注意力(Attention)机制详解(附代码)
Attention机制是深度学习中的一种技术,特别是在自然语言处理(NLP)和计算机视觉领域中得到了广泛的应用。它的核心思想是模仿人类的注意力机制,即人类在处理信息时会集中注意力在某些关键部分上,而忽略其他不那么重要的信息。在机器学习模型中,这可以帮助模型更好地捕捉到输入数据中的关键信息。
一、Attention机制的基本原理
1.输入表示
在自然语言处理(NLP)任务中,输入数据通常是文本形式的,我们需要将这些文本转换为模型可以处理的数值形式。这个过程称为嵌入(Embedding)。嵌入层将每个单词映射到一个高维空间中的向量,这些向量被称为词向量。词向量能够捕捉单词的语义信息,并且可以被神经网络处理。
# 定义一个简单的嵌入层
class EmbeddingLayer(nn.Module):def __init__(self, vocab_size, embed_dim):super(EmbeddingLayer, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)def forward(self, x):return self.embedding(x)# 随机生成一个输入序列
input_seq = torch.randint(0, vocab_size, (32, 50)) # (batch_size, seq_len)# 获取输入表示
input_repr = embedding_layer(input_seq) 在代码中,我们定义了一个EmbeddingLayer类,它包含一个nn.Embedding层,用于将输入的索引转换为对应的词向量。然后,我们生成一个随机的输入序列input_seq,它模拟了一个批量大小为32,序列长度为50的文本数据。通过嵌入层,我们将这些索引转换为词向量,得到输入表示input_repr。
2.计算注意力权重
注意力机制允许模型在处理序列数据时,动态地聚焦于当前步骤最相关的信息。在自注意力(Self-Attention)中,每个元素都会计算与其他所有元素的关联程度,这通过计算查询(Q)、键(K)和值(V)的线性变换来实现。
class Attention(nn.Module):def __init__(self, embed_dim):super(Attention, self).__init__()self.query = nn.Linear(embed_dim, embed_dim)self.key = nn.Linear(embed_dim, embed_dim)self.value = nn.Linear(embed_dim, embed_dim)def forward(self, x):Q = self.query(x)K = self.key(x)V = self.value(x)attention_scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(embed_dim)attention_weights = F.softmax(attention_scores, dim=-1)return attention_weights 在这段代码中,我们定义了一个Attention类,它包含三个线性层,分别用于计算Q、K和V。然后,我们通过矩阵乘法和softmax函数计算注意力权重,这些权重表示序列中每个元素对当前元素的重要性。
3.加权求和
一旦我们有了注意力权重,我们就可以使用它们来加权求和序列中的元素,从而生成一个综合了所有元素信息的表示。
def weighted_sum(attention_weights, input_repr):return torch.matmul(attention_weights, input_repr) 这个简单的函数weighted_sum接受注意力权重和输入表示作为输入,然后通过矩阵乘法计算加权求和,得到一个综合了序列中所有元素信息的新表示。
4.输出
最后,我们使用一个输出层将加权求和得到的表示转换为最终的输出,这可以是分类任务的类别概率,也可以是其他任务的预测结果。
class OutputLayer(nn.Module):def __init__(self, embed_dim, output_dim):super(OutputLayer, self).__init__()self.fc = nn.Linear(embed_dim, output_dim)def forward(self, x):return self.fc(x) 在这个代码段中,我们定义了一个OutputLayer类,它包含一个线性层,用于将模型的内部表示映射到输出空间。例如,在分类任务中,我们可以将嵌入维度的表示映射到类别数量的输出空间,并通过softmax函数或其他激活函数得到最终的预测概率。
5.实例代码
以下是使用Python和PyTorch实现上述内容的示例代码。这段代码将展示如何使用一个简单的Transformer模型来处理文本数据,包括输入表示、计算注意力权重、加权求和以及输出。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TransformerBlock(nn.Module):def __init__(self, embed_dim, num_heads, dropout=0.1):super(TransformerBlock, self).__init__()self.attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)self.ffn = nn.Sequential(nn.Linear(embed_dim, 4 * embed_dim),nn.GELU(),nn.Linear(4 * embed_dim, embed_dim),)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x):# 输入表示# x: (seq_len, batch_size, embed_dim)attn_output, _ = self.attn(x, x, x) # 自注意力,输入和输出都是xattn_output = self.dropout(attn_output)x = self.norm1(x + attn_output) # 加权求和和残差连接# 前馈网络ffn_output = self.ffn(x)ffn_output = self.dropout(ffn_output)x = self.norm2(x + ffn_output) # 加权求和和残差连接return xclass TextTransformer(nn.Module):def __init__(self, vocab_size, embed_dim, num_heads, num_layers, dropout=0.1):super(TextTransformer, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.positional_encoding = nn.Parameter(torch.randn(1, 1, embed_dim))self.encoder = nn.Sequential(*[TransformerBlock(embed_dim, num_heads, dropout) for _ in range(num_layers)])self.fc_out = nn.Linear(embed_dim, vocab_size) # 假设是分类任务def forward(self, x):# 输入表示embeds = self.embedding(x) # (batch_size, seq_len, embed_dim)embeds = embeds + self.positional_encoding[:, :embeds.size(1), :] # 添加位置编码embeds = embeds.transpose(0, 1) # (seq_len, batch_size, embed_dim)# 计算注意力权重和加权求和out = self.encoder(embeds)# 输出out = out.transpose(0, 1) # (batch_size, seq_len, embed_dim)out = self.fc_out(out[:, -1, :]) # 假设只取序列的最后一个向量进行分类return out# 模型参数
vocab_size = 10000 # 词汇表大小
embed_dim = 256 # 嵌入层维度
num_heads = 8 # 注意力头数
num_layers = 6 # Transformer层数# 实例化模型
model = TextTransformer(vocab_size, embed_dim, num_heads, num_layers)# 随机生成一个输入序列
input_seq = torch.randint(0, vocab_size, (32, 100)) # (batch_size, seq_len)# 前向传播
output = model(input_seq)
print(output.shape) # 应该输出 (batch_size, vocab_size) 这段代码首先定义了一个TransformerBlock类,它包含了自注意力机制和前馈网络,然后定义了一个TextTransformer类,它包含了嵌入层、位置编码、编码器和输出层。在TextTransformer的前向传播中,我们首先将输入序列转换为嵌入表示,然后通过Transformer编码器进行处理,最后通过一个全连接层输出结果。这个例子展示了如何使用Transformer模型处理文本数据,并进行分类任务。
二、Attention机制的类型
1.Soft Attention
这种类型的注意力机制会输出一个概率分布,每个输入元素都有一个对应的权重,这些权重的和为1。Soft attention通常可以微分,因此可以用于梯度下降。Soft Attention输出一个概率分布,可以通过梯度下降进行优化。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SoftAttention(nn.Module):def __init__(self, embed_dim):super(SoftAttention, self).__init__()self.weight = nn.Parameter(torch.randn(embed_dim, 1))def forward(self, x):# x: (batch_size, seq_len, embed_dim)scores = torch.matmul(x, self.weight).squeeze(-1) # (batch_size, seq_len)weights = F.softmax(scores, dim=-1) # Softmax to get probabilitiesreturn weights# 示例使用
embed_dim = 128
soft_attn = SoftAttention(embed_dim)
input_seq = torch.randn(32, 50, embed_dim) # (batch_size, seq_len, embed_dim)
attention_weights = soft_attn(input_seq)
print("Soft Attention Weights:", attention_weights.sum(dim=1)) # 应该接近于12.Hard Attention
与soft attention不同,hard attention会随机或确定性地选择一个输入元素,并只关注这个元素。Hard attention通常不可微分,因此训练时可能需要使用强化学习或变分方法。Hard Attention随机选择一个输入元素,这里我们使用一个简单的采样策略。
import torchclass HardAttention(nn.Module):def __init__(self, embed_dim):super(HardAttention, self).__init__()def forward(self, x):# x: (batch_size, seq_len, embed_dim)probs = torch.rand(x.size(0), x.size(1), device=x.device)_, idx = torch.topk(probs, k=1, dim=1)selected = torch.gather(x, 1, idx.unsqueeze(-1).expand(-1, -1, x.size(-1)))return selected.squeeze(1)# 示例使用
hard_attn = HardAttention(embed_dim)
selected_elements = hard_attn(input_seq)
print("Hard Attention Selected Elements:", selected_elements.shape) # (batch_size, embed_dim)3.Self-Attention
即自注意力机制,这是一种特殊的注意力机制,它允许输入序列中的元素相互之间计算注意力权重,这在Transformer模型中得到了广泛应用。Self-Attention允许输入序列中的元素相互之间计算注意力权重。
class SelfAttention(nn.Module):def __init__(self, embed_dim):super(SelfAttention, self).__init__()self.query = nn.Linear(embed_dim, embed_dim)self.key = nn.Linear(embed_dim, embed_dim)self.value = nn.Linear(embed_dim, embed_dim)def forward(self, x):# x: (batch_size, seq_len, embed_dim)Q = self.query(x)K = self.key(x)V = self.value(x)attention_scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(embed_dim)attention_weights = F.softmax(attention_scores, dim=-1)output = torch.matmul(attention_weights, V)return output, attention_weights# 示例使用
self_attn = SelfAttention(embed_dim)
output, weights = self_attn(input_seq)
print("Self Attention Output:", output.shape) # (batch_size, seq_len, embed_dim)4.Multi-Head Attention
在Transformer模型中,为了捕捉不同子空间中的信息,会使用多头注意力机制,即并行地运行多个自注意力机制,然后将结果合并。Multi-Head Attention并行地运行多个自注意力机制,然后将结果合并。
class MultiHeadAttention(nn.Module):def __init__(self, embed_dim, num_heads):super(MultiHeadAttention, self).__init__()self.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"self.query = nn.Linear(embed_dim, embed_dim)self.key = nn.Linear(embed_dim, embed_dim)self.value = nn.Linear(embed_dim, embed_dim)self.fc_out = nn.Linear(embed_dim, embed_dim)def forward(self, x):# x: (batch_size, seq_len, embed_dim)batch_size, seq_len, embed_dim = x.size()Q = self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)K = self.key(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)V = self.value(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)attention_scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(self.head_dim)attention_weights = F.softmax(attention_scores, dim=-1)output = torch.matmul(attention_weights, V).transpose(1, 2).contiguous()output = output.view(batch_size, seq_len, embed_dim)output = self.fc_out(output)return output# 示例使用
num_heads = 8
multi_head_attn = MultiHeadAttention(embed_dim, num_heads)
multi_head_output = multi_head_attn(input_seq)
print("Multi-Head Attention Output:", multi_head_output.shape) # (batch_size, seq_len, embed_dim)Soft Attention和Self-Attention可以直接用于梯度下降优化,而Hard Attention由于其不可微分的特性,可能需要特殊的训练技巧。Multi-Head Attention则通过并行处理捕捉更丰富的信息。
三、Attention机制的应用
1.机器翻译
机器翻译是注意力机制最著名的应用之一。在这个任务中,模型需要将一种语言(源语言)的文本转换为另一种语言(目标语言)的文本。注意力机制在这里的作用是在生成目标语言的每个单词时,动态地聚焦于源语言中相关的部分,这有助于捕捉长距离依赖关系,并提高翻译的准确性和流畅性。
import torch
import torch.nn as nn
import torch.optim as optimclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.dropout = nn.Dropout(dropout)def forward(self, src):embedded = self.dropout(self.embedding(src))outputs, (hidden, cell) = self.rnn(embedded)return hidden, cellclass Attention(nn.Module):def __init__(self, enc_hid_dim, dec_hid_dim):super().__init__()self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)self.v = nn.Linear(dec_hid_dim, 1, bias=False)def forward(self, hidden, encoder_outputs):hidden = hidden.repeat(encoder_outputs.shape[0], 1).transpose(0, 1)encoder_outputs = encoder_outputs.transpose(0, 1)attn_energies = self.score(hidden, encoder_outputs)return F.softmax(attn_energies, dim=-1)def score(self, hidden, encoder_outputs):energy = torch.tanh(self.attn(torch.cat([hidden, encoder_outputs], dim=2)))energy = self.v(energy).squeeze(2)return energyclass Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.output_dim = output_dimself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.attention = Attention(hid_dim, hid_dim)self.fc_out = nn.Linear(hid_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, input, hidden, cell, encoder_outputs):input = input.unsqueeze(0)embedded = self.dropout(self.embedding(input))attn_weights = self.attention(hidden, encoder_outputs)context = attn_weights.bmm(encoder_outputs.transpose(0, 1))rnn_input = torch.cat((embedded, context), dim=2)output, (hidden, cell) = self.rnn(rnn_input, (hidden, cell))output = output.squeeze(0)out = self.fc_out(output)return out, hidden, cell# 假设参数
input_dim = 1000 # 源语言词汇表大小
output_dim = 1000 # 目标语言词汇表大小
emb_dim = 256 # 嵌入层维度
hid_dim = 512 # 隐藏层维度
n_layers = 2 # LSTM层数
dropout = 0.1 # Dropout# 实例化模型
encoder = Encoder(input_dim, emb_dim, hid_dim, n_layers, dropout)
decoder = Decoder(output_dim, emb_dim, hid_dim, n_layers, dropout)# 假设输入
src = torch.randint(0, input_dim, (10, 32)) # (seq_len, batch_size)
input = torch.randint(0, output_dim, (1, 32)) # (seq_len, batch_size)# 前向传播
hidden, cell = encoder(src)
output, hidden, cell = decoder(input, hidden, cell, src)
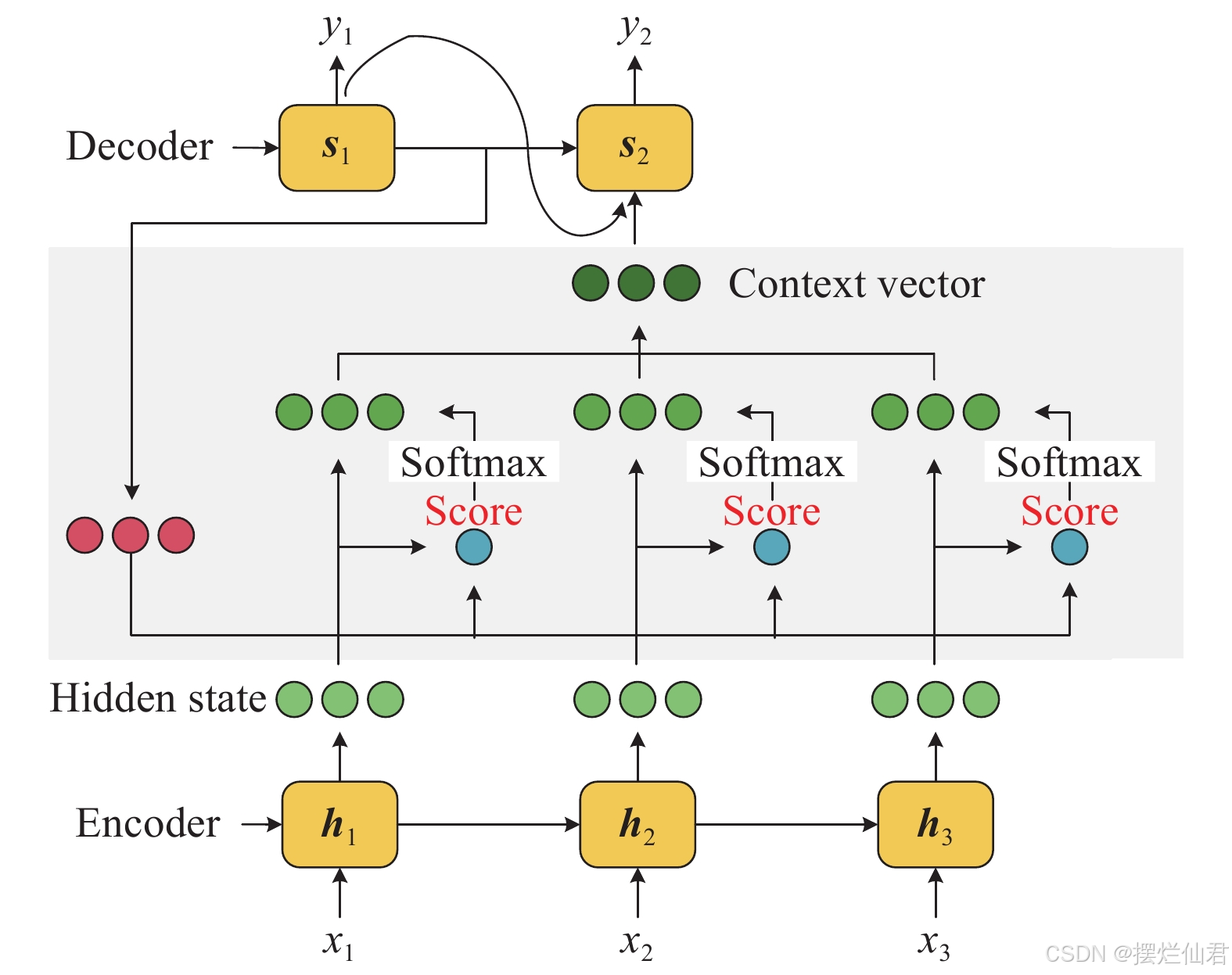
print("Translation Output:", output.shape) # (batch_size, output_dim)在示例代码中,我们定义了一个基于注意力的Seq2Seq模型,它由一个编码器和一个解码器组成。编码器读取源语言文本,并输出一个上下文向量和隐藏状态。解码器则使用这个上下文向量来生成目标语言文本,同时更新隐藏状态。注意力机制通过计算源语言文本中每个单词的重要性,并将这些信息合并到解码器的每一步中,从而允许模型在生成每个单词时“回顾”源语言文本的相关部分。
2.文本摘要
在自动文本摘要任务中,模型需要从长文本中提取关键信息,并生成一个简短的摘要。注意力机制可以帮助模型识别哪些句子或短语对于理解全文内容最为重要,从而在生成摘要时保留这些关键信息。
import torch
import torch.nn as nn
import torch.optim as optimclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.dropout = nn.Dropout(dropout)def forward(self, src):embedded = self.dropout(self.embedding(src))outputs, (hidden, cell) = self.rnn(embedded)return hidden, cellclass Attention(nn.Module):def __init__(self, enc_hid_dim, dec_hid_dim):super().__init__()self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)self.v = nn.Linear(dec_hid_dim, 1, bias=False)def forward(self, hidden, encoder_outputs):hidden = hidden.repeat(encoder_outputs.shape[0], 1).transpose(0, 1)encoder_outputs = encoder_outputs.transpose(0, 1)attn_energies = self.score(hidden, encoder_outputs)return F.softmax(attn_energies, dim=-1)def score(self, hidden, encoder_outputs):energy = torch.tanh(self.attn(torch.cat([hidden, encoder_outputs], dim=2)))energy = self.v(energy).squeeze(2)return energyclass Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.output_dim = output_dimself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.attention = Attention(hid_dim, hid_dim)self.fc_out = nn.Linear(hid_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, input, hidden, cell, encoder_outputs):input = input.unsqueeze(0)embedded = self.dropout(self.embedding(input))attn_weights = self.attention(hidden, encoder_outputs)context = attn_weights.bmm(encoder_outputs.transpose(0, 1))rnn_input = torch.cat((embedded, context), dim=2)output, (hidden, cell) = self.rnn(rnn_input, (hidden, cell))output = output.squeeze(0)out = self.fc_out(output)return out, hidden, cell# 假设参数
input_dim = 1000 # 源语言词汇表大小
output_dim = 1000 # 目标语言词汇表大小
emb_dim = 256 # 嵌入层维度
hid_dim = 512 # 隐藏层维度
n_layers = 2 # LSTM层数
dropout = 0.1 # Dropout# 实例化模型
encoder = Encoder(input_dim, emb_dim, hid_dim, n_layers, dropout)
decoder = Decoder(output_dim, emb_dim, hid_dim, n_layers, dropout)# 假设输入
src = torch.randint(0, input_dim, (10, 32)) # (seq_len, batch_size)
input = torch.randint(0, output_dim, (1, 32)) # (seq_len, batch_size)# 前向传播
hidden, cell = encoder(src)
output, hidden, cell = decoder(input, hidden, cell, src)
print("Translation Output:", output.shape) # (batch_size, output_dim)虽然示例代码没有详细展示,但可以想象,一个基于注意力的文本摘要模型会有一个编码器来处理输入文本,并生成一系列隐藏状态。然后,一个解码器会使用这些隐藏状态和注意力权重来生成摘要,同时关注输入文本中与当前生成摘要最相关的部分。这样,生成的摘要不仅包含了原文的核心信息,而且更加紧凑和连贯。
3.图像识别
在图像识别任务中,模型的目标是识别图像中的对象。注意力机制可以帮助模型集中注意力在图像中的关键特征上,例如人脸的眼睛或汽车的轮子,这些特征对于识别任务至关重要。
import torchvision.models as modelsclass AttentionCNN(nn.Module):def __init__(self):super().__init__()self.cnn = models.resnet18(pretrained=True)self.fc = nn.Linear(512, 1000) # 假设有1000个类别def forward(self, x):x = self.cnn(x)# 假设我们添加一个简单的注意力层attention_weights = torch.sigmoid(self.cnn.fc.weight)x = torch.sum(x * attention_weights, dim=1)x = self.fc(x)return x# 实例化模型
attention_cnn = AttentionCNN()# 假设输入
input_image = torch.randn(32, 3, 224, 224) # (batch_size, channels, height, width)# 前向传播
output = attention_cnn(input_image)
print("Image Recognition Output:", output.shape) # (batch_size, num_classes)在示例代码中,我们定义了一个带有简单注意力层的CNN模型。这个注意力层通过学习图像中不同区域的重要性,为每个特征分配权重。这样,模型就可以更加关注于对分类任务最重要的特征,而不是平等对待图像中的所有像素。这种方法可以提高模型对图像中关键信息的敏感性,从而提高识别的准确性。
4.语音识别
语音识别是将语音信号转换为文本的任务。在这个任务中,模型需要理解语音中的语义信息,并将其转换为书面语言。注意力机制可以帮助模型在处理语音信号时,关注那些携带重要信息的部分,例如特定的音素或单词。
class SpeechRecognitionModel(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, output_dim, n_layers, dropout):super().__init__()self.rnn = nn.LSTM(input_dim, emb_dim, n_layers, dropout=dropout, batch_first=True)self.attention = Attention(emb_dim, emb_dim)self.fc_out = nn.Linear(emb_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, x):# x: (batch_size, seq_len, input_dim)outputs, (hidden, cell) = self.rnn(x)attn_weights = self.attention(hidden, outputs)context = torch.bmm(attn_weights, outputs)output = self.fc_out(context.squeeze(1))return output# 假设参数
input_dim = 128 # 特征维度
output_dim = 1000 # 词汇表大小# 实例化模型
speech_recognition = SpeechRecognitionModel(input_dim, emb_dim, hid_dim, output_dim, n_layers, dropout)# 假设输入
speech_signal = torch.randn(32, 100, input_dim) # (batch_size, seq_len, input_dim)# 前向传播
output = speech_recognition(speech_signal)
print("Speech Recognition Output:", output.shape) # (batch_size, output_dim)在示例代码中,我们定义了一个基于注意力的RNN模型,用于处理语音信号。模型的RNN部分处理序列化的语音特征,而注意力机制则帮助模型在生成每个单词时,关注语音信号中最相关的部分。这样,模型可以更准确地捕捉到语音中的语义信息,并将其转换为正确的文本输出。
相关文章:
机制详解(附代码))
注意力(Attention)机制详解(附代码)
Attention机制是深度学习中的一种技术,特别是在自然语言处理(NLP)和计算机视觉领域中得到了广泛的应用。它的核心思想是模仿人类的注意力机制,即人类在处理信息时会集中注意力在某些关键部分上,而忽略其他不那么重要的…...

国内外Agent产品进展汇总
MCP(Model Context Protocol)是一个开放标准协议,旨在标准化应用程序向大型语言模型提供上下文信息的方式。通过集成MCP扩展,Agent可以访问和利用各种外部工具和服务,丰富了Agent的功能范围,使其能够执行更…...

AI Workflow
AI Workflow(人工智能工作流)指的是在构建、部署和管理AI模型与应用时所涉及的一系列步骤和流程。它将数据处理、模型训练、评估、部署及监控等环节有机结合起来,以实现高效、可重复的AI解决方案开发过程。以下是对AI Workflow核心组成部分及…...

MySQL OCP 认证限时免费活动 7 月 31 日 前截止!!!
为庆祝 MySQL 数据库发布 30 周年,Oracle 官方推出限时福利:2025 年 4 月 20 日至 7 月 31 日期间,所有人均可免费报考 MySQL OCP(Oracle Certified Professional)认证考试。该认证验证持证者在 MySQL 数据库管理、优化…...

【无标题】MPC软件
MPC软件是一款先进的多变量预测控制解决方案 专为复杂工业过程优化设计 **核心功能** 实时动态建模 多变量协调控制 滚动时域优化 自适应调整策略 干扰抑制 鲁棒性强 适用于时变系统 **技术优势** 基于模型预测算法 提前计算最优控制序列 处理输入输出约束 保障系…...

【EasyPan】loadDataList方法及checkRootFilePid方法解析
【EasyPan】项目常见问题解答(自用&持续更新中…)汇总版 一、loadDataList方法概览 /*** 文件列表加载接口* param session HTTP会话对象* param shareId 必须参数,分享ID(使用VerifyParam进行非空校验)* param …...

Java程序题案例分析
目录 一、基础语法 1. 类与对象 2. 接口与抽象类 二、面向对象语法 1. 继承与多态 2. 四种访问修饰符 三、设计模式相关语法 一、策略模式(接口回调实现) 1. 完整实现与解析 二、工厂模式(静态工厂方法实现) 1. 完整实…...

【Lanqiao】数位翻转
题目: 思路: 写蓝桥不能不写dp,就像.... 题目数据给的不大,所以我们可以考虑一种 n*m 的做法,那么对于这种题目可以想到的是用dp来写,但是如何构造转移方程与状态是个难事 由于这题对于任意一个数我们有两…...
实现(图形界面)校园导览系统)
基于QT(C++)实现(图形界面)校园导览系统
校园导览系统 一、任务描述 大学校园充满着忙忙碌碌的学生和老师们,但是有时候用户宝贵的时间会被复杂的道路和愈来愈多的建筑物的阻碍而浪费,为了不让同学们在自己的目的地的寻路过程中花费更多的时间,我们着手开发这样一款校园导览系统。…...

【C/C++】虚函数
📘 C 虚函数详解(Virtual Function) 📌 什么是虚函数? 虚函数(Virtual Function) 是 C 中实现运行时多态(Runtime Polymorphism) 的核心机制。 它允许派生类 重写&…...

no main manifest attribute, in xxx.jar
1、问题: Spring Boot项目在idea中可以正常运行,但是运行Spring Boot生成的jar包,报错: 1、no main manifest attribute, in xxx.jar 2、xxx.jar中没有主清单属性 2、解决办法: 删除pom.xml中<configuration&g…...

使用 AI 如何高效解析视频内容?生成思维导图或分时段概括总结
一、前言 AI 发展的如此迅速,有人想通过 AI 提效对视频的解析,怎么做呢? 豆包里面有 AI 视频总结的功能,可以解析bilibili网站上部分视频,如下图所示: 但有的视频解析时提示: 所以呢&#x…...

比较入站和出站防火墙规则
组织需要仔细配置防火墙规则,监控网络的传入和传出流量,从而最大限度降低遭受攻击的风险。在有效管理入站和出站防火墙规则前,了解入站与出站流量的区别至关重要。 一、什么是入站流量? 入站流量指的是并非源自网络内部…...

开放式耳机什么品牌的好用?性价比高的开放式耳机品牌推荐一下
这几年蓝牙耳机发展得很快,从最早的入耳式,到现在流行的开放式,选择越来越多。我自己是比较偏向佩戴舒适的类型,用过开放式之后就回不去了。它不堵耳、不压迫,戴着轻松不累,对我这种耳朵容易不适的人来说太…...

WPF之高级绑定技术
文章目录 引言多重绑定(MultiBinding)基本概念实现自定义IMultiValueConverterMultiBinding在XAML中的应用示例使用StringFormat简化MultiBinding 优先级绑定(PriorityBinding)基本概念PriorityBinding示例实现PriorityBinding的后…...

k8s高可用集群,自动化更新证书脚本
#!/bin/bash # 切换到证书目录 cd /etc/kubernetes/pki || exit # 备份原有证书(重要!) sudo cp -r apiserver.crt apiserver.key \ apiserver-etcd-client.crt apiserver-etcd-client.key \ apiserver-kubelet-client…...

【Python 函数】
Python 中的函数(Function)是可重复使用的代码块,用于封装特定功能并提高代码复用性。以下是函数的核心知识点: 一、基础语法 1. 定义函数 def greet(name):"""打印问候语""" # 文档字符串&…...

Filecoin矿工资金管理指南:使用lotus-shed actor withdraw工具
Filecoin矿工资金管理指南:使用lotus-shed actor withdraw工具 引言lotus-shed actor withdraw命令概述命令语法参数选项详解常见使用场景1. 提取全部可用余额2. 提取指定数量的FIL3. 通过受益人地址发送交易 最佳实践资金安全管理操作流程优化 常见问题与解决方案提…...

AI辅助DevOps与自动化测试:重构软件工程效率边界
随着AI技术渗透至软件开发生命周期,DevOps与自动化测试领域正经历颠覆性变革。本文系统性解析AI在需求分析、测试用例生成、部署决策、异常检测等环节的技术实现路径,结合微软Azure DevOps、Tesla自动驾驶测试等典型场景,探讨AI如何突破传统效…...

css内容省略——text-overflow: ellipsis
title: css内容省略 date: 2025-05-07 19:41:17 tags: css text-overflow: ellipsis text-overflow: ellipsis用于在文本溢出容器时显示省略号(…) 1.单行省略 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"&g…...

nginx性能优化与深度监控
一、性能调优方向 1. 系统层面优化 内核参数调整 TCP队列与连接管理: net.core.somaxconn(最大连接队列长度,建议设为65535)net.ipv4.tcp_max_syn_backlog(SYN队列长度,建议65535)net.ipv4.tc…...
)
leetcode 70.爬楼梯(c++详细最全解法+补充知识)
目录 题目 解答过程 补充哈希表知识 哈希表基本特性 常用成员函数 基本用法 实现代码 1.递归 2.循环遍历 3.哈希表 题目 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1&#…...

护照阅读器简介
护照阅读器简介 护照阅读器(Passport Reader)是一种专用设备,用于快速、准确地读取护照、身份证、签证等旅行证件的机读区(MRZ)和芯片(ePassport)信息,广泛应用于出入境管理、机场安…...

切片和边缘计算技术分析报告
切片和边缘计算技术分析报告 一、引言 随着 5G 通信技术的快速发展,网络切片和边缘计算技术逐渐成为通信领域的热点研究方向。网络切片技术通过将物理网络划分为多个逻辑上的虚拟网络,以满足不同业务场景对网络性能的差异化需求。边缘计算则将计算、存…...
)
vue3笔记(自存)
1. Vue3简介 2020年9月18日,Vue.js发布版3.0版本,代号:One Piece(n 经历了:4800次提交、40个RFC、600次PR、300贡献者 官方发版地址:Release v3.0.0 One Piece vuejs/core 截止2023年10月,最…...

多线服务器具有什么优势
在当今数字化飞速发展的时代,多线服务器宛如一位低调的幕后英雄,默默为我们的网络世界提供着强大的支持。那么,多线服务器到底具有哪些令人瞩目的优势呢 首先,多线服务器的最大优势之一就是网络访问的高速与稳定。想象一下&#x…...

Azure OpenAI 聊天功能全解析:Java 开发者指南
Azure OpenAI 聊天功能全解析:Java 开发者指南 前言 在当今人工智能飞速发展的时代,AI 驱动的文本生成技术正深刻改变着众多应用场景。Azure OpenAI 作为这一领域的重要参与者,由 ChatGPT 提供支持,不仅具备传统 OpenAI 的功能&…...

【情感关系】健全自我
一些看到后深有感触的文字 请大家无论如何也不要相信这种:“童年/原生家庭经历决定人生走向”的论调。 过去可以影响我们但是无法主宰我们,人是有主观能动意识的,认识自己的问题就是改变人生轨迹的第一步。 后来我们会发现,对于…...

SLAM:单应矩阵,本质矩阵,基本矩阵详解和对应的c++实现
单应矩阵(Homography Matrix) 单应矩阵(Homography Matrix)是计算机视觉中描述同一平面在不同视角下投影变换的核心工具,广泛应用于图像校正、拼接、虚拟广告牌替换等场景。以下从原理、求解方法和C++实现三方面展开详解: 一、单应矩阵的数学原理 定义与作用 单应矩阵是…...
与虚电路(Virtual Circuit)的区别)
数据报(Datagram)与虚电路(Virtual Circuit)的区别
数据报(Datagram)与虚电路(Virtual Circuit)的区别 数据报和虚电路是计算机网络中两种不同的通信方式,主要区别体现在 连接方式、路由选择、可靠性、延迟和适用场景 等方面。以下是它们的详细对比: 1. 基本…...

工业现场ModbusTCP转EtherNETIP网关引领生物现场领新浪潮
生物质发生器是一种能够产生、培养生物的设备。客户现场需要将生物发生器连接到罗克韦尔系统,但是二者协议无法直接通讯,需要通过ModbusTCP转Ethernet/IP网关将两者进行通讯连接,生物质发生器以其独特的工作原理和优势,使得生物的…...

DeepSeek的100个应用场景
在春节前夕,浙江杭州的AI企业DeepSeek推出了其开源模型DeepSeek-R1,以仅相当于Open AI最新模型1/30的训练成本,在数学、编程等关键领域展现出媲美GPT-o1的出色性能。发布仅数日,DeepSeek-R1便迅速攀升至中美两国苹果应用商店免费榜…...

【Linux 系统调试】Linux 调试工具strip使用方法
目录 一. strip 工具的定义与核心作用 1. strip 是什么? 2. strip 工具调试符号的作用 3. strip 工具调试符号的重要性 二. 如何确认文件是否被 strip 处理? 1. 通过 file 命令检查文件状态 2. strip 的典型用法 基础命…...

Solana批量转账教程:提高代币持有地址和生态用户空投代币
前言 Solana区块链因其高吞吐量和低交易费用成为批量操作(如空投)的理想选择。本教程将介绍几种在Solana上进行批量转账的方法,帮助您高效地向多个地址空投代币。 solana 账户模型 在Solana中有三类账户: 数据账户,…...

leetcode hot100 技巧
如有缺漏谬误,还请批评指正。 1.只出现一次的数字 利用异或运算相同得0的特点。所有出现过两次的数字都会在异或运算累加过程中被抵消。、 class Solution { public:int singleNumber(vector<int>& nums) {int res0;for(int i0;i<nums.size();i) re…...

搭建spark伪分布集群
1.先查看虚拟机的默认名称,将其修改为vm01 2.更改了主机名,还需要修改/etc/hosts文件,在这个文件设定了IP地址与主机名的对应关系,类似DNS域名服务器的功能 3.修改spark相关配置文件,包括spark-env.sh和slave两个文件 …...

vue3自定义audio音频播放【进度条,快进,后退,音量加减,播放速度】
本文将介绍如何使用Vue3构建一个功能完备的自定义音频播放器,包含进度条控制、快进/后退、音量调节和播放速度控制等功能。相比使用浏览器默认的audio控件,自定义播放器可以提供更一致的用户体验和更灵活的设计空间,复制粘贴即可使用…...

学习基本开锁知识
本文主要内容 目前市面上锁的种类有哪些 机械锁 钥匙开锁 :这是最常见的传统开锁方式,通过插入匹配的钥匙转动来开锁,如常见的家用门锁、汽车门锁等,钥匙形状和齿纹各异,有单排齿的一字锁、双排齿的双面锁,…...

泛微ECOLOGY9 流程表单中添加按钮的方法
使用场景介绍 有时需要在流程表单中添加一个按钮来实现弹窗、打开指定的页面等需求。 实现方式一:通过ID 在流程表单中想要生成按钮的地方指定一个ID,然后再到ecode中创建按钮及方法。 具体步骤如下: 一、表单中指定ID为 exceldc 二、在ecode中实现按钮及功能。 1.建立…...

小刚说C语言刷题—1331 做彩纸花边
1.题目描述 李晓芳用一条长为 n 米的彩纸制作花边,每朵花李晓芳用一条长为 n 米的彩纸制作花边,每朵花的宽度为 x 厘米,花与花之间的间隔为 y 厘米。请问 n 米的彩纸最多能做多少朵花的花边。 如,图中的案例花的宽度为 4.5cm &a…...

【Python】读取excel文件的时候,遇到“Excel file format cannot be determined”的问题
使用os.path 读取路径下的文件,并拼接文件名,可能会遇到这个问题: ValueError: Excel file format cannot be determined, you must specify an engine manually. 因为我用的是相对路径的拼接的方法,读取出来会有这样的问题&#…...

天气预报、天气查询API接口文档 | 实时天气 | 七日天气 | 15日天气查询
天气预报、天气查询API接口文档 | 实时天气 | 七日天气 | 15日天气查询 这篇文章详细介绍了一种天气查询服务,提供了实时天气(1天)、7天预报和15天预报三个RESTful接口,支持通过地区名称、编码、IP或经纬度等多种方式查询,返回数据包含温度、…...

Linux中的线程安全与线程同步详解
在Linux系统中,线程安全性是指在多个线程同时访问共享资源时,能够确保这些共享资源不被破坏或者产生数据错误。线程同步是一种机制,用于保证多个线程之间的操作次序和协调,以避免竞态条件、死锁等问题。 以下是线程安全和线程同步…...

qwen2.5vl
多模态大模型通用架构: 在通用的MM-LLM(Multi-Modality LLM)框架里,共有五个模块,整体以LLM为核心主干,分别在前后有一个输入、输出的投影模块(Projector),投影模块主要…...

国产Word处理控件Spire.Doc教程:在Java中为Word文本和段落设置边框
在 Word 文档中添加边框是一种突显重点信息的有效方式,尤其适用于包含大量文本的内容场景。相比普通格式,给字符或段落添加边框不仅能强化视觉层次,还能提升文档的专业感与可读性。E-iceblue旗下Spire系列产品是国产文档处理领域的优秀产品&a…...

【CUDA C实战演练】CUDA介绍、安装、C代码示例
文章目录 0. 前言1. 并行计算与异构计算1.1 并行计算(Parallel Computing)1.2 异构计算(Heterogeneous Computing) 2. CUDA 的核心概念2.1 主机(Host)与设备(Device)2.2 线程层次结构…...

滑动窗口——无重复字符最长的字串
题目: 子字符串,我们也可以看成子数组。 题意不难理解,这个题我们暴力枚举的思路是把每一个字符遍历存到hash桶中,如果放两次就进行结果更新。 但这个题我们有更优化的方法,利用数组代替hash(重点不在这&…...

QT中connect高级链接——指针、lambda、宏
1、connect使用指针 connect(button,&QPushButton::released,this,&MainWidget::mySlot); //【抬起】按钮button时,修改按钮b2的标题 2、使用lambda表达式 引入lambda表达式,类似内联函数,可以用于不会被重用的短代码片段&#x…...

说说es配置项的动态静态之分和集群配置更新API
这天因为某件工作来到了es官网某个参数配置相关的页面,注意到了下图圆圈里的“Dynamic”: 链接:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cluster.html#misc-cluster-settings 显然这是对配置项的一个描述&am…...

如何有效防御服务器DDoS攻击
分布式拒绝服务(DDoS)攻击通过大量恶意流量淹没服务器资源,导致服务瘫痪。本文将提供一套结合代码实现的主动防御方案,涵盖流量监控、自动化拦截和基础设施优化。 1. 实时流量监控与告警 目标:检测异常流量并触发告警…...