day18 python聚类分析对数据集模型性能影响
聚类后的分析:推断簇的类型
知识点回顾:
- 推断簇含义的2个思路:先选特征和后选特征
- 通过可视化图形借助ai定义簇的含义
- 科研逻辑闭环:通过精度判断特征工程价值
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
聚类分析的概念
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。
也就是说, 聚类的目标是得到较高的簇内相似度和较低的簇间相似度,使得簇间的距离尽可能大,簇内样本与簇中心的距离尽可能小
聚类得到的簇可以用聚类中心、簇大小、簇密度和簇描述等来表示
-
聚类中心是一个簇中所有样本点的均值(质心)
-
簇大小表示簇中所含样本的数量
-
簇密度表示簇中样本点的紧密程度
-
簇描述是簇中样本的业务特征
聚类的过程
-
数据准备:包括特征标准化和降维;
-
特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中;
-
特征提取:通过对所选择的特征进行转换形成新的突出特征;
-
聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量,而后执行聚类或分组;
-
聚类结果评估:是指对聚类结果进行评估,评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。
1.导入库
#导入库
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC #支持向量机分类器
from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
from sklearn.linear_model import LogisticRegression #逻辑回归分类器
import xgboost as xgb #XGBoost分类器
import lightgbm as lgb #LightGBM分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from catboost import CatBoostClassifier #CatBoost分类器
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯分类器
from sklearn.metrics import make_scorer,accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息2.数据预处理:
from sklearn.preprocessing import StandardScaler,MinMaxScaler
data=pd.read_csv('heart.csv')
#定义离散变量与连续变量
discrete_features=['sex', 'cp', 'fbs', 'restecg', 'exang','slope','thal']
continuous_features=['age','trestbps','chol','thalach','oldpeak']
print('离散变量:',discrete_features)
print('连续变量:',continuous_features)#对连续变量进行归一化
min_max_scaler=MinMaxScaler()
data[continuous_features]=min_max_scaler.fit_transform(data[continuous_features])
print(data.head())
from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签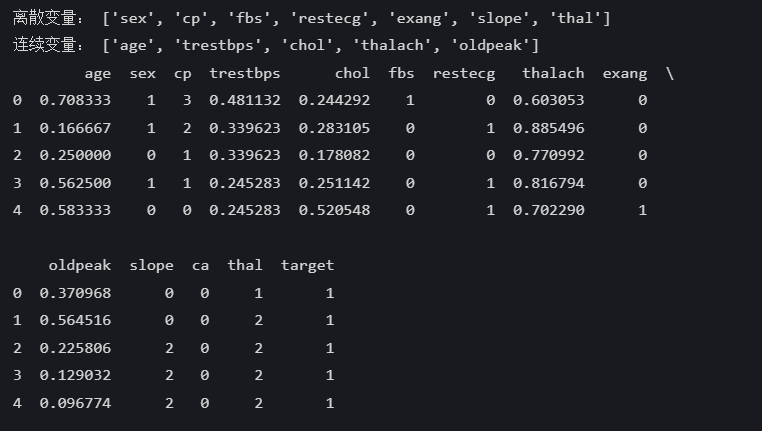
3.KMeans聚类结果
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import zscore# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 评估不同 k 值下的指标
k_range = range(2, 21) # 测试 k 从 2 到 20
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)#计算K值kmeans_labels = kmeans.fit_predict(X_scaled)#kmeans_labels包含了X_scaled中每个样本所属的聚类标签inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)(簇内误差平方和wcss)惯性值越小说明效果越好silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数,取值范围在 -1 到 1 之间,越接近 1 表示聚类效果越好。silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数,值越大表示聚类效果越好。ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数,DB 指数衡量了不同聚类之间的相似度,值越小表示聚类效果越好。db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")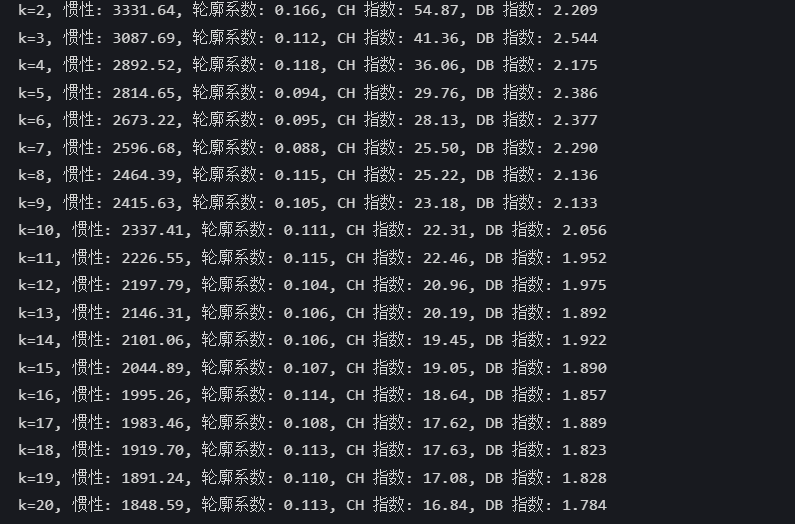
selected_k = 2# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())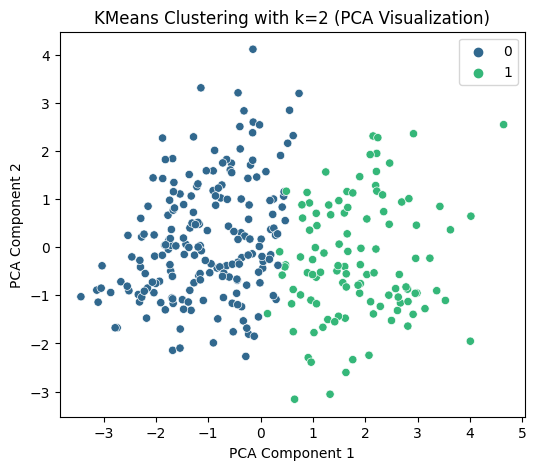
KMeans Cluster labels (k=2) added to X:
KMeans_Cluster
0 194 1 109
Name: count,
dtype: int64
4.判断簇类型:
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型n_estimators=100代表随机森林模型中包含多少颗决策树
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了
shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()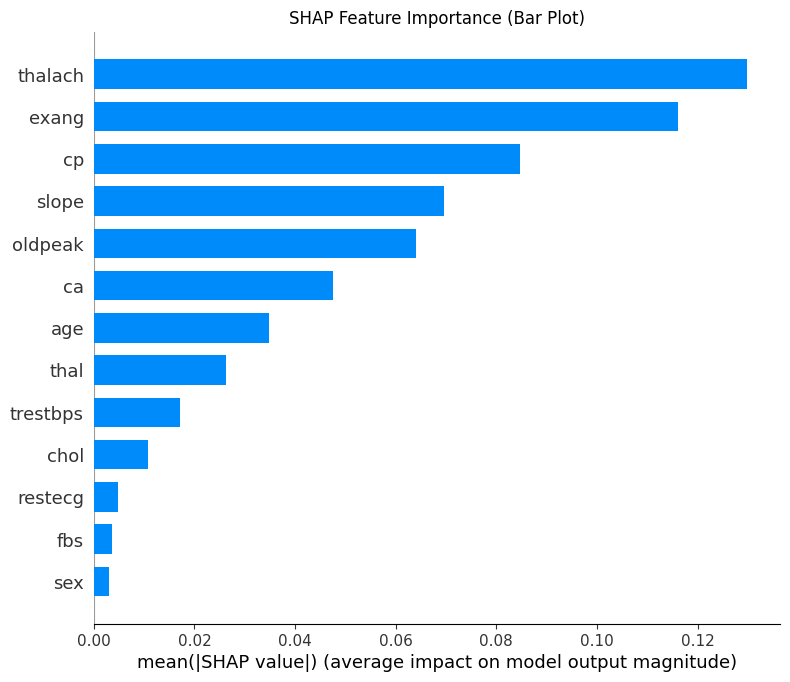
选择前9个重要的特征进行分析
# 此时判断一下这几个特征是离散型还是连续型(特征比较多的情况下用)
import pandas as pd
selected_features = ['thalach', 'exang','cp','slope',
'oldpeak', 'ca','age','thal','trestbps']for feature in selected_features:unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值
# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')
import matplotlib.pyplot as plt# 总样本中的前9个重要性的特征分布图
fig, axes = plt.subplots(3, 3, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()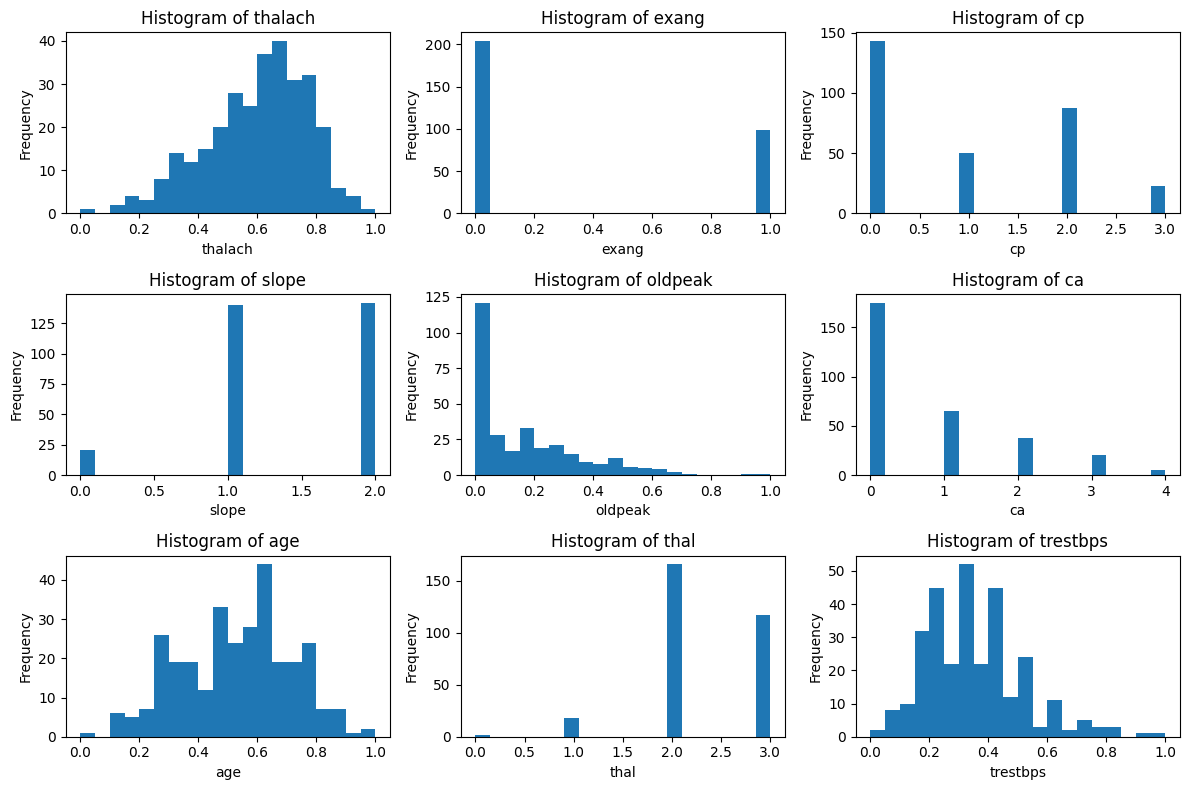
绘制簇0的分布图
# 分别筛选出每个簇的数据
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
# 先绘制簇0的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 3, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()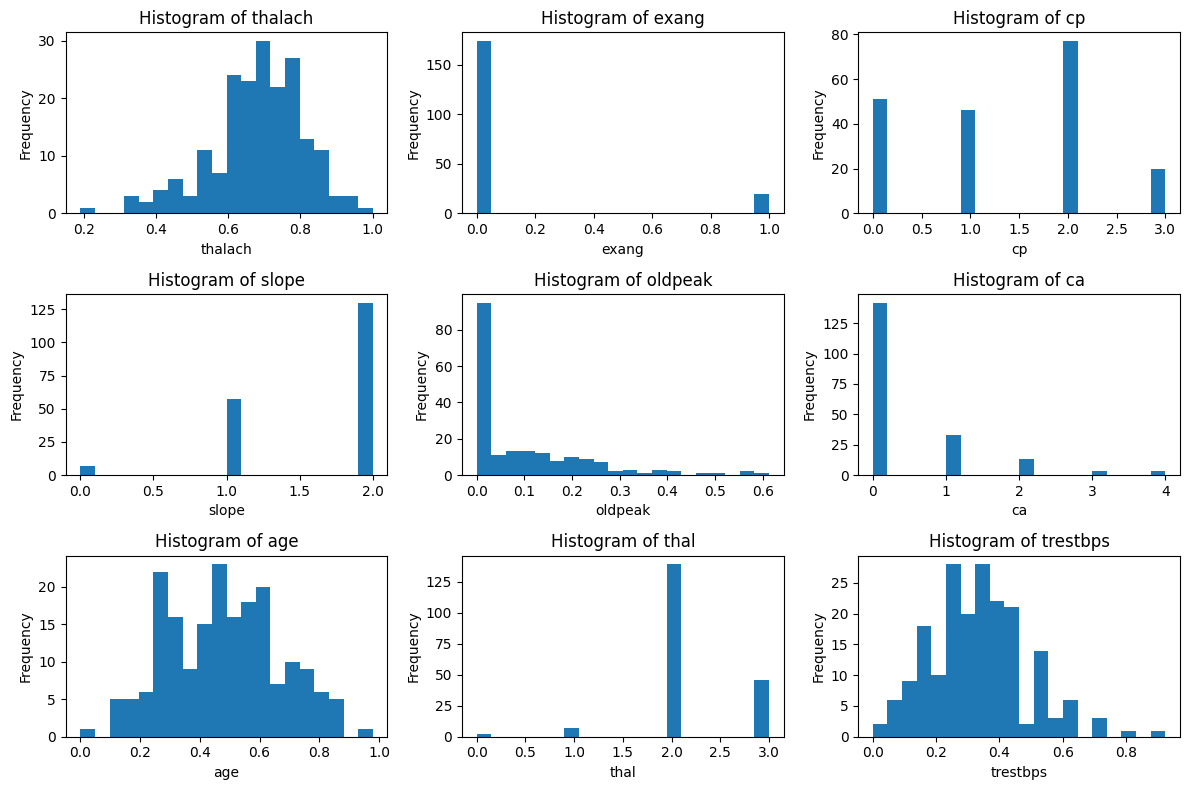
绘制簇1的分布图
# 先绘制簇1的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 3, figsize=(12, 8))for i, feature in enumerate(selected_features):row=i//3col=i%3axes[row,col].hist(X_cluster1[feature], bins=20)axes[row,col].set_title(f'Histogram of {feature}')axes[row,col].set_xlabel(feature)axes[row,col].set_ylabel('Frequency')plt.tight_layout()
plt.show() 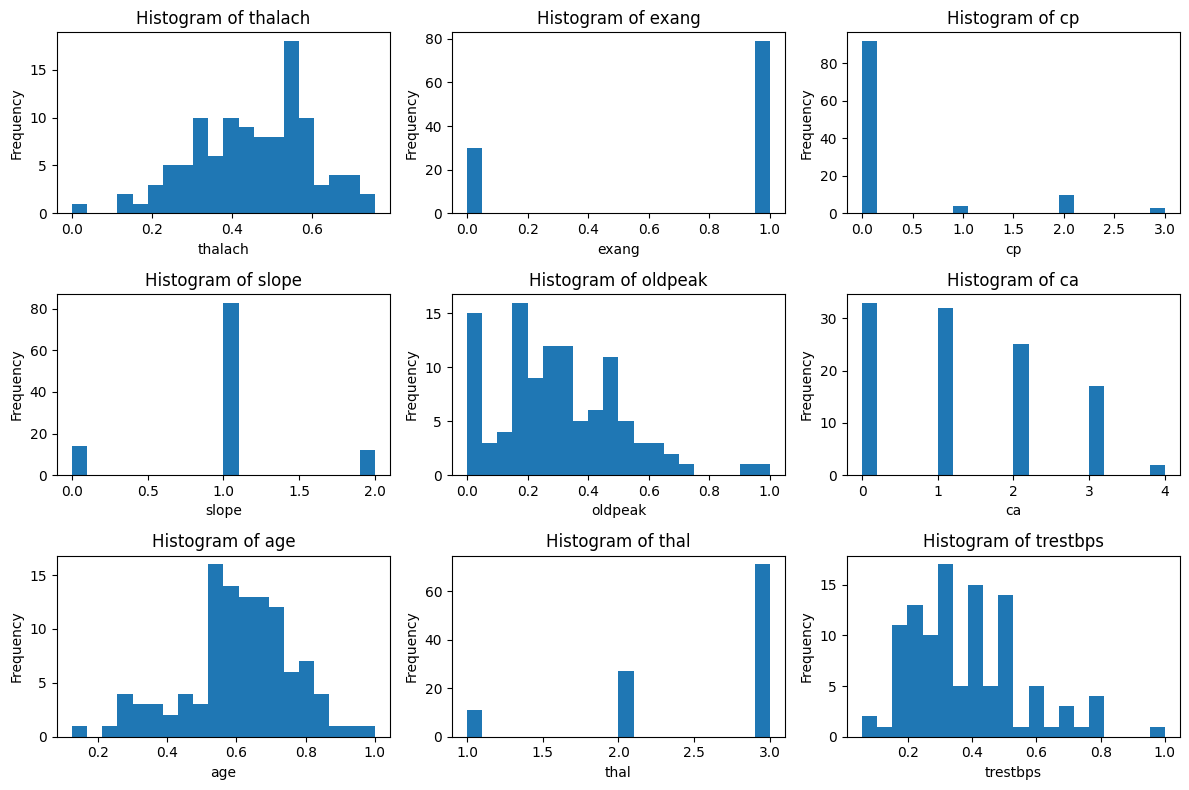
当然,以下是对两个簇特征分布的简洁分析:
X_cluster0 分析:
X_cluster0 群体的特征显示出一种相对一致的模式。大多数成员的最大心率(thalach)和年龄(age)都处于较低的区间,表明这一群体可能较为年轻且心脏反应温和。静息血压(trestbps)和运动引起的ST段变化(oldpeak)也普遍较低,这通常与较低的心血管疾病风险相关。此外,胸痛类型(cp)和ST段坡度(slope)的集中趋势暗示该群体可能经历较少或较轻微的心脏问题。总体来看,X_cluster0 可能代表了一个心脏健康风险较低的群体。
X_cluster1 分析:
相比之下,X_cluster1 群体的特征分布更为广泛和多变。最大心率(thalach)、运动诱发心绞痛(exang)、胸痛类型(cp)和ST段坡度(slope)的分布表明该群体的心脏健康状况差异较大。特别是,运动诱发心绞痛的发生率较高,可能意味着这一群体的心脏疾病风险较高。此外,年龄(age)和主要血管数量(ca)的广泛分布进一步表明该群体的健康状况复杂多变。X_cluster1 可能包含了一些具有较高心脏疾病风险的个体,需要进一步的医疗评估和关注。
5.利用随机森林模型看看特征工程后模型性能是否增强
默认随机森林
import time
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix# 假设 X 和 y 已经被定义并包含了特征和目标变量# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))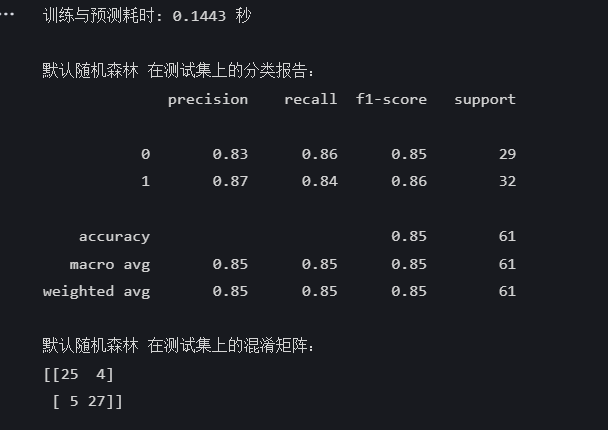
聚类之后的随机森林
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
x1_train, x1_test, y1_train, y1_test = train_test_split(x1, y1, test_size=0.2, random_state=42)
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(x1_train, y1_train) # 在训练集上训练
rf_pred = rf_model.predict(x1_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y1_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y1_test, rf_pred))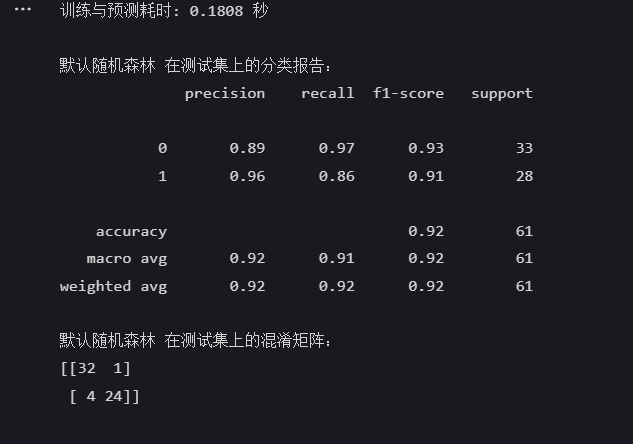
在我的分析过程中,我发现聚类分析对随机森林模型的表现有着显著的正面影响。在我没有应用聚类技术之前,模型在测试集上的准确率是85%,然而,在我对数据进行聚类处理之后,模型的准确率提高到了92%。具体到每个类别,类别0的召回率从86%显著提升至97%,而类别1的精确度也从87%上升到了96%,这说明经过聚类,模型在识别这两类样本方面变得更加精确和细致。此外,聚类后的模型在宏平均和加权平均指标上也显示出了全面提升,其中精确度、召回率和F1分数均达到了0.92,这进一步证实了模型整体性能得到了增强。通过对比混淆矩阵,聚类的效果更是显而易见:在聚类前,模型有9个分类错误,而在聚类后,这个数字减少到了5个,这表明模型的预测准确性有了显著的提升。这些结果让我相信,聚类过程有效地改善了数据的结构,使得随机森林模型能够更有效地捕捉数据中的模式,进而在分类任务中表现得更加出色。
@浙大疏锦行
参考文章
相关文章:

day18 python聚类分析对数据集模型性能影响
聚类后的分析:推断簇的类型 知识点回顾: 推断簇含义的2个思路:先选特征和后选特征通过可视化图形借助ai定义簇的含义科研逻辑闭环:通过精度判断特征工程价值 作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征…...

vue3的新特性
vue2 data属性和方法名散落于各个位置,量大了不好找 顺序变了,script在最前面 setup vue3中不用this,setup的执行时期比beforeCreate还要早,所以不要用this setup中写代码的特点 必须要有return,才能在上面使用 什么…...

NX二次开发——BlockUI 弹出另一个BlockUI对话框
最近在研究,装配体下自动导出BOM表格中需要用到BlockUI 弹出另一个BlockUI对话框。通过对网上资料进行整理总结,具体如下: 1、明确主对话框、子对话框1和子对话框2 使用BlockUI创建.cpp和.hpp文件,dlx文件内容如下所示 主对话框…...

《Overlapping Experiment Infrastructure: More, Better, Faster》论文阅读笔记
文章目录 1 背景2 三个核心概念3 Launch层:特性发布的专用机制4 流量分发策略和条件筛选4.1 四种流量分发类型4.2 条件筛选机制 5 工具链与监控体系6 实验设计原则7 培训参考与推荐 1 背景 谷歌(Google)以数据驱动著称,几乎所有可…...

【Machine Learning Q and AI 读书笔记】- 05 利用数据减少过拟合现象
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图. 本文是Machine Learning Q and AI 读书笔记的第5篇,对应原…...
)
前端面试测试题目(一)
一、Vue的双向绑定机制(v-model底层实现原理) Vue的双向绑定核心由 响应式系统 和 指令语法糖 共同实现,具体原理如下: 响应式系统 Vue通过数据劫持和依赖收集实现数据变化到视图的同步: • 数据劫持:在Vue…...

最优化方法Python计算:无约束优化应用——线性回归分类器
一、线性回归分类器 假设样本数据为 ( x i , y i ) (\boldsymbol{x}_i, y_i) (xi,yi),其中 i 1 , 2 , … , m i 1, 2, \dots, m i1,2,…,m。标签 y i y_i yi 取值于 k k k 个整数 { 1 , 2 , … , k } \{1, 2, \dots, k\} {1,2,…,k},从而构…...

【汇正自控阀门集团】签约智橙PLM,智橙助泵阀“以国代进”
签约智橙,汇正阀门的“以国代进”举措 随着阀门市场竞争日益激烈、市场需求日益多样化,无论是出口海外、以国代进,还是进军新能源、造船、油气等投资景气的下游市场,阀门企业能否在快速迭代产品、保持技术领先的同时,…...

【macOS】iTerm2介绍
iTerm2 和 iTerm 是 macOS 上两个不同的终端模拟器,虽然名字相似,但它们是两个独立的项目,且 iTerm2 是 iTerm 的现代化继承者。以下是它们的核心区别和演进关系: 1. 历史背景 项目诞生时间状态开发者iTerm2002 年已停止维护Greg…...

2025年五一假期旅游市场新趋势:理性消费、多元场景与科技赋能
2025年五一假期,国内旅游市场再次迎来爆发式增长,官方数据显示,假期期间国内出游人次达3.14亿,游客总消费1802.69亿元。尽管数据规模亮眼,但深入分析可发现,旅游市场正经历结构性变革——消费行为趋于理性、…...

第3章 模拟法
3.1 模拟法概述 模拟法设计思想 模拟法通过将现实问题抽象成计算机可识别的符号与操作,按逻辑顺序“模拟”其过程,从而得到结果;它不依赖复杂公式或高深技巧,只需理清问题背景与实现步骤即可。 示例:鸡兔同笼问题 题…...

16.状态模式:思考与解读
原文地址:状态模式:思考与解读 更多内容请关注:深入思考与解读设计模式 引言 在开发软件系统时,特别是当对象的行为会随着状态的变化而变化时,系统往往会变得复杂。你是否遇到过这样的情况:一个对象的行为在不同的状…...
)
ActiveMQ 源码剖析:消息存储与通信协议实现(二)
四、KahaDB 消息存储实现细节 (一)存储原理分析 KahaDB 作为 ActiveMQ 从 5.4 版本开始的默认消息存储引擎,其基于日志文件的存储原理具有独特的设计和优势 。在 KahaDB 的存储目录(如${activemq.data}/kahadb)下&am…...

明远智睿SD2351核心板:工业AIoT时代的创新引擎
在当今工业互联网飞速发展的浪潮中,人工智能(AI)与物联网(IoT)的深度融合正以前所未有的态势重塑着传统制造业的格局。从自动化生产线的精准控制到智能仓储的高效管理,从设备运行的实时监测到产品质量的严格…...

iPhone 和 Android 在日期格式方面的区别
整篇文章由iPhone 和 Android 在日期格式方面有所不同引起,大致介绍了,两种时间标准,以及在 JavaScript 下的格式转换方法。 Unix 时间戳是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。 iPhone 和 Android 在日期格式方面有所不同。其中,iPhone(iOS)使…...

使用VSCode在Windows 11上编译运行项目
使用VSCode在Windows 11上编译运行项目 VSCode是一个功能强大的跨平台代码编辑器,可以很好地支持C/C项目开发。以下是使用VSCode在Windows 11上编译运行此项目的详细步骤。 1. 安装VSCode 访问VSCode官网下载并安装VSCode安装完成后,启动VSCode 2. 安…...

边缘计算,运维架构从传统的集中式向分布式转变
在当今数字化时代,边缘计算的崛起正在改变着运维的格局。随着物联网、5G 等技术的快速发展,越来越多的数据和应用正在向边缘设备迁移,这给运维团队带来了新的挑战和机遇。 一、边缘计算崛起带来的运维挑战 边缘计算将计算和数据存储靠近数据…...

【基础篇】prometheus热更新解读
文章目录 本篇内容讲解热更新参数源码解读本篇总结本篇内容讲解 prometheus热更新源码解读 热更新参数 –web.enable-lifecycle : 代表开启热更新配置 修改配置文件发http请求# curl -X POST -vvv localhost:9090/-/reload * About to connect() to localhost port 9090 (…...
——纯CSS静态卡片案例)
为了结合后端而学习前端的学习日志(1)——纯CSS静态卡片案例
前端设计专栏 使用纯CSS创建简洁名片卡片的学习实践 在这篇技术博客中,我将分享我的前端学习过程,如何使用纯HTML和CSS创建一个简洁美观的名片式卡片,就像我博客首页展示的那样。这种卡片设计非常适合作为个人简介、产品展示或团队成员介绍…...

汽车服务小程序功能点开发
汽车养护服务功能 智能保养预约:根据车辆品牌、型号及行驶里程,自动推荐保养项目,支持线上预约 4S 店或合作维修厂,选择服务时间与地点。故障诊断与维修:车主上传车辆故障现象,系统智能初步诊断࿰…...

SENSE2020BSI sCMOS科学级相机主要参数及应用场景
SENSE2020BSI sCMOS科学级相机是一款面向宽光谱成像需求的高性能科学成像设备,结合了背照式(Back-Side Illuminated, BSI)CMOS技术与先进信号处理算法,适用于天文观测、生物医学成像、工业检测等领域。以下是其核心特点及技术细节…...

《汽车噪声控制》复习重点
题型 选择 填空 分析 计算 第一章 噪声定义 不需要的声音,妨碍正常工作、学习、生活,危害身体健康的声音,统称为噪声 噪声污染 与大气污染、水污染并称现代社会三大公害 声波基本概念 定义 媒质质点的机械振动由近及远传播&am…...

物流无人机结构与载货设计分析!
一、物流无人机的结构与载货设计模块运行方式 1.结构设计特点 垂直起降与固定翼结合:针对复杂地形(如山区、城市)需求,采用垂直起降(VTOL)与固定翼结合的复合布局,例如“天马”H型无人机&am…...
的详细步骤)
docker创建一个centOS容器安装软件(以宝塔为例)的详细步骤
备忘:后续偶尔忘记了docker虚拟机与宿主机的端口映射关系,来这里查看即可: docker run -d \ --name baota \ --privilegedtrue \ -p 8888:8888 \ -p 8880:80 \ -p 8443:443 \ -p 8820:20 \ -p 8821:21 \ -v /home/www:/www/wwwroot \ centos…...

D盘出现不知名文件
各位大佬,电脑D盘去年还干干净净的,后来突然就出现了所圈部分的几个不知名文件,请问这是什么东西?是否可以删除?...

Rust 中 Arc 的深度分析:从原理到性能优化实践
在 Rust 的并发编程中,Arc(Atomic Reference Counted) 是一个非常关键的智能指针类型,用于在多个线程之间共享数据的所有权。它通过原子操作维护引用计数,确保在多线程环境下安全地管理堆内存资源。然而,很…...

qsort函数
在本篇中,将深入了解qsort函数的用法。 1.qsort函数的基础知识 该函数是用来排序的,这是一个可以直接用来排序数据的库函数(#include<stdlib.h>),底层使用的是快速排序的方式。 常见的排序方式有: …...

01 一文了解大数据存储框架:数据库、数据仓库、数据集市、数据网格、数据湖、数据湖仓
1. 大数据存储框架 1.1 定义 数据库(Database):数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。数据仓库(Data Warehouseÿ…...
)
QT —— QWidget(2)
QT —— QWidget(2) windowTitlewindowIconQt 资源系统 (qrc 机制) 详解基本概念使用方法1. 创建 .qrc 文件 设置背景windowOpacity 我们今天继续来学习QWidget,如果大家上一次的博客还没有看过,可以点击这里: https:/…...

微信小程序预览文件 兼容性苹果
uni.request({url: url,method: GET,header: {Authorization: token,responseType: blob,},responseType: "arraybuffer",success: (res) > {uni.hideLoading()const fs wx.getFileSystemManager(); //获取全局唯一的文件管理器let index url.lastIndexOf("…...

QT:qt5调用打开exe程序并获取调用按钮控件实例2025.5.7
为实现在 VS2015 的 Qt 开发环境下打开外部 exe,列出其界面按钮控件的序号与文本名,然后点击包含特定文本的按钮控件。以下是更新后的代码: #include <QCoreApplication> #include <QProcess> #include <QDebug> #include…...

Flink + Kafka 数据血缘追踪与审计机制实战
一、引言 在实时数据系统中,“我的数据从哪来?去往何处?” 是业务方最关心的问题之一。 尤其在以下场景下: 📉 金融风控:模型出现预警,需回溯数据源链路。 🧾 合规审计:监管要求提供数据全流程路径。 🛠 运维排查:Kafka Topic 数据乱序或错发后快速定位来源。 …...

【图书管理系统】详细讲解用户登录:后端代码实现及讲解、前端代码讲解
1. 约定前后端交互接口 [请求] /user/login [参数] userName&password [响应] 登录成功返回–true;登录失败返回–false 2. 后端代码 2.1 后端代码的逻辑 Controller层: (1)从请求和参数可以得出,前端通过127.0.…...

uni-app实现完成任务解锁拼图功能
界面如下 代码如下 <template><view class"puzzle-container"><view class"puzzle-title">任务进度 {{completedCount}}/{{totalPieces}}</view><view class"puzzle-grid"><viewv-for"(piece, index) in…...
)
鸿蒙开发——1.ArkTS声明式开发(UI范式基本语法)
鸿蒙开发——1、ArkTS声明式开发:UI范式基本语法 [TOC](鸿蒙开发——1、ArkTS声明式开发:UI范式基本语法)一、ArkTS的基本组成(1)核心概念(像贴标签一样控制组件)(2)基础工具包(现成的积木块&am…...

ChatGPT-4o:临床医学科研与工作的创新引擎
技术点目录 2024大语言模型最新进展介绍ChatGPT-4o提示词使用方法与技巧ChatGPT-4o助力临床医学日常生活、学习与工作ChatGPT-4o助力临床医学课题申报、论文选题及实验方案设计ChatGPT-4o助力信息检索、总结分析、论文写作与投稿、专利idea构思与交底书的撰写ChatGPT-4o助力临床…...

Excel点击单元格内容消失
Excel点击单元格内容消失 前言一、原因说明二、解决方案1.菜单栏中找到“审阅”,选择“撤销工作表保护”2.输入密码3.解除成功 前言 Excel想要编辑单元格内容时,无论是单击还是双击单元格内容都莫名其妙的消失了 一、原因说明 单击或者双击Excel中单元…...

单片机-STM32部分:7、GPIO输入 按键
飞书文档https://x509p6c8to.feishu.cn/wiki/RtuVw6GgZiuwyBkxmdDcdsAFnKk 根据原理图,找到KEY1对应的PC3 找到CubeMX中的PC3,设置为GPIO_Input 右击,修改引脚名称为KEY1 或者在GPIO配置属性中修改 引脚模式:这里默认为输入模式&…...

从创意到变现:独立创造者的破局之路——解码《Make:独立创造者手册》
在创业浪潮奔涌的时代,独立创造者正成为商业领域中一股不可忽视的新兴力量。他们凭借对创新的执着、对问题的敏锐洞察,以及对自由创业模式的追求,试图在竞争激烈的市场中开辟属于自己的天地。《Make:独立创造者手册》如同一位经验丰富的创业导师,为独立创造者们提供了一套…...

14前端项目----登录/注册
登录/注册 assets用户注册模块登录模块tokenlogin组件业务token校验获取用户登录信息 登录成功---Header组件 assets assets文件夹:一般也是放置静态资源–>一般是多个组件共用的静态资源 webpack 会把 assests 静态资源当作是一个模块,打包到 js 文件里,不存在a…...

【FreeRTOS-消息队列】
参照正点原子以及以下gitee笔记整理本博客,并将实验结果附在文末。 https://gitee.com/xrbin/FreeRTOS_learning/tree/master 一、队列简介 1、FreeRTOS中的消息队列是什么 答:消息队列是任务到任务、任务到中断、中断到任务数据交流的一种机制(消息传…...
,b树,b+树,红黑树)
二叉查找树,平衡二叉树(AVL),b树,b+树,红黑树
🌲 一、二叉查找树(Binary Search Tree,简称 BST) 📌 定义 二叉查找树是一棵二叉树,它满足这样的特性: 每个节点最多有两个子节点(左、右)对于任意一个节点: 它左子树的所有节点值都比它小它右子树的所有节点值都比它大📈 举个例子 复制代码 10/ \5 20/ \ …...
以及进程地址空间第二讲【Linux操作系统】)
可执行文件格式(ELF格式)以及进程地址空间第二讲【Linux操作系统】
文章目录 可执行文件的格式可执行文件中存储了什么可执行文件中的虚拟地址以及加载 进程地址空间第二讲CPU如何执行进程的代码再谈进程地址空间的区域划分 可执行文件的格式 源文件被编译器编译之后的可执行文件,并不是只有代码和数据,还有一定的格式&a…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】8.1 基础图表绘制(折线图/柱状图/散点图)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据分析实战:基础图表绘制(折线图/柱状图/散点图)8.1 基础图表绘制8.1.1 折线图:展现数据趋势数据准备图表绘制步…...
详解)
Yii2.0 模型规则(rules)详解
一、基本语法结构 public function rules() {return [// 规则1[[attribute1, attribute2], validator, options > value, ...],// 规则2[attribute, validator, options > value, ...],// 规则3...]; }二、规则类型分类 1、核心验证器(内置验证器࿰…...

Notepad++中XML格式化插件介绍
Notepad++中XML格式化插件介绍 背景安装指南安装步骤验证安装成功安装失败可尝试使用说明XML文件格式正确时格式化错误格式检查XML Tools插件核心功能盘点常见问题格式化后没变化中文显示乱码拯救杂乱XML格式!Notepad++这个神器插件,必须接收!背景 接手别人写的XML,缩进乱成…...
的数据)
在 R 中,清除包含 NA(缺失值)的数据
在 R 中,清除包含 NA(缺失值)的数据可以通过多种方式实现,具体取决于你希望如何处理这些缺失值。以下是几种常见的方法,包括删除包含 NA 的行、删除包含 NA 的列,或者用特定值填充 NA。 1. 删除包含 NA 的…...
基础命令和操作)
Linux复习笔记(一)基础命令和操作
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 一、Linux中的基础命令和操作(约30%-40%) 1.用户和组(5%左右) 1.1用户简介(了解) 要求:了解,知道有三个用户…...

多线程的出现解决了什么问题?深入解析多线程的核心价值
多线程的出现解决了什么问题?深入解析多线程的核心价值 1. 引言 在计算机科学中,多线程(Multithreading) 是一种重要的并发编程技术,它允许一个进程同时执行多个任务,从而提高程序的性能和响应能力。那么,多线程究竟是为了解决哪些问题而诞生的?它的核心价值是什么?…...

java集合菜鸟教程
1、Java集合的分类 1Java中的集合类可以分为两大类: (1)实现Collection接口,Collection是一个基本的集合接口,Collection中可以容纳一组集合元素(Element),图1是Collection与子类的…...