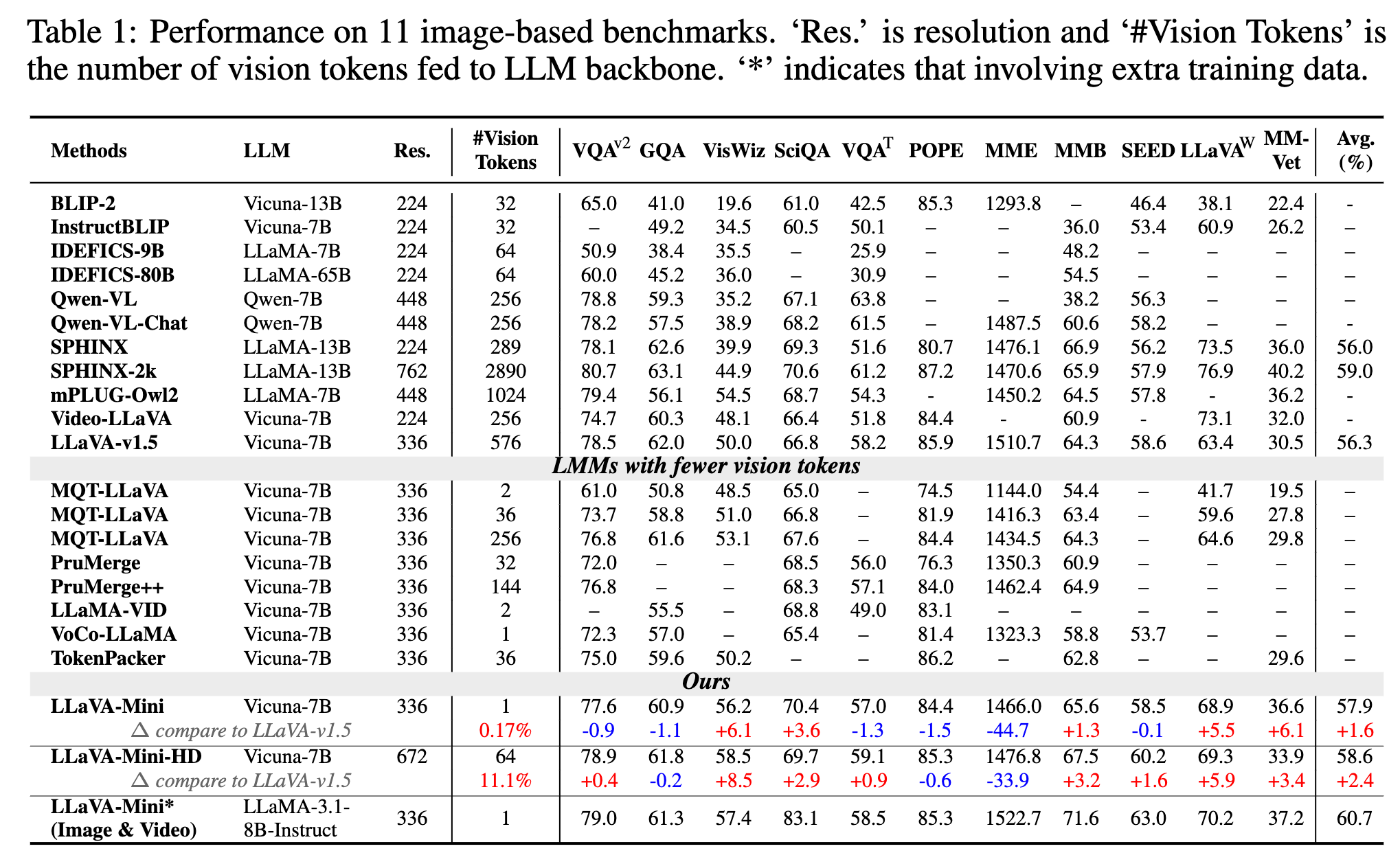
- 实验表明 LLaVA-Mini 仅用 1 个视觉令牌(而非 576 个)即可达到与 LLaVA-v1.5 相当的性能,实现 0.17% 的视觉令牌压缩率
- LLaVA-Mini 的 计算效率提高显著(FLOPs 下降 77%),并且 GPU 内存占用从 360MB 降至 0.6MB/图像
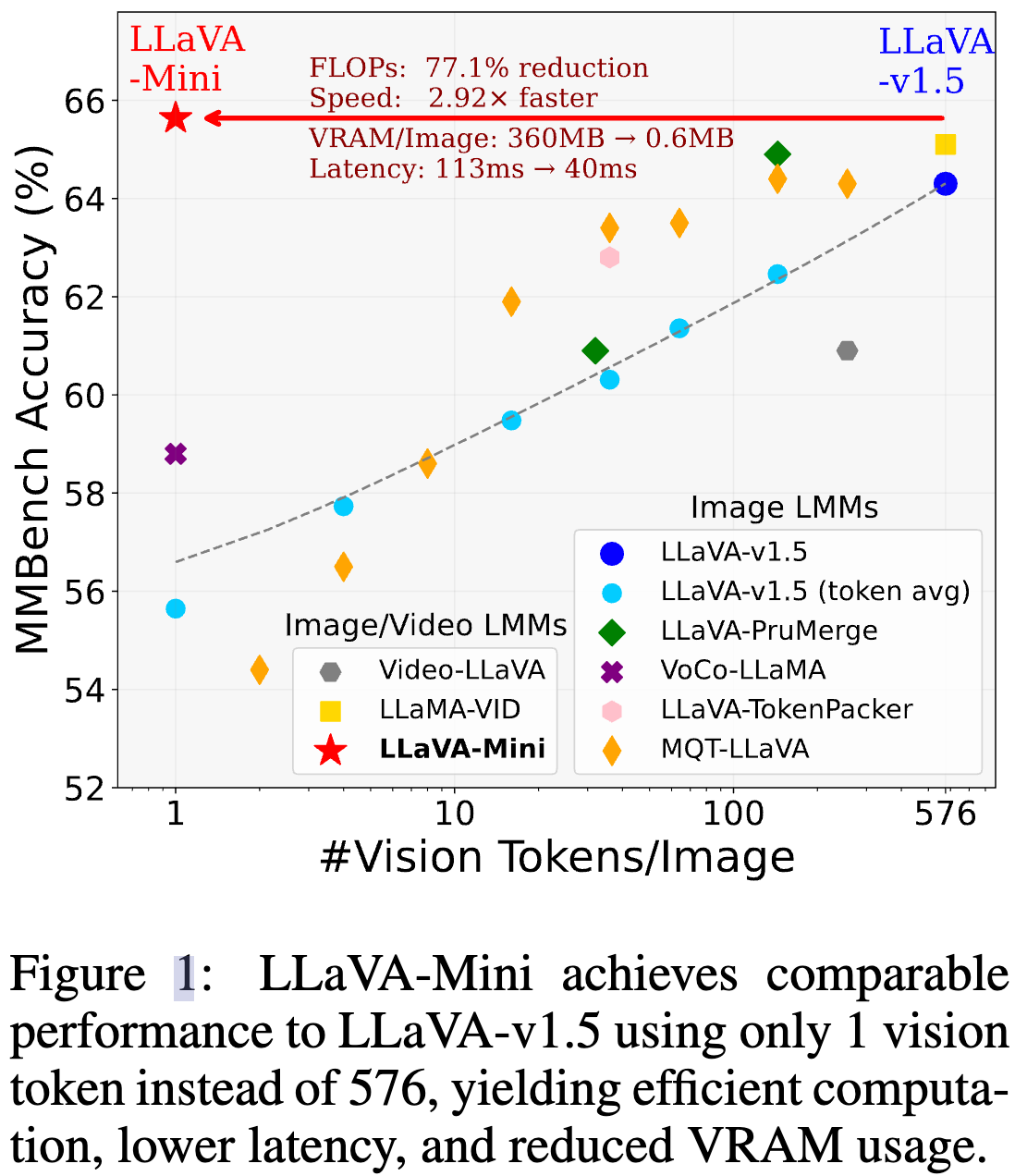
出发点
-
LLaVA 如何理解视觉令牌?(从基于注意力(attention-based) 的角度进行探讨)
- 视觉 token 在 LMMs 早期层中更为关键:
- 视觉 token 的重要性在 LLM 的不同层次间有所变化。在 LLM 的早期层,视觉 token 起到了关键作用,文本 token(如用户输入的指令和模型的响应)会对其施加较高的注意力。然而,随着层数加深,视觉 token 所获得的注意力急剧下降,大多数注意力会逐渐转向输入指令
- 在早期层中,文本 token 会从视觉 token 中融合视觉信息
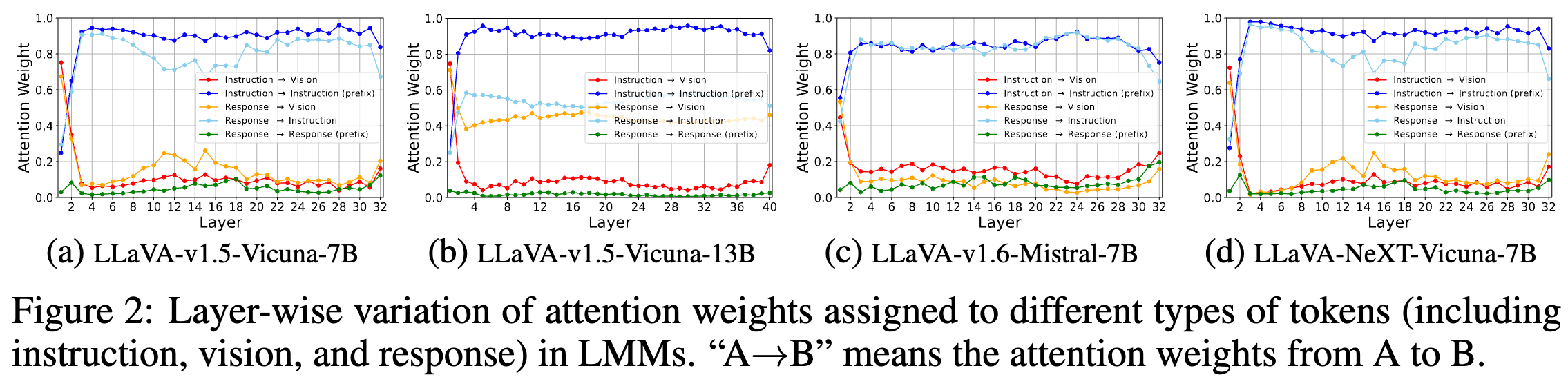
- 视觉 token 在 LMMs 早期层中更为关键:
-
大多数视觉 token 在早期层被高度关注
- 计算了各层对视觉 token 注意力分布的熵(entropy)
- 在 LMM 的早期层,视觉 token 的注意力熵值较高,表明所有视觉 token 均被均匀关注。
- 在后续层,视觉 token 的注意力熵值下降,意味着仅部分视觉 token 仍然具有影响力,而多数视觉 token 已被忽略
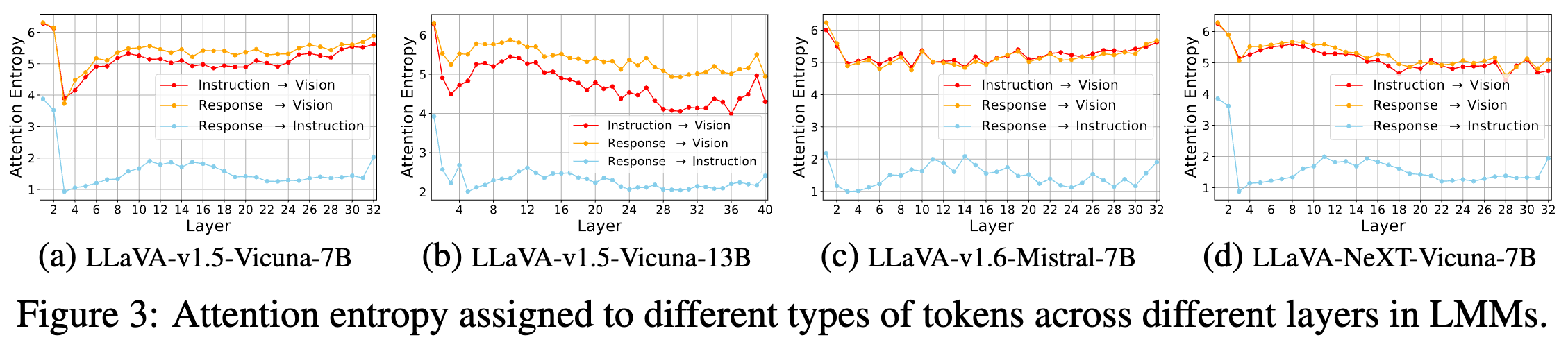
- 计算了各层对视觉 token 注意力分布的熵(entropy)
-
更直观展示视觉 token 在不同层级的重要性变化
- 几乎所有视觉 token 在早期层都获得了广泛的注意力。
- 但在后续层,仅部分视觉 token 仍然受到关注。
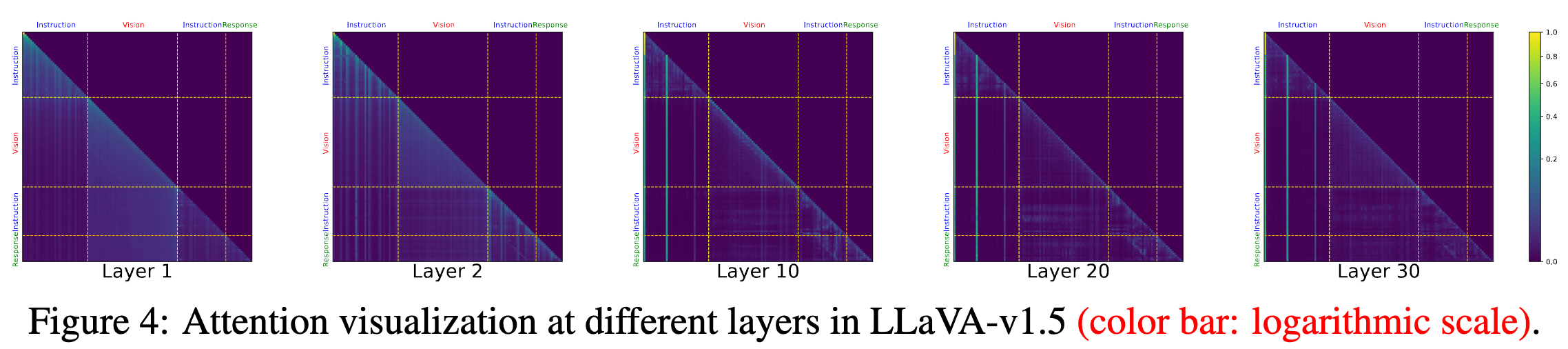
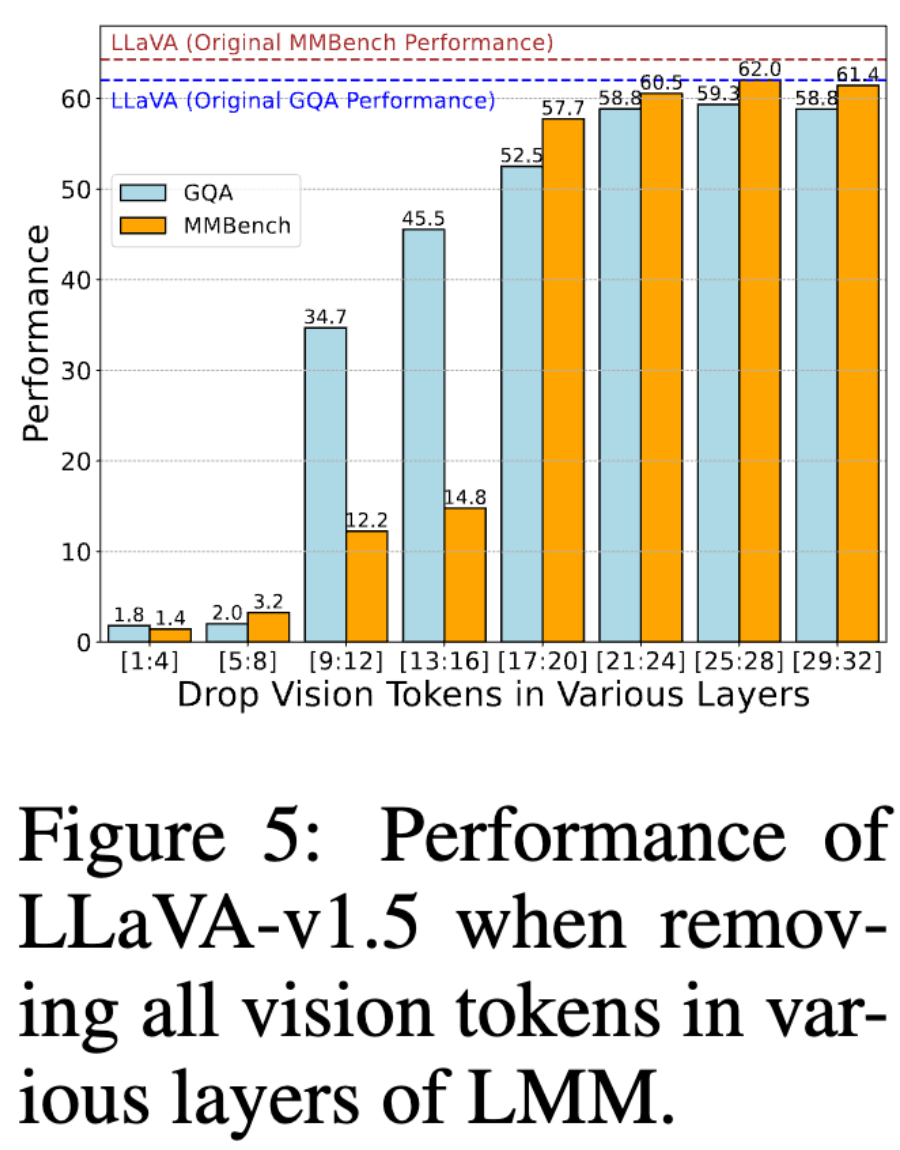
- 不同层次丢弃视觉 token 的影响:为了进一步验证视觉 token 在早期层的重要性,我们在不同层次丢弃视觉 token,并评估 LLaVA 在 GQA 任务上的性能
- 在早期层(1-4层)移除视觉 token,模型完全丧失视觉理解能力
- 在后续层(25 层之后)移除视觉 token,对性能影响较小,模型仍能保持大部分原有的理解能力
模型架构
基于前述研究表明视觉 token 在 LLM 早期层中起到关键的视觉信息融合作用,LLaVA-Mini 在 LLM 主干之前引入了模态预融合(modality pre-fusion)模块,将视觉信息预先融合到文本 token 中,从而减少 LLM 处理的视觉 token 数量
- 压缩是 query-based compression,引入 CxC 个可学习的压缩查询,通过 cross-attention 提取视觉信息,引入了 2D 正弦位置编码来保留图像的空间信息
- 模块预融合让文本 token 在输入 LLM 之前融合所有视觉 token 信息,该模块的结构和超参数与 LLM 主干相同,层数可能会有变化,本文设置为 4 层
- 两阶段训练
- 视觉-语言预训练(Stage 1: Vision-Language Pretraining),不使用压缩和模态预融合,使用 caption 训练,对齐视觉与语言表达。仅优化投影模块。
- 指令微调(Stage 2: Instruction Tuning):引入压缩和模态预融合,使用 instruciton data 训练。除视觉编码器外,所有模块进行端到端优化
实验分析
-
实验配置:
- LLaVA-Mini 视觉编码器采用与 LLaVA-v1.5 相同配置(CLIP ViT-L/336px)
- LLM 主干使用 Vicuna-v1.5-7B
- 视觉 token 压缩为 1 个
- 训练数据使用和 LLaVA-v1.5 相同的数据
-
图像任务评估:仅使用 1 个视觉 token 的性能和 LLaVA-v1.5 相当
-
视频任务评估
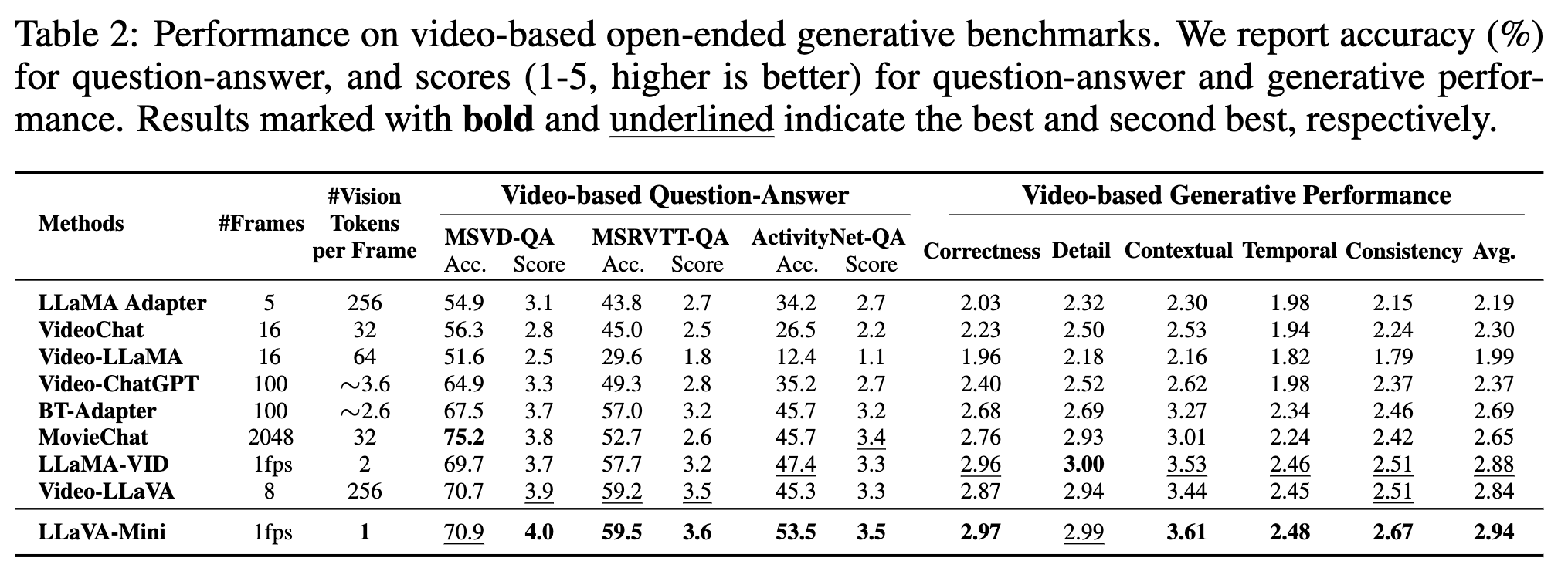
总结
- 很有创新的探索,视觉 token 得到极大压缩的情况下精度基本上没有降低。
VideoLLaMA 3
- 论文名称
- VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
- 论文/项目链接
- https://arxiv.org/pdf/2501.13106
- 论文信息
- 作者团队:阿里达摩
背景
- 大规模视频-文本数据集通常质量较低且标注困难,使得视频 MLLMs 更具挑战性
- 考虑到图像和视频模态之间的内在联系——视频本质上是一系列具有时间相关性的图像,我们优先提升图像理解能力,从而提高视频理解的性能。与视频-文本数据相比,图像-文本数据更易于收集且确保了更高的数据质量
方法介绍
- 有较强的 video 理解能力,同时文档理解能力和多模态数学推理能力也有比较好的保持

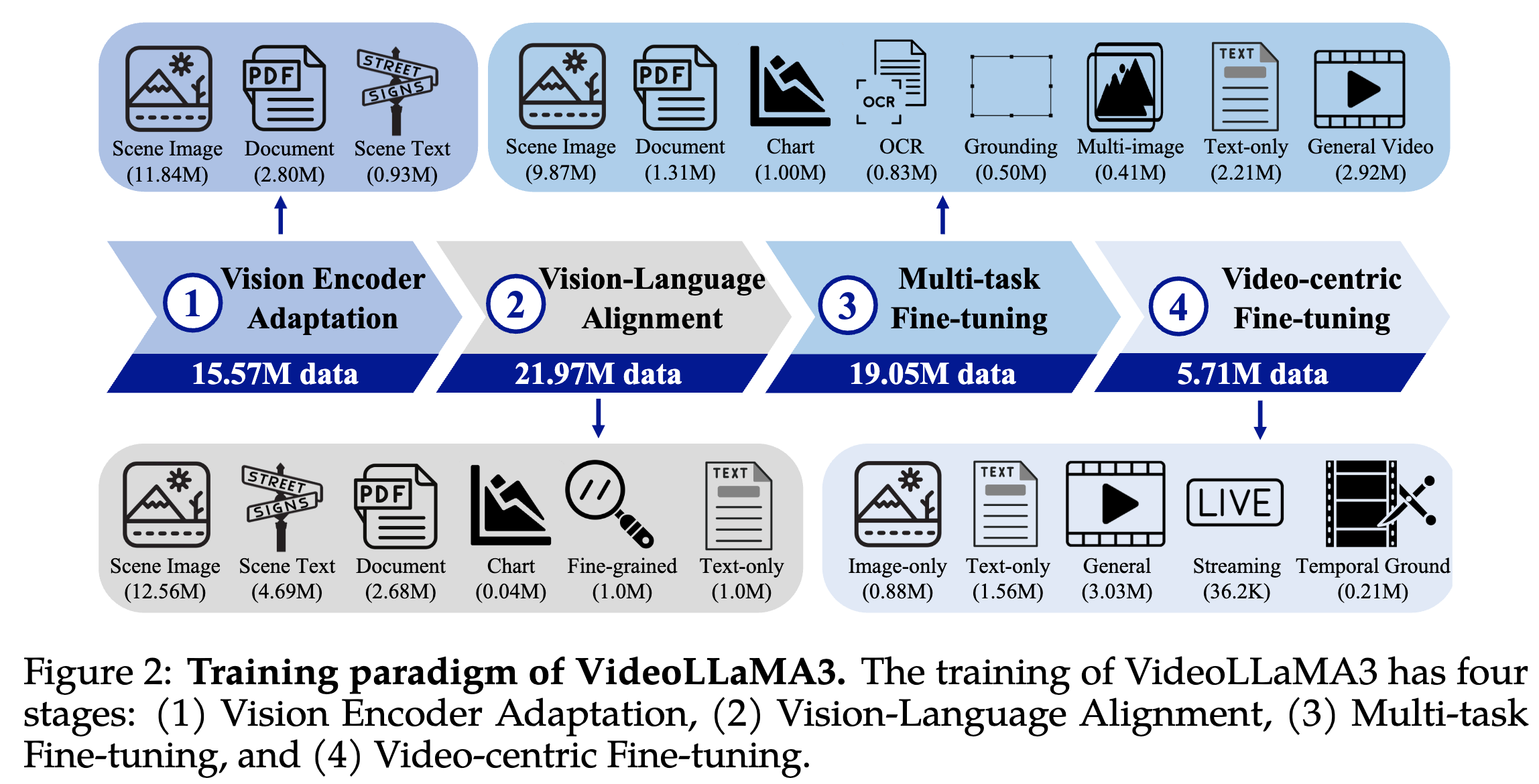
- 四阶段训练
- 视觉编码器适配:该阶段使视觉编码器的特征空间与 LLMs 对齐。视觉编码器的输入从固定分辨率转变为动态分辨率。利用带有简短描述的场景图像来增强编码器性能,同时利用文档和场景文本图像使编码器能够捕捉细粒度的视觉细节。
- 视觉语言对齐:该阶段利用详尽的图像-文本数据建立多模态理解的基础。场景图像配以详细描述,文档和图表数据包含广泛的解释。为了增强空间推理,使用了带有边界框的细粒度图像-文本数据。此外,包含少量仅文本数据以保留模型的语言能力。在此阶段,所有参数均处于可训练状态。
- 多任务微调:在该阶段中,模型针对下游任务(如交互式问答)进行微调。使用带有问答的图像-文本数据,以及通用视频描述数据,为模型的视频感知做好准备。令人惊讶的是,使用通用视频描述数据还提升了图像理解的性能。
- 以视频为中心的微调:最后阶段旨在提升模型在视频理解和视频问答方面的性能。训练数据包括通用视频、流媒体视频、带有时间定位信息的视频,以及仅图像和仅文本数据。
模型架构
-
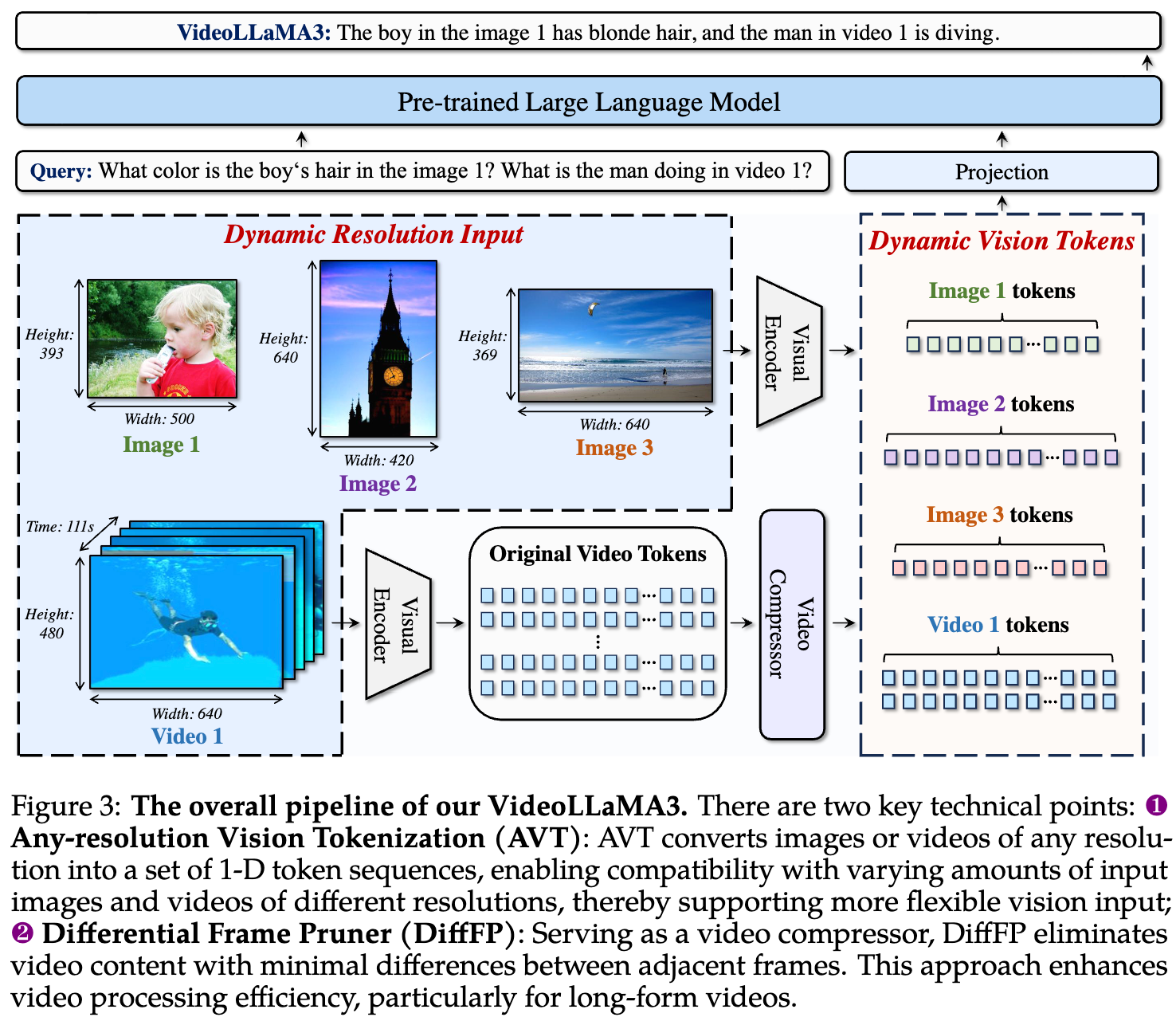
模型架构
- LLM 使用 Qwen2.5-7B/Qwen2.5-2B
- SigLIP 作为视觉编码器的初始化
- 视频压缩器用于减少视频的 token 数量
- 投影器作为视觉编码器和 LLM 之间传递特征的桥梁
-
VideoLLaMA3 包含两项关键技术:
- 任意分辨率视觉标记化(Any-resolution Vision Tokenization,AVT)
- 将 ViT 中的绝对位置嵌入替换为 2D-RoPE
- 差异帧剪枝器(Differential Frame Pruner,DiffFP)
- 通过双线性插值对每帧进行 2×2 的空间下采样
- 差异帧剪枝器(DiffFP)来剪枝视频标记。受到 RLT 启发,比较了像素空间中时间上相邻补丁的 1-范数距离来进行剪枝
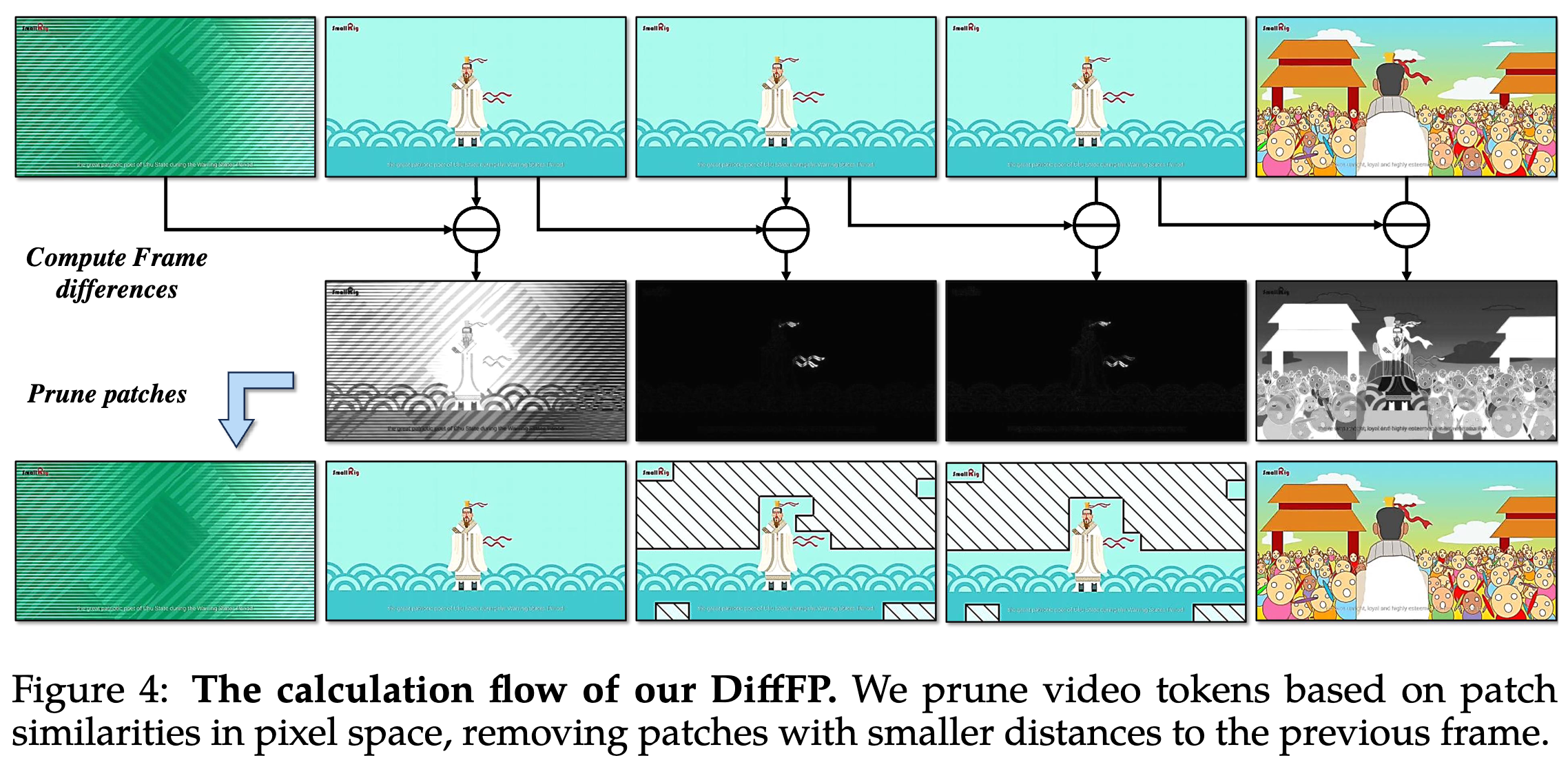
- 任意分辨率视觉标记化(Any-resolution Vision Tokenization,AVT)
实验分析
- image 理解评测
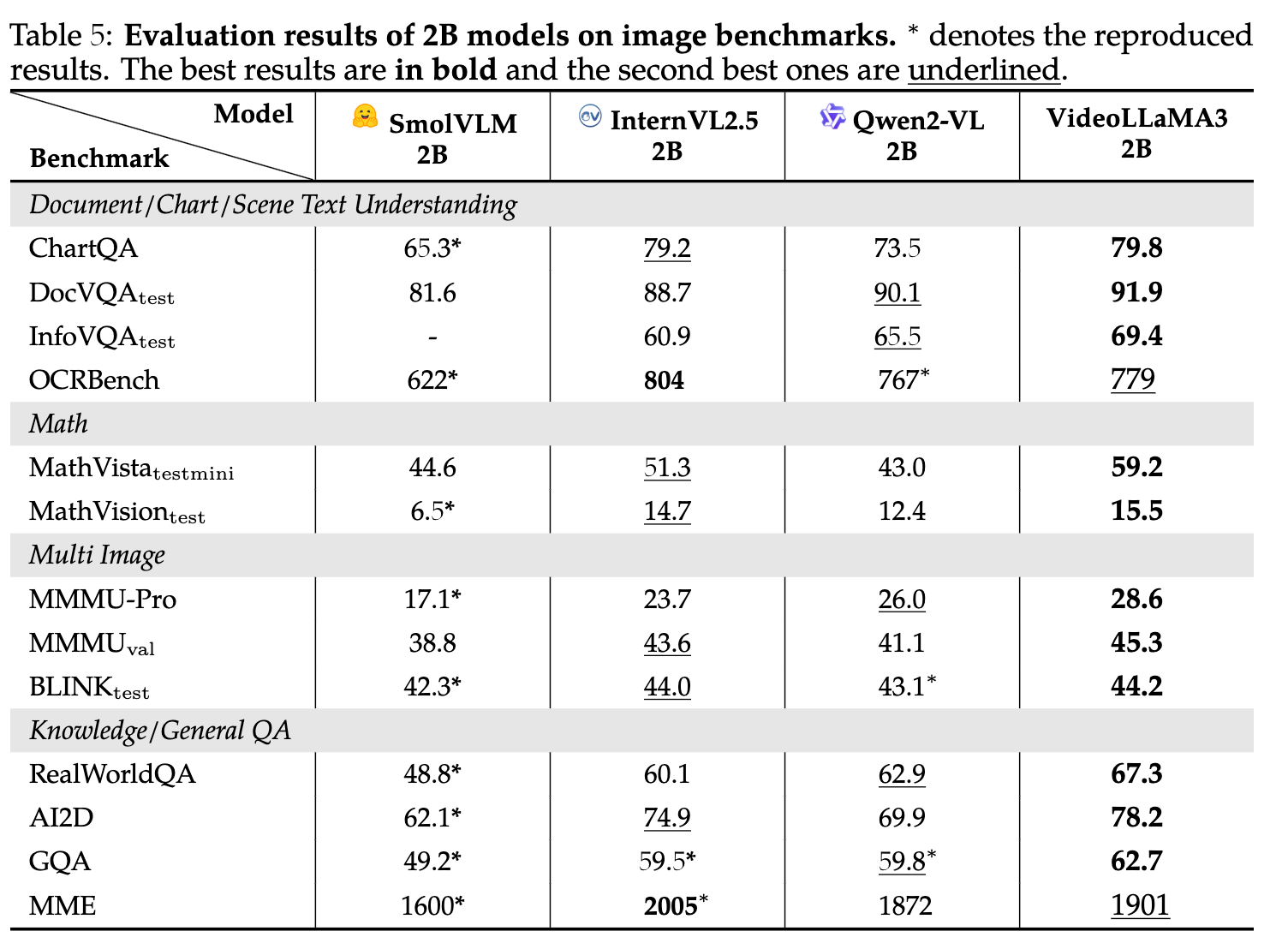
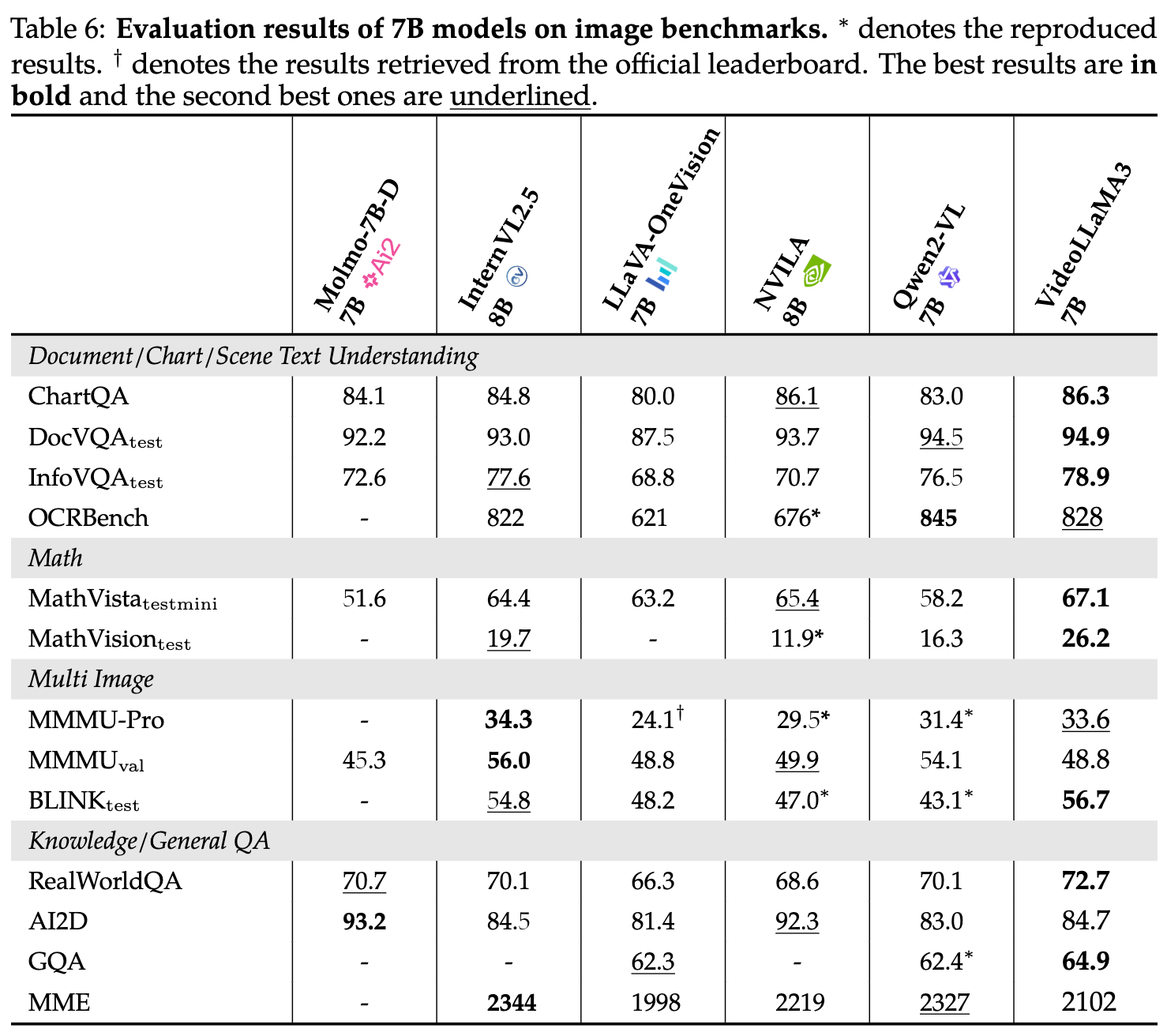
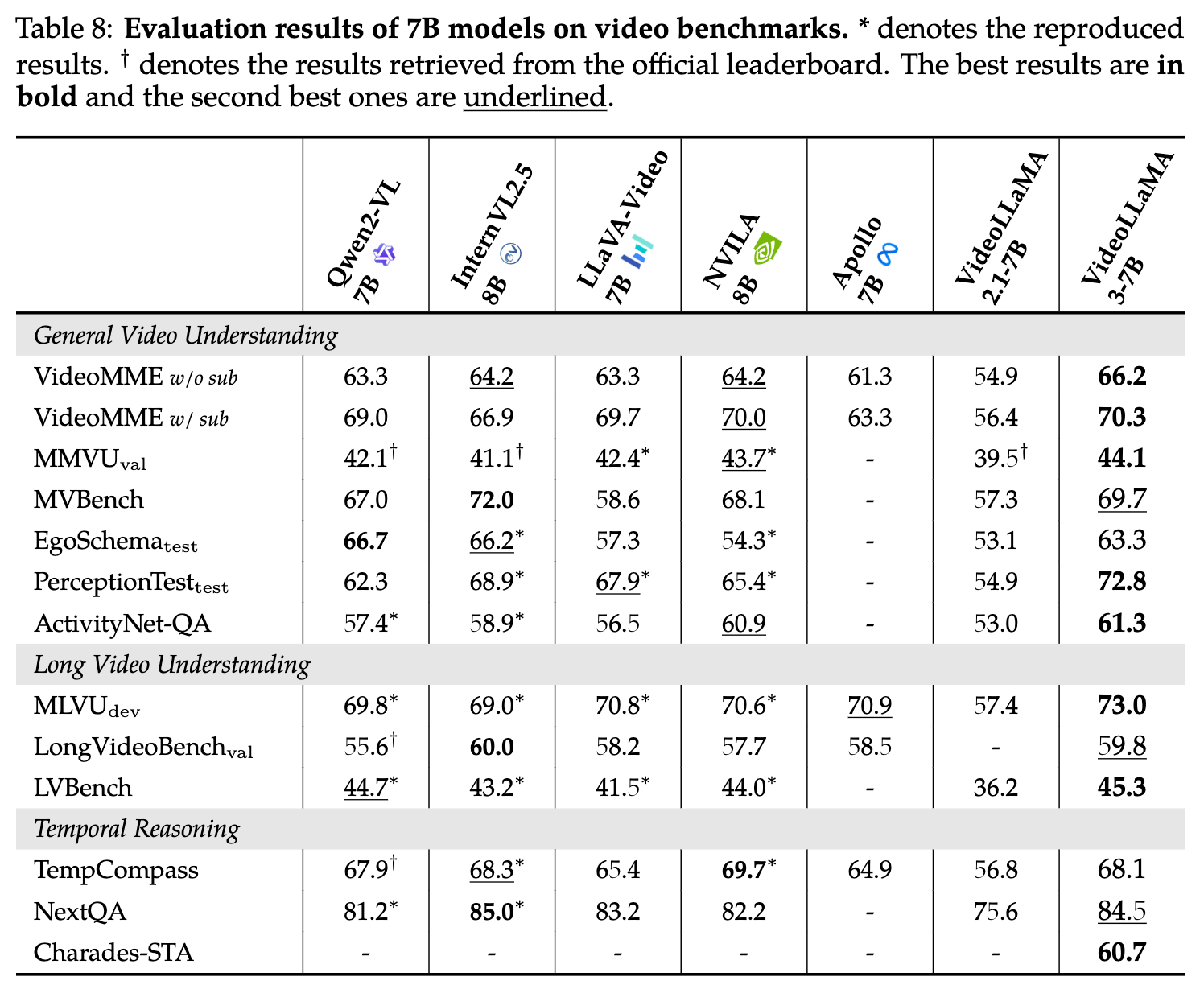
- video 理解评测
总结
- 整体架构上的改动不多,主要还是数据上的改动
TiTok
- 论文名称
- An Image is Worth 32 Tokens for Reconstruction and Generation
- 论文/项目链接
- https://github.com/bytedance/1d-tokenizer
- https://yucornetto.github.io/projects/titok.html
- 论文信息
- 作者团队:字节,慕尼黑工业大学
背景
- 标准的图像标记化器(Tokenizer)和去标记化器(De-Tokenizer)。这些模型利用不同形式的标记化图像表示(连续向量/离散向量),将原始像素转换到潜在空间(Latent Space)
- 标记化器普遍假设潜在空间应保留 2D 结构,这种设计限制了标记化器充分利用图像中的冗余信息,从而构建更紧凑的潜在空间。
- 本文提出一个核心问题:“图像标记化是否必须依赖 2D 结构?”
方法介绍
- 提出 TiTok:基于 Transformer 的一维标记化器

- TiTok 能够在图像生成任务中达到最先进的性能,同时潜在空间大小比传统方法缩小 8× 至 64×,训练和推理阶段均显著加速。相比当前最先进的扩散模型(如 DiT),TiTok 生成速度提升 410 倍,同时保证相似或更高的图像质量
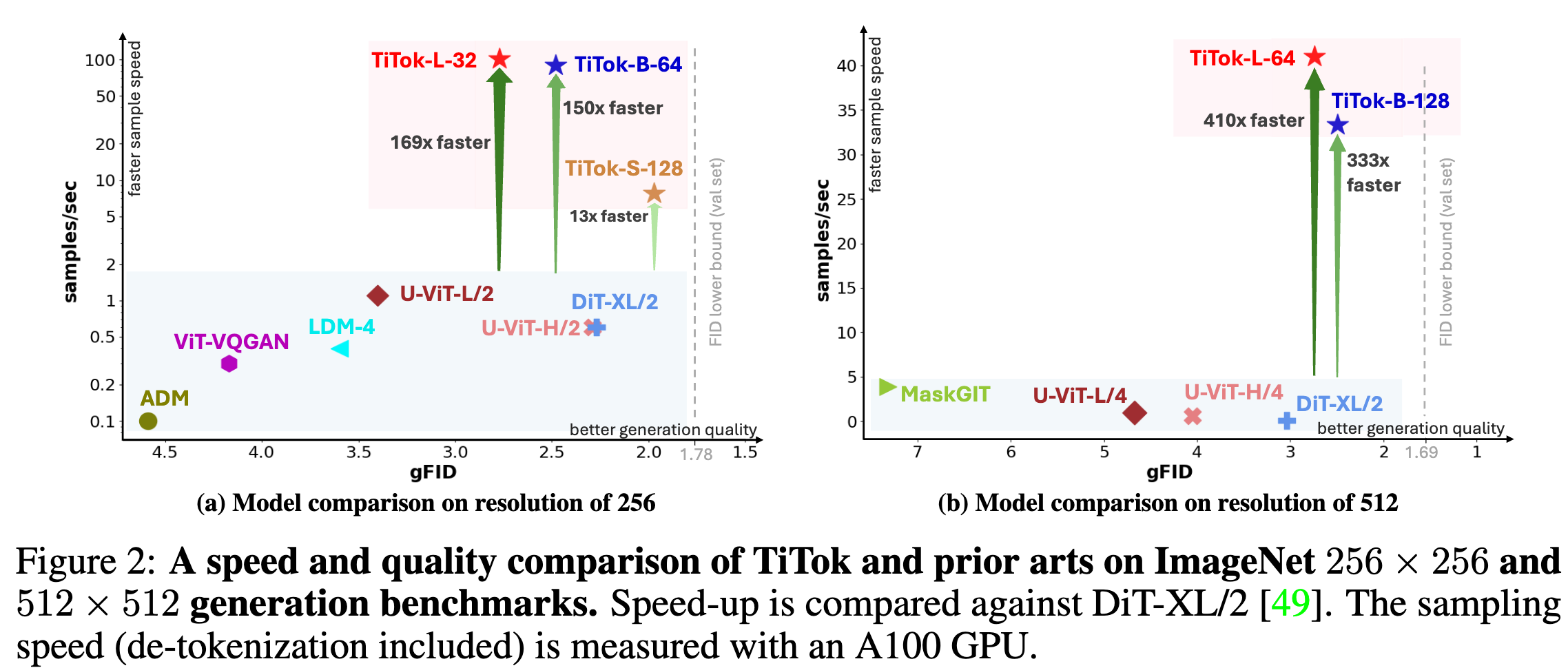
模型架构
核心架构包括:
- ViT 编码器(Vision Transformer Encoder)
- ViT 解码器(Vision Transformer Decoder)
- 向量量化模块(Vector Quantizer),遵循典型的 VectorQuantized(VQ) 模型设计
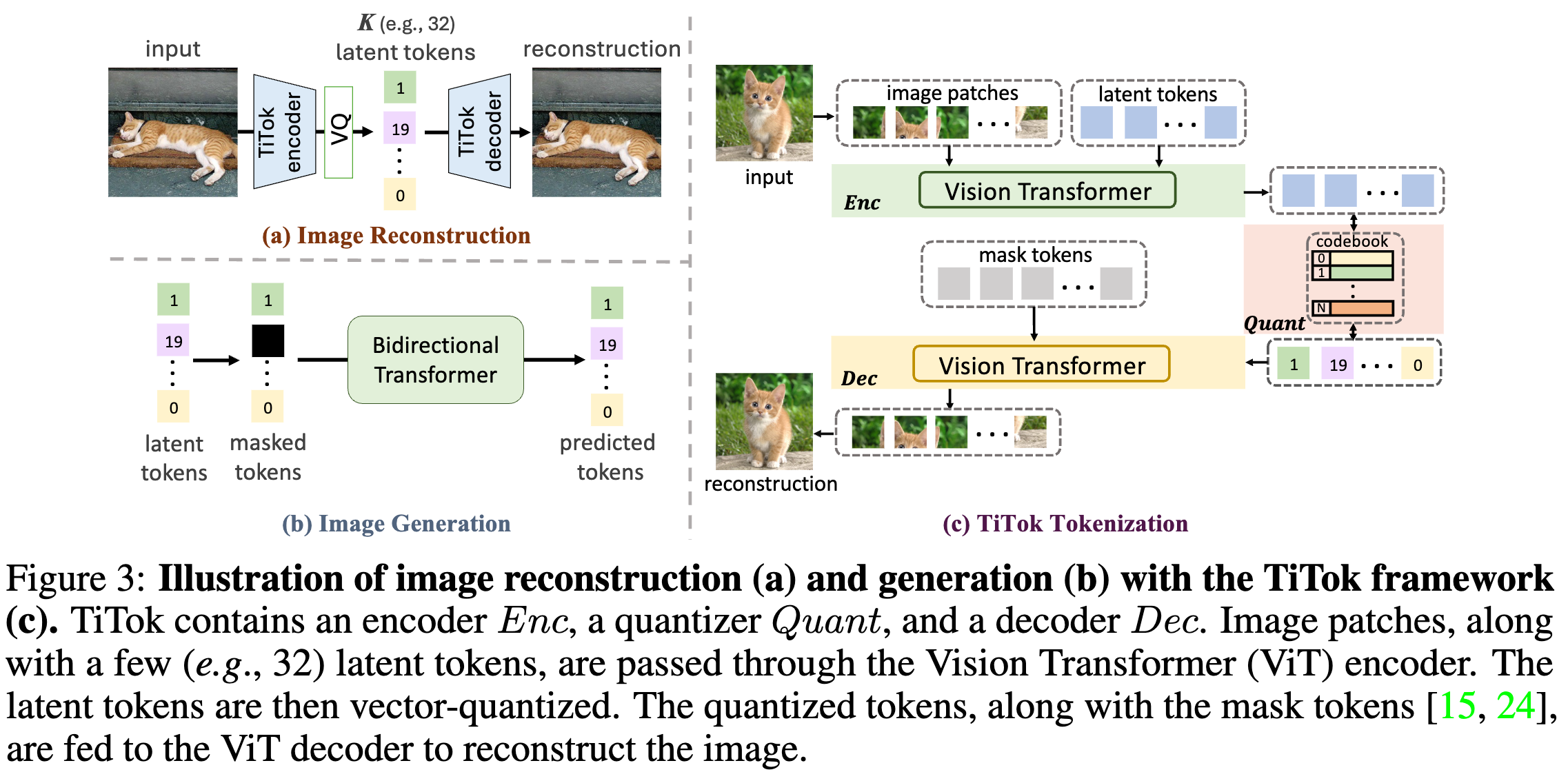
在标记化阶段: - 原始图像被分割并展平为一系列图像块(Patches),然后与一维潜在标记序列进行拼接。
- 经过 ViT 编码器处理后,这些潜在标记形成图像的潜在表示。
- 经过向量量化(Vector Quantization) [61, 19] 之后,ViT 解码器从被掩码的标记序列重新构建图像。
生成阶段使用 MaskGIT,将其 VQGAN 标记化器替换为 TiTok,其他架构不进行调整
两阶段训练
- 第一阶段:预训练(Warm-up)
- 传统方法直接优化 RGB 值回归 并引入复杂损失函数,而我们选择:
- 使用 MaskGIT-VQGAN 生成的离散代码(Proxy Codes) 训练 1D VQ 模型
- 绕过复杂损失函数和 GAN 训练架构
- 这种方法 不影响 TiTok 的标记化和量化功能,但简化了解码器处理流程。
- 传统方法直接优化 RGB 值回归 并引入复杂损失函数,而我们选择:
- 第二阶段:解码器微调(Decoder Fine-Tuning)
- 受 Muse,SDXL 启发,冻结编码器和量化器,仅训练解码器,直接优化像素空间的重建质量。
- 这一阶段显著提升训练稳定性和重建质量。
实验分析
-
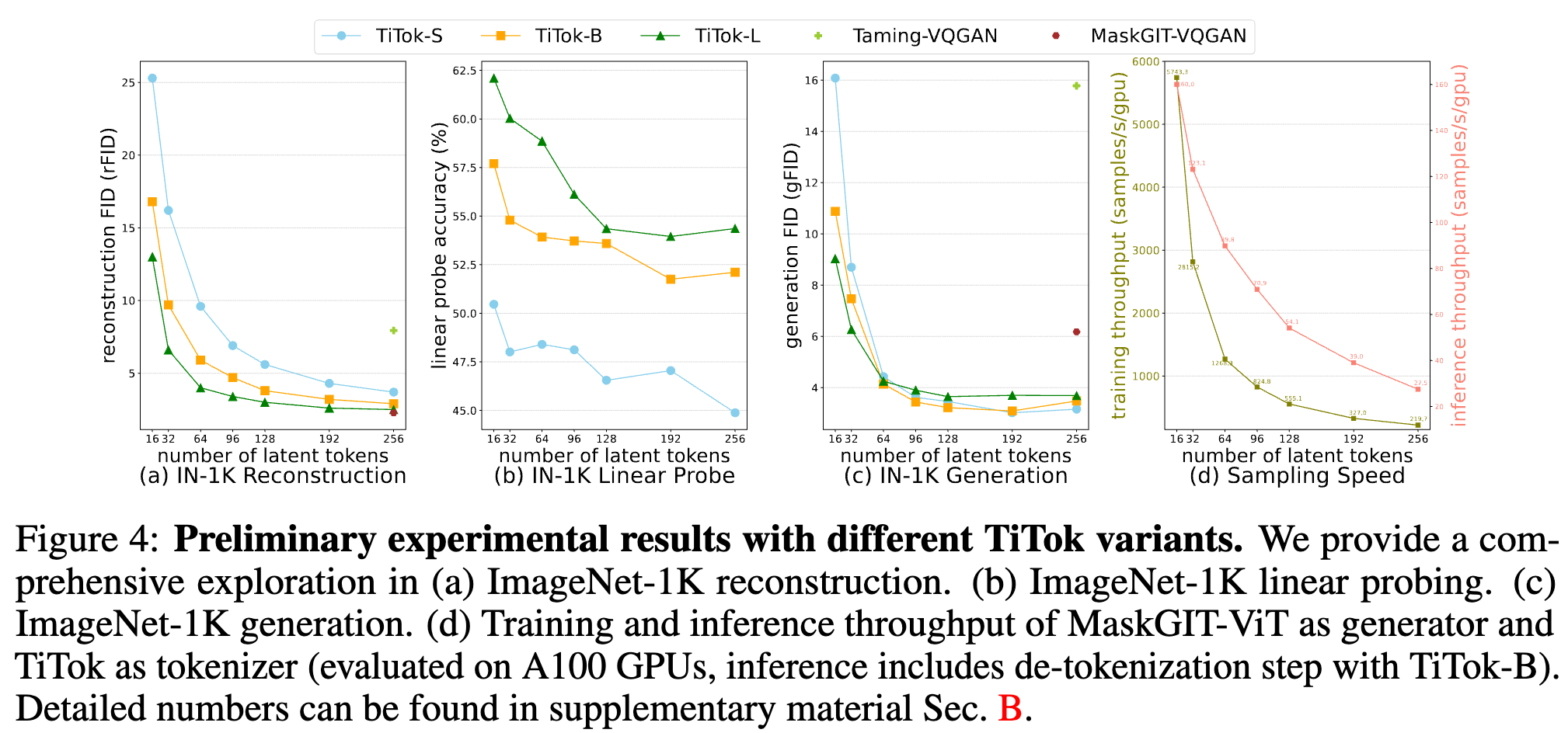
token 数目 32 确实看起来够用,但是增加到 64 和 128 还是有一定收益的
-
生成精度还挺高的
总结
- TiTok 通过 1D 序列标记化 取代了传统的 2D 标记化,这种压缩能力和使用 transformer 架构应该有比较大的关系
- 32 token 重建结果和原图细节差异还是比较大,但是整体看起来还是很相似
LARP
- 论文名称
- LARP: TOKENIZING VIDEOS WITH A LEARNED
AUTOREGRESSIVE GENERATIVE PRIOR
- LARP: TOKENIZING VIDEOS WITH A LEARNED
- 论文/项目链接
- https://hywang66.github.io/larp/
- 论文信息
- 作者团队:University of Maryland
- ICLR 2025 (Oral)
- 训练代码开源
背景
-
背景1:现有的 visual tokenizer 直接应用于自回归 (AR) 模型不够直观
- visual tokenizers 目前大多数是基于 patch 的 token 化范式,其中离散 token 是从原始视觉输入的编码 patch 中量化得到的。
- 这种方式对于空间或时空结构的视觉数据直观有效,但是限制了捕捉整个输入全局和整体表征的能力。这一限制在应用于依赖顺序处理的自回归模型时变得更加明显,因为自回归模型要求将局部编码的 token 转换为线性的 1D 序列
- visual tokenizers 目前大多数是基于 patch 的 token 化范式,其中离散 token 是从原始视觉输入的编码 patch 中量化得到的。
-
背景2:生成保真度和重建保真度之间的差距关联没有被彻底研究和解决
- 虽然视觉分词器的重构保真度为AR模型的生成保真度设定了上限,但决定二者之间差距的因素仍不清楚。
- 较高的重构质量有时会导致较差的生成保真度,凸显了以重构为中心的视觉分词器设计的局限性,并强调了确保分词器潜在空间具备理想特性的必要性
- 虽然视觉分词器的重构保真度为AR模型的生成保真度设定了上限,但决定二者之间差距的因素仍不清楚。
方法介绍
-
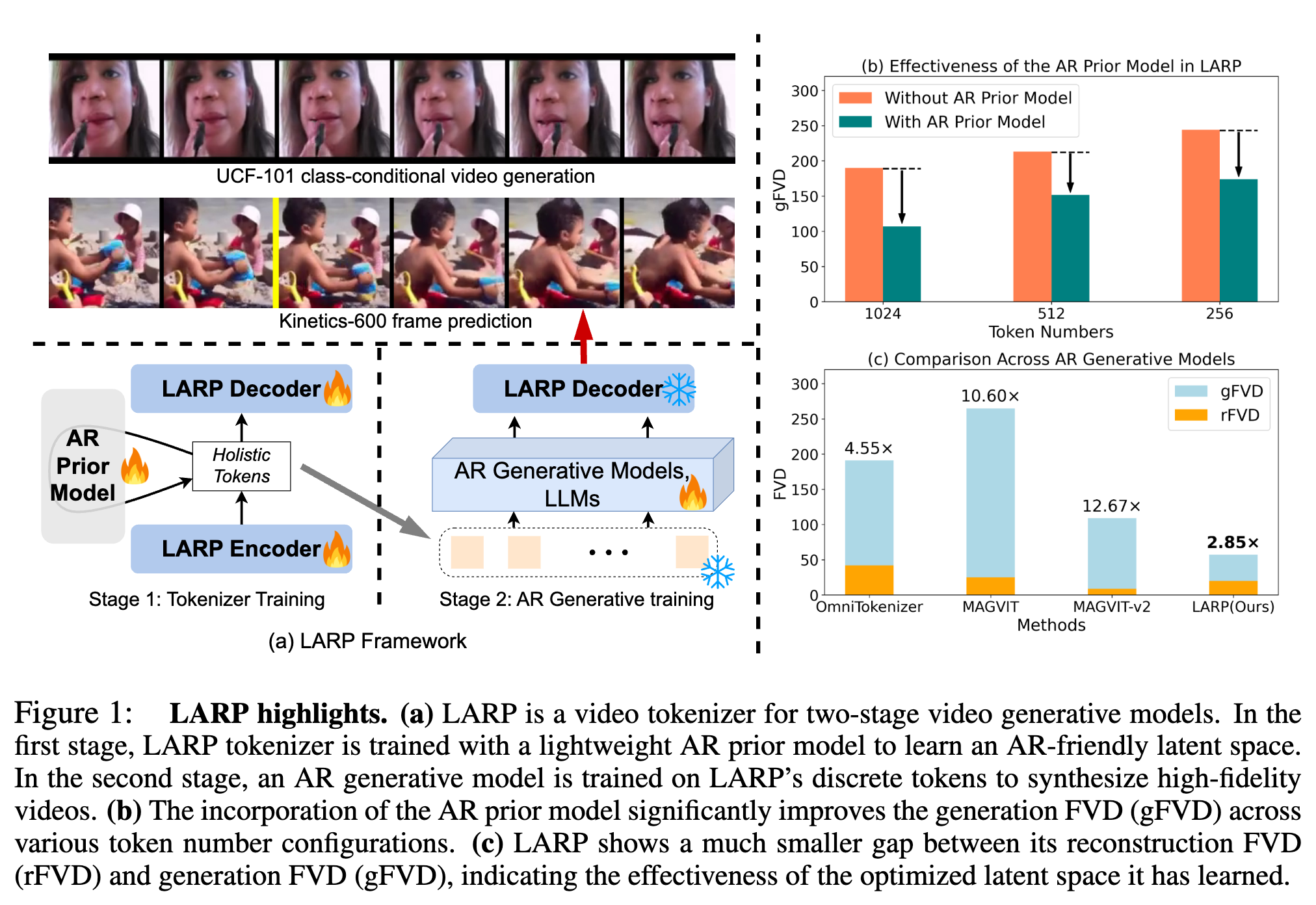
提出了 LARP,一种新颖的视频 tokenizer, 生成更具语义性和全局性的视频表示。并且通过联合训练 AR 先验模型,有效地使 LARP 的 latent space 和下游 AR 生成任务对齐。
-
模型架构
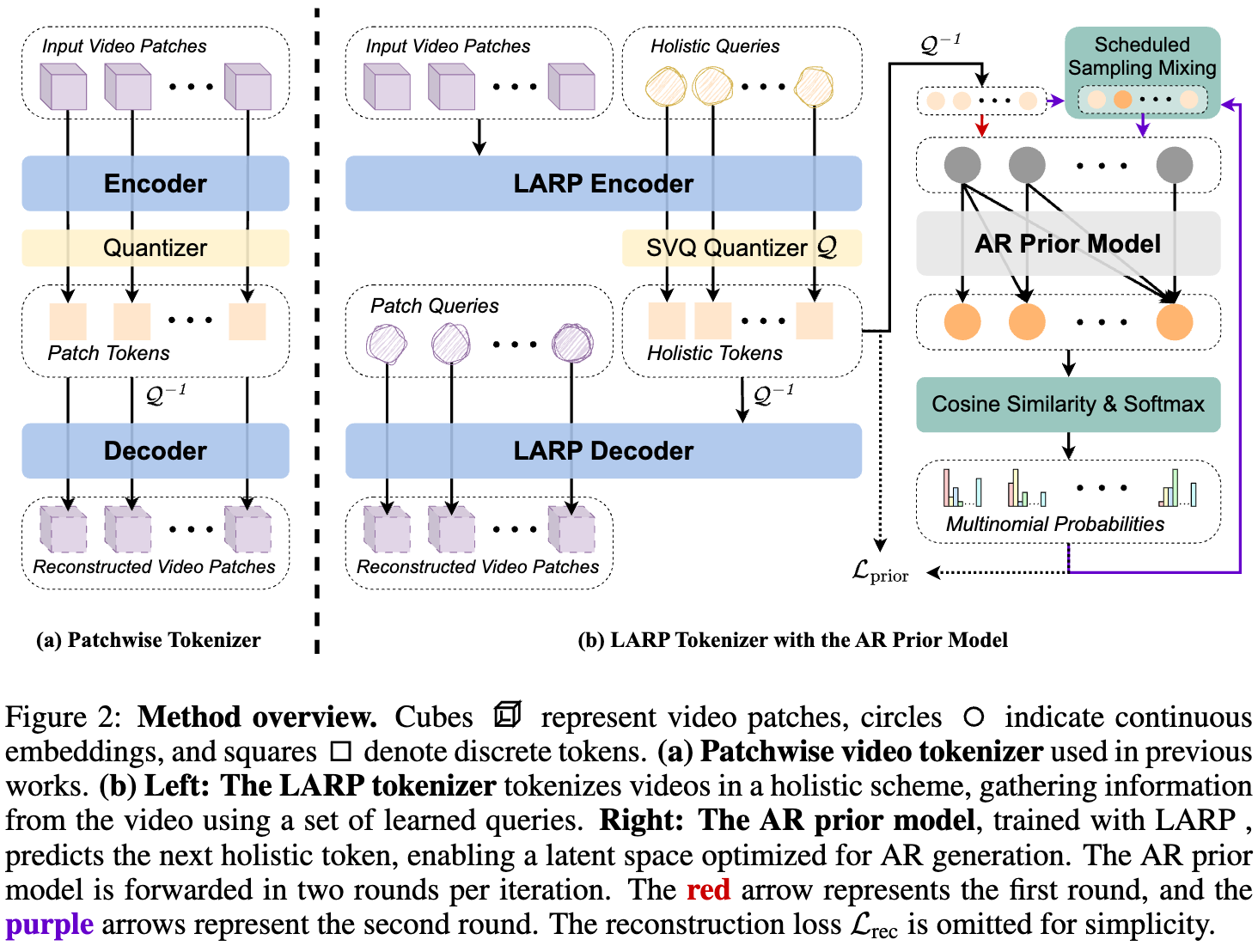
- Patch 化:使用 ViT 框架,将视频拆分为时空 Patch 后进行线性编码,给到 transformer 进行编码
- 基于 Query 的 Transformer 进行全局特征提取:参考 Blip2 等思路,引入一组固定的输入 query 来从视频中捕获整体信息。使用 transformer encoder 架构,在 in-context conditioning 下,patch token 与 query token 之间信息可以相互融合
- SVQ 量化:通过随机向量量化(SVQ) 进行量化
- 解码:同样采用 transformer encoder 架构,融合反量化后的编码信息后重建视频
- 学习自回归生成先验:引入了一个轻量级的 AR Transformer 作为先验模型,为 LARP 的训练提供梯度,使其潜在空间结构适应 AR 生成任务。这里将标准 AR Transformer 修改为连续 AR Transformer 从而解决标准 AR Transformer 离散性导致的梯度无法回传的问题。
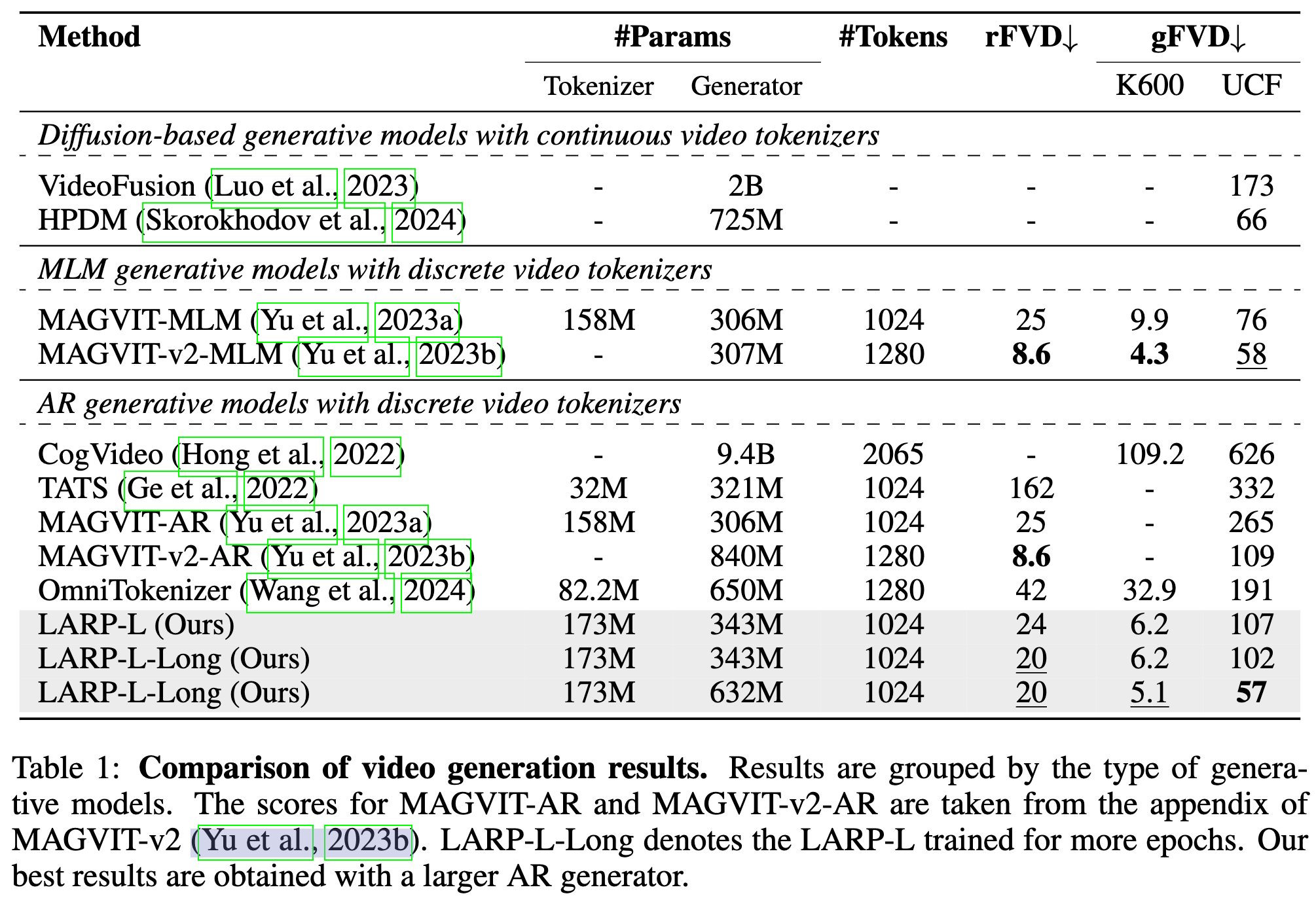
实验分析
-
性能方面重建指标 rFVD 并不是很高,但是生成指标 gFVD 是最好的
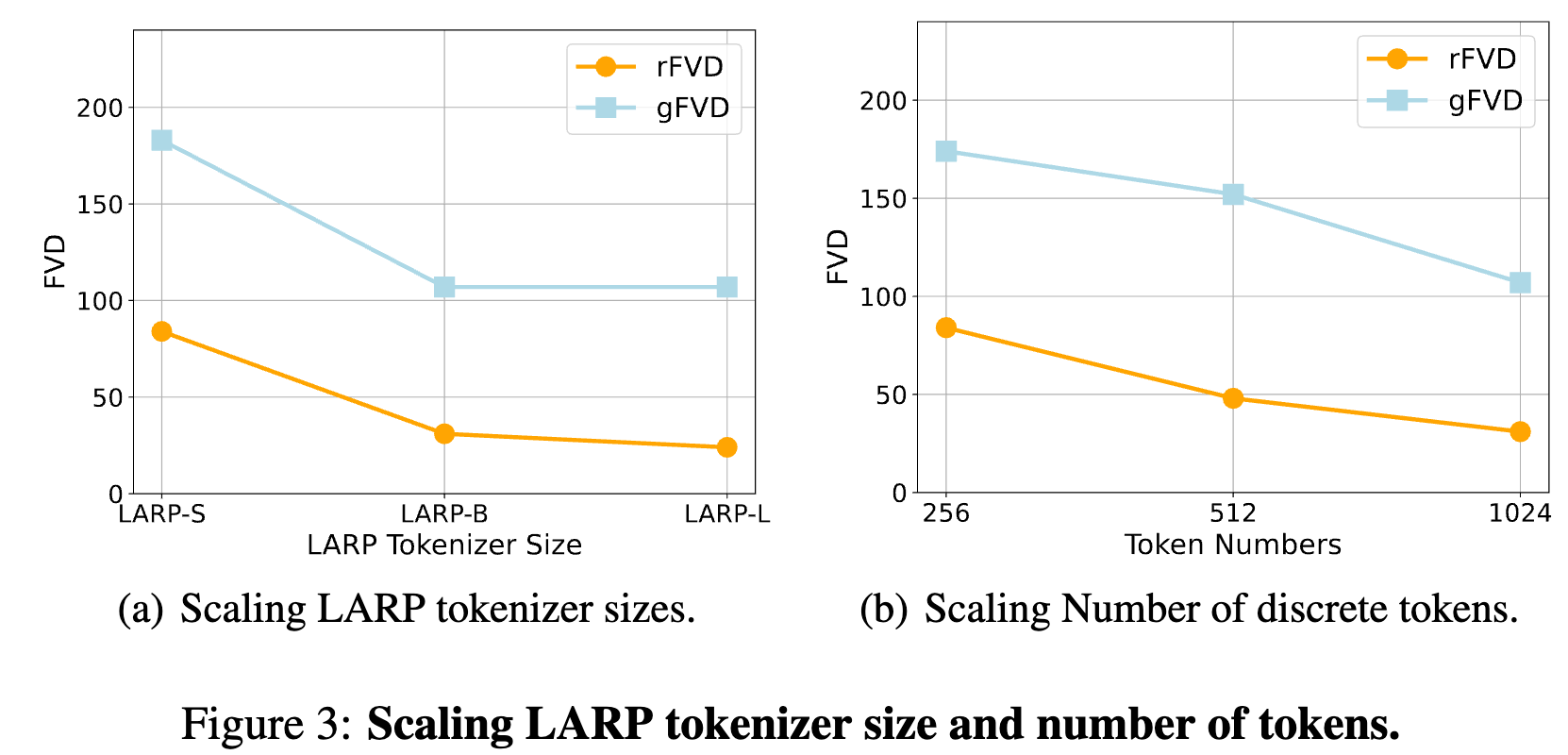
-
scaling 实验:rFVD 随着分词器规模增大而持续下降(重建质量提高)。gFVD 在 LARP-B 到 LARP-L 之间趋于饱和,说明生成质量的提升可能与重建能力趋势不同。
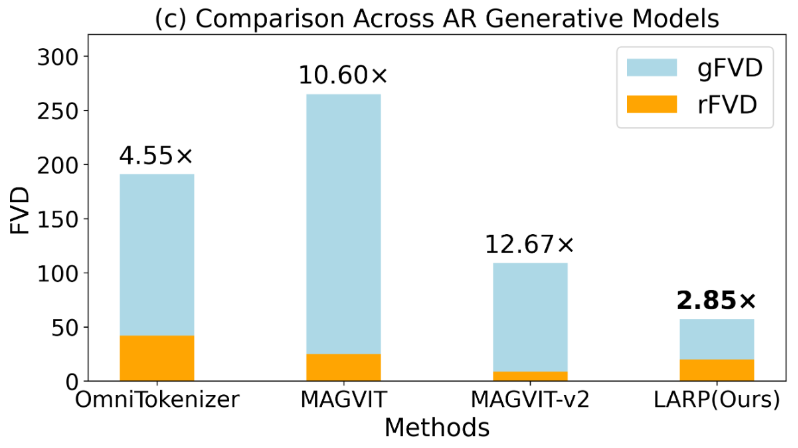
-
LARP 具有最小的 rFVD 和 gFVD 之间的差距
总结
- 专门为自回归(AR)生成模型设计的视频分词器,如何让视频分词器的 latent space 更容易建模是个值得不断研究的问题
Ola
-
论文名称
- Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment
-
论文/项目链接
- https://ola-omni.github.io/
-
论文信息
- 作者团队:清华大学 + 腾讯混元
背景
- 自 GPT-4o 以来,引发了对全模态(omni-modal)模型开发的浓厚兴趣
- 训练全模态大语言模型的核心挑战在于不同模态的建模以及设计高效的学习流程
- 现有 omni-model 的缺陷
- 在特定领域或任务上的能力不足;
- 需要大量数据;
- 用户交互延迟;
- 模态之间的对齐不充分。
方法介绍
-
提出了 Ola 模型,探索如何训练一个全模态大语言模型,使其能够在性能上可与最先进的专门 LLMs 相媲美,同时具备实时交互能力和高效的数据对齐策略。
- 渐进式模态对齐策略:从两个最基础、相互独立的模态——图像和文本——入手,然后逐步扩展训练集:包括:
- 视频帧数据:增强视觉理解能力
- 语音数据:连接语言和音频知识
- 带音频的视频数据:全面融合语言、视频和音频信息
- 渐进式模态对齐策略:从两个最基础、相互独立的模态——图像和文本——入手,然后逐步扩展训练集:包括:
-
在仅 7B 参数的情况下,Ola 在主流多模态基准测试中表现出色

模型架构
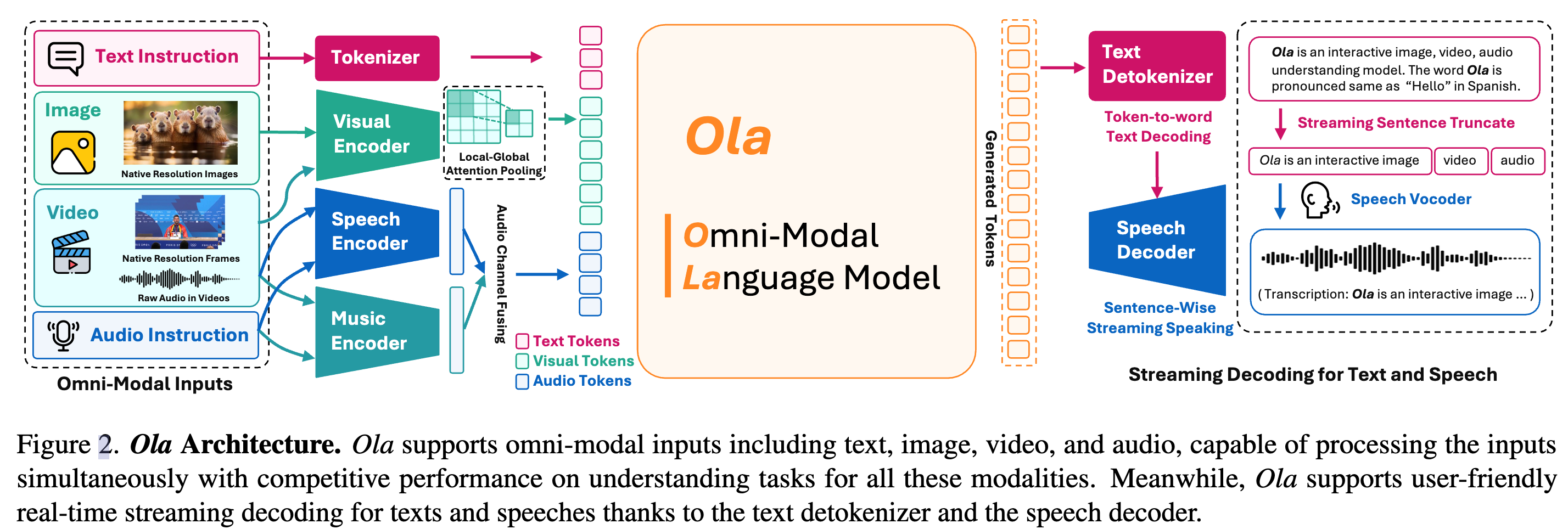
- 支持读、听、看、写、说
- 支持全模态输入,同时实现流式文本和语音输出
- 模型架构
- 文本编码
- 基于 Qwen2.5-7B
- 视觉编码
- 采用 OryxViT,基于 SigLIP-400M 预训练权重训练得到,保留原始长宽比以适应任意分辨率
- 视频逐帧提前特征
- 音频编码(语音/音乐)
- 采用双编码器:whisperv3 作为语音编码器(输入 Mel 频谱)。BEATs 作为音乐编码器(输入原始音频)。
- 由于 Whisper 仅支持固定长度的音频输入,我们将音频按 16,000Hz 采样率 切分为 30 秒片段,并进行批量编码
- 语音/音乐编码器的嵌入特征在通道维度上拼接,生成完整的音频特征
- 文本编码
-
视觉-音频联合对齐
- 为了提高效率并减少视觉特征的 token 长度,基于结构化降采样(Structural Downsampling)提出了局部-全局注意力池化层(Local-Global Attention Pooling)
- 视觉、音频特征通过双层 MLP 投影到同一的 token 形式,与文本 tokens 自由组合供 LLM 解码
-
流式语音生成
- 采用 CosyVoice 作为高质量语音解码器,支持流式解码
- 实时检测生成文本 tokens,一旦检测到标点符号,即截断句子并传入语音解码器进行语音合成
- 认为外部 TTS 解码器是更高效、高质量、且无需额外训练的方案。
- 采用 CosyVoice 作为高质量语音解码器,支持流式解码
训练流程
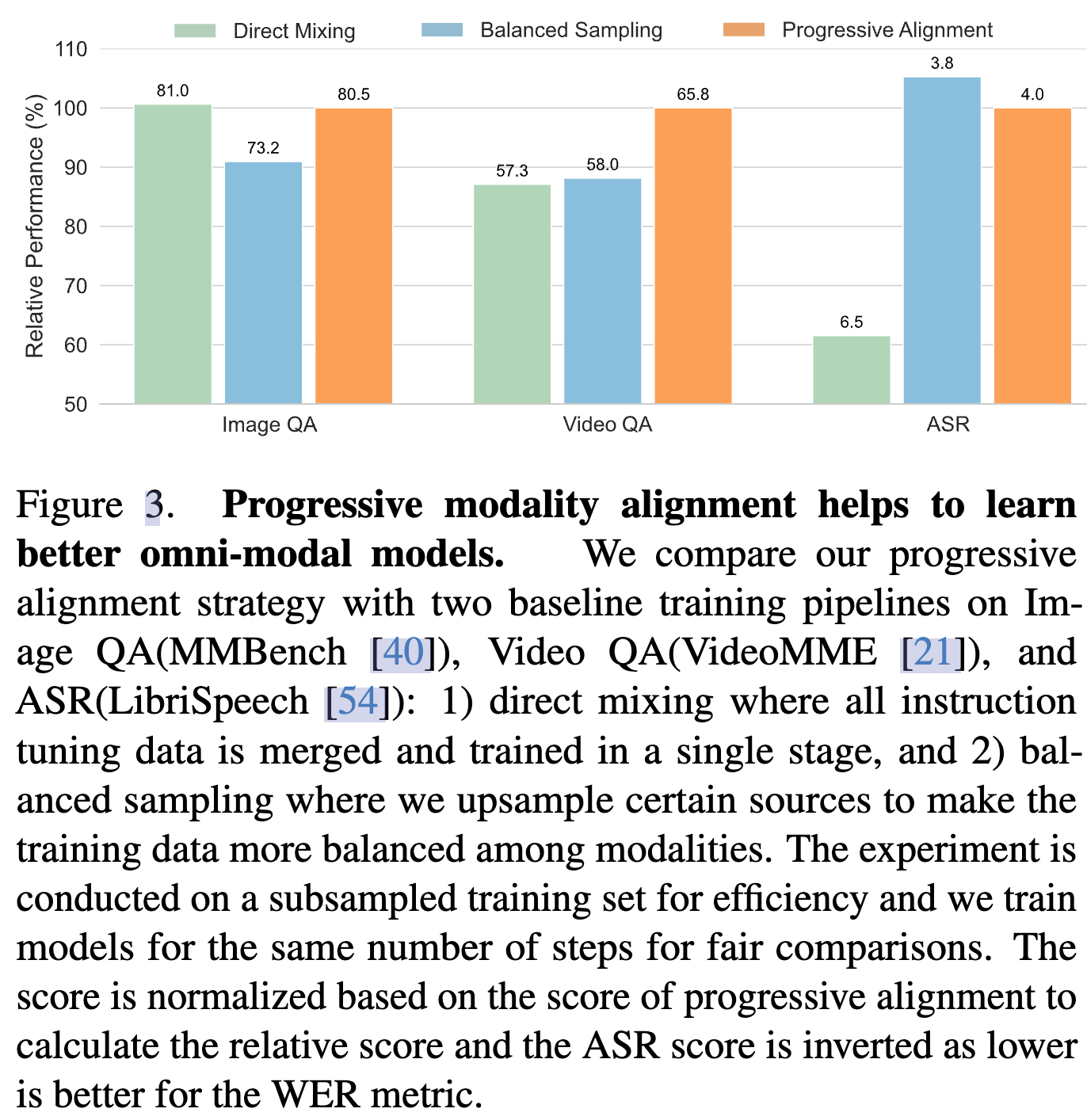
-
直接混合训练、平衡采样训练、本文提出的渐进对齐训练的效果对比,为了公平都是训练相同的 iteration
-
渐进式全模态对齐
- 阶段 1:文本-图像训练(Text-Image Training)
- MLP 对齐:初始化视觉 MLP 适配器,并冻结其他 MLP 参数,使用图像标注(image captioning)任务进行对齐。
- 大规模预训练:解冻所有参数(包括视觉编码器)进行全模态训练。
- 监督微调:进一步优化视觉-文本理解能力。
- 降采样模块优化:在文本-图像训练阶段,训练 2x 视觉数据压缩模块,确保后续视频和图像数据能更高效地处理。
- 阶段 2:图像与视频的持续训练(Continuous Training for Images and Videos)
- 冻结视觉编码器
- 混合图像和视频数据,在不损害原始文本-图像能力的情况下,增强视频理解能力
- 阶段 3:通过视频连接视觉和音频(Bridging Vision and Audio with Videos)
- 音频 MLP 适配器使用语音识别(ASR)任务来初始化
- 训练任务包括:文本语音理解、文本音乐理解、音频视频联合理解、文本图像多模态任务
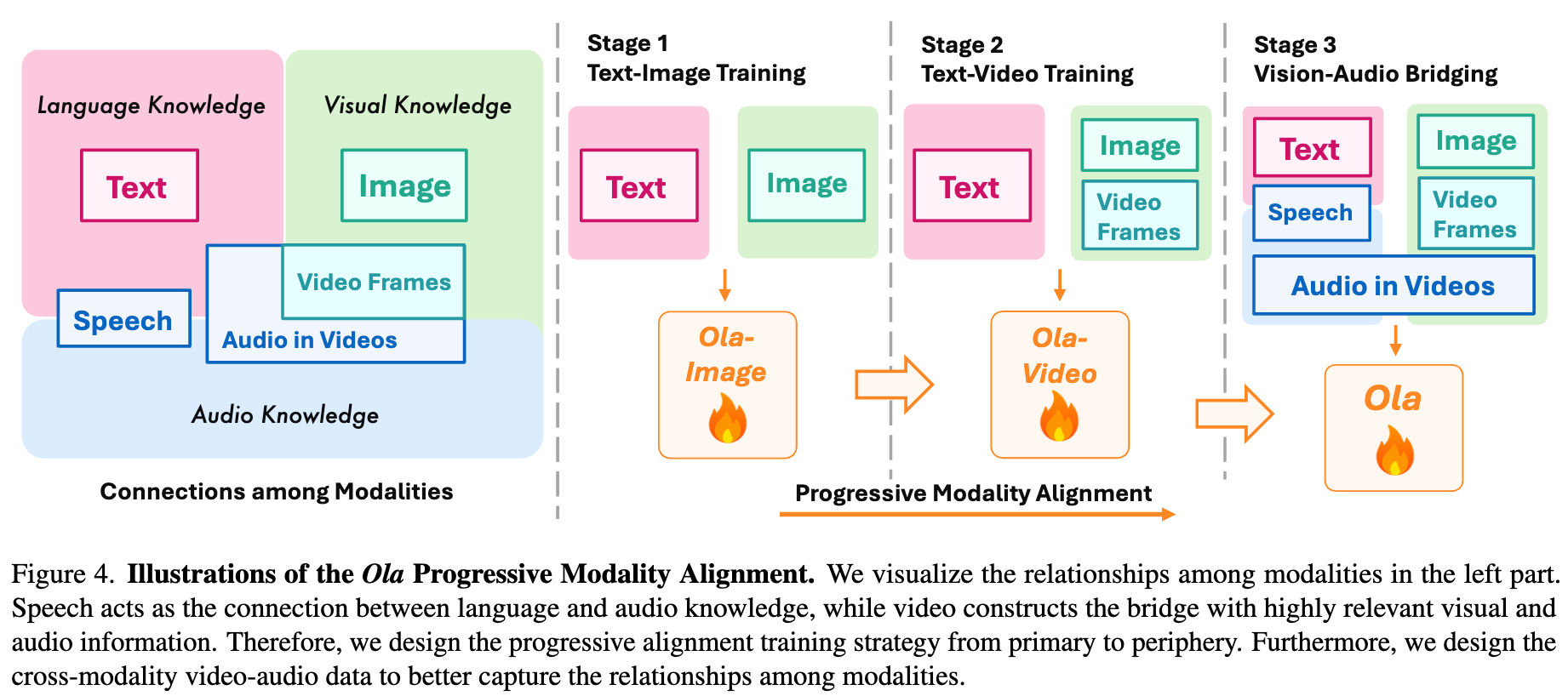
- 阶段 1:文本-图像训练(Text-Image Training)
训练数据
-
开源学术数据集的监督微调数据
- MLP 对齐数据:从 LAION 数据集收集 80 万张图像-文本对
- 大规模预训练数据:从开源 & 内部数据收集 2000 万组文本-图像数据,用于建立基本的视觉-文本理解能力
- 监督微调数据:caption、对话、OCR 等,来源于 LLaVA-OneVision、Cauldron 等,共 730 万张图像训练数据
- 视频数据(Video Data):来源于 LLaVA-Video-178K、VideoChatGPT-Plus 等,共 190 万个视频对话样本
- 音频数据(Audio Data):总计 110 万条音频训练数据
- 语音识别(ASR):LibriSpeech、GigaSpeech
- 音频 caption:AudioCaps、Clotho
- 语音问答:LibriSpeech
- 音频问答:WavCaps、AudioCaps
- 音乐 caption:MusicCaps
- 音乐问答:MillionSong、MusicNet
-
设计了一条跨模态视频-音频数据生成流程
- 现有的视频数据 仅基于图像帧生成标注,忽略了音频信息。
- 设计了新的数据
- 视频-音频问答
- 视频语音识别
- 数据来源:LLaVA-Video-178K、FineVideo
- whisper-v3 生成 caption
- Qwen2-VL-72B 生成视频-字幕问答数据
- 额外增加 8.3 万条视频字幕任务,提升嘈杂环境下的 ASR 能力
实验分析
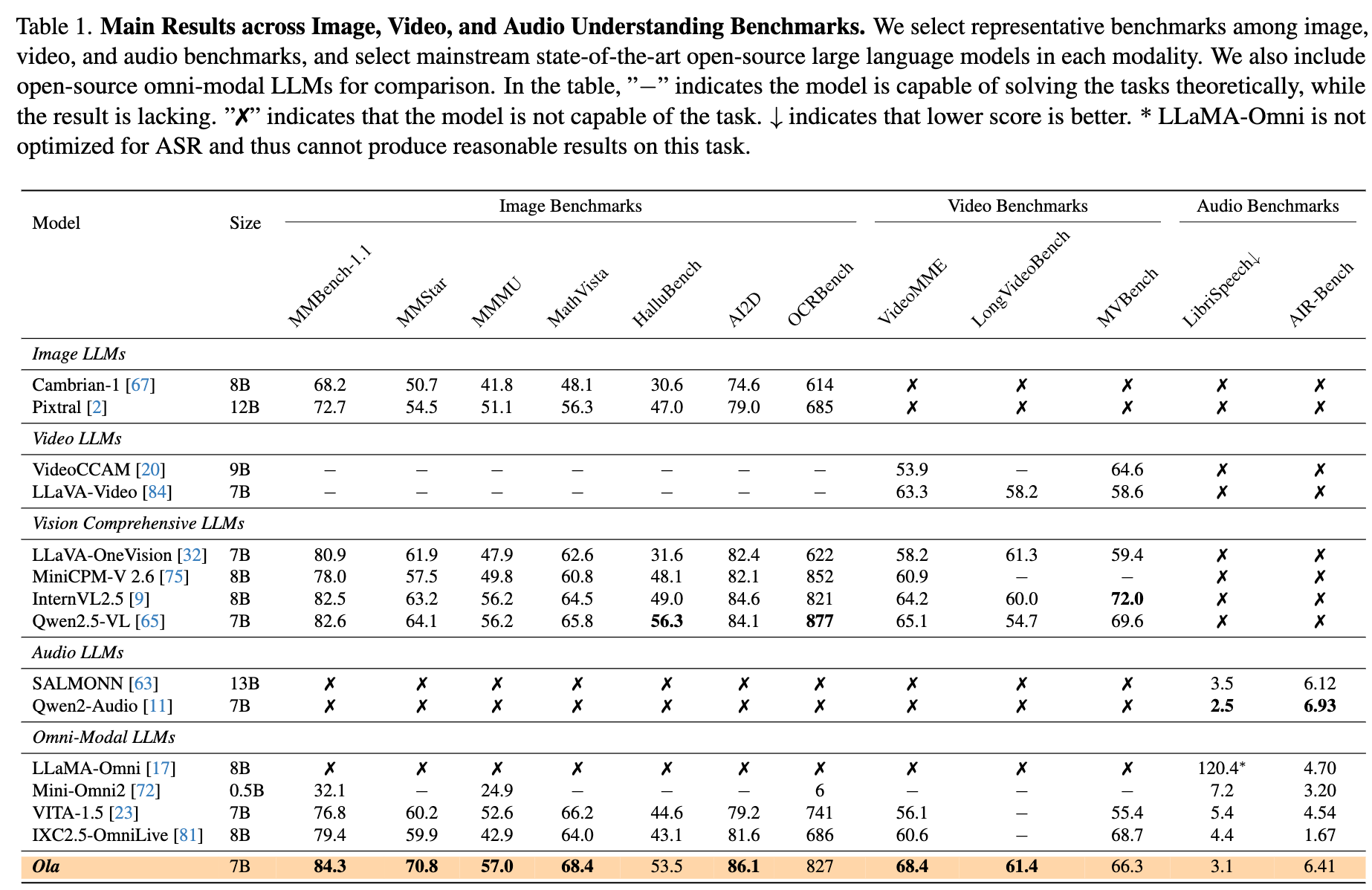
-
主流理解评测集上的评测效果,部分榜单和单模态专用模型比有差距,但是多个模态上的综合性能很强
-
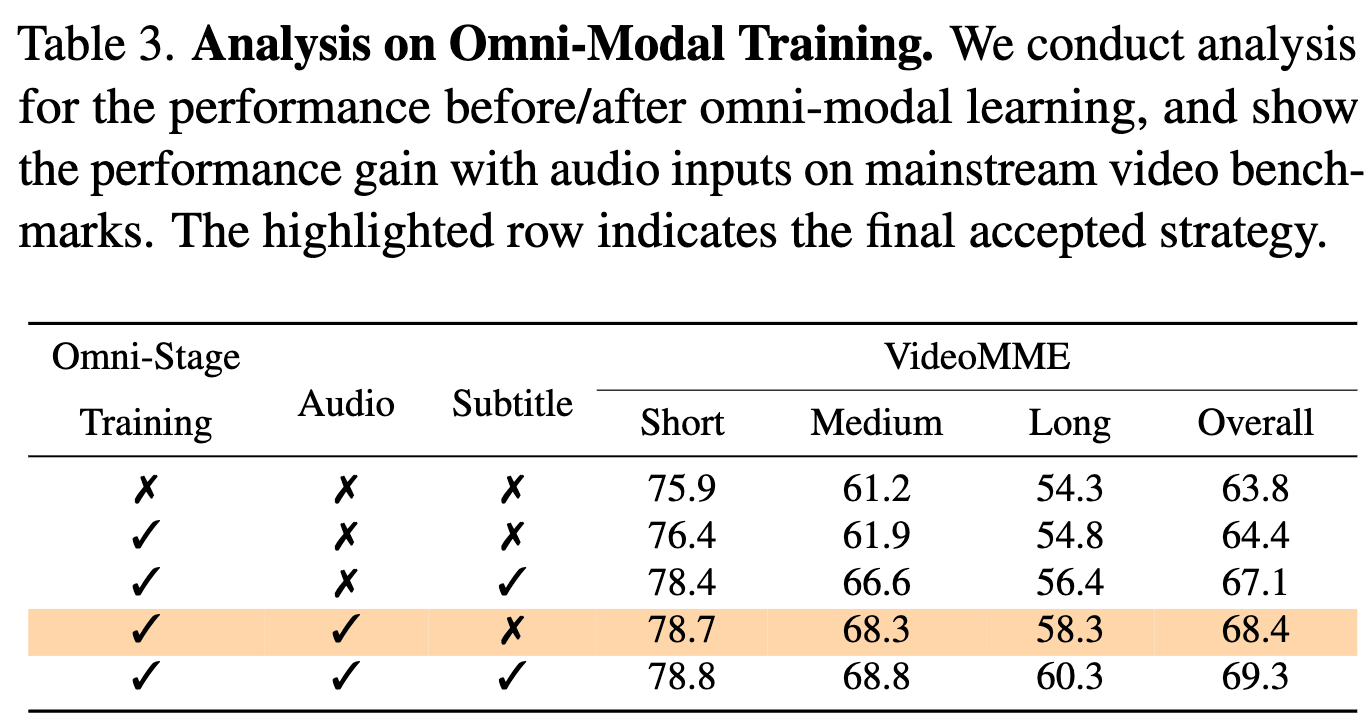
audio 模态对于视频理解任务有用
-
omni 模型相比于 vision LLM 的优势,能准确认出德约科维奇,解释了他代表塞尔维亚等信息。

总结
- 渐进式模态对齐策略感觉挺合理的,相比于所有模态一起训练有一定优势。模型架构上整体来看没有太大的创新
- Omni-model 能够结合音频内容补充更多信息
总结
本文分析的 8 项研究从不同角度突破了多模态生成的技术边界:
- MAETok 通过掩码自编码构建判别性潜在空间,证明变分约束并非必要;
- FlexTok 创新性地将图像压缩至 1-256 个有序 token,实现生成质量与效率的平衡;-- TiTok 用一维序列取代传统 2D 分词,在 32-token 极简表示下达到 SOTA 生成效果;
- Emu3 坚持纯自回归范式,验证了单阶段训练支持图文视频生成的可行性;
- LLaVA-Mini 通过预融合机制,仅用 1 个视觉 token 实现与 576-token 模型相当的性能;
- LARP 联合训练分词器与 AR 先验模型,首次将生成保真度与重建质量解耦;
- VideoLLaMA 3 和 Ola 则通过渐进式多模态对齐,在 7B 参数规模下实现全模态理解与交互。
这些工作共同指向三个趋势:
- (1)潜在空间设计从保真度优先转向生成友好
- (2)动态 token 压缩技术突破计算瓶颈
- (3)统一架构逐步取代多模型组合
相关文章:
前沿研究介绍)
多模态大模型中的视觉分词器(Tokenizer)前沿研究介绍
文章目录 引言MAETok背景方法介绍高斯混合模型(GMM)分析模型架构 实验分析总结 FlexTok背景方法介绍模型架构 实验分析总结 Emu3背景方法介绍模型架构训练细节 实验分析总结 InternVL2.5背景方法介绍模型架构 实验分析总结 LLAVA-MINI背景方法介绍出发点…...

车载电子电器架构 --- 汽车网关概述
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

JVM对象创建内存分配
对象创建的主要流程: 检查加载类–》分配内存–》初始化–》设置对象头–》实例化,执行init方法。 在内存分配中,虚拟机将为新生对象内存分配 Minor GC : 新生代垃圾收集,特点是频繁,回收速度快; Full GC …...
)
project从入门到精通(五)
目录 创建资源的基本信息 在project中创建资源工作表 编辑信息详解 最大单位 标准费率与加班费率 每次使用成本 成本累算 基准日历 三类资源工作表的总结——不同的资源必须要设置的属性 除了资源名称是必须设置的之外,剩余的资源的可设置选项如下图所…...
管理文化)
研发效率破局之道阅读总结(5)管理文化
研发效率破局之道阅读总结(5)管理文化 Author: Once Day Date: 2025年5月10日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: 程序的艺术_Once-Day…...

Java常用类概述
Java常用类概述 一、字符串三剑客1. String(不可变字符串)2. StringBuilder(可变,线程不安全)3. StringBuffer(可变,线程安全) 二、日期时间类(重点掌握新版APIÿ…...

202535| Kafka架构与重要概念+幂等性+事务
好的!以下是关于 Kafka 架构 以及其 重要概念 的详细介绍,结合 Mermaid 图形 和 表格,帮助你更好地理解各个概念的关系和作用。 Kafka 架构与重要概念 Kafka 是一个分布式消息系统,广泛应用于日志收集、流处理、事件驱动架构等场…...

MySQL 索引和事务
目录 一、MySQL 索引介绍 1、索引概述 2、索引作用 3、索引的分类 (1)普通索引 (2)唯一索引 (3)主键索引 (4)组合索引(最左前缀) (5&…...

IPFS与去中心化存储:重塑数字世界的基石
引言 在数据爆炸式增长的数字时代,中心化存储的弊端日益凸显——数据垄断、隐私泄露、单点故障等问题频发。IPFS(InterPlanetary File System) 作为一种去中心化存储协议,正与区块链技术共同推动一场存储革命。本文将深入解析IPF…...

Web3 学习全流程攻略
目录 🧭 Web3 学习全流程攻略 🌱 第一阶段:打好基础(Web3 入门) 🧠 目标: 📚 学习内容: ✅ 推荐资源: 🧑💻 第二阶段:技术栈搭建(成为 Web3 开发者) 🧠 目标: 📚 学习内容: ✅ 推荐资源: 🌐 第三阶段:构建完整 DApp(去中心化应用)…...

AUTODL Chatglm2 langchain 部署大模型聊天助手
资源申请 注册登录 进入下面的链接 AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDLAutoDL为您提供专业的GPU租用服务,秒级计费、稳定好用,高规格机房,7x24小时服务。更有算法复现社区,一键复现算法。https://autodl.com/ho…...

牛客练习赛138
牛客练习赛138 A.小s的签到题 思路:过题人数最多的就是签到题 #include <bits/stdc.h> using namespace std; typedef long long ll; typedef pair<int, char> PII;bool cmp(PII a, PII b) {return a.first > b.first; }void solve() {int n;cin …...

【脑机接口临床】脑机接口手术的风险?脑机接口手术的应用场景?脑机接口手术如何实现偏瘫康复?
脑机接口的应用 通常对脑机接口感兴趣的两类人群,一类是适应症患者 ,另一类是科技爱好者。 1 意念控制外部设备 常见的外部设备有:外骨骼、机械手、辅助康复设备、电刺激设备、电脑光标、轮椅。 2 辅助偏瘫康复或辅助脊髓损伤患者意念控制…...
)
普通IT的股票交易成长史--股价起伏的真相-缺口(2)
声明:本文章的内容只是自己学习的总结,不构成投资建议。价格行为理论学习可参考简介中的几位,感谢他们的无私奉献。 送给自己的话: 仓位就是生命,绝对不能满仓!!!!&…...

基于NI-PXI的HIL系统开发
基于NI-PXI平台的汽车电控单元HIL系统开发全解析 引言:HIL系统如何成为汽车电控开发的“效率倍增器”? 某车企通过基于NI-PXI的HIL系统,将悬架控制器的测试周期从3个月压缩至2周,故障检出率提升65%。这背后是硬件在环技术对汽车电…...

IOC和Bean
IOC IOC将对象的创建,依赖关系的管理和生命周期的控制从应用程序代码中解耦出来了 IOC容器的依赖注入(DI) 在程序运行过程中动态的向某个对象中注入他所需要的其他对象 依赖注入是基于反射实现的 Spring IOC 容器使用的是Map(concorrentMapÿ…...

助力你的Neovim!轻松管理开发工具的魔法包管理器来了!
在现代编程环境中,Neovim 已经成为许多开发者的编辑器选择。而针对 Neovim 的各种插件与功能扩展,则是提升开发体验的重要手段。今天我们要介绍的就是一个强大而便捷的开源项目——mason.nvim,一个旨在简化和优化 Neovim 使用体验的便携式包管…...

AI与机器人学:从SLAM到导航的未来
AI与机器人学:从SLAM到导航的未来 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 AI与机器人学:从SLAM到导航的未来摘要引言技术路线对比1. 传感器融合架构:纯激光 vs 多模态2. …...

C++学习之模板初阶学习
今天我们来学习C中模板的学习。但是模板是C中比较难的部分,因此本节我们直接出相对比较初阶的部分。 目录 泛型编程 函数模板 函数模板格式 函数模板的原理 函数模板的特性 函数模板的实例化 模板参数的匹配原则 类模板 类模板定义格式 类模板实例化 泛型…...

专业级软件卸载工具:免费使用,彻底卸载无残留!
在数字生活节奏日益加快的今天,我们的电脑就像每天都在"吃进"各种软件。但您是否注意到,那些看似消失的程序其实悄悄留下了大量冗余文件?就像厨房角落里积攒的调味瓶空罐,日积月累就会让系统变得"消化不良"。…...

JSON|cJSON 介绍以及具体项目编写
一、JSON介绍 JSON(JavaScript Object Notation 即JavaScript对象表示法)是一种轻量级的数据交换格式。采用完全独立于编程语言的文本格式来存储和表示数据。 JSON是一种数据交换格式.JSON独立于编程语言(你不必学习JavaScript).JSON表达数据的方式对通…...

Cell | 大规模 单细胞图谱 揭示非小细胞肺癌抗PD-1治疗后的免疫微环境异质性
–https://doi.org/10.1016/j.cell.2025.03.018 A single-cell atlas reveals immune heterogeneity in anti-PD-1-treated non-small cell lung cancer 留意更多内容:组学之心 研究简介 背景与问题 非小细胞肺癌(NSCLC)术后复发率高。新…...

光流 | 基于深度学习的光流估计算法汇总,原理,公式,流程图,代码
基于深度学习的光流算法 一、光流估计的基本原理二、基于深度学习的光流估计算法1. **FlowNet系列**2. **FlowNet 2.0**3. **PWC-Net**4. **RAFT(Recurrent All-Pairs Field Transformers)**5. **LiteFlowNet系列**三、算法流程图示例FlowNet2.0架构PWC-Net金字塔处理流程四、…...

常见的算法介绍
算法概述线性回归(Linear Regression)线性回归是一种通过属性的线性结合来进行预测的线性模型, 其目的是找到一条直线, 一个平面或者更高维的超平面, 使预测值和真实值之间的误差最小化逻辑回归(Logistic Regression)逻辑回归是一种分类模型, 入二分类公式 P ( Y 1 ∣ X ) e …...

【基于 LangChain 的异步天气查询1】异步调用 Open-Meteo API 查询该城市当前气温
目录 一、功能概述 二、文件结构 三、城市天气实时查询(运行代码) weather_runnable.py main.py 运行结果 四、技术亮点 五、使用场景 一、功能概述 它实现了以下主要功能: 用户输入地点(城市名) 构造提示词…...

深入解析JavaScript变量作用域:var、let、const全攻略
在JavaScript中,变量作用域是一个核心概念,它决定了变量的可访问性和生命周期。理解变量作用域对于编写清晰、高效且无错误的代码至关重要。本文将深入探讨JavaScript中不同类型的变量声明方式(var、let、const等),分析…...

C33-函数嵌套及编码实战
我们以一个编程题目的实践来学习此部分内容 题目:输入四个数,以函数的方式找出最大值 思维:使用两个数找出较大值→较大值与第三个数比较得出新的较大值→新的较大值与第四个数比较得出最大值 代码 #include <stdio.h>//内层函数的封装int GetMaxFromTwoNums(int a,int…...

clangd与clang-tidy
Clangd是基于Clang的Language Server,主要用于提供代码补全、跳转定义、错误提示等IDE功能。而Clang-Tidy则是静态代码分析工具,用于检查代码中的潜在问题,比如风格违规、潜在bug等。 clangd 核心工作原理 1. 基于编译器的精准解析 底层引擎…...

【Linux】冯诺依曼体系结构和操作系统的理解
目录 冯诺依曼体系结构一个例子来深入理解 初识操作系统操作系统的作用设计操作系统的目的操作系统之上和之下分别有啥 管理的精髓,先描述,再组织 冯诺依曼体系结构 我们知道,计算机这个东西发明出来就是帮助人们快速解决问题的。那如果我们想…...

Windows系统Jenkins企业级实战
目标 在Windows操作系统上使用Jenkins完成代码的自动拉取、编译、打包、发布工作。 实施 1.安装Java开发工具包(JDK) Jenkins是基于Java的应用程序,因此需要先安装JDK。可以从Oracle官网或OpenJDK下载适合的JDK版本。推荐java17版本&#x…...

服务预热原理
Java、Spring、Springboot工程启动后,第一次访问比较慢,而从第二次访问开始就快很多,这通常是由以下几个原因导致的: 类加载与初始化开销 类加载过程:Java程序在启动时需要加载大量的类文件到内存中,包括…...

Python核心编程深度解析:作用域、递归与匿名函数的工程实践
引言 Python作为现代编程语言的代表,其作用域管理、递归算法和匿名函数机制是构建高质量代码的核心要素。本文基于Python 3.11环境,结合工业级开发实践,深入探讨变量作用域的内在逻辑、递归算法的优化策略以及匿名函数的高效应用,…...

python环境搭建和pycharm的安装配置以及使用face_recognition与cv2
一.python环境的搭建: 1.下载python(这里以python3.11为例) step 1:打开下载网址:https://www.python.org/downloads/windows/ step 2:我这里选着python3.11.9的版本 2. 安装我就不说了,网上很多 二.pycharm的安装…...

养生:为健康生活筑牢根基
养生并非遥不可及的目标,而是贯穿于日常生活的点滴之中。从饮食、运动到心态调节,每一个环节都对我们的健康有着重要意义。以下为你详细介绍养生的实用策略,助力你开启健康生活模式。 饮食养生:科学搭配,滋养生命 合…...
)
linux-----------Ext系列⽂件系统(上)
1.理解硬盘 1-1 磁盘、服务器、机柜、机房 机械磁盘是计算机中唯⼀的⼀个机械设备 磁盘--- 外设 慢 容量⼤,价格便宜 1-2 磁盘物理结构 1-3 磁盘的存储结构 扇区:是磁盘存储数据的基本单位,512字节,块设备 如何定位⼀个扇区呢…...

ts装饰器
TypeScript 装饰器是一种特殊类型的声明,能够被附加到类声明、方法、访问符、属性或参数上。它本质上是一个函数,会在运行时被调用,并且被装饰的声明信息会作为参数传递给装饰器函数。 装饰器的分类 类装饰器 类装饰器作用于类构造函数&…...

未来通信中的大型人工智能模型:基础、应用与挑战的全面综述
题目:A Comprehensive Survey of Large AI Models for Future Communications: Foundations, Applications and Challenges 作者:江沸菠,潘存华,董莉,王可之,Merouane Debbah,Dusit Niyato&…...
)
青藏高原七大河流源区径流深、蒸散发数据集(TPRED)
时间分辨率 月空间分辨率 1km - 10km共享方式 开放获取数据大小 83.27 MB数据时间范围 1998-07-01 — 2017-12-31元数据更新时间 2024-07-22 数据集摘要 通过构建耦合积雪、冻土、冰川等冰冻圈水文物理过程的WEB-DHM模型(Water and Energy Budget-based Distribute…...

5.2 参数管理
目标 访问参数,用于调试、诊断和可视化;参数初始化;在不同模型组件间共享参数。 模型:单隐藏层的MLP import torch from torch import nnnet nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1)) X torch.rand(size…...

Best Video下载器——抖音视频去水印工具
在浏览抖音时,我们常常会遇到一些精彩的短视频,想要保存下来作为创作素材或与朋友分享。然而直接下载的视频往往带有平台水印,影响观看体验。今天就为大家介绍几种简单实用的去水印方法,让你轻松获取高清无水印视频。 目前市面上…...

C语言_程序的段
在 C 语言程序中,内存通常被分为多个逻辑段,每个段存储不同类型的数据。理解这些段的结构和功能,有助于你更高效地编写、调试和优化程序。以下是 C 语言程序中主要的内存段及其特点: 1. 代码段(Text Segment) 存储内容:编译后的机器指令(程序代码)。特性: 只读:防止…...
2025大陆版安装教程)
Google Earth Pro(谷歌地球)2025大陆版安装教程
软件介绍 【名称】:Google Earth Pro(谷歌地球)2025 【大小】:63.6M 【语言】:简体中文 【安装环境】:Win/Win8/Winxp/Win10/Win11 谷歌地球(Google Earth) 是由Google公司开发的地图软件。谷歌地球采用了…...

2025年数维杯赛题C题专家 组委会C题专家疑集锦
1、段前段后距,行间距有要求嘛 C题专家:一般是单倍行距 2、请问参考文献和附录上方也要有图示页眉吗?ai使用报告放在附录里还是附录之后? C题专家:附录 3、第三问的那个三天都在一个城市可以吗?这样我们列两份城市的清明自由行,还是说…...

C.循环函数基础
循环函数基础 1. 循环函数基础1.1 循环的定义与作用1.1.1 `for` 循环语法示例1.1.2 `while` 循环语法示例1.1.3 `do-while` 循环语法示例1.1.4 循环的比较1.1.5 循环的应用场景2.1 for 循环语法结构执行流程示例应用场景优点缺点2.2 while 循环语法结构执行流程示例应用场景优点…...

spark-Join Key 的基数/rand函数
在数据处理中,Join Key 的基数 是指 Join Key 的唯一值的数量(也称为 Distinct Key Count)。它表示某个字段(即 Join Key)在数据集中有多少个不同的值。 1. Join Key 基数的意义 高基数:Join Key 的唯一值…...
)
【Oracle认证】MySQL 8.0 OCP 认证考试英文版(MySQL30 周年版)
文章目录 1、MySQL OCP考试介绍2、考试注册流程3、考试复习题库 Oracle 为庆祝 MySQL 30 周年,截止到2025.07.31 之前。所有人均可以免费考取原价245美元 (约1500)的MySQL OCP 认证。 1、MySQL OCP考试介绍 OCP考试 OCP认证是Oracle公司推…...

不同环境下运行脚本如何解决pythonpath问题
目录 问题背景: 方法一:在 Dockerfile 中设置 PYTHONPATH: 方法二: 本地脚本内动态地设置 sys.path,以确保 Python 程序在运行时能够找到项目中的模块 注意: 问题背景: 脚本在windows环境定义 然后因为…...

照片to谷歌地球/奥维地图使用指南
软件介绍 照片to谷歌地球/奥维地图是一款由WTSolutions开发的跨平台图片处理工具,能够将带有GPS信息的照片导入Google Earth(谷歌地球)或奥维地图。该软件支持Windows、Mac、iOS、Linux和Android系统,无需下载安装,直…...

visual studio 2015 安装闪退问题
参考链接: VS2012安装时启动界面一闪而过问题解决办法 visual studio 2015 安装闪退问题...

Kubernetes 使用 containerd 实现 GPU 支持及 GPU Operator 部署指南
目录 Kubernetes 使用 containerd 实现 GPU 支持及 GPU Operator 部署指南 一、为什么 containerd 是趋势? 二、目标 三、前提条件 四、方式一:containerd nvidia-container-toolkit(基础方式) 1️⃣ 安装 NVIDIA Containe…...