MindSpore框架学习项目-ResNet药物分类-数据增强
目录
1.数据增强
1.1设置运行环境
1.1.1数据预处理
数据预处理代码解析
1.1.2数据集划分
数据集划分代码说明
1.2数据增强
1.2.1创建带标签的可迭代对象
1.2.2数据预处理与格式化(ms的data格式)
从原始图像数据到 MindSpore 可训练 / 评估的数据集的完整构建流程
1.2.3加载数据
加载数据代码说明
1.2.4类别标签说明
1.3数据可视化
数据可视化代码说明
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为‘一般流程’,同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
1.数据增强
1.1设置运行环境
要求:设置执行设备为GPU mindspore还支持CPU/Ascend
import mindspore# 要点1-1-1:设置使用的设备
mindspore.set_context(device_target='GPU') # CPU/Ascend
print(mindspore.get_context(attr_key='device_target'))这里返回GPU
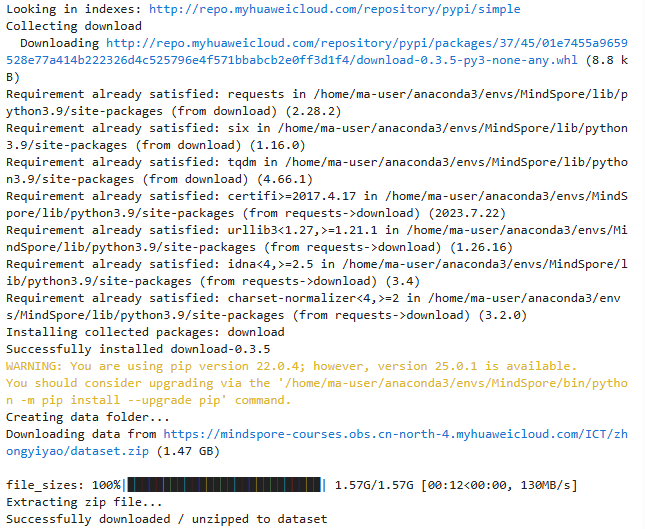
# 下载数据
!pip install download
from download import download
import os
url = "https://mindspore-courses.obs.cn-north-4.myhuaweicloud.com/ICT/zhongyiyao/dataset.zip"
if not os.path.exists("dataset"):
download(url, "dataset", kind="zip")
1.1.1数据预处理
原图片尺寸为4k比较大,预处理将图片resize到1000*1000
from PIL import Image
import numpy as np
data_dir = "dataset/zhongyiyao/zhongyiyao"
new_data_path = "dataset1/zhongyiyao"
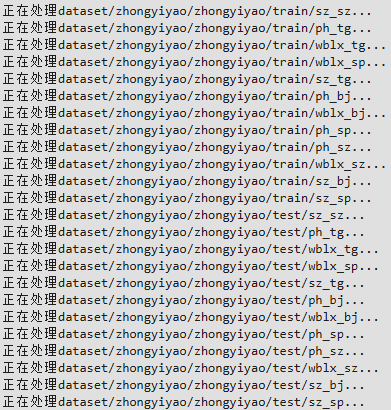
if not os.path.exists(new_data_path):for path in ['train','test']:
data_path = data_dir + "/" + path
classes = os.listdir(data_path)for (i,class_name) in enumerate(classes):
floder_path = data_path+"/"+class_nameprint(f"正在处理{floder_path}...")for image_name in os.listdir(floder_path):try:
image = Image.open(floder_path + "/" + image_name)
image = image.resize((1000,1000))
target_dir = new_data_path+"/"+path+"/"+class_nameif not os.path.exists(target_dir):
os.makedirs(target_dir)if not os.path.exists(target_dir+"/"+image_name):
image.save(target_dir+"/"+image_name)except:pass
数据预处理代码解析
1. 核心功能
将原始数据集(dataset/zhongyiyao/zhongyiyao)中的图像按类别整理到新路径(dataset1/zhongyiyao),统一图像尺寸为1000×1000,并跳过损坏文件,为后续模型训练准备标准格式数据。
2. 关键代码说明
(1) 数据目录初始化
data_dir = "dataset/zhongyiyao/zhongyiyao" # 原始数据集根目录(含train/test子目录)
new_data_path = "dataset1/zhongyiyao" # 目标数据集根目录(整理后的数据存放路径)
作用:定义原始数据路径和目标路径,确保后续处理围绕固定目录展开。
项目意义:统一数据入口 / 出口路径,避免硬编码,方便后续数据集加载(如 MindSpore 的ds.ImageFolderDataset要求类别子目录结构)。
(2) 遍历原始数据目录
for path in ['train','test']: # 处理训练集和测试集
data_path = data_dir + "/" + path # 拼接原始数据路径(如dataset/zhongyiyao/zhongyiyao/train)
classes = os.listdir(data_path) # 获取类别目录(如"ph_sp"、"sz_bj"等中药材类别)
逻辑:按 “数据集类型(train/test)→ 类别→ 图像” 三级结构遍历,符合图像分类任务的标准数据组织格式(类别作为子目录)。
MindSpore 关联:MindSpore 的ds.ImageFolderDataset要求数据按[root]/[split]/[class]/[image]结构存储,此处代码直接生成该格式,便于后续数据集加载。
(3) 图像尺寸统一与保存
image = Image.open(floder_path + "/" + image_name) # 读取图像
image = image.resize((1000, 1000)) # 统一尺寸(模型输入预处理第一步)
target_dir = new_data_path+"/"+path+"/"+class_name # 目标路径(如dataset1/zhongyiyao/train/ph_sp)
os.makedirs(target_dir, exist_ok=True) # 创建目标类别目录(自动处理多级目录)
image.save(target_dir+"/"+image_name) # 保存处理后的图像
核心操作:尺寸统一:深度学习模型要求输入图像尺寸一致,先调整为 1000×1000(后续可在数据管道中进一步缩放到模型所需尺寸,如 224×224)。
目录创建:exist_ok=True避免重复创建目录报错,确保鲁棒性。
(4) 损坏文件处理
try:# 图像读取、处理、保存逻辑
except:pass # 跳过无法读取的损坏文件(数据清洗关键步骤)
作用:避免因个别损坏图像导致整个数据处理流程中断,确保数据集的可用性(训练时若遇到损坏文件会直接报错,预处理阶段清洗可提前规避)。
3. 在项目中的定位(深度学习流程)
阶段:数据导入与预处理(项目的基础环节,直接影响模型训练效果)。
目标:整理数据目录结构,适配 MindSpore 的ds.ImageFolderDataset加载格式。
统一图像尺寸,完成基础数据清洗(过滤损坏文件),为后续数据增强(如随机裁剪、翻转)和模型输入做准备。
4. 与 MindSpore 的关联(框架差异支线)
数据加载适配:
MindSpore 的数据集加载接口(如ds.ImageFolderDataset)依赖 “类别子目录” 结构,此处代码生成的dataset1/zhongyiyao/train/[class]格式可直接被识别,无需额外转换。预处理灵活性:
图像尺寸可在 MindSpore 数据管道中动态调整(如ds.vision.Resize((224, 224))),此处预处理阶段统一为 1000×1000 是为了标准化原始数据,后续可通过管道灵活处理。
1.1.2数据集划分
导入sklearn(机器学习库)的model_selection模块的数据集划分方法train_test_split;
shutil是 Python 的标准库,主要用于文件和目录的高级操作,如文件复制、移动、删除,以及目录的递归操作等。
from sklearn.model_selection import train_test_split
import shutil
定义数据集切分函数,符合python函数式编程的范式,也方便代码复用
def split_data(X, y, test_size=0.2, val_size=0.2, random_state=42):
"""将数据集划分为训练集、验证集和测试集
"""# 先以8:2的比例划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)# 再从训练集中抽取 25% 作为验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=val_size/(1-test_size), random_state=random_state) return X_train, X_val, X_test, y_train, y_val, y_test
定义数据的目标路径和数据存储的结构
data_dir = "dataset1/zhongyiyao"
floders = os.listdir(data_dir)
target = ['train','test','valid']
判断不同情况下需要进行的文件系统操作
if set(floders) == set(target):pass
elif 'train' in floders:
floders = os.listdir(data_dir)
new_data_dir = os.path.join(data_dir,'train')
classes = os.listdir(new_data_dir)# 不要让ipython的缓存文件在数据集里,会影响到训练环节if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')# 图像识别项目 数据为图片imgs和标签labels
imgs = []
labels = []for (i,class_name) in enumerate(classes):
new_path = new_data_dir+"/"+class_name# 逐张添加图片、标签(保持两者的对应关系)for image_name in os.listdir(new_path):
imgs.append(image_name)
labels.append(class_name) imgs_train,imgs_val,labels_train,labels_val = X_train, X_test, y_train, y_test = train_test_split(imgs, labels, test_size=0.2, random_state=42)print("划分训练集图片数:",len(imgs_train))print("划分验证集图片数:",len(imgs_val)) target_data_dir = os.path.join(data_dir,'valid')if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)for (img,label) in zip(imgs_val,labels_val):
source_path = os.path.join(data_dir,'train',label)
target_path = os.path.join(data_dir,'valid',label)if not os.path.exists(target_path):
os.mkdir(target_path)
source_img = os.path.join(source_path,img)
target_img = os.path.join(target_path,img)
shutil.move(source_img,target_img)else:
phones = os.listdir(data_dir)
imgs = []
labels = []for phone in phones:
phone_data_dir = os.path.join(data_dir,phone)
yaowu_list = os.listdir(phone_data_dir)for yaowu in yaowu_list:
yaowu_data_dir = os.path.join(phone_data_dir,yaowu)
chengdu_list = os.listdir(yaowu_data_dir)for chengdu in chengdu_list:
chengdu_data_dir = os.path.join(yaowu_data_dir,chengdu)for img in os.listdir(chengdu_data_dir):
imgs.append(img)
label = ' '.join([phone,yaowu,chengdu])
labels.append(label)
imgs_train, imgs_val, imgs_test, labels_train, labels_val, labels_test = split_data(imgs, labels, test_size=0.2, val_size=0.2, random_state=42)
img_label_tuple_list = [(imgs_train,labels_train),(imgs_val,labels_val),(imgs_test,labels_test)]for (i,split) in enumerate(spilits):
target_data_dir = os.path.join(data_dir,split)if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)
imgs_list,labels_list = img_label_tuple_list[i]for (img,label) in zip(imgs_list,labels_list):
label_split = label.split(' ')
source_img = os.path.join(data_dir,label_split[0],label_split[1],label_split[2],img)
target_img_dir = os.path.join(target_data_dir,label_split[1]+"_"+label_split[2])if not os.path.exists(target_img_dir):
os.mkdir(target_img_dir)
target_img = os.path.join(target_img_dir,img)
shutil.move(source_img,target_img)
数据集划分代码说明
这段代码主要功能是将原始图片数据按比例划分为训练集(train)、验证集(valid)、测试集(test),并自动整理文件目录结构。
核心目标
将原始图片数据按比例(默认测试集20%、验证集20%)划分到`train`、`valid`、`test`三个子目录中,解决不同原始目录结构下的数据整理问题,方便后续机器学习模型的训练与评估
代码结构与关键逻辑
代码分为数据划分函数和目录结构处理逻辑两部分:
数据划分函数 `split_data`
def split_data(X, y, test_size=0.2, val_size=0.2, random_state=42):
"""将数据划分为训练集、验证集、测试集"""
# 第一步:划分训练集和测试集(test_size=0.2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
# 第二步:从训练集中划分验证集(val_size/(1-test_size) 是因为验证集占原数据的20%,但此时训练集剩余80%)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=val_size/(1-test_size), random_state=random_state)
return X_train, X_val, X_test, y_train, y_val, y_test
输入:特征数据`X`(图片路径列表)、标签数据`y`(标签列表)、测试集比例`test_size`(默认20%)、验证集比例`val_size`(默认20%)。
输出:训练集、验证集、测试集的特征与标签(共6个集合)。
逻辑:先划分出测试集(占整体20%),再从剩余训练集中划分验证集(占整体20%,因此实际从训练集的80%中取20%/80%=25%)。
实际比例计算:初始训练集占原数据的 80%(即1-test_size=0.8)。
第二次划分时,test_size=val_size/(1-test_size)=0.2/0.8=0.25,即从 80% 的训练集中再抽取 25% 作为验证集。
最终验证集占原数据的比例为:0.8×0.25=0.2(即 20%)。
因此,实际划分比例为 原数据的 60%(训练集):20%(验证集),而非注释中的 “6:2”(60%:20% 是整体比例,而非 “训练集中的 6:2”)。
最终划分比例
正确比例:训练集:60%(原数据的 60%)
验证集:20%(原数据的 20%,来自第一次划分后的训练集)
测试集:20%(原数据的 20%)
目录结构处理逻辑
代码根据原始数据集的目录结构不同,分3种情况处理:
情况1:目录已包含标准划分(train/test/valid)
if set(floders) == set(target):
pass # 无需处理,直接跳过
如果原始目录`dataset1/zhongyiyao`下已经有`train`(训练集)、`test`(测试集)、`valid`(验证集)三个子目录,直接跳过处理
情况2:目录包含train但缺少valid/test
elif 'train' in floders:
# 步骤1:收集训练集中的所有图片和标签
new_data_dir = os.path.join(data_dir,'train') # 原始训练集路径
classes = os.listdir(new_data_dir) # 类别(如不同中药材)
classes.remove('.ipynb_checkpoints') # 移除Jupyter临时文件
imgs = [] # 存储所有图片名
labels = [] # 存储对应标签(类别名)
for class_name in classes:
class_path = os.path.join(new_data_dir, class_name)
for image_name in os.listdir(class_path):
imgs.append(image_name)
labels.append(class_name) # 步骤2:划分训练集和验证集(测试集可能已存在或需额外处理)
imgs_train, imgs_val, labels_train, labels_val = train_test_split(imgs, labels, test_size=0.2, random_state=42) # 步骤3:将验证集图片从原训练集目录移动到valid目录
target_data_dir = os.path.join(data_dir,'valid') # 验证集目标路径
if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)
for img, label in zip(imgs_val, labels_val):
# 原始路径:dataset1/zhongyiyao/train/[类别]/[图片]
source_path = os.path.join(data_dir, 'train', label, img)
# 目标路径:dataset1/zhongyiyao/valid/[类别]/[图片]
target_path = os.path.join(data_dir, 'valid', label)
if not os.path.exists(target_path):
os.mkdir(target_path)
shutil.move(source_path, os.path.join(target_path, img)) # 移动文件
场景:原始目录只有`train`子目录(可能测试集已单独存在,或需后续处理)。
操作:从`train`目录中提取所有图片和标签,按2:8划分出验证集(占原训练集的20%),并将验证集图片移动到新创建的`valid`目录下对应的类别子目录中。
情况3:原始目录是多层嵌套结构(未划分)
else:
# 步骤1:遍历多层嵌套目录,收集所有图片和标签
phones = os.listdir(data_dir) # 一级目录(如不同设备/场景,phone可能指拍摄设备)
imgs = [] # 存储所有图片名
labels = [] # 标签由多级目录组合:phone_yaowu_chengdu(设备_药材_程度)
for phone in phones:
phone_dir = os.path.join(data_dir, phone)
yaowu_list = os.listdir(phone_dir) # 二级目录(药材类型)
for yaowu in yaowu_list:
yaowu_dir = os.path.join(phone_dir, yaowu)
chengdu_list = os.listdir(yaowu_dir) # 三级目录(药材状态/程度,如“完整”“破损”)
for chengdu in chengdu_list:
chengdu_dir = os.path.join(yaowu_dir, chengdu)
for img in os.listdir(chengdu_dir):
imgs.append(img)
# 标签由三级目录组合(如 "phone1 当归 完整")
labels.append(' '.join([phone, yaowu, chengdu])) # 步骤2:使用split_data函数划分训练集、验证集、测试集(各占60%、20%、20%)
imgs_train, imgs_val, imgs_test, labels_train, labels_val, labels_test = split_data(imgs, labels, test_size=0.2, val_size=0.2) # 步骤3:将划分后的图片移动到对应的train/valid/test目录
# 目标划分目录:train、valid、test(对应split)
splits = ['train','valid','test'] # 注意:原代码中变量名可能拼写错误(spilits应为splits)
img_label_tuple_list = [(imgs_train,labels_train), (imgs_val,labels_val), (imgs_test,labels_test)]
for i, split in enumerate(splits):
target_dir = os.path.join(data_dir, split) # 如 dataset1/zhongyiyao/train
if not os.path.exists(target_dir):
os.mkdir(target_dir)
imgs_list, labels_list = img_label_tuple_list[i]
for img, label in zip(imgs_list, labels_list):
# 解析标签:原标签是 "phone yaowu chengdu",拆分后获取多级目录
label_parts = label.split(' ') # 如 ["phone1", "当归", "完整"]
# 原始图片路径:dataset1/zhongyiyao/phone1/当归/完整/[图片]
source_img = os.path.join(data_dir, label_parts, img) # label_parts解包为多级路径
# 目标类别目录:train/当归_完整(合并药材和程度作为新类别)
target_subdir = os.path.join(target_dir, f"{label_parts[1]}_{label_parts[2]}") # 如 "当归_完整"
if not os.path.exists(target_subdir):
os.mkdir(target_subdir)
# 移动图片到目标路径
shutil.move(source_img, os.path.join(target_subdir, img))
场景:原始目录是多层嵌套结构(如`phone(设备)→ yaowu(药材)→ chengdu(状态)`三级目录),未做任何划分。
操作:
1. 收集数据:遍历所有嵌套目录,提取所有图片路径,并生成复合标签(如`"phone1 当归 完整"`)。
2. 数据划分:使用`split_data`函数按6:2:2划分训练集、验证集、测试集。
3. 整理目录:为每个划分集(train/valid/test)创建目录,并将图片移动到对应目录下的新类别子目录(合并`yaowu`和`chengdu`作为类别名,如`当归_完整`),简化后续模型输入结构。
1.2数据增强
要求:
补充如下代码中的空白处
主要完成:
1. 使用GeneratorDataset接口将数据转换为Dataset
2. 定义相应的裁剪策略,对数据集进行裁剪操作
3. 定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
4. 输出数据集的size大小
1.2.1创建带标签的可迭代对象
导入GeneratorDataset接口将数据转换为Dataset
from mindspore.dataset import GeneratorDataset
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
数据加载与标签生成
class Iterable:
def __init__(self,data_path):
self._data = []
self._label = []
self._error_list = []
if data_path.endswith(('JPG','jpg','png','PNG')):
image = Image.open(data_path)
self._data.append(image)
self._label.append(0)
else:
classes = os.listdir(data_path)
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
for (i,class_name) in enumerate(classes):
new_path = data_path+"/"+class_name
for image_name in os.listdir(new_path):
try:
image = Image.open(new_path + "/" + image_name)
self._data.append(image)
self._label.append(i)
except:
pass def __getitem__(self, index):
return self._data[index], self._label[index] def __len__(self):
return len(self._data) def get_error_list(self,):
return self._error_list
1.2.2数据预处理与格式化(ms的data格式)
def create_dataset_zhongyao(dataset_dir,usage,resize,batch_size,workers):
data = Iterable(dataset_dir)
# 要点1-2-1:使用GeneratorDataset接口将数据转换为Dataset
data_set = GeneratorDataset(source=data, column_names=['image','label'])
trans = []
# 要点1-2-2:定义相应的裁剪策略,对数据集进行裁剪操作
# RandomCrop:
# 1.size (Union[int, Sequence[int]]) - 裁剪图像的输出尺寸大小。设置为700;
# 2.padding (Union[int, Sequence[int]], 可选) - 图像各边填充的像素数。设置为一个包含4个其值为4的元组。
# RandomHorizontalFlip:
# 1.prob (float, 可选) - 图像被翻转的概率设置为0.5
if usage == "train":
trans += [
vision.RandomCrop(size=700, padding=(4,4,4,4)),
vision.RandomHorizontalFlip(prob=0.5)
] trans += [
vision.Resize((resize,resize)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
# 要点1-2-3:定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
vision.HWC2CHW()
] target_trans = transforms.TypeCast(mstype.int32)
data_set = data_set.map(
operations=trans,
input_columns='image',
num_parallel_workers=workers) data_set = data_set.map(
operations=target_trans,
input_columns='label',
num_parallel_workers=workers) data_set = data_set.batch(batch_size,drop_remainder=True) return data_set
从原始图像数据到 MindSpore 可训练 / 评估的数据集的完整构建流程
1. 数据加载与标签生成(Iterable类)
Iterable类作为数据迭代器,负责:
读取原始数据:支持两种输入格式:单个图像文件(如data_path="a.jpg"):直接加载图像,标签默认设为 0。
类别目录(如data_path="train",内部含class1/, class2/子目录):按子目录遍历图像,标签为子目录的索引(如class1→0, class2→1)。
数据清洗:跳过无法读取的损坏图像(try-except),确保数据可靠性。
2. 数据预处理与格式化(create_dataset_zhongyao函数)
该函数将Iterable加载的原始数据转换为 MindSpore 的Dataset对象,并完成以下关键操作:
数据增强(训练模式):
若usage="train",添加随机裁剪(RandomCrop,尺寸 700,填充 4 像素)和随机水平翻转(RandomHorizontalFlip,概率 0.5),提升模型泛化能力。通用预处理:统一缩放到目标尺寸(resize,如 224×224)
像素归一化(Rescale:0-255→0-1;Normalize:按均值 / 标准差标准化)
通道转换(HWC2CHW):将图像格式从[H, W, C]转为 MindSpore 要求的[C, H, W]
标签处理:将标签类型转换为int32(适配 MindSpore 计算)
分批处理:按batch_size打包数据,丢弃不足一批的剩余样本(drop_remainder=True)
一句话讲:Iterable类把还只是图片的数据先 -> 可迭代的(图片+1个对应标签);数据预处理与格式化(create_dataset_zhongyao函数)把‘可迭代的(图片+1个对应标签)’转换成mindspore输入需要的数据格式(data_set = GeneratorDataset(source=data, column_names=['image','label']))
1.2.3加载数据
对数据集使用定义好的方式进行加载
import mindspore as ms
import random
经过1.2.2的处理,现在每一份数据(图片+1个标签)都是ms的支持数据类型,为此将数据放到我们需要的文件目录下(符合ms在进行训练时对数据的结构化提取范式)
data_dir = "dataset1/zhongyiyao"
train_dir = data_dir+"/"+"train"
valid_dir = data_dir+"/"+"valid"
test_dir = data_dir+"/"+"test"
batch_size = 32
image_size = 224
workers = 4
num_classes = 12
# 要点1-2-4:输出数据集的size大小
dataset_train = create_dataset_zhongyao(dataset_dir=train_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_train = dataset_train.get_batch_size() # 返回batch的数量dataset_val = create_dataset_zhongyao(dataset_dir=valid_dir,
usage="valid",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_val = dataset_val.get_batch_size() # 返回batch的数量dataset_test = create_dataset_zhongyao(dataset_dir=test_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
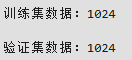
step_size_test = dataset_test.get_batch_size() # 返回batch的数量print(f'训练集数据:{step_size_train*batch_size}\n')
print(f'验证集数据:{step_size_val*batch_size}\n')
print(f'测试集数据:{step_size_test*batch_size}\n')
ps:
代码功能:step_size_train * batch_size计算的是训练集总数据量(同理step_size_val * batch_size是验证集、step_size_test * batch_size是测试集),而非 “每个 epoch 的数据量”。每个 epoch 的数据量本身就是数据集总样本数,与代码计算的结果一致。
训练集、验证集、测试集数据量关系:
三者数据量无需相同,训练也不会因它们不同而 “出现问题”。例如,常见的划分比例(如 6:2:2)会使三者数据量不同,这是正常且合理的,分别用于模型训练、超参数调整和性能评估,功能不同,数据量无需一致。
加载数据代码说明
1. 创建数据集对象
通过create_dataset_zhongyao函数创建训练集、验证集、测试集的数据集对象:
dataset_train = create_dataset_zhongyao(dataset_dir=train_dir, usage="train", ...)
dataset_val = create_dataset_zhongyao(dataset_dir=valid_dir, usage="valid", ...)
dataset_test = create_dataset_zhongyao(dataset_dir=test_dir, usage="test", ...)
函数作用:假设create_dataset_zhongyao是一个自定义的数据加载函数,可能包含以下功能:从指定目录(如train_dir)加载图片和标签;
预处理(resize、归一化、数据增强等,usage="train"时可能包含随机翻转 / 裁剪等增强操作,验证集 / 测试集不增强);
封装为可迭代的数据集对象(如 PyTorch 的DataLoader或 MindSpore 的Dataset),支持按批量输出数据。
2. 获取批量数量1epoch中step--batch,batch的数据容量--batch_size,数据量step*batch_szie
通过get_batch_size()方法获取每个数据集的批量数量(即每个 epoch 需要迭代的次数):
# 训练集的批量数量
step_size_train = dataset_train.get_batch_size()
step_size_val = dataset_val.get_batch_size()
step_size_test = dataset_test.get_batch_size()
mindspore中get_batch_size()是返回batch的数量,和参数设置里‘batch_size = 32’的功能不相同,参数设置里的是每个batch的容量,数据总量=batch的数量*每个batch的容量
1.2.4类别标签说明
- ph-sp:蒲黄-生品
- ph_bj:蒲黄-不及
- ph_sz:蒲黄-适中
- ph_tg:蒲黄-太过
- sz_sp:山楂-生品
- sz_bj:山楂-不及
- sz_sz:山楂-适中
- sz_tg:山楂-太过
- wblx_sp:王不留行-生品
- wblx_bj:王不留行-不及
- wblx_sz:王不留行-适中
- wblx_tg:王不留行-太过
index_label_dict = {}
classes = os.listdir(train_dir)
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
for i,label in enumerate(classes):
index_label_dict[i] = labelindex_label_dict
初始化空字典 index_label_dict
index_label_dict = {}
创建一个空字典,用于存储 “整数索引 → 原始标签名称” 的映射关系(后续用于将模型输出的索引转换为实际标签)
获取训练集的类别目录列表
classes = os.listdir(train_dir)
train_dir是训练集的根目录(如"dataset1/zhongyiyao/train")。
os.listdir(train_dir)会列出该目录下的所有子目录 / 文件,这里假设train_dir的子目录是类别目录(例如ph_sp、sz_bj等,每个目录存储对应类别的图片)。
移除 Jupyter 临时文件
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
.ipynb_checkpoints是 Jupyter Notebook 自动生成的临时文件目录,并非实际的类别目录。
若存在该目录,则从classes列表中移除,避免干扰后续类别标签的统计。
构建 “索引→原始标签” 映射字典
for i, label in enumerate(classes):
index_label_dict[i] = label
使用enumerate(classes)遍历类别列表,i是自动生成的整数索引(从 0 开始),label是类别名称(如ph_sp)。
最终index_label_dict的格式为:{0: 'ph_sp', 1: 'ph_bj', 2: 'ph_sz', ...},即每个类别对应一个唯一的整数索引(模型中常用这种方式表示类别)。
定义 “原始标签→中文标签” 映射字典 label2chin
label2chin = {
'ph_sp':'蒲黄-生品', 'ph_bj':'蒲黄-不及', 'ph_sz':'蒲黄-适中', 'ph_tg':'蒲黄-太过',
'sz_sp':'山楂-生品', 'sz_bj':'山楂-不及', 'sz_sz':'山楂-适中', 'sz_tg':'山楂-太过',
'wblx_sp':'王不留行-生品', 'wblx_bj':'王不留行-不及', 'wblx_sz':'王不留行-适中', 'wblx_tg':'王不留行-太过'
}
键是原始标签(如ph_sp),值是对应的中文标签(如 “蒲黄 - 生品”)。
作用:将模型中使用的原始标签(可能是英文缩写)转换为更易理解的中文描述,方便后续可视化、报告生成或人工检查。
输出 index_label_dict
index_label_dict
直接输出该字典,展示索引与原始标签的对应关系
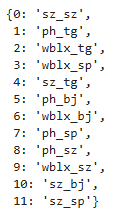
# 预设中文标签,方便后续可视化和人工检查
label2chin = {'ph_sp':'蒲黄-生品', 'ph_bj':'蒲黄-不及', 'ph_sz':'蒲黄-适中', 'ph_tg':'蒲黄-太过', 'sz_sp':'山楂-生品',
'sz_bj':'山楂-不及', 'sz_sz':'山楂-适中', 'sz_tg':'山楂-太过', 'wblx_sp':'王不留行-生品', 'wblx_bj':'王不留行-不及',
'wblx_sz':'王不留行-适中', 'wblx_tg':'王不留行-太过'}
1.3数据可视化
要求:
补充如下代码的空白处
主要完成:
1. 利用create_dict_iterator API创建数据迭代器,并打印label列表
2. 利用transpose接口将通道维度移动到最后:CHW -> HWC
- 反归一化操作:利用std和mean对image_trans进行反归一化运算
导入可视化库matplotlib.pyplot和科学计算库numpy
import matplotlib.pyplot as plt
import numpy as np
创建数据迭代器,并打印label列表
# 要点1-3-1:利用create_dict_iterator API创建数据迭代器,并打印label列表
data_iter = dataset_train.create_dict_iterator() batch = next(data_iter)
images = batch["image"].asnumpy()
labels = batch["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}")
![]()
数据可视化,反归一化,matplotlib需要HWC格式呈现正常的图像数据(而AI框架一般为了性能和高效的数据处理需要图像数据为CHW)
plt.figure(figsize=(12, 5))
for i in range(24):
plt.subplot(3, 8, i+1)
# 要点1-3-2:利用transpose接口将通道维度移动到最后:CHW -> HWC
image_trans = np.transpose(images[i], (1,2,0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
# 要点1-3-3:反归一化操作:利用std和mean对image_trans进行反归一化运算
image_trans = image_trans*std + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(index_label_dict[labels[i]])
plt.imshow(image_trans)
plt.axis("off")
plt.show()

ps:

重点说明:
归一化操作--图像数据预处理:image =(image-mean)/std
反归一化操作--重新回到原来的图像进行数据可视化:image = image*std + mean
数据可视化代码说明
1. 创建画布并设置尺寸
plt.figure(figsize=(12, 5))
功能:创建一个 Matplotlib 画布(figure),用于容纳后续的子图。
figsize=(12,5):设置画布的宽度为 12 英寸,高度为 5 英寸(根据 24 张子图的布局调整尺寸,确保图像清晰)。
2. 循环绘制 24 张子图
for i in range(24):
plt.subplot(3, 8, i+1)
功能:在画布上划分 3 行 8 列的子图网格(共 3×8=24 个位置),循环遍历每个位置绘制一张图片。
plt.subplot(3,8,i+1):指定当前子图的位置(第i+1个位置,索引从 1 开始)。例如,i=0时绘制第 1 个位置(第 1 行第 1 列),i=23时绘制第 24 个位置(第 3 行第 8 列)。
3. 调整图像通道维度顺序(CHW → HWC)
image_trans = np.transpose(images[i], (1,2,0))
背景:在深度学习框架(如 PyTorch)中,图像数据通常以[C, H, W](通道数 × 高度 × 宽度)的格式存储(简称 CHW);但 Matplotlib 的plt.imshow要求图像格式为[H, W, C](高度 × 宽度 × 通道数,简称 HWC)。
操作:使用np.transpose调整维度顺序。(1,2,0)表示将原维度索引(假设images[i]的形状为(3, 224, 224),即 C=3, H=224, W=224)的第 1 维(H)、第 2 维(W)、第 0 维(C)重新排列,得到(224, 224, 3)的 HWC 格式。
4. 反归一化恢复原始图像像素值
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = image_trans * std + mean
image_trans = np.clip(image_trans, 0, 1)
背景:在模型训练前,图像通常会进行归一化预处理(公式:(image - mean) / std),将像素值缩放到[0,1]区间并符合模型输入要求。但归一化后的图像无法直接可视化(像素值偏离真实颜色),因此需要反归一化恢复原始像素。
反归一化公式:image = image_normalized * std + mean(逆向操作归一化公式)。
np.clip(image_trans, 0, 1):由于浮点运算误差,反归一化后的像素值可能略微超出[0,1]范围(如 - 0.001 或 1.002),使用clip将其限制在[0,1]内,避免显示异常(如颜色失真)。
5. 设置子图标题并显示图像
plt.title(index_label_dict[labels[i]])
plt.imshow(image_trans)
plt.axis("off")
plt.title(...):设置子图的标题为当前图像的类别标签。labels[i]是图像的类别索引(如 0、1、2...),通过index_label_dict映射为实际类别名称(如ph_sp)。
plt.imshow(image_trans):显示处理后的图像(HWC 格式,像素值已恢复)。
plt.axis("off"):关闭子图的坐标轴显示,使图像更整洁。
6. 显示最终画布
plt.show()
将所有子图绘制到画布上并显示(如在 Jupyter Notebook 中会直接渲染,在脚本中会弹出窗口)。
ps:前面数据处理-数据增强部分使用的图像归一化操作
数据增强部分(训练集专用)
if usage == "train":
trans += [
vision.RandomCrop(size=700, padding=(4,4,4,4)),
vision.RandomHorizontalFlip(prob=0.5)]
功能:这部分代码是专门针对训练集的数据增强操作。
详细解释:vision.RandomCrop(size=700, padding=(4,4,4,4)):对图像进行随机裁剪。首先在图像周围填充 4 个像素,然后随机裁剪出一个大小为 700x700 的区域。这样可以增加数据的多样性,使模型学习到不同位置的特征。
vision.RandomHorizontalFlip(prob=0.5):以 0.5 的概率对图像进行水平翻转。这也是一种常见的数据增强方式,能让模型学习到图像在水平方向上的不同表现。
通用预处理部分
trans += [
vision.Resize((resize,resize)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),# 题目1-2-3:定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
vision.HWC2CHW()
]
功能:这部分代码是对所有数据集(训练集、验证集、测试集)都进行的通用预处理操作。
详细解释:
vision.Resize((resize,resize)):将图像的尺寸调整为 resize x resize 大小,确保所有输入图像的尺寸一致,以适应模型的输入要求。
vision.Rescale(1.0 / 255.0, 0.0):将图像的像素值从 [0, 255] 范围缩放到 [0, 1] 范围。这是因为大多数深度学习模型更适合处理在 [0, 1] 范围内的输入数据。
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]):对图像进行归一化操作。通过减去均值 [0.4914, 0.4822, 0.4465] 并除以标准差 [0.2023, 0.1994, 0.2010],将图像的像素值进一步标准化,有助于模型更快地收敛。
vision.HWC2CHW():将图像的通道维度从 (H, W, C)(高度、宽度、通道数)转换为 (C, H, W)(通道数、高度、宽度)。这是因为很多深度学习框架(如 PyTorch)要求输入图像的格式为 (C, H, W)。
相关文章:

MindSpore框架学习项目-ResNet药物分类-数据增强
目录 1.数据增强 1.1设置运行环境 1.1.1数据预处理 数据预处理代码解析 1.1.2数据集划分 数据集划分代码说明 1.2数据增强 1.2.1创建带标签的可迭代对象 1.2.2数据预处理与格式化(ms的data格式) 从原始图像数据到 MindSpore 可训练 / 评估的数…...

python打卡day20
特征降维------特征组合(以SVD为例) 知识点回顾: 奇异值的应用: 特征降维:对高维数据减小计算量、可视化数据重构:比如重构信号、重构图像(可以实现有损压缩,k 越小压缩率越高&#…...

2025数维杯数学建模B题完整限量论文:马拉松经济的高质量发展思路探索
2025数维杯数学建模B题完整限量论文:马拉松经济的高质量发展思路探索,先到先得 B题完整论文https://www.jdmm.cc/file/2712066/ 近年来,我国马拉松赛事数量呈现 “ 先井喷、后调整、再复苏 ” 的显著 变化。据中国田径协会数据, …...

深入解析WPF中的3D图形编程:材质与光照
引言 在Windows Presentation Foundation (WPF) 中创建三维(3D)图形是一项既有趣又具有挑战性的任务。为了帮助开发者更好地理解如何使用WPF进行3D图形的渲染,本文将深入探讨GeometryModel3D类及其相关的材质和光源设置。 1、GeometryModel3D类简介 GeometryMode…...

python格式化小数加不加f的区别
一直好奇这个f是必须加的吗,但是不论是搜索还是ai都给不出准确的回复,就自己测试了一下 结论是不带f指定的是总的数字个数,包含小数点前的数字 带f的就是仅指小数点后数字个数 需要注意的是不带f的话数字是会用科学计数法表示的ÿ…...

【MySQL】存储引擎 - FEDERATED详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

window 显示驱动开发-线性内存空间段
线性内存空间段是显示硬件使用的经典段类型。 线性内存空间段符合以下模型: 它虚拟化位于图形适配器上的视频内存。GPU 直接访问它;也就是说,无需通过页面映射进行重定向。它在一维地址空间中以线性方式进行管理。 驱动程序将DXGK_SEGMENTDESCRIPTOR结…...

uniapp-商城-46-创建schema并新增到数据库
在后台页面中,数据管理是关键。最初,数据可能是通过代码硬编码在页面中,但这种方式缺乏灵活性和扩展性。为了适应实际需求,应使用数据库来存储数据,允许用户自行添加和更新信息。通过数据库,后台页面可以动…...

Go语言的宕机恢复,如何防止程序奔溃
Go语言中的panic机制用于处理程序中无法继续执行的严重错误。当程序触发panic时,当前函数的执行会立即停止,程序开始逐层向上回溯调用栈,执行每个函数的defer语句,直到到达recover函数或者程序崩溃退出。通过recover函数ÿ…...

阅文集团C++面试题及参考答案
能否不使用锁保证多线程安全? 在多线程编程中,锁(如互斥锁、信号量)是实现线程同步的传统方式,但并非唯一方式。不使用锁保证多线程安全的核心思路是避免共享状态、使用原子操作或采用线程本地存储。以下从几个方面详…...

三款实用电脑工具
今天为大家精心推荐三款实用软件,分别是人声伴奏分离软件、文件夹迁移软件和文字转拼音软件。 第一款:NovaMSS NovaMSS是一款功能强大的人声伴奏分离软件,它提供社区版和专业版,社区版永久免费。 该软件能够一键提取人声、伴奏、…...

【图片识别内容改名】图片指定区域OCR识别并自动重命名,批量提取图片指定内容并重命名,基于WPF和阿里云OCR识别的解决
基于WPF和阿里云OCR的图片区域识别与自动重命名解决方案 应用场景 电商商品管理:批量处理商品图片,从固定区域识别商品名称、型号、价格等信息,重命名为"商品名称_型号_价格.jpg"格式档案数字化:扫描后的合同、文件等图片,从固定位置识别合同编…...

可再生能源中的隔离栅极驱动器:光伏逆变器的游戏规则改变者
在迈向可持续未来的征程中,可再生能源已成为全球发展的基石。在可再生能源中,太阳能以其可及性和潜力脱颖而出。光伏(PV)逆变器是太阳能系统的核心,它严重依赖先进技术将太阳能电池板的直流电转换为可用的交流电。隔离栅极驱动器就是这样一种…...

解决:EnvironmentNameNotFound: Could not find conda environment?
明明创建了环境却找不到? conda env list 查看所有环境 使用绝对路径激活 conda activate /home/guokaiyin/miniconda3/envs/synthocc...
——抽象类接口)
Java SE(10)——抽象类接口
1.抽象类 1.1 概念 在之前讲Java SE(6)——类和对象(一)的时候说过,所有的对象都可以通过类来抽象。但是反过来,并不是说所有的类都是用来抽象一个具体的对象。如果一个类本身没有足够的信息来描述一个具体的对象,而…...
)
数据结构与算法—顺序表和链表(1)
数据结构与算法—顺序表(1) 线性表顺序表概念与结构分类静态顺序表动态顺序表 动态顺序表的实现 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。线性表是⼀种在实际中⼴泛使⽤的数据结构,常⻅的…...

软件测试的概念
需求的概念 开发模型 测试模型 1. 什么是需求 在多数软件公司,会有两部分需求,⼀部分是⽤⼾需求,⼀部分是软件需求。 1.1 ⽤⼾需求 ⽤⼾需求:可以简单理解为甲⽅提出的需求,如果没有甲⽅,那么就是终端⽤⼾…...

基于Qwen-14b的基础RAG实现及反思
1、概览 本文主要介绍RAG的基础实现过程,给初学者提供一些帮助,RAG即检索增强生成,主要是两个步骤:检索、生成,下面将基于这两部分进行介绍。 2、检索 检索的主要目的是在自定义的知识库kb中查询到与问题query相关的候…...

TikTok广告投放优化指南
1. 广告账户时区设置 在创建广告账户时,建议优先选择美国太平洋时区(UTC-8洛杉矶时间),这有助于与国际投放节奏保持一致。 2. 达人视频授权问题解答 当在广告后台选择"Affiliate post"却找不到已授权的达人视频时,这种情况确实会…...

WorkManager与Kotlin后台任务调度指南
在Android开发中,使用WorkManager和Kotlin可以高效管理后台任务。以下是分步指南及关键概念: 1. 添加依赖项 在build.gradle文件中添加依赖: dependencies {implementation("androidx.work:work-runtime-ktx:2.7.1") }2. 创建Wor…...

生信服务器如何安装cellranger|生信服务器安装软件|单细胞测序软件安装
一.Why cellranger Cell Ranger 是由 10x Genomics 公司开发的一款用于处理其单细胞测序(single-cell RNA-seq, scRNA-seq)数据的软件套件。它主要用于将原始测序数据(fastq 文件)转换为可以用于下游分析的格式,比如基…...

Spring Web MVC基础理论和使用
目录 什么是MVC 什么是SpringMVC SpringMVC基础使用 建立连接 RequestMapping介绍 请求 传递参数 传递对象 参数重命名 传递数组 传递JSON数据 获取URL中参数 上传文件 获取Cookie/Session 获取Header 响应 返回静态页面 RestController和Controller的区别 返…...

Go Modules 的基本使用
在 Go Modules 项目中,首次运行时下载依赖包的正确流程需要根据项目情况区分处理。以下是详细步骤和最佳实践: 一、首次初始化项目的标准流程 1.1 创建项目目录并初始化模块 mkdir myproject && cd myproject go mod init github…...
:等保测评的那些事)
等保系列(三):等保测评的那些事
一、等保测评主要做什么 1、测评准备阶段 (1)确定测评对象与范围 明确被测系统的边界、功能模块、网络架构及承载的业务。 确认系统的安全保护等级(如二级、三级)。 (2)签订测评合同 选择具备资质的测…...

一种海杂波背景下前视海面目标角超分辨成像方法——论文阅读
一种海杂波背景下前视海面目标角超分辨成像方法 1. 专利的研究目标与实际问题1.1 研究目标1.2 实际意义2. 专利的创新方法、公式及优势2.1 总体思路2.2 关键公式及技术细节2.2.1 运动几何模型2.2.2 方位卷积模型2.2.3 贝叶斯反演与迭代方程2.2.4 参数估计2.3 与传统方法的对比优…...

在线caj转换word
CAJ格式是中国知网特有的一种文献格式,在学术研究等领域广泛使用,但有时我们需要将其转换为Word格式,方便编辑、引用文献。本文分享如何轻松将CAJ转换为word的转换工具,提高阅读和办公效率。 如何将CAJ转换WORD? 1、使用CAJ转换…...

考研英一学习笔记 2018年
2018 年全国硕士研究生招生考试 英语 (科目代码:201) Section Ⅰ Use of English Directions: Read the following text. Choose the best word(s) for each numbered blank and mark A, B, C or D on the ANSWER SHEET. (10 points) Trust i…...

如何工作的更有职业性
职场中的人,如何让对方对你的评价是你很职业?如何让对方认为你更专业? 这里的职业是形容词 与人沟通的职业性,首当其冲的是你的表达,不管是直接的交流沟通还是文字沟通都清晰明了。 文字沟通 写出来的文字应该尽可…...
transformer 笔记 tokenizer moe
(超爽中英!) 2025吴恩达大模型【Transformer】原理解析教程!附书籍代码 DeepLearning.AI_哔哩哔哩_bilibili 自回归就是上文全部阅读 好像学过了,向量互乘好像 transformer不需要rnn 掩码自注意力 训练bert import torch import torch.nn as nn import …...

6.01 Python中打开usb相机并进行显示
本案例介绍如何打开USB相机并每隔100ms进行刷新的代码,效果如下: 一、主要思路: 1. 打开视频流、读取帧 self.cam_cap = cv2.VideoCapture(0) #打开 视频流 cam_ret, cam_frame = self.cam_cap.read() //读取帧。 2.使用定时器,每隔100ms读取帧 3.显示到Qt的QLabel…...

什么是AIOps
AIOps(Artificial Intelligence for IT Operations,智能运维)是以人工智能技术为核心的新型IT运维模式,通过整合机器学习、大数据分析等技术,实现运维流程的自动化与智能化,从而提升系统稳定性、降低运营成…...

javax.net.ssl.SSLHandshakeException: No appropriate protocol
大家好,我是 程序员码递夫。 我有个SpringBoot项目用到邮件发送功能, 在开发环境运行,一切正常,但是我 部署jar 包,在本机上运行时却报错了, 提示: javax.mail.MessagingException: Could not…...

【身份证识别表格】批量识别身份证扫描件或照片保存为Excel表格,怎么大批量将身份证图片转为excel表格?基于WPF和腾讯OCR的识别方案
以下是基于WPF和腾讯OCR的身份证批量识别与导出Excel的完整方案: 一、应用场景 企业人事管理 新员工入职时需批量录入数百份身份证信息,传统手动录入易出错且耗时。通过OCR自动提取姓名、身份证号等字段,生成结构化Excel表格…...

Java+Selenium+快代理实现高效爬虫
目录 一、前言二、Selenium简介三、环境准备四、代码实现4.1 创建WebDriver工厂类4.2 创建爬虫主类4.3 配置代理的注意事项 六、总结与展望 一、前言 在Web爬虫技术中,Selenium作为一款强大的浏览器自动化工具,能够模拟真实用户操作,有效应对…...
:ReAct Agent集成Bing和Google搜索功能,采用推理与执行交替策略,增强处理复杂任务能力)
掌握Multi-Agent实践(三):ReAct Agent集成Bing和Google搜索功能,采用推理与执行交替策略,增强处理复杂任务能力
一个普遍的现象是,大模型通常会根据给定的提示直接生成回复。对于一些简单的任务,大模型或许能够较好地应对。然而,当我们面对更加复杂的任务时,往往希望大模型能够表现得更加“智能”,具备适应多样场景和解决复杂问题的能力。为此,AgentScope 提供了内置的 ReAct 智能体…...

【愚公系列】《Manus极简入门》028-创业规划顾问:“创业导航仪”
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

SpringBoot统一功能处理
一.拦截器(实现两个接口,并重写方法) 1. 定义拦截器 ⾃定义拦截器: 实现HandlerInterceptor接⼝, 并重写其所有⽅法 preHandle()⽅法:⽬标⽅法执⾏前执⾏. 返回true: 继续执⾏后续操作; 返回false: 中断后…...
:监视器(Monitor))
并发设计模式实战系列(19):监视器(Monitor)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十九章监视器(Monitor),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 监视器三要素模型 2. 线程调度…...

Oracle Fusion常用表
模块表名表描述字段说明sodoo_headers_all销售订单头表sodoo_lines_all销售订单行表sodoo_fulfill_lines_all销售订单明细行表popo_headers_all采购订单头表popo_lines_all采购订单行表popo_line_locations_all采购订单分配表popo_distributions_all采购订单发运表invEGP_SYSTE…...

虚假AI工具通过Facebook广告传播新型Noodlophile窃密木马
网络安全公司Morphisec的研究人员发现,攻击者正利用虚假人工智能(AI)平台传播名为Noodlophile Stealer的新型信息窃取木马。这种复杂攻击手法利用AI工具的热度诱骗用户下载恶意软件,窃取浏览器凭证、加密货币钱包,并可…...

华为云Flexus+DeepSeek征文|从开通到应用:华为云DeepSeek-V3/R1商用服务深度体验
前言 本文章主要讲述在华为云ModelArts Studio上 开通DeepSeek-V3/R1商用服务的流程,以及开通过程中的经验分享和使用感受帮我更多开发者,在华为云平台快速完成 DeepSeek-V3/R1商用服务的开通以及使用入门注意:避免测试过程中出现部署失败等问…...

在Cline上调用MCP服务之MCP实践篇
目录 引言一、准备工作1、安装 Visual Studio Code2、安装Cline插件配置支持模型 二、安装MCP Server并调用MCP Server三、本地手动安装MCP Server结尾 引言 上一篇《模型上下文协议(Model Context Protocol,MCP)初见概念篇》我们说到什么是…...

大模型应用开发之模型架构
一、Transformer 架构 1. 编码器Encoder(“阅读理解大师”) 1)核心任务:编码器的唯一目标就是彻底理解输入的句子。它要把输入的每个词(或者说词元 Token)都转化成一个充满上下文信息的“向量表示”&#…...

敦普水性无铬锌铝涂层:汽车紧固件防锈15年,解决螺栓氢脆腐蚀双痛点
汽车紧固件低能耗涂装 在汽车工业体系中,紧固件承担着连接关键部件的重任。螺栓的抗拉强度、螺母的锁紧力矩,直接决定着整车的可靠性。当前,传统涂层技术始终面临一道难题:如何在保障防锈性能的同时,实现真正的环保无有…...
 2876. 有向图访问计数)
基环树(模板) 2876. 有向图访问计数
对于基环树,我们可以通过拓扑排序去掉所有的树枝,只剩下环,题目中可能会有多个基环树 思路:我们先利用拓扑排序将树枝去掉,然后求出每个基环树,之后反向dfs求得所有树枝的长度即可 class Solution { publi…...
)
26考研——中央处理器_指令执行过程(5)
408答疑 文章目录 二、指令执行过程指令周期定义指令周期的多样性指令执行的过程注意事项 指令周期的数据流取指周期间址周期执行周期中断周期 指令执行方案单周期处理器多周期处理器流水线处理器 八、参考资料鲍鱼科技课件26王道考研书 九、总结 二、指令执行过程 指令周期 …...
输入系统全解析:鼠标、键盘与轴控制)
Unity基础学习(九)输入系统全解析:鼠标、键盘与轴控制
目录 一、Input类 1. 鼠标输入 2. 键盘输入 3. 默认轴输入 (1) 基础参数 (2)按键绑定参数 (3)输入响应参数 (4)输入类型与设备参数 (5)不同类型轴的参…...

如何清除windows 远程桌面连接的IP记录
问题 在远程桌面连接后,会在输入列表留下历史IP记录,无用的IP多了会影响我们查找效率,也不安全。 现介绍如何手动删除这些IP记录。 解决方案 1、打开注册表 按 Win R,输入 regedit,回车定位到远程桌面记录的注册表…...

C#参数数组全解析
在C#编程中,参数数组是一个重要的概念,它为方法调用提供了更大的灵活性。下面我们将详细介绍参数数组的相关内容。 参数数组的基本规则 在本书所述的参数类型里,通常一个形参需严格对应一个实参,但参数数组不同,它允…...
)
设计模式-策略模式(Strategy Pattern)
设计模式-策略模式(Strategy Pattern) 一、概要 在软件设计中,策略模式(Strategy Pattern)是一种非常重要的行为型设计模式。它的核心思想是将算法或行为封装在不同的策略类中,使得它们可以互换ÿ…...