【论文阅读】HunyuanVideo: A Systematic Framework For Large Video Generative Models
HunyuanVideo: A Systematic Framework For Large Video Generative Models
-
原文摘要
-
研究背景与问题
-
视频生成的变革性影响:近期视频生成技术的进步深刻改变了个人生活与行业应用。
-
闭源模型的垄断:主流视频生成模型(如Runway Gen-3、Luma 1.6等)均为闭源,导致工业界与开源社区之间存在显著的性能差距。
-
-
核心贡献:HunyuanVideo模型
-
开源视频基础模型:提出首个性能媲美甚至超越闭源模型的开放视频生成框架。
-
四大关键技术:
- 数据策展(curation):高质量数据集的构建与优化。
- 先进架构设计:创新的模型结构设计。
- 渐进式训练与扩展:通过分阶段训练和参数缩放提升性能。
- 高效基础设施:支持大规模训练与推理的底层系统优化。
-
-
模型规模与性能
-
参数量:超过130亿参数,为当前开源领域最大的视频生成模型。
-
性能优势:在视觉质量、运动动态、文本-视频对齐、专业拍摄技巧等方面表现优异,经专业人工评估,超越SOTA闭源模型(如Runway Gen-3)及3个中国顶尖视频模型。
-
-
实验与设计亮点
-
针对性优化:通过大量实验验证了模型在关键指标(如动态效果、文本对齐)上的优越性。
-
专业评估:采用人工评估(非自动化指标)确保结果可靠性。
-
-
-
Hunyuan Training System
1.Introduction
-
技术背景
-
扩散模型的优势:
- 相比传统GAN方法,扩散模型在图像/视频生成质量上表现更优,已成为主流生成范式。
- 图像生成领域的繁荣:开源生态活跃(如Stable Diffusion),催生大量算法创新和应用(如ControlNet、LoRA)。
-
视频生成的滞后:
- 基于扩散模型的视频生成技术发展缓慢,开源社区缺乏能与闭源模型(如Gen-3)竞争的基础模型。
- 关键瓶颈:缺乏像T2I(Text-to-Image)领域那样强大的开源视频基础模型。
-
-
问题分析:闭源垄断
-
闭源vs开源的不平衡:
- 闭源视频模型(如MovieGen)性能领先但未开源,压制了开源社区的创新潜力。
- 现有开源视频模型(如MovieGen)虽表现良好,但未形成稳定开源生态。
-
技术挑战:
- 直接扩展图像生成方法(如简单Transformer+Flow Matching)效率低下,计算资源消耗大。
-
-
HunyuanVideo的提出
-
核心目标:
- 构建首个高性能、全栈开源的视频生成基础模型,填补开源空白。
-
系统性框架:
- 训练基础设施:优化分布式训练与推理效率。
- 数据治理:互联网规模图像/视频的精选与预处理。
- 架构优化:突破简单Transformer的局限,设计高效缩放策略。
- 渐进式训练:分阶段预训练+微调,平衡资源与性能。
-
关键技术突破:
- 高效缩放策略:减少5倍计算资源,同时保持模型性能。
- 超大规模训练:成功训练130亿参数模型(当前开源最大)。
-
-
Hunyuan性能验证
-
四大核心指标:
- 视觉质量、运动动态、视频-文本对齐、语义场景切换(scene cut)。
-
评测结果:
- 评测规模:60人团队使用1,500+文本提示,对比Gen-3、Luma 1.6及3个中国商业模型。
- 关键结论:HunyuanVideo综合满意度最高,运动动态表现尤为突出。
-
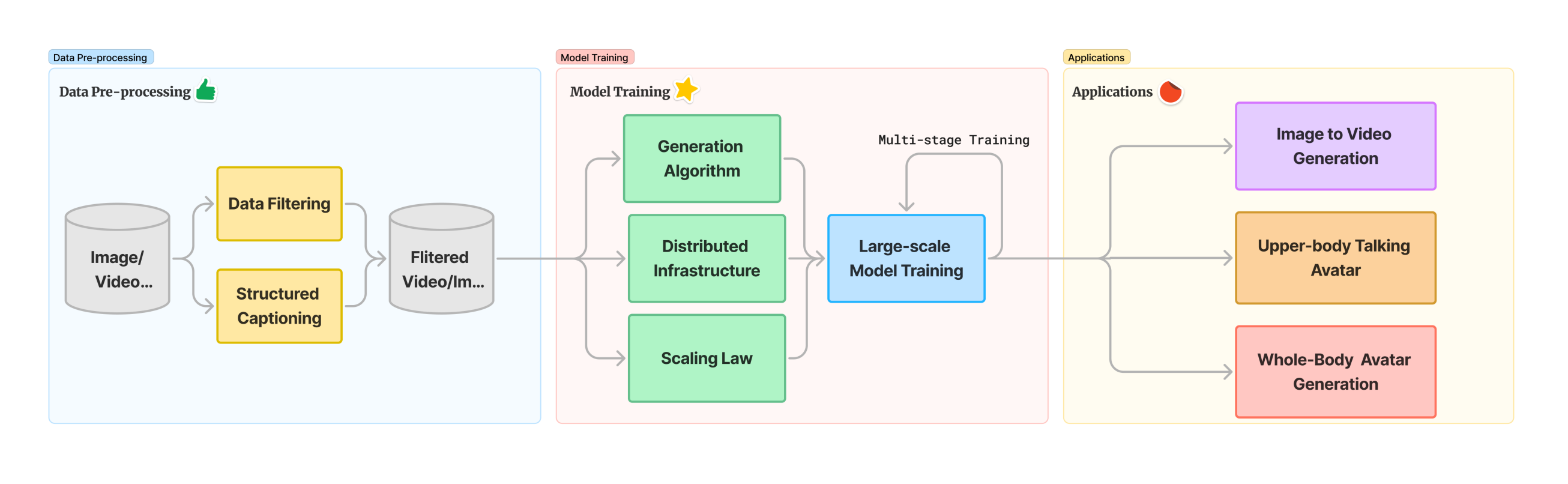
2. Data Pre-processing
- 数据来源&整体策略
- 训练策略:图像视频联合训练
- 数据分类:视频(5类)+ 图像(2类),针对性优化训练
- 合规保障:GDPR + 隐私计算技术,确保数据安全
- 高质量筛选:专业级标准(构图/色彩/曝光)提升模型表现
- 实验验证:高质量数据对模型性能有显著增益
2.1 Data Filtering

2.1.1 视频数据预处理
-
初始处理(Raw Video Processing)
-
单镜头分割:使用 PySceneDetect将原始视频拆分成单镜头片段(single-shot clips),避免跨镜头内容干扰。
-
清晰帧提取:通过 OpenCV 的 Laplacian 算子检测最清晰的帧作为片段的起始帧。
-
视频嵌入计算:使用内部 VideoCLIP 模型计算每个片段的嵌入向量(embeddings),用于:
- 去重:基于余弦相似度(Cosine distance)剔除重复/高度相似的片段。
- 概念平衡:通过 k-means 聚类生成约 1 万个概念中心(concept centroids),用于数据重采样,避免某些概念过拟合。
-
-
分层过滤(Hierarchical Filtering Pipeline)
-
通过多级过滤器逐步提升数据质量,最终生成 5 个训练数据集(对应后文的 5 个训练阶段)。关键过滤器包括:
-
美学质量评估
- 使用 Dover从**美学(构图、色彩)和技术(清晰度、曝光)**角度评分,剔除低质量视频。
- 训练专用模型检测模糊帧,移除不清晰的片段。
-
运动动态筛选
- 基于光流估计optical flow计算运动速度,过滤静态或运动过慢的视频。
-
场景边界检测
- 结合 PySceneDetect和 Transnet v2精确识别场景切换,确保片段连贯性。
-
文本与敏感信息处理
-
OCR 模型:移除含过多文字(如字幕)的片段,并裁剪字幕区域。
-
YOLOX类检测器:去除水印、边框、logo 等敏感或干扰元素。
-
-
-
实验验证
- 用小规模 HunyuanVideo 模型测试不同过滤器的效果,动态调整阈值(如严格度),优化最终流程。
-
-
渐进式数据增强
-
分辨率提升:从 256×256(65帧)逐步增加到 720×1280(129帧),适应不同训练阶段需求。
-
过滤严格度:早期阶段放宽标准保留多样性,后期逐步收紧(如更高美学/运动要求)。
-
-
微调数据集(Fine-tuning Dataset)
- 人工精选 100 万样本,聚焦高质量动态内容:
- 美学维度:色彩协调、光影、主体突出、空间布局。
- 运动维度:速度适中、动作完整性、无运动模糊。
- 人工精选 100 万样本,聚焦高质量动态内容:
2.1.2 图像数据过滤
-
复用视频的大部分过滤器(排除运动相关),构建 2 个图像数据集:
-
初始预训练数据集
- 规模:数十亿图文对,经过基础过滤(如清晰度、美学)。
- 用途:文本到图像(T2I)的第一阶段预训练。
-
第二阶段预训练数据集
-
规模:数亿精选样本,过滤阈值更严格(如更高分辨率、更优构图)。
-
用途:提升 T2I 模型的细节生成能力。
-
-
2.2 Data Annotaion
2.2.1 Structured Captioning
-
背景与问题
-
传统标注的缺陷:
- 简短标注(Brief Captions):信息不完整(如仅描述主体,忽略背景/风格)。
- 密集标注(Dense Captions):冗余或噪声多(如重复描述同一物体)。
-
需求:需兼顾全面性(多维度描述)、信息密度(无冗余)和准确性(与视觉内容严格对齐)。
-
-
解决方案:基于VLM的结构化标注
-
开发内部视觉语言模型(VLM),生成JSON格式的结构化标注,涵盖以下维度:
字段 描述 示例 Short Description 场景主要内容摘要 “A woman running in a park.” Dense Description 细节描述(含场景过渡、摄像机运动) “Camera follows a woman jogging through a sunlit park with trees.” Background 环境背景(地理位置、时间、天气等) “Sunny afternoon in Central Park.” Style 视频风格(纪录片、电影感、写实、科幻等) “Cinematic, shallow depth of field.” Shot Type 镜头类型(特写、中景、航拍等) “Medium shot, low angle.” Lighting 光照条件(自然光、背光、高对比度等) “Golden hour lighting.” Atmosphere 氛围(紧张、温馨、神秘等) “Energetic and lively.” Metadata Tags 从元数据提取的附加标签(来源、质量评分等) “Source: professional DSLR, Quality: 4.5/5” -
实现细节
-
多样性增强:通过随机丢弃(Dropout)和排列组合策略,生成不同长度/模式的变体,防止模型过拟合单一标注风格。
-
例如:同一视频可能生成以下两种标注:
// 变体1:强调运动与镜头 {"Dense Description": "Camera pans left to follow a cyclist...", "Shot Type": "Pan left"} // 变体2:强调风格与氛围 {"Style": "Documentary", "Atmosphere": "Gritty urban vibe"}
-
-
全数据覆盖:所有训练图像/视频均通过此标注器处理,确保数据一致性。
-
-
2.2.2 Camera Movement Types
-
研究动机
-
摄像机运动是视频动态表现的核心,但现有生成模型缺乏对其的显式控制能力。
-
需高精度分类以支持生成时的运动控制(如“镜头向右平移”)。
-
-
训练运动分类器
-
训练专用模型,预测以下14种运动类型:
运动类型 描述 应用场景 Zoom in/out 推近/拉远 突出主体或展示环境 Pan (up/down/left/right) 水平/垂直平移镜头 跟随运动或展示广阔场景 Tilt (up/down/left/right) 倾斜调整视角 创造戏剧化视角(如仰拍反派) Around left/right 环绕拍摄 3D场景展示(如产品展示) Static shot 固定镜头 对话场景或稳定画面 Handheld shot 手持抖动镜头 模拟纪实风格(如战争片) -
高置信度预测结果直接写入结构化标注JSON中
-
3. Model Design
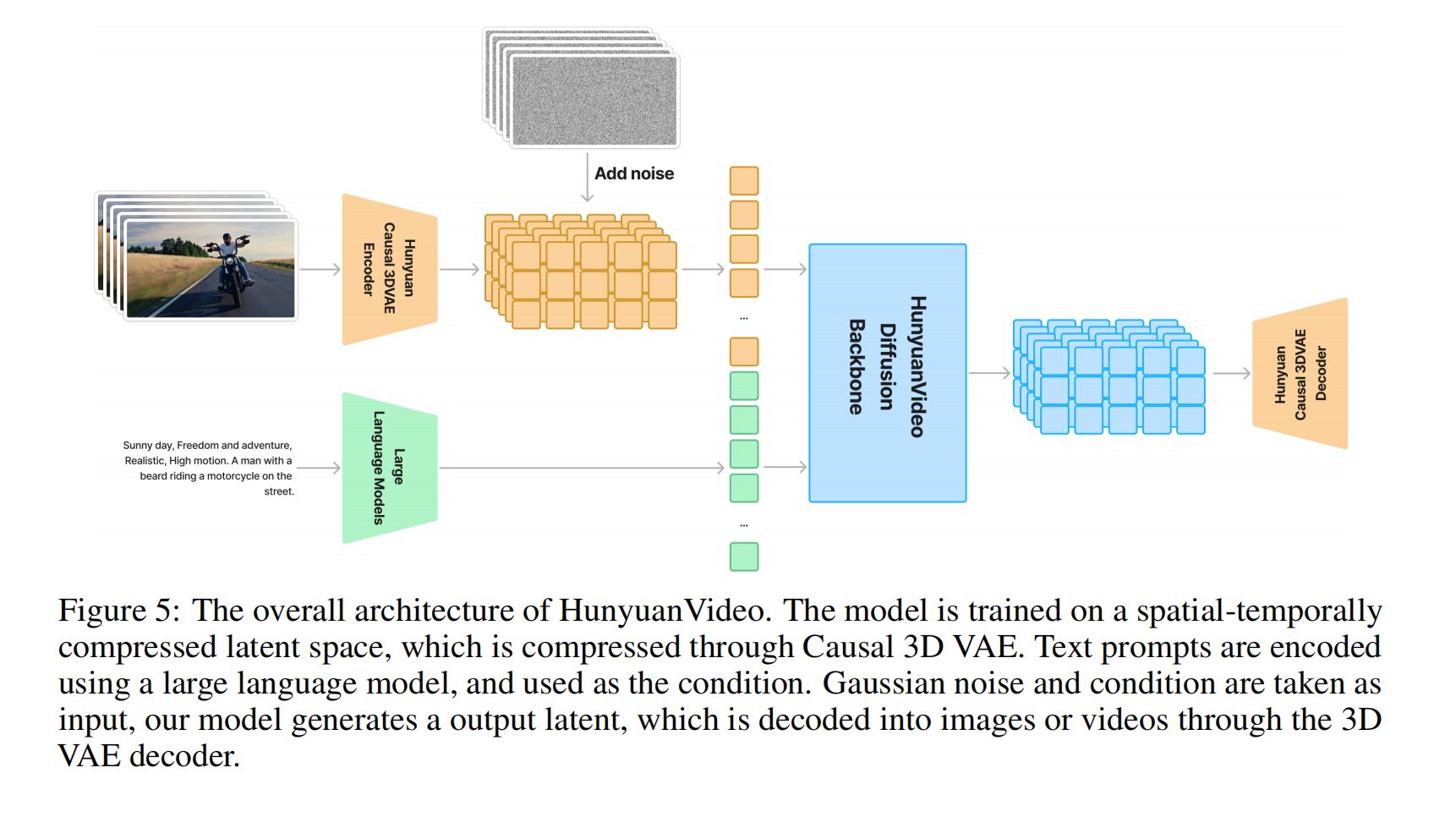
3.1 3D VAE Design
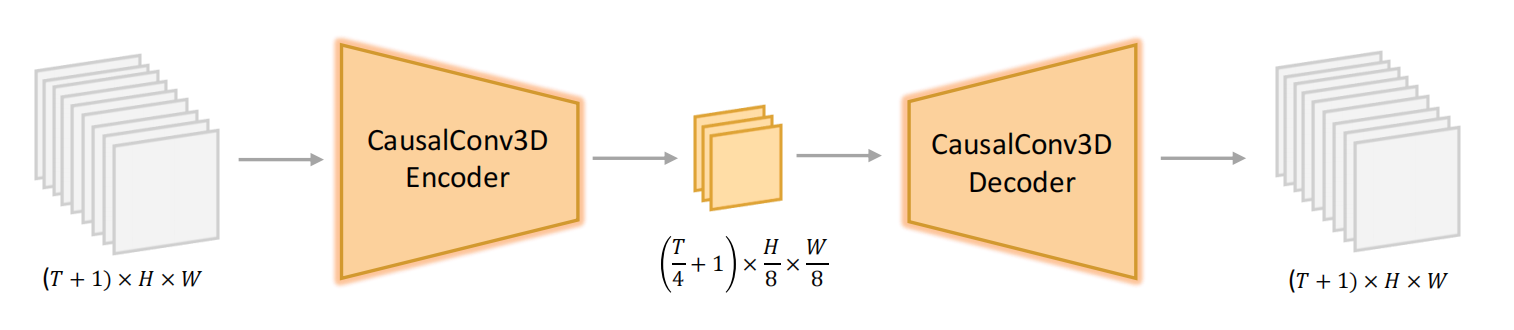
-
为了同时处理视频和图像,文章使用了CausalConv3D
-
网络架构设计
-
输入与输出格式
-
输入视频:形状为 ( T + 1 ) × 3 × H × W (T+1)×3 × H × W (T+1)×3×H×W
-
输出潜变量:形状为 ( T / c t + 1 ) × C × ( H / c s ) × ( W / c s ) (T/cₜ + 1) × C × (H/cₛ) × (W/cₛ) (T/ct+1)×C×(H/cs)×(W/cs)
cₜ:时间下采样因子(temporal stride),默认为 4(即每4帧压缩为1个隐变量帧)。cₛ:空间下采样因子(spatial stride),默认为 8(如输入256×256 → 隐空间32×32)。C:隐变量通道数,默认为 16。
-
-
3D卷积编码器:
- 采用 CausalConv3D(因果3D卷积),确保时间维度上的因果性(当前帧仅依赖过去帧)。
- 层级式下采样结构,逐步压缩时空维度(类似3D版U-Net)。
-
3D卷积解码器:
- 对称结构,通过转置3D卷积(Transpose3DConv)重建原始分辨率视频。
-
为什么输入是T+1帧
- 要以第一帧作为参考帧,来实现因果卷积
-
3.1.1 Training
-
训练数据与初始化
-
不从预训练图像VAE初始化:
- HunyuanVideo 从头训练 3DVAE,避免预训练图像VAE的偏差。
- 原因:视频数据具有时空连续性,直接复用图像VAE参数会限制模型对运动信息的建模能力。
-
数据混合比例:
- 视频与图像数据按 4:1 混合训练,平衡时空动态(视频)与静态细节(图像)的学习。
-
-
损失函数设计
Loss = L 1 + 0.1 L lpips + 0.05 L adv + 1 0 − 6 L kl \text{Loss} = L_{1} + 0.1 L_{\text{lpips}} + 0.05 L_{\text{adv}} + 10^{-6} L_{\text{kl}} Loss=L1+0.1Llpips+0.05Ladv+10−6Lkl-
L1重建损失:
- 约束像素级重建精度,保留低频结构信息。
-
Llpips感知损失:
- 通过预训练VGG网络计算特征相似性,提升细节和纹理质量。
-
Ladv对抗损失:
- 添加判别器区分真实与重建帧,增强生成逼真度。
-
KL散度损失:
- 约束隐变量分布接近标准高斯(权重10⁻⁶),避免后验坍塌。
-
-
渐进式课程学习(Curriculum Learning)
-
分阶段训练: 逐步提升分辨率
- 低分辨率短视频(如256×256,16帧)→ 学习基础时空特征。
- 逐步提升至高清长视频(如720×1280,128帧),避免直接训练高难度数据的收敛问题。
-
动态帧采样:
- 随机从 1~8帧间隔 均匀采样,强制模型适应不同运动速度的视频(如快速动作或静态场景)。
- 若
k=1:取所有帧(处理原始运动速度)。 - 若
k=4:每4帧取1帧(模拟4倍速运动)。 - 若
k=8:每8帧取1帧(极端高速运动测试)。
- 若
- 随机从 1~8帧间隔 均匀采样,强制模型适应不同运动速度的视频(如快速动作或静态场景)。
-
3.1.2 Inference
-
问题背景:
- 高分辨率长视频(如4K)在单GPU上直接编码/解码会内存溢出(OOM)。
-
解决方案:
-
时空分块(Tiling):
- 将输入视频在时空维度切分为重叠块,各块单独编码和解码。
- 输出时通过线性混合重叠区消除接缝。
-
分块感知微调:
-
问题:直接分块推理会导致训练-测试不一致(出现边界伪影)。
-
改进:在训练中随机启用/禁用分块,使模型同时适应分块与非分块输入。
-
-
3.2 Unified Image and Video Generative Architecture
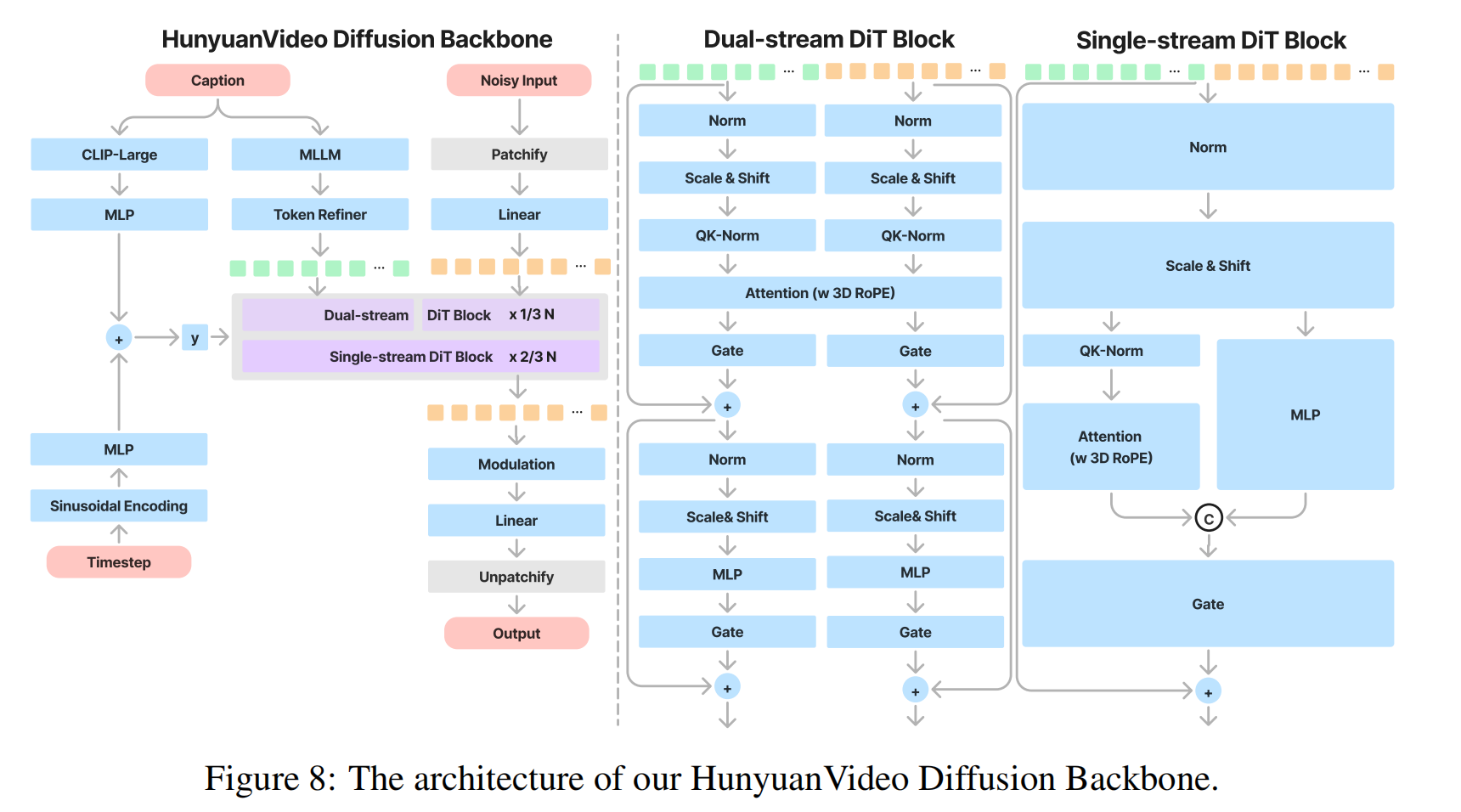
-
架构设计动机
-
统一架构的好处
-
性能优势:实验证明,全注意力机制(Full Attention)比分离的时空注意力生成质量更高,尤其在跨模态对齐上。
-
训练简化:图像(单帧)和视频(多帧)使用同一套参数,避免维护多个模型。
-
硬件友好:复用LLM的注意力优化技术(如FlashAttention),提升训练/推理效率。
-
-
输入统一化
-
图像视为单帧视频:
- 视频输入:
T × C × H × W(T帧,C通道,H×W分辨率)。 - 图像输入:
1 × C × H × W(T=1)。
- 视频输入:
-
潜空间压缩:通过3DVAE将像素空间映射到低维潜空间
-
-
3.2.1 Inputs
-
视频
-
3D Patch嵌入:
- 使用 3D卷积(核大小
kt × kh × kw)将潜变量切分为时空块(Patch)。 - 例如:
kt=2, kh=16, kw=16→ 每2帧×16×16像素区域转为1个Token。 - Token序列长度:
(T/kt) × (H/kh) × (W/kw)。
- 使用 3D卷积(核大小
-
示例计算:
- 输入潜变量:
16×16×32×32(T=16, H=W=32),kt=kh=kw=2→ Token数:8×16×16=2048。
- 输入潜变量:
-
-
文本
-
细粒度语义编码:
- 用 LLM将文本转为Token序列(如512维向量)。
-
全局语义补充:
- 通过 CLIP 提取文本的全局嵌入,与时间步嵌入融合后输入模型。
- 这里和stable diffusion不同,hunyuan将clip的token向量(L,D)进行全局池化后变成了包含全局语义信息的(1,D)向量
- 通过 CLIP 提取文本的全局嵌入,与时间步嵌入融合后输入模型。
-
3.2.2 Model Design
-
双流阶段(Dual-stream)
-
独立处理模态:
- 视频Token流:通过多层Transformer块学习时空特征。
- 文本Token流:通过另一组Transformer块提取语言特征。
-
目的:
- 避免早期融合导致模态干扰(如文本噪声污染视觉特征)。
-
-
单流阶段(Single-stream)
-
Token拼接:将视频Token和文本Token合并为单一序列。
- 例如:
[Video_Tokens; Text_Tokens]→ 总长度2048+512=2560。
- 例如:
-
跨模态注意力:
- 通过Transformer块计算视频-文本交叉注意力,实现细粒度对齐(如物体属性与描述匹配)。
-
3.2.3 Position Embedding
-
RoPE的三维扩展
-
分通道计算:
- 将 Query/Key 的通道分为三组: d t , d h , d w d_t,d_h,d_w dt,dh,dw,对应时间T、高度H、宽度W。
-
旋转矩阵应用:
- 对每组通道分别乘以对应的旋转频率矩阵(如时间频率、空间频率)。
-
拼接与注意力:
- 合并三组通道后的Query/Key用于注意力计算,显式编码时空位置关系。
- 公式示意:
RoPE3D ( Q , K ) = Concat ( Rotate ( Q d t , T ) , Rotate ( Q d h , H ) , Rotate ( Q d w , W ) ) \text{RoPE3D}(Q,K) = \text{Concat}(\text{Rotate}(Q_{d_t}, T), \text{Rotate}(Q_{d_h}, H), \text{Rotate}(Q_{d_w}, W)) RoPE3D(Q,K)=Concat(Rotate(Qdt,T),Rotate(Qdh,H),Rotate(Qdw,W))
-
3.3 Text Encoder
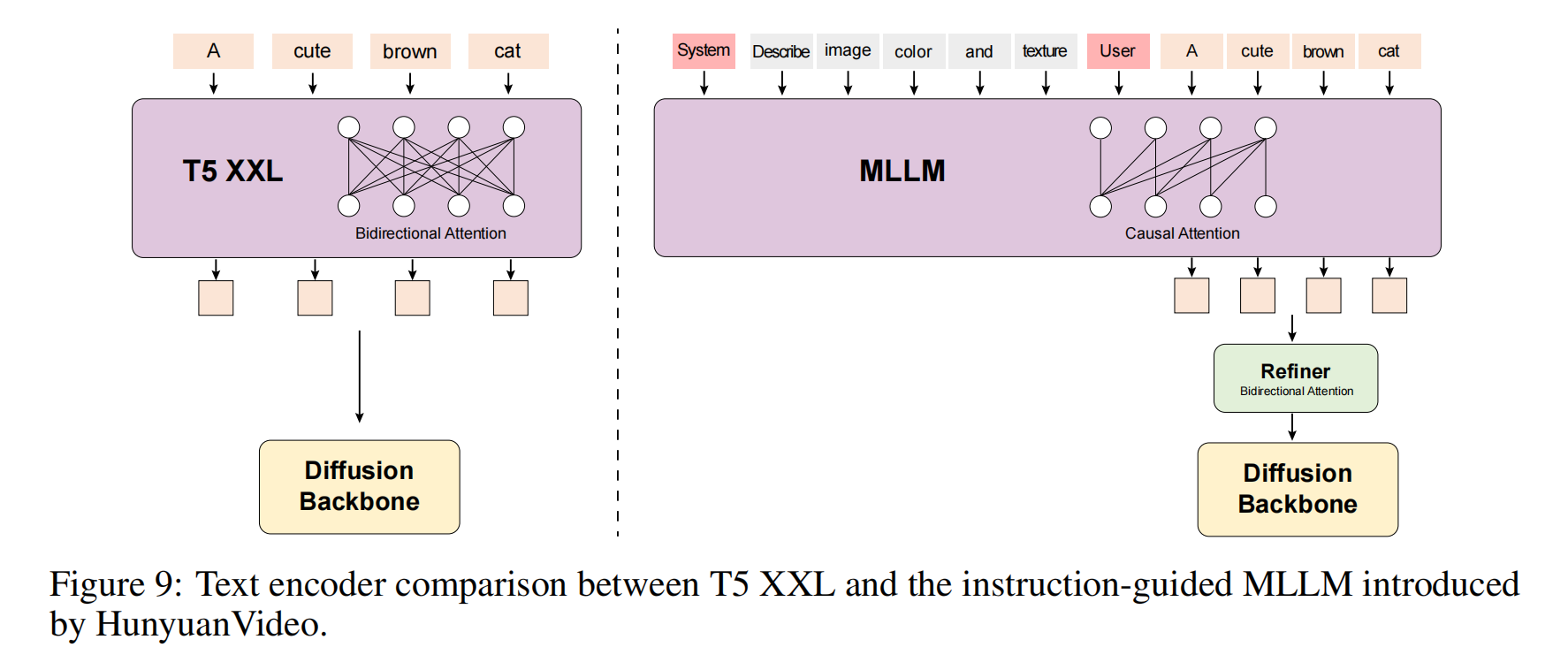
-
选择MLLM的原因
-
图像-文本对齐优势:
- MLLM 经过 视觉指令微调,其文本特征在隐空间中与视觉内容对齐更佳,缓解了扩散模型“指令跟随不准”的问题(如忽略细节描述)。
-
复杂推理能力:
- MLLM 在图像细节描述(如“猫的绿色眼睛”)和逻辑推理(如“A 在 B 左侧”)上优于 CLIP 和 T5。
-
零样本学习:
- 通过添加系统指令前缀(如“生成一个视频,包含以下元素:…”),MLLM 能自动聚焦关键信息,抑制无关描述。
-
-
MLLM 的设计
-
因果注意力的局限性
-
问题:Decoder-Only 结构(如 GPT)的因果注意力只能关注历史 Token,导致文本特征缺乏全局上下文。
-
解决方案:
- 引入 双向 Token 优化器(Bidirectional Token Refiner),对 MLLM 输出的文本特征进行后处理,增强上下文感知。
-
作用:
- 弥补 Decoder-Only 模型在双向语义理解上的不足,提升提示词之间的关联性(如“红色”和“苹果”)。
-
-
-
CLIP 辅助作用
-
CLIP 特征的提取
-
输入:与 MLLM 相同的文本提示。
-
处理:
- 通过 CLIP-Large 的文本编码器生成 Token 序列。
- 取最后一个非填充 Token 的向量作为全局特征(形状
[1, D])。
-
用途:
- 作为全局条件信号,与 MLLM 的细粒度特征互补,注入 DiT 的双流和单流阶段。
-
-
CLIP的作用
-
稳定性:CLIP 的对比学习训练使其全局特征在风格控制(如“科幻”、“写实”)上更鲁棒。
-
多模态对齐:CLIP 的文本-图像对齐能力可约束 MLLM 的输出,避免生成偏离语义的内容。
-
-
3.4 Model-pretraining
3.4.1 Training Objective
HunyuanVideo 采用 Flow Matching 框架训练图像和视频生成模型,其核心思想是通过 概率密度变换 和 速度场预测,将简单分布(如高斯噪声)逐步映射到复杂数据分布(如图像/视频潜空间)。
-
Flow Matching 的核心思想
-
基本定义
-
目标:学习一个连续变换路径(Flow),将简单分布 p 0 p_0 p0(如高斯噪声)转换为数据分布 p 1 p_1 p1(如真实图像/视频的潜变量)。
-
数学形式:通过时间 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1] 参数化的概率密度变换:
p t = Transform ( p 0 , t ) p_t = \text{Transform}(p_0, t) pt=Transform(p0,t)- 其中 p t p_t pt 是从 p 0 p_0 p0 到 p 1 p_1 p1 的中间状态。
-
-
-
训练过程的数学推导
-
样本构造
-
输入数据:从训练集采样真实潜变量 x 1 x_1 x1(通过3DVAE编码的图像/视频)。
-
噪声初始化:采样 $x_0 \sim \mathcal{N}(0, I) $。
-
时间采样:从 logit-normal 分布 采样 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1],偏好两端 ( t ≈ 0 或 t ≈ 1 ) ( t \approx 0 或 t \approx 1) (t≈0或t≈1)以强化困难样本学习。
-
线性插值:构造中间样本 ( x_t ):
x t = t x 1 + ( 1 − t ) x 0 x_t = t x_1 + (1-t) x_0 xt=tx1+(1−t)x0
- 当 t = 0 t=0 t=0: x t = x 0 x_t = x_0 xt=x0(纯噪声)。
- 当 t = 1 t=1 t=1: x t = x 1 x_t = x_1 xt=x1(真实数据)。
-
-
速度场预测
-
真实速度(Ground Truth):
- 对线性插值路径,真实速度为:
u t = d x t d t = x 1 − x 0 u_t = \frac{dx_t}{dt} = x_1 - x_0 ut=dtdxt=x1−x0
-
模型预测:
- 神经网络 v θ v_\theta vθ 预测速度场 v t = v θ ( x t , t ) v_t = v_\theta(x_t, t) vt=vθ(xt,t)。
-
损失函数:最小化预测速度与真实速度的均方误差(MSE):
L generation = E t , x 0 , x 1 ∥ v t − u t ∥ 2 \mathcal{L}_{\text{generation}} = \mathbb{E}_{t,x_0,x_1} \| v_t - u_t \|^2 Lgeneration=Et,x0,x1∥vt−ut∥2- 物理意义:强制模型学习如何将任意 x t x_t xt 推回真实数据 x 1 x_1 x1。
-
-
-
推理过程的实现
-
从噪声生成数据
-
初始化:采样噪声 x 0 ∼ N ( 0 , I ) x_0 \sim \mathcal{N}(0, I) x0∼N(0,I)。
-
ODE求解:
-
使用一阶欧拉方法(Euler ODE Solver)数值求解:
x t + Δ t = x t + v θ ( x t , t ) ⋅ Δ t x_{t+\Delta t} = x_t + v_\theta(x_t, t) \cdot \Delta t xt+Δt=xt+vθ(xt,t)⋅Δt -
从 t = 0 t=0 t=0 到 t = 1 t=1 t=1 积分,得到最终样本 x 1 x_1 x1 。
-
-
输出:将 x 1 x_1 x1 输入3DVAE解码器,生成图像/视频。
-
-
3.4.2 Image Pre-training
-
第一阶段:256px 低分辨率训练
-
目的:建立基础语义映射(文本→图像),学习低频概念(如物体形状、布局)。
-
关键技术:
- 多长宽比训练(Multi-aspect Training):
- 避免裁剪导致的文本-图像错位(如“全景图”被裁剪后丢失关键内容)。
- 示例:256px 锚定尺寸下,支持 1:1(正方形)、16:9(宽屏)等多种比例。
- 多长宽比训练(Multi-aspect Training):
-
-
第二阶段:256px+512px 混合尺度训练
-
问题:直接微调512px会导致模型遗忘256px生成能力,影响后续视频训练。
-
解决方案:
- 动态批量混合(Mix-scale Training):
- 每个训练批次包含不同分辨率的图像(如256px和512px),按比例分配GPU资源。
- 锚定尺寸扩展:以256px和512px为基准,分别构建多长宽比桶(Aspect Buckets)。
- 动态批量大小:
- 高分辨率分配较小批量,低分辨率分配较大批量,最大化显存利用率。
- 动态批量混合(Mix-scale Training):
-
3.4.3 Video-Image Joint Training
-
数据分桶(Bucketization)
-
分桶策略:
- 时长分桶(BT buckets):如 16帧、32帧、64帧。
- 长宽比分桶(BAR buckets):如 4:3、16:9、1:1。
- 总桶数:BT × BAR(如3时长×3比例=9桶)。
-
动态批量分配:
- 每个桶根据显存限制设置最大批量(如16帧视频批量大,64帧视频批量小)。
- 训练时随机从不同桶采样,增强模型泛化性。
-
-
渐进式课程学习
训练阶段 目标 低清短视频 建立文本-视觉基础映射,学习短程运动 低清长视频 建模复杂时序 高清长视频 提升分辨率与细节质量 - 图像数据的作用:
- 缓解视频数据不足,防止模型遗忘静态场景语义(如物体纹理、光照)。
- 图像数据的作用:
3.5 Prompt Rewrite
- 训练无关的上下文重写
- 多语言适配:该模块旨在处理和理解各种语言的用户提示,确保保留意义和上下文。
- 结构标准化:该模块重述提示,使其符合标准化的信息架构。
- 术语简化:将口语或专业术语转化为生成模型熟悉的表达。
- 自修正技术(Self-Revision)
- 对比原始提示与重写结果,通过语义相似度检测和自动修正,确保意图一致性。
- 轻量化微调(LoRA)
- 基于高质量重写样本对 Hunyuan-Large 进行低秩适配器(LoRA)微调,提升重写精度和效率,支持实时处理。
4. Image-to-Video
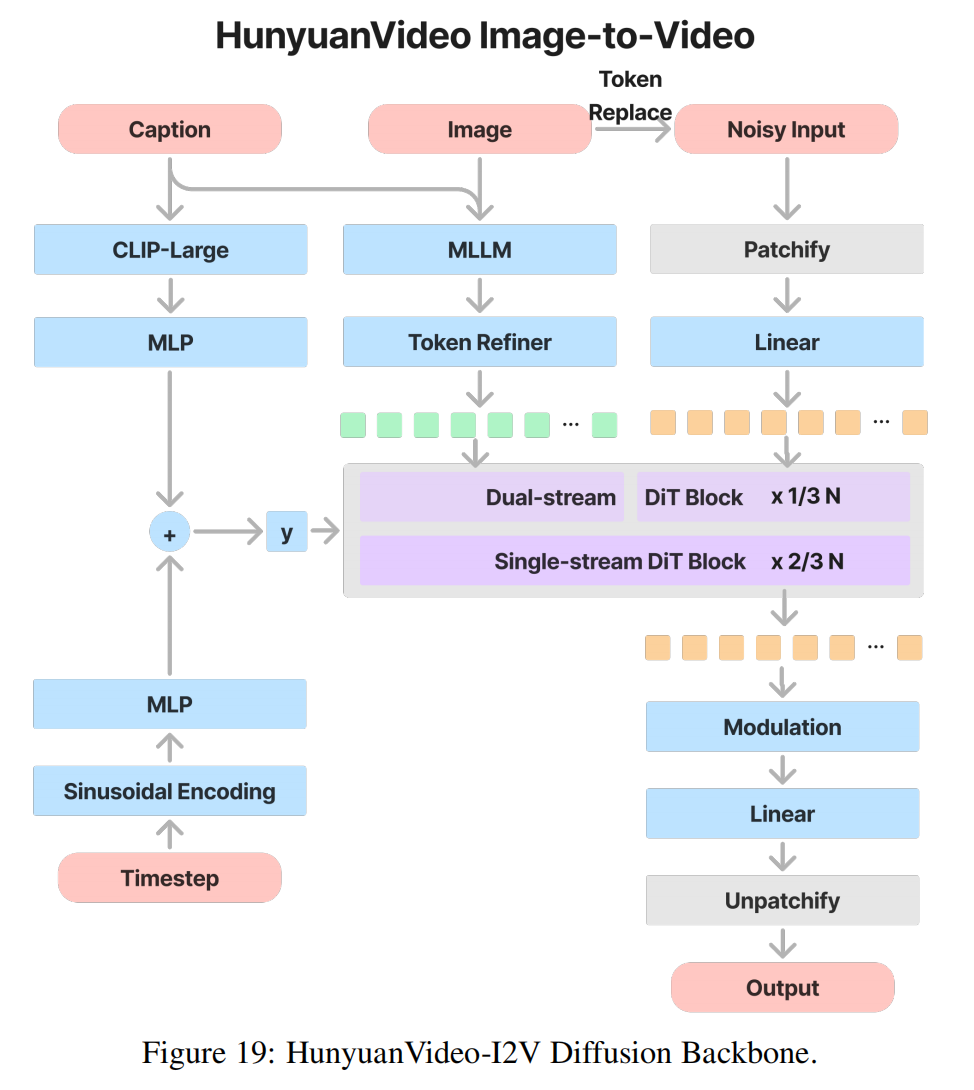
-
核心架构设计
-
图像潜变量替换(Token Replace)
- 输入处理:
- 将参考图像通过 3DVAE 编码器 转换为潜变量 z image z_{\text{image}} zimage(形状: C × H × W C \times H \times W C×H×W )。
- 替换首帧:在生成视频的潜变量序列中,强制将第一帧替换为 z image z_{\text{image}} zimage ,并设置其时间步 t = 0 t=0 t=0(表示完全保留图像信息)。
- 该帧参与attention机制,用于被别的帧参考;但不会参与去噪,即每个timestep都不会被更改。
- 后续帧生成:其余帧通过 T2V 的 Flow Matching 框架生成,确保运动连贯性。
- 输入处理:
-
语义图像注入模块(Semantic Image Injection)
- 多模态对齐:
- 将输入图像输入 MLLM(多模态大模型),提取语义 Token
- 将这些 Token 与视频潜变量拼接,参与 全注意力计算(Full-Attention),确保生成视频的语义与图像一致。
- 多模态对齐:
-
-
训练策略
-
预训练阶段
- 数据:使用与 T2V 相同的数据集,但将部分样本的首帧替换为图像,并添加图像描述作为附加条件。
-
下游任务微调(人像视频生成)
-
数据筛选:
- 使用 人脸和人体检测器 过滤训练视频:
- 移除超过 5 人的视频(避免群体动作干扰)。
- 移除主体过小的视频(确保主要人物清晰)。
- 人工审核保留高质量人像视频(约 200 万条)。
- 使用 人脸和人体检测器 过滤训练视频:
-
渐进式微调:
- 初始阶段:仅微调与图像注入相关的模块(如 MLLM 的投影层)。
- 后期阶段:逐步解冻更多层(如时空注意力层),平衡人像生成与通用性。
-
-
相关文章:

【论文阅读】HunyuanVideo: A Systematic Framework For Large Video Generative Models
HunyuanVideo: A Systematic Framework For Large Video Generative Models 原文摘要 研究背景与问题 视频生成的变革性影响:近期视频生成技术的进步深刻改变了个人生活与行业应用。 闭源模型的垄断:主流视频生成模型(如Runway Gen-3、Luma …...

Search After+PIT 解决ES深度分页问题
1.深分页和search after 原理 深分页 (from/size)search_after数据定位全局排序后跳过前 N 条基于上一页最后一条的排序值定位排序开销每次请求重新全局排序 (O(N))仅首次全局排序,后续游标跳转 (O(1))内存消耗堆内存存储完整结果集 (高风险OOM)无堆内存累积 (安全…...
)
c语法高阶—(联合体,枚举,位域,编译器,宏定义,条件编译,条件编译,头文件)
目录 一 联合体(重要) 特性 总结 二 枚举(重要) 特性 总结: 三 位域(了解) 定义 特性 使用场景 优缺点分析表 位域的特点和使用方法 总结: 四 编译器(linux…...

SQL Server To Paimon Demo by Flink standalone cluster mode
需求:使用 Flink CDC 测试 SQL Server 连接 Paimon 操作:启动 Flink standalone cluster 后,接着启动 Flink SQL Client,则通过 Flink SQL Client 提交 insert & select job 到该 8081 cluster Flink SQL Client 执行案例 -…...

常用设计模式在 Spring Boot 项目中的实战案例
引言 在当今的软件开发领域,Spring Boot 以其高效、便捷的特性成为构建 Java 应用程序的热门框架。而设计模式作为软件开发中的宝贵经验总结,能够显著提升代码的可维护性、可扩展性和可复用性。本文将深入探讨几种常用设计模式在 Spring Boot 项目中的…...

4、反应釜压力监控系统 - /自动化与控制组件/reaction-vessel-monitor
76个工业组件库示例汇总 反应釜压力监控组件 这是一个用于反应釜压力监控的自定义组件,专为化工厂反应釜压力监控设计。采用苹果工业风格界面,简洁优雅,功能实用,易于使用。 功能特点 实时压力可视化:直观展示反应…...
)
五、Hadoop集群部署:从零搭建三节点Hadoop环境(保姆级教程)
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 前言: 想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。 …...
)
详细剖析传输层协议(TCP和UDP)
详细讲解传输层的网络协议,为什么TCP是可靠连接协议,凭什么能做到不丢包,有哪些机制保证可靠呢? TCP/UDP UDPTCP**三次握手和四次挥手****滑动窗口****拥塞控制**(socket套接字)**listen的第二个参数** UD…...

ZYNQ移植FreeRTOS与OpenAMP双核开发实践指南
ZYNQ系列芯片凭借其“ARM处理器(PS)+ FPGA(PL)”的异构架构,在嵌入式系统中被广泛应用于高性能计算与实时控制场景。然而,如何高效利用其双核资源并实现实时操作系统(如FreeRTOS)的移植与双核通信,是开发者面临的关键挑战。本文将深入探讨FreeRTOS移植、双核固化启动以…...

VUE+ElementUI 使用el-input类型type=“number” 时,取消右边的上下箭头
项目场景: 提示:这里简述项目相关背景: 在项目中有时候需要输入框的type“number”,这个时候,输入框的右边就会出现两个按钮,这两个按钮可以递增/递减,但是这样输入框看上去就不太美观&#x…...

RabbitMQ高级特性
1.消息的可靠投递 在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两种方式用来控制消息的投递可靠性模式。 1.confirm 确认模式 2.return 退回模式 rabbitmq 整个消息投递的路径为: producer…...

在Python中调用C/C++函数并与MPI集成
在Python中调用C/C函数并与MPI集成 要在Python环境中调用C/C函数并让Python和C/C端都能使用MPI进行通信,有几种方法可以实现。下面我将介绍几种常见的方法。 方法一:使用mpi4py C/C MPI扩展 1. 准备工作 首先确保你已安装: MPI实现 (如OpenMPI或MP…...

软件架构评估方法全面解析
介绍 在软件开发过程中,架构设计的好坏直接影响系统的可维护性、可扩展性和性能。因此,软件架构评估(Software Architecture Evaluation)成为确保架构质量的关键步骤。本文将介绍几种主流的架构评估方法,包括ATAM、SA…...

场景可视化与数据编辑器:构建数据应用情境
场景可视化是将数据与特定的应用场景相结合,借助数据编辑器对数据进行灵活处理和调整,通过模拟和展示真实场景,使企业能够更直观地理解数据在实际业务中的应用和影响,为企业的决策和运营提供有力支持。它能够将抽象的数据转化为具…...

MATLAB导出和导入Excel文件表格数据并处理
20250507 1.MATLAB使用table函数和writetable函数将数据导出Excel表格文件 我们以高斯函数为例子,高斯函数在数学和工程领域有着广泛的应用,它的一般形式为: 其中是均值,决定了函数的中心位置; 是标准差,决…...
(题目+回答))
2025年渗透测试面试题总结-渗透岗位全职工作面试(附回答)(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 一、通用基础类问题 1. 自我介绍 2. 职业动机与规划 3. 加班/出差接受度 二、安全技术类问题 1. 漏…...

【django.db.utils.OperationalError: unable to open database file】
解决platform.sh 环境下,无法打开数据库问题 场景 在platform.sh 执行python manage.py createsuperuser是提示 django.db.utils.OperationalError: unable to open database file 错误 原因 由于settings.py文件中 本地数据库配置在线上配置后,导致…...

【人工智能】解锁AI潜能:LM Studio多模型并行运行DeepSeek与开源大模型的实践指南
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着大语言模型(LLM)的快速发展,LM Studio作为一款本地化部署工具,以其简单易用的图形化界面和强大的模型管理能力受到广泛关注。本文深…...

集群免密登录
免密登录原理 核心步骤 在hadoop100上 生成密钥对。把hadoop100的公钥发到hadoop101上。在hadoop100上登录hadoop101,验证效果 具体操作 登录 hadoop100。使用finalshell连接。在hadoop100上,运行命令:ssh-keygen -t rsa。然后根据提示连续敲…...
/FormatMessage 的区别)
【C/C++】errno/strerror 和 GetLastError()/FormatMessage 的区别
strerror 和 errno 详解 printf("Error: %s\n", strerror(errno));这行代码用于在 C 语言中输出系统错误信息,但它与 Windows 的 GetLastError() 有重要区别。下面我将详细解释每个部分及其工作原理。 1. 组件解析 errno 定义:errno 是一个…...

ASP.NET MVC4 技术单选及多选题目汇编
一、单选题(共50题,每题2分) 1、ASP.NET MVC4 的核心架构模式是什么? A. MVP B. MVVM C. MVC D.三层架构 答案:C 2、在 MVC4 中,默认的路由配置文件名是? A. Global.asax B. RouteConfig.cs C.…...

趣味编程:梦幻万花筒
目录 1.效果展示 2.源码展示 3.代码逻辑详解 3.1 头文件与宏定义 3.2 HSV函数转RGB颜色函数 3.3 主函数 初始化部分 循环部分 线条绘制部分 刷新和延时部分 结束部分 4.小结 本篇博客主要介绍趣味编程用C语言实现万花筒小程序。 1.效果展示 2.源码展示 #define…...

使用 Selenium 截图功能,截不到原生 JavaScript 弹窗
本篇内容源自ai注意甄别 Selenium WebDriver 的标准截图 (getScreeenshotAs) 捕获的是浏览器渲染的 DOM 内容,而 JavaScript 的 alert()、confirm()、prompt() 这类弹窗是浏览器级别的原生 UI 元素,它们不属于页面的 DOM 结构。 为什么会这样ÿ…...

dubbo-token验证
服务提供者过滤器 import java.util.Map; import java.util.Objects;/*** title ProviderTokenFilter* description 服务提供者 token 验证* author zzw* version 1.0.0* create 2025/5/7 22:17**/ Activate(group CommonConstants.PROVIDER) public class ProviderTokenFilt…...

C++入门之认识整型
目录 一、变量 1.导入 2.变量 2.1 变量的作用 2.2 变量的定义方式 2.3 变量的“规矩” 二、数据类型 1.概念 2.int整型 三、C的常见运算 四、输入操作 4.1 cin 4.2 try 1 try 4.2.1 cin>> 4.2.2 定义的整数类型,输入字母会怎么样? …...

【数据结构入门训练DAY-28】蓝桥杯算法提高VIP-产生数
文章目录 前言一、题目二、解题思路结语 前言 本次训练内容 训练高精度乘法。训练解题思维。 一、题目 给出一个整数 n 和 k 个变换规则。规则:一位数可变换成另一个一位数:规则的右部不能为零。例如:n234。有规则(k&…...
)
学习笔记:黑马程序员JavaWeb开发教程(2025.3.29)
11.5 案例-文件上传-阿里云OSS-入门 出现报错:Process exited with an error: 1 (Exit value: 1),点击exec那一行,出现错误原因:Command execution failed. 在CSDN上找到了解决方法: 之后出现新的报错:Caug…...

大语言模型中的“温度”参数到底是什么?如何正确设置?
近年来,市面上涌现了大量调用大模型的工具,如 Dify、Cherry Studio 等开源或自研平台,几乎都提供了 “温度”(Temperature) 选项。然而,很多人在使用时并不清楚该如何选择合适的温度值。 今天,…...

【C++】C++中的类型转换
🚀write in front🚀 📜所属专栏: C学习 🛰️博客主页:睿睿的博客主页 🛰️代码仓库:🎉VS2022_C语言仓库 🎡您的点赞、关注、收藏、评论,是对我最大…...

Go语言基础学习详细笔记
文章目录 初步了解Go语言Go语言诞生的主要问题和目标Go语言应用典型代表Go语言开发环境搭建经典HelloWorld 基本程序结构编写学习变量常量数据类型运算符 条件语句if语句switch 语句 跳转语句常用集合和字符串数组切片Map实现Set**字符串** 函数**基本使用用例验证** 面向对象编…...
)
初始图形学(7)
上一章完成了相机类的实现,对之前所学的内容进行了封装与整理,现在要学习新的内容。 抗锯齿 我们放大之前渲染的图片,往往会发现我们渲染的图像边缘有尖锐的"阶梯"性质。这种阶梯状被称为"锯齿"。当真实的相机拍照时&a…...

Linux 安装交叉编译器后丢失 `<asm/errno.h>` 的问题及解决方案
前言 在 Linux (Ubuntu等)环境下安装某些软件或开发环境时,我们可能会意外地引入交叉编译工具链,尤其是用于 ARM 架构的交叉编译器,比如 gcc-arm-linux-gnueabi 等。而这种行为会修改系统原有的开发环境,甚至导致无法编译原生程序。本文记录一次在 Ubuntu 18.04 上编译 …...

无人机上的热成像相机可以单独使用吗?
想知道无人机上的热成像相机是否可以单独使用,这需要从多个方面来分析。首先,得理解热成像相机的工作原理和依赖条件。热成像本身需要传感器和处理器来捕捉和处理红外辐射,所以无人机是否必须作为载体呢? 无人机上的热成像相机是否…...

go基于redis+jwt进行用户认证和权限控制
go基于redisjwt进行用户认证和权限控制: 基于 jwt 实现用户认证 基于 redis 记录用户的角色和权限 效果 实现 用户认证 和 权限控制 核心实现 下面的例子:有三个用户,分别为三个角色:admin、user、manager 路由: …...

深入理解Java三大特性:封装、继承和多态
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

复刻低成本机械臂 SO-ARM100 上位机控制调试
视频讲解: 复刻低成本机械臂 SO-ARM100 上位机控制调试 SO-ARM100机械臂组装并且标定完成后,下一步就是整臂的调试,由于只做了follower这个从臂,所以要使用lerobot仓库中遥操作控制的方式就不行了,这里发现了bambot这个…...

代码随想录图论part4
图论part04 字符串接龙 代码随想录 该题本质是最短路径问题,方法:广搜 通过逐个修改字符完成从一点到另一点的变换 具体是通过对栈顶字符串的每个字符用26个字母逐个替换 每次替换要判断是否抵达终点 抵达终点返回结果 没有抵达终点就判断是否是已…...

台州智惠自动化签约智橙PLM,让创新持续发生
日前,台州智惠自动化科技有限公司(以下简称“智惠自动化”)正式签约了智橙PLM,本次签约是工业自动化领域的革新者和工业研发创新平台的“新新联合”,对“制造之都”台州的制造业转型有着重要意义和深远影响。 智惠自动…...

南京大学OpenHarmony技术俱乐部正式揭牌 仓颉编程语言引领生态创新
2025年4月24日,由OpenAtom OpenHarmony(以下简称“OpenHarmony”)项目群技术指导委员会与南京大学软件学院共同举办的“南京大学OpenHarmony技术俱乐部成立大会暨基础软件与生态应用论坛”在南京大学仙林校区召开。 大会聚焦国产自主编程语言…...

实现一个漂亮的Three.js 扫光地面 圆形贴图扫光
实现一个漂亮的Three.js 扫光地面 圆形贴图扫光 https://threehub.cn/#/codeMirror?navigationThreeJS&classifyshader&idcircleWave import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControls.js import { GUI } fr…...
与运维开发实践)
第16章 Python数据类型详解:列表(List)与运维开发实践
文章目录 第16章 Python数据类型详解:列表(List)与运维开发实践一、列表的基础和入门1. 基本操作2. 常用方法3. 列表推导式(List Comprehension)二、AIOps运维视角下的列表应用1. 日志分析与异常检测2. 时间序列数据处理3. 自动化决策与响应三、DevOps运维开发视角下的列表…...

浅谈广告投放从业者底层思维逻辑
世界上的人分为两种:一种是“思辨者”,而另一种就是“吃瓜群众”。——周国元 绝大多数人因潜意识懒惰和不愿走出思维舒适区放弃思考,乐于成为“吃瓜群众”。 深以为然。 工作中,我接触的投手较多,有时候和投手A交谈…...

报表的那些事:四部演进史——架构视角下的技术跃迁与实战思考
引言 作为企业数据流转的核心载体,报表系统的设计与演进始终面临高性能、灵活性、可扩展性的平衡挑战。本文从架构师视角,以四阶段演进为脉络,结合电商等高并发场景,分享报表系统从定制化开发到混合计算体系的演进实践&#x…...
)
Pdf转Word案例(java)
Pdf转Word案例(java) 需要导入aspose-pdf.jar 需要先手动下载jar包到本地,然后通过systemPath在pom文件中引入。 下载地址:https://releases.aspose.com/java/repo/com/aspose/aspose-pdf/25.4/ <dependency><groupId&…...

HTML基础2-空元素,元素属性与页面的结构
目录 空元素(Void Element) 元素属性 (Attribute) 页面结构 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"w…...
)
2025FIC初赛(手机)
前言 记录一下自己的学习过程,网上已经有很多大佬出来全篇教程,但是我还是写出小部分,希望自己可以以点破面,什么都会等于不会,肯定是拿自己和大佬比,大佬都是全栈的。 手机取证 1. 请分析检材二&#x…...

《Python星球日记》 第43天:机器学习概述与Scikit-learn入门
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、什么是机器学习?1. 机器学习的三大类型1.1 监督学习1.2 无监督学习1.3 强化学习二、Scikit…...

Carlink 技术:搭建汽车与手机的智能桥梁
随着汽车智能化浪潮的推进,手机与车机的无缝连接已成为现代出行体验的重要组成部分。在这一背景下,ICCOA联盟推出的Carlink技术应运而生。 一、什么是Carlink Carlink是由智慧车联开放联盟(ICCOA)主导开发的新一代车机互联协议,旨在实现安卓…...

嵌入式学习--江协51单片机day2
今天学的不多,内容为:静态、动态数码管的控制,模块化编程和lcd1602调试工具 数码管的控制 由于内部电路的设计,数码管每次只能显示一个位置的一个数字,动态的实现是基于不同位置的闪烁频率高。 P2_4,P2_3,P2_2控制位…...

LLaMA-Omni 2:基于 LLM 的自回归流语音合成实时口语聊天机器人
LLaMA-Omni 2 是基于 Qwen2.5-0.5B/1.5B/3B/7B/14B/32B-Instruct 模型的一系列语音语言模型。与 LLaMA-Omni 类似,它可以同时生成文本和语音应答,从而实现高质量、低延迟的语音交互。通过新引入的流式自回归语音解码器,LLaMA-Omni 2 与 LLaMA…...