为特定领域微调嵌入模型:打造专属的自然语言处理利器
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
想象一下,你在开发一个医学领域的问答系统。你希望它能够准确地检索出与用户问题相关的医学文章。但通用的嵌入模型可能会在处理高度专业化的医学术语及其细微差别时感到吃力。
这就是微调派上用场的时候啦!
在本文中,我们将深入探讨如何为特定领域(如医学、法律或金融)微调嵌入模型。我们将为你的领域生成一个专门的数据集,并用它来训练模型,使其更好地理解你所选择领域的语言模式和概念。
到文章结束时,你将拥有一个针对你的领域优化的更强大的嵌入模型,从而在你的自然语言处理任务中实现更准确的检索和更好的结果。
嵌入:理解概念
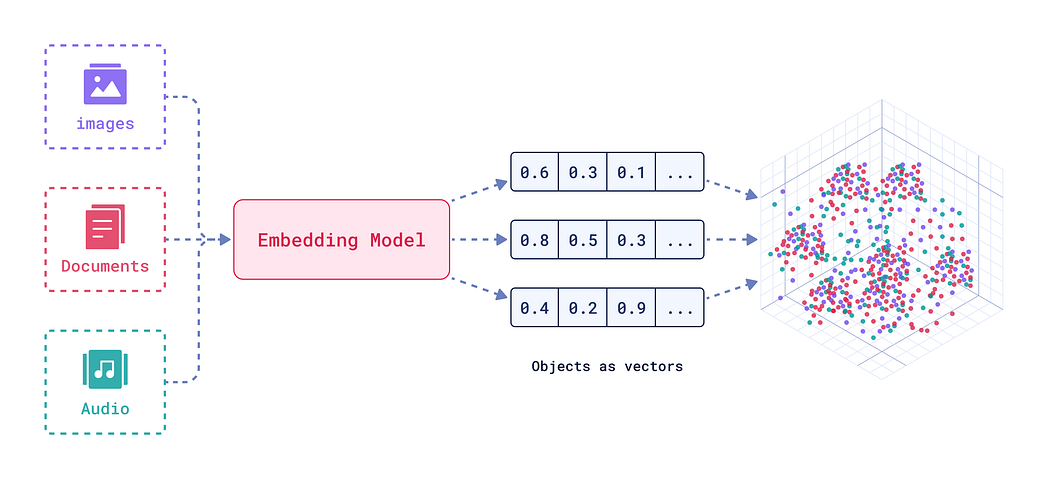
嵌入是强大的数值文本或图像表示,能够捕捉语义关系。想象一下,将文本或音频视为多维空间中的一个点,相似的单词或短语会比不相似的更接近。
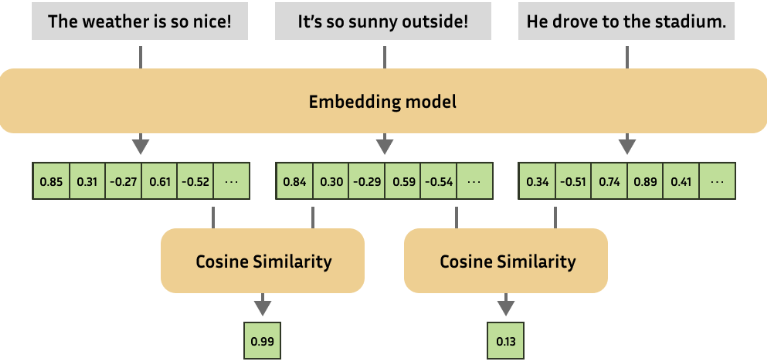
嵌入在许多自然语言处理任务中都非常重要,例如:
语义相似性:判断两段文本或图像的相似程度。
文本分类:根据文本的含义将其归类。
问答:找到最相关的文档来回答问题。
检索增强生成(RAG):结合嵌入模型用于检索和语言模型用于文本生成,以提高生成文本的质量和相关性。
套娃表示学习(Matryoshka Representation Learning)
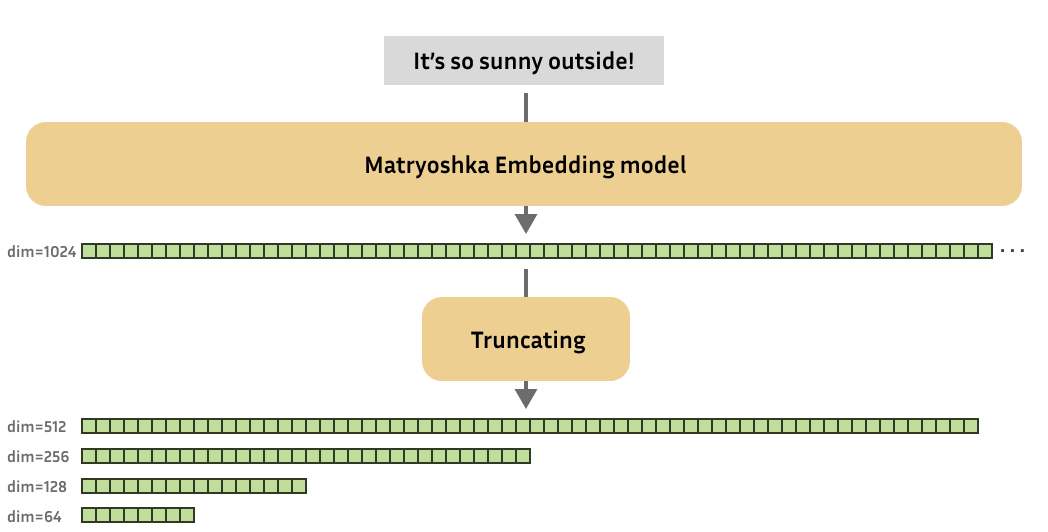
套娃表示学习(Matryoshka Representation Learning, MRL)是一种用于创建“可截断”嵌入向量的技术。想象一系列嵌套的套娃,每个套娃里面都有一个更小的套娃。MRL以这种方式嵌入文本,即前面的维度(就像外层的套娃)包含最重要的信息,后续的维度则添加细节。这使得你可以在需要时只使用嵌入向量的一部分,从而减少存储和计算成本。
Bge-base-en
由北京人工智能研究院(BAAI)开发的[BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5)模型是一个强大的文本嵌入模型。它在各种自然语言处理任务中表现出色,并且在MTEB和C-MTEB等基准测试中表现良好。bge-base-en模型是计算资源有限的应用场景(比如我的情况)的不错选择。
为什么需要微调嵌入?
为特定领域微调嵌入模型对于优化RAG系统至关重要。这一过程确保模型对相似性的理解与你领域的具体上下文和语言细微差别保持一致。经过微调的嵌入模型能够更好地检索出与问题最相关的文档,从而让你的RAG系统生成更准确、更相关的回答。
数据集格式:为微调奠定基础
你可以使用多种数据集格式进行微调。
以下是几种常见类型:
- 正样本对**:**一对相关的句子(例如问题和答案)。
- 三元组:(锚点,正样本,负样本)三元组,其中锚点与正样本相似,与负样本不相似。
- 带相似度分数的对**:**一对句子及其相似度分数,表示它们之间的关系。
- 文本与类别**:**文本及其对应的类别标签。
在本文中,我们将创建一个问题-答案对的数据集,用于微调我们的bge-base-en-v1.5模型。
损失函数:引导训练过程
损失函数对于训练嵌入模型至关重要。它们衡量模型预测与实际标签之间的差异,为模型调整权重提供信号。
不同的数据集格式适用于不同的损失函数:
- 三元组损失:用于(锚点,正样本,负样本)三元组,鼓励模型将相似的句子放得更近,不相似的句子放得更远。
- 对比损失:用于正样本和负样本对,鼓励相似的句子靠近,不相似的句子远离。
- 余弦相似性损失:用于带有相似度分数的句子对,鼓励模型生成的嵌入向量的余弦相似性与给定的分数一致。
- 套娃损失**:**一种专门用于创建套娃嵌入的损失函数,嵌入向量可以被截断。
代码示例
安装依赖项
我们首先安装必要的库。我们将使用datasets、sentence-transformers和google-generativeai来处理数据集、嵌入模型和文本生成。
apt-get -qq install poppler-utils tesseract-ocr
pip install datasets sentence-transformers google-generativeai
pip install -q --user --upgrade pillow
pip install -q unstructured["all-docs"] pi_heif
pip install -q --upgrade unstructured
pip install --upgrade nltk
我们还将安装unstructured用于PDF解析,以及nltk用于文本处理。
PDF解析和文本提取
我们将使用unstructured库从PDF文件中提取文本和表格。
import nltk
import os
from unstructured.partition.pdf import partition_pdf
from collections import Counter
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('punkt_tab') def process_pdfs_in_folder(folder_path):total_text = [] # 用于累积所有PDF中的文本pdf_files = [f for f in os.listdir(folder_path) if f.endswith('.pdf')] # 获取文件夹中所有PDF文件for pdf_file in pdf_files:pdf_path = os.path.join(folder_path, pdf_file)print(f"正在处理:{pdf_path}")elements = partition_pdf(pdf_path, strategy="auto") # 应用分割逻辑text = "\n\n".join([str(el) for el in elements]) # 将元素组合成文本total_text.append(text)return "\n\n".join(total_text)folder_path = "data"
all_text = process_pdfs_in_folder(folder_path)
我们遍历指定文件夹中的每个PDF文件,并将其内容分割为文本、表格和图表。
然后我们将文本元素组合成一个单一的文本表示。
自定义文本分块
我们将使用nltk将提取的文本分割成便于处理的块。这对于使文本更适合语言模型处理至关重要。
import nltk
nltk.download('punkt')def nltk_based_splitter(text: str, chunk_size: int, overlap: int) -> list:"""将输入文本分割成指定大小的块,可以选择是否让块之间有重叠。参数:- text:要分割的输入文本。- chunk_size:每个块的最大大小(以字符数计)。- overlap:连续块之间的重叠字符数。返回:- 一个包含文本块的列表,可以选择是否包含重叠。"""from nltk.tokenize import sent_tokenizesentences = sent_tokenize(text) # 将输入文本分割成单独的句子chunks = []current_chunk = ""for sentence in sentences:if len(current_chunk) + len(sentence) <= chunk_size:current_chunk += " " + sentenceelse:chunks.append(current_chunk.strip()) # 去掉前导空格current_chunk = sentenceif current_chunk:chunks.append(current_chunk.strip())if overlap > 0:overlapping_chunks = []for i in range(len(chunks)):if i > 0:start_overlap = max(0, len(chunks[i - 1]) - overlap)chunk_with_overlap = chunks[i - 1][start_overlap:] + " " + chunks[i]overlapping_chunks.append(chunk_with_overlap[:chunk_size])else:overlapping_chunks.append(chunks[i][:chunk_size])return overlapping_chunksreturn chunkschunks = nltk_based_splitter(text=all_text,chunk_size=2048,overlap=0)
数据集生成器
在这一部分,我们定义了两个函数:
prompt函数为Google Gemini创建一个提示,请求基于提供的文本块生成一个问题及其对应的答案。
import google.generativeai as genai
import pandas as pd# 替换为你的有效Google API密钥
GOOGLE_API_KEY = "xxxxxxxxxxxx"# 明确请求结构化输出的提示生成器
def prompt(text_chunk):return f"""根据以下文本,生成一个问题及其对应的答案。请按照以下格式输出:问题:[你的问题]答案:[你的答案]文本:{text_chunk}"""# 与Google的Gemini交互并返回QA对的函数
def generate_with_gemini(text_chunk: str, temperature: float, model_name: str):genai.configure(api_key=GOOGLE_API_KEY)generation_config = {"temperature": temperature}gen_model = genai.GenerativeModel(model_name, generation_config=generation_config)response = gen_model.generate_content(prompt(text_chunk))try:question, answer = response.text.split("答案:", 1)question = question.replace("问题:", "").strip()answer = answer.strip()except ValueError:question, answer = "N/A", "N/A" # 处理响应格式异常的情况return question, answer
generate_with_gemini函数与Gemini模型交互,使用创建的提示生成QA对。
运行QA生成
使用process_text_chunks函数,我们为每个文本块使用Gemini模型生成QA对。
def process_text_chunks(text_chunks: list, temperature: int, model_name=str):"""处理文本块列表,使用指定模型生成问题和答案。参数:- text_chunks:要处理的文本块列表。- temperature:控制生成输出随机性的采样温度。- model_name:用于生成问题和答案的模型名称。返回:- 一个包含文本块、问题和答案的Pandas DataFrame。"""results = []for chunk in text_chunks:question, answer = generate_with_gemini(chunk, temperature, model_name)results.append({"Text Chunk": chunk, "Question": question, "Answer": answer})df = pd.DataFrame(results)return df# 处理文本块并获取DataFrame
df_results = process_text_chunks(text_chunks=chunks,temperature=0.7,model_name="gemini-1.5-flash")
df_results.to_csv("generated_qa_pairs.csv", index=False)
这些结果随后被存储在一个Pandas DataFrame中。
加载数据集
接下来,我们将从CSV文件中加载生成的QA对到HuggingFace数据集,并确保数据格式适合微调。
from datasets import load_dataset# 将CSV文件加载到Hugging Face数据集
dataset = load_dataset('csv', data_files='generated_qa_pairs.csv')def process_example(example, idx):return {"id": idx, # 根据索引添加唯一ID"anchor": example["Question"],"positive": example["Answer"]}dataset = dataset.map(process_example,with_indices=True,remove_columns=["Text Chunk", "Question", "Answer"])
加载模型
我们从HuggingFace加载BAAI/bge-base-en-v1.5模型,并确保选择合适的设备(CPU或GPU)进行执行。
import torch
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import (InformationRetrievalEvaluator,SequentialEvaluator,
)
from sentence_transformers.util import cos_sim
from datasets import load_dataset, concatenate_datasets
from sentence_transformers.losses import MatryoshkaLoss, MultipleNegativesRankingLossmodel_id = "BAAI/bge-base-en-v1.5"# 加载模型
model = SentenceTransformer(model_id, device="cuda" if torch.cuda.is_available() else "cpu"
)
定义损失函数
这里,我们配置套娃损失函数,指定用于截断嵌入的维度。
# 重要:从大到小matryoshka_dimensions = [768, 512, 256, 128, 64]
inner_train_loss = MultipleNegativesRankingLoss(model)
train_loss = MatryoshkaLoss(model, inner_train_loss, matryoshka_dims=matryoshka_dimensions
)
内部损失函数MultipleNegativesRankingLoss帮助模型生成适合检索任务的嵌入。
定义训练参数
我们使用SentenceTransformerTrainingArguments定义训练参数。这包括输出目录、训练轮数、批量大小、学习率和评估策略。
from sentence_transformers import SentenceTransformerTrainingArguments
from sentence_transformers.training_args import BatchSamplers# 定义训练参数
args = SentenceTransformerTrainingArguments(output_dir="bge-finetuned", # 输出目录和Hugging Face模型IDnum_train_epochs=1, # 训练轮数per_device_train_batch_size=4, # 训练批量大小gradient_accumulation_steps=16, # 全局批量大小为512per_device_eval_batch_size=16, # 评估批量大小warmup_ratio=0.1, # 预热比例learning_rate=2e-5, # 学习率,2e-5是一个不错的选择lr_scheduler_type="cosine", # 使用余弦学习率调度器optim="adamw_torch_fused", # 使用融合的AdamW优化器tf32=True, # 使用TF32精度bf16=True, # 使用BF16精度batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss受益于批量中没有重复样本eval_strategy="epoch", # 每轮训练后评估save_strategy="epoch", # 每轮训练后保存logging_steps=10, # 每10步记录一次save_total_limit=3, # 只保存最后3个模型load_best_model_at_end=True, # 训练结束时加载最佳模型metric_for_best_model="eval_dim_128_cosine_ndcg@10", # 优化128维度的ndcg@10分数
)
注意:如果你使用的是Tesla T4并且在训练过程中遇到错误,尝试注释掉tf32=True和bf16=True这两行代码,以禁用TF32和BF16精度。
创建评估器
我们创建一个评估器,用于在训练过程中衡量模型的性能。评估器使用InformationRetrievalEvaluator评估模型在每个维度上的检索性能。
corpus = dict(zip(dataset['train']['id'],dataset['train']['positive'])
) # 我们的语料库(cid => 文档)
queries = dict(zip(dataset['train']['id'],dataset['train']['anchor'])
) # 我们的查询(qid => 问题)# 为每个查询创建相关文档的映射(1个相关文档)
relevant_docs = {}
for q_id in queries:relevant_docs[q_id] = [q_id]matryoshka_evaluators = []# 遍历不同维度
for dim in matryoshka_dimensions:ir_evaluator = InformationRetrievalEvaluator(queries=queries,corpus=corpus,relevant_docs=relevant_docs,name=f"dim_{dim}",truncate_dim=dim, # 截断到指定维度score_functions={"cosine": cos_sim},)matryoshka_evaluators.append(ir_evaluator)# 创建顺序评估器
evaluator = SequentialEvaluator(matryoshka_evaluators)
微调前评估模型
我们在微调之前评估基础模型,以获取一个性能基线。
results = evaluator(model)
for dim in matryoshka_dimensions:key = f"dim_{dim}_cosine_ndcg@10"print(f"{key}: {results[key]}")
定义训练器
我们创建一个SentenceTransformerTrainer对象,指定模型、训练参数、数据集、损失函数和评估器。
from sentence_transformers import SentenceTransformerTrainertrainer = SentenceTransformerTrainer(model=model, # 我们的嵌入模型args=args, # 上面定义的训练参数train_dataset=dataset.select_columns(["positive", "anchor"]),loss=train_loss, # 套娃损失evaluator=evaluator, # 顺序评估器
)
开始微调
trainer.train()方法启动微调过程,使用提供的数据和损失函数更新模型的权重。
# 开始训练
trainer.train()# 保存最佳模型
trainer.save_model()
训练完成后,我们将表现最佳的模型保存到指定的输出目录。
微调后评估
最后,我们加载微调后的模型,并使用相同的评估器衡量其性能提升。
from sentence_transformers import SentenceTransformerfine_tuned_model = SentenceTransformer(args.output_dir, device="cuda" if torch.cuda.is_available() else "cpu"
)
# 评估模型
results = evaluator(fine_tuned_model)
# 打印主要分数
for dim in matryoshka_dimensions:key = f"dim_{dim}_cosine_ndcg@10"print(f"{key}: {results[key]}")
通过为你的领域微调嵌入模型,你为你的自然语言处理应用赋予了对该领域语言和概念的更深入理解,这可以在问答、文档检索和文本生成等任务中带来显著的改进。
本文讨论的技术,例如利用MRL和使用强大的bge-base-en模型,为构建特定领域的嵌入模型提供了一条实用的路径。虽然我们专注于微调过程,但请记住,数据集的质量同样重要。精心策划一个准确反映你领域细微差别的数据集,对于实现最佳结果至关重要。
随着自然语言处理领域的不断发展,我们可以期待看到更强大的嵌入模型和微调策略的出现。通过保持关注并调整你的方法,你可以充分利用嵌入模型的潜力,构建高质量的自然语言处理应用,以满足你的特定需求。
祝微调愉快!
相关文章:

为特定领域微调嵌入模型:打造专属的自然语言处理利器
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

SQLite 转换为 MySQL 数据库
一、导出 SQLite 数据库 1. 使用 SQLite 命令行工具 • 打开终端(在 Linux 或 macOS 上)或命令提示符(在 Windows 上)。 • 输入sqlite3 your_database_name.db(将 your_database_name.db 替换为你的 SQLite 数据库…...

cnas软件检测实验室质量管理体系文件思维导图,快速理清全部文件
软件检测实验室在申请CNAS资质时,需要根据认可文件的要求,建立实验室质量管理体系,明晰地展示组织架构、合理地安排人员岗位职责和能力要求、全面地覆盖认可文件要求的质量要素。这是一项非常庞大的工作,涉及到的文件类型非常多&a…...

31【干货】Arcgis属性表常用查询表达式实战大全
GIS数据属性表的查询在工作中常常用到,本文对常见的基本运算符进行详细介绍,并以实例的形式,针对SQL查询常用的语句进行实例分类解析,大家可以结合项目需求,自行更改对应的语句,提高工作效率。特别注意文末…...

uniapp 不同路由之间的区别
在UniApp中,路由跳转是实现页面导航的核心功能,常见的路由跳转方式包括navigateTo、redirectTo、reLaunch、switchTab和navigateBack。这些方法在跳转行为和适用场景上有所不同。 一、路由跳转的类型与区别 1. uni.navigateTo(OBJECT) 特点࿱…...

前台--Android开发
在 Android 开发中,“前台(Foreground)” 是一个非常重要的概念,它用于描述当前用户正在与之交互的组件或应用状态。理解“前台”的含义有助于更好地管理资源、生命周期和用户体验。 ✅ 一、什么是前台? 简单定义&…...
 函数的用法和例子)
python: update() 函数的用法和例子
Python 中 update() 函数的用法和例子 在 Python 中,update() 函数通常用于字典(dictionary)对象,以更新其键值对。该函数会将另一个字典或可迭代对象中的元素添加到当前字典中,如果键已经存在,则覆盖对应…...
)
动态规划-62.不同路径-力扣(LeetCode)
一、题目解析 机器人只能向下或向左,要从Start位置到Finish位置。 二、算法原理 1.状态表示 我们要求到Finish位置一共有多少种方法,记Finish为[i,j],此时dp[i,j]表示:到[i,j]位置时,一共有多少种方法,满…...

排序算法总结
在讲解排序算法之前,我们需要先了解一下排序 所谓排序,就是将数据按照我们的想法将其按照一定规律组合在一起 稳定性:一组数据中的数据是否在排序前后都保持的一定的前后顺序关系,比如在排序前a[3]2 a[5]2,这时他们有着…...
深入研究(三)——事务详解及代码实例))
kafka学习笔记(四、生产者、消费者(客户端)深入研究(三)——事务详解及代码实例)
1.事务简介 Kafka事务是Apache Kafka在流处理场景中实现Exactly-Once语义的核心机制。它允许生产者在跨多个分区和主题的操作中,以原子性(Atomicity)的方式提交或回滚消息,确保数据处理的最终一致性。例如,在流处理中…...

【Git】查看tag
文章目录 1. 查看当前提交是否有tag2. 查看最近的tag3. 查看所有tag 有时候需要基于某个tag拉分支,记录下怎么查看tag。 1. 查看当前提交是否有tag git tag --points-at HEAD该命令可直接检查当前提交(HEAD)是否关联了任何tag。 若当前提交…...

开源数字人框架 AWESOME - DIGITAL - HUMAN:技术革新与行业标杆价值剖析
一、项目核心价值:解锁数字人技术新境界 1. 技术普及:降低准入门槛,推动行业民主化 AWESOME - DIGITAL - HUMAN 项目犹如一场技术春雨,为数字人领域带来了普惠甘霖。它集成了 ASR、LLM、TTS 等关键能力,并提供模块化扩展接口,将原本复杂高深的数字人开发流程,转化为一…...

Android系统架构模式分析
本文系统梳理Android系统架构模式的演进路径与设计哲学,希望能够借此探索未来系统的发展方向。有想法的同学可以留言讨论。 1 Android层次化架构体系 1.1 整体分层架构 Android系统采用五层垂直架构,各层之间通过严格接口定义实现解耦: 应用…...

【MYSQL错误连接太多】
com.mysql.cj.exceptions.CJException: null, message from server: "Host 192.168.0.200 is blocked because of many connection errors; unblock with mysqladmin flush-hosts"方法一:通过配置文件永久更改 找到你的 MySQL 配置文件(通常…...

C23 与 MISRA C:2025:嵌入式 C 语言的进化之路
引言 在 Rust、Go 等现代语言蓬勃发展的今天,C 语言依然以 27.7% 的 TIOBE 指数(2024 年 6 月数据)稳居编程语言前三甲。其核心竞争力不仅在于高效的底层控制能力,更在于持续进化的标准体系。2024 年发布的 C23(ISO/I…...

HunyuanCustom, 腾讯混元开源的多模态定制视频生成框架
HunyuanCustom是一款由腾讯混元团队开发的多模态驱动定制视频生成框架,能够支持图像、音频、视频和文本等多种输入方式。该框架专注于生成高质量的视频,能够实现特定主体和场景的精准呈现。 HunyuanCustom是什么 HunyuanCustom是腾讯混元团队推出的一种…...

el-menu 折叠后小箭头不会消失
官方示例 <template><el-radio-group v-model"isCollapse" style"margin-bottom: 20px"><el-radio-button :value"false">expand</el-radio-button><el-radio-button :value"true">collapse</el-ra…...

Spring Boot中的拦截器!
每次用户请求到达Spring Boot服务端,你是否需要重复写日志、权限检查或请求格式化代码?这些繁琐的“前置后置”工作让人头疼!好在,Spring Boot拦截器如同一道智能关卡,统一处理请求的横切逻辑,让代码优雅又…...

Docker宿主机IP获取
1.Linux: ip addr show docker0 2. macOS/Windows 环境(Docker Desktop) 在Docker Desktop中,宿主机(你的物理机)通过host.docker.internal主机名暴露给容器,无需手动查找IP。 方法1:在容器…...

Flink之Table API
Apache Flink 的 Table API 是 Flink 提供的一种高级抽象,用于以声明式方式处理批处理和流处理数据。它是基于关系模型的 API,用户可以像编写 SQL 一样,以简洁、类型安全的方式编写数据处理逻辑。 一、基本概念 1. 什么是 Table API…...

Kubernetes生产实战:NodePort端口范围的隐藏规则与调优指南
在Kubernetes中暴露服务时,很多开发者第一次看到NodePort的端口号都会惊呼:"为什么我的服务被分配了3万多的端口?"。这背后隐藏着Kubernetes设计者的深思熟虑,今天我们就来揭开这个"数字谜团"。 一、默认端口…...

读取传感器发来的1Byte数据:分低位先行和高位先行的处理方法
目录 一、写在前面 二、伪代码的逻辑实现 1、从高位到低位 2、从低位到高位 一、写在前面 在接收数据之前我们需要事先知道数据的发送规则,是高位先行还是低位先行,并按照规则接收数据,否则收到的数据很可能是错的 高位先行:…...

在 Ubuntu 上安装并运行 ddns-go 教程
在 Ubuntu 上安装并运行 ddns-go 教程 什么是 ddns-go? ddns-go 是一款开源的轻量级 DDNS(动态域名解析)客户端,支持多家 DNS 服务商(如阿里云、腾讯云、Cloudflare、Dnspod 等),适合在家用宽…...

2025.05.07-淘天算法岗-第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 信号增强最小操作次数 问题描述 卢小姐正在进行一项信号处理实验。她有一个长度为 n n n...

边缘大型语言模型综述:设计、执行和应用
(2025-08-31) A Review on Edge Large Language Models: Design, Execution, and Applications (Edge 大型语言模型综述:设计、执行和应用) 作者: Yue Zheng; Yuhao Chen; Bin Qian; Xiufang Shi; Yuanchao Shu; Jiming Chen;期刊: ACM Computing Surveys (发表日期: 2025-08…...

谷云科技iPaaS发布 MCP Server加速业务系统API 跨入 MCP 时代
在数字化浪潮中,集成技术与 AI 技术的融合成为企业智能化转型的关键。谷云科技作为 iPaaS 集成技术领域的佼佼者,我们率先在iPaaS中全新推出 MCP Server,这不仅是对谷云科技现有产品线的有力补充,更是我们顺应 AI 发展潮流、深化集…...

rabbitmq学习笔记快速使用
主要是快速了解使用,对于强要求比如说数据安全(也就是spring配置先不要求) 那么开始 引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>…...

PMIC电源管理模块的PCB设计
目录 PMU模块简介 PMU的PCB设计 PMU模块简介 PMIC(电源管理集成电路)是现代电子设备的核心模块,负责高效协调多路电源的转换、分配与监控。它通过集成DC-DC降压/升压、LDO线性稳压、电池充电管理、功耗状态切换等功能,替代传统分…...

云原生CAE软件
云原生CAE软件是一种在设计和实现时就充分考虑了云环境特点的软件,能够充分利用云资源,实现高效、可扩展和灵活的仿真分析。 定义和特点 云原生CAE软件是一种在云端构建和运行的CAE(Computer Aided Engineering,计算机辅助工…...

计算机视觉】OpenCV项目实战:eye_mouse_movement:基于opencv实战眼睛控制鼠标
eye_mouse_movement:基于视觉追踪的实时眼控交互系统 一、项目概述与技术背景1.1 项目核心价值1.2 技术指标对比1.3 技术演进路线 二、环境配置与系统部署2.1 硬件要求2.2 软件安装基础环境搭建关键组件说明 2.3 模型文件部署 三、核心算法解析3.1 系统架构设计3.2 …...

《大规模电动汽车充换电设施可调能力聚合评估与预测》MATLAB实现计划
模型概述 根据论文,我将复刻实现结合长短期记忆网络(LSTM)和条件变分自编码器(CVAE)的预测方法,用于电动汽车充换电设施可调能力的聚合评估与预测。 实现步骤 1. 数据预处理 导入充电数据 (Charging_Data.csv)导入天气数据 (Weather_Data.csv)导入电…...

【C++进阶】第2课—多态
文章目录 1. 认识多态2. 多态的定义和实现2.1 构成多态的必要条件2.2 虚函数2.3 虚函数的重写或覆盖2.4 协变(了解)2.5 析构函数的重写2.6 override和final关键字2.7 重载、重写、隐藏对比 3. 纯虚函数和抽象类4. 多态原理4.1 虚函数表指针4.2 多态的实现4.3 静态绑定和动态绑定…...

Mysql--基础知识点--91.2--processlist
在 MySQL 中,SHOW PROCESSLIST 是一个常用命令,用于查看当前数据库服务器上所有正在运行的线程(进程)信息。以下是关键点说明: 1. 命令用法 SHOW FULL PROCESSLIST;输出字段: 列名含义Id线程唯一标识符&am…...

【阿里云免费领取域名以及ssl证书,通过Nginx反向代理web服务】
文章目录 前言一、申请域名1.1 访问阿里云官网1.2 输入自定义域名1.3 创建个人模板1.4 支付1元可以使用域名1年1.5 按照提示实名认证1.6 实名认证成功 二、域名解析2.1 选择域名解析2.2 解析设置2.3 快速添加解析2.4 选择对应类型2.5 解析成功 三、申请免费ssl证书3.1 访问阿里…...

Mamba 状态空间模型 笔记 llm框架 一维卷积
动画讲解 Mamba 状态空间模型_哔哩哔哩_bilibili 旧文本向量乘权重加残差 感觉好像transformer 过个llm head输出y 卷积真的很快 参考一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba(被誉为Mamba最佳解读)_mamba模型-CSDN博客 偷了 Transformer的二次复…...

WPF内嵌其他进程的窗口
WPF内嵌其他进程窗口的常见方法有 HwndHost SetParent 和 WindowsFormsHost WinForms Panel SetParent 推荐使用自定义HwndHost 两者的对比区别 示例代码 public class MyWndHost : HwndHost {const int WS_CHILD 0x40000000;const int WS_VISIBLE 0x10000000;const i…...

1、mongodb-- BSON 学习和JSON性能对比
BSON 是什么 MongoDB 作为一款流行的文档数据库,采用 BSON 格式来支持文档模型。 BSON 全称是 Binary JSON,和 JSON 很像,但是采用二进制格式进行存储。相比 JSON 有以下优势: 访问速度更快:BSON 会存储 Value 的类…...
、位图的实现和布隆过滤器的介绍)
19、HashTable(哈希)、位图的实现和布隆过滤器的介绍
一、了解哈希【散列表】 1、哈希的结构 在STL中,HashTable是一个重要的底层数据结构, 无序关联容器包括unordered_set, unordered_map内部都是基于哈希表实现 哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。哈希函数:负责将…...
多平面格式 单缓冲读取图像并显示)
鱼眼摄像头(一)多平面格式 单缓冲读取图像并显示
鱼眼摄像头(一)多平面格式 单缓冲读取图像并显示 1.摄像头格式 1. 单平面格式(Single Plane):各通道数据保存在同一个平面(缓冲),图像数据按行连续存储a. mjpeg,yuyv等…...

wpf UserControl 更换 自定义基类
在WPF中实现UserControl更换自定义基类的操作,需注意以下关键步骤及注意事项 实现步骤 创建自定义基类 新建继承自UserControl的基类(如CustomBaseUserControl),并添加通用逻辑: public class BaseUserControl: UserControl {// 添加共享逻辑(如事件处理、初始化…...

Linux C语言线程编程入门笔记
目录 开发环境准备 线程基础概念 进程与线程的关系 线程生命周期 创建线程 等待线程结束 线程函数和参数 互斥锁与共享资源保护 总结 开发环境准备 操作系统:以 Linux 为例(Ubuntu/CentOS 等主流发行版)。请确保系统已安装 GNU C 编…...

网络安全体系架构:核心框架与关键机制解析
以下是关于网络安全体系架构设计相关内容的详细介绍: 一、开放系统互联安全体系结构 开放系统互联(OSI)安全体系结构是一种基于分层模型的安全架构,旨在为开放系统之间的通信提供安全保障。它定义了安全服务、安全机制以及它们在…...

SecureCRT网络穿透/代理
场景 公司的办公VPN软件只有Windows系统版本,没有Macos系统版本,而日常开发过程中需要先登录VPN后,然后才能登录应用服务器。 目的:Macos系统在使用SecureCRT时,登录服务器,需要走Parallels Desktop进行网络…...

Typora+PicGo+Gitee图床配置教程 自动图片上传
配置步骤 #mermaid-svg-aPUbWs43XR5Rh7vf {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-aPUbWs43XR5Rh7vf .error-icon{fill:#552222;}#mermaid-svg-aPUbWs43XR5Rh7vf .error-text{fill:#552222;stroke:#552222;}#…...
带论文文档1万字以上,文末可获取,系统界面在最后面。)
基于vue框架的电子商城m8qu8(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,商品类型,商品信息,商城公告 开题报告内容 基于Vue框架的电子商城开题报告 一、研究背景与意义 随着互联网技术的飞速发展,电子商务已成为全球商业领域的重要增长点。根据艾瑞咨询数据,中国网络购物用户规…...

线段树:数据结构中的超级英雄
在数据结构的世界里,线段树就像是一位超级英雄,能够高效地解决区间查询和更新问题。作为 C 算法小白,今天我就带大家一起认识这位超级英雄,揭开线段树的神秘面纱。 什么是线段树? 线段树是一种二叉树数据结构&#x…...

【MySQL】存储引擎 - ARCHIVE、BLACKHOLE、MERGE详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

麦科信获评CIAS2025金翎奖【半导体制造与封测领域优质供应商】
在苏州举办的2025CIAS动力能源与半导体创新发展大会上,深圳麦科信科技有限公司凭借在测试测量领域的技术积累,入选半导体制造与封测领域优质供应商榜单。本届大会以"新能源芯时代"为主题,汇集了来自功率半导体、第三代材料应用等领…...

开目新一代MOM:AI赋能高端制造的破局之道
导读 INTRODUCTION 在高端制造业智能化转型的深水区,企业正面临着个性化定制、多工艺场景、动态生产需求的敏捷响应以及传统MES柔性不足的考验……在此背景下,武汉开目信息技术股份有限公司(简称“开目软件”)正式发布新一代开目…...

wsl - install RabbiqMQ
下载erlang $ sudo apt -y install erlang 安装软件包 $ sudo apt -y install rabbitmq-server 修改配置文件 $ sudo vi /etc/rabbitmq/rabbitmq-env.conf # Defaults to rabbit. This can be useful if you want to run more than one node # per machine - RABBITMQ_NODENAME…...