MySQL核心内容【持续更新中】
MySQL核心内容
文章目录
- MySQL核心内容
- 1.MySQL核心内容目录
- 2.MySQL知识面扩展
- 3.MySQL安装
- 4.MySQL配置目录介绍
- Mysql配置远程ip连接
- 5.MySQL基础
- 1.MySQL数据类型
- 1.数值类型
- 2.字符串类型
- 3.日期和时间类型
- 4.enum和set
- 2.MySQL运算符
- 1.算数运算符
- 2.逻辑运算符
- 3.比较运算符
- 3.MySQL完整性约束
- 1.主键,自增键,非空,默认值约束
- 2.外键
- 6.表设计原则
- 1.一对一
- 2.一对多
- 3.多对多
- 7.关系型数据库的范式设计
- 1.第一范式(1NF)
- 2.第二范式(2NF)
- 3.第三范式(3NF)
- 4.BC范式(BCNF)
- 5.第四范式(4NF)
- 6.总结
- 8.MySQL核心SQL
- 1.检查MySQL服务器状态
- 2.库操作
- 3.表操作
- 4.CRUD操作
- 5.select查询
- 6.limit分页查询
- 1.limit基本用法
- 2.limit效率优化
- 3.limit分页
- 7.order by排序
- 8.group by分组
- 9.SQL语句常见面试题
- 9.连接查询SQL
- 1.内连接查询
- 1.内连接的基本使用
- 2.内连接和limit的结合
- 3.内连接流程复习及效率分析
- 2.外连接查询
- 1.左连接
- 2.右连接
- 3.外连接的应用
- 10.MySQL存储引擎
- 1.什么是存储引擎
- 2.各存储引擎的区别
- 11.MySQL索引
- 1.索引分类
- 2.索引创建和删除
- 3.B树索引
- 4.B+树索引
- 5.InnoDB的主键和二级索引树
- 6.聚集索引和非聚集索引
- 7.哈希索引
- 8.InnoDB自适应哈希索引
- 9.索引常见问题
- 10.索引和慢查询日志
- 12.MySQL事务
- 1.事务概念
- 2.事务的ACID特性
- 3.事务并发存在的问题
- 4.事务的隔离级别
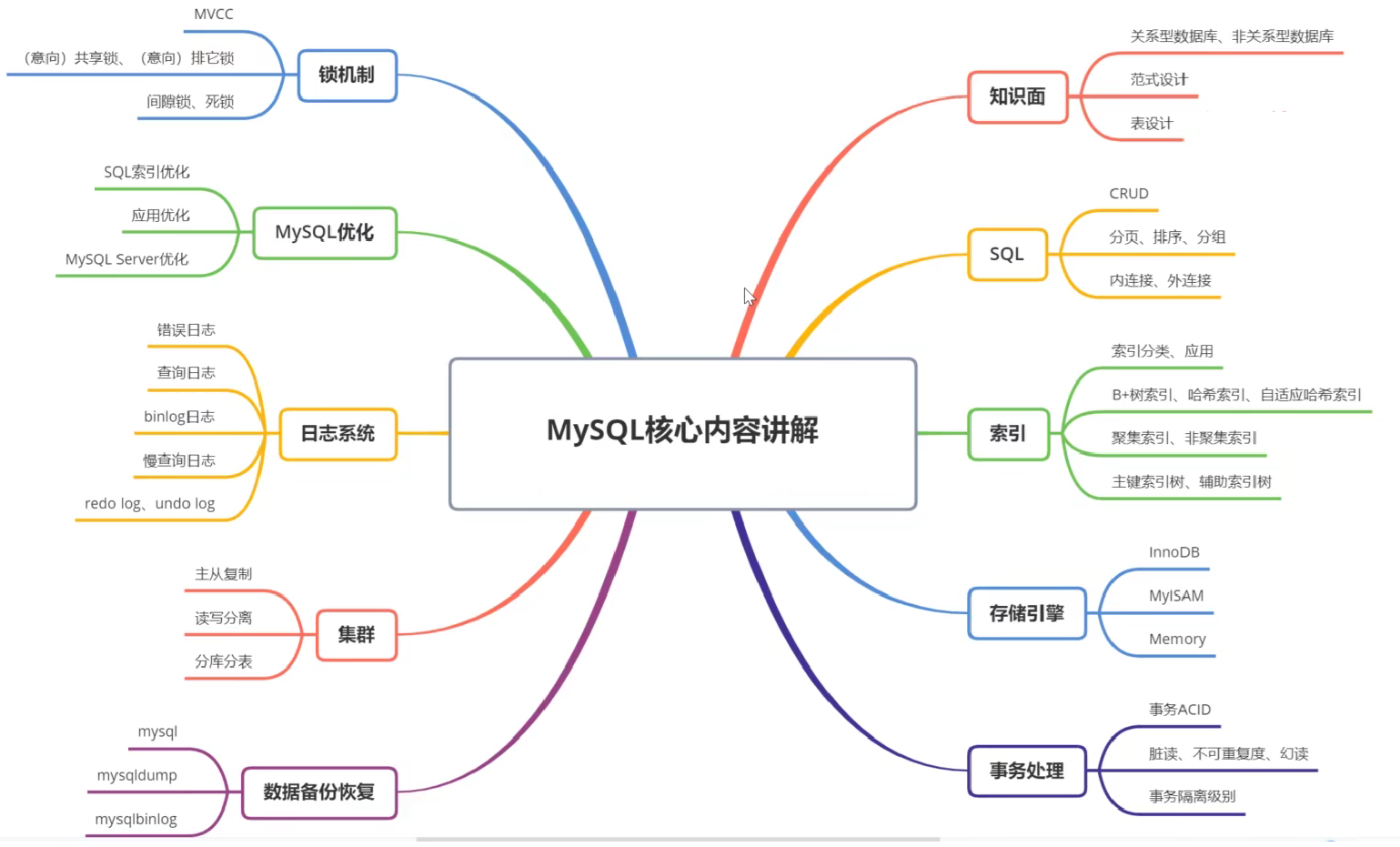
1.MySQL核心内容目录
2.MySQL知识面扩展
- 关系型数据库 SQLite(安卓上的) ,NoSQL(key-value):redis、 leveldb、rocksdb、大数据分析列式数据库 Hbase、ceph开源的分布式db
- MySQL目前属于Oracle,大家熟悉的关系型数据库还有SQL Server、Oracle、MySQL,MariaDB(和MySQL一个作者)、DB2(金融行业)
- MySQL分为企业版和社区版,其中社区版是完全免费并且开源的
- MySQL区别于其他关系型数据库很大的一个特点就是支持插件式的存储引擎,支持如InnoDB,MyISAM,Memory等
- 目前google、腾讯、淘宝、百度、新浪、facebook等公司都在使用MySQL作为数据存储层方案
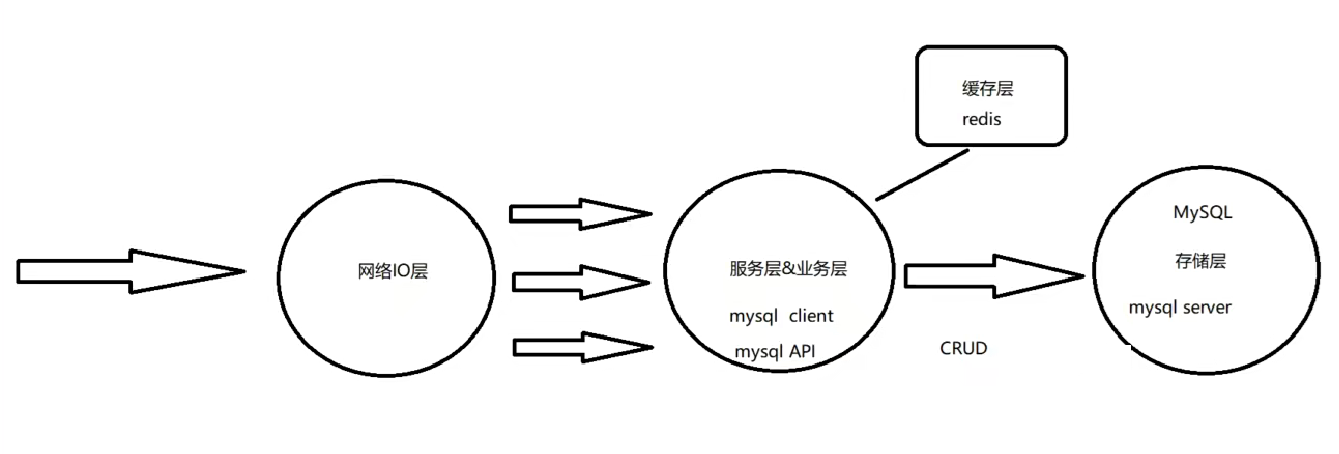
- MySQL设计成C/S模型 mysqlclient、mysqlserver
- MySQL的服务器模型采用的是I/O复用+可伸缩的线程池,是实现网络服务器的经典模型,使用的是 select+线程池!为什么不用epoll,Linux uring呢?因为MySQL还涉及磁盘IO,业务处理很慢,网络IO不需要那么强的能力,这里面的网络IO能力只要能和数据库的磁盘IO能力相匹配就行了!
经典的mysql通信的整体结构如下:
3.MySQL安装
博主使用的是华为云服务器(华为云打钱bushi),Linux版本为:Ubuntu 22.04.4 LTS,安装的MySQ版本是5.7,安装方法参考:ubuntu22.04安装mysql5.7.29 - 卷心菜的奇妙历险 - 博客园 即可!
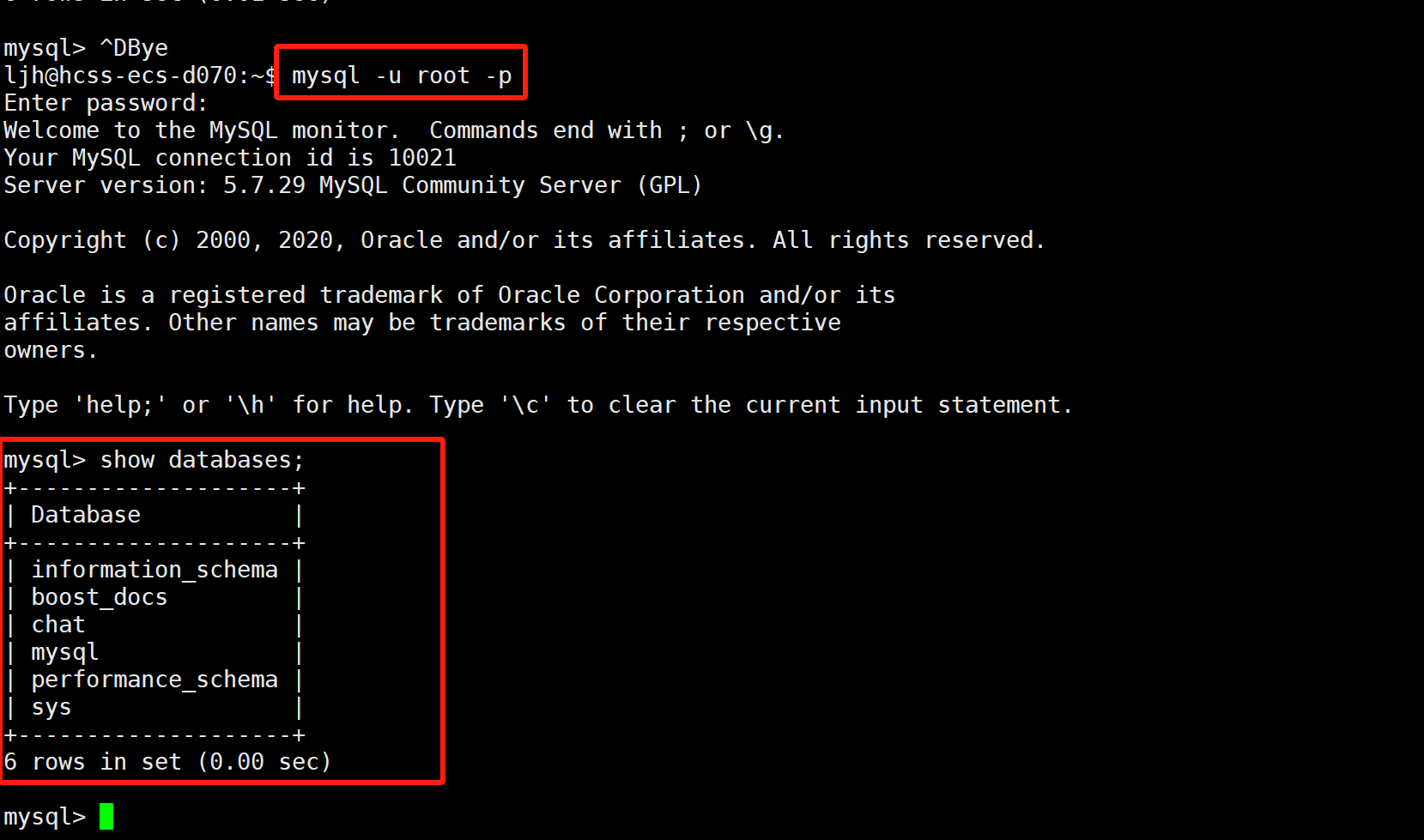
博主一开始是只要apt-get直接下载mysql,下载的版本是mysl8.0,但博主毕竟(贫穷),服务器配置只有2核2G,跑mysql8.0太吃内存了,故换成mysq5.7,当然感兴趣的同学也可以修改mysql8.0的相关配置降低其消耗。安装成功后 mysql -u root -p,输入密码登录即可。
如果需要对服务重启:service mysqld restart即可。
4.MySQL配置目录介绍
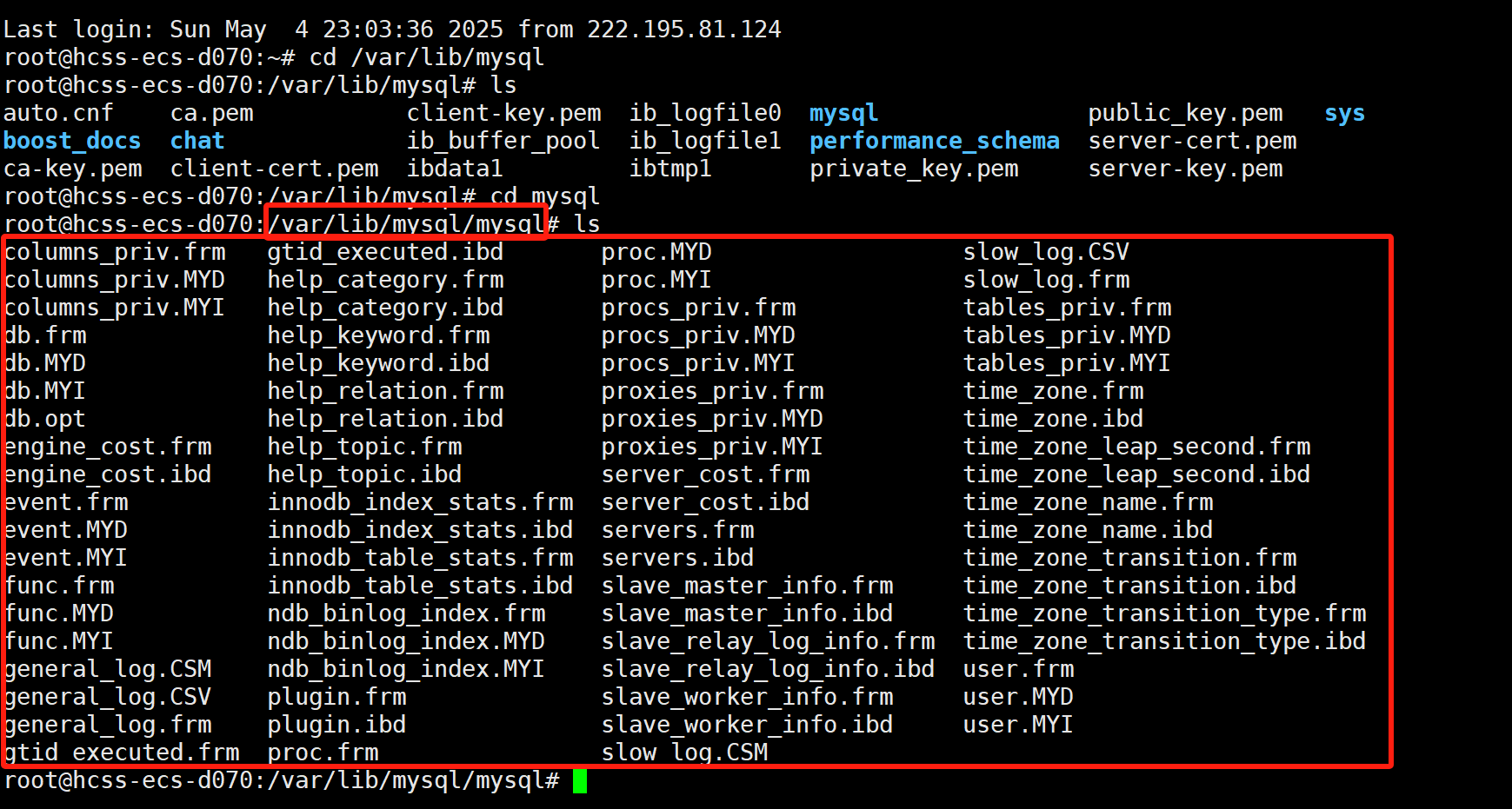
Mysql的系统表一般放在/var/lib/mysql/mysql中
Mysql的配置文件一般放在/etc/mysql/mysql.conf.d下的mysqld.cnf中,如果有需要进行修改或者添加的配置项,写入到这个my.cnf文件即可!

我们可以打开该文件进行查看,里面记录了详细的mysql配置信息:
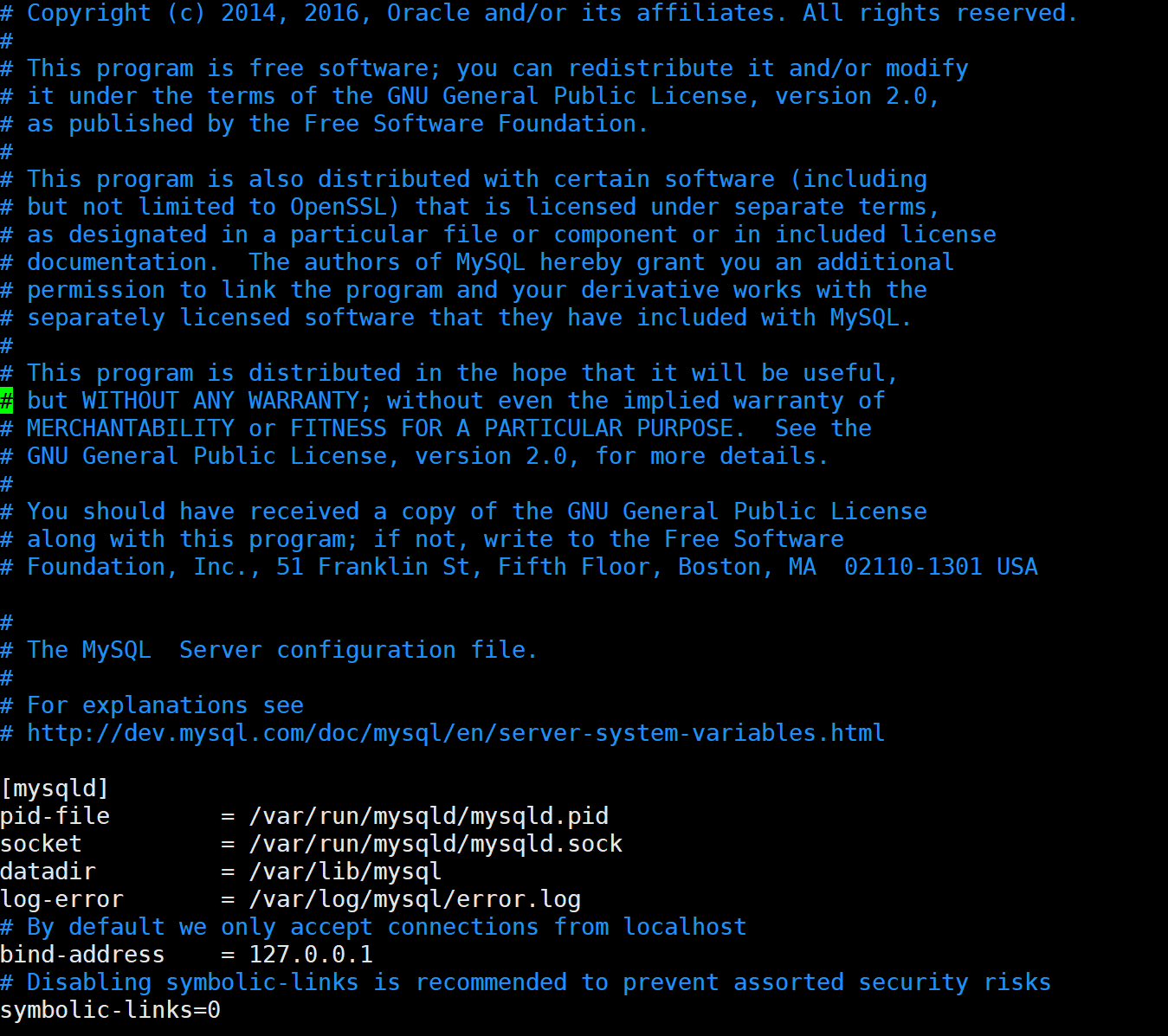
我们一般需要进行如下两条配置:
- 允许所有的IP连接(默认绑定的是127.0.0.1)
- 跳过名称解析(提升连接速度)
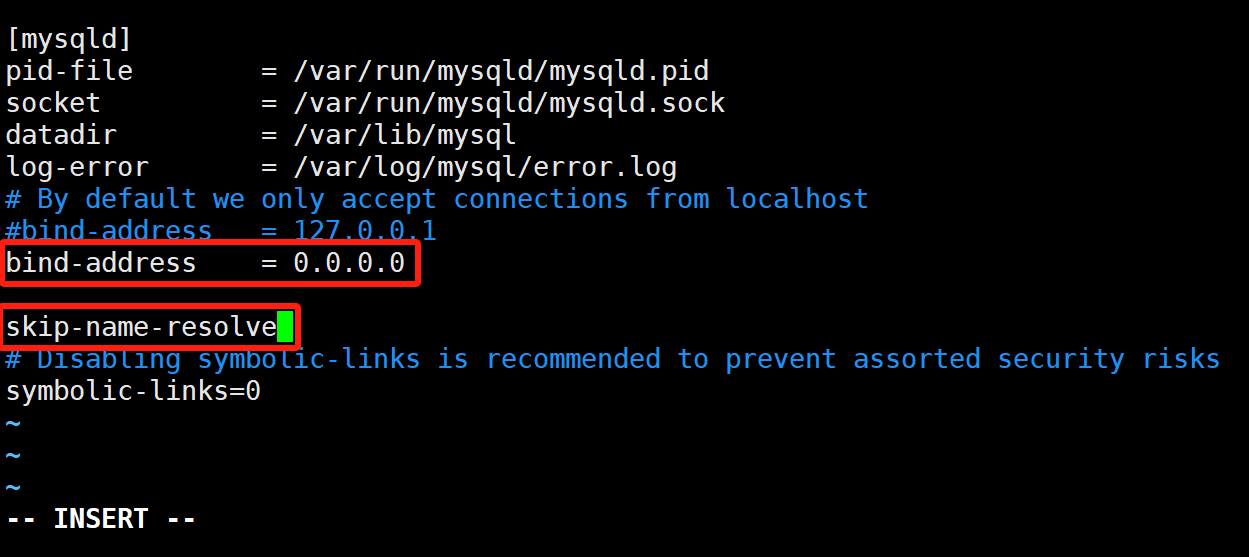
更新完配置以后,需要重启服务才能生效:sudo systemctl restart mysql
Mysql配置远程ip连接
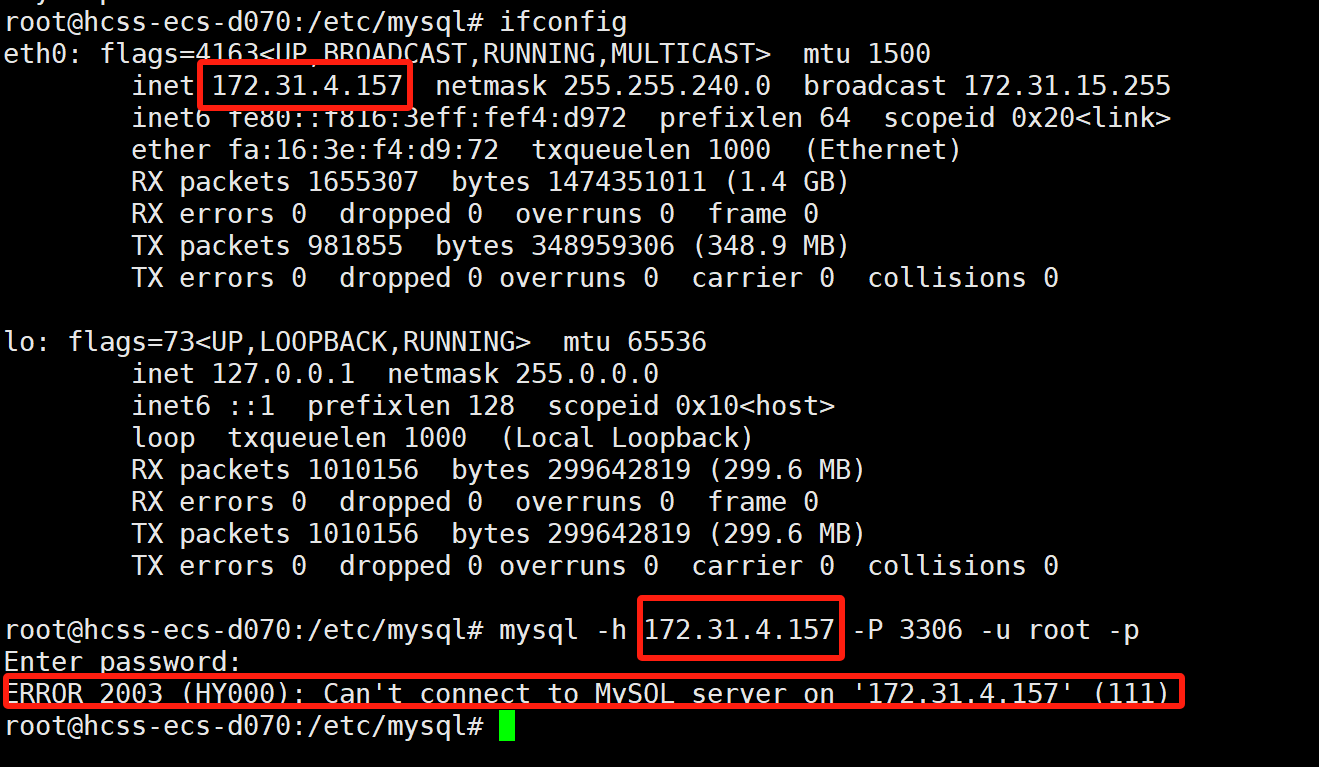
按理说,Mysql是要支持远程ip的连接的,通过mysql -h ip -P 3306 -u root -p,可是当前试了下并不行,需要我们进行配置!
我们先本地登录,进入mysql数据库中,通过select Host,User,authentication_string from user;查看配置
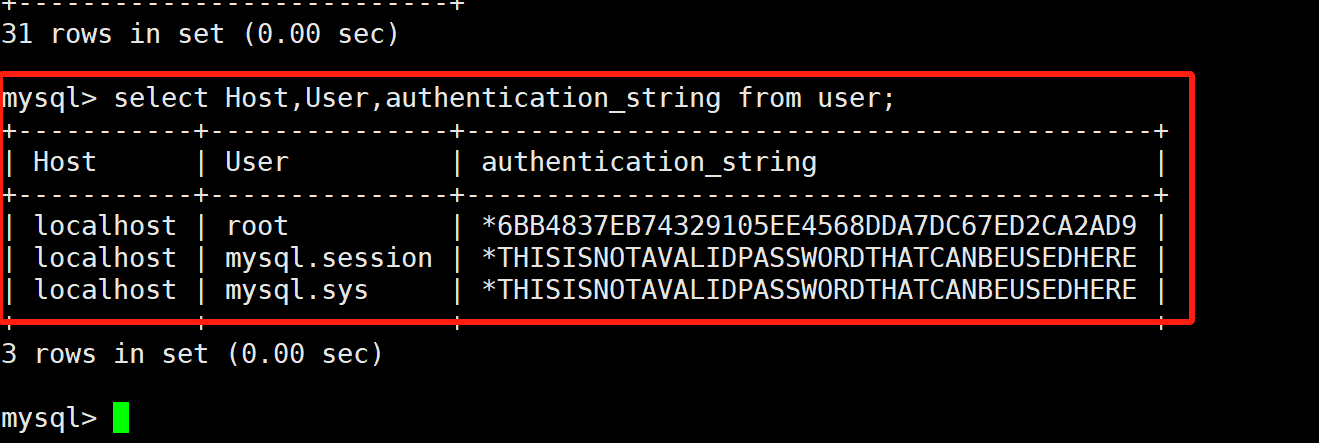
可以看到,目前的用户只支持localhost,自然无法被远程用户所访问了!我们可以通过 grant all privileges on *.* to 'root'@'%' identified by 'XXXXXX' with grant option,便可以让远程用户也进行访问了!
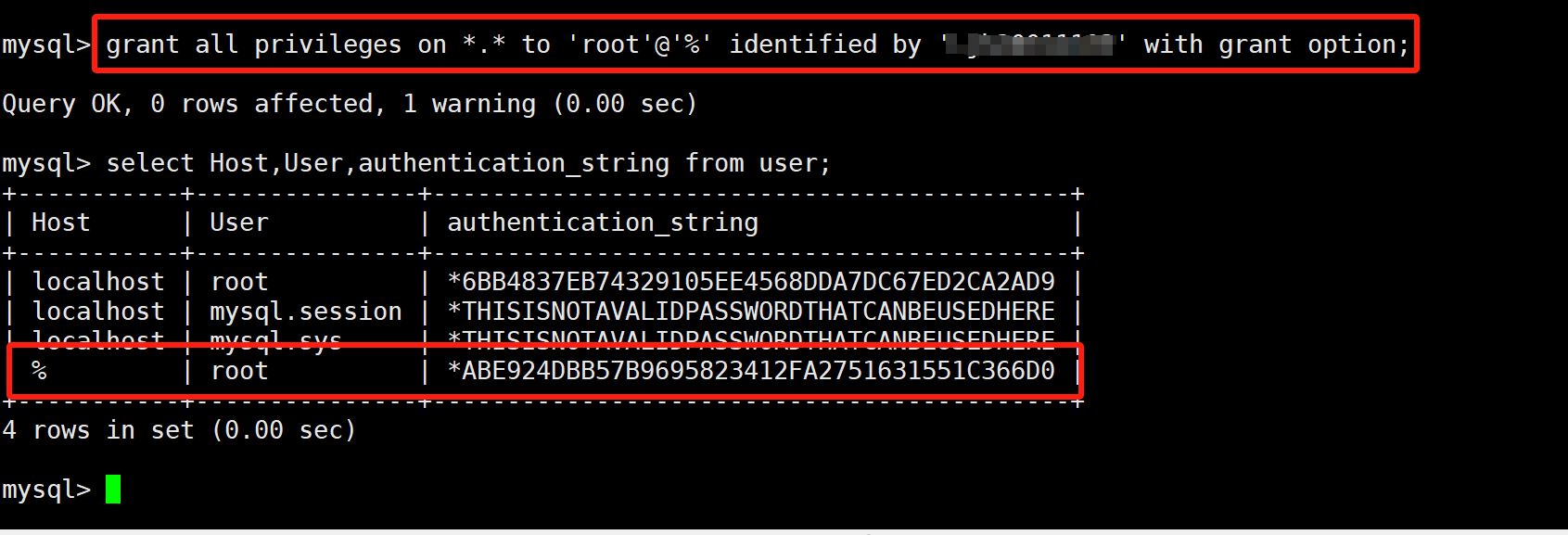
此时我们再去查看user表的相关表项,发现多了一行所有用户可连接!此时我们对配置进行刷新!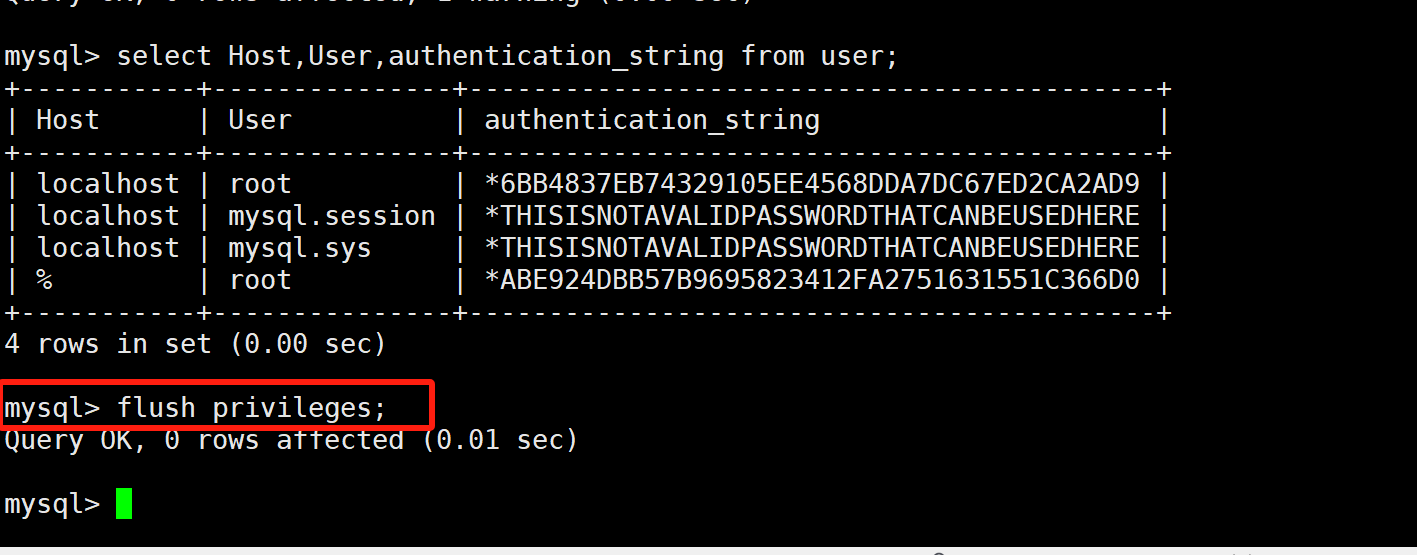
再次尝试下远程登录,输入前面自己授权时设置的密码,发现就可以登录成功了!【如果不行,可能是mysql的配置没有改,mysql网络配置上设置了只允许本地连接】
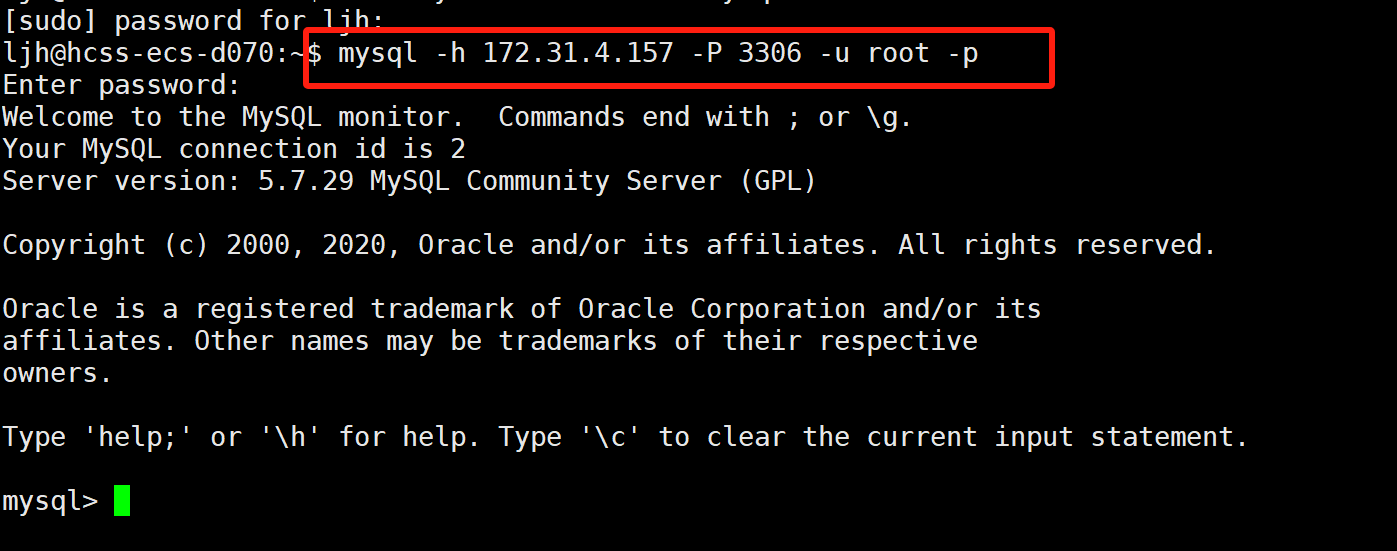
5.MySQL基础
1.MySQL数据类型
MySQL中数据和索引都存储在磁盘上,MySQL数据类型定义了数据大小范围,因此使用时选择合适的类型,不仅会降低表占用的磁盘空间,间接减少了磁盘I/O的次数,提高了表的访问效率,而且索引的效率也和数据的类型相关。
1.数值类型
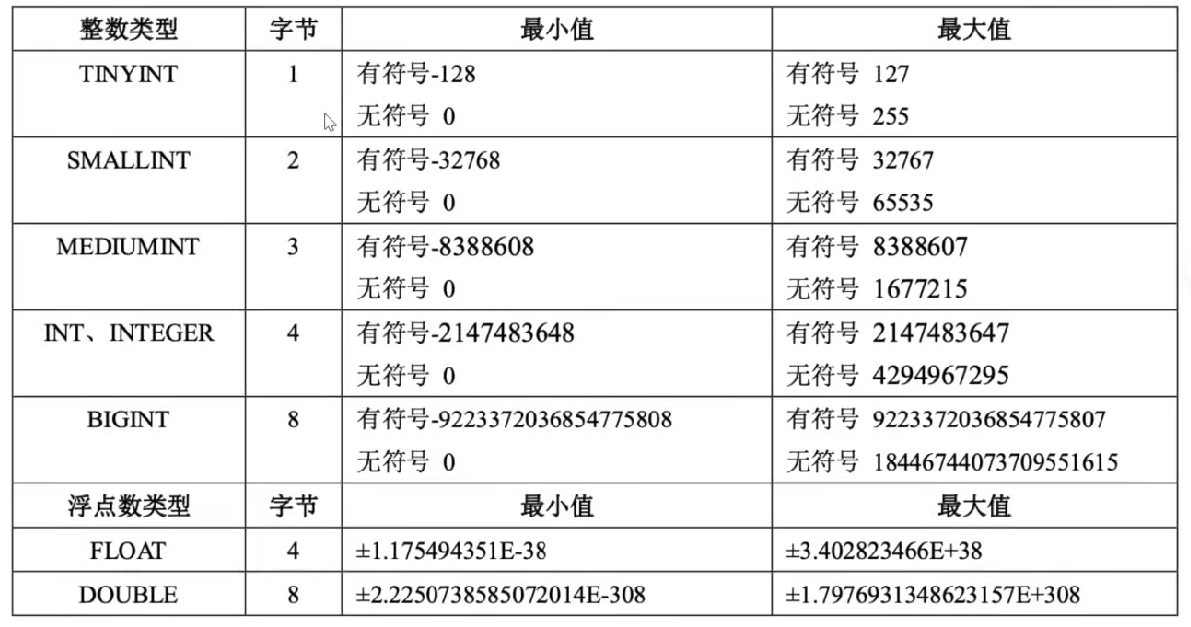
- 在金融计算中,浮点数类型推荐使用decimal类型(保存为字符串格式),数据溢出会报错,而FLOAT/DOUBLE数据溢出是截断
- 一般 TINYINT unsigned类型就非常适合用来定义年龄
create table(age TINYINT unsigned not null default 0);
2.字符串类型
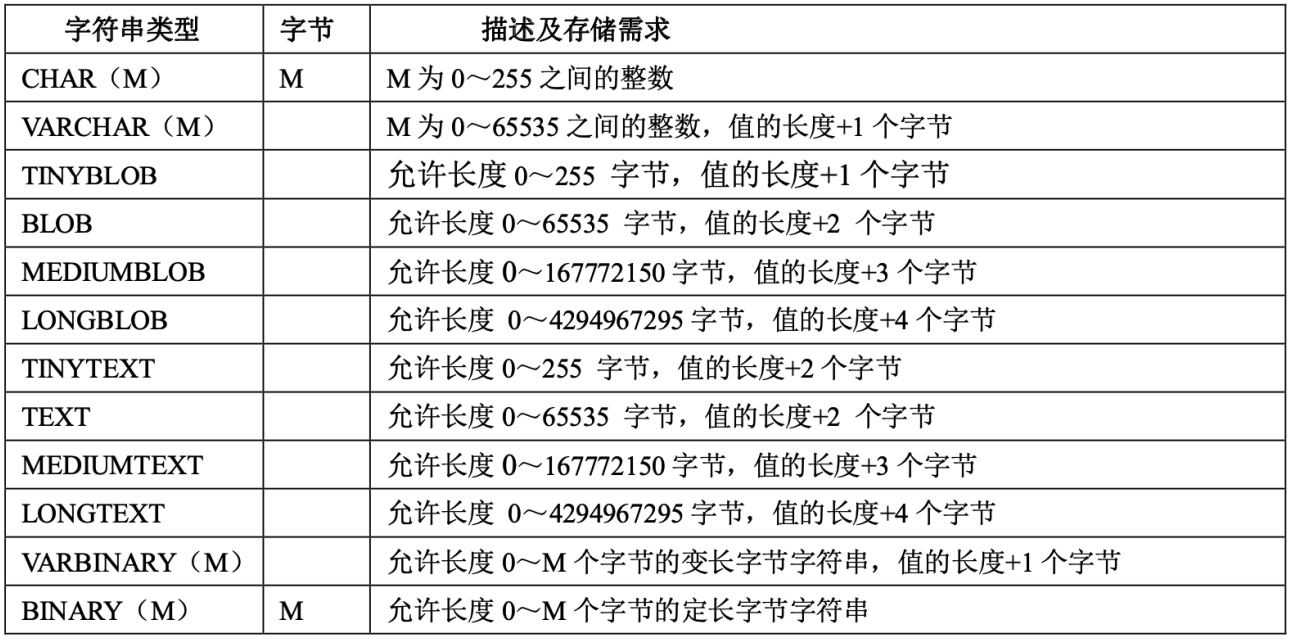
- 经常被问的点:age INT(8),这里这个8是什么意思?整形占用内存的大小是固定的,和具体的类型是强相关的,(M)只是表示整数显示的宽度。
- char(12)和varchar(12),如果存的是“hello”,在char(12)用的是12个字符,而varchar(12)会去适配“hello”,一般占6个字符。
- TEXT一般用于存储文本信息,聊天记录什么的,大家总结的工作报告一般来说用TEXT就不够了,微博留言框限制字数一般就是这个原因。
- 字符串因为拼接操作经常会被注入式攻击!
3.日期和时间类型

- 我们一般很少用MySQL的相关操作,MySQL会遇到磁盘IO,我们一般都让MySQL做最少的事情,像存储过程,存储函数,触发器,外键约束,让MySQL帮我们执行一些逻辑,这是需要避免的!我们尽量只让他做CRUD,其他的通过服务层去控制,不要给MySQL server徒增压力。
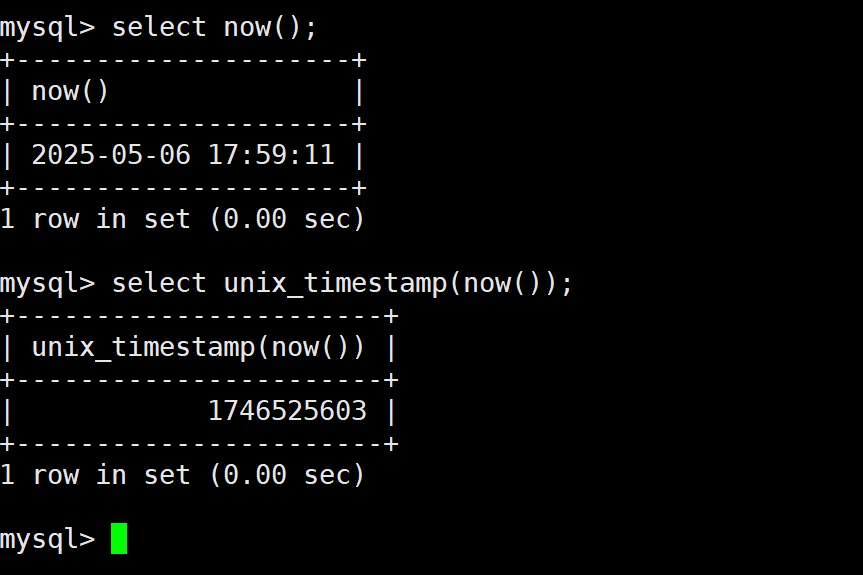
- 查看时间和时间戳,我们在业务中使用的最多的就是时间戳
4.enum和set
- 这两个类型,都是限制该字段只能取固定的值,但是枚举字段只能取一个唯一的值,而集合字段可以取任意个值。
- 用法是用来限制值:比如性别
sex enum(‘M’,’W’) default ‘M’
2.MySQL运算符
1.算数运算符
举例:常用到的updata user set age = age + 1;
2.逻辑运算符
举例:常用到逻辑与and select * from user where sex=‘M’ and score >= 90.0;,男生并且成绩大于90的
3.比较运算符
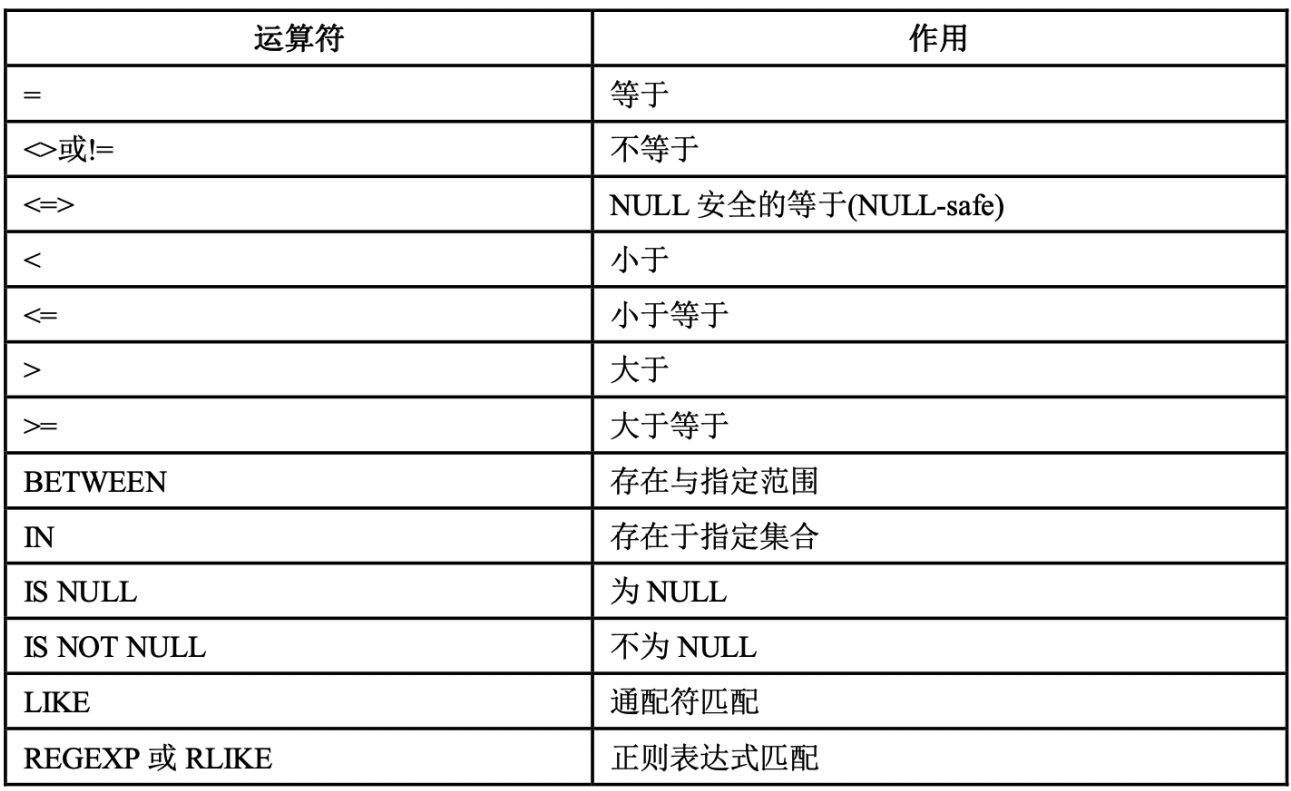
举例:常用select * from user where age between 20 and 22; 年龄在20到22之间 select * from user where score in(99.0,100.0);只能是99.0和100.0中的其中一个,如果有99.5的话就选不到了。
如何判断一个字段能不能为空,select * from user where score is not NULL;,另外,在外连接查询的时候也会经常的出现NULL。
通配符LIKE也非常常见,select * from user where name like ‘zhang%’;,‘zheng_’匹配一个字符,%匹配多个字符。LIKE能不能用到索引?答:通配符加到后面能用到索引,加到前面用不到索引!
3.MySQL完整性约束
1.主键,自增键,非空,默认值约束
primary key,主键:不能为空,不能重复,我们将主键设置为自增,之后在插入数据的时候就不用考虑插入id了。一个表里面只能创建一个主键,但可以创建多个唯一键。唯一键要求不能重复,但可以为空。
CREATE TABLE user(id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '用户的主键id',nickname varchar(50) UNIQUE NOT NULL COMMENT '用户的昵称',age TINYINT UNSIGNED NOT NULL DEFAULT 18,sex ENUM('male','female')
);
建表成功后我们通过desc查看表就是下面这样的:
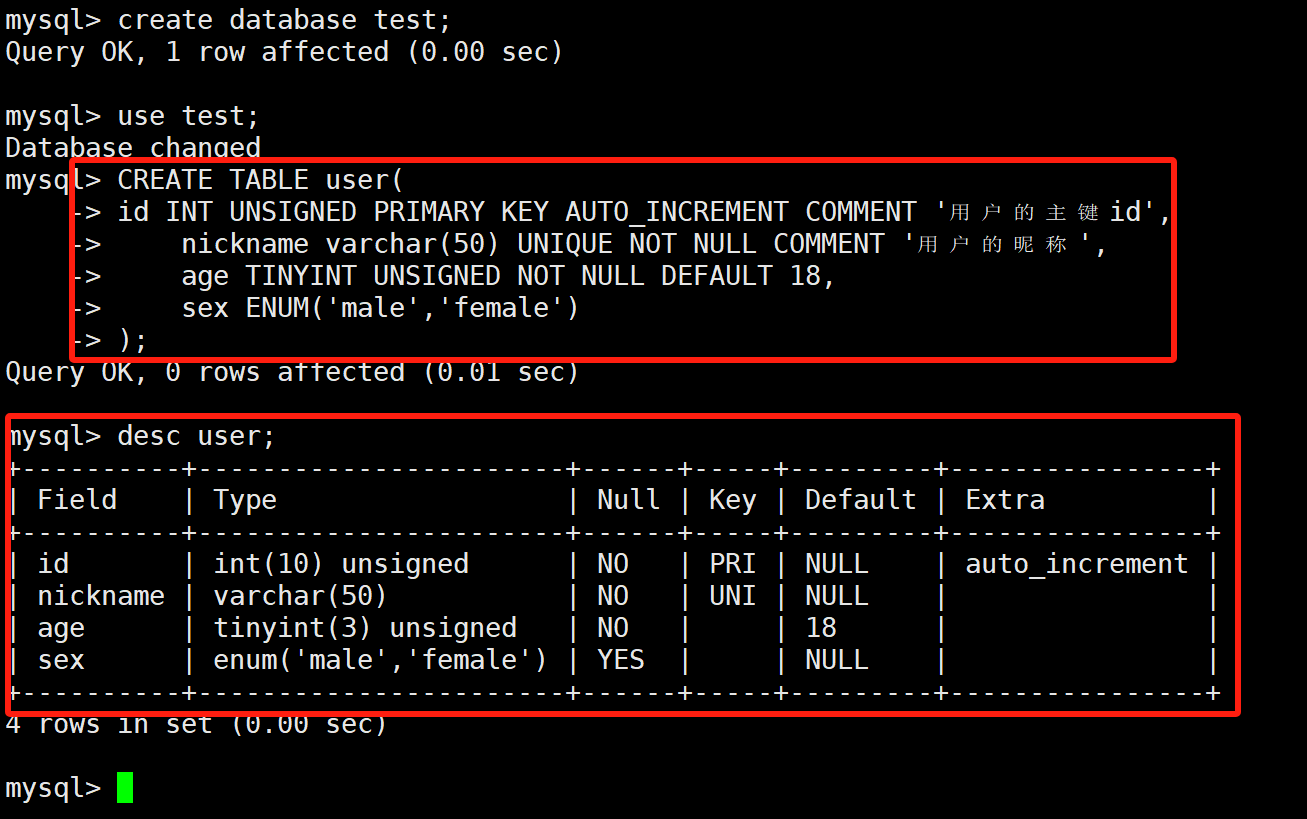
通过desc user\G;查看表格就是下面的逐行形式;

2.外键
表1:学生信息表,张三,年龄 ,xxx(父表)
表2:考试信息表,张三id,考试成绩(子表)
两张表的信息是有关联的!如果张三被退学了,学生信息表中张三的信息被删除了,那考试信息表中的张三的信息怎么办?我删除张三的时候,要么应该出错,要么应该把别的表中的张三的数据也删除!这里就要用到外键!主表的id字段 关联 子表的id字段,让他们产生关联关系。
但我们之前也说过,外键,存储函数,存储过程,触发器这些限制逻辑,代码逻辑是由MySQL本身控制的。会限制MySQL存储层的性能,这些逻辑我们一般都放到业务层上去做。所以MySQL的外键我们一般不用。
6.表设计原则
1.一对一
一对一关系:
用户User:【父表】
| uid | name | age | sex |
|---|---|---|---|
| 1000 | zhang | 20 | M |
| 1020 | liu | 21 | W |
| 2010 | wang | 22 | M |
身份信息Info:
| cardid | addrinfo |
|---|---|
| 112233 | aaa |
| 334455 | bbb |
我们在身份信息表中增加一列,叫做uid【子表】
| uid | cardid | addrinfo |
|---|---|---|
| 1020 | 112233 | aaa |
| 2010 | 334455 | bbb |
子表中的uid关联了父表的uid,实现一对一的关系。当有一对一关系的表进行关联时,在子表中增加一列,关联父表的主键。注意必须要类型相同!这样以后在查询时:select * form Info where uid=2010;便可以找到子表中的父表uid为2010的信息。
2.一对多
我现在要做一个电商系统,涉及的实体为用户User,商品Product,订单Order。分析如下:
用户-商品:没有关系!
用户-订单:一对多的关系,一个用户可以有多个订单!
商品-订单:多对多的关系,一个商品可以属于多个订单,一个订单可以有多个商品!
用户User表:
| uid | name | age | sex |
|---|---|---|---|
| 1000 | zhang | 20 | M |
| 1020 | liu | 21 | W |
| 2010 | wang | 22 | M |
商品Product:
| pid | pname | price | amount |
|---|---|---|---|
| 1 | 手机 | 600.0 | 100 |
| 2 | 笔记本 | 2000.0 | 50 |
| 3 | 电池 | 10.0 | 200 |
订单Order:
| orderid | pid | number | money | totalprice | addrinfo |
|---|---|---|---|---|---|
| O1000 | 1 | 1 | 600.0 | 4640.0 | 海淀区 |
| O1000 | 2 | 2 | 4000.0 | 4640.0 | 海淀区 |
| O1000 | 3 | 4 | 40.0 | 4640.0 | 海淀区 |
| O2000 | 2 | 1 | 2000.0 | 2000.0 | 平谷区 |
当前的设计中:Order明显存在数据冗余!先不考虑这个,我们先看订单Order表如何跟用户User表关联起来呢?
答:一对多和一对一关系一样,在子表【订单Order】中加入一列uid,关联父表【用户User表】中的id,这样就产生Order表和User表中的关联关系了。
| orderid | uid | pid | number | money | totalprice | addrinfo |
|---|---|---|---|---|---|---|
| O1000 | 1000 | 1 | 1 | 600.0 | 4640.0 | 海淀区 |
| O1000 | 1000 | 2 | 2 | 4000.0 | 4640.0 | 海淀区 |
| O1000 | 1000 | 3 | 4 | 40.0 | 4640.0 | 海淀区 |
| O2000 | 2010 | 2 | 1 | 2000.0 | 2000.0 | 平谷区 |
总结:对于一对多的关系的处理与一对一相同,在子表中增加一列数据去关联父表中的id字段。
3.多对多
对于上例中的用户-商品 没有关系 以及 用户-订单:一对多的关系,都是通过在子表中增加一列关联父表的主键。而对于 商品-订单 这种多对多的关系,则需要增加一个中间表。
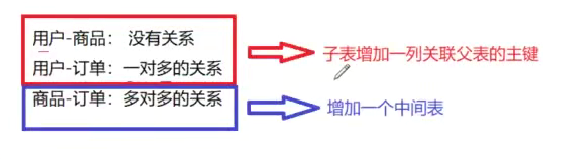 从上面的例子中,我们可以很明显的看出来:一个订单并不需要存那么多相同的orderid,totalprice,addrinfo。我们可以通过产生中间表来解决这个问题。
从上面的例子中,我们可以很明显的看出来:一个订单并不需要存那么多相同的orderid,totalprice,addrinfo。我们可以通过产生中间表来解决这个问题。
我们对订单Order这个表进行拆表,产生中间表的同时还可以解决Order表自身数据冗余的问题。
具体拆解方法如下:
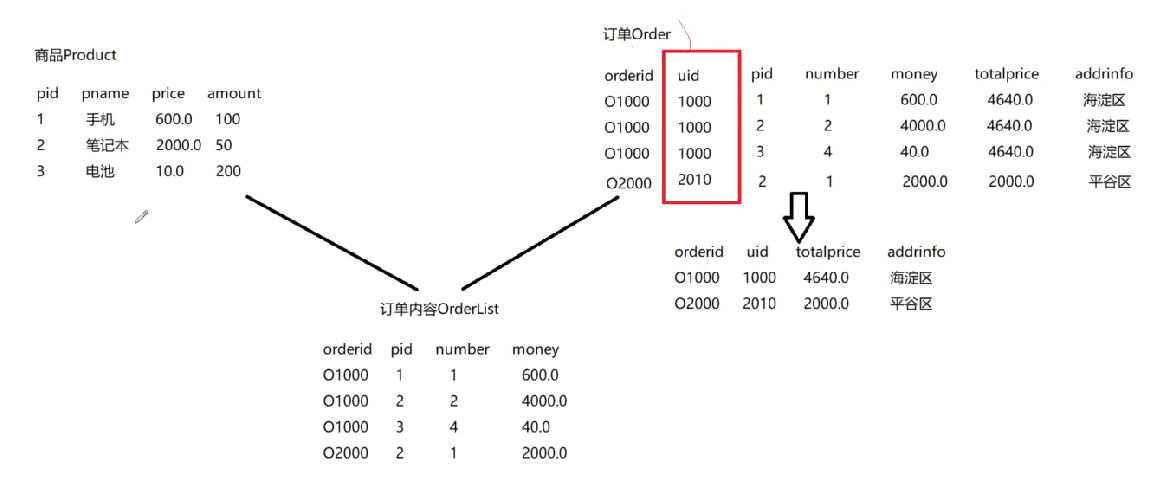
在商品Product表中,pid是主键,订单Order表中orderid作为主键,而在中间表订单内容OrderList表中【orderid+pid】联合作为主键。
解决完多对多的关系后,我们总共得到了三张表:
订单Order表:
| orderid | uid | totalprice | addrinfo |
|---|---|---|---|
| O1000 | 1000 | 4640.0 | 海淀区 |
| O2000 | 2010 | 2000.0 | 平谷区 |
订单内容OrderList表
| orderid | pid | number | money |
|---|---|---|---|
| O1000 | 1 | 1 | 60.0 |
| O1000 | 2 | 2 | 4000.0 |
| O1000 | 3 | 4 | 40.0 |
| O2000 | 2 | 1 | 2000.0 |
以及最初的用户User表,和商品Product表,一共四张表,解决了所有的一对多关系,多对多关系。
7.关系型数据库的范式设计
应用数据库范式可以带来许多好处,但是最重要的好处归结于三点:
- 减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
- 消除异常(插入异常,更新异常,删除异常)
- 让数据组织的更加和谐
但是数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就越大,SQL的效率就变低。
1.第一范式(1NF)
每一列都要保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。例如表中的地址字段,可以再细分为省、市、区等不可再分割(即原子特性)的字段,如下:
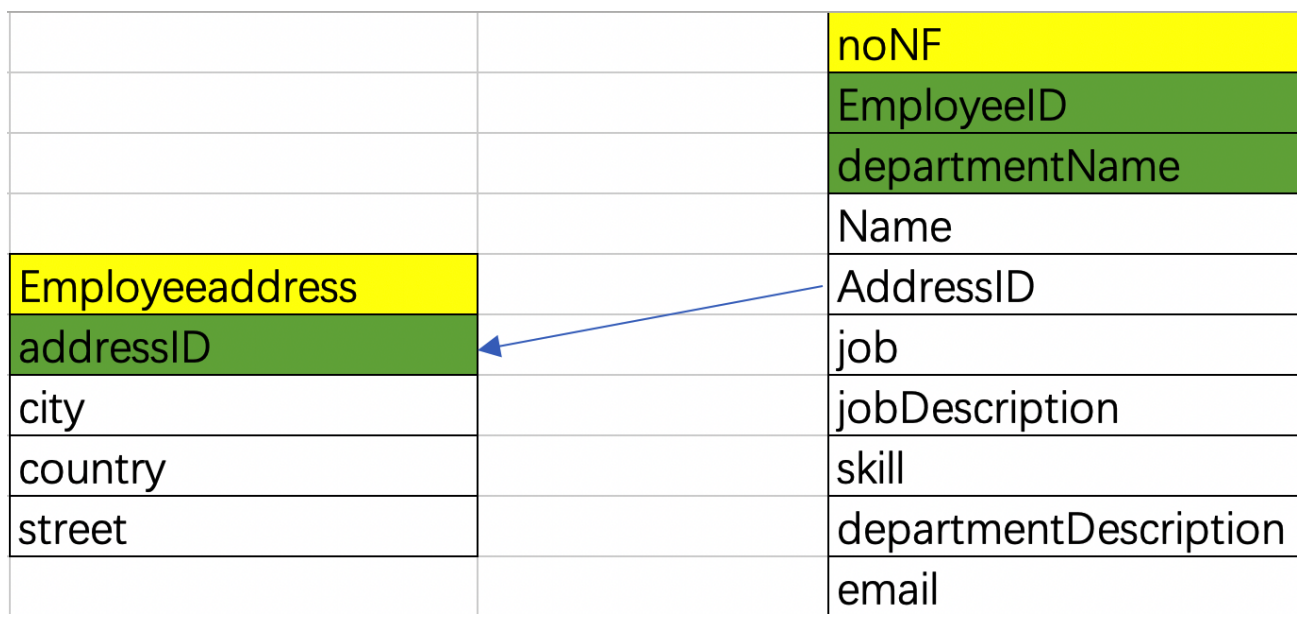
上图的表就是把地址字段分成了更详细的city,country,street三个字段【附表】,通过addressid字段将主表和附表关联。注意,不符合第一范式不能称作关系型数据库【非关系型数据库,比如key-value型数据库】。在查询时可以使用下面的带in的子查询来建立两张表之间的连接。
select * from Employeeaddress where addressID in (select AddressID from noNF where EmployeeID=1);
2.第二范式(2NF)
属性完全依赖于主键 - 主要针对联合主键
非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
例如:选课关系表为SelectCourse(学号,姓名,年龄,课程名称,成绩,学分),(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,同理:姓名和年龄也只跟学号有关,和课程名称无关,相当于只依赖联合主键的其中一个字段,不符合第二范式。
为什么数据冗余?因为学分并不依赖于学号,不同学生,只要选的是同一门课,课程学分并不会根据所选择的学生不同而不同 !
如何解决呢?要解决学号和课程名称之间多对对的关系,我们想到前面提到的建立中间表!将原表拆分为:学生表(学号,姓名,年龄),课程表(课程id,课程名称,学分),以及中间表:选课关系/情况(学号,课程id,成绩)。
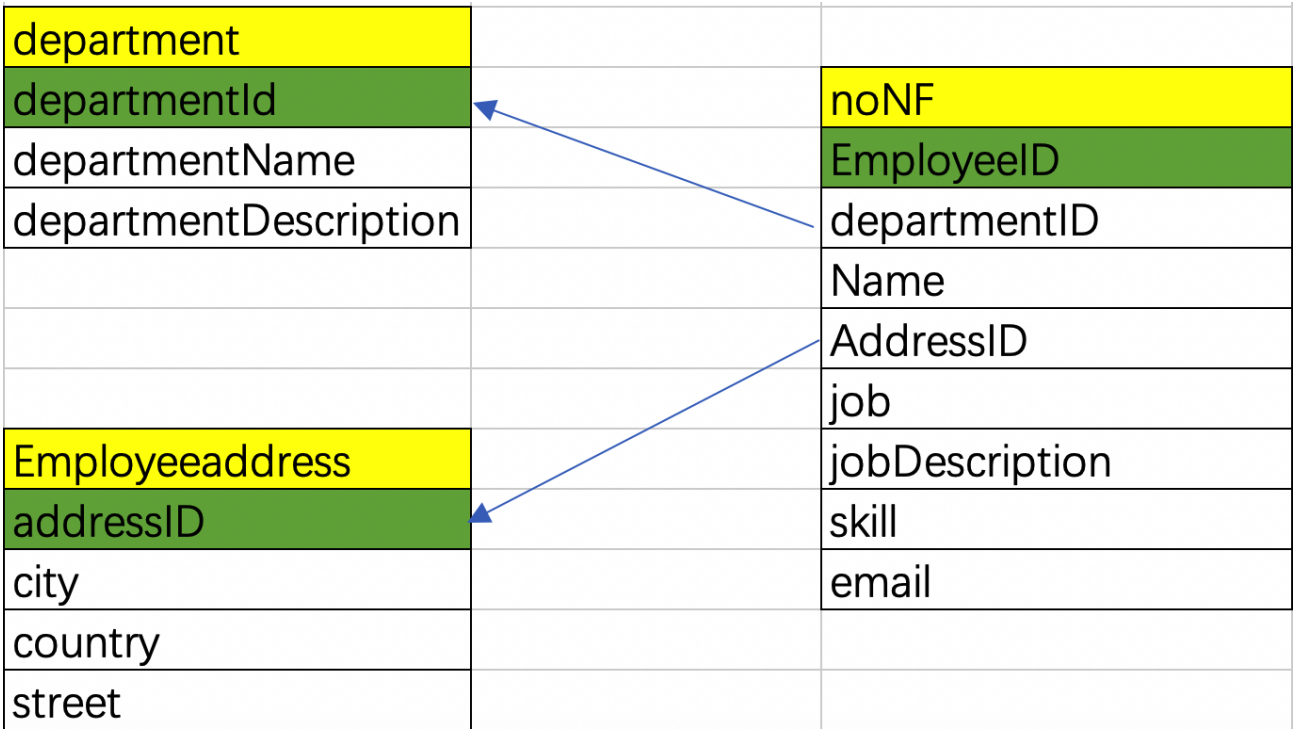
下图也展示了一个常见的第二范式的设计:但是这里面jobDescription仅依赖job,不符合第三范式(3NF)
3.第三范式(3NF)
属性不依赖于其他非主属性
要求一个数据库表中不包含已在其他表中已包含的非主关键字信息。
示例:学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),学号是主键,但是学院电话只依赖于所在学院,并不依赖于主键学号,因此该设计不符合第三范式,应该把学院专门设计成一张表,学生表和学院表,两个是一对多的关系。
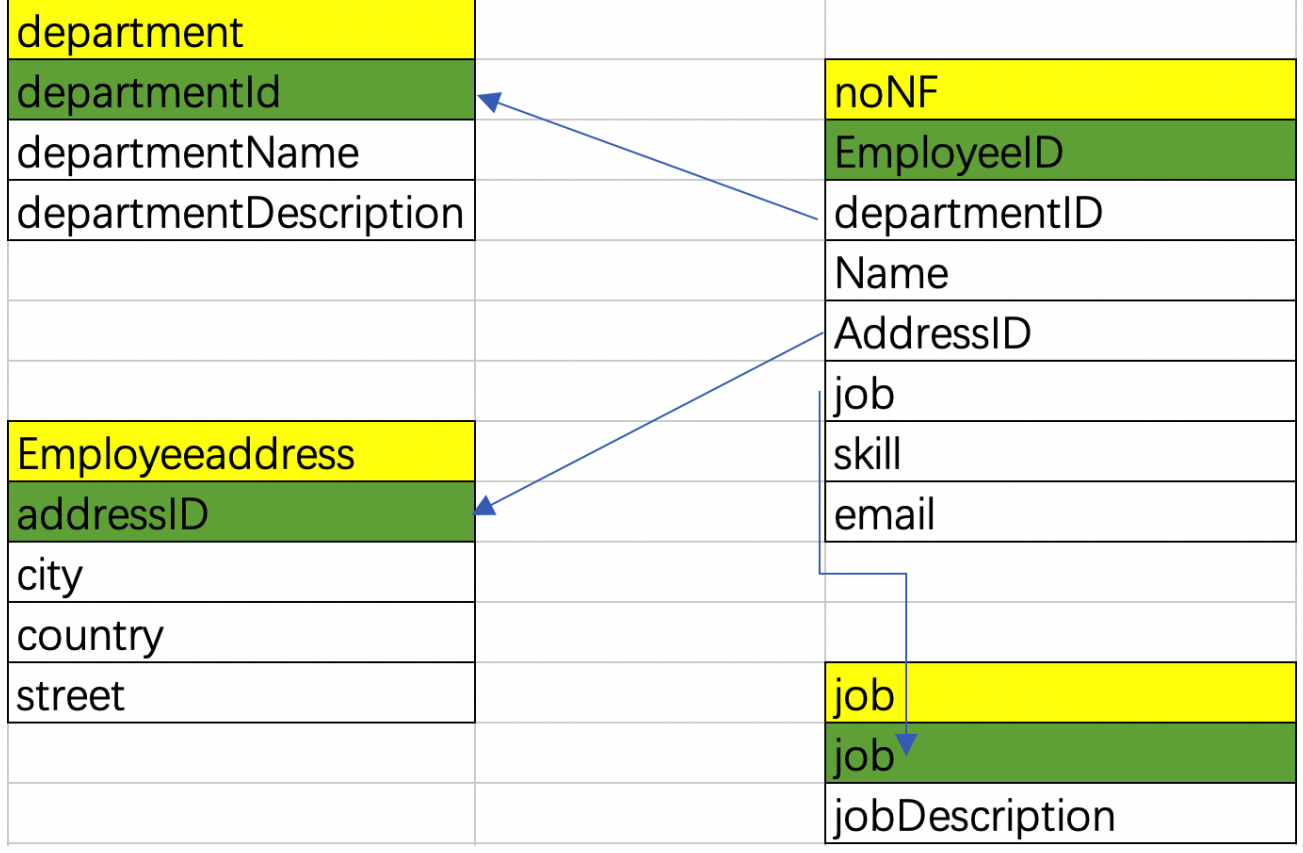
设计原则,把所有不依赖于主键的属性都单独的抽离出来!如下图,把job,department拆出来。但也有缺陷,因为拆出来的表越多,多表查询时的效率就越低!
4.BC范式(BCNF)
每个表中只有一个候选键(能标识唯一性的键)
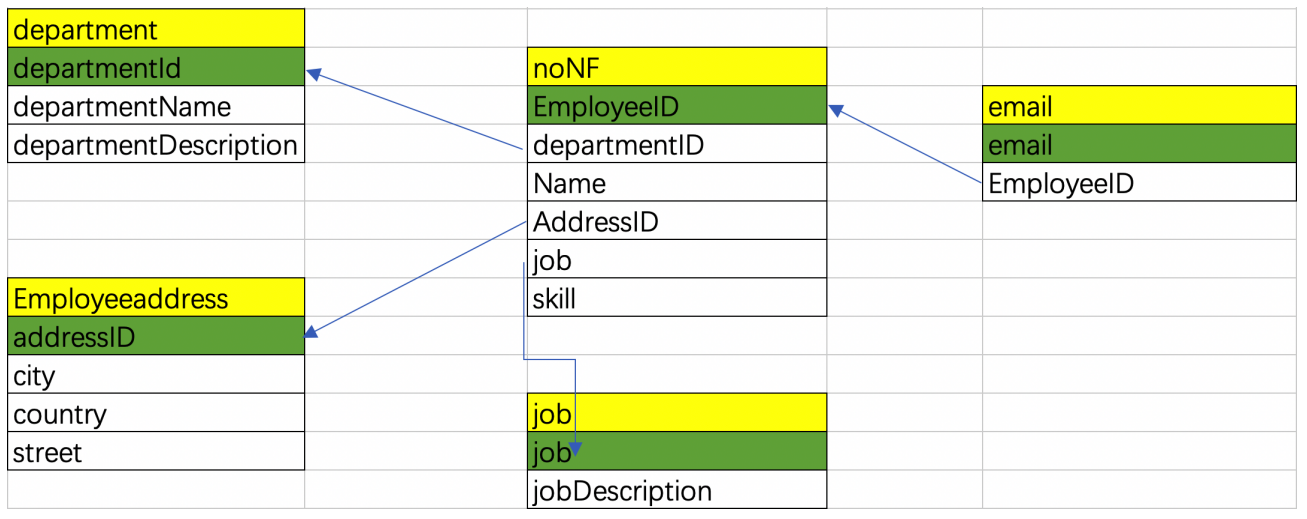
简单的说,BC范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的noNF表(上面图3)中可以看出,每一个员工的email都是唯一的(不可能两个人用同一个email),则此表不符合BC范式,对其进行BC范式化后的关系图为:
5.第四范式(4NF)
消除表中的多值依赖
简单来说,第四范式就是要消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。比如下图中的noNF表中的skill技能这个字段,有的人是“java,mysql”,有的人描述的是“Java,MySQL”,这样数据就不一致了,解决办法就是将多值属性放入一个新表,所以满足第四范式的关系图如下:
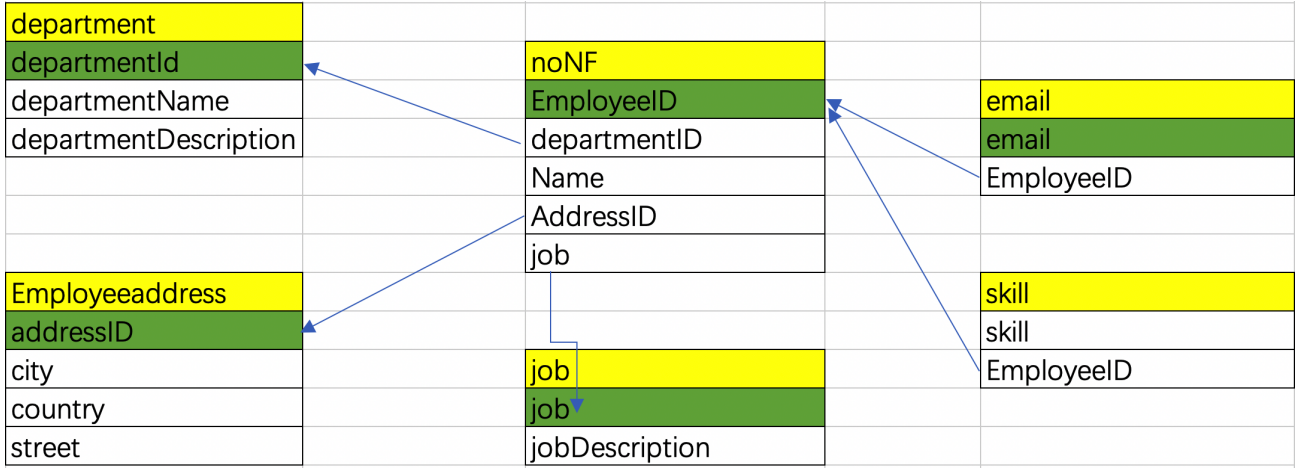
在拆出来的skill表里面,就不存多值了,存储方式如下,这样一来就解决了数据不一致的问题(大小写的问题!)
| skill | EmployeeID |
|---|---|
| C++ | 1000 |
| Java | 1000 |
| MySQL | 2000 |
| Golang | 2000 |
6.总结
从上面对于数据库范式进行分解的过程中不难看出,应用的范式越高,表越多。表多会带来很多问题:
1、 查询时需要连接多个表,增加了书写SQL查询语句的复杂度
2 、查询时需要连接多个表,降低了数据库查询性能
因此,并不是应用的范式越高越好,视实际情况而定。第三范式已经很大程度上减少了数据冗余,并且基本预防了数据插入异常,更新异常,和删除异常了。
8.MySQL核心SQL
SQL是结构化查询语言(Structure Query Language),它是关系型数据库的通用语言。
SQL主要可以划分为以下3个类别:
- DDL(Data Definition Languages)语句
数据定义语言,这些语言定义了不同的数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括create、drop、alter等。 - DML(Data Manipulation Language)语句
数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括insert、delete、updata和select等。 - DCL(Data Control Language)语句
数据控制语句,用于控制不同的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke等。
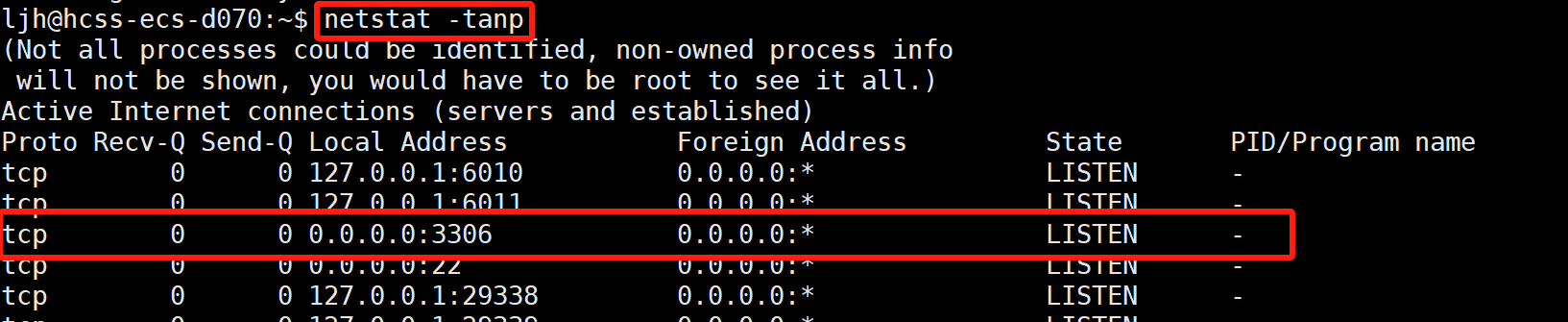
1.检查MySQL服务器状态
检查下MySQL服务是否启动:netstat -tanp
2.库操作
查询数据库
show databases;
创建数据库
create database ChatDB;
删除数据库
drop database ChatDB;
选择数据库
use ChatDB;
3.表操作
查看表
show tables;
创建表,默认的engine和charset可以去mysql的配置文件/etc/mysql/mysql.conf.d中修改,前面已经提到过了。
create table user(id int unsigned primary key not null auto_increment,name varchar(50) unique not null,age tinyint not null,sex enum('M','W') not null)engine=INNODB default charset=utf8;
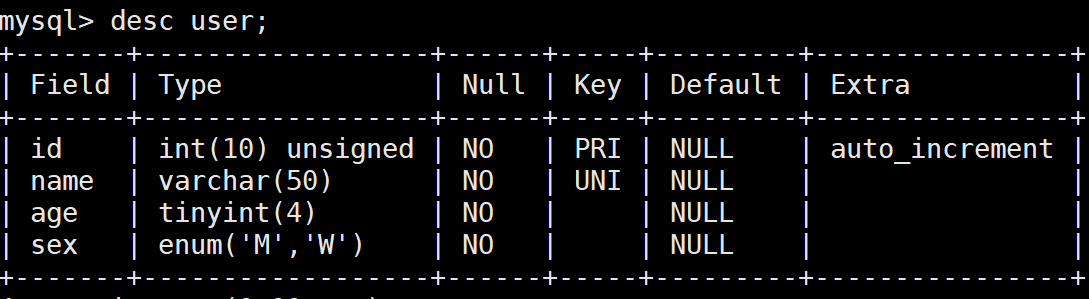
查看表结构,有两种显示格式
desc user;
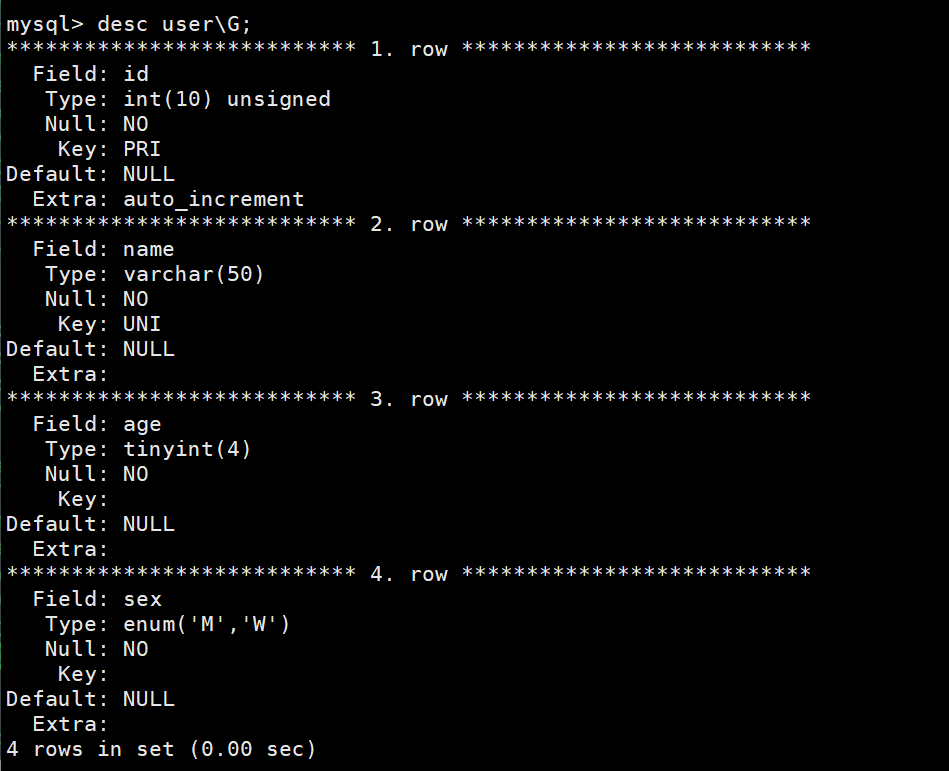
desc user\G;
第一种显示格式:
另一种显示格式:
查看建表sql,相当完整
show create table user\G;
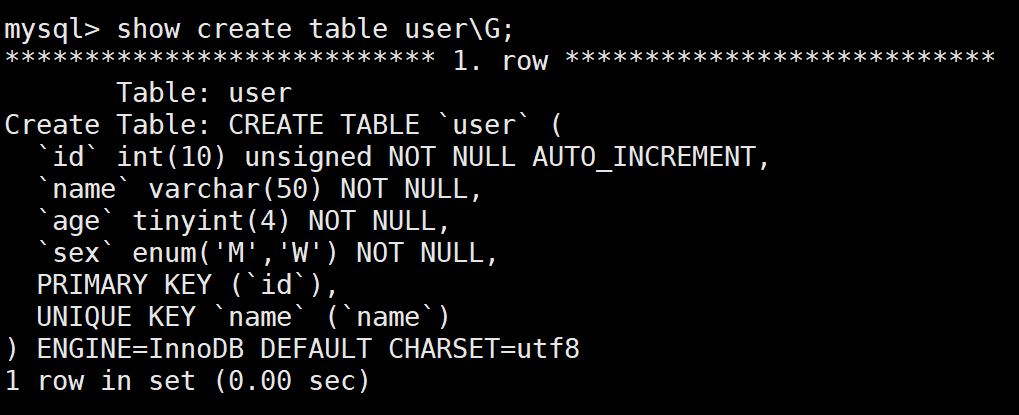
删除表【使用这个操作一定要注意,整个表都没有了!】
drop table user;
4.CRUD操作
insert增加
# 建议不要这样写,这样写就必须按照建表时字段的顺序逐个给值,但我们的id是自增的,其实不需要给他赋值
insert into user values()# 推荐的写法1
insert into user(name,age,sex) values('zhang san',22,'M');
# 推荐的写法2
insert into user(name,age,sex) values('li si',21,'W'),('gao yang','20','M');
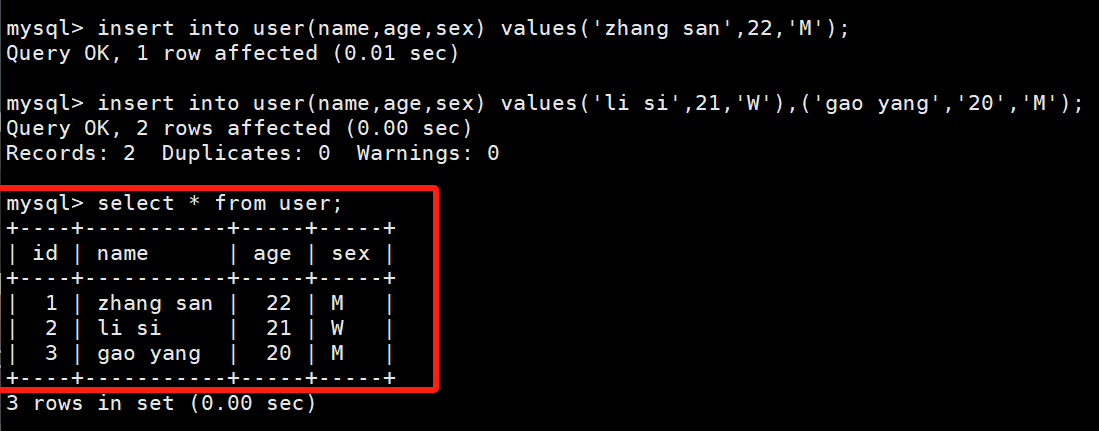
我们再来看一个很有意思的问题:
我们将写法1重复操作两次,和将写法2操作一次,最终表里面存放的数据都是一样的,那请问了,他们到底有什么区别???
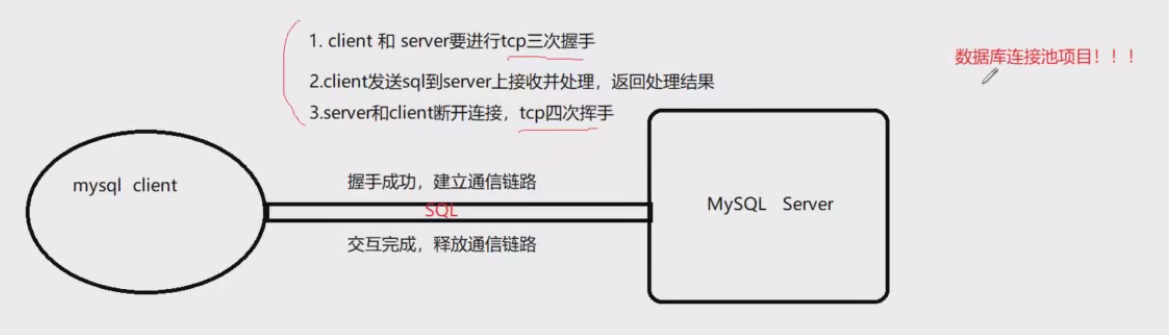
我们客户端的每次sql请求,都要经历三个阶段:
- client和server要进行tcp三次握手
- client发送sql到server上接收并处理,返回处理结果
- server和client断开连接,tcp四次挥手
所以写法1相当于进行了2*(3)个步骤,但是写法2只有 1 *(3)个步骤,写法2更快!!!在实际项目中,我们都会通过数据库连接池,提前创建一些数据库连接,以备使用。
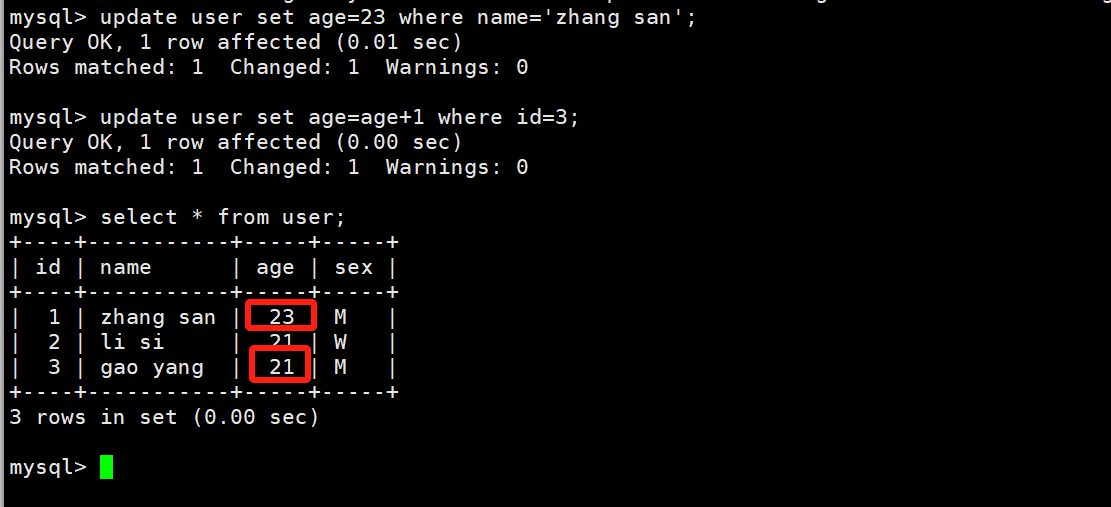
update修改
update user set age=23 where name='zhang san';
update user set age=age+1 where id=3;
delete删除
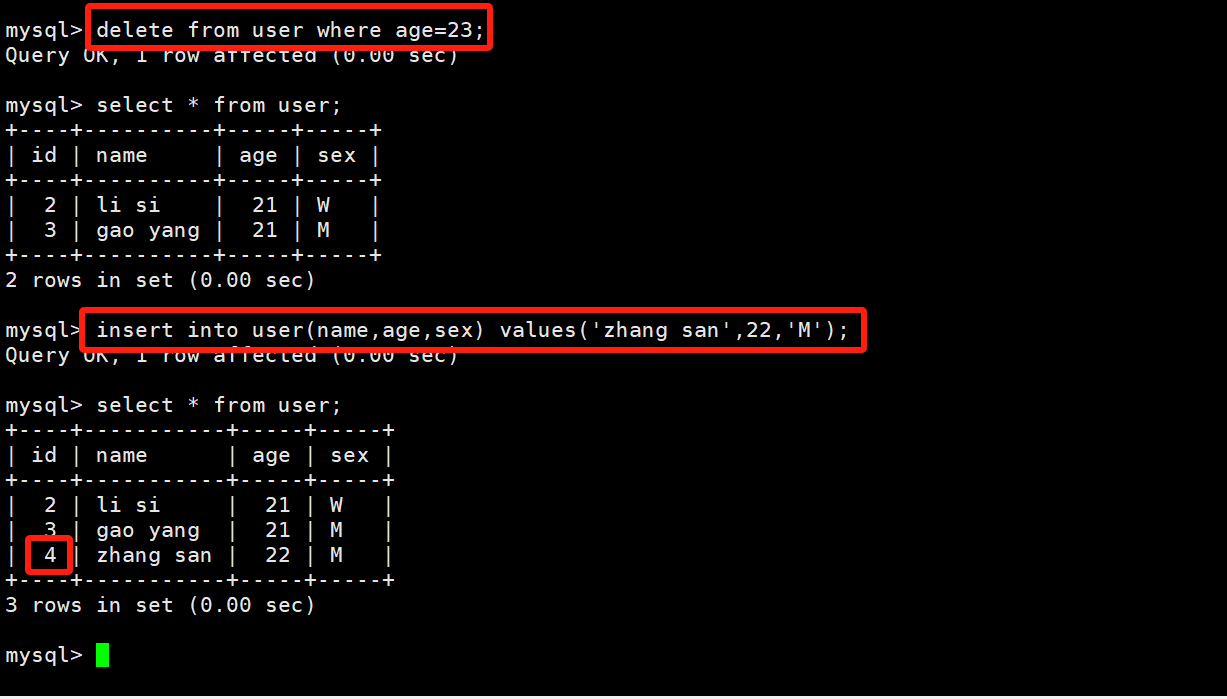
delete from user where age=23;
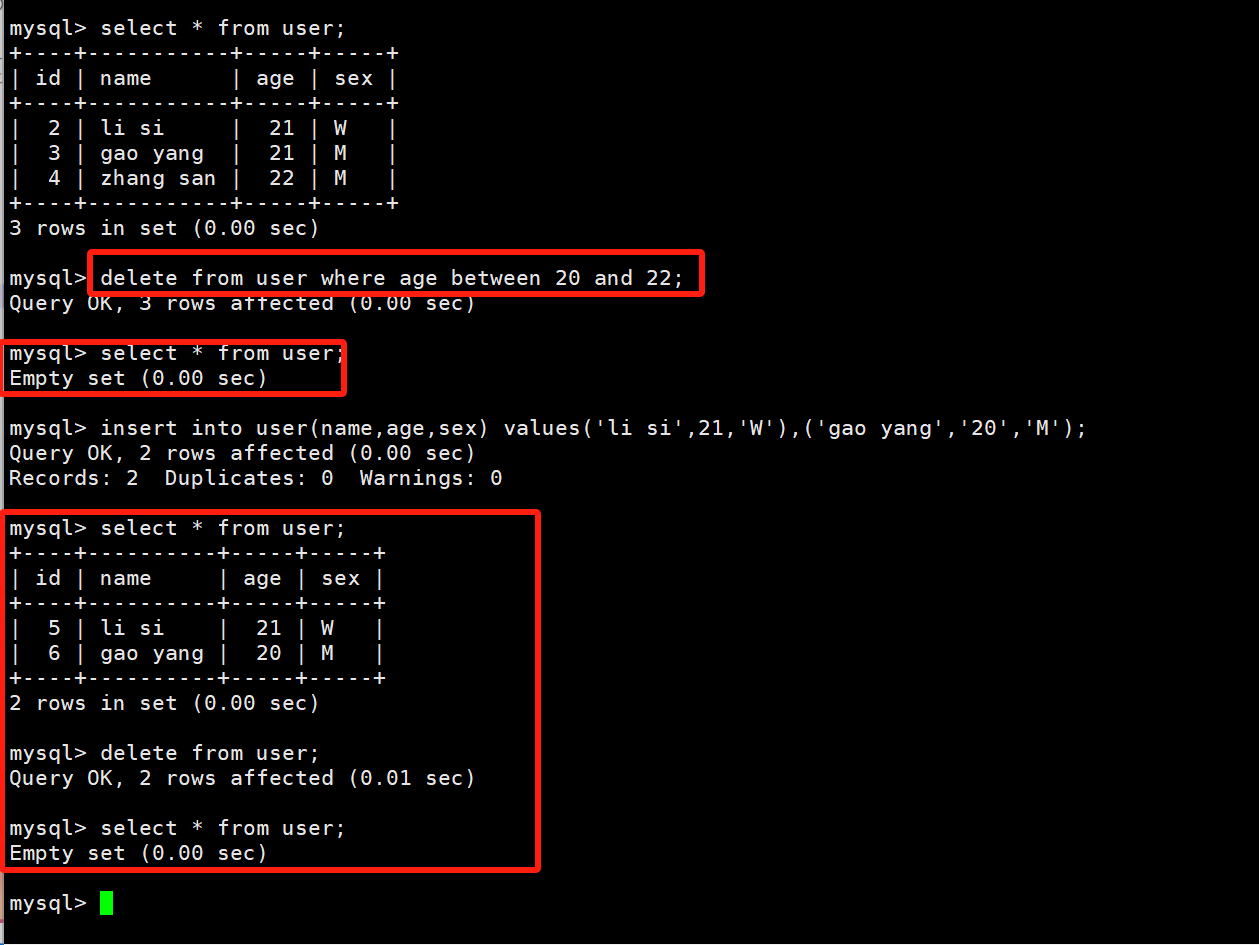
delete from user where age between 20 and 22;
# 将表中的数据全部删除
delete from user;
这里有一个很有意思的问题,当我们删除掉张三后,我们再去插入一个张三,这时候的id是1呢,还是3呢,还是递增呢?答案:递增!我们的自增id是一个开弓没有回头箭的东西!这个id是会不断增加的,如果表中要存储的数据过多的话,在表创建的时候还是尽量把id设置成bigint类型(8字节)
下面是范围删除以及全部删除
5.select查询
简单的select查询
# 不推荐,加大查询数量的大小,增加Mysql的压力
select * from user;# 推荐的写法——制定需要选择的列
select name,age,sex from user;# 过滤数据
select name from user where age>21;
select name,age,sex from user where age>=21;
select name,age,sex from user where age>=21 and sex='M';
select name,age,sex from user where age>=21 or sex='M';# between包含左右断点
select name,age,sex from user where age between 20 and 22;# like+通配符 后缀匹配,前缀匹配,部分匹配
select name,age,sex from user where name like "zhang%";
select name,age,sex from user where name like "zhang_";# 带in的子查询
select name,age,sex from user where age in(20,21);
# 等价于 select name,age,sex from user where age=20 or age=21;
select name,age,sex from user where age not in(20,21);
去重distinct
# 查看有多少不重复的age
select distinct age from user;
空值查询
# 判断null
select name,age,sex from user where name is null;
select name,age,sex from user where name is not null;
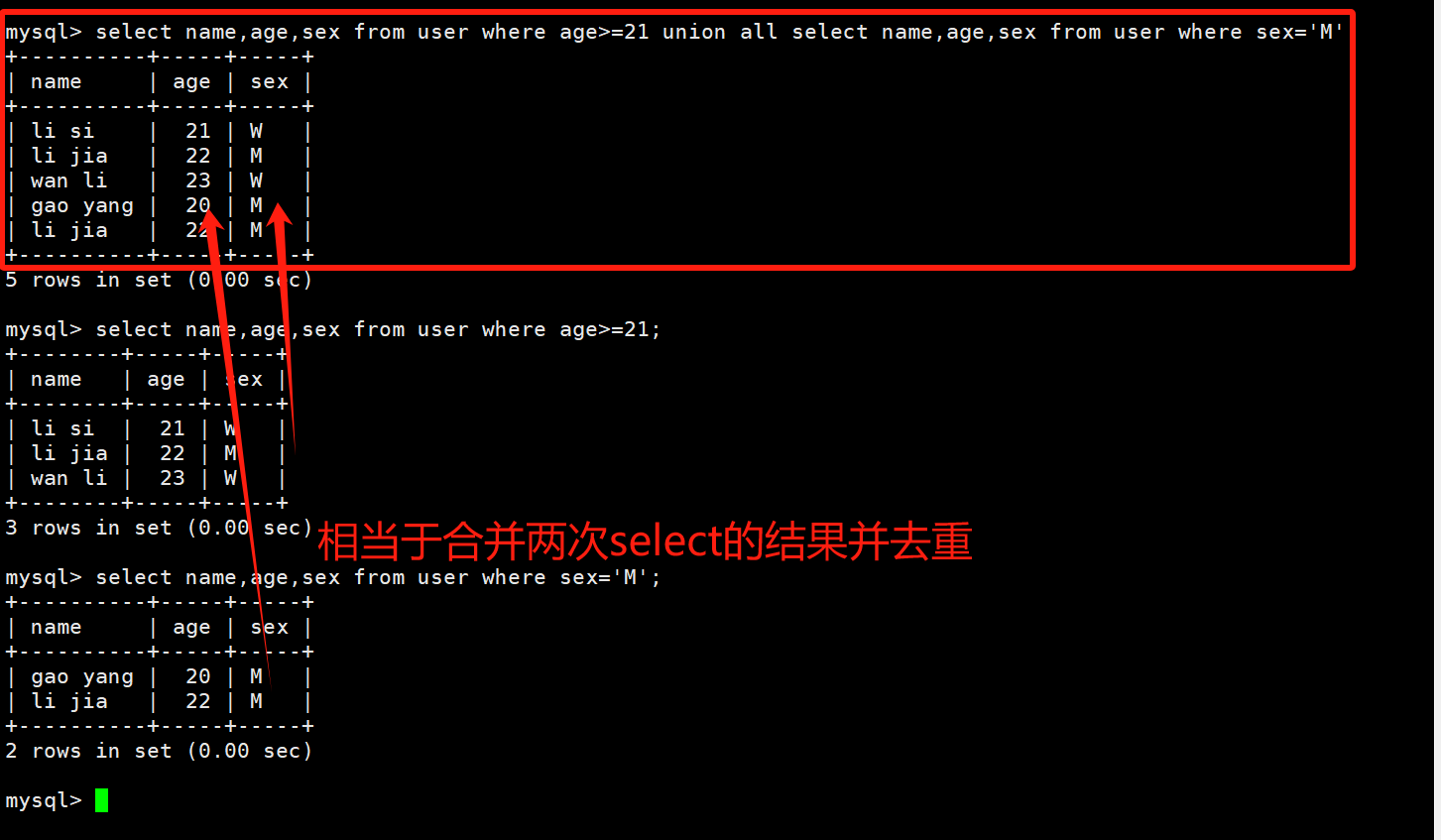
union合并查询,UNION [ALL | DISTINCT] # 注意:union默认去重,不用修饰distinct,all表示显示所有重复值,union all在效果上其实就等于 or
# 把两个select的结果union all
select name,age,sex from user where age>=21 union all select name,age,sex from user where sex='M';
注意:网上会有些人说or用不到索引,and可以用到索引,这是错的!MySQL可以对or进行优化,优化为union all,而union all的操作相当于进行两次select,然后对结果进行合并,是可以用到索引的!
6.limit分页查询
1.limit基本用法
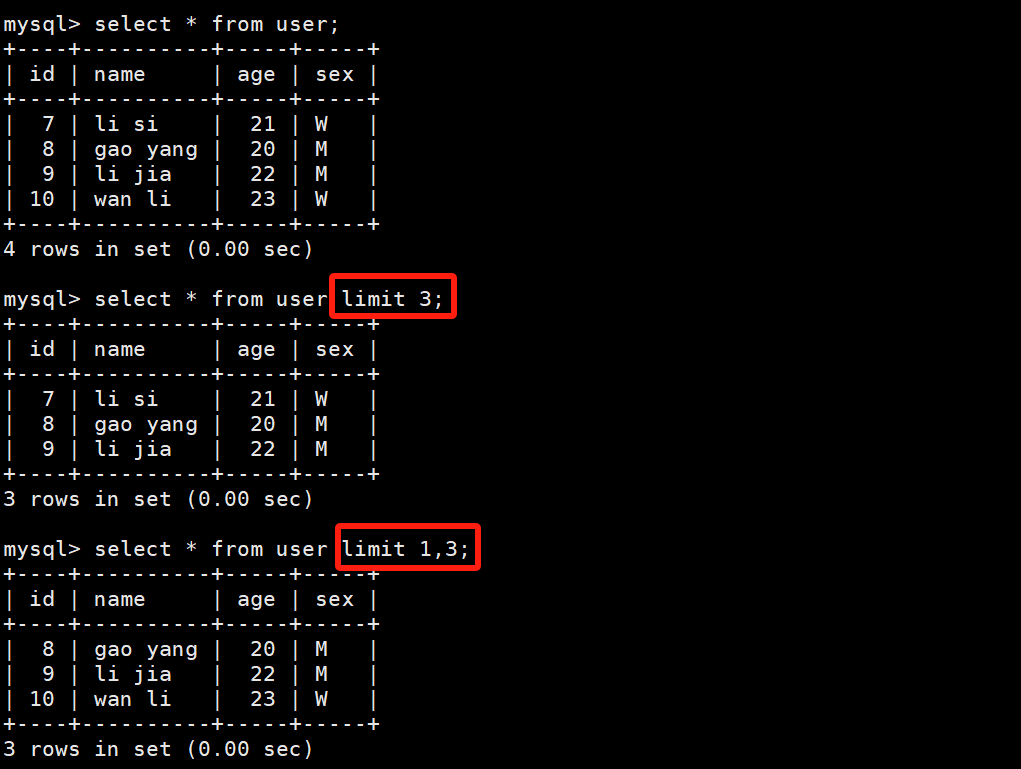
select * from user limit N;把整表数据拿出来,只显示前N个。
select * from user limit M,N; M表示offset,N表示lines
select * from user limit N offset M; 和上面等价
# 默认是limit 0,3
select * from user limit 3;
# 偏移一个,再取三个
select * from user limit 1,3;
select * from user limit 3 offset 1;# 两种写法等价
2.limit效率优化
思考:limit只是对select的结果的显示条数加以限制吗?对查询的效率有没有提升?
explian:查看SQL语句的执行计划【看不到MySQL做的优化】,我们查询下数据表的第一行数据,加上explian,查看结果 当我们查询age时,发现没有用到索引,并且进行了整表搜索
当我们查询age时,发现没有用到索引,并且进行了整表搜索
那如果,我们没有索引的情况下,还想要提升效率,应该怎么做?我们如果只是想查表中的前几行,但是没有索引,就可以使用limit N来优化【前提是我们知道需要查询的数据再前N行当中】,于是我们便写出了下面这样的sql语句【age=21对应的是第一行数据】,效率非常的高!
select * from user where age=21 limit 1;
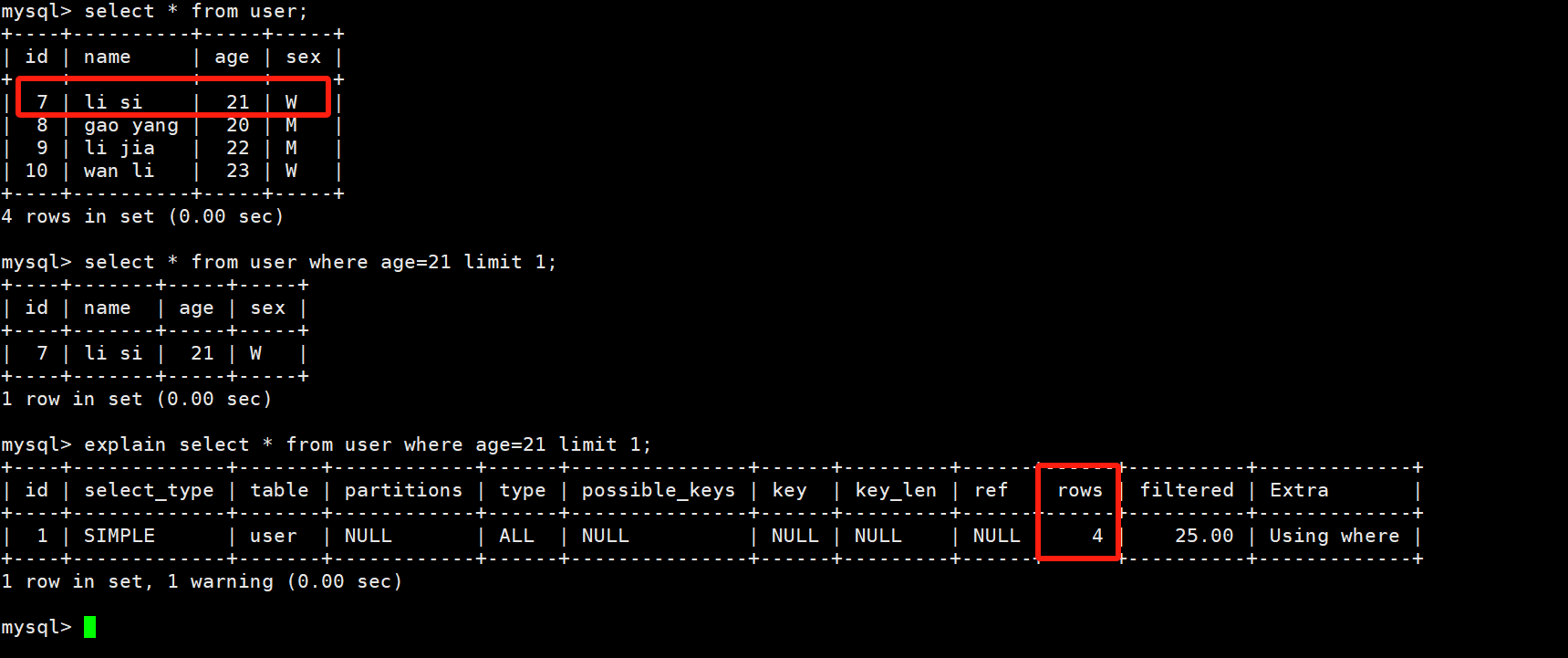
但是非常的遗憾啊,这里explain并不能识别到MySQL在这里做的优化。这里我创建一个新的表,插入大量的数据进行测试,下面我创建了一个只有主键索引的t_user表来进行测试:
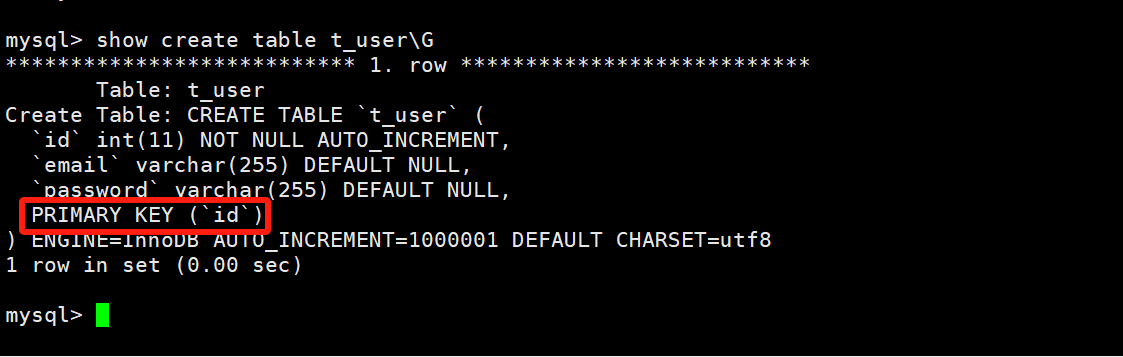
我写一个存储过程的逻辑代码,向t_user表中添加数据
# 修改结束标识符
delimiter $create procedure add_t_user(IN n INT)
BEGIN
DECLARE i INT;
SET i=0;WHILE i<n DO
INSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@fixbug.com'),i+1);
SET i=i+1;
END WHILE;
END$# 恢复结束标识符
delimiter ;# 增加200w行数据
call add_t_user_2(2000000);
根据下图的测试结果,在大量数据的情况下,借助limit N,在查询键没有索引的情况下,确实可以提升效率。
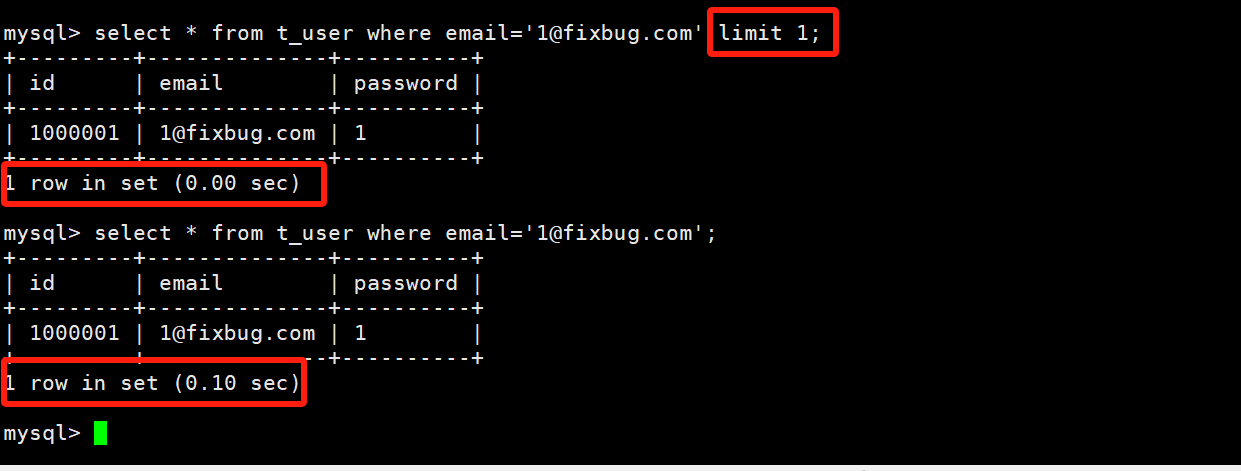
我们再通过explain查看,发现explain确实是没有解释到MySQL的优化行为。但并不影响我们的结论。

3.limit分页
pageno:一共多少页,pagenum:一页中有多少行
select * from t_user limit (pageno-1)*pagenum,pagenum;
但是我们简单的以这样的方式进行分页显示的话,效率是不均等的!处于前面的页会更快的被遍历到,效率低在M的偏移!
我们一般的做法是:借助主键过滤!
select * from t_user where id > 上一页最后一条数据的id值 limit pagenum;
这种方式会借助主键的索引,可以通过比较均匀的时间获取到每一页中的数据。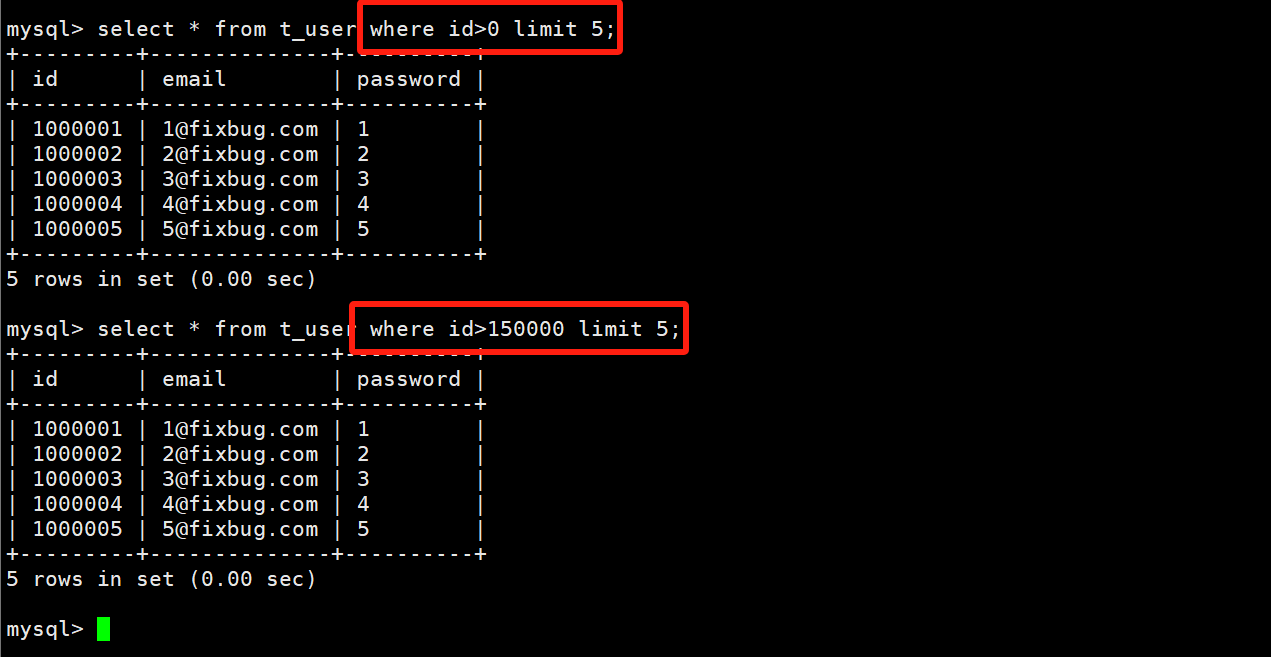
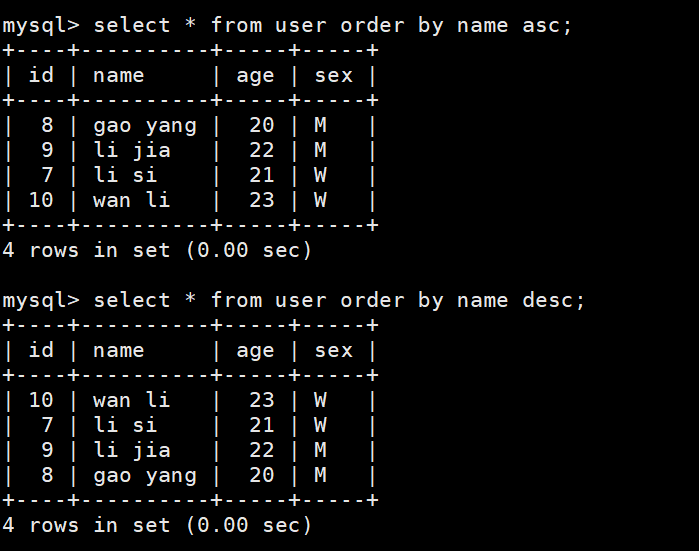
7.order by排序
# 升序排序【默认的】
select * from user order by XXX asc;# 降序排序
select * from user order by xxx desc;# 多字段排序
select * from user order by xxx,xxx [asc|desc];# 数据过滤 + 排序
select * from user where sex='M' order by name;
当我们在过滤数据的时候,如果是通过无索引字段过滤的,会发生什么呢?我们可以通过explain进行解释来看看:

type:整表搜索,using filesort:文件排序!【n路归并排序,磁盘IO高】,这会导致性能非常的低!
但是我们的name字段是有索引的,我们如果只select name,再根据name进行排序的时候,就可以用到索引了【其实只遍历的辅助索引树,没有进行回表操作!】

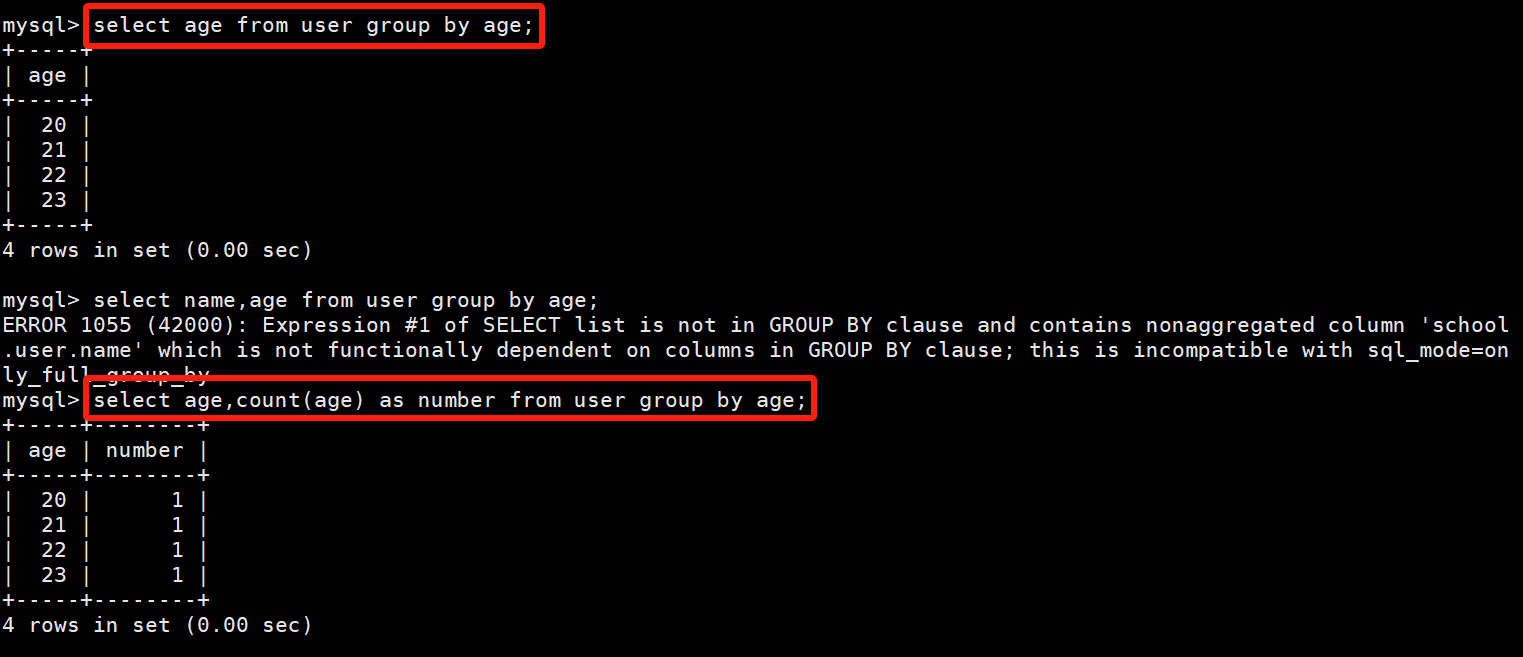
8.group by分组
对某一个字段进行分组,统计
# 统计有多少种年龄分布情况
select age from user group by age;#分组并且统计个数,group by+聚合函数的使用
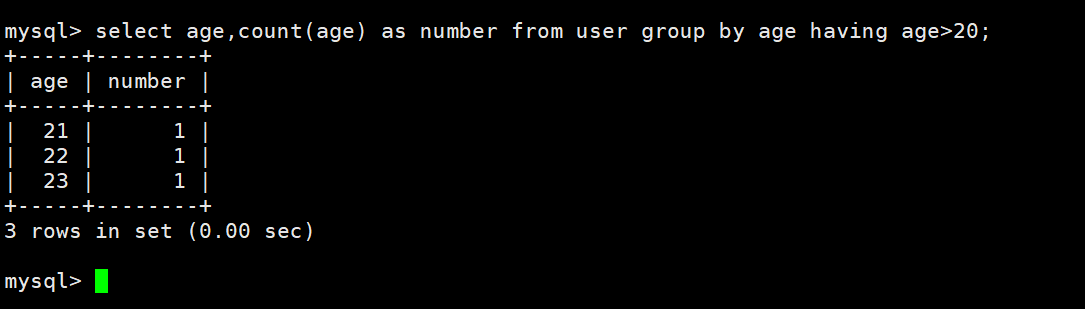
select age,count(age) as number from user group by age;# 分组并且剔除掉不符合规定的数据(只保留年龄大于20的数据)
select age,count(age) as number from user group by age having age>20;
# 效果等价于
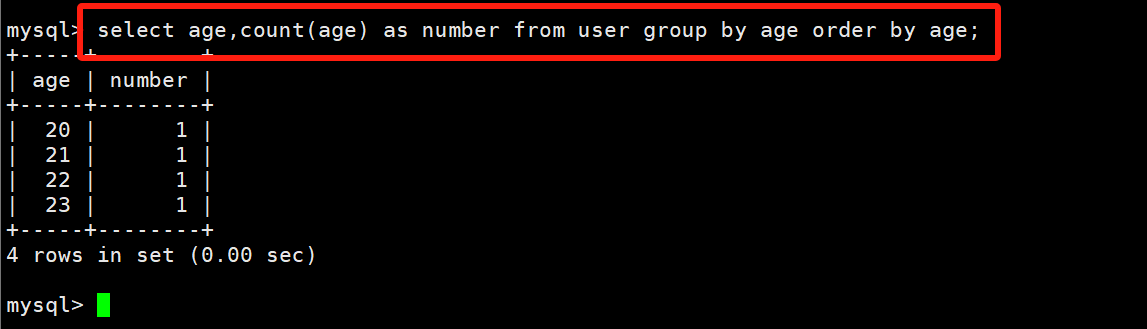
select age,count(age) as number from user where age>20 group by age;# 分组+排序
select age,count(age) as number from user group by age order by age;
我们前面谈到,order by是会涉及到索引的,那么group by是否会涉及到索引呢?相同的,我们再通过explain进行查看:

filesort:涉及外排序,产生磁盘IO。通过explain分析的时候,group by虽然不是order by,但是group by也涉及到了using filesort,说明group by也是会对分组后的结果进行排序的!
我们再对有索引的name字段进行group by试一试,发现group by也是会使用到索引的!效率相当的快!

9.SQL语句常见面试题
下表bank_bill是某银行代缴话费的主流水表结构:
| 字段名 | 描述 |
|---|---|
| serno | 流水号 |
| date | 交易日期 |
| accno | 账号 |
| name | 姓名 |
| amount | 金额 |
| brno | 缴费网点 |
- 统计表中缴费的总笔数和总金额
- 给出一个sql,按网点和日期统计每个网点每天的营业额,并按照营业额进行倒序排序
我们进入我们的mysql进行演示:
create table bank_bill(serno bigint unsigned primary key not null auto_increment,date DATE not null,accno varchar(100) not null,name varchar(50) not null,amount decimal(10,1) not null,brno varchar(150) not null);
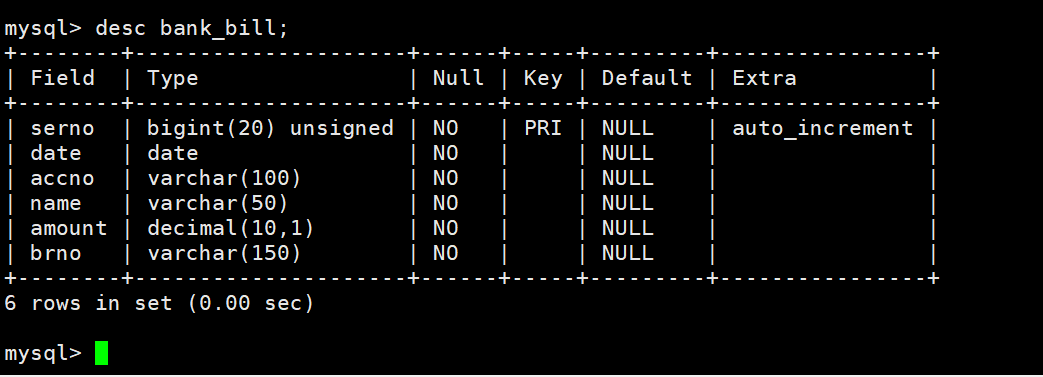
向表中插入数据,一次操作插入多行效率优于多次插入;
INSERT INTO bank_bill VALUES
('101000','2021-3-1','111','zhang',100,'Beijing'),
('101001','2021-3-1','222','qian',200,'Shanghai'),('101002','2021-3-2','333','sun',300,'Anhui'),('101003','2021-3-2','444','li',500,'Beijing'),('101004','2021-3-3','555','zhou',600,'Anhui');
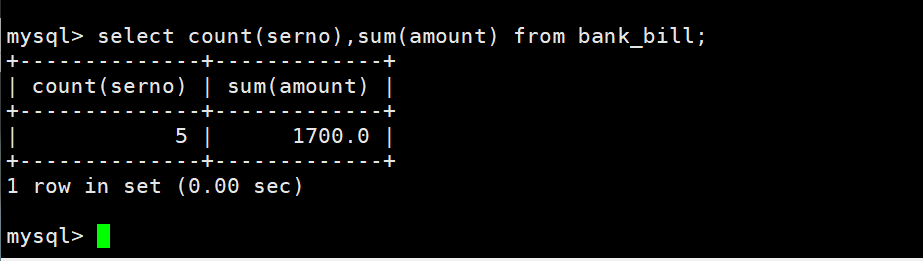
第一题sql代码:
select count(serno),sum(amount) from bank_bill;
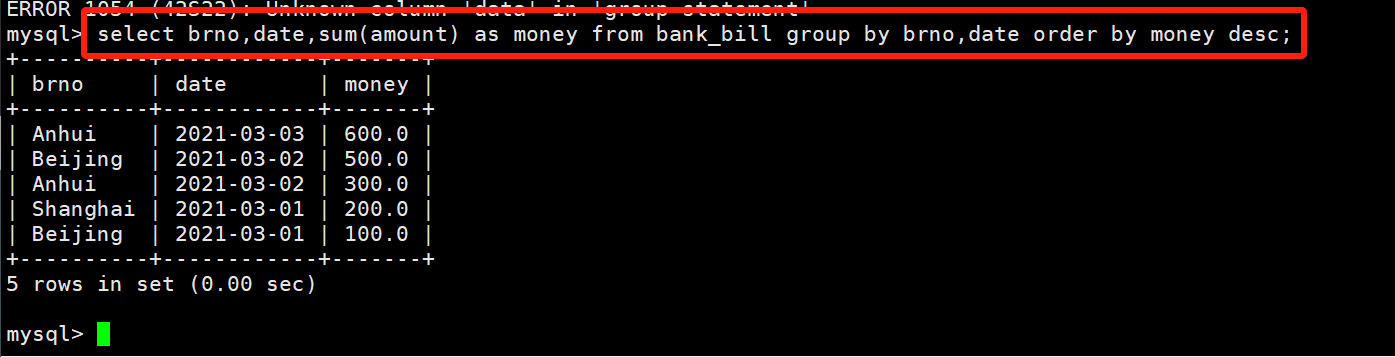
第二题sql代码:
select brno,date,sum(amount) as money from bank_bill group by brno,date order by money desc;
9.连接查询SQL
为什么需要连接查询?为什么不能拆分成两次查询呢?
- mysql-client每次向mysql-server查询都是网络通信,要进行tcp三次握手,四次挥手等过程,浪费效率。
对于内连接查询(inner join)如下图所示:
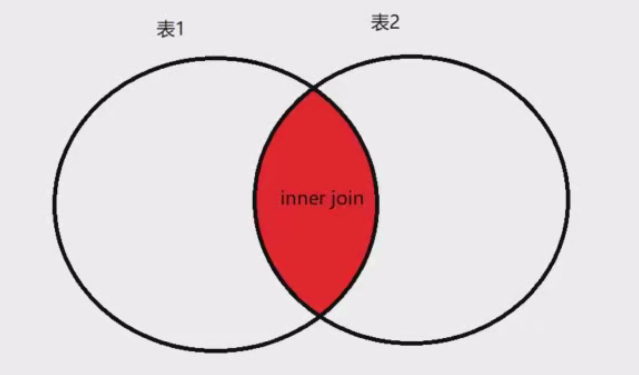
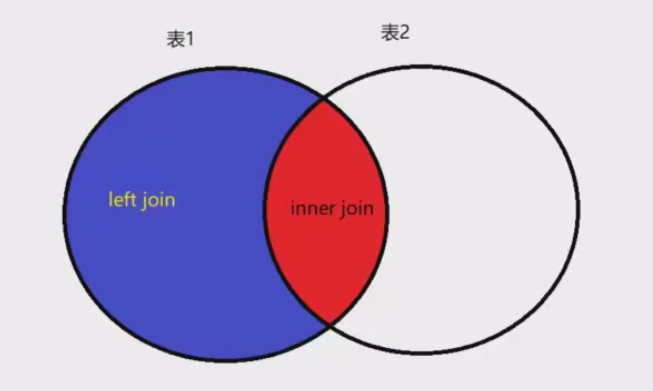
对于左连接查询(left join),查询的是下图中蓝色区域的数据,即下图中的蓝色区域(表1特有的数据);
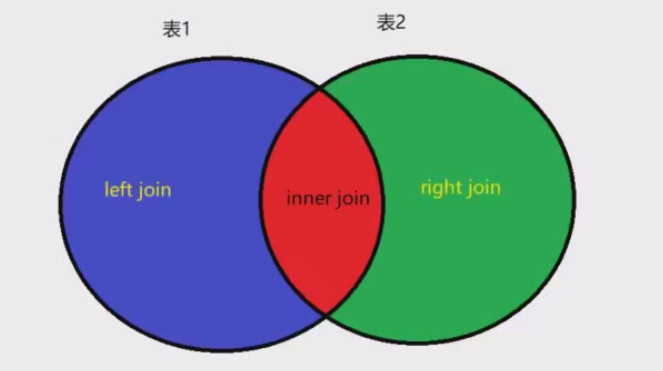
对于右连接查询(right join),查询的是下图中绿色区域中的数据(表2特有的数据)
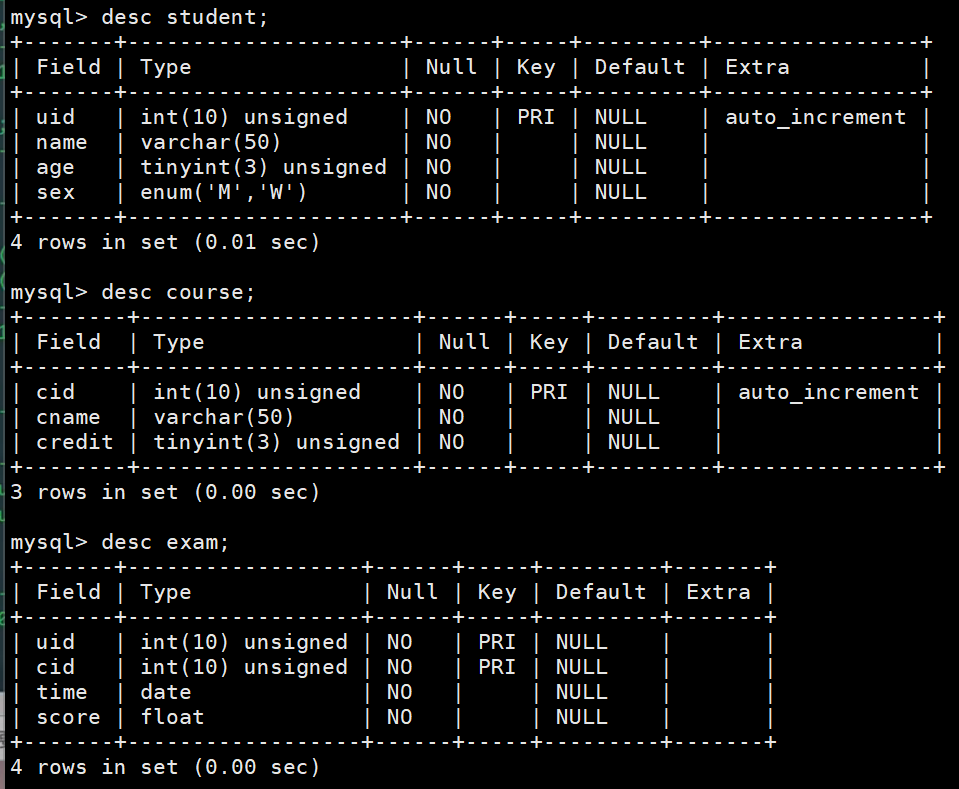
场景1:学生,课程,考试结果
# student:uid,name,age,sex
create table student(uid int unsigned primary key not null auto_increment,name varchar(50) not null,age tinyint unsigned not null,sex enum('M','W') not null
);# course: cid,cname,credit
create table course(cid int unsigned primary key not null auto_increment,cname varchar(50) not null,credit tinyint unsigned not null
);# exam:uid,time,score
create table exam(uid int unsigned not null,cid int unsigned not null,time date not null,score float not null,primary key(uid,cid)
);
创好表之后就是下面这样的:
我们向创建好的表中增加一些数据:
insert into student(name,age,sex) values
('zhangsan',18,'M'),
('gaoyang',20,'W'),
('chenwei',22,'M'),
('linfeng',21,'W'),
('liuxiang',19,'W');insert into course(cname,credit) values
('C++base',5),
('C++enhance',10),
('C++project',8),
('C++algrathm',12);insert into exam(uid,cid,time,score) values
(1,1,'2021-04-09',99.0),
(1,2,'2021-04-10',80.0),
(2,2,'2021-04-10',90.0),
(2,3,'2021-04-12',85.0),
(3,1,'2021-04-09',56.0),
(3,2,'2021-04-10',93.0),
(3,3,'2021-04-12',89.0),
(3,4,'2021-04-11',100.0),
(4,4,'2021-04-11',99.0),
(5,2,'2021-04-10',59.0),
(5,3,'2021-04-12',94.0),
(5,4,'2021-04-11',95.0);
-
查看张三同学某一门课的成绩(张三的学号uid:1,cid:2)
select score from exam where uid=1 and cid=2;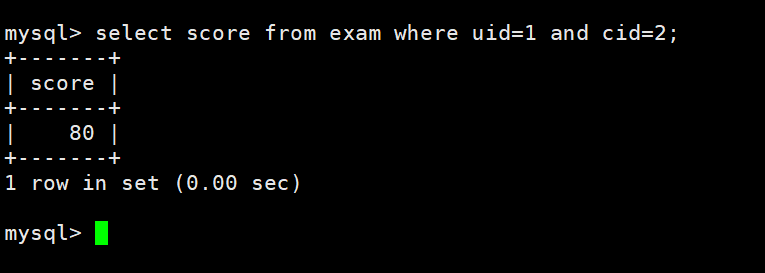
1.内连接查询
1.内连接的基本使用
内连接查询的标准语法:
SELECT a.属性名1,a.属性名2,...,b,属性名1,b.属性名2... FROM table_name1 a inner join table_name2
b on a.id = b.id where a.属性名 满足某些条件;
- 现在我们除了张三同学的成绩信息,如果我们还想拿到张三同学的其他信息呢?
select a.uid,a.name,a.age,a.sex from student as a where a.uid=1;select c.score from c.exam as c where c.uid=1 and c.cid=2;# 通过【内连接】合并上面两条查询信息
select a.uid,a.name,a.age,a.sex,c.score from student a inner join exam c on a.uid=c.uid where c.uid=1 and c.cid=2;
-
on a.uid=c.uid 时连接的过程:首先需要区分大表和小表,按照表的数据量来区分!小表永远是整表扫描(建索引也没用!),然后去大表搜索(一定要建索引!)
-
具体过程:判断student表和exam表的数据量,显然student表是小表,而exam表为大表,接着从student这个小表中取出所有的a.uid,然后拿着这些uid去exam大表中搜索。
-
最后,通过where进行条件筛选,找到张三

我们通过explain指令进行分析,发现在查询的过程中也确实使用了我们建表时创建的主键索引/联合索引。

-
如果我们还想要拿到张三同学选修的course信息的话,应该如何去做呢?答:再去inner join course表,但这时需要注意的是,必须把具有联合索引字段的exam表放在inner join查询语句的最前面,因为只有这张表上既有cid又有uid。写出来的sql语句为:
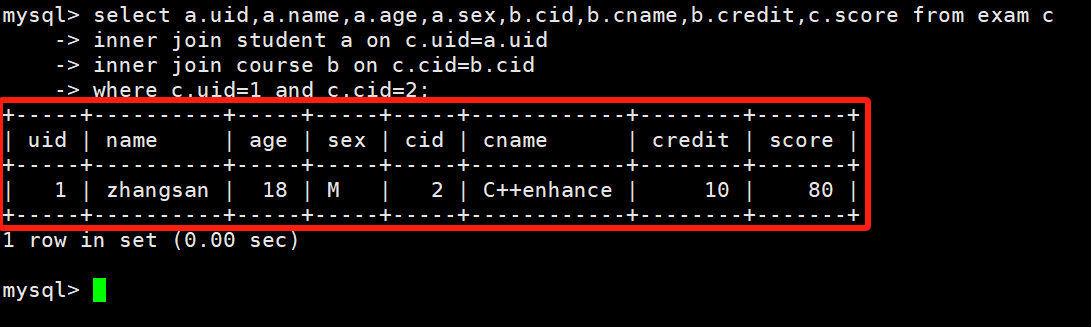
select a.uid,a.name,a.age,a.sex,b.cid,b.cname,b.credit,c.score from exam c inner join student a on c.uid=a.uid inner join course b on c.cid=b.cid where c.uid=1 and c.cid=2; 查询结果如下:
-
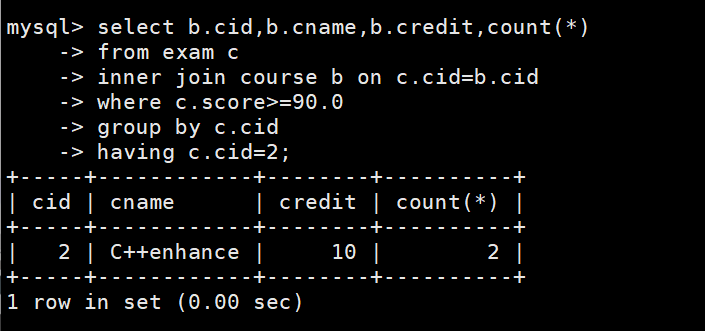
现在我想查看C++enhance这门课程有多少人考到了90分以上,但是我不需要知道具体的学生下姓名,那么便可以写出如下的sql语句出来:
select b.cid,b.cname,b.credit,count(*) from exam c inner join course b on c.cid=b.cid where c.score>=90.0 # 筛选出所有成绩大于90的课 group by c.cid having c.cid=2; # 指定是C++enhance这门课查询结果如下:
2.内连接和limit的结合
还记得我们之前创建的t_user表吗,我们现在有一个业务场景,我们只能使用limit M,N的方式,但是想要优化下面两种查询方式,让他们的效率相近,应该如何去做呢?
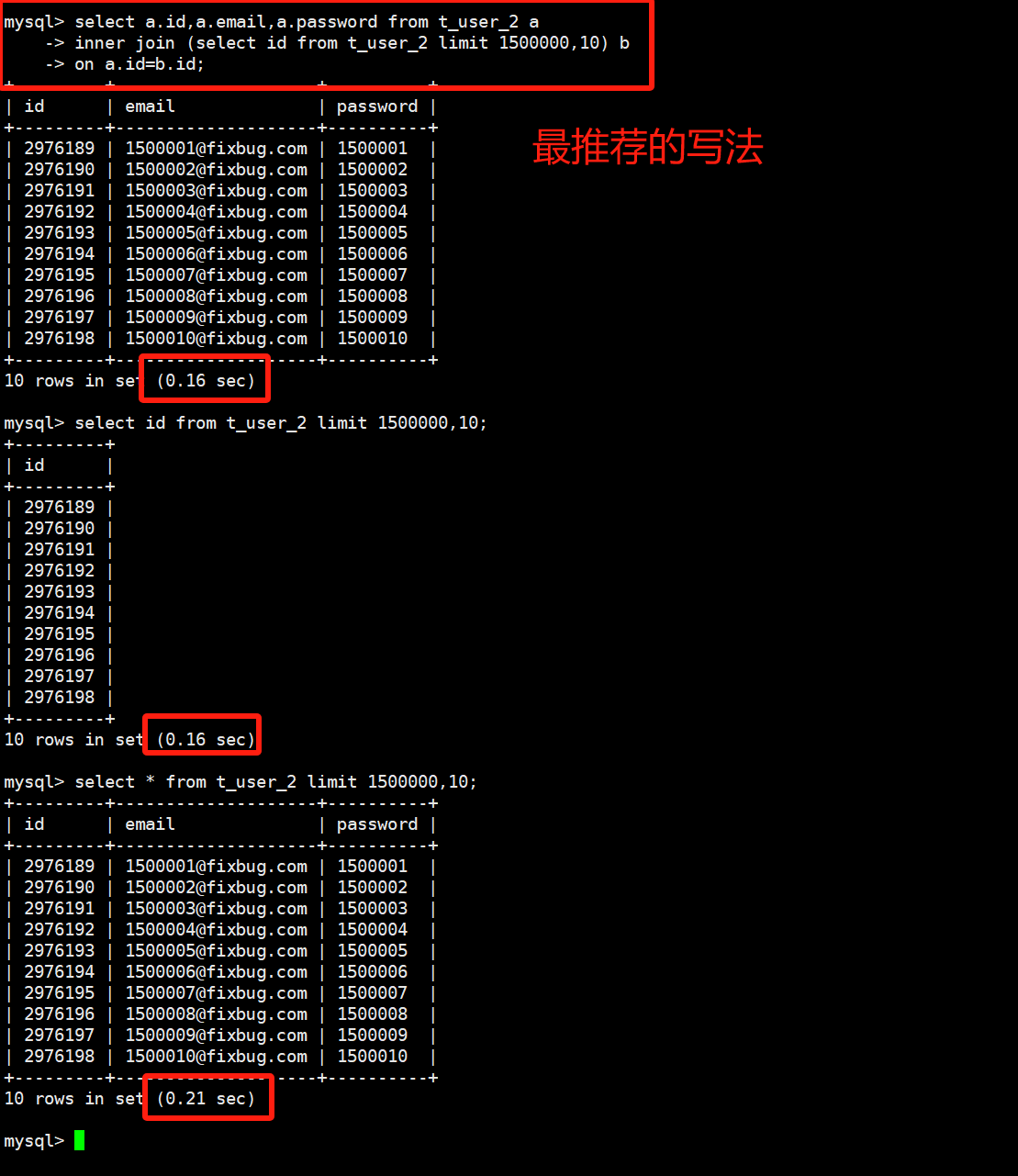
select * from t_user limit 1500000,10;# 方法1:只查询索引,但是字段少
select id from t_user limit 1500000,10;# 方法2:之前的优化方案,借助有索引的id字段过滤
select * from t_user where id>2500000 limit 10;# 方法3:inner join 临时表
select a.id,a.email,a.password from t_user_2 a
inner join (select id from t_user_2 limit 1500000,10) b
on a.id=b.id;
实践看效率:
3.内连接流程复习及效率分析
首先先看下面这条sql语句:
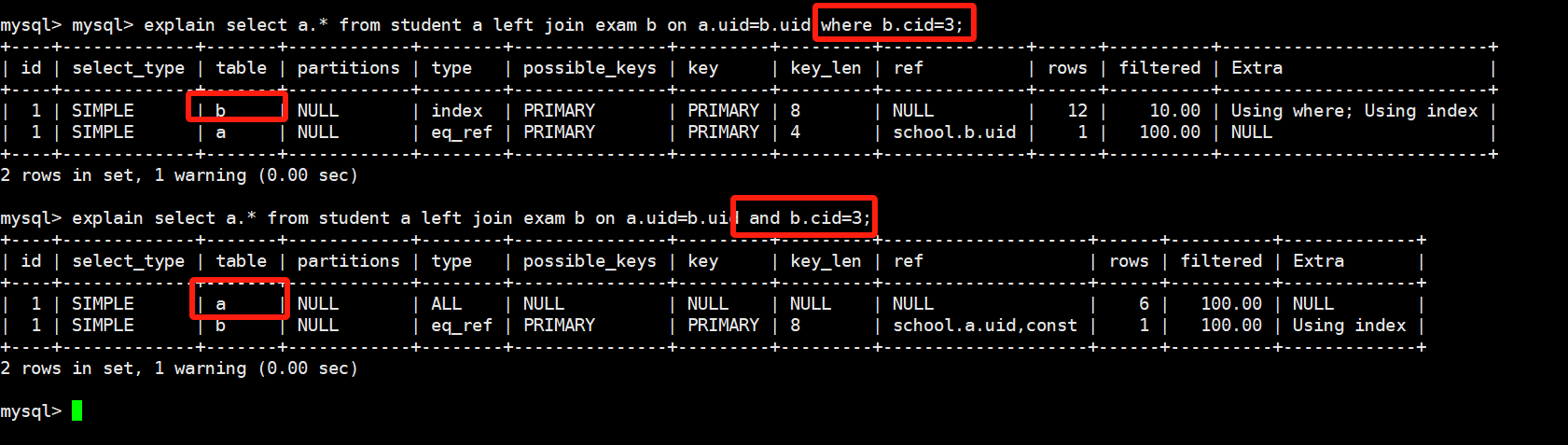
select a.*,b.* from student a inner join exam b on a.uid=b.uid;
显然,student表是小表,exam表是大表,所以这条查询语句会遍历一遍student表,然后根据student表的uid,通过索引去exam表中的uid去匹配,我们通过explain指令也能分析出来:

那现在我们想要转换一下角色,让student表变为大表,exam表变为小表应该怎么做呢,只需要加入一个where筛选条件就可以啦
select a.*,b.* from student a inner join exam b on
a.uid=b.uid where b.cid=3;

我们分析explain的分析结果,发现确实会先去遍历exam表,但是没用用到索引!这不对啊,我们之前在创表的时候不是建立的(uid,cid)的联合索引了嘛,这里到后面讲索引的时候会提,使用联合索引时,必须要包含联合索引的第一个字段uid,才会使用到索引!
最后,还有人会写出这样的sql语句,下面这条语句和上面使用where在结果上看是一样的,过程中有什么区别吗?我们通过explain分析:
select a.*,b.* from student a inner join exam b on
a.uid=b.uid and b.cid=3;

从explain的结果中可以看出,使用and也会被sql解释为使用where!执行过程是一模一样的!
2.外连接查询
为了表示内连接和外连接的区别,我们这里再向之前的student表中增加一个数据:
insert into student(name,age,sex) values
('weixie',20,'M');
1.左连接
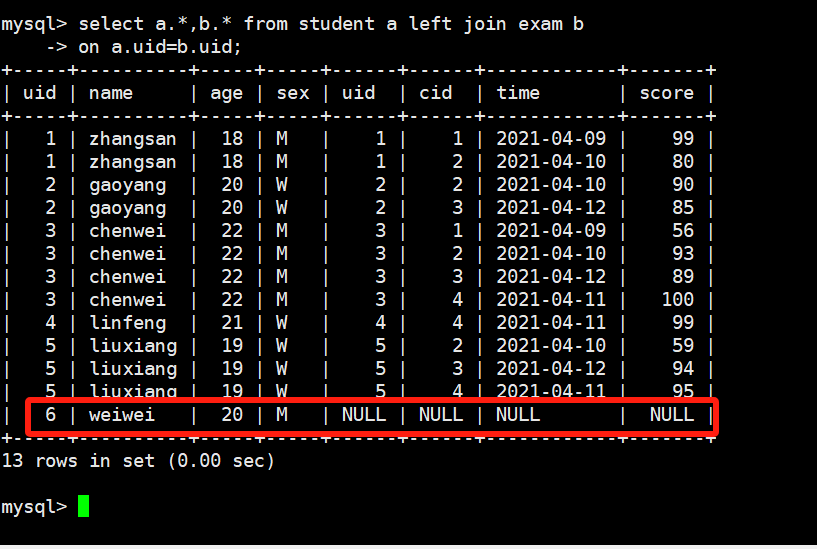
把left这边的表所有的数据显示出来,右表中不存的数据就显示为NULL,sql语法如下:
select a.*,b.* from student a left join exam b
on a.uid=b.uid;
常用于查询判断那些同学没有考过试!
但是我们通过带in的子查询也可以实现这样的功能,为什么不推荐使用呢?主要有两点原因,我们先看下面的sql语句:
select * from student where uid not in
(select distinct uid from exam);
- select distinct uid from exam => 会产生一张中间表存储结果供外面的sql来查询
- not in对索引的命中率并不高
推荐优化为下面的左连接:
select a.* from student a left join exma b
on a.uid=b.uid where b.cid is null;
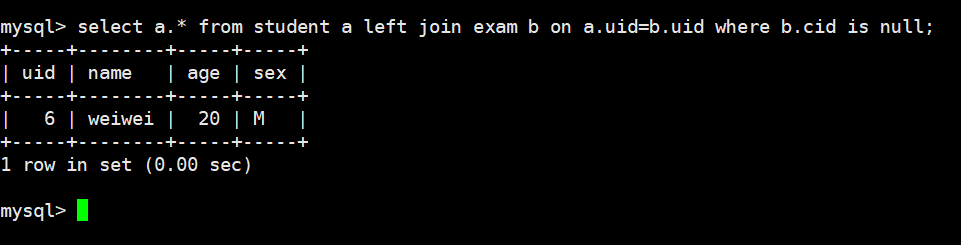
2.右连接
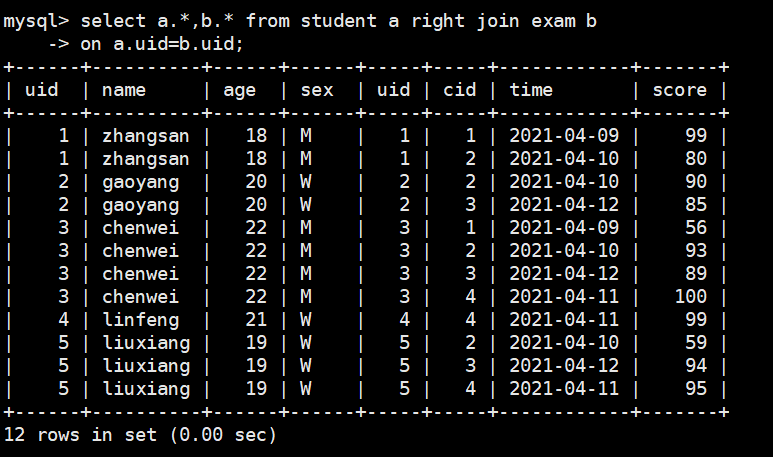
把right这边的表所有的数据都显示出来,左表中不存在的数据就显示为NULL,sql语法如下:
select a.*,b.* from student a right join exam b
on a.uid=b.uid;
当然在我们的设计中,所有考试记录当然都能匹配到学生,所以这里右连接和内连接没用区别。
3.外连接的应用
如果我们现在想要查询,那些同学没有考过cid=3的这门课,应该如何去写sql语句呢?
select a.* from student a left join exam b
on a.uid = b.uid
and b.cid=3
where b.cid is null;
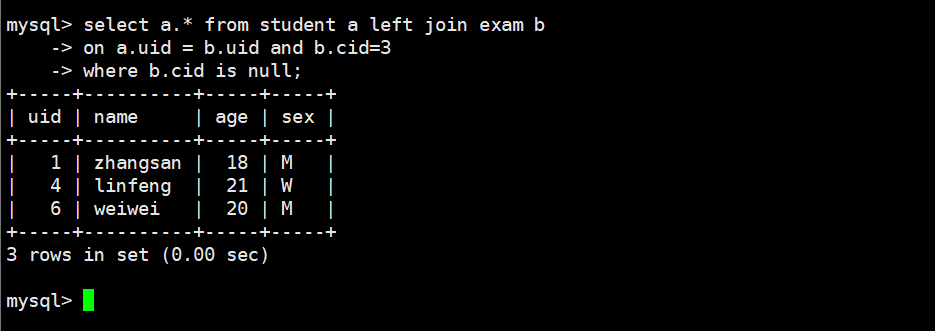
但是为什么不是这条sql呢,为什么调换where和and的顺序后,结果就出错了呢?
select a.* from student a left join exam b
on a.uid=b.uid
where b.cid=3
and b.cid is null;
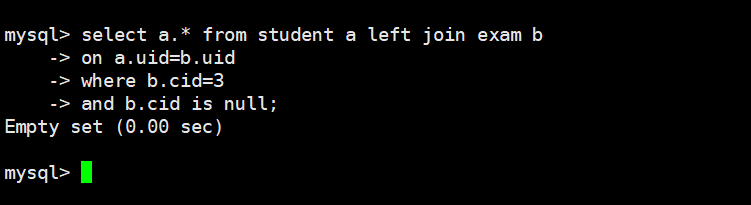
我们还是通过explain去分析,我们发现,如果我们把where过滤放到前面,那么left join并没有先去按照我们理解中的先去a表做整表查询,然后保留住a中的数据,去b表中做匹配,而是直接通过where语句过滤了b的整表数据,然后用b的数据去a中查询,整体过程就跟内连接是一样的了,在内连接中,我们已经把b表中的数据筛的只剩下cid=3的了,那我们后面再跟and b.cid is null自然就找不到数据。所以这里就要注意了,在外连接的情况下,如果我们要进行条件查询,and一定要写在where的前面!
10.MySQL存储引擎
1.什么是存储引擎
存储引擎直接影响:表的结构、数据、索引的存储方式。
我们可以通过show engines命令查看当前mysql所支持的索引:
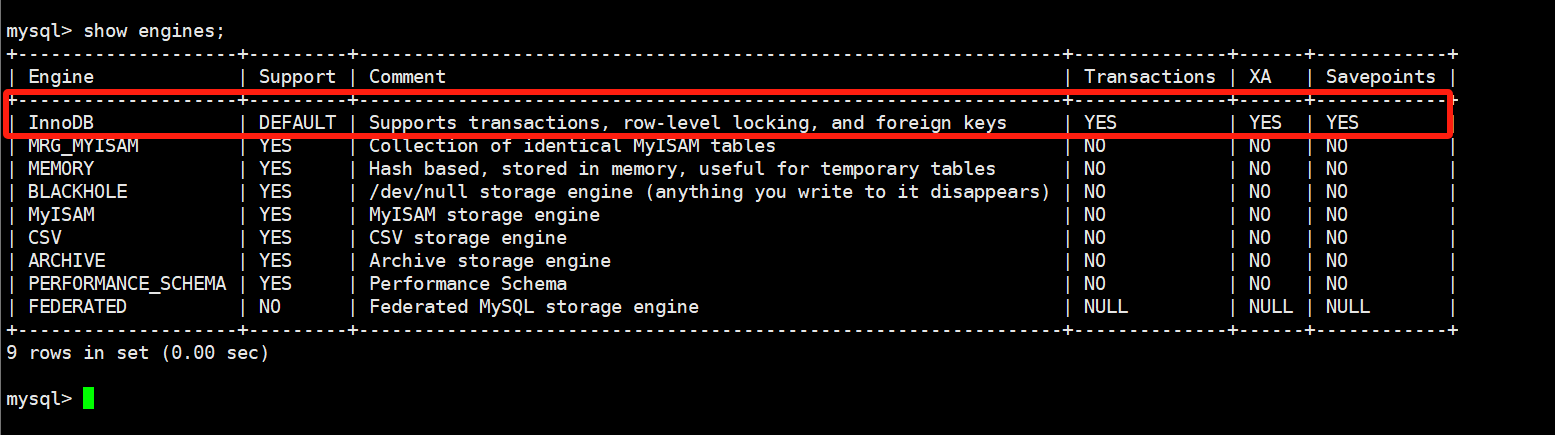
mysql5.7是一个分水岭,5.7之前用的一般都是MyISAM,5.7之后使用的是非常强大的InnoDB存储引擎,这也是我选择MySQL5.7版本的原因。如何去修改:我们需要去mysql的配置文件当中可以对齐进行修改。
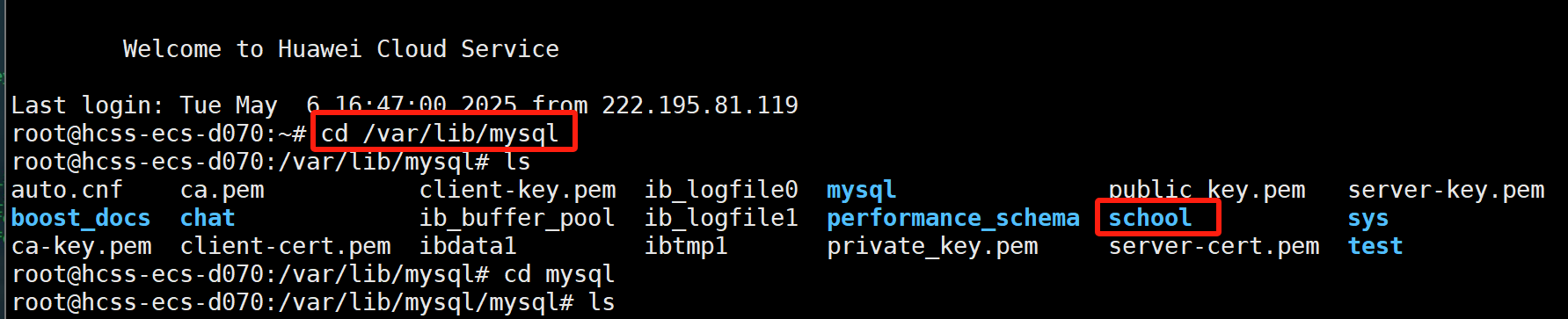
我们进入/var/lib/mysql路径下,发现我们在mysql中创建的所有的数据库都会创建在这个路径下,而所有的表都是会根据存储引擎的不同而不同。
对于MyISAM存储引擎,一张表会创建三个文件,分别是表名.frm(表结构)、表名.MYD(表数据)、和表名.MYI(表索引)这三个文件。而对于InnoDB存储引擎,分别是表名.frm(表结构)、表名.idb(表数据+表索引)。
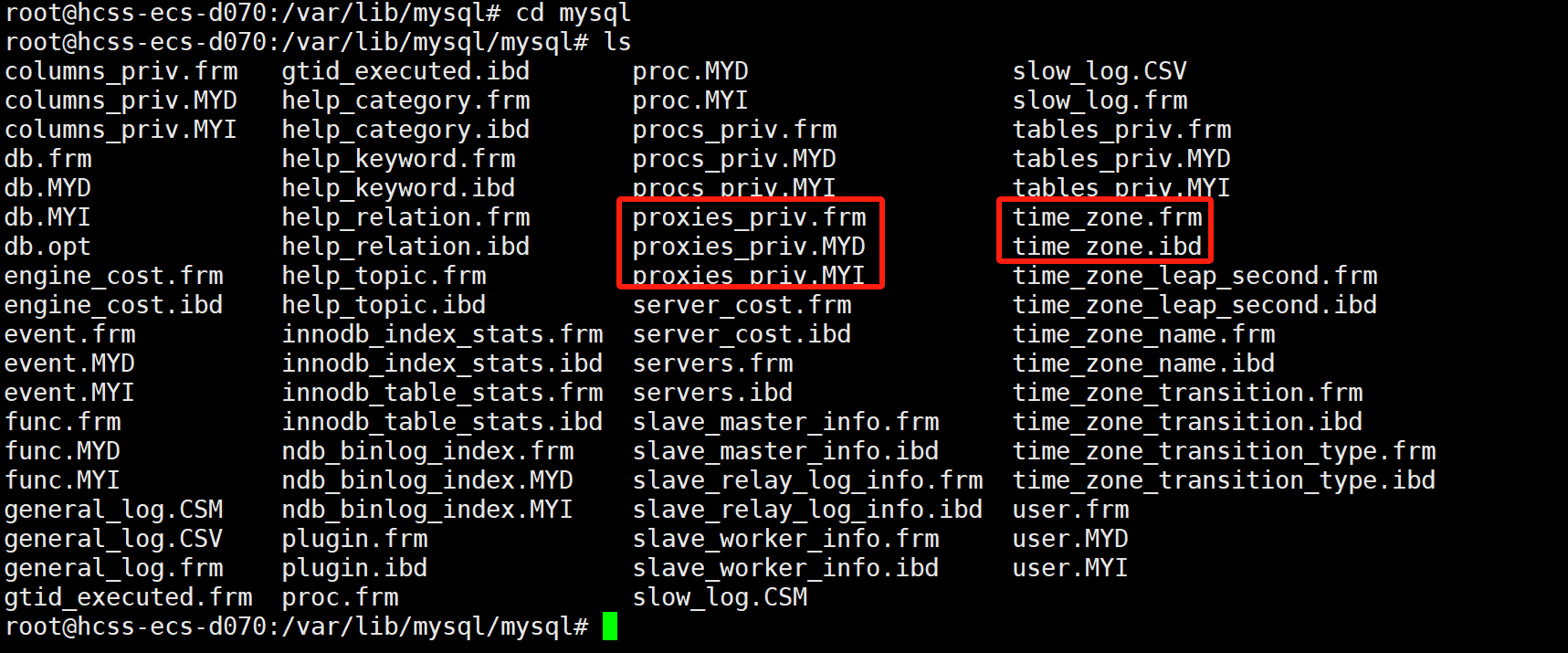
这里就有一个常见的面试题:为什么InnoDB存储引擎情况下,建表的话没有加主键都会自动生成一个主键,但是MyISAM你加主键才会有主键,不会自动增加主键?就是因为MyISAM存储引擎数据和索引的存储的分开的,没有强相关。但是在InnoDB中,索引和数据放在一起,没有索引的话数据就没地方放!
2.各存储引擎的区别
在回答“MySQL“不同的存储引擎有哪些区别?这样的问题时,主要从以下几点来回答就可以(问题的核心):
| 种类 | 锁机制 | B树/哈希索引 | 外键 | 事务 | 索引/数据缓存 |
|---|---|---|---|---|---|
| MyISAM | 表锁 | 支持/不支持 | 不支持 | 不支持 | 支持/不支持 |
| InnoDB | 行锁 | 支持/不支持 | 支持 | 支持 | 支持/支持 |
| Memory | 表锁 | 支持/支持 | 不支持 | 不支持 | 支持/支持 |
- 锁机制:表示数据库在并发请求访问的时候,多个事务在操作时并发的粒度
- B树/哈希索引:加速SQL的查询速度
- 外键:子表的字段依赖父表的主键,设置两张表的依赖关系。
- 事务:多个SQL语句,保证他们共同执行时的原子操作,要么成功,要么失败,不能只成功一部分,失败需要进行回滚操作。
- 索引/数据缓存:和MySQL Server的查询缓存相关,在没有对数据和索引做修改之前,重复查询可以不用进行磁盘I/O(数据库的性能提升,目的是为了减少磁盘I/O操作来提升数据库访问效率),读取上一次内存中查询的缓存就可以了。
11.MySQL索引
索引也是一个数据结构,当我们不使用的时候,他也是存储在磁盘中的,不仅读数据要花费磁盘IO,使用索引也是需要花费磁盘IO的!所以并不是索引越多越好!
1.索引分类
索引是创建在表上的,是对数据库表中一列或者多列的值进行排序的结果。索引的核心是提高查询的速度!
- 索引的优点:提高查询效率
- 索引的缺点:索引并非越多越好,过多的索引会导致CPU使用率居高不下,由于数据的改变,会造成索引文件的改动,过多的磁盘I/O造成CPU负荷太重。
物理上(聚集索引&非聚集索引)/ 在逻辑上分为以下一些类别:
- 普通索引(二级索引):没有任何限制条件,可以给任何类型的字段创建普通索引( 创建新表&已创建表,数量不限,但一张表的一次sql查询只能使用一个索引)
- 唯一性索引:使用unique修饰的字段,值不能够重复,主键索引就隶属唯一性索引
- 主键索引:使用primary key修饰的字段会自动创建主键索引
- 单列索引:在一个字段上创建索引
- 多列索引:在表的多个字段上创建索引;比如我们之前exam表中的(uid+cid)索引,多列索引必须使用到第一个列,才能用到多列索引,否则索引用不上
- 全文索引:使用FULLTEXT参数可以设置全文索引,只支持char,varchar,和text类型的字段上,常用于数据量较大的字符串类型上,可以提高查询速度(线上项目支持专门的搜索功能,给后台服务器增加专门的搜索引擎,支持快速高效的搜索,elasticsearch简称es,跟mysql一样C/S架构,搜狗的workflow)。
2.索引创建和删除
创建表的时候指定索引字段:
create table index1(id int,name varchar(20),sex enum('male','female'),index `index name` (id,name),index(sex)
);
在已经创建的表上添加索引:
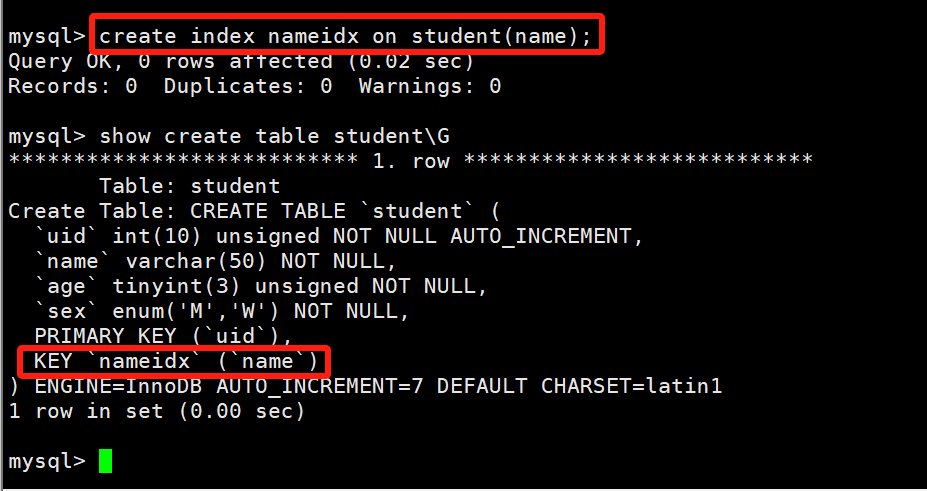
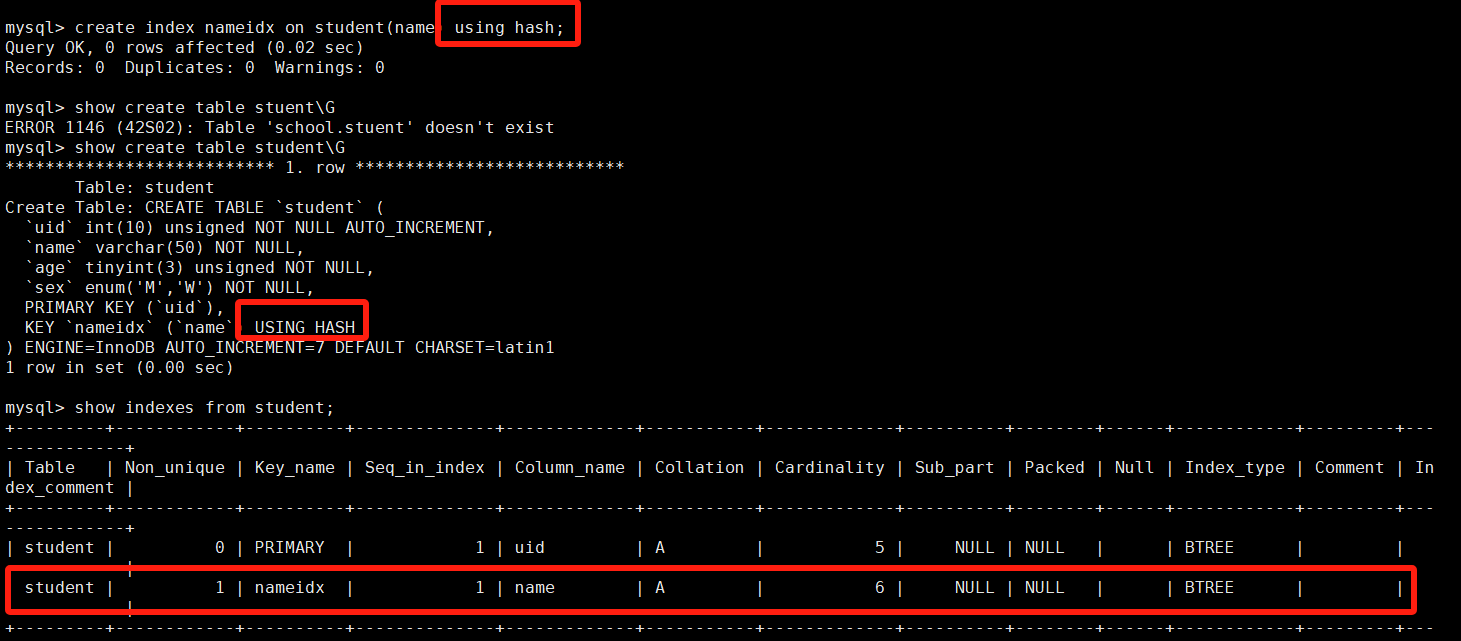
create [unique] index `index name` on `table name` (属性名(length) [ASC|DESC]);# 给name字段增加索引
create index nameidx on student(name);
下图中,为什么我们给password字段创建了索引,但是在查询的时候却没有用到呢?
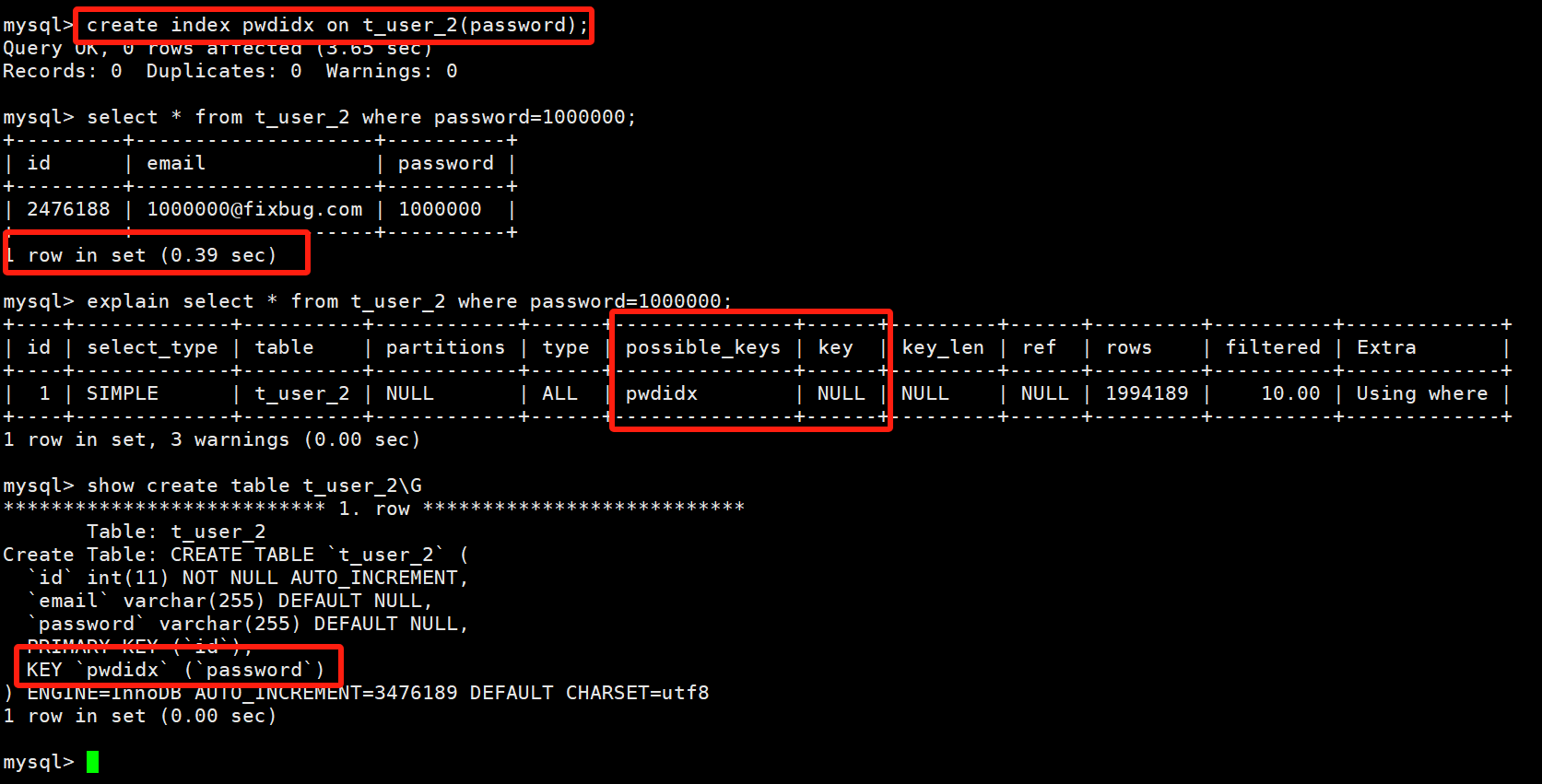
那是因为我们在通过where作为过滤字段的时候,写的是password=1000000;这个1000000会发生类型转换,由1000000转换为‘1000000’,因为发生了类型转换,所以就不会查询索引了。我们修改sql语句发现就改好了。

总结三点规则:
- 经常作为where条件过滤的字段考虑添加索引
- 字符串列创建索引时,尽量规定索引的长度,而不能让索引值的长度key_len过长
- 索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了
当我们不再需要使用索引时,通过下面的sql语句删除索引即可:
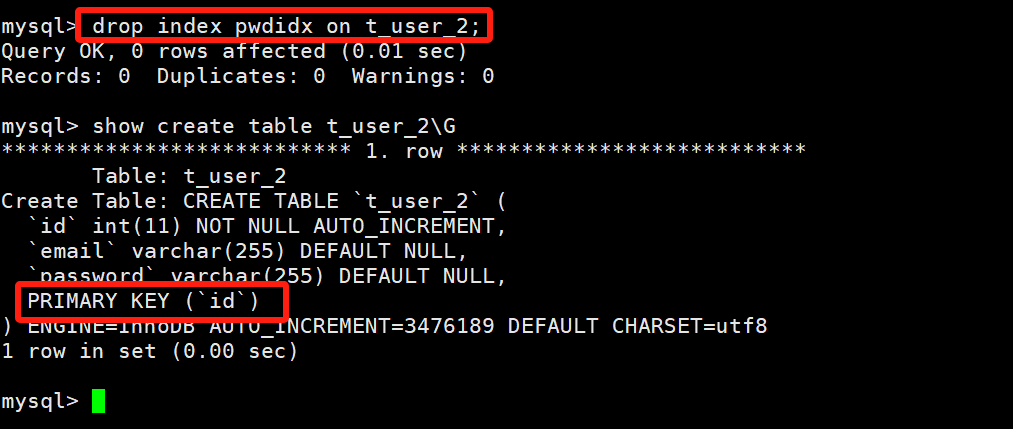
DROP INDEX 索引名 ON 表名;drop index pwdidx on t_user_2;
3.B树索引
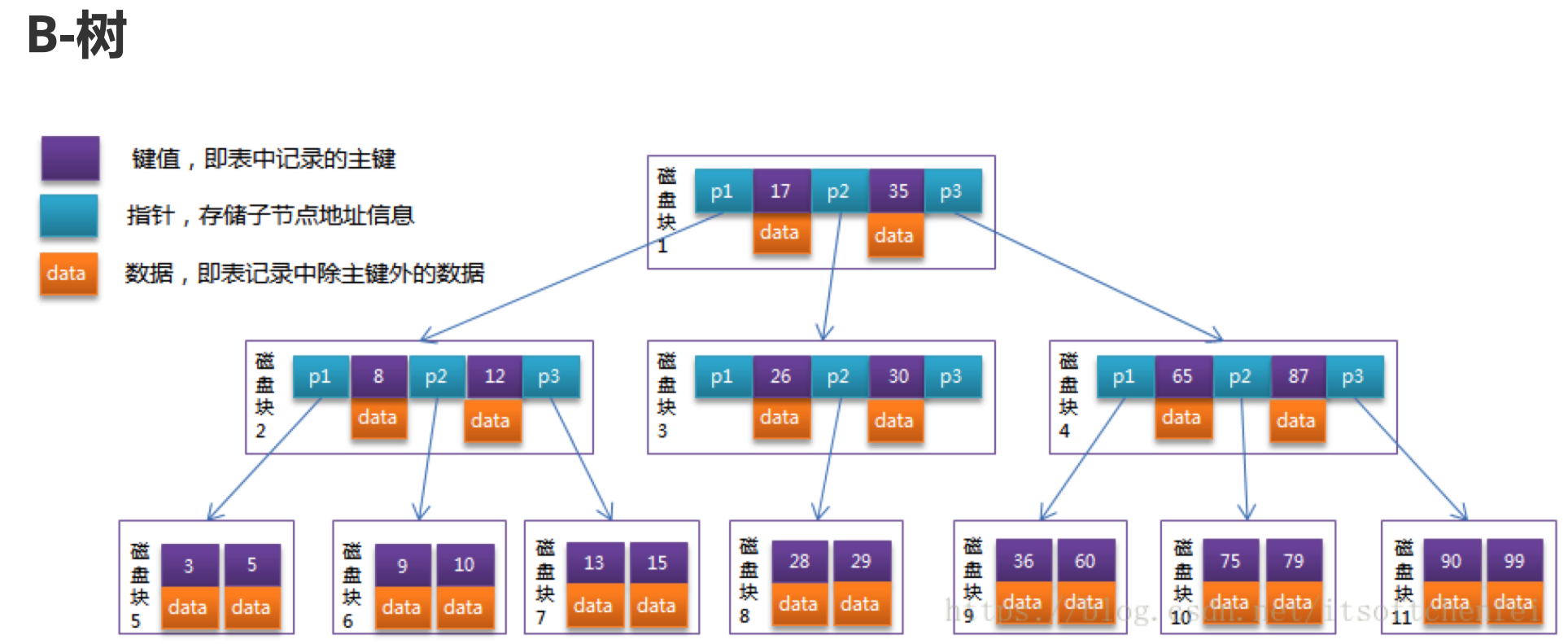
B树是一种m阶平衡树,m一般取值为300~500,叶子节点都在同一层,由于每一个节点存储的数据量比较大,索引整个B树的层数是非常低的,基本上不超过三层。
由于磁盘的读取是按block块操作的,因此B树的节点大小一般设置为和磁盘块大小一致,这样一个B树节点,就可以通过一次磁盘I/O把一个磁盘块的数据全部存储下来。对于2000W的数据量,如果使用m = 500 阶的B树,最多花费三次磁盘I/O即可。如果使用AVL树存储,构建下来有25层,最多花费二十五次磁盘I/O,这是让人无法接受的!
对于我们之前的student表,主键uid会自动创建索引,当我们执行select * from student where uid = 5;
uid有索引 => 存储引擎 => kernel => 磁盘I/O(读索引文件)=> 内存上 => 用索引的数据构建B树加速搜索
B树中的data:存储的是数据本身内容?还是在磁盘上的地址? 取决于使用什么样的存储引擎,如果是MyISAM,因为数据和索引是分开存储的,所以索引中data存放的是数据在磁盘上的地址。如果是InnoDB,数据和索引一起存放,所以data中存储的是数据内容本身。
m-阶,表示一个节点有500个指针域,499个数据域。如果要找图中的28,分两步
- 磁盘I/O,通过B树
- 将整个块加载到内存,在内存中搜索(二分搜索logN)
4.B+树索引
常问:为什么MySQL(MyISAM和InnoDB)索引底层选择B+树而不是B树???
- 在B树中,索引+数据的内存 全部分散在不同的节点上,各个节点中的数据互不重复,离根节点近,搜索的快,离根节点远,搜索的就慢!花费的磁盘I/O次数不平均,每一行数据搜索花费的时间也不平均。
- 每一个非叶子节点上,不仅仅要存储索引(key),还要存储索引值所在的那一行的data数据。一个节点所能够存放的索引key值的个数,比只存储key值的节点的个数要少得多!!!
- 这颗树不方便做范围搜索,整表遍历看起来也不方便。
由于上面的三个原因 ====》我们选择使用B+树,我们来看看B+树是如何解决这三个问题的!B+树的结构图如下:
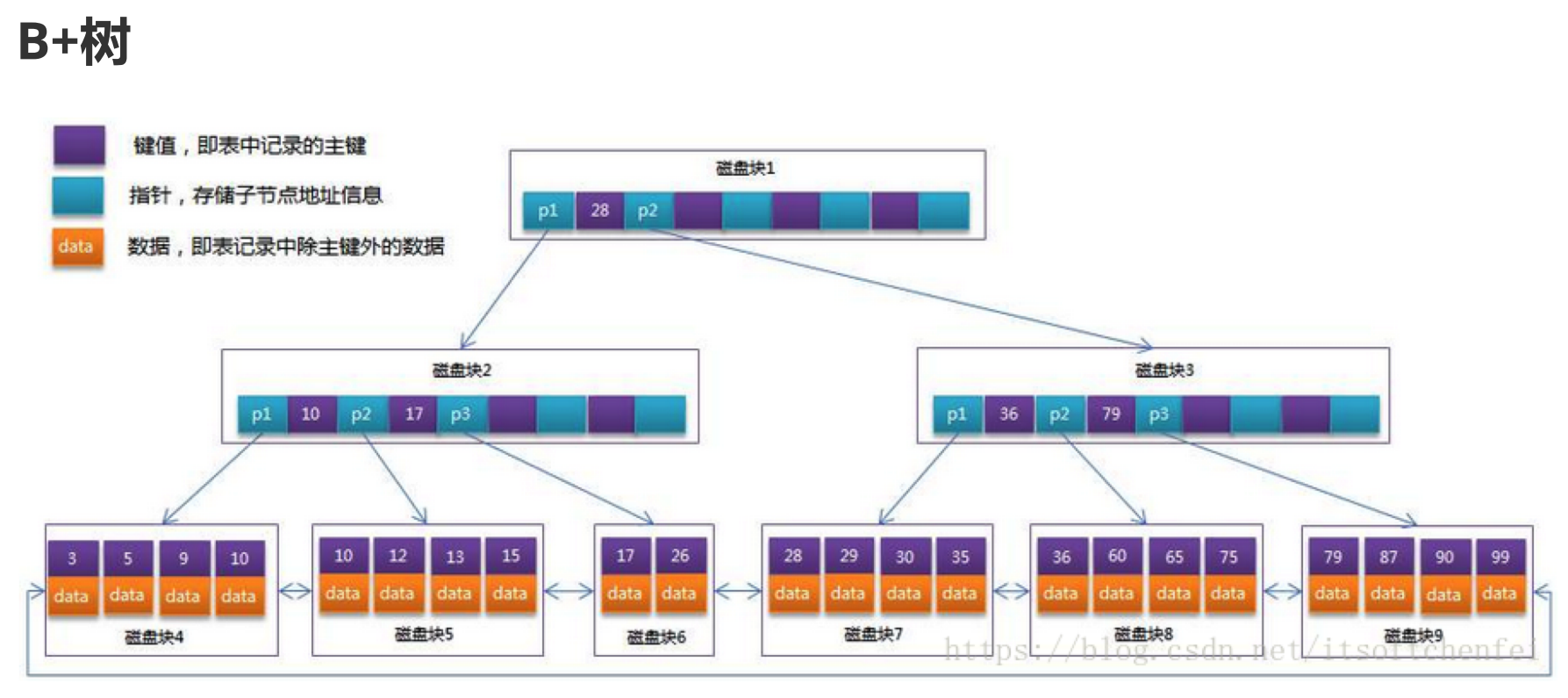
- B+树中,每一个非叶子节点,只存储key,不存储data!好处就是一个节点存放的key值更多【因为磁盘块的大小是固定的!】,B+树在理论上来说,层数会更低一些,搜索的效率会更好一些!
- 叶子节点上存储了所有的索引值和数据data:搜索每一个索引对于的值data,都需要跑到叶子节点上,这样一行记录搜索的时间是非常平均的!
- 此外,B+树所有叶子节点被连接成了有序链表结构,因此做整表遍历和区间查找是非常容易的。
5.InnoDB的主键和二级索引树
InnoDB存储引擎,数据和索引存储在一起,比如我们之前的student表,有student.frm(表结构)和student.idb(数据和索引)两个文件。
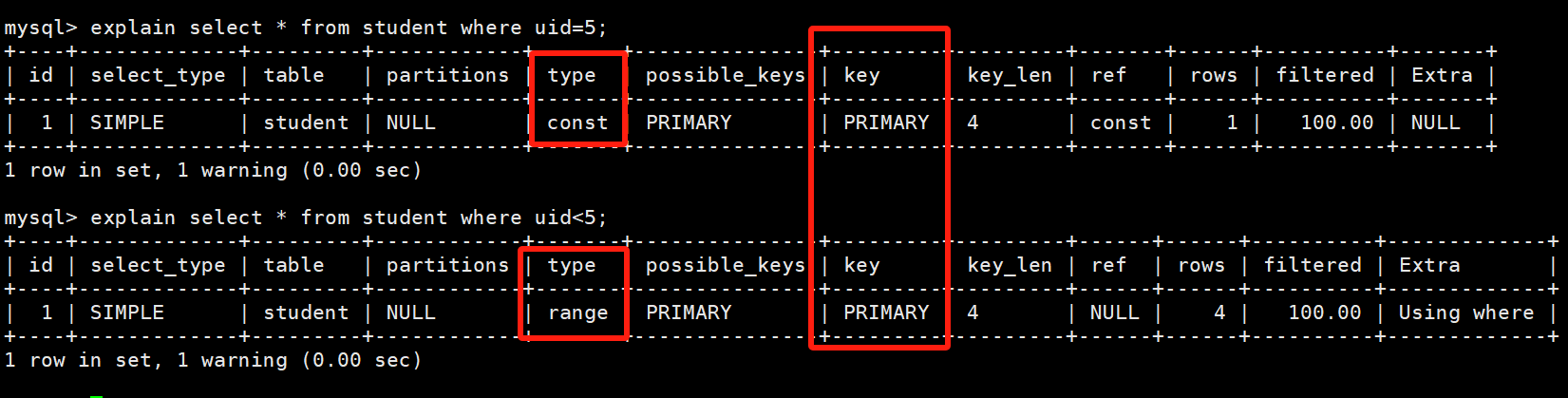
场景一:uid是主键,select * from student;搜索的是整个索引树。那么就直接去B+树的叶子节点组织起来的双链表中去遍历。
如果是select * from student where uid = 5; 等值查询,select * from student where uid < 5; 范围查询。那么就走B+树的索引结构。
场景二:uid是主键,name创建了普通索引(二级索引),如下图所示:
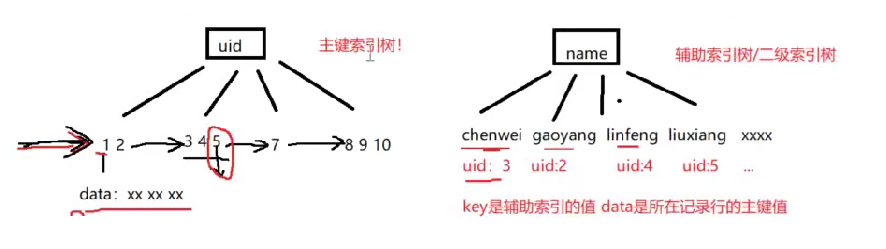
所以现在查询分为以下三种情况:
select name from student where name=‘linfeng’; 因为只获取name字段,所以直接查询辅助索引树/二级索引树 便可以获取到。select uid,name from student where name=‘linfeng’;索引二级索引树,也可以拿到name和uid,所以只搜索二级索引树。select * from student where name=‘linfeng’;因为搜索的是*(全部字段),所以会执行下面的操作:- 搜索name的二级索引树,找到linfeng对应的主键uid:4
- 再拿uid=4回表在主键索引树上搜索uid那一行的记录。
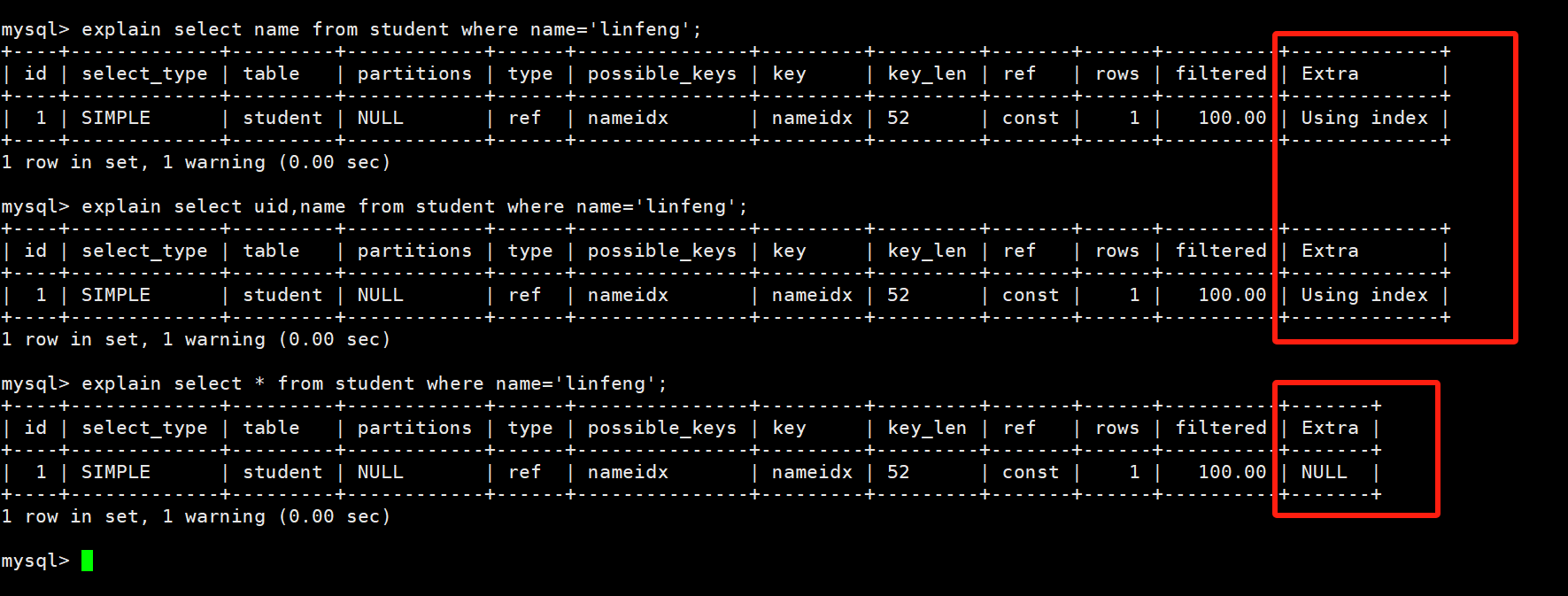 前两种情况,因为只查询了辅助索引树,所以extra上显示的是using index,第三种情况由于进行了回表操作,所以extra列上是NULL。
前两种情况,因为只查询了辅助索引树,所以extra上显示的是using index,第三种情况由于进行了回表操作,所以extra列上是NULL。
如果现在select * from student where age=20 order by name;如果只给age添加索引,行不行,还有什么没考虑到呢?
我们先看下没加索引是什么样的:

我们对age字段加上索引后,发现确实用到了age的索引,但是也进行了回表操作,相比之前已经优化了,但是filesort还是存在!有人提出可以给name也加索引,不可以!因为一次搜索只会用到一个二级索引!

能不能让这个二级索引树上,存储age+name呢?联合索引!key:age+name 多列索引(联合索引) 先按age排序,再按name排序,age相同时,按name进行排序!

我们发现确实跟我们分析的一样!因为在索引树上,当第一个索引相同时,就会对第二个索引进行排序!
6.聚集索引和非聚集索引
对应MyISAM存储引擎,主键索引树和辅助索引树是什么样的呢?
场景:uid是主键索引,name是二级索引时,MyISAM和InnoDB有什么区别呢?
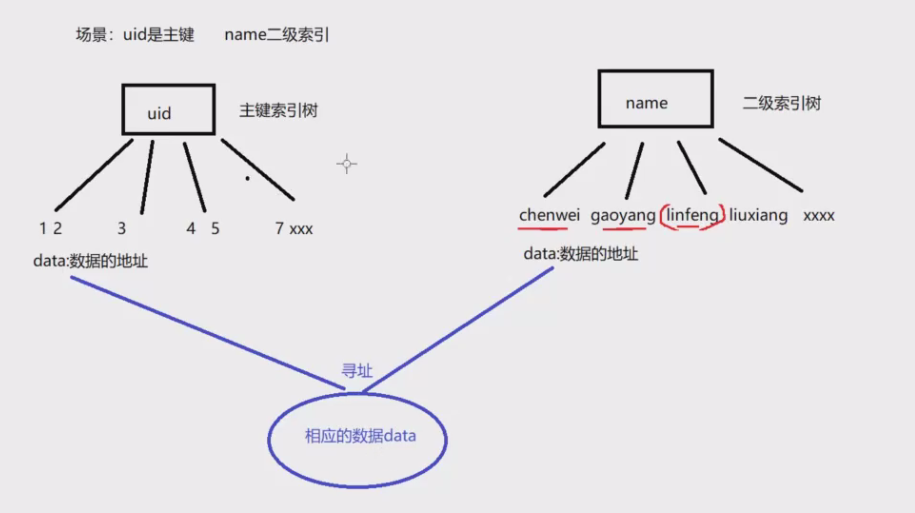
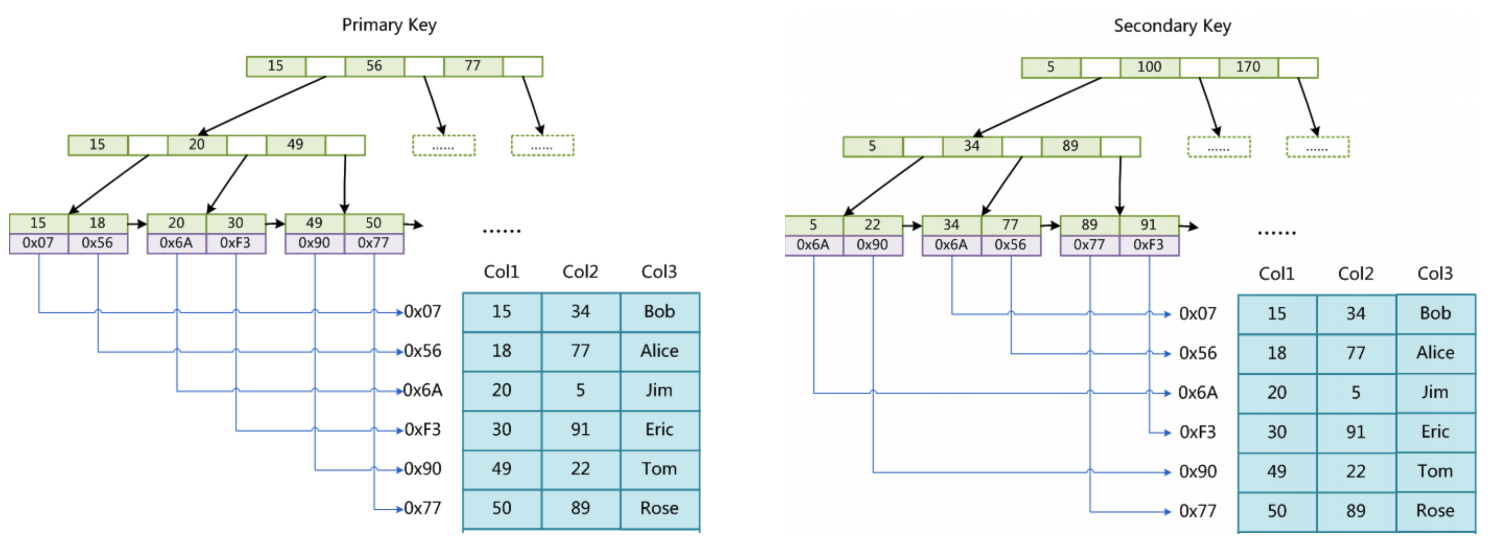
区别就是,在MyISAM存储引擎下,二级索引树下key是name,value不是主键索引uid!而是直接指向name所在数据data,存放的是name所在数据data的地址信息!
因为MyISAM存储引擎,索引和数据没有放在一起,所以叫做非聚集索引,而InnoDB存储引擎,索引和数据放在一起存储,紧密相连,叫做聚集索引!
7.哈希索引
哈希索引(Memory存储引擎)VS B+树索引(InnoDB和MyISAM)
- 哈希索引搜索的效率更好 O(1)
- 磁盘I/O花费要少
我们如何在MySQL中创建哈希索引:
哈希索引的结构(key存放索引键,value/data存储的是指针):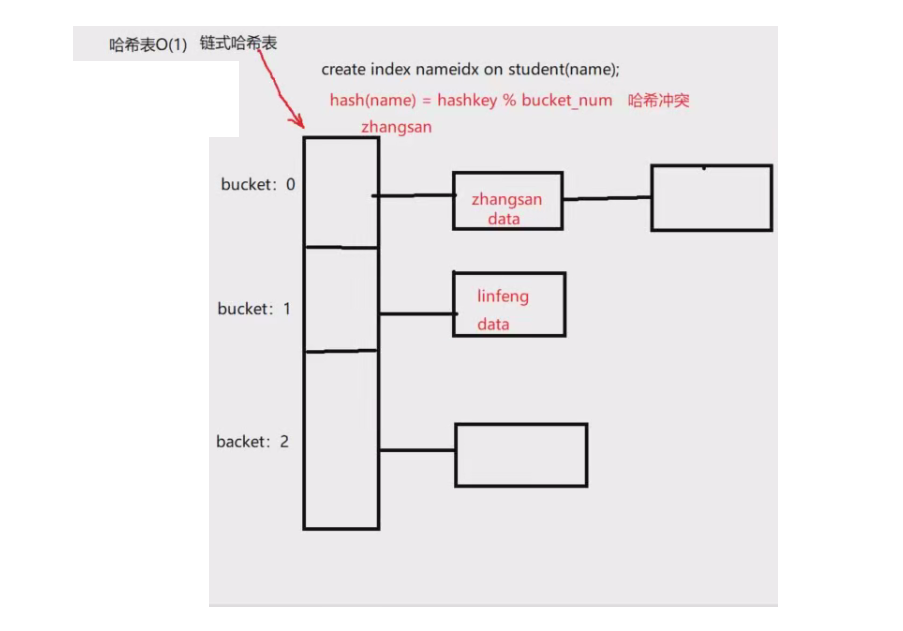
因为哈希表中的元素没有任何顺序可言!所以只能进行等值比较,那下面的语句就无法用到索引了!
# 可以走索引
select * from student where name='zhangsan';
# 不能走索引
select * from student where name like'zhang%';
# 范围查询,前缀查询,order by排序 这些操作,哈希索引都不适合。
另外:哈希索引在磁盘上的存储也是个大问题,B+树一个磁盘块一般是16K,磁盘组织形式一个页面一般是4K,一个磁盘块block中有4个page,但是在哈希表中,离的很近的元素也可能在磁盘上距离很远,没有顺序可言。所以哈希索引只是适用于内存上,并且只适用于等值比较。
综上,哈希索引有如下缺点:
- 没办法处理磁盘上的数据,加载到内存上构建高效的搜索数据结构,因为他没有办法减少范围查询时I/O的次数
- 只适合做等值搜索,其他的范围、排序等不适合。
面试:你知道B+树索引和哈希索引吗??
8.InnoDB自适应哈希索引
InnoDB存储引擎监测到同样的二级索引不断被使用,那么它会根据这个二级索引,在内存上根据二级索引树(B+树)上的二级索引值,在内存上构建一个哈希索引,来加速搜索【等值比较】。
自适应哈希索引的结构如下:
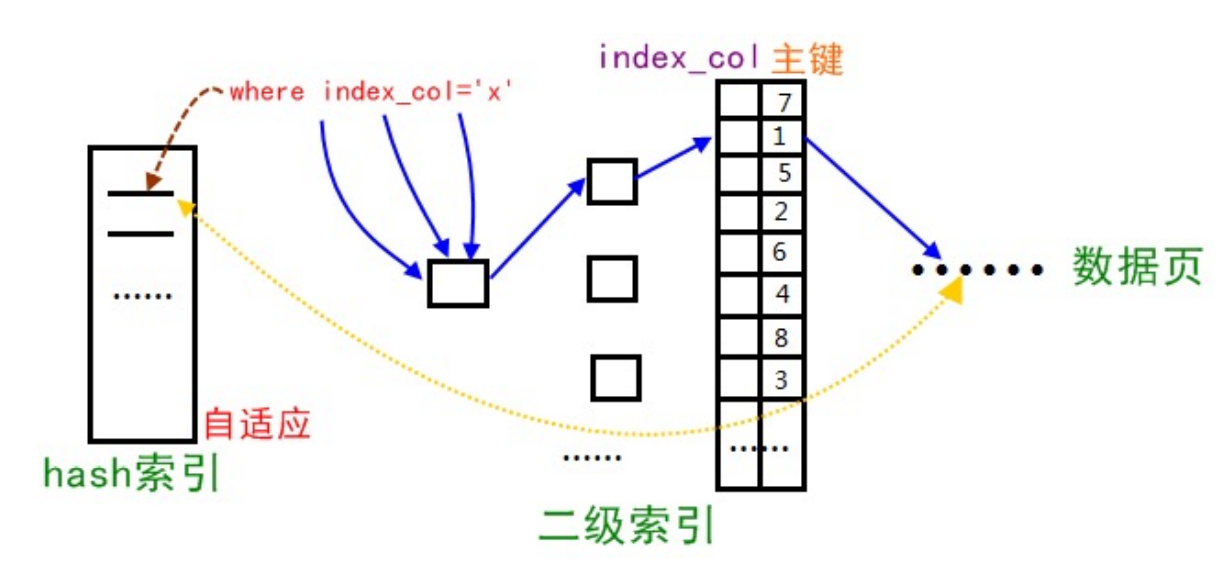
- 正常流程:where index_col【二级索引】先查二级索引树,拿到主键索引值,然后去主键索引树,取到数据页。
- 走hash索引【替代磁盘上的二级索引】,where index_col 直接和数据页交互。
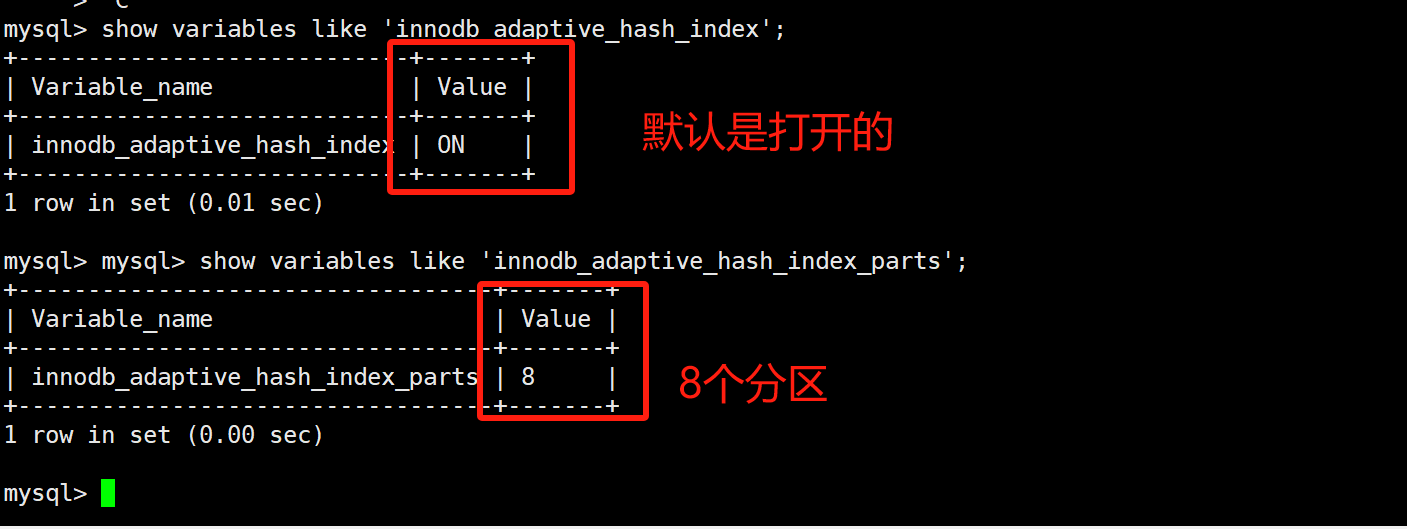
自适应哈希索引本身的数据维护也是要耗费性能的,并不 是说自适应哈希索引在任何情况下都会提升二级索引的查询性能,根据参数指标来具体分析是否打开或者关闭自适应哈希索引。这个哈希索引是存储引擎自动创建,是创建在二级索引的B+树上面的!为了提高这个二级索引回表查询的效率!
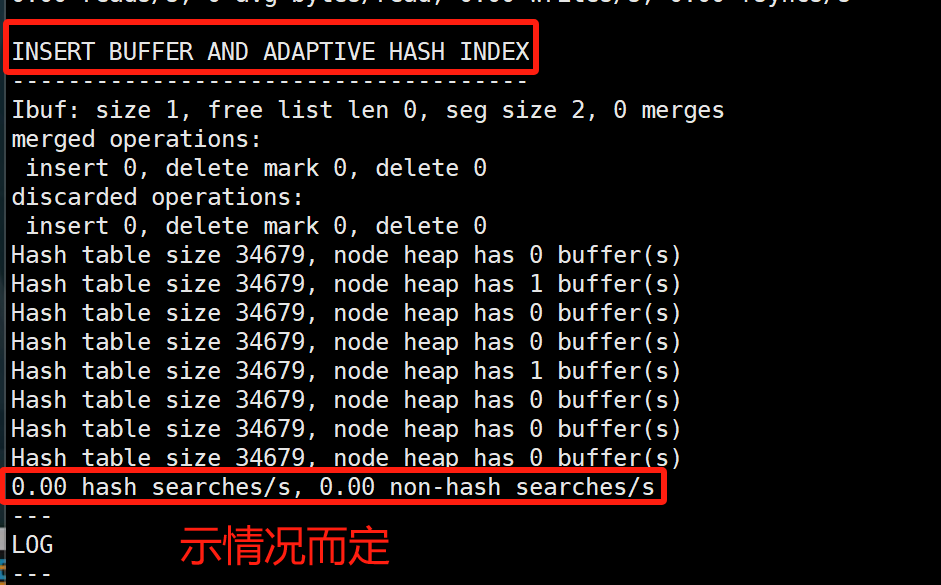
show engine innodb status\G,能看到两个比较重要的信息;
- RW-latch等待的线程数量(自适应哈希索引默认分配了8个分区,不同分区中可以并发操作),同一个分区等待的线程数量过多就会降低自适应哈希索引的效率
- 走自适应哈希索引搜索的频率(低)和二级索引树搜索的频率(高)=> it might be useful to disable adaptive hash indexing.
9.索引常见问题
- 比如淘宝我的宝贝那个页面,如果要按照时间排序
select * from xxx where userid = 123 order by addtime desc,这个索引应该怎么加?- 创建(userid,addtime)的联合索引,解决filesort问题。
- addtime建立索引 与 没有索引 这样排序的性能会有多大差别?
- filesort,通过userid选择出来的数据越多,则filesort的排序性能越差。
- 对于某些区分度高的字段,整表搜索的效率足够高了,mysql可能就不会走索引,比如
enum(‘M’,’W’)
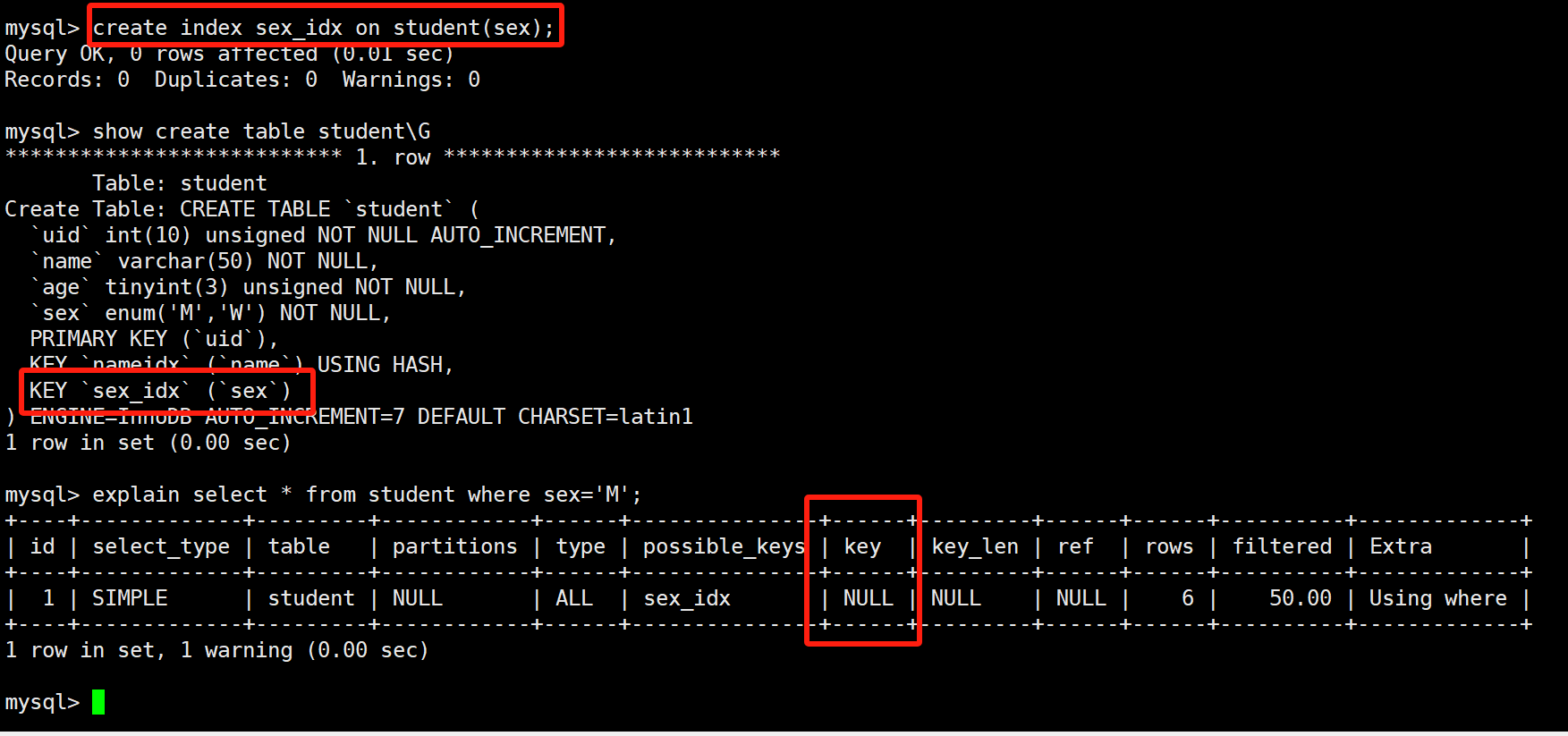
- 如果查询条件有多个字段,有部分创建索引的,比如
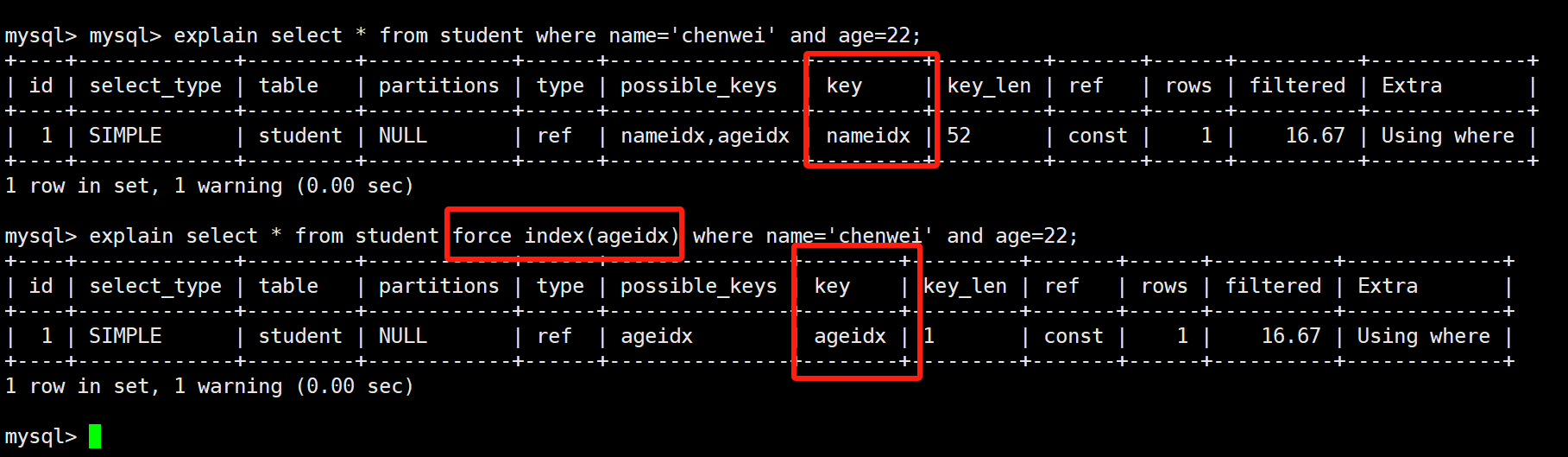
a=1 and b=2 and c=3,a和b分别有单独的索引,一定会优先找有索引的先查询缩小数据量吗,还是根据sql语句写的顺序来的。- 和顺序无关,MySQL会看看到底是按a筛选掉的数据多,还是按b筛选掉的数据多。
- 可以强制指定使用某个索引,
select * from xxx force index(ix_addtime),这样就是死活都会走addtime的索引。
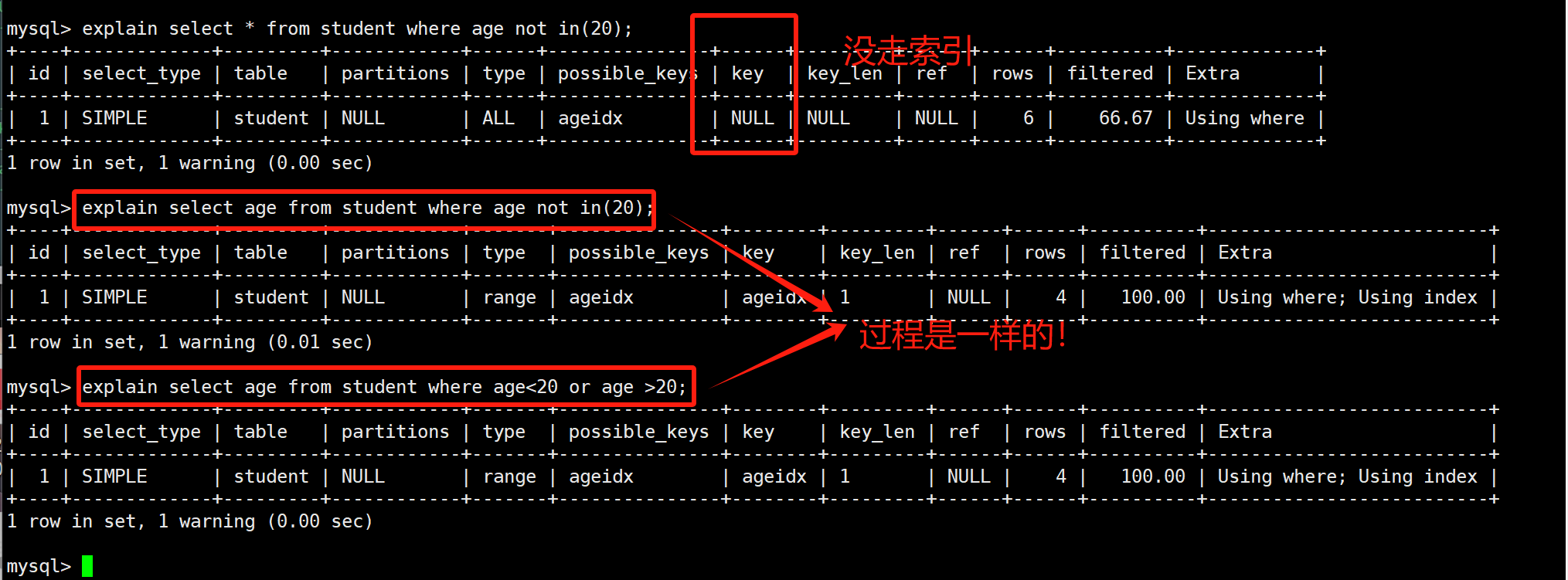
not in不一定不会走索引,就比如select age from student where age not in(20)会被mysql优化为一个范围查询select age from student where age<20 or age>20,演示如下:
- 当被问到索引的优化问题时,怎么切入?
- 从 什么地方【?】能够获取哪些运行时间长,耗性能的sql,然后再用explain去分析它!索引和慢查询日志
10.索引和慢查询日志
如何获取到项目中哪些sql语句执行速度慢,需要被优化!这里就需要使用慢查询日志!slow_query_log,这个日志的最大作用就是帮我我们寻找哪些sql语句在拖后腿,然后我们再通过加索引去优化!
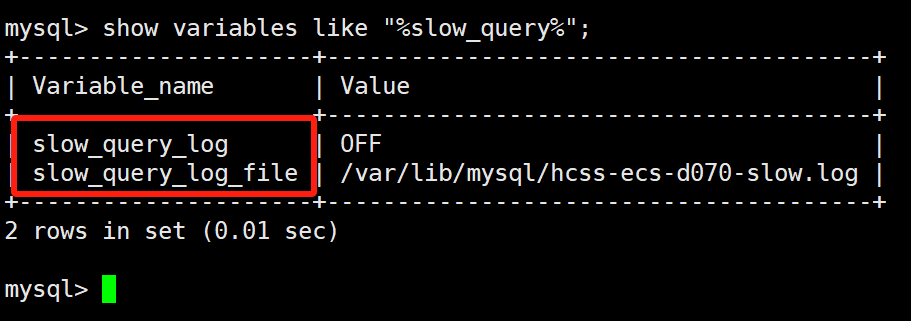
慢查询日志的相关参数如下所示:
show variables like "%slow_query%";
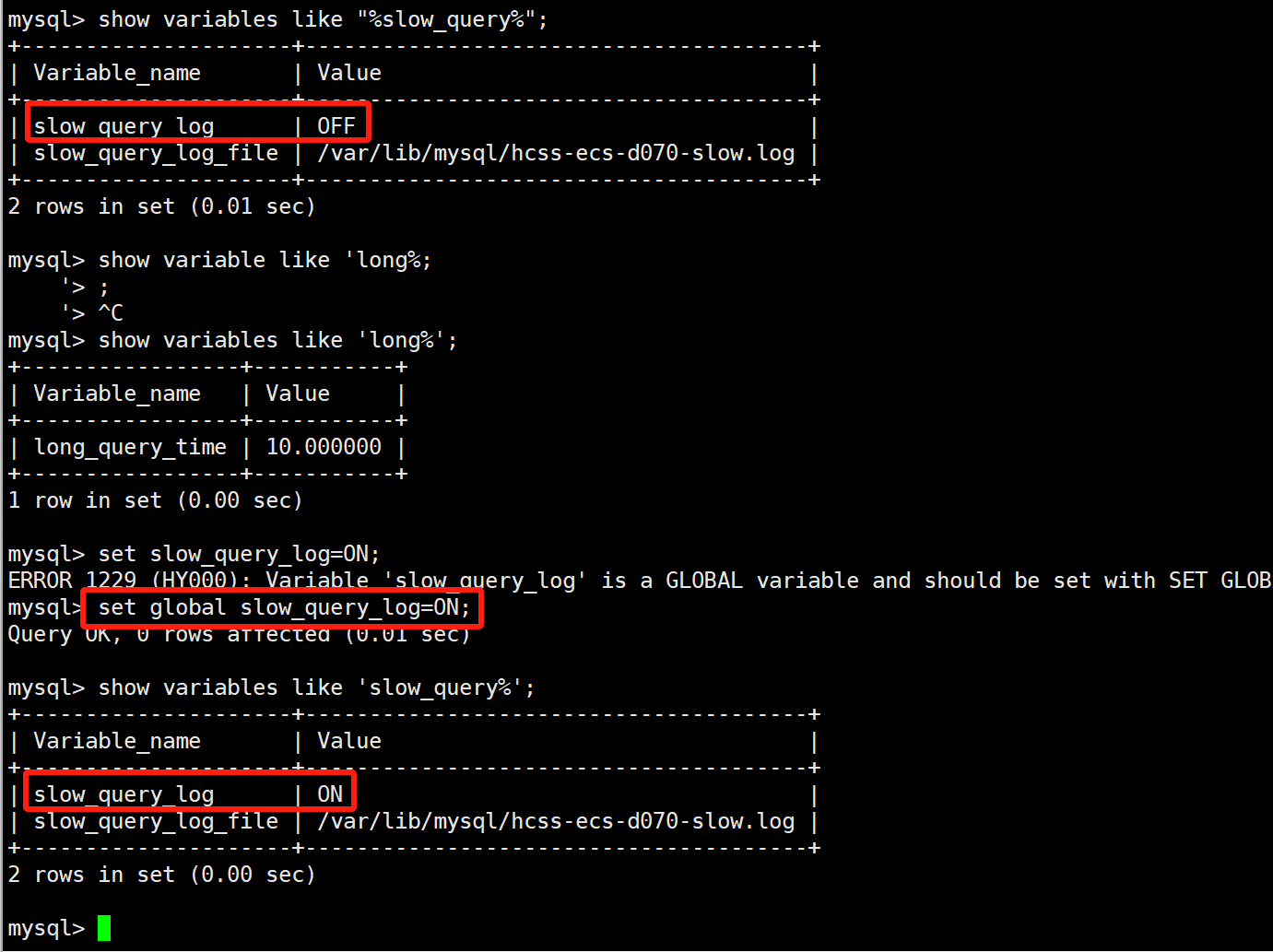
如果需要打开慢查询日志的开关:
set global slow_query=ON;
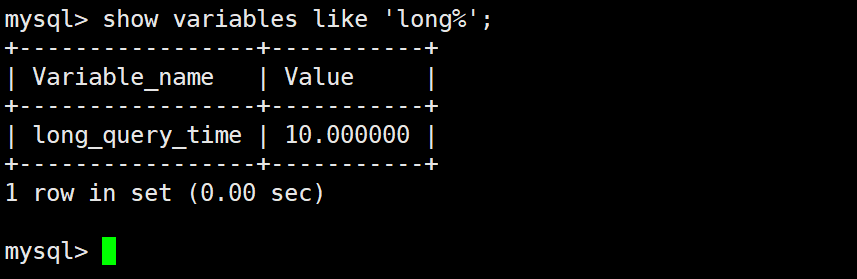
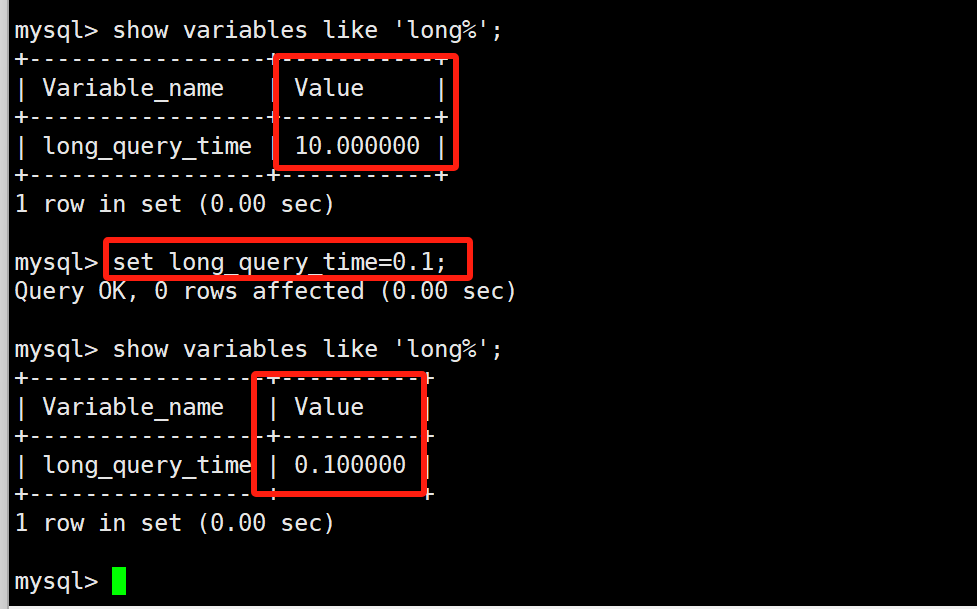
慢查询日志记录了包含所有执行时间超过参数long_query_time(单位:秒)所设置的SQL语句的日志,在MySQL上用命令可以查看,如下:
show variables like 'long%';
这个值是可以修改的,注意,这里在设置的时候没有加global语句,所以设置的结果仅在当前session中有效。
set long_query_time=1; # 注意:单位是秒
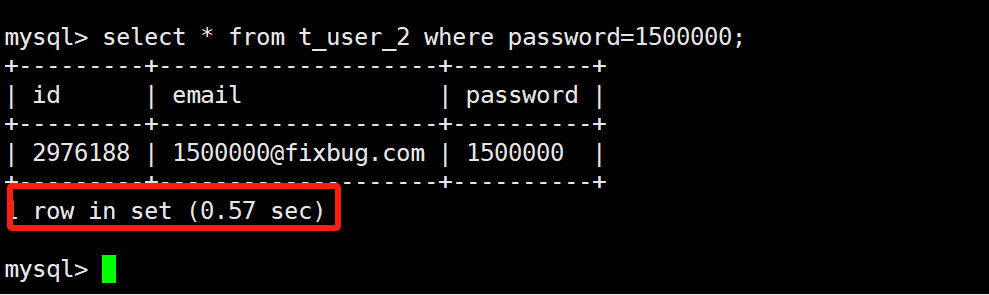
 我们故意制造一条不走索引的慢查询记录:
我们故意制造一条不走索引的慢查询记录:
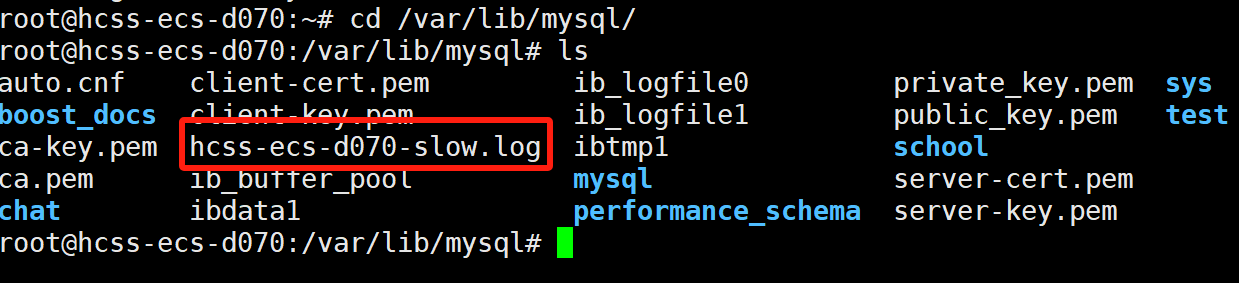
我们进入目录下找到慢查询日志:
打开查看:
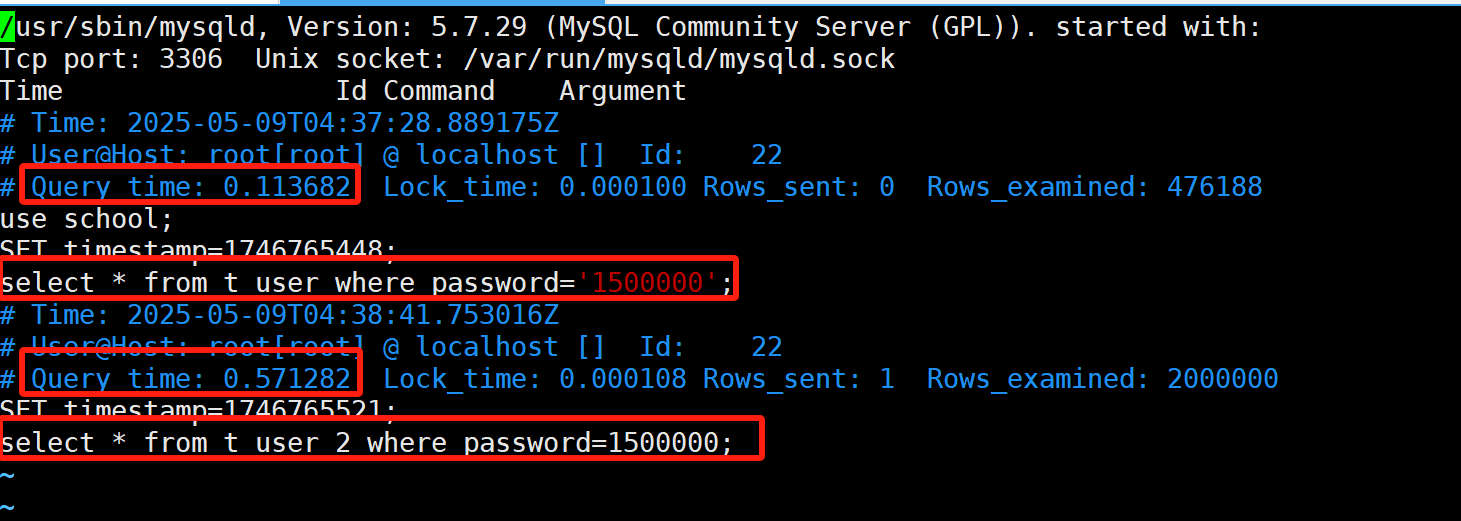
我们在日志文件中看哪些日志超出了我们预期的时间,然后再通过explain进行分析,分析是否使用索引,是否有filesort等等。这就是通过实践分析优化sql的过程。总结如下:
- 慢查询日志!设置合理的、业务可以接受的慢查询时间!
- 压测执行各种业务!!
- 查看慢查询日志,找出所有执行耗时的sql
- 用explain分析这些耗时的sql
- 举自己实际项目中解决问题的例子
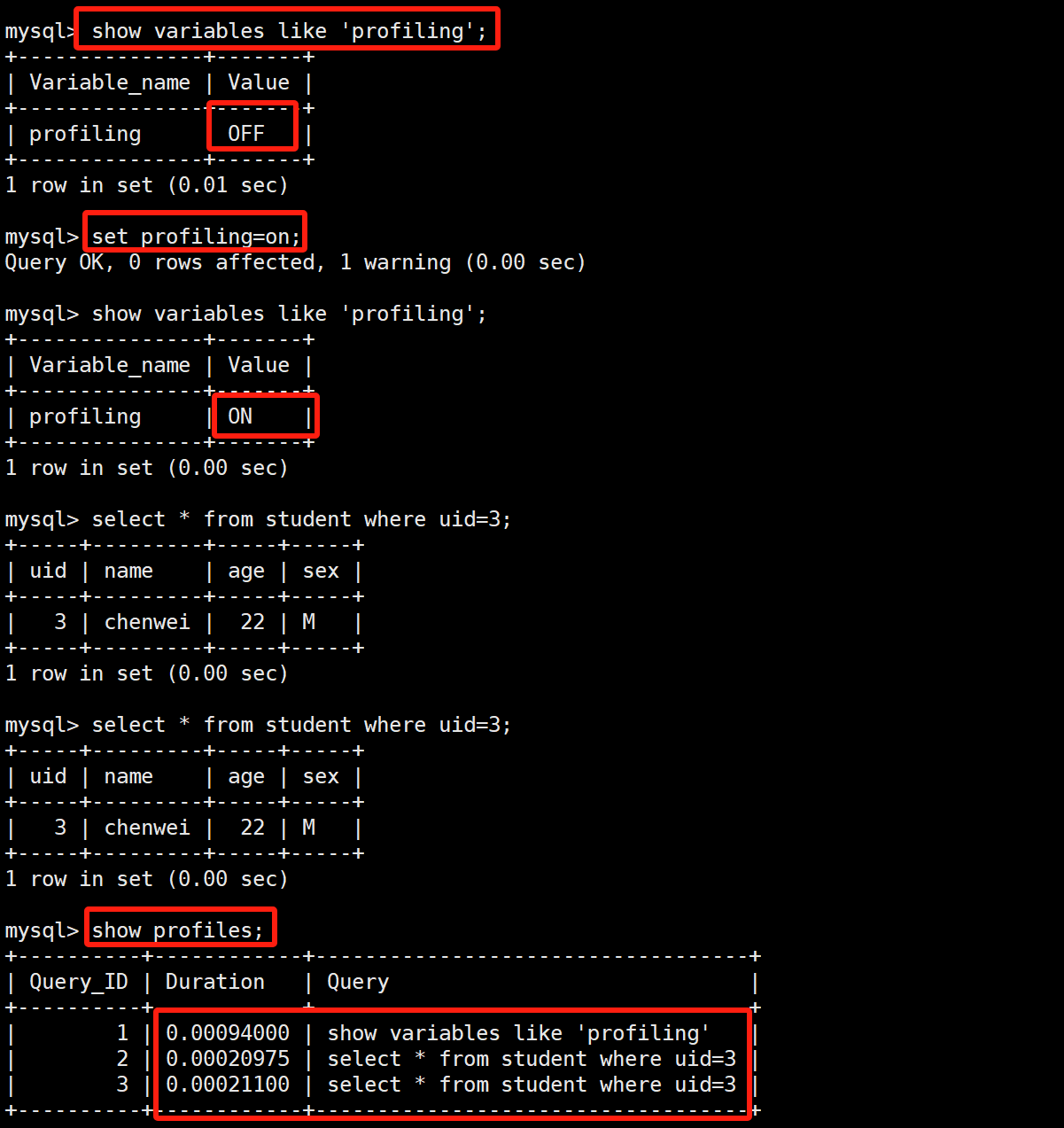
另外,对于某些语句的执行小于0,00秒,我们应该如何去得知他具体的执行时间是多少呢?通过profiling
# 查看是否启动了profiling
show variables like 'profiling';
# 设置开启
set profiling=on;
# 查询profiling启用后语句的详细执行时间
show profiles;
12.MySQL事务
1.事务概念
一个事务是由一条或者多条对数据库操作的SQL语句所组成的一个不可分割的单元,只有当事务中的所有操作都正常执行完了,整个事务才会被提交给数据库;如果有部分事务处理失败,那么事务就要回退到最初的状态,因此,事务要么全部执行成功,要么全部失败。
假如现在表account表中,有(zhangsan,100)和(liuchao,200)这两个账户,在service层进行业务处理 -> 转账操作时,zhangsan -> liuchao 转账50.0钱,事务的逻辑代码表示如下:
# try中的内容组成一个完整的事务
try{begin; # 开启一个事务update account set money=money-50.0 where name='zhangsan';update account set money=money+50 where name='liuchao';# ...commit; # 提交一个事务
}catch{ ...rollback; #回滚一个事务,事务恢复到事务开始前的状态
}
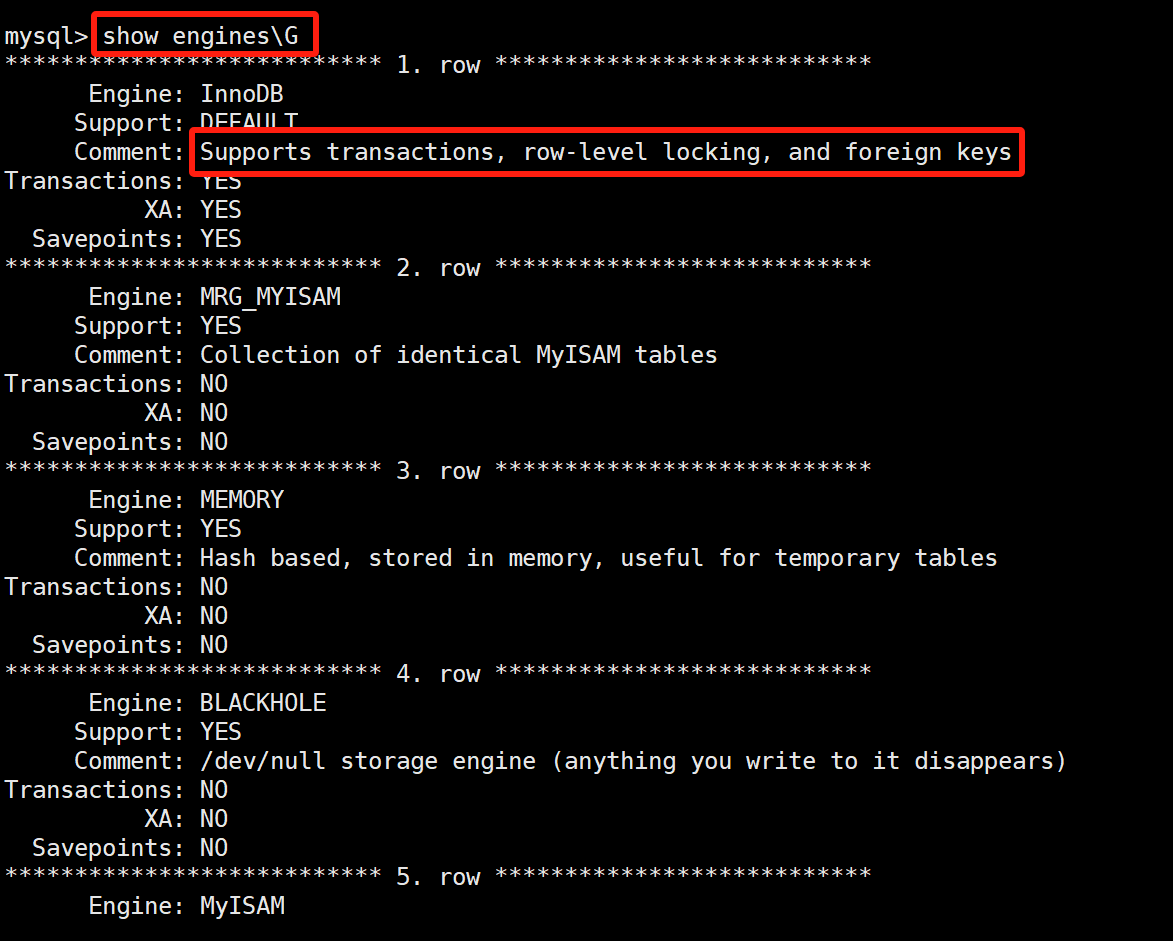
MyISAM是不支持事务的,InnoDB:最大的特点:支持事务,支持行锁,支持外键,我们可以通过show engines\G,查看下当前mysql支持的存储引擎:
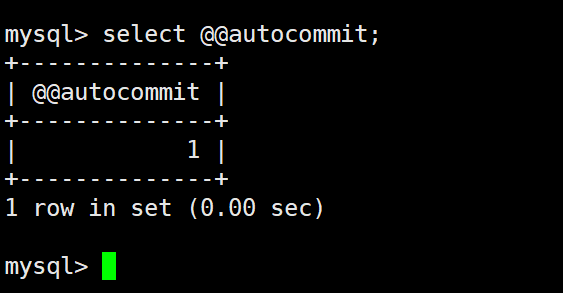
我们可以通过select @@autocommit;指令来查看下当前mysql自动提交事务的状态。
如果我们需要使用事务,第一件事就是要通过set autocommit=0;把autocommit设置成0,改为我们手动的提交事务。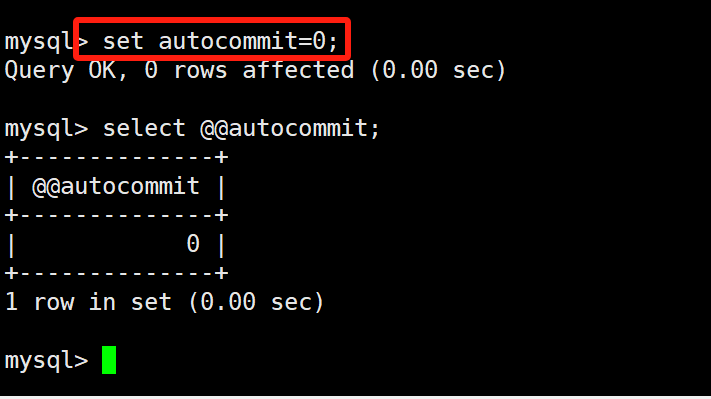
所以记住事务的几个基本概念,如下:
- 事务是一组SQL语句的执行,要么全部成功,要么全部失败,不能出现部分成功,部分失败的结果。保证事务执行的原子操作。
- 事务的所有SQL语句全部执行成功,才能提交(commit)事务,把结果写回磁盘上。
- 事务执行过程中,有的SQL出现错误,那么事务必须要回滚(rollback)到最初的状态。
2.事务的ACID特性
每一个事务必须满足下面的4个特性:
- 事务的原则性(Atomic):事务是一个不可分割的整体,事务必须具有原子特性,及当数据修改时,要么全执行,要么全不执行,即不允许事务部分的完成。
- 事务的一致性(Consistency):一个事务执行之前和执行之后,数据库数据必须保持一致性状态。由并发控制机制实现。就拿网上购物来说,你只有让商品出库,又让商品进入顾客的购物车才能构成一个完整的事务。
- 事务的隔离性(Isolation):当两个或者多个事务并发执行时,为了保证数据的安全性,将一个事务内部的操作与其他事务的操作隔离起来,不被其他正在执行的事务所看到,使得并发执行的各个事务之间不能互相影响。
- 事务的持久性(Durability):事务完成(commit)以后,DBMS保证它对数据库中的数据的修改是永久性的,即使数据库因为故障出错,也应该能够恢复数据。db写数据 => cache缓存 => 磁盘I/O,假如在cache缓存向磁盘I/O写入的过程中,停电了/宕机了/重启了,通过redo log:重做日志【故障恢复后mysql自动通过该日志恢复数据】,来保证数据库的持久性!mysql最重要的是日志,不是数据!
总结事务的ACID特性:
- ACD:是由mysql的redo log 和 undo log机制来保证的
- I:隔离性,是由mysql事务的锁机制来实现保证的
3.事务并发存在的问题
事务处理不经隔离,并发执行事务时通常会发生以下的问题:
- **脏读(Dirty Read):**一个事务读取了另一个事务未提交的数据,假如当事务A和事务B并发执行时,当事务A更新但未提交时,事务B查询读到A尚未提交的数据【中间态数据】,此时事务A回滚,那么事务B读到的就是无效的数据。有问题!
- 不可重复读(NonRepeatable Read):一个事务的操作导致另一个事务前后两次读到不同的数据。例如当事务A和事务B并发执行时,当事务B查询读取数据后,事务A更新操作更改了事务B查询到的数据,此时事务B再次读取该数据,发现前后两次读的数据不一样。(事务B读取事务A已提交的数据)看业务需求
- **幻读(Pahantom Read):**一个事务的操作导致另一个事务前后两次查询的结果数据量不同。例如当事务A和事务B并发执行时,当事务B查询读取数据后,事务A新增或者删除了一条满足事务B查询条件的记录,此时事务B再次查询,发现了事务前一次不存在的记录,获取前一次查询的一些记录不见了。(事务B读取了事务A新增的数据或者读不到事务A删除的数据)看业务需求
我们现在开启两个终端,把两个终端中的自动提交都关掉,然后来演示下事务并发存在的问题:
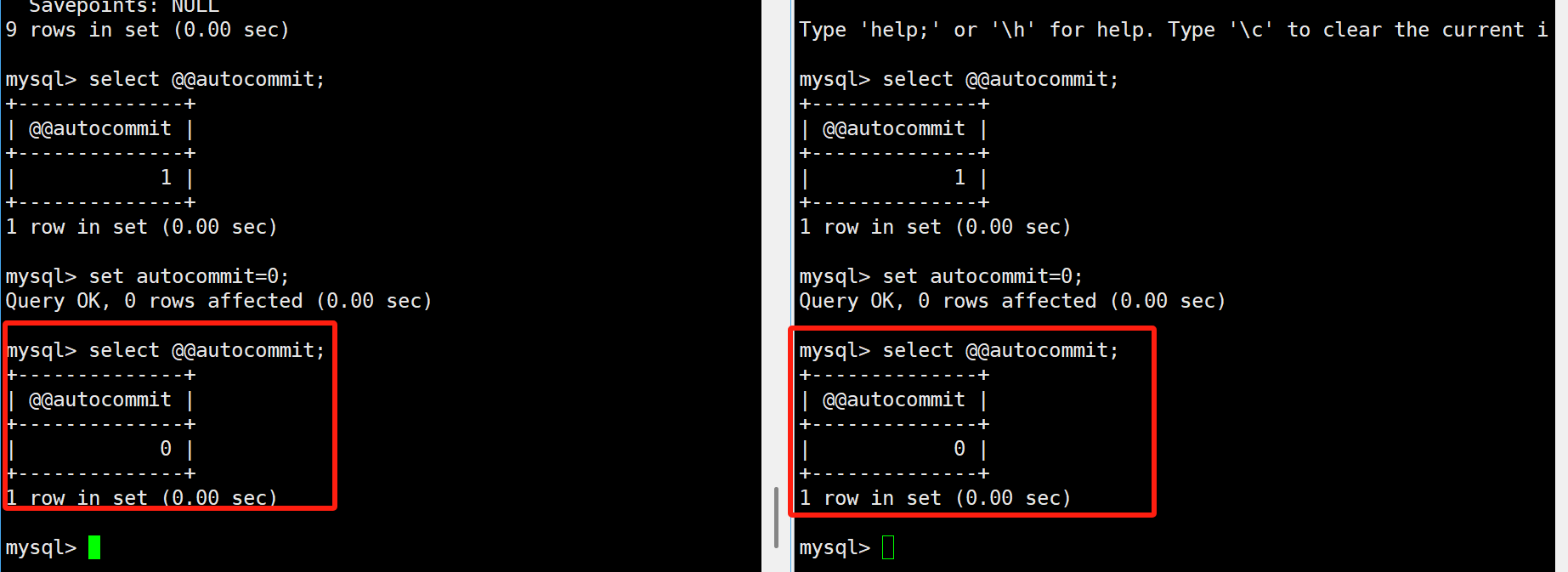
4.事务的隔离级别
MySQL支持的四种隔离级别是:
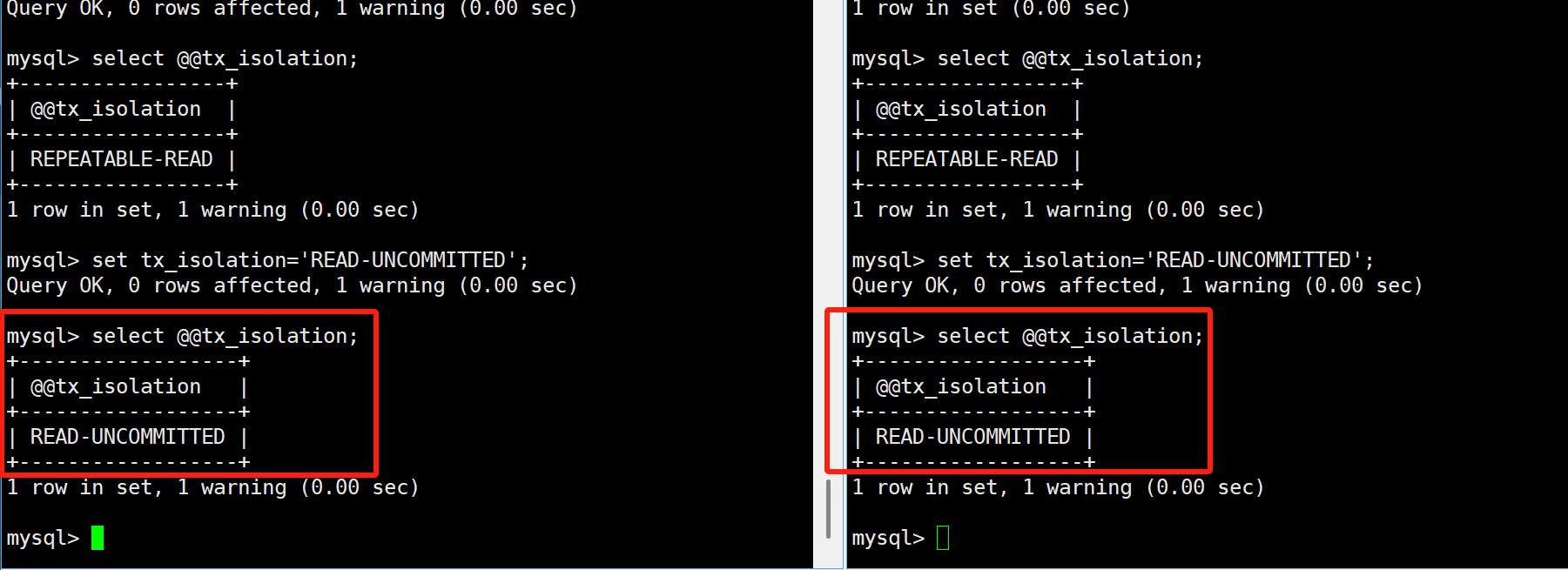
- TRANSACTION_READ_UNCOMMITTED。未提交读。说明在提交前一个事务可以看到另一个事务的变化。这样读脏数据【不可接受】,不可重复读和虚读都是被允许的。
- TRANSACTION_READ_COMMITTED。已提交读。说明读取未提交的数据是不允许的。这个级别仍然允许不可重复读和虚读产生。【oracle默认的工作级别】
- TRANSACTION_REPEATABLE_READ。可重复读。说明事务保证能够再次读取相同的数据而不会失败,但虚读仍然会出现。【mysql的默认工作级别】
- TRANSACTION_SERIALIZABLE。串行化。是最高的事务级别,它防止读脏数据,不可重复读和虚读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | 可以 | 可以 | 可以 |
| 已提交读 | 不可以 | 可以 | 可以 |
| 可重复读 | 不可以 | 不可以 | 可以(update) |
| 串行化 | 不可以 | 不可以 | 不可以 |
备注:
- 事务隔离级别越高,为避免冲突所花费的性能也就越多。
- 在“可重复读”级别,实际上可以解决部分的虚读问题,但是不能防止update更新产生的虚读问题,要禁止幻读产生,还是需要设置串行化隔离级别。
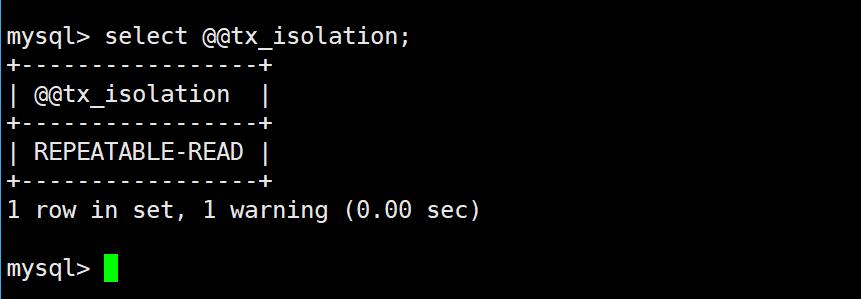
我们看下mysql的默认工作级别select @@tx_isolation:
我们先来演示下最低的隔离级别,将两个终端的mysql隔离级别都设置成未提交读:
左边开启事务,并修改li si的age,但未提交,但是右边却读到了左边事务还未提交的数据。
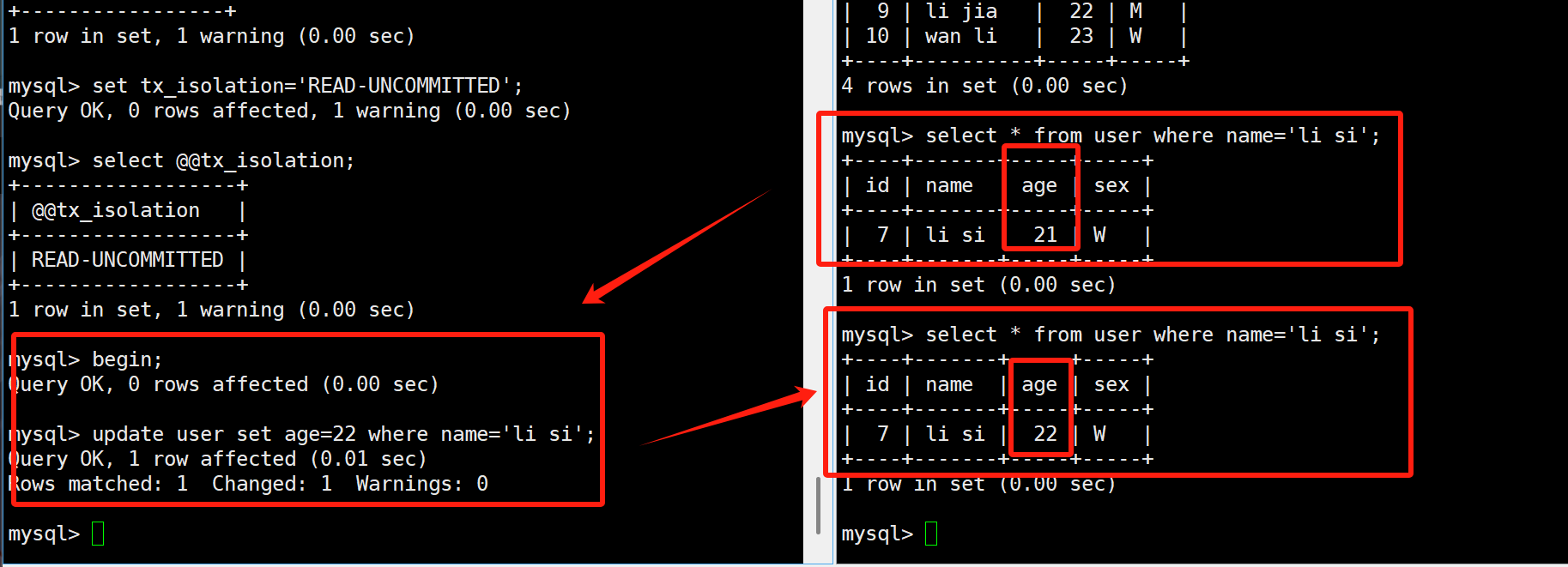
然后当左边事务进行回滚,右边再次查询数据由恢复了,但是在左边事务回滚前,已经处理的逻辑全部都是错的!
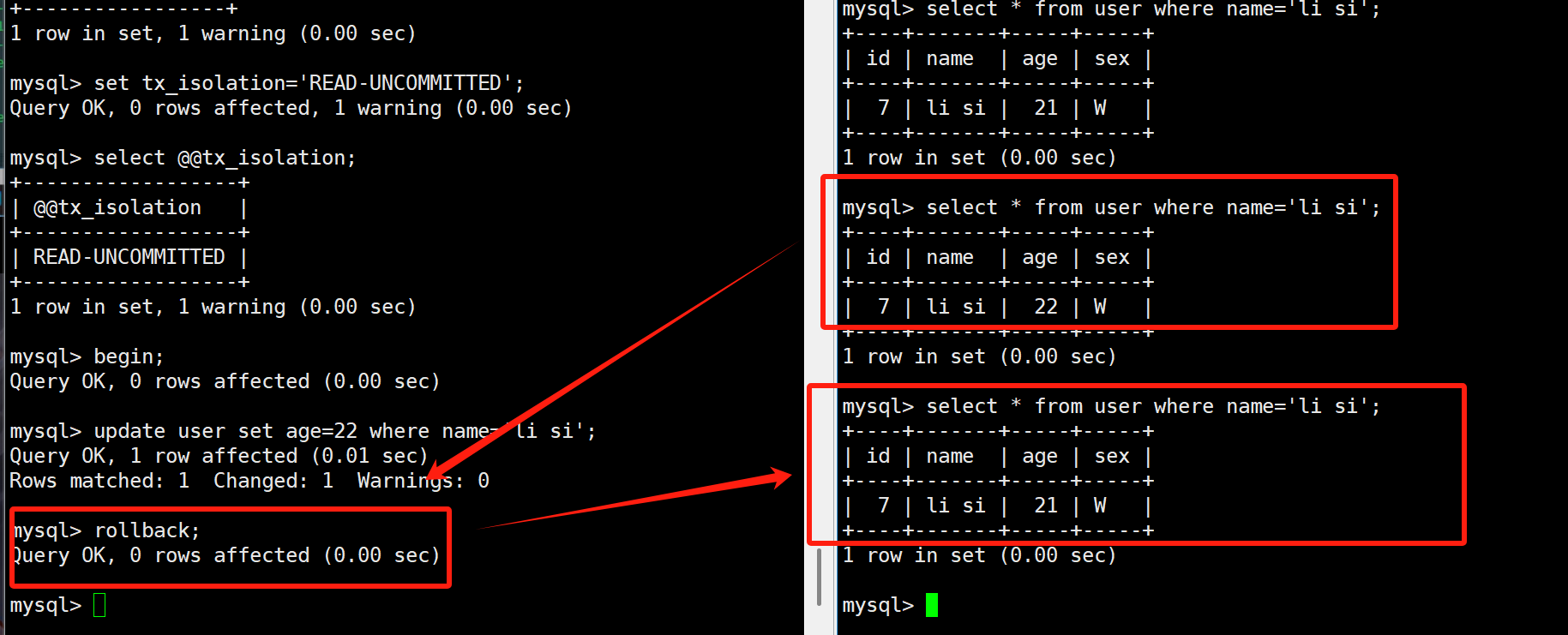
当我们提升事务的隔离级别为已提交读后,就不会发生脏读了。
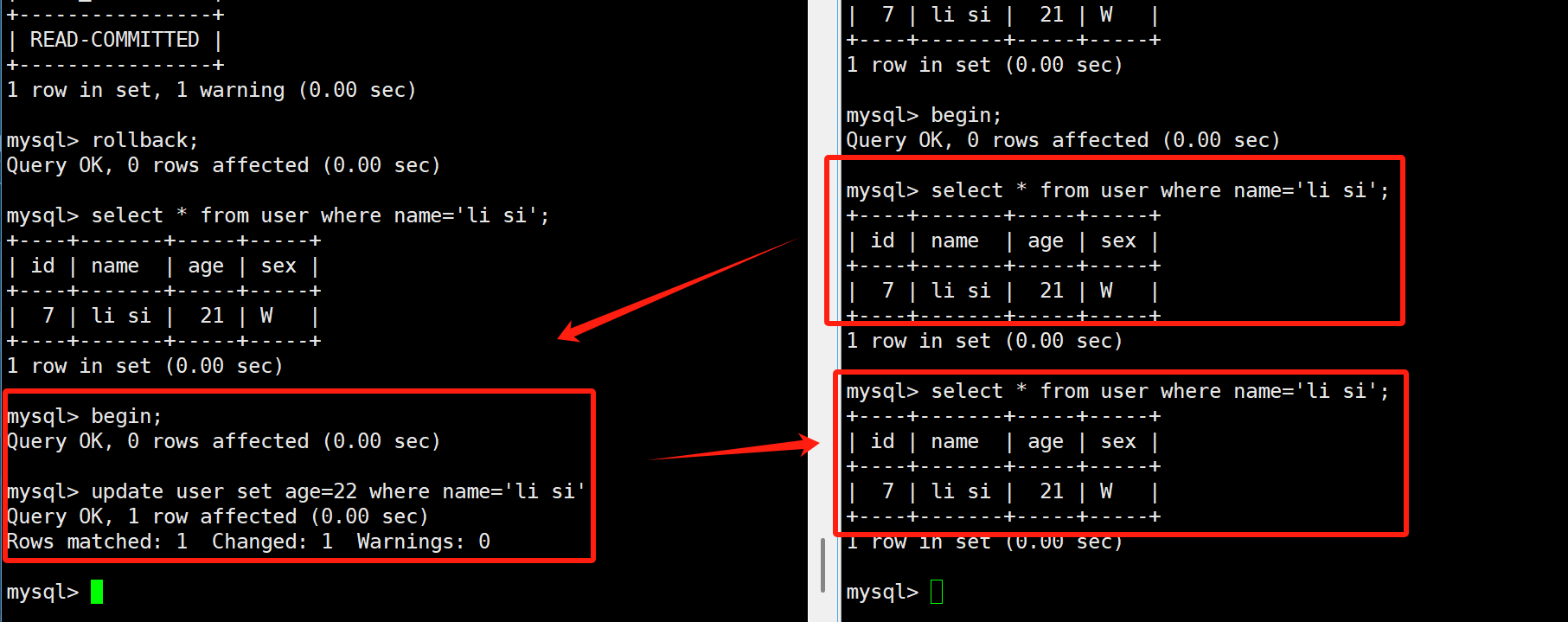
左边已提交的数据,右边可以看到。出现了不可重复读,但这个我们站在上帝视角应该理解为对的,虽然对于右边来说很懵,因为两次读取的结果不一样。
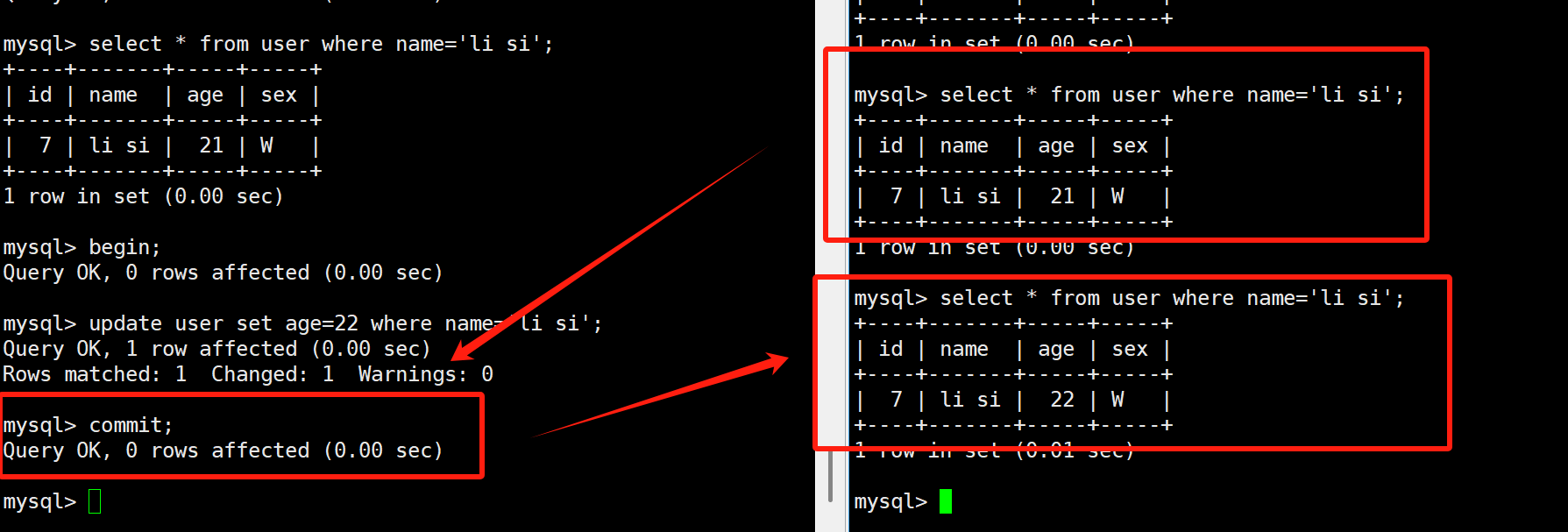
我们在把事务隔离级别进行提升为可重复读【mysql的默认隔离级别】,就不会发生不可重复读了。下面来进行操作:
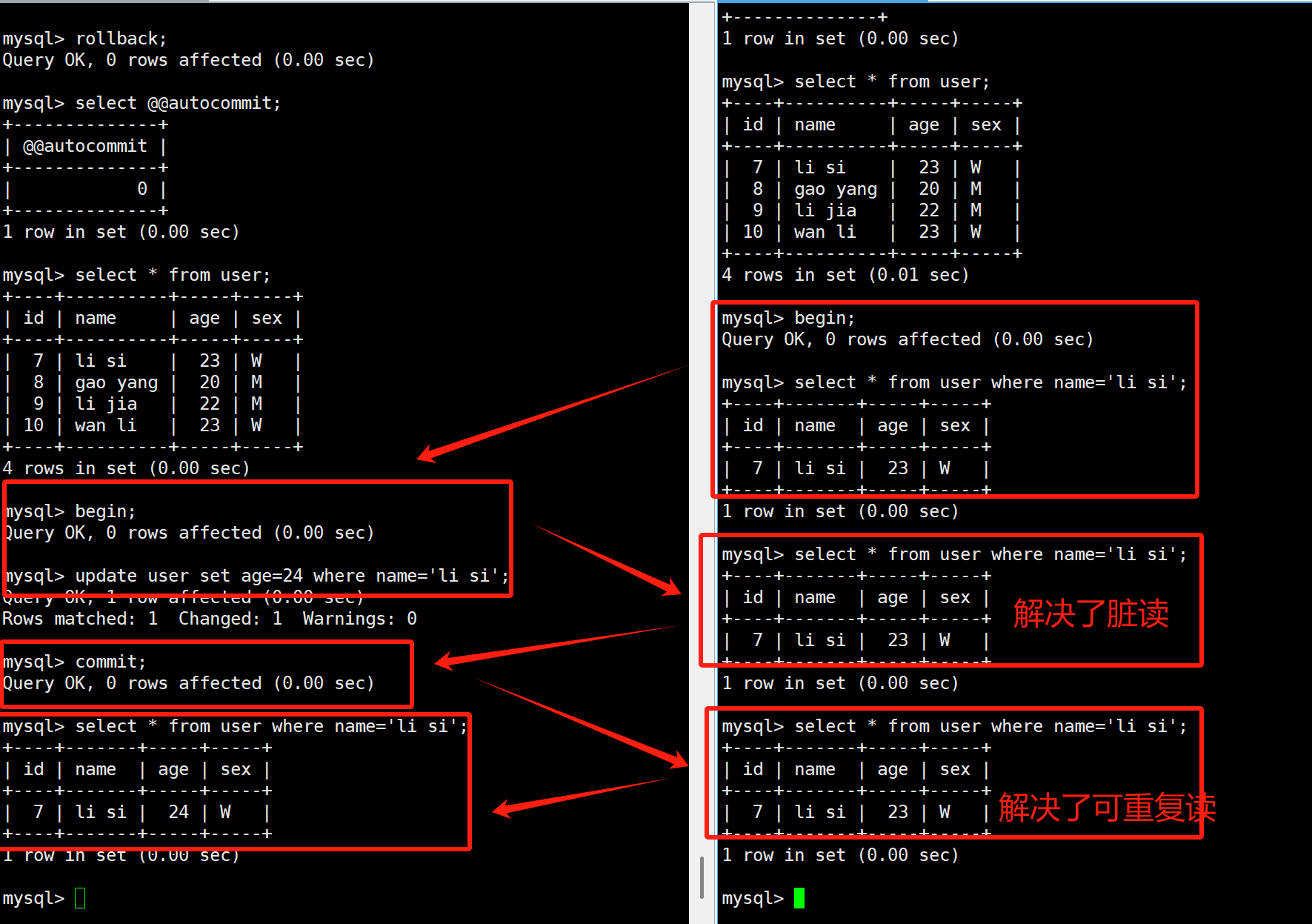
其实,在可重复读的隔离级别下,已经解决了一部分的幻读,但是没有解决彻底,通常情况下,在可重复读的隔离级别下,insert语句和delete语句是不会发生幻读的!
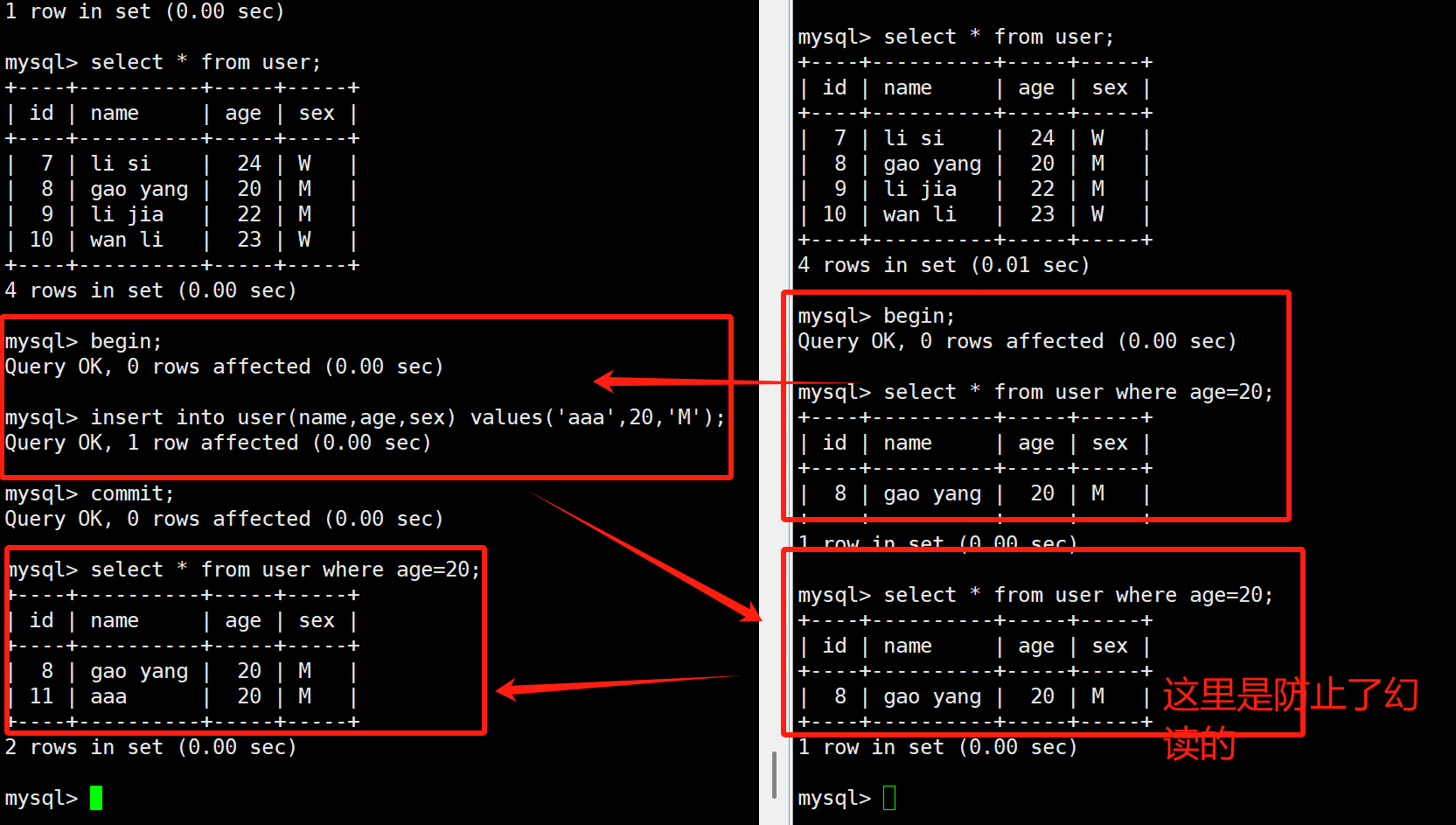
但是他防止不了update,下面我来演示下在可重复读隔离级别下出现的幻读:
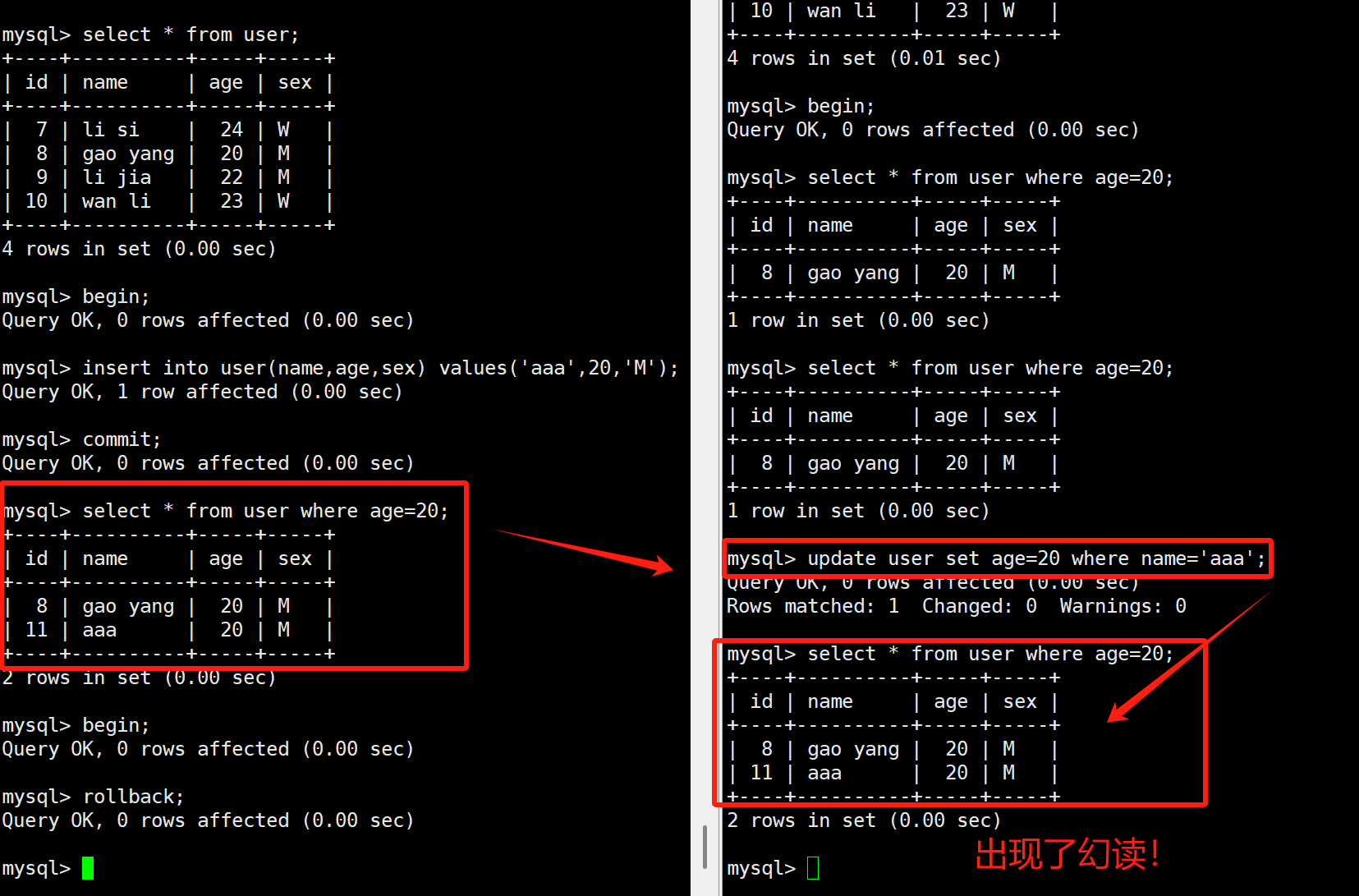
如果我们连幻读都不想要,那就工作在串行化隔离级别。
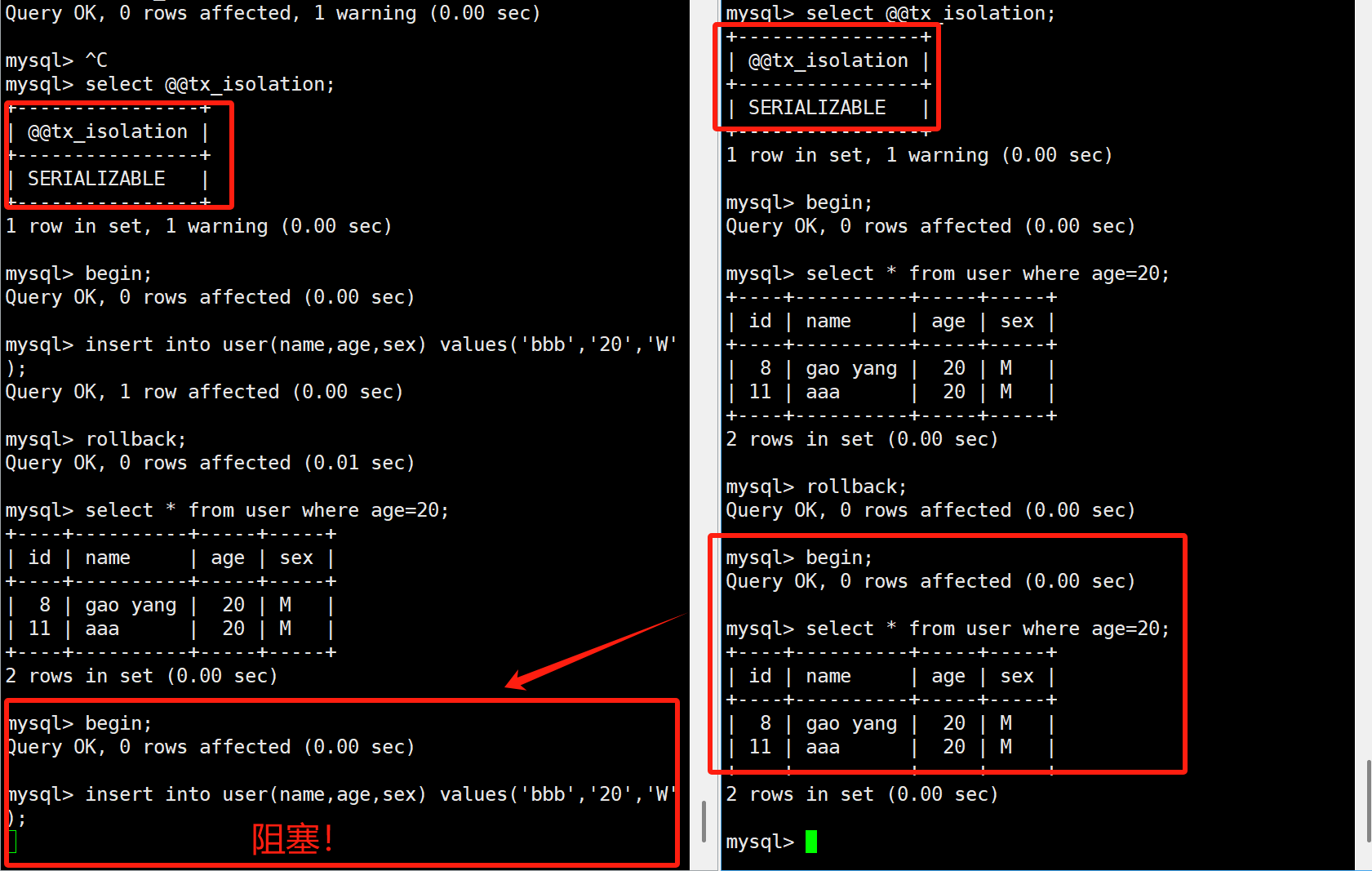
但也不会一直的被阻塞,会有一个超时时间,如果阻塞超过了超时时间,就报下面的错误。
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
相关文章:

MySQL核心内容【持续更新中】
MySQL核心内容 文章目录 MySQL核心内容1.MySQL核心内容目录2.MySQL知识面扩展3.MySQL安装4.MySQL配置目录介绍Mysql配置远程ip连接 5.MySQL基础1.MySQL数据类型1.数值类型2.字符串类型3.日期和时间类型4.enum和set 2.MySQL运算符1.算数运算符2.逻辑运算符3.比较运算符 3.MySQL完…...

【高级IO】多路转接之单线程Reactor
这里写目录标题 一.Epoll的两种工作模式二.单线程Reactor1.Connection模块2.Reactor服务器模块2.1初始化Init2.2启动循环服务器Loop2.3事件派发Dispatcher2.4连接管理器Accepter2.5事件管理器Receiver2.6发送管理器Sender 3.上层业务模块定制协议业务处理 代码 一.Epoll的两种工…...

基于设备指纹识别的反爬虫技术:给设备办 “身份证”
传统的封禁 IP、验证码等反爬虫手段已逐渐失效,基于设备指纹识别的反爬虫技术应运而生,成为守护数据安全的新防线。它如同给每个设备办一张独一无二的 “身份证”,精准区分正常用户与爬虫工具。 一、基础参数采集:构建设备指纹的…...

公开模型一切,优于DeepSeek-R1,英伟达开源Llama-Nemotron家族
在大模型飞速发展的今天,推理能力作为衡量模型智能的关键指标,更是各家 AI 企业竞相追逐的焦点。 但近年来,推理效率已成为模型部署和性能的关键限制因素。 基于此,英伟达推出了 Llama-Nemotron 系列模型(基于 Meta …...

CI/CD面试题及答案
一、CI/CD 基础概念 1. 什么是 CI/CD?CI 和 CD 的区别是什么? 答案: CI(持续集成):开发人员提交代码后,自动构建并运行测试,确保代码集成无冲突。CD(持续交付 / 部署&am…...
)
解决 Ubuntu DNS 无法解析问题(适用于虚拟机 长期使用)
解决 Ubuntu DNS 无法解析问题 在使用 Ubuntu 虚拟机(尤其是在国内)时,经常会遇到这样的错误: Temporary failure resolving cn.archive.ubuntu.com但是此时又能成功 ping 通 IP,这说明网络是正常的,问题…...

如何通过C# 获取Excel单元格的数据类型
在处理 Excel 文件时,了解单元格的数据类型有助于我们正确地解析和处理数据。Free Spire.XLS 是一款功能强大且免费的.NET 组件,支持高效地操作 Excel 文件,包括读取单元格类型。本文将详细介绍如何使用 Free Spire.XLS 来获取 Excel 单元格的…...

Spring Boot初级教程:从零搭建企业级Java应用
一、Spring Boot是什么?为什么学它? 定义:Spring Boot是Spring框架的轻量级快速开发工具,基于“约定优于配置”原则,简化Spring应用的搭建与部署。核心优势: 零配置起步:内置Tomcat/Jetty,无需手动部署Web服务器。自动装配:自动扫描依赖、注入Bean,减少XML/注解冗余代…...
使用教程第六讲)
IBM BAW(原BPM升级版)使用教程第六讲
一、事件:Undercover Agent 在 IBM Business Automation Workflow (BAW) 中,Undercover Agent (UCA) 是一个非常独特和强大的概念,旨在实现跨流程或系统的事件处理和触发机制。Undercover Agent 主要用于 事件驱动的流程自动化,它…...

[250509] x-cmd 发布 v0.5.11 beta:x ping 优化、AI 模型新增支持和语言变量调整
目录 X-CMD 发布 v0.5.11 beta📃Changelog🧩 ping🧩 openai🧩 gemini🧩 asdf🧩 mac✅ 升级指南 X-CMD 发布 v0.5.11 beta 📃Changelog 🧩 ping 调整 x ping 默认参数为 bing.com&a…...
)
Web前端VSCode如何解决打开html页面中文乱码的问题(方法2)
Web前端—VSCode如何解决打开html页面中文乱码的问题(方法2) 1.打开VScode后,依次点击 文件 >> 首选项 >> 设置 2.打开设置后,依次点击 文本编辑器 >> 文件(或在搜索框直接搜索“files.autoGuessEnc…...

打造专属AI好友:小智AI聊天机器人详解
打造专属AI好友:小智AI聊天机器人详解 在当下的科技热潮中,AI正迅速改变着我们的生活,成为了科技领域的新宠。而今,借助开源项目的力量,你可以亲手打造一个智能小助手——小智AI聊天机器人。它不仅是一个技术探索的窗…...

Spring,SpringMVC,SpringBoot,SpringCloud的区别
Spring Spring 是一个基础框架,为 Java 应用提供了 IoC(控制反转)和 AOP(面向切面编程)功能。其主要特点如下: IoC 容器:借助依赖注入,降低了组件间的耦合度。AOP 支持:…...

从投入产出、效率、上手难易度等角度综合对比 pytest 和 unittest 框架
对于选择python作为测试脚本开发的同学来说,pytest和python unittest是必需了解的两个框架。那么他们有什么区别?我们该怎么选?让我们一起来了解一下吧! 我们从投入产出、效率、上手难易度等角度综合对比 pytest 和 unittest 框架…...

无人机电池储存与操作指南
一、正确储存方式 1. 储存电量 保持电池在 40%-60% 电量(单片电压约3.8V-3.85V)存放,避免满电或空电长期储存。 满电存放会加速电解液分解,导致鼓包;**空电**存放可能引发过放(电压低于3.0V/片会永久…...

CSS实现图片垂直居中方法
html <div class"footer border-top-row"><div class"footer-row"><span class"footer-row-col01">制单人:{{ printData[pageIndex - 1].rkMaster.makerName}}<img :src"getPersonSignImgSrc(printData[pa…...

多账号管理与自动化中的浏览器指纹对抗方案
多账号管理与自动化中的浏览器指纹对抗方案 在日常的开发工作中,如果你曾涉及自动化脚本、多账号运营、数据抓取,或是在安全研究方向摸爬滚打过,应该对“浏览器指纹识别”这几个字不会陌生。 指纹识别:不是你以为的那种“指纹”…...
)
[6-1] TIM定时中断 江协科技学习笔记(45个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 TRGO是“Trigger Output”的缩写,中文意思是“触发输出”。在STM32微控制器中,TRGO是一个非常重要的功能,它允许定时器(Timer)在特定事件发生时输出一个触发信号。这个触发信号可以用…...

Flutter 3.29.3 花屏问题记录
文章目录 Flutter 3.29.3 花屏问题记录问题记录解决尝试解决 Flutter 3.29.3 花屏问题记录 问题记录 flutter版本3.29.3,代码大致为: ShaderMask(shaderCallback: (Rect bounds) {return LinearGradient(begin: Alignment.topCenter,end: Alignment.bo…...
硬盘官方检测工具 - SeaTools(1.4.0.7))
[Windows] 希捷(Seagate)硬盘官方检测工具 - SeaTools(1.4.0.7)
[Windows] 希捷(Seagate)硬盘官方检测工具 - SeaTools 链接:https://pan.xunlei.com/s/VOPpN9A3Tn_rVktEMu6Lg9q9A1?pwdh8rz# 希望能修复好硬盘...

YOLOv8目标检测性能优化:损失函数改进的深度剖析
文章目录 YOLOv8 简介损失函数在 YOLOv8 中的关键作用SlideLoss 的原理与应用原理代码实例 FocalLoss 分类损失函数的优化原理代码实例 SlideLoss 与 FocalLoss 在 YOLOv8 中的协同作用实验结果与分析 YOLOv8 简介 YOLO(You Only Look Once)系列目标检测…...
)
docker 日志暴露方案 (带权限 还 免费 版本)
接到了一个需求,需求的内容是需要将测试环境的容器暴露给我们的 外包同事,但是又不能将所有的容器都暴露给他们。 一开始,我分别找了 Portainer log-pilot dpanel 它们都拥有非常良好的界面和容器情况可视化。 但,缺点是&am…...

水印云:AI赋能,让图像处理变得简单高效
水印云是一款基于超强AI技术的图像处理工具,提供丰富的图像编辑功能,将复杂的图像处理极简化,真正实现简单高效的图像处理。无论是去除水印、智能抠图、添加水印,还是提升画质,水印云都能轻松应对,满足不同…...

使用 ECharts GL 实现交互式 3D 饼图:技术解析与实践
一、效果概览 本文基于 Vue 3 和 ECharts GL,实现了一个具有以下特性的 3D 饼图: 立体视觉效果:通过参数方程构建 3D 扇形与底座动态交互:支持点击选中(位移效果)和悬停高亮(放大效果ÿ…...
)
allure生成测试报告(搭配Pytest、allure-pytest)
文章目录 前言allure简介allure安装软件下载安装配置环境变量安装成功验证 allure运行流程allure装饰器函数基本说明装饰器函数使用allure.attach 命令行运行利用allure-pytest生成中间结果json 查看测试报告总览页面每个tab页的说明类别页面测试套图表页面时间刻度功能页面包 …...
)
一场陟遐自迩的 SwiftUI + CoreData 性能优化之旅(下)
概述 自从 SwiftUI 诞生那天起,我们秃头码农们就仿佛打开了一个全新的撸码世界,再辅以 CoreData 框架的鼎力相助,打造一款持久存储支持的 App 就像探囊取物般的 Easy。 话虽如此,不过 CoreData 虽好,稍不留神也可能会…...
)
java的输入输出模板(ACM模式)
文章目录 1、前置准备2、普通输入输出API①、输入API②、输出API 3、快速输入输出API①、BufferedReader②、BufferedWriter 案例题目描述代码 面试有时候要acm模式,刷惯leetcode可能会手生不会acm模式,该文直接通过几个题来熟悉java的输入输出模板&…...

浏览器自动化与网络爬虫实战:工具对比与选型指南
浏览器自动化与网络爬虫实战:工具对比与选型指南 摘要 在当今数字化时代,浏览器自动化和网络爬虫技术已成为数据收集与测试的重要工具。本文深入剖析了多种主流浏览器自动化工具和爬虫框架的特点、优缺点及其适用场景,包括 Selenium、Puppe…...

“双非” “退伍” “材料” “学验证” 拿到Dream Offer
大家好,我是2024年路科验证V2X春季班的学员。在春季班的课上完后,觉得自己的基础大部分已经被路科给弥补了,但是很多课程中关于框架的搭建和一些细节还是不够扎实,有所欠缺,于是又重修了秋季班的课程。这两次课程给我的…...

python 上海新闻爬虫, 上观新闻 + 腾讯新闻
1. 起因, 目的: 继续爬上海新闻, 增加新闻来源。昨天写了: 东方网 澎湃新闻今天增加2个来源: 上观新闻 腾讯新闻此时有4个来源,我觉得已经差不多了。 2. 先看效果 3. 过程: 代码 1, 上观新闻 这里也有一个有趣的…...

【LUT技术专题】ECLUT代码解读
目录 原文概要 1. 训练 2. 转表 3. 测试 本文是对ECLUT技术的代码解读,原文解读请看ECLUT。 原文概要 ECLUT通过EC模块增大网络感受野,提升超分效果,实现SRLUT的改进,主要是2个创新点: 提出了一个扩展卷积&…...

Wsl2 网络模式介绍
每个模式说明参考下面连接 使用 WSL 访问网络应用程序 | Microsoft Learn...

项目高压生存指南:科学重构身体与认知系统的抗压算法
引言:压力重构的工程学思维 在项目管理的高压熔炉中,优秀从业者与普通执行者的核心差异不在于抗压能力的高低,而在于是否掌握压力管理的系统化算法。本文摒弃传统的鸡汤式减压建议,从人体工程学、神经科学和认知心理学角度&#…...

Java设计模式之工厂方法模式:从入门到精通
1. 工厂方法模式概述 1.1 定义与核心思想 工厂方法模式(Factory Method Pattern) **定义:**是一种创建型设计模式,它定义了一个用于创建对象的接口,但让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。 **核心思想:**工厂模式的核心思想是将对象的创建…...

生成自定义的androidjar文件具体操作
在Androidsdk目录下的platform找到对应的api的android源码包路径,如android-32拷贝里面的android.jar文件到目录,如 C:\Users\xxxxxxx\Desktop\android\new_android_jar,然后解压android.jar到目录new_android_jar下。在编译后的aosp源码中找…...

在一台CentOS服务器上开启多个MySQL服务
1. 创建目录 mkdir -p /data/mysql3307/{data,tmp,logs} # 赋权 chown -R mysql:mysql /data/mysql3307 chmod -R 750 /data/mysql3307 2.修改 /etc/my.cnf ,添加[mysqld3307]实例配置组 [mysqld3307] # MySQL服务的端口 port 3307 # 套接字文件存放路径 socket /…...

相机的方向和位置
如何更好的控制相机按照我们需要来更好的观察我们需要的地貌呢? 使用 // setview瞬间到达指定位置,视角//生成position是天安门的位置var position Cesium.Cartesian3.fromDegrees(116.397428,39.90923,100)viewer.camera.setView({//指定相机位置destination: position, 在…...

云原生架构下的微服务通信机制演进与实践
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:通信机制是微服务架构的基础 随着软件系统复杂度的提升,“单体架构 → 微服务架构 → 云原生架构”逐步成为企业数字化转型的演进主线。而在微服务架构中,“服务间通信机制”决定了系统的稳定性…...

Git标签删除脚本解析与实践:轻松管理本地与远程标签
Git 标签删除脚本解析与实践:轻松管理本地与远程标签 在 Git 版本控制系统中,标签常用于标记重要的版本节点,方便追溯和管理项目的不同阶段。随着项目的推进,一些旧标签可能不再需要,此时就需要对它们进行清理。本文将通过一个完整的脚本,详细介绍如何删除本地和远程的 …...

5G让媒体传播更快更智能——技术赋能内容新时代
5G让媒体传播更快更智能——技术赋能内容新时代 在5G时代,媒体传播已经不再是传统的“电视纸媒网站”模式,而是演变成超低延迟、高速传输、智能交互的全新生态。无论是直播、短视频、VR/AR内容还是AI驱动的个性化推荐,5G的高速连接能力都在让…...

数字IC前端学习笔记:锁存器的综合
相关阅读 数字IC前端专栏https://blog.csdn.net/weixin_45791458/category_12173698.html?spm1001.2014.3001.5482 锁存器是一种时序逻辑,与寄存器相比面积更小,但它的存在会使静态时序分析(STA)变得更加复杂,因此懂得什么样的设计会综合出…...

Spring Boot快速开发:从零开始搭建一个企业级应用
Spring Boot快速开发:从零开始搭建一个企业级应用 在当今的软件开发领域,Spring Boot已经成为构建企业级应用的首选框架之一。它不仅简化了Spring应用的初始搭建以及开发过程,还提供了许多开箱即用的功能,使得开发者能够快速地构…...

ATH12K驱动框架架构图
ATH12K驱动框架架构图 ATH12K驱动框架架构图(分层描述)I. 顶层架构II. 核心数据结构层次关系III. 主要模块详解1. 核心模块 (Core)2. 硬件抽象层 (HAL)3. 无线管理接口 (WMI)4. 主机目标通信 (HTC)5. 复制引擎 (CE)6. MAC层7. 数据路径 (DP)IV. 关键数据流路径1. 发送数据流 …...

数字信号处理|| 离散序列的基本运算
一、实验目的 (1)进一步了解离散时间序列时域的基本运算。 (2)了解MATLAB语言进行离散序列运算的常用函数,掌握离散序列运算程序的编写方法。 二、实验涉及的MATLAB子函数 (1)find 功能:寻找非零元素的索…...

集成管理工具Gitlab
GitLab 是一个功能强大的开源代码托管和协作平台,集成 GitLab 可以显著提升团队的开发效率。下面我将为你介绍如何集成 GitLab,包括安装配置和基本使用流程。 一、GitLab 安装与配置 GitLab 有多种安装方式,推荐使用官方 Omnibus 包安装&am…...

2025 年数维杯数学建模 C 题完整论文代码模型:清明时节雨纷纷,何处踏青不误春
《2025 年数维杯数学建模 C 题完整论文代码模型》 C题完整论文 一、问题重述 1.1 问题背景 2025 年第十届数维杯大学生数学建模挑战赛 C 题,将我们带入“清明时节雨纷纷,何处踏青不误春”的诗意情境。清明节,这个处于每年 4 月 4 日至 6 …...

2025数维杯数学建模C题完整限量论文:清明时节雨纷纷,何处踏青不误春?
2025数维杯数学建模C题完整限量论文:清明时节雨纷纷,何处踏青不误春? 清明节,在每年 4 月 4 日至 6 日之间,既是自然节气,也是我国重要 的传统节日,承载着中华民族千年的文化记忆与情感寄托。此…...

POSE识别 神经网络
Pose 识别模型介绍 Pose 识别是计算机视觉领域的一个重要研究方向,其目标是从图像或视频中检测出人体的关键点位置,从而估计出人体的姿态。这项技术在许多领域都有广泛的应用,如动作捕捉、人机交互、体育分析、安防监控等。 Pose 识别模型的…...
)
Missashe高数强化学习笔记(随时更新)
Missashe高数强化学习笔记 说明:这篇笔记用于博主对高数强化课所学进行记录和总结。由于部分内容写在博主的日记博客里,所以博主会不定期将其重新copy到本篇笔记里。 第一章 函数极限连续 第二章 一元函数微分学 第三章 一元函数积分学 第一节 不定…...

如何从极狐GitLab 容器镜像库中删除容器镜像?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 从容器镜像库中删除容器镜像 (BASIC ALL) 您可以从您的容器镜像库中删除容器镜像。 要基于特定标准自动删除容器镜像&#x…...