第8章-1 查询性能优化-优化数据访问
上一篇:《 下一篇:《第7章-3 维护索引和表》》
在前面的章节中,我们介绍了如何设计最优的库表结构、如何建立最好的索引,这些对于提高性能来说是必不可少的。但这些还不够——还需要合理地设计查询。如果查询写得很糟糕,即使库表结构再合理、索引再合适,也无法实现高性能。
查询优化、索引优化、库表结构优化需要齐头并进,一个不落。在获得编写MySQL查询的经验的同时,你还将学习到如何为高效的查询设计表和索引。同样地,你也可以学习到在优化库表结构时会影响到哪些类型的查询。这个过程需要时间,建议大家在学习后面章节的时候多回头看看这些章节的内容。
本章将从查询设计的一些基本原则开始——这也是在发现查询效率不高的时候首先需要考虑的因素。然后会介绍一些更深的查询优化的技巧,并会介绍一些MySQL优化器内部的机制。我们将展示MySQL是如何执行查询的,你也将学会如何去改变一个查询的执行计划。
最后,我们要看一下MySQL优化器在哪些方面做得还不够,并探索查询优化的模式,以帮助MySQL更有效地执行查询。
本章的目标是帮助大家更深刻地理解MySQL如何真正地执行查询,并明白高效和低效的原因何在,这样才能充分发挥MySQL的优势,并避开它的弱点。
为什么查询速度会慢
在尝试编写快速的查询之前,需要清楚一点,真正重要的是响应时间。如果把查询看作一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间。如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减少子任务的执行次数,要么让子任务运行得更快。
通常来说,查询的生命周期大致可以按照如下顺序来看:从客户端到服务器,然后在服务器上进行语法解析,生成执行计划,执行,并给客户端返回结果。其中,“执行”可以被认为是整个生命周期中最重要的阶段,这其中包括大量为了检索数据对存储引擎的调用以及调用后的数据处理,包括排序、分组等。
在完成这些任务的时候,查询需要在不同的地方花费时间,包括网络、CPU计算、生成统计信息和执行计划、锁等待(互斥等待)等操作,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作、CPU操作和内存不足时导致的I/O操作上消耗时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
在每一个消耗大量时间的查询案例中,我们都能看到一些不必要的操作、某些操作被额外地重复了很多次、某些操作执行得太慢等。优化查询的目的就是减少和消除这些操作所花费的时间。
再次声明一点,对于一个查询的全部生命周期,上面列得并不完整。这里我们只是想说明:了解查询的生命周期和清楚查询的时间消耗情况对于优化查询有很大意义。有了这些概念,我们再一起来看看如何优化查询。
慢查询基础:优化数据访问
一条查询,如果性能很差,最常见的原因是访问的数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不常见。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤来分析总是很有效:
1. 确认应用程序是否在检索大量且不必要的数据。这通常意味着访问了太多的行,但有时候也可能是访问了太多的列。
2. 确认MySQL服务器层是否在分析大量不需要的数据行。
是否向数据库请求了不需要的数据
有些查询会请求超过实际需要的数据,然后这些多余的数据会被应用程序丢弃。这会给MySQL服务器带来额外的负担,并增加网络开销 (如果应用服务器和数据库不在同一台主机上,网络开销就十分明显。即使是在同一台服务器上,也仍然会有数据传输的开销),另外,这也会消耗应用服务器的CPU和内存资源。
以下是一些典型案例。
查询了不需要的记录
一个常见的错误是,常常会误以为MySQL只会返回需要的数据,实际上MySQL却是先返回全部结果集再进行计算。我们经常会看到一些了解其他数据库系统的人会设计出这类应用程序。这些开发者习惯使用这样的技术,先使用SELECT语句查询大量的结果,然后获取前面的N行后关闭结果集(例如,在新闻网站中取出100条记录,但是只是在页面上显示前面10条)。他们认为MySQL会执行查询,并只返回他们需要的10条数据,然后停止查询。
实际情况是,MySQL会查询出全部的结果集,客户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。最简单有效的解决方法就是在这样的查询后面加上LIMIT子句。
多表联接时返回全部列
如果你想查询所有在电影Academy Dinosaur中出现的演员,千万不要按下面的写法编写查询:
SELECT * FROM actor
INNER JOIN film_actor USING(actor_id)
INNER JOIN film USING(film_id)
WHERE film.title = 'Academy Dinosaur';这将返回这三个表的全部数据列。正确的方式应该是像下面这样只取需要的列:
SELECT actor.* FROM actor...;总是取出全部列
每次看到SELECT*的时候都需要用怀疑的眼光审视,是不是真的需要返回全部的列,很可能不是必需的。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU的消耗。因此,一些DBA严格禁止SELECT*的写法,这样做有时候还能避免某些列被修改而带来的问题。
当然,查询返回超过需要的数据也不总是坏事。在我们研究过的许多案例中,人们会告诉我们,这种有点浪费数据库资源的方式可以简化开发,因为能提高相同代码片段的复用性,如果清楚这样做对性能的影响,那么这种做法也是值得考虑的。如果应用程序使用了某种缓存机制,或者有其他考虑,获取超过需要的数据也可能有其好处,但不要忘记这样做的代价是什么。获取并缓存所有的列的查询,相比多个独立的只获取部分列的查询可能更有好处。
重复查询相同的数据
如果你不够小心,很容易出现这样的错误——不断地重复执行相同的查询,然后每次都返回完全相同的数据。例如,在用户评论的地方需要查询用户头像的URL,那么在用户多次评论的时候,可能就会反复查询这个数据。比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出,这样性能显然会更好。
MySQL是否在扫描额外的记录
在确定查询只返回需要的数据以后,接下来应该看看查询为了返回结果是否扫描了过多的数据。对于MySQL,最简单的衡量查询开销的三个指标如下:
● 响应时间
● 扫描的行数
● 返回的行数
没有哪个指标能够完美地衡量查询的开销,但它们大致反映了MySQL在内部执行查询时需要访问多少数据,并可以大概推算出查询运行的时间。这三个指标都会被记录到MySQL的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法。
响应时间
要记住,响应时间只是一个表面上的值。这样说可能看起来和前面关于响应时间的说法有矛盾,其实并不矛盾,响应时间仍然是最重要的指标,这有一点复杂,后面细细道来。
响应时间是两部分之和:服务时间和排队时间。服务时间是指数据库处理这个查询真正花了多长时间。排队时间是指服务器因为等待某些资源而没有真正执行查询的时间——可能是等I/O操作完成,也可能是等待行锁,等等。遗憾的是,我们无法把响应时间细分到上面这些部分,除非有什么办法能够逐个测量这些消耗,这很难做到。最常见和重要的是I/O等待和锁等待,但是实际情况更加复杂。实际上,I/O等待和锁等待非常重要,因为它们对于性能有着至关重要的影响。
所以在不同类型的应用压力下,响应时间并没有一致的规律或者公式。诸如存储引擎的锁(表锁、行锁)、高并发资源竞争、硬件响应等诸多因素都会影响响应时间。所以,响应时间既可能是一个问题的结果也可能是一个问题的原因,不同案例情况不同。
当你看到一个查询的响应时间时,首先需要问问自己,这个响应时间是否是一个合理的值。实际上可以使用“快速上限估计”法来估算查询的响应时间,这是在Tapio Lahdenmaki和Mike Leach编写的Relational Database Index Design and the Optimizers(Wiley出版社出版)一书中提到的技术,限于篇幅,在这里不会详细展开。概括地说,了解这个查询需要哪些索引以及它的执行计划是什么,然后计算大概需要多少个顺序和随机I/O,再用其乘以在具体硬件条件下一次I/O的消耗时间。最后把这些消耗都加起来,就可以获得一个大概参考值来判断当前响应时间是不是一个合理的值。
扫描的行数和返回的行数
分析查询时,查看该查询扫描的行数是非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。对于找出那些“糟糕”的查询,这个指标可能还不够完美,因为并不是所有行的访问代价都是相同的。较短的行的访问速度更快,内存中的行比磁盘中的行的访问速度要快得多。
理想情况下扫描的行数和返回的行数应该是相同的,但实际中这种“美事”并不多。例如,在做一个联接查询时,服务器必须要扫描多行才能生成结果集中的一行。扫描的行数与返回的行数的比率通常很低,一般在1:1到10:1之间,不过有时候这个值也可能非常非常大。
扫描的行数和访问类型
在评估查询开销的时候,需要考虑从表中找到某一行数据的成本。MySQL有好几种访问方式可以查找并返回一行结果。有些访问方式可能需要扫描很多行才能返回一行结果,也有些访问方式可能无须扫描就能返回结果。
EXPLAIN语句中的type列反映了访问类型。访问类型有很多种,从全表扫描到索引扫描、范围扫描、唯一索引查询、常数引用等。这里列出的这些,速度从慢到快,扫描的行数从多到少。你不需要记住这些访问类型,但需要明白扫描表、扫描索引、范围访问和单值访问的概念。
如果你没办法找到合适的访问类型,那么最好的解决办法通常就是增加一个合适的索引,这也正是我们前一章讨论过的问题。现在应该明白为什么索引对于查询优化如此重要了吧。索引让MySQL以最高效、扫描行数最少的方式找到需要的记录。
例如,我们看一下示例数据库Sakila中的一个查询案例:
SELECT * FROM film_actor WHERE film_id = 1;这个查询将返回10行数据,从EXPLAIN的结果可以看到,MySQL在索引idx_fk_film_id上使用了ref访问类型来执行查询:
EXPLAIN SELECT * FROM film_actor WHERE film_id = 1;![]()
EXPLAIN的结果还显示MySQL预估需要访问10行数据。换句话说,查询优化器认为这种访问类型可以高效地完成查询。如果没有合适的索引会怎样呢?MySQL就不得不使用一种糟糕的访问类型,下面来看看如果删除对应的索引再来运行这个查询会发生什么情况:
ALTER TABLE film_actor DROP FOREIGN KEY fk_film_actor_film;
ALTER TABLE film_actor DROP KEY idx_fk_film_id;
EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1;![]()
正如我们预测的,访问类型变成了一个全表扫描(ALL),现在MySQL预估需要扫描5462条记录来完成这个查询。这里的“Using where”表示MySQL将通过WHERE条件来筛选存储引擎返回的记录。
一般地,MySQL能够使用如下三种方式应用WHERE条件,从好到坏依次为:
● 在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。
● 使用索引覆盖扫描(在Extra列中出现了Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层完成的,但无须再回表查询记录。
● 从数据表中返回数据,然后过滤不满足条件的记录(在Extra列中出现Using where)。这在MySQL服务器层完成,MySQL需要先从数据表中读出记录然后过滤。
上面这个例子说明了好的索引多么重要。好的索引可以让查询使用合适的访问类型,尽可能地只扫描需要的数据行。但也不是说增加索引就能让扫描的行数等于返回的行数。例如,下面是使用聚合函数COUNT() 的查询:
SELECT actor_id, COUNT(*)
FROM film_actor GROUP BY actor_id;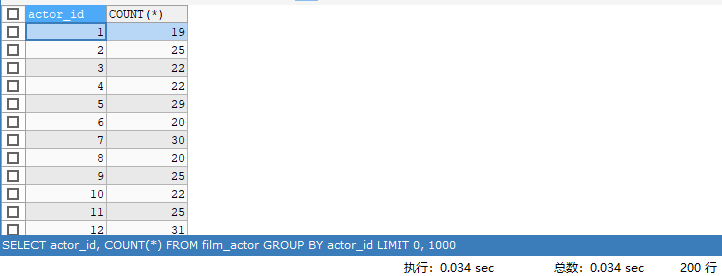
这条查询语句仅需返回200条记录,但是,它实际读取了多少条记录呢?用EXPLAIN语句来查看一下:
EXPLAIN SELECT actor_id, COUNT(*)
FROM film_actor GROUP BY actor_id;![]()
哇!获取200条记录却需要读取几千行记录,这就意味着,读取了太多不必要的记录。因为WHERE子句中没有过滤掉对应的记录,所以,在这个案例中,索引并不能减少需要扫描的记录行数。
不幸的是,MySQL不会告诉我们生成结果实际上需要扫描多少行数据,而只会告诉我们生成结果时一共扫描了多少行数据。扫描的行中的大部分都很可能是被WHERE条件过滤掉的,对最终的结果集并没有贡献。在上面的例子中,我们删除索引后,看到MySQL需要扫描所有记录然后根据WHERE条件过滤,最终只返回10行结果。理解一个查询需要扫描多少行和实际需要使用的行数需要先去理解这个查询背后的逻辑和思想。
如果发现查询需要扫描大量的数据但只返回少数行,那么通常可以尝试下面的技巧去优化它:
● 使用索引覆盖扫描,把所有需要用的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果了(在第7章中我们已经讨论过了)。
● 改变库表结构。例如,使用单独的汇总表(这是我们在第6章中讨论的办法)。
● 重写这个复杂的查询,让MySQL优化器能够以更优化的方式执行这个查询(这是本章后续需要讨论的问题)。
重构查询的方式
在优化有问题的查询时,目标应该是找到获得实际需要的结果的替代方法——但这并不一定意味着从MySQL返回完全相同的结果集。有时候,可以将查询转换为返回相同结果的等价形式,以获得更好的性能。但是,如果可以获得更好的效率,还应该考虑重写查询以检索不同的结果。通过修改应用代码和查询,最终达到一样的目的。这一节我们将介绍如何通过这种方式来重构查询,并展示何时需要使用这样的技巧。
一个复杂查询还是多个简单查询
设计查询的时候,一个需要考虑的重要问题是,是否需要将一个复杂的查询分成多个简单的查询。在传统实现中,总是强调需要数据库层完成尽可能多的工作,这样做的逻辑在于以前人们总是认为网络通信、查询解析和优化是一件代价很高的事情。
但是这样的想法对于MySQL并不适用,因为MySQL从设计上让连接和断开连接都很轻量,在返回一个小的查询结果方面很高效。现代的网络速度比以前要快很多,能在很大程度上降低延迟。在某些版本的MySQL中,即使在一台通用服务器上,也能够运行每秒超过10万次的简单查询,即使是一个千兆网卡也能轻松满足每秒超过2000次的查询。所以运行多个小查询现在已经不是大问题了。
在MySQL内部,每秒能够扫描内存中上百万行的数据,相比之下,MySQL响应数据给客户端就慢得多了。在其他条件都相同的时候,使用尽可能少的查询当然是更好的。但是有时候,将一个大查询分解为多个小查询是很有必要的。别害怕这样做,好好衡量一下这样做是不是会减少工作量。稍后我们将通过一个示例来展示这个技巧的优势。
不过,在设计应用的时候,如果在一个查询能够胜任时还将其写成多个独立的查询是不明智的。例如,我们看到有些应用对一个数据表做10次独立的查询来返回10行数据,每个查询返回一条结果,查询10次,这时可以使用单个查询获取10行数据。有的应用甚至每次只查询一个字段,获取一行数据就需要执行多次查询。
切分查询
有时候对于一个大查询,我们需要“分而治之”,将大查询切分成小查询,每个查询的功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
删除旧的数据就是一个很好的例子。定期清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。将一个大的DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL的性能,同时还可以降低MySQL复制的延迟。例如,我们需要每个月运行一次下面的查询:
DELETE FROM messages
WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH);那么可以用类似下面的办法来完成同样的工作:
rows_affected = 0
do {rows_affected = do_query("DELETE FROM messages WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONTH)LIMIT 10000")
} while rows_affected > 0一次删除一万行数据一般来说是一个比较高效而且对服务器 [3] 影响最小的做法(如果是事务型引擎,很多时候小事务能够更高效)。同时,需要注意的是,如果每次删除数据后,都暂停一会儿再做下一次删除,也可以将服务器上原本一次性的压力分散到一个很长的时间段中,可以大大降低对服务器的影响,还可以大大减少删除时锁的持有时间。
分解联接查询
很多高性能的应用都会对联接查询进行分解。简单地说,可以对每一个表进行一次单表查询,然后将结果在应用程序中进行联接。例如,下面这个查询:
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';可以分解成下面这些查询来代替:
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);到底为什么要这样做?乍一看,这样做并没有什么好处,原本一条查询,这里却变成多条
查询,返回的结果又是一模一样的。事实上,用分解联接查询的方式重构查询有如下优势:
● 让缓存的效率更高。许多应用程序可以方便地缓存单表查询对应的结果对象。例如,上面查询中的tag mysql已经被缓存了,那么应用就可以跳过第一个查询。再例如,应用中已经缓存了ID为123、567、9098的内容,那么第三个查询的IN()中就可以少几个ID。
● 将查询分解后,执行单个查询可以减少锁的竞争。
● 在应用层做联接,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
● 查询本身的效率也可能会有所提升。在这个例子中,使用IN()代替联接查询,可以让MySQL按照ID顺序进行查询,这可能比随机的联接要更高效。
● 可以减少对冗余记录的访问。在应用层做联接查询,意味着对于某条记录应用只需要查询一次,而在数据库中做联接查询,则可能需要重复地访问一部分数据。从这点看,这样的重构还可能会减少网络和内存的消耗。
在有些场景下,在应用程序中执行联接操作会更加有效。比如,当可以缓存和重用之前查询结果中的数据时、当在多台服务器上分发数据时、当能够使用IN()列表替代联接查询大型表时、当一次联接查询中多次引用同一张表时。
相关文章:

第8章-1 查询性能优化-优化数据访问
上一篇:《 下一篇:《第7章-3 维护索引和表》》 在前面的章节中,我们介绍了如何设计最优的库表结构、如何建立最好的索引,这些对于提高性能来说是必不可少的。但这些还不够——还需要合理地设计查询。如果查询写得很糟糕&a…...

每日一题洛谷P1025 [NOIP 2001 提高组] 数的划分c++
P1025 [NOIP 2001 提高组] 数的划分 - 洛谷 (luogu.com.cn) #include<iostream> using namespace std; int n, k; int res 0; void dfs(int num,int step,int sum) {//判断if (sum n) {if (step k) {res;return;}}if (sum > n || step k)return;//搜索for (int i …...

【python】使用Python和BERT进行文本摘要:从数据预处理到模型训练与生成
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着信息爆炸时代的到来,海量文本数据的高效处理与理解成为亟待解决的问题。文本摘要作为自然语言处理(NLP)中的关键任务,旨在自动生成…...

WHAT - Rust 智能指针
文章目录 常见的智能指针类型1. Box<T> — 堆上分配的数据2. Rc<T> — 引用计数的共享所有权(单线程)3. Arc<T> — 原子引用计数(多线程)4. RefCell<T> — 运行时可变借用(单线程)…...
--- 版本1(Client端))
用go从零构建写一个RPC(仿gRPC,tRPC)--- 版本1(Client端)
这里我们来实现这个RPC的client端 为了实现RPC的效果,我们调用的Hello方法,即server端的方法,应该是由代理来调用,让proxy里面封装网络请求,消息的发送和接受处理。而上一篇文章提到的服务端的代理已经在.rpc.go文件中…...

CentOS 安装 Zellij 终端复用器教程
CentOS 安装 Zellij 终端复用器教程 简介 Zellij 是一个现代化的终端复用器,使用 Rust 语言编写。它提供了类似 tmux 的功能,但具有更友好的用户界面和更现代化的特性。本教程将详细介绍如何在 CentOS 7.9 系统上安装 Zellij。 前置条件 CentOS 7.9 …...

基于 SpringBoot + Vue 的校园管理系统设计与实现
一、项目简介 本系统以校园组织管理为主线,结合用户权限分离机制与模块化设计,实现对“单位类别、单位、通知推送、投票信息、用户回复”等内容的全流程管理,广泛适用于教育局、高校及下属组织的信息管理工作。 🎯 项目亮点&…...

如何减少锁竞争并细化锁粒度以提高 Rust 多线程程序的性能?
在并发编程中,锁(Lock)是一种常用的同步机制,用于保护共享数据免受多个线程同时访问造成的竞态条件(Race Condition)。然而,不合理的锁使用会导致严重的性能瓶颈,特别是在高并发场景…...

【人工智能agent】--dify通过mcp协议调用工具
MCP Client 发起工具调用的实体,也就是 Dify 工作流或 Agent。它通过 Dify 平台提供的标准化接口(工具节点)来请求服务。 MCP Server / Host 提供实际服务的端点。在这个例子中,就是模拟 API 服务器 上的各个API (/api/pump/st…...

Review --- Redis
Redis redis是什么? Redis是一个开源的,使用C语言编写的,支持网络交互的,key-value数据结构存储系统,支持多种语言的一种非关系型数据库,它可以用作数据库(存储一些简单的数据,例如新闻点赞量),**缓存(秒…...
)
Sql刷题日志(day8)
一、笔试 1、right:提取字符串右侧指定数量的字符 right(string,length) /*string:要操作的字符串。length:要从右侧提取的字符数 */ 2、curdate():返回当前日期,格式通常为 YYYY-MM-DD 二、面试 1、自变量是不良体验反馈,因…...

【Science Advances】普林斯顿大学利用非相干光打造可重构纳米光子神经网络
(导读 ) 人工智能对计算性能需求剧增,电子微处理器发展受功耗限制。光学计算有望解决这些问题,光学神经网络(ONNs)成为研究热点,但现有 ONNs 因设计缺陷,在图像分类任务中精度远低于现代电子神经网络&#…...

2025-05-07 Unity 网络基础8——UDP同步异步通信
文章目录 1 UDP 概述1.1 通信流程1.2 TCP 与 UDP1.3 UDP 分包1.4 UDP 黏包 2 同步通信2.1 服务端2.2 客户端2.3 测试 3 异步通信3.1 Bgin / End 方法3.2 Async 方法 1 UDP 概述 1.1 通信流程 客户端和服务端的流程如下: 创建套接字 Socket。用 Bind() 方法将套…...

K8S - 金丝雀发布实战 - Argo Rollouts 流量控制解析
一、金丝雀发布概述 1.1 什么是金丝雀发布? 金丝雀发布(Canary Release)是一种渐进式部署策略,通过逐步将生产流量从旧版本迁移至新版本,结合实时指标验证,在最小化风险的前提下完成版本迭代。其核心逻辑…...

手持小风扇方案解说---【其利天下技术】
春去夏来,酷暑时节,小风扇成为外出必备的解暑工具,近年来,随着无刷电机的成本急剧下降,小风扇也逐步从有刷变无刷化了。 数量最大的如一箱无刷马达,其次三相低压无刷电机也大量被一些中高端风扇大量采用。…...

Qt开发:枚举的介绍和使用
文章目录 一、概述二、Qt 中定义和使用枚举2.1 普通枚举的定义方式2.2 使用枚举 三、配合 Qt 元对象系统使用枚举3.1 使用 Q_ENUM(Qt 5.5 及以上)3.2 示例:枚举值转字符串3.4 示例:字符串转枚举值 四、枚举与字符串相互转换五、枚…...

HarmonyOS运动开发:如何集成百度地图SDK、运动跟随与运动公里数记录
前言 在开发运动类应用时,集成地图功能以及实时记录运动轨迹和公里数是核心需求之一。本文将详细介绍如何在 HarmonyOS 应用中集成百度地图 SDK,实现运动跟随以及运动公里数的记录。 一、集成百度地图 SDK 1.引入依赖 首先,需要在项目的文…...

“胖都来”商标申请可以通过注册不!
近日“胖都来”被网友认为是蹭“胖东来”品牌流量在互联网上引起争议,看到许多自媒体说浙江这家公司已拿到“胖都来”的注册商标,普推知产商标老杨经检索后发现是没有的,只是申请受理。 对于商城类主要类别是在35类广告销售,核心是…...

【Django】中间件
Django 中间件是 Django 框架里一个轻量级、可插拔的组件,它能在全局范围内对 Django 的请求和响应进行处理。中间件处于 Django 的请求处理流程之中,在请求抵达视图函数之前以及视图函数返回响应之后执行特定操作。以下是关于 Django 中间件的详细介绍&…...

电子电器架构 --- 48V架构的一丢丢事情
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

什么是Blender?怎么获取下载Blender格式文件模型
glbxz.com glbxz.com 官方可以下载Blender格式文件模型 BlenderBlender 是一个免费的开源程序,用于建模和动画,最初由一家名为 Neo Geo 的动画工作室作为内部应用程序开发,后来作为自己的程序发布。这是一个称职的程序,近年来由于…...

Ubuntu安装pgsql
一、通过 APT 安装(推荐) 更新软件包列表 sudo apt update 安装 PostgreSQL 核心包及工具 sudo apt install postgresql postgresql-client postgresql-contrib • postgresql:数据库服务端 • postgresql-client:命令行…...

Qwen2-VL详解
一、引言 在人工智能领域,多模态大模型的发展备受关注。Qwen2-VL 作为一款先进的多模态模型,致力于克服现有方法在处理图像和视频数据时存在的不足,显著提升多模态信息的理解与交互能力。本文将全面且深入地阐述 Qwen2-VL 的创新理念、精妙的模型架构、严谨的训练流程、卓越…...

定长滑动窗口---初阶篇
目录 滑动窗口核心思想 定长滑动窗口套路 定长滑动窗口习题剖析 1456. 定长子串中元音的最大数目 643. 子数组最大平均数 I 1343. 大小为 K 且平均值大于等于阈值的子数组数目 2090. 半径为 k 的子数组平均值 2379. 得到 K 个黑块的最少涂色次数 2841. 几乎唯一子数组…...

以pytest_addoption 为例,讲解pytest框架中钩子函数的应用
钩子函数(Hook Function)的概念 钩子函数(Hook Function)是软件框架中预定义的回调接口,允许开发者在程序执行的特定阶段插入自定义逻辑,以扩展或修改框架的默认行为。在 pytest 中,钩子函数覆…...

数据智能重塑工业控制:神经网络在 MPC 中的四大落地范式与避坑指南
一、引言:工业控制的范式革命 在工业 4.0 的浪潮中,传统基于物理模型的控制方法(如 PID、线性二次型调节器 LQR)正面临前所未有的挑战。以石化行业为例,某炼油厂的催化裂化装置(FCCU)因反应机理…...

AB测试面试题
AB测试面试题 常考AB测试问答题(1)AB测试的优缺点是什么?(2)AB测试的一般流程/介绍一下日常工作中你是如何做A/B实验的?(3)第一类错误 vs 第二类错误 vs 你怎么理解AB测试中的第一、二类错误?(4)统计显著=实际显著?(5)AB测试效果统计上不显著?(6)实验组优于对…...

phpstudy升级新版apache
1.首先下载要升级到的apache版本,这里apache版本为Apache 2.4.63-250207 Win64下载地址:Apache VS17 binaries and modules download 2.将phpstudy中原始apache复制备份Apache2.4.39_origin 3.将1中下载apache解压, 将Apache24复制一份到ph…...

民宿管理系统6
普通管理员管理: 新增普通管理员: 前端效果: 前端代码: <body> <div class"layui-fluid"><div class"layui-row"><div class"layui-form"><div class"layui-f…...
——内存对齐原理)
【iOS】源码阅读(三)——内存对齐原理
文章目录 前言获取内存大小的三种常用方式sizeofclass_getInstanceSizemalloc_size 总结 前言 之前学习alloc相关源码,涉及到内存对齐的相关内容,今天笔者详细学习了一下相关内容并写了此篇博客。 获取内存大小的三种常用方式 获取内存大小的方式有很多…...

在 Ubuntu 中配置 Samba 实现「特定用户可写,其他用户只读」的共享目录
需求目标 所有认证用户可访问 Samba 共享目录 /path/to/home;**仅特定用户(如 developer)**拥有写权限;其他用户仅允许读取;禁止匿名访问。 配置步骤 1. 设置文件系统权限 将目录 /home3/guest 的所有权设为 develo…...

配置指定地址的conda虚拟Python环境
创建指定路径的 Conda 环境 在创建环境时,使用 --prefix 参数指定自定义路径: conda create --prefix/your/custom/path/my_env python3.8 说明: /your/custom/path/my_env:替换为你希望存放环境的路径(如 D:\projec…...

从彼得·蒂尔四象限看 Crypto「情绪变迁」:从密码朋克转向「标准化追求者」
作者:Techub 精选编译 撰文:Matti,Zee Prime Capital 编译:Yangz,Techub News 我又带着一篇受彼得蒂尔(Peter Thiel)启发的思想杂烩回来了。作为自封的「蒂尔学派」信徒,我常透过他…...

VS Code 常用插件
React Auto Import - ES6, TS, JSX, TSX Auto Rename Tag ES7 React/Redux/React-Native snippets Markdown Markdown All in One Markdown Preview Enhanced Other Prettier - Code formatter 格式化代码 Live Server 本地服务器实时预览与自动刷新...

深入探讨 UDP 协议与多线程 HTTP 服务器
深入探讨 UDP 协议与多线程 HTTP 服务器 一、UDP 协议:高效但“不羁”的传输使者 UDP 协议以其独特的特性在网络传输中占据一席之地,适用于对实时性要求高、能容忍少量数据丢失的场景。 1. UDP 的特点解析 无连接:无需提前建立连接&…...

Node.js入门指南:开启JavaScript全栈开发之旅
Hi,我是布兰妮甜 !Node.js让JavaScript突破了浏览器的限制,成为全栈开发的利器。作为基于V8引擎的高性能运行时,它彻底改变了JavaScript只能做前端开发的局面。本文将带你快速掌握Node.js的核心用法:环境搭建与模块系统…...

【STM32F1标准库】理论——通信协议:串口
目录 一、简介 二、连接方式 三、串口参数与时序 1.参数 2.时序 四、STM32实现串口通信的方法 1.使用软件模拟 2.使用硬件外设 杂谈 1.通信的目的 2.常见可以使用串口通信的模块 3.串口常用电平标准 4.串口从波形反推数据 5.奇偶校验 一、简介 命名:USART&#…...

轻松管理房间预约——启辰智慧预约小程序端使用教程
欢迎您使用《启辰智慧预约》场所预约小程序,您可以通过本小程序预约会议室/活动室等,并在预约审批通过后,获取临时开锁密码,开锁密码会在预约时间前30分钟生效。以下是本程序的使用流程。 一、创建单位(新用户注册&am…...

如何在自己的服务器上部署静态网页并通过IP地址进行访问
文件放置 cd /var目录 新建www目录 进入www目录 新建html目录用于放置文件以及相关资源 修改配置文件 sudo nano /etc/nginx/sites-available/default修改index部分的html文件名 修改端口映射避免80冲突 重启Nginx sudo systemctl restart nginx打开浏览器访问即可 h…...

802.11s Mesh 组网框架流程
协议标准 使用 802.11s (标准 Mesh 协议) 基础流程框架 连接流程本质:Beacon → Peer Link → HWMP 路径发现 → 数据传输。mesh与easymesh的区别 阶段详解 阶段1:Beacon广播 作用:周期性宣告Mesh网络存在,同步参数(如Mesh …...
 in commit)
gitcode 上传文件报错文件太大has exceeded the limited size (10 MiB) in commit
登陆gitcoe,在项目设置->提交设置 ,勾选提交文件限制,修改限制的大小。 修改完后,重新提交代码。...
【LeetCode 242】)
C++代码随想录刷题知识分享-----判断两个字符串是否为字母异位词(Anagram)【LeetCode 242】
✨ 题目描述 给定两个字符串 s 和 t,请判断 t 是否是 s 的字母异位词。 📌 示例 1: 输入:s "anagram", t "nagaram" 输出:true📌 示例 2: 输入:s "…...

Canal mysql to mysql 增加 online 库同步配置指南
Canal 增加新库 online 的配置指南 1. 停止 Canal Adapter 服务 ./bin/stop.sh2. 数据库备份与导入 备份源数据库 mysqldump -h 127.0.0.1 -P 3307 --single-transaction -uroot -p -B online > online.sql导入到目标数据库 mysql -h 127.0.0.1 -P 3308 -uroot -p <…...

Spring MVC中Controller是如何把数据传递给View的?
在 Spring MVC 中,Controller 负责请求的处理,准备需要展示的数据,并将这些数据传递给 View,由 View 负责最终的页面渲染。数据从 Controller 传递到 View 主要通过模型 (Model) 实现。 Spring MVC 提供了以下几种方式让 Control…...

FAST-LIO笔记
1.FAST-LIO FAST-LIO 是一个计算效率高、鲁棒性强的激光-惯性里程计系统。该系统通过紧耦合的迭代扩展卡尔曼滤波器(IEKF)将激光雷达特征点与IMU数据进行融合,使其在快速运动、噪声较大或环境复杂、存在退化的情况下仍能实现稳定的导航。 1…...

挑战用豆包教我学Java01天
今天是豆包教我学Java的第一天,废话不多说直接开始。 1.每日题目: 基础语法与数据类型 题目:编写一个 Java 程序,从控制台读取两个整数,然后计算它们的和、差、积、商,并输出结果。题目:编写…...

基于RT-Thread的STM32G4开发第二讲第二篇——ADC
文章目录 前言一、RT-Thread工程创建二、ADC工程创建三、ADC功能实现1.ADC.c2.ADC.h3.mian.c 四、效果展示和工程分享总结 前言 本文使用的是RT-Thread最新的驱动5.1.0,兼容下面的所有驱动。使用的开发板是蓝桥杯嵌入式国信长安的开发板,MCU是STM32G431…...
)
居民健康监测小程序|基于微信小程序的居民健康监测小程序设计与实现(源码+数据库+文档)
居民健康监测小程序 目录 基于微信小程序的居民健康监测小程序设计与实现 一、前言 二、系统设计 三、系统功能设计 1、用户信息管理 2、健康科普管理 5.3公告类型管理 3、论坛信息管理 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 …...

电商双11美妆数据分析
图中展示的是在Jupyter Notebook环境下的Python代码及运行结果。代码利用 seaborn 和 matplotlib 库,以 datal 数据集为基础,绘制上下两个子图。上方子图呈现各店铺中各大类的销售量,下方子图展示各店铺中各大类的销售额,通过条形…...
)
Spark-Core(双Value类型)
一、RDD转换算子(双Value类型) 1、intersection 函数签名: def intersection(other: RDD[T]): RDD[T] 函数说明:对源 RDD 和参数 RDD 求交集后返回一个新的 RDD 举栗: val dataRDD1 sparkContext.makeRDD(List(…...