C++之set和map的运用
目录
序列式容器和关联式容器
熟识set
在STL中的底层结构:
set的构造和迭代器
set的增删查
multiset和set的差异
练习题:
熟识map
map类的介绍
pair类型介绍
map的构造
map的增删查
map的数据修改
测试样例:
multimap和map的差异
练习
序列式容器和关联式容器
前⾯我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,⽐如交换⼀下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
关联式容器也是⽤来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是⾮线性结构,两个位置有紧密的关联关系,交换⼀下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
本章节讲解的map和set底层是红⿊树,红⿊树是⼀颗平衡⼆叉搜索树。set是key搜索场景的结构,map是key/value搜索场景的结构。
熟识set
在STL中的底层结构:
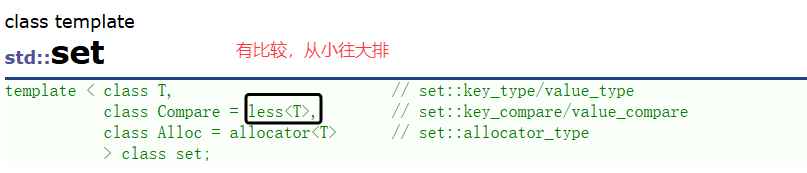
set默认要求T⽀持⼩于⽐较,如果不⽀持或者想按⾃⼰的需求⾛可以⾃⾏实现仿函数传给第⼆个模版参数。
set底层存储数据的内存是从空间配置器申请的,如果需要可以⾃⼰实现内存池,传给第三个参数。 ⼀般情况下,我们都不需要传后两个模版参数。
set底层是⽤红⿊树实现,增删查效率是 O(logN) ,迭代器遍历是⾛的搜索树的中序,所以是有序的。
set的构造和迭代器
⽀持迭代器就意味着⽀持范围for,set的iterator和const_iterator都不⽀持迭代器修改数据,修改
关键字数据,破坏了底层搜索树的结构。set迭代器是一个双向迭代器(支持的操作:*(解引用)、++(递增)、--(递减)、==和!=(比较))。
set的构造我们关注以下⼏个接⼝即可。
// empty (1) ⽆参默认构造
explicit set (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// range (2) 迭代器区间构造
template <class InputIterator>
set (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());
// copy (3) 拷⻉构造
set (const set& x);
// initializer list (5) initializer 列表构造
set (initializer_list<value_type> il,
const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// 迭代器是⼀个双向迭代器
iterator
-> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();测试用例:
void test_set()
{//无参默认构造set<int> s1;//迭代器区间构造vector<int> v1;for (int i = 0; i < 10; i++){v1.push_back(i);}set<int> s2(v1.begin(), v1.end());for (auto& e : s2){cout << e<<' ';}cout << endl;//拷贝构造set<int> s3(s2);for (auto& e : s3){cout << e <<' ';}cout << endl;//列表构造set<int> s4({ 4,5,6,7,8 });for (auto& e : s4){cout << e << ' ';}cout << endl;
}set的增删查
set的增删查关注以下⼏个接⼝即可:
Member types
key_type
-> The first template parameter (T)
value_type -> The first template parameter (T)
// 单个数据插⼊,如果已经存在则插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find (const value_type& val);
// 查找val,返回Val的个数
size_type count (const value_type& val) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
// 返回大于等于val位置的迭代器
iterator lower_bound (const value_type& val) const;
// 返回小于val位置的迭代器
iterator upper_bound (const value_type& val) const;测试用例:
void test_set()
{ int a[] = { 3,1,4,6,7,9,2,5,9,5,1 };set<int> s1;for(auto& e:a){//单个数据插入s1.insert(e);}for (auto& e : s1){cout << e << ' ';}cout << endl;set<int>s2;//列表插入s2.insert({ 3,1,4,6,7,9,2,5,9,5,1 });for (auto& e : s1){cout << e << ' ';}cout << endl;vector<int> v1;for (int i = 0; i < 10; i++){v1.push_back(i);}set<int>s3;//迭代器区间插入//s3.insert(v1.begin(), v1.end());s3.insert(s1.begin(), s1.end());for (auto& e : s3){cout << e << ' ';}cout << endl;auto it = s1.lower_bound(2);auto it1 = s1.upper_bound(5);//删除大于等于2小于等于5的区间s1.erase(it, it1);for (auto& e : s1){cout << e << ' ';}cout << endl;//find//用算法库寻找O(N)auto pos1=find(s1.begin(), s1.end(), 9);//用set的成员函数寻找O(logN)auto pos2=s1.find(9);//利用count快速寻找int x;//set不冗余,所以即使有相同的,在s1中存在的个数都为1cin >>x ;if (s1.count(x)){cout << "在" << endl;}else{cout << "不在" << endl;}
}multiset和set的差异
multiset和set的使⽤基本完全类似,主要区别点在于multiset⽀持值冗余,那么
insert/find/count/erase都围绕着⽀持值冗余有所差异,具体参看下⾯的样例代码理解。
#include<iostream>
#include<set>
using namespace std;
int main()
{
// 相⽐set不同的是,multiset是排序,但是不去重
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
// 相⽐set不同的是,count会返回x的实际个数
cout << s.count(x) << endl;
// 相⽐set不同的是,erase给值时会删除所有的x
s.erase(x);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
}练习题:
349. 两个数组的交集
思路:先让两个数组用set排序,再去遍历两个对象中的数据,如果第一个对象中的数比第二个对象中的数据要大,那么这时候我们就要让第二个对象向后走;同理,如果第一个对象中的数比第二个对象中的数据要小,那么这时候我们就要让第一个对象向后走;如果相同我们就尾插进vector对象中,同时记得set对象同时都要向后走。
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {set<int>s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());vector<int> v1;auto it1=s1.begin();auto it2=s2.begin();while(it1!=s1.end()&&it2!=s2.end()){if(*it1<*it2){it1++;}else if(*it1>*it2){it2++;}else{v1.push_back(*it1);it1++;it2++;}}return v1;}
};142. 环形链表 II
当时在学习数据结构的时候我们也遇到过这道题,当时我们运用了快慢指针,即快指针走三步,而慢指针走一步。
但今天我们学习了set,就可以轻松解决这道题。在上面学习count成员函数的时候,我们可以直接用count来查找val是否存在。
思路:定义一个存放节点指针的对象,对链表进行循环的过程中用count成员函数检查set中是否存在节点,如果没有就插入进对象中,如果有就返回该节点(进入环的节点)。如果遍历完了链表还没有找到,那么就是单链表,不存在环,返回nullptr。
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*>s1;ListNode*cur=head;while(cur){if(s1.count(cur)){return cur;}s1.insert(cur);cur=cur->next;}return nullptr;}
};熟识map
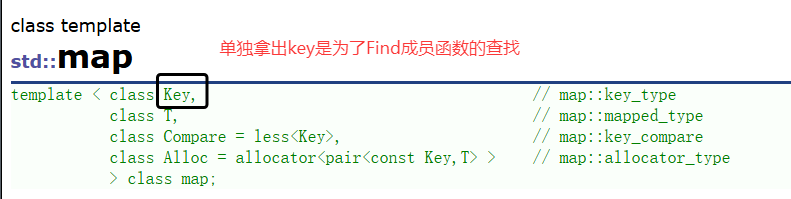
map类的介绍
map的声明如下,Key就是map底层关键字的类型,T是map底层value的类型,set默认要求Key⽀持⼩于⽐较,如果不⽀持或者需要的话可以⾃⾏实现仿函数传给第⼆个模版参数,map底层存储数据的内存是从空间配置器申请的。⼀般情况下,我们都不需要传后两个模版参数。map底层是⽤红⿊树实现,增删查改效率是 O(logN) ,迭代器遍历是⾛的中序,所以是按key有序顺序遍历的。
pair类型介绍
map底层的红⿊树节点中的数据,使⽤pair<Key, T>存储键值对数据。
typedef pair<const Key, T> value_type;
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
template<class U, class V>
pair (const pair<U,V>& pr): first(pr.first), second(pr.second)
{}
};
template <class T1,class T2>
inline pair<T1,T2> make_pair (T1 x, T2 y)
{
return ( pair<T1,T2>(x,y) );
}map的构造
map的⽀持正向和反向迭代遍历,遍历默认按key的升序顺序,因为底层是⼆叉搜索树,迭代器遍历⾛的中序;⽀持迭代器就意味着⽀持范围for,map⽀持修改value数据,不⽀持修改key数据,修改关键字数据,破坏了底层搜索树的结构。//pair(key,value)
// empty (1) ⽆参默认构造
explicit map (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// range (2) 迭代器区间构造
template <class InputIterator>
map (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());
// copy (3) 拷⻉构造
map (const map& x);
// initializer list (5) initializer 列表构造
map (initializer_list<value_type> il,
const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// 迭代器是⼀个双向迭代器
iterator
-> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();map的增删查
map接⼝,插⼊的pair键值对数据,跟set所有不同,但是查和删的接⼝只⽤关键字key跟set是完全类似的,不过find返回iterator,不仅仅可以确认key在不在,还找到key映射的value,同时通过迭代还可以修改value.
Member types
key_type
-> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type
-> pair<const key_type,mapped_type>
// 单个数据插⼊,如果已经key存在则插⼊失败,key存在相等value不相等也会插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find (const key_type& k);
// 查找k,返回k的个数
size_type count (const key_type& k) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除k,k存在返回0,存在返回1
size_type erase (const key_type& k);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
// 返回⼤于等k位置的迭代器
iterator lower_bound (const key_type& k);
// 返回⼤于k位置的迭代器
const_iterator lower_bound (const key_type& k) const;map的数据修改
map第⼀个⽀持修改的⽅式时通过迭代器,迭代器遍历时或者find返回key所在的iterator修改,map还有⼀个⾮常重要的修改接⼝operator[],但是operator[]不仅仅⽀持修改,还⽀持插⼊数据和查找数据,所以他是⼀个多功能复合接⼝.
需要注意从内部实现⻆度,map这⾥把我们传统说的value值,给的是T类型,typedef为
mapped_type。⽽value_type是红⿊树结点中存储的pair键值对值。⽇常使⽤我们还是习惯将这⾥的T映射值叫做value。
Member types
key_type
-> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type
-> pair<const key_type,mapped_type>
// 查找k,返回k所在的迭代器,没有找到返回end(),
//如果找到了通过iterator可以修改key对应mapped_type值
iterator find (const key_type& k);
// ⽂档中对insert返回值的说明
// insert插⼊⼀个pair<key, T>对象
// 1、如果key已经在map中,插⼊失败,则返回⼀个pair<iterator,bool>对象,返回pair对象
first是key所在结点的迭代器,second是false
// 2、如果key不在在map中,插⼊成功,则返回⼀个pair<iterator,bool>对象,返回pair对象
first是新插⼊key所在结点的迭代器,second是true
// 也就是说⽆论插⼊成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭
代器
// 那么也就意味着insert插⼊失败时充当了查找的功能,正是因为这⼀点,insert可以⽤来实现
operator[]
// 需要注意的是这⾥有两个pair,不要混淆了,⼀个是map底层红⿊树节点中存的pair<key, T>,另
⼀个是insert返回值pair<iterator,bool>
pair<iterator,bool> insert (const value_type& val);
mapped_type& operator[] (const key_type& k);
// operator的内部实现
mapped_type& operator[] (const key_type& k)
{
// 1、如果k不在map中,insert会插⼊k和mapped_type默认值,同时[]返回结点中存储
mapped_type值的引⽤,那么我们可以通过引⽤修改返映射值。所以[]具备了插⼊+修改功能
// 2、如果k在map中,insert会插⼊失败,但是insert返回pair对象的first是指向key结点的
迭代器,返回值同时[]返回结点中存储mapped_type值的引⽤,所以[]具备了查找+修改的功能
pair<iterator, bool> ret = insert({ k, mapped_type() });
iterator it = ret.first;
return it->second;
}测试样例:
void map_test()
{map<string, string>dict;dict.insert(make_pair ("sort", "排序"));dict.insert({ "left","左边" });dict.insert(pair<string, string>("second", "第二"));pair<string, string>kv("right", "右边");dict.insert(kv);//插入失败,冗余了dict.insert({ "left","左边,剩余" });auto it = dict. begin();while (it != dict.end()){cout << it->first << "->" << it->second<<endl;it++;}cout << endl;for (auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;string str;while (cin >> str){auto ret = dict.find(str);if (ret != dict.end()){cout << "找到了" << endl;}elsecout << "没找到" << endl;}}
void map_test1()
{//测试迭代器和[]运算符的使用string arr[] = { "苹果", "西⽠", "苹果", "西⽠", "苹果", "苹果", "西⽠",
"苹果", "⾹蕉", "苹果", "⾹蕉" };map<string, int> countMap;/*for (auto& e : arr){auto ret = countMap.find(e);if (ret != countMap.end()){ret->second++;}else{countMap.insert({ e,1 });}}for (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;*///[]的用法//1.插入map<string, string> dict;dict["left"];//2.修改dict["right"] = "右边";dict["right"] = "右边,向右";//3.插入加修改dict["sort"] = "排序";for (auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;//上面的countMap可以运用[]计算个数for (auto& e : arr){countMap[e]++;}for (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;
}
int main()
{//map_test();map_test1();return 0;
}multimap和map的差异
multimap和map的使⽤基本完全类似,主要区别点在于multimap⽀持关键值key冗余,那么
insert/find/count/erase都围绕着⽀持关键值key冗余有所差异,这⾥跟set和multiset完全⼀样,⽐如find时,有多个key,返回中序第⼀个。其次就是multimap不⽀持[],因为⽀持key冗余,[]就只能⽀持插⼊了,不能⽀持修改。
void multimap_test()
{multimap<string, string> dict;dict.insert({ "left","左边" });dict.insert({ "left","剩余" });for (auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;//dict["left"] = "激进分子";//报错,multimap中[]不能修改value值。
}
int main()
{multimap_test();return 0;
}练习
138.随机链表的复制
在之前我们用C语言写这道题的时候,代码要敲很多,今天我们学习了map,就可以用map类轻松解决。
思路:我们建立一个map对象,pair中放两个节点的指针,当我们在遍历链表的时候,让新链表和原链表构成映射关系。(新链表和原链表有着一一对应的关系,可以通过原链表的节点就可以找到新链表的节点,且节点内容相同)
1.遍历链表。往新链表中插入节点,并让新链表的节点和原链表的节点构成映射关系。
2.处理random。在重新遍历数组,让新链表中的节点的random成员等于原链表中的节点的random。
class Solution {
public:Node* copyRandomList(Node* head) {//先复制单链表Node*cur=head;map<Node*,Node*>copyNode;Node*copyhead=nullptr;Node*copytail=nullptr;while(cur){if(copyhead==nullptr){copyhead=copytail=new Node(cur->val);}else{copytail->next=new Node(cur->val);copytail=copytail->next;}copyNode[cur]=copytail;//成映射关系cur=cur->next;}//复制cur=head;Node*pre=copyhead;while(cur){if(cur->random==nullptr){pre->random=nullptr;}else{pre->random=copyNode[cur->random];//不可pre->random=cur->random,
//指向的地址不一样,相当于pre节点的random指针指向了原链表,不是指向新链表。}cur=cur->next;pre=pre->next;}return copyhead;}
};692. 前K个⾼频单词 - ⼒扣(LeetCode)
题目中让我们按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。在排序之前我们应该对数组中的字符串进行统计个数,然后才能按照它的要求排序。
该题有三种排序思路:
1.运用算法库中的sort函数进行排序。sort函数是运用快排的思想,是不稳定的,所以在仿函数的时候我们不仅要比较字典顺序还要比较出现频率。
2.运用stable_sort函数进行排序。在插入map对象的时候,map对象里的字符串都已经按照字典顺序进行排序了,而stable_sort函数具有稳定性,那么在仿函数中我们只需要比较出现的频率就可以了。
3.运用priority_queue容器适配器进行建大堆实现。在前面的学习中我们就了解到priority_queue是优先级队列,每个元素都会有一个优先级概念,会按照固定的顺序定义。 在C++ STL中,默认情况下,优先级队列(priority_queue)的首元素始终是最大的元素。
思路1:
class Solution {
public:
struct compare
{bool operator()(pair<string,int> v1,pair<string,int>v2){return (v1.second==v2.second&&v1.first<v2.first)||v1.second>v2.second;}
};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int>mapsort;for(auto&e:words){mapsort[e]++;}vector<pair<string,int>>v(mapsort.begin(),mapsort.end());sort(v.begin(),v.end(),compare());vector<string>v1;for(int i=0;i<k;i++){v1.push_back(v[i].first);}return v1;}
};思路2:
class Solution {
public:
struct compare
{bool operator()(pair<string,int> v1,pair<string,int>v2){return v1.second>v2.second;}
};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int>mapsort;for(auto&e:words){mapsort[e]++;}vector<pair<string,int>>v(mapsort.begin(),mapsort.end());stable_sort(v.begin(),v.end(),compare());vector<string>v1;for(int i=0;i<k;i++){v1.push_back(v[i].first);}return v1;}
};思路3:
class Solution {
public:
struct compare
{bool operator()(pair<string,int> v1,pair<string,int>v2){//要注意优先级队列底层是反的,⼤堆要实现⼩于⽐较,所以这⾥次数相等,想要字典//序⼩的在前⾯,要⽐较字典序⼤的为真return (v1.second==v2.second&&v1.first>v2.first)||v1.second<v2.second;}
};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int>mapsort;for(auto&e:words){mapsort[e]++;}//创建一个优先队列 p,其元素类型是 pair<string, int>。//使用 vector<pair<string, int>> 作为底层容器。//使用自定义的比较函数 Compare 来确定元素的优先级顺序。//将 mapsort 中的所有键值对初始化到优先队列 p 中,并按照 Compare 的规则进行排序。priority_queue<pair<string,int>,vector<pair<string,int>>,compare>p(mapsort.begin(),mapsort.end());vector<string>v1;for(int i=0;i<k;i++){v1.push_back(p.top().first);p.pop();}return v1;}
};相关文章:

C++之set和map的运用
目录 序列式容器和关联式容器 熟识set 在STL中的底层结构: set的构造和迭代器 set的增删查 multiset和set的差异 练习题: 熟识map map类的介绍 pair类型介绍 map的构造 map的增删查 map的数据修改 测试样例: multimap和map的差…...
)
基于智能家居项目 RGB彩灯(P9813)
一、P9813 是什么? P9813 是一颗专门用来控制 RGB LED灯珠 的芯片,也就是说,它能控制红色、绿色、蓝色三种灯光的亮度,从而调出各种颜色。它最常见的用途就是在各种“会变色”的灯带中。 它的通信方式非常简单,只需要…...

EMQX 作为 MQTT Broker,支持 MQTT over TCP 和 MQTT over WebSocket 两种协议
1. EMQX 支持的协议与端口 协议类型默认端口用途说明MQTT over TCP1883标准的 MQTT 协议,基于 TCP 传输(用于后端服务、物联网设备等)。MQTT over TLS8883加密的 MQTT over TCP(TLS/SSL 加密,安全性更高&am…...

软件测试学习笔记
第1章 绪论 软件测试 本质上说,就是寻找软件的缺陷、错误,对其质量度量的方法与过程。软件测试的一切活动都围绕着两个目标(验证是否符合需求,识别差异)而行进。它是测试思维、策略方针、设计实施的基本出发点。 学…...
)
Vue3 + Node.js 实现客服实时聊天系统(WebSocket + Socket.IO 详解)
Node.js 实现客服实时聊天系统(WebSocket Socket.IO 详解) 一、为什么选择 WebSocket? 想象一下淘宝客服的聊天窗口:你发消息,客服立刻就能看到并回复。这种即时通讯效果是如何实现的呢?我们使用 Vue3 作…...

python 上海新闻爬虫
1. 起因, 目的: 继续做新闻爬虫。我之前写过。此文先记录2个新闻来源。后面打算进行过滤,比如只选出某一个类型新闻。 2. 先看效果 过滤出某种类型的新闻,然后生成 html 页面,而且,自动打开这个页面。 比如科技犯罪…...

【Axure高保真原型】中继器表格批量上传数据
今天和大家分享中继器表格批量上传数据的原型模板,效果包括: 点击上传按钮,可以真实的打开本地文件夹选择文件; 选择的文件如果不是表格格式(xls、xlsx、xlt、csv),就会显示提示弹窗࿱…...
)
复刻低成本机械臂 SO-ARM100 单关节控制(附代码)
视频讲解: 复刻低成本机械臂 SO-ARM100 单关节控制(附代码) 代码仓库:GitHub - LitchiCheng/SO-ARM100: Some Test code on SO-ARM100 昨天用bambot的web的方式调试了整个机械臂,对于后面的仿真的sim2real来说&#x…...

视频编解码学习7之视频编码简介
视频编码技术发展历程与主流编码标准详解 视频编码技术是现代数字媒体领域的核心技术之一,它通过高效的压缩算法大幅减少了视频数据的体积,使得视频的存储、传输和播放变得更加高效和经济。从早期的H.261标准到最新的AV1和H.266/VVC,视频编码…...

【NextPilot日志移植】整体功能概要
整体日志系统的实现功能 该日志系统主要实现了飞行日志的记录功能,支持多种日志记录模式,可将日志存储到文件或通过 MAVLink 协议传输,同时具备日志加密、空间管理、事件记录等功能。具体如下: 日志记录模式:支持按武…...
)
Windows系统下使用Kafka和Zookeeper,Python运行kafka(二)
1.配置 Zookeeper 进入解压后的 Zookeeper 目录(例如 F:\zookeeper\conf),复制 zoo_sample.cfg 文件并命名为 zoo.cfg(如果 zoo.cfg 已经存在,则直接编辑该文件)。 打开 zoo.cfg 文件,配置相关…...

《构建社交应用用户激励引擎:React Native与Flutter实战解析》
React Native凭借其与JavaScript和React的紧密联系,为开发者提供了一个熟悉且灵活的开发环境。在构建用户等级体系时,它能够充分利用现有的前端开发知识和工具。通过将用户在社交应用中的各种行为进行量化,比如发布动态的数量、点赞评论的次数…...

Oracle OCP认证考试考点详解083系列13
题记: 本系列主要讲解Oracle OCP认证考试考点(题目),适用于19C/21C,跟着学OCP考试必过。 61. 第61题: 题目 解析及答案: 关于基于RPM的Oracle数据库安装,以下哪两项是正确的? A) …...

【AI】DeepWiki 页面转换成 Markdown 保存 - Chrome 扩展
GitHub: https://github.com/zxmfke/deepwiki-md-chrome-extension 背景 个人比较喜欢整理项目架构,更多都是保存成 markdown 的格式保存,然后发博客。deepwiki 刚好把 github 仓库代码的架构输出出来了,不过没有办法下载成 markdown 格式&…...

HTTP 状态码是服务器对客户端请求的响应标识,用于表示请求的处理结果
以下是完整的 HTTP 状态码分类和常见状态码详解: 一、状态码分类(5大类) 分类范围描述常见场景1xx100-199信息性响应请求已被接收,继续处理2xx200-299成功响应请求成功处理3xx300-399重定向响应需要进一步操作4xx400-499客户端错…...

【AI论文】FlexiAct:在异构场景中实现灵活的动作控制
摘要:动作定制涉及生成视频,其中主体执行由输入控制信号指示的动作。 当前的方法使用姿势引导或全局运动定制,但受到空间结构(如布局、骨架和视点一致性)严格约束的限制,降低了在不同主题和场景下的适应性。…...

ubuntu24.04安装anaconda
1. ubuntu安装ananconda 进入官网:添加链接描述 直接点击Download下载,它会自动匹配合适的版本 打开保存下载文件,点击右键,选择在终端打开,输入 bash Anaconda3-2024.10-1-Linux-x86_64.sh不断点击Enter,…...

六、Hadoop初始化与启动
成功部署一个Hadoop集群并不仅仅是安装好软件那么简单。在它真正能够为我们处理海量数据之前,还需要一系列精心的初始化和启动步骤。这些步骤确保了各个组件能够正确协同工作。完成启动后,Hadoop还提供了便捷的 Web 用户界面 (Web UI),帮助我…...
)
边缘网关(边缘计算)
边缘网关是边缘计算架构中的关键组件,充当连接终端设备(如传感器、IoT设备)与云端或核心网络的桥梁。它在数据源头附近进行实时处理、分析和过滤,显著提升效率并降低延迟。 核心功能 协议转换 ○ 支持多种通信协议(如…...

学成在线之课程管理
一:业务概述 我负责的课程管理这一块,可以发布课程,可以对课程列表进行一个管理,发布课程这分为三步:首先是需要进行填写课程相关的信息,再设计这个课程的大纲,最后是选择发布这门课程ÿ…...

python里面的class,类,方法,函数,def
一、ds 好的!我将用专业术语结合通俗解释来梳理这些概念,并用结构化方式呈现它们的关系: 1. 核心概念解析 类 (Class) 定义:类是面向对象编程(OOP)中的核心概念,是创建对象的模板(蓝图)。它封装了一组属性(数据)和方法(行为),用于描述具有相同特征和功能的对象…...

复盘20250508
根据行业趋势、政策支持、公司基本面及技术壁垒,我推荐以下两支最可能持续上涨的个股,并深度分析原因: 1. 奥普光电(机器视觉光刻机芯片) 核心逻辑: 光刻机国产化核心标的:控股股东长春光机所…...
)
数据结构 - 10( B- 树 B+ 树 B* 树 4000 字详解 )
一:B- 树 1.1 B- 树的引入 在使用二叉搜索树对数据进行排序时,存在一个缺陷:随着数据量的增大,二叉搜索树的高度也会随之增加。虽然在数据量较小时,这种情况并不明显,但当数据量变得庞大时,树…...

算法与数据结构 - 常用图算法总结
在图论中,图算法非常重要,广泛应用于计算机科学、网络分析、社交网络、地理信息系统等领域。下面是一些常用的图算法,按不同功能和应用场景分类: 1. 图的遍历 图遍历算法用于遍历图中的节点和边。主要有两种常见的图遍历方法&am…...

涨薪技术|0到1学会性能测试第53课-Tomcat配置
前面的推文我们掌握了Tomcat服务器的3种监控技术知识。今天给大家分享Tomcat调优技术。后续文章都会系统分享干货,带大家从0到1学会性能测试。 01Tomcat配置 当Tomcat服务器安装好并开始运行后,需要对服务器进行一些基本配置,通常关于Tomcat服务器的配置包括两部分: 第一:…...

亚马逊推出新型仓储机器人 Vulcan:具备“触觉”但不会取代人类工人
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

后退n帧协议
滑动窗口机制(Sliding Window) 发送方有一个发送窗口,最多可以连续发送 N 个未确认的帧(N 就是窗口大小)。 接收方通常只有一个接收窗口,只接收按序到达的帧,不接受乱序帧。 累计确认机制&…...

R9周:RNN实现阿尔茨海默病诊断
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 一、导入数据 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import torch import torch.nn as nn f…...

node.js 实战——在express 中将input file 美化,并完成裁剪、上传进度条
美化上传按钮 在ejs 页面 <!DOCTYPE html> <html> <head><meta charset"utf-8"></meta><title><% title %></title><link relstylesheet href/stylesheets/form.css/><!-- 本地 Bootstrap 引入方式 -->…...

Linux环境下部署MaxScale
测试环境:两台服务器,Mysql版本 8.0,linux版本:Ubuntu 20.04.3; 介绍 在我之前的文章里面有介绍MySql主从服务器的配置,我们项目通常使用.NET开发Server端,如果是代码直接去管理主从服务器的访…...

新能源汽车CAN通信深度解析:MCU、VCU、ECU协同工作原理
1. 什么是CAN通信? CAN(Controller Area Network,控制器局域网) 是一种广泛应用于汽车电子系统的串行通信协议,由德国Bosch公司在1980年代开发,主要用于实现车内电子控制单元(ECU)之…...
**这种需求)
按句子切分文本、保留 token 对齐信息、**适配 tokenizer(如 BERT)**这种需求
在之前的文章中我解释了 把长文本切分成一句一句的小段(chunk),每一段尽量是一个完整的句子,而不是强行按字数截断。 但是这个方法自己写会比较复杂,有很多处理这种场景的工具可以直接拿来用。 下面就 处理按句子切分…...
:三级缓存)
缓存(1):三级缓存
三级缓存是指什么 我们常说的三级缓存如下: CPU三级缓存Spring三级缓存应用架构(JVM、分布式缓存、db)三级缓存 CPU 基本概念 CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断…...

Kubernetes client-go 客户端类型与初始化指南
Kubernetes client-go 客户端类型与初始化指南 在 Kubernetes 的 client-go 库中,存在多种客户端用于与 API 服务器交互。以下介绍主要客户端类型,包括用途、初始化方式及 Demo。 1. RESTClient 用途 RESTClient 是底层 REST 客户端,直接…...

【金仓数据库征文】金仓数据库:创新驱动,引领数据库行业新未来
一、引言 在数字化转型的时代洪流中,数据已跃升为企业的核心资产,宛如企业运营与发展的 “数字命脉”。从企业日常运营的精细化管理,到战略决策的高瞻远瞩制定;从客户关系管理的深度耕耘,到供应链优化的全面协同&…...
)
图漾相机——Sample_V2示例程序(待补充)
文章目录 1.SDK支持的平台类型1.1 Windows 平台1.2 Linux平台 2.Sample_V2编译流程2.1 Windows环境2.2 Linux环境编译 3.Sample_V2示例程序测试3.1 ListDevice_v23.2 DepthStream_v23.3 ExposureTimeSetting_v23.4 ForceDeviceIP_v23.5 GetCalibData_v23.6 NetStatistic_v23.7 …...

手写 vue 源码 ===:自定义调度器、递归调用规避与深度代理
目录 引言 自定义调度器(Scheduler) 什么是调度器? 调度器的实现原理 自定义调度器的实际应用 切面编程(AOP)思想在调度器中的应用 递归调用规避 递归调用的问题 Vue 如何规避递归调用 深度代理(D…...

WPF实时调试的一种实现方法
在WPF程序中,如果我们需要对程序进行调试,一般是使用断点/单步或输出日志之类的调试方法。 如果我们需要实时查看程序输出,可以将程序的输出类型修改为控制台应用程序 这样我们在程序运行后,就可以得到一个控制台窗口。 然后再配…...

数据库操作
本篇会加入个人的所谓鱼式疯言 ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接…...

学习笔记:数据库——事务
1.内容: 基于现有数据库设计检查点实验,观察比较提交前后执行结果并分析。 2.实现 源码 -- 开启事务 START TRANSACTION;-- 插入一条订单记录(客户ID为10002) INSERT INTO orders (o_date, c_id) VALUES (NOW(), 10002);-- 获…...

企业级可观测性实现:OpenObserve云原生平台的本地化部署与远程访问解析
文章目录 前言1. 安装Docker2. 创建并启动OpenObserve容器3. 本地访问测试4. 公网访问本地部署的OpenObserve4.1 内网穿透工具安装4.2 创建公网地址 5. 配置固定公网地址 前言 嘿,各位小伙伴们,今天要给大家揭秘一个在云原生领域里横扫千军的秘密法宝—…...

【Linux系统】第三节—权限
Hello,好久不见—— 云边有个稻草人-CSDN个人博客主页 Linux-本节文章所属专栏-欢迎订阅-持续更新中~~~ 目录 hi!在这里—本节课重要知识点详解 一、Shell命令以及运行原理 二、Linux权限 2.1 Linux权限的概念 2.2 Linux权限管理 2.3 ⽂件权限值的…...

@Data和 @NoArgsConstructor注解详解
Data 和 NoArgsConstructor 注解详解 1. Data 注解 作用:Data 是 Lombok 提供的一个复合注解,用于自动生成 Java 类的常用方法,减少样板代码。生成的内容: Getter 和 Setter:为所有非静态、非 final 字段生成 getter…...

《云计算》第三版总结
《云计算》第三版总结 云计算体系结构 云计算成本优势 开源云计算架构Hadoop2.0 Hadoop体系架构 Hadoop访问接口Hadoop编程接口 Hadoop大家族 分布式组件概述ZooKeeperHbasePigHiveOozieFlumeMahout 虚拟化技术 服务器虚拟化存储虚拟化网络虚拟化桌面虚拟化OpenStack开源虚…...

滚珠导轨:电子制造领域精密运动的核心支撑
电子制造正朝着高精度、高效率方向飞速发展,滚珠导轨在这一进程中扮演着重要角色。滚珠导轨在电子制造领域中具有广泛且重要的应用,主要体现在以下几个方面: 1、印刷电路板(PCB)制造设备:滚珠导轨在PCB制造…...

Spark缓存--cache方法
在Spark 中,cache() 是用于优化计算性能的核心方法之一,但它有许多细节需要深入理解。以下是关于 cache() 的详细技术解析: 1. cache() 的本质 简化的 persist():cache() 是 persist(StorageLevel.MEMORY_ONLY) 的快捷方式&#x…...

kafka logs storage
Kafka 会将日志文件按段(Segment)存储。 Segment是Kafka的最小存储单元,它是一个可追加的文件,用于存储Kafka分区中的一部分消息。 在文件系统中,Partition 是目录名,而Segment 是文件名。 Segment可以通过…...

数据分析平台选型与最佳实践:如何打造高效、灵活的数据生态?
数据分析平台选型与最佳实践:如何打造高效、灵活的数据生态? 在大数据时代,数据分析平台已经成为企业决策的核心支撑。从传统 BI(商业智能)到现代 AI 驱动的数据分析,选择合适的平台不仅影响数据处理效率,也决定了企业的数字化竞争力。面对市场上的众多解决方案(如 Ap…...

MYSQL之索引结构,为何要用B+树
索引的目的就是为了提高查询效率 索引的结构是B树,那么说到B树,必须提一下其他三种结构,分别是:二叉查找树、平衡二叉树、B树 我们来看看各自的结构特征 二叉查找树 特点:任何节点的左子节点的值都小于当前节点的值,右…...

OpenCV 中用于背景分割的一个类cv::bgsegm::BackgroundSubtractorLSBP
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::bgsegm::BackgroundSubtractorLSBP 是 OpenCV 中用于背景分割的一个类,它基于局部样本二进制模式(Local Sample Bina…...