信赖域策略优化TRPO算法详解:python从零实现
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
引言
信任区域策略优化(Trust Region Policy Optimization,简称 TRPO)是一种高级的策略梯度方法,用于强化学习。它解决了简单方法(如 REINFORCE)中存在的一个关键不稳定性问题:如果策略更新过大且选择不当,可能会大幅降低性能,有时甚至会导致灾难性的崩溃。TRPO 的目标是通过将策略更新的大小限制在一个由 Kullback-Leibler(KL)散度定义的“信任区域”内,来保证(或高度可能)策略性能的单调改进。
TRPO 是什么?
TRPO 是一种迭代算法,旨在改进由参数 θ \theta θ 参数化的随机策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)。在每次迭代中,它解决一个受约束的优化问题:
- 最大化 一个目标函数(即替代优势),该函数近似预期的性能改进。
- 受约束于 一个条件,即策略的变化(通过旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 和新策略 π θ \pi_{\theta} πθ 之间的平均 KL 散度来衡量)小于一个小常数 δ \delta δ。
max θ E s ∼ ρ θ old , a ∼ π θ old [ π θ ( a ∣ s ) π θ old ( a ∣ s ) A π θ old ( s , a ) ] \max_{\theta} \quad \mathbb{E}_{s \sim \rho_{\theta_{\text{old}}}, a \sim \pi_{\theta_{\text{old}}}} \left[ \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} A^{\pi_{\theta_{\text{old}}}}(s,a) \right] θmaxEs∼ρθold,a∼πθold[πθold(a∣s)πθ(a∣s)Aπθold(s,a)]
subject to E s ∼ ρ θ old [ D KL ( π θ old ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ] ≤ δ \text{subject to} \quad \mathbb{E}_{s \sim \rho_{\theta_{\text{old}}}} [D_{\text{KL}}(\pi_{\theta_{\text{old}}}(\cdot|s) || \pi_{\theta}(\cdot|s))] \le \delta subject toEs∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
这里, A π θ old ( s , a ) A^{\pi_{\theta_{\text{old}}}}(s,a) Aπθold(s,a) 是在旧策略下估计的优势函数,而 ρ h e t a o l d \rho_{ heta_{old}} ρhetaold 是由旧策略诱导的状态分布。
TRPO 并不直接求解这个复杂的受约束问题,而是通过近似和使用共轭梯度(CG)算法结合线搜索来找到一个满足约束条件的同时近似最大化目标的策略更新。
为何要用信任区域进行策略优化?
普通的策略梯度方法(如 REINFORCE)会按照固定学习率跟随梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)。关键问题包括:
- 对步长敏感:如果步长过大,可能会将策略带入一个糟糕的区域,从而无法恢复;如果步长过小,则会导致学习缓慢。
- 没有性能保证:梯度上升步骤并不能保证性能的提升,尤其是在使用函数近似和噪声梯度估计时。
TRPO 通过以下方式解决这些问题:
- 使用替代目标:这个目标函数使用重要性采样 π θ ( a ∣ s ) π θ old ( a ∣ s ) \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} πθold(a∣s)πθ(a∣s) 来利用旧策略下的数据估计新策略的性能。
- 施加 KL 约束:这限制了策略分布一次变化的幅度。通过将新策略保持在旧策略的附近(在信任区域 δ \delta δ 内),替代目标函数能够更好地近似真实的性能改进,从而更有可能实现单调改进。
TRPO 的使用场景和方法
TRPO 在策略优化方面是一个重要的进步,在复杂的连续控制任务中表现出色,特别是在模拟机器人学(MuJoCo 基准测试)中。
- 连续控制:其稳定性使其适用于具有挑战性的连续动作空间问题。
- 机器人模拟:广泛用于学习行走和操作技能。
- PPO 的基础:尽管 TRPO 的效果很好,但由于其实现复杂性(尤其是 CG 和 FVP),促成了近端策略优化(Proximal Policy Optimization,PPO)的发展。PPO 通过使用更简单的裁剪目标或自适应 KL 惩罚来实现类似的稳定性,因此在当今更为流行。
当以下情况适用时,TRPO 是一个不错的选择:
- 稳定性和可靠的策略改进至关重要。
- 计算 CG 和 FVP 的计算开销是可以接受的。
- 可以生成 on-policy 数据。
- 动作空间可以是离散的或连续的。
TRPO 的数学基础
策略梯度回顾
标准的策略梯度是 g = ∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] g = \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} [\sum_t \nabla_\theta \log \pi_\theta(a_t|s_t) A^{\pi_\theta}(s_t, a_t)] g=∇θJ(θ)=Eτ∼πθ[∑t∇θlogπθ(at∣st)Aπθ(st,at)]。
普通策略梯度的问题
如果步长 α \alpha α 过大,策略更新 θ new = θ old + α g \theta_{\text{new}} = \theta_{\text{old}} + \alpha g θnew=θold+αg可能会导致性能不佳;如果步长过小,则会导致收敛缓慢。对于一个状态或策略来说效果良好的步长 α \alpha α,对于另一个状态或策略来说可能非常糟糕。
替代目标函数
TRPO 的目标是最大化新策略 π θ \pi_\theta πθ 相对于旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 的预期优势,使用来自 π θ old \pi_{\theta_{\text{old}}} πθold 的样本。设 L θ old ( θ ) L_{\theta_{\text{old}}}(\theta) Lθold(θ) 为这个替代目标:
L θ old ( θ ) = E s ∼ ρ θ old , a ∼ π θ old [ π θ ( a ∣ s ) π θ old ( a ∣ s ) A π θ old ( s , a ) ] L_{\theta_{\text{old}}}(\theta) = \mathbb{E}_{s \sim \rho_{\theta_{\text{old}}}, a \sim \pi_{\theta_{\text{old}}}} \left[ \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} A^{\pi_{\theta_{\text{old}}}}(s,a) \right] Lθold(θ)=Es∼ρθold,a∼πθold[πθold(a∣s)πθ(a∣s)Aπθold(s,a)]
注意, ∇ θ L θ old ( θ ) ∣ θ = θ old = ∇ θ J ( θ ) ∣ θ = θ old = g \nabla_\theta L_{\theta_{\text{old}}}(\theta)|_{\theta=\theta_{\text{old}}} = \nabla_\theta J(\theta)|_{\theta=\theta_{\text{old}}} = g ∇θLθold(θ)∣θ=θold=∇θJ(θ)∣θ=θold=g。在当前参数下,梯度与标准策略梯度相匹配。
信任区域约束(KL 散度)
为了确保 L θ old ( θ ) L_{\theta_{\text{old}}}(\theta) Lθold(θ) 能够很好地近似真实的性能改进,策略的变化是通过平均 KL 散度来约束的:
D ˉ KL ( θ old ∣ ∣ θ ) = E s ∼ ρ θ old [ D KL ( π θ old ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ] ≤ δ \bar{D}_{\text{KL}}(\theta_{\text{old}} || \theta) = \mathbb{E}_{s \sim \rho_{\theta_{\text{old}}}} [D_{\text{KL}}(\pi_{\theta_{\text{old}}}(\cdot|s) || \pi_{\theta}(\cdot|s))] \le \delta DˉKL(θold∣∣θ)=Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
其中 D KL ( P ∣ ∣ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) D_{\text{KL}}(P || Q) = \sum_x P(x) \log \frac{P(x)}{Q(x)} DKL(P∣∣Q)=∑xP(x)logQ(x)P(x) 是离散分布的 KL 散度公式。
近似和优化问题
直接求解 L θ old ( θ ) L_{\theta_{\text{old}}}(\theta) Lθold(θ)的受约束最大化问题非常困难。TRPO 使用一阶和二阶泰勒展开在 θ old \theta_{\text{old}} θold 附近对目标和约束进行近似:
- L θ old ( θ ) ≈ L θ old ( θ old ) + g T ( θ − θ old ) L_{\theta_{\text{old}}}(\theta) \approx L_{\theta_{\text{old}}}(\theta_{\text{old}}) + g^T (\theta - \theta_{\text{old}}) Lθold(θ)≈Lθold(θold)+gT(θ−θold)(忽略 L θ old ( θ old ) L_{\theta_{\text{old}}}(\theta_{\text{old}}) Lθold(θold),因为它为 0)
- D ˉ KL ( θ old ∣ ∣ θ ) ≈ 1 2 ( θ − θ old ) T F ( θ − θ old ) \bar{D}_{\text{KL}}(\theta_{\text{old}} || \theta) \approx \frac{1}{2} (\theta - \theta_{\text{old}})^T F (\theta - \theta_{\text{old}}) DˉKL(θold∣∣θ)≈21(θ−θold)TF(θ−θold)
其中 g = ∇ θ L θ old ( θ ) ∣ θ = θ old g = \nabla_\theta L_{\theta_{\text{old}}}(\theta)|_{\theta=\theta_{\text{old}}} g=∇θLθold(θ)∣θ=θold 是策略梯度,而 F = ∇ θ 2 D ˉ KL ( θ old ∣ ∣ θ ) ∣ θ = θ old F = \nabla^2_\theta \bar{D}_{\text{KL}}(\theta_{\text{old}} || \theta)|_{\theta=\theta_{\text{old}}} F=∇θ2DˉKL(θold∣∣θ)∣θ=θold 是在 θ old \theta_{\text{old}} θold 处评估的费舍尔信息矩阵(Fisher Information Matrix,FIM)。
优化问题变为:
max Δ θ g T Δ θ subject to 1 2 Δ θ T F Δ θ ≤ δ \max_{\Delta\theta} \quad g^T \Delta\theta \quad \text{subject to} \quad \frac{1}{2} \Delta\theta^T F \Delta\theta \le \delta ΔθmaxgTΔθsubject to21ΔθTFΔθ≤δ
其中 Δ θ = θ − θ old \Delta\theta = \theta - \theta_{\text{old}} Δθ=θ−θold。该问题的解为 Δ θ ∝ F − 1 g \Delta\theta \propto F^{-1} g Δθ∝F−1g。确切的步长为 Δ θ = 2 δ g T F − 1 g F − 1 g \Delta\theta = \sqrt{\frac{2\delta}{g^T F^{-1} g}} F^{-1} g Δθ=gTF−1g2δF−1g。
费舍尔信息矩阵(FIM)
F = E s ∼ ρ θ old , a ∼ π θ old [ ∇ θ log π θ old ( a ∣ s ) ∇ θ log π θ old ( a ∣ s ) T ] F = \mathbb{E}_{s \sim \rho_{\theta_{\text{old}}}, a \sim \pi_{\theta_{\text{old}}}} [\nabla_\theta \log \pi_{\theta_{\text{old}}}(a|s) \nabla_\theta \log \pi_{\theta_{\text{old}}}(a|s)^T] F=Es∼ρθold,a∼πθold[∇θlogπθold(a∣s)∇θlogπθold(a∣s)T]。它表示策略对数似然的曲率,并作为参数空间上的度量张量,定义了“自然梯度”。
求解受约束问题:共轭梯度
计算并求解可能非常大的 FIM F F F 的逆矩阵是不可行的。TRPO 使用共轭梯度(CG)算法来高效地计算更新方向 s ≈ F − 1 g s \approx F^{-1} g s≈F−1g,通过迭代求解线性系统 F x = g Fx = g Fx=g。CG 只需要计算形式为 F v Fv Fv 的矩阵-向量乘积,这被称为费舍尔-向量乘积(Fisher-Vector Product,FVP)。
FVP F v Fv Fv 可以通过自动微分高效地计算,而无需显式形成 F F F。一种方法是:
- 计算 D KL ( π θ old ∣ ∣ π θ ) D_{\text{KL}}(\pi_{\theta_{\text{old}}} || \pi_{\theta}) DKL(πθold∣∣πθ)(对状态求平均)。
- 计算梯度 k = ∇ θ D KL ∣ θ = θ old k = \nabla_\theta D_{\text{KL}}|_{\theta=\theta_{\text{old}}} k=∇θDKL∣θ=θold。
- 计算方向导数 ( k T v ) (k^T v) (kTv)。
- 计算这个标量关于 θ \theta θ 的梯度: ∇ θ ( k T v ) ∣ θ = θ old \nabla_\theta (k^T v)|_{\theta=\theta_{\text{old}}} ∇θ(kTv)∣θ=θold。这给出了 F v Fv Fv。
为了数值稳定性,通常会添加一个阻尼项 β v \beta v βv: ( F + β I ) v (F+\beta I)v (F+βI)v。
确保约束条件:回溯线搜索
由于优化问题使用了近似,提出的步长 Δ θ = α s \Delta \theta = \alpha s Δθ=αs(其中 s = F − 1 g s=F^{-1}g s=F−1g 且 α = 2 δ / ( s T F s ) \alpha = \sqrt{2\delta / (s^T F s)} α=2δ/(sTFs) 是初始步长)可能违反原始的 KL 约束条件或降低性能。因此,需要执行回溯线搜索:
- 从完整步长 θ new = θ old + Δ θ \theta_{\text{new}} = \theta_{\text{old}} + \Delta\theta θnew=θold+Δθ 开始。
- 检查 D ˉ KL ( θ old ∣ ∣ θ new ) ≤ δ \bar{D}_{\text{KL}}(\theta_{\text{old}} || \theta_{\text{new}}) \le \delta DˉKL(θold∣∣θnew)≤δ 以及 L θ old ( θ new ) ≥ 0 L_{\theta_{\text{old}}}(\theta_{\text{new}}) \ge 0 Lθold(θnew)≥0(或某个预期改进阈值)是否满足。
- 如果不满足,则减小步长( Δ θ ← β Δ θ \Delta\theta \leftarrow \beta \Delta\theta Δθ←βΔθ,其中 β < 1 \beta < 1 β<1)并重复步骤 2。
优势估计:GAE
TRPO 需要对优势函数 A π θ old ( s , a ) A^{\pi_{\theta_{\text{old}}}}(s,a) Aπθold(s,a) 有良好的估计。虽然可以使用简单的蒙特卡洛回报( G t − V ( s t ) G_t - V(s_t) Gt−V(st)),但通常更倾向于使用广义优势估计(Generalized Advantage Estimation,GAE),因为它可以减少方差:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A^{\text{GAE}}_t = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} AtGAE=l=0∑∞(γλ)lδt+l
其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st) 是 TD 误差, γ \gamma γ 是折扣因子,而 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1] 是平滑参数( λ = 0 \lambda=0 λ=0 给出 TD(0) 优势, λ = 1 \lambda=1 λ=1 给出蒙特卡洛优势)。GAE 需要学习一个状态价值函数 V ( s ) V(s) V(s)(即 Critic)。
TRPO 的逐步解释
- 初始化:策略网络 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)(Actor)、价值网络 V ( s ; ϕ ) V(s; \phi) V(s;ϕ)(Critic)、超参数( γ , λ , δ \gamma, \lambda, \delta γ,λ,δ,CG 参数,线搜索参数,价值学习率)。
- 对于每次迭代:
a. 收集轨迹:使用当前策略 π θ old \pi_{\theta_{\text{old}}} πθold,收集一批轨迹(状态、动作、奖励、下一个状态、完成标志、旧对数概率)。
b. 估计价值:使用当前 Critic 计算批次中所有状态的 V ( s t ; ϕ old ) V(s_t; \phi_{\text{old}}) V(st;ϕold)。
c. 估计优势:使用收集到的奖励和价值估计计算 TD 误差 δ t \delta_t δt 和 GAE 优势 A t GAE A^{\text{GAE}}_t AtGAE。
d. 计算策略梯度( g g g):计算 g = 1 N ∑ batch ∇ θ log π θ ( a t ∣ s t ) ∣ θ old A t GAE g = \frac{1}{N} \sum_{\text{batch}} \nabla_\theta \log \pi_\theta(a_t|s_t)|_{\theta_{\text{old}}} A^{\text{GAE}}_t g=N1∑batch∇θlogπθ(at∣st)∣θoldAtGAE。
e. 计算更新方向( s s s):使用共轭梯度求解 ( F + β I ) s = g (F+\beta I)s = g (F+βI)s=g,其中 F F F 涉及计算 FVPs。得到 s ≈ F − 1 g s \approx F^{-1}g s≈F−1g。
f. 计算初始步长:计算 α = 2 δ s T F s \alpha = \sqrt{\frac{2\delta}{s^T F s}} α=sTFs2δ(其中 s T F s s^T F s sTFs 使用另一个 FVP 计算)。
g. 执行线搜索:找到最大的步长 β ∈ [ 0 , 1 ] \beta \in [0, 1] β∈[0,1],使得 θ new = θ old + β α s \theta_{\text{new}} = \theta_{\text{old}} + \beta \alpha s θnew=θold+βαs 同时满足以下两个条件:
- D ˉ KL ( θ old ∣ ∣ θ new ) ≤ δ \bar{D}_{\text{KL}}(\theta_{\text{old}} || \theta_{\text{new}}) \le \delta DˉKL(θold∣∣θnew)≤δ
- L θ old ( θ new ) ≥ 0 L_{\theta_{\text{old}}}(\theta_{\text{new}}) \ge 0 Lθold(θnew)≥0(或足够的改进)
h. 更新策略:设置 θ ← θ new \theta \leftarrow \theta_{\text{new}} θ←θnew。
i. 更新价值函数:使用收集到的批次数据,通过梯度下降更新 Critic 参数 ϕ \phi ϕ,以最小化 V ( s t ; ϕ ) V(s_t; \phi) V(st;ϕ) 和经验回报(例如, A t GAE + V ( s t ; ϕ old ) A^{\text{GAE}}_t + V(s_t; \phi_{\text{old}}) AtGAE+V(st;ϕold))之间的均方误差(MSE)损失。通常执行多次更新。 - 重复:直到收敛。
TRPO 的关键组成部分
策略网络(Actor)
- 参数化随机策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)。
- 输出动作概率(例如,通过 Softmax 为离散动作输出概率)。
价值网络(Critic)
- 参数化状态价值函数 V ( s ; ϕ ) V(s; \phi) V(s;ϕ)。
- 用于计算 TD 误差和 GAE 优势。
- 通过回归(例如,MSE 损失)进行训练。
轨迹收集(On-Policy)
- 使用当前策略 π θ old \pi_{\theta_{\text{old}}} πθold 收集一批经验(轨迹)。
- 存储状态、动作、奖励、完成标志以及在用于轨迹收集的策略下的对数概率 log π θ old ( a ∣ s ) \log \pi_{\theta_{\text{old}}}(a|s) logπθold(a∣s)。
优势估计(GAE)
- 使用收集到的数据和价值网络计算优势估计 A t A_t At。
- 与纯蒙特卡洛方法相比,GAE 提供了方差降低的估计。
策略梯度计算
- 计算在 θ old \theta_{\text{old}} θold 处的目标函数的梯度 g g g,并按估计的优势进行加权。
费舍尔-向量乘积(FVP)
- 不形成完整的费舍尔信息矩阵 F F F 来计算 F v Fv Fv 的函数。
- 对于共轭梯度步骤至关重要。使用自动微分。
共轭梯度(CG)算法
- 迭代方法,用于近似求解 F s = g Fs = g Fs=g 以获得更新方向 s s s。
- 避免直接求解 FIM 的逆。
回溯线搜索
- 确保最终的策略步长 Δ θ \Delta \theta Δθ 满足 KL 约束条件并改进(近似的)目标函数。
- 从约束条件导出的初始步长开始,并逐步缩小步长,直到满足条件。
价值函数更新
- 使用收集到的批次数据,通过梯度下降更新 Critic 网络 ϕ \phi ϕ,通常使用 Adam 或类似的优化器对 MSE 损失进行优化。
超参数
- TRPO 引入了几个新的超参数:KL 约束 δ \delta δ、GAE λ \lambda λ、CG 阻尼因子、CG 迭代次数、线搜索衰减因子、价值函数学习率、每次策略更新的价值函数更新步数。
- 调整这些超参数可能比较复杂。
实际示例:自定义网格世界
为了保持一致性,我们使用相同的自定义网格世界。虽然 TRPO 对于这种简单环境来说有些大材小用,但它有助于说明实现机制,符合所要求的风格。
环境描述:(与之前相同)
- 网格大小:10x10。
- 状态: [ r o w / 9 , c o l / 9 ] [row/9, col/9] [row/9,col/9]
- 动作:4 个离散动作(上、下、左、右)。
- 起点:(0, 0),终点:(9, 9)。
- 奖励:到达终点 +10,碰到墙壁 -1,每步 -0.1。
- 终止条件:到达终点或达到最大步数。
设置环境
导入必要的库。需要注意的是,仅使用基本库和 PyTorch 来实现 TRPO(尤其是 FVP 和 CG)并非易事,但我们还是坚持这样做。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
from torch.nn.utils.convert_parameters import parameters_to_vector, vector_to_parameters# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用的设备:{device}")# 设置随机种子以确保可重复性
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)%matplotlib inline
使用的设备:cpu
创建自定义环境
重复使用完全相同的 GridEnvironment 类。
# 自定义网格世界环境(与 DQN/REINFORCE 笔记本中的完全相同)
class GridEnvironment:"""一个简单的 10x10 网格世界环境。属性:- rows (int): 网格的行数。- cols (int): 网格的列数。- start_state (Tuple[int, int]): 代理的起始状态(行,列)。- goal_state (Tuple[int, int]): 代理的目标状态(行,列)。- state (Tuple[int, int]): 代理的当前状态(行,列)。- state_dim (int): 状态表示的维度。- action_dim (int): 可能动作的数量。- action_map (Dict[int, Tuple[int, int]]): 将动作映射到其在网格上的效果。"""def __init__(self, rows: int = 10, cols: int = 10) -> None:"""初始化 GridEnvironment。参数:- rows (int): 网格的行数。默认为 10。- cols (int): 网格的列数。默认为 10。"""self.rows: int = rowsself.cols: int = colsself.start_state: Tuple[int, int] = (0, 0)self.goal_state: Tuple[int, int] = (rows - 1, cols - 1)self.state: Tuple[int, int] = self.start_stateself.state_dim: int = 2self.action_dim: int = 4self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), # 上1: (1, 0), # 下2: (0, -1), # 左3: (0, 1) # 右}def reset(self) -> torch.Tensor:"""将环境重置为起始状态。返回:- torch.Tensor: 起始状态的归一化状态张量。"""self.state = self.start_statereturn self._get_state_tensor(self.state)def _get_state_tensor(self, state_tuple: Tuple[int, int]) -> torch.Tensor:"""将状态(行,列)转换为归一化的状态张量。参数:- state_tuple (Tuple[int, int]): 作为元组(行,列)的状态。返回:- torch.Tensor: 归一化的状态张量 [行/行数-1, 列/列数-1]。"""norm_row: float = state_tuple[0] / (self.rows - 1) if self.rows > 1 else 0.0norm_col: float = state_tuple[1] / (self.cols - 1) if self.cols > 1 else 0.0normalized_state: List[float] = [norm_row, norm_col]return torch.tensor(normalized_state, dtype=torch.float32, device=device)def step(self, action: int) -> Tuple[torch.Tensor, float, bool]:"""根据给定的动作在环境中采取一步。参数:- action (int): 要采取的动作(0:上,1:下,2:左,3:右)。返回:- Tuple[torch.Tensor, float, bool]:- torch.Tensor: 采取动作后的归一化状态张量。- float: 采取动作的奖励。- bool: 是否结束(是否到达目标)。"""if self.state == self.goal_state:# 如果已经在目标位置,则返回当前状态且不给予奖励return self._get_state_tensor(self.state), 0.0, True# 根据动作确定下一个状态dr, dc = self.action_map[action]current_row, current_col = self.statenext_row, next_col = current_row + dr, current_col + dc# 初始化奖励并检查是否碰撞墙壁reward: float = -0.1 # 默认步罚hit_wall: bool = Falseif not (0 <= next_row < self.rows and 0 <= next_col < self.cols):# 如果下一个状态超出边界,则保持在当前状态next_row, next_col = current_row, current_colreward = -1.0 # 碰撞墙壁的惩罚hit_wall = True# 更新状态self.state = (next_row, next_col)next_state_tensor: torch.Tensor = self._get_state_tensor(self.state)# 检查是否到达目标状态done: bool = (self.state == self.goal_state)if done:reward = 10.0 # 到达目标的奖励return next_state_tensor, reward, donedef get_action_space_size(self) -> int:"""返回可能动作的数量。返回:- int: 动作数量(4 个,分别对应上、下、左、右)。"""return self.action_dimdef get_state_dimension(self) -> int:"""返回状态表示的维度。返回:- int: 状态的维度(2 个,对应 [行,列])。"""return self.state_dim
实例化并测试环境。
custom_env = GridEnvironment(rows=10, cols=10)
n_actions_custom = custom_env.get_action_space_size()
n_observations_custom = custom_env.get_state_dimension()print(f"自定义网格环境:")
print(f"大小:{custom_env.rows}x{custom_env.cols}")
print(f"状态维度:{n_observations_custom}")
print(f"动作维度:{n_actions_custom}")
print(f"起始状态:{custom_env.start_state}")
print(f"目标状态:{custom_env.goal_state}")
start_state_tensor = custom_env.reset()
print(f"示例状态张量(0,0):{start_state_tensor}")
自定义网格环境:
大小:10x10
状态维度:2
动作维度:4
起始状态:(0, 0)
目标状态:(9, 9)
示例状态张量(0,0):tensor([0., 0.])
实现 TRPO 算法
定义 Actor(策略网络)和 Critic(价值网络),然后是核心的 TRPO 函数。
定义策略网络(Actor)
输出动作概率(类似于 REINFORCE)。
# 定义策略网络(Actor)
class PolicyNetwork(nn.Module):""" 用于 TRPO 的 MLP Actor 网络 """def __init__(self, n_observations: int, n_actions: int):super(PolicyNetwork, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, n_actions)def forward(self, x: torch.Tensor) -> Categorical:"""前向传播,返回一个 Categorical 分布。参数:- x (torch.Tensor): 输入状态张量。返回:- Categorical: 一个动作上的分布对象。"""if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)if x.dim() == 1: # 如果需要,添加批次维度x = x.unsqueeze(0)x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))action_logits = self.layer3(x)# 返回一个分布对象,便于轻松进行采样和 log_prob 计算return Categorical(logits=action_logits)
定义价值网络(Critic)
输出一个单一值,表示估计的状态价值 V ( s ) V(s) V(s)。
# 定义价值网络(Critic)
class ValueNetwork(nn.Module):""" 用于 TRPO 的 MLP Critic 网络 """def __init__(self, n_observations: int):super(ValueNetwork, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, 1) # 输出一个单一值def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播,返回估计的状态价值。参数:- x (torch.Tensor): 输入状态张量。返回:- torch.Tensor: 估计的状态价值 $V(s)$。"""if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)if x.dim() == 1: # 如果需要,添加批次维度x = x.unsqueeze(0)x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))state_value = self.layer3(x)return state_value
计算 KL 散度
计算两个策略分布(由策略网络表示的 Categorical 分布)之间的平均 KL 散度。
def calculate_kl_divergence(old_policy_dist: Categorical, new_policy_dist: Categorical) -> torch.Tensor:"""计算两个 Categorical 分布之间的平均 KL 散度。KL(old || new) = sum(old_probs * (log(old_probs) - log(new_probs)))参数:- old_policy_dist (Categorical): 更新前的策略分布。- new_policy_dist (Categorical): 更新后的策略分布。返回:- torch.Tensor: 一个标量张量,表示平均 KL 散度。"""old_log_probs = old_policy_dist.logitsnew_log_probs = new_policy_dist.logitsold_probs = old_policy_dist.probs# 计算每个状态在批次中的 KL 散度kl = torch.sum(old_probs * (F.log_softmax(old_log_probs, dim=1) - F.log_softmax(new_log_probs, dim=1)), dim=1)# 返回批次中平均的 KL 散度return kl.mean()
计算广义优势估计(GAE)
使用奖励、完成标志和价值估计计算 GAE 优势。
def compute_gae(rewards: torch.Tensor, values: torch.Tensor, next_values: torch.Tensor, dones: torch.Tensor, gamma: float, lambda_gae: float, standardize: bool = True) -> torch.Tensor:"""计算广义优势估计(GAE)。参数:- rewards (torch.Tensor): 每一步的奖励张量。- values (torch.Tensor): 每一步的状态价值估计 $V(s_t)$。- next_values (torch.Tensor): 每一步的下一个状态价值估计 $V(s_{t+1})$。- dones (torch.Tensor): 每一步的完成标志张量。- gamma (float): 折扣因子。- lambda_gae (float): GAE 的 $\lambda$ 参数。- standardize (bool): 是否标准化优势。返回:- torch.Tensor: 每一步的 GAE 优势张量。"""advantages = torch.zeros_like(rewards)last_advantage = 0.0for t in reversed(range(len(rewards))):# 计算 TD 误差:$\delta_t = r_t + \gamma \cdot V(s_{t+1}) \cdot (1 - \text{done}_t) - V(s_t)$mask = 1.0 - dones[t] # 如果完成,则掩码为 0,否则为 1delta = rewards[t] + gamma * next_values[t] * mask - values[t]# 计算优势:$A_t = \delta_t + \gamma \cdot \lambda \cdot A_{t+1} \cdot (1 - \text{done}_t)$advantages[t] = delta + gamma * lambda_gae * last_advantage * masklast_advantage = advantages[t]# 标准化优势(可选但推荐)if standardize:mean_adv = torch.mean(advantages)std_adv = torch.std(advantages) + 1e-8 # 添加 epsilon 以确保稳定性advantages = (advantages - mean_adv) / std_advreturn advantages
计算费舍尔-向量乘积(FVP)
这是 TRPO 使用共轭梯度的关键函数。它计算 F v Fv Fv,其中 F F F 是 FIM, v v v 是一个任意向量,而不显式形成 F F F。
def fisher_vector_product(actor: PolicyNetwork, states: torch.Tensor, vector: torch.Tensor, cg_damping: float) -> torch.Tensor:"""计算费舍尔-向量乘积(Fvp)$Fv = H_{\text{KL}} v$,使用自动微分。包括阻尼:$(F + \text{damping} \cdot I)v = Fv + \text{damping} \cdot v$参数:- actor (PolicyNetwork): 策略网络(必须输出 Categorical 分布)。- states (torch.Tensor): 用于计算 KL 散度的批次状态。- vector (torch.Tensor): 要乘以 FIM 的向量 $v$。- cg_damping (float): 阻尼因子,添加到 FIM 的对角线上。返回:- torch.Tensor: 费舍尔-向量乘积 $(F + \text{damping} \cdot I)v$ 的结果。"""actor.zero_grad() # 确保梯度是新的# 获取给定状态下的策略分布(固定旧策略以进行 KL 计算)with torch.no_grad():old_policy_dist = actor(states) # 再次获取策略分布(这个将用于梯度计算)new_policy_dist = actor(states)# 计算平均 KL 散度 $KL(\text{old} || \text{new})$mean_kl = calculate_kl_divergence(old_policy_dist, new_policy_dist)# 计算 KL 散度关于网络参数的梯度# 梯度 = $d(\text{KL}) / d(\theta)$gradients = torch.autograd.grad(mean_kl, actor.parameters(), create_graph=True)flat_gradients = torch.cat([grad.view(-1) for grad in gradients])# 计算梯度与输入向量 $v$ 的点积# $gv = (d(\text{KL})/d(\theta))^T \cdot v$gv = torch.dot(flat_gradients, vector)# 计算点积关于网络参数的梯度# 这给出了 FVP:$Fv = d/d(\theta) [ (d(\text{KL})/d(\theta))^T \cdot v ]$fvp = torch.autograd.grad(gv, actor.parameters())flat_fvp = torch.cat([grad.contiguous().view(-1) for grad in fvp]) # 展平结果# 添加阻尼:$Fv + \text{damping} \cdot v$damped_fvp = flat_fvp + cg_damping * vectorreturn damped_fvp
实现共轭梯度算法
通过共轭梯度方法迭代求解线性系统 A x = b Ax = b Ax=b,其中 A A A 是 FIM(通过 FVP 隐式定义), x x x 是所需的步长方向 s s s,而 b b b 是策略梯度 g g g。
def conjugate_gradient(fvp_func: Callable[[torch.Tensor], torch.Tensor], b: torch.Tensor, cg_iters: int, residual_tol: float = 1e-10) -> torch.Tensor:"""使用共轭梯度方法求解线性系统 $Ax = b$。这里,$A$ 通过费舍尔-向量乘积函数 `fvp_func` 隐式定义。参数:- fvp_func (Callable): 一个函数,计算费舍尔-向量乘积 $Ax$(例如,$Fv$)。- b (torch.Tensor): 右侧向量(例如,策略梯度 $g$)。- cg_iters (int): 共轭梯度的最大迭代次数。- residual_tol (float): 基于残差范数的停止容忍度。返回:- torch.Tensor: $Ax = b$ 的近似解 $x$。"""x = torch.zeros_like(b) # 初始猜测解r = b.clone() # 初始残差($r = b - Ax$,当 $x=0$ 时)p = b.clone() # 初始搜索方向rdotr = torch.dot(r, r) # 残差的平方范数for i in range(cg_iters):Ap = fvp_func(p) # 计算费舍尔-向量乘积($A$ 对 $p$ 的作用)alpha = rdotr / (torch.dot(p, Ap) + 1e-8) # 计算步长(添加 epsilon 以确保稳定性)x += alpha * p # 更新解r -= alpha * Ap # 更新残差new_rdotr = torch.dot(r, r) # 计算新的平方残差范数# 检查是否收敛if torch.sqrt(new_rdotr) < residual_tol:break# 计算用于更新搜索方向的 $\beta$beta = new_rdotr / (rdotr + 1e-8) # 添加 epsilon 以确保稳定性p = r + beta * p # 更新搜索方向rdotr = new_rdotr # 存储新的平方残差范数return x
实现回溯线搜索
找到一个合适的步长,沿着 CG 计算的方向,满足 KL 约束条件,并改进替代目标。
def backtracking_line_search(actor: PolicyNetwork,states: torch.Tensor,actions: torch.Tensor,advantages: torch.Tensor,old_log_probs: torch.Tensor,step_direction: torch.Tensor,initial_step_size: float,max_kl: float,line_search_decay: float,max_line_search_iters: int) -> Tuple[Optional[torch.Tensor], bool]:"""执行回溯线搜索,以找到满足 KL 约束条件并确保非负替代优势改进的步长。参数:- actor (PolicyNetwork): 策略网络。- states (torch.Tensor): 批次状态。- actions (torch.Tensor): 批次中采取的动作。- advantages (torch.Tensor): 批次中计算的优势。- old_log_probs (torch.Tensor): 旧策略下的动作对数概率。- step_direction (torch.Tensor): 提议的更新方向(例如,来自 CG)。- initial_step_size (float): 要尝试的初始步长($\alpha$)。- max_kl (float): 允许的最大 KL 散度($\delta$)。- line_search_decay (float): 步长衰减因子($\beta < 1$)。- max_line_search_iters (int): 回溯步的最大次数。返回:- Tuple[Optional[torch.Tensor], bool]:- 接受的更新向量($\text{step_size} \cdot \text{step_direction}$),如果没有找到合适的步长,则返回 None。- 一个布尔值,指示是否找到了有效的步长。"""# 获取当前参数作为一个向量theta_old = parameters_to_vector(actor.parameters()).detach()# --- 计算在步长为 0 时的预期改进(用于检查改进) ---# grad_dot_step = $g^T s$(其中 $s=\text{step_direction}$)# 这需要策略梯度 $g$,它没有直接传递。# TRPO 通常使用替代目标的改进检查。# $L(\theta_{\text{new}}) - L(\theta_{\text{old}}) \ge 0$# $L(\theta_{\text{old}}) = \mathbb{E}[1 \cdot A] = \text{mean(Advantages)}$ ?? 不是,它在 $\theta=\theta_{\text{old}}$ 时为 0。# 所以我们需要检查 $L(\theta_{\text{new}}) \ge 0$ 大约成立。step_size = initial_step_sizewith torch.no_grad(): # 线搜索检查不需要梯度# 获取旧参数下的策略分布old_policy_dist = actor(states)for i in range(max_line_search_iters):# 计算提议的新参数theta_new_vec = theta_old + step_size * step_direction# 暂时更新 actor 网络参数以评估新策略vector_to_parameters(theta_new_vec, actor.parameters())# --- 检查 KL 散度约束条件 ---with torch.no_grad(): # 检查不需要梯度new_policy_dist = actor(states)kl_div = calculate_kl_divergence(old_policy_dist, new_policy_dist)# --- 检查替代目标的改进 ---# $L(\theta) = \mathbb{E}[\text{ratio} \cdot A]$with torch.no_grad():new_log_probs = new_policy_dist.log_prob(actions)ratio = torch.exp(new_log_probs - old_log_probs) surrogate_objective = torch.mean(ratio * advantages)# 恢复原始参数(如果找到合适的步长,稍后会更新)vector_to_parameters(theta_old, actor.parameters())# --- 检查是否满足约束条件 ---if kl_div <= max_kl and surrogate_objective >= 0: # 检查是否非负改进print(f" 线搜索:在 {i+1} 次迭代后找到步长 {step_size:.2e}。KL={kl_div:.2e}, 目标={surrogate_objective:.2e}")return step_size * step_direction, True # 返回接受的更新向量else:# print(f" LS 迭代 {i}: size={step_size:.2e}, KL={kl_div:.2e} (max={max_kl:.2e}), 目标={surrogate_objective:.2e}") # 调试pass# 如果未满足约束条件,则衰减步长step_size *= line_search_decayprint(f" 线搜索失败,经过 {max_line_search_iters} 次迭代。")return None, False # 没有找到合适的步长
TRPO 更新步骤
这个函数协调计算策略梯度、共轭梯度求解以及线搜索,以更新策略网络(actor)。
def update_policy_trpo(actor: PolicyNetwork,states: torch.Tensor,actions: torch.Tensor,advantages: torch.Tensor,old_log_probs: torch.Tensor,max_kl: float,cg_iters: int,cg_damping: float,line_search_decay: float,max_line_search_iters: int) -> Dict:"""执行策略网络(actor)的 TRPO 更新。返回:- Dict: 包含更新统计信息的字典(例如,最终的 KL 散度、目标值)。"""# --- 1. 计算策略梯度($g$) ---policy_dist = actor(states)log_probs = policy_dist.log_prob(actions)ratio = torch.exp(log_probs - old_log_probs) # $\pi_\theta(a|s) / \pi_{\theta_{\text{old}}}(a|s)$# 替代目标 $L = \mathbb{E}[\text{ratio} \cdot A]$# 我们需要梯度 $g = dL/d\theta | \theta_{\text{old}}$。这简化了,因为当 $\theta=\theta_{\text{old}}$ 时,比率等于 1。# $g = \mathbb{E}[d/d\theta(\log \pi(a|s)) \cdot A] | \theta_{\text{old}}$# 注意:PyTorch 需要一个标量来进行 backward()。我们计算损失 = $-\text{mean}(\log\_prob \cdot A_{\text{detached}})$# 以获得负梯度,然后将其取反。actor.zero_grad()policy_loss = -(policy_dist.log_prob(actions) * advantages.detach()).mean()policy_loss.backward()policy_gradient = parameters_to_vector([p.grad for p in actor.parameters()]).detach()actor.zero_grad() # 清除计算后的梯度# 策略梯度 $g$ 是 $-\text{policy_gradient}$,因为优化器最小化损失g = -policy_gradient if torch.isnan(g).any():print("警告:策略梯度包含 NaN。跳过更新。")return {'status': 'grad_nan', 'kl': -1, 'objective': -1}# --- 2. 定义 FVP 函数 ---# 需要一个闭包,用于 CG,捕获 actor、states 和 dampingdef fvp(vector):return fisher_vector_product(actor, states, vector, cg_damping)# --- 3. 使用共轭梯度求解 $Fs = g$ ---step_direction = conjugate_gradient(fvp, g, cg_iters)if torch.isnan(step_direction).any():print("警告:步长方向包含 NaN(CG 失败)。跳过更新。")return {'status': 'cg_nan', 'kl': -1, 'objective': -1}# --- 4. 计算初始步长 $\alpha = \sqrt{2\delta / s^T F s}$ ---s_dot_Fs = torch.dot(step_direction, fvp(step_direction)) # $s^T F s = s^T (F s)$if s_dot_Fs < 0: # 理论上应该是正定的,但阻尼有助于稳定print(f"警告:$s^T F s = {s_dot_Fs:.2e}$ 是负数。使用 $s^T F s = 0$。")s_dot_Fs = torch.tensor(0.0, device=device)# 处理这种情况:也许跳过更新或使用默认的小步长?# 当前,我们让初始步长变得很大/无穷大,线搜索应该能够处理它。initial_step_size = torch.sqrt(2 * max_kl / (s_dot_Fs + 1e-8)) # 添加 epsilon 以确保稳定性# --- 5. 执行回溯线搜索 ---final_update_vec, success = backtracking_line_search(actor, states, actions, advantages, old_log_probs,step_direction, initial_step_size, max_kl, line_search_decay, max_line_search_iters)# --- 6. 更新策略网络参数 ---final_kl = -1final_obj = -1if success and final_update_vec is not None:theta_old = parameters_to_vector(actor.parameters()).detach()theta_new_vec = theta_old + final_update_vecvector_to_parameters(theta_new_vec, actor.parameters()) # 应用更新# 可选地计算最终的 KL 和目标值以供记录with torch.no_grad():old_dist = actor(states) # 需要重新计算旧分布,因为参数可能在回溯线搜索之前已经更新old_dist = Categorical(logits=old_dist.logits.detach()) # 分离旧的 logitsnew_dist = actor(states)final_kl = calculate_kl_divergence(old_dist, new_dist).item()new_log_probs_final = new_dist.log_prob(actions)ratio_final = torch.exp(new_log_probs_final - old_log_probs)final_obj = torch.mean(ratio_final * advantages).item()status = 'success'else:status = 'line_search_failed'return {'status': status, 'kl': final_kl, 'objective': final_obj}
价值函数优化步骤
使用 MSE 损失更新 Critic 网络。
def update_value_function(critic: ValueNetwork,critic_optimizer: optim.Optimizer,states: torch.Tensor,returns_to_go: torch.Tensor,num_epochs: int) -> float:"""更新价值函数(Critic)网络。参数:- critic (ValueNetwork): 价值网络。- critic_optimizer (optim.Optimizer): 价值网络的优化器。- states (torch.Tensor): 批次状态。- returns_to_go (torch.Tensor): 批次目标值(例如,经验回报)。- num_epochs (int): 在批次上进行更新的轮数。返回:- float: 更新轮数上的平均损失。"""total_loss = 0.0for _ in range(num_epochs):# 预测状态的价值predicted_values = critic(states).squeeze() # 确保形状与目标匹配# 计算 MSE 损失loss = F.mse_loss(predicted_values, returns_to_go)# 优化 Criticcritic_optimizer.zero_grad()loss.backward()critic_optimizer.step()total_loss += loss.item()return total_loss / num_epochs
运行 TRPO 算法
设置超参数,初始化网络和优化器,然后运行 TRPO 训练循环。
超参数设置
TRPO 需要仔细调整其特定的参数。
# TRPO 在自定义网格世界上的超参数
GAMMA_TRPO = 0.99 # 折扣因子
GAE_LAMBDA = 0.97 # GAE 的 $\lambda$ 参数
MAX_KL = 0.01 # KL 散度约束($\delta$)
CG_ITERS = 10 # 共轭梯度的最大迭代次数
CG_DAMPING = 0.1 # FVP 的阻尼因子
LINE_SEARCH_DECAY = 0.8 # 线搜索的步长衰减因子($\beta$)
MAX_LINE_SEARCH_ITERS = 10 # 线搜索的最大迭代次数
CRITIC_LR = 1e-3 # Critic 的学习率
CRITIC_EPOCHS = 10 # 每次策略更新时 Critic 的训练轮数
STANDARDIZE_ADV = True # 是否标准化优势NUM_ITERATIONS_TRPO = 150 # TRPO 迭代次数(策略更新次数)
STEPS_PER_ITERATION = 1000 # 每次迭代收集的环境步数
MAX_STEPS_PER_EPISODE_TRPO = 200 # 每次迭代中每集的最大步数
初始化
初始化 Actor(策略网络)、Critic(价值网络)以及 Critic 的优化器。
# 重新实例化环境
custom_env: GridEnvironment = GridEnvironment(rows=10, cols=10)
n_actions_custom: int = custom_env.get_action_space_size()
n_observations_custom: int = custom_env.get_state_dimension()# 初始化 Actor(策略网络)和 Critic(价值网络)
actor: PolicyNetwork = PolicyNetwork(n_observations_custom, n_actions_custom).to(device)
critic: ValueNetwork = ValueNetwork(n_observations_custom).to(device)# 初始化 Critic 的优化器
critic_optimizer: optim.Adam = optim.Adam(critic.parameters(), lr=CRITIC_LR)# 用于绘图的列表
iteration_rewards = []
iteration_avg_ep_lens = []
iteration_critic_losses = []
iteration_kl_divs = []
iteration_surr_objs = []
训练循环
TRPO 循环涉及收集一批数据,计算优势,通过 CG+线搜索更新策略,以及更新价值函数。
print("开始在自定义网格世界上训练 TRPO...")# --- TRPO 训练循环 ---
for iteration in range(NUM_ITERATIONS_TRPO):# --- 1. 收集轨迹(Rollout 阶段) ---batch_states: List[torch.Tensor] = []batch_actions: List[int] = []batch_log_probs_old: List[torch.Tensor] = []batch_rewards: List[float] = []batch_next_states: List[torch.Tensor] = []batch_dones: List[float] = [] # 用于后续掩码,存储为浮点数episode_rewards_in_iter: List[float] = []episode_lengths_in_iter: List[int] = []steps_collected = 0while steps_collected < STEPS_PER_ITERATION:state = custom_env.reset()episode_reward = 0.0for t in range(MAX_STEPS_PER_EPISODE_TRPO):state_tensor = state # 环境已经返回张量形式的状态# 根据当前策略采样动作with torch.no_grad(): # 在 rollout 过程中不需要梯度policy_dist = actor(state_tensor)action_tensor = policy_dist.sample()action = action_tensor.item()log_prob_old = policy_dist.log_prob(action_tensor)# 存储数据batch_states.append(state_tensor)batch_actions.append(action)batch_log_probs_old.append(log_prob_old)# 与环境交互next_state, reward, done = custom_env.step(action)batch_rewards.append(reward)batch_next_states.append(next_state)batch_dones.append(float(done)) # 将完成标志存储为浮点数(0.0 或 1.0)state = next_stateepisode_reward += rewardsteps_collected += 1if done or steps_collected >= STEPS_PER_ITERATION:episode_rewards_in_iter.append(episode_reward)episode_lengths_in_iter.append(t + 1)break# --- Rollout 阶段结束 ---# 将列表转换为张量states_tensor = torch.stack(batch_states).to(device)actions_tensor = torch.tensor(batch_actions, dtype=torch.long, device=device)log_probs_old_tensor = torch.stack(batch_log_probs_old).to(device)rewards_tensor = torch.tensor(batch_rewards, dtype=torch.float32, device=device)next_states_tensor = torch.stack(batch_next_states).to(device)dones_tensor = torch.tensor(batch_dones, dtype=torch.float32, device=device)# --- 2. 估计价值和优势 ---with torch.no_grad():values_tensor = critic(states_tensor).squeeze()next_values_tensor = critic(next_states_tensor).squeeze()advantages_tensor = compute_gae(rewards_tensor, values_tensor, next_values_tensor, dones_tensor, GAMMA_TRPO, GAE_LAMBDA, standardize=STANDARDIZE_ADV)# 计算用于 Critic 更新的回报(目标 = $A_{\text{gae}} + V_{\text{old}}$)returns_to_go_tensor = advantages_tensor + values_tensor.detach()# --- 3. 使用 TRPO 更新策略(Actor) ---update_stats = update_policy_trpo(actor, states_tensor, actions_tensor, advantages_tensor, log_probs_old_tensor.detach(),MAX_KL, CG_ITERS, CG_DAMPING, LINE_SEARCH_DECAY, MAX_LINE_SEARCH_ITERS)# --- 4. 更新价值函数(Critic) ---critic_loss = update_value_function(critic, critic_optimizer, states_tensor, returns_to_go_tensor.detach(), CRITIC_EPOCHS)# --- 记录和统计 ---avg_reward_iter = np.mean(episode_rewards_in_iter) if episode_rewards_in_iter else np.nanavg_len_iter = np.mean(episode_lengths_in_iter) if episode_lengths_in_iter else np.naniteration_rewards.append(avg_reward_iter)iteration_avg_ep_lens.append(avg_len_iter)iteration_critic_losses.append(critic_loss)iteration_kl_divs.append(update_stats['kl'])iteration_surr_objs.append(update_stats['objective'])# 打印进度if (iteration + 1) % 10 == 0:print(f"迭代 {iteration+1}/{NUM_ITERATIONS_TRPO} | 步数:{steps_collected} | 平均奖励:{avg_reward_iter:.2f} | 平均长度:{avg_len_iter:.1f} | KL:{update_stats['kl']:.2e} | Critic 损失:{critic_loss:.4f} | 状态:{update_stats['status']}")print("自定义网格世界训练完成(TRPO)。")
可视化学习过程
绘制 TRPO 代理的结果。我们绘制每次迭代的平均奖励。
# 绘制自定义网格世界 TRPO 的结果
plt.figure(figsize=(20, 4))# 每次迭代的平均奖励
plt.subplot(1, 3, 1)
valid_rewards = [r for r in iteration_rewards if not np.isnan(r)]
valid_indices = [i for i, r in enumerate(iteration_rewards) if not np.isnan(r)]
plt.plot(valid_indices, valid_rewards)
plt.title('TRPO 自定义网格:每次迭代的平均奖励')
plt.xlabel('迭代次数')
plt.ylabel('平均奖励')
plt.grid(True)
# 如果数据足够,添加移动平均值
if len(valid_rewards) >= 10:rewards_ma_trpo = np.convolve(valid_rewards, np.ones(10)/10, mode='valid')plt.plot(valid_indices[9:], rewards_ma_trpo, label='10 次迭代的移动平均值', color='orange')plt.legend()# 每次迭代的平均回合长度
plt.subplot(1, 3, 2)
valid_lens = [l for l in iteration_avg_ep_lens if not np.isnan(l)]
valid_indices_len = [i for i, l in enumerate(iteration_avg_ep_lens) if not np.isnan(l)]
plt.plot(valid_indices_len, valid_lens)
plt.title('TRPO 自定义网格:每次迭代的平均回合长度')
plt.xlabel('迭代次数')
plt.ylabel('平均步数')
plt.grid(True)
if len(valid_lens) >= 10:lens_ma_trpo = np.convolve(valid_lens, np.ones(10)/10, mode='valid')plt.plot(valid_indices_len[9:], lens_ma_trpo, label='10 次迭代的移动平均值', color='orange')plt.legend()# 每次迭代的 Critic 损失
plt.subplot(1, 3, 3)
plt.plot(iteration_critic_losses)
plt.title('TRPO 自定义网格:每次迭代的 Critic 损失')
plt.xlabel('迭代次数')
plt.ylabel('MSE 损失')
plt.grid(True)
if len(iteration_critic_losses) >= 10:loss_ma_trpo = np.convolve(iteration_critic_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(loss_ma_trpo)) + 9, loss_ma_trpo, label='10 次迭代的移动平均值', color='orange')plt.legend()plt.tight_layout()
plt.show()# 绘制 KL 散度和替代目标(可选 - 检查稳定性)
plt.figure(figsize=(15, 3))
plt.subplot(1, 2, 1)
plt.plot(iteration_kl_divs)
plt.hlines(MAX_KL, 0, len(iteration_kl_divs), linestyles='dashed', colors='r', label=f'最大 KL ({MAX_KL})')
plt.title('TRPO 实际 KL 散度每次迭代')
plt.xlabel('迭代次数')
plt.ylabel('平均 KL')
plt.legend()
plt.grid(True)plt.subplot(1, 2, 2)
plt.plot(iteration_surr_objs)
plt.hlines(0, 0, len(iteration_surr_objs), linestyles='dashed', colors='r', label='零改进')
plt.title('TRPO 替代目标每次迭代')
plt.xlabel('迭代次数')
plt.ylabel('平均替代目标')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()

分析 TRPO 学习曲线(自定义网格世界):
学习曲线为 TRPO 代理在自定义网格世界环境中的性能和行为提供了深刻的见解。
-
平均奖励曲线:
- 观察结果: 该曲线显示了明显的正向学习趋势。每次迭代的平均奖励从较低的值开始,在最初的约 40 次迭代中迅速增加,随后迅速趋于平稳,接近该环境可能获得的最大奖励范围(大约在 8 到 9 之间,考虑到到达目标的 +10 奖励和较小的步罚)。10 次迭代的移动平均值平滑了固有的噪声,证实了这种强劲的上升趋势和在高奖励水平的稳定状态。
- 解释: 这表明了成功的学习。代理有效地学习了一种策略,以导航至目标状态,最大化其累积奖励。相对平稳的增加且没有显著的下降表明了 TRPO 的特征稳定性,避免了在更简单的策略梯度方法中经常看到的灾难性策略崩溃。快速的收敛表明该算法高效地为这个相对简单的任务找到了一个良好的策略。
-
平均回合长度曲线:
- 观察结果: 与奖励曲线相辅相成,平均回合长度从较高的值(接近最大允许步数)开始,在最初的 30 到 40 次迭代中急剧下降。随后稳定在一个非常低的平均长度(大约 18 步),这对应于在 10x10 网格中从起点到终点的最优路径长度(9 步向右,9 步向下)。此后一直保持稳定。
- 解释: 这证实了代理不仅到达了目标,而且高效地做到了这一点。它迅速学会了避免不必要的步骤和潜在的墙壁碰撞,找到了近乎最优的路径。回合长度的快速下降与奖励的快速增加相一致。
-
Critic 损失曲线:
- 观察结果: Critic 网络的均方误差(MSE)损失显示出了一个令人满意的趋势。它从较高的值开始,在早期迭代中大幅下降,最终在一个相对较低的值处波动。移动平均值突出了整体的损失降低趋势。
- 解释: 这表明价值网络(Critic)有效地学习了近似状态价值函数(特别是,从 GAE 导出的目标回报)。准确的价值估计对于计算低方差的优势估计至关重要,而这些优势估计反过来又指导策略更新。损失的稳定表明 Critic 已经收敛到了一个合理的近似值,用于学习到的策略的价值函数。
-
实际 KL 散度图:
- 观察结果: 该图似乎存在问题,很可能表明日志记录或频繁更新存在问题。大多数记录的 KL 散度值为负(大约为 -1.0)。根据定义,KL 散度必须是非负的。预期的行为是 KL 散度为正,但保持在
MAX_KL阈值(0.01,用红色虚线表示)以下。偶尔出现的接近零的峰值可能代表线搜索 成功 的迭代,并且记录了一个有效且非负的 KL 值。 - 解释: 记录的
final_kl值主要为负(大约为 -1.0)强烈表明,在大多数迭代中,backtracking_line_search函数未能找到一个既满足 KL 约束条件(kl_div <= max_kl),又满足替代目标改进(surrogate_objective >= 0)的步长。尽管如此,代理 确实 学习到了,这意味着 某些 更新必须是成功的。该图未能准确地表示所有迭代中约束条件的满足情况。
- 观察结果: 该图似乎存在问题,很可能表明日志记录或频繁更新存在问题。大多数记录的 KL 散度值为负(大约为 -1.0)。根据定义,KL 散度必须是非负的。预期的行为是 KL 散度为正,但保持在
-
替代目标图:
- 观察结果: 与 KL 图类似,该图主要显示值为 -1.0,偶尔出现正值。红色虚线在零处表示替代目标的理论基线,即可以接受的改进。
- 解释: 这进一步证实了 KL 图的解释。记录的
final_obj很可能在失败的迭代中默认为 -1。偶尔出现的正值代表成功的更新,其中选择的步长导致替代目标发生了非负(或正)的变化,满足了线搜索条件的一部分。频繁记录的 -1 值表明,共轭梯度提出的许多更新步骤被线搜索拒绝,可能表明效率低下(许多迭代没有改变策略)或者线搜索参数/检查过于保守。
总体结论:
尽管 KL 散度和替代目标的诊断图表明在实现的处理或记录线搜索结果方面存在问题,但 TRPO 代理成功地学习了自定义网格世界的高效策略,这一点从出色的奖励和回合长度曲线以及收敛的 Critic 损失中可以看出。尽管如此,算法的内在稳定性机制可能阻止了灾难性的更新,从而使得代理最终收敛到了一个良好的策略。
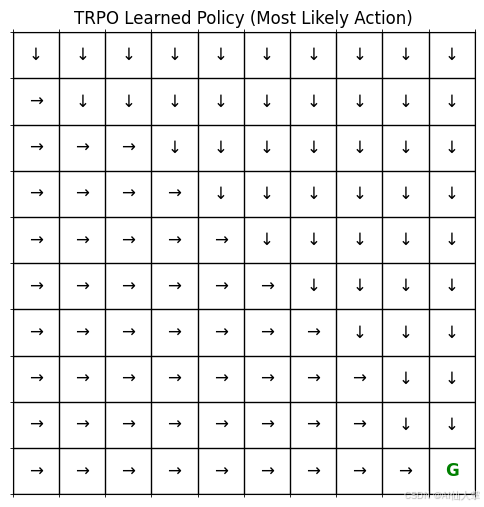
分析学习到的策略(可选可视化)
可视化 TRPO Actor 网络在网格上学习到的策略。
def plot_trpo_policy_grid(policy_net: PolicyNetwork, env: GridEnvironment, device: torch.device) -> None:"""绘制 TRPO 策略网络推导出的贪婪策略。显示每个状态最有可能采取的动作。(与 REINFORCE 绘图函数完全相同,只是为了上下文重新命名)"""rows: int = env.rowscols: int = env.colspolicy_grid: np.ndarray = np.empty((rows, cols), dtype=str)action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'}fig, ax = plt.subplots(figsize=(cols * 0.6, rows * 0.6))for r in range(rows):for c in range(cols):state_tuple: Tuple[int, int] = (r, c)if state_tuple == env.goal_state:policy_grid[r, c] = 'G'ax.text(c, r, 'G', ha='center', va='center', color='green', fontsize=12, weight='bold')else:state_tensor: torch.Tensor = env._get_state_tensor(state_tuple)with torch.no_grad():# 策略网络现在返回一个分布对象action_dist: Categorical = policy_net(state_tensor)# 选择概率最高的动作(贪婪动作)best_action: int = action_dist.probs.argmax(dim=1).item()policy_grid[r, c] = action_symbols[best_action]ax.text(c, r, policy_grid[r, c], ha='center', va='center', color='black', fontsize=12)ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1)ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])ax.set_title("TRPO 学习到的策略(最有可能的动作)")plt.show()# 绘制 TRPO Actor 学习到的策略
print("\n绘制 TRPO 学习到的策略:")
plot_trpo_policy_grid(actor, custom_env, device)
TRPO 的常见挑战及解决方案
挑战:实现复杂性
- 问题: 计算 FVP、实现共轭梯度以及执行线搜索的正确实现难度较大,容易出错。
- 解决方案:
- 使用现有库: 可靠的实现存在于 Stable-Baselines3 或 Tianshou 等库中(尽管这违反了本练习的“基本库”约束)。
- 近端策略优化(PPO): PPO 是 TRPO 的一个更简单的替代方案,通常在不进行严格的二阶计算和复杂的线搜索的情况下,能够实现与 TRPO 相当的性能。
挑战:计算成本
- 问题: 共轭梯度需要每次策略更新时进行多次 FVP 计算,而每次 FVP 都涉及反向传播。线搜索还会增加额外的计算量。
解决方案:- 调整 CG 迭代次数: 减少共轭梯度的迭代次数(在步长方向的准确性与速度之间进行权衡)。
- 并行 rollout: 使用多个工作进程并行收集轨迹,以分摊更新成本(在大规模强化学习中是标准做法)。
- 考虑 PPO: PPO 的更新通常速度更快。
挑战:调整超参数
- 问题: TRPO 引入了几个敏感的超参数( δ \delta δ、 λ \lambda λ、阻尼、线搜索参数)。
解决方案:- 使用常见默认值: 从已知对类似问题有效的值开始(例如, δ = 0.01 \delta=0.01 δ=0.01、 λ = 0.97 \lambda=0.97 λ=0.97、
cg_damping=0.1)。 - 系统性调整: 如有必要,使用超参数优化技术,尽管这计算成本较高。
- 使用常见默认值: 从已知对类似问题有效的值开始(例如, δ = 0.01 \delta=0.01 δ=0.01、 λ = 0.97 \lambda=0.97 λ=0.97、
挑战:on-policy 样本效率低下
- 问题: 与 REINFORCE 一样,TRPO 是 on-policy 的,在每次更新后丢弃数据。
解决方案:- 增加批次大小: 每次迭代收集更多数据(
STEPS_PER_ITERATION),以使每次更新更具代表性。 - off-policy 方法: 如果样本效率至关重要,可以考虑 off-policy 的 actor-critic 方法(例如,DDPG、SAC、TD3),尽管它们也有自己的挑战。
- 增加批次大小: 每次迭代收集更多数据(
结论
信任区域策略优化(TRPO)是策略梯度方法的一个重要的理论进步,引入了使用 KL 散度限制策略更新的想法,以确保更稳定和可靠的学习。通过利用二阶信息(通过 FIM 和共轭梯度近似)以及谨慎的步长选择(通过线搜索),TRPO 旨在实现策略性能的单调改进。
尽管其实现比简单的 REINFORCE 或 DQN 更为复杂,而且已经被更简单的 PPO 算法所取代,但理解 TRPO 提供了对策略优化挑战以及现代 actor-critic 算法背后原理的宝贵见解。它强调了在复杂强化学习任务中控制策略变化以实现稳定学习的重要性。
相关文章:

信赖域策略优化TRPO算法详解:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
)
powershell_bypass.cna 插件(适配 Cobalt Strike 4.0 的免费版本下载地址)
目录 1. powershell_bypass.cna 插件(适配 Cobalt Strike 4.0 的免费版本下载地址) 2. 生成 EXE 文件时出现 "运行异常,请查看 Script Console" 的处理方法 处理步骤 3. powershell_bypass.cna 插件的功能及实际操作步骤 功能…...

从Dockerfile 构建docker镜像——保姆级教程
从Dockfile开始 dockerfile简介开始构建1、编辑dockerfile2、构建镜像3、拉取镜像4、推送到镜像仓库 镜像的优化1、优化的基本原则2、多阶段构建 dockerfile简介 开始构建 1、编辑dockerfile # 使用官方的 Python 3.8 镜像作为基础镜像 FROM python:3.8-slim# 设置工作目录 …...
)
Mac配置php开发环境(多PHP版本,安装Redis)
配置PHP开发环境 配置多版本PHP 因为开发需要,有时需要根据项目及时切换多个版本,除了使用Docker以外,常用的就是直接在mac配置PHP版本 使用 Homebrew Mac 可以通过 Homebrew 来安装或切换 PHP 版本: brew update brew insta…...

Quorum协议原理与应用详解
一、Quorum 协议核心原理 基本定义 Quorum 是一种基于 读写投票机制 的分布式一致性协议,通过权衡一致性(C)与可用性(A)实现数据冗余和最终一致性。其核心规则为: W(写成功副本数) …...

五一旅游潮涌:数字化如何驱动智慧旅游升级
文化和旅游部5月6日公布2025年“五一”假期文化和旅游市场情况,经文化和旅游部数据中心测算,假期5天,全国国内出游3.14亿人次,同比增长6.4%;国内游客出游总花费1802.69亿元,同比增长8.0%。在这组流动的数字…...

WPF 3D图形编程核心技术解析
一、三维坐标系系统 WPF采用右手坐标系系统,空间定位遵循: X 轴 → 右 Y 轴 → 上 Z 轴 → 观察方向 X轴 \rightarrow 右\quad Y轴 \rightarrow 上\quad Z轴 \rightarrow 观察方向 X轴→右Y轴→上Z轴→观察方向 三维坐标值表示为 ( x , y , z ) (x, y,…...

BLURRR剪辑软件免费版:创意剪辑,轻松上手,打造个性视频
BLURRR剪辑软件免费版是一款功能强大、简约易用且充满创意的视频剪辑软件。它集多种功能于一体,无论是新手还是资深用户,都能通过简单的操作剪辑出高质量、富有创意的视频。BLURRR不仅提供了丰富的剪辑工具,还划分了不同的内容模块࿰…...

TIME - MoE 模型代码 3.2——Time-MoE-main/time_moe/datasets/time_moe_dataset.py
源码:GitHub - Time-MoE/Time-MoE: [ICLR 2025 Spotlight] Official implementation of "Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts" 这段代码定义了一个用于时间序列数据处理的 TimeMoEDataset 类,支…...
——正确使用索引)
解决SQL Server SQL语句性能问题(9)——正确使用索引
前述章节中,我们介绍和讲解了SQL调优所需要的基本知识和分析方法,那么,通过前述这些知识和方法定位到问题后,接下来,我们该怎么做呢?那就是本章的内容,给出解决SQL语句性能问题的、科学而合理的方案和方法。 本章主要对解决SQL语句性能问题的几种常用方法进行说明和讲解…...

【论文阅读】FreePCA
FreePCA: Integrating Consistency Information across Long-short Frames in Training-free Long Video Generation via Principal Component Analysis 原文摘要 问题背景 核心挑战: 长视频生成通常依赖在短视频上训练的模型,但由于视频帧数增加会导致数…...

leetcode 383. Ransom Note
题目描述 代码 class Solution { public:bool canConstruct(string ransomNote, string magazine) {vector<int> table(26,0);for(char ch : magazine){table[ch-a];}for(char ch : ransomNote){table[ch-a]--;if(table[ch-a] < 0)return false;}return true;} };...

SAF利用由Varjo和AFormX开发的VR/XR模拟器推动作战训练
通过将AFormX的先进军用飞行模拟器与Varjo的行业领先的VR/XR硬件相结合,斯洛文尼亚武装部队正以经济高效、沉浸式的训练方式培训战斗机飞行员,以提高其战术准备和作战效率。 挑战:获得战术军事航空训练的机会有限 军事航空训练长期以来一直…...

基于公共卫生大数据收集与智能整合AI平台构建测试:从概念到实践
随着医疗健康数据的爆发式增长,如何有效整合、分析和利用这些数据已成为公共卫生领域的重要挑战。传统方法往往难以应对数据的复杂性、多样性和海量性,而人工智能技术的迅猛发展为解决这些挑战提供了新的可能性。基于数据整合与公共卫生大数据的AI平台旨在构建一个全面的生态…...

【Pandas】pandas DataFrame clip
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.clip([lower, upper, axis, inplace])用于截…...
)
深度学习基础--目标检测常见算法简介(R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN、SSD、YOLO)
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C,go语言的世界;在迷茫中寻找光芒🌸 博客主页:羊小猪~~-CSDN博客 内容简介:常见目标检测算法简介…...

嵌套路由~
### 作业 - App.vue vue <script setup></script> <template> <router-link to"/home">首页</router-link> <router-link to"/profile">个人资料</router-link> <router-link to"/posts"&g…...

影楼精修-牙齿美型修复算法解析
本文介绍影楼修图中的牙齿美型修复功能的算法实现。 我们大部分人的牙齿看起来都可能会有一些问题,比如牙齿不平整,大门牙,牙齿泛黄,牙齿发黑,牙齿残缺等等,拍照之后影响美观度,正是这个爱美的…...

k8s之ingress
在前面我们已经知道,Service对集群之外暴露服务的主要方式有两种:NodePort 和 LoadBalance,但是这两种方式,都有一定的缺点 NodePort方式的缺点是会占用很多集群机器的端口,那么当集群服务变多的时候,这个缺点就更加明显,L4转发,无法根据http header和path进行路由转发…...

PDF文档解析新突破:图表识别、公式还原、手写字体处理,让AI真正读懂复杂文档!
要想LLM大模型性能更佳,我们需要喂给模型看得懂的高质量数据。那有没有一种方法,能让我们把各种文档“读懂”,再喂给大模型使用呢? 如果你用传统OCR工具直接从PDF中提取文本,结果往往是乱序、缺失、格式错乱。因为实际…...

Ubuntu 第11章 网络管理_常用的网络配置命令
为了管理网络,Linux提供了许多非常有用的网络管理命令。利用这些命令,一方面可以有效地管理网络,另一方面出现网络故障时,可以快速进行诊断。本节将对Ubuntu提供的网络管理命令进行介绍。 11.2.1 ifconfig命令 关于ifconfig命令&…...

C++ 观察者模式详解
观察者模式(Observer Pattern)是一种行为设计模式,它定义了对象间的一对多依赖关系,当一个对象(主题)状态改变时,所有依赖它的对象(观察者)都会自动得到通知并更新。 核…...

不止是UI库:React如何重塑前端开发范式?
React:引领现代前端开发的声明式UI库 在当今快速发展的前端世界,React以其声明式、组件化和高效的特性,稳坐头把交椅,成为构建交互式用户界面的首选JavaScript库。本文将带你快速了解React的核心魅力、主要优势以及生态发展&…...

MapReduce报错 HADOOP_HOME and hadoop.home.dir are unset.
运行课程讲解内容出现这个报错: 1、在电脑里解压之前发过的Hadoop安装包 2、配置用户变量 3、配置系统变量 4、配置系统Path变量 5、下载链接的两个文件: 链接: https://pan.baidu.com/s/1aCcpGGR1EE4hEZW624rFmQ?pwd56tv 提取码: 56tv –来自百度…...

深入探索Laravel框架中的Blade模板引擎
Laravel是一个广泛使用的PHP框架,以其简洁、优雅和强大的功能著称。Blade是Laravel内置的模板引擎,提供了一套简洁而强大的模板语法,帮助开发者轻松构建视图层。本文将深入探讨Blade模板引擎的特性、使用方法和最佳实践。 1. Blade模板引擎简…...

分析NVIDIA的股价和业绩暴涨的原因
NVIDIA自2016年以来股价与业绩的持续高增长,是多重因素共同作用的结果。作为芯片行业的领军企业,NVIDIA抓住了技术、战略、市场与行业趋势的机遇。以下从技术创新、战略布局、市场需求、财务表现及外部环境等维度,深入分析其成功原因…...

P2572 [SCOI2010] 序列操作 Solution
Description 给定 01 01 01 序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),并定义 f ( l , r ) [ ( ∑ i l r a i ) r − l 1 ] f(l,r)[(\sum\limits_{il}^r a_i)r-l1] f(l,r)[(il∑rai)r−l1]. 执行 m m m 个操作&am…...

初等数论--欧拉函数积性的证明
文章目录 1. 简介2. 证明一:唯一分解定理容斥原理3. 证明二:中国剩余定理4. 引理证明5. 参考 1. 简介 欧拉函数 ϕ ( n ) \phi(n) ϕ(n)表示在小于等于 n n n的正整数中与 n n n互质的个数。 如 ϕ ( 6 ) 2 ( 1 5 ) ϕ ( 12 ) 4 ( 1 5 7 11 ) \phi(…...
是专为LLM(大语言模型)应用设计的标准化协议)
MCP(Model Context Protocol)是专为LLM(大语言模型)应用设计的标准化协议
核心定义 MCP(Model Context Protocol)是专为LLM(大语言模型)应用设计的标准化协议,通过安全可控的方式向AI应用暴露数据和功能。主要提供以下能力: 标准化的上下文管理安全的功能调用接口跨平台的数据交…...

Midscene.js Chrome 插件实战:AI 驱动的 UI 自动化测试「喂饭教程」
Midscene.js Chrome 插件实战:AI 驱动的 UI 自动化测试「喂饭教程」 前言一、Midscene.js 简介二、环境准备与插件安装1. 安装 Chrome 插件2. 配置模型与 API Key三、插件界面与功能总览四、实战演练:用自然语言驱动网页自动化1. 典型场景一(Action):账号登录步骤一:打开…...

Python在大数据机器学习模型的多模态融合:深入探索与实践指南
一、多模态融合的全面概述 1.1 多模态融合的核心概念 多模态融合(Multimodal Fusion)是指将来自不同传感器或数据源(如图像、文本、音频、视频、传感器数据等)的信息进行有效整合,以提升机器学习模型的性能和鲁棒性。在大数据环境下,多模态融合面临着独特的挑战和机遇: 数…...

C++ 访问者模式详解
访问者模式(Visitor Pattern)是一种行为设计模式,它允许你将算法与对象结构分离,使得可以在不修改现有对象结构的情况下定义新的操作。 核心概念 设计原则 访问者模式遵循以下设计原则: 开闭原则:可以添…...
)
实验-有限状态机2(数字逻辑)
目录 一、实验内容 1.1 介绍 1.2 内容 二、实验步骤 2.1 电路原理图 2.2 步骤 2.3 状态图 4.4 状态转换表和输出表 2.5 具体应用场景 三、调试 四、实验使用环境 五、实验小结与思考 5.1 遇到的问题及解决方法 5.2 实验收获 一、实验内容 1.1 介绍 在解决更复…...
)
IC解析之TPS92682-Q1(汽车LED灯控制IC)
目录 1 IC特性介绍2 主要参数3 接口定义4 工作原理分析TPS92682-Q1架构工作模式典型应用通讯协议 控制帧应答帧协议5 总结 1 IC特性介绍 TPS92682 - Q1 是德州仪器(TI)推出的一款双通道恒压横流控制器,同时还具有各种电器故障保护,…...

数据结构-堆
目录 heapq 导入 初始化 插入元素 返回最小值 PriorityQueue 导入 初始化 入队 出队 堆是一颗树,其每个节点都有一个值,且(小根堆:每个父节点都小于等于其子节点 (在进树时不断进行比较 STL中的 priority…...

提升编程效率的利器:Zed高性能多人协作代码编辑器
在当今这个快节奏的开发环境中,一个高效、灵活的代码编辑器无疑对开发者们起着至关重要的支持作用。Zed,作为来自知名编辑器Atom和语法解析器Tree-sitter的创造者的心血之作,正是这样一款高性能支持多人合作的编辑神器。本文将带领大家深入探…...
网络安全基础)
【25软考网工】第六章 网络安全(1)网络安全基础
博客主页: christine-rr-CSDN博客 专栏主页: 软考中级网络工程师笔记 大家好,我是christine-rr !目前《软考中级网络工程师》专栏已经更新二十多篇文章了,每篇笔记都包含详细的知识点,希望能帮助到你! 今日…...

Java中的包装类
目录 为什么要有包装类 包装类的作用 基本数据类型和包装类的对应关系 包装类的核心功能 装箱(Boxing)和拆箱(Unboxing) 装箱: 拆箱: 类型转换 字符串<----->基本类型 进制转换 自动装箱与…...

催缴机器人如何实现停车费追缴“零遗漏”?
面对高达35%的停车欠费率,传统人工催缴模式因效率低、成本高、覆盖有限等问题,难以应对海量欠费订单的挑战。本文带大家探究“催缴机器人”如何实现停车费追缴“零遗漏”,实现从“被动催缴”到“主动管理”的跨越。 智慧停车欠费自动化追缴系…...

Oracle 执行计划中的 ACCESS 和 FILTER 详解
Oracle 执行计划中的 ACCESS 和 FILTER 详解 在 Oracle 执行计划中,ACCESS 和 FILTER 是两个关键的操作类型,它们描述了 Oracle 如何检索和处理数据。理解这两个概念对于 SQL 性能调优至关重要。 ACCESS(访问) ACCESS 表示 Ora…...

使用FastAPI微服务在AWS EKS中构建上下文增强型AI问答系统
系统概述 本文介绍如何使用FastAPI在AWS Elastic Kubernetes Service (EKS)上构建一个由多个微服务组成的AI问答系统。该系统能够接收用户输入的提示(prompt),通过调用其他微服务从AWS ElastiCache on Redis和Amazon DynamoDB获取相关上下文,然后利用AW…...

oracle dblink varchar类型查询报错记录
在使用Oracle DBLink(数据库链接)查询VARCHAR类型数据时,有时会遇到报错问题。这些错误可能与数据类型转换、字符集设置、数据库版本兼容性等因素有关。本文将详细分析常见的报错原因及其解决方法。 一、常见报错及其原因 1. ORA-01722: in…...
)
计算人声录音后电平的大小(dB SPL->dBFS)
计算人声录音后电平的大小 这里笔记记录一下,怎么计算已知大小的声音,经过麦克风、声卡录制后软件内录得的音量电平值。(文章最后将计算过程整理为Python代码,方便复用) 假设用正常说话的声音大小65dB(SP…...

Android kernel日志中healthd关键词意义
Android kernel日志中healthd关键词意义 在kernel的healthd日志中会打印电池信息。通常比较关心的是电池温度,剩余电量,电压,电池健康,电池状况等。 level:剩余电量。 voltage:电压。 temperatureÿ…...
)
操作系统面试问题(4)
32.什么是操作系统 操作系统是一种管理硬件和软件的应用程序。也是运行在计算机中最重要的软件。它为硬件和软件提供了一种中间层,让我们无需关注硬件的实现,把心思花在软件应用上。 通常情况下,计算机上会运行着许多应用程序,它…...

【nestjs】一般学习路线
nestjs中文文档 其实几个月前也对nestjs进行了学习,前前后后看了很多文档、博客,另外也找了相应的代码看了,但最后也还是一知半解,只是知道大概怎么写,怎么用。 这次下定决心再次看一遍,从代码学习到文档…...

多线程面试题总结
基础概念 进程与线程的区别 进程:操作系统资源分配的基本单位,有独立内存空间线程:CPU调度的基本单位,共享进程资源对比: 创建开销:进程 > 线程通信方式:进程(IPC)、线程(共享内存)安全性:进程更安全(隔离),线程需要同步线程的生命周期与状态转换 NEW → RUNNABLE …...
)
面试常考算法2(核心+acm模式)
15. 三数之和 核心代码模式 class Solution {public List<List<Integer>> threeSum(int[] nums) {List<List<Integer>> ansnew ArrayList<>();Arrays.sort(nums);int lennums.length;int pre2000000;for(int i0;i<len-2;i){while(i<len-…...

虚拟文件系统
虚拟文件系统(Virtual File System,VFS)是操作系统内核中的一个抽象层,它为不同的文件系统(如ext4、NTFS、FAT32等)提供统一的访问接口。通过VFS,用户和应用程序无需关心底层文件系统的具体差异…...

机器学习与深度学习的区别与联系:多角度详细分析
机器学习与深度学习的区别与联系:多角度详细分析 引言 随着人工智能技术的快速发展,机器学习和深度学习已成为当今科技领域的核心驱动力。尽管这两个术语经常被一起提及,甚至有时被互换使用,但它们之间存在着明显的区别和紧密的…...