[特征工程]机器学习-part2
1 特征工程概念
特征工程:就是对特征进行相关的处理
一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程
特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
特征工程步骤为:
-
特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
-
无量纲化(预处理)
-
归一化
-
标准化
-
-
降维
-
底方差过滤特征选择
-
主成分分析-PCA降维
-
2 特征工程API
-
实例化转换器对象,转换器类有很多,都是Transformer的子类, 常用的子类有:
DictVectorizer 字典特征提取 CountVectorizer 文本特征提取 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 MinMaxScaler 归一化 StandardScaler 标准化 VarianceThreshold 底方差过滤降维 PCA 主成分分析降维
-
转换器对象调用fit_transform()进行转换, 其中fit用于计算数据,transform进行最终转换
fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data) 可写成 transfer.fit(data) data_new = transfer.transform(data)
3 DictVectorizer 字典列表特征提取
稀疏矩阵
稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。在数学和计算机科学中,当一个矩阵的非零元素数量远小于总的元素数量,且非零元素分布没有明显的规律时,这样的矩阵就被认为是稀疏矩阵。例如,在一个1000 x 1000的矩阵中,如果只有1000个非零元素,那么这个矩阵就是稀疏的。
由于稀疏矩阵中零元素非常多,存储和处理稀疏矩阵时,通常会采用特殊的存储格式,以节省内存空间并提高计算效率。
三元组表 (Coordinate List, COO):三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0
from sklearn.feature_extraction import DictVectorizerdata = [{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]
# 创建一个字典列表特征提取工具
tool = DictVectorizer(sparse=False)
# 字典列表特征提取
data = tool.fit_transform(data)
print(data)
print(tool.feature_names_)
非稀疏矩阵(稠密矩阵)
非稀疏矩阵,或称稠密矩阵,是指矩阵中非零元素的数量与总元素数量相比接近或相等,也就是说矩阵中的大部分元素都是非零的。在这种情况下,矩阵的存储通常采用标准的二维数组形式,因为非零元素密集分布,不需要特殊的压缩或优化存储策略。
-
存储:稀疏矩阵使用特定的存储格式来节省空间,而稠密矩阵使用常规的数组存储所有元素,无论其是否为零。
-
计算:稀疏矩阵在进行计算时可以利用零元素的特性跳过不必要的计算,从而提高效率。而稠密矩阵在计算时需要处理所有元素,包括零元素。
-
应用领域:稀疏矩阵常见于大规模数据分析、图形学、自然语言处理、机器学习等领域,而稠密矩阵在数学计算、线性代数等通用计算领域更为常见。
在实际应用中,选择使用稀疏矩阵还是稠密矩阵取决于具体的问题场景和数据特性。
(1) api
-
创建转换器对象:
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
转换器对象get_feature_names_out()方法获取特征名
(2)示例1 提取为稀疏矩阵对应的数组
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
#创建DictVectorizer对象
transfer = DictVectorizer(sparse=False)
data_new = transfer.fit_transform(data)
# data_new的类型为ndarray
#特征数据
print("data_new:\n", data_new)
#特征名字
print("特征名字:\n", transfer.get_feature_names_out())
data_new:[[ 30. 0. 1. 0. 200.][ 33. 0. 0. 1. 60.][ 42. 1. 0. 0. 80.]] 特征名字:['age' 'city=北京' 'city=成都' 'city=重庆' 'temperature']
import pandas pandas.DataFrame(data_new, columns=transfer.get_feature_names_out())
(3)示例2 提取为稀疏矩阵
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
#创建DictVectorizer对象
transfer = DictVectorizer(sparse=True)
data_new = transfer.fit_transform(data)
#data_new的类型为<class 'scipy.sparse._csr.csr_matrix'>
print("data_new:\n", data_new)
#得到特征
print("特征名字:\n", transfer.get_feature_names_out())
其中(row,col)数据中的col表示特征, 本示例中0表示 ‘age’, 1表示‘city=北京’,……
data_new:(0, 0) 30.0(0, 2) 1.0(0, 4) 200.0(1, 0) 33.0(1, 3) 1.0(1, 4) 60.0(2, 0) 42.0(2, 1) 1.0(2, 4) 80.0 特征名字:['age' 'city=北京' 'city=成都' 'city=重庆' 'temperature']
(4)稀疏矩阵转为数组
稀疏矩阵对象调用toarray()函数, 得到类型为ndarray的二维稀疏矩阵
4 CountVectorizer 文本特征提取
(1)API
sklearn.feature_extraction.text.CountVectorizer
构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)
fit_transform函数的返回值为稀疏矩阵
(2) 英文文本提取
from sklearn.feature_extraction.text import CountVectorizer import pandas as pd data=["stu is well, stu is great", "You like stu"] #创建转换器对象, you和is不提取 transfer = CountVectorizer(stop_words=["you","is"]) #进行提取,得到稀疏矩阵 data_new = transfer.fit_transform(data) print(data_new) import pandas pandas.DataFrame(data_new.toarray(), index=["第一个句子","第二个句子"],columns=transfer.get_feature_names_out())
(3) 中文文本提取
a.中文文本不像英文文本,中文文本文字之间没有空格,所以要先分词,一般使用jieba分词.
b.下载jieba组件, (不要使用conda)
c.jieba的基础
import jieba data = "在如今的互联网世界,正能量正成为澎湃时代的大流量" data = jieba.cut(data) data = list(data) print(data) #['在', '如今', '的', '互联网', '世界', ',', '正', '能量', '正', '成为', '澎湃', '时代', '的', '大', '流量'] data = " ".join(data) print(data) #"在 如今 的 互联网 世界 , 正 能量 正 成为 澎湃 时代 的 大 流量"
使用jieba封装一个函数,功能是把汉语字符串中进行分词(会忽略长度小于等于1的词语,因为它们往往缺乏语义信息,不能很好地表达文本的特征)
import jieba
from sklearn.feature_extraction.text import CountVectorizer
data = ['陶吉吉唱了二十二', '周杰伦唱了园游会', '王力宏唱了爱错']
def fenci(str):return " ".join(list(jieba.cut(str)))
data = [fenci(str) for str in data]
print(data)
cv = CountVectorizer(stop_words=["唱了"])
data = cv.fit_transform(data)
print(data.toarray())
print(cv.get_feature_names_out())5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
(1) 算法
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度

(2) API
sklearn.feature_extraction.text.TfidfVectorizer()
构造函数关键字参数stop_words,表示词特征黑名单
fit_transform函数的返回值为稀疏矩阵
(3) 示例
代码与CountVectorizer的示例基本相同,仅仅把CountVectorizer改为TfidfVectorizer即可
示例中data是一个字符串list, list中的第一个元素就代表一篇文章.
补充:在sklearn库中 TF-IDF算法做了一些细节的优化
词频 (TF)
词频是指一个词在文档中出现的频率。通常有两种计算方法:
-
原始词频:一个词在文档中出现的次数除以文档中总的词数。
-
平滑后的词频:为了防止高频词主导向量空间,有时会对词频进行平滑处理,例如使用
1 + log(TF)。 -
在 TfidfVectorizer 中,TF 默认是:直接使用一个词在文档中出现的次数也就是CountVectorizer的结果
逆文档频率 (IDF)
逆文档频率衡量一个词的普遍重要性。如果一个词在许多文档中都出现,那么它的重要性就会降低。
IDF 的计算公式是:
IDF(t)=\log(\dfrac{总文档数}{包含词t的文档数+1})
在 TfidfVectorizer 中,IDF 的默认计算公式是:
IDF(t)=\log(\dfrac{总文档数+1}{包含词t的文档数+1})+1
在 TfidfVectorizer 中还会进行归一化处理(采用的L2归一化)
L2归一化
x_1归一化后的数据=\dfrac{x_1}{\sqrt{x_1^2+x_2^2+...x_n^2}}
x可以选择是行或者列的数据
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.preprocessing import normalize
from sklearn.preprocessing import StandardScaler
import jieba
import pandas as pd
import numpy as np
def my_cut(text):return " ".join(jieba.cut(text))
data=["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data=[my_cut(i) for i in data]
print(data)
# print("词频",CountVectorizer().fit_transform(data).toarray())
transfer=TfidfVectorizer()
res=transfer.fit_transform(data)
print(pd.DataFrame(res.toarray(),columns=transfer.get_feature_names_out()))
# 手动实现tfidf向量(跟上面的api实现出一样的效果)
def tfidf(data):# 计算词频count = CountVectorizer().fit_transform(data).toarray()print("count",count)print(np.sum(count != 0, axis=0))# 计算IDF,并采用平滑处理idf = np.log((len(data) + 1) / (1 + np.sum(count != 0, axis=0))) + 1# 计算TF-IDFtf_idf = count * idf# L2标准化tf_idf_normalized = normalize(tf_idf, norm='l2', axis=1)#axis=0是列 axis=1是行return tf_idf,tf_idf_normalized
tf_idf,tf_idf_normalized=tfidf(data)
print(pd.DataFrame(tf_idf,columns=transfer.get_feature_names_out()))
print(pd.DataFrame(tf_idf_normalized,columns=transfer.get_feature_names_out()))
6 无量纲化-预处理
无量纲,即没有单位的数据
无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
这是一个男士的数据表:
| 编号id | 身高 h | 收入 s | 体重 w |
|---|---|---|---|
| 1 | 1.75(米) | 15000(元) | 120(斤) |
| 2 | 1.5(米) | 16000(元) | 140(斤) |
| 3 | 1.6(米) | 20000(元) | 100(斤) |
假设算法中需要求它们之间的欧式距离, 这里以编号1和编号2为示例:
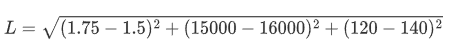
从计算上来看, 发现身高对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
(1) MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
<1>归一化公式:
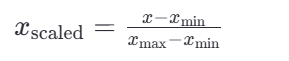
这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
比如 [-1, 1]的公式为:
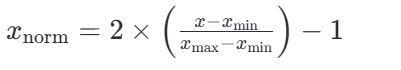
<2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range=(0,1) 归一化后的值域,可以自己设定
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
<3>归一化示例
示例1:原始数据类型为list
from sklearn.preprocessing import MinMaxScaler
tool = MinMaxScaler(feature_range=(0,1))
x = [[100,2],[800,3],[300,7],[230,4]]
x =tool.fit_transform(x)
print(x)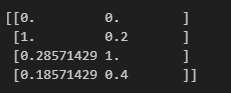
示例2:原始数据类型为DataFrame
from sklearn.preprocessing import MinMaxScaler import pandas as pd; data=[[12,22,4],[22,23,1],[11,23,9]] data = pd.DataFrame(data=data, index=["一","二","三"], columns=["一列","二列","三列"]) transfer = MinMaxScaler(feature_range=(0, 1)) data_new = transfer.fit_transform(data) print(data_new)
示例3:原始数据类型为 ndarray
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import MinMaxScaler
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=False)
data = transfer.fit_transform(data) #data类型为ndarray
print(data)
transfer = MinMaxScaler(feature_range=(0, 1))
data = transfer.fit_transform(data)
print(data)
<4>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
(2)normalize归一化
API
from sklearn.preprocessing import normalize normalize(data, norm='l2', axis=1) #data是要归一化的数据 #norm是使用那种归一化:"l1" "l2" "max #axis=0是列 axis=1是行
<1> L1归一化
绝对值相加作为分母,特征值作为分子
<2> L2归一化
平方相加作为分母,特征值作为分子
<3> max归一化
max作为分母,特征值作为分子
from sklearn.preprocessing import normalize
x = [[100,2],[800,3],[300,7],[230,4]]
x = normalize(x,norm='max',axis=0)
print(x)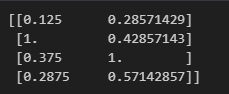
(3)StandardScaler 标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
<1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:
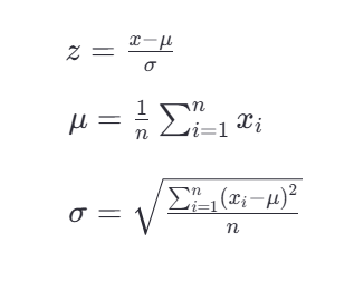
其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的 标准差
<2> 标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
from sklearn.preprocessing import StandardScaler #不能加参数feature_range=(0, 1) transfer = StandardScaler() data_new = transfer.fit_transform(data) #data_new的类型为ndarray
<3>标准化示例
from sklearn.preprocessing import StandardScaler
x = [[100,2],[800,3],[300,7],[230,4]]
tool = StandardScaler()
x = tool.fit_transform(x)
print(x)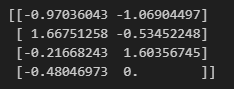
<4> 注意点
在数据预处理中,特别是使用如StandardScaler这样的数据转换器时,fit、fit_transform和transform这三个方法的使用是至关重要的,它们各自有不同的作用:
fit:
这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。这些统计信息随后会被用于数据的标准化。你应当仅在训练集上使用
fit方法。fit_transform:
这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
transform:
这个方法使用已经通过
fit方法计算出的统计信息来转换数据。它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
当你在预处理数据时,首先需要在训练集X_train上使用fit_transform,这样做可以一次性完成统计信息的计算和数据的标准化。这是因为我们需要确保模型是基于训练数据的统计信息进行学习的,而不是整个数据集的统计信息。
一旦scaler对象在X_train上被fit,它就已经知道了如何将数据标准化。这时,对于测试集X_test,我们只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对X_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
总结来说:我们常常是先fit_transform(x_train)然后再transform(x_text)
7 特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
1 .特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
-
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
-
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
-
过滤特征:移除所有方差低于设定阈值的特征
-
-
# 特征降维
from sklearn.feature_selection import VarianceThreshold
tool = VarianceThreshold(threshold=1.5)
x = [[10, 2],[11,6],[10,8],[10,10],[10,19]]
x = tool.fit_transform(x)
print(x)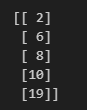
(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
-
如果第一个变量增加,第二个变量也有很大的概率会增加。
-
同样,如果第一个变量减少,第二个变量也很可能会减少。
正相关性并不意味着一个变量的变化直接引起了另一个变量的变化,它仅仅指出了两个变量之间存在的一种统计上的关联性。这种关联性可以是因果关系,也可以是由第三个未观察到的变量引起的,或者是纯属巧合。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
举个例子,假设我们观察到在一定范围内,一个人的身高与其体重呈正相关,这意味着在一般情况下,身高较高的人体重也会较重。但这并不意味着身高直接导致体重增加,而是可能由于营养、遗传、生活方式等因素共同作用的结果。
负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关
不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系. 比如饭量和智商
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 [−1,1],其中:
-
\rho=1 表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
-
\rho=-1 表示完全负相关,即随着一个变量的增加,另一个变量线性减少。
-
\rho=0 表示两个变量之间不存在线性关系。
相关系数\rho的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是
在同一条直线上,当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关
<2>皮尔逊相关系数:pearsonr相关系数计算公式, 该公式出自于概率论
对于两组数据 𝑋={𝑥1,𝑥2,...,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,...,𝑦𝑛},皮尔逊相关系数可以用以下公式计算:
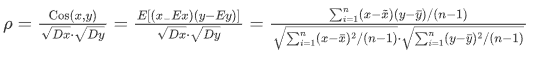
\bar{x}和 \bar{y} 分别是𝑋和𝑌的平均值
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
<3>api:
scipy.stats.personr(x, y) 计算两特征之间的相关性
返回对象有两个属性:
statistic皮尔逊相关系数[-1,1]
pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
<4>示例:
# 皮尔逊相关系数
from scipy.stats import pearsonr
x = [10,20,30,40,50]
x2 =[10,20,1,40,77]
y = [1,2,3,4,5]
res = pearsonr(x2,y)
print(res.statistic) # 相关系数
print(res.pvalue) # p值 越小越好开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分样过程中就包括了求相关系数了。
2.主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
(a) 原理
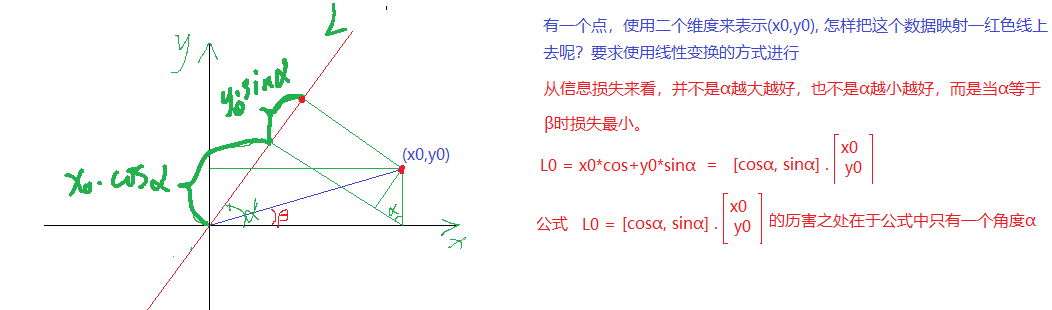
x_0投影到L的大小为x_0*cos \alpha
y_0投影到L的大小为y_0*sin\alpha
使用(x_0,y_0)表示一个点, 表明该点有两个特征, 而映射到L上有一个特征就可以表示这个点了。这就达到了降维的功能 。
投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/原始信息=信息保留的比例
下图中红线上点与点的距离是最大的,所以在红色线上点的方差最大,粉红线上的刚好相反.
所以红色线上点来表示之前点的信息损失是最小的。
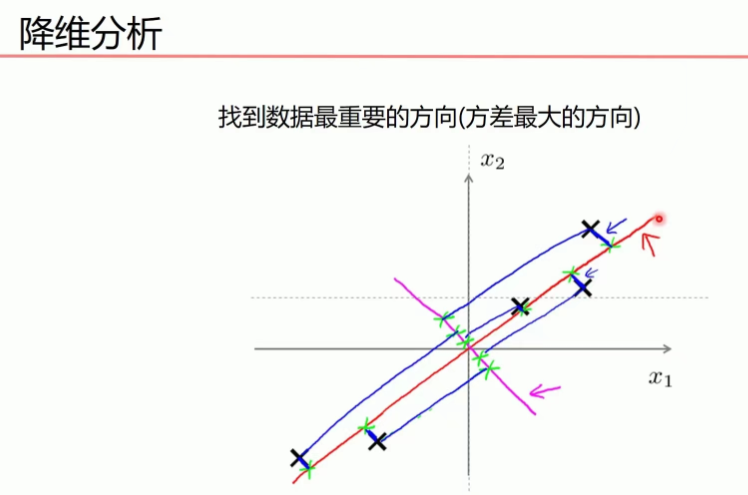
(b) 步骤
-
得到矩阵
-
用矩阵P对原始数据进行线性变换,得到新的数据矩阵Z,每一列就是一个主成分, 如下图就是把10维降成了2维,得到了两个主成分
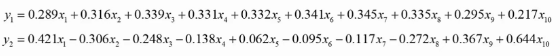
-
根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下。一个特征的多个样本的值如果都相同,则方差为0, 则说明该特征值不能区别样本,所以该特征没有用。
比如下图的二维数据要降为一维数据,图形法是把所在数据在二维坐标中以点的形式标出,然后给出一条直线,让所有点垂直映射到直线上,该直线有很多,只有点到线的距离之和最小的线才能让之前信息损失最小。
这样之前所有的二维表示的点就全部变成一条直线上的点,从二维降成了一维。
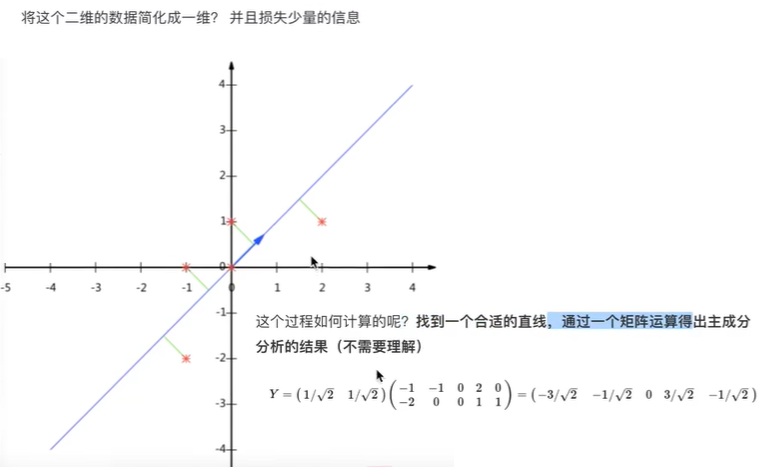
上图是一个从二维降到一维的示例:的原始数据为
| 特征1-X1 | 特征2-X2 |
|---|---|
| -1 | -2 |
| -1 | 0 |
| 0 | 0 |
| 2 | 1 |
| 0 | 1 |
降维后新的数据为
| 特征3-X0 |
|---|
| -3/√2 |
| -1/√2 |
| 0 |
| 3/√2 |
| -1/√2 |
3.api
-
from sklearn.decomposition import PCA
-
PCA(n_components=None)
-
主成分分析
-
n_components:
-
实参为小数时:表示降维后保留百分之多少的信息
-
实参为整数时:表示减少到多少特征
-
-
from sklearn.decomposition import PCA
data = [[2,18,4,5],[6,32,10,8],[5,43,93,1]]
# 信息保留50% 但是不确定会保留几个
pca = PCA(n_components=0.5)
data = pca.fit_transform(data)
print(data)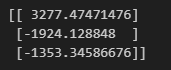
#鸢尾花 特征降维
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
x,y = load_iris(return_X_y=True)
pca = PCA(n_components=2)
# pca.fit(x)
# x_pca = pca.transform(x)
x = pca.fit_transform(x)
print(x.shape)
print(x)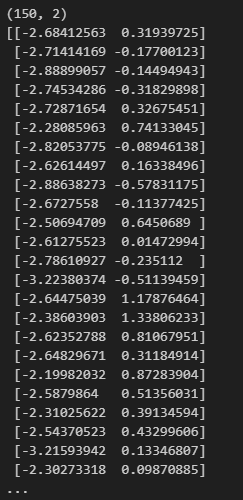
相关文章:

[特征工程]机器学习-part2
1 特征工程概念 特征工程:就是对特征进行相关的处理 一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程 特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。 特征工程步骤…...

布隆过滤器:高效的数据结构与应用详解
引言 在处理大规模数据时,如何高效地判断某个元素是否存在于集合中是一个常见问题。传统的数据结构(如哈希表)虽然可以解决这一问题,但在存储空间和查询效率上可能存在瓶颈。布隆过滤器(Bloom Filter)作为…...

【免杀】C2免杀 | 概念篇
一、什么是 C2 ? Command and Control(命令与控制)的缩写,是指攻击者用来远程控制被入侵设备(如计算机、服务器等)的通信架构。C2 攻击 是指攻击者在目标系统中植入远程控制恶意软件(如木马、僵尸网络、后…...

期刊论文写作注意点
下面给出关于期刊写作的几个关键注意点 一、摘要突出创新点 最重要的是论文的摘要,因为在论文送审的时候,编辑如果没有时间,最先看的就是摘要。摘要要写好。如果投的是顶刊,在摘要里面尽量不要写是在什么方法的基础上进行改进之类…...

范式之殇-关系代数与参照完整性在 Web 后台的落寞
最近参加了一个PostgreSQL相关的茶会,感慨良多。原本话题是PostgreSQL 在 SELECT 场景中凭借其成熟的查询优化器、丰富的功能特性和灵活的执行策略,展现出显著优势。在窗口函数(Window Functions)、JOIN 优化、公共表表达式&#…...

CST矩形喇叭建模
本文介绍了在电磁仿真软件中创建喇叭天线模型的基本步骤。 点击工具栏的Basic Shapes > Brick创建两个长方体(波导部分和喇叭横截面) 点击相对的两个平面,选择Loft命令进行渐变连接 将三者boolen合并 挖去中间实体,先后选…...

Python MNE-Python 脑功能磁共振数据分析
一、什么是Python MNE-Python 脑功能磁共振数据分析 为大脑功能磁共振成像数据分析工具,致力于为神经科学研究提供便捷、高效的数据分析处理工具。MNE-Python提供了处理和分析脑电图(EEG)、…...
)
JVM之内存管理(一)
部分内容来源:JavaGuide二哥Java 图解JVM内存结构 内存管理快速复习 栈帧:局部变量表,动态链接(符号引用转为真实引用),操作数栈(存储中间结算结果),方法返回地址 运行时…...

【AI入门】CherryStudio入门7:引入魔搭中的MCP服务
前言 来吧,继续CherryStudio的实践,前边给Cherry Studio添加知识库,对接思源笔记,以及obsidian笔记,设置了mcp-auto-install 自动安装包服务,本节让我们把魔搭中的MCP服务同步过来😄Ƕ…...

高性能Python Web 框架--FastAPI 学习「基础 → 进阶 → 生产级」
以下是针对 FastAPI 的保姆级教程,包含核心概念、完整案例和关键注意事项,采用「基础 → 进阶 → 生产级」的三阶段教学法: 一、FastAPI介绍 FastAPI 是一个现代化的、高性能的 Python Web 框架,专门用于构建 APIs(应…...

python小区物业管理系统-小区物业报修系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...
)
YOLO数据集标注工具LabelImg(打包Exe版本及使用)
前言: 在计算机视觉领域,YOLO(You Only Look Once)系列算法因其出色的实时目标检测性能而广受欢迎。然而,要训练一个精准的YOLO模型,高质量的数据标注(labling)是不可或缺的基础工作。 LabelImage 是一个开源的图像标注工具&…...
)
【NCCL】DBT算法(double binary tree,双二叉树)
目录 前言 ring 不足,需要 tree 朴素二叉tree只利用了一半带宽,需要 双二叉 tree 双二叉树的构造 ringvs 双二叉树 测试 ring和tree的选择 nccl tree tree搜索 基本概念解释 最大化局部性构建二叉树的方式 这种构建方式的好处 示例说明 前言…...

Java大师成长计划之第16天:高级并发工具类
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在现代Java应用中,处理并…...

【C/C++】C语⾔内存函数
C语言内存函数 1. memcpy使用和模拟实现 memcpy可以代替strcpy void * memcpy ( void * destination, const void * source, size_t num );//void*来接受任意指针,size_t 单位是字节 //memcpy的头文件为<string.h> mem是memory的缩写 是内存的意思功能: …...

SQL JOIN 关联条件和 where 条件的异同
Inner join 对于 inner join,条件写到 on 和 where 部分是一样的。 select count(1) from web_site join web_page on web_site_skwp_web_page_id where web_cityPleasant Hill and wp_access_date_sk1;输出 0select count(1)from web_site join web_page on web…...

kotlin 数据类
一 kotlin数据类与java普通类区别 Kotlin 的 data class 与 Java 中的普通类(POJO)相比,确实大大减少了样板代码(boilerplate),但它的优势不止于自动生成 getter/setter、copy()、equals()、toString()&am…...

云效 MCP Server:AI 驱动的研发协作新范式
作者:黄博文、李晔彬 云效 MCP Server 是什么? 云效 MCP(Model Context Protocol)是阿里云云效平台推出的模型上下文协议标准化接口系统,作为连接 AI 助手与 DevOps 平台的核心桥梁,通过模型上下文协议将…...

复合机器人案例启示:富唯智能如何以模块化创新引领工业自动化新标杆
在国产工业机器人加速突围的浪潮中,富唯智能复合机器人案例凭借其高精度焊接与智能控制技术,成为行业标杆。然而,随着制造业对柔性化、全场景协作需求的升级,复合机器人正从单一功能向多模态协同进化。作为这一领域的创新者&#…...
2025最新(十三)(1))
信息系统项目管理师-软考高级(软考高项)2025最新(十三)(1)
个人笔记整理---仅供参考 信息系统项目理师-软考高级(软考高项)2025最新(十三)(1)第十三章项目资源管理 13.0资源管理概述 13.1管理基础 团队发展阶段背下来 13.2项目资源管理过程 13.3规划资源管...

archlinux 详解系统层面
Arch Linux 深度解析:从设计哲学到系统架构 一、Arch Linux 概述:滚动发行的极客之选 Arch Linux 是一款以 滚动更新(Rolling Release) 为核心特性的 Linux 发行版,强调 轻量、灵活、高度可定制,旨在让用…...

⭐️⭐️⭐️【课时1:大模型是什么?】学习总结 ⭐️⭐️⭐️ for《大模型Clouder认证:基于百炼平台构建智能体应用》认证
一、学习目标 概要 通过学习《课时1:大模型是什么?》,全面了解大模型的基础概念、核心特点、发展脉络及阿里云在大模型领域的布局,为后续基于百炼平台构建智能体应用的实践操作打下坚实的理论基础。 具体目标列表 理解人工智能到大模型的演变逻辑,明确大模型在AI发展历…...

qxl显卡与spice模块笔记
1、qxl虚拟显卡设备创建QemuConsole,并保存在全局变量consoles链表中。 static void qxl_realize_primary(PCIDevice *dev, Error **errp) {PCIQXLDevice *qxl PCI_QXL(dev);VGACommonState *vga &qxl->vga;Error *local_err NULL;qxl_init_ramsize(qxl)…...

Rust 官方文档:人话版翻译指南
鉴于大部分翻译文档都不太会说人话,本专栏主要内容为 rust 程序设计语言、rust 参考手册、std 库 等官方文档的中译中。...

切比雪夫不等式专题习题解析
切比雪夫不等式专题习题解析 前言 本文为概率论习题集专栏的切比雪夫不等式专题习题解析,针对习题篇中的10道题目提供详细解答。希望通过这些解析帮助大家深入理解切比雪夫不等式的应用和意义。 一、基础概念题解析 习题1解析: 错误。切比雪夫不等式适用于任何具有有限方…...

LearnOpenGL01:创建项目
基于LearnOpenGL 相关链接: 工程搭建 hello window 环境 UBUNTU GLFW3.3:负责创建窗口处理输入 GLAD:根据不同操作系统加载不同的OPENGL函数实现 安装GLFW以及编译项 sudo apt update sudo apt install cmake build-essential libglfw3-…...

基于论文《大规模电动汽车充换电设施可调能力聚合评估与预测》开发者说明文档
real_data_model.m 开发者说明文档 脚本概述 本MATLAB脚本实现了基于论文《大规模电动汽车充换电设施可调能力聚合评估与预测》(鲍志远,胡泽春)中提出的预测模型和评估方法。脚本使用真实的充电数据、天气数据和分时电价数据,实现了LSTM与线性模型混合…...

优雅草星云智控系统产品发布会前瞻:SNMP协议全设备开启指南-优雅草卓伊凡
优雅草星云智控系统产品发布会前瞻:SNMP协议全设备开启指南-优雅草卓伊凡 一、发布会重磅预告 1.1 星云智控系统发布会详情 优雅草科技将于2024年5月15日在成都市双流区天府国际生物城会议中心举办”星云智控系统产品发布会“。作为优雅草科技CTO,卓伊…...

【Python】Pycharm中安装库可靠的方法
博主需要在pycharm中安装Python需要的库,发现可以通过两个方法,一个是在terminal中安装,如下图: 另一个,是通过软件包安装。 博主发现,保险起见,还是通过软件包安装会比较稳妥。博主遇见一个库&…...

探索Stream流:高效数据处理的秘密武器
不可变集合 stream流 Stream流的使用步骤: 先得到一条Stream流(流水线),并把数据放上去 使用中间方法对流水线上的数据进行操作 使用终结方法对流水线上的数据进行操作 Stream流的中间方法 注意1:中间方法࿰…...

Debezium RelationalSnapshotChangeEventSource详解
Debezium RelationalSnapshotChangeEventSource详解 1. 类的作用与功能 1.1 核心功能 RelationalSnapshotChangeEventSource是Debezium中用于关系型数据库快照的核心抽象类,主要负责: 数据快照:对数据库表进行全量数据快照模式捕获:捕获数据库表结构事务管理:确保快照过…...

Open CASCADE学习|实现裁剪操作
1. 引言 Open CASCADE (简称OCC) 是一个功能强大的开源几何建模内核,广泛应用于CAD/CAM/CAE领域。裁剪操作作为几何建模中的基础功能,在模型编辑、布尔运算、几何分析等方面有着重要作用。本文将全面探讨Open CASCADE中的裁剪操作实现原理、应用场景及具…...

Microsoft Azure DevOps针对Angular项目创建build版本的yaml
Azure DevOps针对Angular项目创建build版本的yaml,并通过变量控制相应job的执行与否。 注意事项:代码前面的空格是通过Tab控制的而不是通过Space控制的。 yaml文件中包含一下内容: 1. 自动触发build 通过指定code branch使提交到此代码库的…...
)
Navicat 17最新保姆级安装教程(附安装包+永久使用方法)
前言 Navicat Premium 是一套可创建多个连接的数据库开发工具,让你从单一应用程序中同时连接 MySQL、MariaDB、MongoDB、SQL Server、Oracle、PostgreSQL 和 SQLite 。它与 OceanBase 数据库及 Amazon RDS、Amazon Aurora、Amazon Redshift、Microsoft Azure、Orac…...

在 Kotlin 中什么是委托属性,简要说说其使用场景和原理
在 Kotlin 中,属性委托和类委托是两种通过 by 关键字实现的强大特性,它们通过“委托”机制将行为或实现逻辑委托给其他对象,从而实现代码的复用和解耦。 1 属性委托 定义: 允许把属性的 get 和 set 方法的具体实现委托给另一个对…...
)
[Windows] 东芝存储诊断工具1.30.8920(20170601)
[Windows] 东芝存储诊断工具 链接:https://pan.xunlei.com/s/VOPpMjGdWZOLceIjxLNiIsIEA1?pwduute# 适用型号 东芝消费类存储产品: 外置硬盘:Canvio 系列 内置硬盘:HDW****(E300 / N300 / P300 / S300 / V300 / X30…...

按位段拼接十六进制
需求: 给一组位段及对应的值,拼接出该十六进制值。 如, [15] : 0x1 [31:16] : 0xfafa [14:1] : 0x1af0 [0:0] : 0x1 def parse_range(range_str):"""解析位段字符串,返回高位和低位"""parts…...
)
FPGA 41 ,ICMP 协议详细解析之构建网络诊断系统( ICMP 协议与 IP 协议理论详细解析 )
目录 前言 一、ICMP协议介绍 1.1 ICMP协议介绍 1.2 ICMP报文格式 1.3 ICMP地位流程 1.4 为何需要ICMP差错报文 1.5 协议关系 二、FPGA 与 ICMP 2.1 平台选择与环境搭建 2.2 模块化设计 2.3 ICMP 功能设计 (1)ICMP 报文解析 (2&am…...

每天批次导入 100 万对账数据到 MySQL 时出现死锁
一、死锁原因及优化策略 1.1 死锁原因分析 批量插入事务过大: Spring Batch 默认将整个 chunk(批量数据块)作为一个事务提交,100 万数据可能导致事务过长,增加锁竞争。 并发写入冲突: 多个线程或批处理作…...

滑动窗口-窗口中的最大/小值-单调队列
求窗口的最大值 #include <iostream> //滑动窗口最大值用单调队列q[],q存储候选最大值的下标 //队列头是最大值的下标 using namespace std; const int N100010; int nums[N],q[N]; int hh0,tt-1;// hh 是队头指针,tt 是队尾指针,初始…...

Docker Compose 部署 MeiliSearch 指南
Docker Compose 部署 MeiliSearch 指南 目录 环境准备创建 MeiliSearch 配置文件启动 MeiliSearch 服务验证服务状态访问 MeiliSearch安全及防火墙设置...

在 MyBatis 中实现控制台输出 SQL 参数
在 MyBatis 中实现控制台输出 SQL 参数,可通过以下方案实现: # 一、使用 MyBatis-Plus 的 SqlLogInterceptor(推荐) 适用场景:项目已集成 MyBatis-Plus(3.5.3版本) 配置步骤ÿ…...

【MySQL】数据库、数据表的基本操作
个人主页:Guiat 归属专栏:MySQL 文章目录 1. MySQL基础命令1.1 连接MySQL1.2 基本命令概览 2. 数据库操作2.1 创建数据库2.2 查看数据库2.3 选择数据库2.4 修改数据库2.5 删除数据库2.6 数据库备份与恢复 3. 表操作基础3.1 创建表3.2 查看表信息3.3 创建…...

Java中的内部类详解
目录 什么是内部类? 生活中的内部类例子 为什么需要内部类? 生活中的例子 内部类的存在意义 内部类的分类 1. 成员内部类 什么是成员内部类? 成员内部类的特点 如何使用成员内部类? 成员内部类访问外部类同名成员 2. …...

【LangChain全栈开发指南】从LLM集成到智能体系统构建
目录 🌟 前言🏗️ 技术背景与价值💢 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🔍 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🧩 关键技术模块说明⚖️ 技术选…...

《内存单位:解锁数字世界的“度量衡”》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、基础单位:字节(Byte)二、进阶单位:千字节(KB)、兆字节(MB)…...

Spring Boot + MyBatis-Plus 高并发读写分离实战
引言 在高并发场景下,单一数据库实例往往成为性能瓶颈。数据库读写分离通过将读操作和写操作分配到不同的数据库实例,有效缓解主库压力,提升系统吞吐量。MyBatis-Plus 作为一款强大的持久层框架,结合 Spring Boot 能够轻松实现读…...

STC32G12K128-旋转编码器-软件去抖
STC32G12K128-旋转编码器-软件去抖 简介代码 简介 EC11旋转编码器是一种可以连续旋转的器件A,B,C为旋转编码引脚,带按键的有D,E引脚。引脚功能: A:编码器A相;B:编码器B相;C:公共端-一般接到GN…...

第J7周:对于ResNeXt-50算法的思考
目录 思考 一、代码功能分析 1. 构建 shortcut 分支(残差连接的旁路) 2. 主路径的第一层卷积(11) 4. 主路径的第三层卷积(11) 5. 残差连接 激活函数 二、问题分析总结:残差结构中通道数不一致的…...

古方焕新潮!李良济盒马联名养生水,以创新赋能中式养生新潮流
今天下午,中华老字号李良济与新零售巨头盒马联名的“五汁饮&暑清元气水”新品发布会,在李良济隆重举行。 新品发布会上,盒马与多家媒体齐聚李良济,通过中医文化体验、新品品鉴、生产全链路探秘、媒体采访等环节,不…...